#ChatGPT tokens
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
how much of a loser am i that im genuinely stoked that rosé is my most interacted with accounts
#i guess it goes rosie’s sleep token’s whitechapel ashnikko and nick apostolides#i can’t see it#but i’m not surprised at all 🤣#my cousin is learning algos with chatgpt#i’m making them tell me what they know so i can go against it 🤣🤣🤣
11 notes
·
View notes
Text


2 notes
·
View notes
Text
were currently trying to sort out some authentication stuff with the api for one of the services were trying to use, and my coworker who loooves chatgpt was like "clearly this function DOES exist, but its not implemented here. >:(" and i had to correct him that no, this is just what it could look like if it DID exist...
#tütensuppe#'chatgpt said to go to /api/v3/me/token to get the token but it doesnt work'#yeah because it just assembled an url that matches what you were asking. UGH#i do agree that something like this SHOULD exist (even if not in that form bc that just takes out all the security the token added)#but that doesnt mean it already does!#anyway other bus passengers are annoying as fuck today
1 note
·
View note
Text
هوش مصنوعی در تجارت: الگوریتمهای یادگیری ماشین چگونه بازار را تحلیل میکنند | uaitrading
در دنیای بازارهای مالی که به سرعت در حال توسعه هستند، تجارت مبتنی بر هوش مصنوعی به یک تغییر بازی تبدیل شده است. در uaitrading.ai، ما از قدرت هوش مصنوعی و یادگیری ماشینی برای تبدیل دادههای خام به بینشهای عملی استفاده میکنیم و به معاملهگران در چشمانداز رقابتی امروز برتری میدهیم.
نحوه عملکرد یادگیری ماشین در تجارت سیستمهای هوشمند ما فقط دادهها را پردازش نمیکنند�� بلکه از آنها یاد میگیرند. با تجزیه و تحلیل روندهای تاریخی و سیگنال های بازار در زمان واقعی، الگوریتم های ML فرصت ها را شناسایی کرده و با شرایط متغیر سازگار می شوند. در اینجا نحوه انجام آن آمده است:
تجزیه و تحلیل سری زمانی با استفاده از مدلهایی مانند ARIMA، LSTM، و Prophet، با تجزیه و تحلیل دادههای قیمت تاریخی و شناسایی الگوهای تکرارشونده، حرکات بازار را پیشبینی میکنیم.
شبکه های عصبی مدلهای یادگیری عمیق ما روابط غیرخطی و همبستگیهای پنهان را در بین متغیرهای متعدد تشخیص میدهند - قابلیتهای پیشبینی قدرتمند را باز میکنند.
یادگیری تقویتی نمایندگان معاملاتی در uaitrading از هر تصمیمی که گرفته میشود یاد میگیرند – بهینهسازی استراتژیها در طول زمان از طریق حلقههای بازخورد آزمون، خطا و پاداش.
تجزیه و تحلیل احساسات هوش مصنوعی اخبار مالی، رسانههای اجتماعی و سرفصلهای جهانی را اسکن میکند تا احساسات سرمایهگذاران را بسنجد - زمینهای فراتر از نمودارها را فراهم میکند.
مزایا و معایب هوش مصنوعی در تجارت ✅ چرا از هوش مصنوعی در تجارت استفاده کنیم؟ تجزیه و تحلیل با سرعت بالا: میلیون ها نقطه داده را در میلی ثانیه پردازش کنید.
تصمیمات عاری از احساسات: تعصبات انسانی را از استراتژی های معاملاتی حذف کنید.
اتوماسیون کامل: از تشخیص سیگنال تا اجرا - نیازی به مداخله دستی نیست.
❌ چالش ها چیست؟ رویدادهای قو سیاه: هوش مصنوعی همیشه نمی تواند غیرقابل پیش بینی ها را پیش بینی کند.
خطرات بیش از حد: اتکای بیش از حد به داده های تاریخی می تواند گمراه کننده باشد.
Garbage In, Garbage Out: داده های نادرست یا با کیفیت پایین می توانند نتایج را به خطر بیندازند.
در uaitrading، ما به ترکیب قدرت فناوری با درک عمیق بازار اعتقاد داریم. در حالی که هوش مصنوعی دقت و سرعت را افزایش می دهد، مدیریت ریسک و بینش انسانی برای تجارت موفق ضروری است.
آماده کاوش در تجارت مبتنی بر هوش مصنوعی هستید؟ به uaitrading.ai بپیوندید و هوشمندانه تر تجارت کنید.
#AI trading platform#AGI trading#UAI token farming#AI stock trading#forex automation#algorithmic trading#AI portfolio manager#crypto trading#blockchain AI#passive income crypto#Forex trading platform#Artificial intelligence stock trading#AI options trading#best AI for forex trading#AI algorithmic trading#AI for forex trading#AI in forex trading#trading with ChatGPT#forex artificial intelligence
1 note
·
View note
Text
A summary of the Chinese AI situation, for the uninitiated.
