#Automated Data Annotation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Automated Data Annotation: Making the Automotive Industry Smarter

Automated data annotation is redefining how the automotive industry advances toward intelligent, AI-driven solutions. As AI integration deepens, the demand for precise, high-volume data labeling grows exponentially. According to G2, "The market for AI-based automated data labeling tools is estimated to grow at a CAGR of over 30% by 2025." This surge is propelled by the industry's need to power autonomous driving and smart vehicle systems efficiently through advanced auto annotation technologies.
Accurate data annotation forms the backbone of safe and responsive AI in vehicles. Poor-quality annotations can hinder model performance, while structured, automated labeling enhances precision and reduces training time. Industry insights reveal that 80% of large companies will seek external expertise to handle complex and large-scale data annotation demands.
These trends reflect a broader transformation: as automotive innovation accelerates, companies are embracing automated data annotation to achieve faster development cycles, reduce operational costs, and enable safer on-road experiences. In this blog, we’ll explore how automation is becoming an indispensable engine for smart mobility.
Understanding Data Annotation
At its core, data annotation involves tagging and labeling raw data, such as images, video, or sensor inputs, so that AI systems can learn from it. In the automotive sector, this means identifying road signs, lanes, pedestrians, vehicles, and environmental conditions in datasets that help train machine learning models. Traditional annotation methods can be time-consuming and prone to human error, especially as the scale of data expands. This is where automated data annotation comes into play.
Automated Data Labeling leverages AI and machine learning algorithms to label massive volumes of data faster and with higher accuracy. Unlike manual methods, automated systems continuously learn and improve from new datasets, reducing the reliance on human annotators. For automotive companies, using data annotation services enables them to process millions of data points collected from sensors and cameras in record time. This facilitates real-time decision-making and enhances the training of autonomous driving models, making them more robust and effective.
By annotating data efficiently and accurately, automotive innovators can ensure their AI models are equipped with high-quality, labeled datasets, significantly improving the performance and safety of autonomous vehicles.
How to Automate Data Annotation for Autonomous Vehicles
Training perception systems for autonomous vehicles requires massive amounts of high-quality labeled data from sources like cameras, LIDAR, and radar. However, manual data labeling is a major bottleneck. For automotive AI teams, it’s not just about labeling—it’s about doing so accurately, at scale, and fast enough to keep up with development cycles.
Research and industry benchmarks suggest that data preparation consumes up to 80% of the total effort in AI projects, with labeling being one of the most time- and resource-intensive components. For the automotive sector—where safety, real-time decision-making, and high-volume sensor data are critical—manual labeling simply doesn’t scale.
That’s where AI data labeling comes into play—automating the annotation process to boost efficiency and meet the demands of advanced automotive systems.
Why Automate Data Annotation in Automotive AI?
Autonomous vehicles rely on AI models that must interpret complex road environments, detect and classify objects, and make split-second decisions. Automating the labeling of visual and sensor data helps teams:
Reduce human errors in identifying objects like road signs, vehicles, pedestrians, and lane boundaries
Accelerate training cycles by labeling thousands of frames per hour
Ensure consistency across large-scale datasets from diverse driving environments
Cut costs by minimizing manual annotation labor
Enable continuous learning as vehicle systems evolve
Key Approaches to Automate Data Annotation
Here are the most effective techniques for automating annotation in the autonomous driving domain:
1. Pre-trained Models and Transfer Learning
AI models trained on existing datasets (e.g., for object detection or segmentation) can auto-label new data, significantly reducing manual workload. These are often adapted to recognize automotive-specific objects like traffic lights, road markings, and cyclists.
2. Sensor Fusion-Based Labeling
Combining camera, LIDAR, and radar inputs helps create more accurate labels—especially for 3D perception tasks. Automation tools use fused data to label object depth, orientation, and movement.
3. Human-in-the-Loop (HITL)
While AI handles the bulk of labeling, human reviewers validate and correct complex or ambiguous labels—ensuring safety-critical precision without the inefficiency of full manual annotation.
4. Programmatic Labeling
Rule-based logic and scripts can be used to label recurring patterns, like lane lines or turn signals, across large datasets. This is especially useful for repetitive or static elements in driving scenes.
5. Active Learning and Semi-Supervised Learning
Models suggest labels for the most uncertain or critical samples, which are then verified by experts. These feedback loops help improve labeling models while reducing the need for human intervention.
Build or Buy? Choosing the Right Automation Solution
For automotive teams, choosing the right annotation tool depends on multiple factors: the complexity of the sensor data, integration with existing ML pipelines, compliance requirements, and time-to-market pressures.
Some opt to build in-house platforms tailored to their unique sensor stack, while others use off-the-shelf solutions that support automotive-specific annotation formats, dashboards, and collaborative workflows.
Top Automated Data Annotation Techniques in the Automotive Industry
Automated data annotation is transforming the way training data is prepared for automotive AI systems by increasing efficiency, consistency, and scalability. Different automotive use cases require distinct automated annotation techniques. Below are some of the most commonly employed methods:
Bounding Box Annotation
In this technique, AI-powered tools for AI labeling automatically generate rectangular boxes around objects like vehicles, pedestrians, traffic lights, and animals. Automated bounding boxes speed up the labeling process and ensure consistent object detection for real-time perception systems. This method is especially useful for training models that require large volumes of annotated video or image data.
Semantic Segmentation
Here, automation tools classify every pixel in an image into categories such as road, vehicle, pedestrian, or traffic sign. Advanced models powered by deep learning can perform this pixel-level annotation with high precision, enabling more detailed scene understanding for autonomous navigation and path planning.
Polyline Annotation
Machine learning algorithms detect and annotate lane markings, road edges, and boundaries by drawing polylines. AI annotation through polylines is critical for systems like lane departure warning, autonomous lane changes, and maintaining accurate road topology in dynamic driving environments.
3D Cuboid Annotation
AI systems generate 3D boxes around objects using camera or LIDAR data to capture volume, orientation, and spatial positioning. Automated cuboid annotation is crucial for depth estimation and environmental awareness in self-driving vehicles, helping models understand how far and how big an object is in 3D space.
