
Statistics
We looked inside some of the posts by essentialquest and here's what we found interesting.
Average Info
Notes Per Post
6
Likes Per Post
3
Reblog Per Post
1
Reply Per Post
2
Time Between Posts
2 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
知識的蒐集癖和自我感覺良好的「不」學習
有本書叫「菊花與劍」(也有譯作「菊與刀」) ,內容主要是在講日本文化和民族性。
裡面有個段落講日本文化很懂得「收藏」,但相較於旁邊的中國文化,在編目索引方面就沒有做得很好。
相對地,中國文化很會做各種編目和索引,但���被編入目錄的那本書究竟在哪裡?這就不是中國人在意的問題了。
所以有許多在中國只存在於某書目裡,真本已經亡迭的古籍名著,往往會在日本的某個古寺或是神社裡意外找到保存良好的擅本。
我常常從這個角度觀察我們的文化表現,也可以發現,在深受日本與中華文化影響的台灣,的確可以看到類似的東西。
在 AI 的圈子裡,很多人喜歡發表和轉貼「最齊全的 OO 主題連結、某主題論文清單、最熱門的討論列表...」然後,雖然按讚的人人多,但真的去讀的人很少。
這和編書目索引的行為是一樣的。有編,就認為我已窺見了知識系統的框架,只要假以時日,就可以把內容讀完,成為一方大家。
不會,那個假以時日永遠不會到來。
還有一些人,則是喜歡放集各種可以下載的資源。不論是電子書、訓練資料集或是機器學習模型。但載下來以後,也不會真的去研讀它或研究它。只是放在某個硬碟的角落,或是書架上,便覺得自己已經擁有了那個知識。假以時日,要用到的時候再去翻一翻就可以了。
不會,這個假以時日也永遠不會到來。
知識的建構,既是材料的蒐集,也是編目的結果之外,它更是再思辨,自我辯證,再擴充後,重新編目的結晶。唯有到這個時候,才能說「啊...我摸到一點怎麼產生知識的方法了。」
對,知識是思考的原料,就像準備了柴火,就是要點燃它,才有用。而不是用來堆放和編目,以為都知道柴薪都堆在哪裡,只要假以時日...就會派上用場的。
你蒐集了一堆地圖,你常常更新地圖,但只要你沒有真的揮汗踏上旅程,那你永遠不會抵達目的地。
0 notes
Text
禪修營回想之三
前言:禪修是一種很特殊的體驗。因為需要時時清楚專注當下,所以現在回想禪修的過程…其實是沒有特別記得什麼東西。
但是這三個晚上的記憶倒是很清楚…
第三夜是最慘烈的一晚!
當你以為 5 個人打呼,不過是像室內銅管五重奏的音量時,別忘了,打呼的人同時還可以放屁!
剎時間,像是有 2 倍的銅管五重奏室內樂團的 battle 一樣,音符和氣味迷漫在空氣中。

幸而我的鋪位在窗邊,而且我早早開了電扇向內輸送著冷冽而清新的氧氣…直到 12 點,昏沉了一個多小��的我突然發現,不知道是哪一位堅持表演品質的樂手,起身將場內會發出噪音的電器都關掉了 -- 呼呼的風聲和新鮮空氣的供應,陡.然.停.止!
也許是對氧氣的依賴,從翻身時床板的咯吱聲和嘆息聲裡,我算出寢室裡至少有 3 人醒了過來。
正當我想著「少了幾個樂手,今晚應該不用團練了吧?」正要重新戴上耳塞,耳邊竟傳來如古典樂進行曲般的長笛聲…只是它是用屁演奏的。
接著,金山區的山道機車族的引擎轟鳴聲帶入了主旋律。這遠近皆有聲響,像是約好的快閃表演似的夜之樂章,就此展開。
此時,原本醒來的室友之一,竟咕噥了一聲後,又沉沉睡去。不一會兒,重拾樂器加入了演奏。
其後的細節 (和氣味) 過於濃烈,請容我不再回想。
但在窗外的機車陣轟鳴聲 (共 2 批次) 和警笛的過場 (共 1 批次) 以及本室用打呼和放屁代替樂器的室友們的賣力演奏中,我拿下已經失效的耳塞,聽見另一位室友也和我一樣因失眠而翻身嘆息著…直至天明。
由於禁語的緣故,沒有交流互動的我並不認得室友的臉孔。但次日早課結束時,我卻一眼認出了昨晚一起失眠的室友是哪位。
正如諾曼第大空降中的台詞所述,讓我改編如下「今天和我一起在降降鼾聲中失眠的,都是我兄弟。」
如果說第一夜的鼾聲吵得令人殺生的心都有了,那麼第三夜的鼾聲就是令我望著窗外連想死的念頭都有了。三天沒好好睡了…真的好痛苦呀…
禪修,果然就是在生死之間的大聲。
0 notes
Text
禪修營回想之二
前言:禪修是一種很特殊的體驗。因為需要時時清楚專注當下,所以現在回想禪修的過程…其實是沒有特別記得什麼東西。
但是這三個晚上的記憶倒是很清楚…
早齋後,有約一小時的休息時間供大家刷牙洗臉後休息或提早到禪堂用功。我刷完牙後,就在鋪位上睡著了。猛地一驚醒,第一個念頭就是…
「誰是哪裡?這是誰?」然後發現昨晚打呼得最大聲的那位早已精神飽滿地去禪堂打坐用功了。剩下的都像我一樣早就不支倒床…

「人生果然是痛苦的。要嘛,自己痛苦,要嘛,帶給別人痛苦。」我看著其它幾位和我一樣昨晚睡不好的修行同學,有感而發。
而我已經比他們更幸運許多了。至少…
昨天夜裡的天色十分晴明,是一種特別的藍色… 昨天夜裡的天色十分晴明,是一種特別的藍色… 昨天夜裡的天色十分晴明,是一種特別的藍色… 昨天夜裡的天色十分晴明,是一種特別的藍色… 昨天夜裡的天色十分晴明,是一種特別的藍色…
這不是跳針,而是我伴著床板的震動和身歷其境 (如字面意義) 的鼾聲,盯著窗外這片夜空四個多小時裡心裡唯一想的事情。
相到我的鋪位至少是靠窗呢,其它人的心聲,就只能是…
昨晚的天花板十分乾淨,是一種特別的灰色… 昨晚的天花板十分乾淨,是一種特別的灰色… 昨晚的天花板十分乾淨,是一種特別的灰色…
人生雖然是痛苦的,但境隨心轉,我們總能找到比自己更痛苦的人。
大悲心起 (誤)
0 notes
Text
禪修營回想之一
前言:禪修是一種很特殊的體驗。因為需要時時清楚專注當下,所以現在回想禪修的過程…其實是沒有特別記得什麼東西。
但是這三個晚上的記憶倒是很清楚…
禪修期間禁語,即便是同寢室的修行同學之間也無交談或互動。但這似乎並不妨礙晚上就寢後大家用鼾聲組成室內銅管五重奏的默契。
幸好,我有備而來,早早就翻出耳塞並戴上了。Easy peasy, sleep like a baby...
等等!如果我戴了耳塞,為什麼我聽得出他們合奏的默契?我不是戴著耳塞我…我的右耳塞咧?
遍尋不著後,我���掩耳盜鈴的心態重新躺下,心想「只要我裝作沒聽到,那是不是就能繼續安眠了呢?」
10 分鐘後…

原來,少了 50% 的耳塞,就是少了 100% 的功能啊!
想到入睡前還在想…報到時好像沒有做危險物品的檢查,要是有神經病睡到半夜爬起來,把室友的脖子都抹了怎麼辦?