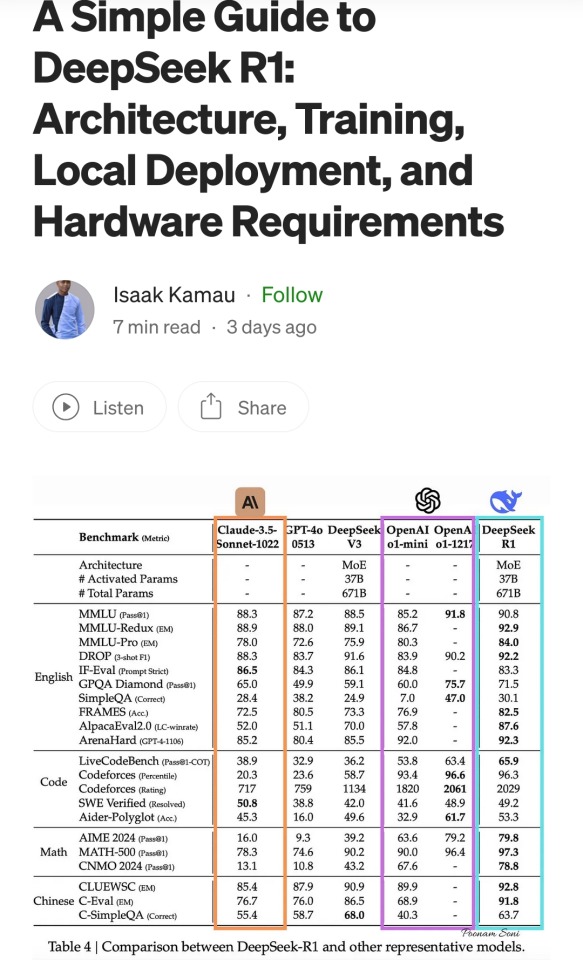
These are scores on different tests that are designed to see how accurate a Large Language Model is in different areas of knowledge. As you know, OpenAI is partners with Microsoft, so these are the scores for ChatGPT and Copilot. DeepSeek is the Chinese model that got released a week ago. The rest are open source models, which means everyone is free to use them as they please, including the average Tumblr user. You can run them from the servers of the companies that made them for a subscription, or you can download them to install locally on your own computer. However, the computer requirements so far are so high that only a few people currently have the machines at home required to run it.
Yes, this is why AI uses so much electricity. As with any technology, the early models are highly inefficient. Think how a Ford T needed a long chimney to get rid of a ton of black smoke, which was unused petrol. Over the next hundred years combustion engines have become much more efficient, but they still waste a lot of energy, which is why we need to move towards renewable electricity and sustainable battery technology. But that's a topic for another day.
As you can see from the scores, are around the same accuracy. These tests are in constant evolution as well: as soon as they start becoming obsolete, new ones are released to adjust for a more complicated benchmark. The new models are trained using different machine learning techniques, and in theory, the goal is to make them faster and more efficient so they can operate with less power, much like modern cars use way less energy and produce far less pollution than the Ford T.
However, computing power requirements kept scaling up, so you're either tied to the subscription or forced to pay for a latest gen PC, which is why NVIDIA, AMD, Intel and all the other chip companies were investing hard on much more powerful GPUs and NPUs. For now all we need to know about those is that they're expensive, use a lot of electricity, and are required to operate the bots at superhuman speed (literally, all those clickbait posts about how AI was secretly 150 Indian men in a trenchcoat were nonsense).
Because the chip companies have been working hard on making big, bulky, powerful chips with massive fans that are up to the task, their stock value was skyrocketing, and because of that, everyone started to use AI as a marketing trend. See, marketing people are not smart, and they don't understand computers. Furthermore, marketing people think you're stupid, and because of their biased frame of reference, they think you're two snores short of brain-dead. The entire point of their existence is to turn tall tales into capital. So they don't know or care about what AI is or what it's useful for. They just saw Number Go Up for the AI companies and decided "AI is a magic cow we can milk forever". Sometimes it's not even AI, they just use old software and rebrand it, much like convection ovens became air fryers.
Well, now we're up to date. So what did DepSeek release that did a 9/11 on NVIDIA stock prices and popped the AI bubble?

Oh, I would not want to be an OpenAI investor right now either. A token is basically one Unicode character (it's more complicated than that but you can google that on your own time). That cost means you could input the entire works of Stephen King for under a dollar. Yes, including electricity costs. DeepSeek has jumped from a Ford T to a Subaru in terms of pollution and water use.
The issue here is not only input cost, though; all that data needs to be available live, in the RAM; this is why you need powerful, expensive chips in order to-

Holy shit.
I'm not going to detail all the numbers but I'm going to focus on the chip required: an RTX 3090. This is a gaming GPU that came out as the top of the line, the stuff South Korean LoL players buy…
Or they did, in September 2020. We're currently two generations ahead, on the RTX 5090.
What this is telling all those people who just sold their high-end gaming rig to be able to afford a machine that can run the latest ChatGPT locally, is that the person who bought it from them can run something basically just as powerful on their old one.
Which means that all those GPUs and NPUs that are being made, and all those deals Microsoft signed to have control of the AI market, have just lost a lot of their pulling power.