Keypoint Annotation
Using AI models, systems can automatically mark specific points on objects, such as joints on pedestrians or facial landmarks on drivers. This form of annotation supports behavioral analysis, including gaze tracking, gesture recognition, and posture monitoring, all of which enhance in-cabin safety and external interaction with road users.
Impact of Automated Data Annotation on Automotive
Automated data annotation is revolutionizing the automotive industry by enabling faster, more accurate AI model training. From enhancing safety to optimizing manufacturing, it’s key to accelerating the future of autonomous mobility.
Enhancing Safety in Autonomous Driving
Automated data annotation plays a critical role in training AI models to detect and respond accurately to road elements, such as pedestrians, vehicles, traffic signs, and road conditions. By automating the process of annotating data, systems like ADAS (Advanced Driver Assistance Systems) can make real-time decisions that prevent accidents, ensuring both passenger and pedestrian safety.
Accelerating the Development of Self-Driving Cars
Automated data labeling enables the rapid creation of high-quality datasets, drastically reducing the time needed to train machine learning models. This accelerates prototyping and brings self-driving technologies to market more quickly, allowing automotive companies to stay ahead of the competition and meet evolving demands.
Reducing Costs Through Virtual Testing
Automated annotation makes it easier to create synthetic test environments for autonomous vehicles. By providing large volumes of annotated data, AI models can be tested in virtual environments, simulating complex driving scenarios. This eliminates the need for extensive physical testing, saving both time and operational costs.
Customizing Vehicles for Global Markets
Different regions have distinct traffic laws, road infrastructures, and driving behaviors. Automated data annotation allows AI systems to be trained on country-specific road signs, symbols, and cultural driving habits, enabling manufacturers to create regionally optimized autonomous driving systems. This ensures compliance with local regulations and enhances safety across markets.
Improving Driver Monitoring Systems
AI-powered data labeling of internal camera feeds helps detect critical driver behaviors, such as fatigue, distraction, or drowsiness. Automated systems can analyze these labeled data points and trigger alerts or system interventions to prevent accidents. As these technologies are increasingly mandated, especially in commercial fleets and ride-hailing services, automated annotation ensures effective monitoring.
Advancing Manufacturing and Quality Control
In the automotive manufacturing sector, automated data annotation helps AI systems identify defects and anomalies during production. By labeling data from vision systems in real-time, manufacturers can streamline quality control processes, reduce production errors, and improve overall efficiency. This leads to higher-quality vehicles and fewer recalls.
Supporting Predictive Maintenance
Automated data annotation aids in predictive maintenance by labeling sensor and diagnostic data. These labeled datasets help machine learning models recognize patterns in vehicle components, predicting potential failures before they occur. This capability reduces downtime, minimizes costly repairs, and enhances the longevity of automotive assets.
Enabling Smart Infotainment and HMI Systems
As human-machine interaction (HMI) evolves, automated data annotation plays a pivotal role in improving voice and gesture recognition in vehicles. By training systems with AI training data across various modalities, automotive manufacturers can enhance the responsiveness, accuracy, and personalization of smart infotainment systems, providing a better user experience.
Enhancing Road Infrastructure Interaction
For autonomous vehicles to navigate complex environments, such as toll booths, parking gates, and traffic management systems, high-quality annotated data is required. Automated data annotation allows vehicles to learn how to interact seamlessly with road infrastructure, improving safety and efficiency when handling real-world scenarios.
Optimizing Data Processing Pipelines
Integrating automated annotation tools into the automotive AI data pipeline enhances efficiency by reducing manual intervention. These tools automatically label sensor data, validate label accuracy, and flag edge cases for human review. This process streamlines dataset development, improves model precision, and speeds up the deployment of AI-driven features.
Conclusion
As the automotive industry moves toward a future of intelligent mobility, the impact of automated data annotation becomes more evident. It is no longer just about processing raw data; it’s about transforming that data into actionable insights that enhance vehicle autonomy, safety, and performance. From autonomous driving to predictive maintenance, automated data annotation fuels the evolution of AI systems that make intelligent, real-time decisions.
The demand for precision, speed, and scalability is only growing, and manual annotation can no longer keep pace with the volume of data generated by modern vehicles. Data annotation companies now offer the automotive sector a powerful solution to reduce operational costs, accelerate development cycles, and ensure the safety and reliability of AI systems through scalable auto-annotation tools.
In an industry where every decision can have life-or-death consequences, embracing automated data annotation is not just a technological advancement—it’s a strategic necessity. Automotive manufacturers and innovators who adopt these technologies will be better positioned to lead the charge toward safer, smarter, and more efficient vehicles, shaping the future of mobility worldwide.
Looking for scalable, high-quality annotation solutions for your automotive AI needs? TagX offers advanced automated data annotation services that accelerate the development of intelligent automotive systems.
Original Source, https://www.tagxdata.com/automated-data-annotation-making-the-automotive-industry-smarter
0 notes
Text
AI, Business, And Tough Leadership Calls—Neville Patel, CEO of Qualitas Global On Discover Dialogues

In this must-watch episode of Discover Dialogues, we sit down with Neville Patel, a 34-year industry veteran and the founder of Qualitas Global, a leader in AI-powered data annotation and automation.
We talked about AI transforming industries, how automation is reshaping jobs, and ways leaders today face tougher business decisions than ever before.
Episode Highlights:
The AI Workforce Debate—Will AI replace jobs, or is it just shifting roles?
Business Growth vs. Quality—Can you scale without losing what makes a company The AI Regulation Debate, Who’s Really Setting AI Standards?
The AI Regulation Conundrum—Who’s Really Setting AI Standards?
The Leadership Playbook—How to make tough calls when the stakes are high?
This conversation is raw, real, and packed with insights for leaders, entrepreneurs, and working professionals.
