#makefile tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Hey everyone! Just wanted to share an amazing tutorial on writing and porting drivers on the NXP i.MX8MP platform. It takes you through the entire process from creating the directory and files, configuring Kconfig and Makefile, integrating into the kernel build system, compiling the driver, and finally testing it.
A must-read for those interested in driver development!

0 notes
Text
Boost Go Build Performance with Makefiles and Tasks Optimization
Introduction Boosting Your Go Build Process with Makefiles and Tasks is a technique used to improve the efficiency and flexibility of building and managing Go projects. By leveraging the power of Makefiles and tasks, developers can automate repetitive tasks, reduce build times, and increase overall productivity. In this tutorial, we will explore the concept of Makefiles and tasks in the context…
0 notes
Text
Project Updates - 5/7/24
Looks like it's time for my bi-yearly "remember this blog exists and post an update"! 😄It's been another few months of off and on work due to my day job and other life things going on, but still trying to chip away at things.
More on the individual projects under the cut~
libtcod tutorials
Since my first crack at writing up the C++ tutorials for libtcod, I've mostly been trying to decide what I want to show for them. Part of the feedback I received on the first tutorial was that it didn't have a clear audience, whether it was for beginners to programming or to more advanced developers. I've gone back and forth on this, and I think I've settled on making it more accessible to newer programmers, though that does mean I have some reworking to do. On the upside, I was able to fairly easily change the code on the early tutorials to account for newer versions of libtcod.
I have also been working through reimplementing later tutorials. Most recently worked on the fourth tutorial, where I decided to introduce an event handling system using double dispatch (specifically using the way outlined in this blog post). This approach is a bit complex to implement and describe since it uses certain template patterns, but overall it should allow for the rest of the tutorials to easily add functionality by simply adding events and new event handlers. Actually implementing it took a couple of days of trial and error due to a lot of factors (mostly trying to understand how it all worked myself), but now it's in a good state and pretty easily extendable! Explaining it in the tutorial, however, will be a different story 😅
OpenHomeworld
This is mostly still in the rough design phase still. Most of the tinkering I've done has been around loading and listing the Bigfile contents, and optimizations around that. I'm tempted to start working on a GUI archive tool to display items as well as insert and extract files from the Bigfile, though I'm not sure if I want to make something in Qt or try my hand at making a plugin for Godot. The Qt tool would probably end up being pretty simple and just show a list of files like how 7zip or WinRAR work, which itself would be just a UI around a command line tool, really. If I tried creating a Godot plugin, I'd also want to handle viewing and editing the files extracted from the Bigfile, too, and that would probably also require implementing the way to handle the Homeworld texture, mesh, script, and other files that have their own format internally. The Godot option is tempting, since I would want to have some sort of editor for the project at some point, but I'll probably keep is simple at this point and just make some small command line utilities. Options, though!
At the same time, I've been playing with the source port of the original game and trying my hand at updating the build system to CMake. This has gone mostly smoothly, except for one snag that I have yet to figure out a good way to handle. You see, the old Homeworld source code is written in C, but the game levels were created in a scripting language that the Relic devs used called KAS (which I think stands for Kick-Ass Scripts lol). Essentially these KAS files would get converted into C code and compiled into the main game executable, and the way the game is built with Makefiles makes it pretty easy to hook in calls to the utility programs to convert these files. In all my messing around, though, I have not been able to successfully replicate that process using CMake. I might need to specify all of the mission files explicitly to have them build and link properly, but I worry I'll end up running into a situation where the build will fail due to things being run out of order in multi-threaded builds (which is already a problem with the source port process though). Analysis continues...
Metal Max Redux - GBC game project
In my last devlog, I mentioned that I was interested in making a game based on a series of obscure JRPGs. The Metal Max/Metal Saga games are ones that I found last year and fell in love with, so much so that I wanted to create a game based off them. The first game in the series was an NES game that was never released in North America, but has a wonderful fan translation patch that I was playing through, but have not actually completed quite yet. It's a fun little RPG where you can drive tanks around a post-apocalyptic world fighting monsters, and has a pretty open structure to it, not unlike the first Dragon Quest or Final Fantasy.
Last year I also came across GB Studio, a free and open source all-included editor for creating GameBoy and GameBoy Color games from scratch, and this gave me a great idea: since I was a huge fan of the GBC port of Dragon Quest I+II, I thought I would make a similar port of Metal Max. So Metal Max Redux was born!
I'm still mostly in the beginning stages with this project still, but I've created a basic mock-up of overworld movement and triggering random battles. The random battle system took a while to puzzle out, and at one point I thought I was going to have to extend the engine that GB Studio uses, but I was able to make it work using a step counter attached to an invisible player object that seems to work well enough. Next steps will probably be analyzing how the NES battle code worked, so I'll be looking at lots of assembly. Fun times! 😄
Free City-States - lewd city management game
Finally, a project to earn my screenname 😄 I really enjoy city builder and management games like the Caesar series and Dwarf Fortress, and within the last few years games like Crusader Kings and Stellaris.
A while back, I was starting to help out with a project called Free Cities Reborn, itself a reimagining of an HTML game called Free Cities, a lewd management game with some city building aspects. I couldn't continue with FCR after a while due to some growing reservations about the content and focus of the game which extends somewhat to the original too, since its core gameplay is around the raising, training, and sale of sex slaves. It's a fun indulgence, if somewhat of a guilty pleasure, and it's certainly not the first game that's concerned with the subject matter, but I still felt weird contributing to a project where it was so focused on that. But at the same time I started to think about creating my own spin on the core ideas, and creating my own lewd game in general.
So that's how Free City-States came to be envisioned. The core game concept in my mind is more akin to Crusader Kings and Stellaris than to Caesar and Dwarf Fortress, but focused on the management of a fantasy city-state. I've created a small mock-up in Godot as my first real foray into that game engine so far, and hoping to continue chipping away at it as the concept becomes more fleshed out 😊
Wow, this ended up way longer than I thought it would, and this doesn't even cover all the small ideas and tinkerings I've been working on! Putting it down into words, I guess I really did do a lot between the last post and this one 😅 Hopefully future posts will be a little shorter, but this was a fun way to reflect on the things that I'm working on. I think I'll try to make fortnightly updates if I can, going forward.
0 notes
Text
C standard library is abysmal and every part of it was misdesigned, I can pick a random part of it and see it all fall apart.
The way locales are done means you can't reliably print out formatted numbers in a locale-indepenent fashion as there's no locale-accepting version of say, printf.
string.h is an embarrassment. strncpy is not a string function as its post-condition does not create a string at its destination in every case. It is also not a "safe version of strcpy" either, wrongly misleading people into thinking it is. The intended use of strcat results in O(n^2) performance when concatenating many strings. While the null-terminated string representation has problems on its own, string.h compounds them significantly.
