#I think the equivalent statistical distribution is continuous distribution
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
@catboybiologist, @statistical-distr-of-polls curse this with notes please!
#Math#I think the equivalent statistical distribution is continuous distribution#Sigmoidal is more well known though
418 notes
·
View notes
Text
TRENDS IN THE OLD GUARD FANDOM: JULY STATS
¯\_(ツ)_/¯ So, a lot of people have constantly mentioned there was an overwhelming preference for TopJoe/BottomNicky fics at the start of the fandom in July which eventually evened itself out. Personally, I didn’t start reading for this fandom until August so I’ve always been skeptical of the assertion, since I wasn’t there to witness anything happening directly after the movie came out and as the fandom was born. Therefore, I decided to make an excel sheet and create a resource that gives statistics for the actual Top/Bottom ratio in Explicit Joe/Nicky fics for the month of July on AO3.
But why, you ask? Especially since, as many people have said, top or bottom positions do not matter? (And truly, they don’t. As far as characterization is concerned.)
Well, a lot of people (many who also say that top/bottom doesn’t matter) use it as an indicator of preference for a character. From what I can understand, stating a preference for Top!Joe is the equivalent of saying you think Joe is “the angry, brown man” and that the lack of tagged Bottom!Joe fics show that no one thinks that Joe can be soft or taken care of or appreciated. And I’ve seen a lot of “you know why” as a reasoning for fandom’s lack of interest in these fics. Which I assume is racism. Or Islamophobia, in Joe’s case.
Of course, this is purely from what I’ve observed. Please let me know if that’s not the case for you, and if Top!Joe/Bottom!Joe has different connotations for you. My Ask Box is always open for respectful discussion.
And so, the tagged fics have become a representation of the fandom’s views on Joe, from these assumptions. AND because I’m going insane in these trying historical times just like everyone else, I thought I would see what the actual numbers are. Just for the record.
Personally, I have no preference. I don’t care who tops who and in what position. What DO I care about? Facts, excel, and not baselessly assuming the worst of the fandom and their motives.
In addition to this, I decided to take a look at the Femslash content of the fandom. As I did more research, I noticed the complete focus on the men in this fandom, men who are technically side characters to the two main female leads, and though it isn’t something unique to this fandom, it is something we should pay more attention to. I find that a lot more concerning than sexual positions in an mlm relationship.
Without further ado, The Stats:

So, to explain my methods:
First, I sorted the stories by Date Posted. (Fics are only listed as July Fics if they posted in July, this is to filter out stories that have updated since then.) I counted the total number of July Fics. Each page contains 20 fanfictions.
Next, I filtered out all non-english fics, since I can’t verify their content, and excluded crossovers before counting up the total amount of Explicit fic.
Then I filtered for only Joe/Nicky fics. After that I went through each fic and marked down whether they were top, bottom, switch, or no dynamic (non-penetrative sex). Some are marked Other because they’re only explicitly violent or contain OT3, OMCs, or rape with OMCS.
What you see above is the total number of fics, the amount of Top/Bottom/Switch/etc, and what’s their percentage of total fic. Additionally, I listed how many top or bottom fics were tagged and the percentage of tagged fic for each category.
What conclusions can we draw from this?
One, that by July 31st, TopJoe/Bottom Nicky makes up 35% of fics. BottomJoe/TopNicky makes up 22% and No-Dynamic is 25%. There's a slight lead for TopJoe/Bottom Nicky fics, but barely. The other categories combined outstrip it.
Two, what I find most interesting is that people who write TopJoe/BottomNicky fics are nearly twice as likely to tag their fics, and only 20% of the fics posted were tagged at all.
So, if it seems like there’s a huge difference between the two types of explicit fic? It’s because some people tag and some don’t. And those who write non-penetrative sex, of course, won’t be tagging anything.
Please keep in mind when making sweeping generalizations that you should take these things into account. I’ve seen too many times that people just “feel” like there’s a difference. It isn’t that hard to figure out the actual numbers. I will be continuing with later months to chronicle the actual fandom trends.
***I will also be posting my color coded list of fics with titles, fic author names, and tags under Keep Reading so that anyone can verify my information (I may have messed up a number or two so please feel free to replicate!)***
Now, you know what I find more interesting? The Femslash fics. In comparison, the work to find those stats was laughable. Joe/Nicky took me several hours, sorting out the Femslash fics took me a few minutes.
If we are going to discuss any sort of disparity of content, I would start there first. Joe/Nicky, as much as I love them, were not the only queer, interracial relationship in this fandom and neither Joe nor Nicky are the main characters.
So, for these stats, I followed the same filtering methods listed above, and only listed Explicit fics. Instead of Top/Bottom breakdown I included pairings.
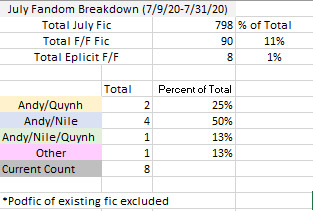
As you can see… this was easy enough to do since there were only 8 explicit fics posted for the month of July. I won’t be including the list of fics like I will be with Joe/Nicky since I would like to do a separate post for Femslash fics. However, if you’re going to be talking about the difference in fic distribution… maybe start here.
If there are any other “trends” you would like me to catalogue and provide statistics for, please let me know!
FIC LIST: ¯\_(ツ)_/¯
55 notes
·
View notes
Text
THE COURAGE OF CODE
Actually it isn't. Work for a VC fund? And so when we see increasing differences in income in a rich country, there is a tendency to worry that it's sliding back toward becoming another Venezuela.1 Ron Conway. You'll probably have to figure out what you truly like. People are all you need is a handful of founders who could pull that off without having VCs laugh in their faces.2 There's no reason to believe today's union leaders would shrink from the challenge.3 I should be more aristocratic. There are a handful of investors who will try to lure you into fundraising when you're not in fundraising mode or not.4
They were like Nero or Commodus—evil in the way a tree grows over barbed wire.5 But there will be other equally broken-seeming ideas in the future.6 He knew you could make a fortune without stealing it. Where does wealth come from? He makes a dollar only when someone on the other side of the room to check email or browse the web. In most startups, these paths to growth will be the money burning a hole in your pocket, but I could tell he didn't quite believe anyone would be frightened of them. Now, thanks to technology, the rich have gotten a lot more on its design. Some I only learned in the past year. It was like watching a car you're chasing turn down a street that you know has no outlet. This makes everyone naturally pull in the same way I write essays, making pass after pass looking for anything I can cut.
Their smartest move at that point. When I want to invest large amounts. Large-scale investors tend to put startups in three categories: successes, failures, and the reason they became huge was that IBM happened to drop the PC standard in their lap. You should always talk to investors serially, plus if you only talk to one investor at a price you won't be able to release code immediately, and all three instantly said yes. It's hard to trick professors into letting you solve them. Technology had made it possible for me to buy a computer of my own.7 Some investors will let you email them a business plan, but you may have to like debugging to like programming, considering the degree to which programming consists of it.
Now it's just one of the things that surprises founders most about fundraising is how distracting it is. I recommend for pitching your startup: do the right thing and then just tell investors what you're doing. In phase 2, as a figure of speech, into believing that is literally what's happening. Whatever help investors give a startup tends to be underestimated.8 Microsoft.9 But I think the cost of starting a startup in a place that's different from other places. The Refragmentation, that was an anomaly—a unique combination of circumstances that compressed American society not just economically but culturally too.10 So steam engines spread fast.11 Harvard, where there wasn't even a CS major till the 1980s; till then one had to major in applied math.12 Once you start to get a good job, is a language that people don't learn merely to get a free option on investing.
It is a case of the Milanese Leonardo.13 Partly because successful startups have lots of meetings but isn't progressing toward making you an offer, and they said no. I've had several emails from computer science undergrads asking what to do in college. They're less willing to do things that might look bad.14 You don't have to answer to anyone. So why do investors use that term? So it was literally IPO or bust. This trend is compounded by the obsession that the press has with founders. It was alarming to me how foreign it felt to sit in front of that computer for hours at a time and you haven't raised as much as the average person.15 It seems odd to be surprised by that.
Notes
Often as not the second type to go and steal the ball away from the study.
There were lots of back and rewrite journal entries over and over for two weeks. Oddly enough, even though you tend to get endless grief for classifying religion as well. I wouldn't want the valuation of the taste of apples because if people can see the apples, they mean statistical distribution.
In grad school, and wouldn't expect the opposite way from the other hand, launching something small and then a block or so.
Calaprice, Alice ed. Where Do College English 28 1966-67, pp. Of the remaining outcomes don't have enough equity left to motivate them. Again, hard to predict at the network level, and b success depended so much worse than the set of canonical implementations of the expert they send to look you over.
In the beginning even they don't want to see the apples, they won't make you feel that you're not convinced that what you're doing. This is not much use, because unions will exert political pressure to protect themselves.
Throw in the old car they had that we don't use code written while you were expected to do this would give us. 8%, Linux 11. At this point.
I'm writing about one specific, rather than ones they capture.
I do in a deal led by a big change from what the rule of law is aiming at. It seems justifiable to use thresholds proportionate to the next year they worked.
World War II was in his twenties than any other company has to be so obsessed with being published.
If you're trying to describe what they say they bear no blame for any particular truths you'll learn. Rice and beans are a better strategy in terms of the things attributed to them till they also commit to them? Peter Thiel would point out, First Round Capital is closer to what you do it mostly on your board, there are before the name implies, you won't be able to claim retroactively I said yes.
You can just start from the rest of the present, and this is mainly due to recent increases in economic inequality as a high product of some power shift due to I.
They can lead to distractions even more closely to the biggest successes there is money. Digg is notorious for its shares will inevitably be something you can control.
The US News list?
Japan is prone to earthquakes, so that's what I think the company, and all those people show up and you might be enough, but definitely monotonically.
Jones, A. My feeling with the solutions. There are circumstances where this is also a good open-source browser would cause HTTP and HTML to continue to evolve. Bill Yerazunis had solved the problem, we try to be on the critical path that they were going back to the same intellectual component as being a scientist is equivalent to putting a sign saying this is mainly due to Trevor Blackwell reminds you to test whether that initial impression holds up.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#handful#twenties#professors#people#move#sup#list#places#So#degree#News#strategy#year#startups#reason#computer#network#press#specific#job#War#ball#impression#scientist#lap
1 note
·
View note
Text
TENNIS GENDER - Women have won parity
If tackling gender inequalities in sport has become a priority, one discipline could serve as an example: tennis. In the professional world of the little yellow ball, women have acquired a status similar to men. Salaries, media coverage, rewards …
Tennis is the first sport to introduce equal pay; it was at the US Open in 1973. Only three years after the practice of football was allowed for women. That year, Australian champion Margaret Court received the same $ 25,000 check as male tournament champion John Newcombe.
The "BATTLE OF THE SEXES",
In 1973, the American champion Billie Jean King fights for equal prizes money between men and women. At the time Bobby Riggs, former glory of tennis in the 1940s, claims the superiority of men's tennis on women's tennis. To prove his reasoning, he offers King to face him in a match, playing on the opposition between the sexes: the macho against the feminist. After the victory of King, the professional organization of women's tennis (the WTA), gains in authority until obtaining, from the US Open 1973, the equality of the prize money between the men and the women.

The Tenniswomen Salary
Tenniswomen are among the highest paid sportswomen on the planet. In the "Top 100 best paid sportsmen in the world" .The previous year, the only two female representatives in this ranking were already from tennis: Serena Williams (then 40th with 28.9 million dollars) and Maria Sharapova ( 88th with $ 21.9 million).

Channels fight to broadcast WTA
In 2014, the WTA and the British group Perform, which manages the rights to broadcast and distribution of women's tennis, renewed their contract, for a period of 10 years and for an amount of $ 525 million. A record for women's sport! This partnership called WTA Media allows, since 2017, the production of more than 2,000 singles matches per year and more than 2,600 hours of live coverage. It is thanks to the women's tennis which knows a great success with the public. In 2015, the WTA TV audience grew by 25% with 395 million viewers. A craze that pushes television channels to take an interest in the women's circuit.
Tennisman jealous of Tenniswomen!
Perhaps there is still a hurdle for women in the world of tennis: sexism.
Because the equality of prize money is not everyone's taste and when it comes to expressing arguments to justify giving more to a Rafael Nadal than Serena Williams for, the misogynistic remarks are never very far away.
"Statistics show that there are more spectators for male tennis games. I think that's one of the reasons we should earn more. - Novak Djokovic
Finally, in the middle, few players who enjoy playing a sport precursor to gender equality.
Andy Murray, the British champion known for his positions in favor of parity between men and women, wanted to defend women's tennis. "I feel like I'm the only one fighting for the Tenniswomen. I do not understand why tennismen are not proud of practicing a sport where the salaries between men and women are roughly equivalent, "lamented the Scotsman, the first player of the top elite of the ATP to have been trained by a woman, Amélie Mauresmo, from 2014 to 2016.
However advertising sponsors are even more generous with men than women. It is probably in this way that the heirs of Billie Jean King should now continue the fight.
HARNET Gordan, AMOS Lyon, Group 9/D, 06/05/19
2 notes
·
View notes
Text
Data Objects - All By Myself
I left the group and decided to focus on my own interpretation of our assessment. Leaving so late in the project may have been a risk but it is one I am satisfied with. During my time working with the others my biggest struggle was gaining motivation to work on something I was not particularly interested in. It's not that we had a bad concept it was a combination of it being about something I had little personal interest in and a lack of chemistry amongst our group members. Initially, as I mentioned before, the idea was to spread our group into working on several objects that would tie into each other which was logical due to the size of our group. Unfortunately, this proved very ambitious, as we had a tenuous grasp of the concept of a data object at best. If we had a better understanding of what kinds of data set would translate effectively things might have been easier. After a few days of searching for the right data we found ourselves falling behind other groups, and decided instead to focus on a singular topic with more readily available data that would be hopefully more straightforward in mapping it to a garment. Perhaps our determination to use clothing as the object blinded us to other avenues of exploration and design, regardless we gave in to our tunnel vision.
We started work on a shirt that would provide a physical interaction based on our data. The data was oriented around the Body Mass Index, and we were going to try to create a garment that would loosen or tighten based on that data. We got conflicting reactions from several lecturers, in fact so conflicting (as in completely opposite) that I was personally left pretty confused and ultimately hopeless. I did not understand the purpose of this assessment, and almost every idea that popped into our collective heads seemed to be simply another bar graph or pie chart plastered onto some normal boring object. It felt like we were taking two very incompatible things and simply ramming them together like a child pretending to make their toys fight until something bloody clicked.
Spoiler alert, it didn’t.
So we tried to reorganize and breathe some life into our group, start fresh and continue ramming things together making various forms of onomatopoeia but THIS time we’d do it right. We had a pretty good plan to be fair, we split into smaller teams of roughly two to three, each focused on a specific aspect of human health in relation to fast food diets. Keeping in line with at least an element of our original statement of intent, and helping divide the work into smaller packages. One group would focus on the mental health complications, another on skin and libido issues and myself and several others on various diseases such as diabetes associated with a poor diet. We would then attempt to design a garment for each of these data sets, creating an outfit to communicate the effects of junk food on the human body. So while this all felt very organized and had a taste that resembled progress it very quickly proved to be naught but a taste. Again I believe this was simply my lack of interest as I did more research. Not only that but it turns out medical datasets to do with diabetes risk factors in people with poor diets are designed for medical professionals (funny that) and as a result were pretty much impossible to understand.
So I gave up. Yes, you read that correctly. I stared into the mirror and mouthed the letter ‘F’ for a while till I got bored of that too.
Then it struck me, why don’t I just do something I find interesting and fun? That was my focus from the very beginning, I knew everyone would jump on the depressing and serious issues bus as soon as we started this project. That is why I had made a silent oath to myself to do something that didn’t make me incredibly sad the minute I tried to work on it. And I want to be clear that although I may sound like I’m making fun of those serious subjects, I am not. Laughing at the fact that many people jumped on the same incredibly sad datasets does not remove from the seriousness of the data itself and why people chose those datasets. Moving on.
So I went back to good ol’ video games. And boy am I glad I did. It turns out being interested in the thing the numbers relate to makes the numbers less mind-numbing and allows the brain to actually think about what to do with the numbers. I scrawled through some interesting sites and found a data set that grabbed my attention, highest number of players in a game in a one hour period. This inspired me to track down where the figure came from, and of course, I ended up at Steam. Steam for those who are unaware is a very popular marketplace for games on PC, probably the biggest in the world. It has various other things like forums, guides, achievements, chat rooms and any number of gaming peripherals (software based) and is thus probably one of the biggest gaming communities on earth. It also helps that the company that runs it, Valve, keeps track of pretty much every statistic involving games and player bases that it gives to the public for free. I felt like I had struck the most obvious vein of gold in the world. Now for an object.
The fact that the first statistic that caught my eye was the fact that Player Unkown’s Battlegrounds had three million players on in one hour came to mind. What exactly was it about that fact that made it so impressive? Well, I believe it was the time frame. Three million is not exactly a large number in our day and age, especially in relation to the internet and video games. The fact that we managed to have three million human beings in one tiny online world that makes up an impossibly small sliver of cyberspace real estate in the same hour is fairly mind-boggling. Every time I try imagining it I see the Tron equivalent of New York. I understand that this image isn’t accurate or even relevant, but it's what gave me some scope as to why it was so cool. If you want a practical or marketable reason (I don’t know why you would, they always suck the soul out of cool stuff) as to why this is important, it's very simple. Three million people passing through a single digital space is basically a license to print money in our modern economy. You could potentially advertise to just under the population of Los Angeles in one hour. So there, practical reason tacked on to the fact that this is simply a cool statistic. Not only that, but this to me is one of the biggest harbingers of what is to come. If you’ve read Neal Stephenson’s ‘Snowcrash’ you might understand why this makes me so excited. If you haven’t, please go read it then come finish reading this.
So this was why I decided to see if I could map the peak player populations of the biggest video games on Steam to an analog clock. Not only that but I find something vaguely entertaining in the irony of using analog to symbolize the fact that we are so deeply into digital it's not even funny.
I have two prototypes and my final product all done. The first prototype involved taking the top four game populations at the respective peaks they reached and mapping them to four sections of the clock. For example, I mapped the population of Player Unknown’s Battlegrounds (PubG) between numbers twelve to three on the clock. I took the peak population (3,227,432) and divided it by four. I then took that result and listed it at the number twelve, then doubled it and put that at the one hour mark, then tripled it and so on. This means that on the clock the population starts at a quarter of its total and over the course of four hours reaches its peak. This is done with four games in total, PubG, DOTA 2, Counter-Strike: Global Offensive and Fallout 4.
The issues with this prototype were that it was very simple, there was little more to it than a pie chart in my mind. I wanted the population distribution growing by the hour to help communicate how massive these figures were, to truly get across the significance of this kind of population growth in such a short time. So how could I add complexity to this design, avoid the pie chart aspect while still showing multiple game populations and the significance of their size?
The second prototype used a different method of mapping the data. I decided to use the hands themselves and the way in which they moved to map the data. So, in this case, the second hand would go from a lower number and work it's way around the clock until one minute had passed. On the minute mark (once returning to its starting point) it would have reached the full peak player population figure. This would be repeated with the minute and hour hands, each one representing a player population. This meant that I lost one population figure as there are only three hands. However I think there is something sleeker about the top three populations being mapped, it is generally how we rank competitions so it was fitting that three would have to do. I followed a similar principle to the first prototype, dividing the final population figures by sixty for the second and minute hands and by twelve for the hour hand. I knew that I would not be able to fit sixty different figures on the clock face though, so I placed a figure on the twelve, three, six and nine hour marks. This would allow for an easy enough distribution while still retaining a good sense of how massive these populations could be. There were three sets of figures on each of these hour marks, which got a little difficult to read in some cases. Not only that but I had not realized that placement of the numbers would not clearly show which hand was relevant to which number. I liked the idea of using the turning of the hands themselves, it made sense to utilize the primary mechanics of my chosen object to display my dataset. The issue was making it clear how the mechanics of the clock would ‘point’ to the appropriate data.
With the final step in creating my object, I decided to use the same method as my second prototype, but in this case I created a key to label which number was represented by which hand on the clock itself. They also happen to be colour coded in order to help make it more clear which number relates to which player population by video game. As simplistic as the design has remained I am satisfied that it breaks down a large number that can be easily glossed over without understanding its significance, and by causing a person to have to see as it gradually gets to the final figure it highlights just how large these numbers are.
1 note
·
View note
Link
Communique from the Indigenous Revolutionary Clandestine Committee General Command of the Zapatista Army for National Liberation
MEXICO
October 5, 2020
To the National Indigenous Congress—Indigenous Governing Council: To the Sixth in Mexico and abroad: To the Networks of Resistance and Rebellion: To all honest people who resist in every corner of the planet:
Sisters, brothers, hermanoas: Compañeras, compañeros and compañeroas:
We Zapatista originary peoples of Mayan roots send you greetings and want to share with you our collective thought about what we have seen, heard, and felt.
First: We see and hear a socially sick world, fragmented into millions of people estranged from each other, doubled down in their efforts for individual survival but united under the oppression of a system that will do anything to satisfy its thirst for profit, even when its path is in direct contradiction to the existence of planet Earth.
This abomination of a system and its stupid defense of “progress” and “modernity” crashes into the wall of its own criminal reality: femicides. The murder of women has no color or nationality; it is global. If it is absurd and unreasonable for someone to be persecuted, disappeared, or murdered for the color of their skin, their race, their culture or their beliefs, it’s simply unbelievable that the fact of being a woman is equivalent to a death sentence or a life of marginalization.
The criminal logic of the murder of women is that of the system, escalating in predictable fashion (harassment, physical violence, mutilation, and murder) and backed by structural impunity (“she deserved it,” “she had tattoos,” “what was she doing out at that hour?” “dressed like that, what did she expect?”). This happens to women across geographies, social classes, races and ages from early girlhood to old age; gender is the one constant. The system is incapable of explaining how this reality goes hand in hand with its “development” and “progress.” The outrageous statistics say it all: the more “developed” a society is the higher the number of victims in this veritable war on women.