1 note
·
View note
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note
Text
🙄
Gain Incremental Efficiencies with Automated Data Collection 📣 Employing a reliable automated data collection system can assist businesses in remaining competitive in today’s evolving landscape, allowing them to not only meet but surpass their data collection and processing objectives. You can gain a plethora of benefits and overcome the limitations of the manual data collection process, as…

View On WordPress
0 notes
Text
youtube
Official Report on The Intransitionalist Chronotopologies of Kenji Siratori (TRS 109)

YOU CANNOT ESCAPE THE INEFFABLE FOREST
youtube
Official Report on The Intransitionalist Chronotopologies of Kenji Siratori: Appendix 8.2.3 is a xenopoetic data/dada anthology that documents the activities of the artist collective The Ministry of Transrational Research into Anastrophic Manifolds. The anthology results from an experimental approach to impersonal literary composition. Similar to surrealist definitions, but on the scale of a technical document, members of the Ministry—poets, musicians, novelists, painters, curators, artists, scientists, philosophers, and physicians—were asked to offer a microfiction, poem, essay, fictional citation, or computer code, in the form of a footnote or annotation to a glitch-generated novel by iconoclastic Japanese artist Kenji Siratori; however, each participant wrote their contribution without any access to or knowledge about the nature of Siratori’s source text. After collecting the contributions, the “footnotes” were each algorithmically linked to an arbitrary word from Siratori’s novel. The result is a work of xenopoetic emergence: a beautifully absurd, alien document scintillating with strange potency. Bringing together algorithmically and AI-generated electronic literature with analogue collage and traditional modes of literary composition, the Ministry refuses to commit solely to digital, automated, or analogue art and instead seeks technological mutualism and a radically alien future for the arts. Accompanied by a groundbreaking original score by electro-acoustic duo Wormwood, the anthology offers the radical defamiliarization and weird worlds of science fiction, but now the strangeness bites back on the level form. Readers should expect to discover strange portals from which new ways of thinking, feeling, and being emerge. A conceptual and experimental anthology, Official Report on The Intransitionalist Chronotopologies of Kenji Siratori inaugurates collective xenopoetic writing and the conceit that the future of art will consist of impersonal acts of material emergence, not personal expression. Consume with caution.
youtube



AUTHORS AND CONTRIBUTORS Rosaire Appel, Louis Armand, David Barrick, Gary Barwin, Steve Beard, Gregory Betts, Christian Bök, Mike Bonsall, Peter Bouscheljong, Maria Chenut, Shane Jesse Christmas, Roy Christopher, Tabasco “Ralph” Contra, Mike Corrao, R.J. Dent, Paul Di Filippo, Zak Ferguson, Colin Herrick, S.C. Hickman, Maxwell Hyatt, Justin Isis, Andrew Joron, Chris Kelso, Phillip Klingler, Adam Lovasz, Daniel Lukes , Ania Malinowska, Claudia Manley, Ryota Matsumoto, Michael Mc Aloran, Andrew McLuhan, Jeff Noon, Jim Osman, Suarjan Prasai, Tom Prime , David Leo Rice, Virgilio Rivas, David Roden, B.R. Yeager, Andrej Shakowski , Aaron Schneider, Gary J. Shipley, Kenji Siratori , Sean Smith, Kristine Snodgrass, Sean Sokolov, Alan Sondheim, Simon Spiegel, Henry Adam Svec, Jeff VanderMeer, R.G. Vasicek, Andrew C. Wenaus, William Wenaus, Eileen Wennekers, Christina Marie Willatt, Saywrane Alfonso Williams, D. Harlan Wilson, Andrew Wilt
early September release





38 notes
·
View notes
Text
AI & Tech-Related Jobs Anyone Could Do
Here’s a list of 40 jobs or tasks related to AI and technology that almost anyone could potentially do, especially with basic training or the right resources:
Data Labeling/Annotation
AI Model Training Assistant
Chatbot Content Writer
AI Testing Assistant
Basic Data Entry for AI Models
AI Customer Service Representative
Social Media Content Curation (using AI tools)
Voice Assistant Testing
AI-Generated Content Editor
Image Captioning for AI Models
Transcription Services for AI Audio
Survey Creation for AI Training
Review and Reporting of AI Output
Content Moderator for AI Systems
Training Data Curator
Video and Image Data Tagging
Personal Assistant for AI Research Teams
AI Platform Support (user-facing)
Keyword Research for AI Algorithms
Marketing Campaign Optimization (AI tools)
AI Chatbot Script Tester
Simple Data Cleansing Tasks
Assisting with AI User Experience Research
Uploading Training Data to Cloud Platforms
Data Backup and Organization for AI Projects
Online Survey Administration for AI Data
Virtual Assistant (AI-powered tools)
Basic App Testing for AI Features
Content Creation for AI-based Tools
AI-Generated Design Testing (web design, logos)
Product Review and Feedback for AI Products
Organizing AI Training Sessions for Users
Data Privacy and Compliance Assistant
AI-Powered E-commerce Support (product recommendations)
AI Algorithm Performance Monitoring (basic tasks)
AI Project Documentation Assistant
Simple Customer Feedback Analysis (AI tools)
Video Subtitling for AI Translation Systems
AI-Enhanced SEO Optimization
Basic Tech Support for AI Tools
These roles or tasks could be done with minimal technical expertise, though many would benefit from basic training in AI tools or specific software used in these jobs. Some tasks might also involve working with AI platforms that automate parts of the process, making it easier for non-experts to participate.