Null-terminated strings and string.h are a symptom of a larger problem of C that is an utter lack of sensible buffer management, like some form of a slice type, contained within a single variable. But also you can't write one because the type system does not have any form of expressing a "generic type" like the built-in array types, or pointer types. Every such type has to be provided by the base language and this results in a situation where complex numbers, atomics and others are introduced as a language feature (!).
The type system is a joke and will let you assign integers to pointer variables, and this will only result in a compiler warning.
Compiler warnings are something you _have_ to enable in order to have any form of reasonable software development experience, but this is once again a something you have to remember while writing your Makefiles. -Wall does not enable "all warnings" because it broke somebody important's code when compiled together with "-Werror" and so "all warnings" in this context means "enable all warnings the compiler had in like nineteen-ninety-something". Newbies will not know to do enable warnings, as most tutorials are written by people who have no clue themselves. The solution to this problem would be introducing a concept "so okay, compiler, give me a reasonable set of warning flags as you believe is appropriate for 2024" and later on when you're feeling up to grabbing more diagnostics to warn about, you bump the warning wave into a next number, but such thing is yet to be introduced.
The way C99 variable length arrays interact with sizeof operator makes me cringe (if any part of the expression touches a VLA, sizeof becomes a runtime operation instead of compile time one), to the point I am glad that C11 no longer makes VLAs mandatory so I hope most implementations will nope out of them.
The C language syntax is also a joke and has its own thorns.
The most reasonable way to use C language is to avoid touching the C standard library at all, but this results in bespoke solutions incompatible with other people's bespoke solutions. Check a random project you will likely see it reimplement a string type.
In some ways you could dismiss these issues and treat C as a some form of portable assembler ("the language that provides you a mechanism but no policy, you're the one responsible for policy"), but you will be hindered by the gradual change of how undefined behaviour is treated both by the community and by the compilers over the years. It used to mean "several compilers did it differently so we're leaving it up to them" but nowadays is interpreted as "compiler will assume that every code path that leads to the code that would exhibit undefined behaviour is assumed to never happen" which leads to "interesting" situations where null checks are optimized away out of the produced binary code, increasing the severity of security holes many many times, and making the mapping from C code to assembly not obvious, making the supposed advantage of C illusory.
And then when you point all of this out the community will victim blame you and say that you should have been more careful.
Chat gimmick blogs are interacting with me what does this mean
2K notes
·
View notes
Text
CSCI 2122 Assignment 4
CSCI 2122 Assignment 4 Due date: 11:59pm, Friday, March 22, 2024, submitted via git Objectives The purpose of this assignment is to practice your coding in C, and to reinforce the concepts discussed in class on program representation. In this assignment1 you will implement a binary translator2 like Rosetta3. Your program will translate from a simple instruction set (much simpler than x86) to x86 and generate x86 assembly code. The code will then be tested by assembling and running it. This assignment is divided into two parts to make it simpler. In the first part, you will implement the loader and a simple translator, which代做CSCI 2122、代写 Python/c++程序语言 translates the simpler in- structions. In the second part, you will extend the translator to translate more complex instructions. Preparation:
Complete Assignment 0 or ensure that the tools you would need to complete it are installed.
Clone your assignment repository: https://git.cs.dal.ca/courses/2024-winter/csci-2122/assignment-4/????.git where ???? is your CSID. Please see instructions in Assignment 0 and the tutorials on Brightspace if you are not sure how. Inside the repository there is one directory: xtra, where code is to be written. Inside the directory is a tests directory that contains tests that will be executed each time you submit your code. Please do not modifythetestsdirectoryorthe.gitlab-ci.ymlfilethatisfoundintherootdirectory. Modifying these files may break the tests. These files will be replaced with originals when the assignments are graded. You are provided with sample Makefile files that can be used to build your program. If you are using CLion, a Makefile will be generated from the CMakeLists.txt file generated by CLion. Background: For this assignment you will translate a binary in a simplified RISC-based 16-bit instruction set to x86-64 assembly. Specifically, the X instruction set comprises a small number (approximately 30) instructions, most of which are two bytes (one word) in size. The X Architecture has a 16-bit word-size and 16 general purpose 16-bit registers (r0 . . . r15 ). Nearly all instructions operate on 16-bit chunks of data. Thus, all values and addresses are 16 bits in size. All 16-bit values are also encoded in big-endian format, meaning that the most-significant byte comes first. Apart from the 16 general purpose registers, the architecture has two special 16-bit registers: a program counter (PC), which stores the address of the next instruction that will be executed, and the status (F), which stores bit-flags representing the CPU state. The least significant bit of the status register (F) is the condition flag, which represents the truth value of the last logical test operation. The bit is set to true if the condition was true, and to false otherwise. 1 The idea for this assignment came indirectly from Kyle Smith. 2 https://en.wikipedia.org/wiki/Binary_translation 3 https://en.wikipedia.org/wiki/Rosetta_(software)
Additionally, the CPU uses the last general-purpose register, r15, to store the pointer to the program stack. This register is incremented by two when an item is popped off the stack and decremented by two when an item is pushed on the stack. The program stack is used to store temporary values, arguments to a function, and the return address of a function call. The X Instruction Set The instruction set comprises approximately 30 instructions that perform arithmetic and logic, data move- ment, stack manipulation, and flow control. Most instructions take registers as their operands and store the result of the operation in a register. However, some instructions also take immediate values as oper- ands. Thus, there are four classes of instructions: 0-operand instructions, 1-operand instructions, 2-oper- and instructions, and extended instructions, which take two words (4 bytes) instead of one word. All but the extended instructions are encoded as a single word (16 bits). The extended instructions are also one word but are followed by an additional one-word operand. Thus, if the instruction is an extended instruction, the PC needs an additional increment of 2 during the instruction’s execution. As mentioned previously, most instructions are encoded as a single word. The most significant two bits of the word indicates whether the instruction is a 0-operand instruction (00), a 1-operand instruction (01), a 2-operand instruction (10), or an extended instruction (11). For a 0-operand instruction encoding, the two most sig- nificant bits are 00 and the next six bits represent the instruction identifier. The second byte of the instruction is 0. For a 1-operand instruction encoding, the two most significant bits are 01, the next bit indicates whether the operand is an immediate or a register, and the next five bits represent the instruction identifier. If the third most significant bit is 0, then the four most significant bits of the second byte encode the register that is to be operated on (0… 15). Otherwise, if the third most significant bit is 1, then the second byte encodes the immediate value. For a 2-operand instruction encoding, the two most significant bits are 10, and the next six bits represent the instruction identifier. The second byte encodes the two register operands in two four-bit chunks. Each of the 4-bit chunks identifies a register (r0 … r15). For an extended instruction encoding, the two most significant bits are 11, the next bit indicates whether a second register operand is used, and the next five bits represent the instruction identifier. If the third most significant bit is 0, then the instruction only uses the one-word immedi- ate operand that follows the instruction. Otherwise, if the third most significant bit is 1, then the four most significant bits of the second byte encode a register (1 … 15) that is the second operand. The instruction set is described in Tables 1, 2, 3, and 4. Each description includes the mnemonic (and syntax), the encoding of the instruction, the instruction’s description, and function. For example, the add, loadi, and push instructions have the following descriptions: loadi V, rD 11100001 D 0 Load immediate value or address V into rD ← memory[PC] register rD. PC ← PC + 2 Mnemonic Encoding Description Function add rS, rD 10000001 S D Add register rS to register rD. rD ← rD + rS push rS 01000011 S 0 Push register rS onto program stack. r15 ← r15 - 2 memory[r15 ] ← rS