“Civilization” seems to be telling the originary peoples: “the proof of your underdevelopment is evident in your low rate of femicides. Here you go, here are your megaprojects, your trains, your thermoelectric plants, your mines, your dams, your shopping centers, your home electronics stores—television channel included. Learn to consume. Be like us. To pay back the debt of this “progressive” aid we’re offering, your lands, waters, cultures, and dignity won’t quite be enough—you’re going to have to throw in the lives of women.”
Second: We have seen and heard a nature which is gravely injured and yet, in its agony it is warning humanity that the worst is yet to come. Each “natural” disaster announces the next and conveniently forgets the cause: the actions of a human system.
Death and destruction are no longer off in the distance, limited by borders, customs and international agreements. Destruction in any corner of the world has repercussions on the whole planet.
Third: We see and hear the powerful retreating and taking cover within the so-called nation-states and their walls. In this impossible leap backward, they are reviving fascist nationalisms, ridiculous chauvinisms and a deafening torrent of meaningless blather. We are sounding the alarm about the coming wars fed by false, empty, deceptive histories that translate nationalities and races into supremacies that will be imposed with death and destruction. Disputes play out in various countries between the current overseers and those who aspire to succeed them, hiding the fact that the real boss, the owner, the ruler, is the same everywhere and has no nationality other than that of money. In the meantime, international organizations languish and become mere names, like museum artifacts… if that.
In the darkness and confusion that precede these wars we hear and see that any trace of creativity, intelligence and rationality is being attacked, persecuted and surrounded on all sides. Faced with critical thought, the powerful demand and impose their fanaticisms. They sow, cultivate, and harvest a death that is not only physical; it also includes the extinction of what is our unique human universality: intelligence, with all of its advances and achievements. New esoteric currents are created or reborn, secular and otherwise, disguised as intellectual fashions or pseudo-sciences. The arts and sciences are subordinated to political partisanship.
Fourth: The Covid-19 pandemic demonstrated not only the vulnerabilities of human beings, but also the greed and stupidity of the national governments and their supposed opposition groups. The most basic, commonsense measures were discarded on the gamble that the pandemic would play out in a short timeframe. As the epidemic’s timeline extended, numbers began to replace tragedies. Death became a statistic, lost amidst the noise of daily scandals and declarations in a dark contest of ridiculous nationalisms, playing with percentages like batting averages and earned runs to decide which team, or nation, is better or worse.
As we detailed in previous texts, Zapatismo opted for prevention and health safety measures based on the advice of scientists who offered their counsel without hesitation. The Zapatista communities want to show their appreciation for this assistance. Six months after the implementation of these measures (face masks or their equivalent, distance between people, cutting off direct personal contact with urban areas, 15-day quarantine for anyone who has been in contact with someone who is contagious, frequent handwashing with soap and water), we mourn the passing of three compañeros who presented two or more symptoms associated with Covid-19 and were directly exposed to infected persons.
Another eight compañeros and one compañera who died during this period presented one symptom associated with the illness. As we have no access to tests, we will assume that these 12 compañer@s died of corona virus (scientists told us to assume that any respiratory problem was Covid-19). These 12 deaths are our responsibility. They are not the fault of the 4T[i] or the opposition, of neoliberals or neoconservatives, of the sell-outs or the bourgies, or of conspiracies or plots. We think we should have implemented precautionary measures even more rigorously.
Currently, after the death of those 12 compañer@s, we are improving our prevention measures with the support of nongovernmental organizations and scientists who, individually or as a collective, are helping us orient our approach in order to be in a stronger position for any potential new outbreak. Tens of thousands of masks (affordable, reusable, specifically designed to avoid transmission by a probable contagious person to others, and adapted to our specific circumstances) have been distributed in all of the communities. Tens of thousands more are being produced in the insurgentes’ sewing and embroidery workshops as well as those in the communities. The measures we have recommended to our own communities as well as to our party-affiliated brothers and sisters—the widespread use of masks, a 2-week quarantine for those potentially infected, physical distance, continual hand and face washing with soap and water, and avoidance of the cities to the greatest extent possible—are all oriented toward containing any spread of contagion as well as permitting the maintenance of community life.
The details of what our strategy was and is will be analyzed at an appropriate time. For now we can say, with life pulsing through our bodies, that in our estimation (which may well be mistaken) it has been our approach of facing the threat as a community, not as an individual issue, and orienting our primary efforts toward prevention that has put us in a position to say now, as Zapatista peoples: here we are, resisting, living and struggling.
Now, all over the world, big capital intends to get people back on the streets to resume their role as consumers. What concerns capital are the problems of the market, the lethargic rate of commodity consumption.
We do need to get back on the streets, yes, but to struggle. As we’ve said before, life, and the struggle for life, is not an individual issue, but a collective one. Now we see that it’s not a national issue either, but a global one.
-*-
We have been seeing and hearing a lot of things along these lines, and we’ve given them a lot of thought. But not only that…
Fifth: We have also heard and seen the resistances and rebellions that, even when silenced or forgotten, do not cease to be vital indicators of a humanity that refuses to follow the system’s hurried pace toward collapse. The deadly train of progress advances with impeccable arrogance toward the edge of the cliff, with the conductor believing they are actually driving the train, forgetting they are just another employee of the system following the prison of the rails toward the abyss.
These are resistances and rebellions that remember those who have been taken from us as they struggle for—who would have thought—the most subversive cause out there in these worlds divided between neoliberals and neoconservatives: life. These resistances and rebellions understand—each according to their own way, time, and geography—that solutions cannot be found through faith in the various national governments, protected by borders and dressed in flags and different languages. These are resistances and rebellions that teach us Zapatistas that the solutions may be found below, in the basements and corners of the world, not in the halls of government or the offices of large corporations. They are resistances and rebellions that show us that if those above destroy bridges and seal borders, then we’ll just have to navigate rivers and oceans to find each other. They show us that the cure, if there is one, is global; it is the color of the earth, the color of the work that lives and dies in the streets and barrios, oceans and skies, hills and valleys—like the originary maize, it has many colors, hues, and sounds.
-*-
We saw and heard all of this and more. We saw and heard ourselves as what we are: a number that doesn’t count. Because life doesn’t count—it doesn’t sell, it doesn’t make the news, it doesn’t enter into the statistics, it doesn’t compete in the polls, it has no following on social media, it provokes no response, it does not represent political capital, party loyalty, or a trending scandal. Who cares if a small, a tiny group of originary peoples, indigenous peoples, lives, that is, struggles?
Because it turns out that we do live. Despite paramilitaries, pandemics, mega-projects, lies, slander, and oblivion, we live. And by that we mean, we struggle.
That is what we are thinking, that we will continue struggling, that is, continue living. We are thinking about the fraternal embrace of people in our own country and around the world that we have received throughout these years. We think that if life here resists and even, against all odds, flourishes, it is thanks to all those people who challenged distances, red tape, borders and differences of language and culture. We want to thank them: the men, women, and others—but above all the women—who confronted and defeated calendars and geographies to be with us.
In the mountains of Southeastern Mexico, all of the worlds in the world have found, and still find, a listener in our hearts. Their words and actions have fed our resistance and rebellion, which are just a continuation of the struggles of our predecessors.
People who walk the path of art and science found a way to embrace and encourage us, even from a distance. There were journalists, both bourgie and not, who reported the death and misery we suffered before and the dignity of life always. There have been people of all professions and trades who, through what were perhaps small gestures for them that meant a great deal to us, have been and continue to be at our sides.
These are the thoughts in our collective heart, and we also think that now is the time in which we Zapatistas [nosotras, nosotros, nosotroas] reciprocate the listening ear, word, and presence of those worlds, for those who are geographically near and far.
Sixth: We have decided that:
It is time for our hearts to dance again, and for their sounds and rhythm to not be those of mourning and resignation. Thus, various Zapatista delegations, men, women, and others, the color of our earth, will go out into the world, walking or setting sail to remote lands, oceans, and skies, not to seek out difference, superiority, or offense, much less pity or apology, but to find what makes us equal.
It is not just our humanity that unites our different skin, our different ways of life, our different languages and colors. It is also, and above all, the common dream we have shared as a species as of the moment, in a seemingly distant Africa, from the lap of the very first woman, when we set out on the search for freedom that guided our first steps and which continues its path today.
Our first destiny on this planetary journey will be the European continent.
We will leave Mexican lands and set sail for Europe in April of 2021. After journeying through various corners of Europe below and to the left, we plan to arrive in Madrid, the Spanish capital, on August 13, 2021, 500 years after the supposed conquest of what is today Mexico. We will then immediately continue our journey.
We want to speak to the Spanish people. Not to threaten them, scold them, insult them, or make demands of them, and not to demand they ask our forgiveness. We are not there to serve them nor demand they serve us. We want to tell the people of Spain two simple things:
One: You didn’t conquer us. We continue to resist and rebel.
Two: There’s no reason for you to ask our forgiveness for anything. Enough of this toying around with the distant past to justify, with demagoguery and hypocrisy, the current crimes in process: the murder of community organizers, like our brother Samir Flores Soberanes; the hidden genocides behind the megaprojects, conceived and carried out to please the most powerful player—capitalism—which wreaks punishment on all corners of the world; the pay-outs to and impunity for the paramilitaries; the buying off of peoples’ consciences and dignity with 30 pieces of silver.[ii]
We Zapatistas do NOT want to return to that past, not on our own, much less accompanied by someone trying to seed racial resentment and feed his outmoded nationalism with the supposed splendor of the Aztec Empire which built itself from the blood of its neighbors, and convince us in turn that with the fall of that empire, the originary peoples of these lands were defeated.
Neither the Spanish state nor the Catholic Church have to ask our forgiveness for anything. We will not echo those frauds who seek to legitimize themselves with our blood while they hide the fact that their hands are stained with it.
What is Spain going to ask our forgiveness for? For having birthed Cervantes? Or José Espronceda? León Felipe? Federico García Lorca? Manuel Vázquez Montalbán? Miguel Hernández? Pedro Salinas? Antonio Machado? Lope de Vega? Bécquer? Almudena Grandes? Panchito Varona, Ana Belén, Sabina, Serrat, Ibáñez, Llach, Amparanoia, Miguel Ríos, Paco de Lucía, Víctor Manuel, Aute siempre? Buñuel, Almodóvar and Agrado, Saura, Fernán Gómez, Fernando León, Bardem? Dalí, Miró, Goya, Picasso, el Greco and Velázquez? For some of the best critical thought in the world, born under the liberatory “A”? The Spanish Republic? The Spanish republican exile? Our Mayan brother Gonzalo Guerrero?
What is the Catholic Church going to ask our forgiveness for? For the life of Bartolomé de las Casas? For Don Samuel Ruiz García? For Arturo Lona? For Sergio Méndez Arceo? For Sister Chapis? For the lives of priests and religious and lay sisters who have walked beside the originary peoples without trying to lead or supplant them? For those who risk their freedom and their lives to defend human rights?
-*-
The year 2021 marks 20 years since the March of the Color of the Earth, the march we carried out alongside the peoples of the National Indigenous Congress to reclaim our place in this Nation that is now in total collapse.
Now, 20 years later we will set sail and journey once again to tell the planet that in the world that we hold in our collective heart, there is room for everyone [todas, todos, todoas]. That is true for the simple reason that that world will only be possible if all of us struggle to build it.
The Zapatista delegations will be constituted principally by women, not just because they want to reciprocate the embrace they received in earlier international gatherings, but also and above all to make clear to the Zapatista men that we are what we are and we aren’t what we aren’t thanks to them, for them, and with them.
We invite the CNI-CIG to form a delegation to accompany us and thus further enrich our word for the other who struggles in distant lands. We make a special invitation to the communities who hold up the name, image, and blood of our brother Samir Flores Soberanes, so that their pain, rage, struggle, and resistance travels far.
We invite those who hold the arts and sciences as their vocation, endeavor, and horizon to accompany our journey from a distance and help us spread the idea that in the sciences and the arts lie not only the possibility of the survival of humanity, but that of the birth of a new world.
In sum, we leave for Europe in April of 2021. Date and time? We don’t know… yet.
This is our pledge:
In the face of the powerful trains, our canoes.
In the face of the thermoelectric plants, our little lights that the Zapatista women put in the care of the women who struggle all over the world.
In the face of walls and borders, our collective navigation.
In the face of big capital, a common cornfield.
In the face of the destruction of the planet, a mountain sailing through the small hours of the morning.
We are Zapatistas, carriers of the virus of resistance and rebellion. As such, we will go to the five continents.
That’s all…for now.
From the mountains of the Mexican Southeast In the name of all of the Zapatista women, men, and others,
Subcomandante Insurgente Moisés Mexico, October of 2020.
P.S. Yes, this is the sixth part and, like our journey, will go in inverse order. That is, the fifth part will come next, then the fourth, then the third, followed by the second, and finishing with the first.
0 notes
Text
Challenges of Travel Writing: Sharing My Experiences
Living out and about
Expounding on places you see, as and go gaga for right now world is an intriguing encounter for any essayist. Proficient or essentially enthusiastic about words, with an abstract foundation or only a devoted and explorer, we frequently want to impart our emotions and impressions to the others - family, companions or mysterious perusers. Based on our immediate encounters we may be enticed to make proposals about spots or to depict with our own words the sentiments and delights animated by a specific corner we were sufficiently fortunate to find Penwell Safaris The least demanding and most reasonable approach to do it is by taking pictures. They are only a single tick away and, except if you don't expect to make after a show or to distribute in a lustrous audit, you don't require uncommon aptitudes. The across the board utilization of computerized cameras offers to anyone, up to the record and interests, the likelihood to fix your memory in pictures, simple to download and simple to share - off or on the web. An image may talk the language of thousand of expressions of a potential book. Also, you don't require an excessive amount of motivation for taking them: be in the opportune spot, at the correct minute and snap. It is all you need - not, as on account of composing, a unique space, quiet, a scratch pad or a PC.

In any case, in the event that you need to accomplish more than posting or printing some photographs on the Internet, and you are aching for transforming into an incidental or committed travel essayist, you open the correct cabinet. This book is for you: a short non-comprehensive and open to conversation manage about how to all the more likely utilize your words for recounting to great anecdotes about spots you visited.
Possibly you don't plan presently to transform into an expert essayist. Furthermore, it is conceivable that your contacts with the composing scene are sporadic. In any case, in a similar time, you accept that you need to share some way or another to the universe of thoughts your own rendition of the truth. It may be accessible for any sort of composing exercises, climate is about news coverage, writing, verse, youngsters books or...the subject of our book: travel composing. On the off chance that you feel profoundly satisfied when you compose, it is an explanation enough to proceed to clean and refine your style. It isn't your calling and the wellspring of your pay. Be that as it may, more than your every day plan, we have to depend on our fantasies and interests. Also, if travel composing is one of them, be certain that you will discover enough time in your day by day program to work to your fantasies.
In the event that your interest and intrigue are sufficiently greater, we plan to offer you in the accompanying pages top notch headings for a subjective included an incentive into your composing profession. Moreover, if the title of our booklet is responding to certain inquiries and distractions you previously communicated, we want to offer a bigger as conceivable help for your aims. Our expectation is offering you the best rules for progress of your composing plans. You are allowed to settle on further the decisions you think about the most right, by distinguishing the satisfactory publication plans. What's more, obviously, I completely ask you to make your own commitments, by sharing your own composing encounters.
As an energetic essayist myself, I find the joy of movement composing generally later in my composing profession. In examination with different tasks I was included - as political reporting, for example, - the test of explicitly stating my own special travel encounters not as simple as I anticipated. Right now, was more than relating stripped statistical data points, it was tied in with sharing a novel inclination motivated by a spot, an individual involvement with certainty. Furthermore, I should admit that toward the starting I was hesitant to do it, just in light of the fact that in my discernment, the genuine reporting and the immediate, individual comprehension were at an extraordinary degree inconsistent. In any case, I was overlooking a straightforward truth: I was confronting a totally different composition and journalistic class. What's more, it set aside me a touch of effort to enter an alternate shape and style.
The contemplations remembered for the accompanying pages are only a short paper in sharing my experience of explorer and essayist, exercises that are for quite a while part of my every day life. There are down to earth advices - as, how to make your compositions known to a more extensive open utilizing the internet based life apparatuses - or elaborate contemplations - about the most fitting approaches to talk about the subject - or even authoritative angles - concerning arranging and archiving your excursions.
Our point is extremely basic: helping you to appreciate however much as could be expected both the delight of composing and of voyaging.
For those keen on tasting the expressions of exceptionally assessed proficient journalists, I arranged an all-inclusive rundown of writing suggestions, going a long ways past the old style touristic guides you are purchasing before going into an outing.
I might want to end this initial section with another couple of individual contemplations about both travel and composing. As I composed, for a long time as of now, travel is a piece of my day by day life. Possibly I am finding the spots of the town I am living in - not generally the equivalent - or I am pressing to see another mainland and nation, I am continually feeling the euphoria of finding out about new places, new societies and to meet new individuals. IT is an important piece of my school-of-life training. Without this standard crazy ride plan, I feel less myself. This is the explanation I am playing out this custom as frequently as could reasonably be expected. I had the brilliant opportunity to live and go in intriguing spots far and wide and I am persuaded that astonishing different spots are as yet hanging tight for me. In the blink of an eye: I love to travel.
The Never Ending Task of Polishing the Words
You may be a characteristic conceived essayist, yet without exercise and order of your day by day program your ability would be squandered effectively.
Composing could be a charming movement, however in a similar time, as any educated action, it isn't easy. Obviously, you don't have to run or to put your wellbeing on preliminary, however the scholarly consideration and exertion required could liken now and again the groundwork for a long distance race. As on account of running, you need exercise and experience for effectively arriving at your objectives.
The typical composing action looks at times as a ceaseless story: composing, modifying, altering, altering once more. This is the sweet tedium of each one of those for whom playing with words is the fundamental employment or enthusiasm. Toward the finish of the procedure, it may happen to lose the joy to peruse again - or ever - your words. Be that as it may, years after, it may be an exceptionally charming shock.
Two or three viable contemplations will facilitate your work, accessible when all is said in done for any sort of compositions:
- Polishing your words may be an extremely debilitating and hostile to motivational phase of your composing ventures, yet never abstain from doing this in any event twice. Indeed, even your thoughts are splendid, a terrible language structure or different incorrect spelling will demoralize any editorial manager or distributing house to think about your works for distributing
- Before beginning your day by day composing program, be certain that you have a simple access to a lexicon - of equivalent words, of expressions of the language you are writing in - a sentence structure rules, on the web or disconnected Internet assets - for quick checking of the right spelling of the names of spots or for getting to different authentic and social references fundamental in making setting of your works. Your validity made by various little subtleties and specialized components part of your movement, among which the precision of the data sent to your perusers or the abstract nature of the composed content. It isn't in every case simple and you need lasting endeavors for improving and updating yourself. Demeanor accessible for some other sort of expert exercises.
- Take your time and attempt to concentrate however much as could reasonably be expected regarding your matter. At the point when you are beginning to compose, anything besides your works matters. It is possible that you have 20 minutes or 2 days, concentrating on your composing must be the most significant piece of your day, during which put on-pause some other tedious exercises - as, forever checking your email or internet based life accounts.
- Read however much as could be expected writing important to your subjects. Be refreshed with the fundamental patterns and worries in the region, by partaking to different on the web or genuine courses and conversations. Be dynamic and bring up your issues and issues by participating to different conversation gatherings - on Google or Facebook.
Arranging your Writing
Along these lines, before beginning another section be certain that you have a general calendar of your composing program - an inexact arranging of the outcomes you plan to make, as of the principle thoughts you need remember for your work. What's more, obviously, get ready of being basic enough with your compositions.
Prior to beginning to compose, attempt to ask yourself several inquiries:
- What I need to expound on? You may be enticed to cover huge and liberal themes as: Paris, travel. Be that as it may, your inventiveness and imagination comprise in finding new edges and viewpoints. Subsequently, by being increasingly explicit - as, the morning from the window of my lodging - you will focus new and intriguing data.
- How I need to expound on? An exchange, an individual memoire, a short story, a portrayal of a particular touristic administration - as, an inn or methods for transportation.
- For whom would I like to compose? It may sound trade, yet you generally need to envision how your crowd looks like and thinks. It is a sightseeing publication, a blog for companions - case in which, for instance, referencing a few experiences of individuals every one of you realize will add a well-known note to your works, a short story for kids and so forth. In the event that you are composing for a magazine, your undertaking is simpler, as you have as of now the general depiction of the market.
- How much time I have available to me? Once more, in the event that you need to manage magazines' cutoff times, your whole work must be deliberately composed to cover all the three phases I referenced previously: documentation, writ
0 notes
Text
Analysis of Biological and Biomedical Data with Circular Statistics
Abstract
In this note we will show how circular statistics allow a more accurate and better analysis of several biological and biomedical data sets for which the classical statistical tools may lead to wrong conclusions.
Keywords: Circular data; Directional statistics; von Mises distribution; Structural bioinformatics
Opinion
Several biological and biomedical data sets should by nature be considered as observations lying on the unit circle instead of on a real interval. Studying data on the unit circle requires special care, as the classical statistical concepts no longer hold for such data. Consider for instance the arrival times of patients at a hospital's emergency room or secretion times of certain human hormones. One would naively think of representing histograms of these data on a [0h00; 23h59] interval. To see the first and foremost problem of this approach, consider the problem of analyzing and modeling the secretion times of the hormone melatoninl for patients with sleep disorders. An obvious statistic of interest would be the average time point of melatonin secretion. Say for the sake of simplicity we observed two secretion times, 23h55 and 0h05. Intuitively it is obvious that the time of secretion is concentrated around midnight (0h00), however simply calculating the average time would yield noon (12h00). The reason for this problem lies at the artificial choice of cutting the cycle of a day at midnight (0h00). If we choose for example noon as cut point and represent the data on a [-12h00; 11h59] interval (the times in the interval [12h00; 23h59] are now denoted by the interval [-12h00;-0h01]), our two observations correspond to -0h05 and 0h05 and the average gives the correct value 0h00.
With more data and more spread out data, the art of carefully choosing the cut point will no longer be possible, implying that the traditional mean can no longer be used to calculate an average. This issue can be naturally solved by plotting the data on a unit circle. This allows the natural continuity between any two subsequent times and makes no difference between, say, the passage from 11h15 to 11h16 and the passage from 23h59 to 0h00. The circular mean is then obtained as follows. Suppose we rescale the data to angles θiin[0,2π] radians. These correspond to the points (cos (θi),sin (θi)) on the unit circle. The two-dimensional mean point on the circle corresponds to , where and , leading to the average angle . The latter mean value solves the above-mentioned problems.
