#replicate data sql serve to snowflake
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Steps to Load SQL Server Data to Snowflake
This post will go through the steps to load SQL Server data to Snowflake which can be done either through the tedious manual process or by using optimized tools in a few clicks only. The reason why organizations migrate data SQL Server to Snowflake is that Snowflake, a data warehousing solution has addressed the problems inherent in traditional systems. Moreover, Snowflake is based in the cloud and offers users separate computing and storage facilities which can be scaled up or down. Further, the same data is available to multiple users working with multiple workloads without any lag or drop in performance.

Microsoft SQL Server database supports applications on a single machine either on a local area network or across the web. It combines data seamlessly into the Microsoft ecosystem, supporting Microsoft’s .NET framework. Steps to migrate data SQL Server to Snowflake – • Extract data from SQL Server – Generally, those working with databases use queries for extracting the data from the SQL Server. Select statements are utilized to sort, filter, and limit the data that needs to be retrieved. However, the Microsoft SQL Server Management Studio tool is deployed for exporting bulk data or entire databases in formats such as SQL queries, text, or CSV. • Process data for Snowflake – Before you migrate data SQL Server to Snowflake, the data has to be processed and prepared for loading. This step depends largely on the data structures which have to be verified to know whether this data type is supported by Snowflake for seamless migration and loading. However, for loading JSON or XML type data into Snowflake, no schema has to be specified beforehand. • The Staging Process – Before data can be loaded from SQL Server to Snowflake, the data files have to be first stored in a temporary location. There are two possibilities here. >Internal Stage – For ensuring greater flexibility while migrating data from SQL Server, an exclusive internal stage is created with respective SQL statements. Quick data loading is thereby ensured by assigning file format to named stages. >External Stage – Presently, only two external staging locations are supported by Snowflake, namely Microsoft Azure and Amazon S3. • Migrating data into Snowflake – A part of Snowflake’s documentation is Data Loading Overview. It guides the user through the whole process to migrate data SQL Server to Snowflake. For small databases, utilizing the data loading wizard is advisable. When the data to be loaded is very large, the following options should be used. > Use the PUT command to stage files. > Copy from Amazon S3 or the local drive when the data is lodged in an external stage > Use the COPY INTO table command when processed data has to be loaded into an intended table. An advantage of this process is that you can make a virtual warehouse that powers this migration activity.
0 notes
Text
Ready to migrate to Snowflake? Read this before getting started!
The power of data is immense, and irrespective of the industry, data-driven businesses, and enterprises are storing, managing, and learning from massive amounts of data more than ever. Further, the complexity of this data continues to increase with each update and change in a hyper-competitive world. For storing and managing data, analyzing it, and deriving valuable insights from it, businesses need to follow the right database management solutions to make data work for them. This is where Amazon Web Services comes in as a cloud service used for the development and deployment of applications for various purposes and use cases.
Simply having a cloud computing platform like AWS doesn’t make things easier for data analysts and managers, as managing massive data can be difficult. Further, extracting useful insights from a database is another key challenge for businesses. To solve this, businesses need to make use of cloud infrastructure and leverage a fully managed data warehousing system. Snowflake is an example of one such platform which enables businesses to store and access data from a central, cloud-based repository, therefore, helping businesses to save time, eliminate redundancies and streamline processes with more flexibility and ease. If you’re a legacy business that wants to embrace the power of cloud-based database management systems, it’s time to learn more about the benefits of AWS DMS Snowflake migration and why you should consider it.
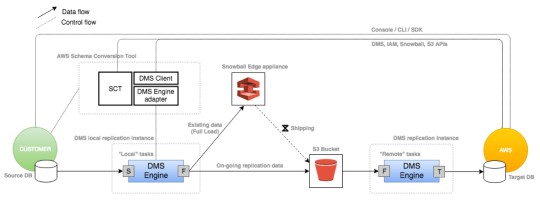
Snowflake has extraordinary scaling capacities, and since it works on a SaaS model, it can be easily scaled up or down depending on the volume of data at hand. To make the most of this powerful cloud platform, one must start from the first step i.e. storing the data in a virtual Snowflake warehouse. Using Snowflake, database operators and administrators can run powerful SQL queries, and easily access, manage and manipulate complex data to automate tasks. In order to load data from AWS DMS to Snowflake, you can choose from two different approaches.