First, observe that the add instruction takes two register operands and adds the first register to the sec- ond. All 2-operand instructions operate only on registers and the second register is both a source and destination, while the first is the source. It is a 2-operand instruction; hence the first two bits are 10, its instruction identifier is 000001 hence the first byte of the instruction is 0x81. Second, the loadi instruction is an extended instruction that takes a 16-bit immediate and stores it in a register. Hence, the first two bits are 11, the register bit is set to 1, and the instruction identifier is 00001. Hence, the first byte is encoded as 0xE1. Third, the push instruction is a 1-operand instruction, taking a single register operand. Hence, the first two bits are 01, the immediate bit is 0, and the instruction identifier is 00011. Hence, the first byte is encoded as 0x43. Note that S and D are 4-bit vectors representing S and D. Table 1: 0-Operand Instructions Mnemonic Encoding Description Function ret 00000001 0 Return from a procedure call. P C ← memory[r15 ] r15 ← r15 + 2 cld 00000010 0 Table 1: 1-Operand Instructions Stop debug mode Logically negate register rD . Decrement rD . Pop value from stack into register rD. Branch relative to label L if condition bit is true. Subtract register rS from register rD. And register rS with register rD . Xor register rS with register rD . See Debug Mode below. rD ←!rD rD ← rD – 1 rD ← memory[r15 ] r15 ← r15 + 2 if F & 0x0001 == 0x001: PC ← PC + L – 2 rD ← rD - rS rD ← rD & rS rD ← rD ^ rS std 00000011 S 0 Start debug mode See Debug Mode below. Mnemonic Encoding Description Function neg rD 01000001 D 0 Negate register rD . rD ← −rD not rD dec rD pop rD br L 01000010 D 0 01001001 D 0 01000100 D 0 01100001 L inc rD 01001000 D 0 Increment rD . rD ← rD + 1 push rS 01000011 S 0 Push register rS onto the pro- gram stack. r15 ← r15 – 2 memory[r15] ← rS out rS 01000111 S 0 Output character in rS to std- out. output ← rS (see below) jr L 01100010 L Jump relative to label L. PC ← PC + L – 2 Table 3: 2-Operand Instructions Mnemonic Encoding Description Function add rS , rD 10000001 S D Add register rS to register rD . rD ← rD + rS sub rS , rD and rS , rD xor rS , rD 10000010 S D 10000101 S D 10000111 S D mul rS , rD 10000011 S D Multiply register rD by register rS. rD ← rD * rS or rS , rD 10000110 S D Or register rS with register rD . rD ← rD | rStest rS1, rS2
10001010 S D Set condition flag to true if and only if rS1 ∧ rS2 is not 0. ifrS1 &rS2 !=0: F ← F | 0x0001 else: F ← F & 0xFFFE cmp rS1, rS2 10001011 S D Set condition flag to true if and only If rS1 < rS2. if rS1 < rS2: F ← F | 0x0001 else: F ← F & 0xFFFE equ rS1, rS2 10001100 S D Set condition flag to true if and only if rS1 == rS2. if rS1 == rS2: F ← F | 0x0001 else: F ← F & 0xFFFE mov rS , rD stor rS , rD 10001101 S D 10001111 S D 10010001 S D Table 3: Extended Instructions Copy register rS to register rD . Store word from register rS to memory at address in register rD. Store byte from register rS to memory at address in register rD. rD ← rS memory[rD] ← rS (byte)memory[rD] ← rS load rS , rD 10001110 S D Load word into register rD from memory pointed to by register rS. rD ← memory[rS] loadb rS , rD 10010000 S D Load byte into register rD from memory pointed to by register rS. rD ← (byte)memory[rS] storb rS , rD Mnemonic Encoding Description Function jmp L 11000001 0 Absolute jump to label L. PC ← memory[PC] call L 11000010 0 Absolute call to label L.. r15 ← r15 – 2 memory[r15] ← PC + 2 PC ← memory[PC] loadi V, rD 11100001 D 0 Load immediate value or address V into register rD. rD ← memory[PC] PC ← PC + 2 Note that in the case of extended instructions, the label L or value V are encoded as a single word (16-bit value) following the word containing the instruction. The 0 in the encodings above represents a 4-bit 0 vector. An assembler is provided for you to use (if needed). Please see the manual at the end of the assignment. The Xtra Translation Specification (IMPORTANT) The binary translation is conducted in the following manner. The translator
Opens the specified file containing the X binary code.
Outputs a prologue (see below), which will be the same for all translations. 3. It then enters a loop that a. Reads the next instruction from the binary b. Decodes the instruction, and c. Outputs the corresponding x86 assembly instruction(s). If the instruction is an extended, an additional two bytes will need to be read. d. The loop exits when the instruction composed of two 0 bytes is read.
Outputs an epilogue.
Prologue The translator first outputs a simple prologue that is the same for all translations. The prologue is shown on the right. Epilogue After the translator finishes translating, it outputs a simple ep- ilogue that is the same for all translations. The epilogue is shown on the right. Translation Each X instruction will need to be translated into the corresponding instruction or instructions in x86-64 assembly. See table on right for examples. Most instructions will have a direct corresponding instruction in x86 assembly so the translation will beeasy. Someinstructions,liketheequ,test,andcmp,instructions may require multiple x86 instructions for a single X instruction. Note: The translator will need to perform a register mapping. Register Mapping The X architecture has 16 general and the F status register. In x86-64 there are also 16 general purpose registers. The register mapping on the right must be used when translating from X to x86-64. Note that for this exercise register r13 will not be used by the X executables. In- stead of r13 (X) being mapped to r15 (x86), the F register (X) is mapped to register r15 (x86). Note: for this assignment, It is ok to map 16-bit registers to 64-bit registers. r9 Debug mode STD and CLD .globl test test: push %rbp mov %rsp, %rbp pop %rbp ret mov $42, %rax add %rax, %rdi %rbx %rdx %rdi %r9 %r11 %r13 %r15 %rsp call debug X Instruction Output x86 Assembly mov r0, r1 mov %rax, %rdi loadi 42, r0 add r0, r1 push r0 push %rax X Registers x86 Registers r0 %rax r1 r3 r5 r7 r2 %rcx r4 %rsi r6 %r8 r8 %r10 r10 %r12 The std and cld X instructions enable and disable debug mode on the X architecture. However, debug mode does not exist in x86-64. Instead, when a std instruction is encountered, the translator should set an internal debug flag in the translator and, clear the debug flag when it encounters the cld instruction. When the debug flag is true, the translator should output the assembly code on the right before translating each X instruction. Output and the OUT Instruction (For Task 2) r11 F r15 r12 %r14 r14 %rbp On the X architecture, the out rN instruction outputs to the screen the character stored in register rN. However, no such instruction exists in x86-64. Instead, the out instruction is translated to a call to the function outchar(char c), which performs this function. Recall that the first argument is passed in register %rdi. Consequently, the corresponding translation code will need to save the current value of %rdi on the stack, move the byte to be printed into %rdi, call outchar, and restore %rdi. Your task will be to implement the Xtra binary translator which is used to translate into x86 assembly programs assembled with the X assembler.
