#sqoop import example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Big Data and Data Engineering
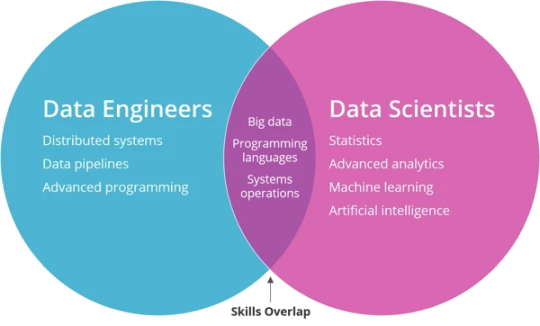
Big Data and Data Engineering are essential concepts in modern data science, analytics, and machine learning.
They focus on the processes and technologies used to manage and process large volumes of data.
Here’s an overview:
What is Big Data? Big Data refers to extremely large datasets that cannot be processed or analyzed using traditional data processing tools or methods.
It typically has the following characteristics:
Volume:
Huge amounts of data (petabytes or more).
Variety:
Data comes in different formats (structured, semi-structured, unstructured). Velocity: The speed at which data is generated and processed.
Veracity: The quality and accuracy of data.
Value: Extracting meaningful insights from data.
Big Data is often associated with technologies and tools that allow organizations to store, process, and analyze data at scale.
2. Data Engineering:
Overview Data Engineering is the process of designing, building, and managing the systems and infrastructure required to collect, store, process, and analyze data.
The goal is to make data easily accessible for analytics and decision-making.
Key areas of Data Engineering:
Data Collection:
��Gathering data from various sources (e.g., IoT devices, logs, APIs). Data Storage: Storing data in data lakes, databases, or distributed storage systems. Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Integration:
Combining data from multiple sources to create a unified dataset for analysis.
3. Big Data Technologies and Tools
The following tools and technologies are commonly used in Big Data and Data Engineering to manage and process large datasets:
Data Storage:
Data Lakes: Large storage systems that can handle structured, semi-structured, and unstructured data. Examples include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Distributed File Systems:
Systems that allow data to be stored across multiple machines. Examples include Hadoop HDFS and Apache Cassandra.
Databases:
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra, HBase).
Data Processing:
Batch Processing: Handling large volumes of data in scheduled, discrete chunks.
Common tools:
Apache Hadoop (MapReduce framework). Apache Spark (offers both batch and stream processing).
Stream Processing:
Handling real-time data flows. Common tools: Apache Kafka (message broker). Apache Flink (streaming data processing). Apache Storm (real-time computation).
ETL (Extract, Transform, Load):
Tools like Apache Nifi, Airflow, and AWS Glue are used to automate data extraction, transformation, and loading processes.
Data Orchestration & Workflow Management:
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. Kubernetes and Docker are used to deploy and scale applications in data pipelines.
Data Warehousing & Analytics:
Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse Analytics are popular cloud data warehouses for large-scale data analytics.
Apache Hive is a data warehouse built on top of Hadoop to provide SQL-like querying capabilities.
Data Quality and Governance:
Tools like Great Expectations, Deequ, and AWS Glue DataBrew help ensure data quality by validating, cleaning, and transforming data before it’s analyzed.
4. Data Engineering Lifecycle
The typical lifecycle in Data Engineering involves the following stages: Data Ingestion: Collecting and importing data from various sources into a central storage system.
This could include real-time ingestion using tools like Apache Kafka or batch-based ingestion using Apache Sqoop.
Data Transformation (ETL/ELT): After ingestion, raw data is cleaned and transformed.
This may include:
Data normalization and standardization. Removing duplicates and handling missing data.
Aggregating or merging datasets. Using tools like Apache Spark, AWS Glue, and Talend.
Data Storage:
After transformation, the data is stored in a format that can be easily queried.
This could be in a data warehouse (e.g., Snowflake, Google BigQuery) or a data lake (e.g., Amazon S3).
Data Analytics & Visualization:
After the data is stored, it is ready for analysis. Data scientists and analysts use tools like SQL, Jupyter Notebooks, Tableau, and Power BI to create insights and visualize the data.
Data Deployment & Serving:
In some use cases, data is deployed to serve real-time queries using tools like Apache Druid or Elasticsearch.
5. Challenges in Big Data and Data Engineering
Data Security & Privacy:
Ensuring that data is secure, encrypted, and complies with privacy regulations (e.g., GDPR, CCPA).
Scalability:
As data grows, the infrastructure needs to scale to handle it efficiently.
Data Quality:
Ensuring that the data collected is accurate, complete, and relevant. Data
Integration:
Combining data from multiple systems with differing formats and structures can be complex.
Real-Time Processing:
Managing data that flows continuously and needs to be processed in real-time.
6. Best Practices in Data Engineering Modular Pipelines:
Design data pipelines as modular components that can be reused and updated independently.
Data Versioning: Keep track of versions of datasets and data models to maintain consistency.
Data Lineage: Track how data moves and is transformed across systems.
Automation: Automate repetitive tasks like data collection, transformation, and processing using tools like Apache Airflow or Luigi.
Monitoring: Set up monitoring and alerting to track the health of data pipelines and ensure data accuracy and timeliness.
7. Cloud and Managed Services for Big Data
Many companies are now leveraging cloud-based services to handle Big Data:
AWS:
Offers tools like AWS Glue (ETL), Redshift (data warehousing), S3 (storage), and Kinesis (real-time streaming).
Azure:
Provides Azure Data Lake, Azure Synapse Analytics, and Azure Databricks for Big Data processing.
Google Cloud:
Offers BigQuery, Cloud Storage, and Dataflow for Big Data workloads.
Data Engineering plays a critical role in enabling efficient data processing, analysis, and decision-making in a data-driven world.

0 notes
Text
What is a Data Lake?
A data lake refers to a central storage repository used to store a vast amount of raw, granular data in its native format. It is a single store repository containing structured data, semi-structured data, and unstructured data.
A data lake is used where there is no fixed storage, no file type limitations, and emphasis is on flexible format storage for future use. Data lake architecture is flat and uses metadata tags and identifiers for quicker data retrieval in a data lake.
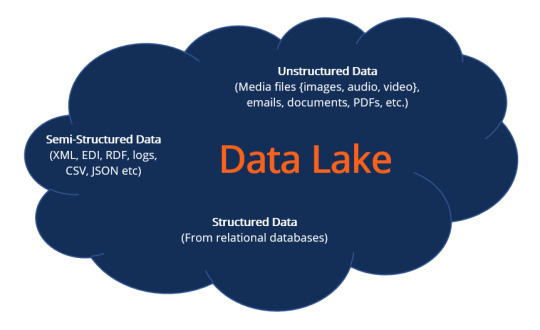
The term “data lake” was coined by the Chief Technology Officer of Pentaho, James Dixon, to contrast it with the more refined and processed data warehouse repository. The popularity of data lakes continues to grow, especially in organizations that prefer large, holistic data storage.
Data in a data lake is not filtered before storage, and accessing the data for analysis is ad hoc and varied. The data is not transformed until it is needed for analysis. However, data lakes need regular maintenance and some form of governance to ensure data usability and accessibility. If data lakes are not maintained well and become inaccessible, they are referred to as “data swamps.”
Data Lakes vs. Data Warehouse
Data lakes are often confused with data warehouses; hence, to understand data lakes, it is crucial to acknowledge the fundamental distinctions between the two data repositories.
As indicated, both are data repositories that serve the same universal purpose and objective of storing organizational data to support decision-making. Data lakes and data warehouses are alternatives and mainly differ in their architecture, which can be concisely broken down into the following points.
Structure
The schema for a data lake is not predetermined before data is applied to it, which means data is stored in its native format containing structured and unstructured data. Data is processed when it is being used. However, a data warehouse schema is predefined and predetermined before the application of data, a state known as schema on write. Data lakes are termed schema on read.
Flexibility
Data lakes are flexible and adaptable to changes in use and circumstances, while data warehouses take considerable time defining their schema, which cannot be modified hastily to changing requirements. Data lakes storage is easily expanded through the scaling of its servers.
User Interface
Accessibility of data in a data lake requires some skill to understand its data relationships due to its undefined schema. In comparison, data in a data warehouse is easily accessible due to its structured, defined schema. Many users can easily access warehouse data, while not all users in an organization can comprehend data lake accessibility.
Why Create a Data Lake?
Storing data in a data lake for later processing when the need arises is cost-effective and offers an unrefined view to data analysts. The other reasons for creating a data lake are as follows:
The diverse structure of data in a data lake means it offers a robust and richer quality of analysis for data analysts.
There is no requirement to model data into an enterprise-wide schema with a data lake.
Data lakes offer flexibility in data analysis with the ability to modify structured to unstructured data, which cannot be found in data warehouses.
Artificial intelligence and machine learning can be employed to make profitable forecasts.
Using data lakes can give an organization a competitive advantage.
Data Lake Architecture
A data lake architecture can accommodate unstructured data and different data structures from multiple sources across the organization. All data lakes have two components, storage and compute, and they can both be located on-premises or based in the cloud. The data lake architecture can use a combination of cloud and on-premises locations.
It is difficult to measure the volume of data that will need to be accommodated by a data lake. For this reason, data lake architecture provides expanded scalability, as high as an exabyte, a feat a conventional storage system is not capable of. Data should be tagged with metadata during its application into the data lake to ensure future accessibility.
Below is a concept diagram for a data lake structure:

Data lakes software such as Hadoop and Amazon Simple Storage Service (Amazon S3) vary in terms of structure and strategy. Data lake architecture software organizes data in a data lake and makes it easier to access and use. The following features should be incorporated in a data lake architecture to prevent the development of a data swamp and ensure data lake functionality.
Utilization of data profiling tools proffers insights into the classification of data objects and implementing data quality control
Taxonomy of data classification includes user scenarios and possible user groups, content, and data type
File hierarchy with naming conventions
Tracking mechanism on data lake user access together with a generated alert signal at the point and time of access
Data catalog search functionality
Data security that encompasses data encryption, access control, authentication, and other data security tools to prevent unauthorized access
Data lake usage training and awareness
Hadoop Data Lakes Architecture
We have singled out illustrating Hadoop data lake infrastructure as an example. Some data lake architecture providers use a Hadoop-based data management platform consisting of one or more Hadoop clusters. Hadoop uses a cluster of distributed servers for data storage. The Hadoop ecosystem comprises three main core elements:
Hadoop Distributed File System (HDFS) – The storage layer whose function is storing and replicating data across multiple servers.
Yet Another Resource Negotiator (YARN) – Resource management tool
MapReduce – The programming model for splitting data into smaller subsections before processing in servers
Hadoop supplementary tools include Pig, Hive, Sqoop, and Kafka. The tools assist in the processes of ingestion, preparation, and extraction. Hadoop can be combined with cloud enterprise platforms to offer a cloud-based data lake infrastructure.

Hadoop is an open-source technology that makes it less expensive to use. Several ETL tools are available for integration with Hadoop. It is easy to scale and provides faster computation due to its data locality, which has increased its popularity and familiarity among most technology users.
Data Lake Key Concepts
Below are some key data lake concepts to broaden and deepen the understanding of data lakes architecture.
Data ingestion – The process where data is gathered from multiple data sources and loaded into the data lake. The process supports all data structures, including unstructured data. It also supports batch and one-time ingestion.
Security – Implementing security protocols for the data lake is an important aspect. It means managing data security and the data lake flow from loading, search, storage, and accessibility. Other facets of data security such as data protection, authentication, accounting, and access control to prevent unauthorized access are also paramount to data lakes.
Data quality – Information in a data lake is used for decision making, which makes it important for the data to be of high quality. Poor quality data can lead to bad decisions, which can be catastrophic to the organization.
Data governance – Administering and managing data integrity, availability, usability, and security within an organization.
Data discovery – Discovering data is important before data preparation and analysis. It is the process of collecting data from multiple sources and consolidating it in the lake, making use of tagging techniques to detect patterns enabling better data understandability.
Data exploration – Data exploration starts just before the data analytics stage. It assists in identifying the right dataset for the analysis.
Data storage – Data storage should support multiple data formats, be scalable, accessible easily and swiftly, and be cost-effective.
Data auditing – Facilitates evaluation of risk and compliance and tracks any changes made to crucial data elements, including identifying who made the changes, how data was changed, and when the changes took place.
Data lineage – Concerned with the data flow from its source or origin and its path as it is moved within the data lake. Data lineage smoothens error corrections in a data analytics process from its source to its destination.