而現在,在這夜深人不靜的佛門清淨地裡,起了殺心的神經病就是我。
想到這裡,床板竟然傳來一陣震動!咦?不對啊,大家的手機都上繳了,為什麼床板會震動?
再觀察了一會兒,不是手機,是某人的打呼聲頻率竟然和床板的 natural frequency 一樣而使得床板開始震動了起來。
就在我開始回想那個「為什麼飯店的雙人床都有四顆枕頭的笑話時 (必要時你可能得要用其中一個悶死那個躺在你旁邊打呼的人)」
我突然想起來總護法師有提到「…茶水間有耳塞…」想到這裡,我幾乎看到了「室內五重奏大屠殺」的歷史軌跡從這個宇宙的時間線上消失了。
我安靜 (但迅速) 地爬下床,走到廊道上,準備往茶水間出發,此時才發現…原來今晚團練的並不只一組樂團!從各間寢室傳出來的鼾聲此起彼落,前後呼應,這裡根本就像 Hans Zimmer 的現場演奏般震撼!
我參加禪修營的主要目標就是「休息」!要是連��覺都做不到,那我到底來幹嘛咧?
2 分鐘後,順利在茶水間裡拿到耳塞的我,像是拯救了世界般 (就某方面而言啦) 往回走,走入夢鄉裡…
然而,耳塞並不防震。
0 notes
Text
AI 是湧現了智慧,還是你又在腦補?

從 ChatGPT 以來,很多人在談「湧現」,但沒有人從本質上去談類神經網路究竟在幹嘛。反而只從表面上看到「只要訓練的參數夠大,就會自然產生智慧。我們就叫它湧現!」。
我不這麼認為。
任何一個模型都要在「訓練資料」和「實際資料」之間找到一個微妙的平衡。一方面要避免模型「全面和訓練資料一致」而成為「過擬合 (over-fitting),另一方面又希望模型可以「儘量透過訓練資料來呈現實際資料」,在兩相拉扯之下,如果這一次的訓練,剛好讓模型在某個微妙的點上時,它的表現很像有智慧,學到了什麼抽象的知識。一般人稱這個為「湧現」,但我認為這只是表現能力像是有智慧而已。
我們其實可以清楚地「湧現」定義成: 『模形的多層神經連結剛好能產出某一種折衷的表現,這種折衷的表現正好符合人類的需��,並被人類察覺到的時候』,人類稱之為「湧現」。
在某些文章裡,似乎提出了一個定義,說湧現是「在較小的模型中不出現,而在較大的模型中出現的能力,則可以稱之為emergent.」 這種定義四平八穩地,聽君一席話,如聽一席話,並沒有解釋「為什麼會產生湧現」。
我的個人意見是:「湧現不該被視為是智力的表現。而應該反過來視為是人類腦補的表現。」
如果我們教人類兒童「 2 到 5 的乘法表」,從 2x1=2, 2x2=4…一直到 5x9 = 45。且假設此時這個人類兒童因此能計算「一部份 6 到 9 的乘法」,但是無法計算「10 以上」的乘法 (有沒有發現這很像 AI 的湧現?它很像會做某些沒有學過的事情,但又不是全部都會) 。 此時,我們不會說這個兒童「湧現了智慧」。 他說不定只是發現了 2x3 和 3x2 都是他背過的東西,而且兩者都是 6,所以為了記誦的方便,或是他根本就記不清楚順序,所以順序就變得相對不重要(反正記不住)。因此問他 6 x 3 的時候,他會以背過的 3 x 6 來回答。
在他只有背 2~5 的乘法的情況下,如果我們問他「那 6 x 9 是多少?」他因為沒背過「 9 x 6 的答案,所以答不出來或是答錯」,那我們就能知道他其實只是產生了「想要省下背誦的力氣,因此對順序不敏感」的表現。
這個表現會讓他很像學會了乘法的「交換律」這種更抽象,更普遍的知識。但藉由觀察到他其實「並沒辦法全面地應用這個知識」就能知道: 不,他真正學會的是「順序好像不太重要」,而不是學會了「交換律」。 而這種對一定距離內的順序不是很敏感的現象,其實正是接龍模型的本質。不信你可以看看把你的 Prompt 重新亂排列,其實效果是一樣的。[連結]

這樣理解 LLM 表現的方式,比說得玄之又玄的「湧現」清楚多了。
0 notes
Text
AI 時代下的語言學家
幾天前, OpenAI 的老闆 Sam Altman 發了一篇推文說「想要有所建樹,做個經驗主義者;想要看起來很聰明,當個理性主義者」

我接受的是理論語言學的訓練,所以我對自己的理解是一位「理性主義者」,而帶領人類文明走出中世紀黑暗時代的理性主義,怎麼會如此不堪地被形容成只是「sounding smart」呢?。對 Skinner 學派的經驗主義大戰,大家都很熟了,這裡就先壓下不表。結論是:經驗主義永遠不會消失,但也永遠無法解決問題。(它們會把理性的累積當成經驗的功勞)
在台大讀博的那幾年,學的是統計模型和資料模型,有一位學長的專長就是統計模型/機器學習的 NLP。我們��邊經過兩三年的深入討論後,學長最後的結論是「做研究的話,統計模型/資料模型這個方法可以做。因為永遠有論文可以寫,有實驗可以做,有研究經費可以申請。但是要走向業界的實用的話,語言學的方法才是實際的做法。因為你們要更動任何東西,可以很輕易地更動。」
我以「怎麼」為例,psudocode 原理大概像這樣… (這部份我已經拿到專利了,歡迎教學時使用。提醒一下同學可以不要再重造輪子就好了。我們不像資工系有那麼多人,實在沒有那樣有餘裕可以重造一次。)

懂語言學的人一看,就會看懂這段程式就是一個 X-bar 結構的運算過程。
在 doSomeMarking() 裡,就不是簡單地掃個 dist 而言,而是用 regex 來解析後面的字串,這麼一來才能處理子句的問題。 這個當然不是最漂亮的解,因為 regex 的解析可能不是一個合理的詞組結構。也可以會有多組解。但沒關係,我們還知道一個完整的句子的 syntax tree 長什麼樣子。再把這多組解拿來湊看看,看它哪一個可以達到的節點最高,最接近 CP,就當做輸出的結果。
有時候會有多個結構都可以達到一樣的高度,這就是為什麼偶爾有些句子或是詞組,會有多個語意理解的原因 (吧?)。
只是在 Articut 裡,我用 ascii 排序,然後把第一順位輸出。但真實的人類大腦裡,可能每個人���有不同的排序法也不一定。 所以,走到最後,如果不懂語言學,那這個程式還真的寫不出來。而有了語言學的知識,Articut 改起來很簡單是因為:
我們只要調整 doSomeMarking() 裡的幾行程式,就能調整輸出的標記。
我們避免了編寫字典的工法,所以兼容了「怎何/如麼/如樣…」這些目前不存在,但又很難說將來會不會出現的詞彙。而,就算將來出現了,我們也不用特別再做什麼處理。除非是音譯的外來語,否則新的詞彙必然需要符合現代白話中文的構詞律,新的詞彙的詞彙仍要符合這個語言的句法律。而只要它符合句法,我們就能計算它的語意。
我們在 headLIST 裡只列了 functional head (for syntax) 和 word stem (for morphology),這把一個「永遠做不完,需要整理大量資料」的字典法和資料模型法,壓縮成了一個 "rule-driven" 的工作。Linguistics Rules 是學得完的,甚至我們大概就花個兩年就能教完,不然碩士生會來不及寫論文。於是,一個原本「無垠發散」的事情,變成了「有限收斂」的工作。
當初學長問了一個問題:「理論語言學這麼厲害,為什麼用來寫程式的人這麼少?」這個問題我想了很久,最後的答案其實在某個方面呼應了 Sam Altman 的說法。
「理論語言學的訓練是理論的訓練,我們會一個一個被訓練成理性主義份子。我們喜歡思考,樂於思考,但鮮少動手去大規模實做可用於證明的工程。所以只有非常非常少數的理論語言學家會寫程式。再者,Chomsky 以來的理論語言學家幾乎都是在學術界服務的,主要的工作是做研究和發論文,我們形成了一個思考的圈子,但沒有做工程的風氣。有做系統工程的風氣的是語料庫語言學和計算機語言學,但這兩個子類別在方法論上是和理論語言學比較疏遠的。相較之下,他們更樂意採用編字典、做統計或是資料模型方法,而不太理會語言學理論走到什麼地方了。」
最後,我想這十年下來的資料模型法,大概也讓我們看到了「這個方法大概可以做到哪些事情」。但它仍然沒辦法回答我們真正想問的: 「語言是什麼?語言系統是怎麼運作的?我們怎麼知道對方說的話的意義是什麼?」
���別說像 ChatGPT 這麼一個大型語言模型,也仍然為了龐大的運作成本 (不包括多模態,目前是每天 70 萬美元,約兩千兩百萬台幣) 而無法獲利,我都有點懷疑它這樣燒下去,最後會不會是曇花一現後,就資金耗金,然後如流星墜落呢?