Task 1: Implement the Simple Xtra Your first task is to implement a simple version of the translator that works for the simple instructions. The source file main.c should contain the main() function. The translator should:
Take one (1) argument on the command line: The argument is the object/executable file of the program to translate. For example, the invocation ./xtra hello.xo instructs the translator to translate the program hello.xo into x86-64 assembly.
Open for reading the file specified on the command-line.
Output (to stdout) the prologue.
In a loop, a. Read in instruction. b. If the instruction is 0x00 0x00, break out of the loop. c. Translate the instruction and output (to stdout) the x86-64 assembly.
Output (to stdout) the epilogue. Input The input to the program is via the command line. The program takes one argument, the name of the file containing the assembled X code. Processing All input shall be correct. All program files shall be at most 65536 bytes (64KB). The translator must be able to translate all instructions except: Instruction Description ret Return from a procedure call. br L jmp L load rS , rD loadb rS , rD out rS Branch relative to label L if condition bit is true. Absolute jump to label L. Load word into register rD from memory pointed to by register rS. Load byte into register rD from memory pointed to by register rS. Output character in rS to stdout. jr L Jump relative to label L. call L Absolute call to label L. stor rS , rD Store word from register rS to memory at address in register rD. storb rS , rD Store byte from register rS to memory at address in register rD. Recommendation: While no error checking is required, it may be helpful to still do error checking, e.g., make sure files are properly opened because it will help with debugging as well. Output Output should be to stdout. The output is the translated assembly code. The format should ATT style assembly. The exact formatting of the assembly is up to you, but the assembly code will be passed through the standard assembler (as) on timberlea. See next section for how to test your code. (See example) Testing To test your translator, the test scripts will assembler, link, and run the translated code! J A runit.sh script is provided. The script takes an X assembly file as an argument: ./runit.sh foo.xas The script:
Assembles the .xas file with the provided (xas) to create a .xo file.
Runs xtra on the .xo file, to create a corresponding x86 .s assembly file.
Assembles, compiles, and links the generated assembly file with some runner code, creating an executable. Therunneriscomposedofrunner.c,regsdump.s,andthetranslated.sfile. Please DO NOT delete the first two files.
Runs the executable. This script is used by the test scripts and is also useful for you to test your code. Most of the tests use the std instruction to turn on debugging and output the state of the registers after each instruction is executed. For most of the tests the output being compared are the register values. Example Original X assembly code Translated x86 code loadi 2, r0 loadi 3, r1 loadi 4, r2 loadi 5, r3 loadi 7, r5 std # turn debugging on add r2, r3 mul r2, r1 cld # turn debugging off neg r0 inc r5 .literal 0 .globl test test: push %rbp mov %rsp, %rbp mov $2, %rax mov $3, %rbx mov $4, %rcx mov $5, %rdx mov $7, %rdi call debug add %rcx, %rdx call debug imul %rcx, %rbx call debug neg %rax inc %rdi pop %rbp ret Task 2: The Full Translator Your second task is to extend xtra to translate the instructions exempted in Task 1. lation for the following instructions. Implement trans- Instruction Description ret Return from a procedure call. br L jmp L load rS , rD loadb rS , rD out rS Branch relative to label L if condition bit is true. Absolute jump to label L. Load word into register rD from memory pointed to by register rS. Load byte into register rD from memory pointed to by register rS. Output character in rS to stdout. jr L Jump relative to label L. call L Absolute call to label L. stor rS , rD Store word from register rS to memory at address in register rD. storb rS , rD Store byte from register rS to memory at address in register rD.
Input The input is the same as Task 1. Processing The processing is the same as for Task 1. The challenge is that translation is a bit more challenging. First, for many of the additional instructions you will need to emit more than one assembly instruction. This is particularly true for the conditional branching and output instructions. Second, for the branching instructions you will need to compute the labels where to branch to. The easy solution is to create a label for each instruction being translated. The label should encode the address in the name. For example, L1234 would be the label for the X instruction at address 1234. By doing this, you will not need to keep a list or database of labels. Third, the addresses used by the load and store are full 64-bit values. Output The output is the same as Task 1. Example Original X assembly code Translated x86 code loadi 1, r0 jmp j1 j2: loadi 3, r0 jmp j3 j1: loadi 2, r0 jmp j2 j3: std # turn debugging on loadi 4, r0 .literal 0 .globl test test: push %rbp mov %rsp, %rbp .L0000: mov $1, %rax .L0004: jmp .L0010 .L0008: mov $3, %rax .L000c: jmp .L0018 .L0010: mov $2, %rax .L0014: jmp .L0008 .L0018: .L001a: call debug mov $4, %rax .L001e: call debug pop %rbp ret Hints and Suggestions
Use the unsigned short type for all registers and indices.
Use two files: one the main program and one for the translator loop.
Start early, this is the hardest assignment of the term and there is a lot to digest in the assignment specifications.