The first one involves writing custom scripts and knowing coding to connect these two different database solutions together. This method has advantages but it requires significant overheads and resources for seamless execution. The second approach is to choose a third-party solution like Bryteflow.
Using Bryteflow’s real-time, self-serve no-code technology, businesses can easily leverage the scale and potential of Snowflake’s virtual data warehouses. Bryteflow supports direct integrations with DMS along with dozens of other data sources to continuously and seamlessly replicate your business data to Snowflake.
It’s time to leverage the infinite flexibility and robust functionality of Bryteflow’s CDC for Amazon DMS to Snowflake data migration. Built for security and performance, with Bryteflow, you can experience a plug-and-play, no-code platform for managing your business’s entire data pipeline.
0 notes
Text
Data virtualization service Varada raises $12M
Varada, a Tel Aviv-based startup that focuses on making it easier for businesses to query data across services, today announced that it has raised a $12 million Series A round led by Israeli early-stage fund MizMaa Ventures, with participation by Gefen Capital.
“If you look at the storage aspect for big data, there’s always innovation, but we can put a lot of data in one place,” Varada CEO and co-founder Eran Vanounou told me. “But translating data into insight? It’s so hard. It’s costly. It’s slow. It’s complicated.”
That’s a lesson he learned during his time as CTO of LivePerson, which he described as a classic big data company. And just like at LivePerson, where the team had to reinvent the wheel to solve its data problems, again and again, every company — and not just the large enterprises — now struggles with managing their data and getting insights out of it, Vanounou argued.
Image Credits: Varada
The rest of the founding team, David Krakov, Roman Vainbrand and Tal Ben-Moshe, already had a lot of experience in dealing with these problems, too, with Ben-Moshe having served at the Chief Software Architect of Dell EMC’s XtremIO flash array unit, for example. They built the system for indexing big data that’s at the core of Varada’s platform (with the open-source Presto SQL query engine being one of the other cornerstones).
Image Credits: Varada
Essentially, Varada embraces the idea of data lakes and enriches that with its indexing capabilities. And those indexing capabilities is where Varada’s smarts can be found. As Vanounou explained, the company is using a machine learning system to understand when users tend to run certain workloads and then caches the data ahead of time, making the system far faster than its competitors.
“If you think about big organizations and think about the workloads and the queries, what happens during the morning time is different from evening time. What happened yesterday is not what happened today. What happened on a rainy day is not what happened on a shiny day. […] We listen to what’s going on and we optimize. We leverage the indexing technology. We index what is needed when it is needed.”
That helps speed up queries, but it also means less data has to be replicated, which also brings down the cost. AÅs Mizmaa’s Aaron Applebaum noted, since Varada is not a SaaS solution, the buyers still get all of the discounts from their cloud providers, too.
In addition, the system can allocate resources intelligently to that different users can tap into different amounts of bandwidth. You can tell it to give customers more bandwidth than your financial analysts, for example.
READ MORE
Snowflake and JFrog raise IPO ranges as tech markets stay hot
Databricks acquires Redash, a visualizations service for data scientists
Datafold is solving the chaos of data engineering
“Data is growing like crazy: in volume, in scale, in complexity, in who requires it and what the business intelligence uses are, what the API uses are,” Applebaum said when I asked him why he decided to invest. “And compute is getting slightly cheaper, but not really, and storage is getting cheaper. So if you can make the trade-off to store more stuff, and access things more intelligently, more quickly, more agile — that was the basis of our thesis, as long as you can do it without compromising performance.”
Varada, with its team of experienced executives, architects and engineers, ticked a lot of the company’s boxes in this regard, but he also noted that unlike some other Israeli startups, the team understood that it had to listen to customers and understand their needs, too.
“In Israel, you have a history — and it’s become less and less the case — but historically, there’s a joke that it’s ‘ready, fire, aim.’ You build a technology, you’ve got this beautiful thing and you’re like, ‘alright, we did it,’ but without listening to the needs of the customer,” he explained.
The Varada team is not afraid to compare itself to Snowflake, which at least at first glance seems to make similar promises. Vananou praised the company for opening up the data warehousing market and proving that people are willing to pay for good analytics. But he argues that Varada’s approach is fundamentally different.
