#usr1
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Constructing TPC-C Initial Data|openGauss
Constructing TPC-C Initial Data
**1. **Modify benchmark configurations.Copy props.pg and rename it props.opengauss.1000w. Edit the file and replace the following configuration in the file:cp props.pg props.opengauss.1000w vim props.opengauss.1000w db=postgres driver=org.postgresql.Driver // Modify the connection string, including the IP address, port number, and database. conn=jdbc:postgresql://ip:port/tpcc1000?prepareThreshold=1&batchMode=on&fetchsize=10 // Set the user name and password for logging in to the database. user=user password=****** warehouses=1000 loadWorkers=200 // Set the maximum number of concurrent tasks, which is the same as the maximum number of work tasks on the server. terminals=812 //To run specified transactions per terminal- runMins must equal zero runTxnsPerTerminal=0 //To run for specified minutes- runTxnsPerTerminal must equal zero runMins=5 //Number of total transactions per minute limitTxnsPerMin=0 //Set to true to run in 4.x compatible mode. Set to false to use the //entire configured database evenly. terminalWarehouseFixed=false //The following five values must add up to 100 //The default percentages of 45, 43, 4, 4 & 4 match the TPC-C spec newOrderWeight=45 paymentWeight=43 orderStatusWeight=4 deliveryWeight=4 stockLevelWeight=4 // Directory name to create for collecting detailed result data. // Comment this out to suppress. resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS osCollectorScript=./misc/os_collector_linux.py osCollectorInterval=1 // Collect OS load information. //[email protected] //osCollectorDevices=net_enp3s0 blk_nvme0n1 blk_nvme1n1 blk_nvme2n1 blk_nvme3n1
**2. **Prepare for importing TPC-C data.(1) Replace the tableCreats.sql file.Download the tableCreates.sql file (at https://blog.opengauss.org/zh/post/optimize/images/tableCreates.sql). Use this file to replace the corresponding file in benchmarksql-5.0/run/sql.common/ of the benchmark SQL.The file is modified as follows:◾ Two tablespaces are added.CREATE TABLESPACE example2 relative location 'tablespace2'; CREATE TABLESPACE example3 relative location 'tablespace3'; ◾ The bmsql_hist_id_seq sequence is deleted.◾ The FACTOR attribute is added to each table.create table bmsql_stock ( s_w_id integer not null, ..... s_dist_10 char(24) ) WITH (FILLFACTOR=80) tablespace example3; (2) Modify the indexCreates.sql file.Modify the run/sql.common/indexCreates.sql file.Modify the content in the red box in the preceding figure as follows:Add the content in red in the following figure to the file so that the data can be automatically generated in different data tablespaces when the benchmark tool automatically generates data. If the content is not added, modify the data in the database after the benchmark tool generates data for disk division.(3) Modify the runDatabaseBuild.sh file. Modify the content in the following figure to avoid unsupported foreign keys during data generation.
**3. **Import data.Execute runDatabaseBuild.sh to import data.
**4. **Back up data.To facilitate multiple tests and reduce the time for importing data, you can back up the exported data. A common method is to stop the database and copy the entire data directory. The reference script for restoration is as follows:#!/bin/bash rm -rf /ssd/omm108/gaussdata rm -rf /usr1/omm108dir/tablespace2 rm -rf /usr2/omm108dir/tablespace3 rm -rf /usr3/omm108dir/pg_xlog cp -rf /ssd/omm108/gaussdatabf/gaussdata /ssd/omm108/ & job0=$! cp -rf /usr1/omm108dir/tablespace2bf/tablespace2 /usr1/omm108dir/ & job1=$! cp -rf /usr2/omm108dir/tablespace3bf/tablespace3 /usr2/omm108dir/ & job2=$! cp -rf /usr3/omm108dir/pg_xlogbf/pg_xlog /usr3/omm108dir/ & job3=$! wait $job1 $job2 $job3 $job0
**5. **Partition data disks.During the performance test, data needs to be distributed to different storage media to increase the I/O throughput. The data can be distributed to the four NVMe drives on the server. Place the pg_xlog, tablespace2, and tablespace3 directories on the other three NVMe drives and provide the soft link pointing to the actual location in the original location. pg_xlog is in the database directory, and tablespace2 and tablespace3 are in the pg_location directory. For example, run the following commands to partition tablespace2:mv $DATA_DIR/pg_location/tablespace2 $TABSPACE2_DIR/tablespace2 cd $DATA_DIR/pg_location/ ln -svf $TABSPACE2_DIR/tablespace2 ./
**6. **Run the TPC-C program.numactl –C 0-19,32-51,64-83,96-115 ./runBenchmark.sh props.opengauss.1000w
**7. **Monitor performance.Use htop to monitor the CPU usage of the database server and TPC-C client. In the extreme performance test, the CPU usage of each service is greater than 90%. If the CPU usage does not meet the requirement, the core binding mode may be incorrect and needs to be adjusted.In the preceding figure, the CPU in the yellow box is used to process network interruption.
**8. **View the monitoring status after tuning.The htop state after tuning is reliable.Database tuning is a tedious task. You need to continuously modify configurations, run TPC-C, and perform commissioning to achieve the optimal performance configuration.TPC-C running result:
0 notes
Link

A scientific illustration of the Upward Sun River camp in what is now Interior AlaskaILLUSTRATION BY ERIC S. CARLSON IN COLLABORATION WITH BEN A. POTTER
At the end of the last ice age, about 11,500 years ago, ancient people buried two infants at a residential campsite called Upward Sun River (USR) in what is currently central Alaska. Now, the whole genome sequence of one of the infants—a six-week-old named Xach’itee’aanenh T’eede Gaay, or Sunrise Child-girl by local Native Americans and USR1 by researchers—has revealed that she was part of a distinct and previously unknown group descended from the same founding population as all other Native Americans. The findings were published today (January 3) in Nature.
“USR1 really provides the most definitive evidence for all Native American populations in North and South America deriving from a single population,” says University of Florida geneticist Connie Mulligan, who did not participate in the study. “In other words, there was only one wave of migration over to the New World to settle both continents until much more recent times. It’s the final data in support of a single migration.”
Researchers usually agree that humans arrived in the Americas through Beringia—the area encompassing parts of present-day East Asia and North America, connected by what was the Bering Land Bridge. But the scientists must rely on inferences from both archaeological and genomic data to figure out how and when this migration occurred.
“These are only the second-oldest human remains in the New World where we have this full nuclear genomic analysis, so this is really kind of new territory,” explains coauthor Ben Potter, an archaeologist at the University of Alaska Fairbanks. “With archaeology, we have bits of detritus left behind. We get clues that we [use] to build inferential arguments in a forensic sort of way. Just the fact that we have these human remains opens up amazing windows” into these people’s lives, he adds.
Geneticist and coauthor Eske Willerslev of the Natural History Museum of Denmark and colleagues sequenced the USR1 genome, but were unable to sequence the full genome of the second infant, Yełkaanenh T’eede Gaay (Dawn Twilight Child-girl) or USR2, who was younger than USR1 and likely stillborn or born preterm.
Genomic comparisons suggest that USR1 and USR2 were related—probably first cousins—and that the USR1 genome is most closely related to contemporary Native American genomes. The researchers inferred that USR1 is part of a unique population they call Ancient Beringians, who descended from the same ancestors, but stopped interacting and sharing DNA with the populations of other Native Americans between 18,000 and 22,000 years ago. Genetic analysis of the proportions of components of the USR1 genome shared with Native Americans, Siberians, and East Asians also showed that a single founding population of all Native Americans split from East Asian ancestors gradually between about 25,000 and 36,000 years ago.

Members of the archaeology field team watch as University of Alaska Fairbanks professors Ben Potter and Josh Reuther excavate at the Upward Sun River site.UAF PHOTO COURTESY OF BEN POTTER
Ongoing work in Potter’s group focuses on investigating multiple aspects of how the Ancient Beringians lived, including changes in their diets over time, how they used plants, and how they organized themselves. “So rarely do we get an opportunity to begin to explore what we thought we knew with better information about populations and perhaps some insights into movement, migration, and overall adaptation,” he says.
This study “will begin to set up some great models for understanding founding populations of First Nations peoples here in North America,” says Cynthia Zutter, an anthropologist at MacEwan University in Alberta, Canada, who was not involved in the work. One inherent limitation is the dearth of samples, she explains, but while these findings are based on just two individuals, they nonetheless carry implications for the movement and longevity of several groups of Native peoples in Beringia.
“We need more samples,” agrees Texas A&M archaeologist Kelly Graf, who did not participate in the work. “We are all trying to make [interpretations] about populations based on one individual from that population,” she says, but “one person in a population doesn’t represent the entire genetic makeup of that group by any means. It’s problematic, but there’s a lot territory out there that needs to be explored. It’s going to take some real effort to do it, but we’ll keep trying.”
70 notes
·
View notes
Text
Cap 146 : Cultura Blancos Mal'ta en Rusia es Ancestra de Paleoindios
.