3 notes
·
View notes
Text
我們必需去,但不一定回來

Netflix 最近上架了 HBO 的「諾曼第大空降」和「太平洋戰爭」。雖然太平洋戰爭受到的注意和追捧遠遠不及諾曼地大空降,但如果在台灣發生戰事的話,其實後者的戰場刻畫會更有參考價值。 除了像國際橋牌社一樣的各種軍中狗屁倒灶的事情都拍出來以外,在太平洋戰場裡還有熱得要死,後勤供水卻跟不上的戰場上戰鬥;雨下得全身濕透,濕到有人受不了,直接自盡;菜兵搞不清楚重點,用自己破掉的防雨布,換下彈藥箱的防雨布,結果弄得彈藥泡水無法擊發;身先士卒的長官,啪地一聲被狙擊手幹掉;本來像戰神一樣在槍林彈雨中來去自如的老士官長,在戰場上終於心態崩潰… 在這麼惡劣的環境裡,士兵還是一直前進。 最近有一位中研院的學者在節目裡說「打完就沒有人是贏的了, 因為就像現在死掉的俄國人或烏克蘭人, 他們已經輸了, 打了就是輸了。」 戰爭不是靠投降打贏的。每一個在戰場上死掉的士兵,不是為了自己的輸贏,而是有更遠大的目標要他們獻身。那個目標叫做「國人的未來」。 這可能和讀書求學以來一直都只考慮「自己的未來」的某些大學者的思維習慣不太一樣,所以他們也無法理解吧。
2 notes
·
View notes
Text
「現在 AI 沒意識,不代表以後沒有!」就像在說現在人類沒有時光機,不代表以後沒有一樣。
在網路媒體上讀到這一篇報導:
而我覺得這論文實在是濫用了一般民眾對「科學家」專業的信任。
但要說整篇都沒有可取之處嗎?也不是。
首先,我覺得這段講得滿誠實的:
研究者同時寫道,「我們研究的證據表明,如果心智計算主義是正確的,有意識的AI系統實際上可以在近期內建立起來。」
我是不知道為什麼這些資訊專家如 Bengio 們都喜歡拿 1960 年代以後就不太更新的心理學或是認知科學理論來論證 2023 年甚至以後的認知科技發展。好像從 1960 ~ 2023 的這六十年間,只有資訊科學家在做研究,其它認知科學家都在地上躺平裝死似的。 簡單地說,「心智計算主義」假設「認知就是輸入與輸出的關係」。如文中所述的:
心智計算主義認為,精神世界是基於一個使用諸如資訊、計算(思考)、記憶(儲存)和反饋等概念的物理系統
就像是「某人按下標記著 7 的按鈕,他心裡想著 7 樓,而電梯就剛好帶他到 7 樓。於是他就認為『這個電梯有了認知能力。因為它的輸入 (數字 7 的按鈕),和計算這個按鈕背後觸發的電路、載入的齒輪轉動圈數與方向 (記憶) 和反饋能力 (車廂移動到 7 樓並打開車廂門) 剛好符合了教科書級的「心智計算理論」所描述的意識行為。
但我們絕對不會認為「電梯有意識」的!
即便我們把 ChatGPT 裝在電梯上,而且要用特別的 Prompt Engineering 來提示這個電梯究竟要到幾樓,我們也不會覺得這個電梯是「有意識」的。
換言之,前述的:「…如果心智計算主義是正確的…」條件就是不成立的,因此其後的「…有意識的AI系統實際上可以在近期內建立起來…」也不是正確的。
人類的意識最特別之處並不是在輸入與輸出,而是在「覺察到自身正在處理輸入與輸出」。其重點不在後半句的「輸入與輸出」,而是前半句的「覺察能力」。
貓、狗甚至鯨豚或是大象都有很高的智力,牠們也能感受到許多人類特有的情緒,如想念、悲傷…等。但人類除了「感受」以外,還能「覺察到自己正在感受,甚至主動跳脫出這些感受」。
就像在思考數學問題時,在思考詩詞排列時,在思考抽象的概念時,我們不只是思考,我們還「知道自己在思考」。 這才是意識。
ps. 用 htop 指令或是打開工作管理員看到 CPU loading 很高,那不是「電腦知道自己在思考」,電腦只知道「CPU loading 很高」,至於它是真的在計算某個有終點的問題,還是困在某個無限迴圈裡面出不來,它不會知道,因為它不知道自己在思考。
0 notes
Text
商業化的必要性做為一個社會實驗
大半的中秋連假裡,我都在打字,連個月亮的影子都沒看到。打什麼字呢?把白話字的拼音和字符之間的對應關係打成檔案,以便做後續的拼音轉譯時查詢和反查的功能。
為什麼要用人工打?哦…因為要遵守「授權」的緣故。
我知道很多人只要「網路上抓得到」的檔案,都當做是「免費隨我用」的,但我個人乃至卓騰語言科技都是非常嚴格遵守各種授權規定的。
這次遇到的授權裡說的是「如果你要再散佈,那麼只能再散佈編譯後的版本」。那麼我希望我正在寫的這個 Articut_Taigi 是開源的外掛,讓大家都看到究竟裡面都寫了什麼,不要再整天懷疑「你是不是藏了什麼秘密?(報告將軍,這裡沒有秘密,只有智力上的差異,這個我實在沒辦法)」,我勢必得要散佈未編譯的版本。
看來就只剩下自己重新把所有可能的組合拼打一次的方法了 (事實上我算是拼打了兩次。因為除了用數字標記聲調的台羅拼法以外,我另外還做了用調性符號標記聲調的台羅拼法)。
其實要打造台閩語、客語的 NLP 基礎工具,網路上散見許多可以整合的資源。但絕大多數都是「禁止商業使用」的授權模式。看著這麼多前輩花了好幾年的力氣和時間去整理資料,做出種種數位化的資料以後,再宣告「這個不能商用哦!」的授權。
我不能理解的是「商業有什麼不好?」為什麼大家一看到「要出錢的東西」就反射性地覺得「這是缺點」?