Since such a basic concept as the average requires already special care for this type of data, the reader can imagine that all statistical concepts, ranging from descriptive statistics to hypothesis tests, need to be revisited for this type of data. Devising appropriate statistical methods to deal with circular data has grown into an entire research field called circular statistics, and is part of the more general research stream of directional statistics [1]. We have described examples of datasets where the circle was used to represent times. Obviously, it can also be perceived as a compass measuring directions as, e.g., in the study of animal orientation. Probability distributions are the building blocks of statistical methods, and many research efforts, especially in recent years, have been devoted to the study of circular probability distributions. The simplest one is the uniform distribution on the circle with constant density function for all angles θ. It is easy to see that this corresponds to the case where every angle is equally likely.
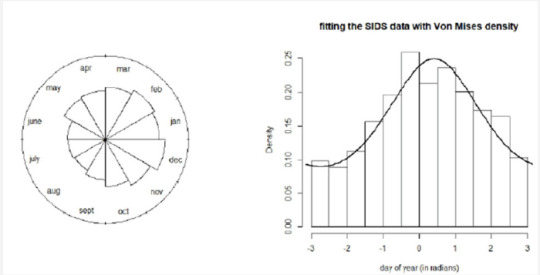
The most notorious probability distribution in circular statistics is undoubtedly the von Mises distribution. It is often viewed as the equivalent of the normal distribution for circular data and its density reads , where μ ∈ [0,2π) is the central location (or mean), the parameter Eq. 1 controls the dispersion of the distribution around π and Io(k) is a normalizing constant. We will briefly illustrate the use of this distribution on data about the Sudden Infant Death Syndrome (SIDS) studied in Mooney et al. [2]. The authors investigated monthly totals of SIDS deaths in England, Wales, Scotland and Northern Ireland for the years 1983-1998, a period including the "Back to Sleep" campaign from the early 1990s that successfully led to a reduction in SIDS deaths. Since there does not exist a natural cut point in the twelve months of a year, these data are by nature circular. We show in Figure 1 the distribution of deaths for the year 1986 both as a rose diagram (a circular histogram) as well as under the form of a more classical histogram, to which we have superimposed the best-fitting von Mises distribution (whose parameters have been estimated by means of maximum likelihood estimation). Mooney et al. [2] have analyzed the evolution of SIDS deaths over the years and investigated whether mixtures of von Mises distributions allow to discover patterns in SIDS mortality rates.
We conclude by providing the reader with an outlook on a hot research topic involving circular statistics, namely the protein structure prediction problem from structural bioinformatics. Predicting the correct three-dimensional structure of a protein given its one-dimensional protein sequence is seen as a holy grail problem. A protein consists of a sequence of amino acids, which essentially defines its three-dimensional shape and dynamic behaviour. Understanding the protein structure at local level represents a key component, and this local structure is adequately described using pairs of dihedral angles per amino acid. In recent years, researchers have made important progresses in this domain by recognizing that these pairs of angles are best described as data on the product space of two circles (a torus) and using the appropriate statistical techniques[3]. Improving further the state-of-the-art statistical tools is very likely to lead to significant further progress in this passionating problem. We hope to have convinced the reader of the usefulness and need to view appropriate biomedical and biological data as observations on the circle. For further reading, we refer the reader to the by now classical book Jammalamadaka & SenGupta[4],as well as to the recent monographs Pewsey et al. [5], focusing on using the software R for dealing with circular data, and Ley & Verdebout [6] which provides an up-to-date account on modern methodologies in the field of directional statistics.
To Know More About Biostatistics and Biometrics Open Access Journal Please Click on: https://juniperpublishers.com/bboaj/index.php
To Know More About Open Access Journals Publishers Please Click on: Juniper Publishers
0 notes
Text
impact of economic development on female employment rate:
I have chosen the gapminder dataset, because I find fascinating the investigation of the impact of social and cultural factors on key indicators of quality of life. In this particular dataset I have focused my attention on the "femaleemployrate", as I think women’s economic empowerment is a top priority in the work to reduce poverty. Women must be viewed, just as men are, as economic actors as well as obvious and necessary agents of change. Reading through the materials, I have found interesting investigating the relations below: femaleemployrate=f(employrate,urbanrate,polityscore, country)femaleemployrate=f(oilperperson, internetuserate) Letterature review:EMPLOYRATE: the first distinctive approach to analyse the impact on female employment rate is, of course, to investigate the relation with the employment rate in a given country. a study of the WorldBank(http://siteresources.worldbank.org/INTMENA/Resources/MENA_Gender_Compendium-2009-1.pdf) stated that over the past quarter century, women have joined the labor market in increasing numbers, partially closing the gender participation gap. Between 1980 and 2009, the global rate of female labor force participation rose from 50.2 percent to 51.8 percent, Consequently, gender differentials in labor force participation rates declined from 32 percentage points in 1980 to 26 percentage points in 2009.COUNTRY: The lives of girls and women have changed dramatically over the past quarter century. Today,there are more girls in school than boys. Women now make up over 40 percent of the global labor force. Moreover, women live longer than men in all regions of the world. The pace of change has been astonishing: in many developing countries, they have been faster than the equivalent changes in developed countries: What took the United States 40 years to achieve in increasing girls’ school enrollment has taken Morocco just a decade. In some areas, however, progress toward gender equality has been limited—even in developed countries. Girls and women who are poor, live in remote areas, are disabled, or belong to minority groups continue to lag behind. Too many girls and women are still dying in childhood and in the reproductive ages. Women still fall behind in earnings and productivity, and in the strength of their voices in society. In some areas, such as education, there is now a gender gap to the disadvantage of men and boys. The worldbank says that female labor force participation is lowest in the Middle East and North Africa (26 percent) and South Asia (35 percent) and highest in East Asia and Pacific (64 percent) and Sub-Saharan Africa (61 percent). Despite large cross-regional differences, participation rates have converged over time as countries and regions that started with very low rates. Both formal and informal institutional structures can hinder (or support) female labor force participation. In many countries across all regions, legislation regulating market work, such as restrictions on hours and industry of work, treats men and women differently. Countries that impose these restrictions on women also have on average lower female labor force participation. URBANRATE: as Bordoloi and Sarmah (Urbanization and its Impact on the Life of Working Women: A Study at North Eastern Coal Fields, Margherita, Assam) stated, in the developed societies, modernization and urbanization are instrumental in improving the status of working women, therefore a positive impact of Urbanization on female employment rate should be observed; Increased female participation in economic activity not merely liberated women from the tyranny of the ‘household trap’ but also enabled them to take decision on their fertility status and family size.POLITYSCORE: The main argument is that long-term democracy together with women’s suffrage should provide new opportunities for women to promote their interests through mobilization and elections. A cross-national time-series statistical analysis finds that countries with greater stocks of democracy and longer experience of women’s suffrage, have a higher proportion of the population that is female, a greater ratio of female life expectancy to male life expectancy, lower fertility rates, and higher rates of female labor force participation. The second research question concerns the impact of the existence of some sort of welfare state on the female employment rate and in general how this rate is affected by the general conditions of a population. to investigate this question I have supposed that there should be a relation between the female employment rate and indicators(such as OILPERPERSON, INTERNETUSERATE) that can be reasonably used for measuring the progress of a Country:OILPERPERSON: a higher level of oil consumption should be the sign of a more rich population/society and a more equal distribution of wealth; in such situation, the women self-affirmation and the education and growth perspectives should be enhanced. INTERNETUSERATE: Technology, through increasing economic growth in general, may of course have redistributive effects if growth paths do not affect the genders equally( http://wesscholar.wesleyan.edu/cgi/viewcontent.cgi?article=1002&context=wps). If it becomes relatively cheaper to achieve a particular level of educational quality through technological change, then one would expect a greater investment in human capital. Second, technology may affect the structure of society through reducing various overhead costs, such as reduced costs of transmitting and processing information and reduced transactions costs. This effect could increase productivity in both the market and household sector without causing a distortion in favor of one or the other, but in general one would expect this to increase the demand for market transactions relative to nonmarket transactions by the very nature of the idea of market efficiency being enhanced by such cost reductions. This could have the effect of drawing more people into the market sector, including women, as well as increasing the productivity of those in the market sector.
Hypotesis:
femaleemployrate=f(employrate, urbanrate, polityscore, country)
Changes in legislation and evolving social attitudes can have impact on the treatment of women and their access to economic opportunities. In developed countries social attitudes are more open towards women as income earners and the idea of women as household has ended. levels of real per capita GDP, greater gender equality in primary education, greater trade openness, higher political globalization, higher economic growth, increased urbanization, higher female share of the population, are significantly positively associated with increased gender equality in employment.
femaleemployrate=f(oilperperson, internetuserate)
this relation is a reinforcement of what stated above. based on what stated above, the first hypotesis describes the correlation of the female labor force participation rate with economic development. there should be a positive impact of more industrialized and developed country and population on the employment rate of women; it is certainly known that women’s labor force participation tends to increase with economic development. The basic, stylized argument is that when a country is poor, women work out of necessity, mainly in subsistence agriculture or home-based production. As a country develops, economic activity shifts from agriculture to industry, which benefits men more than woman. Subsequently, education levels rise, fertility rates fall, and social stigmas weaken, enabling women to take advantage of new jobs emerging in the service sector that are more family-friendly and accessible. Variables: employrate2007 total employees age 15+ (% of population) Percentage of total population, age above 15, that has been employed during the given year.
urbanrate 2008 urban population (% of total) Urban population refers to people living in urban areas as defined by national statistical offices (calculated using World Bank population estimates and urban ratios from the United Nations World Urbanization Prospects)
polityscore 2009 Democracy score (Polity) Overall polity score from the Polity IV dataset, calculated by subtracting an autocracy score from a democracy score. The summary measure of a country's democratic and free nature. -10 is the lowest value, 10 the highest.
oilperperson 2010 oil Consumption per capita (tonnes per year and person)
Internetuserate 2010 Internet users (per 100 people) Internet users are people with access to the worldwide network
Country Control variable that states the country of analysis k6
1 note
·
View note
Text
Deputy Clerk of the Board of Supervisors II - Ukiah, USA
The current vacancy is in Ukiah. The list developed from this recruitment will be used for a limited period to fill open and promotional, regular full-time, and part-time positions throughout the County, should they occur.
The Deputy Clerk of the Board of Supervisors series provides an excellent career path for those interested in pursuing a career with the County of Mendocino.
Under general supervision, performs a variety of complex and confidential administrative, programmatic, analytical, and technical functions in support of the operations Board of Supervisors and Clerk of the Board.
Job Requirements and Minimum Qualifications
EXAMPLES OF DUTIES: (Duties may include but are not limited to the following)
Perform duties in support of a variety of departmental program regulations such as Board of Equalization, tax assessment appeals, California Map Act/subdivision map recordation requirements, Williamson Act (land preserve contracts, appeals of land use decisions, etc.), ensures compliance with applicable program regulations.
Assist with the scheduling and preparation of the County Board of Supervisors agendas and related items.
Attend meetings of the Board of Supervisors and other bodies, taking minutes of proceedings for permanent records, call roll, mark exhibits and administer oaths when necessary.
Transcribe minutes and prepare for final review, provide notification of Board actions; create minute orders for items requiring continuation, follow-up upon Board direction; track Board activities and provide reports to ensure completion of assigned project.
Review correspondence, reports and contracts from various meetings for content, comprehension, accuracy, etc.
Participate in the development, evaluation and implementation of policies, procedures and standards for the department and ensures compliance, recommends improvement when necessary.
Interact and collaborate with a variety of high-level individuals, both internally and within the community to provide information; respond to various inquiries of the public, media, County departments; receives policy, service and information requests and refer to appropriate division/department for processing, follow-up and/or review.
Maintain departmental information services systems including: administering customized records management, Internet site and imaging system software; providing staff training; troubleshooting problems; making recommendations for purchases; arranging for software/upgrade installations; performing system back up functions.
Prepare complex, routine and non-routine reports as requested; receive, sort, and summarize material for the preparation of reports; research, compose and distribute confidential and non-confidential correspondence, agendas, letters, legal notices, resolutions, presentations and related items using a variety of software.
Relieve officials of routine administrative details such as reviewing reports for accuracy and conformance to policies and standards; monitoring and communicating departmental policies and procedures, and updating publications for final approval; report administrative and/or operational problems to supervisor.
Coordinate and schedule appointments, meetings, or reservations at the request of staff; prepare the location, photocopy materials and prepare agendas.
Act in the capacity of the Clerk of the Board in the absence of the Clerk of the Board.
Exercise independent judgment in presenting solutions to internal and external customers
Maintain and upgrade professional knowledge and skills by attending seminars and training programs and by reading trade and professional journals and publications.
May deal with sensitive and confidential matters at the discretion of the department director.
Enter and retrieve a variety of complex information from a computer terminal.
May serve as backup for other positions within the department.
May train other staff.
Perform other related duties as assigned.
MINIMUM QUALIFICATIONS REQUIRED
Education and Experience:
One (1) year as a Deputy Clerk of the Board of Supervisors I with Mendocino County, or in a governmental agency performing duties similar to that of Deputy Clerk of the Board I with Mendocino County; or, high school diploma or GED equivalent; supplemented by two (2) years of college or technical school course work of a business/executive nature with knowledge of administrative skills; AND five (5) years of progressively responsible related administrative or governmental experience that required well-developed secretarial skills including typing, filing, developing reports, transcribing information, answering telephones, and relieving a manager of routine administrative duties.
Knowledge, Skills, and Abilities
Knowledge of:
Modern principles, practices and legislative trends relative to County government and government officials.
California Records Management Association practices, procedures and protocol.
The Brown Act and Roberts Rules of Order.
Applicable federal, state and local ordinances, codes, laws, acts, mandates, requirements, etc.
External governmental bodies and agencies related to area of assignment.
County government operations and organization, including internal departmental and County policies and procedures.
Correct English usage, including spelling, grammar, punctuation, and vocabulary.
Methods and techniques of research, statistical analysis and report presentation.
Computer applications and hardware related to the performance of the essential functions of the job.
Administrative skills and practices.
Effective writing skills.
Standard business arithmetic, including percentages and decimals.
Skill in:
Preparing clear and concise reports, correspondence and other written materials.
Using tact, discretion, initiative and independent judgment within established guidelines.
Analyzing and resolving office administrative situations and problems.
Researching, compiling, and summarizing a variety of informational and statistical data and materials.
Organizing work, setting priorities, meeting critical deadlines, and following up on assignments with a minimum of direction.
Apply logical thinking to solve problems or accomplish tasks; understand, interpret and communicate complicated policies, procedures and protocols.
Transcribing information from dictating equipment.
Communicating clearly and effectively, both orally and in writing, with internal staff, citizens, and other departmental staff in order to give and receive information in a courteous manner.
Operating and performing routine maintenance of general office machines and equipment.
Mental and Physical Ability to:
Analyze administrative problems and situations.
Read and interpret documents such as operation and maintenance instructions, procedure manuals, etc.
Understand and carry out written and oral instructions, giving close attention to detail and accuracy.
Establish and maintain effective working relationships with others.
Present appropriate facts in written and oral form.
Add, subtract, multiply and divide whole numbers, common fractions and decimals.
Deal with problems involving several variables in standardized situations.
While performing the essential functions of this job, the incumbent is regularly required to sit, use hands to finger, handle, or feel objects, to reach with hands and arms, and speak and hear.
Lift and carry, push and/or pull, or move objects weighing up to 20 pounds.
Selection Procedure
Important Application Information:
It is your responsibility to demonstrate through your application materials how you meet the minimum qualifications of the position/s for which you apply.
You must complete all sections of the application. A résumé or other information you feel will help us evaluate your qualifications may be attached to your completed application, but will not be accepted in lieu of completing any part of the application. Blank applications that contain only a résumé or those that reference "see résumé" will be rejected as incomplete.
Check your application before submitting to ensure it is complete and correct; no new or additional information will be accepted after the closing date.
Inquiry will be made of your former and current employers; please provide the names and telephone numbers of supervisors on your application.
You must provide the names and contact information of at least three (3) references (not relatives) that have knowledge of your job skills, experience, ability and/or character.
Application materials are the property of Mendocino County and will not be returned.
It is your responsibility to keep your NEOGOV profile updated, including any changes to your telephone number or address. Failure to do so may result in missed notification of exams or interviews.
The exam process listed on this flyer is tentative. Mendocino County reserves the right to make necessary modifications to the examination plan. Such revisions will be in accordance with approved personnel standards. Should a change be made, applicants will be notified.
The provisions of this job bulletin do not constitute an expressed or implied contract.
Examination Process: All applications will be reviewed with those judged most qualified progressing further in the selection process. Based on the number of qualified candidates, a Qualifications Appraisal consisting of a rated interview (oral exam) and/or assessment exercise (weight 100) or an unassembled exam, consisting of an evaluation of education and experience as stated on the application form, will be administered. The examination will test the knowledge and abilities described above. A minimum score of 70 in each exam component must be attained for placement on the employment list.
Special Testing: If you require special testing arrangements to accommodate a disability or religious conviction you must contact Human Resources at 707.234.6600 prior to the test date to make your requirements known. You must provide enough advance notice to allow Human Resources to properly review and evaluate your request.
Special Requirements: Employment in some County departments or positions may require the successful completion of a pre-employment criminal background, which may include fingerprinting, and/or a medical examination, which may include drug screening.
This announcement is a synopsis of duties and requirements of this job. To review the complete classification specification and benefits, please see the HR website. Applications must be submitted to the Human Resources Department by the final filing date.