Benefits of a Data Lake
A data lake is an agile storage platform that can be easily configured for any given data model, structure, application, or query. Data lake agility enables multiple and advanced analytical methods to interpret the data.
Being a schema on read makes a data lake scalable and flexible.
Data lakes support queries that require a deep analysis by exploring information down to its source to queries that require a simple report with summary data. All user types are catered for.
Most data lakes software applications are open source and can be installed using low-cost hardware.
Schema development is deferred until an organization finds a business case for the data. Hence, no time and costs are wasted on schema development.
Data lakes offer centralization of different data sources.
They provide value for all data types as well as the long-term cost of ownership.
Cloud-based data lakes are easier and faster to implement, cost-effective with a pay-as-you-use model, and are easier to scale up as the need arises. It also saves on space and real estate costs.
Challenges and Criticism of Data Lakes
Data lakes are at risk of losing relevance and becoming data swamps over time if they are not properly governed.
It is difficult to ensure data security and access control as some data is dumped in the lake without proper oversight.
There is no trail of previous analytics on the data to assist new users.
Storage and processing costs may increase as more data is added to the lake.
On-premises data lakes face challenges such as space constraints, hardware and data center setup, storage scalability, cost, and resource budgeting.
Popular Data Lake Technology Vendors
Popular data lake technology providers include the following:
Amazon S3 – Offers unlimited scalability
Apache – Uses Hadoop open-source ecosystem
Google Cloud Platform (GCP) – Google cloud storage
Oracle Big Data Cloud
Microsoft Azure Data Lake and Azure Data Analytics
Snowflake – Processes structured and semi-structured datasets, notably JSON, XML, and Parquet
More Resources
To keep learning and developing your knowledge base, please explore the additional relevant resources below:
Business Intelligence
Data Mart
Scalability
Data Protection
1 note
·
View note
Text
7 Main Malaysian Universities Where You'll Be Able To Study Data Science

Data science is a vast subject and people cannot achieve experience in it inside six months or a year. Learning information science requires specialized technical skills together with information of programming basics and analytics tools to get started. However, this Data Science course explains all the relevant concepts from scratch, so you can see it easy to place your new abilities to make use of. This Data Science certification coaching will familiarize you with programming languages like Python, R, and Scala, as well as knowledge science instruments like Apache Spark, HBase, Sqoop, Hadoop, and Flume.
You’ll probably find that this profession path can generally be stuffed with frustration, so a hearty dose of stubbornness is an efficient thing. When things get powerful and it looks as if there couldn’t presumably be a solution to the problem, a great knowledge scientist will hold reorganizing, reanalyzing, and dealing the information in the hopes that a brand new perspective will lead to a “Eureka! They often create extremely superior algorithms which are used to determine patterns and take the information from a jumble of numbers and stats to something that may be helpful for a enterprise or organization. At its core, knowledge science is the follow of looking for which means in mass quantities of information.
360digitmghas top-of-the-line applications available online to earn real-world expertise that are in demand worldwide. I simply completed the Machine Learning Advanced Certification course, and the LMS was excellent. Upskilling with 360digitmgwas an excellent expertise that additionally resulted in a brand new job opportunity for me with an excellent salary hike.
R programming is most popular as a result of it's widely used for solving statistical applications. Even though it has a steep studying curve, 43% of data scientists use R for data analysis. When the quantity of knowledge is far more than the out there memory, a framework like Hadoop and Spark is used. Apart from the data of framework and programming language, having an understanding of databases is required as properly.
KnowldgeHut's training session included everything that had been promised. The trainer was very knowledgeable and the practical sessions covered each subject. My trainer was very educated and I appreciated his sensible means of instructing. The course which I took from 360digitmgwas very useful and helped me to realize my objective. The course was designed with advanced concepts and the tasks in the course of the course given by the trainer helped me to step up in my career. Virtualenv can also be used for creation of isolated python environments and python dependency supervisor referred to as pipeny.
Understand various forecasting parts similar to Level, Trend, Seasonality & Noise. Also, learn about various error capabilities and which one is the most effective given a business state of affairs. Finally, construct various forecasting models ranging from linear to exponential to additive seasonality to multiplicative seasonality. Black field machine learning algorithms are extraordinarily important in the field of machine learning.
Problem solving just isn't a task, however an intellectually-stimulating journey to a solution. Data scientists are passionate about what they do, and reap nice satisfaction in taking up challenge. For example, if a Hypermarket or Supermarket could use the data collected every day from their clients such as past shopping for history, once they shop, what they like to buy, how much they spend, age, earnings, and so forth. Then, the Hypermarket can analyse the information to make methods on which products to inventory more, the way to worth the products, when to have gross sales to extend the client walk in, and so on. Students after SPM or O-Levelsmay go for theFoundation in Computing at Asia Pacific Universityfor 1 year earlier than persevering with on to the three-12 months Bachelor of Science in Computer Science with specialism in Data Analytics diploma. To enter the Bsc Statistical Data Science degree at Heriot-Watt University Malaysia after SPM or O-Levels, students will enter theFoundation in Businessfirst.
For these specialized methods, expert Data Scientists are employed to concentrate on a selected piece of data or data which is useful. While we see advancing technologies like Artificial Intelligence and Machine Learning, this has additionally elevated the demand for expert professionals. The corporations hiring a group of individuals with some mounted set of expertise which are wanted at present will not be needed 5 to 10 years from now. This era wants a new set of abilities in a very practiced and exact way.
Learn about the implementation of a Regression methodology based mostly on the business issues to be solved. Understand about Linear Regression as well as Logistic Regression methods used to handle steady as well as discrete output prediction. Evaluation techniques by understanding the measure of Error , issues whereas constructing a Regression Model like Collinearity, Heteroscedasticity, overfitting, and Underfitting are explained in detail. They should be proficient in tools corresponding to Python, R, R Studio, Hadoop, MapReduce, Apache Spark, Apache Pig, Java, NoSQL database, Cloud Computing, Tableau, and SAS. A Data Scientist should be a person who loves taking part in with numbers and figures.
Xavier Phang, Software Engineering Graduate from Asia Pacific University Some non-public universities in Malaysia offer knowledge science levels, which is an obvious alternative. This degree will give you the mandatory skills to process and analyze a posh set of data, and will contain plenty of technical information related to statistics, computer systems, evaluation strategies, and more. Most information science applications will also have a creative and analytical element, allowing you to make judgment choices primarily based on your findings.
Explore more on -Data Science Training in Malaysia
INNODATATICS SDN BHD (1265527-M)
360DigiTMG - Data Science, IR 4.0, AI, Machine Learning Training in Malaysia
Level 16, 1 Sentral, Jalan Stesen Sentral 5, KL Sentral, 50740, Kuala Lumpur, Malaysia.
+ 601 9383 1378 / + 603 2092 9488
Hours: Sunday - Saturday 7 AM - 11 PM
#data scientist course#data science training in malaysia#data scientist certification malaysia#data science courses in malaysia
0 notes
Text
What Expertise Do You Should Turn Into A Data Scientist?
It is amongst the most important skills for Data Scientists to have hands-on expertise. Data integration is vital for organizations because it allows them to research information for business intelligence. Thus, being equipped with Data Integration will permit you to land a Data Science job in a reputed group. Data Ingestion is the process of importing, transferring, loading, and processing knowledge for later use or storage in a database. Being in a position to carry out Data Ingestion is likely certainly one of the most important Data Scientist ability sets you have to turn out to be a Data Scientist. Apache Flume and Apache Sqoop are two most popular knowledge ingestion instruments you would want to master.
visit to know more about : data science training in hyderabad To start with you must be conversant in plots like Histogram, Bar charts, pie charts, after which transfer on to advanced charts like waterfall charts, thermometer charts, and so on. These plots are available very useful during the stage of exploratory knowledge analysis. The univariate and bivariate analyses become much simpler to grasp utilizing colourful charts. So, on this article, I am mentioning 14 abilities you'll require to turn into a profitable information scientist and a few Data Science Training Online to perform them. The world machine studying market is predicted to succeed in $20.83 Billion by the 12 months 2024. For example, if a knowledge scientist is engaged on a project to assist the advertising group present insightful research, the skilled must be nicely adept at handling social media as well. Moving ahead, allow us to discuss what are the technical skills required for a data scientist function. Nowadays, every organization is deploying Deep Learning fashions as it possesses the flexibility to solve limitations of traditional Machine Learning approaches. One of the important abilities for Data Scientist is Data Manipulation. It includes the method of fixing and organizing knowledge to make it simpler to read. To start, you must be snug with basic plots similar to histograms, bar charts, and pie charts, before moving on to extra superior charts such as waterfall charts, thermometer charts, and so forth. During the exploratory data analysis stage, these graphs are extraordinarily helpful. Colorful graphics make univariate and bivariate research much simpler to comprehend. R is an integrated suite of software facilities for information manipulation, calculation, and graphical display. Since data scientists are knee-deep in techniques designed to analyze and course of knowledge, they have to additionally understand the systems’ internal workings. Learn and apply the languages which might be most relevant to your position, industry, and business challenges. Data science is a continuously evolving subject, and it is rather important to keep updating your knowledge science expertise to turn out to be an professional in the domain. Now that you are aware of the talents required to turn into a knowledge scientist, under is tips on how to make a profession in knowledge science. Companies are sitting over a mine of knowledge, for which they want people with data science skills. Here are some in style information science jobs in demand in the present business milieu. To be an information scientist you’ll want a stable understanding of the industry you’re working in, and know what business issues your company is trying to unravel. Data Wrangling is the process of cleaning and unifying messy and sophisticated knowledge collections for straightforward access and evaluation. You’ll save a few minutes, but it’s not probably the most environment friendly method, and your clothes shall be ruined as well. Instead, spend a couple of minutes ironing and stacking your garments. It might be significantly more environment friendly, and your clothing will last more. S disseminating to your group what steps you wish to observe to get from A to B with the data, or giving a presentation to business leadership, communication could make all the distinction in the outcome of a project. Like most careers, the extra advanced your position, the higher suite of abilities you’ll must be profitable. You grasp the tool in the future and it will get run over by a sophisticated device the following day. The selections that they take at the moment are solely dependent on the proposed data and they’re serving to them to take useful choices. This has triggered the massive leap of such professionals over the past few years and continues to be dominating the business. Due to this, the pay scale is fairly respectable for data scientists and that’s one of the main the cause why people are paving their method towards this area. Having a deep understanding of machine studying and artificial intelligence is a should to need to implement tools and techniques in numerous logic, decision timber, etc. Having these skill units will enable any knowledge scientist to work and clear up complex issues particularly which might be designed for predictions or for deciding future objectives. Those who possess these abilities will surely stand out as proficient professionals. But for being proficient would require having a particular aligned course for knowledge science similar to Data Science – Live Course that is well tailor-made to prepare any individual right from scratch. The major motive for deep studying being profitable with NLP is its accuracy in supply. One should perceive that deep learning is an artwork that requires a set of particular tools to show its caliber. Companies mostly use data science to improve their business and decision-making capabilities. Data science can also be used to get correct insights into totally different processes and capabilities of a business, spot problems, make predictions, and suggest ways to improve. Essentially, you will be collaborating together with your team members to develop use cases in order to know the business objectives and information that might be required to resolve issues. You will need to know the right approach to deal with the use circumstances, the info that is wanted to unravel the problem and the method to translate and present the result into what can easily be understood by everybody involved. You will literally have to work with everyone in the group, together with your customers. This knowledge needs to be translated right into a format that will be straightforward to comprehend.

Statistics is defined as the study of the collection, evaluation, interpretation, presentation, and organizing of knowledge, according to Wikipedia. As a end result, it ought to come as no shock that data scientists require statistical knowledge in their profession. It is important to know the ideas of descriptive statistics similar to imply, median, mode, variance, and normal deviation. Then there are likelihood distributions, pattern and inhabitants, CLT, skewness and kurtosis, and inferential statistics, such as speculation testing and confidence intervals. Therefore, information scientists want enterprise acumen to make a difference in the company. Having business acumen will help them acquire a greater understanding in regards to the enterprise and make higher knowledge and predictive fashions to extend efficiency. Data scientists convert giant knowledge sets into easy-to-understand info that can be utilized to make important enterprise choices. Therefore, data scientists should know the method to simplify complex ideas and information findings and convey the same to different departments. Data scientists want a strong basis in mathematics and statistics. The most common fields of study in information science are mathematics, statistics, pc science, and engineering. In this article, we discussed the 14 most necessary expertise needed to become a profitable knowledge scientist. Data Science remains to be evolving and it let me inform you crucial thing – Learning by no means stops on this area.