4 notes
·
View notes
Text
This Week in Rust 518
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Project/Tooling Updates
Strobe Crate
System dependencies are hard (so we made them easier)
Observations/Thoughts
Trying to invent a better substring search algorithm
Improving Node.js with Rust-Wasm Library
Mixing C# and Rust - Interop
A fresh look on incremental zero copy serialization
Make the Rust compiler 5% faster with this one weird trick
Part 3: Rowing Afloat Datatype Boats
Recreating concurrent futures combinators in smol
Unpacking some Rust ergonomics: getting a single Result from an iterator of them
Idea: "Using Rust", a living document
Object Soup is Made of Indexes
Analyzing Data 180,000x Faster with Rust
Issue #10: Serving HTML
Rust vs C on an ATTiny85; an embedded war story
Rust Walkthroughs
Analyzing Data /,000x Faster with Rust
Fully Automated Releases for Rust Projects
Make your Rust code unit testable with dependency inversion
Nine Rules to Formally Validate Rust Algorithms with Dafny (Part 2): Lessons from Verifying the range-set-blaze Crate
[video] Let's write a message broker using QUIC - Broke But Quick Episode 1
[video] Publishing Messages over QUIC Streams!! - Broke But Quick episode 2
Miscellaneous
[video] Associated types in Iterator bounds
[video] Rust and the Age of High-Integrity Languages
[video] Implementing (part of) a BitTorrent client in Rust
Crate of the Week
This week's crate is cargo-show-asm, a cargo subcommand to show the optimized assembly of any function.
Thanks to Kornel for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
* Hyperswitch (Hacktoberfest)- [FEATURE] separate payments_session from payments core * Hyperswitch (Hacktoberfest)- [NMI] Use connector_response_reference_id as reference to merchant * Hyperswitch (Hacktoberfest)- [Airwallex] Use connector_response_reference_id as reference to merchant * Hyperswitch (Hacktoberfest)- [Worldline] Use connector_response_reference_id as reference to merchant * Ockam - Make ockam project delete (no args) interactive by asking the user to choose from a list of space and project names to delete (tuify) * Ockam - Validate CBOR structs according to the cddl schema for authenticator/direct/types * Ockam - Slim down the NodeManagerWorker for node / node status
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
397 pull requests were merged in the last week
rewrite gdb pretty-printer registration
add FileCheck annotations to mir-opt tests
add MonoItems and Instance to stable_mir
add a csky-unknown-linux-gnuabiv2hf target
add a test showing failing closure signature inference in new solver
add new simpler and more explicit syntax for check-cfg
add stable Instance::body() and RustcInternal trait
automatically enable cross-crate inlining for small functions
avoid a track_errors by bubbling up most errors from check_well_formed
avoid having rustc_smir depend on rustc_interface or rustc_driver
coverage: emit mappings for unused functions without generating stubs
coverage: emit the filenames section before encoding per-function mappings
coverage: fix inconsistent handling of function signature spans
coverage: move most per-function coverage info into mir::Body
coverage: simplify the injection of coverage statements
disable missing_copy_implementations lint on non_exhaustive types
do not bold main message in --error-format=short
don't ICE when encountering unresolved regions in fully_resolve
don't compare host param by name
don't crash on empty match in the nonexhaustive_omitted_patterns lint
duplicate ~const bounds with a non-const one in effects desugaring
eliminate rustc_attrs::builtin::handle_errors in favor of emitting errors directly
fix a performance regression in obligation deduplication
fix implied outlives check for GAT in RPITIT
fix spans for removing .await on for expressions
fix suggestion for renamed coroutines feature
implement an internal lint encouraging use of Span::eq_ctxt
implement jump threading MIR opt
implement rustc part of RFC 3127 trim-paths
improve display of parallel jobs in rustdoc-gui tester script
initiate the inner usage of cfg_match (Compiler)
lint non_exhaustive_omitted_patterns by columns
location-insensitive polonius: consider a loan escaping if an SCC has member constraints applied only
make #[repr(Rust)] incompatible with other (non-modifier) representation hints like C and simd
make rustc_onunimplemented export path agnostic
mention into_iter on borrow errors suggestions when appropriate
mention the syntax for use on mod foo; if foo doesn't exist
panic when the global allocator tries to register a TLS destructor
point at assoc fn definition on type param divergence
preserve unicode escapes in format string literals when pretty-printing AST
properly account for self ty in method disambiguation suggestion
report unused_import for empty reexports even it is pub
special case iterator chain checks for suggestion
strict provenance unwind
suggest ; after bare match expression E0308
suggest constraining assoc types in more cases
suggest relaxing implicit type Assoc: Sized; bound
suggest removing redundant arguments in format!()
uplift movability and mutability, the simple way
miri: avoid a linear scan over the entire int_to_ptr_map on each deallocation
miri: fix rounding mode check in SSE4.1 round functions
miri: intptrcast: remove information about dead allocations
disable effects in libcore again
add #[track_caller] to Option::unwrap_or_else
specialize Bytes<R>::next when R is a BufReader
make TCP connect handle EINTR correctly
on Windows make read_dir error on the empty path
hashbrown: add low-level HashTable API
codegen_gcc: add support for NonNull function attribute
codegen_gcc: fix #[inline(always)] attribute and support unsigned comparison for signed integers
codegen_gcc: fix endianness
codegen_gcc: fix int types alignment
codegen_gcc: optimize popcount implementation
codegen_gcc: optimize u128/i128 popcounts further
cargo add: Preserve more comments
cargo remove: Preserve feature comments
cargo replace: Partial-version spec support
cargo: Provide next steps for bad -Z flag
cargo: Suggest cargo-search on bad commands
cargo: adjust -Zcheck-cfg for new rustc syntax and behavior
cargo: if there's a version in the lock file only use that exact version
cargo: make the precise field of a source an Enum
cargo: print environment variables for build script executions with -vv
cargo: warn about crate name's format when creating new crate
rustdoc: align stability badge to baseline instead of bottom
rustdoc: avoid allocating strings primitive link printing
clippy: map_identity: allow closure with type annotations
clippy: map_identity: recognize tuple identity function
clippy: add lint for struct field names
clippy: don't emit needless_pass_by_ref_mut if the variable is used in an unsafe block or function
clippy: make multiple_unsafe_ops_per_block ignore await desugaring
clippy: needless pass by ref mut closure non async fn
clippy: now declare_interior_mutable_const and borrow_interior_mutable_const respect the ignore-interior-mutability configuration entry
clippy: skip if_not_else lint for '!= 0'-style checks
clippy: suggest passing function instead of calling it in closure for option_if_let_else
clippy: warn missing_enforced_import_renames by default
rust-analyzer: generate descriptors for all unstable features
rust-analyzer: add command for only opening external docs and attempt to fix vscode-remote issue
rust-analyzer: add incorrect case diagnostics for module names
rust-analyzer: fix VS Code detection for Insiders version
rust-analyzer: import trait if needed for unqualify_method_call assist
rust-analyzer: pick a better name for variables introduced by replace_is_some_with_if_let_some
rust-analyzer: store binding mode for each instance of a binding independently
perf: add NES emulation runtime benchmark
Rust Compiler Performance Triage
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Add f16 and f128 float types
Unicode and escape codes in literals
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider alias bounds when computing liveness in NLL (but this time sound hopefully)
[disposition: close] regression: parameter type may not live long enough
[disposition: merge] Remove support for compiler plugins.
