#Hadoop monitoring services Cluster monitoring
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
What are the benefits of Amazon EMR? Drawbacks of AWS EMR

Benefits of Amazon EMR
Amazon EMR has many benefits. These include AWS's flexibility and cost savings over on-premises resource development.
Cost-saving
Amazon EMR costs depend on instance type, number of Amazon EC2 instances, and cluster launch area. On-demand pricing is low, but Reserved or Spot Instances save much more. Spot instances can save up to a tenth of on-demand costs.
Note
Using Amazon S3, Kinesis, or DynamoDB with your EMR cluster incurs expenses irrespective of Amazon EMR usage.
Note
Set up Amazon S3 VPC endpoints when creating an Amazon EMR cluster in a private subnet. If your EMR cluster is on a private subnet without Amazon S3 VPC endpoints, you will be charged extra for S3 traffic NAT gates.
AWS integration
Amazon EMR integrates with other AWS services for cluster networking, storage, security, and more. The following list shows many examples of this integration:
Use Amazon EC2 for cluster nodes.
Amazon VPC creates the virtual network where your instances start.
Amazon S3 input/output data storage
Set alarms and monitor cluster performance with Amazon CloudWatch.
AWS IAM permissions setting
Audit service requests with AWS CloudTrail.
Cluster scheduling and launch with AWS Data Pipeline
AWS Lake Formation searches, categorises, and secures Amazon S3 data lakes.
Its deployment
The EC2 instances in your EMR cluster do the tasks you designate. When you launch your cluster, Amazon EMR configures instances using Spark or Apache Hadoop. Choose the instance size and type that best suits your cluster's processing needs: streaming data, low-latency queries, batch processing, or big data storage.
Amazon EMR cluster software setup has many options. For example, an Amazon EMR version can be loaded with Hive, Pig, Spark, and flexible frameworks like Hadoop. Installing a MapR distribution is another alternative. Since Amazon EMR runs on Amazon Linux, you can manually install software on your cluster using yum or the source code.
Flexibility and scalability
Amazon EMR lets you scale your cluster as your computing needs vary. Resizing your cluster lets you add instances during peak workloads and remove them to cut costs.
Amazon EMR supports multiple instance groups. This lets you employ Spot Instances in one group to perform jobs faster and cheaper and On-Demand Instances in another for guaranteed processing power. Multiple Spot Instance types might be mixed to take advantage of a better price.
Amazon EMR lets you use several file systems for input, output, and intermediate data. HDFS on your cluster's primary and core nodes can handle data you don't need to store beyond its lifecycle.
Amazon S3 can be used as a data layer for EMR File System applications to decouple computation and storage and store data outside of your cluster's lifespan. EMRFS lets you scale up or down to meet storage and processing needs independently. Amazon S3 lets you adjust storage and cluster size to meet growing processing needs.
Reliability
Amazon EMR monitors cluster nodes and shuts down and replaces instances as needed.
Amazon EMR lets you configure automated or manual cluster termination. Automatic cluster termination occurs after all procedures are complete. Transitory cluster. After processing, you can set up the cluster to continue running so you can manually stop it. You can also construct a cluster, use the installed apps, and manually terminate it. These clusters are “long-running clusters.”
Termination prevention can prevent processing errors from terminating cluster instances. With termination protection, you can retrieve data from instances before termination. Whether you activate your cluster by console, CLI, or API changes these features' default settings.
Security
Amazon EMR uses Amazon EC2 key pairs, IAM, and VPC to safeguard data and clusters.
IAM
Amazon EMR uses IAM for permissions. Person or group permissions are set by IAM policies. Users and groups can access resources and activities through policies.
The Amazon EMR service uses IAM roles, while instances use the EC2 instance profile. These roles allow the service and instances to access other AWS services for you. Amazon EMR and EC2 instance profiles have default roles. By default, roles use AWS managed policies generated when you launch an EMR cluster from the console and select default permissions. Additionally, the AWS CLI may construct default IAM roles. Custom service and instance profile roles can be created to govern rights outside of AWS.
Security groups
Amazon EMR employs security groups to control EC2 instance traffic. Amazon EMR shares a security group for your primary instance and core/task instances when your cluster is deployed. Amazon EMR creates security group rules to ensure cluster instance communication. Extra security groups can be added to your primary and core/task instances for more advanced restrictions.
Encryption
Amazon EMR enables optional server-side and client-side encryption using EMRFS to protect Amazon S3 data. After submission, Amazon S3 encrypts data server-side.
The EMRFS client on your EMR cluster encrypts and decrypts client-side encryption. AWS KMS or your key management system can handle client-side encryption root keys.
Amazon VPC
Amazon EMR launches clusters in Amazon VPCs. VPCs in AWS allow you to manage sophisticated network settings and access functionalities.
AWS CloudTrail
Amazon EMR and CloudTrail record AWS account requests. This data shows who accesses your cluster, when, and from what IP.
Amazon EC2 key pairs
A secure link between the primary node and your remote computer lets you monitor and communicate with your cluster. SSH or Kerberos can authenticate this connection. SSH requires an Amazon EC2 key pair.
Monitoring
Debug cluster issues like faults or failures utilising log files and Amazon EMR management interfaces. Amazon EMR can archive log files on Amazon S3 to save records and solve problems after your cluster ends. The Amazon EMR UI also has a task, job, and step-specific debugging tool for log files.
Amazon EMR connects to CloudWatch for cluster and job performance monitoring. Alarms can be set based on cluster idle state and storage use %.
Management interfaces
There are numerous Amazon EMR access methods:
The console provides a graphical interface for cluster launch and management. You may examine, debug, terminate, and describe clusters to launch via online forms. Amazon EMR is easiest to use via the console, requiring no scripting.
Installing the AWS Command Line Interface (AWS CLI) on your computer lets you connect to Amazon EMR and manage clusters. The broad AWS CLI includes Amazon EMR-specific commands. You can automate cluster administration and initialisation with scripts. If you prefer command line operations, utilise the AWS CLI.
SDK allows cluster creation and management for Amazon EMR calls. They enable cluster formation and management automation systems. This SDK is best for customising Amazon EMR. Amazon EMR supports Go, Java,.NET (C# and VB.NET), Node.js, PHP, Python, and Ruby SDKs.
A Web Service API lets you call a web service using JSON. A custom SDK that calls Amazon EMR is best done utilising the API.
Complexity:
EMR cluster setup and maintenance are more involved than with AWS Glue and require framework knowledge.
Learning curve
Setting up and optimising EMR clusters may require adjusting settings and parameters.
Possible Performance Issues:
Incorrect instance types or under-provisioned clusters might slow task execution and other performance.
Depends on AWS:
Due to its deep interaction with AWS infrastructure, EMR is less portable than on-premise solutions despite cloud flexibility.
#AmazonEMR#AmazonEC2#AmazonS3#AmazonVirtualPrivateCloud#EMRFS#AmazonEMRservice#Technology#technews#NEWS#technologynews#govindhtech
0 notes
Text
Essential Elements of Data Science: A Practical Guide
Data science is a transformative field that enables organizations to unlock the potential of their data. Whether you're new to the field or looking to deepen your understanding, it's important to familiarize yourself with the essential elements that make up the data science process. This guide breaks down the key components of data science and their practical applications. With a Data Science Course in Coimbatore, professionals can gain the skills and knowledge needed to harness the capabilities of Data Science for diverse applications and industries.

1. Data Collection: The Foundation of Data Science
Data collection is the starting point in any data science project. It involves gathering data from multiple sources, including databases, APIs, social media platforms, and IoT devices. High-quality data forms the backbone of successful analysis and predictions.
2. Data Cleaning and Preprocessing
Raw data is often riddled with errors, inconsistencies, and missing values. Data cleaning involves removing inaccuracies, filling in missing values, and standardizing formats to prepare the dataset for analysis. This ensures the reliability of insights derived from the data.
3. Exploratory Data Analysis (EDA): Uncovering Insights
EDA is a crucial step where data scientists examine and visualize data to identify patterns, relationships, and anomalies. By using tools like Python's Matplotlib, Seaborn, or Tableau, data scientists can better understand the dataset and inform their next steps.
4. Data Visualization: Communicating Insights
Visualization tools transform complex datasets into easy-to-understand graphics, such as charts and dashboards. This makes it easier to communicate findings to stakeholders and supports data-driven decision-making.
5. Statistical Analysis: Building the Analytical Base
Statistics form the foundation of data science. Key techniques, including hypothesis testing, regression analysis, and probability modeling, enable data scientists to draw conclusions and quantify the likelihood of various outcomes. To master the intricacies of Data Science and unlock its full potential, individuals can benefit from enrolling in the Data Science Certification Online Training.

