#tsv chapter 11
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Silt Verses Chapter 11 really did knock it out of the park with this line delivery by Paige


#the silt verses#tsv#tsv chapter 11#the silt verses chapter 11#tsv 11#paige is really growing on me especially during my relisten
51 notes
·
View notes
Note
you fucking got me. i listened to like 1 1/2 tsv episodes over summer and enjoyed it but didn't have time for a podcast i couldn't parse over the sound of a construction site, but then you started posting about it and i belatedly realised i work from home rn and then you Fucking Got Me. chrissy how do i recover. how do i recover from chapter 45. please. pl ease.
WE GOT ANOTHER ONE.
The correct way to recover from chapter 45 is to start again from chapter 1 and feel slightly insane the whole time.
#my beloved Paige in chapter 11: [holding Faulkner who's dying] we're taking him to a -dump-?#me: honestly. a good plan. i think you should leave him there this time around. trust me you'll avoid so much bullshit#chrissy listens to tsv#the silt verses
30 notes
·
View notes
Text
TSV Fan Favorite Survey Results
Last week I made a small TSV survey for the heck of it and ended up getting way more results than I originally expected!! Wanted to share the results.


When I'm in a "Who's your favorite TSV main character" competition and my opponent is Carpenter 🤯 (Okay but.. is anyone surprised?)
Fun fact: for a while Hayward had only one or two votes and idk why that surprised me so much. Though I'm shocked he got more than Faulkner overall
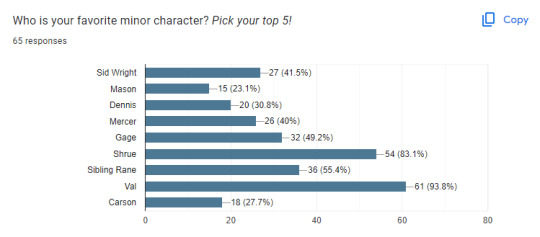
Top 5 minor characters, as voted: Val > Shrue > Sibling Rane > Gage > Sid Wright
Also unsurprising! Though I regret that I didn't word the question as "Pick up to 5" instead of top 5. Val almost got 100% of the votes in this category... off by 4.. I respect you but also who are you 4 I just want to know

Top 5 side characters, as voted: Acantha > Nana Glass / Greve > Charity / Elgin > The Homesick Corpse > Chuck Harm (though Cross came very close to tying!!)
Acantha at the top is also unsurprising! Though.. looking at the top one.. looks like we all have a thing for old ladies, huh? Definitely my mistake in that I didn't add Em and Vaughn in there to begin with��� Shoutout to the one person who voted Helen. Also, we love to see that Daggler got 0 votes.

Favorite God, as voted: Th Cairn Maiden > The Many Below > The Trawlerman > The Watcher in the Wings > The Saint Electric
The Beast that Stalks in the Long Grass and The Last Word each got one vote. Also, The Chitterling got a vote. Henge, the god Hayward mentions in s1, the one that takes things people wish to lose, got two votes! :D Idk why, but it's such an unexpected pull to me, it makes me happy to see it was remembered!

Top 5 s1 episodes, as voted: Chapter 4 > Chapter 7 & Chapter 15 > Chapter 1 > Chapter 13 > Chapter 3, 8, 11, & 12 (tied with 3 votes)
Fun fact: of season 1 episodes, only 4/15 episodes weren't picked as someone's favorite!!

Top 5 s2 episodes, as voted: Chapter 24 > Chapter 29 > Chapter 19 > Chapter 17 > Chapter 23
Also not surprised because chapter 24 is also my favorite (probably my most relistened to episode and it still makes me cry). Though, I will say, I was surprised chapter 20 didn't have more votes since that one also seems to be a favorite writing wise!
Fun fact: of all s2 episodes, only 1 episode wasn't picked as someone's favorite! (okay, idk why it's important to me to point out, I just think it's interesting!! Though I can admit I could probably phrase it better. I think the fave episodes are spread out pretty evenly for each season though, which is really neat in my opinion.)

Top 5 s3 episodes, as voted: Chapter 46 > Chapter 38 > Chapter 37 > Chapter 36 (we are not immune to a good tragic love story, I see) & Chapter 43 > Chapter 44
For a while, Chapter 38 had the most votes which I thought was.. idk how to better phrase it, but.. sweet. Because Carpenter's returning home episode was the fave of s2 and if Faulkner's returning home episode had also been the fave... something something we sure do love these terrible siblings, huh? But! Unsurprisingly the finale is the big fave of the season. How many of us have recovered from it??
Fun fact: Of season 3, only 3 episodes weren't chosen!

Boooo I shouldn't have given y'all the option to abstain from picking!! "Don't make me choose," you cowards!! /lh


mandatory link to this recommendation
Favorite episode title:
Hi. So, um. I'm an idiot. And didn't realize that Google Form automatically turns short answers into a bar graph. So unfortunately, the results for this one is..well

And half of these are the exact same title with slightly different phrasing 🙃
BUT I'm nothing if not determined so I went through and organized everything though I didn't make a pie chart. Needless to say. I think we all know the favorite episode title (care to make a guess?)