For more information: best institute for data science in hyderabad 360DigiTMG - Data Analytics, Data Science Course Training Hyderabad Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081 099899 94319
Visit on map : https://g.page/Best-Data-Science
0 notes
Text
Benefits of Taking Up a Data Science Course
Data science is the process of cleansing, aggregating, and altering data in order to do advanced data analysis. The results can then be reviewed by analytic apps and data scientists to uncover patterns and allow company leaders to make informed decisions.
Companies have access to a wealth of information. Data volumes have expanded as contemporary technology has facilitated the creation and storage of ever-increasing amounts of data. 90% of the world's data was created in the last two years, according to estimates. Every hour, for example, Facebook users post 10 million images.
Data Science Certification equips you with 'in-demand' Big Data technologies
Data Science Training prepares students for the growing demand for Big Data skills and technologies. It provides experts with data management tools such as Hadoop, R, Flume, Sqoop, Machine Learning, Mahout, and others. Knowledge and experience in the abilities are an extra benefit for a more successful and competitive career.
Data Scientists: Job Titles
Database Administrators
They are those in charge of databases. Managing the obtained data is a crucial role for making decisions in businesses. They store and arrange data using a variety of software tools in preparation for subsequent investigation.
Data Architects
Data Architects must have a foundation in traditional programming and Business Intelligence, as well as the ability to cope with data ambiguity. They are frequently exposed to unstructured and unclear data and statistics. Data Architects are also capable of using data in novel ways in order to gain fresh insights.
Data Visualizers
Data Visualizers are technicians who convert data analytics into useful knowledge for businesses. They are able to communicate the results of data analytics in layman's terms to all parts of the firm.
Data Engineers
The heart and soul of 'Data Science' are data engineers.. They are in charge of planning, constructing, and maintaining the Big Data infrastructure. They play an important role in building the architecture for analysing and processing data based on business requirements.
Data Ecologists
They come in handy when you're having trouble finding a specific file on your overburdened system! Data ecologists create and manage data on both public and private clouds, ensuring that it is easily available.
Data Scientist Salary in India
An entry-level Data Scientist with less than one year of experience may expect to make a total remuneration of $529,677 (including tips, bonuses, and overtime pay). The average total compensation for a Data Scientist with 1-4 years of experience is $787,149. The average total income for a mid-career Data Scientist with 5-9 years of experience is $1,384,025. A Data Scientist with 10 to 19 years of experience makes an average of $1,759,961 in total compensation. Employees with a late career (20 years or more) earn an average total remuneration of $1,100,000.
Benefits of taking a Data science course
1. High demand
2. Abundant number of positions.
3. A high paying profession.
4. Data science can be applied to a wide range of situations.
5. Data Science Improves the quality of information.
6. Data Scientists have a high salary.
7. You won't have to deal with any tedious tasks any longer.
8. Data Science enables smarter products.
9. Data science can help people live longer.
10. Data Science can improve your personality
11. Career growth.
12. Flexibility, freedom and options.
13. Keeps you updated on the latest industry trends.
14. Easily showcase your expertise.
However, most of this data is languishing untouched in databases and data lakes. The vast amounts of data collected and saved by these technologies have the potential to revolutionise businesses and communities all around the world but only if we can understand it.
0 notes
Text
Data Scientist course
Data Science Course In city
As a Business System Engineer, I’m chargeable for coming up with, developing and maintaining applications software system and integrations for internal solutions. we tend to ought to realize this job chance through prof Hindu deity Narvekar (Assistant prof – information Science, SP Jain). The interview was rigorous and targeted on reasoning, industrial information and technical information.
FrequenciesIn this lesson, you'll currently learn to calculate the frequency of information and analyze the info once dynamic it from frequency to density. ImagesIn this lesson, you'll learn to gift the info within the image format. so as to try to to that, you'll 1st import the info within the image type then gift the info through the image.
As a school with WILP, he teaches courses like Introduction to applied mathematics ways, Advanced applied mathematics Techniques for Analytics, data processing and Machine Learning for varied programmes. Dr Y V K is AN prof with the reckon Science and knowledge Systems cluster of labor Integrated Learning Programmes Division, BITS - Pilani. He did his M.Sc from Sri Venkateswara University, A.P and PhD from Osmania University, Hyderabad. He has printed regarding fifty analysis papers in varied national and international journals.
Data Scientist course
Enrolling yourself for the most effective information Science program offered by a trustworthy institute would be the most effective thanks to build your dream come back true. Constant learning and follow would get you the work of your dreams. Also, students following or holding management degrees like BBA or Master in Business Administration will apply for information science and analytics courses. Our teaching assistants square measure a zealous team of material specialists to assist you get certified in information Science on your 1st try. They interact students proactively to confirm the course path is being followed and assist you enrich your learning expertise, from category onboarding to project mentoring and job help. This information Science certification coaching can familiarise you with programming languages like Python, R, and Scala, additionally as information science tools like Apache Spark, HBase, Sqoop, Hadoop, and Flume.
The content of this Datacamp machine learning track looks very comprehensive and covers loads of ground that isn’t sometimes educated in alternative courses. As an information scientist/analyst, filtering information supported shopper necessities are some things I do on a usual, therefore the content of this course is de facto necessary to know. the most important face of this course is that it teaches you loads of information assortment and storage techniques that square measure essential for an information soul to understand. Next, you'll learn to access and manipulate databases with Python. you'll learn to figure with SQL databases with a Python library known as SQLite3. No previous SQL or info expertise is needed to require this course.
He worked on a range of model validation comes to spot key risks for money models utilized in USAA, as well as P&C models, operational risk models, investment models, market risk models and member demographic models. Learn what being a Lambda faculty student is de facto like from the those who grasp our information science courses the most effective – our alumni. the type of content it provides extremely helps in building your logic and the way to approach a drag in world too. Ankush sir has done a beautiful job in explaining the core thought of exhausting topics. You study ideas and ways primarily through keynote lectures and tutorials victimization case studies and examples. important reflection is vital to eminent drawback determination and essential to the inventive method.
Once you graduate, you belong to a worldwide school community and have access to our on-line platform to stay learning and growing. At the top of the bootcamp, you're welcome to affix our Career Week. on provides you the tools you wish to require ensuing steps in your career, whether or not it's finding your 1st job in school, building a contract career, or launching a start-up. Unveil the magic behind Deep Learning by understanding the design of neural networks and their parameters . Become autonomous to make your own networks, particularly to figure with pictures, times and text, whereas learning the techniques and tricks that build Deep Learning work. find out how to formulate a decent question and the way to answer it by building the correct SQL question.
This was done by making a Machine Learning Model victimization varied supervised, unsupervised and Reinforcement Learning techniques like Neural Network, Random Forest, call Tree, KNN etc. Master analytical tools and gain experience in one amongst the most effective skills of today’s market. thorough program designed to change the candidates with information and experience. select the program that matches your specifications with regards to the course length, timings, and more.
Excelr on-line course contains all the topics that square measure needed and vital to find out so you'll master this technology. This information Science course contains each basic and advanced-level ideas concerned during this technology so you'll learn them and master the talents to pursue a career during this domain. Moreover, the trainers of this course square measure specialists within the domain UN agency pay time and energy to show you all the ideas very well. Some folks believe that it's potential to become an information soul while not knowing a way to code, however others disagree. you may argue that it's a lot of necessary to know a way to use the algorithms than a way to code them yourself.
For More details visit us:
Name: ExcelR Solutions
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 09632156744
direction : Data Scientist course
0 notes
Text
How to use data analytics to improve your business operations

There is a hovering need for professionals with Analytics capacities that can find, examine, and also interpret Big Data. The need for logical experts in Hyderabad is on a higher swing. Presently, there is a large shortage within the variety of experienced Big Data experts. We at 360DigiTMG layout the educational program around trending topics for data analytics course in hyderabad so that it'll be very easy for professionals to obtain a work. The Qualified Data Analytics program in Hyderabad from 360DigiTMG used in-depth understanding about Analytics by palms-on experience like study as well as campaigns from diverse sectors.
We do give Fast-Track Big Information Analytics Training in Hyderabad and One-to-One data analytics courses in hyderabad. 360DigiTMG presents added programs in Tableau and also Service Analytics with R to enhance your research as well as obtain you on the career path to becoming an Information Expert. This training program provides you step-by-step details to master all the subjects that a Data Expert needs to understand.
360DigiTMG Course in Information Analytics

This Tableau certification training course assists you understand Tableau Desktop 10, a global utilized understanding visualization, reporting, and also organization knowledge tool. Advance your occupation in analytics by discovering Tableau and just how to ideal use this coaching in your job.
In addition to the academic data, you'll deal with tasks which can make you business-prepared. data analytics course hyderabad is specifically curated to convey these expertise that employers actually consider beneath data expert credentials.
We got to discover every module of Digital marketing together with live examples right below. 360DigiTMG is a remarkable location where you can be instructed to complete & every concept of digital advertising and marketing. A committed online survey was developed and the link was sent to above 30 knowledge scientific research colleges, of which 21 responded throughout the stated time.
360DigiTMG data analytics training
Throughout the initial couple of weeks, you'll study the important suggestions of Big Data, and also you they'll carry on to learning about different Big Information engineering systems, Big Information handling as well as Big Data Analytics. You'll work with Big Information tools, including Hadoop, Hive, Hbase, Flicker, Sqoop, Scala, Tornado, as well as.
The need for Service analytics is huge in both home and also global job markets. According to Newscom, India's analytics market would certainly boost two circumstances to INR Crores by the end of 2019.
The EMCDSA accreditation demonstrates a person's capacity to participate and add as an information scientific research staff member on huge understanding tasks. Python is coming to be significantly popular due to a lot of reasons. It is also thought-about that it is mandatory to understand the Python phrase structure earlier than doing something interesting like info scientific research. Though, there are a lot of causes to find out about Python, nevertheless one of the vital reasons is that it's the greatest language to comprehend if you want to examine the data or enter the sphere of understanding assessment and scientific research. In order to start your detailed science journey, you will need to initially learn the naked minimum phrase structure.
Machine learning algorithms are used to develop anticipating styles utilizing Regression Evaluation and a Data Researcher has to develop experience in Neural Networks and Feature Design. 360DigiTMG provides an excellent Accreditation Program on Life Sciences and Healthcare Analytics meant for medical professionals. Medical professionals will certainly find out to analyze Electronic Health and wellness Record (EHR) information types and also buildings and also apply anticipating modelling on the same. Along with this, they'll be educated to make use of artificial intelligence methods to healthcare understanding.
But, discovering Python in order to use it for information sciences would possibly take a while, although, it totally rates it. Most entry level details experts work a minimum of a bachelor's diploma. Nonetheless, having a master's level in understanding analytics is helpful. Many folks from technological histories start at entry-level settings similar to an analytical aide, venture help analyst, procedures expert, or others, which supply them invaluable on-the-job training as well as experience.
For more information
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Call us@+91 99899 94319
youtube
0 notes
Photo

Hadoop Big data Training at RM Infotech Laxmi Nagar Delhi NCR
History:
In 2006, the hadoop project was founded by Doug Cutting, It is an open source implementations of internal systems which is now being used to manage and process massive data(s) volumes. In short,
With Hadoop , a large amount of data of all varieties is continually stored and added multiple processing and analytics frameworks rather than moving the data(s) because moving data is typical and very expensive.
What are the career prospects in Hadoop?
Do you know that in next 3 years more than half of the data in this world will move to Hadoop? No wonder McKinsey Global Institute estimates shortage of 1.7 million Big Data professionals over next 3 years.
Hadoop Market is expected to reach $99.31B by 2022 at a CAGR of 42.1% -Forbes
Average Salary of Big Data Hadoop Developers is $135k (Indeed.com salary data)
According to experts – India alone will face a shortage of close to 2 Lac Data Scientists. Experts predict, a significant gap in job openings and professionals with expertise in big data skills. Thus, this is the right time for IT professionals to make the most of this opportunity by sharpening their big data skill set.
Who should take this course?
This course is designed for anyone who:-
wants to get into a career in Big Data
wants to analyse large amounts of unstructured data
wants to architect a big data project using Hadoop and its eco system components
Why from RM Infotech
100% Practical and Job Oriented
Experienced Training having 8+ yrs of Industry Expertise in Big Data.