Nuevamente recordamos que se definen como Paleoindios solo la primera ola de Beringianos que llegó al Continente Americano y eran muy pocos según los Genetistas y sus Cálculos Matemáticos.
.
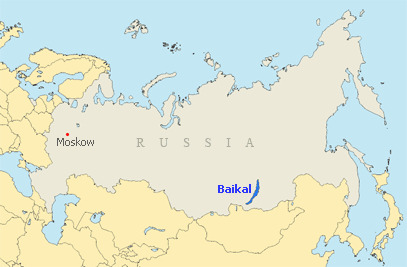
En esta Aldea de Mal'ta junto al Lago Baikal en Rusia. Cerca queda la Cultura de Mal'ta–Buret'. Al examinar la Genética del Esqueleto de un Muchacho de hace 24,000 Años todo el Mundo quedó asombrado. Pues es Genética ancestral a los Nativos Americanos.
.
.
Los Antiguos Norte Euroasiáticos ANE ( ver mas abajo ) dieron Genes a la Cultura Mal'ta pero también los dieron a la Cultura Yamnaya Milenios mas tarde. Yamnaya son los Proto Indo Europeos. Aquí vemos que la Aldea de Mal'ta es pegadita del Lago Baikal :
.

.
Aquí vemos que este Yacimiento Arqueológico de Mal'ta queda muy lejos de la Tierra de Beringia y de Alaska.
.

.
********************************
.
Los Antiguos Norte Euroasiáticos ANE
En arqueogenética, el término euroasiáticos nórdicos antiguos (ANE, por sus siglas en inglés) es el nombre dado al componente genético ancestral asociado con la cultura de Mal'ta-Buret o a poblaciones estrechamente emparentadas con ella (como Afontova Gora), y sus descendientes. Este componente genético ANE desciende parcialmente de los euroasiáticos orientales.
................
El linaje ANE se ha definido por asociación con la composición genética del "chico de Mal'ta" (usualmente etiquetado como MA-1), un individuo que vivió hace 24000 años en Siberia, durante el Último Máximo Glacial, y que fue descubierto en la década de 1920. Las poblaciones genéticamente similares a MA-1 han contribuido significativamente a la composición genética de los americanos nativos, europeos, asiáticos centrales,, asiáticos del sur y algunos asiáticos del este, por orden de relevancia de dicha contribución.
Lazaridis et al. (2016:10) han notado "una clina de ascendencia ANE a lo largo de la dirección este-oeste de Eurasia". Flegontov et al. (2015) encontraron que el máximo global de ascendencia ANE corresponde con las poblaciones contemporáneas de los americanos nativos, kets y mansi. Además esta componente ha sido encontrada en culturas del Bronce antiguo como Yamnaya y Afanasevo.
El 42% de la ascendencia de los americanos nativos del sur tiene origen en los ANE5?, mientras que entre el 14% y 38% de la ascendencia americana nativa del norte tendría origen en el flijo genético de estas gentes de Mal'ta-Buret. Esta diferencia está causada por la posterior penetración en América de migraciones de origen siberiano, siendo el menor porcentaje de ascendencia ANE el encontrado en los esquimales y en los nativos Alaska, dado que estos grupos son el resultado de migraciones a América hace aproximadamente 5000 años. El resto de la composición genética de los americanos nativos parece tener origen en el este de Eurasia. La secuenciación genética de otras gentes siberianas sud-centrales (Afontova Gora-2) que datan de hace aproximadamente 17,000 años, revelados una composición autosomal similar a la del chico de Mal'ta-1, sugiriendo que la ocupación humana de esta región fue continua durante el Último Máximo Glacial.
Los estudios genéticos también indican que ANE fue introducido a Europa por medio de la cultura Yamna/Yamnaya, mucho tiempo después del Paleolítico. El componente genético ANE es visible en los análisis de los Yamnaya, y representa 50% de su ascendencia indirectamente. Este componente también se encuentra en los europoes contemporáneos (7%–25% de mezcla ANE), pero no en los europeos anteriores a la Edad de Bronce.
.
Población antigua descendiente de ANE ( Antiguo Norte Euroasiáticos ) : Antiguos Beringianos/Ancestral Nativo Americano (AB/ANA)
Antiguos Beringianos/Ancestral Nativo Americano son abolengos arqueogenéticos concretos, basados en el genoma de un niño encontrado en el sitio de Upward Sun River (bautizado USR1), datado con una antigüedad 11,500 años.12? El linaje AB diverge del Nativoamericanos Ancestral (ANA) aproximadamente hace 20,000 años. El linaje de ANA fue formado 20,000 hace por una mezcla de Proto-Mongoloide y ANE (42-43%) compatible con el modelo del poblamiento de las Américas vía Beringia durante el Último Máximo Glacial.
Euroasiáticos del norte antiguos
https://es.wikipedia.org/wiki/Euroasi%C3%A1ticos_del_norte_antiguos
.
********************************
.
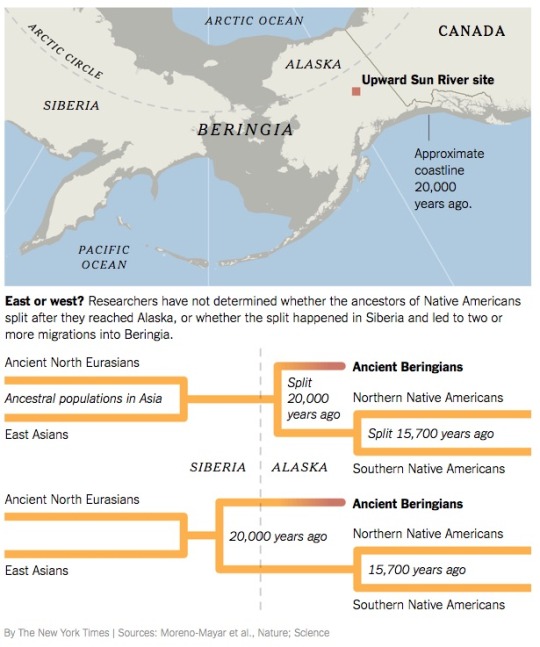
Próxima Imagen : Los Ancient North Siberians fueron un Grupo Racial que contribuyá al Niño de Mal'ta y a la Cultura de Yana Rhinoceros Horn. ( ver Mapa ).
Los Antiguos Norte Siberianos y el Subgrupo de Asiáticos Este convergieron. Trazas de Humanos en Bluefish Caves en el Yukon ( Alaska ), y en el Lago E5, también en Norteamérica. sugieren que las dos Ramas Asiáticas ( con Flechas Rojas ) se juntaron en Asia o por lo menos en Beringia y no en Norteamérica.
Esta Convergencia creó dos Grupos cuyos Restos han sido encontrados y secuenciandos para el ADN : Los Antiguos Beringios se extinguieron, pero los Ancestrales Nativos Americanos poblaron el Nuevo Mundo.
.

.
Este Mapa fue hecho por Daniel P. Huffman
.
Fuente :
Genomes Reveal Humanity’s Journey into the Americas
https://ideahuntr.com/genomes-reveal-humanitys-journey-into-the-americas/
.
********************************
.
INFOBAE La extraña conexión entre un niño de Siberia y los indígenas mexicanos 9 de Mayo de 2018
Estudios genéticos practicados a indígenas mexicanos muestran coincidencias con el llamado niño de Mal'ta que habitó en Siberia hace más de 23.000 años, determinó un estudio científico realizado por especialistas de distintas instituciones reconocidas en el país.
.................
Los restos del llamado Niño de Mal'ta fueron encontrados en 1958 cerca del lago Baikal en el este de Siberia. Murió entre los 3 y 4 años de edad. Aunque no quedaron restos de su piel o su cabello, el ADN reveló que pudo haber tenido ojos y cabello oscuros con pecas en la piel.
Estudios practicados en 2013 por científicos de Dinamarca revelaron que el ADN del niño coincidía con el de los europeos occidentales y con algunas razas de nativos americanos.
https://www.infobae.com/america/mexico/2018/05/09/la-extrana-conexion-entre-un-nino-de-siberia-y-los-indigenas-mexicanos/
.
********************************
.
Antiguos Beringios
Este o Oeste ? : Los Investigadores no han determinado si los Ancestros de los Nativos Americanos se dividieron en dos Ramas después que llegaron a Alaska o si se partieron en Siberia y entraron en dos o mas Migraciones a Beringia.
Una de las dos Divisiones fueron llamados “Antiguos Beringios” por los Investigadores. Estos se extinguieron.
El Esqueleto de una Niña de seis Semanas fue encontrado en “Upward Sun River site” en Alaska. Esta Niña tenía una Genética nunca antes vista. Y su Población fue llamada “Antiguos Beringios. Esta Niña es Pariente de todos los Paleoindios ( la primera ola de Llegada a América ) pero su Genética es muy distinta y no se parece en forma cercana sinó a los Nativos Americanos.
Esta Niña murió hace 11,500 Años. Fue enterrada con Cornamentas y con Pinturas de Ocre Rojo, un entierro con Respeto y Cariño. La Tumba nunca fue molestada hasta que llegaron los Arqueólogos.