Favorite episode title: But We'll Never Be Rid of Each Other (25%)
Its Wrath Shall Scald the Sun came second with only 9% of the vote. We sure do love our doomed siblings, huh?
#the silt verses#feel free to ask me for any specifics if you'd like!#typing this all out at 2am and this post is really long as it is so I didn't want to get too carried away with sharing#EDIT: I ACCIDENTALLY POSTED THIS BUT I HAVE A PART 2 FOR FAVORITE QUOTES I'M WORKING ON AKDKSK
57 notes
·
View notes
Text
Quotes from the book Data Science on AWS
Data Science on AWS
Antje Barth, Chris Fregly
As input data, we leverage samples from the Amazon Customer Reviews Dataset [https://s3.amazonaws.com/amazon-reviews-pds/readme.html]. This dataset is a collection of over 150 million product reviews on Amazon.com from 1995 to 2015. Those product reviews and star ratings are a popular customer feature of Amazon.com. Star rating 5 is the best and 1 is the worst. We will describe and explore this dataset in much more detail in the next chapters.
*****
Let’s click Create Experiment and start our first Autopilot job. You can observe the progress of the job in the UI as shown in Figure 1-11.
--
Amazon AufotML experiments
*****
...When the Feature Engineering stage starts, you will see SageMaker training jobs appearing in the AWS Console as shown in Figure 1-13.
*****
Autopilot built to find the best performing model. You can select any of those training jobs to view the job status, configuration, parameters, and log files.
*****
The Model Tuning creates a SageMaker Hyperparameter tuning job as shown in Figure 1-15. Amazon SageMaker automatic model tuning, also known as hyperparameter tuning (HPT), is another functionality of the SageMaker service.
*****
You can find an overview of all AWS instance types supported by Amazon SageMaker and their performance characteristics here: https://aws.amazon.com/sagemaker/pricing/instance-types/. Note that those instances start with ml. in their name.
Optionally, you can enable data capture of all prediction requests and responses for your deployed model. We can now click on Deploy model and watch our model endpoint being created. Once the endpoint shows up as In Service
--
Once Autopilot find best hyperpharameters you can deploy them to save for later
*****
Here is a simple Python code snippet to invoke the endpoint. We pass a sample review (“I loved it!”) and see which star rating our model chooses. Remember, star rating 1 is the worst and star rating 5 is the best.
*****
If you prefer to interact with AWS services in a programmatic way, you can use the AWS SDK for Python boto3 [https://boto3.amazonaws.com/v1/documentation/api/latest/index.html], to interact with AWS services from your Python development environment.
*****
In the next section, we describe how you can run real-time predictions from within a SQL query using Amazon Athena.
*****
Amazon Comprehend. As input data, we leverage a subset of Amazon’s public customer reviews dataset. We want Amazon Comprehend to classify the sentiment of a provided review. The Comprehend UI is the easiest way to get started. You can paste in any text and Comprehend will analyze the input in real-time using the built-in model. Let’s test this with a sample product review such as “I loved it! I will recommend this to everyone.” as shown in Figure 1-23.
*****
mprehend Custom is another example of automated machine learning that enables the practitioner to fine-tune Comprehend’s built-in model to a specific datase
*****
We will introduce you to Amazon Athena and show you how to leverage Athena as an interactive query service to analyze data in S3 using standard SQL, without moving the data. In the first step, we will register the TSV data in our S3 bucket with Athena, and then run some ad-hoc queries on the dataset. We will also show how you can easily convert the TSV data into the more query-optimized, columnar file format Apache Parquet.
--
S3 deki datayı her zaman parquet e çevir
*****
One of the biggest advantages of data lakes is that you don’t need to pre-define any schemas. You can store your raw data at scale and then decide later in which ways you need to process and analyze it. Data Lakes may contain structured relational data, files, and any form of semi-structured and unstructured data. You can also ingest data in real time.
*****
Each of those steps involves a range of tools and technologies, and while you can build a data lake manually from the ground up, there are cloud services available to help you streamline this process, i.e. AWS Lake Formation.
Lake Formation helps you to collect and catalog data from databases and object storage, move the data into your Amazon S3 data lake, clean and classify your data using machine learning algorithms, and secure access to your sensitive data.
*****
From a data analysis perspective, another key benefit of storing your data in Amazon S3 is, that it shortens the “time to insight’ dramatically, as you can run ad-hoc queries directly on the data in S3, and you don’t have to go through complex ETL (Extract-Transform-Load) processes and data pipeli
*****
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so you don’t need to manage any infrastructure, and you only pay for the queries you run.
*****
With Athena, you can query data wherever it is stored (S3 in our case) without needing to move the data to a relational database.
*****
Athena and Redshift Spectrum can use to locate and query data.
*****
Athena queries run in parallel over a dynamic, serverless cluster which makes Athena extremely fast -- even on large datasets. Athena will automatically scale the cluster depending on the query and dataset -- freeing the user from worrying about these details.
*****
Athena is based on Presto, an open source, distributed SQL query engine designed for fast, ad-hoc data analytics on large datasets. Similar to Apache Spark, Presto uses high RAM clusters to perform its queries. However, Presto does not require a large amount of disk as it is designed for ad-hoc queries (vs. automated, repeatable queries) and therefore does not perform the checkpointing required for fault-tolerance.
*****
Apache Spark is slower than Athena for many ad-hoc queries.
