#verticalscaling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
The Scaling with Node js

In this article, we will discuss the effective scaling practices of developing Node.js web applications. Most Developers are familiar with the Node.js implementation and we will focus on some advanced tactics to scale per the number of users.
Node.js
Node.js is a JavaScript run-time environment built on Chrome’s V8 JavaScript engine; it implements the reactor pattern, a non-blocking, event-driven I/O paradigm. Node.js is well good for building fast, scalable network applications, as it’s capable of handling a huge number of simultaneous requests with high throughput.
The way to improve the scalability
Before entering into the concept, let’s know what is Scalable? A word Scalable refers to expandable, which means the number of users will access the application from anywhere at the same time. Ensure your application is highly scalable; it can handle a large increase in users, workload or transactions without undue strain.
Regarding increasing the scalable, we are going to explain the options for concurrent users.

1. Localhost
Any application that runs on a developer machine for development purpose is hosting application locally. Generally, it is for the use of only one user, so there is no need to worry about scaling factor.
2. Single server
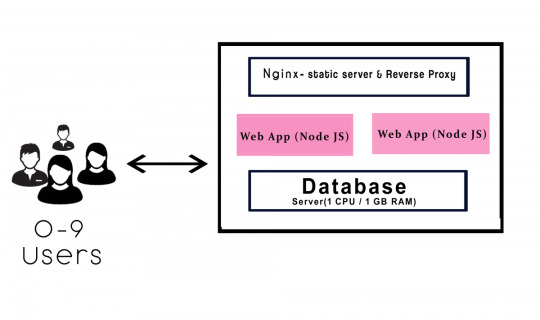
A single server system can accommodate around 1 to 9 concurrent users. Assume, your application will be used locally then the deployment will be carried out locally. It’s fine to do in a single server. For hosting the node.js application one can use Nginx as the webserver.
If you are using a single server application for few users well enough. It is simple to implement the single server and very much efficient for a few users. The requirements consist of only one CPU and 1 GB RAM, which is equivalent to web server AWS t2.micro / t2.nano.
3. Vertical scaling
The term “vertical” states that to manage by adding extra capability or power to a single component. When the server begins to start slower or longer time to execute at the level we will transform to the vertical scaling. In vertical scaling the requirements consist of 4 GB RAM, which is equivalent to web service t2. medium.
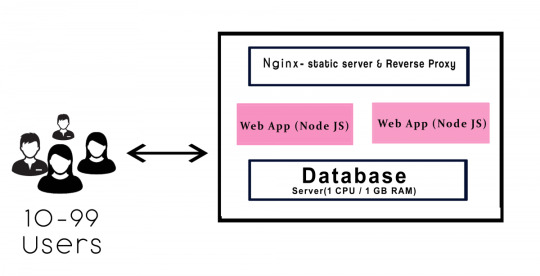
The above diagram explains the workflow in the vertical scaling.
a. It consists of two instances of Node.js which runs to deploy/update within zero downtime.
b. The function of Nginx handles the load balance.
c. If server 1 works to upgrade, then the other server keeps serving the requests. Continue this process until the buffer will get empty.
d. The purpose in Nginx takes into account of all the user requests, It consists of two functions such as a static file server and reverses proxy.
Static — The static files like CSS, JS, Images, this will not disturb the web app.
Reverse Proxy — It will access the request for the needs the application to resolve which redirects it.
4. Horizontal scaling
The Scaling horizontally, which means adding more machines to scale up your pool of resources. This concept will work out in the enterprise from the level of 100 to 1000 employees. Whenever the app responses get slowdown from the database you have to upgrade to 16 GB RAM. Cassandra, MongoDB is suitable for horizontal scaling. It provides for implementing a scale from smaller to a bigger machine.
Companies like Google, Facebook, eBay and Amazon are using horizontal scaling.