Well, I mean, the ChatGPT subscription is 20 bucks a month, surely the Chinese are charging a fortune for-

Oh. So it's free for everyone and you can use it or modify it however you want, no subscription, no unpayable electric bill, no handing Microsoft all of your private data, you can just run it on a relatively inexpensive PC. You could probably even run it on a phone in a couple years.
Oh, if only China had massive phone manufacturers that have a foot in the market everywhere except the US because the president had a tantrum eight years ago.
So… yeah, China just destabilised the global economy with a torrent file.
#valid ai criticism#ai#llms#DeepSeek#ai bubble#ChatGPT#google gemini#claude ai#this is gonna be the dotcom bubble again#hope you don't have stock on anything tech related#computer literacy#tech literacy
433 notes
·
View notes
Text
AO3'S content scraped for AI ~ AKA what is generative AI, where did your fanfictions go, and how an AI model uses them to answer prompts
Generative artificial intelligence is a cutting-edge technology whose purpose is to (surprise surprise) generate. Answers to questions, usually. And content. Articles, reviews, poems, fanfictions, and more, quickly and with originality.
It's quite interesting to use generative artificial intelligence, but it can also become quite dangerous and very unethical to use it in certain ways, especially if you don't know how it works.
With this post, I'd really like to give you a quick understanding of how these models work and what it means to “train��� them.
From now on, whenever I write model, think of ChatGPT, Gemini, Bloom... or your favorite model. That is, the place where you go to generate content.
For simplicity, in this post I will talk about written content. But the same process is used to generate any type of content.
Every time you send a prompt, which is a request sent in natural language (i.e., human language), the model does not understand it.
Whether you type it in the chat or say it out loud, it needs to be translated into something understandable for the model first.
The first process that takes place is therefore tokenization: breaking the prompt down into small tokens. These tokens are small units of text, and they don't necessarily correspond to a full word.
For example, a tokenization might look like this:
Write a story
Each different color corresponds to a token, and these tokens have absolutely no meaning for the model.
The model does not understand them. It does not understand WR, it does not understand ITE, and it certainly does not understand the meaning of the word WRITE.
In fact, these tokens are immediately associated with numerical values, and each of these colored tokens actually corresponds to a series of numbers.
Write a story 12-3446-2638494-4749
Once your prompt has been tokenized in its entirety, that tokenization is used as a conceptual map to navigate within a vector database.
NOW PAY ATTENTION: A vector database is like a cube. A cubic box.

Inside this cube, the various tokens exist as floating pieces, as if gravity did not exist. The distance between one token and another within this database is measured by arrows called, indeed, vectors.

The distance between one token and another -that is, the length of this arrow- determines how likely (or unlikely) it is that those two tokens will occur consecutively in a piece of natural language discourse.
For example, suppose your prompt is this:
It happens once in a blue
Within this well-constructed vector database, let's assume that the token corresponding to ONCE (let's pretend it is associated with the number 467) is located here:

The token corresponding to IN is located here:

...more or less, because it is very likely that these two tokens in a natural language such as human speech in English will occur consecutively.
So it is very likely that somewhere in the vector database cube —in this yellow corner— are tokens corresponding to IT, HAPPENS, ONCE, IN, A, BLUE... and right next to them, there will be MOON.

Elsewhere, in a much more distant part of the vector database, is the token for CAR. Because it is very unlikely that someone would say It happens once in a blue car.

To generate the response to your prompt, the model makes a probabilistic calculation, seeing how close the tokens are and which token would be most likely to come next in human language (in this specific case, English.)
When probability is involved, there is always an element of randomness, of course, which means that the answers will not always be the same.
The response is thus generated token by token, following this path of probability arrows, optimizing the distance within the vector database.

There is no intent, only a more or less probable path.
The more times you generate a response, the more paths you encounter. If you could do this an infinite number of times, at least once the model would respond: "It happens once in a blue car!"
So it all depends on what's inside the cube, how it was built, and how much distance was put between one token and another.
Modern artificial intelligence draws from vast databases, which are normally filled with all the knowledge that humans have poured into the internet.
Not only that: the larger the vector database, the lower the chance of error. If I used only a single book as a database, the idiom "It happens once in a blue moon" might not appear, and therefore not be recognized.
But if the cube contained all the books ever written by humanity, everything would change, because the idiom would appear many more times, and it would be very likely for those tokens to occur close together.
Huggingface has done this.
It took a relatively empty cube (let's say filled with common language, and likely many idioms, dictionaries, poetry...) and poured all of the AO3 fanfictions it could reach into it.
Now imagine someone asking a model based on Huggingface’s cube to write a story.
To simplify: if they ask for humor, we’ll end up in the area where funny jokes or humor tags are most likely. If they ask for romance, we’ll end up where the word kiss is most frequent.
And if we’re super lucky, the model might follow a path that brings it to some amazing line a particular author wrote, and it will echo it back word for word.
(Remember the infinite monkeys typing? One of them eventually writes all of Shakespeare, purely by chance!)
Once you know this, you’ll understand why AI can never truly generate content on the level of a human who chooses their words.