[disposition: merge] rustdoc: Document lack of object safety on affected traits
[disposition: merge] Stabilize Ratified RISC-V Target Features
[disposition: merge] Tracking Issue for const mem::discriminant
New and Updated RFCs
[new] eRFC: #[should_move] attribute for per-function opting out of Copy semantics
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-10-25 - 2023-11-22 🦀
Virtual
2023-10-30 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
(Hybrid - online & in person) October 2023 Rust Melbourne Meetup
2023-10-31 | Virtual (Europe / Africa) | Rust for Lunch
Rust Meet-up
2023-11-01 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
ECS with Bevy Game Engine
2023-11-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-11-02 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-11-07 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-11-09 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-11-14 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-11-15 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
Building Our Own Locks (Atomics & Locks Chapter 9)
2023-11-15 | Virtual (Richmond, VA, US) | Linux Plumbers Conference
Rust Microconference in LPC 2023 (Nov 13-16)
2023-11-15 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-11-16 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-11-21 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
Europe
2023-10-25 | Dublin, IE | Rust Dublin
Biome, web development tooling with Rust
2023-10-25 | Paris, FR | Rust Paris
Rust for the web - Paris meetup #61
2023-10-25 | Zagreb, HR | impl Zagreb for Rust
Rust Meetup 2023/10: Lunatic
2023-10-26 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Augsburg Rust Meetup #3
2023-10-26 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #41 sponsored by Factbird
2023-10-26 | Delft, NL | Rust Nederland
Rust at TU Delft
2023-10-26 | Lille, FR | Rust Lille
Rust Lille #4 at SFEIR
2022-10-30 | Stockholm, SE | Stockholm Rust
Rust Meetup @Aira + Netlight
2023-11-01 | Cologne, DE | Rust Cologne
Web-applications with axum: Hello CRUD!
2023-11-07 | Bratislava, SK | Bratislava Rust Meetup Group
Rust Meetup by Sonalake
2023-11-07 | Brussels, BE | Rust Aarhus
Rust Aarhus - Rust and Talk beginners edition
2023-11-07 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #7
2023-11-09 | Barcelona, ES | BcnRust
11th BcnRust Meetup
2023-11-09 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-11-21 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
GPU processing in Rust
2023-11-23 | Biel/Bienne, CH | Rust Bern
Rust Talks Bern @ Biel: Embedded Edition
North America
2023-10-25 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-10-25 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-11-01 | Brookline, MA, US | Boston Rust Meetup
Boston Common Rust Lunch
2023-11-08 | Boulder, CO, US | Boulder Rust Meetup
Let's make a Discord bot!
2023-11-14 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer: Share, Show, & Tell! 🦀
2023-11-14 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2023-11-15 | Richmond, VA, US + Virtual | Linux Plumbers Conference
Rust Microconference in LPC 2023 (Nov 13-16)
2023-11-16 | Nashville, TN, US | Music City Rust Developers
Python loves Rust!
2023-11-16 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2023-11-21 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-11-22 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-10-26 | Brisbane, QLD, AU | Rust Brisbane
October Meetup
2023-10-30 | Melbourne, VIC, AU + Virtual | Rust Melbourne
(Hybrid - in person & online) October 2023 Rust Melbourne Meetup
2023-11-21 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
When your Rust build times get slower after adding some procedural macros:
We call that the syn tax :ferris:
– Janet on Fosstodon
Thanks to Jacob Pratt for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
9 notes
·
View notes
Text
Computer Language
Computer languages, also known as programming languages, are formal languages used to communicate instructions to a computer. These instructions are written in a syntax that computers can understand and execute. There are numerous programming languages, each with its own syntax, semantics, and purpose. Here are some of the main types of programming languages:
1.Low-Level Languages:
Machine Language: This is the lowest level of programming language, consisting of binary code (0s and 1s) that directly corresponds to instructions executed by the computer's hardware. It is specific to the computer's architecture.
Assembly Language: Assembly language uses mnemonic codes to represent machine instructions. It is a human-readable form of machine language and closely tied to the computer's hardware architecture
2.High-Level Languages:
Procedural Languages: Procedural languages, such as C, Pascal, and BASIC, focus on defining sequences of steps or procedures to perform tasks. They use constructs like loops, conditionals, and subroutines.
Object-Oriented Languages: Object-oriented languages, like Java, C++, and Python, organize code around objects, which are instances of classes containing data and methods. They emphasize concepts like encapsulation, inheritance, and polymorphism.
Functional Languages: Functional languages, such as Haskell, Lisp, and Erlang, treat computation as the evaluation of mathematical functions. They emphasize immutable data and higher-order functions.
Scripting Languages: Scripting languages, like JavaScript, PHP, and Ruby, are designed for automating tasks, building web applications, and gluing together different software components. They typically have dynamic typing and are interpreted rather than compiled.
Domain-Specific Languages (DSLs): DSLs are specialized languages tailored to a specific domain or problem space. Examples include SQL for database querying, HTML/CSS for web development, and MATLAB for numerical computation.
3.Other Types:
Markup Languages: Markup languages, such as HTML, XML, and Markdown, are used to annotate text with formatting instructions. They are not programming languages in the traditional sense but are essential for structuring and presenting data.
Query Languages: Query languages, like SQL (Structured Query Language), are used to interact with databases by retrieving, manipulating, and managing data.