Learn how to analyze large amounts of data to bring out insights
Relevant examples and cases make the learning more effective and easier
Gain hands-on knowledge through the problem solving based approach of the course along with working on a project at the end of the course
Placement Assistance
Training Certificate
Course Contents
Lectures 30 X 2 hrs. (60 hrs) Weekends. Video 13 Hours Skill level all level Languages English Includes Lifetime access Money back guarantee! Certificate of Completion * Hadoop Distributed File System * Hadoop Architecture * MapReduce & HDFS * Hadoop Eco Systems * Introduction to Pig * Introduction to Hive * Introduction to HBase * Other eco system Map * Hadoop Developer * Moving the Data into Hadoop * Moving The Data out from Hadoop * Reading and Writing the files in HDFS using java * The Hadoop Java API for MapReduce o Mapper Class o Reducer Class o Driver Class * Writing Basic MapReduce Program In java * Understanding the MapReduce Internal Components * Hbase MapReduce Program * Hive Overview * Working with Hive * Pig Overview * Working with Pig * Sqoop Overview * Moving the Data from RDBMS to Hadoop * Moving the Data from RDBMS to Hbase * Moving the Data from RDBMS to Hive * Market Basket Algorithms * Big Data Overview * Flume Overview * Moving The Data from Web server Into Hadoop * Real Time Example in Hadoop * Apache Log viewer Analysis * Introduction In Hadoop and Hadoop Related Eco System. * Choosing Hardware For Hadoop Cluster nodes * Apache Hadoop Installation o Standalone Mode o Pseudo Distributed Mode o Fully Distributed Mode * Installing Hadoop Eco System and Integrate With Hadoop o Zookeeper Installation o Hbase Installation o Hive Installation o Pig Installation o Sqoop Installation o Installing Mahout * Horton Works Installation * Cloudera Installation * Hadoop Commands usage * Import the data in HDFS * Sample Hadoop Examples (Word count program and Population problem) * Monitoring The Hadoop Cluster o Monitoring Hadoop Cluster with Ganglia o Monitoring Hadoop Cluster with Nagios o Monitoring Hadoop Cluster with JMX * Hadoop Configuration management Tool * Hadoop Benchmarking 1. PDF Files + Hadoop e Books 2. Life time access to videos tutorials 3. Sample Resumes 4. Interview Questions 5. Complete Module & Frameworks Code
Hadoop Training Syllabus
Other materials provided along with the training
* 13 YEARS OF INDUSTRY EXPERIENCE * 9 YEARS OF EXPERIENCE IN ONLINE AND CLASSROOM TRAINING
ABOUT THE TRAINER
Duration of Training
Duration of Training will be 12 Weeks (Weekends) Saturday and Sunday 3 hrs.
Course Fee
Course Fee in 15,000/- (7,500/- X 2 installments) 2 Classes are Free as Demo. 100% Money back Guarantee if not satisfied with Training. Course Fee includes Study Materials, Videos, Software support, Lab, Tution Fee.
Batch Size
Maximum 5 candidates in a single batch.
Contact Us
To schedule Free Demo Kindly Contact :-
Parag Saxena.
RM Infotech Pvt Ltd,
332 A, Gali no - 6, West Guru Angad Nagar,
Laxmi Nagar, Delhi - 110092.
Mobile : 9810926239.
website : http://www.rminfotechsolutions.com/javamain/hadoop.html
#hadoop big data training#Hadoop Big data Training in Delhi#Hadoop Big data Training in Laxmi Nagar#Hadoop Course Content#Hadoop Course Fees in Delhi#Hadoop Jobs in Delhi#Hadoop Projects in Delhi
3 notes
·
View notes
Text
300+ TOP BIG DATA Interview Questions and Answers
BIG Data Interview Questions for freshers experienced :-
1. What is Big Data? Big Data is relative term. When Data can’t be handle using conventional systems like RDBMS because Data is generating with very high speed, it is known as Big Data. 2. Why Big Data? Since Data is growing rapidly and RDBMS can’t control it, Big Data technologies came into picture. 3. What are 3 core dimension of Big Data. Big Data have 3 core dimensions: Volume Variety Velocity 4. Role of Volume in Big Data Volume: Volume is nothing but amount of data. As Data is growing with high speed, a huge volume of data is getting generated every second. 5. Role of variety in Big Data Variety: So many applications are running nowadays like mobile, mobile sensors etc. Each application is generating data in different variety. 6. Role of Velocity in Big Data Velocity: This is speed of data getting generated. for example: Every minute, Instagram receives 46,740 new photos. So day by day speed of data generation is getting higher. 7. Remaining 2 less known dimension of Big Data There are two more V’s of Big Data. Below are less known V’s: Veracity Value 8. Role of Veracity in Big Data Veracity: Veracity is nothing but the accuracy of data. Big Data should have some accurate data in order to process it. 9. Role of Value in Big Data Value: Big Data should contain some value to us. Junk Values/Data is not considered as real Big Data. 10. What is Hadoop? Hadoop: Hadoop is a project of Apache. This is a framework which is open Source. Hadoop is use for storing Big data and then processing it.

BIG DATA Interview Questions 11. Why Hadoop? In order to process Big data, we need some framework. Hadoop is an open source framework which is owned by Apache organization. Hadoop is the basic requirement when we think about processing big data. 12. Connection between Hadoop and Big Data Big Data will be processed using some framework. This framework is known as Hadoop. 13. Hadoop and Hadoop Ecosystem Hadoop Ecosystem is nothing but a combination of various components. Below are the components which comes under Hadoop Ecosystem’s Umbrella: HDFS YARN MapReduce Pig Hive Sqoop, etc. 14. What is HDFS. HDFS: HDFS is known as Hadoop Distributed File System. Like Every System have one file system in order to see/manage files stored, in the same way Hadoop is having HDFS which works in distributed manner. 15. Why HDFS? HDFS is the core component of Hadoop Ecosystem. Since Hadoop is a distributed framework and HDFS is also distributed file system. It is very well compatible with Hadoop. 16. What is YARN YARN: YARN is known as Yet Another Resource Manager. This is a project of Apache Hadoop. 17. Use of YARN. YARN is use for managing resources. Jobs are scheduled using YARN in Apache Hadoop. 18. What is MapReduce? MapReduce: MapReduce is a programming approach which consist of two steps: Map and Reduce. MapReduce is the core of Apache Hadoop. 19. Use of MapReduce MapReduce is a programming approach to process our data. MapReduce is use to process Big Data. 20. What is Pig? This is a project of Apache. It is a platform using which huge datasets are analyzed. It runs on the top of MapReduce. 21. Use of Pig Pig is use for the purpose of analyzing huge datasets. Data flow are created using Pig in order to analyze data. Pig Latin language is use for this purpose. 22. What is Pig Latin Pig Latin is a script language which is used in Apache Pig to create Data flow in order to analyze data. 23. What is Hive? Hive is a project of Apache Hadoop. Hive is a dataware software which runs on the top of Hadoop. 24. Use of Hive Hive works as a storage layer which is used to store structured data. This is very useful and convenient tool for SQL user as Hive use HQL. 25. What is HQL? HQL is an abbreviation of Hive Query Language. This is designed for those user who are very comfortable with SQL. HQL is use to query structured data into hive. 26. What is Sqoop? Sqoop is a short form of SQL to Hadoop. This is basically a command line tool to transfer data between Hadoop and SQL and vice-versa. Q27) Use of Sqoop? Sqoop is a CLI tool which is used to migrate data between RDBMS to Hadoop and vice-versa. Q28) What are other components of Hadoop Ecosystem? Below are other components of Hadoop Ecosystem: a) HBase b) Oozie c) Zookeeper d) Flume etc. Q29) Difference Between Hadoop and HDFS Hadoop is a framework while HDFS is a file system which works on the top of Hadoop. Q30) How to access HDFS below is command: hdfs fs or hdfs dfs Q31) How to create directory in HDFS below is command: hdfs fs -mkdir Q32) How to keep files in HDFS below is command: hdfs fs -put or hdfs fs -copyfromLocal Q33) How to copy file from HDFS to local below is command: hdfs fs -copyToLocal Q34) How to Delete directory from HDFS below is command: hdfs fs -rm Q35) How to Delete file from HDFS below is command: hdfs fs -rm Become an Big Data Hadoop Certified Expert in 25Hours Q36) How to Delete directory and files recursively from HDFS below is command: hdfs fs -rm -r Q37) How to read file in HDFS below is command: hdfs fs -cat Managed/internal table Here once the table gets deleted both meta data and actual data is deleted –>external table Here once the table gets deleted only the mata data gets deleted but not the actual data. Q63) How to managed create a table in hive? hive>create table student(sname string, sid int) row format delimited fileds terminated by ‘,’; //hands on hive>describe student; Q64) How to load data into table created in hive? hive>load data local inpath /home/training/simple.txt into table student; //hands on hive> select * from student; Q65) How to create/load data into exteranal tables? *without location hive>create external table student(sname string, sid int) row format delimited fileds terminated by ‘,’; hive>load data local inpath /home/training/simple.txt into table student; *With Location hive>create external table student(sname string, sid int) row format delimited fileds terminated by ‘,’ location /Besant_HDFS; Here no need of load command Became an Big Data Hadoop Expert with Certification in 25hours Q66) Write a command to write static partitioned table. hive>create table student(sname string, sid int) partitioned by(int year) row format delimited fileds terminated by ‘,’; Q67) How to load a file in static partition? hive>load data local inpath /home/training/simple2018.txt into table student partition(year=2018); Q68) Write a commands to write dynamic partitioned table. Answer: –> create a normal table hive>create table student(sname string, sid int) row format delimited fileds terminated by ‘,’; –>load data hive>load data local inpath /home/training/studnetall.txt into table student ; –>create a partitioned table hive>create table student_partition(sname string, sid int) partitioned by(int year) row format delimited fileds terminated by ‘,’; –>set partitions hive>set hive.exec.dynamic.partition.mode = nonstrict; –>insert data hive>insert into table student_partition select * from student; –>drop normal table hive>drop table student; Q69) What is pig? Answer:Pig is an abstraction over map reduce. It is a tool used to deal with huge amount of structured and semi structed data. Q70) What is atom in pig? its a small piece of data or a filed eg: ‘shilpa’ Q71) What is tuple? ordered set of filed (shilpa, 100) Q72) Bag in pig? un-ordered set of tuples eg.{(sh,1),(ww,ww)} Q73) What is relation? bag of tuples Q74) What is hbase? its a distributed column oriented database built on top of hadoop file system it is horizontally scalable Q75) Difference between hbase and rdbms RDMBS is schema based hbase is not RDMBS only structured data hbase structured and semi structured data. RDMBS involves transactions Hbase no transactions Q76) What is table in hbase? collection of rows Q77) What is row in hbase? collection of column families Q78) Column family in hbase? Answer:collection of columns Q79) What is column? Answer:collection of key value pair Q80) How to start hbase services? Answer: >hbase shell hbase>start -hbase.sh Q81) DDL commands used in hbase? Answer: create alter drop drop_all exists list enable is_enabled? disable is_disbled? Q82) DML commands? Answer: put get scan delete delete_all Q83) What services run after running hbase job? Answer: Name node data node secondary NN JT TT Hmaster HRegionServer HQuorumPeer Q84) How to create table in hbase? Answer:>create ’emp’, ‘cf1′,’cf2’ Q85) How to list elements Answer:>scan ’emp’ Q86) Scope operators used in hbase? Answer: MAX_FILESIZE READONLY MEMSTORE_FLUSHSIZE DEFERRED_LOG_FLUSH Q87) What is sqoop? sqoop is an interface/tool between RDBMS and HDFS to importa nd export data Q88) How many default mappers in sqoop? 4 Q89) What is map reduce? map reduce is a data processing technique for distributed computng base on java map stage reduce stage Q90) list few componets that are using big data Answer: facebook adobe yahoo twitter ebay Q91) Write a quert to import a file in sqoop $>sqoop-import –connect jdbc:mysql://localhost/Besant username hadoop password hadoop table emp target_dir sqp_dir fields_terminated_by ‘,’ m 1 Q92) What is context in map reduce? it is an object having the information about hadoop configuration Q93) How job is started in map reduce? To start a job we need to create a configuration object. configuration c = new configuration(); Job j = new Job(c,”wordcount calculation); Q94) How to load data in pig? A= load ‘/home/training/simple.txt’ using PigStorage ‘|’ as (sname : chararray, sid: int, address:chararray); Q95) What are the 2 modes used to run pig scripts? local mode pig -x local pig -x mapreduce Q96) How to show up details in pig ? dump command is used. grunt>dump A; Q97) How to fetch perticular columns in pig? B = foreach A generate sname, sid; Q100) How to restrict the number of lines to be printed in pig ? c=limit B 2; Get Big Data Hadoop Online Training Q101) Define Big Data Big Data is defined as a collection of large and complex of unstructured data sets from where insights are derived from the Data Analysis using open-source tools like Hadoop. Q102) Explain The Five Vs of Big Data The five Vs of Big Data are – Volume – Amount of data in the Petabytes and Exabytes Variety – Includes formats like an videos, audio sources, textual data, etc. Velocity – Everyday data growth which are includes conversations in forums,blogs,social media posts,etc. Veracity – Degree of accuracy of data are available Value – Deriving insights from collected data to the achieve business milestones and new heights Q103) How is Hadoop related to the Big Data ? Describe its components? Apache Hadoop is an open-source framework used for the storing, processing, and analyzing complex unstructured data sets for the deriving insights and actionable intelligence for businesses. The three main components of Hadoop are- MapReduce – A programming model which processes large datasets in the parallel HDFS – A Java-based distributed file system used for the data storage without prior organization YARN – A framework that manages resources and handles requests from the distributed applications Q104) Define HDFS and talk about their respective components? The Hadoop Distributed File System (HDFS) is the storage unit that’s responsible for the storing different types of the data blocks in the distributed environment. The two main components of HDFS are- NameNode – A master node that processes of metadata information for the data blocks contained in the HDFS DataNode – Nodes which act as slave nodes and a simply store the data, for use and then processing by the NameNode. Q105) Define YARN, and talk about their respective components? The Yet Another Resource Negotiator (YARN) is the processing component of the Apache Hadoop and is responsible for managing resources and providing an execution environment for said of processes. The two main components of YARN are- ResourceManager– Receives processing requests and allocates its parts to the respective Node Managers based on processing needs. Node Manager– Executes tasks on the every single Data Node Q106) Explain the term ‘Commodity Hardware? Commodity Hardware refers to hardware and components, collectively needed, to run the Apache Hadoop framework and related to the data management tools. Apache Hadoop requires 64-512 GB of the RAM to execute tasks, and any hardware that supports its minimum for the requirements is known as ‘Commodity Hardware. Q107) Define the Port Numbers for NameNode, Task Tracker and Job Tracker? Name Node – Port 50070 Task Tracker – Port 50060 Job Tracker – Port 50030 Q108) How does HDFS Index Data blocks? Explain. HDFS indexes data blocks based on the their respective sizes. The end of data block points to address of where the next chunk of data blocks get a stored. The DataNodes store the blocks of datawhile the NameNode manages these data blocks by using an in-memory image of all the files of said of data blocks. Clients receive for the information related to data blocked from the NameNode. 