Differences
In horizontal scaling, you can add more machines to scale dynamically. If any system fails, then another system will handle the process. No worry about the process failing. It will bring high I/O concurrency, reducing the load on existing nodes and improve disk capacity.
In vertical scaling, the data resides on a single node, it gets easy to slow down when the load increases. If the system fails to process, then the whole system may get a collapse. Horizontal scaling is little bit cost-effective than the vertical scaling.
5. Multi-servers
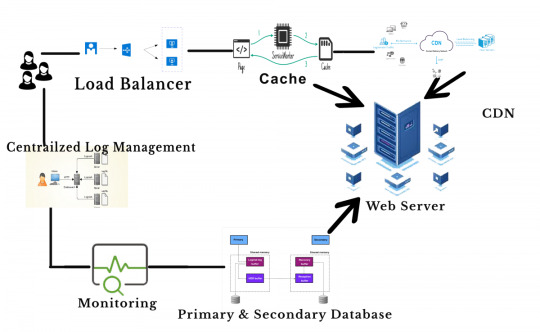
As the business grows, it’s time to add more servers to host the node.js application. The capacity of multi-servers can accommodate above 1000’s of concurrent users. Are you like to transform the previous server to the multi-servers? If Yes, continue with the following steps
1. First, add a load balancer and app units.
2. Set up multiple availability zones (AZ) in a region which one is connected through low latency links.
3. By splitting up the static files for easier maintenance.
4. CDN is one of the servers, which is used to manage files like images, videos, CSS, JS etc.,
Amazon provides load balancing through Elastic Load Balancer (ELB). It is available for the entire availability zone. This service routes to the active host only and can able to manage 1000 instances. By this set up you can use horizontally either vertically.
6. Microservices
Most of the giant companies like Netflix, Uber, Amazon are using microservices. The goals of microservice are to separate the services like search, build, configure and other management functionalities from database instances and deploy them as a separate microservices. Each of these services will take care of their tasks and can communicate with other services via API.
Traditionally we use the monolithic database. In monolithic, we can’t extend our application for several users. All modules are composed together in a single piece. As your business growing up, you have to move on the microservices. This will take to the next level in your production.
Conclusion
Hope this article helped you with scalability issues and helped you understand a bit better of how you can use the available services perfectly.
0 notes
Text
How Do AutoScaling & Load Balancing Differ From Each Other?