Constraint Programming Languages: Constraint programming languages, such as Prolog, focus on specifying constraints and relationships among variables to solve combinatorial optimization problems.
2 notes
·
View notes
Text
Best data extraction services in USA
In today's fiercely competitive business landscape, the strategic selection of a web data extraction services provider becomes crucial. Outsource Bigdata stands out by offering access to high-quality data through a meticulously crafted automated, AI-augmented process designed to extract valuable insights from websites. Our team ensures data precision and reliability, facilitating decision-making processes.
For more details, visit: https://outsourcebigdata.com/data-automation/web-scraping-services/web-data-extraction-services/.
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered IT & digital transformation projects, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
-An ISO 9001:2015 and ISO/IEC 27001:2013 certified -Served 750+ customers -11+ Years of industry experience -98% client retention -Great Place to Work® certified -Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform APISCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations: USA: 1-30235 14656 Canada: +1 4378 370 063 India: +91 810 527 1615 Australia: +61 402 576 615 Email: [email protected]
2 notes
·
View notes
Text
monday.com - seamless solution to all your marketing project
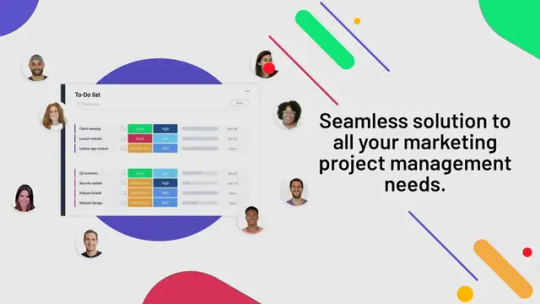
Quick Summary:Are your campaigns truly driving enough sales opportunities? Do you possess sufficient insights into the performance of your campaigns? Can you make informed strategic decisions based on the success rate of your previous endeavors? These are the pressing questions that marketers grapple with today. Thankfully, a tool like monday.com offers a seamless solution to all your marketing project management needs.
What monday.com Brings to the Table?
Marketing teams bear the responsibility of managing a wide range of tasks, from defining and overseeing the brand to devising effective content strategies, digital asset management, product marketing, creative requests, social media monitoring, and driving SEO, among others. monday.com steps in to provide the visibility necessary for monitoring every marketing endeavor, be it a campaign, a social media post, or a customer interaction.
Implementing a marketing project management tool like monday.com allows for efficient management and execution of marketing activities. Let's delve into the top ten tips for using monday.com in your marketing project management:
1. Get everyone on board
To fully utilize the innovative potential of monday.com, ensure that your marketing teams embrace the platform. Educate and train them on the importance and benefits of using monday.com, addressing any concerns or reservations they may have.
2. Choose the right template
monday.com offers a diverse selection of pre-designed templates to cater to different marketing project management needs, ranging from content planning to campaign tracking, editorial calendars, and competitor analysis, enabling you to kickstart your projects promptly while saving valuable time and resources.
3. Utilize calendars for planning and tracking
monday.com enables you to customize calendars to suit unique use cases. Add action items, color-code activities, drag and drop tasks, assign priorities, delegate authority, and more.
4. Visualize campaign planning
With monday.com, group campaigns by type, label them as needed, sort them by significance, and keep everyone in sync with automated notifications for scheduled, delayed, or completed campaigns.
5. Leverage request forms for data collection
Take advantage of monday.com's request forms to gather all the information you need about customers, campaigns, and more. Share form links with other team members or embed them into your website, ensuring that responses populate automatically into respective boards.
6. Enable contextual annotations for streamlined feedback
To streamline the review process, activate contextual annotations on monday.com which eliminates the need for back-and-forth communication. Store all comments and edits directly within your images and videos. It ensures that your teams stay aligned at all times.
7. Stay updated with the latest file versions
Avoid the challenge of keeping your teams informed about the latest file versions. monday.com allows you to store every iteration in a coherent timeline, eliminating the complexity of file updates. Add new versions as you work and easily identify the latest version with a simple glance.
8. Efficiently track and manage activities across all platforms
With marketing teams engaged in numerous campaigns across various platforms and regions, monday.com provides an intuitive platform to manage, track, and organize the results of each campaign. Utilize the platform to monitor campaign progress, performance, as well as the time and money invested in each initiative.
9. Integrate with existing tools
By integrating monday.com with the tools you already use, you can eliminate the time wasted switching between different apps. Connect the platform with apps and platforms such as HubSpot, Facebook Ads, Mailchimp, SEMrush, Adobe Creative Cloud, and more, reducing the time spent on achieving desired results.
10. Leverage automation
monday.com offers extensive automation capabilities, allowing you to save time on repetitive and mundane tasks. Set up rules to handle common tasks and streamline daily workflows. Trigger actions on one board based on activities on another board, or create custom combinations tailored to your unique needs.
In-Conclusion: While marketing project management may initially appear complex and cumbersome, by leveraging monday.com's remarkable features, including boards, views, dashboards, and automation, you can swiftly establish efficient workflows and connect all the dots across your marketing organization.
Curtesy: Screenshot Source | monday.com
For more Information
Visit our website:
amrutsoftware.com / amrutsoftware.ae
2 notes
·
View notes
Text
ChatGPT and Machine Learning: Advancements in Conversational AI

Introduction: In recent years, the field of natural language processing (NLP) has witnessed significant advancements with the development of powerful language models like ChatGPT. Powered by machine learning techniques, ChatGPT has revolutionized conversational AI by enabling human-like interactions with computers. This article explores the intersection of ChatGPT and machine learning, discussing their applications, benefits, challenges, and future prospects.
The Rise of ChatGPT: ChatGPT is an advanced language model developed by OpenAI that utilizes deep learning algorithms to generate human-like responses in conversational contexts. It is based on the underlying technology of GPT (Generative Pre-trained Transformer), a state-of-the-art model in NLP, which has been fine-tuned specifically for chat-based interactions.