Assignment Submission Submission and testing are done using Git, Gitlab, and Gitlab CI/CD. You can submit as many times as you wish, up to the deadline. Every time a submission occurs, functional tests are executed, and you can view the results of the tests. To submit use the same procedure as Assignment 0. Grading If your program does not compile, it is considered non-functional and of extremely poor quality, mean- ing you will receive 0 for the solution. The assignment will be graded based on three criteria: Functionality: “Does it work according to specifications?”. This is determined in an automated fashion by running your program on several inputs and ensuring that the outputs match the expected outputs. The score is determined based on the number of tests that your program passes. So, if your program passes t/T tests, you will receive that proportion of the marks. Quality of Solution: “Is it a good solution?” This considers whether the approach and algorithm in your solution is correct. This is determined by visual inspection of the code. It is possible to get a good grade on this part even if you have bugs that cause your code to fail some of the tests. Code Clarity: “Is it well written?” This considers whether the solution is properly formatted, well docu- mented, and follows coding style guidelines. A single overall mark will be assigned for clarity. Please see the Style Guide in the Assignment section of the course in Brightspace. The following grading scheme will be used: Task 100% 80% 60% 40% 20% 0% Functionality (20 marks) Equal to the number of tests passed. Solution Quality Task 1 (15 marks) Implemented correctly. Code is robust. Implemented cor- rectly. Code is not robust. Some minor bugs. Major flaws in implementation An attempt has been made. Solution Quality Task 2 (5 marks) Implemented correctly. Code is robust. Implemented cor- rectly. Code is not robust. Some minor bugs. Major flaws in implementation An attempt has been made Code Clarity (10 marks) Indentation, for- matting, naming, comments Code looks pro- fessional and fol- lows all style guidelines Code looks good and mostly fol- lows style guide- lines. Code is mostly readable and mostly follows some of the style guidelines Code is hard to read and fol- lows few of the style guidelines Code is not legible No code submitted or code does not compile
Assignment Testing without Submission Testing via submission can take some time, especially if the server is loaded. You can run the tests without submittingyourcodebyusingtheprovidedruntests.shscript. Runningthescriptwithnoarguments will run all the tests. Running the script with the test number, i.e., 00, 01, 02, 03, … 09, will run that specific test. Please see below for how run the script. Get your program ready to run If you are developing directly on the unix server,
SSH into the remote server and be sure you are in the xtra directory. 2. Be sure the program is compiled by running make. If you are using CLion
Run your program on the remote server as described in the CLion tutorials. 2. Open a remote host terminal via Tools → Open Remote Host Terminal If you are using VSCode
Run your program on the remote server as described in VSCode tutorials.
Click on the Terminal pane in the bottom half of the window or via Terminal → New Terminal Run the script
Run the script in the terminal by using the command: ./runtest.sh to run all the tests, or specify the test number to run a specific test, e.g. : ./runtest.sh 07 You will see the test run in the terminal window. The X Assembler (xas) An assembler (xas) is provided to allow you to write and compile programs for the X Architecture. To make the assembler, simply run “make xas” in the xtra directory. To run the assembler, specify the assembly and executable file on the command-line. For example, ./xas example.xas example.xo Assembles the X assembly file example.xas into an X executable example.xo. The format of the assembly files is simple.
Anything to the right of a # mark, including the #, is considered a comment and ignored.
Blank lines are ignored.
Each line in the assembly file that is not blank must contains a directive, a label and/or an instruc- tion. If the line contains both a label and an instruction, the label must come first. 4. A label is of the form identifier: where identifier consists of any sequence of letters (A-Za-z), digits (0-9), or underscores ( ) as long the first character is not a digit. A colon (:) must terminate the label. A label represents the corre- sponding location in the program and may be used to jump to that location in the code.
An instruction consists of a mnemonic, such as add, loadi, push, etc., followed by zero or more operands. The operand must be separated from the mnemonic by one or more white spaces. Multiple operands are separated by a comma.
If an operand is a register, then it must be in the form r# where # ranges between 0 and 15 inclu- sively. E.g., r13.
If the instruction is an immediate, then the argument may either be a label, or an integer. Note: labels are case-sensitive. If a label is specified, no colon should follow the label.
Directives instruct the assembler to perform a specific function or behave in a specific manner. All directives begin with a period and are followed by a keyword. There are three directives: .lit- eral, .words and .glob, each of which takes an operand. (a) The .literal directive encodes a null terminated string or an integer at the present location in the program. E.g., mystring: .literal "Hello World!" myvalue: .literal 42 encodes a nil-terminated string followed by a 16-bit (1 word) value representing the dec- imal value 42. In this example, there are labels preceding each of the encodings so that it is easy to access these literals. That is, the label mystring represents the address (rel- ative to the start of the program) where the string is encoded, and the label myvalue represents the address (relative to the start of the program) of the value. This is used in the hello.xas example. (b) The.wordsdirectivesetsasideaspecifiednumberofwordsofmemoryatthepresent location in the program. E.g., myspace: .words 6 allocates 6 words of memory at the present point in the program. This space is not initial- ized to any specific value. Just as before, the label preceding the directive represents the address of the first word, relative to the start of the program. This is used in xrt0.xas to set aside space for the program stack. (c) The .glob directive exports the specified symbol (label) if it is defined in the file and imports the specified symbol (label) if it is used but not defined in the file. E.g., .glob foo .glob bar … loadi bar, r0 … foo: .literal "Hello World!" declares two symbols (labels) foo and bar. Symbol foo is declared in this file, so it will be exported (can be accessed) in other files. The latter symbol, bar, is used but not defined. When this file is linked, the linker looks for the symbol (label) definition in other files makes all references to the symbol refer to where it is defined. Note: it is recommended that you place literals and all space allocations at the end of your program, so that they will not interfere with program itself. If you do place literals in the middle of your program, you will need to ensure that your code jumps around these allocations. There are several example assembly files provided (ending in .xas). You can assemble them by invoking the assembler, for example: ./xas example.xas example.xo This invocation will cause the assembler to read in the file example.xas and generate an output file example.xo. Feel free weixin: codehelp
0 notes
Text
WEEK 1 LAB
1. Execute and familiarize with Linux environment and commands Getting used to basic commands on Linux Operating System – Process creation, Process monitoring, Process states, Linux File system tree, Linux File system commands Write a C program to display an array in reverse using index. Create Makefile (ex: make.mk below) and other files as shown below: (Hint: Refer to Makefile tutorial sent…

View On WordPress
0 notes
Text
0 notes
Link
0 notes
Text
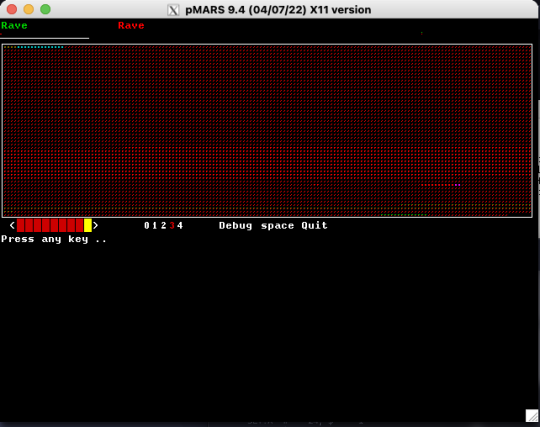
Playing Core War - The Programming Game
So I'm trying to start playing Core War, which is a programming game where two or more programs written in a special assembly language battle against each other to kill the other program in the memory of a virtual computer. I decided to document how to start playing, after I had trouble just installing the simulator.
I found this website, where I downloaded the source code for the simulator, a.k.a MARS (Memory Array Redcode Simulator). The one that I used in this tutorial is called pmars (portable MARS).
It seems like there are download links for windows users, so that you don't have to compile anything like I did, but there also seems to be different simulators that have more features and are (maybe?) easier to use.
The following instructions worked on my mac, but I'm not so sure if they would work on Linux or Windows. If you manage to get it working on either of those, lmk and I'll try to add it.
