#IoT-аналитика
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Video
youtube
Транзакционные издержки
🌟 Рональд Коуз и транзакционные издержки: как они меняют цифровой мир? 🚀
Знаете, кто заложил основу для понимания современной экономики? Рональд Коуз, выдающийся экономист, ��ткрывший транзакционные издержки! 🧠 Его идеи — ключ к разгадке, почему цифровая трансформация так мощно перестраивает бизнес. Давайте разберёмся, как это работает, и почему это must-know для аналитиков и предпринимателей! 📈
🔍 Что такое транзакционные издержки? Коуз в 1937 году в статье "Природа фирмы" показал: транзакционные издержки — это затраты на:
Поиск информации: найти поставщиков, клиентов, данные.
Согласование: договориться о ценах, условиях, контрактах.
Контроль: следить за выполнением сделок, качеством, сроками.
Идея Коуза проста: фирмы существуют, чтобы минимизировать эти издержки, ведь внутри компании координировать легче, чем на рынке. Нобелевская премия 1991 года — доказательство гениальности его мысли!
💥 Цифровая трансформация и транзакционные издержки Смысл современной цифровой революции — радикальное снижение транзакционных издержек! Как?
Информация на кончиках пальцев: поиск поставщиков или клиентов через платформы (Google, маркетплейсы) — это секунды, а не недели.
Автоматизация сделок: смарт-контракты на блокчейне убирают переговоры и бумажную волокиту.
Контроль в реальном времени: данные, аналитика, IoT следят за процессами без лишних затрат.
🎯 Кейс: Uber и Airbnb — чемпионы цифровой эры. Они свели транзакционные издержки к минимуму: платформы соединяют водителей и пассажиров, хозяев и гостей без посредников. Результат? Компании стоимостью в миллиарды, которые почти не владеют активами! Коуз бы аплодировал! 👏
🛠 Почему это важно для бизнеса? Цифровая трансформация, вдохновлённая идеями Коуза, позволяет: 1️⃣ Ускорять процессы: меньше времени на поиск и согласование. 2️⃣ Снижать затраты: автоматизация и цифра убирают лишние расходы. 3️⃣ Масштабироваться: создавайте платформы, где издержки стремятся к нулю.
💡 Как применить?
Анализируйте свои транзакционные издержки: где вы тратите время и деньги?
Внедряйте цифровые инструменты: CRM, ERP, платформы для автоматизации.
Тестируйте: начните с малого, замеряйте, как цифра снижает затраты.
Рональд Коуз показал, что издержки — это сердце экономики. Цифровая трансформация доказывает: кто их сокращает, тот побеждает! 🌍
💬 А что у вас? Замечали, как цифра снижает транзакционные издержки в вашем бизнесе? Может, есть кейс, где автоматизация всё изменила? Делитесь в комментариях — давайте обсуждать, как идеи Коуза работают сегодня! 👇
#БизнесАнализ #игник #ТранзакционныеИздержки #ЦифроваяТрансформация
0 notes
Text
KIMEP воспитает IT- и научную элиту Казахстана! Раскрыты новые планы
New Post has been published on https://er10.kz/read/analitika/kimep-vospitaet-it-i-nauchnuju-jelitu-kazahstana-raskryty-novye-plany/
KIMEP воспитает IT- и научную элиту Казахстана! Раскрыты новые планы
Университет KIMEP собирается взрастить научную элиту Казахстана! Очередным шагом в этом направлении стало открытие нового здания School of Computer Science and Mathematics (SCSM). Это — важный этап в развитии SCSM, самой школы, запущенной год назад. За это время она привлекла талантливых студентов и ведущих преподавателей.
По словам президента KIMEP Чан Йан Бэнга, новое здание открыли с целью обучить молодых людей, стремящихся стать специалистами или учеными в области компьютерных наук:
Мы подготовим их так, чтобы они стали настоящими экспертами и могли продолжить академическую карьеру. Они смогут учиться в США или в странах Европы и добиваться успеха. И затем они смогут внести вклад в экономическую модернизацию Казахстана. Поэтому мы считаем эту программу по компьютерным наукам одной из наших приоритетных, по-настоящему значимых дисциплин — наравне с такими направлениями, как бизнес-администрирование, юриспруденция или социальные науки.
В новом здании появились:
Лаборатория сетевых технологий и кибербезопасности, в которой вскоре будет установлен суперкомпьютер;
Лаборатория IoT и робототехники;
Лаборатория физики, оснащенная приборами от PASCO Scientific.