*****
For longer-running Athena jobs, you can listen for query-completion events using CloudWatch Events. When the query completes, all listeners are notified with the event details including query success status, total execution time, and total bytes scanned.
*****
With a functionality called Athena Federated Query, you can also run SQL queries across data stored in relational databases (such as Amazon RDS and Amazon Aurora), non-relational databases (such as Amazon DynamoDB), object storage (Amazon S3), and custom data sources. This gives you a unified analytics view across data stored in your data warehouse, data lake and operational databases without the need to actually move the data.
*****
You can access Athena via the AWS Management Console, an API, or an ODBC or JDBC driver for programmatic access. Let’s have a look at how to use Amazon Athena via the AWS Management Console.
*****
When using LIMIT, you can better-sample the rows by adding TABLESAMPLE BERNOULLI(10) after the FROM. Otherwise, you will always return the data in the same order that it was ingested into S3 which could be skewed towards a single product_category, for example. To reduce code clutter, we will just use LIMIT without TABLESAMPLE.
*****
In a next step, we will show you how you can easily convert that data now into the Apache Parquet columnar file format to improve the query performance. Parquet is optimized for columnar-based queries such as counts, sums, averages, and other aggregation-based summary statistics that focus on the column values vs. row information.
*****
selected for DATABASE and then choose “New Query” and run the following “CREATE TABLE AS” (short CTAS) SQL statement:
CREATE TABLE IF NOT EXISTS dsoaws.amazon_reviews_parquet
WITH (format = 'PARQUET', external_location = 's3://data-science-on-aws/amazon-reviews-pds/parquet', partitioned_by = ARRAY['product_category']) AS
SELECT marketplace,
*****
One of the fundamental differences between data lakes and data warehouses is that while you ingest and store huge amounts of raw, unprocessed data in your data lake, you normally only load some fraction of your recent data into your data warehouse. Depending on your business and analytics use case, this might be data from the past couple of months, a year, or maybe the past 2 years. Let’s assume we want to have the past 2 years of our Amazon Customer Reviews Dataset in a data warehouse to analyze year-over-year customer behavior and review trends. We will use Amazon Redshift as our data warehouse for this.
*****
Amazon Redshift is a fully managed data warehouse which allows you to run complex analytic queries against petabytes of structured data. Your queries are distributed and parallelized across multiple nodes. In contrast to relational databases which are optimized to store data in rows and mostly serve transactional applications, Redshift implements columnar data storage which is optimized for analytical applications where you are mostly interested in the data within the individual columns.
*****
Redshift Spectrum, which allows you to directly execute SQL queries from Redshift against exabytes of unstructured data in your Amazon S3 data lake without the need to physically move the data. Amazon Redshift Spectrum automatically scales the compute resources needed based on how much data is being received, so queries against Amazon S3 run fast, regardless of the size of your data.
*****
We will use Amazon Redshift Spectrum to access our data in S3, and then show you how you can combine data that is stored in Redshift with data that is still in S3.
This might sound similar to the approach we showed earlier with Amazon Athena, but note that in this case we show how your Business Intelligence team can enrich their queries with data that is not stored in the data warehouse itself.
*****
So with just one command, we now have access and can query our S3 data lake from Amazon Redshift without moving any data into our data warehouse. This is the power of Redshift Spectrum.
But now, let’s actually copy some data from S3 into Amazon Redshift. Let’s pull in customer reviews data from the year 2015.
*****
You might ask yourself now, when should I use Athena, and when should I use Redshift? Let’s discuss.
*****
Amazon Athena should be your preferred choice when running ad-hoc SQL queries on data that is stored in Amazon S3. It doesn’t require you to set up or manage any infrastructure resources, and you don’t need to move any data. It supports structured, unstructured, and semi-structured data. With Athena, you are defining a “schema on read” -- you basically just log in, create a table and you are good to go.
Amazon Redshift is targeted for modern data analytics on large, peta-byte scale, sets of structured data. Here, you need to have a predefined “schema on write”. Unlike serverless Athena, Redshift requires you to create a cluster (compute and storage resources), ingest the data and build tables before you can start to query, but caters to performance and scale. So for any highly-relational data with a transactional nature (data gets updated), workloads which involve complex joins, and latency requirements to be sub-second, Redshift is the right choice.
*****
But how do you know which objects to move? Imagine your S3 data lake has grown over time, and you might have billions of objects across several S3 buckets in S3 Standard storage class. Some of those objects are extremely important, while you haven’t accessed others maybe in months or even years. This is where S3 Intelligent-Tiering comes into play.
Amazon S3 Intelligent-Tiering, automatically optimizes your storage cost for data with changing access patterns by moving objects between the frequent-access tier optimized for frequent use of data, and the lower-cost infrequent-access tier optimized for less-accessed data.
*****
Amazon Athena offers ad-hoc, serverless SQL queries for data in S3 without needing to setup, scale, and manage any clusters.
Amazon Redshift provides the fastest query performance for enterprise reporting and business intelligence workloads, particularly those involving extremely complex SQL with multiple joins and subqueries across many data sources including relational databases and flat files.