Instructions for mac (& maybe? linux):
(BTW, whenever things are in quotes, please ignore them)
I downloaded pmars version 0.9.4 from here.
On macOS, I had to download XQuartz, for the UI of the simulator to start.
I used GCC to compile the program, so install homebrew, and run "brew install gcc make" inside your terminal to install both GCC & Make.
Once unzipped, I read the README file (might be helpful)
Open the file called Makefile within the src directory, and edit the line that starts with "CFLAGS" so that it becomes "CFLAGS = -O -DEXT94 -DXWINGRAPHX -DPERMUTATE -DRWLIMIT -I/usr/X11/include/"
Also change the line at the top from "CC = gcc" to "CC = gcc-12" only if on macOS
First try to compile by running "make" within the "src" directory. If it works, great! If not, try the following after running "make clean".
edit the file "sim.c" and find the line that contains "sighandler"
Change "sighandler(0);" to "sigaction(0);"
Try to run "make" again within the "src" directory
For me, that was how I compiled the program. This may or may not work on M1 and M2 macs, as I don't have access to one. Once compiled, you can move the file called pmars to an easily accesible directory (Ex. Create a directory called "bin" in your home folder and put it there). Make sure to put the "warriors" directory somewhere you could find it easily (such as your "Documents" folder)
To run a game (for mac), first open the XQuartz application.
Change directory to the folder where the program is stored and run:
"./pmars PATH_TO_FIRST_WARRIOR PATH_TO_SECOND_WARRIOR"
An example would be: "./pmars ~/Documents/warriors/aeka.red ~/Documents/warriors/rave.red"
A window should pop up containing the memory contents of the Virtual Machine!
Voila! Your very own MARS simulator!
Some resources for creating your own programs to battle:
A Core War Website Strategy Guide Wikipedia Article Tutorial that I found that explains things really well
Hope this works, and Happy Programming! :D
#corewar#programming#programming game#virtual machine#game#assembly#coding#coding game#program#code#blabla#tutorial#I'm looking forward to playing this w/ someone#Hope someone benefits from this post
1 note
·
View note
Text
간단한 Makefile 만들기
간단한 Makefile 만들기
무려 2006년도 자료이긴 하나 원칙이 변하나~ 특히 임베디드 계통에는 기본이 중요!!
http://forum.falinux.com/zbxe/index.php?document_srl=405822&mid=gcc
링크에서는 설명을 위해 아래와 같이 6개의 소스 파일을 컴파일 & 빌드하는 예제를 들어 설명하고 있다.
main.c와 main.h tcp.c와 tcp.h rs232.c와 rs232.h
매크로를 불러쓰기 위해서는 외계어 같은 것들을 일단 이해해야 한다.
$@ - 목표 이름 $* - 목표 이름에서 확장자가 없는 이름 $< - 조건 파일 중 첫번째 파일 $? - 목표 파일 보다 더 최근에 갱신된 파일 이름
최종으로는 아래와 같은 Makefile 을 만들어 쓰면 된다.
TARGET = sample OBJS = main.o tcp.o rs232.o CC = -I/home/jwjw/prjs/include -g -c $(TARGET : $(OBJS) gcc -lm -o $@ $^ .c.o: gcc $(CC) $< main.o: main.c main.h rs232.h rs232.o: rs232.c rs232.h tcp.o: tcp.c tcp.h
쉽게 얻으려 말고, 일단 방문해서 읽어 보도록 하자! 조금 길지만 이해도는 쑤욱!!
0 notes
Text
Cmake Makefile

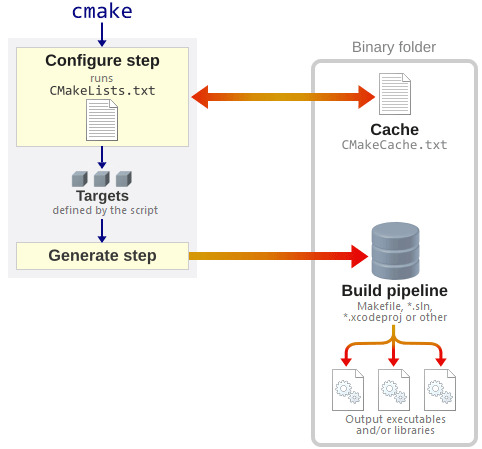
Description
Makefile Syntax. A Makefile consists of a set of rules.A rule generally looks like this: targets: prerequisites command command command. The targets are file names, separated by spaces. Typically, there is only one per rule. The concept of CMake. CMake makes your makefile. Cmake relies on a top level file called CMakeLists.txt; now we can first delete our makefile and out in the previous section. First check our cmake version. 1: cmake -version: You can also use the command cmake to check the usage.
This is a very simple C++ Makefile example and associated template, that can be used to get small to medium sized C++ projects up and running quickly and easily. The Makefile assumes source code for the project is broken up into two groups, headers (*.hpp) and implementation files (*.cpp). The source code and directory layout for the project is comprised of three main directories (include, src and build), under which other directories containing code would reside. The layout used in the example is as follows:
Directory Purpose Project / include Header files (*.hpp, *.h, *.hxx, *.h++)Project / src Implementation files (*.cpp)Project / build / objectsObject files (*.o)Project / build / apps Executables
The Makefile
The Makefile supports building of a single target application called program which once built will be placed in the build/apps directory. All associated objects will be placed in the build/objects directory. The following is a listing of the Makefile in its entirety:
The Makefile and a complete example including source code and directory layout can be downloaded from: HERE
Makefile Commands
The following commands can be used with this Makefile:
make all
make clean
make program
make build
make release
make debug
make info
Example Run
The following is the expected output when the command 'make clean all' is executed:
CMake Version
A CMake based build configuration of the above mentioned project structure can be found HERE
Preface Introduction Under the hood of Visual Studio GNU/Linux Equivalent Visual Studio to Make Utility mapping Example Source Structure Build Run Makefile Details Targets Dependencies Contents NMake Conclusion External Links
If you develop software only on Windows using Visual studio, it’s a luxury. Enjoy it while it lasts. Sooner than later, you will come across Makefiles, maybe exploring some software on Linux or the misfortune of having a build system that uses make with Cygwin on Windows.
Now you figure out that Makefiles are text files and open it in an editor hoping to get some insight into its workings. But, what do you see? Lots of cryptic hard to understand syntax and expressions. So, where do you start? Internet searches for make and Makefiles provide a lot of information but under the assumption that you come from a non-IDE Unix/Linux development environment. Pampered Visual Studio developers are never the target audience.
Here I will try to relate to the Visual Studio build system which will hopefully give an easier understanding of Makefiles. The goal is not to provide yet another tutorial on makefiles (because there are plenty available on the internet) but to instill the concept by comparison.
Visual Studio provides features that are taken for granted until you have to read/create a classic Makefile. For example, Visual Studio auto-magically does the following.