Difference between auto scaling and load balancing
Although both load balancing and autoscaling are automated procedures that aid in the development of scalable and economical systems, their primary goals and modes of operation are different:
Concentrate
Whereas auto scaling concentrates on resource management, load balancing concentrates on traffic management.
How they operate
While auto scaling adjusts the number of servers in response to demand, load balancing divides traffic among several servers.
How they collaborate
Auto scaling can start new instances for load balancing to attach connections to, while load balancing can assist auto scaling by redirecting connections from sick instances.
Additional information regarding load balancing and auto scaling is provided below:
Balancing loads
Distributes requests among several servers using algorithms. Each instance’s health can be checked by load balancers, which can also route requests to other instances and halt traffic to unhealthy ones.
Auto-scaling
Determines when to add or delete servers based on metrics. Application requirements for scaling in and out instances can serve as the basis for auto scaling strategies.
Advantages
Auto scaling can optimize expenses and automatically maintain application performance.
Application autoscaling is strongly related to elastic load balancing. Load balancing and application autoscaling both lessen backend duties, including monitoring server health, controlling traffic load between servers, and adding or removing servers as needed. Load balancers with autoscaling capabilities are frequently used in systems. However, auto-scaling and elastic load balancing are two different ideas.
Here’s how an application load balancer auto scaling package complements it. You can reduce application latency and increase availability and performance by implementing an auto scaling group load balancer. Because you may specify your autoscaling policies according to the needs of your application to scale-in and scale-out instances, you can control how the load balancer divides the traffic load among the instances that are already running.
A policy that controls the number of instances available during peak and off-peak hours can be established by the user using autoscaling and predetermined criteria. Multiple instances with the same capability are made possible by this; parallel capabilities can grow or shrink in response to demand.
An elastic load balancer, on the other hand, just connects each request to the proper target groups, traffic distribution, and instance health checks. An elastic load balancer redirects data requests to other instances and terminates traffic to sick instances. It also keeps requests from piling up on any one instance.
In order to route all requests to all instances equally, autoscaling using elastic load balancing involves connecting a load balancer and an autoscaling group. Another distinction between load balancing and autoscaling in terms of how they function independently is that the user is no longer required to keep track of how many endpoints the instances generate.
The Difference Between Scheduled and Predictive Autoscaling
Autoscaling is a reactive decision-making process by default. As traffic measurements change in real time, it adapts by scaling traffic. Nevertheless, under other circumstances, particularly when things change rapidly, a reactive strategy could be less successful.
By anticipating known changes in traffic loads and executing policy responses to those changes at predetermined intervals, scheduled autoscaling is a type of hybrid method to scaling policy that nonetheless operates in real-time. When traffic is known to drop or grow at specific times of the day, but the shifts are usually abrupt, scheduled scaling performs well. Scheduled scaling, as opposed to static scaling solutions, keeps autoscaling groups “on notice” so they can jump in and provide more capacity when needed.
Predictive autoscaling uses predictive analytics, such as usage trends and historical data, to autoscale according to future consumption projections. Particular applications for predictive autoscaling include:
Identifying significant, impending demand spikes and preparing capacity a little beforehand
Managing extensive, localized outages
Allowing for greater flexibility in scaling in or out to adapt to changing traffic patterns over the day
Auto scaling Vertical vs Horizontal
The term “horizontal auto scaling” describes the process of expanding the auto scaling group by adding additional servers or computers. Scaling by adding more power instead of more units for instance, more RAM is known as vertical auto scaling.
There are a number of things to think about when comparing vertical and horizontal auto scaling.
Vertical auto scaling has inherent architectural issues because it requires increasing the power of an existing machine. The application’s health is dependent on the machine’s single location, and there isn’t a backup server. Downtime for upgrades and reconfigurations is another need of vertical scaling. Lastly, while vertical auto scaling improves performance, availability is not improved.
Due to the likelihood of resource consumption and growth at varying rates, decoupling application tiers may help alleviate some of the vertical scaling difficulty. Better user experience requests and adding more instances to tiers are best handled by stateless servers. This also enables more effective scaling of incoming requests across instances through the use of elastic load balancing.
Requests from thousands of users are too much for vertical scaling to manage. In these situations, the resource pool is expanded using horizontal auto scaling. Effective horizontal auto scaling includes distributed file systems, load balancing, and clustering.
Stateless servers are crucial for applications that usually have a large user base. It is preferable for user sessions to be able to move fluidly between several servers while retaining a single session, rather than being restricted to a single server. Better user experience is made possible by this type of browser-side session storage, which is one outcome of effective horizontal scalability.
Applications that use a service-oriented architecture should include self-contained logical units that communicate with one another. This allows you to scale out blocks individually according to need. To lower the costs of both vertical and horizontal scalability, microservice design layers should be distinct for applications, caching, databases, and the web.
Due to the independent creation of new instances, horizontal auto scaling does not require downtime. Because of this independence, it also improves availability and performance.
Don’t forget that not every workload or organization can benefit from vertical scaling solutions. Horizontal scaling is demanded by many users, and depending on user requirements, a single instance will perform differently on the same total resource than many smaller instances.
Horizontal auto scaling may boost resilience by creating numerous instances for emergencies and unforeseen events. Because of this, cloud-based organizations frequently choose this strategy.
Read more on Govindhtech.com
#AutoScaling#loadbalancers#trafficmeasurements#Scaling#verticalscaling#applications#Database#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
1 note
·
View note
Text
The two extremes of scalability and what you have to consider while using them.
The two extremes of scalability and what you have to consider while using them.
Scaling is the term everyone must have heard of if you are working in the IT industry. So what exactly is scaling, we are not going to discuss scaling in-depth instead we will see the very basics of scaling and the two extremes of scalability. What is scalability? Scalability is the property of the system and its ability to increase or decrease as your application’s demand increase or…

View On WordPress
0 notes
Link
Do you want to expand the reach of your application? Should you scale vertically or horizontally for it? Here’s a guide that will help you to select the right option for scaling your application.
0 notes