歷史上,我們試過用道德、用法律、用社會共識甚至是夢想去驅動「辦成一件事情」,但到目前為止,唯二有效的動力,一是來自奴隸,二是來自商業。只要一件事情有「能夠被商業化的機會」,自然而然就會有許多資源投入,讓它運轉起來。
但是,我們仍然持續看到亞洲 (主要是華人)社會的反商情緒。那麼從我們這個物種的文明發展史來看,亞洲人 (主要還是華人) 建構出一個活得像奴隸的社會,好像就是個不可避免的趨勢。(寫到這裡,突然想到會不會是因為古時代各朝代的帝王都希望保持死老百姓的奴性,所以才會持續倡導反商的價值觀呢?)
總之,我對商業化的看法是「如果你覺得這件事情很重要,付錢啦!把錢投下去表示你『真心』覺得這件事很重要,不然其它的都只是嘴炮而已」。
所以,我不打算用什麼道德、規定、社會共識甚至是夢想來驅動你。我直接跟你說「做 NLP 基礎工具,我有信心我是做得最好的」。你想要看到台語 NLP 基礎工具出現嗎?我想要知道你有多認真 (I want to know how serious you are.)。
為了觀察這個趨勢,做為社會實驗,我去申請了一個個人的抖內連結 (抖內連結:http://paypal.me/donatepeterwolf),在做這個 project 的過程裡,我會時不時地和大家分享這個社會的奴家本性實驗觀察。
0 notes
Text
要是…Formalism Linguistics 錯了怎麼辦?
在 Formal Linguistics 的研究和應用 (尤其是應用) 的路上走了十幾年了,偶爾會遇到以前一起讀書的同學、朋友說:「我後來覺得做研究像是做信仰一樣。要是我們的信仰是錯的怎麼辦?」
什麼是信仰?什麼是科學?兩者之間是否有差別呢?我在 2013 年思考過這個問題。信仰的部份,事涉個人經驗和主觀判斷,我沒有太多意見。但什麼是「科學」,這個就有明確的定義了。具有可以被「證偽」(Falsifiability) 的性質,凡事皆值得懷疑、皆可假設、皆可測試、皆可列出證偽條件,是科學的基本要件。(別忘了,聖經上說過「不可試探主,你的神」)
我對這個問題的思考最後濃縮成以下這兩點。
Formalism 錯誤的話,有幾個條件要先發生:
(1). 另一個能更簡潔地說明「為什麼人類幼童可以產生他不曾聽過的合理且正確句子/詞彙」的解釋出現。
(2). 另一個能說明知識本體之間沒有邏輯關係,事件之間的因果只是人類��想像的系統出現。
接著,我對這兩點進行廣泛的考察,經過考察後,得到以下觀察
對於 (1), 我唯一遇過比 Formalism 更簡潔的解釋是「那是前世的記憶」。
對於 (2), 我唯一遇過更有說服力的解釋是「老高與小茉」。
ML (機器學習) 的 AI 不會產生知識,是因為「知識本體之間具有上下層關係,事件之間的因果也具有邏輯關係」而所有的上下層關係都無法靠高維分佈呈現。但 ML 就是在擬合資料的高維分佈結果。它處理「結果」而不處理「因果」。
講「高維」好像很玄,我們就講立體的「空間三維」就好了。假設我們有一個記錄器,記下你的位置。那麼你身處在房間的 A1 點,和你在房間的 A2 點,以及你在房間的 A3 點…直到你在房間的 An 點,每一個點之間都是獨立事件。沒辦法推斷因果關係。
如果我們觀察兩個事件,你身處在房間的 A1 點,你兒子在房間的 B1 點,直到你在房間的 An 點和你兒子在房間的 Bm 點。這所有的 A 與 B 之間的關係,仍然是「共現關係」,一樣沒有「因果關係」。
我們把維度拉高,再加上時間 T。
你在 T1A1,你在 T2A2…直到你在 TkAn 都被記錄下來。我們仍然無法解釋「為什麼」("WHY" 是因果關係) 你在 Tk 時間點時,會在 An 這個空間位置上。
因此我們可以說 (而講得最大聲的就是 Marcus) 「ML 不會產生知識,也學不會知識」是因為它所採用的公理即限制了它的發展,它是接觸不到知識的。
相對地,ML 錯誤的話,有幾個條件要發生…哦,抱歉,ML 不會錯,因為它無法被證偽,只要「偏向你想要的模樣」的資料夠多,它自然就能「長出你想要的模型」。所以它永遠可以說「我的模型表示,天鵝都是白的」是正確的,因為它基於「我的訓練資料裡,天鵝都是白的」。訓練資料以外的東西,對模型而言不存在,因此無從證偽。
ps. 所以 Judea Pearl 教授才會說「我那個貝氏網路(機率) 不是拿來做 AI 的,你們要做 AI 的話,請用我另外發明的因果網路!」也正是因為因果網路才能產生知識,因此它被寫在 "The book of WHY" 一書裡面。
0 notes
Text
覆 [標準重要嗎?] 一文
讀到一篇 [人工智慧與自然語言處理想要說什麼?標準重要嗎?] 的 blog 文。文章中提出的議題,基本上沒有什麼大問題,的確有好幾個是重要的 NLP 課題。但是既然其中提到了「語言學」,那麼有些容易導致誤解的小細節就要拿出來說明釐清一下了。
對於現在的 NLP 應用工具,在評估「有沒有用」的時候,的確會有原作者提到的兩個問題:
一是用來比對的句子本身就是錯的…
二是怎麼分才算對的問題…
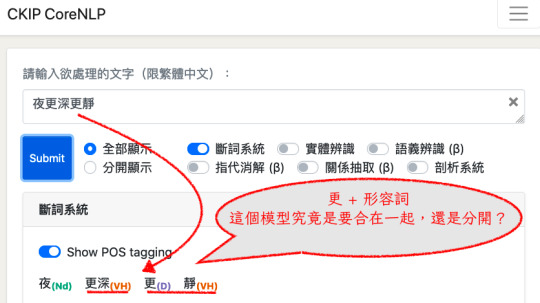
對於第一點,即便是目前大家最常用的 SIGHAN 2005 資料集的標準答案裡,也有這種 「/夜/比/之前/更深/更/靜/」的結果。這就是作者說的「比對的句子本身就是錯的。
這個句子哪裡有錯呢?它錯在把「更深」和「更/靜」標成了兩個不同的結果。前者是「單一詞彙 (更深) 」而後者則是「兩個詞彙 (更 + 靜)」。如果以這個做為標準答案,那麼就像是同一個題目,卻有兩個答案。我早上問你,你給我答案是「 "更" 和後面的形容詞要合在一起成為一個詞彙」;而下午問你,你給我的答案是「 "更" 和後面的形容詞要分開成為兩個詞彙」。
而我做為裁判官,卻要對你的兩個答案都評出「答對!給分!」的評判結果。如此一來,雖然這個模型可以拿到高分,但註定在面對應用落地問題的時候,無法派上用場。
在 SIGHAN 2005 標準答案集裡拿到高分的 CKIP 就有這個問題:
不可否認地,輸出「合在一起」的分數也拿到,「分開」的分數也拿到,就能得到超高的良率得分,但在實務上,這兩種結果會出現在同一個輸出結果裡,就表示它的輸出結果無法被預測。一個輸出結果無法被預測的模型,怎麼用呢?
這個問題,也連帶地會引出���二個問題「有的人覺得要合在一起,有的人覺得要分開」的時候,那麼…哪一個才是正確的結果?