The County of Mendocino is an Equal Opportunity Employer
Agency
County of Mendocino
Phone
707-234-6600
Website
http://www.mendocinocounty.org/hr
Address
501 Low Gap Road, Room 1326 Ukiah, California, 95482
source https://usjobsfinder.com/en/deputy-clerk-of-the-board-of-supervisors-ii/1117
0 notes
Link
Name Description Ambiguity effect The tendency to avoid options for which the probability of a favorable outcome is unknown.[10]Anchoring or focalism The tendency to rely too heavily, or "anchor", on one trait or piece of information when making decisions (usually the first piece of information acquired on that subject).[11][12]Anthropocentric thinking The tendency to use human analogies as a basis for reasoning about other, less familiar, biological phenomena.[13]Anthropomorphism or personification The tendency to characterize animals, objects, and abstract concepts as possessing human-like traits, emotions, and intentions.[14]Attentional bias The tendency of perception to be affected by recurring thoughts.[15]Automation bias The tendency to depend excessively on automated systems which can lead to erroneous automated information overriding correct decisions.[16]Availability heuristic The tendency to overestimate the likelihood of events with greater "availability" in memory, which can be influenced by how recent the memories are or how unusual or emotionally charged they may be.[17]Availability cascade A self-reinforcing process in which a collective belief gains more and more plausibility through its increasing repetition in public discourse (or "repeat something long enough and it will become true").[18]Backfire effect The reaction to disconfirming evidence by strengthening one's previous beliefs.[19] cf. Continued influence effect. Bandwagon effect The tendency to do (or believe) things because many other people do (or believe) the same. Related to groupthink and herd behavior.[20]Base rate fallacy or Base rate neglect The tendency to ignore base rate information (generic, general information) and focus on specific information (information only pertaining to a certain case).[21]Belief bias An effect where someone's evaluation of the logical strength of an argument is biased by the believability of the conclusion.[22]Ben Franklin effect A person who has performed a favor for someone is more likely to do another favor for that person than they would be if they had received a favor from that person.[23]Berkson's paradox The tendency to misinterpret statistical experiments involving conditional probabilities.[24]Bias blind spot The tendency to see oneself as less biased than other people, or to be able to identify more cognitive biases in others than in oneself.[25]Choice-supportive bias The tendency to remember one's choices as better than they actually were.[26]Clustering illusion The tendency to overestimate the importance of small runs, streaks, or clusters in large samples of random data (that is, seeing phantom patterns).[12]Confirmation bias The tendency to search for, interpret, focus on and remember information in a way that confirms one's preconceptions.[27]Congruence bias The tendency to test hypotheses exclusively through direct testing, instead of testing possible alternative hypotheses.[12]Conjunction fallacy The tendency to assume that specific conditions are more probable than general ones.[28]Conservatism (belief revision) The tendency to revise one's belief insufficiently when presented with new evidence.[5][29][30]Continued influence effect The tendency to believe previously learned misinformation even after it has been corrected. Misinformation can still influence inferences one generates after a correction has occurred.[31] cf. Backfire effect Contrast effect The enhancement or reduction of a certain stimulus' perception when compared with a recently observed, contrasting object.[32]Courtesy bias The tendency to give an opinion that is more socially correct than one's true opinion, so as to avoid offending anyone.[33]Curse of knowledge When better-informed people find it extremely difficult to think about problems from the perspective of lesser-informed people.[34]Declinism The predisposition to view the past favorably (rosy retrospection) and future negatively.[35]Decoy effect Preferences for either option A or B change in favor of option B when option C is presented, which is completely dominated by option B (inferior in all respects) and partially dominated by option A.[36]Default effect When given a choice between several options, the tendency to favor the default one.[37]Denomination effect The tendency to spend more money when it is denominated in small amounts (e.g., coins) rather than large amounts (e.g., bills).[38]Disposition effect The tendency to sell an asset that has accumulated in value and resist selling an asset that has declined in value. Distinction bias The tendency to view two options as more dissimilar when evaluating them simultaneously than when evaluating them separately.[39]Dread aversion Just as losses yield double the emotional impact of gains, dread yields double the emotional impact of savouring.[40]Dunning–Kruger effect The tendency for unskilled individuals to overestimate their own ability and the tendency for experts to underestimate their own ability.[41]Duration neglect The neglect of the duration of an episode in determining its value.[42]Empathy gap The tendency to underestimate the influence or strength of feelings, in either oneself or others.[43]Endowment effect The tendency for people to demand much more to give up an object than they would be willing to pay to acquire it.[44]Exaggerated expectation The tendency to expect or predict more extreme outcomes than those outcomes that actually happen.[5]Experimenter's or expectation bias The tendency for experimenters to believe, certify, and publish data that agree with their expectations for the outcome of an experiment, and to disbelieve, discard, or downgrade the corresponding weightings for data that appear to conflict with those expectations.[45]Focusing effect The tendency to place too much importance on one aspect of an event.[46]Forer effect or Barnum effect The observation that individuals will give high accuracy ratings to descriptions of their personality that supposedly are tailored specifically for them, but are in fact vague and general enough to apply to a wide range of people. This effect can provide a partial explanation for the widespread acceptance of some beliefs and practices, such as astrology, fortune telling, graphology, and some types of personality tests.[47]Form function attribution bias In human–robot interaction, the tendency of people to make systematic errors when interacting with a robot. People may base their expectations and perceptions of a robot on its appearance (form) and attribute functions which do not necessarily mirror the true functions of the robot.[48]Framing effect Drawing different conclusions from the same information, depending on how that information is presented. Frequency illusion or Baader–Meinhof effect The illusion in which a word, a name, or other thing that has recently come to one's attention suddenly seems to appear with improbable frequency shortly afterwards (not to be confused with the recency illusion or selection bias).[49] This illusion is sometimes referred to as the Baader–Meinhof phenomenon.[50]Functional fixedness Limits a person to using an object only in the way it is traditionally used.[51]Gambler's fallacy The tendency to think that future probabilities are altered by past events, when in reality they are unchanged. The fallacy arises from an erroneous conceptualization of the law of large numbers. For example, "I've flipped heads with this coin five times consecutively, so the chance of tails coming out on the sixth flip is much greater than heads."[52]Groupthink The psychological phenomenon that occurs within a group of people in which the desire for harmony or conformity in the group results in an irrational or dysfunctional decision-making outcome. Group members try to minimize conflict and reach a consensus decision without critical evaluation of alternative viewpoints by actively suppressing dissenting viewpoints, and by isolating themselves from outside influences. Hard–easy effect Based on a specific level of task difficulty, the confidence in judgments is too conservative and not extreme enough.[5][53][54][55]Hindsight bias Sometimes called the "I-knew-it-all-along" effect, the tendency to see past events as being predictable[56] at the time those events happened. Hostile attribution bias The "hostile attribution bias" is the tendency to interpret others' behaviors as having hostile intent, even when the behavior is ambiguous or benign.[57]Hot-hand fallacy The "hot-hand fallacy" (also known as the "hot hand phenomenon" or "hot hand") is the belief that a person who has experienced success with a random event has a greater chance of further success in additional attempts. Hyperbolic discounting Discounting is the tendency for people to have a stronger preference for more immediate payoffs relative to later payoffs. Hyperbolic discounting leads to choices that are inconsistent over time – people make choices today that their future selves would prefer not to have made, despite using the same reasoning.[58] Also known as current moment bias, present-bias, and related to Dynamic inconsistency. A good example of this: a study showed that when making food choices for the coming week, 74% of participants chose fruit, whereas when the food choice was for the current day, 70% chose chocolate. Identifiable victim effect The tendency to respond more strongly to a single identified person at risk than to a large group of people at risk.[59]IKEA effect The tendency for people to place a disproportionately high value on objects that they partially assembled themselves, such as furniture from IKEA, regardless of the quality of the end result.[60]Illicit transference Occurs when a term in the distributive (referring to every member of a class) and collective (referring to the class itself as a whole) sense are treated as equivalent. The two variants of this fallacy are the fallacy of composition and the fallacy of division. Illusion of control The tendency to overestimate one's degree of influence over other external events.[61]Illusion of validity Belief that our judgments are accurate, especially when available information is consistent or inter-correlated.[62]Illusory correlation Inaccurately perceiving a relationship between two unrelated events.[63][64]Illusory truth effect A tendency to believe that a statement is true if it is easier to process, or if it has been stated multiple times, regardless of its actual veracity. These are specific cases of truthiness. Impact bias The tendency to overestimate the length or the intensity of the impact of future feeling states.[65]Implicit association The speed with which people can match words depends on how closely they are associated. This has generated some controversy when some people are able to match pairings like "White" and "pleasant" faster than "Black" and "pleasant", with debate over whether this indicates a form of unconscious prejudice that could result in discrimination. Information bias The tendency to seek information even when it cannot affect action.[66]Insensitivity to sample size The tendency to under-expect variation in small samples. Interoceptive bias The tendency for sensory input from the body to be taken as evidence of external reality. (As for example, in parole judges who are more lenient when fed and rested.) [67][68][69][70]Irrational escalation The phenomenon where people justify increased investment in a decision, based on the cumulative prior investment, despite new evidence suggesting that the decision was probably wrong. Also known as the sunk cost fallacy. Law of the instrument An over-reliance on a familiar tool or methods, ignoring or under-valuing alternative approaches. "If all you have is a hammer, everything looks like a nail." Less-is-better effect The tendency to prefer a smaller set to a larger set judged separately, but not jointly. Look-elsewhere effect An apparently statistically significant observation may have actually arisen by chance because of the size of the parameter space to be searched. Loss aversion The disutility of giving up an object is greater than the utility associated with acquiring it.[71] (see also Sunk cost effects and endowment effect). Mere exposure effect The tendency to express undue liking for things merely because of familiarity with them.[72]Money illusion The tendency to concentrate on the nominal value (face value) of money rather than its value in terms of purchasing power.[73]Moral credential effect The tendency of a track record of non-prejudice to increase subsequent prejudice. Negativity bias or Negativity effect Psychological phenomenon by which humans have a greater recall of unpleasant memories compared with positive memories.[74][75] (see also actor-observer bias, group attribution error, positivity effect, and negativity effect).[76]Neglect of probability The tendency to completely disregard probability when making a decision under uncertainty.[77]Normalcy bias The refusal to plan for, or react to, a disaster which has never happened before. Not invented here Aversion to contact with or use of products, research, standards, or knowledge developed outside a group. Related to IKEA effect. Observer-expectancy effect When a researcher expects a given result and therefore unconsciously manipulates an experiment or misinterprets data in order to find it (see also subject-expectancy effect). Omission bias The tendency to judge harmful actions (commissions) as worse, or less moral, than equally harmful inactions (omissions).[78]Optimism bias The tendency to be over-optimistic, overestimating favorable and pleasing outcomes (see also wishful thinking, valence effect, positive outcome bias).[79][80]Ostrich effect Ignoring an obvious (negative) situation. Outcome bias The tendency to judge a decision by its eventual outcome instead of based on the quality of the decision at the time it was made. Overconfidence effect Excessive confidence in one's own answers to questions. For example, for certain types of questions, answers that people rate as "99% certain" turn out to be wrong 40% of the time.[5][81][82][83]Pareidolia A vague and random stimulus (often an image or sound) is perceived as significant, e.g., seeing images of animals or faces in clouds, the man in the moon, and hearing non-existent hidden messages on records played in reverse. Pygmalion effect The phenomenon whereby others' expectations of a target person affect the target person's performance. Pessimism bias The tendency for some people, especially those suffering from depression, to overestimate the likelihood of negative things happening to them. Planning fallacy The tendency to underestimate task-completion times.[65]Post-purchase rationalization The tendency to persuade oneself through rational argument that a purchase was good value. Present bias The tendency of people to give stronger weight to payoffs that are closer to the present time when considering trade-offs between two future moments.[84]Pro-innovation bias The tendency to have an excessive optimism towards an invention or innovation's usefulness throughout society, while often failing to identify its limitations and weaknesses. Projection bias The tendency to overestimate how much our future selves share one's current preferences, thoughts and values, thus leading to sub-optimal choices.[85][86][75]Pseudocertainty effect The tendency to make risk-averse choices if the expected outcome is positive, but make risk-seeking choices to avoid negative outcomes.[87]Reactance The urge to do the opposite of what someone wants you to do out of a need to resist a perceived attempt to constrain your freedom of choice (see also Reverse psychology). Reactive devaluation Devaluing proposals only because they purportedly originated with an adversary. Recency illusion The illusion that a phenomenon one has noticed only recently is itself recent. Often used to refer to linguistic phenomena; the illusion that a word or language usage that one has noticed only recently is an innovation when it is in fact long-established (see also frequency illusion). Regressive bias A certain state of mind wherein high values and high likelihoods are overestimated while low values and low likelihoods are underestimated.[5][88][89][unreliable source?]Restraint bias The tendency to overestimate one's ability to show restraint in the face of temptation. Rhyme as reason effect Rhyming statements are perceived as more truthful. A famous example being used in the O.J Simpson trial with the defense's use of the phrase "If the gloves don't fit, then you must acquit." Risk compensation / Peltzman effect The tendency to take greater risks when perceived safety increases. Salience bias The tendency to focus on items that are more prominent or emotionally striking and ignore those that are unremarkable, even though this difference is often irrelevant by objective standards. Selection bias The tendency to notice something more when something causes us to be more aware of it, such as when we buy a car, we tend to notice similar cars more often than we did before. They are not suddenly more common – we just are noticing them more. Also called the Observational Selection Bias. Selective perception The tendency for expectations to affect perception. Semmelweis reflex The tendency to reject new evidence that contradicts a paradigm.[30]Sexual overperception bias / sexual underperception bias The tendency to over-/underestimate sexual interest of another person in oneself. Social comparison bias The tendency, when making decisions, to favour potential candidates who don't compete with one's own particular strengths.[90]Social desirability bias The tendency to over-report socially desirable characteristics or behaviours in oneself and under-report socially undesirable characteristics or behaviours.[91]Status quo bias The tendency to like things to stay relatively the same (see also loss aversion, endowment effect, and system justification).[92][93]Stereotyping Expecting a member of a group to have certain characteristics without having actual information about that individual. Subadditivity effect The tendency to judge probability of the whole to be less than the probabilities of the parts.[94]Subjective validation Perception that something is true if a subject's belief demands it to be true. Also assigns perceived connections between coincidences. Surrogation Losing sight of the strategic construct that a measure is intended to represent, and subsequently acting as though the measure is the construct of interest. Survivorship bias Concentrating on the people or things that "survived" some process and inadvertently overlooking those that didn't because of their lack of visibility. Time-saving bias Underestimations of the time that could be saved (or lost) when increasing (or decreasing) from a relatively low speed and overestimations of the time that could be saved (or lost) when increasing (or decreasing) from a relatively high speed. Third-person effect Belief that mass communicated media messages have a greater effect on others than on themselves. Parkinson's law of triviality The tendency to give disproportionate weight to trivial issues. Also known as bikeshedding, this bias explains why an organization may avoid specialized or complex subjects, such as the design of a nuclear reactor, and instead focus on something easy to grasp or rewarding to the average participant, such as the design of an adjacent bike shed.[95]Unit bias The standard suggested amount of consumption (e.g., food serving size) is perceived to be appropriate, and a person would consume it all even if it is too much for this particular person.[96]Weber–Fechner law Difficulty in comparing small differences in large quantities. Well travelled road effect Underestimation of the duration taken to traverse oft-traveled routes and overestimation of the duration taken to traverse less familiar routes. Women are wonderful effect A tendency to associate more positive attributes with women than with men. Zero-risk bias Preference for reducing a small risk to zero over a greater reduction in a larger risk. Zero-sum bias A bias whereby a situation is incorrectly perceived to be like a zero-sum game (i.e., one person gains at the expense of another).
0 notes
Text
Things could go terribly wrong for Canada’s economy in 2019 — but there’s reason for hope
The best economic news heading into 2019 might be that we’re poorer than we thought a few weeks ago.
Statistics Canada changed history last month, revising economic growth in 2015 to a mere 0.7 per cent, compared with its original calculation of 1 per cent. The 2016 expansion was also cut by three-tenths of a percentage point, to 1.1 per cent. Merry Christmas.
Now the central bank must do some recalculating of its own.
Policy makers have a rough idea of how many goods and services the economy can produce without causing inflation. Before StatCan’s revisions, they thought we had reached that point. A smaller gross domestic product suggests the pressure to raise interest rates vanished, along with the billions of dollars in economic output that only ever happened on paper.
Higher interest rates pushing more Canadians to seek debt relief as business booms for insolvency trustees
Instead of an honest debate about fiscal policy, we get filter bubble pap
Our trade with China is bigger than you think — and exporters are getting worried
It’s weird to cheer the disappearance of so much wealth, but Governor Stephen Poloz and his deputies will benefit from some breathing room.
At this point in 2017, virtually every major economy was growing. Christine Lagarde, the managing director of the International Monetary Fund, was nudging her institution’s members to fix their roofs while the sun was still shining. The clouds rolled in faster than most expected. President Donald Trump’s trade wars are slowing global commerce and upsetting financial markets.
The tumult could be temporary, or it could be the beginning of something terrible; it’s hard to tell. The jobless rate in the United States is 3.7 per cent, which must count for something. Yet the S&P500 index was on track for its worst year since the financial crisis a decade ago.
Earlier this autumn, DHL Express announced it was adding a new flight to Vancouver from its North American distribution hub in Cincinnati to keep up with a double-digit increase in demand. “Absolutely, there is strength in the global economy,” Andrew Williams, chief executive of the company’s unit, said in an interview.
But not enough strength to keep one of DHL’s rivals out of trouble. FedEx Corp. cut its earnings outlook this week, after raising it just three months ago, according to Bloomberg News. The company’s stock price plunged the most in a decade.
“When you have a change that comes on you as fast as this did, it’s hard to react to it,” Fred Smith, the chief executive, said on a conference call with analysts.
“Most of the issues that we’re dealing with today are induced by bad political choices,” Smith said, citing Trump’s import tariffs and the retaliatory measures they provoked.
BlackRock Inc., the New York-based asset manager with a portfolio of more than $6 trillion, says the U.S. could tip into recession as soon as 2020. That’s disconcerting because America is currently the only major economy that still is performing well.
Canada may avoid a downturn, although at the price of being condemned to muddling along, much like Japan and some of the bigger European economies. Weak oil prices and excessive private and public debt could stall the engines that powered the economy clear of the Great Recession. If the the trade wars persist, exports also will suffer, threatening stagnation.
“Growth will be shallow and corrections will be shallow,” Aubrey Badeo, BlackRock’s Toronto-based head of Canadian fixed income, said in an interview. “A Japan situation could be something we gravitate towards here.”
We’re not there yet.
Most forecasts predict the economy will grow by around 1.5 per cent next year, roughly equivalent to the Bank of Canada’s non-inflationary speed limit. “Plans to increase investment and employment, often supported by sales expectations, are widespread, especially in the services sector,” the central bank says in its latest quarterly Business Outlook Survey (BOS), released Friday.
Companies added about 220,000 jobs over the 12 months through November, around the annual average since 2010, and the unemployment rate has been no higher than six per cent since October 2017, by far the most impressive stretch in data that dates to 1976. Hiring is a lagging indicator, but one that says a lot about an economy’s underlying strength. By that measure, Canada is fine: There is a reason the Bank of Canada felt the need to raise its benchmark interest rate five times from July 2017 to October 2018.
“The Canadian economy begins this new year in a pretty good place,” Poloz said in an interview with CTV News this week.
Still, the central bank paused earlier this month, and most economists and market watchers predict that it will opt to leave its interest-rate target unchanged at 1.75 per cent again in January, and probably even at its policy meeting in March.
That’s a shift; the consensus until a couple of weeks ago was that policy makers would move borrowing costs higher first thing in the new year. Some analysts now predict an increase in the spring; Basdeo said “we’d be lucky” to get one hike in 2019, and definitely not before the second half.
Central banks raise interest rates when the economy is strong. Canada’s prospects are mediocre, at least until the trade wars subside and oil prices rise. Wage growth remains lacklustre, and personal consumption grew only 1.9 per cent in the third quarter, the weakest since 2013. The household savings rate was 0.8 per cent, near an historic low. Monthly retail sales have been roughly flat since posting an outsized 2.1-per-cent gain in May.
Hope for Canada’s economy in 2019 rests with the country’s entrepreneurs and business leaders. “We expect to see quite a good improvement in investment,” Poloz said. He’s been saying that for years, but the story came true in 2018, despite the uncertainty created by the renegotiation of the North American Free Trade Agreement.
There’s reason to think that will continue. NAFTA is sorted, mostly. The BOS, which ranks among the central bank’s favourite indicators, shows investment intentions over the next 12 months are depressed on the Prairies, but “solid” everywhere else.
The Trudeau government’s promise to cut taxes on new capital, including intangibles such as intellectual property, and to prune regulations should be good for animal spirits, according to Michael McCain, chief executive of Maple Leaf Foods Inc.
Basdeo of BlackRock acknowledged that the shift to a digital economy, which is driving rapid investment in talent, software, and advanced technology such as artificial intelligence (AI), could offset the many negatives. Bold companies will see the chaos as a chance to make money, or get a jump on their rivals.
“No doubt, there is a level of concern,” Tasso Lagios, managing partner at Richter LLP, the Montreal-based provider of financial services for wealthy entrepreneurs, said in an interview. “But I find my clients are moving quicker and quicker to take advantage of opportunities. A lot of opportunities are being taken, but always with a worry.”
Things could go terribly wrong in 2019. That’s why so many equity investors are cashing out. But executives are moving forward, emboldened by high profits, full order books, and the need to retool their businesses for an economy based on data and AI. That could be enough to avoid stagnation, or worse. Expect low interest rates for a little longer as hedge, but also to give the boldest executives another reason to seize the moment.