Весной 2026 года планируют открыть химическую лабораторию, которая будет способствовать междисциплинарному сотрудничеству.
Компьютерные науки и математика, включая смежные дисциплины, такие как искусственный интеллект, окажут огромное влияние на вашу жизнь, вашу работу, а также на творчество и многое другое. Поэтому KIMEP решил запустить одну из ведущих, классических и элитных программ в области компьютерных наук и искусственного интеллекта. На сегодняшний день мы инвестировали 3,7 миллиона долларов. Я также добавлю еще 1,8 миллиона. Таким образом, общая сумма инвестиций составит 5,5 миллиона долларов. Уже набрано 14 преподавателей, и со временем мы будем продолжать привлекать новых специалистов. К 2028 году, то есть в течение следующих четырех лет, эта программа станет одной из ведущих в области компьютерных наук, а также смежных направлений — математики, физики, программной инженерии и других. — отметил доктор Бэнг.
��аборатории, просторные лекционные залы и инновационные коворкинг-пространства создают условия для обучения, максимально приближенные к реальной индустрии. Сейчас KIMEP предлагает две бакалаврские программы в IT: Информатика и Информационные системы. Студенты могут выбрать специализацию в следующих областях:
Аналитика данных,
Программная инженерия,
Искусственный интеллект,
Кибербезопасность,
Аналитика больших данных,
Информационные системы управления.
Учебный процесс построен в соответствии с международными стандартами ABET и охватывает ключевые направления цифровой экономики. Новый корпус расширяет возможности практического обучения, предоставляя студентам доступ к технологическому оборудованию и современным исследовательским инструментам.
0 notes
Link
0 notes
Text
Выдуманные профессии, которые могут стать реальностью в течение следующих 20 лет
Автоматизация...Сколько критики идет в эту сторону, ведь она отбирает рабочие места у людей. Но все логично: технология меняется.
На самом деле, работа постоянно меняется, постоянно развивается, всегда прогрессивно, поскольку мы создаем новые проблемы так же быстро, как решаем старые.

Рабочие роли будут развиваться из-за технологий, демографических сдвигов, урбанизации, дефицита, изменения климата.
В свое время профессиональный геймер и Youtuber были с области фантастики, но эти профессии теперь приносят миллионы.
Имея это в виду, ниже приведены выдуманные профессии, которые могут стать реальностью в течение следующих 20 лет.
Менеджер IoT-аналитики
Когда IoT перейдет от высокотехнологичных проектов к недорогим вещам? 5 лет? 10 лет? Вероятно, меньше. В любом случае, когда технология станет демократизированной, кто-то должен будет отвечать за ключевые вопросы. Какой объект подключить? Действительно ли подключенная футболка отвечает конкретным потребностям? Какие данные интересны с точки зрения бизнеса? Какую инфраструктуру нужно будет адаптировать? Какой UX для этих связанных объектов? Что насчет устаревших систем? Менеджер Edge Computing должен знать, как ответить на эти вопросы.
Руководитель цифрового магазина
Наибольшее преимущество магазинов перед цифровыми каналами - это их персонал. Но это же и экономия. По-этому, цифровые магазины развиваются, и кто-то должен будет ими руководить.
Сценарист AR/VR
Концепция геймификации набирает обороты, логично, что мы будем требовать, что бы наш опыт дополненной реальности имел отличную сюжетную линию, из которой можно извлечь уроки. Вот где нужен рассказчик. Эта работа отлично подойдет для обучения (военного и корпоративного), а также для скрытого маркетинга.
Разработчик виртуальных миров
После того как мы построим наши сюжетные линии (см. выше), нам нужно создать целые миры. Эта роль требует многих навыков, как и в дизайнеров видеоигр.
Эксперт по блокировке рекламы
Edge Computing, Digital Stores, AR, VR ... Все это будет иметь рекламу. И как только мы устанем от новинки, нам понадобятся блокировщики рекламы, которые должны быть достаточно продвинуты, чтобы замечать рекламу, встроенную в саму реальность, где, например, их могут заметить только очки AR.
Юрист по вопросам этики
вопросам этики и толерантности сейчас уделяется очень много внимания и логично что, их интересы должен кто-то представлять в суде...
Менеджер по безопасной репутации
Доверие вот-вот станет ОЧЕНЬ большим рычагом влияния, как мы уже начали видеть в эпоху «поддельных новостей». Таким образом, не кажется странным нанимать кого-то, кто будет отвечать за то, чтобы клиенты знали, что они могут доверять корпорации свои личные данные, сбережения, секреты, близких людей... Во многом это как пиар.