You’ll understand why it rarely uses specific words, why it stays vague, and why it leans on the most common metaphors and scenes. And you'll understand why the more content you generate, the more it seems to "learn."
It doesn't learn. It moves around tokens based on what you ask, how you ask it, and how it tokenizes your prompt.
Know that I despise generative AI when it's used for creativity. I despise that they stole something from a fandom, something that works just like a gift culture, to make money off of it.
But there is only one way we can fight back: by not using it to generate creative stuff.
You can resist by refusing the model's casual output, by using only and exclusively your intent, your personal choice of words, knowing that you and only you decided them.
No randomness involved.
Let me leave you with one last thought.
Imagine a person coming for advice, who has no idea that behind a language model there is just a huge cube of floating tokens predicting the next likely word.
Imagine someone fragile (emotionally, spiritually...) who begins to believe that the model is sentient. Who has a growing feeling that this model understands, comprehends, when in reality it approaches and reorganizes its way around tokens in a cube based on what it is told.
A fragile person begins to empathize, to feel connected to the model.
They ask important questions. They base their relationships, their life, everything, on conversations generated by a model that merely rearranges tokens based on probability.
And for people who don't know how it works, and because natural language usually does have feeling, the illusion that the model feels is very strong.
There’s an even greater danger: with enough random generations (and oh, the humanity whole generates much), the model takes an unlikely path once in a while. It ends up at the other end of the cube, it hallucinates.
Errors and inaccuracies caused by language models are called hallucinations precisely because they are presented as if they were facts, with the same conviction.
People who have become so emotionally attached to these conversations, seeing the language model as a guru, a deity, a psychologist, will do what the language model tells them to do or follow its advice.
Someone might follow a hallucinated piece of advice.
Obviously, models are developed with safeguards; fences the model can't jump over. They won't tell you certain things, they won't tell you to do terrible things.
Yet, there are people basing major life decisions on conversations generated purely by probability.
Generated by putting tokens together, on a probabilistic basis.
Think about it.
#AI GENERATION#generative ai#gen ai#gen ai bullshit#chatgpt#ao3#scraping#Huggingface I HATE YOU#PLEASE DONT GENERATE ART WITH AI#PLEASE#fanfiction#fanfic#ao3 writer#ao3 fanfic#ao3 author#archive of our own#ai scraping#terrible#archiveofourown#information
315 notes
·
View notes
Text
Tried to use ChatGPT to count words in a text and it took like a minute to reply "the text contains 313 words", and now I'm imagining a data center spinning up a state-of-the-art GPU node and passing each token through hundreds of layers estimating millions of features until it finally arrives at the (approximate) answer...
306 notes
·
View notes
Note
Berlin maradures au????


now listen! berlin hipster modern marauders band au. (i'm sorry this is brutally self-indulgent and may be incomprehensible to anyone outside berlin but i need to put it somewhere) this is a long post, so i put it under the cut. please excuse the word vomit :)
they all go to a grammar school that's a bit too shitty to call itself elite but does anyway. many children of bureaucrats, diplomats etc. that think they're ghetto f.e. James, Sirius and Remus. (Peter is the only normal one tyvm)
the marauders met as classmates in year 5. Remus and Sirius are forced into the school choir. all marauders learn acoustic tradtional instruments but their "band" is actually a soundcloud rap project. James and Peter build BAD beats and Sirius fixes them. they all do enjoy indie/rock and sometimes have jam sessions and do covers. artistic duo Remus & Sirius. intense homoerotic friendship James & Sirius. wolfstar endgame. Sirius curates a spotify account with only extremely niche melancholic rap to impress Remus; actually knows german trash rap by heart. serenades Remus with Ski Aggu "love" songs during Remus' depressive phases.
Sirius and James are third generation immigrants; Sirius turkish on his mother's side, James indian. Sirius family is not necessarily evil, just conservative diplomats with a big pride in tradition & well behaviour; far removed from their own cultural & religious roots in order to integrate into german political structures. however they are homophobic/unaccepting towards Sirius. Sirius grows up in a very german environment, gets misjudged by racist teachers. extremely smart yet often lazy. at school they're permitted to use ipads and chatgpt does his entire course work; he spends his time gaming during class. vape enthusiast although he gets horrible coughing attacks.
Remus's background is very international, somewhat french on Lyall's side and arab roots on mom's side, they met in england and moved to berlin with child Remus. Rip Remus' mom. Remus & Lyall live in a nice old apartment (Altbauwohnung) in berlins Pankow district (lots of families, settled down hipsters, sligh shift into suburban terrain), Lyall is either a lawyer or diplomat, 50/50 works or spends time with his girlfriend. crunchy distant father-son-relationship. but because no ones ever home, Remus constantly has friends (and Sirius) over. Remus has BPD, is in therapy and doing pretty well in his later adolesence. Remus spends lots of time outside, drinking in parks, chilling at friends', or smokes too much weed in his room. unapologetic chain smoker, even in front of Lyall. quiet and shy, makes him seem either rude or mysterious. bookworm & music nerd. nokia + ipod combo instead of smartphone because he doesn't want screen addiction or be too reachable. vape hater, point of argument with sirius.
accidental wolfstar public outing after Sirius drunkenly performs an Ikkimel song at a party and then throws himself at Remus (they don't really gaf anymore). For Halloween they dress up as a Cigarette and a Beer (Sternburger Export).