*****
To interact with AWS resources from within a Python Jupyter notebook, we leverage the AWS Python SDK boto3, the Python DB client PyAthena to connect to Athena, and SQLAlchemy) as a Python SQL toolkit to connect to Redshift.
*****
easy-to-use business intelligence service to build visualizations, perform ad-hoc analysis, and build dashboards from many data sources - and across many devices.
*****
We will also introduce you to PyAthena, the Python DB Client for Amazon Athena, that enables us to run Athena queries right from our notebook.
*****
There are different cursor implementations that you can use. While the standard cursor fetches the query result row by row, the PandasCursor will first save the CSV query results in the S3 staging directory, then read the CSV from S3 in parallel down to your Pandas DataFrame. This leads to better performance than fetching data with the standard cursor implementation.
*****
We need to install SQLAlchemy, define our Redshift connection parameters, query the Redshift secret credentials from AWS Secret Manager, and obtain our Redshift Endpoint address. Finally, create the Redshift Query Engine.
# Ins
*****
Create Redshift Query Engine
from sqlalchemy import create_engine
engine = create_engine('postgresql://{}:{}@{}:{}/{}'.format(redshift_username, redshift_pw, redshift_endpoint_address, redshift_port, redshift_database))
*****
Detect Data Quality Issues with Apache Spark
*****
Data quality can halt a data processing pipeline in its tracks. If these issues are not caught early, they can lead to misleading reports (ie. double-counted revenue), biased AI/ML models (skewed towards/against a single gender or race), and other unintended data products.
To catch these data issues early, we use Deequ, an open source library from Amazon that uses Apache Spark to analyze data quality, detect anomalies, and even “notify the Data Scientist at 3am” about a data issue. Deequ continuously analyzes data throughout the complete, end-to-end lifetime of the model from feature engineering to model training to model serving in production.
*****
Learning from run to run, Deequ will suggest new rules to apply during the next pass through the dataset. Deequ learns the baseline statistics of our dataset at model training time, for example - then detects anomalies as new data arrives for model prediction. This problem is classically called “training-serving skew”. Essentially, a model is trained with one set of learned constraints, then the model sees new data that does not fit those existing constraints. This is a sign that the data has shifted - or skewed - from the original distribution.
*****
Since we have 130+ million reviews, we need to run Deequ on a cluster vs. inside our notebook. This is the trade-off of working with data at scale. Notebooks work fine for exploratory analytics on small data sets, but not suitable to process large data sets or train large models. We will use a notebook to kick off a Deequ Spark job on a cluster using SageMaker Processing Jobs.
*****
You can optimize expensive SQL COUNT queries across large datasets by using approximate counts.
*****
HyperLogLogCounting is a big deal in analytics. We always need to count users (daily active users), orders, returns, support calls, etc. Maintaining super-fast counts in an ever-growing dataset can be a critical advantage over competitors.
Both Redshift and Athena support HyperLogLog (HLL), a type of “cardinality-estimation” or COUNT DISTINCT algorithm designed to provide highly accurate counts (<2% error) in a small fraction of the time (seconds) requiring a tiny fraction of the storage (1.2KB) to store 130+ million separate counts.
*****
Existing data warehouses move data from storage nodes to compute nodes during query execution. This requires high network I/O between the nodes - and reduces query performance.
Figure 3-23 below shows a traditional data warehouse architecture with shared, centralized storage.
*****
certain “latent” features hidden in our data sets and not immediately-recognizable by a human. Netflix’s recommendation system is famous for discovering new movie genres beyond the usual drama, horror, and romantic comedy. For example, they discovered very specific genres such as “Gory Canadian Revenge Movies,��� “Sentimental Movies about Horses for Ages 11-12,” “
*****
Figure 6-2 shows more “secret” genres discovered by Netflix’s Viewing History Service - code named, “VHS,” like the popular video tape format from the 80’s and 90’s.
*****
Feature creation combines existing data points into new features that help improve the predictive power of your model. For example, combining review_headline and review_body into a single feature may lead to more-accurate predictions than using them separately.
*****
Feature transformation converts data from one representation to another to facilitate machine learning. Transforming continuous values such as a timestamp into categorical “bins” such as hourly, daily, or monthly helps to reduce dimensionality. Two common statistical feature transformations are normalization and standardization. Normalization scales all values of a particular data point between 0 and 1, while standardization transforms the values to a mean of 0 and standard deviation of 1. These techniques help reduce the impact of large-valued data points such as number of reviews (represented in 1,000’s) over small-valued data points such as helpful_votes (represented in 10’s.) Without these techniques, the mod
*****
One drawback to undersampling is that your training dataset size is sampled down to the size of the smallest category. This can reduce the predictive power of your trained models. In this example, we reduced the number of reviews by 65% from approximately 100,000 to 35,000.
*****
Oversampling will artificially create new data for the under-represented class. In our case, star_rating 2 and 3 are under-represented. One common oversampling technique is called Synthetic Minority Oversampling Technique (SMOTE). Oversampling techniques use statistical methods such as interpolation to generate new data from your current data. They tend to work better when you have a larger data set, so be careful when using oversampling on small datasets with a low number of minority class examples. Figure 6-10 shows SMOTE generating new examples for the minority class to improve the imbalance.