109. What are Edge Nodes in Hadoop? Edge nodes are gateway nodes in the Hadoop which act as the interface between the Hadoop cluster and external network.They run client applications and cluster administration tools in the Hadoop and are used as staging areas for the data transfers to the Hadoop cluster. Enterprise-class storage capabilities (like 900GB SAS Drives with Raid HDD Controllers) is required for the Edge Nodes,and asingle edge node for usually suffices for multiple of Hadoop clusters. Q110) What are some of the data management tools used with the Edge Nodes in Hadoop? Oozie,Ambari,Hue,Pig and Flume are the most common of data management tools that work with edge nodes in the Hadoop. Other similar tools include to HCatalog,BigTop and Avro. Q111) Explain the core methods of a Reducer? There are three core methods of a reducer. They are- setup() – Configures different to parameters like distributed cache, heap size, and input data. reduce() – A parameter that is called once per key with the concerned on reduce task cleanup() – Clears all temporary for files and called only at the end of on reducer task. Q112) Talk about the different tombstone markers used for deletion purposes in HBase.? There are three main tombstone markers used for the deletion in HBase. They are- Family Delete Marker – Marks all the columns of an column family Version Delete Marker – Marks a single version of an single column Column Delete Marker– Marks all the versions of an single column Q113) How would you transform unstructured data into structured data? How to Approach: Unstructured data is the very common in big data. The unstructured data should be transformed into the structured data to ensure proper data are analysis. Q114) Which hardware configuration is most beneficial for Hadoop jobs? Dual processors or core machines with an configuration of 4 / 8 GB RAM and ECC memory is ideal for running Hadoop operations. However, the hardware is configuration varies based on the project-specific workflow and process of the flow and need to the customization an accordingly. Q115) What is the use of the Record Reader in Hadoop? Since Hadoop splits data into the various blocks, RecordReader is used to read the slit data into the single record. For instance, if our input data is the split like: Row1: Welcome to Row2: Besant It will be read as the “Welcome to Besant” using RecordReader. Q116) What is Sequencefilein put format? Hadoop uses the specific file format which is known as the Sequence file. The sequence file stores data in the serialized key-value pair. Sequencefileinputformat is an input format to the read sequence files. Q117) What happens when two users try to access to the same file in HDFS? HDFS NameNode supports exclusive on write only. Hence, only the first user will receive to the grant for the file access & second that user will be rejected. Q118) How to recover an NameNode when it’s are down? The following steps need to execute to the make the Hadoop cluster up and running: Use the FsImage which is file system for metadata replicate to start an new NameNode. Configure for the DataNodes and also the clients to make them acknowledge to the newly started NameNode. Once the new NameNode completes loading to the last for checkpoint FsImage which is the received to enough block reports are the DataNodes, it will start to serve the client. In case of large of Hadoop clusters, the NameNode recovery process to consumes a lot of time which turns out to be an more significant challenge in case of the routine maintenance. Q119) What do you understand by the Rack Awareness in Hadoop? It is an algorithm applied to the NameNode to decide then how blocks and its replicas are placed. Depending on the rack definitions network traffic is minimized between DataNodes within the same of rack. For example, if we consider to replication factor as 3, two copies will be placed on the one rack whereas the third copy in a separate rack. Q120) What are the difference between of the “HDFS Block” and “Input Split”? The HDFS divides the input data physically into the blocks for processing which is known as the HDFS Block. Input Split is a logical division of data by the mapper for mapping operation. Q121) DFS can handle a large volume of data then why do we need Hadoop framework? Hadoop is not only for the storing large data but also to process those big data. Though DFS (Distributed File System) tool can be store the data, but it lacks below features- It is not fault for tolerant Data movement over the network depends on bandwidth. Q122) What are the common input formats are Hadoop? Text Input Format – The default input format defined in the Hadoop is the Text Input Format. Sequence File Input Format – To read files in the sequence, Sequence File Input Format is used. Key Value Input Format – The input format used for the plain text files (files broken into lines) is the Key Value for Input Format. Q123) Explain some important features of Hadoop? Hadoop supports are the storage and processing of big data. It is the best solution for the handling big data challenges. Some of important features of Hadoop are 1. Open Source – Hadoop is an open source framework which means it is available free of cost Also,the users are allowed to the change the source code as per their requirements. 2. Distributed Processing – Hadoop supports distributed processing of the data i.e. faster processing. The data in Hadoop HDFS is stored in the distributed manner and MapReduce is responsible for the parallel processing of data. 3. Fault Tolerance – Hadoop is the highly fault-tolerant. It creates three replicas for each block at different nodes, by the default. This number can be changed in according to the requirement. So, we can recover the data from the another node if one node fails. The detection of node of failure and recovery of data is done automatically. 4. Reliability – Hadoop stores data on the cluster in an reliable manner that is independent of the machine. So, the data stored in Hadoop environment is not affected by the failure of machine. 5. Scalability – Another important feature of Hadoop is the scalability. It is compatible with the other hardware and we can easily as the new hardware to the nodes. 6. High Availability – The data stored in Hadoop is available to the access even after the hardware failure. In case of hardware failure, the data can be accessed from the another path. Q124) Explain the different modes are which Hadoop run? Apache Hadoop runs are the following three modes – Standalone (Local) Mode – By default, Hadoop runs in the local mode i.e. on a non-distributed,single node. This mode use for the local file system to the perform input and output operation. This mode does not support the use of the HDFS, so it is used for debugging. No custom to configuration is needed for the configuration files in this mode. In the pseudo-distributed mode, Hadoop runs on a single of node just like the Standalone mode. In this mode, each daemon runs in the separate Java process. As all the daemons run on the single node, there is the same node for the both Master and Slave nodes. Fully – Distributed Mode – In the fully-distributed mode, all the daemons run on the separate individual nodes and thus the forms a multi-node cluster. There are different nodes for the Master and Slave nodes. Q125) What is the use of jps command in Hadoop? The jps command is used to the check if the Hadoop daemons are running properly or not. This command shows all the daemons running on the machine i.e. Datanode, Namenode, NodeManager, ResourceManager etc. Q126) What are the configuration parameters in the “MapReduce” program? The main configuration parameters in “MapReduce” framework are: Input locations of Jobs in the distributed for file system Output location of Jobs in the distributed for file system The input format of data The output format of data The class which contains for the map function The class which contains for the reduce function JAR file which contains for the mapper, reducer and the driver classes Q127) What is a block in HDFS? what is the default size in Hadoop 1 and Hadoop 2? Can we change the block size? Blocks are smallest continuous of data storage in a hard drive. For HDFS, blocks are stored across Hadoop cluster. The default block size in the Hadoop 1 is: 64 MB The default block size in the Hadoop 2 is: 128 MB Yes,we can change block size by using the parameters – dfs.block.size located in the hdfs-site.xml file. Q128) What is Distributed Cache in the MapReduce Framework? Distributed Cache is an feature of the Hadoop MapReduce framework to cache files for the applications. Hadoop framework makes cached files for available for every map/reduce tasks running on the data nodes. Hence, the data files can be access the cache file as the local file in the designated job. Q129) What are the three running modes of the Hadoop? The three running modes of the Hadoop are as follows: Standalone or local: This is the default mode and doesn’t need any configuration. In this mode, all the following components for Hadoop uses local file system and runs on single JVM – NameNode DataNode ResourceManager NodeManager Pseudo-distributed: In this mode, all the master and slave Hadoop services is deployed and executed on a single node. Fully distributed: In this mode, Hadoop master and slave services is deployed and executed on the separate nodes. Q130) Explain JobTracker in Hadoop? JobTracker is a JVM process in the Hadoop to submit and track MapReduce jobs. JobTracker performs for the following activities in Hadoop in a sequence – JobTracker receives jobs that an client application submits to the job tracker JobTracker notifies NameNode to determine data node JobTracker allocates TaskTracker nodes based on the available slots. It submits the work on the allocated TaskTracker Nodes, JobTracker monitors on the TaskTracker nodes. Q131) What are the difference configuration files in Hadoop? The different configuration files in Hadoop are – core-site.xml – This configuration file of contains Hadoop core configuration settings, for example, I/O settings, very common for the MapReduce and HDFS. It uses hostname an port. mapred-site.xml – This configuration file specifies a framework name for MapReduce by the setting mapreduce.framework.name hdfs-site.xml – This configuration file contains of HDFS daemons configuration for settings. It also specifies default block for permission and replication checking on HDFS. yarn-site.xml – This configuration of file specifies configuration settings for the ResourceManager and NodeManager. Q132) What are the difference between Hadoop 2 and Hadoop 3? Following are the difference between Hadoop 2 and Hadoop 3 – Kerberos are used to the achieve security in Hadoop. There are 3 steps to access an service while using Kerberos, at a high level. Each step for involves a message exchange with an server. Authentication – The first step involves authentication of the client to authentication server, and then provides an time-stamped TGT (Ticket-Granting Ticket) to the client. Authorization – In this step, the client uses to received TGT to request a service ticket from the TGS (Ticket Granting Server) Service Request – It is the final step to the achieve security in Hadoop. Then the client uses to service ticket to authenticate an himself to the server. Q133) What is commodity hardware? Commodity hardware is an low-cost system identified by the less-availability and low-quality. The commodity hardware for comprises of RAM as it performs an number of services that require to RAM for the execution. One doesn’t require high-end hardware of configuration or super computers to run of Hadoop, it can be run on any of commodity hardware. Q134) How is NFS different from HDFS? There are a number of the distributed file systems that work in their own way. NFS (Network File System) is one of the oldest and popular distributed file an storage systems whereas HDFS (Hadoop Distributed File System) is the recently used and popular one to the handle big data. Q135) How do Hadoop MapReduce works? There are two phases of the MapReduce operation. Map phase – In this phase, the input data is split by the map tasks. The map tasks run in the parallel. These split data is used for analysis for purpose. Reduce phase – In this phase, the similar split data is the aggregated from the entire to collection and shows the result. Q136) What is MapReduce? What are the syntax you use to run a MapReduce program? MapReduce is a programming model in the Hadoop for processing large data sets over an cluster of the computers, commonly known as the HDFS. It is a parallel to programming model. The syntax to run a MapReduce program is the hadoop_jar_file.jar /input_path /output_path. Q137) What are the different file permissions in the HDFS for files or directory levels? Hadoop distributed file system (HDFS) uses an specific permissions model for files and directories. 1. Following user levels are used in HDFS – Owner Group Others. 2. For each of the user on mentioned above following permissions are applicable – read (r) write (w) execute(x). 