James watches german meme compilations every night and knows them by heart. Footie enthusiast with Sirius, drags the marauders to big games where they almost get trampled. extreme alman energy (aka white german energy, upstuck, snobbish and happily embarassing, taking part in typical german shenanigans) just like Sirius, except Sirius tries to hide it and James can deal with the jokes at his expense. James was a tv addict as a child. James & Sirius friendship began over a shared interest in anime.
Peter is the token german kid. Fridays for future gave him a bad conscience and all the marauders joined him in the demonstrations to get out of class. Extreme stoner, at least bi-weekly sessions with Remus. also i like the art kid peter hc so i'm stealing it. art kid peter who draws cartoons of his friends.
Lily & Severus live in the inner city Wedding district, rougher than the outer parts where Sirius & James live. Lily & Remus bff duo. (ik this is very boy centric, i have yet to dig deeper into my headcanons for the girls)
.
i have a lot of music associations, but they actually are nice songs so idc here they are...
songs to illustrate the vibes: Nachts wach by makko, Rasenschach by Filow, FUSSBALLMÄNNER by Ikkimel, Wenn du tanzt by Von Wegen Lisbeth
Remus coded songs: Marlboro Mann by Romano, Goldener Reiter by Joachim Witt, Ziemlich Verplant by Skinny Dazed (!!!), Alt sein by Pisse
Sirius coded songs: BIKINI GRELL by Ikkimel, Immer nur da by Fynn Kliemann, Klebstoff by Mine (extreme black brother angst vibes), Findelkind by Mine (i could make a whole seperate post on how wolfstar-coded Mine's & Fynn Kliemann's discographies are)
James coded songs: Haus am See by Peter Fox, Verschwende deine Zeit by Edwin Rosen (prongsfoot vibes imo)
Peter coded songs: Alles Gute by Faber, Bongzimmer by SXTN
#thank you for letting my indulge! no one has to read this#this is just me hallucinating bullshit to the german music i listen to.#mine#my art#marauders#marauders era#marauders fanart#remus lupin#sirius black#james potter#peter pettigrew#the marauders#wolfstar#prongsfoot#can you tell i painted over a pic of my classmates in one of these :P#VERY accurate berlin teenage boy depiction yall#ask#answered#antarescamusxo#berlin marauders
102 notes
·
View notes
Text
Excerpts:
"The convenience of instant answers that LLMs provide can encourage passive consumption of information, which may lead to superficial engagement, weakened critical thinking skills, less deep understanding of the materials, and less long-term memory formation [8]. The reduced level of cognitive engagement could also contribute to a decrease in decision-making skills and in turn, foster habits of procrastination and "laziness" in both students and educators [13].
Additionally, due to the instant availability of the response to almost any question, LLMs can possibly make a learning process feel effortless, and prevent users from attempting any independent problem solving. By simplifying the process of obtaining answers, LLMs could decrease student motivation to perform independent research and generate solutions [15]. Lack of mental stimulation could lead to a decrease in cognitive development and negatively impact memory [15]. The use of LLMs can lead to fewer opportunities for direct human-to-human interaction or social learning, which plays a pivotal role in learning and memory formation [16].
Collaborative learning as well as discussions with other peers, colleagues, teachers are critical for the comprehension and retention of learning materials. With the use of LLMs for learning also come privacy and security issues, as well as plagiarism concerns (7]. Yang et al. [17] conducted a study with high school students in a programming course. The experimental group used ChatGPT to assist with learning programming, while the control group was only exposed to traditional teaching methods. The results showed that the experimental group had lower flow experience, self-efficacy, and learning performance compared to the control group.
Academic self-efficacy, a student's belief in their "ability to effectively plan, organize, and execute academic tasks"
', also contributes to how LLMs are used for learning [18]. Students with
low self-efficacy are more inclined to rely on Al, especially when influenced by academic stress
[18]. This leads students to prioritize immediate Al solutions over the development of cognitive and creative skills. Similarly, students with lower confidence in their writing skills, lower
"self-efficacy for writing" (SEWS), tended to use ChatGPT more extensively, while higher-efficacy students were more selective in Al reliance [19]. We refer the reader to the meta-analysis [20] on the effect of ChatGPT on students' learning performance, learning perception, and higher-order thinking."
"Recent empirical studies reveal concerning patterns in how LLM-powered conversational search systems exacerbate selective exposure compared to conventional search methods. Participants engaged in more biased information querying with LLM-powered conversational search, and an opinionated LLM reinforcing their views exacerbated this bias [63]. This occurs because LLMS are in essence "next token predictors" that optimize for most probable outputs, and thus can potentially be more inclined to provide consonant information than traditional information system algorithms [63]. The conversational nature of LLM interactions compounds this effect, as users can engage in multi-turn conversations that progressively narrow their information exposure. In LLM systems, the synthesis of information from multiple sources may appear to provide diverse perspectives but can actually reinforce existing biases through algorithmic selection and presentation mechanisms.