6. Machine Learning: Turning Data into Predictions
Machine learning algorithms help identify patterns and make predictions from data. Supervised learning (e.g., classification and regression), unsupervised learning (e.g., clustering), and deep learning are powerful techniques used across industries like healthcare, finance, and retail.
7. Big Data Tools: Handling Massive Datasets
As data volumes grow, leveraging big data tools like Hadoop, Apache Spark, and cloud computing becomes essential. These technologies allow data scientists to process and analyze vast datasets efficiently.
8. Programming for Data Science: Essential Skills
Programming languages like Python and R are indispensable for data manipulation, analysis, and building machine learning models. SQL is equally important for querying and managing structured data in relational databases.
9. Cloud Computing: Scalability and Flexibility
Cloud platforms like AWS, Google Cloud, and Microsoft Azure provide scalable storage and processing capabilities. These services make it easier to manage resources, collaborate, and deploy models in production.
10. Domain Knowledge: Contextualizing the Data
Understanding the specific industry or domain is crucial to ensure that data science solutions address real-world challenges. Domain expertise helps data scientists apply the right techniques and interpret results meaningfully.
11. Data Ethics and Privacy: Ensuring Responsible Use
With data science comes great responsibility. Adhering to ethical principles and privacy regulations, such as GDPR, is vital to protect user data and build trust. Responsible data use promotes transparency and accountability in analytics.
12. Model Deployment and Monitoring: Delivering Actionable Results
Once a model is built, it needs to be deployed to deliver real-world insights. Continuous monitoring ensures that the model adapts to new data and remains accurate over time. This step bridges the gap between analysis and practical implementation.
Practical Applications of Data Science
Healthcare: Predicting patient outcomes, diagnosing diseases, and optimizing treatments.
Finance: Fraud detection, risk management, and investment analysis.
Retail: Personalizing customer experiences, inventory management, and sales forecasting.
Marketing: Targeted campaigns, customer segmentation, and sentiment analysis.
Conclusion
Data science is a multifaceted discipline that integrates data collection, analysis, machine learning, and domain expertise to solve complex problems. By mastering these essential elements, professionals can unlock the true potential of data and create meaningful impact across industries. Whether you're starting your data science journey or advancing your career, understanding and applying these components will help you succeed in this dynamic field.
#data science#data science course#data science training#data science certification#data science career#data science online course
0 notes
Text
A good understanding of Hadoop Architecture is required to leverage the power of Hadoop. Below are few important practical questions which can be asked to a Senior Experienced Hadoop Developer in an interview. I learned the answers to them during my CCHD (Cloudera Certified Haddop Developer) certification. I hope you will find them useful. This list primarily includes questions related to Hadoop Architecture, MapReduce, Hadoop API and Hadoop Distributed File System (HDFS). Hadoop is the most popular platform for big data analysis. The Hadoop ecosystem is huge and involves many supporting frameworks and tools to effectively run and manage it. This article focuses on the core of Hadoop concepts and its technique to handle enormous data. Hadoop is a huge ecosystem and referring to a good hadoop book is highly recommended. Below list of hadoop interview questions and answers that may prove useful for beginners and experts alike. These are common set of questions that you may face at big data job interview or a hadoop certification exam (like CCHD). What is a JobTracker in Hadoop? How many instances of JobTracker run on a Hadoop Cluster? JobTracker is the daemon service for submitting and tracking MapReduce jobs in Hadoop. There is only One Job Tracker process run on any hadoop cluster. Job Tracker runs on its own JVM process. In a typical production cluster its run on a separate machine. Each slave node is configured with job tracker node location. The JobTracker is single point of failure for the Hadoop MapReduce service. If it goes down, all running jobs are halted. JobTracker in Hadoop performs following actions(from Hadoop Wiki:) Client applications submit jobs to the Job tracker. The JobTracker talks to the NameNode to determine the location of the data The JobTracker locates TaskTracker nodes with available slots at or near the data The JobTracker submits the work to the chosen TaskTracker nodes. The TaskTracker nodes are monitored. If they do not submit heartbeat signals often enough, they are deemed to have failed and the work is scheduled on a different TaskTracker. A TaskTracker will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job elsewhere, it may mark that specific record as something to avoid, and it may may even blacklist the TaskTracker as unreliable. When the work is completed, the JobTracker updates its status. Client applications can poll the JobTracker for information. How JobTracker schedules a task? The TaskTrackers send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive. These message also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated. When the JobTracker tries to find somewhere to schedule a task within the MapReduce operations, it first looks for an empty slot on the same server that hosts the DataNode containing the data, and if not, it looks for an empty slot on a machine in the same rack. What is a Task Tracker in Hadoop? How many instances of TaskTracker run on a Hadoop Cluster A TaskTracker is a slave node daemon in the cluster that accepts tasks (Map, Reduce and Shuffle operations) from a JobTracker. There is only One Task Tracker process run on any hadoop slave node. Task Tracker runs on its own JVM process. Every TaskTracker is configured with a set of slots, these indicate the number of tasks that it can accept. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. The TaskTracker monitors these task instances, capturing the output and exit codes. When the Task instances finish, successfully or not, the task tracker notifies the JobTracker. The TaskTrackers also send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive.
These message also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated. What is a Task instance in Hadoop? Where does it run? Task instances are the actual MapReduce jobs which are run on each slave node. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. Each Task Instance runs on its own JVM process. There can be multiple processes of task instance running on a slave node. This is based on the number of slots configured on task tracker. By default a new task instance JVM process is spawned for a task. How many Daemon processes run on a Hadoop system? Hadoop is comprised of five separate daemons. Each of these daemon run in its own JVM. Following 3 Daemons run on Master nodes NameNode - This daemon stores and maintains the metadata for HDFS. Secondary NameNode - Performs housekeeping functions for the NameNode. JobTracker - Manages MapReduce jobs, distributes individual tasks to machines running the Task Tracker. Following 2 Daemons run on each Slave nodes DataNode – Stores actual HDFS data blocks. TaskTracker - Responsible for instantiating and monitoring individual Map and Reduce tasks. What is configuration of a typical slave node on Hadoop cluster? How many JVMs run on a slave node? Single instance of a Task Tracker is run on each Slave node. Task tracker is run as a separate JVM process. Single instance of a DataNode daemon is run on each Slave node. DataNode daemon is run as a separate JVM process. One or Multiple instances of Task Instance is run on each slave node. Each task instance is run as a separate JVM process. The number of Task instances can be controlled by configuration. Typically a high end machine is configured to run more task instances. What is the difference between HDFS and NAS ? The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. Following are differences between HDFS and NAS In HDFS Data Blocks are distributed across local drives of all machines in a cluster. Whereas in NAS data is stored on dedicated hardware. HDFS is designed to work with MapReduce System, since computation are moved to data. NAS is not suitable for MapReduce since data is stored seperately from the computations. HDFS runs on a cluster of machines and provides redundancy usinga replication protocal. Whereas NAS is provided by a single machine therefore does not provide data redundancy. How NameNode Handles data node failures? NameNode periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode. When NameNode notices that it has not recieved a hearbeat message from a data node after a certain amount of time, the data node is marked as dead. Since blocks will be under replicated the system begins replicating the blocks that were stored on the dead datanode. The NameNode Orchestrates the replication of data blocks from one datanode to another. The replication data transfer happens directly between datanodes and the data never passes through the namenode. Does MapReduce programming model provide a way for reducers to communicate with each other? In a MapReduce job can a reducer communicate with another reducer? Nope, MapReduce programming model does not allow reducers to communicate with each other. Reducers run in isolation. Can I set the number of reducers to zero? Yes, Setting the number of reducers to zero is a valid configuration in Hadoop. When you set the reducers to zero no reducers will be executed, and the output of each mapper will be stored to a separate file on HDFS.