3. Above mentioned permissions work on differently for files and directories. For files The r permission is for reading an file The w permission is for writing an file. For directories The r permission lists the contents of the specific directory. The w permission creates or deletes the directory. The X permission is for accessing the child directory. Q138) What are the basic parameters of a Mapper? The basic parameters of a Mapper is the LongWritable and Text and Int Writable Q139) How to restart all the daemons in Hadoop? To restart all the daemons, it is required to the stop all the daemons first. The Hadoop directory contains sbin as directory that stores to the script files to stop and start daemons in the Hadoop. Use stop daemons command /sbin/stop-all.sh to the stop all the daemons and then use /sin/start-all.sh command to start all the daemons again. Q140) Explain the process that overwrites the replication factors in HDFS? There are two methods to the overwrite the replication factors in HDFS – Method 1: On File Basis In this method, the replication factor is the changed on the basis of file using to Hadoop FS shell. The command used for this is: $hadoop fs – setrep –w2/my/test_file Here, test_file is the filename that’s replication to factor will be set to 2. Method 2: On Directory Basis In this method, the replication factor is changed on the directory basis i.e. the replication factor for all the files under the given directory is modified. $hadoop fs –setrep –w5/my/test_dir Here, test_dir is the name of the directory, then replication factor for the directory and all the files in it will be set to 5. Q141) What will happen with a NameNode that doesn’t have any data? A NameNode without any for data doesn’t exist in Hadoop. If there is an NameNode, it will contain the some data in it or it won’t exist. Q142) Explain NameNode recovery process? The NameNode recovery process involves to the below-mentioned steps to make for Hadoop cluster running: In the first step in the recovery process, file system metadata to replica (FsImage) starts a new NameNode. The next step is to configure DataNodes and Clients. These DataNodes and Clients will then acknowledge of new NameNode. During the final step, the new NameNode starts serving to the client on the completion of last checkpoint FsImage for loading and receiving block reports from the DataNodes. Note: Don’t forget to mention, this NameNode recovery to process consumes an lot of time on large Hadoop clusters. Thus, it makes routine maintenance to difficult. For this reason, HDFS high availability architecture is recommended to use. Q143) How Is Hadoop CLASSPATH essential to start or stop Hadoop daemons? CLASSPATH includes necessary directories that contain the jar files to start or stop Hadoop daemons. Hence, setting the CLASSPATH is essential to start or stop on Hadoop daemons. However, setting up CLASSPATH every time its not the standard that we follow. Usually CLASSPATH is the written inside /etc/hadoop/hadoop-env.sh file. Hence, once we run to Hadoop, it will load the CLASSPATH is automatically. Q144) Why is HDFS only suitable for large data sets and not the correct tool to use for many small files? This is due to the performance issue of the NameNode.Usually, NameNode is allocated with the huge space to store metadata for the large-scale files. The metadata is supposed to be an from a single file for the optimum space utilization and cost benefit. In case of the small size files, NameNode does not utilize to the entire space which is a performance optimization for the issue. Q145) Why do we need Data Locality in Hadoop? Datasets in HDFS store as the blocks in DataNodes the Hadoop cluster. During the execution of the MapReducejob the individual Mapper processes to the blocks (Input Splits). If the data does not reside in the same node where the Mapper is the executing the job, the data needs to be copied from DataNode over the network to mapper DataNode. Now if an MapReduce job has more than 100 Mapper and each Mapper tries to copy the data from the other DataNode in cluster simultaneously, it would cause to serious network congestion which is an big performance issue of the overall for system. Hence, data proximity are the computation is an effective and cost-effective solution which is the technically termed as Data locality in the Hadoop. It helps to increase the overall throughput for the system. Enroll Now! Q146) What’s Big Big Data or Hooda? Only a concept that facilitates handling large data databases. Hadoop has a single framework for dozens of tools. Hadoop is primarily used for block processing. The difference between Hadoop, the largest data and open source software, is a unique and basic one. Q147) Big data is a good life? Analysts are increasing demand for industry and large data buildings. Today, many people are looking to pursue their large data industry by having great data jobs like freshers. However, the larger data itself is just a huge field, so it’s just Hadoop jobs for freshers Q148) What is the great life analysis of large data analysis? The large data analytics has the highest value for any company, allowing it to make known decisions and give the edge among the competitors. A larger data career increases the opportunity to make a crucial decision for a career move. Q149) Hope is a NoSQL? Hadoop is not a type of database, but software software that allows software for computer software. It is an application of some types, which distributes noSQL databases (such as HBase), allowing thousands of servers to provide data in lower performance to the rankings Q150) Need Hodop to Science? Data scientists have many technical skills such as Hadoto, NoSQL, Python, Spark, R, Java and more. … For some people, data scientist must have the ability to manage using Hoodab alongside a good skill to run statistics against data set. Q151)What is the difference between large data and large data analysis? On the other hand, data analytics analyzes structured or structured data. Although they have a similar sound, there are no goals. … Great data is a term of very large or complex data sets that are not enough for traditional data processing applications Q152) Why should you be a data inspector? A data inspector’s task role involves analyzing data collection and using various statistical techniques. … When a data inspector interviewed for the job role, the candidates must do everything they can to see their communication skills, analytical skills and problem solving skills Q153) Great Data Future? Big data refers to the very large and complex data sets for traditional data entry and data management applications. … Data sets continue to grow and applications are becoming more and more time-consuming, with large data and large dataprocessing cloud moving more Q154) What is a data scientist on Facebook? This assessment is provided by 85 Facebook data scientist salary report (s) employees or based on statistical methods. When a factor in bonus and extra compensation, a data scientist on Facebook expected an average of $ 143,000 in salary Q155) Can Hedop Transfer? HODOOP is not just enough to replace RDGMS, but it is not really what you want to do. … Although it has many advantages to the source data fields, Hadoopcannot (and usually does) replace a data warehouse. When associated with related databases. However, this creates a powerful and versatile solution. Get Big Data Hadoop Course Now! Q156) What’s happening in Hadoop? MapReduce is widely used in I / O forms, a sequence file is a flat file containing binary key / value pairs. Graphical publications are stored locally in sequencer. It provides Reader, Writer and Seater classes. The three series file formats are: Non-stick key / value logs. Record key / value records are compressed – only ‘values’ are compressed here. Pressing keys / value records – ‘Volumes’ are collected separately and shortened by keys and values. The ‘volume’ size can be configured. Q157) What is the Work Tracker role in Huda? The task tracker’s primary function, resource management (managing work supervisors), resource availability and monitoring of the work cycle (monitoring of docs improvement and wrong tolerance). This is a process that runs on a separate terminal, not often in a data connection. The tracker communicates with the label to identify the location of the data. The best mission to run tasks at the given nodes is to find the tracker nodes. Track personal work trackers and submit the overall job back to the customer. MapReduce works loads from the slush terminal. Q158) What is the RecordReader application in Hutch? Since the Hadoop data separates various blocks, recordReader is used to read split data in a single version. For example, if our input data is broken: Row1: Welcome Row2: Intellipaat It uses “Welcome to Intellipaat” using RecordReader. Q159)What is Special Execution in Hooda? A range of Hadoop, some sloping nodes, are available to the program by distributing tasks at many ends. Tehre is a variety of causes because the tasks are slow, which are sometimes easier to detect. Instead of identifying and repairing slow-paced tasks, Hopep is trying to find out more slowly than he expected, then backs up the other equivalent task. Hadoop is the insulation of this backup machine spectrum. This creates a simulated task on another disk. You can activate the same input multiple times in parallel. After most work in a job, the rest of the functions that are free for the time available are the remaining jobs (slowly) copy copy of the splash execution system. When these tasks end, it is reported to JobTracker. If other copies are encouraging, Hudhoft dismays the tasktakers and dismiss the output. Hoodab is a normal natural process. To disable, set mapred.map.tasks.speculative.execution and mapred.reduce.tasks.speculative.execution Invalid job options Q160) What happens if you run a hood job? It will throw an exception that the output file directory already exists. To run MapReduce task, you need to make sure you do not have a pre-release directory in HDFS. To delete the directory before you can work, you can use the shell: Hadoop fs -rmr / path / to / your / output / or via Java API: FileSystem.getlocal (conf) .delete (outputDir, true); Get Hadoop Course Now! Q161) How can you adjust the Hadoopo code? Answer: First, check the list of currently running MapReduce jobs. Next, we need to see the orphanage running; If yes, then you have to determine the location of the RM records. Run: “ps -ef | grep -I ResourceManager” And search result log in result displayed. Check the job-id from the displayed list and check if there is any error message associated with the job. Based on RM records, identify the employee tip involved in executing the task. Now, log on to that end and run – “ps -ef | grep -iNodeManager” Check the tip manager registration. Major errors reduce work from user level posts for each diagram. Q162) How should the reflection factor in FFAS be constructed? Answer: Hdfs-site.xml is used to configure HDFS. Changing the dfs.replication property on hdfs-site.xml will change the default response to all files in HDFS. You can change the reflection factor based on a file you are using Hadoop FS shell: $ hadoopfs -setrep -w 3 / n / fileConversely, You can also change the reflection factors of all the files under a single file. $ hadoopfs-setrep -w 3 -R / my / dir Now go through the Hadoop administrative practice to learn about the reflection factor in HDFS! Q163) How to control the release of the mapper, but does the release issue not? Answer: To achieve this summary, you must set: conf.set (“mapreduce.map.output.compress”, true) conf.set (“mapreduce.output.fileoutputformat.compress”, incorrect) Q164) Which companies use a hoop? Learn how Big Data and HADOOP have changed the rules of the game in this blog post. Yahoo (the largest contribution to the creation of the hawkop) – Yahoo search engine created for Hadoop, Facebook – Analytics, Amazon, Netflix, Adobe, Ebay, Spadys, Twitter, Adobe. Q165) Do I have to know Java to learn the habit? The ability of MapReduce in Java is an additional plus but not needed. … learn the Hadoop and create an excellent business with Hadoo, knowing basic basic knowledge of Linux and Java Basic Programming Policies Q166) What should you consider when using the second name line? Secondary mode should always be used on a separate separate computer. This prevents intermittent interaction with the mainstream. Q167) Name the Hadoop code as executable modes. There are various methods to run the Hadoop code – Fully distributed method Pseudosiphrit method Complete mode Q168)Name the operating system supported by the hadoop operation. Linux is the main operating system. However, it is also used as an electric power Windows operating system with some additional software. Q169) HDFS is used for applications with large data sets, not why Many small files? HDFS is more efficient for a large number of data sets, maintained in a file Compared to smaller particles of data stored in multiple files. Saving NameNode The file system metadata in RAM, the amount of memory that defines the number of files in the HDFS file System. In simpler terms, more files will generate more metadata, which means more Memory (RAM). It is recommended that you take 150 bytes of a block, file or directory metadata. Q170) What are the main features of hdfssite.xml? There are three important properties of hdfssite.xml: data.dr – Identify the location of the data storage. name.dr – Specify the location of the metadata storage and specify the DFS is located On disk or remote location. checkpoint.dir – for the second name name. Q171) What are the essential hooping tools that improve performance? Big data? Some of the essential hoopoe tools that enhance large data performance – Hive, HDFS, HBase, Avro, SQL, NoSQL, Oozie, Clouds, Flume, SolrSee / Lucene, and ZooKeeper Q172) What do you know about Fillil soon? The sequence is defined as a flat file containing the binary key or value pairs. This is important Used in MapReduce’s input / output format. Graphical publications are stored locally SequenceFile. Several forms of sequence – Summary of record key / value records – In this format, the values are compressed. Block compressed key / value records – In this format, the values and keys are individually The blocks are stored and then shortened. Sticky Key / Value Entries – In this format, there are no values or keys. Get 100% Placement Oriented Training in Hadoop! Q173) Explain the work tracker’s functions. In Hadoop, the work tracker’s performers perform various functions, such as – It manages resources, manages resources and manages life cycle Tasks. It is responsible for finding the location of the data by contacting the name Node. It performs tasks at the given nodes by finding the best worker