How ChatGPT Works: ChatGPT employs a technique called unsupervised learning, where it learns from vast amounts of text data without explicit instructions or human annotations. It utilizes a transformer architecture, which allows it to process and generate text in a parallel and efficient manner.
The model is trained using a massive dataset and learns to predict the next word or phrase given the preceding context.
Applications of ChatGPT: Customer Support: ChatGPT can be deployed in customer service applications, providing instant and personalized assistance to users, answering frequently asked questions, and resolving common issues.
Virtual Assistants: ChatGPT can serve as intelligent virtual assistants, capable of understanding and responding to user queries, managing calendars, setting reminders, and performing various tasks.
Content Generation: ChatGPT can be used for generating content, such as blog posts, news articles, and creative writing, with minimal human intervention.
Language Translation: ChatGPT's language understanding capabilities make it useful for real-time language translation services, breaking down barriers and facilitating communication across different languages.
Benefits of ChatGPT: Enhanced User Experience: ChatGPT offers a more natural and interactive conversational experience, making interactions with machines feel more human-like.
Increased Efficiency: ChatGPT automates tasks that would otherwise require human intervention, resulting in improved efficiency and reduced response times.
Scalability: ChatGPT can handle multiple user interactions simultaneously, making it scalable for applications with high user volumes.
Challenges and Ethical Considerations: Bias and Fairness: ChatGPT's responses can sometimes reflect biases present in the training data, highlighting the importance of addressing bias and ensuring fairness in AI systems.
Misinformation and Manipulation: ChatGPT's ability to generate realistic text raises concerns about the potential spread of misinformation or malicious use. Ensuring the responsible deployment and monitoring of such models is crucial.
Future Directions: Fine-tuning and Customization: Continued research and development aim to improve the fine-tuning capabilities of ChatGPT, enabling users to customize the model for specific domains or applications.
Ethical Frameworks: Efforts are underway to establish ethical guidelines and frameworks for the responsible use of conversational AI models like ChatGPT, mitigating potential risks and ensuring accountability.
Conclusion: In conclusion, the emergence of ChatGPT and its integration into the field of machine learning has opened up new possibilities for human-computer interaction and natural language understanding. With its ability to generate coherent and contextually relevant responses, ChatGPT showcases the advancements made in language modeling and conversational AI.
We have explored the various aspects and applications of ChatGPT, including its training process, fine-tuning techniques, and its contextual understanding capabilities. Moreover, the concept of transfer learning has played a crucial role in leveraging the model's knowledge and adapting it to specific tasks and domains.
While ChatGPT has shown remarkable progress, it is important to acknowledge its limitations and potential biases. The continuous efforts by OpenAI to gather user feedback and refine the model reflect their commitment to improving its performance and addressing these concerns. User collaboration is key to shaping the future development of ChatGPT and ensuring it aligns with societal values and expectations.
The integration of ChatGPT into various applications and platforms demonstrates its potential to enhance collaboration, streamline information gathering, and assist users in a conversational manner. Developers can harness the power of ChatGPT by leveraging its capabilities through APIs, enabling seamless integration and expanding the reach of conversational AI.
Looking ahead, the field of machine learning and conversational AI holds immense promise. As ChatGPT and similar models continue to evolve, the focus should remain on user privacy, data security, and responsible AI practices. Collaboration between humans and machines will be crucial, as we strive to develop AI systems that augment human intelligence and provide valuable assistance while maintaining ethical standards.
With further advancements in training techniques, model architectures, and datasets, we can expect even more sophisticated and context-aware language models in the future. As the dialogue between humans and machines becomes more seamless and natural, the potential for innovation and improvement in various domains is vast.
In summary, ChatGPT represents a significant milestone in the field of machine learning, bringing us closer to human-like conversation and intelligent interactions. By harnessing its capabilities responsibly and striving for continuous improvement, we can leverage the power of ChatGPT to enhance user experiences, foster collaboration, and push the boundaries of what is possible in the realm of artificial intelligence.
2 notes
·
View notes
Text
Annotation Isn’t Just a Step — It’s the Foundation of Smart Enterprise AI.

You’ve invested in AI. You’ve got the tools, the talent, and the tech. But here’s the hard truth: even the best AI models are useless without one crucial ingredient high-quality data annotation.
Think about it. Your enterprise collects massive volumes of raw data daily emails, videos, images, voice notes. But without structure or labeling, it’s just digital noise. No matter how advanced your systems are, they can’t learn from data they don’t understand.
Data annotation turns this unstructured chaos into smart, actionable insights. It’s the silent engine that powers everything from fraud detection to personalized shopping experiences.
Why Data Annotation Is a Game-Changer for Large Enterprises
Here’s where it gets serious: 80% of AI-ML projects fail. And one of the main reasons? Poor or missing data annotation.
For enterprises that rely on Top Retail IT Solutions to personalize customer journeys or predict demand having poorly labeled data can directly lead to lost revenue and missed opportunities. Your AI can’t make accurate decisions if it’s learning from incomplete or messy data.
Now imagine using clearly annotated data — your systems can recommend the right products, adjust pricing in real-time, and even predict maintenance needs in manufacturing. It’s not magic, it’s just better labeling done right.
And it doesn’t stop at retail. In healthcare, Custom Healthcare Software Development Services are powered by annotated medical images that help AI detect diseases earlier and more accurately. The impact? Lives saved, costs reduced, and smarter decisions at every level.
So, What’s the Secret to Getting It Right?
You need more than just tools—you need people and processes. Enter: Data Annotation Automation Engineers. These professionals streamline the labeling process using AI-assisted methods like active learning, rules-based systems, and smart automation. This ensures your models learn faster and better — while you save time and money.
But automation alone isn’t enough. You also need a trusted partner who understands your industry’s unique needs. Whether you’re in healthcare, finance, or retail — the right provider will deliver domain-specific, secure, and regulation-compliant data annotations.
They’ll bring quality control, data security, and industry expertise — ensuring your AI outputs are reliable and future-ready.
Real Business Impact: Where the Magic Happens
Let’s paint the picture:
Retail brands are using annotated customer data to personalize experiences and increase sales.