.
.
The Girl was just six weeks old when she died. Her body was buried on a bed of antler points and red ocher, and she lay undisturbed for 11,500 years.
..........
The researchers had luck with the Girl. Eventually, they managed to put together an accurate reconstruction of her entire genome. To analyze it, Dr. Willerslev and Dr. Potter collaborated with a number of geneticists and anthropologists.
The Girl they discovered, was more closely related to living Native Americans than to any other living people or to DNA extracted from other extinct lineages. But she belonged to neither the northern or southern branch of Native Americans.
Instead, the Girl was part of a previously unknown population that diverged genetically from the ancestors of Native Americans about 20,000 years ago, Dr. Willerslev and his colleagues concluded. They now call these people Ancient Beringians.
.
Fuente : In the Bones of a Buried Child, Signs of a Massive Human Migration to the AmericasFebruary 19, 2018 Chris Gill
https://pitchstonewaters.com/in-the-bones-of-a-buried-child-signs-of-a-massive-human-migration-to-the-americas/
.
********************************
.
Pintura de Frank Weir
Un Enterramiento de un miembro de la Tribu Paleoindia hace Miles de Años. Un Shamán hace sonar Instrumentos de Ruido. Puedes abrir la Imagen en una Pestaña nueva de Windows para verla mas en Detalle.
,

,
********************************
.
.
0 notes
Text
Instalar Postal Mail Server en Ubuntu 18.04 / 20.04

Instalar Postal Mail Server en Ubuntu 18.04 / 20.04. Tal vez no lo conozcas, pero Postal Mail Server es un servidor de correo muy completo, que cuenta con todas las funciones necesarias para manejar las cuentas de mail tanto de sitios web como de servidores específicos para ello. Seguro que conoces Sendgrid, Mailgun o Postmark, con Postal Mail Server puedes lograr algo similar. El servidor del que hoy hablamos, nos proporciona una API HTTP que permite integrarlo con otros servicios y enviar correos electrónicos desde diferentes sitios o aplicaciones web. Destacamos su alta detección de spam y virus. Instalar y configurar Postal Mail Server es una tarea sencilla si lo comparamos con otros alternativas. El único requisito que debes cumplir es que los registros del dominio principal apunten de manera efectiva al servidor antes de comenzar su instalación.

Instalar Postal Mail Server
Instalar Postal Mail Server en Ubuntu
Comenzamos actualizando el sistema para continuar con la instalación de MariaDB. sudo apt update sudo apt dist-upgrade Instalar MariaDB sudo apt install mariadb-server libmysqlclient-dev Iniciamos y habilitamos MariaDB. sudo systemctl start mariadb.service sudo systemctl enable mariadb.service Ahora aseguramos el servidor de base de datos. sudo mysql_secure_installation Una manera efectiva de proteger MariaDB es siguiendo los pasos que te indico a continuación. Enter current password for root (enter for none): Pulsa Enter Set root password? : Y New password: Introduce el password Re-enter new password: Repite el password Remove anonymous users? : Y Disallow root login remotely? : Y Remove test database and access to it? : Y Reload privilege tables now? : Y Reiniciamos MariaDB. sudo systemctl restart mariadb.service Crear una base de datos Creamos una base de datos en blanco para Postal Mail Server, te pedira la password que insertaste en el paso anterior. sudo mysql -u root -p La nueva base de datos se llamará "postal" (como ejemplo). CREATE DATABASE postal CHARSET utf8mb4 COLLATE utf8mb4_unicode_ci; Ahora creamos el usuario "postaluser" y una nueva contraseña para el. CREATE USER 'postaluser'@'localhost' IDENTIFIED BY 'tu_password'; Le damos permisos de acceso al nuevo usuario. GRANT ALL ON postal.* TO 'postaluser'@'localhost' WITH GRANT OPTION; Solo nos falta guardar y salir de la consola de MariaDB. FLUSH PRIVILEGES; EXIT; Instalar Ruby, Erlang y RabbitMQ Los paquetes Ruby, Erlang y RabbitMQ (necesarios), no están disponibles en los repositorios oficiales de Ubuntu, los instalamos manualmente. Para instalar Ruby sigue los pasos indicados. sudo apt-get install software-properties-common sudo apt-add-repository ppa:brightbox/ruby-ng sudo apt update sudo apt install ruby2.3 ruby2.3-dev build-essential Continuamos con Erlang. wget -O- https://packages.erlang-solutions.com/ubuntu/erlang_solutions.asc | sudo apt-key add - # Cuidado con el siguiente paso, si no usas Ubuntu Bionic debes modificar por tu version echo "deb https://packages.erlang-solutions.com/ubuntu bionic contrib" | sudo tee /etc/apt/sources.list.d/erlang.list sudo apt-get update sudo apt-get install erlang Terminamos con la instalación de RabbitMQ. sudo sh -c 'echo "deb https://dl.bintray.com/rabbitmq/debian $(lsb_release -sc) main" >> /etc/apt/sources.list.d/rabbitmq.list' wget -O- https://dl.bintray.com/rabbitmq/Keys/rabbitmq-release-signing-key.asc | sudo apt-key add - wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add - sudo apt update sudo apt install rabbitmq-server Iniciamos y habilitamos RabbitMQ. sudo systemctl enable rabbitmq-server sudo systemctl start rabbitmq-server Este paso es opcional, pero si quieres administrar RabbitMQ vía web también es posible con el siguiente comando. sudo rabbitmq-plugins enable rabbitmq_management Puedes acceder desde la siguiente url: http://dominio-o-ip:15672 El usuario y password de acceso es "guest", pero ojo... solo funciona si trabajas en local. Para concluir la configuración de RabbitMQ agregamos nuestro usuario (postal) y la pass. sudo rabbitmqctl add_vhost /postal sudo rabbitmqctl add_user postal tu-password sudo rabbitmqctl set_permissions -p /postal postal ".*" ".*" ".*" Instalar Nodejs en Ubuntu Para un funcionamiento perfecto del servidor de correo, es recomendable instalar Nodejs. sudo apt install curl curl -sL https://deb.nodesource.com/setup_10.x | sudo bash sudo apt-get install nodejs Instalar Postal Mail Server Por fin llegamos a los pasos finales, solo nos falta instalar y configurar el servidor Postal Mail Server. Creamos la cuenta del servicio y damos permiso a Ruby para que pueda escuchar. sudo useradd -r -m -d /opt/postal -s /bin/bash postal sudo setcap 'cap_net_bind_service=+ep' /usr/bin/ruby2.3 Necesitamos unos paquetes adicionales. sudo gem install bundler sudo gem install procodile sudo gem install nokogiri -v '1.7.2' Creamos el directorio principal de Postal Mail Server, descargamos la última versión, la extraemos y le damos acceso a nuestro usuario. sudo mkdir -p /opt/postal/app sudo wget https://postal.atech.media/packages/stable/latest.tgz sudo tar xvf latest.tgz -C /opt/postal/app sudo chown -R postal:postal /opt/postal sudo ln -s /opt/postal/app/bin/postal /usr/bin/postal Iniciamos los archivos de configuración. sudo postal bundle /opt/postal/vendor/bundle sudo postal initialize-config Vamos a editar el archivo de configuración con nuestros datos reales. sudo nano /opt/postal/config/postal.yml Asegurate de que los datos sean validos y que el dominio apunte al servidor o vps. web: # The host that the management interface will be available on host: postal.midominio.com # The protocol that requests to the management interface should happen on protocol: https fast_server: # This can be enabled to enable click & open tracking on emails. It is disabled by # default as it requires a separate static IP address on your server. enabled: false bind_address: general: # This can be changed to allow messages to be sent from multiple IP addresses use_ip_pools: false main_db: # Specify the connection details for your MySQL database host: 127.0.0.1 username: postaluser password: password base de datos database: postal message_db: # Specify the connection details for your MySQL server that will be house the # message databases for mail servers. host: 127.0.0.1 username: postaluser password: password base de datos prefix: postal rabbitmq: # Specify the connection details for your RabbitMQ server. host: 127.0.0.1 username: postal password: password de rabbitmq vhost: /postal dns: Guarda el archivo y cierra el editor. Ahora inicializamos el servicio y creamos una cuenta de usuario. sudo postal initialize sudo postal make-user Arrancamos postal y verificamos el status del servicio. sudo -u postal postal start sudo -u postal postal status ejemplo de salida... Procodile Version 1.0.26 Application Root /opt/postal/app Supervisor PID 18589 Started 2020-04-13 18:25:07 -0500 || web || Quantity 1 || Command bundle exec puma -C config/puma.rb || Respawning 5 every 3600 seconds || Restart mode usr1 || Log path none specified || Address/Port none || => web.1 Running 18:25 pid:18589 respawns:0 port:- tag:- Ya tenemos listo nuestro servidor Postal Mail Server, si quieres manejarlo a través de su portal gráfico necesitamos un servidor. Nosotros instalamos Nginx que es rápido y ligero. Instalar Nginx La instalación de Nginx es fácil, tan solo debes seguir los pasos indicados. sudo apt install nginx sudo cp /opt/postal/app/resource/nginx.cfg /etc/nginx/sites-available/default Creamos un certificado SSL autofirmado. sudo mkdir /etc/nginx/ssl/ sudo openssl req -x509 -newkey rsa:4096 -keyout /etc/nginx/ssl/postal.key -out /etc/nginx/ssl/postal.cert -days 365 -nodes Introduce tus datos válidos. Generating a RSA private key ……………………………++++ …………++++ writing new private key to '/etc/nginx/ssl/postal.key' You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. Country Name (2 letter code) :ES State or Province Name (full name) :HU Locality Name (eg, city) :Monzon Organization Name (eg, company) : Organizational Unit Name (eg, section) : Common Name (e.g. server FQDN or YOUR name) :postal.midominio.com Email Address : Bien... para concluir editas el archivo de configuración de Nginx e insertas tu dominio. sudo nano /etc/nginx/sites-available/default ejemplo... server { listen :80; listen 0.0.0.0:80; server_name postal.midominio.com; return 301 https://$host$request_uri; } Reiniciamos el servidor Nginx. sudo systemctl reload nginx Accedemos a Postal Mail Server Acceder al panel del servidor es tan simple como introducir el dominio que configuramos anteriormente. https://midominio.com https://panel.midominio.com

Login Postal Media Server Canales de Telegram: Canal SoloLinux – Canal SoloWordpress Espero que este articulo te sea de utilidad, puedes ayudarnos a mantener el servidor con una donación (paypal), o también colaborar con el simple gesto de compartir nuestros artículos en tu sitio web, blog, foro o redes sociales. Read the full article
#administrarRabbitMQ#APIHTTP#deteccióndespam#Erlang#InstalarNodejs#InstalarPostalMailServer#Mailgun#PostalMailServer#Postmark#RabbitMQ#ruby#Sendgrid#servidordecorreo#servidorPostalMailServer
0 notes
Text
Lock Down Your Laptop With OpenBSD: Part 2
So you've got a nice fresh OpenBSD install on your laptop, and you're excited to use it. However the desktop environment it comes with is absolutely horrifying to use. Following up from the installation of OpenBSD found on This Blog Post, it is time to tweak out OpenBSD to have a nice and custom desktop tailored to your needs.