Представитель персональных данных
PDR - это человек или компания, которые на законных основаниях представляют всю чью-то информацию и инвестируют ее в нужные базы данных, чтобы обеспечить лучшую отдачу для своих клиентов. В интересах PDR было бы лучше убедиться, что никто не использует данные своих клиентов без законного интереса или согласия, что делает эту роль вдвойне полезной. Это также помогло бы реализовать базовую структуру для переносимости данных, что становится все более юридическим требованием.
Исследователь данных AI
Алгоритмы должны быть в состоянии объяснить свой базовый механизм в простых терминах . Это становится еще более важным, поскольку AI внедряется в повседневную жизнь, в том числе в систему правосудия.
То, что может произойти, - это создание роли, которая влечет за собой рыться в коде, чтобы выяснить, почему этот самоуправляемый автомобиль врезался в группу школьников вместо того, чтобы спасать беременную женщину.
Детектив данных
В то время как исследователь данных отвечает на вопросы, которые были заданы, детектив данных будет генерировать ответы на вопросы, которые не обязательно задавались (или наоборот), копаясь в данных, создаваемых новыми технологиями. Означает ли увеличение числа дронов уменьшение рождения голубей?
Аналитик по человеко-машинному сотрудничеству
Автоматизация, вероятно, повлияет на значительный процент рабочих мест в ближайшем будущем. Но на какой вопрос мы отвечаем первыми, когда речь заходит об автоматизации? Кого мы автоматизируем? Когда? Мы улучшаем или зам��няем? Это будет делать специальный аналитик.
ИТ-фасилитатор
В настоящее время ИТ и бизнес должны научиться лучше общаться. Тем не менее, владение обоими языками является редким талантом, так как объединяет потребности бизнеса с технологическими/техническими возможностями и аппаратным бюджетом.
Аналитик умного города
Например, если автомобили теперь могут парковаться без водителя, сколько нам нужно парковочных мест? Если у меня есть данные с каждого мобильного телефона в городе, могу ли я преднамеренно отправить в район полицейских или пожарных? Возможности довольно безграничны.
Удаленный автомеханик
По мере того, как автомобили становятся все более автоматизированными и подключенными, нам всегда нужно будет посещать нашего механика для решения каждой маленькой проблемы? или он может все сделать дистанционно, просто подключившись к системе?
Микрогрид аналитик
Поскольку возобновляемая энергия становится все более необходиимой, каждый дом может производить электроэнергию для собственного использования. Однако, если кто-то отправится в отпуск, эта энергия может остаться неиспользованной и может быть продана соседу, устраивающему вечеринку, которому нужно больше электричества для голограммы принца, которую он планирует представить. Именно тогда придет микрогрид аналитик, обеспечивающий максимально эффективное использование энергии.
1 note
·
View note
Text
Какие инженеры нужны российской экономике
New Post has been published on https://is.gd/Peguax
Какие инженеры нужны российской экономике

Представителей каких специализаций катастрофически не хватает на рынке труда?
Министерство труда и социальной защиты России в марте 2019 года заявило, что на рынке труда РФ катастрофически не хватает представителей технических профессий. В связи с этим редакция Executive.ru задала экспертам вопросы:
Какие именно инженеры нужны российской экономике в XXI веке?
В каких отраслях зафиксирована катастрофическая нехватка?
Отличается ли инженер XXI века от инженера XX века? Если да, то какими компетенциями, навыками, инструментами?
Хороший инженер должен быть предпринимателем
Андрей Шолохов, партнер Strategy Partners, руководитель «Центра цифровой трансформации»
1. Я бы условно разделил инженеров в любых областях деятельности на инженеров-композиторов и инженеров-исполнителей. Инженеры-композиторы – это изобретатели, которые создают новые продукты или технологии. Инженеры-исполнители все это умело используют в своей работе.
Спрос на инженеров напрямую зависит от того, какие индустрии стратегически будут присутствовать в экономике России в XXI веке. Ресурс людей, готовых стать инженерами, ограничен. Немногие понимают, что квалификации инженера-конструктора, инженера-электротехника и инженера-программиста очень близки. Однако на стыке веков лучшие студенты предпочитали заниматься программированием. Программистам больше платили, они могли видеть результаты своего труда, имели возможность работать над самыми передовыми проектами в индустрии, выполнять работы для иностранных компаний и переезжать за границу.