tracker. Work Tracker Manages to monitor all task audits individually and then submit The overall job for the customer. It is responsible for supervising local servicemen from Macpute’s workplace Node. Q174) The FASAL is different from NAS? The following points distinguish HDFS from NAS – Hadoop shared file system (HDFS) is a distributed file system that uses data Network Attached Storage (NAS) is a file-wide server Data storage is connected to the computer network. HDFS distributes all databases in a distributed manner As a cluster, NAS saves data on dedicated hardware. HDFS makes it invaluable when using NAS using materials hardware Data stored on highhend devices that include high spending The HDFS work with MapReduce diagram does not work with MapReduce Data and calculation are stored separately. Q175)Does the HDFS go wrong? If so, how? Yes, HDFS is very mistaken. Whenever some data is stored in HDFS, name it Copying data (copies) to multiple databases. Normal reflection factor is 3. It needs to be changed according to your needs. If DataNode goes down, NameNode will take Copies the data from copies and copies it to another node, thus making the data available automatically. TheThe way, as the HDFS is the wrong tolerance feature and the fault tolerance Q176) Distinguish HDFS Block and Input Unit. The main difference between HDFS Block and Input Split is HDFS Black. While the precise section refers to the input sector, the business section of the data is knownData. For processing, HDFS first divides the data into blocks, and then stores all the packages Together, when MapReduce divides the data into the first input section then allocate this input and divide it Mapper function. Q177) What happens when two clients try to access the same file on HDFS? Remember that HDFS supports specific characters Only at a time). NName client nameNode is the nameNode that gives the name Node Lease the client to create this file. When the second client sends the request to open the same file To write, the lease for those files is already supplied to another customer, and the name of the name Reject second customer request. Q178) What is the module in HDFS? The location for a hard drive or a hard drive to store data As the volume. Store data blocks in HDFS, and then distributed via the hoodo cluster. The entire file is divided into the first blocks and stored as separate units. Q179) What is Apache? YARN still has another resource negotiation. This is a hoodup cluster Management system. It is also the next generation introduced by MapReduce and Hoodab 2 Account Management and Housing Management Resource Management. It helps to further support the hoodoop Different processing approaches and wide-ranging applications. Q180) What is the terminal manager? Node Manager is TARStracker’s YARN equivalent. It takes steps from it Manages resourceManager and single-source resources. This is the responsibility Containers and ResourceManager monitor and report their resource usage. Each Single container processes operated at slavery pad are initially provided, monitored and tracked By the tip manager associated with the slave terminal. Q181) What is the recording of the Hope? In Hadoop, RecordReader is used to read a single log split data. This is important Combining data, Hatopo divides data into various editions. For example, if input data is separated Row1: Welcome Line 2: The Hoodah’s World Using RecordReader, it should be read as “Welcome to the Hope World”. Q182) Shorten up the mappers do not affect the Output release? Answer: In order to minimize the output of the maple, the output will not be affected and set as follows: Conf.set (“mapreduce.map.output.compress”, true) Conf.set (“mapreduce.output.fileoutputformat.compress”, incorrect) Q183) A Reducer explain different methods. Answer: Various methods of a Reducer include: System () – It is used to configure various parameters such as input data size. Syntax: general vacuum system (environment) Cleaning () – It is used to clean all temporary files at the end of the task. Syntax: General Vacuum Cleanup (Eco) Reduce () – This method is known in the heart of Rezar. This is used once A key to the underlying work involved. Syntax: reduce general void (key, value, environment) Q184) How can you configure the response factor in the HDFL? For the configuration of HDFS, the hdfssite.xml file is used. Change the default value The reflection factor for all the files stored in HDFS is transferred to the following asset hdfssite.xml dfs.replication Q185) What is the use of the “jps” command? The “Jps” command is used to verify that the Hadoop daemons state is running. TheList all hadoop domains running in the command line. Namenode, nodemanager, resource manager, data node etc Q186) What is the next step after Mapper or Mumpask?: The output of the map is sorted and the partitions for the output will be created. The number of partitions depends on the number of disadvantages. Q187) How do we go to the main control for a certain reduction? Any Reducer can control the keys (through which posts) by activating the custom partition. Q188) What is the use of the coordinator? It can be specified by Job.setCombinerClass (ClassName) to make local integration with a custom component or class, and intermediate outputs, which helps reduce the size of the transfers from the Mapper to Reducer. Q189) How many maps are there in specific jobs? The number of maps is usually driven by total inputs, that is, the total volume of input files. Usually it has a node for 10-100 maps. The work system takes some time, so it is best to take at least a minute to run maps. If you expect 10TB input data and have a 128MB volume, you will end up with 82,000 maps, which you can control the volume of the mapreduce.job.maps parameter (this only provides a note structure). In the end, the number of tasks are limited by the number of divisions returned by the InputFormat.getSplits () over time (you can overwrite). Q190) What is the use of defect? Reducer reduces the set of intermediate values, which shares one key (usually smaller) values. The number of job cuts is set by Job.setNumReduceTasks (int). Q191) Explain Core modalities of deficiency? The Reducer API is similar to a Mapper, a run () method, which modes the structure of the work and the reconfiguration of the reconfiguration framework from reuse. Run () method once (), minimize each key associated with the task to reduce (once), and finally clean up the system. Each of these methods can be accessed using the context structure of the task using Context.getConfiguration (). As for the mapper type, these methods may be violated with any or all custom processes. If none of these methods are violated, the default reduction action is a symbolic function; Values go further without processing. Reducer heart is its reduction (method). This is called a one-time one; The second argument is Iterable, which provides all the key related values. Q192) What are the early stages of deficiency? Shake, sort and lower. 193) Shuffle’s explanation? Reducer is a sorted output of input mappers. At this point, the configuration receives a partition associated with the output of all the mappers via HTTP. 194) Explain the Reducer’s Line Stage? Structured groups at this point are Reducer entries with the keys (because different movers may have the same key output). Mixed and sequence phases occur simultaneously; They are combined when drawing graphic outputs (which are similar to the one-sequence). 195) Explain Criticism? At this point the reduction (MapOutKeyType, Iterable, environment) method is grouped into groups for each group. Reduction work output is typically written to FileSystem via Context.write (ReduceOutKeyType, ReduceOutValType). Applications can use application progress status, set up application level status messages, counters can update, or mark their existence. Reducer output is not sorted. Big Data Questions and Answers Pdf Download Read the full article
0 notes
Link
Ingestion of Big Data Using Apache Sqoop & Apache Flume ##elearning ##freetutorials #Apache #Big #Data #Flume #Ingestion #Sqoop Ingestion of Big Data Using Apache Sqoop & Apache Flume This course provides basic and advanced concepts of Sqoop. This course is designed for beginners and professionals. Sqoop is an open source framework provided by Apache. It is a command-line interface application for transferring data between relational databases and Hadoop. This course includes all topics of Apache Sqoop with Sqoop features, Sqoop Installation, Starting Sqoop, Sqoop Import, Sqoop where clause, Sqoop Export, Sqoop Integration with Hadoop ecosystem etc. Flume is a standard, simple, robust, flexible, and extensible tool for data ingestion from various data producers (webservers) into Hadoop. In this course, we will be using simple and illustrative example to explain the basics of Apache Flume and how to use it in practice. This wonderful online course on Sqoop Training is a detailed course which will help you understand all the important concepts and topics of Sqoop Training. Through this Sqoop Training, you will learn that Sqoop permits quick and rapid import as well as export of data from data stores which are structured such as relational databases, NoSQL systems and enterprise data warehouse. 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/ingestion-of-big-data-using-apache-sqoop-apache-flume/
0 notes
Text
Big Data Hadoop Training Course

Introduction to big data hadoop: Big Data Hadoop has ability to record the data in a format. With information volumes going bigger step by step with the development of online life, considering this innovation is essential. A place where hadoop used are scenario. There has available versions of Hadoop are 1. x & 2. x. The overview of batch processing and real-time data analytics using Hadoop vendors–Apache, Cloudera, Hortonworks. Hadoop services–HDFS, MapReduce, YARN Introduction to Hadoop Ecosystem components (Hive, Hbase, Pig, Sqoop, Flume, Zookeeper, Oozie, Kafka, Spark).
Cluster setup:
It is a Linux VM installation on system for Hadoop cluster using Oracle Virtual-box. It Preparing a node for Hadoop and VM setting and Install Java and configure password less SSH across nodesasic Linux command. The Hadoop1.x single node deployment is work on Hadoop Daemons–NameNode, JobTacker, DataNode, Task tracker, Secondary Name Node. Hadoop configuration files and running. The Important web URLs and Logs for Hadoop Run HDFS and Linux command Hadoop 1. x multi-mode deployment Run sample jobs in Hadoop single and multi-node clusters.
HDFS concepts:
HDFS Design Goals are understand Blocks and how to configuration the block size. Block replication and replication factor are to understand the Hadoop Rack Awareness and configure racks in Hadoop. The hadoop File read and write anatomy in HDFSE enable HDFS, Trash Configure, HDFS Name and space Quota Configure and use of WebHDFS (Rest API For HDFS). In the health monitoring using FSCK command those understand NameNode Safemode, File system image and edits Configure Secondary NameNode and use check pointing process to provide NameNode fail-over HDFS DFSAdmin and File system shell commands. Hadoop NameNode / DataNode directory structure HDFS permissions modelHDFS Offline Image Viewer.
YARN (Yet Another Resource Negotiator):
Yarn has Components they are–Resource Manager, Node Manager, Job History Server, Application Timeline Server. They understood MR and Configure Capacity/ Fair Schedulers in YARN.The Define and configure Queues Job History Server / Application Timeline Server YARN Rest API Writing and executing YARN application.
APACHE:
Apache Hadoop is an accumulation of open-source programming utilities that encourage using a system of many PCs to tackle issues including enormous measures of information and calculation.
Apache flume
Apache pig
Apache sqoop
Apache zookeeper
Apache oozie
Apache hbase
Apache spark, storm and Kafka.
Conclusion:
Big Data Hadoop Training Classes
gives you a chance to ace the ideas of the Hadoop structure and sets you up for Cloudera CCA175 Big information confirmation. With our online Hadoop preparing, you will figure out how the segments of the Hadoop biological community, for example, Hadoop 3.4, Yarn, MapReduce, HDFS, Pig, Impala, HBase, Flume, Apache Spark, and so forth fit in with the Big Data handling life-cycle. Execute genuine tasks in banking, telecom, web-based social networking, protection, and web-based business on CloudLab.
0 notes
Text
February 11, 2020 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/37kIn4G #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
Apache Sqoop in Hadoop
Rainbow Training Institute provides the best Big Data and Hadoop online training. Enroll for big data Hadoop training in Hyderabad certification, delivered by Certified Big Data Hadoop Experts. Here we are offering big data Hadoop training across global.
What is SQOOP in Hadoop?
Apache Sqoop (SQL-to-Hadoop) is intended to help mass import of data into HDFS from organized data stores, for example, social databases, undertaking data stockrooms, and NoSQL frameworks. Sqoop depends on a connector engineering that underpins modules to give network to new outside frameworks.
A model use instance of Sqoop is an undertaking that runs a daily Sqoop import to stack the day's data from a creation value-based RDBMS into a Hive data distribution center for additional examination.
Sqoop Architecture
All the current Database Management Systems are planned in light of SQL standard. In any case, every DBMS varies as for lingo somewhat. In this way, this distinction presents difficulties with regard to data moves over the frameworks. Sqoop Connectors are segments that help conquer these difficulties.
Data move among Sqoop and outside stockpiling framework is made conceivable with the assistance of Sqoop's connectors.
Sqoop has connectors for working with a scope of mainstream social databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Every one of these connectors realizes how to collaborate with its related DBMS. There is additionally a conventional JDBC connector for interfacing with any database that supports Java's JDBC convention. Moreover, Sqoop gives improved MySQL and PostgreSQL connectors that utilization database-explicit APIs to perform mass exchanges effectively.
What is Sqoop? What is FLUME - Hadoop
Sqoop Architecture
What's more, Sqoop hosts different third-gathering connectors for data stores, going from big business data distribution centers (counting Netezza, Teradata, and Oracle) to NoSQL stores, (for example, Couchbase). Be that as it may, these connectors don't accompany the Sqoop group; those should be downloaded independently and can be added effectively to a current Sqoop establishment.