[This is different from the condition when reducers are set to a number greater than zero and the Mappers output (intermediate data) is written to the Local file system(NOT HDFS) of each mappter slave node.] Where is the Mapper Output (intermediate kay-value data) stored ? The mapper output (intermediate data) is stored on the Local file system (NOT HDFS) of each individual mapper nodes. This is typically a temporary directory location which can be setup in config by the hadoop administrator. The intermediate data is cleaned up after the Hadoop Job completes. What are combiners? When should I use a combiner in my MapReduce Job? Combiners are used to increase the efficiency of a MapReduce program. They are used to aggregate intermediate map output locally on individual mapper outputs. Combiners can help you reduce the amount of data that needs to be transferred across to the reducers. You can use your reducer code as a combiner if the operation performed is commutative and associative. The execution of combiner is not guaranteed, Hadoop may or may not execute a combiner. Also, if required it may execute it more then 1 times. Therefore your MapReduce jobs should not depend on the combiners execution. What is Writable & WritableComparable interface? org.apache.hadoop.io.Writable is a Java interface. Any key or value type in the Hadoop Map-Reduce framework implements this interface. Implementations typically implement a static read(DataInput) method which constructs a new instance, calls readFields(DataInput) and returns the instance. org.apache.hadoop.io.WritableComparable is a Java interface. Any type which is to be used as a key in the Hadoop Map-Reduce framework should implement this interface. WritableComparable objects can be compared to each other using Comparators. What is the Hadoop MapReduce API contract for a key and value Class? The Key must implement the org.apache.hadoop.io.WritableComparable interface. The value must implement the org.apache.hadoop.io.Writable interface. What is a IdentityMapper and IdentityReducer in MapReduce ? org.apache.hadoop.mapred.lib.IdentityMapper Implements the identity function, mapping inputs directly to outputs. If MapReduce programmer do not set the Mapper Class using JobConf.setMapperClass then IdentityMapper.class is used as a default value. org.apache.hadoop.mapred.lib.IdentityReducer Performs no reduction, writing all input values directly to the output. If MapReduce programmer do not set the Reducer Class using JobConf.setReducerClass then IdentityReducer.class is used as a default value. What is the meaning of speculative execution in Hadoop? Why is it important? Speculative execution is a way of coping with individual Machine performance. In large clusters where hundreds or thousands of machines are involved there may be machines which are not performing as fast as others. This may result in delays in a full job due to only one machine not performaing well. To avoid this, speculative execution in hadoop can run multiple copies of same map or reduce task on different slave nodes. The results from first node to finish are used. When is the reducers are started in a MapReduce job? In a MapReduce job reducers do not start executing the reduce method until the all Map jobs have completed. Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The programmer defined reduce method is called only after all the mappers have finished. If reducers do not start before all mappers finish then why does the progress on MapReduce job shows something like Map(50%) Reduce(10%)? Why reducers progress percentage is displayed when mapper is not finished yet? Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The progress calculation also takes in account the processing of data transfer which is done by reduce process, therefore the reduce progress starts
showing up as soon as any intermediate key-value pair for a mapper is available to be transferred to reducer. Though the reducer progress is updated still the programmer defined reduce method is called only after all the mappers have finished. What is HDFS ? How it is different from traditional file systems? HDFS, the Hadoop Distributed File System, is responsible for storing huge data on the cluster. This is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS is designed to support very large files. Applications that are compatible with HDFS are those that deal with large data sets. These applications write their data only once but they read it one or more times and require these reads to be satisfied at streaming speeds. HDFS supports write-once-read-many semantics on files. What is HDFS Block size? How is it different from traditional file system block size? In HDFS data is split into blocks and distributed across multiple nodes in the cluster. Each block is typically 64Mb or 128Mb in size. Each block is replicated multiple times. Default is to replicate each block three times. Replicas are stored on different nodes. HDFS utilizes the local file system to store each HDFS block as a separate file. HDFS Block size can not be compared with the traditional file system block size. What is a NameNode? How many instances of NameNode run on a Hadoop Cluster? The NameNode is the centerpiece of an HDFS file system. It keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the data of these files itself. There is only One NameNode process run on any hadoop cluster. NameNode runs on its own JVM process. In a typical production cluster its run on a separate machine. The NameNode is a Single Point of Failure for the HDFS Cluster. When the NameNode goes down, the file system goes offline. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives. What is a DataNode? How many instances of DataNode run on a Hadoop Cluster? A DataNode stores data in the Hadoop File System HDFS. There is only One DataNode process run on any hadoop slave node. DataNode runs on its own JVM process. On startup, a DataNode connects to the NameNode. DataNode instances can talk to each other, this is mostly during replicating data. How the Client communicates with HDFS? The Client communication to HDFS happens using Hadoop HDFS API. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file on HDFS. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives. Client applications can talk directly to a DataNode, once the NameNode has provided the location of the data. How the HDFS Blocks are replicated? HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time. The NameNode makes all decisions regarding replication of blocks.
HDFS uses rack-aware replica placement policy. In default configuration there are total 3 copies of a datablock on HDFS, 2 copies are stored on datanodes on same rack and 3rd copy on a different rack. Can you think of a questions which is not part of this post? Please don't forget to share it with me in comments section & I will try to include it in the list.
0 notes
Text
Big Data Meets Machine Learning: Exploring Advanced Data Science Applications
Introduction
The combination of Big Data and Machine Learning is changing industries and expanding opportunities in today's data-driven society. With the increase in data volumes and complexity, advanced data science is essential to converting this data into insights that can be put to use. Big Data's enormous potential combined with machine learning's capacity for prediction is transforming industries including healthcare, banking, and retail. This article examines how these technologies work together and provides examples of practical uses that show how Advanced Data Science can be used to tackle difficult problems.
How Big Data Enhances Machine Learning
1. Leveraging Massive Datasets for Model Accuracy
Big Data offers the enormous volumes of data required to build reliable models, and machine learning thrives on data. These datasets are tailored for machine learning algorithms thanks to advanced data science approaches including feature selection, dimensionality reduction, and data pretreatment. Businesses use this synergy to increase the accuracy of applications such as consumer segmentation, fraud detection, and personalized suggestions. Businesses can now find previously unattainable patterns because of the capacity to examine large datasets.
2. Real-Time Analytics with Streaming Data
Real-time analytics, made possible by the marriage of Big Data and Machine Learning, is revolutionary for sectors that need quick insights. Data scientists can process streaming data and quickly implement machine learning models with the help of sophisticated tools like Apache Kafka and Spark Streaming. This capacity is commonly used in industries such as logistics for delivery route optimization, healthcare for patient monitoring, and e-commerce for dynamic pricing. Data-driven and fast judgments are guaranteed by real-time data analytics.
3. Scalability and Distributed Learning
The scalability of big data and machine learning's requirement for processing power complement each other well. With the help of distributed frameworks like Hadoop and TensorFlow, data scientists can handle large datasets without sacrificing performance by training models across clusters. This scalability is advantageous for advanced data science applications, such as risk assessment in banking and predictive maintenance in manufacturing. Distributed learning guarantees that models can efficiently adjust to increasing data quantities.
Applications of Advanced Data Science in Big Data and Machine Learning
4. Predictive Analytics for Business Optimization
Businesses may anticipate future trends with the help of predictive analytics, which is fueled by big data and machine learning. Retailers utilize it to improve consumer experiences, optimize inventory, and estimate demand. It helps with portfolio management and credit rating in the financial industry. Organizations may keep ahead of market developments and make well-informed decisions by using past data to predict outcomes.
5. Personalized Customer Experiences
Highly customized consumer interactions are made possible by the combination of machine learning and big data. Sophisticated recommendation systems examine user behavior to make pertinent product or service recommendations using techniques like collaborative filtering and neural networks. This technology is used by online education providers, e-commerce companies, and streaming platforms to increase customer pleasure and engagement. Customization exemplifies how data-driven innovation can revolutionize an industry.
6. Fraud Detection and Security
One of the most important uses of advanced data science in the digital age is fraud detection. Machine learning algorithms can detect possible threats in real time by searching through massive databases for abnormalities and odd patterns. These models are used by cybersecurity companies and financial institutions to protect sensitive data and transactions. Across sectors, the combination of Big Data and Machine Learning improves security and reduces risk.
Conclusion
New horizons in advanced data science are being opened by the combination of big data and machine learning. Their combined potential revolutionizes how companies function and innovate, from real-time decision-making to predictive analytics. Gaining proficiency in these technologies and completing Advanced Data Science training programs are essential for those looking to take the lead in this field. Take part in the revolution influencing the direction of technology by enrolling in a program now to investigate the intersection of Big Data and Machine Learning.
0 notes
Text
What is data science?
Data science is an interdisciplinary field that involves using scientific methods, algorithms, processes, and systems to extract knowledge and insights from structured and unstructured data. It combines elements of statistics, computer science, domain expertise, and data engineering to analyze large volumes of data and derive actionable insights.
Key Components of Data Science:
Data Collection
Definition: Gathering data from various sources, which can include databases, APIs, web scraping, sensors, and more.
Types of Data:
Structured Data: Organized in tables (e.g., databases).
Unstructured Data: Includes text, images, videos, etc.