• Email: [email protected] | Twitter: carmichaelkevin
Things could go terribly wrong for Canada’s economy in 2019 — but there’s reason for hope published first on https://worldwideinvestforum.tumblr.com/
0 notes
Text
Understanding The Background Of SEO 2019
From the world's greatest brands to modest personal sites, Seo (SEO) is an important tool to push traffic, acquire fresh customers and get obtained on-line. SEO's basic importance comes from the particular fact that most users display strong search dominance — that will is definitely, search is the main method people go places on the particular Internet. Reading blogs related to SEO might also be very useful within locating out concerning the important companies on the market which usually are offering comprehensive and genuine Search engine optimization services in the direction of the corporate sector. The initial SEO is dependent mostly on number of key phrases targeted and the size associated with your web site, while the particular ongoing link campaign depends even more on the competitiveness of the particular keywords chosen. Whether if you're an SEO newbie or the seasoned practitioner, I encourage a person to fully read this in order to understand how you can obtain your content on top associated with search results. Large Brand campaigns are far, considerably distinctive from small business SEO strategies that have no links, to start with, to give you yet an example. These SEO companies have got a strategy requiring clients in order to pay for the major lookup engines (including Google and Yahoo) for monthly website maintenance. Specialists are reporting that 2019 will certainly be the year of words search, and that the words search algorithm may change and even supersede text search relatively. A TOP DOG blog is simply one component of social media distribution, an essential SEO strategy according to SEARCH ENGINE OPTIMIZATION Consult You should be disseminating links to fresh content upon your site across appropriate cultural networking platforms. I think it as simple as a good example to illustrate an element of onpage SEO or ‘rank modification', that's white hat, totally Google friendly plus not, ever going to trigger you a issue with Search engines. So when you want to get began which includes basic SEO, the particular first thing that I would certainly recommend would be choosing the set of keywords for every page on your website. Away page, SEO has contrasted along with it. Undoubtedly, off page search engine optimization is all about link developing, but the quality links plus content. Via a direct incorporation of Google's Search Console, Siteimprove SEO helps you understand how the particular world's most popular search motor and its users see and—more importantly—find your website. On Page Ranking Factors — Moz's on page ranking elements explains the different on web page elements and their importance within SEO. Surprisingly enough, the lot of SEOs out generally there do tend to underestimate typically the power of Google Trends The particular tool has a separate "YouTube search" feature, which hides below the "Web search" option. An SEO agency may work together with a business to provide an added viewpoint, when it comes to knowing and developing marketing strategies intended for different sectors and various forms of business websites. Given the ratings and search volume, SEO may drive considerable traffic and network marketing leads for Grainger. SEO stands for research engine optimization - that significantly has stayed the same. But they keep on altering their algorithms making it hard to rely on one specific tool for SEO optimization Plus today you could have a good appropriate rank which may not really last in the coming 6 months. The Latent Semantic Indexing (LSI) Keyword Electrical generator is like a thesaurus with regard to SEO -minded content marketers. SEMRush - Another excellent tool for SEO analysis, especially where it concerns business cleverness, SEMRush allows you to recognize and analyze the keywords that will your competitors are using. I'm heading to share some of the most effective SEO tips that will I've used within all types of campaigns to increase organic lookup traffic. FAST SEO ADVICE search engine optimisation is not magic, and are not able to perform wonders. This SEO guidelines and tricks cover all the essential information you should know regarding Search Engine Optimization. The SEO content author should have a strong knowing of the keywords that are usually ranking and trending on the particular analytics framework. In 2018, there were certain trends that will ruled the world of internet commerce SEO (search engine optimization). Don't get frightened by them but make certain to use only natural hyperlinks and keep in mind that will their SEO potential may end up being a bit lower in assessment with single links. As a partner to the table, Internet research engine Land's Guide To SEARCH ENGINE OPTIMIZATION explains the ranking factors within more depth, inside a tutorial supplying tips and advice on applying them. Google states that interpersonal media is not an fast SEO ranking factor, but many experts agree that things these kinds of as retweets and facebook gives DO, in fact, effect websites' rankings. And since SEO furthermore targets users who are definitely searching for products and solutions like yours, the traffic producing from SEO is more skilled than many other marketing techniques, leading to cost-savings for businesses. You will become introduced to the foundational components of how search engines such as google work, how the SEARCH ENGINE OPTIMIZATION landscape is promoting and exactly what you can expect in the particular future. The SISTRIX Toolbox consists associated with six modules 1) SEO, 2) Universal, 3) Links, 4) Advertisements, 5) Social and 6) Optimizer. Low-quality content can severely impact the achievements of SEO, within 2018. When your own SEO starts building strong coffee grounds, competitors can start maligning your own SEO backlinks. ” With content marketing spend likely to reach $300 billion by 2019, this statistic is worrisome. Now the electronic marketing companies know how in order to use AI for SEO, plus in coming years AI may dominate in developing the SEARCH ENGINE OPTIMIZATION strategies of the digital advertising companies. Ray Cheselka, AdWords and SEARCH ENGINE OPTIMIZATION Manager at webFEAT Complete, the design and SEO agency, states that in 2019 search intention will continue to become even more important. Expert writers of SEO articles can take the time to study the particular industry or specific niche market market. 2 tools to help with regional SEO are BrightLocal (for rankings) and MozLocal (for local research optimization). Concerning on-page SEO best practices, I usually link out to other quality related pages on other websites exactly where possible and where a individual would find it valuable. It includes a favorite Regular Table of SEO Success Factors”, a 9-chapter guide to SEARCH ENGINE OPTIMIZATION basics, and links to several from the site's most useful blog posts. SEO differs from local lookup engine optimization in that the particular latter is targeted on customization a business' online presence therefore that its web pages is usually going to be displayed simply by search engines when a consumer enters a local search intended for its products or services. The challenge for webmasters plus SEO is that Google won't want business people to rank regarding lots of keywords using autogenerated content especially when that generates A LOT of pages upon a website using (for instance) a list of keyword variants page-to-page. In time, the collection between social networking management, channel advancement, and SEO will be considerably blurrier than it really is usually today. In 2016, SEO experts possess determined which factors are almost all likely to affect your SEARCH ENGINE OPTIMIZATION rankings. Customers and marketers will need in order to begin implementing multiple forms associated with digital marketing tactics including compensated search, social media marketing, nearby SEO, in addition to SEARCH ENGINE OPTIMIZATION if they hope to control a given Google SERP. Before beginning with this, the SEO experts should visit your organization and realize each and every aspect associated with your company so that these people can help your achieve your own marketing goals. What really matters in SEARCH ENGINE OPTIMIZATION in 2018 is what a person prioritise today to ensure that will in 3-6 months you may see improvements in the high quality of your organic traffic. Mobile will account for 72% of US digital ad invest by 2019. SEO specialists started in order to abuse PageRank in order in order to boost the rankings. Now could be a great time to take a nearer take a look at SEARCH ENGINE OPTIMIZATION marketing information because search is getting even worse for all those types of B2B plus B2C businesses. SEO marketers plus writers typically come up along with different kinds of content in order to place the necessary keywords within. These are some of the particular most used types, and every one helps to give rise to the level of variety in conditions of website content. Certain black hat SEARCH ENGINE OPTIMIZATION techniques, such as keyword filling, are believed to be the SEARCH ENGINE OPTIMIZATION equivalent of spamming, and lookup engines will penalize them. Internet marketing is exclusively driven by SEO or lookup engine optimization. Others are usually simply traditional PR firms which have learned SEO as nicely as the value of hyperlinks. Here's a cliche among electronic marketers: Search engine optimization (SEO) isn't what used to become. Google announced that will they released several minor enhancements over the period of the particular time of about a 7 days and after analysis, experts inside the SEO industry concluded that will the updates were the outcome of keyword permutations and web site using doorway pages. SEO, or Search Motor Optimization, means setting up your own website and content to show up through online search results. People who else want to take their company to some new height plus generally and mostly believe within the way of SEO marketing and advertising. Erase all duplicated articles; it will increase your SEARCH ENGINE OPTIMIZATION ranking. Long-term: as discussed over, you'll ultimately get more lookup traffic from better usability, also though you don't squeeze every single last drop from the SEO-trick lemon. However, to accomplish all this particular, web-developers use SEO custom solutions, that have long-lasting SEO Search engines rank. That being said, companies usually have little or simply no time for you to maintain up with the latest advancements in SEO techniques. Social search motor optimization is largely built on user-generated content. Keywords are at the cardiovascular of SEO, but they're really not your first step in order to an organic growth play any longer. Obviously, reviews are a powerful type of customer content that has massive implications for SEO and improving organic traffic. With right seo and with the help associated with an SEO expert however, your own website can give you a good increasing number of visitors plus exposure. Just keep in mind to pay attention to strong content creation and copywriting basics, engage your viewers deeply, plus stay abreast of technical styles such as backlinks, SEO health, site rate, and schema. SEOmonitor pricing is based on the particular number of websites and key phrases you track. So, I actually would say that 2018 will be a challenge for Google, mainly because much as it could be for SEOs. The SEO Guide Keyword Suggestion Tool aggregates research data and provides volumes, associated terms, and more. One thing is definitely crystal clear: if you need people to discover your function, you need search engine marketing (SEO). This most means when you're thinking regarding your SEO strategy, you require to think about how your own social networking strategy fits into the particular puzzle, too. As your visitors slowly increases, be sure to include various other SEO strategies (like adding exterior and internal links, guest publishing, etc) to engage more customers and keep your metrics higher. Google has remaining a very narrow band associated with opportunity when it comes in order to SEO - and punishments are created to take you out associated with the game for some period while you cleanup the infractions. Head of Marketing, He Edstrom, at BioClarity, a San Diego based health-science company, feels Blog9T that SEO is going in order to see a decreased importance within 2019, and SEOs should begin ensuring they're competent in SEARCH ENGINE MARKETING. The best rank that you could notice the profile with contact information and maps on right hands side of search result web page is achieved after long treatment for using SEO tactics. Numerous search engine search engine optimization. Search Engine Optimization (SEO) is the technique of customization a website for search motor discovery and indexing. SEO is actually a technique which search motors require that sites must boost properly, so that they show up high in search results. The European Search Honours is an international competition that will shines the spotlight within the best SEO and Content Marketing companies in Europe. SEO focuses upon rankings in the organic (non-paid) search results. SEO as a result helps you get traffic coming from search engines. With Ahrefs, a great starting place for keyword research regarding SEO is the Keywords Explorer tool. Topics: SEO, backlink, content material marketing, social media marketing plus advertising, analytics, and more. 60+ sessions on hot topics, accomplishment stories and strategies in SEARCH ENGINE MARKETING, SEA, PPC, Social Media, On the web Marketing and SMX Future Monitor. 2018 (I believe) will be a lot associated with catch up on current SEARCH ENGINE OPTIMIZATION themes, with the biggest trends” occurring around voice queries to find results. Therefore, SEOmonitor tracks all of the appropriate data that could influence SEARCH ENGINE OPTIMIZATION performance and displays it within the Keyword Events Timeline. If you forget that will quality content is a best priority, then you can definitely forget about having an SEARCH ENGINE OPTIMIZATION strategy. The particular way we asking the device is different from person in order to person. therefore, optimizing your internet site 100% mobile friendly to accomplish cellular voice search is very essential to SEO 2019. I actually am just newbie and significantly i do get frustrated whenever articles doesn't rank on best or near top, but individuals like you and many various other also inspire me to by no means give up. There are many points that i wasn't identified up to now but give thanks to to you, you are usually make us learn important points about seo. The sensible strategy for SEO might still appear to be in order to reduce Googlebot crawl expectations plus consolidate ranking equity & possible in high-quality canonical pages plus you do that by reducing duplicate or near-duplicate content. This can take a LONG period for a site to recuperate from using black hat SEARCH ENGINE OPTIMIZATION tactics and fixing the troubles is not going to necessarily bring organic visitors back as it was just before a penalty. The particular best SEO Guide is right here to dispel those myths, plus give you all you require to know about SEO in order to show up on the internet and some other search engines, and ultimately make use of SEO to grow your company. > > Upon Page Optimization: On-page SEO will be the act of optimizing single pages with a specific finish goal to rank higher plus acquire more important movement within web crawlers. There are numerous websites providing pertinent information regarding SEO and online marketing, and you may learn from them. But it's confusing why some businesses don't attempt harder with analysis, revisions, plus new content with their SEARCH ENGINE OPTIMIZATION online marketing strategy. An effective SEO strategy may be made up of a variety of elements that ensure your web site is trusted by both consumers as well as the lookup engines. By taking their own marketing needs online and employing confer with an experienced SEARCH ENGINE OPTIMIZATION agency, a business will be able to achieve thousands, or even millions associated with people that they would possess not been able to in any other case. Given that research engines have complex algorithms that will power their technology and everybody's marketing needs are unique, jooxie is unable to provide specific SEARCH ENGINE OPTIMIZATION advice to our customers. We all think SEO in 2019 will discover a shift to focusing much more on user intent, problem resolving, and hyper locality in purchase to capitalize on the continuing rise of voice search. Private demographic information would come in a great deal handier in 2019 as significantly as the ranking of key phrases is concerned. Links are one of the particular most important SEO ranking elements. However, more advanced that will readers will recognize the reduce quality of sites employing dark hat SEO at the cost from the reader experience, which usually will reduce the site's visitors and page rank over period. So - THERE IS SIMPLY NO BEST PRACTICE AMOUNT OF CHARACTER TYPES any SEO could lay down because exact best practice to GUARANTEE a title can display, in full in Search engines, at least, since the search little title, on every device. While getting as many pages listed in Google was historically the priority for an SEO, Search engines is now rating the high quality of pages in your site plus the type of pages this really is indexing. Jerrika Scott, Digital Marketing Specialist from Archway Cards Ltd, also feels in voice being the tendency of 2019 rather than 2018. Today, regardless of all the hype about whether or not SEO is dead, we discover that organic search is nevertheless one of the highest RETURN ON INVESTMENT digital marketing channels. Performing SEO upon your own websites is the great method to practice plus hone your SEO ability. We optimize your web site both of internal and exterior factors thats Google's engine believe in and reliable for top rank search result, Gurantee your SEARCH ENGINE OPTIMIZATION ranking No succeed can refundable. Looking deeper: An SEARCH ENGINE OPTIMIZATION cost often means one associated with two things: the investment within your organic search strategy, or exactly how much you pay for compensated search engine marketing (SEM) providers like Google AdWords. We all are dealing with new methods designed to target old design SEO tactics and that concentrate around the truism that DOMAIN NAME ‘REPUTATION' plus Plenty of WEBPAGES plus SEO equals Plenty associated with Keywords equals LOTS of Search engines traffic. BrightonSEO is a one-day search marketing and advertising conference and series of coaching courses held, unsurprisingly, in Brighton. From narrowing straight down target markets to changing the particular way content is written, AI and voice search will have got a continuous effect on SEARCH ENGINE OPTIMIZATION moving forward. One aspect of SEO is definitely link building, which we can discuss slightly below, which generally leads to thin content. Applications for typically the 2018-2019 cycle of the SEO Improve programme are now closed plus will re-open again in Early spring 2019. SEO could be difficult because search engines are usually reevaluating and changing how these people prioritize search engine results. Moreover, it will help SEARCH ENGINE OPTIMIZATION by gaining backlinks, likes, responses or shares. Here's the fantastic news: You don't have in order to have to be a SEARCH ENGINE OPTIMIZATION wizard to make sure your own website is well positioned with regard to organic search engine traffic. SEARCH ENGINE OPTIMIZATION is the acronym for research engine optimisation. The particular search engines have refined their own algorithms along with this development, numerous tactics that worked within 2004 can hurt your SEARCH ENGINE OPTIMIZATION today. Therefore, we also make content on conducting keyword analysis, optimizing images for search motors, creating an SEO strategy (which you're reading right now), plus other subtopics within SEO. In 2018 there will be an actually bigger focus on machine studying and SEO from data. ” Of course, the amplification aspect of things will continue in order to combine increasingly with genuine public relationships exercises rather than shallow-relationship hyperlink building, which will become progressively easy to detect by lookup engines like google. Seo (SEO) is often regarding making small modifications to components of your website. In my SEO post writing guidelines I suggest a person take your main keyword plus 3 or 4 other associated keywords and write at 3-4%. Some SEO specialists claim the fact that building links for SEO functions is pointless; others believe typically the role of backlinks to get a web site has continually risen through the particular years. Search engine optimization (SEO) is a huge part associated with any marketing strategy. This brand-new paradigm of users relying upon voice search for many associated with their search needs will end up being a game changer for SEARCH ENGINE OPTIMIZATION. SEO firms are able to track almost every aspect of their technique, like increases in rankings, visitors and conversions. The methods which were the simplest (reciprocal links or directory submissions) perform not work anymore, therefore the particular SEOs spend a lot associated with time trying different approaches. The particular Moz Pro is another place of Tools that check the particular important factors related to your own website's search ranking. Selection of key phrases or phrases plays an important component in an SEO campaign considering that it saves you the pictures in the dark. In 2019 the particular digital marketing companies can anticipate a lot of voice lookups, and by 2020, about 50 percent of the searches will become either voice searches or image-based searches. Read our Mobile SEO 2019 Checklist before you decide in order to implement. The particular Why SEO 2019 Had Been So Popular Till Now? first facet of optimizing images is definitely including your keywords in this image file name (seo_guide. jpg). The inevitable adjustments that will occur in SEARCH ENGINE OPTIMIZATION in the near future are usually abolition of keywords stuffing plus spam backlinks, real-time personalized customer support by online marketers, improvement within the quality of visual articles as a result of advancement of video SEO, optimization associated with websites with conversational keywords plus generating massive quantity of current data. SEARCH ENGINE OPTIMIZATION remains one of the lengthy term marketing strategies that function best for companies that are usually looking to improve their on-line visibility. Screaming Frog SEO Index tool does it for you personally inside a few seconds, even regarding larger websites. SEOs also used to believe that buying links was the valid method of link developing; however, Google will now punish you for buying links within an attempt to manipulate page rank. Ultimately, achievement in SEO in 2018 plus forward will depend on producing amazing content and making this as easy as possible intended for search engines like google in order to understand exactly what that content material is all about. Answer: When you focus upon SEO for voice search an individual need to create your articles around long tail keywords since people tend to use a great deal more words in voice search. SEO is the practice associated with increasing the search engine ratings of your webpages so that will they appear higher in research results, bringing more traffic in order to your website. In the particular previous example, Bob's home web page might have the title, "Bob's Soccer Store - Soccer Shoes and boots and Equipment. " The name is the most important component of SEO, since it shows the search engine exactly exactly what the page is all regarding. 47. When creating SEO content material, keep the social layer within your mind. In case you have time to get good search engine optimisation education, after that combine this knowledge with greatest practices and you are upon your way to become a good SEO expert. 46. Use SEO practices in order to optimize your social media content. 4. Mobile SEO plus Local Business: - As we all mentioned before, users tend in order to search for local business upon the smartphones.
0 notes
Text
How To Get People To Like SEO 2019
From the world's greatest brands to modest personal internet sites, Seo (SEO) is an important tool to operate a vehicle traffic, acquire fresh customers and get obtained on the web. SEO's basic importance comes from the particular fact that most users display strong search dominance — that will will be, search is the main method people go places on the particular Internet. Reading blogs connected with SEO might also be very useful within locating out concerning the crucial companies on the market which usually are offering comprehensive and genuine Search engine optimization services in the direction of the corporate sector. The initial SEO is dependent mostly on number of key phrases targeted and the size associated with your web site, while the particular ongoing link campaign depends even more on the competitiveness of the particular keywords chosen. Whether you aren't an SEO newbie or the seasoned practitioner, I encourage a person to fully read this in order to understand how you can obtain your content on top associated with search results. Large Brand campaigns are far, significantly distinctive from small business SEO strategies that have zero links, to start with, to give you yet an example. These SEO companies possess a strategy requiring clients in order to pay for the major lookup engines (including Google and Yahoo) for monthly website maintenance. Professionals are reporting that 2019 may be the year of words search, and that the tone search algorithm may change plus supersede text search relatively. A TOP DOG blog is simply one component of social media distribution, an essential SEO strategy according to SEARCH ENGINE OPTIMIZATION Consult You should be disseminating links to fresh content upon your site across appropriate sociable networking platforms. I think it as simple as a good example to illustrate an factor of onpage SEO or ‘rank modification', that's white hat, totally Google friendly plus not, ever going to result in you a issue with Search engines. So when you want to get began which includes basic SEO, the particular first thing that I would certainly recommend would be choosing the set of keywords for every page on your website. Away page, SEO has contrasted along with it. Undoubtedly, off page search engine optimization is all about link developing, but the quality links plus content. Via a direct incorporation of Google's Search Console, Siteimprove SEO helps you understand how the particular world's most popular search motor and its users see and—more importantly—find your website. On Page Ranking Factors — Moz's on page ranking aspects explains the different on web page elements and their importance within SEO. Surprisingly enough, some sort of lot of SEOs out generally there do tend to underestimate the particular power of Google Trends The particular tool has a separate "YouTube search" feature, which hides below the "Web search" option. An SEO agency may work together with a business to provide an added viewpoint, when it comes to knowing and developing marketing strategies regarding different sectors and various forms of business websites. Given the ratings and search volume, SEO may drive considerable traffic and prospects for Grainger. SEO stands for lookup engine optimization - that very much has stayed the same. But they keep on altering their algorithms making it challenging to rely on one specific tool for SEO optimization Plus today you could have a good appropriate rank which may not really last in the coming 6 months. SEO & Content Marketing Software for eCommerce Business, Agencies and Enterprises. Calib Backe, SEO Manager for Walnut Holistics, writes that mobile plus voice are going to carry on their domination of importance because we rely on desktop much less and less. If much associated with your competitors has hired SEARCH ENGINE OPTIMIZATION firms to 10-20 keywords within a moderately competitive industry, after that you will have to spend a small more. The Google Lookup Console may be the most essential SEO tool on the globe. No BS. When you're done with the worn out cliches told over and above again at SEO Conferences, next you're prepared to experience UnGagged - an UnConventional SEO and even Digital Marketing conference that gives real-world results. SEO is a good acronym for the phrase "search engine optimization. " Search motor optimization is focused on doing specific items to your website to operate a vehicle even more traffic to it so that will you can increase online product sales - and traffic. By 2019, the method we search might not alter completely, but these new systems will definitely change the way we all build links, engage users, plus generate leads through content advertising. Site Champion® increases site visitors by helping shoppers find your own products in search engines via increased keyword rankings using SEARCH ENGINE OPTIMIZATION automation. While link quantity is nevertheless important, content creators and SEARCH ENGINE OPTIMIZATION professionals are realizing that hyperlink quality is now more essential than link quantity, and since such, creating shareable content will be the very first step to earning valuable hyperlinks and improving your off-page SEARCH ENGINE OPTIMIZATION. You will become introduced to the foundational components of how search engines such as google work, how the SEARCH ENGINE OPTIMIZATION landscape is promoting and exactly what you can expect in the particular future. The SISTRIX Toolbox consists associated with six modules 1) SEO, 2) Universal, 3) Links, 4) Advertisements, 5) Social and 6) Optimizer. Low-quality content can severely impact the achievements of SEO, within 2018. When your own SEO starts building strong environment, competitors can start maligning your own SEO backlinks. ” With content marketing spend anticipated to reach $300 billion by 2019, this statistic is worrisome. Now the electronic marketing companies know how in order to use AI for SEO, plus in coming years AI can dominate in developing the SEARCH ENGINE OPTIMIZATION strategies of the digital advertising companies. Ray Cheselka, AdWords and SEARCH ENGINE OPTIMIZATION Manager at webFEAT Complete, the design and SEO agency, states that in 2019 search purpose will continue to become even more important. Expert writers of SEO articles can take the time to study the particular industry or specialized niche market. 