For what reason do we need Sqoop?
Scientific preparation utilizing Hadoop requires the stacking of gigantic measures of data from assorted sources into Hadoop groups. This procedure of mass data load into Hadoop, from heterogeneous sources and afterward preparing it, accompanies a specific arrangement of difficulties. Keeping up and guaranteeing data consistency and guaranteeing productive use of assets, are a few elements to consider before choosing the correct methodology for data load.
Significant Issues:
1. Data load utilizing Scripts
The conventional methodology of utilizing contents to stack data isn't appropriate for mass data load into Hadoop; this methodology is wasteful and very tedious.
2. Direct access to outer data through Map-Reduce application
Giving direct access to the data living at outer systems(without stacking into Hadoop) for map-lessen applications muddles these applications. Thus, this methodology isn't possible.
3. Notwithstanding being able to work with huge data, Hadoop can work with data in a few distinct structures. Thus, to load such heterogeneous data into Hadoop, various devices have been created. Sqoop and Flume are two such data stacking apparatuses.
0 notes
Text
300+ TOP FLUME Interview Questions and Answers
FLUME Interview Questions and Answers :-
1. What is Flume? Flume is a distributed service for collecting, aggregating, and moving large amounts of log data. 2. Explain about the core components of Flume. The core components of Flume are – Event- The single log entry or unit of data that is transported. Source- This is the component through which data enters Flume workflows. Sink- It is responsible for transporting data to the desired destination. Channel- it is the duct between the Sink and Source. Agent- Any JVM that runs Flume. Client- The component that transmits event to the source that operates with the agent. 3. Which is the reliable channel in Flume to ensure that there is no data loss? FILE Channel is the most reliable channel among the 3 channels JDBC, FILE and MEMORY. 4. How can Flume be used with HBase? Apache Flume can be used with HBase using one of the two HBase sinks – HBaseSink (org.apache.flume.sink.hbase.HBaseSink) supports secure HBase clusters and also the novel HBase IPC that was introduced in the version HBase 0.96. AsyncHBaseSink (org.apache.flume.sink.hbase.AsyncHBaseSink) has better performance than HBase sink as it can easily make non-blocking calls to HBase. Working of the HBaseSink – In HBaseSink, a Flume Event is converted into HBase Increments or Puts. Serializer implements the HBaseEventSerializer which is then instantiated when the sink starts. For every event, sink calls the initialize method in the serializer which then translates the Flume Event into HBase increments and puts to be sent to HBase cluster. Working of the AsyncHBaseSink- AsyncHBaseSink implements the AsyncHBaseEventSerializer. The initialize method is called only once by the sink when it starts. Sink invokes the setEvent method and then makes calls to the getIncrements and getActions methods just similar to HBase sink. When the sink stops, the cleanUp method is called by the serializer. 5. What is an Agent? A process that hosts flume components such as sources, channels and sinks, and thus has the ability to receive, store and forward events to their destination. 6. Is it possible to leverage real time analysis on the big data collected by Flume directly? If yes, then explain how? Data from Flume can be extracted, transformed and loaded in real-time into Apache Solr servers usingMorphlineSolrSink 7. Is it possible to leverage real time analysis on the big data collected by Flume directly? If yes, then explain how. Data from Flume can be extracted, transformed and loaded in real-time into Apache Solr servers using MorphlineSolrSink 8. What is a channel? It stores events,events are delivered to the channel via sources operating within the agent.An event stays in the channel until a sink removes it for further transport. 9. Explain about the different channel types in Flume. Which channel type is faster? The 3 different built in channel types available in Flume are- MEMORY Channel – Events are read from the source into memory and passed to the sink. JDBC Channel – JDBC Channel stores the events in an embedded Derby database. FILE Channel –File Channel writes the contents to a file on the file system after reading the event from a source. The file is deleted only after the contents are successfully delivered to the sink. MEMORY Channel is the fastest channel among the three however has the risk of data loss. The channel that you choose completely depends on the nature of the big data application and the value of each event. 10. What is Interceptor? An interceptor can modify or even drop events based on any criteria chosen by the developer.

FLUME Interview Questions 11. Explain about the replication and multiplexing selectors in Flume. Channel Selectors are used to handle multiple channels. Based on the Flume header value, an event can be written just to a single channel or to multiple channels. If a channel selector is not specified to the source then by default it is the Replicating selector. Using the replicating selector, the same event is written to all the channels in the source’s channels list. Multiplexing channel selector is used when the application has to send different events to different channels. 12. Does Apache Flume provide support for third party plug-ins? Most of the data analysts use Apache Flume has plug-in based architecture as it can load data from external sources and transfer it to external destinations. 13. Apache Flume support third-party plugins also? Yes, Flume has 100% plugin-based architecture, it can load and ships data from external sources to external destination which seperately from Flume. SO that most of the bidata analysis use this tool for sreaming data. 14. Differentiate between FileSink and FileRollSink The major difference between HDFS FileSink and FileRollSink is that HDFS File Sink writes the events into the Hadoop Distributed File System (HDFS) whereas File Roll Sink stores the events into the local file system. 15. How can Flume be used with HBase? Apache Flume can be used with HBase using one of the two HBase sinks – HBaseSink (org.apache.flume.sink.hbase.HBaseSink) supports secure HBase clusters and also the novel HBase IPC that was introduced in the version HBase 0.96. AsyncHBaseSink (org.apache.flume.sink.hbase.AsyncHBaseSink) has better performance than HBase sink as it can easily make non-blocking calls to HBase. Working of the HBaseSink – In HBaseSink, a Flume Event is converted into HBase Increments or Puts. Serializer implements the HBaseEventSerializer which is then instantiated when the sink starts. For every event, sink calls the initialize method in the serializer which then translates the Flume Event into HBase increments and puts to be sent to HBase cluster. Working of the AsyncHBaseSink- AsyncHBaseSink implements the AsyncHBaseEventSerializer. The initialize method is called only once by the sink when it starts. Sink invokes the setEvent method and then makes calls to the getIncrements and getActions methods just similar to HBase sink. When the sink stops, the cleanUp method is called by the serializer. 16. Can Flume can distribute data to multiple destinations? Yes. It support multiplexing flow. The event flows from one source to multiple channel and multiple destionations, It is acheived by defining a flow multiplexer/ 17. How multi-hop agent can be setup in Flume? Avro RPC Bridge mechanism is used to setup Multi-hop agent in Apache Flume. 18. Why we are using Flume? Most often Hadoop developer use this too to get lig data from social media sites. Its developed by Cloudera for aggregating and moving very large amount if data. The primary use is to gather log files from different sources and asynchronously persist in the hadoo cluster. 19. What is FlumeNG A real time loader for streaming your data into Hadoop. It stores data in HDFS and HBase. You’ll want to get started with FlumeNG, which improves on the original flume. 20. Can fume provides 100% reliablity to the data flow? Yes, it provide end-to-end reliability of the flow. By default uses a transactional approach in the data flow. Source and sink encapsulate in a transactional repository provides by the channels. This channels responsible to pass reliably from end to end flow. so it provides 100% reliability to the data flow. 21. What is sink processors? Sinc processors is mechanism by which you can create a fail-over task and load balancing. 22. Explain what are the tools used in Big Data? Tools used in Big Data includes Hadoop Hive Pig Flume Mahout Sqoop 23. Agent communicate with other Agents? NO each agent runs independently. Flume can easily horizontally. As a result there is no single point of failure. 24. Does Apache Flume provide support for third party plug-ins? Most of the data analysts use Apache Flume has plug-in based architecture as it can load data from external sources and transfer it to external destinations. 25. what are the complicated steps in Flume configurations? Flume can processing streaming data. so if started once, there is no stop/end to the process. asynchronously it can flows data from source to HDFS via agent. First of all agent should know individual components how they are connect to load data. so configuration is trigger to load streaming data. for example consumer key, consumer secret access Token and access Token Secret are key factor to download data from twitter. 26. Which is the reliable channel in Flume to ensure that there is no data loss? FILE Channel is the most reliable channel among the 3 channels JDBC, FILE and MEMORY. 27. What are Flume core components Cource, Channels and sink are core components in Apache Flume. When Flume source recieves event from externalsource, it stores the event in one or multiple channels. Flume channel is temporarily store and keep the event until’s consumed by the Flume sink. It act as Flume repository. Flume Sink removes the event from channel and put into an external repository like HDFS or Move to the next flume. 28. What are the Data extraction tools in Hadoop? Sqoop can be used to transfer data between RDBMS and HDFS. Flume can be used to extract the streaming data from social media, web log etc and store it on HDFS. 29. What are the important steps in the configuration? Configuration file is the heart of the Apache Flume’s agents. Every Source must have atleast one channel. Every Sink must have only one channel Every Components must have a specific type. 30. Differentiate between File Sink and File Roll Sink? The major difference between HDFS File Sink and File Roll Sink is that HDFS File Sink writes the events into the Hadoop Distributed File System (HDFS) whereas File Roll Sink stores the events into the local file system. 31. What is Apache Spark? Spark is a fast, easy-to-use and flexible data processing framework. It has an advanced execution engine supporting cyclic data flow and in-memory computing. Spark can run on Hadoop, standalone or in the cloud and is capable of accessing diverse data sources including HDFS, HBase, Cassandra and others. 32. What is Apache Flume? Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data source. Review this Flume use case to learn how Mozilla collects and Analyse the Logs using Flume and Hive. Flume is a framework for populating Hadoop with data. Agents are populated throughout ones IT infrastructure – inside web servers, application servers and mobile devices, for example – to collect data and integrate it into Hadoop. 33. What is flume agent? A flume agent is JVM holds the flume core components(source, channel, sink) through which events flow from an external source like web-servers to destination like HDFS. Agent is heart of the Apache Flime. 34. What is Flume event? A unit of data with set of string attribute called Flume event. The external source like web-server send events to the source. Internally Flume has inbuilt functionality to understand the source format. Each log file is consider as an event. Each event has header and value sectors, which has header information and appropriate value that assign to articular header. 35. What are the Data extraction tools in Hadoop? Sqoop can be used to transfer data between RDBMS and HDFS. Flume can be used to extract the streaming data from social media, web log etc and store it on HDFS. 36. Does Flume provide 100% reliability to the data flow? Yes, Apache Flume provides end to end reliability because of its transactional approach in data flow. 37. Why Flume.? Flume is not limited to collect logs from distributed systems, but it is capable of performing other use cases such as Collecting readings from array of sensors Collecting impressions from custom apps for an ad network Collecting readings from network devices in order to monitor their performance. Flume is targeted to preserve the reliability, scalability, manageability and extensibility while it serves maximum number of clients with higher QoS 38. can you explain about configuration files? The agent configuration is stored in local configuration file. it comprises of each agents source, sink and channel information. Each core components such as source, sink and channel has properties such as name, type and set properties 39. Tell any two feature Flume? Fume collects data eficiently, aggrgate and moves large amount of log data from many different sources to centralized data store. Flume is not restricted to log data aggregation and it can transport massive quantity of event data including but not limited to network traffice data, social-media generated data , email message na pretty much any data storage. FLUME Questions and Answers pdf Download Read the full article
0 notes
Link
Big Data Ingestion Using Sqoop and Flume - CCA and HDPCD ##UdemyFreeCourses #Big #CCA #Data #Flume #HDPCD #Ingestion #Sqoop Big Data Ingestion Using Sqoop and Flume - CCA and HDPCD In this course, you will start by learning what is hadoop distributed file system and most common hadoop commands required to work with Hadoop File system. Then you will be introduced to Sqoop Import Understand lifecycle of sqoop command. Use sqoop import command to migrate data from Mysql to HDFS. Use sqoop import command to migrate data from Mysql to Hive. Use various file formats, compressions, file delimeter,where clause and queries while importing the data. Understand split-by and boundary queries. Use incremental mode to migrate the data from Mysql to HDFS. Further, you will learn Sqoop Export to migrate data. What is sqoop export Using sqoop export, migrate data from HDFS to Mysql. Using sqoop export, migrate data from Hive to Mysql. Finally, we will start with our last section about Apache Flume Understand Flume Architecture. Using flume, Ingest data from Twitter and save to HDFS. Using flume, Ingest data from netcat and save to HDFS. Using flume, Ingest data from exec and show on console. Describe flume interceptors and see examples of using interceptors. Who this course is for: Who want to learn sqoop and flume or who are preparing for CCA and HDPCD certifications 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/big-data-ingestion-using-sqoop-and-flume-cca-and-hdpcd/
0 notes