而這,就是語言學可以進來回答的問題了。
在現代語言學的研究裡,語言不是「線性結構」的,而是「樹狀結構」的。在線性結構的眼裡,我們就只能看到「更-深-更-靜」這樣的關係,但從樹狀結構的角度,我們就能看到兩種結果:

一是從「詞 (word)」的角度來看,是一個「更」的程度指示詞 (Degree Specifier) 再加上一個修飾詞 (形容詞/副詞) 的「深」和「靜」。因此就能得到「更/深/更/靜」的輸出結果。
另一個是則是從「詞組 (phrase)」的角度來看,因為詞組不是看節點的下端,而是節點的上端,如此就能得到「更深/更靜」兩個詞組的輸出結果。
因此,有的人會覺得是「分開成兩個詞才對」,而有的人會覺得是「合在一起一個詞組」才對,這兩個語感都是存在的,而且現代語言學已有理論可以解釋這個現象。
兩個都是對的,但它���會同時輸出。你可以選擇「以詞彙」 做為輸出結果,或是「以詞組」做為輸出結果,但就是不該「同時輸出詞彙和詞組。因為它們不是同一個等級的東西。這麼一來會讓後續奠基於斷詞結果的 NLP 應用的良率開始瘋狂下跌。
問題是,當現代語言學已經可以解釋這個問題的時候,絕大多數的中文斷詞系統並沒有跟上。即便少數已經發現語言似乎有兩種內在模式的斷詞系統,仍然是以調整字符結合統計機率閾值來區分出「粗粒度」和「細粒度」,而無法完全符合現代語言學理論的發現。
目前世界上唯二採用現代語言學研發 NLP 工具的,只有 Bitext.com 和 Droidtown.co (卓騰語言科技)。
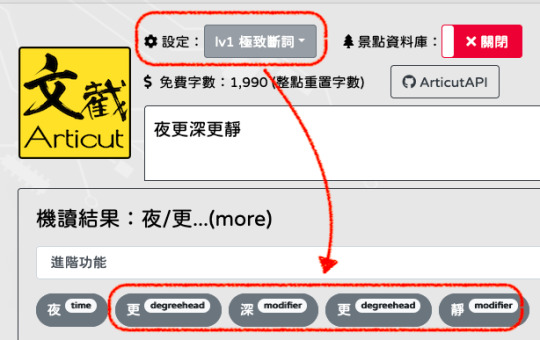
以下是卓騰語言科技的 Articut 中文 NLP 系統的分析結果:
詞的角度斷詞:
詞組的角度斷詞:

由此,我們可以發現原文中所述的「…關於什麼是「詞」的標準至今無法得出一個大家都能遵循的標準!」一事,在現代語言學中已經有解了。
在這裡既然提到了「現代語言學」,那麼就不得不再針對這一段「…而事實上在語言學界,甚至有為了某些詞的詞性爭論不休的情況,一個詞應該是副詞、形容詞尚且無法認定,試問詞性標註的標準又何在?」加以回覆。
現代語言學不編字典。所以在現代語言學裡沒有「 X 這個詞應該是副詞或是形容詞」的問題。現代語言學的研究重點在於通用語法的句法樹結構。
通用語法 (Universal Grammar) 指的是「全人類共有的一套抽象語法的運作規則」。
在這個架構下,你把一個詞放在「名詞」的句法樹位置,它就是名詞;你把一個詞放在「形容詞」的句法樹位置,它就是形詞。
因此,「一部機車」指裡的「機車」是名詞。因為這個詞出現在名詞的位置;同理「他很機車」的「機車」是副詞,因為這個詞出現在形容詞的位置。至於「機車」這個字究竟應該編成什麼詞性,這不是現代語言學關心的問題,而是字典學家在乎的問題。
許多 NLP 工具仍然沒跟上現代語言學的研究成果,因此仍然用傳統語言學的「編字典、擴充資料庫、用更多的語料」的方向企圖解決 NLP 的應用需求問題。當解決不了的時候,這不是語言學的問題,而是基本的假設和認知就沒有跟上新的語言學理論發現而已。
我們並不會因為「反正你們都是看星星的」,然後就把星座預測的失準,擴大責怪所有觀測天文的天文物理學家都是錯的。自然不能因為「反正你們都是搞語言的」,然後就把依傳統語言學的做不出結果的 NLP 應用失敗,擴大理解成「現代語言學的研究也是錯的」。
最後,原 blog 文的結論似乎是兩個:
BERT 沒有斷詞,所以 BERT 避開了中文斷詞系統不夠好造成的錯誤。
有些 NLP 任務仍然需要斷詞。
這兩個乍看之下好像彼此矛盾的結論,其實也可以從語言學的角度繼續解釋。如果在某個粗略分類的任務情境下,BERT 就可以得到不錯的效果。就像你不需要精讀報紙財經股市版的每一句,只要瞄一眼每則新聞的標題,就知道大盤是漲是跌了。
這也是為什麼利用 BERT 做的自動回覆機,往往只能把 "Answering" 這個涉及語意理解和因果推論的問題,變成 "Alignment" 問題以後,忽略因果推論和邏輯語意,直接把「問題 <=> 原文」做了一個「對齊 (alignment) 」的操作以後,就讓人類使用者去評分「這個段落裡的資訊,是否有回答你的問題?」
而忽略了人類使用者回答「有」的時候,事實上在腦袋裡做了很多的因果推論和邏輯語意的理解。簡言之,藉由「偷換概念」的操作,BERT 巧妙地避開了 "Answering" 的基本需求,而改以 "Alignment" 代之。它得出來的高分,並不是完成了 "Answering" 的任務,而是因為 "Alignment" 得來的。 問題是,如果你要處理的是細膩的自然語言理解 (NLU) 或是因果推論呢?這類問題在產生 BERT 的語言模型的過程中,早就已經剝除了上下文的語意脈絡 (只留下來字符的前後出現脈絡),那麼想從已剝除了語意的模型裡,再挖掘出語意、邏輯甚至是因果關係,就變成一種緣木求魚的操作了。
從這裡延伸下去,還可以討論許多 NLP 和語言學的問題,不過到這裡已經不深不淺地帶出兩個需要思考消化以後才能吸收的議題了。就先在這裡打住。
如果有機會的話,我們再聊聊 BERT 和語言學在中文裡可以如何結合來做 Hybrid AI;為什麼 Articut 的 F1-Score 不超過 95%,但在各種 NLP 落地應用的時候,效果都比其它號稱 97%、98% 的中文斷詞系統來得更好,且更靈活吧。
1 note
·
View note
Text
中文母語流利者的語言障礙
依 1994 年中國友誼出版社的「中���字海」這本字典的收錄量,中文有 85568 個字 (按:當然這裡指的是「字符」,也就是說「蚯蚓」是兩個字符,但「蚯蚓」依現代語言學的分析方法來看,應該只能算是一個字。)
八萬多個國字符號,和英文只有區區的 26 個字母符號相比,在極端的二字詞、三字詞的長度限制下,應該可以創造出更多詞彙吧?
然而…關於語言 (language),我們就只有少得可憐的那幾個字符可以用。在現代白話中文裡,大致上就是「字、詞、語、話、講、說、言」,然後…沒有了。
於是乎,我們就用著這個稀哩呼嚕的語言,交換著稀哩呼嚕的概念,覺得只要有沾到上面這幾個辣椒紅的字符的詞彙,都是差不多的意思,然後就能各自回家,彼此安好,一天又這麼平安地過去了。
-- 以上前言背景說明 --
在這樣的前提以及因緣聚會的大宇宙意志干涉下,讓我看到了「活出語言來 - 語言人類學導論」這本書。還有網路上諸多的書評、讀後心得裡都提到這本書在講「語言學」。

啊不是啊…它不就說了它講的是「語言人類學」,那充其量,也應該是「人類學」,怎麼會是語言學?難道只是因為書名出現了兩次「語言」嗎?