Data Cleaning and Preparation
Definition: Processing and transforming raw data into a clean format suitable for analysis. This step involves handling missing values, removing duplicates, and correcting errors.
Importance: Clean data is crucial for accurate analysis and model building.
Exploratory Data Analysis (EDA)
Definition: Analyzing the data to discover patterns, trends, and relationships. This involves statistical analysis, data visualization, and summary statistics.
Tools: Common tools for EDA include Python (with libraries like Pandas and Matplotlib), R, and Tableau.
Data Modeling
Definition: Building mathematical models to represent the underlying patterns in the data. This includes statistical models, machine learning models, and algorithms.
Types of Models:
Supervised Learning: Models that are trained on labeled data (e.g., classification, regression).
Unsupervised Learning: Models that find patterns in unlabeled data (e.g., clustering, dimensionality reduction).
Reinforcement Learning: Models that learn by interacting with an environment to maximize some notion of cumulative reward.
Model Evaluation and Tuning
Definition: Assessing the performance of models using metrics such as accuracy, precision, recall, F1 score, etc. Model tuning involves optimizing the model parameters to improve performance.
Cross-Validation: A technique used to assess how the results of a model will generalize to an independent dataset.
Data Visualization
Definition: Creating visual representations of data and model outputs to communicate insights clearly and effectively.
Tools: Matplotlib, Seaborn, D3.js, Power BI, and Tableau are commonly used for visualization.
Deployment and Monitoring
Definition: Implementing the model in a production environment where it can be used to make real-time decisions. Monitoring involves tracking the model's performance over time to ensure it remains accurate.
Tools: Cloud services like AWS, Azure, and tools like Docker and Kubernetes are used for deployment.
Ethics and Privacy
Consideration: Ensuring that data is used responsibly, respecting privacy, and avoiding biases in models. Data scientists must be aware of ethical considerations in data collection, analysis, and model deployment.
Applications of Data Science:
Business Intelligence: Optimizing operations, customer segmentation, and personalized marketing.
Healthcare: Predicting disease outbreaks, personalized medicine, and drug discovery.
Finance: Fraud detection, risk management, and algorithmic trading.
E-commerce: Recommendation systems, inventory management, and price optimization.
Social Media: Sentiment analysis, trend detection, and user behavior analysis.
Tools and Technologies in Data Science:
Programming Languages: Python, R, SQL.
Machine Learning Libraries: Scikit-learn, TensorFlow, PyTorch.
Big Data Tools: Hadoop, Spark.
Data Visualization: Matplotlib, Seaborn, Tableau, Power BI.
Databases: SQL, NoSQL (MongoDB), and cloud databases like Google BigQuery.
Conclusion
Data science is a powerful field that is transforming industries by enabling data-driven decision-making. With the explosion of data in today's world, the demand for skilled data scientists continues to grow, making it an exciting and impactful career path.
data science course in chennai
data science institute in chennai
data analytics in chennai
data analytics institute in chennai
0 notes
Text
Top 15 Open Source Data Analytics Tools in 2024
In the rapidly evolving data analytics landscape, open-source tools have become indispensable for businesses and organizations seeking efficient, cost-effective solutions. These tools offer many features, functionalities, and flexibility, empowering users to extract valuable insights from data. Here’s a quick overview of the top 15 open-source data analytics tools in 2024, exploring their key features, use cases, pros, and cons.
1. Python (with Pandas, NumPy, and Scikit-learn)
Features:
Extensive libraries for data science.
Object-oriented programming capabilities.
Use Cases:
Data analysis and manipulation.
Machine learning.
Pros:
Easy to learn, versatile.
Extensive libraries.
Cons:
Can be slower for computationally intensive tasks.
2. R
Features:
Powerful statistical analysis tools.
Strong focus on reproducibility.
Use Cases:
Statistical analysis and modeling.
Biostatistics.
Pros:
Excellent for statistics.
Strong visualization capabilities.
Cons:
Steeper learning curve.
Smaller general-purpose library collection.
3. Matplotlib
Features:
Wide variety of plot types.
Customization options for plot elements.
Use Cases:
Creating charts and graphs.
Pros:
Versatile, well-documented.
Integrates well with the Python ecosystem.
Cons:
Complex for advanced visualizations.
Requires some coding knowledge.
4. Apache Spark
Features:
In-memory processing.
Spark SQL for querying data.
Use Cases:
Real-time data analytics.
Large-scale machine learning.
Pros:
Fast in-memory computations.
Supports diverse data formats.
Cons:
Requires distributed computing infrastructure.
Steeper learning curve.
5. Apache Hadoop
Features:
Distributed storage (HDFS).
Parallel data processing (MapReduce).
Use Cases:
Large-scale data storage and management.
Big data analytics pipelines.
Pros:
Scalable storage and processing.
Reliable and fault-tolerant.
Cons:
Complex to set up and manage.
Requires cluster administration expertise.
6. Apache Kafka
Features:
Real-time data streaming.
Scales horizontally.
Use Cases:
Real-time fraud detection.
Log stream processing.
Pros:
Enables real-time data processing.
Scalable and fault-tolerant.
Cons:
Requires expertise in distributed systems.
Complex to set up for large-scale deployments.
7. Apache Airflow
Features:
Defines tasks and dependencies.
Schedules and monitors pipelines.
Use Cases:
Orchestrating complex data pipelines.
Pros:
Scalable workflow management.
Robust scheduling features.
Cons:
Requires coding knowledge for workflows.
Can be complex for simple tasks.
8. Qlik
Features:
Interactive data visualization.
Associative data model.
Use Cases:
Business intelligence and analytics.
Pros:
User-friendly interface.
Powerful data integration capabilities.
Cons:
Costly licensing.
Steeper learning curve for advanced analytics.
9. Microsoft SSIS
Features:
ETL capabilities.
Visual development environment.
Use Cases:
Data integration and consolidation.
Pros:
Intuitive visual interface.
Broad connectivity options.
Cons:
Requires SQL knowledge.
Limited advanced analytics functionalities.
10. Amazon Redshift
Features:
Columnar data storage.
Massive parallel processing (MPP).
Use Cases:
Data warehousing and analytics.
Pros:
High-performance data processing.
Integration with AWS services.
Cons:
Requires SQL expertise.
Limited support for real-time data streaming.
11. PostgreSQL
Features:
ACID-compliant RDBMS.
JSON and JSONB data types.
Use Cases:
Data storage and management.
Pros:
Open-source with strong community.
Robust security features.
Cons:
Requires SQL knowledge.
Limited support for unstructured data.
12. KNIME
Features:
Visual drag-and-drop interface.
Integrated workflows.
Use Cases:
Data cleaning and transformation.
Pros:
Easy to use.
Good for beginners.
Cons:
Limited flexibility.
Not suitable for complex tasks.
13. Power BI
Features:
Data visualization and analytics.
AI-powered analytics.
Use Cases:
Business intelligence.
Pros:
User-friendly interface.
Integration with Microsoft ecosystem.
Cons:
Costly licensing.
Limited customization options.
14. Tableau
Features:
Data visualization platform.
Advanced analytics.
Use Cases:
Exploratory data analysis.
Pros:
Intuitive interface.
Wide range of visualization options.
Cons:
Costly licensing.
Performance issues with large datasets.
15. Apache Flink
Features:
Stream processing framework.
Batch processing capabilities.
Use Cases:
Real-time data analytics.
Pros:
High throughput and low-latency processing.
Scalability.
Cons:
Requires expertise in distributed systems.
Steeper learning curve.
Conclusion
Open-source data analytics tools are essential for businesses looking to leverage data effectively. By evaluating your specific needs and considering factors like functionality, community support, and future trends, you can choose the right tool to align with your goals and objectives.
0 notes
Text
Unlock Savings: Your Definitive Guide to AWS EC2 Pricing and Optimization

Amazon Elastic Compute Cloud (AWS EC2) is the most frequently used service on AWS. With hundreds of instance kinds at varying price points it can be difficult to choose the appropriate compute resource to meet your budget and needs. This blog will go over your options, outline the costs and deliver desirable ways to manage your EC2 use.
What is AWS EC2?
AWS EC2 is a cloud computing service that provides compute power within the cloud. The core of this service is an EC2 instance. It is a virtual machine which run an operating system that is built on top of hardware resources such as memory, CPU and hard disks, for example. With EC2 it is easy to set up an instance that is secure and has the required software to run your business and is accessible in just a few moments.