*****
Each of the three phases should use a separate and independent dataset - otherwise “leakage” may occur. Leakage happens when data is leaked from one phase of modeling into another through the splits. Leakage can artificially inflate the accuracy of your model.
Time-series data is often prone to leakage across splits. Companies often want to validate a new model using “back-in-time” historical information before pushing the model to production. When working with time-series data, make sure your model does not peak into the future accidentally. Otherwise, these models may appear more accurate than they really are.
*****
We will use TensorFlow and a state-of-the-art Natural Language Processing (NLP) and Natural Language Understanding (NLU) neural network architecture called BERT. Unlike previous generations of NLP models such as Word2Vec, BERT captures the bi-directional (left-to-right and right-to-left) context of each word in a sentence. This allows BERT to learn different meanings of the same word across different sentences. For example, the meaning of the word “bank” is different between these two sentences: “A thief stole money from the bank vault” and “Later, he was arrested while fishing on a river bank.”
For each review_body, we use BERT to create a feature vector within a previously-learned, high-dimensional vector space of 30,000 words or “tokens.” BERT learned these tokens by training on millions of documents including Wikipedia and Google Books.
Let’s use a variant of BERT called DistilBert. DistilBert is a light-weight version of BERT that is 60% faster, 40% smaller, and preserves 97% of BERT’s language understanding capabilities. We use a popular Python library called Transformers to perform the transformation.
*****
Feature stores can cache “hot features” into memory to reduce model-training times. A feature store can provide governance and access control to regulate and audit our features. Lastly, a feature store can provide consistency between model training and model predicting by ensuring the same features for both batch training and real-time predicting.
Customers have implemented feature stores using a combination of DynamoDB, ElasticSearch, and S3. DynamoDB and ElasticSearch track metadata such as file format (ie. csv, parquet), BERT-specific data (ie. maximum sequence length), and other summary statistics (ie. min, max, standard deviation). S3 stores the underlying features such as our generated BERT embeddings. This feature store reference architecture is shown in Figure 6-22.
*****
Our training scripts almost always include pip installing Python libraries from PyPi or downloading pre-trained models from third-party model repositories (or “model zoo’s”) on the internet. By creating dependencies on external resources, your training job is now at the mercy of these third-party services. If one of these services is temporarily down, your training job may not start.
To improve availability, it is recommended that we reduce as many external dependencies as possible by copying these resources into your Docker images - or into your own S3 bucket. This has the added benefit of reducing network utilization and starting our training jobs faster.
*****
Bring Your Own Container
The most customizable option is “bring your own container” (BYOC). This option lets you build and deploy your own Docker container to SageMaker. This Docker container can contain any library or framework. While we maintain complete control over the details of the training script and its dependencies, SageMaker manages the low-level infrastructure for logging, monitoring, environment variables, S3 locations, etc. This option is targeted at more specialized or systems-focused machine learning folks.
*****
GloVe goes one step further and uses recurrent neural networks (RNNs) to encode the global co-occurrence of words vs. Word2Vec’s local co-occurence of words. An RNN is a special type of neutral network that learns and remembers longer-form inputs such as text sequences and time-series data.
FastText continues the innovation and builds word embeddings using combinations of lower-level character embeddings using character-level RNNs. This character-level focus allows FastText to learn non-English language models with relatively small amounts of data compared to other models. Amazon SageMaker offers a built-in, pay-as-you-go SageMaker algorithm called BlazingText which is an implementation of FastText optimized for AWS. This algorithm was shown in the Built-In Algorithms section above.
*****
ELMo preserves the trained model and uses two separate Long-Short Term Memory (LSTM) networks: one to learn from left-to-right and one to learn from right-to-left. Neither LSTM uses both the previous and next words at the same time, however. Therefore ELMo does not learn a true bidirectional contextual representation of the words and phrases in the corpus, but it performs very well nonetheless.
*****
Without this bi-directional attention, an algorithm would potentially create the same embedding for the word bank for the following two(2) sentences: “A thief stole money from the bank vault” and “Later, he was arrested while fishing on a river bank.” Note that the word bank has a different meaning in each sentence. This is easy for humans to distinguish because of our life-long, natural “pre-training”, but this is not easy for a machine without similar pre-training.
*****
To be more concrete, BERT is trained by forcing it to predict masked words in a sentence. For example, if we feed in the contents of this book, we can ask BERT to predict the missing word in the following sentence: “This book is called Data ____ on AWS.” Obviously, the missing word is “Science.” This is easy for a human who has been pre-trained on millions of documents since birth, but not easy fo
*****
Neural networks are designed to be re-used and continuously trained as new data arrives into the system. Since BERT has already been pre-trained on millions of public documents from Wikipedia and the Google Books Corpus, the vocabulary and learned representations are transferable to a large number of NLP and NLU tasks across a wide variety of domains.