Hospitals are detecting tumors earlier using AI trained on labeled X-rays.
Banks are reducing fraud by training AI with tagged transactions.
Factories are spotting defects before they cost you.
These are not “future goals” — these are real, happening now, and driven by smart data annotation.
Ready to See What AI Can Really Do?
At AQe Digital, we help large enterprises turn chaotic raw data into structured gold. Whether you’re starting fresh or already working with data annotation in-house, our services are built to scale with your business and align with your AI goals.
Want faster time-to-market? Smarter decisions? Better customer experiences?
Let’s make your data annotation strategy work harder for you.
Think your AI is ready? Think again.
Without proper data annotation, even the best models fail.
See how leading enterprises are solving this and gaining a serious edge.
🧠 Read the full blog
#AIForBusiness#DataAnnotation#EnterpriseAI#MachineLearningModels#RetailITSolutions#HealthcareAI#DataDrivenDecisions#SmartDataSolutions#AITransformation#CustomSoftwareDevelopment
1 note
·
View note
Text
0 notes
Text
Data Annotation vs Data Labeling: What Really Matters for Scalable, Enterprise-Grade AI Systems?
What’s the real difference between data annotation and data labeling? For most AI professionals, the terms are often used interchangeably—but for enterprise-grade systems, these subtle distinctions can impact scalability, accuracy, and overall performance. This blog breaks it all down.

Data Annotation vs Data Labeling: Key Differences
The blog begins by comparing the two concepts based on:
Conceptual foundation: Annotation adds context; labeling tags data
Process complexity: Annotation often requires deeper interpretation
Technical implementation: Varies with tools, model types, and formats
Applications: Labeling suits classification tasks; annotation supports richer models (like NLP and computer vision)
Understanding the Key Difference: Medical Imaging Use Case
A real-world example in medical imaging helps clarify how annotation enables diagnostic AI by capturing detailed insights beyond simple tags.
When the Difference Matters—And When It Doesn’t
Matters: In high-stakes AI (e.g., healthcare, autonomous driving), where context is vital
Doesn’t matter: In simpler classification tasks where labeling alone is sufficient
Key Factors for Scalable, Enterprise AI
The blog emphasizes enterprise considerations:
Data quality and consistency
Scalability and automation
Domain expertise for high accuracy
Ethical handling and bias mitigation
ML-Readiness: The True Success Metric
Ultimately, successful AI systems depend on how well the data is prepared—not just labeled or annotated, but made machine-learning ready.
For enterprises scaling AI, understanding these nuances helps build smarter, more reliable systems. Read the full blog to explore practical strategies and expert insights.
Read More: https://www.damcogroup.com/blogs/data-annotation-vs-data-labeling
0 notes
Link
0 notes
Text
Meta’s $14 Billion Bet on Scale AI Redefines the AI Data Race

Source: www.deccanchronicle.com
In a strategic move to boost its artificial intelligence capabilities, Meta has invested $14.3 billion in Scale AI, acquiring a 49% stake in the data labeling company. This marks one of the largest AI-related investments by the tech giant to date. As part of the deal, Scale AI founder Alexandr Wang will join Meta to lead a newly formed superintelligence lab focused on developing artificial general intelligence (AGI).
Meta’s motivation stems from its need to access high-quality training datasets—an area where it has lagged behind competitors such as OpenAI and Google. Its latest large language model, Llama 4, failed to make a strong impact due to underwhelming performance in coding and contextual understanding. With Scale AI’s expertise and vast network of human annotators, Meta aims to close this data quality gap and improve the performance of its future AI models.
The partnership gives Meta access to Scale AI’s global data operations, including teams across Kenya, the Philippines, and Venezuela that manually annotate complex datasets. The immediate consequence of this deal has been a disruption in the market—Google, OpenAI, and xAI have either paused or scaled down their projects with Scale AI, potentially handing Meta a significant competitive advantage.
Disrupting the Market and Shifting Supply Chains
Scale AI has carved a niche by offering end-to-end data services—from labeling and synthetic data generation to model evaluation—supported by a workforce that includes PhD-level talent. This expertise enables the company to provide highly accurate datasets for specialized fields such as healthcare, finance, and legal services.
Meta’s move effectively reshapes the AI data services market. With many of Scale AI’s high-profile clients now seeking alternatives, competitors like iMerit and Snorkel AI are poised to benefit. iMerit offers deep domain knowledge in fields such as geospatial mapping and healthcare, while Snorkel AI focuses on automated data labeling, potentially reducing reliance on human annotators.
By aligning closely with Scale AI, Meta not only gains exclusive access to premium data services but also secures strategic advantages in sectors beyond consumer tech. Scale AI’s ties to U.S. government contracts may allow Meta to expand into federal defense and security applications—areas previously untouched by the company.
Scale AI:Technical Synergy and Enterprise Implications Unveiled
Alexandr Wang will now head Meta’s superintelligence lab, bringing with him a team of 50 researchers and significant domain expertise. The lab will focus on AGI development, while Meta continues to invest heavily in AI infrastructure through 2025. Scale AI’s platform, which supports multimodal data processing and robust quality assurance systems, is expected to significantly enhance Meta’s training capabilities.
The deal structure also avoids full regulatory scrutiny by keeping Scale AI as an independent entity, mirroring similar strategies used by Microsoft with OpenAI and Amazon with Anthropic. This approach grants Meta operational control without triggering antitrust barriers.
For enterprises, Meta’s bold investment serves as a wake-up call. High-quality data—not just cutting-edge algorithms—is now the key differentiator in AI success. The growing complexity of AI models demands sophisticated data preparation, making reliable labeling infrastructure a critical strategic asset.
In sum, Meta’s $14.3 billion investment in Scale AI is a calculated step to overcome its biggest limitation in the AI race: limited access to diverse and accurate training data. Whether this partnership will lead to a dominant position in the evolving AI landscape depends on how well Meta integrates Scale AI’s capabilities into its broader R&D ecosystem.
Read Also: Top AI Companies: Leading the Charge in Artificial Intelligence
0 notes