Compiles all the sources in the project file
Create an output directory and puts all the intermediate object files in it
Manages dependencies between the source and object files
Manages dependencies between the object files and binaries
Links the object files and external dependent libraries to create binaries
All of the above have to be explicitly specified in a Makefile. The make utility in some ways is the equivalent of Visual Studio devenv.exe (without the fancy GUI).
Visual Studio is essentially a GUI over the compilation and link process. It utilizes an underlying command line compiler cl.exe and linker link.exe. Additionally, it provides a source code editor, debugger and other development tools.
A simple win32 console application project in Visual Studio is shown below. You have a solution file which contains a project file.
Invoking a build on the solution in Visual Studio calls something like the following under the hood. Yes, it looks ugly! But that is the the project properties translated to compiler/linker flags and options.
It is very similar in GNU/Linux. The equivalent of a compiler and linker is gcc, the GNU project C and C++ compiler. It does the preprocessing, compilation, assembly and linking.
Shown below is a very simple Makefile which can be accessed from GitHub https://github.com/cognitivewaves/Simple-Makefile.
Invoking the make command to build will output the following.
Below is a table relating Visual Studio aspects to Make utility. At a high level, the Project file is equivalent to a Makefile.
Visual Studiomake UtilityCommanddevenv.exemakeSource structure Solution (.sln) has project files (typically in sub-directories)Starting at the root, each Makefile can indicate where other Makefiles (typically in sub-directories) existLibrary build dependencySolution (.sln) has projects and build orderMakefileSource files listProject (.vcproj)MakefileSource to Object dependencyProject (.vcproj)MakefileCompile and Link optionsProject (.vcproj)MakefileCompilercl.exegcc, g++, c++ (or any other compiler, even cl.exe)Linkerlink.exegcc, ld (or any other linker, even link.exe)
Download the example sources from GitHub at https://github.com/cognitivewaves/Makefile-Example. Note that very basic Makefile constructs are used because the focus is on the concept and not the capabilities of make itself.
Source Structure
Build
Visual Studiomake UtilityBuilding in Visual Studio is via a menu item in the IDE or invoking devenv.exe on the .sln file at the command prompt. This will automatically create the necessary directories and build only the files modified after the last build.Initiating a build with makefiles is to invoke the make command at the shell prompt. Creating output directories has to be explicitly done either in the Makefile or externally.
Cmake Command Line
In this example, to keep the makefiles simple, the directories are created at the shell prompt.
The make utility syntax is shown below. See make manual pages for details.
Execute the command make and specify the “root” Makefile. However, it is more common to change to directory where the “root” Makefile exists and call make. This will read the file named Makefile in the current directory and call the target all by default. Notice how make enters sub-directories to build. This is because of nested Makefiles which is explained later in the Makefiles Details section.
Run
Once the code is built, run the executable. This is nothing specific to makefiles but has been elaborated in case you are not familiar with Linux as you will notice that by default is will fail to run with an error message.
This is because the executable app.exe requires the shared object libmath.so which is in a different directory and is not in the system path. Set LD_LIBRARY_PATH to specify the path to it.
Makefile Details
The basis of a Makefile has a very simple structure.
The (tab) separator is very important! Spaces instead of a (tab) is not the same. You will see rather obscure error messages as shown below. Makefile:12: *** missing separator. Stop.

Targets
Here target is a physical file on disk. When the target is more of a label, then it has to be tagged as .PHONY to indicate that the target is not an actual file.
Visual Studiomake UtilityVisual Studio by default provides options to clean and rebuild a project or solution.Clean and rebuild have to be explicitly written in a makefile as targets which can then be invoked.

A typical case would be to clean before rebuilding.
Dependencies
Dependencies can be files on disk or other targets (including phony targets).
Visual Studiomake UtilityVisual Studio by default supports implicit dependencies (source to object files) within a project. Library(project) dependencies have to specified in the solution fileEvery dependency has to be explicitly defined in makefiles
Cmake Makefile Generator
For example, the target all, depends on app.exe which in turn depends on libmath.so. If you remove app.exe, make is capable of recognizing that libmath.so need not be built again.
Contents
Cmake Makefile Link
File: Makefile
File: math/Makefile
Cmake Makefile Difference
File: app/Makefile
NMake is the native Windows alternative to the *nix make utility. The syntax is very similar to *nix makefiles. However, this does not mean that *nix makefiles can be executed seamlessly on Windows. See Makefiles in Windows for a discussion.
Makefiles are very powerful and gives a lot of control and flexibility compared to Visual Studio, but the content is not easily understandable. As an alternative, CMake has adopted similar concepts but the script is much easier and more readable. See CMake and Visual Studio.
1 note
·
View note
Text
WEEK 1 LAB
Execute and familiarize with Linux environment and commands Getting used to basic commands on Linux Operating System – Process creation, Process monitoring, Process states, Linux File system tree, Linux File system commands Write a C program to display an array in reverse using index. Create Makefile (ex: make.mk below) and other files as shown below: (Hint: Refer to Makefile tutorial…

View On WordPress
0 notes
Text
Clion tutorial

#CLION TUTORIAL FOR FREE#
#CLION TUTORIAL HOW TO#
#CLION TUTORIAL INSTALL#
#CLION TUTORIAL FULL#
#CLION TUTORIAL SOFTWARE#
Sort the packages using the robotic arm of the factory codingame.
The project details depend on the project type. The screen would look like something similar if you have any already created projects. Voila! We’re on the main window of CLion. Click on the New Project + button to create a brand new project.
#CLION TUTORIAL FULL#
Here, you can easily configure them according to your needs.Īs it’s the first time installation, we have to “Evaluate for free”. CLion exposes the full power of GDB and/ or LLDB (even on Windows, where we have built an MSVC compatible debugger on top of LLDB), and even builds on it wit. In your case, there may be more than one.ĬLion comes up with a default plugin set. My system only includes GCC, so it’s the only entry available. You also have to select the C/C++ compiler you’d like to work with. I’m the original author of Catch and am now working at JetBrains so this seems to be an ideal match As of the 2017.1 release I’m pleased to say that. Catch is a cross-platform test framework for C++.
#CLION TUTORIAL HOW TO#
This tutorial describes how to use CLion as an IDE for developing ROS2 applications built with colcon.If you are working with an older ROS distribution, which uses catkin build tools, please refer to the previous tutorial. CLion is a cross-platform IDE for C++ development (which happens to have a built in test runner). I prefer the darker ones as they’re more comfortable when you’re looking at your code for a longer period of time. ROS2 is the newest version of ROS, Robot Operating System, which is a set of libraries and tools designed for robot applications. You can choose whether you want to share usage statistics with JetBrains or not. Or directly point CLion to a Makefile in the Open dialog. You can open a folder as a project and CLion will search for the top-level Makefile (as well as CMakeList.txt or compilecommands.json files) and suggest opening it as a project. (changes since CLion 2016.2) Learn how to attach for debug to local process started not from the CLion (from CLion v2016.1). with the output of bash commands Code examples and tutorials for C Printf. Here’s a look at some of the core debugging features that are supported. Then, agree with the JetBrains user agreement. To open a Makefile project in CLion: Select the project in File Open. CLion supports the debugging experience using the GDB debugger (and LLDB on OS X since version 1.1 and on Linux since version 2016.2).