「可是裡面有提到很多什麼語言的基本問題、讀寫能力、語言與性別… blah blah 的。這不是語言學嗎?」
它的書名就講了它是「人類學」,你不能因為它在人類學前面加了「語言」,於是就自動跳過「人類」,把它當成「語言學」呀!
「那���難道它真的就不是語言學嗎?」
嚴格地說,它不是「現代語言學」。
在遠古遠古的冷戰時代初期以前,對「語言的研究」是人類學的一個分支。當時就有許多對人類社會如何使用語言,語言如何反映社會、語言如何反映時代思維、文化…等等面向有諸多深入的研究。但那時候就算用了 "linguistics" (語言學) 這個詞彙,它指的就是這些比較傾向社會研究的東西。也許我們可以更強調其祖制不可改的道統精神,稱之為「傳統語言學」。[註:我這裡用的「傳統」二字是為了凸顯其出現的時間更早。而不是用上了一般中文語境裡面的「傳統」即為負面表述詞彙的用法啊!請各位道統維護者不要激動!] 當然,這些面向的研究現在還有,像是 "sociolinguistics" (社會語言學) 這類的研究領域,仍然有著人文社會面的關懷。但從 1957 年開始,現代語言學開始,語言學走上了一個典範轉移的方向。
自那之後,「現代語言學」關心的重點不再是「男生這麼說,其實他在想什麼;女生想聽你這麼說;受壓迫的人會怎麼說話、單/多語主義的國族想像…blah blah」這些 GQ 或是 The News Lens 關鍵評論網喜歡拿來寫個誘人又平易好補的文章 (是,是「好補」,而不是「好讀」。因為現在的文章要寫得讓人容易腦補,才會有人讀。) ,現代語言學轉而研究「語言這個系統是怎麼運作的?」
(我才講了一句而已,別急著打哈欠啊!)
用交通問題來類比說明,如果「傳統語言學」研究的是「為什麼 A 地和 B 地之間會開設高速公路。而 A 地和 C 地之間只有平面道路」;那麼「現代語言學」研究的就是「車輛設計的工程科學」。輪子要用寬的還是窄的,怎麼計算抓地力和油耗?引擎的燃油效率要怎麼提升?內裝的舒適度重點在哪裡…等等。至於車子要開去哪裡,那不是現代語言學的重點。
當傳統語言學研究的重點落在描述語言的溝通功能時,現代語言學研究的重心放在「語言系統」是怎麼運作的?
所以,現在許多做機器學習 NLP (自然語言處理) 的教材和文章都講「語言學在第一波 AI 革命時失敗。無法用符號邏輯描述全部的現象…云云」時。那講的是傳統語言學企圖「窮舉所有影響 A-B 以及 A-C 之間道路規劃的條件」所遇到的困難。
現代語言學沒有這個問題。現代語言學所採用的符號邏輯只計算車輛的移動效率。剩下的是在這樣的效率條件下,你想花多少時間在 AB 之間移動,又想花多少時間在 AC 之間移動了。
這也是為什麼「現代語言學」相較於「傳統語言學」的社會學科道統更像「科學」,也更能輕易地被工程化,撰寫成程式碼來運作的原因。
0 notes
Text
Chomsky's Forever War?
一場戰爭會打成 "forever",那麼一定有一方是強者,而另一方是笨蛋!
最近讀到一篇書摘心得 (Chomsky's Forever War),冒出很多想法,但一方面我沒有讀過這本書,另一方面我也不打算讀。畢竟,從書摘裡看,我覺得那作者好像搞錯了很多事。所以…在把自己的想法寫成 blog 以前,看看別人怎麼說的好了。
結果,就在其它地方,找到某個人想用這篇文章來支持他自己的 "Chomsky 是錯的!自然語言沒有那麼複雜的規則!" 的想法。
這篇文章裡也說 "Chomsky 一干語言學家們假設的語言習得機制非常複雜 (原文 "...learning (language) is impossible without a highly constrained hypothesis space...")
[糟糕…寫到這裡已經太長了,沒人要讀了...]
我的幾個想法是:
這些人是搞錯了什麼?我讀書的時候學習的理論語言學的大前提觀察就是「幼童語言能力的習得只需要少量的正確例子的刺激」。這和這篇文章提出來的方法是一致的呀,所以…反對在哪裡?
理論語言學的目標是以「極簡化」的運作規則 (minimal program, MP)。此外,即便是細究 MP 的運作,它也就是在說:
a). Functional Category (功能詞類) 在句法上會對其它的 Content Category (實義詞類) 造成影響。
b). 這個影響可以出現在表層形式 (用語音的方式,比如英文第三人稱單數加 -s) 或是底層形式 (以語意的方式,比如中文不加 -ed,但你會知道在語意上它是不是已完成的動作)。
c). 語意這一層尚有其它的百��知識 (e.g., 你知道「白馬是馬,斑馬不是馬」) 以及邏輯形式的推理運作 (e.g., 俄羅斯攻擊烏克蘭,所以「俄羅斯」是攻擊的主事者,而「烏克蘭」是攻擊的受事者。這個邏輯描述裡的「事」指的就是「攻擊」這件事。)
就這三個觀念!雖然 MP 這本書,我每次都讀到睡著,但它翻來覆去就是這三個觀念的各種版本說明而已。
就這「三.個.觀.念」,請問是在複雜到哪裡?
只是讀完這三件以後,還要給你符合科學公理的定義,什麼叫 "functional category" 什麼叫 "content category",所以你要學構詞學,要學句法一、句法二還有句法專題;你要知道什麼是表層形式,所以要學語音學、要學音韻學;你要知道什麼底層形式,所以要去修語意學概論和形式語意學 (哦,這兩個是很不一樣的東西)。
當你都學完這些以後,才能看懂「哦…原來這三個觀念這麼簡單。」
你以為數學就不用嗎?絕大部份的人,從小一就開始學什麼是數列級數,學什麼是整數、什麼是小數、什麼是有理數、無理數、實數、虛數、角度、幾何,直到微積分,然後這大部份人中的少數,才會接觸到機器學習演算法。
相較之下,絕大部份的人都沒有接觸過構詞學、句法學、語音學、音韻學乃至語意、邏輯語意和語用學。當然第一次看到上面的那「功能詞類對實義詞類在句法上…」的時候,當然會覺得困難。因為你不知道什麼是功能詞,不知道怎麼判斷什麼是實義詞,更不知道怎麼區分「語法、句法、文法」三個詞彙的定義有什麼不一樣。
再回到這篇被提出來「挑戰」Chomsky 的句法學理論 (Chomsky 真是樹大招風) 的文章。一方面說「語言學理論好複雜哦 (就那三個概念,是有多複雜)」另一方面又說「我想到一個新的方法,還有實驗證明可以用簡單的邏輯形式和集合論就能學會一些簡單的句子哦!」(我在 2021 PyConTW 分享的「PEP 634 Structural Pattern Matching 參上,你終究還是要用語言學來做 NLP 齁」就是在講這件事啊!
到底… -_-
0 notes
Text
科技寫作的盲腸
有些大學裡的中/外文系裡尋求「和科技沾上一點邊」的方式是開設「科技寫作*」這樣的課程。其內容著重在「訓練學生撰寫科技產品的操作說明文件」。我覺得這個方向有一點好笑…
好笑的點在於,根本就沒有什麼人在讀文件。不論是視覺上都是文字,顯得較為枯燥 API 操作說明文件,還是圖文並茂的 GUI 操作流程說明…
根.本.沒.人.讀!