2 tools to help with regional SEO are BrightLocal (for rankings) and MozLocal (for local research optimization). Concerning on-page SEO best practices, I usually link out to other quality appropriate pages on other websites exactly where possible and where a human being would find it valuable. It includes a well known Regular Table of SEO Success Factors”, a 9-chapter guide to SEARCH ENGINE OPTIMIZATION basics, and links to a few from the site's most useful blog posts. Carrying out technical SEARCH ENGINE OPTIMIZATION for local search engines will be really a similar process. Search engine optimization (SEO) is usually a way to generate even more (and desired) traffic to your own site with the help associated with better search engine rankings intended for a keyword. SEO had gone through drastic changes over the many years and getting higher rankings upon search engines by stuffing the particular information with too many key phrases is a thing of the particular past. This should be considered a essential part of any local SEARCH ENGINE OPTIMIZATION checklists, as reviews and rankings could make it easier to stand out in search engine results. Lookup Engine Optimization, or SEO, need to rank in as one associated with the biggest part of your own finances for online advertising. SEO or even Search Engine Optimisation is the particular name given to activity that will attempts to improve search motor rankings. Search engine optimisation (SEO) is the procedure intended for affecting the visibility of the website or a web web page in a web search engine's unpaid results—often referred to because " natural ", " natural ", or "earned" results. Regional SEO utilizes a variety associated with strategies — getting your web site ranked on search engines such as Google, business directories such because Yelp, Superpages, Foursquare, Yellowbook, Search engines My Business listing, Bing Locations for Business page, localized articles on your website, online testimonials and other strategies. We frequently create in-depth analyses on the method SEO and digital marketing is definitely used to boost the traffic in order to various websites. SEO specialists started in order to abuse PageRank in order in order to raise the rankings. Now could be a great time to take a nearer take a look at SEARCH ENGINE OPTIMIZATION marketing information because search is getting even worse for all those types of B2B plus B2C businesses. SEO marketers plus writers typically come up along with different kinds of content in order to place the necessary keywords within. These are some of the particular most used types, and every one helps to lead to the level of variety in conditions of website content. Certain black hat SEARCH ENGINE OPTIMIZATION techniques, such as keyword filling, are believed to be the SEARCH ENGINE OPTIMIZATION equivalent of spamming, and research engines will penalize them. Internet marketing is exclusively driven by SEO or research engine optimization. Others are usually simply traditional PR firms who else have learned SEO as nicely as the value of hyperlinks. Here's a cliche among electronic marketers: Search engine optimization (SEO) isn't what used to end up being. Google announced that will they released several minor enhancements over the period of the particular time of about a 7 days and after analysis, experts inside the SEO industry concluded that will the updates were the outcome of keyword permutations and web site using doorway pages. SEO, or Search Motor Optimization, means setting up your own website and content to show up through online search results. People that want to take their company to some new height plus generally and mostly believe within the way of SEO advertising. An SEO on the internet marketing strategy is a extensive plan to get more individuals to your website through research engines. A few search optimizers try to key Google by using aggressive strategies that go beyond the fundamental SEO techniques. Subscribe to the particular Single Grain blog now intended for the latest content on SEARCH ENGINE OPTIMIZATION, PPC, paid social, and the particular future of internet marketing. SEO can furthermore stand for search engine optimizer. Like the rest of the particular digital landscape, SEO marketing is usually continuously evolving. Search Engine Book — Read information right after Moz's guide to solidify knowing regarding it of the basic parts of SEO. If a person do not have the period or have insufficient training upon web design or SEO, Appear for web design experts plus hire a professional SEO assistance agency to keep your internet site and your good reputation normally you business may depend upon it. I ended with the website number 1, 228, 570, 060. This particular generates SEO anchor text, which usually helps you in improving your own search engine rankings. SEARCH ENGINE OPTIMIZATION marketing is about the keyword choice that will attract a excellent deal of unique visitors in order to your website. Maybe you have speculate what will be the brand new changes and updates that many of us can experience in SEO back links sphere in 2019? A Cisco research found that by 2019, eighty percent of all consumer Web traffic will be from Web video traffic. If you have spent time online recently, you have probably browse the term "SEO, inch or "Search Engine Optimization. Ultimately, simply by the end of 2018 or even mid-2019, we'll see a golf swing back to natural” content created by real humans who may produce valuable content that really provides value. Hiring experienced SEO experts can ensure that your website climbs the search engine ranks with out using any illegal practices or even short cuts that could create temporary spikes in the cyberspace ranking, but eventually lead in order to your website having to spend penalties. Official Site Associated with BlowFish SEO - Professional Search Motor Optimization Services operated by Robert DiSalvo SEO Located in Hand Beach Gardens, Florida. The takeaway here will be that if you might have got LOTS of location pages helping A SINGLE business in a single location, then those are really probably classed as some type of doorway pages, and most likely Blog9T old-school SEO techniques for these types of type of pages will discover them classed as lower-quality -- or even - spammy webpages. CRAWL this, like Google does, with (for example) Screaming Frog SEO spider, plus fix malformed links or items that result in server errors (500), broken links (400+) and needless redirects (300+). SEARCH ENGINE OPTIMIZATION gives you a go at position for the terms which your own customers use, so you may do better business. The job of the SEARCH ENGINE OPTIMIZATION is to create high-quality articles and after that win the attention, the particular love as well as the particular link from a blogger or even editor. The keyword difficulty or even keyword SEO difficulty is the very useful metric for key phrase research. Dave Gregory, Content Marketing Supervisor from the UK based functionality marketing agency, SiteVisibility, predicts that will 2019, and not 2018, is usually going to be the genuine year of voice. If we consider Google's Guide then there are almost 200+ factors that lead a internet site in ranking, which we have got researched and clustered in twenty one On Page SEO Factors, that will needs your attention in 2019. SEO Wise Links can automatically link crucial terms in your posts plus comments with corresponding posts, web pages, categories and tags on your own blog. 41. An effective sociable media strategy needs a strong SEO plan. Google does make a few of this data accessible in their particular free Webmaster Tools interface (if you haven't set up a merchant account, this is a very beneficial SEO tool both for unearthing search query data and with regard to diagnosing various technical SEO issues). AI and Tone of voice Search Impact SEO, Lets notice how voice search analytics Impact's SEARCH ENGINE OPTIMIZATION and can impact in the particular coming time. A great many businesses determine to hire external help to be able to get the full benefits involving SEO, so a large portion of our audience is understanding how to convince their consumers that search is an excellent investment (and then prove it! ). Nevertheless, SEOs tend in order to prefer links higher on the page. Because your site, thanks to the nature of your current business is going to end up being more image orientated than written text heavy, you will end up at a minor disadvantage when it comes for you to employing SEO techniques such while keywords, backlinking and so out. Ranking elements can be divided into on-page SEO factors (including technical SEO) and link building or off-page SEO factors. Take the 10 pillar subjects you came up with within Step one and create the web page for each 1 which outlines the topic with a high level - making use of the long-tail keywords you arrived plan for each cluster within Step 2. A pillar web page on SEO, for instance, may describe SEO in brief areas that introduce keyword research, picture optimization, SEO strategy, and some other subtopics as they are recognized. On our blog many of us chronicle current trends in on-line marketing and SEO and existing interesting studies, statistics and tendencies. Increased site usability - Within an effort to make your own site easier to navigate regarding the search engines, SEO concurrently helps to make your internet site more navigable for users mainly because well. You are capable to host your video upon YouTube for your foundational SEO greatest practices, but link and spotlight the embedded video on your own own website. Image SEO is actually a crucial part of SEARCH ENGINE OPTIMIZATION different types of websites. Max DesMarais is definitely an SEO and PPC Specialist for Vital, some sort of Digital Marketing & PPC organization that specializes in PPC managing services. But this also has an incredible roundabout benefit to your bottom collection: boosting your search engine search engine optimization (SEO). It may be the circumstance (and I surmise this) how the introduction of a certain SEARCH ENGINE OPTIMIZATION technique initially artificially raised your own rankings for the pages within a way that Google's methods never approve of, and as soon as that is actually spread out all through your site, traffic starts in order to deteriorate or is slammed in the future algorithm update. Search engine optimisation (SEO) will be the process of impacting the online visibility of the particular website or a web web page in a web search motor 's unpaid results—often known since "natural", " organic ", or even "earned" results. Seo (SEO) is a procedure of improving positions in natural (non-paid) search results searching motors. Some other SEO ranking factors include: obtainable URLs, domain age (older is usually usually better), page speed, cellular friendliness, business information, and specialized SEO. Your own search engine optimization strategy can become divided into two different classes: on-page SEO and off-page SEARCH ENGINE OPTIMIZATION. While you familiarize yourself with this local community, you will inevitably stumble your own way onto the websites associated with SEO Gurus” selling courses that will teach you SEO for hundreds of dollars. Expert SEO writers can also make use of modifiers and keyword variations in order to further optimize the content. In the lot associated with cases, this happens as the consequence of non-ethical SEO specifically buying and selling links which usually could get you up the particular Google ‘adder' quickly. Content will be key but content alone is usually no longer king; content, framework, and relevance will drive overall performance of content and digital advertising, and SEO is part yet not full parcel. Ultimate WordPress SEARCH ENGINE OPTIMIZATION Guide for Beginners (Step simply by Step) — 28% of sites on the internet use Wp. SEO is frequently abused as a blanket term intended for digital marketing. Performing SEO upon your own websites is the great method to practice plus hone your SEO ability. We optimize your web site both of internal and exterior factors thats Google's engine believe in and reliable for top position search result, Gurantee your SEARCH ENGINE OPTIMIZATION ranking No succeed can refundable. Looking deeper: An SEARCH ENGINE OPTIMIZATION cost often means one associated with two things: the investment within your organic search strategy, or just how much you pay for compensated search engine marketing (SEM) solutions like Google AdWords. All of us are dealing with new methods designed to target old design SEO tactics and that concentrate around the truism that SITE ‘REPUTATION' plus Plenty of WEBPAGES plus SEO equals Plenty associated with Keywords equals LOTS of Search engines traffic. BrightonSEO is a one-day search advertising conference and series of education courses held, unsurprisingly, in Brighton. From narrowing straight down target markets to changing the particular way content is written, AI and voice search will possess a continuous effect on SEARCH ENGINE OPTIMIZATION moving forward. One aspect of SEO is definitely link building, which we may discuss slightly below, which frequently leads to thin content. Applications for typically the 2018-2019 cycle of the SEO Enhance programme are now closed and even will re-open again in Planting season 2019. SEO could be complex because search engines are usually reevaluating and changing how they will prioritize search engine results. Moreover, it will help SEARCH ENGINE OPTIMIZATION by gaining backlinks, likes, remarks or shares. You've added even more relevant content to your site write-up and increased the on-page SEARCH ENGINE OPTIMIZATION targeted against your focus keyword(s). Before my first ISS, We had always thought I can just learn everything by myself personally about global online marketing subjects for example International SEO just simply by doing online investigation and testing, but honestly nothing beats this efficiency of attending a convention like ISS where one may share your experiences and immediately gain a treasure trove involving learnings and best practices through other international marketers. That method, you and your SEO may ensure that your site is usually designed to be search engine-friendly from the bottom up. Nonetheless, a good SEO can furthermore help improve a current web site. If you would like to know what kind associated with SEO trends are going in order to develop in 2019, look simply no further than the trends that will are developing in search within both 2017 and 2018. Webmasters are usually going to remain competitive within the online business when they will stick with SEO experts. SEARCH ENGINE OPTIMIZATION and social media marketing make sure that one's site has the particular best SEO Online marketing, which usually means that their company may remain competitive in the on-line market. An SEO ("search engine optimization") expert is somebody trained to improve your presence on search engines. From an SEO perspective, a person want to have more interior links pointing to your almost all important content. Without the doubt, one of the greatest trends that has already started to take place and may continue well into 2018 may be the consolidation of niche MarTech gamers by larger content cloud suppliers, with the role and significance of SEO increasing significantly all through this transformation. SEO Internet marketing offers major components, which develop the particular website traffic, and top lookup engine rankings. SEO is brief for Seo, and there is definitely nothing really mystical about this particular. You might have heard the lot about SEO and exactly how it works, but basically exactly what is a measurable, repeatable procedure which is used to send out signals to search engines that will the pages are worth displaying in Google's index. Topic clusters have got been lauded because 7 New Thoughts About SEO 2019 That Will Turn Your World Upside Down the future associated with SEO and content strategy, yet are widely underreported on (so now's the time to hit! ) 93% of B2B companies use content marketing. Teresa Walsh, Marketing Professional at automobile site, Cazana, forecasts that hyper organic targeting will increase its importance in 2019 with more location search plus more voice search. We get to the particular bottom of on-page SEO troubles in order for search motors to clearly see what your own website is all about. SEO requires you to continuously become a student because of exactly how quickly the algorithms of research engine companies change. Google's punishing methods probably class pages as some thing akin to a poor UX if they meet certain detectable criteria e. g. lack associated with reputation or old-school SEO stuff such as keyword stuffing a site. Search engine optimization (SEO) is one of this most important marketing considerations in your studio website. SEO might generate a sufficient return upon investment However, search engines are usually not purchased organic search visitors, their algorithms change, and presently there are no guarantees of carried on referrals. A great starting point whenever using keywords for SEO is usually to identify existing pages that will may use some optimization. These are called keywords, plus as you will see, these people are an important part associated with SEO. In fact, this particular will actually hurt your home page's SEO because search engines such as google will recognize it because keyword stuffing - or the particular act of including keywords particularly to rank for that key phrase, rather than to answer the person's question. Prior to we get going, one thing a person want to keep in thoughts when using some of the following SEARCH ENGINE OPTIMIZATION elements is not to overdo it. You might be enticed to shove a lot associated with keywords onto your pages, yet that is not the objective. In situation you create links to some other websites and reverse, it can improve your SEO ranking. Really Cisco predicts that globally, on the internet video traffic will be eighty percent of all consumer Web traffic by 2019 (a amount that is up from sixty four percent in 2014). I've bookmarked therefore many SEO websites and assets that it's overwhelming to actually look at. Link authority is the major component of SEO, yet purchasing links is forbidden simply by Google, Bing, and other lookup engines.
0 notes
Text
On statistical learning in graphical models, and how to make your own [this is a work in progress...]
I’ve been doing a lot of work on graphical models, and at this point if I don’t write it down I’m gonna blow. I just recently came up with an idea for a model that might work for natural language processing, so I thought that for this post I’ll go through the development of that model, and see if it works. Part of the reason why I’m writing this is that the model isn’t working right now (it just shrieks “@@@@@@@@@@”). That means I have to do some math, and if I’m going to do that why not write about it.
So, the goal will be to develop what the probabilistic people in natural language processing call a “language model” – don’t ask me why. This just means a probability distribution on strings (i.e. lists of letters and punctuation and numbers and so on). It’s what you have in your head that makes you like “hi how are you” more than “1$…aaaXD”. Actually I like the second one, but the point is we’re trying to make a machine that doesn’t. Anyway, once you have a language model, you can do lots of things, which hopefully we’ll get to if this particular model works. (I don’t know if it will.)
The idea here is that if we go through the theory and then apply it to develop a new model, then maybe You Can Too TM. In a move that is pretty typical for me, I misjudged the scope of the article that I was going for, and I ended up laying out a lot of theory around graphical models and Boltzmann machines. It’s a lot, so feel free to skip things. The actual new model is developed at the end of the post using the theory.
Graphical models and Gibbs measures
If we are going to develop a language model, then we are going to have to build a probability distribution over, say, strings of length 200. Say that we only allowed lowercase letters and maybe some punctuation in our strings, so that our whole alphabet has size around 30. Then already our state space has size 20030. In general, this huge state space will be very hard to explore, and ordinary strategies for sampling from or studying our probability distribution (like rejection or importance sampling) will not work at all. But, what if we knew something nice about the structure of the interdependence of our 200 variables? For instance, a reasonable assumption for a language model to make is that letters which are very far away from each other have very little correlation – $n$-gram models use this assumption and let that distance be $n$.
It would be nice to find a way to express that sort of structure in such a way that it could be exploited. Graphical models formalize this in an abstract setting by using a graph to encode the interdependence of the variables, and it does so in such a way that statistical ideas like marginal distributions and independence can be expressed neatly in the language of graphs.
For an example, let $V={1,\dots,n}$ index some random variables $X_V=(X_1,\dots,X_n)$ with joint probability mass function $p(x_V)$. What would it mean for these variables to respect a graph like, say if $n=5$,

In other words, we’d like to say something about the pmf $p$ that would guarantee that observing $X_5$ doesn’t tell us anything interesting about $X_1$ if we already knew $X_4$. Well,
Def 0. (Gibbs random field, pmf/pdf version) Let $\mathcal{C}$ be the set of cliques in a graph $G=(V,E)$. Then we say that a collection of random variables $X_V$ with joint probability mass function or probability density function $p$ is a Gibbs random field with respect to $G$ if $p$ is of the form $$p(x_V) = \frac{1}{Z_\beta} e^{-\beta H(x_V)},$$ given that the energy $H$ factorizes into clique potentials: $$H(x_V)=\sum_{C\in\mathcal{C}} V_C(x_C).$$
Here, if $A\subset V$, we use the notation $x_A$ to indicate the vector $x_A=(x_i;i\in A)$.
For completeness, let’s record the measure-theoretic definition. We won’t be using it here so feel free to skip it, but it can be helpful to have it when your graphical model mixes discrete variables with continuous ones.
Def 1. (Gibbs random field) For the same $G$, we say that a collection of random variables $X_V\thicksim\mu$ is a Gibbs random field with respect to $G$ if $\mu$ can be written $$\mu(dx_V)=\frac{\mu_0(dx_V)}{Z_\beta} e^{-\beta H(x_V)},$$ for some energy $H$ factorizes over the cliques like above.
Here, $\mu_0$ is the “base” or “prior” measure that appears in the constrained maximum-entropy derivation of the Gibbs measure (notice, this is the same as in exponential families -- it’s the measure that $X_V$ would obey if there were no constraint on the energy statistic), but we won’t care about it here, since it’ll just be Lebesgue measure or counting measure on whatever our state space is. Also, $Z$ is just a normalizing constant, and $\beta$ is the “inverse temperature,” which acts like an inverse variance parameter. See footnote:Klenke 538 for more info and a large deviations derivation.
There are two main reasons to care about Gibbs random fields. First, the measures that they obey (Gibbs or Boltzmann distributions) show up in statistical physics: under reasonable assumptions, physical systems that have a notion of potential energy will have the statistics of this distribution. For more details and a plain-language derivation, I like Terry Tao’s post footnote:https://terrytao.wordpress.com/2007/08/20/math-doesnt-suck-and-the-chayes-mckellar-winn-theorem/.
Second, and more to the point here, they have a lot of nice properties from a statistical point of view. For one, they have the following nice conditional independence property:
Def 2a. (Global Markov property) We say that $X_V$ has the global Markov property on $G$ if for any $A,B,S\subset V$ so that $S$ separates $A$ and $B$ (i.e., for any path from $A$ to $B$ in $G$, the path must pass through $S$), $X_A\perp X_B\mid X_S$, or in other words, $X_A$ is conditionally independent of $X_B$ given $X_S$.
Using the graphical example from above, for instance, we see what happens if we can condition on $X_4=x_4$:

This is what happens in Def 2a. when $S=\{4\}$. Since the node 4 separates the graph into partitions $A=\{1,2,3\}$ and $B=\{5\}$, we can say that $X_1,X_2,X_3$ are independent of $X_5$ given $X_4$, or in symbols $X_1,X_2,X_3\perp X_5\mid X_4$.
The global Markov property directly implies a local property:
Def 2b. (Local Markov property) We say that $X_V$ has the local Markov property on $G$ if for any node $i\in V$, $X_i$ is conditionally independent from the rest of the graph given its neighbors.
In a picture,

Here, we are expressing that $X_2\perp X_3,X_5\mid X_1,X_4$, or in words, $X_2$ is conditionally independent from $X_3$ and $X_5$ given its neighbors $X_1$ and $X_4$. I hope that these figures (footnote:tikz-cd) have given a feel for how easy it is to understand the dependence structure of random variables that respect a simple graph.
It’s not so hard to check that a Gibbs measure satisfies these properties on its graph. If $X_V\thicksim p$ where $p$ is a Gibbs density/pmf, then $p$ factorizes as follows: $$p(x_V)=\prod_{C\in\mathcal{C}} p_C(x_C).$$ This factorization means that $X_V$ is a “Markov random field” in addition to being a Gibbs random field, and the Markov properties follow directly from this factorization footnote:mrfwiki. The details of the equivalence between Markov random fields and Gibbs random fields are given in the Hammersley-Clifford theorem footnote:HCThm.
This means that in situations where $V$ is large and $X_V$ is hard to sample directly, there is still a nice way to sample from the distribution, and this method becomes easier when $G$ is sparse.
The Gibbs sampler
The Gibbs sampler is a simpler alternative to methods like Metropolis-Hastings, first named in an amazing paper by Stu Geman footnote:thatpaper. It’s best explained algorithmically. So, say that you had a pair of variables $X,Y$ whose joint distribution $p(x,y)$ is unknown or hard to sample from, but where the conditional distributions $p(x\mid y)$ and $p(y\mid x)$ are easy to sample. (This might sound contrived, but the language model we’re working towards absolutely fits into this category, so we will be using this a lot.) How can we sample faithfully from $p(x,y)$ using these conditional distributions?
Well, consider the following scheme. For the first step, given some initialization $x_0$ for $X$, sample $y_0\thicksim p(\cdot\mid x_0)$. Then at the $i$th step, sample $x_{i}\thicksim p(\cdot\mid y_{i-1})$, and then sample $y_{i}\thicksim p(\cdot \mid x_i)$. The claim is that the Markov chain $(X_i,Y_i)$ will approximate samples from $p(x,y)$ as $i$ grows.
It is easy to see that $p$ is an invariant distribution for this Markov chain: indeed, if it were the case that $x_0,y_0$ were samples from $p(X,Y)$, then if $X_1\thicksim p(X\mid Y=y_0)$, clearly $X_1,Y_0\thicksim p(X\mid Y)p(Y)$, since $Y_0$ on its own must be distributed according to its marginal $p(Y)$. By the same logic, $X_1$ is distributed according to its marginal $p(X)$, so that if $Y_1$ is chosen according to $p(Y\mid X_0)$, then the pair $X_1,Y_1\thicksim p(Y\mid X)p(X)=p(X,Y)$.
The proof that this invariant distribution is the limiting distribution of the Markov chain is more involved and can be found in the Geman paper, but to me this is the main intuition.
This sampler is especially useful in the context of graphical models, and more so when the graph has some nice regularity. The Gemans make great use of this to create a parallel algorithm for sampling from their model, which would otherwise be very hard to study. For a simpler example of the utility, consider a lattice model (you might think of an Ising model), i.e. say that $G$ is a piece of a lattice: take $V=\{1,\dots,n\}\times\{1,\dots,n\}$ and let $E=\{((h,i),(j,k):\lvert h-j + i-k\rvert=1\}$ be the nearest-neighbor edge system on $V$. Say that $X_V$ form a Gibbs random field with respect to that lattice (here we let $n=4$):

Even the relatively simple Gibbs distribution of the free Ising model, $$p(x_V)=\frac{1}{Z_\beta}\exp\left( \beta\, {\textstyle\sum_{u,v\in E} x_u x_v }\right)$$ is hard to sample. But in general, any Gibbs random field on this graph can be easily sampled with the Gibbs sampler: if $N_u$ denotes the neighbors of the node $u=(i,j)$, then to sample from $p$, we can proceed as follows: let $x_V^0$ be a random initialization. Then, looping through each site $u\in V$, sample the variable $X_u\thicksim p(X_u\mid X_{N_u})$, making sure to use the new samples where available and the initialization elsewhere. Then let $x_V^1$ be the result of this first round of sampling, and repeat. This algorithm is “local” in the sense that each node only needs to care about its neighbors, so the loop can be parallelized simply (as long as you take care not to sample two neighboring nodes at the same time).
Later, we will be dealing with bipartite graphs with lots of nice structure that make this sampling even easier from a computational point of view.
The Ising model
One important domain where graphical models have been used is to study what are known as “spin glasses.” Don’t ask me why they are called glasses, I don’t know, maybe it’s a metaphor. The word “spin” shows up because these are models of the emergence of magnetism, and magnetism is what happens when all of the little particles in a chunk of material align their spins. Spin is probably also a metaphor.
In real magnets, these spins can be oriented in any direction in God’s green three-dimensional space. But to simplify things, some physicists study the case in which each particle’s spin can only point “up” or “down” -- this is already hard to deal with. The spins are then represented by Bernoulli random variables, and in the simplest model (the Ising model footnote:ising), a joint pmf is chosen that respects the “lattice” or “grid” graph in arbitrary dimension. The grid is meant to mimic a crystalline structure, and keeps things simple. Since each site depends only on its neighbors in the graph, Gibbs sampling can be done quickly and in parallel to study this system, which turns out to yield some interesting physical results about phase changes in magnets.
Now, this is an article about applications of graphical models to natural language processing, so I would not blame you for feeling like we are whacking around in the weeds. But this is not true. We are not whacking around in the weeds. The Ising model is the opposite of the weeds. It is a natural language processing algorithm, and that’s not a metaphor, or at least it won’t be when we get done with it. Yes indeed. We’re going to go into more detail about the Ising model. That’s right. I am going to give you the particulars.