When you start the EC2 instance you need to select the type of instance (e.g. T3) and the size (e.g. large,). This determines the capacities of the device as well as the hourly price. This can be done by hand using the Management Console of AWS or by programming. The only time you are charged is for instances as they are running. When you're finished running your own instances you'll be able to reduce them and stop paying for them.
Amazon family type EC2
Every AWS EC2 instance family has an application profile for target applications in one of the following categories:
Amazon describe an instance by naming it the type of instance first, and then the size. For instance, c5.large means that the instance is part of the type of C5 instances (which is part of the family of compute optimized). It is possible to infer that it's a fifth-generation type, and the size of it is big.
Let's go over a brief review of the different EC2 instances and families.
Families of M and T The M and T families: General use
The T and M families are the primary workhorses of AWS EC2. The M family offers an excellent balance of RAM, CPU, and disk performance, making it the accurate option for those with constant performance requirements. If you aren't sure you'll be working on a high-end RAM/CPU/IO task, you should begin using an instance of M, and then monitor its performance over a few minutes. If you notice that the instance is limiting performance due to some of the hardware attributes it is possible to switch to a more targeted family.
The T family is a cheaper opportunity as compared to that of the M family. It's also targeted at general-purpose tasks, but is also able to handle bursts. The instances are designed to run at a lower base performance for large chunks of time. They can automatically boost performance when required. It's possible to think of this the bursting process as an inherent elasticity. The method is perfect to use it for programs that don't need much performance for the majority of the time, but have some periods when they're in use. You could employ T instances for T instance to run lower-throughput apps such as administrative apps and websites with low traffic, as well as testing and development.
C family Optimized compute
The Compute Optimized instances can be used best suited for applications that require enough compute power that have a higher proportion of vCPUs to memory, and the lowest price per vCPU. Examples of applications best suited to the C family are front-end systems for high-traffic websites, online batch processing and dispersed analytics, video encoding and high-performance engineering and science applications.
X R, z1d the High Memory and X families of memory: Optimized memory
These X1, X2, X4 (R5, R6) and z1d instances are designed for applications that require many memory. They have the lowest cost per gigabyte of RAM, which makes them an ideal choice for your application is memory-dependent.
The R family is ideal for data mining and real-time processing of nonstructured large data or clusters of Hadoop/Spark. The X1 and the X2 instances are intended for larger-scale applications in memory like SAP HANA. They possess a higher percentage of memory than R family.
Z1d instances offer superior single-thread performance and the ability to sustain all core frequencies that can reach 4.0 GHz -- the fastest cloud instance. This outcome in instances of high compute performance as well as high memory. Z1d is a good choice for instances such as EDA, electronic design automation (EDA), gaming, or other database-related workloads that have the cost of licensing per core that is high.
The instances of the High Memory family offer the largest memories of all EC2 instance and are used to store large databases in memory. They range from 3 to 24 TiB in memory The instances were initially made available to SAP HANA deployments with fixed-term commitments. Since mid-2021, they've been made available for purchase on demand and are now able to serve a larger variety of usage cases.
Families H D family, as well as I: Optimized storage
The H, D, and I families are great choices when your application requires superior performance from local storage. This is in contrast to many instances, including general purpose and compute optimized models, which don't contain local storage, but use connected EBS volume instead. The families that are optimized for storage offer the widest range of sizes for storage, either orally supported by HDDs as well as SSDs. H1 can provide the capacity of up to 16TB storage space on hard drives. It's a great choice for those who work with MapReduce or streaming platforms like Apache Kafka.
D3 provides the possibility of up to 48TB storage space on hard drives. This family is ideal for applications that require massively parallel processing of data storage, Hadoop, and distributed file systems.
I3 instances comprise Non-Volatile Memory Express (NVMe) SSD-based storage for instance storage. This type of storage is designed for very low latency, high I/O performance at random and a the ability to read sequentially at a high rate. It's an ideal choice for NoSQL databases such as in-memory databases and data warehouses, Elasticsearch, and analytics applications.
The families of P and G The G and P families: Computing with speed
If your application is graphics processing intense or use machines learning algorithms, take a look at the G and P families for the highest performance and cost efficiency. P instances are specifically designed for the majority of general-purpose GPU applications and are great to edit videos. The G instance is optimized for GPU-intensive applications, such as automated speech recognition and language translation. Additionally, there's an F1 family with adjustable hardware acceleration.
Summary of instances of AWS EC2
Here is a table listing the EC2 families and the associated categories, as well as the links to their specifications on AWS website (where they are available).
Tips to choose the best AWS E2 instance
Here are some things to consider when you're choosing which one to choose:
A final note on the notation of instance types: In the past, all instances were made up of two elements: an alphabet to indicate the type and a number to represent the generation. For instance, C4, C5, M4 or M5, for example. These types of instances were generally supported with Intel processors. The latest generation of instance types come with a third element to indicate the processor's type such as M6a, M6i and M6g for identifying those running AMD, Intel, and Graviton versions of the M6 instance.
Once you've chosen those EC2 instances that are appropriate for your requirements then you'll need to determine which method to pay. AWS provides a range of EC2 instances pricing options.
AWS EC2 pricing: on-demand pricing
On-Demand pricing implies that you pay only for the amount of compute you require without making any commitments for the long term. You can use the instance the time you require it, and then you can shut it down. Pricing on-demand is computed per second (with the minimum cost of 30 seconds) regardless of whether the prices listed on the AWS website is per hour. Prices differ based on the size and type of an instance, its region along with the OS.
For instance, the On-Demand rates for an m6a.large instance within the US West (Oregon) region are as follows:
Prices on-Demand for the same scenario within the EU (Ireland) region appear like this:
On-Demand provides convenience and is the most popular pricing option however it's one of the more expensive opportunity. The flexibility offered by On-Demand can be worth the extra costs when you're developing and testing unpredictable workloads, or applications.
AWS EC2 Pricing Saves Plans and Reserved Instances
One way to reduce the cost of your EC2 expenses is to reduce the actual hourly rates charged using purchasing commitment-based discounts provided by AWS. For EC2 the instruments are savings Plans (SP) as well as Reserved Instances (RI). In this article we will focus on SPs that were introduced in the second quarter of 2019 and created to be much simpler to manage, and usually will result in greater savings when compared to the RIs. Because of these advantages the majority of organizations have switched to buying SPs. It is important to note that the fundamental principlecommitment to a continuous level of use in order to earn the benefit of a discount percentage of each instrument is consistent and a number of purchasing specifics remain the same. For instance, the term duration and the payment choices are identical, as do savings rates are also identical (Compute SPs correspond to Convertible RIs and the EC2 Instance SPs are matched to Standard the RIs).
Payment options
When you purchase an SP you have three options for payment:
The more upfront you pay and upfront, the greater your savings rate. What you don't have to pay upfront is repaid monthly throughout the term of the agreement.
Time length
You can choose one-year or three-year terms when you buy an SP. The three-year choice offers significantly higher savings rates -typically at least 50% greater savings rate than one-year, based on the type. However, it does require greater confidence that the workload will be in operation over the longer term.
Example discount
For instance, let's say your together an m6i.xlarge in the West of the United States (Oregon) Region. The cost of on-demand payments for this particular instance is $0.192 per hour. One-year EC2 Instance SP that has a partial upfront payment of $530 upfront, and $44.15 per month, for the total cost of $1,060. It's an effective hourly cost of $0.121 that's an average discount of 37% in comparison to on-demand. If an m6i.xlarge instance were to run for each hour during the course of one year, the SP that covers it SP will save you the user $622. It's easy to see the way this discounting could really be significant in the event that SPs cover a large collection of use. It's important to note that unused SP hours (a typical scenario when the workloads change) over the course of time aren't recoverable, and the savings rate could be lower than the stated figure.
EC2 Instance Savings Plans vs. Compute Savings Plans
The most crucial factor to consider in purchasing SPs is whether you want to maximise saving (EC2 Instance SP) or increase the coverage (Compute). This decision requires understanding the savings rates available and the particular usage that you will be committed to.
Tips for buying Savings Plans
AWS EC2 pricing: Spot Instances
Another choice to reduce the hourly EC2 prices is to utilize Spot Instances. Spot Instances can add the greatest chance of saving off On-Demand prices which can be as high as 90% under the appropriate conditions. With Spot Instances you can bid to place your instances to AWS's surplus compute capacity. Prices fluctuate based on demand and supply. If the EC2 instances you're interested in are highly sought-after in a specific region You'll need to raise your bid to be competitive, however you are able to decide on your maximum bid. If the price at which you can bid on the instance is lower than your maximum bid, and the capacity is there, then your request has been fulfilled.