I will be configuring i3 window manager, although the setup process for a more well-known desktop environment (like GNOME or XFCE) is very similar in terms of setup.
Since I opted for i3, there's a lot more manual configuration- but the reward is much greater in terms of the ability to customize it. Anyways, this machine doesn't configure itself- so lets dive right in!
Installing Required Software
I wanted for a somewhat custom look, so this is what I set out to install:
i3-gaps
i3status
rofi
rxvt-unicode
chromium (yes, it's modded by the developers)
irssi
w3m
vim
openbsd-backgrounds (because it contains the xwallpaper app)
To install these, I logged in as root and ran the following command in the terminal (once connected to internet):
pkg_add i3-gaps i3status rofi rxvt-unicode chromium irssi w3m vim openbsd-backgrounds
With this completed and out of the way, configuration of the OS is now much easier and we're ready to actually begin configuration.
First Tweaks
There's a console at the login prompt that isn't my taste, so I wanted to disable it. To do so, run:
sed -i 's/xconsole/#xconsole/' /etc/X11/xenodm/Xsetup_0 echo 'xset b off' >> /etc/X11/xenodm/Xsetup_0
The first command comments out the execution of XConsole at the login screen, while the second one disables system beeps at the prompt.
Next thing is enabling the ability to save us some battery life, since we are installing on a laptop:
rcctl enable apmd rcctl set apmd flags -A rcctl start apmd
Apmd is the Advanced Power Management Daemon, and automatically handles the power draw for your system for you.
Since I created a user other than root during installation (let's call the username joe), it's critical to give the account access to doas.
echo 'permit persist keepenv joe' > /etc/doas.conf
The doas command on OpenBSD is actually slated to be the successor to sudo on most platforms, due to it's simplicity and ease of use. Many Linux systems already provide doas as an alternative to sudo due to how well it runs, and this one line just grants the same access you would normally have when using it. However, you can also restrict the access to specific commands depending on the user.
We want to also make the user a member of the staff group, as this group has access to more system resources than plain old users:
usermod -G staff joe
While we're at it, we might as well bump up some of the resource limits even further so our system will run like a dream.
Modify the staff: entry in /etc/login.conf to look like this:
staff:\ :datasize-cur=1024M:\ :datasize-max=8192M:\ :maxproc-cur=512:\ :maxproc-max=1024:\ :openfiles-cur=4096:\ :openfiles-max=8192:\ :stacksize-cur=32M:\ :ignorenologin:\ :requirehome@:\ :tc=default:
Then, append this to /etc/sysctl.conf:
# shared memory limits (chrome needs a ton) kern.shminfo.shmall=3145728 kern.shminfo.shmmax=2147483647 kern.shminfo.shmmni=1024 # semaphores kern.shminfo.shmseg=1024 kern.seminfo.semmns=4096 kern.seminfo.semmni=1024 kern.maxproc=32768 kern.maxfiles=65535 kern.bufcachepercent=90 kern.maxvnodes=262144 kern.somaxconn=2048
NOTE: If a setting exists already and is already higher than what you plan to replace it with, don't touch it. You'll just slow the system down.
What this does is allow for larger amounts of memory to be used by the user and allows the OS to have larger amounts of shared memory.
Awesome, Now let's get suspend working! First we need to run
mkdir /etc/apm
and then append the following to /etc/apm/suspend:
#!/bin/sh pkill -USR1 xidle
We can now run chmod +x /etc/apm/suspend and it will work properly.
Reboot to apply these changes.
FINALLY Setting Up The Desktop
First things first, we will want to configure GTK because the default keybindings are that of emacs- and ~~it stinks~~ gets the job done, but I don't prefer it. To switch to more normal keybindings, run the command
mkdir -p ~/.config/gtk-3.0
and then append the following to ~/.config/gtk-3.0/settings.ini:
[Settings] gtk-theme-name=Adwaita gtk-icon-theme-name=Adwaita gtk-font-name=Arimo 9 gtk-toolbar-style=GTK_TOOLBAR_ICONS gtk-toolbar-icon-size=GTK_ICON_SIZE_SMALL_TOOLBAR gtk-button-images=1 gtk-menu-images=1 gtk-enable-event-sounds=1 gtk-enable-input-feedback-sounds=1 gtk-xft-antialias=1 gtk-xft-hinting=1 gtk-xft-hintstyle=hintslight gtk-xft-rgba=rgb gtk-cursor-theme-size=0 gtk-cursor-theme-name=Default gtk-key-theme-name=Default
Now we need to copy the default i3status to /etc:
cp /usr/local/share/examples/i3status.conf /etc
Failure to do this will cause i3status to crash on launch.
Lastly, let's configure i3 to actually launch. Open /etc/X11/xenodm/Xsession in a text editor and go to the end of the text file. There will be a portion saying exec fvwm. Remove that line entirely and replace it with exec i3. Now search for anything in this file saying xconsole and remove it (this prevents automatic launching of a console in your desktop.)
If running Intel Integrated Graphics, it may be wise to do one final modification to prevent screen tearing. To do this, run the following command:
mkdir /etc/X11/xorg.conf.d
This makes the xorg.conf.d directory. Now append the following contents to /etc/X11/xorg.conf.d/intel.conf:
Section "Device" Identifier "drm" Driver "intel" Option "TearFree" "true" EndSection
This configures OpenBSD to play more nicely with your Intel Integrated Graphics.
Finally, type reboot to reboot your system. You should be able to log in as your normal user and have access to i3 window manager. It will provide a "first startup" wizard to go through. If unfamiliar with i3, it is a tiling window manager that uses keyboard shortcuts to manipulate windows.
Once the configuration has been generated, we will need to configure i3 a bit further to allow for rofi and urxvt to work. To tweak these, we first need to edit our /etc/.Xdefaults file and add the following contents (note- this is the longest part of the entire task of getting a desktop working):
! === Rofi colors rofi.color-window : argb:c82d303b, #7c8389, #1d1f21 rofi.color-normal : argb:3c1d1f21, #c4cbd4, argb:96404552, #4084d6, #f9f9f9 rofi.color-urgent : argb:2c1d1f21, #cc6666, argb:e54b5160, #a54242, #f9f9f9 rofi.color-active : argb:2c1d1f21, #65acff, argb:e44b5160, #4491ed, #f9f9f9 rofi.font : Noto Sans 14 rofi.hide-scrollbar : true ! === URXVT URxvt*geometry : 80x30 "URxvt.font : 9x15 !Special Xft*dpi : 96 Xft*antialias : true Xft*hinting : true Xft*hintstyle : hintslight Xft*rgba : rgb URxvt.cursorUnderline : true URxvt*font : xft:Monospace:size=14:antialias=true URxvt*letterSpace : -2 URxvt.background : #1d1f21 URxvt.foreground : #c5c8c6 URxvt.cursorColor : #c5c8c6 urxvt*transparent : tue urxvt*shading : 30 URxvt*saveLines : 0 URxvt*scrollBar : false !black urxvt.color0 : #282a2e urxvt.color8 : #373b41 !red urxvt.color1 : #a54242 urxvt.color9 : #cc6666 !green urxvt.color2 : #8c9440 urxvt.color10 : #b5bd68 !yellow urxvt.color3 : #de835f urxvt.color11 : #f0c674 !blue urxvt.color4 : #5f819d urxvt.color12 : #81a2be !magenta urxvt.color5 : #85678f urxvt.color13 : #b294bb !cyan urxvt.color6 : #5e8d87 urxvt.color14 : #8abeb7 !white urxvt.color7 : #707880 urxvt.color15 : #c5c8c6
This chunk of configuration sets rofi (our app launcher) into dark mode, and changes the default terminal colors to be a little easier on the eyes with a dark theme instead of a eye-scorching manilla color... Only one change to go!