“We embrace the data lake. So if you are Mr. Customer, your data is your data. We’re not going to take it, move it, copy it. This is your single source of truth,” he said. And in addition, the data can stay in the company’s virtual private cloud. He also argues that Varada isn’t so much focused on the business users but the technologists inside a company.
0 notes
Text
Data virtualization service Varada raises $12M
Varada, a Tel Aviv-based startup that focuses on making it easier for businesses to query data across services, today announced that it has raised a $12 million Series A round led by Israeli early-stage fund MizMaa Ventures, with participation by Gefen Capital. “If you look at the storage aspect for big data, there’s always innovation, but we can put a lot of data in one place,” Varada CEO and co-founder Eran Vanounou told me. “But translating data into insight? It’s so hard. It’s costly. It’s slow. It’s complicated.” That’s a lesson he learned during his time as CTO of LivePerson, which he described as a classic big data company. And just like at LivePerson, where the team had to reinvent the wheel to solve its data problems, again and again, every company — and not just the large enterprises — now struggles with managing their data and getting insights out of it, Vanounou argued. Image Credits: Varada The rest of the founding team, David Krakov, Roman Vainbrand and Tal Ben-Moshe, already had a lot of experience in dealing with these problems, too, with Ben-Moshe having served at the Chief Software Architect of Dell EMC’s XtremIO flash array unit, for example. They built the system for indexing big data that’s at the core of Varada’s platform (with the open-source Presto SQL query engine being one of the other cornerstones). Image Credits: Varada Essentially, Varada embraces the idea of data lakes and enriches that with its indexing capabilities. And those indexing capabilities is where Varada’s smarts can be found. As Vanounou explained, the company is using a machine learning system to understand when users tend to run certain workloads and then caches the data ahead of time, making the system far faster than its competitors. “If you think about big organizations and think about the workloads and the queries, what happens during the morning time is different from evening time. What happened yesterday is not what happened today. What happened on a rainy day is not what happened on a shiny day. […] We listen to what’s going on and we optimize. We leverage the indexing technology. We index what is needed when it is needed.” That helps speed up queries, but it also means less data has to be replicated, which also brings down the cost. AÅs Mizmaa’s Aaron Applebaum noted, since Varada is not a SaaS solution, the buyers still get all of the discounts from their cloud providers, too. In addition, the system can allocate resources intelligently to that different users can tap into different amounts of bandwidth. You can tell it to give customers more bandwidth than your financial analysts, for example. READ MORE Snowflake and JFrog raise IPO ranges as tech markets stay hot Databricks acquires Redash, a visualizations service for data scientists Datafold is solving the chaos of data engineering “Data is growing like crazy: in volume, in scale, in complexity, in who requires it and what the business intelligence uses are, what the API uses are,” Applebaum said when I asked him why he decided to invest. “And compute is getting slightly cheaper, but not really, and storage is getting cheaper. So if you can make the trade-off to store more stuff, and access things more intelligently, more quickly, more agile — that was the basis of our thesis, as long as you can do it without compromising performance.” Varada, with its team of experienced executives, architects and engineers, ticked a lot of the company’s boxes in this regard, but he also noted that unlike some other Israeli startups, the team understood that it had to listen to customers and understand their needs, too. “In Israel, you have a history — and it’s become less and less the case — but historically, there’s a joke that it’s ‘ready, fire, aim.’ You build a technology, you’ve got this beautiful thing and you’re like, ‘alright, we did it,’ but without listening to the needs of the customer,” he explained. The Varada team is not afraid to compare itself to Snowflake, which at least at first glance seems to make similar promises. Vananou praised the company for opening up the data warehousing market and proving that people are willing to pay for good analytics. But he argues that Varada’s approach is fundamentally different. “We embrace the data lake. So if you are Mr. Customer, your data is your data. We’re not going to take it, move it, copy it. This is your single source of truth,” he said. And in addition, the data can stay in the company’s virtual private cloud. He also argues that Varada isn’t so much focused on the business users but the technologists inside a company. http://feedproxy.google.com/~r/techcrunch/startups/~3/teCvkkZKBQI/
0 notes
Text
SQL Server to Snowflake – The Need for Replication
When you have a system in place that has served your data retrieval and storage needs for long, why would you want to switch to another comparatively new solution?