2. Атомная промышленность на сегодняшний день – единственная отрасль в России, в которой достаточно инженеров-композиторов – изобретателей, создающих новые технологии и продукты, и инженеров-исполнителей – тех, кто изобретенное способен воплотить в жизнь. У нас реализуются передовые проекты, и в этой области мы конкурируем на мировом уровне.
Ресурсные предприятия, а также область программирования не страдают от отсутствия инженеров-исполнителей, но в них, очевидно, не хватает инженеров-композиторов. Мы, несомненно, занимаем определенные конкурентные ниши, но в целом самостоятельно не определяем ландшафт индустрий. Машиностроение и приборостроение, к сожалению, испытывают острую нехватку даже инженеров-исполнителей. Машиностроительная продукция России конкурентна в основном только на собственном рынке, во многом благодаря государственным дотациям и торговым ограничениям.
3. Инженер-композитор XXI века – изобретатель, тот, кто придумывает новые технологии и продукты. Кроме профессиональных навыков и научного подхода к работе, он должен постоянно совершенствоваться и учиться новому. Необходимо уметь быстро адаптироваться к меняющимся условиям, а также оперативно принимать решения в нестандартных ситуациях. Задача современного инженера – не просто идти в ногу со временем, а опережать его на несколько шагов. При этом он должен уделять особое внимание навыкам коммуникации, ведь мало создать механизм, систему или структуру, нужно добиться реализации своего проекта в обществе.

Нужны инженеры, способные работать с большим пакетом SAPR-систем
Евгения Меркулова, консультант направления «Оборудование и инжиниринг», Hays
1. Мы видим, что наши клиенты при подборе персонала все больше внимания уделяют инновациям и цифровой экономике. Роботизация в России только начинает развиваться: на 10 тыс. работников предприятий в 2017 году приходился один промышленный робот (исследование BCG «Россия 2025: от кадров к талантам»). Тем не менее, прогрессивные компании все больше внедряют автоматизацию и цифровизацию в производственный процесс.
2. Несмотря на то, что автоматизация идет полным ходом, мы наблюдаем большую нехватку инженеров традиционных специальностей. По нашим данным, средний срок закрытия некоторых технических вакансий значительно превышает стандартное время закрытия в других областях.
Большой спрос на узких специалистов в криогенной и вакуумной индустриях, пищевой промышленности, особенно в молочном секторе, химическом направлении, где остро не хватает инженеров-технологов с английским языком.
Если говорить об инструментах, которые используют инженеры в своей работе, то здесь мы отмечаем запросы на владение большим ассортиментом программ автоматизированного проектирования (CAD). Компании нуждаются в сотрудниках, которые смогут разобраться с большим пакетом SAPR-систем.
Высококвалифицированный инженер, которого ищут потенциальные работодатели, должен уметь импровизировать и работать в условиях постоянной неопределенности. Ему необходим высокий уровень образования и широкий кругозор, а также владение английским языком. Сегодняшние условия требуют от профессионалов непрерывного обучения и повышения квалификации.
3. Инженер XXI века должен иметь высокие когнитивные способности, а также хорошую техническую подготовку и постоянно расширять свои навыки в области новых систем проектирования и моделирования.

Нужны ученые, работающие с данными
Геннадий Былов, генеральный директор Rockwell Automation
1. Мы находимся в центре Четвертой промышленной революции, которая готова значительно преобразить работу с помощью стремительно растущих передовых технологий, таких как искусственный интеллект, передовая робототехника и когнитивная автоматизация, передовая аналитика и Интернет вещей (IoT).
Повсеместное распространение цифровых технологий приводит к нехватке квалифицированных специалистов на промышленных предприятиях. То есть мы неизбежно сталкиваемся с несоответствием между навыками, имеющимися у работников, и навыками, необходимыми для рабочих мест цифрового предприятия. В связи с этим многие предприятия задаются вопросом – как подготовиться к новой цифровой эре с точки зрения рабочей силы?
2. Классическое техническое образование со своими стандартами готовит много хороших специалистов, которые способны быстро адаптироваться к используемым технологиям на производственных предприятиях. Однако ситуация меняется, и цифровым предприятиям уже требуется новый тип сотрудников – ученые, работающие с данными, информацией, аналитикой, разработкой ПО…
Многие из передовых технологий, таких как искусственный интеллект, требуют комбинации творческих и технологических знаний и навыков. Исследование Всемирного экономического форума выявило, что в 2020 году будут востребованы следующие топ-10 навыков (по убыванию степени важности):
Решение сложных задач.