However, there's a caveat with the low price. AWS may disrupt you from your Spot Instance when the Spot price is greater than your maximum or as the need for Spot Instances increases or when the supply of Spot Instances decreases. There are options to minimize the risk with AWS Hibernate and Pause-Stop functions, however every work load in the Spot Instance must be designed to limit the impact of interruptions.
AWS EC2 Dedicated Hosts
Amazon EC2 Dedicated host is an actual server that's capacity for EC2 instances is completely dedicated for your particular application. Dedicated Hosts are able to benefit with the requirements for compliance and permit you to utilize your existing server-bound software licences.
As with other EC2 options, you are able to switch Dedicated Hosts on and off at any time as well as purchase reservations to reduce costs. However, there are a few significant distinctions. When you create an Dedicated Host it is a matter of choosing a configuration that decides on the type and quantity of instances you can use it for. The cost is hourly for every active Dedicated Host instead of being invoiced per instance. The cost per hour varies based what configuration is used for the dedicated host.
Make sure you give the EC2 backbone the help it needs
EC2 is the basis of many cloud-based architectures. The more you can manage your EC2 use and costs more efficient your cloud will become -and the greater value you'll gain from it. If you have the right plan and management techniques you'll be able to obtain everything you require at a fraction of the cost, leaving you with money which can spur innovation in your business. Download our ebook Selecting the Right Amazon EC2 EC2 instances to Optimize Your Cloud to further read.
0 notes
Text
Cloudera Hadoop

You are interested in information about Cloudera’s Hadoop offerings. Cloudera provides a suite of tools and services around Hadoop, an open-source software framework for the storage and large-scale processing of data sets on clusters of commodity hardware. Their offerings typically include:
Cloudera Distribution of Hadoop (CDH): An integrated suite of Hadoop-based applications, including the core elements of Hadoop like the Hadoop Distributed File System (HDFS), YARN, and MapReduce, along with additional components like Apache Spark, Apache Hive, and Apache HBase.
Cloudera Manager: A management tool for easy administration of Hadoop clusters. It provides capabilities for configuring, managing, and monitoring Hadoop clusters.
Cloudera Data Science Workbench: An environment for data scientists to create, manage, and deploy data science projects using Hadoop and Spark.
Support and Training: Cloudera also offers professional support, consulting, and training services to help businesses implement and use their Hadoop solutions effectively.
If you want to incorporate this information into a bulk email, ensuring that the content is clear, concise, and valuable to the recipients is essential. Also, to avoid spam filters, having a clean mailing list, personalizing your emails, avoiding using too many sales-like phrases, and ensuring you comply with email regulations like the CAN-SPAM Act is crucial. Remember, regular and meaningful engagement with your audience can improve your email’s deliverability.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
Data Engineer Course in Ameerpet | Data Analyst Course in Hyderabad
Analyse Big Data with Hadoop
AWS Data Engineering with Data Analytics involves leveraging Amazon Web Services (AWS) cloud infrastructure to design, implement, and optimize robust data engineering pipelines for large-scale data processing and analytics. This comprehensive solution integrates AWS services like Amazon S3 for scalable storage, Amazon Glue for data preparation, and AWS Lambda for server less computing. By combining data engineering principles with analytics tools such as Amazon Redshift or Athena, businesses can extract valuable insights from diverse data sources. Analyzing big data with Hadoop involves leveraging the Apache Hadoop ecosystem, a powerful open-source framework for distributed storage and processing of large datasets. Here is a general guide to analysing big data using Hadoop
AWS Data Engineering Online Training

Set Up Hadoop Cluster:
Install and configure a Hadoop cluster. You'll need a master node (NameNode) and multiple worker nodes (DataNodes). Popular Hadoop distributions include Apache Hadoop, Cloudera, Hortonworks, and Map.
Store Data in Hadoop Distributed File System (HDFS):
Ingest large datasets into Hadoop Distributed File System (HDFS), which is designed to store massive amounts of data across the distributed cluster.
Data Ingestion:
Choose a method for data ingestion. Common tools include Apache Flume, Apache Sqoop, and Apache NiFi. These tools can help you move data from external sources (e.g., databases, logs) into HDFS.
Processing Data with Map Reduce:
Write Map Reduce programs or use higher-level languages like Apache Pig or Apache Hive to process and analyse data. Map Reduce is a programming model for processing and generating large datasets that can be parallelized across a Hadoop cluster. AWS Data Engineering Training
Utilize Spark for In-Memory Processing:
Apache Spark is another distributed computing framework that can be used for in-memory data processing. Spark provides higher-level APIs in languages like Scale, Python, and Java, making it more accessible for developers.
Query Data with Hive:
Apache Hive allows you to write SQL-like queries to analyse data stored in Hadoop. It translates SQL queries into Map Reduce or Spark jobs, making it easier for analysts familiar with SQL to work with big data.
Implement Machine Learning:
Use Apache Mahout or Apache Spark Millie to implement machine learning algorithms on big data. These libraries provide scalable and distributed machine learning capabilities. Data Engineer Training in Hyderabad
Visualization:
Employ tools like Apache Zeppelin, Apache Superset, or integrate with business intelligence tools to visualize the analysed data. Visualization is crucial for gaining insights and presenting results.
Monitor and Optimize:
Implement monitoring tools like Apache Amari or Cloudera Manager to track the performance of your Hadoop cluster. Optimize configurations and resources based on usage patterns.
Security and Governance:
Implement security measures using tools like Apache Ranger or Cloudera Sentry to control access to data and ensure compliance. Establish governance policies for data quality and privacy. Data Engineer Course in Ameerpet
Scale as Needed:
Hadoop is designed to scale horizontally. As your data grows, add more nodes to the cluster to accommodate increased processing requirements.
Stay Updated:
Keep abreast of developments in the Hadoop ecosystem, as new tools and enhancements are continually being introduced.
Analyzing big data with Hadoop requires a combination of data engineering, programming, and domain expertise. It's essential to choose the right tools and frameworks based on your specific use case and requirements.
Visualpath is the Leading and Best Institute for AWS Data Engineering Online Training, Hyderabad. We AWS Data Engineering Training provide you will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit : https://www.visualpath.in/aws-data-engineering-with-data-analytics-training.html
#AWS Data Engineering Online Training#AWS Data Engineering#Data Engineer Training in Hyderabad#AWS Data Engineering Training in Hyderabad#Data Engineer Course in Ameerpet#AWS Data Engineering Training Ameerpet#Data Analyst Course in Hyderabad#Data Analytics Course Training
0 notes
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
What is Amazon EMR architecture? And Service Layers

Describe Amazon EMR architecture
The storage layer includes your cluster's numerous file systems. Examples of various storage options.
The Hadoop Distributed File System (HDFS) is scalable and distributed. HDFS keeps several copies of its data on cluster instances to prevent data loss if one instance dies. Shutting down a cluster recovers HDFS, or ephemeral storage. HDFS's capacity to cache interim findings benefits MapReduce and random input/output workloads.
Amazon EMR improves Hadoop with the EMR File System (EMRFS) to enable direct access to Amazon S3 data like HDFS. The file system in your cluster may be HDFS or Amazon S3. Most input and output data are stored on Amazon S3, while intermediate results are stored on HDFS.
A disc that is locally attached is called the local file system. Every Hadoop cluster Amazon EC2 instance includes an instance store, a specified block of disc storage. Amazon EC2 instances only store storage volume data during their lifespan.
Data processing jobs are scheduled and cluster resources are handled via the resource management layer. Amazon EMR defaults to centrally managing cluster resources for multiple data-processing frameworks using Apache Hadoop 2.0's YARN component. Not all Amazon EMR frameworks and apps use YARN for resource management. Amazon EMR has an agent on every node that connects, monitors cluster health, and manages YARN items.
Amazon EMR's built-in YARN job scheduling logic ensures that running tasks don't fail when Spot Instances' task nodes fail due to their frequent use. Amazon EMR limits application master process execution to core nodes. Controlling active jobs requires a continuous application master process.
YARN node labels are incorporated into Amazon EMR 5.19.0 and later. Previous editions used code patches. YARN capacity-scheduler and fair-scheduler use node labels by default, with yarn-site and capacity-scheduler configuration classes. Amazon EMR automatically labels core nodes and schedules application masters on them. This feature can be disabled or changed by manually altering yarn-site and capacity-scheduler configuration class settings or related XML files.
Data processing frameworks power data analysis and processing. Many frameworks use YARN or their own resource management systems. Streaming, in-memory, batch, interactive, and other processing frameworks exist. Use case determines framework. Application layer languages and interfaces that communicate with processed data are affected. Amazon EMR uses Spark and Hadoop MapReduce mostly.