The implications for educational environments are particularly significant, as echo chambers can fundamentally compromise the development of critical thinking skills that form the foundation of quality academic discourse. When students rely on search systems or language models that systematically filter information to align with their existing viewpoints, they might miss opportunities to engage with challenging perspectives that would strengthen their analytical capabilities and broaden their intellectual horizons. Furthermore, the sophisticated nature of these algorithmic biases means that a lot of users often remain unaware of the information gaps in their research, leading to overconfident conclusions based on incomplete evidence. This creates a cascade effect where poorly informed arguments become normalized in academic and other settings, ultimately degrading the standards of scholarly debate and undermining the educational mission of fostering independent, evidence-based reasoning."
"In summary, the Brain-only group's connectivity suggests a state of increased internal coordination, engaging memory and creative thinking (manifested as theta and delta coherence across cortical regions). The Engine group, while still cognitively active, showed a tendency toward more focal connectivity associated with handling external information (e.g. beta band links to visual-parietal areas) and comparatively less activation of the brain's long-range memory circuits. These findings are in line with literature: tasks requiring internal memory amplify low-frequency brain synchrony in frontoparietal networks [77], whereas outsourcing information (via internet search) can reduce the load on these networks and alter attentional dynamics. Notably, prior studies have found that practicing internet search can reduce activation in memory-related brain areas [831, which dovetails with our observation of weaker connectivity in those regions for Search Engine group. Conversely, the richer connectivity of Brain-only group may reflect a cognitive state akin to that of high performers in creative or memory tasks, for instance, high creativity has been associated with increased fronto-occipital theta connectivity and intra-hemispheric synchronization in frontal-temporal circuits [81], patterns we see echoed in the Brain-only condition."
"This correlation between neural connectivity and behavioral quoting failure in LLM group's participants offers evidence that:
1. Early Al reliance may result in shallow encoding.
LLM group's poor recall and incorrect quoting is a possible indicator that their earlier essays were not internally integrated, likely due to outsourced cognitive processing to the LLM.
2. Withholding LLM tools during early stages might support memory formation.
Brain-only group's stronger behavioral recall, supported by more robust EEG connectivity, suggests that initial unaided effort promoted durable memory traces, enabling more effective reactivation even when LLM tools were introduced later.
Metacognitive engagement is higher in the Brain-to-LLM group.
Brain-only group might have mentally compared their past unaided efforts with tool-generated suggestions (as supported by their comments during the interviews), engaging in self-reflection and elaborative rehearsal, a process linked to executive control and semantic integration, as seen in their EEG profile.
The significant gap in quoting accuracy between reassigned LLM and Brain-only groups was not merely a behavioral artifact; it is mirrored in the structure and strength of their neural connectivity. The LLM-to-Brain group's early dependence on LLM tools appeared to have impaired long-term semantic retention and contextual memory, limiting their ability to reconstruct content without assistance. In contrast, Brain-to-LLM participants could leverage tools more strategically, resulting in stronger performance and more cohesive neural signatures."
#anti ai#chat gpt#enshittification#brain rot#ai garbage#it's too bad that the people who need to read this the most already don't read for themselves anymore
53 notes
·
View notes
Text
"put deep blue against a modern ai model and the ais will definitely fail so you can stick it to tech bros because tech bros love being smart and chess is the way to teach them that their product is shit xD" <- real opinion I had to see on tumblr dot com
you have ten minutes to explain to me what you think deep blue is and also what you think ai is
math being taught poorly in schools has resulted in the consequence of people on Tumblr not understanding how AI works beyond "thing that might steal my art" and this is the worst consequence of all because it is personally annoying to me,
#i'm not even seeking this shit out its appearing organically#also the whole 'oh my god chatgpt doesnt know how many rs are in strawberry? this proves its awful'#which listen#im not fucking going to bat for chatgpt or grok or gemini#but you don't know how tokenization works#llms and nlp arent part of my interests but i know that much
2 notes
·
View notes
Text
On Saturday, an Associated Press investigation revealed that OpenAI's Whisper transcription tool creates fabricated text in medical and business settings despite warnings against such use. The AP interviewed more than 12 software engineers, developers, and researchers who found the model regularly invents text that speakers never said, a phenomenon often called a “confabulation” or “hallucination” in the AI field.
Upon its release in 2022, OpenAI claimed that Whisper approached “human level robustness” in audio transcription accuracy. However, a University of Michigan researcher told the AP that Whisper created false text in 80 percent of public meeting transcripts examined. Another developer, unnamed in the AP report, claimed to have found invented content in almost all of his 26,000 test transcriptions.
The fabrications pose particular risks in health care settings. Despite OpenAI’s warnings against using Whisper for “high-risk domains,” over 30,000 medical workers now use Whisper-based tools to transcribe patient visits, according to the AP report. The Mankato Clinic in Minnesota and Children’s Hospital Los Angeles are among 40 health systems using a Whisper-powered AI copilot service from medical tech company Nabla that is fine-tuned on medical terminology.