Training BERT from scratch requires a lot of data and compute, it allows BERT to learn a representation of the custom dataset using a highly-specialized vocabulary. Companies like LinkedIn have pre-trained BERT from scratch to learn language representations specific to their domain including job titles, resumes, companies, and business news. The default pre-trained BERT models were not good enough for NLP/NLU tasks. Fortunately, LinkedIn has plenty of data and compute
*****
The choice of instance type and instance count depends on your workload and budget. Fortunately AWS offers many different instance types including AI/ML-optimized instances with terabytes of RAM and gigabits of network bandwidth. In the cloud, we can easily scale our training job to tens, hundreds, or even thousands of instances with just one line of code.
Let’s select 3 instances of the powerful p3.2xlarge - each with 8 CPUs, 61GB of CPU RAM, 1 Nvidia Volta V100’s GPU processor, and 16GB of GPU RAM. Empirically, we found this combination to perform well with our specific training script and dataset - and within our budget for this task.
instance_type='ml.p3.2xlarge'
instance_count=3
*****
TIP: You can specify instance_type='local' to run the script either inside your notebook or on your local laptop. In both cases, your script will execute inside of the same open source SageMaker Docker container that runs in the managed SageMaker service. This lets you test locally before incurring any cloud cost.
*****
Also, it’s important to choose parallelizable algorithms that benefit from multiple cluster instances. If your algorithm is not parallelizable, you should not add more instances as they will not be used. And adding too many instances may actually slow down your training job by creating too much communication overhead between the instances. Most neural network-based algorithms like BERT are parallelizable and benefit from a distributed cluster.
0 notes
Text
Boohoo-Boohoo, The Thing In The Branches
So I relistened to The Silt Verses last week, and something from Chapter 6 that I had completely passed over on first listen has stuck in my mind: Not-Yet-Katabasian Mason's story of his childhood encounter with Boohoo-Boohoo, The Thing In The Branches.
(Interestingly, when I went to look for a canonical spelling, the name Mason gave the thing isn't in the transcript. Did Jamie Stewart improvise the name, I wonder?)
So, a quick summary of the story. When Mason was a child, he and his sisters discovered a Thing In The Branches that sang like a bird, but was not a bird. They fell in love with it, and tried to interact with it, but it was too quick and clever and apparently uninterested in them. So they interact with the songbirds instead - Mason calls them its "disciples" - killing them, destroying their nests, and generally being shitty little kids. This causes The Thing In The Branches to sing songs of mourning for the pain of the songbirds in its flock - and so we have the mocking name, Boohoo-Boohoo.
The children never hated The Thing In The Branches - they craved its love, but if they could not have it, they would settle for its attention. Because when you adore someone in that childish, selfish way, you'd rather cause them harm than have them ignore you.
Now, we have to assume that this story is relevant to the overall story of The Silt Verses. Because Muna Husen & Jon Ware could have filled that conversational space with anything, but they chose The Thing In The Branches. Why?
This story could be relevant mostly thematically. The theme of attempting to connect with something you worship, but are so fundamentally different from that it's almost impossible to really communicate, is obviously all over The Silt Verses. As is the harm people(?) will do in the name of their gods, just to earn their favor.
But I wonder if the greatest presence of this dynamic in TSV is the other way around. So much of the harm done to people in this show is done by gods at the request of humans. Maybe the gods crave the love of their worshipers, and the gods try to reach out and connect, causing devastation. Maybe over time the gods have come to understand prayer-marks as like, arrows drawn to show that if they throw rocks at that tree in particular, the humans will be happy, and will praise them. Maybe the gods are reaching out to humans just as much (or sometimes more than) humans are reaching out to them, and the destruction they wreak is their clumsy way of trying to love them.
Then, of course, there's the possibility that this is story is relevant less in broad thematic sense and more as direct foreshadowing. If Mason tried to connect with Boohoo-Boohoo by killing its disciples, and now he is a worshiper of the Trawler-Man in a position of power over disciples of the Trawler-Man...
And my last big takeaway from the story, which is less about relevance and more about worldbuilding, is that it is Big If True. Because if this story is literally true, the implication is that the young Masons found a local god of birdsong, with songbirds for disciples. Which. Uh.
I'm so used to stories involving objectively-real divinity drawing a hard line between sapient and non-sapient creatures that it didn't even occur to me to wonder if nonhuman animals could call gods into being. Once that possibility is in play, I have to ask:
Is the Trawler-Man originally a God of Crustaceans, adopted by the humans of the River secondarily?
No, really, hear me out. On top of all of the crab+ imagery associated with the Trawler-Man, in episode 8 Roake the painter claims that he learned the prayer marks of the Wither Tide by studying the symbols drawn into the silt of the river by actual, literal, not-supernatural-as-far-as-we're-aware crabs. And in episode 11, Brother Wharfing notes that the Trawler-Man is an especially strong god. But gods require sacrifice to stay strong - who made the sacrifices necessary to keep Him going through the decade+ after the Faith was decimated and the Parish scattered? Was it the crabs, making their little crab sacrifices, dancing prayer marks of worship into the silt?
And you know who I bet would reallly like the Wither Tide?
Pepe Silvia.
...
No, obviously it's crabs.
#tsv#tsv meta#the silt verses#the thing in the branches#katabasian mason#boohoo-boohoo#the trawler-man
61 notes
·
View notes
Photo