Wrap-Up
Open ~/.config/i3/config in your editor and go around 45 down. You will notice a section that says "Start a terminal". We want to change it's corresponding command to this:
bindsym $mod+Return exec /usr/local/bin/urxvt
This sets the i3 hotkey combo to execute urxvt instead of xterm.
Awesome! Since i3-gaps is installed, gaps between windows can be set up and configured if preferred. Otherwise, configuration is done, and you're able to install other software that you might want, such as Libreoffice, VLC, PCManFM, and other useful utilities (or games?)
Lastly, to set your desktop background, download a picture and save it to your preferred directory. In my case, it's located at /home/w00t/Pictures/wallpaper.png. Using my download location, I appended the following line to ~/.config/i3/config:
exec --no-startup-id "xwallpaper --stretch /home/w00t/Pictures/wallpaper.png"
Now my desktop wallpaper automatically sets itself on login.
There's other tweaks you can make- but this is meant to be enough to get to a system that's comfortable to work in and have an enjoyable time with OpenBSD. Until Next Time!
Source For Some Config Files: C0ffee.net
Liked This Content? Check Out Our Discord Community and Become an email subscriber!
#81a2be#7c8389#1d1f21#282a2e#f0c674#85678f#b294bb#f9f9f9#8c9440#b5bd68#a54242#373b41#de835f#5e8d87#8abeb7#xconsole#c4cbd4#cc6666#c5c8c6#5f819d#4084d6#65acff#4491ed
0 notes
Text
4/23 Curtis Mayfield / Roots, Pierre Favre / Santana pip1 など更新しました。
おはようございます。更新完了しました。https://bamboo-music.net
John Coltrane / Village Vanguard Again as9124 Sonny Rollins / 3 Giants pr7821 Bobby Hutcherson / Components bst84213 Thelonious Monk / In Europe vol1 rm002 Thelonious Monk / In Europe vol2 rm003 Mel Turner / a Portrait of Mel Turner 10016 Mike Smith / Dreams of India usr1 Chet Atkins / Progressive Pickin lsp2908 Chet Atkins / Hummm and Strum Along lsp2025 Makam / Kozelitesek Approaches Baby Cortez / the Isley Brothers Way tns3005 Jacques "Crabouif" Higelin / Higelin sh10020 Pierre Favre / Santana pip1 Jean Terrell / I Had to Fall in Love Curtis Mayfield / Roots
0 notes
Text
Requirements report
For week 5, the team further adjusted the requirements:
User requirements
USR1: The disabled individual shall be able to walk unassisted.
USR2: The disabled individual shall be able to put on the solution without personal assistance.
USR3: The disabled individual shall be able to take off the solution without personal assistance.
USR4: The disabled individual shall be able to stand independently for a minimum of 10 minutes.
System Requirements
SR1: The system shall be able to sustain the weight of the disabled individual.
SR2: The system shall be stable while in use.
SR3: The system shall be able to provide omnidirectional movement to the disabled individual.
SR4: The system shall be comfortable for the disabled individual to don without personal assistance.
SR5: The system shall be comfortable for the disabled individual to take off without personal assistance.
SR6: The system shall be comfortable for the disabled individual to use.
These are the changes we made and then put into our requirements document.
0 notes
Text
apache http server - Can I "reload" Apache2 configuration file without issues? - Super User [はてなブックマーク]
apache http server - Can I "reload" Apache2 configuration file without issues? - Super User
Reload does a "Graceful Restart". From the Apache documentation Stopping and Restarting : The USR1 or graceful signal causes the parent process to advise the children to exit after their current reque...
kjw_junichi
from kjw_junichiのブックマーク http://ift.tt/2DBxKQ4
0 notes
Link
L'ADN d'un nourrisson préhistorique dévoile l'origine du peuple américain #ChrisTec Le séquençage du génome d'un enfant préhistorique en Alaska prouve l'existence d'une population inconnue en Amérique du Nord. C'est grâce à l'analyse de l'ADN d'un nourrisson préhistorique retrouvé dans des ossements fossilisés en Alaska qu'une équipe de scientifiques est parvenue à prouver l'existence d'une population jusqu'à maintenant inconnue en Amérique. En effet, en 2013, des scientifiques découvrent les restes fossilisés d'un bébé de sexe féminin mort à l'âge de six semaines. Retrouvé sur le site d'Upward Sun River, les habitants baptisent alors cet enfant préhistorique "petite fille du lever du soleil". Les scientifiques, eux, préfèrent la baptiser USR1. L'enfant est d'ailleurs retrouvé aux côtés d'un autre enfant plus jeune du même sexe. Tous les deux auraient été enterrés il… Lire la suite : L'ADN d'un nourrisson préhistorique dévoile l'origine du peuple américain sur Hitek.fr
0 notes
Photo

ДНК аляскинских бебета разказва историята на един от първите американци В 11,500 години останките на гърдите момиче от Аляска хвърли Нова светлина върху населението на двете Америки. Генетичен анализ на дете, в комбинация с други данни, показват, че тя принадлежи към по-рано неизвестното, древна група. Учените казват, че са научили от ДНК подкрепя идеята, че една вълна от мигранти са се преместили на континент от Сибир малко повече от 20 000 години. Под морското равнище, тогава щеше да е създаден на сушата в Берингово пролив. Той ще отиде само като северните ледници разтопи и се оттегля. Пионери заселници са станали прародители на всички съвременни индианци, да речем проф Эске Виллерслевом и колеги. Него��ият екип публикува своята оценка генетика в списание Nature. Скелет от шест-седмично бебе е бил намерен в археологическа зона на реката на Изгряващото Слънце през 2013 година. Местните местните общности я нарече “Хачын’itee’aanenh т ‘eede гей”, или “Изгрев момичета”. Научен колектив се отнася към нея само като USR1. “Това е останки от човек, намирани някога в Аляска, но най-интересното тук е, че този човек принадлежи към популации от хора, които никога не сме виждали по-рано”, – обясни проф Виллерслевом, който влиза в университетите в Копенхаген и Кеймбридж. “Това население, което е най-тясно свързана със съвременните индианци, но все още далечно отношение към тях. По този начин, може да се ��аже, че тя идва от рано, или най-оригиналните, роден на американска група – първи коренната американска група, която е разнообразна. “И това означава, че тя може да ни каже за предшественици на всички индианци”, – каза той на бибиси. Учените изучават историята на древния населението чрез анализ на мутации, или малки грешки, които се натрупват в ДНК-то от поколение на поколение. Тези модели, в съчетание с демографски моделиране, позволяват да се установи връзка между различните групи хора с течение на времето. Ново проучване показва наличието на предковой популации, които са се превърнали се различават генетично от Източна Азия около 36000 години, и който беше завършен клон на 25 000 – разкриващи Берингово разположени на сушата мост, свързващ Сибир и Аляска са били прехвърлени. Този анализ предполага, че УР1 и нейните колеги древните Beringians след това излязох от пришлых ако отседнете в Аляска в продължение на няколко хиляди години. Други в първата вълна, обаче, са се преместили на юг, за да заемат територии извън лед. Това е и по-нататък-преместване на клон в крайна сметка се превърна в две генетични групи, които са предшественици на сегашните местни народи. Проф Виллерслевом каза: “преди да генома на това момиче, при нас само последните коренните американци и древните хъскита, се опитват да открият връзката и времето за разминаване. Но сега ние имаме индивид с население между двете; и това наистина отваря врати, за да отговори на тези фундаментални въпроси”. По-точни отговори ще бъдат само с откриването на още остава в Североизточната част на Сибир и Аляска, един учен добавя. Че усложнява в случай на северозападната част на американския щат, тъй като на неговата кисели почви са неблагоприятни за запазване на скелети и по-специално ДНК-материал. Нека да блокирате реклама! (Защо?)
0 notes
Text
Mastering the Node.js Core Modules - The Process Module
In this article, we'll take a look at the Node.js Process module, and what hidden gems it has to offer. After you’ve read this post, you’ll be able to write production-ready applications with much more confidence. You’ll know what process states your Node.js apps will have, you’ll be able to do graceful shutdown, and you’ll handle errors much more efficiently.