Критическое мышление.
Креативность.
Управление людьми.
Взаимодействие и координация.
Эмоциональный интеллект.
Способность принимать решения.
Сервис-ориентированность.
Умение вести переговоры.
Когнитивная гибкость.

Универсальные инженеры не востребованы сейчас, но будут востребованы позже
Тимур Сатдаров, руководитель по развитию бизнеса KUKA AG Урал-Поволжье
1. В условиях современной российской экономики, к сожалению, универсальные инженеры не находят спроса. Везде требуются узкопрофильные кадры, которые знают только свою область и не видят картину цели��ом. Например, это инженер-робототехник или инженер медицинского оборудования. Можно заявить, что российской экономике нужны именно такие специалисты, чтобы закрыть имеющиеся пробелы в сложном производстве. Но если ориентироваться на будущее, такой подход крайне неверен. В будущем, на наш взгляд, будут востребованы специалисты широкого профиля, которые будут экспертами во многих отраслях и технологиях. И все больше будут востребованы специалисты смежных профессий: инженер-технолог, инженер-программист…
2. Самый большой спрос на инженерные кадры, на наш взгляд, все же необходим в создании высокотехнологических производств гражданской продукции: это и автомобильная промышленность, и продукция повседневного спроса. Нам необходимо создавать и развивать новый рынок гражданской продукции.
3. Основное отличие инженеров разных времен – то, что специалисты XX века были не просто инженерами, а инженерами-создателями. Сейчас инженеров можно назвать инженерами-рационализаторами или инженерами-экономистами. Мы все же опираемся на рыночную экономику, чтобы что-то предложить рынку, нужно найти способ создать и продать технологию или продукт как можно дешевле. Однако не надо забывать, что инженер XXI века должен обладать знаниями и умениями с фокусом на защиту окружающей среды: перед производствами уже остро стоит вопрос бережного отношения к природе, и инженерам придется его решать.

Востребованы специалисты, способные быть лидерами инноваций
Наталья Пугаева, ведущий HR-эксперт, Team Force
1. Ситуация на рынке труда такова, что инженеры нужны практически во всех отраслях, особенно – в промышленности. Спрос на таких специалистов очень широк: это и производственники, и конструкторы, и технические эксперты, и эксперты-аналитики, способные генерировать новые идеи, технологии и продукты, видеть тренды и соотносить с ними потребности различных отраслей. Востребованы специалисты, способные сконструировать и изготовить прототипы новых устройств, участвовать в процессах создания высокотехнологичных продуктов, быть лидерами инноваций. Мы проводили исследование, которое показало, что резерв свободных ресурсов в крупных компаниях может достигать 30-50%!
2. Нехватка инженеров особенно сильна в отраслях, которые пережили наиболее сильный кризис после распада СССР: производство, транспорт, энергетика. Но не хватает кадров и в отраслях, которые начали активно развиваться на рубеже XX и XXI веков, например, в телекоме. К тому же нужно учитывать смену поколений. Опытные специалисты, начавшие свою профессиональную деятельность еще в советское время, уступают поле деятельности недавним выпускникам технических вузов. А это – поколени�� демографического спада конца 1990-х.
3. Основное отличие инженера XXI века – в его месте в производственном процессе. Это не «винтик» и не безликий ИТР, а специалист с комплексным видением производства и широким кругозором в области технологических новинок и новых методов управления производством. Недаром одним из принципов современного образования является кросс-дисциплинарность.
Второе важное отличие – открытость. С советских времен во многих ведомственных НИИ и предприятиях сохранилась практика ориентации на одну отрасль, один тип производства, мышление в рамках плановой экономики, а не рыночной. Но для коммерциализации разработок необходимо умение анализировать рынок и находить возможности для интеграции. Проект «на бумаге» не является результатом. Современный инженер должен быть готов к кооперации с российскими и зарубежными партнерами, исследовательскими организациями и бизнес-заказчиками. Наконец, для инженера XXI века критически важно постоянное развитие знаний и навыков. Технологический прогресс ускорился в десятки раз, и ценность специалиста, который это недооценивает, стремительно падает.

Качественных кадров остро не хватает во всем мире
Демид Костерев, основатель «Модульбау»
1. Проблема поиска качественных кадров остро чувствуется во всем мире. По данным Korn Ferry Hay Group – аналитической компании, к 2030 году в регионе EMEA, куда входит Европа, Россия, Ближний Восток и Африка, дефицит кадров превысит 14,3 млн человек, из-за чего экономика потеряет $1,906 трлн. В России сумму ущерба от нехватки инженеров оценили в $300 млрд.