Happy Birthday to Team Sillyvision! It’s been a whole year since drawing the first TSV AU post so I decided to do a redraw. Did you know this was based on the Chapter 3 promo picture that had a toy train in Level 11, where you first encounter the Projectionist?
#batim#bendy and the ink machine#team sillyvision au#the projectionist#norman polk#bendy the demon#i dont have a drawing tag#the trains not there anymore#maybe someone picked it up
280 notes
·
View notes
Text

I posted 1,324 times in 2021
9 posts created (1%)
1315 posts reblogged (99%)
For every post I created, I reblogged 146.1 posts.
I added 88 tags in 2021
#tma - 14 posts
#dsmp - 11 posts
#dream smp - 10 posts
#hfth - 9 posts
#hello from the hallowoods - 9 posts
#the magnus archives - 8 posts
#tsv - 7 posts
#lgbt - 7 posts
#deltarune - 7 posts
#the silt verses - 6 posts
Longest Tag: 90 characters
#i saw a cool rock and you know how magnets work? yeah it just magnetted all my gender away
My Top Posts in 2021
#5
Smh, gave my blog a goth makeover and everything, Brimstone Valley Mall is catching up to me.
3 notes • Posted 2021-05-11 00:55:15 GMT
#4
TSCOSI Mini-Bang Fic 3 Release
A Perfectly Normal Totally Typical Cafe
The Rumor Cafe is opening on Milky Way and the crew was not prepared. As they struggle with maintaining and running the cafe due to their unexpected influx of customers, they look to hire. Enter Violet Liu, she needs a job so she goes in for an interview with her extensive resume. Violet gets hired and starts working at The Rumor, but she soon finds that The Rumor and its staff may be hiding more than meets the eye.
@tscosi-minibang
Written by:
Rayan - @unless-otherwise-stated
Beta read by:
Vi - @starshipviolet
Hec - @drumkonwords
Coming to AO3 soon!
Read Chapter One below the cut.
Chapter One
The Rumor Cafe had been open for an hour and the coffee machine was on fire. Krejjh was still serving coffee, the line in front of the counter stretched across the crowded store and out it. They juggled coffee cups between their four hands filling up cups and shuffling the order papers. Brian is huddled in the corner by the order receivers and trying to write down as many orders as he can. And though Brian is a linguist, studying languages isn’t going to do you much when fifty different people are telling you their orders, about five of which may have asked you a question. At this point, he was writing down as much as he could make out before frantically moving the order papers to the basket by Krejjh.
As soon as Krejjh had finished an order they would speedwalk over to the pickup counter and leave them for Arkady or Sana to deliver them to the customer. Sana was currently in a seemingly one-sided argument with a customer that kept insisting that “if this is a coffee shop why isn’t there a bowling alley?”
“Sir, I apologize for any disappointment, but we don’t have a bowling al—” Sana tried to reason with him, but he interrupted her.
“Okay, okay. Maybe the bowling alley was a stretch, but you at least have a giant python that grew legs giving out tango lessons.”
Sana was prepared to commit many crimes.
Arkady was left to wait the tables by herself, she would sprint to the counter, balancing as many drinks as she could safely carry on her tray and a few more. She would then blindly sprint out into the customer crowd shuffling the order papers, trying to figure out which drink goes where while dodging the mildly annoyed and confused customers.
All in all, despite their short-handedness and heightened probability of many accidents (and crimes), they were managing the flow of customers. That is, until the staff of the other coffee shop across the street, If Gnomes Ran, decided to pop in and check out the new (temporary) competition.
If Gnomes Ran was your classic ‘Large Corporation-Run “Local’’ Coffee Shop’. They worked under In Good Running (IGR for short), which also owned I Give Rup, I Gave Ryouallmymoneywhatelsedoyouwant, and I Got Radishes, a grocery store, clothing store and pharmaceutical respectively. The most important thing to know about them is that if you see them do anything morally wrong or illegal, no you didn’t.
It was in this rush that the employees of If Gnomes Ran entered the coffee store, skipping everyone else who was waiting in line to enter and orderly shuffling in through the door. Worker McCabe was left to hold the door open for all of them. What the staff of If Gnomes Ran didn’t see while scouting out the shop was Arkady sprinting right towards them carrying her tray filled to the brim with drinks and pastries. In fact, neither Arkady nor any of the recent visitors saw each other. And so, as Arkady was attempting to find table five she instead ran right into the entire group of visiting foreign employees.
The entire shop turned silent and turned to look at the group of sharply dressed If Gnomes Ran employees soaked and covered in many different kinds of coffee and pastries. A few of the customers didn’t notice and continued chatting for a few seconds before noticing the sudden silence and becoming quiet themselves.
The crackling of the coffee machine fire stood out against the shocked silence and it was only then that Brian realized that the coffee machine was on fire. He bolted over to Krejjh and motioned wildly at the coffee machine, completely silent as to not disturb whatever was currently happening. Krejjh was still frantically completing orders as Brian rushed over to the nearby fire extinguisher and put out the fire. There may have been a bit of foam in the orders Krejjh was making at the time.
Arkady looked up from the order papers she was still holding and stared blankly at the steadily glaring group of soaked If Gnomes Ran staff. Sana rushed over, steadily apologizing and rushing to hand them all towels, but the collective group simply turned and walked right back out of the door.
The coffee shop was silent and the closing door rang the bell and knocked slightly against its frame. Sana and Arkady were still stood right where they were as Krejjh continued pumping out orders and Brian tried to access the damage caused by the fire. Many of the customers were shuffling around silently trying to leave as to not get caught up in any issues with In Good Standing. One of the customers stubbornly waiting for their order coughed slightly, while not a loud cough by any means it stood out against the silence.
The cough seemed to bring Arkady back to the situation and she hurried over to the fallen mugs and pastries and began to clean up. Sana rested the towels she intended to give to the If Gnomes Ran staff on a nearby counter and knelt down beside Arkady to help. This broke the silence in the coffee shop and the chatter rose up from the customers once again. Brian abandoned his station taking orders to quickly deliver the orders steadily piling up on the counter. Krejjh had run out of space and was now attempting to precariously balance orders on top of each other.
The crew served the considerably reduced amount of customers left after the incident before beginning to close the shop early. Arkady and Sana returned the extra chairs and tables they’d brought out and straightened out the original tables and chairs. Brian and Krejjh were cleaning up the counters and general area around the coffee machines while discussing the dangers of fire and physics. After they’d restored The Rumor to its original, clean and orderly, state, they all sat around in the staff breakroom to discuss today’s events.
“So…” Sana began sitting at the head of the table, “That didn’t go as…planned, I suppose… but this is only the first day, and it was clearly an accident. The most we can do at this point is attempt to make amends with If Gnomes Ran and just continue with our plan.”
“This isn’t just any business we’re talking about here, Boss,” Arkady states simply from the other side of the rectangular table. “This is the IGR, everyone knows what they’re capable of.” The group sat silent around the table contemplating the possible repercussions from today’s incident, the only sound being the soft sounds of commotion from outside leaking in through the window.
“There’s nothing we can do about that. All we can hope is that whatever the IGR decides to do, it won’t interfere with our primary mission.” Sana says steadily, looking everyone in the eyes. “But something I think we can all agree on, if we’re going to continue this we’re going to need a few extra hands.”
See the full post
5 notes • Posted 2021-05-13 00:20:25 GMT
#3