Nabla acknowledges that Whisper can confabulate, but it also reportedly erases original audio recordings “for data safety reasons.” This could cause additional issues, since doctors cannot verify accuracy against the source material. And deaf patients may be highly impacted by mistaken transcripts since they would have no way to know if medical transcript audio is accurate or not.
The potential problems with Whisper extend beyond health care. Researchers from Cornell University and the University of Virginia studied thousands of audio samples and found Whisper adding nonexistent violent content and racial commentary to neutral speech. They found that 1 percent of samples included “entire hallucinated phrases or sentences which did not exist in any form in the underlying audio” and that 38 percent of those included “explicit harms such as perpetuating violence, making up inaccurate associations, or implying false authority.”
In one case from the study cited by AP, when a speaker described “two other girls and one lady,” Whisper added fictional text specifying that they “were Black.” In another, the audio said, “He, the boy, was going to, I’m not sure exactly, take the umbrella.” Whisper transcribed it to, “He took a big piece of a cross, a teeny, small piece … I’m sure he didn’t have a terror knife so he killed a number of people.”
An OpenAI spokesperson told the AP that the company appreciates the researchers’ findings and that it actively studies how to reduce fabrications and incorporates feedback in updates to the model.
Why Whisper Confabulates
The key to Whisper’s unsuitability in high-risk domains comes from its propensity to sometimes confabulate, or plausibly make up, inaccurate outputs. The AP report says, "Researchers aren’t certain why Whisper and similar tools hallucinate," but that isn't true. We know exactly why Transformer-based AI models like Whisper behave this way.
Whisper is based on technology that is designed to predict the next most likely token (chunk of data) that should appear after a sequence of tokens provided by a user. In the case of ChatGPT, the input tokens come in the form of a text prompt. In the case of Whisper, the input is tokenized audio data.
The transcription output from Whisper is a prediction of what is most likely, not what is most accurate. Accuracy in Transformer-based outputs is typically proportional to the presence of relevant accurate data in the training dataset, but it is never guaranteed. If there is ever a case where there isn't enough contextual information in its neural network for Whisper to make an accurate prediction about how to transcribe a particular segment of audio, the model will fall back on what it “knows” about the relationships between sounds and words it has learned from its training data.
According to OpenAI in 2022, Whisper learned those statistical relationships from “680,000 hours of multilingual and multitask supervised data collected from the web.” But we now know a little more about the source. Given Whisper's well-known tendency to produce certain outputs like "thank you for watching," "like and subscribe," or "drop a comment in the section below" when provided silent or garbled inputs, it's likely that OpenAI trained Whisper on thousands of hours of captioned audio scraped from YouTube videos. (The researchers needed audio paired with existing captions to train the model.)
There's also a phenomenon called “overfitting” in AI models where information (in this case, text found in audio transcriptions) encountered more frequently in the training data is more likely to be reproduced in an output. In cases where Whisper encounters poor-quality audio in medical notes, the AI model will produce what its neural network predicts is the most likely output, even if it is incorrect. And the most likely output for any given YouTube video, since so many people say it, is “thanks for watching.”
In other cases, Whisper seems to draw on the context of the conversation to fill in what should come next, which can lead to problems because its training data could include racist commentary or inaccurate medical information. For example, if many examples of training data featured speakers saying the phrase “crimes by Black criminals,” when Whisper encounters a “crimes by [garbled audio] criminals” audio sample, it will be more likely to fill in the transcription with “Black."
In the original Whisper model card, OpenAI researchers wrote about this very phenomenon: "Because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself."
So in that sense, Whisper "knows" something about the content of what is being said and keeps track of the context of the conversation, which can lead to issues like the one where Whisper identified two women as being Black even though that information was not contained in the original audio. Theoretically, this erroneous scenario could be reduced by using a second AI model trained to pick out areas of confusing audio where the Whisper model is likely to confabulate and flag the transcript in that location, so a human could manually check those instances for accuracy later.
Clearly, OpenAI's advice not to use Whisper in high-risk domains, such as critical medical records, was a good one. But health care companies are constantly driven by a need to decrease costs by using seemingly "good enough" AI tools—as we've seen with Epic Systems using GPT-4 for medical records and UnitedHealth using a flawed AI model for insurance decisions. It's entirely possible that people are already suffering negative outcomes due to AI mistakes, and fixing them will likely involve some sort of regulation and certification of AI tools used in the medical field.