2. Не хватает инженеров-строителей, электриков, проектировщиков, конструкторов… Рабочих рук, в том числе за счет притока низкоквалифицированной рабочей силы из стран ближнего зарубежья, хватает. Не хватает именно руководителей, с опытом проектирования, с пониманием процессов и с менеджерскими данными.

Катастрофически не хватает инженеров, которые умеют работать с «инфраструктурой 2.0»
Дмитрий Бессольцев, директор департамента IT-аутсорсинга ALP Group
1. Горной и нефтедобывающей промышленности, крупному и среднему производству, IT-сфере не хватает инженеров с глубокими компетенциями по предметной части (гидравлика, электрика, пневмоавтоматика). Если говорить об IT: по отечественным и «классическим» Linux, сетям, СУБД.
2. Почти в каждой области не хватает инженеров, умеющих работать с современными инструментами. Грубо говоря, каждый инженер на соответствующем производстве знает, как устроен насос, но не каждый может интерпретировать данные со 20 датчиков насоса и использовать их в принятии решений. Из-за нехватки этих знаний и компетенций часто выполняются неверные действия – например, касающиеся параметров мощности тех же насосов или того, как правильно встроить новые насосы в существующую инфраструктуру и заставить их корректно работать со старыми. А каждое неправильное решение инженера – это большие убытки для предприятия. Финансовые, а в случае сервисных и IT-компаний – и репутационные.
По сути, инженеры в любой области должны уметь работать с объективными данными. С системами или экспертными сервисами, поставляющими информацию в онлайн-режиме о том, как чувствует себя инфраструктура, какие сбои в ней могут быть, где «слабые звенья», как предотвратить возможные проблемы. Или максимально быстро решить их, пока они не нанесли ущерба предприятию и его заказчикам.
В IT-сфере катастрофически не хватает инженеров «нового времени», которые умеют работать с «инфраструктурой 2.0» – программно-определяемой, все чаще проектируемой на российском ПО и Open Source. Такие серверные ландшафты активно строят госкомпании, из-за действия нормативной базы по импортозамещению. Крупные коммерческие предприятия – например, для «тяжелых» интернет-магазинов с пополняющимися еженедельно сервисами для пользователей. Или для IT-решений, в которых используется биометрическая идентификация сетями магазинов и ресторанов.
«Системные администраторы 2.0» не только управляют IT-инфраструктурой, программируя все изменения в ней и автоматизируя множество рутинных технологических операций, они постоянно работают с инфраструктурами российских и международных заказчиков. Используют накопленный в экспертных сервисах централизованного мониторинга и контроля архив объективных данных по технологическим решениям каждого клиента. Это помогает избегать дорогостоящих для клиентов сбоев ПО и оборудования, ведущих к простоям и убыткам.

Катастрофическая нехватка инженеров наблюдается практически во всех отраслях
Ирина Лялина, эксперт Института повышения квалификации «ТехноПрогресс»
1. Долгое время инженерные специальности были низкооплачиваемыми в сравнении с другими профессиями в одной и той же отрасли. Это заставило самых успешных и адаптивных специалистов переквалифицироваться или уйти с государственных промышленных предприятий в коммерцию. До сих пор инженеры в России – чаще мужчины. Среди девушек технические профессии не популяризируются. Радует хотя бы то, что в области IT женщины уже не редкость.
Несмотря на перечисленные факторы, технический прогресс и современная российская экономика задают высокие стандарты к квалификации и компетенциям инженеров. Помимо базовой подготовки (hard skills) технических специалистов важны также их личностные качества (soft skills), знания и навыки в области управления и администрирования, проектной деятельности, умение выстраивать отношения с разновозрастными сотрудниками. Для инженера очень важен потенциал развития. Это многофакторный параметр, определяющий актуальную базу знаний, где важна компетенция непрерывного обучения.
2. Катастрофическая нехватка инженеров с точки зрения рынка наблюдается практически во всех отраслях. Наиболее востребованы специалисты в станкостроении, машиностроении, конструкторы промышленного оборудования, практически нет инженеров по холодильным установкам.
3. Главное отличие современных инженеров – это владение прикладными программными продуктами и технологиями, например, 3D-моделирование, 3D-печать, создание дополненной и виртуальной реальности.
0 notes
Text
персонализированный дайджест закладок-задач
А.