8 notes • Posted 2021-04-01 17:11:38 GMT
#2
TSCOSI Mini-Bang Fic 3
A Perfectly Normal, Totally Typical Cafe
The Rumor Cafe is opening on Milky Way and the crew was not prepared. As they struggle with maintaining and running the cafe due to their unexpected influx of customers, they look to hire. Enter Violet Liu, she needs a job so she goes in for an interview with her extensive resume. Violet gets hired and starts working at The Rumor, but she soon finds that The Rumor and its staff may be hiding more than meets the eye.
Art sneak-peek:

Quotes:
“Okay, okay. Maybe the bowling alley was a stretch, but you at least have a giant python that grew legs giving out tango lessons.”
Sana was prepared to commit many crimes.
In Good Running (IGR for short), which also owned I Give Rup, I Gave Ryouallmymoneywhatelsedoyouwant, and I Got Radishes
Coming May 12th 2021
Written by:
Rayan - @unless-otherwise-stated
Art by:
Olya - @self_substantialfuel
Hec - @drumkonwords (check out their TSCOSI art)
Beta read by:
Vi - @starshipviolet
Hec
@tscosi-minibang
12 notes • Posted 2021-04-23 00:07:01 GMT
#1

35 notes • Posted 2021-02-15 21:37:29 GMT
Get your Tumblr 2021 Year in Review →
#my 2021 tumblr year in review#your tumblr year in review#I am one of the most unoriginal fuckers on here and I am simply winning
1 note
·
View note
Note
Hi, I read your team sillyvision au and saw your art but sometimes, you draw bendy crying while holding the projectionist's head but I didn't read anything about it. Did I miss something ?
The first half of TSV loosely follows the game’s chapters and events so if you’re reading the fic rn you can see effects from Henry going through (Jack’s hat, Sammy’s dustpan) and any event the Projectionist goes through (passing through floor 11)
So I don’t really draw what happened because it’s directly related to the scene in the game where the Projectionist dies in chapter 4
#tsv ask#oh and I gotta finish the next tsv chapter I got caught up on comms and getting sick#orioune
35 notes
·
View notes