#CLION TUTORIAL INSTALL#
sudo snap install clion -classic Using CLion 2021 About DupeTesting Minecraft 1 This tutorial aims to provide a guide on. I prefer this method than the previous one as installing and managing snap packages is easier than working with other package management system. This will start the basic installation of CLion. Depending on your internet speed, the download duration may vary.Īfter the download is complete, it’s time to run the following commands – cd ~/Downloads/Īfter the extraction is complete, it’s time to unleash the beast! /opt/clion-2018.3/bin/clion.sh It is based on CMake configuration files (e.g 'CMakeLists.txt'). CMake uses scripts called CMakeLists to generate build files. It worked perfectly for me To summarize, there are 2 main steps: Firstly, CLion uses CMake to compile your code.
#CLION TUTORIAL SOFTWARE#
CMake is used to control the software compilation process using (simple platform and compiler independent) configuration files, and generate native makefiles and workspaces that can be used in the compiler environment of your choice. For further usage, you have to get a subscription.įor the Linux platform, CLion is available in 2 ways – snap and a compressed package. CMake is a tool used by Clion for development.
#CLION TUTORIAL FOR FREE#
You can enjoy the full service for free up to 30 days. How about JetBrains CLion? It’s one of the finest and sharpest, professional-grade IDEs in the market. It worked perfectly for me To summarize, there are 2 main steps: Firstly, CLion uses CMake to compile your code. In most cases, it should be named as “gcc”.Īs of C/C++ IDE, there are numerous choices. I am using cmake (within clion ide but that should not matter for this discussion). If the result is negative, then search for the suitable C/C++ compiler package for your Linux distro. Find extensive tutorial, questions and answers for clion.
0 notes
Text
Virtualbox ubuntu for mac

#Virtualbox ubuntu for mac mac os x#
#Virtualbox ubuntu for mac mac os#
SHARED_PATH =~ # Share home directory with the VM VM_HD_PATH = "UbuntuServer.vdi" # The path to VM hard disk (to be created). # Change these variables as needed VM_NAME = "UbuntuServer" UBUNTU_ISO_PATH =~/Downloads/ubuntu-14.04.1-server-amd64.iso We alsoĪttach a network card and set up port forwarding. The commands below will create a virtual machine called "UbuntuServer",Īttach a 32 GB virtual hard drive, attach a DVDĭrive loaded with the Ubuntu Server disk image, and allocate 1 GB of RAM. I've adapted these commands in part from this blog post. You can configure your virtual machine (VM) using the VirtualBox graphical program, but it's quicker to set it up from the command line. Download Ubuntuĭownload the Ubuntu Server 14.04.01 LTS iso image. Instructions below were testing with VirtualBox 4.3.18 on OS X 10.9.5. Install VirtualBoxĭownload and install VirtualBox here. This entire tutorial should take approximately 20 minutes (not including download times). I simply run the VM in the background, and ssh into it from the Mac terminal. I installed Ubuntu Server instead of Ubuntu Desktop because I wanted to run a lightweight Linux environment, which should save laptop resources.
#Virtualbox ubuntu for mac mac os#
I intend to run my application in a Linux environment, so instead of learning the intricacies of porting my code and makefile to Mac OS X, I decided to install a local Ubuntu Server virtual machine (VM) on my MacBook. For example, right now I'm trying to develop a Boost Python module, and I am having trouble compiling it on OS X. While the OS X experience is wonderful, application development can be frustrating. It's my personal laptop, so I use it for everything - browsing, e-mail, and programming. My laptop is a late 2011 MacBook Pro running OS X 10.9 Mavericks.
#Virtualbox ubuntu for mac mac os x#
Ubuntu Server Virtual Machine with SSH using VirtualBox on Mac OS X
0 notes
Text
Install openmp mac osx sierra

INSTALL OPENMP MAC OSX SIERRA INSTALL
INSTALL OPENMP MAC OSX SIERRA SERIES
INSTALL OPENMP MAC OSX SIERRA DOWNLOAD
This will open up a site in Safari and prompt you to log in. Go to the Xcode menu, select “Open Developer Tool”, and choose “More Developer Tools …”. Now, you need to get the command line tools.
INSTALL OPENMP MAC OSX SIERRA INSTALL
Once it has installed, open Xcode, agree to the license, and let it install whatever components it needs. Go ahead and grab a coffee while it’s downloading and installing 4+ GB.
INSTALL OPENMP MAC OSX SIERRA DOWNLOAD
Main steps: 1) Download, install, and prepare XCodeĪs mentioned above, open the App Store, search for Xcode, and start the download / install. As of August 2, 2017, this will download Version 7.1.1. gcc7 (from MacPorts) : This will be an up-to-date 64-bit version of gcc, with support for OpenMP.Download the latest installer (MacPorts-2.3.) here. As of August 2, 2017, this will download Version 2.4.1. You’ll particularly need it for getting gcc. MacPorts: This is a package manager for OSX, which will let you easily download, build and install many linux utilities.Please note that this is a 4.41 GB download! (Search for xcode.) As of January 15, 2016, the App Store will install Version 7.2. Download the latest version in the App Store. Evidently, it is required for both Macports and its competitors (e.g., Homebrew). XCode: This includes command line development tools.I highly recommend using the Homebrew version of this tutorial. This tutorial uses Homebrew: a newer package manager that uses pre-compiled binaries to dramatically speed up the process. Note 2: This process is somewhat painful because MacPorts compiles everything from source, rather than using pre-compiled binaries. Alas, this will not support OpenMP for parallelization. Note 1: OSX / Xcode appears to have gcc out of the box (you can type “gcc” in a Terminal window), but this really just maps back onto Apple’s build of clang. Of course, you can use other compilers and more sophisticated integrated desktop environments, but these instructions will get you a good baseline system with support for 64-bit binaries and OpenMP parallelization. The entire toolchain is free and open source. In the end result, you’ll have a compiler and key makefile capabilities. These instructions were tested with OSX 10.11 (El Capitan), but they should work on any reasonably recent version of OSX. These instructions should get you up and running with a minimal environment for compiling 64-bit C++ projects with OpenMP (e.g., BioFVM and PhysiCell) using gcc. Windows users should use this guide instead.
INSTALL OPENMP MAC OSX SIERRA SERIES
Note: This is the part of a series of “how-to” blog posts to help new users and developers of BioFVM and PhysiCell. Posted in BioFVM, gcc, MacPorts, OpenMP, OSX, PhysiCell - Janu4 Comments
0 notes