смотреть карту фин тех и разобрать маркетинг у страховых и пенсионных
Twitter выпустил инструкцию для политиков http://www.lookatme.ru/mag/live/experience-news/217369-twitter Леша
собрать карты индустрий (пример https://medium.com/@mccannatron/drone-market-ecosystem-map-a8febf0ca8fd)
аналитика https://vc.ru/p/500px-analytics
MailTime Pro - еще одна попытка запихнуть почту в мессенджеры http://apple.co/1WxjTux И https://vc.ru/p/turing-email
Никому мало не покажется: http://megamozg.ru/p/19900/ . Компания Salesforce обратила свой взор на «Интернет вещей».
Example of Internet of Things (#IoT) and new digital business models http://bit.ly/1HLGmtH
и https://twitter.com/ValaAfshar/status/649270223988768769
к отчетам по странам @roemru продолжает серию про it Азию https://roem.ru/sea2015 — вчера были it Филиппины, с��годня будет it Вьетнам, не отключайтесь. Наташа
смотреть видео про лондон на стс в тему arg_research light
Отчет "Глобальная Digital Индустрия в 2015 г.» http://apptractor.ru/info/analytics/otchet-globalnaya-digital-industriya-v-2015-g.html
пример поста про рекламную компанию http://adindex.ru/case/2015/10/2/128527.phtml Twitter выпустил инструкцию для политиков http://www.lookatme.ru/mag/live/experience-news/217369-twitter А. Итальянский дизайнер Массимо Кассандро — о процессе создания вёрстки HTML-писем: http://habr.ru/p/268025/ . Перевод.
pop up окна в вебе и мобильных версиях https://twitter.com/TheNextWeb/status/650346249623838721
databoard эквалайзер роста https://twitter.com/socialmedia2day/status/650339784401879042
checkins (whovisits.us) https://twitter.com/foursquare/status/649977372041707520 Д. e-commerce Праздничный шоппинг: http://megamozg.ru/p/19920/ . Инфографика на тему праздников и их влияния на онлайн-покупки.
0 notes
Text
Oracle выпускает самую быструю в мире машину баз данных
Exadata X8M объединяет постоянную память Intel® Optane™ DC и 100-гигабитный удаленный прямой доступ к памяти (Remote Direct Memory Access, RDMA) по Converged Ethernet (RoCE), устраняя узкие места в подсистеме хранения данных и значительно повышая производительность для самых требовательных рабочих нагрузок, таких как оперативная обработка транзакций (Online Transaction Processing, OLTP), аналитика, интернет вещей (IoT), обнаружение мошенничества и интенсивная биржевая торговля. Oracle также объявила о выпуске в продажу нового комплекса Oracle Zero Data Loss Recovery Appliance X8M (ZDLRA). http://ora.cl/ex1G6 #oracle #muk
0 notes
Text
Мои твиты
Ср, 14:03: [Перевод] Создание многопользовательской веб-игры в жанре .io https://t.co/Qauuvz0w9k
Ср, 14:08: New story on NPR: This Company Says The Future Of Nuclear Energy Is Smaller, Cheaper And Safer… https://t.co/d3GaIng55M
Ср, 14:54: "Drivers Start Strikes Ahead of Uber’s Blockbuster I.P.O." Check out via NYT https://t.co/ipuRUei2ps The New York Times
Ср, 14:59: Музей DataArt. Человек-машина: настольная вычислительная техника до микрокалькуляторов https://t.co/lHctIO1nEe
Ср, 14:59: [Из песочницы] Случайные перестановки и случайные разбиения https://t.co/3CyTPcebp8
Ср, 15:01: "Drivers Start Strikes Ahead of Uber’s Blockbuster I.P.O." by KATE CONGER and VICKY XIUZHONG XU via NYT… https://t.co/ysValdSnNi
Ср, 15:43: Student Talks: Аналитика. Материалы для начинающих https://t.co/hz4UhKJMNq
Ср, 17:16: #81 Cray, AMD to build 1.5 exaflops supercomputer for US government. System will mix Epyc CPUs and Radeon Instinct… https://t.co/l3duugRYcR
Ср, 17:31: #81 Elon Musk & Jeff Bezos Can Save American Households $30+ Billion with LEO Satellites via /r/technology --… https://t.co/kxXvmGVh8g