Microsoft SQL Server is one that has for long met most SME requirements and workloads. It supports most applications across the web or on a local network system on a single machine and blends seamlessly with the full Microsoft ecosystem. Then, why do many organizations today want to replicate data SQL Server to Snowflake?
Snowflake has an advantage if you have big data needs but not much for relatively small datasets or low currency/load. This cloud-based data warehousing solution has almost unlimited storage capacity, a friendly user-interface, and very stringent data control and security measures. All these attributes are expected from a data warehouse but not available fully in Microsoft SQL Server.

There are other benefits to Snowflake. It offers separate computing and storage facilities. Users can scale up or down in either of them, paying only for the resources used. Further, multiple users can work simultaneously on intricate queries and workloads without experiencing any lag or drop in performance.
Basically, Microsoft’s SQL Server is a database server with primary functions being to store and retrieve data. It is a combination of the Relational Database Management System (RDBMS) and the Structured Query Language (SQL). Many specialized versions released recently though cater to a wide range of workloads and demands.
Snowflake, on the other hand, is cloud-based and offered as a Software-as-a-Service product. It runs on AWS, the most popular and commonly used cloud provider. As in other databases, it is possible to query any structured data in Snowflake tables through the standard SQL data types such as NUMBER, BOOLEAN, VARCHAR, TIMESTAMPS, and more. These features are added incentives to replicate data SQL Server to Snowflake.
Tools to replicate data SQL Server to Snowflake
The process of replicating data to Snowflake need not be a long-drawn-out and tedious process if you use the most optimized and effective available tools. Given here are some features of the tools that should be checked before you opt for one.
· Handling large volumes of data – Make sure that the tool you choose is able to handle massive volumes of data effectively and without any performance degradation.
· Completely automated – The tool should automatically merge, transform, and reconcile data through a simple point-and-click interface regardless of the quantum of data being replicated.
· Be able to use SQL Server CDC – By using SQL CDC (Changed Data Capture) the tool should utilize database transaction logs at source and copy modified and changed data only to the Snowflake database. Complete data refreshes every time a change is made is thus not necessary.
Choose the tool carefully to simplify and ease out the process to replicate data SQL Server to Snowflake.
0 notes
Text
Snowflake, now a unicorn, eyes world development for cloud knowledge warehouse
New Post has been published on https://takenews.net/snowflake-now-a-unicorn-eyes-world-development-for-cloud-knowledge-warehouse/
Snowflake, now a unicorn, eyes world development for cloud knowledge warehouse
Fueled by a capital injection of $263 million making it the primary cloud-native knowledge warehouse startup to attain “unicorn” standing, Snowflake is about this 12 months to increase its world footprint, supply cross-regional, data-sharing capabilities, and develop interoperability with a rising set of associated instruments.
With the brand new spherical of funding, introduced Thursday, Snowflake has raised a complete of $473 million at a valuation of $1.5 billion. Based in 2012, the corporate has turn into a startup to observe as a result of it has engineered its knowledge warehouse from the bottom up for the cloud, designing it to take away limits on how a lot knowledge could be processed and what number of concurrent queries could be dealt with.
Snowflake at its core is basically a massively parallel processing (MPP) analytical relational database that’s ACID (Atomicity, Consistency, Isolation, Sturdiness) compliant, dealing with not solely SQL natively but in addition semistructured knowledge in codecs like JSON through the use of a VARIANT customized datatype. The wedding of SQL and semistructured knowledge is essential, as a result of enterprises at this time are awash in machine-generated, semistructured knowledge.
With a novel three-layer structure, Snowflake says it might probably run lots of of concurrent queries on petabytes of knowledge, whereas customers reap the benefits of cloud cost-efficiency and elasticity — creating and terminating digital warehouses as wanted — and even self-provisioning with not more than a bank card and about the identical effort it takes to spin up an AWS EC2 occasion.
Whereas the Snowflake on Demand self-service possibility could also be notably attractive to smaller and medium-size companies (SMBs), Snowflake is well-positioned to serve large enterprises, akin to banks, which are transferring to the cloud, says CEO Bob Muglia, a tech veteran who spent greater than 20 years at Microsoft and two years at Juniper earlier than becoming a member of Snowflake in 2014.