再說,既然沒人看,那麼什麼流暢的書寫能力…云云就不是重點了。重點應該是 git 的版本控制、markdown 格式的掌握以及 CAT 軟體 (Computer-Assisted Translation) 的技術掌握才是。
沒有,這些課程的重點還是擺在「寫作」,好像看幾篇 WIRED 然後寫個評論就算科技寫作了,而課程名稱裡的「科技」像條盲腸一樣掛在那裡不知道幹嘛。
我覺得,人文社會學院的同學們想要尋求自己職涯在「愈來愈小的池子以外」的發展的話,思維的模式要從「我目前的能力 (e.g., 我會寫作) 能做什麼 (就…找個東西來寫?)」調整成「這個世界有什麼問題待解決,我目前的能力 (e.g., 我會寫作) 再加一點什麼,就能提供解決方案」。
不去做「加一點什麼」的那件事,那麼仍然是在同一個池子裡晃來晃去的。
註:這個詞彙的指涉內容還滿多變的。最開始是從「紙筆寫作 => 電腦文書系統寫作」叫科技寫作。後來不知道怎麼地,和「英文學術寫作」的內容摻在一起。於是科技寫作的訓練,就變成了英文學術寫作的訓練。但我想講的都不是這兩種,而是最近開始冒出來的「為科技產品撰寫使用說明文件」這件事。
ps. 說明文件沒人讀的事實,並不表示「不讀說明文件」是正確的啊!新手提問時收到 RTFM 做為回覆的時代已經過去了,在這個玻璃紀元,還是要自我要求去讀文件的。
0 notes
Text
這十三年來,我做了很多事…
他人笑我太瘋癲 我笑他人看不穿
我曾想說也許是語言教育的問題。畢竟我們的語言教育系統一直放在「修辭與美學」的養成以及「文以載道」的誦記。但是對於「語言是一個完整運作的系統」卻從來不曾提過。於是我參加了許多語言教學的活動。然,並無卵用。
我也曾想過,是語言學的能見度太低的問題。所以寫了很多 blog,從語言學的角度來探討各種現象和介紹我們用來分析語言的工具,用各種和其它學科之間的類比企圖讓入門門檻低一些,但閱讀人數非常非常的低。

甚至也參加許多資訊技術人的聚會,希望可以組成某種團隊,我們可以用更聰明的方法來來做 NLP,也能讓有懂語言學的人參與而設計的工具,幫助語言學家能用更短的時間,更平易近人的方式來分析一些具有話題性的問題。但,沒有人參加。
接著,我自己去貸款學習程式設計,在「保証班」裡用「授權中文教材」學了兩年都學不會,班主任受不了了,最後給我「原廠的英文教材」請我不要再來了。我回去翻了翻那些原文手冊,當天下午就會寫程式了。那時才發現,人社院的同學覺得程式語言很困難的原因之一,是因為各種「中文」的教學文件和書籍。
於是,我和朋友開設相關的課程,專門教「非資訊相關領域畢業」的人如何寫程式。當年是 2011 年,教了一年多,我才剛剛寫完基於語音學的自動音節切分程式,BigData 的狂潮就來了。緊接著是機器學習、深度學習…等等技術的興起。
我推了幾年 Linguistics-Based NLP 以後,有一次一個客戶跟我說「你的方法和現在的主流太不一樣了。如果你是個資訊的 Ph. D 的話,我就相信你。」好吧,那麼我就去找機會回學校去讀書。後來也是因故沒能拿到學位。
再來就是把自己原本想做為論文題目的東西,打造成商業應用的程式,拿出來賣。每次���商業展示,都是效果很好,但從 2012 年的 BigData 以來,市場上已經有近十年的 NLP 工程師都是從大一開始就被老師耳提面命地教著「語言學在 1950 年代就失敗啦!你看 "人工智慧" 教科書的作者 Peter Norvig 也在罵 1957 年 Chomsky 的研究沒有用 (從他的 Blog 文裡看來,Norvig 博士好像沒有接觸過 1960 年代以後的語言學)」。然後就有許多資深工程師在想著:「所以…怎麼辦?承認卓騰的技術可以解決機器學習做不好的問題,那是不是間接就承認自己十幾年來學的東西是錯的?」
即便我一再從 Hybrid AI 的角度去說明「在經驗的這一塊,語言學是較為無力的。因為經驗不是語言學的研究重點。因此經驗的部份,是可以由機器學習和資料科學加以補足。」但常人就是這樣,預設值就是二元對立的世界觀。你語言學不是我「大資料科學」,非我族類,其心必異。於是我們也是一次、兩次、三次…一次又一次地出現「效果很好,但是技術主管說不能買單 (不然讓你們卓騰進來,我的位子不就有危險了?)」。然後我們又只能默默看著那個技術部門甚至是整間公司過了兩年以後,專案計劃預算用盡,產品還是做不出來而結束。
最近兩年,則是學校的接觸多了。也許是已經過了十年,「泛語言學」系所 (所有會有「語音學」或是「語概」可以修的科系) 都開始感受到少子化以及產業應用不足的寒意而起心動念想要有所改變。結果是…有好有壞。但這十年來整個世界給我的那些「好好好,你很棒,先這樣,再聯絡。」已經讓我對這些嗤之以鼻的評價沒什麼感覺了。世界上還是有一些人願意打開心胸,分享他們的溫暖。我是數萬年來演化出來的節能生物,不是耗電的 GPU,只要有這一點點能量,我就會繼續撐下去。
幾年前的「語言學 (家) 的出路」論壇裡,最後的結論我聽起來像是「大家好好讀書,努力做研究,事情就會好轉」的時候,不禁想到那句「瘋狂就是重複做相同的事情卻期待不同的結果」。而人類這個物種貴為萬物之靈,卻對「改變」充滿了敵意和抗拒。
改變,不是叫你不要做現在的語言學研究了。而是在做語言學研究之餘,還要多做一個 socket,讓別人可以方便地取用你的知識,知道你在做什麼,進而理解你的研究價值。這個真的很辛苦,但環境已經變了,不跟著調整的話,這就是最後一代了。
於是我繼續一家一家地敲客戶的門,繼續一行一行地敲打著程式碼,繼續一字一句 地寫 Blog 分享著「語言學是什麼,語言是什麼」。當然我的文章裡已經有些東西不是最新的研究發展了,甚至有些東西不是主流大咖所認可的內容。但…我一不是在發表學術論文,二不是在累積什麼來爭取補助經費。我要做的,是讓更多人意識到「語言是一個很複雜的系統。你不會因為自己天生就有心跳,而小看心臟專科的醫生。所以你也不該因為自己天生會講話,就認為語言是一個很簡單的事情。」
Don't be naive. 語言是很複雜的。
以前在讀書時,老師們常常說「語言學就像天文學、像物理化學一樣,是基礎學科。基礎學科就是要花錢去研究的,不要問它能做什麼應用。」問題是,天文學、物理化學這些基礎學科就算最後打出了一個「哦,可以看得更遠的天文望遠鏡,人類真是好棒棒!」之外,在打出這個望遠鏡的過程中,所有的研究成果都可以用來做更有效率的電池、更少阻力的飛行構型、更可靠的控制系統…
那你語言學能幹嘛?要讓電腦把自然語言處理好,語言學家絕對是幫得上忙,也該幫上忙的。而要幫忙,第一步就是把手從自己的口袋裡抽出來,把腳踏出自己的小圈圈。
"AI" 這個詞彙誕生之時,語言學家是在場的。當 "AI" 真的開始思考著「這是哪裡?我是誰?」的那一天,語言學家也不該缺席。
在這個瘋狂的年代,我仍在努力,希望能促成改變的發生。
0 notes
Text
麵製品夾著肉就一定是漢堡嗎?