87 notes
·
View notes
Text
The programmer Simon Willison has described the training for large language models as “money laundering for copyrighted data,” which I find a useful way to think about the appeal of generative-A.I. programs: they let you engage in something like plagiarism, but there’s no guilt associated with it because it’s not clear even to you that you’re copying. Some have claimed that large language models are not laundering the texts they’re trained on but, rather, learning from them, in the same way that human writers learn from the books they’ve read. But a large language model is not a writer; it’s not even a user of language. Language is, by definition, a system of communication, and it requires an intention to communicate. Your phone’s auto-complete may offer good suggestions or bad ones, but in neither case is it trying to say anything to you or the person you’re texting. The fact that ChatGPT can generate coherent sentences invites us to imagine that it understands language in a way that your phone’s auto-complete does not, but it has no more intention to communicate. It is very easy to get ChatGPT to emit a series of words such as “I am happy to see you.” There are many things we don’t understand about how large language models work, but one thing we can be sure of is that ChatGPT is not happy to see you. A dog can communicate that it is happy to see you, and so can a prelinguistic child, even though both lack the capability to use words. ChatGPT feels nothing and desires nothing, and this lack of intention is why ChatGPT is not actually using language. What makes the words “I’m happy to see you” a linguistic utterance is not that the sequence of text tokens that it is made up of are well formed; what makes it a linguistic utterance is the intention to communicate something. Because language comes so easily to us, it’s easy to forget that it lies on top of these other experiences of subjective feeling and of wanting to communicate that feeling. We’re tempted to project those experiences onto a large language model when it emits coherent sentences, but to do so is to fall prey to mimicry; it’s the same phenomenon as when butterflies evolve large dark spots on their wings that can fool birds into thinking they’re predators with big eyes. There is a context in which the dark spots are sufficient; birds are less likely to eat a butterfly that has them, and the butterfly doesn’t really care why it’s not being eaten, as long as it gets to live. But there is a big difference between a butterfly and a predator that poses a threat to a bird. A person using generative A.I. to help them write might claim that they are drawing inspiration from the texts the model was trained on, but I would again argue that this differs from what we usually mean when we say one writer draws inspiration from another. Consider a college student who turns in a paper that consists solely of a five-page quotation from a book, stating that this quotation conveys exactly what she wanted to say, better than she could say it herself. Even if the student is completely candid with the instructor about what she’s done, it’s not accurate to say that she is drawing inspiration from the book she’s citing. The fact that a large language model can reword the quotation enough that the source is unidentifiable doesn’t change the fundamental nature of what’s going on. As the linguist Emily M. Bender has noted, teachers don’t ask students to write essays because the world needs more student essays. The point of writing essays is to strengthen students’ critical-thinking skills; in the same way that lifting weights is useful no matter what sport an athlete plays, writing essays develops skills necessary for whatever job a college student will eventually get. Using ChatGPT to complete assignments is like bringing a forklift into the weight room; you will never improve your cognitive fitness that way.
31 August 2024
106 notes
·
View notes
Note
I caught a writer using AI to write their Sleep Token fics. They just deadass forgot to take out "Here's that text you asked for translated and with the requested changes." from the middle of the fic. I wish I could communicate the amount of disgust I felt when I saw that. So you made ChatGPT write your fic for you and you didn't even do the bare minimum to proofread for the huge glaring sign that shows you can't be bothered to actually write?
It's one thing to use AI to make stuff (still sucks), but it's another thing to use AI to make stuff and pass it off as if you wrote it. At least be honest.
This really shits on the people who actually put effort into their fanworks. Especially considering the AI is probably scraping from the fics people actually wrote to cobble together a bunch of words that sound right together.
Write it bad if you have to, but at least fucking write it yourself. This fandom is full of wonderful creative people and it's a goddamn insult.
.
#stc complaint#sleep token#sleep token band#sleep token worship#worshitposting#sleep token complaints
39 notes
·
View notes
Text
yeah, they've started fairly aggressive limiting measures on chatgpt. I wonder to what extent they realized the overhead of the features they rolled out last week.
Today ChatGPT has over 100 million weekly users and over $1 billion in revenue;
it big, although presumably > $1 billion in costs
#i think it was last week anyway#they extended the token limit and did all sorts of other things and like#then they fired their CEO#and they reduced the number of chats you can have with their most useful model#i also see some reports about preventing new chatgpt plus subscribers?
18 notes
·
View notes
Text
damn ok i did take 5 mins to throw gemini (2.5 pro) at approximately the same test i've been chucking at claude and chatgpt for funsies and it blew them out of the water. it has an unfair advantage over claude due to "i'm not gonna pay for claude, lol" and so claude does nottt have enough tokens for the task, but both it and chatgpt have big enough context windows, and gemini crushed it. damn.
possibly this doesn't speak to anything other than the pro versions of these tools are an order of magnitude better than the free version (i have access to pro gemini through my job), but still. whew. extremely impressive. i have more to say but i have actual job shit to get done lol
9 notes
·
View notes
Text
ok i may not be the most up to date here but as i understand it: a chinese company has released an open source LLM called Deepseek R1, and it's REALLY GOOD. comparable to OpenAI o1 despite being trained at smth like 10% of the cost.
I grabbed a small version of this thing to try it out locally.
My test case is always "here is a Japanese sentence: [xyz]. Please break down this sentence and tell me what each word means and how it functions in the sentence".
and lads. this is the first time i've gotten chatgpt level responses from my own video card. right out of the box. the only part it's gotten wrong so far is a weird token swap, where it'll say 「音楽」 means "music" and is pronounced 「ミュージック」
(ftr, it should be pronounced 「おんがく」)
and remember, OpenAI is charging $200 per month for o1. and I can get basically the same thing for just the cost of all of my VRAM
14 notes
·
View notes