In the new Mastering the Node.js Core Modules series you can learn what hidden/barely known features the core modules have, and how you can use them. By going through the basic elements of these Node.js modules, you’ll have a better understanding of they work and how can you eliminate any errors.
In this chapter, we’ll take a look at the Node.js process module. The process object (which is an instance of the EventEmitter) is a global variable that provides information on the currently running Node.js process.
Events to watch out for in the Node.js process module
As the process module is an EventEmitter, you can subscribe to its events just like you do it with any other instances of the EventEmitter using the .on call:
process.on('eventName', () => { //do something })
uncaughtException
This event is emitted when an uncaught JavaScript exception bubbles back to the event loop.
By default, if no event listeners are added to the uncaughtException handler, the process will print the stack trace to stderr and exit. If you add an event listener, you change this behavior to the one you implement in your listener:
process.on('uncaughtException', (err) => { // here the 1 is a file descriptor for STDERR fs.writeSync(1, `Caught exception: ${err}\n`) })
During the past years, we have seen this event used in many wrong ways. The most important advice when using the uncaughtException event in the process module are the following:
if uncaughtException happens, your application is in an undefined state,
recovering from uncaughtException is strongly discouraged, it is not safe to continue normal operation after it,
the handler should only be used for synchronous cleanup of allocated resources,
exceptions thrown in this handler are not caught, and the application will exit immediately,
you should always monitor your process with an external tool, and restart it when needed (for example, when it crashes).
unhandledRejection
Imagine you have the following code snippet:
const fs = require('fs-extra') fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!'))
What would happen if the source file didn’t exist? Well, the answer depends on the Node.js version you are running. In some of them (mostly version 4 and below), the process would silently fail, and you would just sit there wondering what happened.
In more recent Node.js versions, you would get the following error message:
(node:28391) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): undefined (node:28391) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
This means that we missed the error handling in the Promise we used for copying a file. The example should have been written this way:
fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!')) .catch(err => console.error(err))
The problem with not handling Promise rejections is the same as in the case of uncaughtExceptions - your Node.js process will be in an unknown state. What is even worse, is that it might cause file descriptor failure and memory leaks. Your best course of action in this scenario is to restart the Node.js process.
To do so, you have to attach an event listener to the unhandledRejection event, and exit the process with process.exit(1).
Our recommendation here is to go with Matteo Collina's make-promises-safe package, which solves it for you out of the box.
Node.js Signal Events
Signal events will also be emitted when Node.js receives POSIX signal events. Let's take a look at the two most important ones, SIGTERM and SIGUSR1.
You can find the full list of supported signals here.
SIGTERM
The SIGTERM signal is sent to a Node.js process to request its termination. Unlike the SIGKILL signal, it can be listened on or ignored by the process.
This allows the process to be shut down in a nice manner, by releasing the resources it allocated, like file handlers or database connections. This way of shutting down applications is called graceful shutdown.
Essentially, the following steps need to happen before performing a graceful shutdown:
The applications get notified to stop (received SIGTERM).
The applications notify the load balancers that they aren’t ready for newer requests.
The applications finish all the ongoing requests.
Then, it releases all of the resources (like a database connection) correctly.
The application exits with a "success" status code (process.exit()).
Read this article for more on graceful shutdown in Node.js.
SIGUSR1
By the POSIX standard, SIGUSR1 and SIGUSR2 can be used for user-defined conditions. Node.js chose to use this event to start the built-in debugger.
You can send the SIGUSR1 signal to the process by running the following command:
kill -USR1 PID_OF_THE_NODE_JS_PROCESS
Once you did that, the Node.js process in question will let you know that the debugger is running:
Starting debugger agent. Debugger listening on [::]:5858
Methods and values exposed by the Node.js process module
process.cwd()
This method returns the current working directory for the running Node.js process.
$ node -e 'console.log(`Current directory: ${process.cwd()}`)' Current directory: /Users/gergelyke/Development/risingstack/risingsite_v2
In case you have to change it, you can do so by calling process.chdir(path).
process.env
This property returns an object containing the user environment, just like environ.
If you are building applications that conform the 12-factor application principles, you will heavily depend on it; as the third principle of a twelve-factor application requires that all configurations should be stored in the user environment.
Environment variables are preferred, as it is easy to change them between deploys without changing any code. Unlike config files, there is little chance of them being accidentally checked into the code repository.
It is worth mentioning, that you can change the values of the process.env object, however, it won't be reflected in the user environment.
process.exit([code])
This method tells the Node.js process to terminate the process synchronously with an exit status code. Important consequences of this call::
it will force the process to exit as quickly as possible
even if some async operations are in progress,
as writing to STDOUT and STDERR is async, some logs can be lost
in most cases, it is not recommended to use process.exit() - instead, you can let it shut down by depleting the event loop.
process.kill(pid, [signal])
With this method, you can send any POSIX signals to any processes. You don’t only kill processes as the name suggest - this command acts as a signal sender too (like the kill system call.)
Exit codes used by Node.js
If all goes well, Node.js will exit with the exit code 0. However, if the process exits because of an error, you’ll get one of the following error codes::
1 : Uncaught fatal exception, which was not handled by an uncaughtException handler,
5 : Fatal error in V8 (like memory allocation failures),
9 : Invalid argument, when an unknown option was specified, or an option which requires a value was set without the value.
These are just the most common exit codes, for all the exit codes, please refer to http://ift.tt/2fA8o8c.
Learn more Node.js
These are the most important aspects of using the Node.js process module. We hope that by following the above listed advices, you’ll be able to get the most out of Node.js. In case you have any questions, don’t hesitate to reach out to us in the comments section below.
By studying the core modules, you can quickly get the hang of Node.js! Although, in case you feel that you could use some extra information about the foundations, or you have doubts about how you can implement Node successfully in your organization - we can help!
The team of RisingStack is going to travel around Europe this to hold trainings for those who are interested in working with Node.js. Check out the Beginner Node.js Training Agenda here.
Mastering the Node.js Core Modules - The Process Module published first on http://ift.tt/2fA8nUr
0 notes
Text
Mastering the Node.js Core Modules - The Process Module
In this article, we'll take a look at the Node.js Process module, and what hidden gems it has to offer. After you’ve read this post, you’ll be able to write production-ready applications with much more confidence. You’ll know what process states your Node.js apps will have, you’ll be able to do graceful shutdown, and you’ll handle errors much more efficiently.
In the new Mastering the Node.js Core Modules series you can learn what hidden/barely known features the core modules have, and how you can use them. By going through the basic elements of these Node.js modules, you’ll have a better understanding of they work and how can you eliminate any errors.
In this chapter, we’ll take a look at the Node.js process module. The process object (which is an instance of the EventEmitter) is a global variable that provides information on the currently running Node.js process.
Events to watch out for in the Node.js process module
As the process module is an EventEmitter, you can subscribe to its events just like you do it with any other instances of the EventEmitter using the .on call:
process.on('eventName', () => { //do something })
uncaughtException
This event is emitted when an uncaught JavaScript exception bubbles back to the event loop.
By default, if no event listeners are added to the uncaughtException handler, the process will print the stack trace to stderr and exit. If you add an event listener, you change this behavior to the one you implement in your listener:
process.on('uncaughtException', (err) => { // here the 1 is a file descriptor for STDERR fs.writeSync(1, `Caught exception: ${err}\n`) })
During the past years, we have seen this event used in many wrong ways. The most important advice when using the uncaughtException event in the process module are the following:
if uncaughtException happens, your application is in an undefined state,
recovering from uncaughtException is strongly discouraged, it is not safe to continue normal operation after it,
the handler should only be used for synchronous cleanup of allocated resources,
exceptions thrown in this handler are not caught, and the application will exit immediately,
you should always monitor your process with an external tool, and restart it when needed (for example, when it crashes).
unhandledRejection
Imagine you have the following code snippet:
const fs = require('fs-extra') fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!'))
What would happen if the source file didn’t exist? Well, the answer depends on the Node.js version you are running. In some of them (mostly version 4 and below), the process would silently fail, and you would just sit there wondering what happened.
In more recent Node.js versions, you would get the following error message:
(node:28391) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): undefined (node:28391) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
This means that we missed the error handling in the Promise we used for copying a file. The example should have been written this way:
fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!')) .catch(err => console.error(err))
The problem with not handling Promise rejections is the same as in the case of uncaughtExceptions - your Node.js process will be in an unknown state. What is even worse, is that it might cause file descriptor failure and memory leaks. Your best course of action in this scenario is to restart the Node.js process.
To do so, you have to attach an event listener to the unhandledRejection event, and exit the process with process.exit(1).
Our recommendation here is to go with Matteo Collina's make-promises-safe package, which solves it for you out of the box.
Node.js Signal Events
Signal events will also be emitted when Node.js receives POSIX signal events. Let's take a look at the two most important ones, SIGTERM and SIGUSR1.
You can find the full list of supported signals here.
SIGTERM
The SIGTERM signal is sent to a Node.js process to request its termination. Unlike the SIGKILL signal, it can be listened on or ignored by the process.