Distributed computing employs open-source Hadoop MapReduce. You provide Map and Reduce functions, and it handles all the logic, making parallel distributed applications easier. Map converts data to intermediate results, which are key-value pairs. The Reduce function combines intermediate results and runs additional algorithms to produce the final output. Hive is one of numerous MapReduce frameworks that can automate Map and Reduce operations.
Apache Spark: Spark is a cluster infrastructure and programming language for big data. Spark stores datasets in memory and executes using directed acyclic networks instead of Hadoop MapReduce. EMRFS helps Spark on Amazon EMR users access S3 data. Interactive query and SparkSQL modules are supported.
Amazon EMR supports Hive, Pig, and Spark Streaming. The programs can build data warehouses, employ machine learning, create stream processing applications, and create processing workloads in higher-level languages. Amazon EMR allows open-source apps with their own cluster management instead of YARN.
Amazon EMR supports many libraries and languages for app connections. Streaming, Spark SQL, MLlib, and GraphX work with Spark, while MapReduce uses Java, Hive, or Pig.
#AmazonEMRarchitecture#EMRFileSystem#HadoopDistributedFileSystem#Localfilesystem#Clusterresource#HadoopMapReduce#Technology#technews#technologynews#NEWS#govindhtech
0 notes
Link
https://www.digisurface.co/cloudera-hadoop-monitoring-services/
0 notes
Text
How Mr. Manasranjan Murlidhar Rana Helped Union Bank Switzerland as a Certified Hadoop Administrator
Mr. Manasranjan Murlidhar Rana is a certified Hadoop Administrator and an IT professional with 10 years of experience. During his entire career, he has contributed a lot to Hadoop administration for different organizations, including the famous Union Bank of Switzerland.
Mr. Rana’s Knowledge in Hadoop Architecture and its Components
Mr. Manasranjan Murlidhar Rana has vast knowledge and understanding of various aspects related to Hadoop Architecture and its different components. These are MapReduce, YARN, HDFS, HBase, Pig, Flume, Hive, and Zookeeper. He even has the experience to build and maintain multiple clusters in Hadoop, like the production and development of diverse sizes and configurations.

His contribution is observed in the establishment of rack topology to deal with big Hadoop clusters. In this blog post, we will discuss in detail about the massive contribution of Manasranjan Murlidhar Rana as a Hadoop Administrator to deal with various operations of the Union Bank of Switzerland.
Role of Mr. Rana in Union Bank of Switzerland
Right from the year 2016 to until now, Mr. Manasranjan Murlidhar Rana played the role of a Hadoop Administrator with 10 other members for his client named Union Bank of Switzerland. During about 4 years, he worked a lot to enhance the process of data management for his client UBS.
1. Works for the Set up of Hadoop Cluster
Manasranjan Murlidhar Rana and his entire team were involved in the set up of the Hadoop Cluster in UBS right from the beginning to the end procedure. In this way, the complete team works hard to install, configure, and monitor the complete Hadoop Cluster effectively. Here, the Hadoop cluster refers to a computation cluster designed to store and analyze unstructured data in a well-distributed computational environment.
2. Handles 4 Different Clusters and Uses Ambari Server
Mr. Manasranjan Murlidhar Rana is responsible for handling four different clusters of the software development process. These are DEV, UAT, QA, and Prod. He and his entire team even used the innovative Ambari server extensively to maintain different Hadoop cluster and its components. The Ambari server collects data from a cluster and thereby, controls each host.
3. Cluster Maintenance and Review of Hadoop Log Files
Mr. Manasranjan Murlidhar Rana and his team have done many things to maintain the entire Hadoop cluster, along with commissioning plus decommissioning of data nodes. Moreover, he contributed to monitoring different software development related clusters, troubleshoot and manage the available data backups, while reviewed log files of Hadoop. He also reviewed and managed log files of Hadoop as an important of the Hadoop administration to communicate, troubleshoot, and escalate tons of issues to step ahead in the right direction.
4. Successful Installation of Hadoop Components and its Ecosystem
Hadoop Ecosystem consists of Hadoop daemons. Hadoop Daemons in terms of computation imply a process operating in the background and they are of five types, i.e. DataNode, NameNode, TaskTracker, JobTracker, and Secondary NameNode.
Besides, Hadoop has few other components named Flume, Sqoop and HDFS, all of which have specific functions. Indeed, installation, configuration, and maintenance of each of the Hadoop daemons and Hadoop ecosystem components are not easy.
However, based on the hands-on experience of Mr. Manasranjan Rana, he succeeded to guide his entire team to install Hadoop ecosystems and its components named HBase, Flume, Sqoop, and many more. Especially, he worked to use Sqoop to import and export data in HDFS, while to use Flume for loading any log data directly into HDFS.
5. Monitor the Hadoop Deployment and Other Related Procedures
Based on the vast knowledge and expertise to deal with Hadoop elements, Mr. Manasranjan Murlidhar Rana monitored systems and services, work for the architectural design and proper implementation of Hadoop deployment and make sure of other procedures, like disaster recovery, data backup, and configuration management.
6. Used Cloudera Manager and App Dynamics
Based on the hands-on experience of Mr. Manasranjan Murlidhar Rana to use App Dynamics, he monitored multiple clusters and environments available under Hadoop. He even checked the job performance, workload, and capacity planning with the help of the Cloudera Manager. Along with this, he worked with varieties of system engineering aspects to formulate plans and deploy innovative Hadoop environments. He even expanded the already existing Hadoop cluster successfully.
7. Setting Up of My-SQL Replications and Maintenance of My-SQL Databases
Other than the expertise of Mr. Manasranjan Murlidhar Rana in various aspects of Bigdata, especially the Hadoop ecosystem and its components, he has good command on different types of databases, like Oracle, Ms-Access, and My-SQL.
Thus, according to his work experience, he maintained databases by using My-SQL, established users, and maintained the backup or recovery of available databases. He was also responsible for the establishment of master and slave replications for the My-SQL database and helped business apps to maintain data in various My-SQL servers.
Therefore, with good knowledge of Hadoop Ambari Server, Hadoop components, and demons, along with the entire Hadoop Ecosystem, Mr. Manasranjan Murlidhar Rana has given contributions towards the smart management of available data for the Union Bank of Switzerland.

Find Mr. Manasranjan Murlidhar Rana on Social Media. Here are some social media profiles:-
https://giphy.com/channel/manasranjanmurlidharrana https://myspace.com/manasranjanmurlidharrana https://mix.com/manasranjanmurlidhar https://www.meetup.com/members/315532262/ https://www.goodreads.com/user/show/121165799-manasranjan-murlidhar https://disqus.com/by/manasranjanmurlidharrana/
1 note
·
View note
Text
Hadoop Training In Delhi
Overview of Hadoop
Hadoop is an open-source software framework which is used for storing and running the number of applications on cluster. It was developed by Doug Cutting in the year 2006 and managed by Apache Software Foundation.

Hadoop Ecosystem
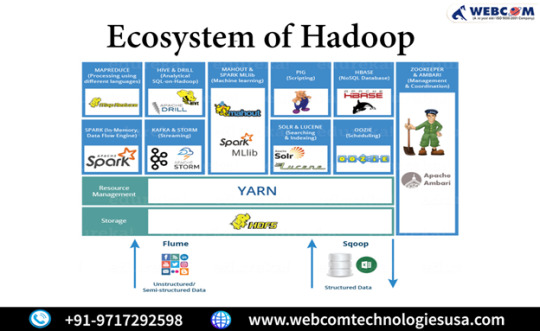
It is a platform that solves big data problems and it can be consider as a set that includes number of services within itself such as storing, ingesting, analyzing and maintaining. For storing the data Hadoop Distributed File System (HDFS) is used and its two main components are NameNode and DataNode. In this article, we’ll have a brief discussion about some of the ecosystems of Hadoop which are followed as;
· HDFS
· YARN
· MaPReduce
· PIG
Hadoop Distributed File System (HDFS)
HDFS is the storage unit of Hadoop. It is completely a cluster of Hadoop formed by DataNode (Commodity Hardware) that are clustered together using the Hadoop framework that automatically leads to the creation of file system where big data is stored is what termed as HDFS.
It can store any type of large datasets irrespective of structured, unstructured or semi-structured. It stores the data across a variety of nodes and it maintains the log files about the stored data.