“It seems that the info warehouse is among the pivot factors, a tentpole factor, that clients have to maneuver as a result of if the info warehouse continues to dwell on premises an enormous variety of programs surrounding that knowledge warehouse will proceed to dwell on premises,” Muglia says.
And even well-funded, large enterprises like banks are interested in cloud cost-efficiencies, Muglia factors out. “When you’ve obtained some quant man who desires to run one thing and hastily wants a thousand nodes and wishes it for 2 hours, it is kinda good to have the ability to do that actually rapidly then have it go away versus paying for them 365 days a 12 months.”
In the meanwhile Snowflake runs on Amazon in 4 areas: US West, US East, Frankfurt and Sydney. It will likely be operating in one other European area inside weeks, Muglia says. The capital infusion will allow the corporate so as to add Asian and South American areas inside a 12 months, he added. Inside that timeframe the corporate additionally plans to:
— Add the flexibility to do cross-region knowledge replication. Proper now, Snowflake’s Knowledge Sharehouse permits for real-time knowledge sharing amongst clients solely inside an Amazon area. The power to copy throughout continents ought to open up doorways to world enterprises.
— Run on one other cloud supplier. Muglia has been coy about which supplier it will likely be, however concedes it is more likely to be Microsoft Azure. Cross-provider replication can also be within the works, Muglia says.
— Proceed to work on the system’s skill to interoperate with varied instruments that its clients use. Clients typically use sure database instruments and add-ons for years, even after distributors cease updating them, and clients need new programs to work with them.
There are, nevertheless, a gaggle of gamers vying to be the web knowledge warehouse of selection for enterprises. Snowflake should cope with, for instance, Microsoft Azure’s SQL Knowledge Warehouse, Google’s BigQuery and Cloud SQL — the place customers can run Oracle’s MySQL — in addition to RedShift from Amazon itself.
However Muglia contends that Snowflake’s distinctive structure permits it to scale well beyond conventional SQL databases, even when they’re run within the cloud. As well as, its doesn’t require particular coaching or abilities, akin to noSQL options like Hadoop.
A lot of the conventional databases, in addition to RedShift and lots of noSQL programs, use shared-nothing structure, which distributes subsets of knowledge throughout all of the processing nodes in a system, eliminating the communications bottleneck suffered by shared-disk programs. The issue with these programs is that compute can’t be scaled independently of storage, and lots of programs turn into overprovisioned, Snowflake notes. Additionally, regardless of what number of nodes are added, the RAM within the machines utilized in these programs limits the quantity of concurrent queries they’ll deal with, Muglia says.
“The problem that clients have at this time is that they’ve an current system that is out of capability, it is overtaxed; in the meantime they’ve a mandate to go to the cloud they usually need to use the transition to the cloud to interrupt freed from their present limitations,” Muglia says.
Snowflake is designed to unravel this drawback through the use of a three-tier structure:
— A knowledge storage layer that makes use of Amazon S3 to retailer desk knowledge and question outcomes;
— A digital warehouse layer that handles question execution inside elastic clusters of digital machines that Snowflake calls digital warehouses;
— A cloud providers layer that manages transactions, queries, digital warehouses, metadata akin to database schemas, and entry management.
This structure lets a number of digital warehouses work on the identical knowledge on the similar time, permitting Snowflake to scale concurrency far past what its shared-nothing rivals can do, Muglia says.
One potential drawback is that the three-tier structure may led to latency points, however Muglia says that a technique the system maintains efficiency is by having the question compiler within the providers layer use the predicates in a SQL question along with the metadata to find out what knowledge must be scanned. “The entire trick is to scan as little knowledge as attainable,” Muglia says.
However make no mistake: Snowflake will not be an OLTP database and it is solely going to rival Oracle or SQL Server for work that’s analytical in nature.
In the meantime, although, it is setting its sights on new horizons. “When it comes to operating and working a worldwide enterprise having a worldwide database an excellent factor and that is the place we’re going,” Muglia says.
Snowflake’s newest enterprise capital spherical was led by ICONIQ Capital, Altimeter Capital and newcomer to the corporate, Sequoia Capital.
0 notes