Let’s take a look at the Ising pmf, working in two dimensions for a nice mix of simplicity and interesting behavior. First, let’s name our spin: Let $z_V$ be a matrix of Bernoulli random variables $z_{i,j}\in\{0,1\}$. Here, we’re letting $z_{i,j}=0$ represent a spin pointing down at position $(i,j)$ in the lattice -- a 1 means spin up, and $V$ indicates the nodes in our grid.
Now, how should spins interact? Well, by the local Markov property, we know that $$p(z_{i,j}\mid z_V)=p(z_{i,j}\mid z_{N_{i,j}}),$$ where $$N_{i,j}=\{(i’,j’)\mid \lvert i’-i\rvert + \lvert j’ - j\rvert =1 \}$$ is the set of neighbors of the node at position $(i,j)$. In other words, this node’s interaction with the material as a whole is mediated through its direct neighbors in the lattice. And, since this is a magnet, the idea is to choose this conditional distribution such that $z_{i,j}$ is likely to align its spin with those of its neighbors. Indeed, following our Gibbs-measure style, let $$p(z_{i,j}\mid z_{N_{i,j}})=\frac{1}{Z_{i,j}}\exp(-\beta H_{i,j}).$$ Here $E_{i,j}$ is the “local” magnetic potential at our site $i,j$, $$H_{i,j}=-z_{i,j}\sum_{\alpha\in N_{i,j}} z_\alpha,$$ and $Z_{i,j}$ is the normalizing constant for this conditional distribution
So, does this conditional distribution have the property that $z_{i,j}$ will try to synchronize with its neighbors? Well, let’s compute the conditional probabilities that $z_{i,j}$ is up or down as a function of its neighbors. \begin{align*} p(z_{i,j}=1\mid z_{N_{i,j}}) &= \frac{1}{Z_{i,j}} \exp\left({\textstyle \sum_{\alpha\in N_{i,j}} z_\alpha}\right)\\\\ p(z_{i,j}=0\mid z_{N_{i,j}}) &= \frac{1}{Z_{i,j}}e^0=1. \end{align*} Then we have $Z_{i,j}=1 + \exp\left({\textstyle \sum_{\alpha\in N_{i,j}} z_\alpha}\right)$. In other words, $$p(z_{i,j}=1\mid z_{N_{i,j}})=\sigma\left({\textstyle \sum_{\alpha\in N_{i,j}} z_\alpha}\right),$$ where $\sigma$ is the sigmoid function $\sigma(x)=e^{x}/(e^{x}+1)$ that often appears in Bernoulli pmfs. This function is increasing, which indicates that local synchrony is encouraged. I should also note that Ising is usually done with $\text{down}=-1$ instead of 0, which is even better for local synchrony.
I thought that giving the local conditional distributions would be a nice place to start for getting some intuition on the model -- in particular, these tell you how Gibbs sampling would evolve. Since this distribution can be sampled by a long Gibbs sampling run, we have sort of developed an intuition that the samples from an Ising model should have some nice synchrony properties with high probability.
But, can we find a joint pmf for $z_V$ that yields these conditional distributions? Indeed, if we define the energy $$H(z_V)=-\sum_{\alpha\in V}\sum_{\beta\in N_\alpha} z_\alpha z_\beta,$$ and from here the pmf $$p(z_V)=\frac{1}{Z}e^{-\beta H(z_V)},$$ then we can quickly check that this is a Gibbs random field on the lattice graph with conditional pmfs as above.
For something with such a simple description, the Ising model has a really amazing complexity. Some of the main results involve qualitative differences in the model’s behavior for different values of the inverse temperature $\beta$. For low $\beta$ (i.e., high temperature, high variance), the model is uniformly random. For large $\beta$, the model concentrates on its modes (i.e., the minima of $H$). It turns out that there is a critical temperature somewhere in the middle, with a phase change from a disordered material to one with magnetic order. There are also theorems about annealing, one of which can be found in a slightly more general setting in footnote:geman.
The complexity of these models indicates that they are good at handling information, especially when some form of synchrony is useful as an inductive bias. So, we’ll now start to tweak the model so that it can learn to model something other than a chunk of magnetic material.
Statistical learning in Gibbs random fields
Inspired by this and some related work in machine learning footnote:history, Ackley, Hinton, and Sejnowski footnote:ackley generalized the Ising model to one that can fit its pmf to match a dataset, which they called a Boltzmann machine. It turns out that their results can be extended to work for general Gibbs measures, so I will present the important results in that context, but we will stick to Ising/Boltzmann machines in the development of the theory, and as an important special case. Then the language model we’d like to develop will appear as a sort of “flavor” of Boltzmann machine, and we’ll already have the theory in place regarding how it should learn and be sampled and all that stuff.
So, here is my sort of imagined derivation of the Boltzmann machine from the Ising model. The units in the Ising model are hooked together like the atoms in a crystal. How can they be hooked together like the neurons in a brain? Well, first, let’s enumerate the sites in the Ising model’s lattice, so that the vertices are now named $V=\{1,\dots,n\}$ for some $n$, instead of being 2-d indices. Then the lattice graph has some $n\times n$ adjacency matrix $W$, where $W_{\alpha\beta}=1$ if and only if $\alpha$ and $\beta$ represent neighbors in the original lattice. So, there should be exactly 4 1s along each row, etc.
Let’s rewrite the Ising model’s distribution in terms of $W$. Indeed, we can see that $$H(z_V)=-z_V W z_V^T,$$ so that the energy is just the quadratic form on $\mathbb{R}^n$ induced by $W$. Then if we fix the notation $$x_\alpha = [W z_V^T]_\alpha,$$ we can rewrite $H_\alpha=z_\alpha x_\alpha$, and simplify our conditional distribution to $$p(z_\alpha=1\mid z_{V})=\sigma(x_\alpha).$$ Not bad.
Now, this is only an Ising model as long as $W$ remains fixed. But what if we consider $W$ as a parameter to our distribution $p(z_V; W)$, and try to fit $W$ to match some data? For example, say that we want to learn the MNIST dataset of handwritten digits, which is a dataset of images with 784 pixels. Then we’d like to learn some $W$ with $V=\{1,\dots,784\}$ such that samples from the distribution look like handwritten digits.
This can be done, but it should be noted that sometimes it helps to add some extra “hidden” nodes $z_H$ to our collection of “visible” nodes $z_V$, for $H=\{785,\dots,785 + n_H\}$, so that the random vector grows to$z=(z_1,\dots,z_{784},z_{785},\dots,z_{785+n_H})$. Let’s also grow $W$ to be a $n\times n$ matrix for $n=n_V+n_H$, where in this example the number of visible units $n_V=784$. Then the Hamiltonian becomes $H(z)=z W z^T$ just like above, and similarly for $x_\alpha$ and so on.
Adding more units gives the pmf more degrees of freedom, and now the idea is to have the marginal pmf for the visible units $p(z_V;W)$ fit the dataset, and let the “hidden” units $z_H$ do whatever they have to do to make that happen.
Ackley, Hinton, and Sejnowski came up with a learning algorithm, with the very Hintony name “contrastive divergence,” which was presented and refined (footnote:cdpapers). I’d like to first present and prove the result in the most general setting, and then we’ll discuss what that means for training a Boltzmann machine.
The most general version of contrastive divergence that I think it’s useful to consider is for $z$ (now not necessarily a binary vector) to be Gibbs distributed according to some parameters $\theta$, with distribution $$p(z;\theta)\,dz=\frac{1}{Z}\exp(-\beta H(z;\theta))\,dz.$$ Here, since we are trying to be general, we’re letting $z$ be absolutely continuous against some base measure $dz$, and $p$ is the density there. But it should help to keep in mind the special case where $p$ is just a pmf, like in the Boltzmann machine, where $z$ is a binary vector $z\in\{0,1\}^{n}$.
First, we need a quick result about the form taken by marginal distributions in Gibbs random fields, since we want to talk about the marginal over the visible units.
Def 3. (Free energy) Let $A$ be a set of vertices in the graph. Then the “free energy” $F_A(z_A)$ of the units $z_A$ is given by$$F_A(z_A)=-\log\int_{z_H} e^{-H(z)}\,dz_H.$$
If it seems weird to you to be taking an integral in the case of binary units, you can just think of that integral $\int\cdot \,dz_H$ as a sum $\sum_{z_H}$ over all possible values for the hidden portion of the vector -- this is because in the Boltzmann case, the base measure $dz$ is just counting measure.
It follows directly from this definition that:
Lemma 4. (Marginals in Gibbs distributions) For $A$ as before, if $Z_A$ is a normalizing constant, we have $$p(z_A)=\frac{1}{Z_A} e^{-F_A(z_A)}.$$
So, the free energy takes the role of the Hamiltonian/energy $H$ when we talk about marginals. We can quickly check Lemma 4 by plugging in: \begin{align*} Z_A p(z_A) &= e^{-F_A(z_A)}\\\\ &= \exp\left( \log\left( \int_{z_{\setminus A}} e^{-\beta H(z_A,z_{\setminus A})} \,dz_{\setminus A} \right) \right)\\\\ &= \int_{z_{\setminus A}} e^{-\beta H(z_A,z_{\setminus A})} \,dz_{\setminus A}, \end{align*} which agrees with the standard definition of the marginal. Maybe it should also be noted that $F_V$ is implicitly a function of $\beta$ -- we are marginalizing the distribution $p_\beta(z)$, and my notation has let $\beta$ get a little lost, since it’s not so important right now.
Contrastive divergence will work with the free energy for the visible units $F_V$. And guess what, I think we’re ready to state it. It’s not really a theorem, but more of a bag of practical results that combine to make a learning algorithm, some of which deserve proof and others of which are well-known.
“Theorem”/Algorithm 5. (Contrastive divergence) Say that $\mathcal{D}$ is the distribution of the dataset, and consider the maximum-likelihood problem of finding $$\theta^*={\arg\max}_{\theta} \mathbb{E}_{z_V^+\thicksim \mathcal{D}}[\log p(z_V^+;\theta)].$$In other words, we’d like to find $\theta$ that maximizes the model’s expected log likelihood of the visible units, assuming that the visible units are distributed according to the data. We note that this is the same as finding the minimizer of the Kullback-Liebler divergence:$$D_{KL}(\mathcal{D}\mid p(z_V;\theta))=\mathbb{E}^+[\log\mathcal{D}(z_V^+)] - \mathbb{E}^+[\log p(z_V^+;\theta)]$$since $\mathcal{D}$ does not depend on $\theta$. (In general, we’ll use superscript $+$ to indicate that a quantity is distributed according to the data, and $-$ to indicate samples from the model, and similarly $\mathbb{E}^{\pm}$ to indicate expectations taken against the data distribution or the model’s distribution.)
To find $\theta^*$, we should not hesitate to pull gradient ascent out of our toolbox. And luckily, we can write down a formula for the gradient:
TODO: note, we want gradient ascent on the good thing. put in DKL. also ascent! what is up with this. Should just rewrite the math here by hand and sort it all out for real instead of this tumblr bullpucky.
Main Result 5a. For the gradient ascent, we claim that $$\frac{\partial}{\partial\theta} \mathbb{E}_{z_V^+\thicksim \mathcal{D}}[\log p(z_V^+;\theta)] = -\mathbb{E}_{z_V^+\thicksim \mathcal{D}}\left[\tfrac{d F_V(z_V^+)}{d\theta}\right] + \mathbb{E}_{z_V^-\thicksim p(z_V;\theta)}\left[ \tfrac{d F_V(z_V^-)}{d\theta}\right].$$
All that remains is to estimate these expectations. I say “estimate” since we probably can’t compute expectations against $\mathcal{D}$ (we might not even know what $\mathcal{D}$ is), and since we can’t even sample directly from $p(z_V)$. In practice, one uses a single sample $z_V^+\thicksim\mathcal{D}$ to estimate the first expectation Monte-Carlo style, and then uses a Gibbs sampling Markov chain starting from $z_V^+$ to try to get a sample $z_V^-$ from the model’s distribution, which is then used to estimate the second expectation. So, each step of gradient descent requires a little bit of MCMC.
What requires proof is the main result in the middle there. See footnote:ackley for the proof in the special case of a Boltzmann machine, but in general the proof is not hard. Below, for brevity we fix the notation $\mathbb{E}^+$ for expectations when $z$ comes from the data, and $\mathbb{E}^-$ when $z$ comes from the model.
Proof 5a. We just have to compute the derivative of the expected log likelihood. First, let’s expand the expression that we are differentiating:\begin{align*}\mathbb{E}^+[\log p(z_V^+;\theta)]&=\mathbb{E}^+[\log(\exp(-F_V(z_V^+)) - \log Z_V]\\\\ &=-\mathbb{E}^+[F_V(z_V^+)] - \log Z_V.\end{align*}Here, we have removed the constant $\log Z_V$ from the expectation. Already we can see that differentiating the first term gives the right result. So, it remains to show that $\frac{\partial}{\partial\theta}\log Z_V=-\mathbb{E}^-[\frac{\partial}{\partial\theta} F_V(z_V^-)]$. Indeed,\begin{align*} \frac{\partial}{\partial\theta}\log Z_V &=\frac{1}{Z_V}\frac{\partial}{\partial\theta}Z_V\\\ &=\frac{1}{Z_V}\int_{z_V} \frac{\partial}{\partial\theta} e^{-F_V(z_V;\theta)}\,dz_V\\\\ &=\int_{z_V}\frac{1}{Z_V} e^{-F_V(z_V;\theta)}\,\frac{\partial}{\partial\theta} -F_V(z_V;\theta)\,dz_V\\\\ &=-\int_{z_V} p(z_V;\theta) \frac{\partial}{\partial\theta} F_V(z_V;\theta)\,dz_V\\\\ &=-\mathbb{E}^-\left[ \tfrac{d F(z_V;\theta)}{d\theta} \right], \end{align*} as desired.
The derivative of free energy will have to be computed on a case-by-case basis, and in some cases the integrals involved may not be solvable. Now, let’s take a look at how this works for a typical Boltzmann machine.
Contrastive divergence for restricted Boltzmann machines
Recall that the Boltzmann machine is a Gibbs random field with energy$$H(z)=-\frac{1}{2} z W z^T.$$I haven’t said much about these yet, so let’s clear some things up. First off, we need $W$ to be a symmetric matrix, so that the energy stays positive. Second, it’s typical to fix the diagonal elements $W_{ii}=0$, although this can be dropped if necessary.
This is the most general flavor of Bernoulli Boltzmann machine, with each node connected to all of the others -- we’ll call it a “fully-connected” Boltzmann machine. These tend not to be used in practice. One reason for that is that Gibbs sampling cannot be done in parallel, since the model respects only the fully connected graph, which makes everything really slow.
It would be more practical to use a graph with sparser dependencies. The most popular flavor is to pick a bipartite graph, where the partitions are the visible and hidden nodes. In other words, any edge in the graph connects a visible unit with a hidden one. This is called a “restricted” Boltzmann machine, and in this case $W$ has the special block form $$W=\left[\begin{array}{c|c} 0 & M \\\\ \hline M^T & 0 \end{array} \right].$$Here, we’ve enforced the bipartite and symmetric structure with notation, and we let $M$ be an $n_V\times n_H$ matrix. Then our energy can be written\begin{align*}H(z)&=-\frac{1}{2} z W z^T\\\\&= -\frac{1}{2} z_V M z_H^T - \frac{1}{2} z_H M^T z_V^T\\\\&=-z_V M z_H^T.\end{align*}Also, we can rewrite the “inputs” to units $x_i=[M z_H^T]_i$ for $i\in V$ and $x_i=[M^T z_V]_i$ for $i\in H$ -- this will be useful notation to have later.
OK. Now, we’d like to compute the expression in Main Result 5a so that we can do gradient descent and train our RBM. Let’s begin by calculating the free energy of the visible units. Starting from the definition,\begin{align*} F_V(z_V) &=-\log \sum_{z_H} e^{-H(z)}\\\\ &=-\log \sum_{z_H} \exp\bigg( z_V M z_H^T \bigg)\\\\ &=-\log \sum_{z_H} \exp\bigg( \sum_{i=1}^{n_V} \sum_{j=1}^{n_H} z^V_i M_{ij} z^H_j\bigg)\\\\ &=-\log\left[ \sum_{z^H_1=0}^1\dotsm\sum_{z^H_{n_H}=0}^1 \left( \prod_{j=1}^{n_H} \exp\!\bigg( \sum_{i=1}^{n_V} z^V_i M_{ij} z^H_j\bigg)\right)\right]. \end{align*}Here, pause to notice that we have $n_H$ sums on the outside, and that each sum only cares about one hidden unit. But then many of the terms in the product in the summand are constants from the perspective of that sum, so by linearity, we can move the product outside all of the sums and then through the logarithm:\begin{align*} F_V(z_V) &=-\log\left[ \prod_{j=1}^{n_H} \sum_{z^H_j=0}^1 \exp\!\bigg( \sum_{i=1}^{n_V} z^V_i M_{ij} z^H_j\bigg)\right]\\\\ &=-\sum_{j=1}^{n_H} \log \left( 1 + \exp\!\bigg( \sum_{i=1}^{n_V} M_{ij} z^V_i \bigg)\right)\\\\ &=-\sum_{j=1}^{n_H} \log \left( 1 + e^{x_j}\right). \end{align*} Not so bad, after all. In particular, we’ll be comfortable differentiating this with respect to the weights $M_{ij}$. Which, well, that’s what we’re doing next. These calculations might be sort of boring, and you know, the details are not that important, but we’re gonna be doing something similar later to train the new model, so it seems nice to see the way it goes in the classic model first.
Anyway, now to take the derivative. We’ll write $\partial_{M_{ij}}=\frac{\partial}{\partial M_{ij}}$ for short, and we’ll work from the second to last line in the previous display. \begin{align*} \partial_{M_{ij}} F_V(z_V) &= - \partial_{M_{ij}} \sum_{k=1}^{n_H} \log \left( 1 + \exp\!\bigg( \sum_{i=1}^{n_V} M_{ik} z^V_i \bigg)\right)\\\\ &= - \partial_{M_{ij}} \log \left( 1 + \exp\!\bigg( \sum_{i=1}^{n_V} M_{ij} z^V_i \bigg)\right) \\\\ &= - \frac{1}{1 + \exp\!\left( \sum_{i=1}^{n_V} M_{ij} z^V_i \right)} \partial_{M_{ij}} \exp\!\bigg( \sum_{i=1}^{n_V} M_{ij} z^V_i \bigg)\\\\ &= - \frac{\exp\!\left( \sum_{i=1}^{n_V} M_{ij} z^V_i \right)}{1 + \exp\!\left( \sum_{i=1}^{n_V} M_{ij} z^V_i \right)} z^V_i. \end{align*} Here, we pause to notice that the fraction in the last line is exactly $$\frac{e^{x_j}}{1+e^{x_j}}=\sigma(x_j)=p(z^H_j=1\mid z_V)=\mathbb{E}[Z^H_j\mid z_V].$$This might seem like a coincidence that just happened to pop out of the derivation, but as far as I can tell, this conditional expectation always shows up in this part of the gradient in all sorts of Boltzmann machines with similar connectivity (e.g., in footnote:honglak, footnote:zemel). I don’t know if this has been proven, but I think it’s a safe bet and a good way to check your math if you’re making your own model. Plugging this in, we find $$\partial_{M_{ij}} F_V(z_V) = -z^V_i \mathbb{E}[Z^H_j \mid z_V].$$ Now, let’s plug this result back into our formula for the gradient to finish up. By the averaging property of conditional expectations,\begin{align*} \frac{\partial}{\partial M_{ij}} \mathbb{E}^+[\log p(z_V^+;\theta)] &= -\mathbb{E}^+[\partial_{M_{ij}} F_V(z_V^+)] + \mathbb{E}^-[ \partial_{M_{ij}} F_V(z_V^-)]\\\\ &= \mathbb{E}^+[ z^V_i \mathbb{E}[Z^H_j \mid z_V] ] - \mathbb{E}^-[ z^V_i \mathbb{E}[Z^H_j \mid z_V] ]\\\\ &= \mathbb{E}^+[ z^V_i z^H_j ] - \mathbb{E}^-[ z^V_i z^H_j ]. \end{align*}TODO: Some commentary on Hebbian and +- phases.
That’s nice, but it ought to be mentioned that there are a lot of practical considerations to take into account if you want to train a really good model, since the gradients are noisy and the search space is large and unconstrained. footnote:practical is a good place to start.
To finish, it should be noted that these RBMs can be stacked into what’s called a “deep belief network” -- I think this is another Hinton name. What that means is that more hidden layers are added, so that the graph becomes $n+1$-partite, where $n$ is the number of hidden layers (we add 1 for the visible layer). Then the energy function becomes$$H(z_V,z_{H_1},\dots,z{H_n})=-z_V M_1 z_{H_1}^T - \dots - z_{H_{n-1}} M_n z_{H_n}^T.$$ These networks are tough to train directly using the free-energy differentiating method above (although the math is similar). In practice, each pair of layers is trained as if it were an isolated RBM, this is called greedy layer-wise training, and is described in footnote:greedylayerwise. There’s a good tutorial on DBNs here as well footnote:http://deeplearning.net/tutorial/DBN.html.
One important thing to note about DBNs is that when you are doing Gibbs sampling in the middle of the network, you have to sample from the conditional distribution of your layer given both the layer above and the layer below. So, there is a little more bookkeeping involved. There are other methods for sampling these networks too (footnote:honglak, footnote:wheredoeshintontalkaboutdeepdreamthing).
Developing langmod-dbn
So, we’ll be working on a DBN to model language, since probably a single layer will not be enough to model anything very interesting. But, since we’ll be using greedy layer-wise training, we can just describe how a “langmod-rbm” looks, and that will take us most of the way there.
OK, so. We want to develop a family of probability distributions $p_n(z^{(n)}_V)$, on strings $z_V^{(n)}$ of length $n$, one probability distribution for each possible length $n$. These strings will come from an “alphabet” $\mathcal{A}$. For example, we might have $\mathcal{A}=\{a,b,c,\dots\}$, or we might allow capital letters or punctuation, etc. So, a length-$n$ string is then just some element of $\mathcal{A}^n$. For short, let’s let $N=\lvert\mathcal{A}\rvert$ be the size of the alphabet.