This allows the process to be shut down in a nice manner, by releasing the resources it allocated, like file handlers or database connections. This way of shutting down applications is called graceful shutdown.
Essentially, the following steps need to happen before performing a graceful shutdown:
The applications get notified to stop (received SIGTERM).
The applications notify the load balancers that they aren’t ready for newer requests.
The applications finish all the ongoing requests.
Then, it releases all of the resources (like a database connection) correctly.
The application exits with a "success" status code (process.exit()).
Read this article for more on graceful shutdown in Node.js.
SIGUSR1
By the POSIX standard, SIGUSR1 and SIGUSR2 can be used for user-defined conditions. Node.js chose to use this event to start the built-in debugger.
You can send the SIGUSR1 signal to the process by running the following command:
kill -USR1 PID_OF_THE_NODE_JS_PROCESS
Once you did that, the Node.js process in question will let you know that the debugger is running:
Starting debugger agent. Debugger listening on [::]:5858
Methods and values exposed by the Node.js process module
process.cwd()
This method returns the current working directory for the running Node.js process.
$ node -e 'console.log(`Current directory: ${process.cwd()}`)' Current directory: /Users/gergelyke/Development/risingstack/risingsite_v2
In case you have to change it, you can do so by calling process.chdir(path).
process.env
This property returns an object containing the user environment, just like environ.
If you are building applications that conform the 12-factor application principles, you will heavily depend on it; as the third principle of a twelve-factor application requires that all configurations should be stored in the user environment.
Environment variables are preferred, as it is easy to change them between deploys without changing any code. Unlike config files, there is little chance of them being accidentally checked into the code repository.
It is worth mentioning, that you can change the values of the process.env object, however, it won't be reflected in the user environment.
process.exit([code])
This method tells the Node.js process to terminate the process synchronously with an exit status code. Important consequences of this call::
it will force the process to exit as quickly as possible
even if some async operations are in progress,
as writing to STDOUT and STDERR is async, some logs can be lost
in most cases, it is not recommended to use process.exit() - instead, you can let it shut down by depleting the event loop.
process.kill(pid, [signal])
With this method, you can send any POSIX signals to any processes. You don’t only kill processes as the name suggest - this command acts as a signal sender too (like the kill system call.)
Exit codes used by Node.js
If all goes well, Node.js will exit with the exit code 0. However, if the process exits because of an error, you’ll get one of the following error codes::
1 : Uncaught fatal exception, which was not handled by an uncaughtException handler,
5 : Fatal error in V8 (like memory allocation failures),
9 : Invalid argument, when an unknown option was specified, or an option which requires a value was set without the value.
These are just the most common exit codes, for all the exit codes, please refer to http://ift.tt/2fA8o8c.
Learn more Node.js
These are the most important aspects of using the Node.js process module. We hope that by following the above listed advices, you’ll be able to get the most out of Node.js. In case you have any questions, don’t hesitate to reach out to us in the comments section below.
By studying the core modules, you can quickly get the hang of Node.js! Although, in case you feel that you could use some extra information about the foundations, or you have doubts about how you can implement Node successfully in your organization - we can help!
The team of RisingStack is going to travel around Europe this to hold trainings for those who are interested in working with Node.js. Check out the Beginner Node.js Training Agenda here.
Mastering the Node.js Core Modules - The Process Module published first on http://ift.tt/2w7iA1y
0 notes
Text
DD
Um comando bem simples, mas útil, que copia bite a bite dados de um arquivo para outro, com ele é possível fazer uma copia de um HD completo ou mesmo um backup da MBR:
Exemplos simples:
Clonar HD -> # dd if=/dev/hda of=/dev/hdb
Backup MBR -> # dd if=/dev/hda of=/dev/fd0/mbr.backup bs=512 count=1
Ele possui muitas outras opções, mas a sintaxe básica é esta:
$ dd if=texto1.txt of=texto2.txt
====================================================
Sending a USR1 signal to a running `dd' process makes it print I/O sta‐ tistics to standard error and then resume copying.
$ dd if=/dev/zero of=/dev/null& pid=$! $ kill -USR1 $pid; sleep 1; kill $pid
18335302+0 records in 18335302+0 records out 9387674624 bytes (9.4 GB) copied, 34.6279 seconds, 271 MB/s
=====================================================
Então abro aqui um parênteses para informar á você que acreditava que o comando Kill só servia para matar aquele processo do mal, não senhor, ele na verdade é um comando que envia sinais de diversos tipos, inclusive o de terminar, como muito utilizado "kill -9 PID", muitos são os sinais, como o de espera, o de parada etc, e temos até 2 espaços para sinais definidos pelos usuários, que ser�� nosso caso aqui.
Neste caso, desejamos saber o progresso, assim, os ilustres criadores do DD Mr. Paul Rubin, Mr. David MacKenzie, and Mr. Stuart Kemp, deixaram que o sinal USR1 (Primeiro sinal definido pelo usuário) fosse encarregado desta função.
Assim, para acompanhar o progresso de sua cópia, envie o sinal ao PID de seu processo:
$ pgrep -l '^dd$'
1234 dd
$ kill -USR1 1234
18335302+0 records in 18335302+0 records out 9387674624 bytes (9.4 GB) copied, 34.6279 seconds, 271 MB/s
E ai está, o progresso de seu processo.
Para saber mais sobre sinais -> $ man 7 signal
Para saber mais sobre dd -> $ man dd
0 notes
Text
Mastering the Node.js Core Modules - The Process Module
In this article, we'll take a look at the Node.js Process module, and what hidden gems it has to offer. After you’ve read this post, you’ll be able to write production-ready applications with much more confidence. You’ll know what process states your Node.js apps will have, you’ll be able to do graceful shutdown, and you’ll handle errors much more efficiently.
In the new Mastering the Node.js Core Modules series you can learn what hidden/barely known features the core modules have, and how you can use them. By going through the basic elements of these Node.js modules, you’ll have a better understanding of they work and how can you eliminate any errors.
In this chapter, we’ll take a look at the Node.js process module. The process object (which is an instance of the EventEmitter) is a global variable that provides information on the currently running Node.js process.
Events to watch out for in the Node.js process module
As the process module is an EventEmitter, you can subscribe to its events just like you do it with any other instances of the EventEmitter using the .on call:
process.on('eventName', () => { //do something })
uncaughtException
This event is emitted when an uncaught JavaScript exception bubbles back to the event loop.
By default, if no event listeners are added to the uncaughtException handler, the process will print the stack trace to stderr and exit. If you add an event listener, you change this behavior to the one you implement in your listener:
process.on('uncaughtException', (err) => { // here the 1 is a file descriptor for STDERR fs.writeSync(1, `Caught exception: ${err}\n`) })
During the past years, we have seen this event used in many wrong ways. The most important advice when using the uncaughtException event in the process module are the following:
if uncaughtException happens, your application is in an undefined state,
recovering from uncaughtException is strongly discouraged, it is not safe to continue normal operation after it,
the handler should only be used for synchronous cleanup of allocated resources,
exceptions thrown in this handler are not caught, and the application will exit immediately,
you should always monitor your process with an external tool, and restart it when needed (for example, when it crashes).
unhandledRejection
Imagine you have the following code snippet:
const fs = require('fs-extra') fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!'))
What would happen if the source file didn’t exist? Well, the answer depends on the Node.js version you are running. In some of them (mostly version 4 and below), the process would silently fail, and you would just sit there wondering what happened.
In more recent Node.js versions, you would get the following error message:
(node:28391) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): undefined (node:28391) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
This means that we missed the error handling in the Promise we used for copying a file. The example should have been written this way:
fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!')) .catch(err => console.error(err))
The problem with not handling Promise rejections is the same as in the case of uncaughtExceptions - your Node.js process will be in an unknown state. What is even worse, is that it might cause file descriptor failure and memory leaks. Your best course of action in this scenario is to restart the Node.js process.
To do so, you have to attach an event listener to the unhandledRejection event, and exit the process with process.exit(1).
Our recommendation here is to go with Matteo Collina's make-promises-safe package, which solves it for you out of the box.
Node.js Signal Events
Signal events will also be emitted when Node.js receives POSIX signal events. Let's take a look at the two most important ones, SIGTERM and SIGUSR1.
You can find the full list of supported signals here.
SIGTERM
The SIGTERM signal is sent to a Node.js process to request its termination. Unlike the SIGKILL signal, it can be listened on or ignored by the process.
This allows the process to be shut down in a nice manner, by releasing the resources it allocated, like file handlers or database connections. This way of shutting down applications is called graceful shutdown.
Essentially, the following steps need to happen before performing a graceful shutdown:
The applications get notified to stop (received SIGTERM).
The applications notify the load balancers that they aren’t ready for newer requests.
The applications finish all the ongoing requests.
Then, it releases all of the resources (like a database connection) correctly.
The application exits with a "success" status code (process.exit()).
Read this article for more on graceful shutdown in Node.js.
SIGUSR1
By the POSIX standard, SIGUSR1 and SIGUSR2 can be used for user-defined conditions. Node.js chose to use this event to start the built-in debugger.