「欸你們讀語言學的,是不是學了電腦以後都想當資工系的語言組啊?」 今年才過去六天,類似的問題就被問了兩次… -_- (長嘆…) 在語言學的世界裡,有幾個比較有歷史的詞彙,會讓人覺得這個子領域和電腦有關。一是「計算機語言學 (Computational Linguistics)」,另一個是「語料庫語言學 (Corpus Linguistics)」。什麼是計算機?應該不是那個上面佈滿數字符號和運算按鈕的電子設備,所以大家想當然爾地就看到旁邊的 "computation" 裡有個和 "computer" 很像的東西,所以這個應該和「電腦」有關吧?! 同理可証,當一般人實在搞不懂什麼是語料庫的時候,最簡單的說法就是「儲存了很多語言資料的資料庫」。哦~資料庫,又一個和電腦有關的東西。

於是乎…傳統上,在語言學的圈圈裡講到「電腦」的時候,大家都會不由自主地把眼神「飄」向計算機語言學家和語料庫語言學家那裡。甚至,最近幾年在資訊領域裡火熱到不行的「機器學習」,也因為它「和電腦有關」,所以語言學圈圈裡那兩個「和電腦有關」的子領域,似乎…好像…也就不得不來用一下「機器學習」來做個什麼東西。
第一個問題是,機器學習和語言的本質、和心智的運作探討一點關係也沒有。
再加上,語言學在國內被分類在「人文社會領域」的,所以研究經費少得可憐。相較於資訊工程領域裡的研究經費,人文社會領域的資源就只能…用一些免費的 Colab,跑一些「數千筆」的資料 (相較於資工領域動不動就是數百萬筆資料),就這麼撐著。
第二問題是,機器學習方法沒有餵給它「巨量」的大數據,它跑出來的效果就是一個走不出實驗室的東西 [註]
這下好了,計算機語言學家沒有「西北夠力」的計算資源;語料庫語言學家沒有「夭壽大包」的語料,都很難做機器學習。
然而,就算做了機器學習,又要常常面對學生會提問「這和語言學有什麼關係?」或是「這和語言的本質,和人類的心智運作,有什麼關係?」
但若是不做機器學習,就很難發 paper。發不了 paper,就算努力做研究或是教學,也很容易被校方認為是「不用功的學者」。那怎麼辦?
你以為只有這兩個子領域的學者這樣兩面不是人而已嗎?不不,其它子領域的語言學家,一旦開始想接觸程式語言,嚐試著想放大自己的專業領域,還會再遇上兩種質疑的聲音:
你學得會嗎?幹嘛不務正業?
你學會了,是不是滿心想著要去當資工系的「語言組」啊!
Gosh...真是夠了…
[[能讀到這裡真是了不起,上面都只是前言而已]]
現代語言學做為一種科學,它的每一個子領域都是「可以被工程化」的項目。就拿我個人最熟悉的形式語意學 (formal semantics) 來講,它的目標就是在計算 (calculate) 語言的真值條件 (truth value),並依此操作定義來取得句子的語意 (meaning)。
既然都是在計算 True 或 False 的值,怎麼可能會無法寫成程式呢?
再拿個例子來看:https://github.com/Droidtown/Linguistic_Training/blob/master/Language_Analysis_Demo.py 這是「國立清華大學 110 學年度語言學研究所入學考試 - 語言分析」的第一題。它就是一個完全可以把「語言學家分析語言」的步驟加以工程化、程式化以便快速驗証大量資料的方法。
沒有寫成程式以前,每做一個假設,就要自己拿著鉛筆和白紙一段一段地推演。現在可以把自己的想法寫成程式碼,只要把語料「倒進去」就能馬上驗証自己的推論是否可行 (viable)。甚至還能在每一個 if...else... 的旁邊加註上「這個條件是根據某年某學者某篇論文中的某個結論」來做驗証。
這是資工系的語言組嗎?不,資工系才不是這樣看待語言的。
這是語言學嗎?是,這種方式,雖然用上了程式碼來加速自己的驗証,但它仍然是語言學,每一個假設、每一個條件、每一筆資料的分類,都有「可解釋性的語言學根據」。
這就是研究「語言的本質」,也是研究「人類心智的運作」,甚至我們可以說 (偷用 Chomsky 教授的說法),語言學就是在研究人類的本質。而這也正是語言學迷人的地方,程式能力只是讓我們在做語言學的研究時,能在這茫茫的思維之海中從以往的手工業進入資訊時代而已。
所以,你看到「語言」看到「電腦」就覺得它一定是「資工系的語言組」嗎?還是說看到「電腦」和「語言」,就覺得這一定就只和「計算機語言學」或是「語料庫語言學」有關呢?
麵製品夾著肉不一定是漢堡呀,別忘了這個世界上還有刈包、三明治和沙威瑪呀!
註:走出實驗室後,想落地實用的話,還有別的東西要考慮。
0 notes
Text
一個魚形,各自表述
我自覺有一個說起來很心理變態的嗜好。 ��看了很多 Youtube 裡殺魚的影片。三更半夜睡不著的時候,我幾乎都在看殺魚的影片… 📷 殺魚,指的不是「取走魚的性命」的那一段,而是把一條魚從完整的「魚形」切割成一塊一塊的「肉塊」的過程。我相信像我這樣的心理變態應該不少,因為網路上竟然找到得 24 小時不間斷播出殺魚錄影的頻道! 看著看著,我竟然看出了一個有點意思的語言和認知問題。 我發現不同的文化、民族和地區的漁人和水產廚師,殺魚的手法是不同的。而這個不同,似乎可以看出來在他的認知裡「魚形」這種立體幾何形狀是被歸屬在哪一類裡。是像肉?像菜?還是像水果? 如果全人類的認知系統運作是一致的,對立體形狀的認知也是一致的這個假設成立的話,我只能猜…會不會是他的語言裡「魚形」和其它的某些形狀是一致的?也因為如此,所以某些魚可能是因為形狀的關係,而在某些「以禁忌食物的形狀來描述」的文化裡,也連帶地被視為是「不可食用」的魚?(e.g., 猶太人不吃鰻魚。Well...很明顯地,它是蛇的形狀。) 比如說,我發現在南亞某些地方,殺魚時是不先去除內臟的。漁販只是「切頭去尾」後,接著把魚身直拉起來,像個鳳梨一樣擺在砧板。他接下來下刀的方式,也像是切鳳梨一樣,然後把魚的內臟像是「去鳳梨心」的方式處理。直到最後,切成一塊一塊的魚肉,也像是切出鳳梨果塊似的近似三角形。 我超級想問,在這個漁販的母語裡,鳳梨和魚的形狀各自是哪一個字?還是根本就同一個字來描述這種立體幾何形? 有的地方,切魚是從魚背下第一刀;有的地方是從魚腹下第一刀! 有些地方,不去鱗,直接像削果皮一樣把魚皮和魚鱗一起削掉 (想想也挺合理的。反正稍後都要去皮,那為什麼要先去鱗?) 有些地方,不去內臟,而是最後把內臟直接淘出來,切碎後拌在某種醬汁裡,那也是一道菜。(可想而知地,某些內臟味道很糟糕的魚,在這個地方就是『不能吃』的魚。) 有的地方,去鰭的方式是由後往前削;有的地方是把魚放平後,像砍掉多餘枝葉似的由上往下砍。反而,像日本水產師傅那樣仔細地保留魚鰭,從左右分別下刀取肉是很少見的。 這些都讓我思考著…會不會語言之間除了描述「顏色」的概念會受語言影響以外,會不會連「幾何形狀」的理解,都會受到語言的影響甚至是限制呢?
0 notes