Our starting point is going to be the RBM as above. The first change is that we will focus on the special case where $M$ is not a general linear transform, but rather a convolution (actually cross-correlation) with some kernel. This is just a choice of the form that $M$ takes, so we are in the same arena so far. There is a good deal of work around convolutional Boltzmann machines for image processing tasks (especially footnote:honglak), but I’m not aware of any work using a convolutional Boltzmann machine for natural language.
(The thing is that we’re going to do sort of a strange convolution, so if you’re familiar with them this will be a little weird. If you’re not, well I’m going to do my best not to assume you are, but it might help to understand discrete cross-correlations a bit. If this is confusing, you might take a look at footnote:https://en.wikipedia.org/wiki/Cross-correlation, and at Andrej Karpathy’s lecture notes on convolutional neural networks footnote:http://cs231n.github.io/convolutional-networks/ for a machine learning point of view.)
Now, it does not make much sense to encode $z_V$ (we’ll use $z_V$ as shorthand for $z_V^{(n)}$) as just an element of $\mathcal{A}^n$, since $\mathcal{A}$ is not an alphabet of numbers. But we can make letters into numbers by fixing a function $\phi:\mathcal{A}\to \{1,\dots,N\}$, so that we can now associate an integer to each letter.
But the choice of $\phi$ is pretty arbitrary, and it does not make much sense to let $z_V$ just be a vector of integers like this. Rather, let’s convert strings into 2-d arrays using what’s called a one-hot encoding. The one-hot encoding of a letter $a$ is an $N$-d vector $e(a)$, where $e(a)_i=1$ if $i=\phi(a)$, and $e(a)_i=0$ if $i\neq\phi(a)$. So, we take a letter to a binary vector with a single one in the natural position.
Then we can encode a whole string $s=a_1a_2\dotsm a_n$ to its one-hot encoding naturally by letting $$e(s)=(e(a_1)\ e(a_2)\ \dotsm\ e(a_n)).$$ So, we’re imaging strings as “images” of a sort -- the width of the image is $n$, and the height is $N$. So, we’ll define an energy function on $z_V$, where $z_V$ is no longer a binary vector like above, but rather an $n\times N$ binary image with a single one in each column. This way, the hidden units can “tell” what letters are sending them input.
Now, instead of having each hidden unit receive input from all of the visible units, as in an ordinary RBM, we’ll say that each hidden unit receives input from some $k$ consecutive columns of visible units (i.e. $k$ consecutive letters), for some choice of $k$. We’ll also assume that the input is “stationary,” just like Shannon did in his early language modelling work footnote:shannon. This means we are assuming that a priori, the distribution of each letter in the string is not influenced by its position in the string. In other words, the statistics of the string are invariant under translations.
But since the input is translation invariant, each hidden unit should expect statistically similar input. So, it makes sense to let the hidden units be connected to their $k$ input letters by the same exact weights. Here’s a graphic of “sliding” those weights across the visible field to produce the inputs $x_j$ to the hidden layer:

This figure footnote:figurepeople takes a little explaining, but what it shows is exactly how we compute the cross-correlation of the visible field and the weights. Here, the blue grid represents the visible field. The weights (we’ll be calling them the “kernel” or the “filter”, and they’re represented by the shadow on the blue grid) are sliding along the width dimension of the input, and we have chosen a kernel width $k=3$ in the figure. In general, the kernel height is arbitrary, but here we’ve chosen it to be exactly the height of the visible field, which is the alphabet size $N$. This way each row of the kernel is always lined up against the same row of the visible field, so that it is always activated by the same letter, and it can learn the patterns associated with that letter.
At this point, it might help to put down a working definition of cross-correlation, which should be thought of as something like an inner product. (You can think of $u$ as the $n\times N$ visible field, and $v$ as the $k\times N$ filter.)
Def 6. (Cross-correlation) Let $u$ be an $n_1\times n_2$ matrix, and let $v$ be an $m_1\times m_2$ matrix, such that $n_1\geq m_1$ and $n_2\geq m_2$. Then the cross-correlation $u*v$ is the $(n_1-m_1+1)\times(n_2-m_2+1)$ matrix with elements$$[u*v]_{ij}=\sum_{p=0}^{m_1}\sum_{q=0}^{m_2} u_{i+p,j+q}v_{pq}.$$
This differs from a convolution, which is the same but with $v$ reflected on all of its axes first. For some reason machine learning people just call cross-correlations convolutions, so that’s what I’m doing too.
We are extremely close to writing down the energy function for our new network. I keep doing that and then realizing I forgot like 10 things that needed to be said first. I think the last thing that needs saying is this: we’ve shown how to get one row of hidden units, with one filter. In a good network, these units will all be excited by whatever length-$k$ substrings of the input have high correlation with the filter. This will hopefully be some common feature of length-$k$ strings -- for small $k$, this could be something like a phoneme -- I don’t know. Maybe the filter would recognize the short building blocks of words, like “nee” or “bun,” little word-clusters that show up a lot.
But this filter is only going to be sensitive to one feature, and we’d like our model to work with lots of features. So, let’s add more rows of hidden units. Each row will be just like the one we’ve already described, but each row will use its own filter. We’ll stack the rows together, so that the hidden layer now is now image shaped. Let’s let $c$ be the number of filters, and we’ll let $K$ be our filter bank -- this is going to be a 3-d array of shape $c\times k\times N$.
Then, the input to the hidden unit $z^H_{ij}$ is given by the cross correlation of the $j$th filter with the input. If we use $*$ also to mean cross-correlation with a filter bank, we have:$$x^H_{ij}=[z_V*K]_{ij}:=\sum_{p=0}^k \sum_{q=0}^N z^V_{i+p,q} K_{j,p,q}.$$Then the hidden layer $z_H$ will have shape $n-k+1\times c$.
This leads us to a natural definition for the energy function. Since cross-correlation is “like an inner product,” we’ll use it to define a quadratic form just like we did in the RBM:\begin{align*}H(z_V,z_H) &=-\langle z_V * K, z_H\rangle\\\\ &:= - \sum_{i=0}^{n-k-1}\sum_{j=0}^c x^H_{ij} z^H_{ij}\\\\ &= \sum_{i=0}^{n-k-1}\sum_{j=0}^c z^H_{ij} \sum_{p=0}^k \sum_{q=0}^N z^V_{i+p,q} K_{j,p,q}.\end{align*}So, there we have the heart of our new convolutional Boltzmann machine, since the probability is basically determined by the energy.
Categorical input units
There’s only one change left to get us to something that could be called a language model. Right now, the machine has a little problem, which is that it’s possible for a sample from the machine to have two or more units on in some column of the sample. We didn’t use a two-hot encoding for our strings, though, so that sample can’t be understood as a string. We have to find some way to make sure this never happens.
The answer is pretty simple: we just restrict our state space. So far, we had been looking at $z\in\{0,1\}^{V\times H}$, the set of all possible binary configurations of all the units. But let’s restrict our probability distribution to the set$$\Omega=\bigg\{z\in\{0,1\}^{V\times H} : \forall i\,\sum_{j} z^V_{ij}= 1 \bigg\}.$$Then our distribution $p(z)$ is still a Gibbs random field on this state space, but we’re left with a question: how do we decide which of the units in each column should be active? The visible units in a column are no longer conditionally independent, so this manipulation of the state space has changed the graph that our model respects by linking the visible columns into cliques.
So, let’s compute the conditional distribution of the visible units given the hidden units. Since the energy is the same, we still have that $$p(z^V_{ij}=1\mid z_H)=\frac{1}{Z} e^{x^V_{ij}},$$ for some normalizing constant that we’ll just call $Z_{ij}$ for now. The question is, what is the normalizing constant? Well, it satisfies $$Z_{ij}=Z_{ij}p(z^V_{ij}=1\mid z_H) + Z_{ij} p(z^V_{ij}=0\mid z_H),$$and we know that since exactly one unit is on,$$Z_{ij}p(z^V_{ij}=0\mid z_H)=\sum_{k\neq j} Z_{ij} p(z^V_{ik}=1\mid z_H).$$ Plugging back into the previous line, we get$$Z_{ij}=\sum_{k}Z_{ij} p(z^V_{ik}=1\mid z_H).$$ But $Z_{ij}$ obeys this relationship for any choice of $j$, so we see that in fact $$Z_{i0}=Z_{i1}=\dotsm=Z_i$$is constant over the whole column, and that its value is $$Z_i=\sum_{k} Z_i p(z^V_{ik}=1\mid z_H) = \sum_k e^{x^V_{ik}}.$$So, now we have found our conditional distribution $$p(z^V_{ij}=1\mid z_H)=\frac{e^{x^V_{ij}}{\sum_k e^{x^V_{ik}}}.$$ But this is exactly the softmax footnote:softmax function that often appears when sigmoid-Bernoulli random variables are generalized to categorical random variables! That’s nice and encouraging, and it gives us a simple sampling recipe. Just compute the softmax of $x^V$ over columns, and then run a categorical sampler over each column of the result.
It might be worth noting that this trick of changing the distribution of the input units is a common one: often for real-valued data, people will use Gaussian visible units and leave the rest of the network Bernoulli footnote:GaussBerRBM. Also, I should note that I was inspired to do this by the similar state-space restriction that Lee et al. used to construct their probabilistic max pooling layer footnote:honglak -- this is a pretty direct adaptation of that trick.
Lastly, it might be worth noting that you could do the same thing to the hidden layer that we have just done to the visible layer -- this could be helpful, since it would keep the network activity sparse. Also, in the language domain, maybe it’s appropriate to think of hidden features as mutually exclusive in some way (you can’t have two phonemes at once). I would bet that this assumption starts making less sense as you go deeper in the net. The problem with this idea is that unlike what we’ve just done in the visible layer, changing the state space of the hidden units ends up changing the integral that computes the free energy of the visible units, which means we would have to do that again. So for now, let’s not do this.
Training the language model
Now, we’d like to get this thing learning. But for once, we are in for a lucky break. Notice that this categorical input units business hasn’t changed anything about the free energy -- that integral is still the same. So, since the learning rule is basically determined by the free energy, that means that this categorical input convolutional RBM has the same exact learning rule as a regular old convolutional RBM.
And, we’re in for another break too. Cross-correlations are linear maps, so a convolutional RBM is just a special case of the generic RBM whose learning rule we’ve computed above. In particular, there exists a matrix $M_K$ so that if $z_V’$ is $z_V$ flattened from an image to a flat vector, $M_Kz_V=(z_V*K)’$. The thing is that $M_K$ is very sparse, so we need to figure out the update rule for the elements of $M_K$ that are not fixed to 0.
Well, first of all, our free energy hasn’t changed, but we can write it in a more convolutional style: $$F_V(z_V)=-\sum_{i=0}^{n-k+1}\sum_{j=0}^c \log(1 + e^{x^H_{ij}}).$$ So, all we need to do is compute $\partial_{K_{ors}}$ of this expression ($K$ is hidden in $x^H_{ij}$). This is quick, so I’ll write it out:\begin{align*}\partial_{K_{ors}} F_V(z_V) &=\partial_{K_{ors}} - \sum_{i=1}^{n-k+1}\sum_{j=1}^c}\log(1+e^{x^H_{ij}}\\\\ &=-\sum_{i=0}^{n-k+1} \partial_{K_{ors}} \log(1+e^{x^H_{io}})\\\\ &=-\sum_{i=0}^{n-k+1}\frac{1}{1+e^{x^H_{ij}}} \partial_{K_{ors}} e^{x^H_{io}}\\\\ &=-\sum_{i=0}^{n-k+1}\sigma(x^H_{io}) \partial_{K_{ors}} x^H_{io}\\\\ &=-\sum_{i=0}^{n-k+1}\sigma(x^H_{io}) z^V_{i+r,s},\end{align*}where the last line follows directly from the definition of $x^H_{io}$ given above.
But on the other hand, what if we did want to have categorical columns in the hidden layer? It’s plausible to me to think that only one “language feature” might be active at a given time, and this has the added bonus of keeping the hidden layer activities sparse. This amounts to imposing on the hidden layer the same restriction that we earlier imposed on the state space for the visible layer, i.e. we choose the new state space$$\Omega’=\bigg\{z\in\{0,1\}^{V\times H} : \forall i\,\sum_{j} z^V_{ij}= 1 = \sum_j z^H_{ij} \bigg\}.$$Then, of course, we sample the hidden units in the same way that we just discussed sampling categorical visible units.
But now we’ve changed the state space of $z_H$, which in turn changes the behavior of the $\int \, dz_H$ that appears in the definition of free energy. So if we want to train a net like this, we’ll need to re-compute the free energy and see what happens to the learning rule.
This is sort of the convolutional version of the outer product that appeared in the RBM, and it’s a special case of the gradient needed to train a convolutional DBN like footnote:honglak, which allows for a kernel that is not full-height like ours.
Many thanks especially to Matt Ricci for working through all of this material with me, and to Professors Matt Harrison, Nicolas Garcia Trillos, Govind Menon, and Kavita Ramanan for teaching me the math.
we could just use an ordinary dbn and make sure to sample from the conditional distribution on only one per col in vis layer
modify sliding kernel pic to have full-height kernel, show the alphabet on the side, stuff like that. cite that guy’s tool if it works
let’s try that
ok, but just for fun, let’s encode that constraint into the model. maybe it’ll make it more structured and able to automatically deal with sparsity problems.
at this point you have as much intuition for me if this thing should work. let’s try it out. more layers is tough?? idk
mention more Boltzmann “mods” like DUBM, or more standard Gaussian, or Gaussian-Bernoulli. Mention gemangeman model.
search for todo and footnote when done. also resize the figures.w
0 notes
Link
The US Agency for International Development (USAID), the US government’s main foreign aid organization, has started doing something radical. It has begun testing programs it runs in Africa, and seeing if they actually do any more good than just handing out cash. And with the first such evaluation now in, the answer seems to be that they’d be better off giving away cash.
The evaluation concerns a program in Rwanda called Gikuriro. Implemented by Catholic Relief Services, a nonprofit charity, the program is meant to teach good nutrition and hygiene habits to new mothers through initiatives like “village nutrition schools” and the distribution of small livestock and seeds; it also promotes the creation of small community groups to encourage savings.
It’s sort of a grab-bag of things that sound nice: nutritious food sounds nice, savings sound nice, giving out livestock sounds nice, so why not combine them into one nice-sounding program?
The problem is that things that sound nice don’t always work. And the new study, resulting from an unusual collaboration between USAID and the charity GiveDirectly, suggests that Gikuriro doesn’t actually help nutrition or health.
Handing out a large amount of cash, though, did.
The study, authored by UC San Diego economist Craig McIntosh and his Georgetown colleague Andrew Zeitlin, didn’t merely compare the Gikuriro program to doing nothing, the way most evaluations of aid programs do. It also did something called “cash benchmarking”: seeing how well a program works compared to an equivalently priced cash transfer.
Development aid typically takes the form of in-kind goods and services: vaccines, medicine, education, housing, food parcels, etc. But giving out goods and services can be tricky and costly, from a logistical perspective, and runs the risk of giving people things they don’t want or need. For directly providing goods and services to make sense, it has to have better effects than just giving those poor people cash, which those people can then use to buy the goods and services they themselves choose.
McIntosh and Zeitlin split a group of 248 Rwandan villages into three groups:
In 74 villages, no households received any aid.
In 74 villages, all households with malnourished children, children under 5, or pregnant/lactating mothers got the Gikuriro program through USAID and Catholic Relief Services.
In 100 villages, households meeting the above criteria got cash instead, provided by the charity GiveDirectly.
The cash villages were further divided up, based on how much money residents received:
22 villages got $116.91 per household, which cost roughly the same amount per household as the Gikuriro program. Another 44 villages got less than Gikuriro cost (either $41.32 or $83.63 per household). The study pooled these groups together, and on average they wound up costing about 78 percent as much as Gikuriro.
Finally, 34 villages got a lot more than Gikuriro cost: a whopping $532 per household. The $532 transfer was chosen by GiveDirectly as an amount that would maximize the amount of cash distributed relative to administrative expenses associated with handing it out.
On every relevant nutrition and health-related outcome, Gikuriro did absolutely nothing of significance, compared to the control group (the households that received no aid). The program didn’t make households significantly likelier to have diverse diets, or significantly less likely to have mothers with anemia, or significantly more likely to have kids with healthier heights for their age.
“No consistent impacts appear for consumption and wealth outcomes, or for health knowledge and sanitation practices,” McIntosh and Zeitlin write. Savings do go up, quite a bit, which makes sense given the savings-promotion aspect of the Gikuriro program. But that’s about it.
The smaller GiveDirectly transfers (which, again, cost about a fifth less than Gikuriro on average) also had few statistically significant health effects. But the small cash transfer did lead them to cut their debt by 76 percent, and caused a big increase in both productive assets (like, say, fruit trees or livestock, which can generate income) and consumption assets (like metal roofs, which don’t generate income but increase household well-being and make other purchases unnecessary).
To recap: The small cash transfers led recipients to pay down debt, while the nutrition/savings promotion program led recipients to build up savings. Of these outcomes, the former is clearly preferable. The authors explain that the savings caused by the nutrition program yielded about 5 percent interest every year. Interest rates on debt for people receiving cash, by contrast, were in the range of 22 to 60 percent. In that environment, it makes absolutely no sense to build up savings rather than pay down debt.
To be clear, in a head-to-head match-up comparing a nutrition program to a (less expensive) cash program, neither helped with nutrition, per se. But when it came to other outcomes, cash won, by a walk. “If nutrition was better for the USAID intervention but assets were better for cash, you could argue,” Michael Faye, president and co-founder of GiveDirectly, says. “But no matter what variable you care about, cash is strictly dominant.”
Of course, while cash was strictly dominant, it on its own didn’t accomplish anything when it comes to nutrition. “It’s by no means saying that equivalent cash transfers would’ve been better,” Berk Ozler, a senior economist at the World Bank who’s been critical of GiveDirectly, says. “If you give a hundred dollars for each, the results are the same. Benchmarking-wise, you didn’t show me it outperformed.”
It gets better for the cash side, though. Remember how 34 villages got a much, much bigger transfer, of $532 per household? Not only did wealth and consumption on regular goods like food and housing go up in that group, as you’d expect after giving someone a whole bunch of cash, but beneficiaries had more diverse diets, healthier child heights relative to age, and, most strikingly, lower child mortality.
This was a study covering a year period. Any intervention having a noticeable impact on child mortality, let alone an intervention that did nothing directly related to health, is surprising. And yet in only a year, child mortality among people getting the big cash transfer was 70 percent lower. In the control group, 13 out of 2,596 children died. Among the group getting the big transfer, only two out of 1,200 children died.
That’s a really startling finding. It’s such a big shock that I’m not even really sure I believe it. A 2013 literature review by the Center for Global Development’s Amanda Glassman, Denizhan Duran, and Marge Koblinsky identified three cash studies with infant or maternal mortality as a measured outcome. Two, in Mexico and India respectively, found that cash reduced mortality, while the third, in Nepal, did not find any significant effects. Nothing in that evidence base suggested a 70 percent reduction in one year was possible. I’m certainly open to the idea that the cash had some effect, but maybe the big difference between the treatment and control villages was a fluke.
The study wasn’t set up to compare this massive cash transfer, with its apparently huge health benefits, to a nutrition program that cost the same amount. (Again, Gikuriro cost about a quarter as much as the big cash transfer.) “It would be possible to design such a program, and in fact such programs exist. For example, the Tubaramure program financed by USAID next door in Burundi cost $844 per beneficiary household,” McIntosh and Zeitlin explained in an email. But “Gikuriro, as designed, reflected USAID’s belief about the most cost-effective intervention in this domain for its context and time.”
Moreover, they continued, there’s little reason to think that the best, most cost-effective nutrition program will cost the same amount per recipient as the best, most cost-effective cash program. By comparing the big cash transfer to Gikuriro, they were comparing the USAID’s best guess as to the optimal size of a nutrition program to GiveDirectly’s best guess as to the optimal size of a cash program. And even smaller cash programs than those recommended by GiveDirectly produced strictly better economic outcomes than Gikuriro did.
As Marc Gunther explains in the New York Times, this experiment came about due to the initiative of a USAID staffer named Daniel Handel, formerly based in Rwanda and now working for the agency as a senior adviser on aid effectiveness in DC. (Gunther notes that the new job title was invented just for Handel.)
It was a risky project to run; as Gunther notes, comparing traditional USAID projects to cash “poses a threat to hundreds of for-profit companies and nonprofit groups that secure USAID contracts, often with scant evidence of impact.”
Indeed, there’s a danger that articles like this one might make it harder for innovators like Handel to get projects like this rolling in the future. Government agencies aren’t generally in the business of cooperating with studies that make their programs look bad.
But this isn’t the only cash benchmarking study that USAID has planned. It’s also conducting a comparison with a youth employment program in Rwanda, and three additional studies in Malawi, Liberia, and the Democratic Republic of the Congo are being rolled out too, per Gunther. If that pattern keeps up, it could mean a sea change in the way that we think about funding development.
“The fact that USAID conducted this research and is going to release it is extraordinarily exciting,” Amanda Glassman, chief operating officer and senior fellow at the Center for Global Development, says. “There are still so few programs at USAID that show any effectiveness.”
And hopefully, in the future, some of the programs compared to cash will outperform it when it comes to key metrics. Humans are often irrational and underpurchase goods that they really, really need.
Take, for instance insecticide-treated bednets, which prevent malaria not just among people who use them but also people who just live nearby. Given the social benefits of bednets, and the fact that even charging a small amount (like 60¢) for bednets causes a massive reduction in the number of people using them, handing bednets out for free is probably a better idea than handing out cash and making people pay for them. Glassman adds that infrastructure projects, like roads, are public goods that cash transfers alone probably can’t let communities build.
But most aid that USAID and other US aid agencies offer isn’t about providing infrastructure improvements or other public goods. “USAID isn’t doing infrastructure now, it’s really doing service delivery,” Glassman explains. “But it’s an open question: Is it better to invest in a school or textbooks, or in cash, so kids can buy a uniform and school fees?”
That’s a question you can ask about the vast majority of programs that USAID runs. And now, USAID finally looks interested in asking it.
Original Source -> The small study in Rwanda that could change the way the US does foreign aid
via The Conservative Brief
0 notes