You can send the SIGUSR1 signal to the process by running the following command:
kill -USR1 PID_OF_THE_NODE_JS_PROCESS
Once you did that, the Node.js process in question will let you know that the debugger is running:
Starting debugger agent. Debugger listening on [::]:5858
Methods and values exposed by the Node.js process module
process.cwd()
This method returns the current working directory for the running Node.js process.
$ node -e 'console.log(`Current directory: ${process.cwd()}`)' Current directory: /Users/gergelyke/Development/risingstack/risingsite_v2
In case you have to change it, you can do so by calling process.chdir(path).
process.env
This property returns an object containing the user environment, just like environ.
If you are building applications that conform the 12-factor application principles, you will heavily depend on it; as the third principle of a twelve-factor application requires that all configurations should be stored in the user environment.
Environment variables are preferred, as it is easy to change them between deploys without changing any code. Unlike config files, there is little chance of them being accidentally checked into the code repository.
It is worth mentioning, that you can change the values of the process.env object, however, it won't be reflected in the user environment.
process.exit([code])
This method tells the Node.js process to terminate the process synchronously with an exit status code. Important consequences of this call::
it will force the process to exit as quickly as possible
even if some async operations are in progress,
as writing to STDOUT and STDERR is async, some logs can be lost
in most cases, it is not recommended to use process.exit() - instead, you can let it shut down by depleting the event loop.
process.kill(pid, [signal])
With this method, you can send any POSIX signals to any processes. You don’t only kill processes as the name suggest - this command acts as a signal sender too (like the kill system call.)
Exit codes used by Node.js
If all goes well, Node.js will exit with the exit code 0. However, if the process exits because of an error, you’ll get one of the following error codes::
1 : Uncaught fatal exception, which was not handled by an uncaughtException handler,
5 : Fatal error in V8 (like memory allocation failures),
9 : Invalid argument, when an unknown option was specified, or an option which requires a value was set without the value.
These are just the most common exit codes, for all the exit codes, please refer to http://ift.tt/2fA8o8c.
Learn more Node.js
These are the most important aspects of using the Node.js process module. We hope that by following the above listed advices, you’ll be able to get the most out of Node.js. In case you have any questions, don’t hesitate to reach out to us in the comments section below.
By studying the core modules, you can quickly get the hang of Node.js! Although, in case you feel that you could use some extra information about the foundations, or you have doubts about how you can implement Node successfully in your organization - we can help!
The team of RisingStack is going to travel around Europe this to hold trainings for those who are interested in working with Node.js. Check out the Beginner Node.js Training Agenda here.
Mastering the Node.js Core Modules - The Process Module published first on http://ift.tt/2fA8nUr
0 notes
Text
Mastering the Node.js Core Modules - The Process Module
In this article, we'll take a look at the Node.js Process module, and what hidden gems it has to offer. After you’ve read this post, you’ll be able to write production-ready applications with much more confidence. You’ll know what process states your Node.js apps will have, you’ll be able to do graceful shutdown, and you’ll handle errors much more efficiently.
In the new Mastering the Node.js Core Modules series you can learn what hidden/barely known features the core modules have, and how you can use them. By going through the basic elements of these Node.js modules, you’ll have a better understanding of they work and how can you eliminate any errors.
In this chapter, we’ll take a look at the Node.js process module. The process object (which is an instance of the EventEmitter) is a global variable that provides information on the currently running Node.js process.
Events to watch out for in the Node.js process module
As the process module is an EventEmitter, you can subscribe to its events just like you do it with any other instances of the EventEmitter using the .on call:
process.on('eventName', () => { //do something })
uncaughtException
This event is emitted when an uncaught JavaScript exception bubbles back to the event loop.
By default, if no event listeners are added to the uncaughtException handler, the process will print the stack trace to stderr and exit. If you add an event listener, you change this behavior to the one you implement in your listener:
process.on('uncaughtException', (err) => { // here the 1 is a file descriptor for STDERR fs.writeSync(1, `Caught exception: ${err}\n`) })
During the past years, we have seen this event used in many wrong ways. The most important advice when using the uncaughtException event in the process module are the following:
if uncaughtException happens, your application is in an undefined state,
recovering from uncaughtException is strongly discouraged, it is not safe to continue normal operation after it,
the handler should only be used for synchronous cleanup of allocated resources,
exceptions thrown in this handler are not caught, and the application will exit immediately,
you should always monitor your process with an external tool, and restart it when needed (for example, when it crashes).
unhandledRejection
Imagine you have the following code snippet:
const fs = require('fs-extra') fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!'))
What would happen if the source file didn’t exist? Well, the answer depends on the Node.js version you are running. In some of them (mostly version 4 and below), the process would silently fail, and you would just sit there wondering what happened.
In more recent Node.js versions, you would get the following error message:
(node:28391) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): undefined (node:28391) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
This means that we missed the error handling in the Promise we used for copying a file. The example should have been written this way:
fs.copy('/tmp/myfile', '/tmp/mynewfile') .then(() => console.log('success!')) .catch(err => console.error(err))
The problem with not handling Promise rejections is the same as in the case of uncaughtExceptions - your Node.js process will be in an unknown state. What is even worse, is that it might cause file descriptor failure and memory leaks. Your best course of action in this scenario is to restart the Node.js process.
To do so, you have to attach an event listener to the unhandledRejection event, and exit the process with process.exit(1).
Our recommendation here is to go with Matteo Collina's make-promises-safe package, which solves it for you out of the box.
Node.js Signal Events
Signal events will also be emitted when Node.js receives POSIX signal events. Let's take a look at the two most important ones, SIGTERM and SIGUSR1.
You can find the full list of supported signals here.
SIGTERM
The SIGTERM signal is sent to a Node.js process to request its termination. Unlike the SIGKILL signal, it can be listened on or ignored by the process.
This allows the process to be shut down in a nice manner, by releasing the resources it allocated, like file handlers or database connections. This way of shutting down applications is called graceful shutdown.
Essentially, the following steps need to happen before performing a graceful shutdown:
The applications get notified to stop (received SIGTERM).
The applications notify the load balancers that they aren’t ready for newer requests.
The applications finish all the ongoing requests.
Then, it releases all of the resources (like a database connection) correctly.
The application exits with a "success" status code (process.exit()).
Read this article for more on graceful shutdown in Node.js.
SIGUSR1
By the POSIX standard, SIGUSR1 and SIGUSR2 can be used for user-defined conditions. Node.js chose to use this event to start the built-in debugger.
You can send the SIGUSR1 signal to the process by running the following command:
kill -USR1 PID_OF_THE_NODE_JS_PROCESS
Once you did that, the Node.js process in question will let you know that the debugger is running:
Starting debugger agent. Debugger listening on [::]:5858
Methods and values exposed by the Node.js process module
process.cwd()
This method returns the current working directory for the running Node.js process.
$ node -e 'console.log(`Current directory: ${process.cwd()}`)' Current directory: /Users/gergelyke/Development/risingstack/risingsite_v2
In case you have to change it, you can do so by calling process.chdir(path).
process.env
This property returns an object containing the user environment, just like environ.
If you are building applications that conform the 12-factor application principles, you will heavily depend on it; as the third principle of a twelve-factor application requires that all configurations should be stored in the user environment.
Environment variables are preferred, as it is easy to change them between deploys without changing any code. Unlike config files, there is little chance of them being accidentally checked into the code repository.
It is worth mentioning, that you can change the values of the process.env object, however, it won't be reflected in the user environment.
process.exit([code])
This method tells the Node.js process to terminate the process synchronously with an exit status code. Important consequences of this call::
it will force the process to exit as quickly as possible
even if some async operations are in progress,
as writing to STDOUT and STDERR is async, some logs can be lost
in most cases, it is not recommended to use process.exit() - instead, you can let it shut down by depleting the event loop.
process.kill(pid, [signal])
With this method, you can send any POSIX signals to any processes. You don’t only kill processes as the name suggest - this command acts as a signal sender too (like the kill system call.)
Exit codes used by Node.js
If all goes well, Node.js will exit with the exit code 0. However, if the process exits because of an error, you’ll get one of the following error codes::
1 : Uncaught fatal exception, which was not handled by an uncaughtException handler,
5 : Fatal error in V8 (like memory allocation failures),
9 : Invalid argument, when an unknown option was specified, or an option which requires a value was set without the value.
These are just the most common exit codes, for all the exit codes, please refer to http://ift.tt/2fA8o8c.
Learn more Node.js
These are the most important aspects of using the Node.js process module. We hope that by following the above listed advices, you’ll be able to get the most out of Node.js. In case you have any questions, don’t hesitate to reach out to us in the comments section below.
By studying the core modules, you can quickly get the hang of Node.js! Although, in case you feel that you could use some extra information about the foundations, or you have doubts about how you can implement Node successfully in your organization - we can help!
The team of RisingStack is going to travel around Europe this to hold trainings for those who are interested in working with Node.js. Check out the Beginner Node.js Training Agenda here.
Mastering the Node.js Core Modules - The Process Module published first on http://ift.tt/2fA8nUr
0 notes