Yarn
YARN is an acronym of Yet Another Resource Negotiator that performs all the processing activities by allotting the resources and scheduling the tasks. There are two services of Yarn; Resource Manager and Node Manager. Resource manager manages the resources & does the scheduling of the applications that are running on the top of the YARN. Node manager manages the containers and monitor the utilization of the resources in each container.
MaPReduce
MaPReduce is the processing unit of Hadoop that write the applications that processes the large datasets with the help of distributed and parallel algorithms. In the program of MaPReduce, Map() is one separate function and Reduce() is one separate function. It performs various functions like sorting, filtering and grouping.
PIG
It is another data processing tool used in Hadoop which has two parts that are Pig Latin which is the language and the Pig runtime used for executing the environment. Compiler converts the pig Latin to the MaPReduce. Pig provides the platform which is used for building the data flow for ETL tool. After loading the data PIG then performs various functions like grouping, filtering, sorting, joining and etc.
Big data Hadoop training in Noida is offered by the most credible IT institute of training SkyWebcom that ranks highly among other institutes for offering the training on the basis of live scenarios. Training of Hadoop is offered by 32 years of experts and they always remain updated with all the latest features brought in by the IT industry in order to provide the advance training. Hadoop course at SkyWebcom is designed by IT experts ranging from basic to advance level covering all the important modules of Hadoop briefly. SkyWebcom offers Hadoop training with 100% placement assistance in top companies and prepare every aspirant for interview rounds as well. So, enroll at SkyWebcom and learn Hadoop with great lab facilities and high tech infrastructure.
1 note
·
View note
Text
AWS CLOUD
AWS CLOUD
Amazon Web Services, Inc. (AWS) is a subsidiary of Amazon that provides on-demand cloud computing platforms and APIs to individuals, companies, and governments, on a metered, pay-as-you-go basis. Often times, clients will use this in combination with autoscaling (a process that allows a client to use more compute in times of high application usage, and then scale down to reduce costs when there is less traffic). These cloud computing web services provide various services related to networking, compute, storage, middleware, IOT and other processing capacity, as well as software tools via AWS server farms. This frees clients from managing, scaling, and patching hardware and operating systems. One of the foundational services is Amazon Elastic Compute Cloud (EC2), which allows users to have at their disposal a virtual cluster of computers, with extremely high availability, which can be interacted with over the internet via REST APIs, a CLI or the AWS console. AWS’s virtual computers emulate most of the attributes of a real computer, including hardware central processing units (CPUs) and graphics processing units (GPUs) for processing; local/RAM memory; hard-disk/SSD storage; a choice of operating systems; networking; and pre-loaded application software such as web servers, databases, and customer relationship management (CRM).
History of AWS
In the year 2002 — AWS services were launched
In the year 2006- AWS cloud products were launched
In the year 2012 — AWS had its first customer event
In the year 2015- AWS achieved $4.6 billion
In the year 2016- Surpassed the $10 billion revenue target
In the year 2016- AWS snowball and AWS snowmobile were launched
In the year 2019- Released approximately 100 cloud services.
How Does AWS Work?
AWS usually works in several different configurations depending on the user’s requirements. However, the user must be able to see the type of configuration used and the particular server map with respect to the AWS service.
Applications of AWS
The most common applications of AWS are storage and backup, websites, gaming, mobile, web, and social media applications. Some of the most crucial applications in detail are as follows:
1. Storage and Backup
One of the reasons why many businesses use AWS is because it offers multiple types of storage to choose from and is easily accessible as well. It can be used for storage and file indexing as well as to run critical business applications.
2. Websites
Businesses can host their websites on the AWS cloud, similar to other web applications.
3. Gaming
There is a lot of computing power needed to run gaming applications. AWS makes it easier to provide the best online gaming experience to gamers across the world.
4. Mobile, Web and Social Applications
A feature that separates AWS from other cloud services is its capability to launch and scale mobile, e-commerce, and SaaS applications. API-driven code on AWS can enable companies to build uncompromisingly scalable applications without requiring any OS and other systems.
5. Big Data Management and Analytics (Application)
Amazon Elastic MapReduced to process large amounts of data via the Hadoop framework.
Amazon Kinesis to analyze and process the streaming data.
AWS Glue to handle, extract, transform and load jobs.
Amazon Elasticsearch Service to enable a team to perform log analysis, and tool monitoring with the help of the open source tool, Elastic-search.
Amazon Athena to query data.
Amazon QuickSight to visualize data.
6. Artificial Intelligence
Amazon Lex to offer voice and text chatbot technology.
Amazon Polly to translate text-to-speech translation such as Alexa Voice Services and echo devices.
Amazon Rekognition to analyze the image and face.
7. Messages and Notifications
Amazon Simple Notification Service (SNS) for effective business or core communication.
Amazon Simple Email Service (SES) to receive or send emails for IT professionals and marketers.
Amazon Simple Queue Service (SQS) to enable businesses to subscribe or publish messages to end users.
8. Augmented Reality and Virtual Reality
Amazon Sumerian service enables users to make the use of AR and VR development tools to offer 3D web applications, E-commerce & sales applications, Marketing, Online education, Manufacturing, Training simulations, and Gaming.
9. Game Development
AWS game development tools are used by large game development companies that offer developer back-end services, analytics, and various developer tools.
AWS allows developers to host game data as well as store the data to analyze the gamer’s performance and develop the game accordingly.
10. Internet of Things
AWS IoT service offers a back-end platform to manage IoT devices as well as data ingestion to database services and AWS storage.
AWS IoT Button offers limited IoT functionality to hardware.
AWS Greengrass offers AWS computing for IoT device installation.
Best AWS CLOUD Training Institute in Noida.

1 note
·
View note
Text
Azure data factory orchestration
What is orchestration?
The conductor, like a real orchestra, simply leads the members of the symphony through the entirety of the piece of music they perform.
Similar to this, ADF will instruct another service, such as a Hadoop Cluster, to execute a Hive query on ADF's behalf rather than carrying out the actual transformation work itself.
Therefore, Hadoop and not ADF would carry out the work in this scenario. The pipelines to move the data to the next destination are provided by ADF, which merely orchestrates the Hive query's execution through Hadoop.
Platform as a Service ADF runs entirely as a PaaS service in the cloud, so it doesn't require a virtual (or real) machine to run an ADF process, unlike some widely used technologies like SSIS.
The scalability of the system is enhanced and deployment complexity and maintenance effort are reduced by eliminating the need for a dedicated machine.
There are no licensing costs, unlike the majority of third-party products. Only usage-based costs apply.
Any existing Enterprise Agreement between the client and Microsoft, whose solution will make use of Sidra, will benefit from its inclusion in the Azure infrastructure.
Open architecture ADF has a lot of built-in features that cover the most common scenarios and keep growing. However, if necessary, it can be expanded with custom actions.ADF also lets.NET code run to meet any needs that aren't covered by the built-in features.
Out-of-the-box monitoring and management The Data Factory service offers a monitoring dashboard with a comprehensive view of services for data movement, processing, and storage.
Using this dashboard, system health and issues can be tracked and corrective actions are taken.
Works with both on-premises and cloud data sources Data Factory works with both cloud and on-premises data sources.
ADF is integrated with Azure Resource Manager and is fully integrated into the Azure infrastructure (ARM). This means that Data Factory makes use of Azure's management and deployment capabilities.
The Azure Data Factory Process
The interaction for Sky blue Information Industrial facility can be summed up by the accompanying realistic:
Through the creation of an object known as a Linked Service, you can connect to a wide range of data sources that Data Factory supports.
You can do this to prepare the data for transformation and/or analysis by ingesting it from a data source. Linked Services can also start to compute services when needed.
For example, if you want to process data using a Hive query, you might need to start an on-demand Hadoop cluster. As a result, Linked Services enables you to define the compute resources that are required to ingest and prepare data, also known as data sources.
A Datasets object is used by Azure Data Factory to acquire data once the linked service has been defined. Within the data store that the Linked Service object is referencing, datasets are the data structures.
An Activity is an ADF process that can also make use of datasets. The Azure Data Factory's work's transformation logic or analysis commands are typically contained in activities.
To transform the data, this could be accomplished by running a stored procedure, a Hive Query, or a Pig script. With Data Lake Analytics, you can perform analysis by either pushing data into a Machine Learning model or using U-SQL.
Data transformation with a SQL stored procedure and then Data Lake Analytics with USQL are two examples of the many activities that can occur simultaneously.
Using an object known as a Pipeline, multiple activities can be logically grouped together.
You can then use Data Factory to publish the final dataset to another linked service using Power BI or Machine Learning technologies once the work is finished.
I hope that my article was beneficial to you. To learn more, click the link here
1 note
·
View note