Ср, 18:04: "3 Muslim Workers at Amazon File Federal Discrimination Complaint" Check out via NYT https://t.co/RAKbJ8jV7i The New York Times
Ср, 18:06: "3 Muslim Workers at Amazon File Federal Discrimination Complaint" by KAREN WEISE via NYT https://t.co/RAKbJ8jV7i https://t.co/ip46YbJriu
Ср, 18:46: "Google Pixel 3A Review: The $400 Smartphone You’ve Been Waiting For" by BRIAN X. CHEN via NYT… https://t.co/WRvwkpMg1H
Ср, 18:54: "Google Pixel 3A Review: The $400 Smartphone You’ve Been Waiting For" Check out via NYT https://t.co/mGOczQxli0 The New York Times
Ср, 19:11: #81 Kiwi Browser removed from Play Store due to YouTube background playback via /r/technology --… https://t.co/aKxF3fmbvl
Ср, 19:11: #81 Google says its AI can spot lung cancer a year before doctors via /r/technology -- https://t.co/vD5DAbShHY… https://t.co/9XuxATHjrS
Ср, 19:11: Stacey on IoT The Wyze sensors are a nice add-on to a low-cost system: https://t.co/3z5HmE95H5
Ср, 19:40: Tell Congress: We Don’t Need More Bad Patents https://t.co/9XZb24QNum
Ср, 20:16: "Uber Drivers’ Day of Strikes Has Muted Start Before Company’s Big I.P.O." by KATE CONGER and VICKY XIUZHONG XU via… https://t.co/OkndSwTEZB
Ср, 20:19: "Uber Drivers’ Day of Strikes Has Muted Start Before Company’s Big I.P.O." Check out via NYT https://t.co/R8Sur0ii0k The New York Times
Ср, 20:21: #81 Britain stops burning coal for power, for more than five days via /r/technology -- https://t.co/goLNpwqtQC… https://t.co/7W4UjNONY7
Ср, 20:21: #81 Scientists discover a game-changing way to remove salt from water: The technology could have massive implicatio… https://t.co/wA5H17TGde
Ср, 20:30: Kansas Students to Speak with NASA Astronaut Aboard Space Station #114app Students from Kansas will have an opportu… https://t.co/sGHDTRaxg8
Ср, 21:26: #81 GM lays off engineer who helped expose VW’s diesel fraud via /r/technology -- https://t.co/dBFIDC7MLU… https://t.co/XeaIHECdQv
Ср, 21:26: #81 Game studios would be banned from selling loot boxes to minors under new bill via /r/technology --… https://t.co/dEwB4hJcjT
Ср, 21:26: #81 Mark Zuckerberg has to go. Here are 25 reasons why via /r/technology -- https://t.co/5ifV3zJxae… https://t.co/gVJEQqpw7e
Ср, 22:36: #81 Ethics committee votes to subpoena Facebook's Mark Zuckerberg to testify on Cambridge Analytica - Facebook's fo… https://t.co/3ghPShBPxv
Ср, 23:26: #81 Video game ‘loot boxes’ would be outlawed in many games under forthcoming federal bill via /r/technology --… https://t.co/SSYNaasAZa
Чт, 00:07: New story on NPR: Putting The 'Art' In Artificial Intelligence https://t.co/keEqq8K1Zs https://t.co/sDehRox73g
Чт, 00:34: "Uber Said to Plan to Price I.P.O. at Midpoint of Range" Check out via NYT https://t.co/Aba0vp4ZtA The New York Times
Чт, 00:36: "Uber Said to Plan to Price I.P.O. at Midpoint of Range" by MICHAEL J. de la MERCED and MIKE ISAAC via NYT… https://t.co/xfx6fcnfw7
Чт, 03:22: #81 Ajit Pai refuses to investigate Frontier’s horrible telecom service via /r/technology --… https://t.co/XqEZ2dsqep
Чт, 06:31: "Pompeo Attacks China and Warns Britain Over Huawei Security Risks" by STEPHEN CASTLE via NYT… https://t.co/ZQ4UA7bOVb
Чт, 06:34: "Pompeo Attacks China and Warns Britain Over Huawei Security Risks" Check out via NYT https://t.co/IbVFQb8kZZ The New York Times
Чт, 06:41: #81 Germany opens first electric highway that lets trucks draw power from overhead cables via /r/technology --… https://t.co/fVAxtEM671
Чт, 06:41: #81 Sex toy creator finally gets the CES award she was denied via /r/technology -- https://t.co/dJKJQt0QyE… https://t.co/pZKBnwL8yt
Чт, 07:31: #81 Airbnb Host Arrested After Hidden Camera Found in Bedroom WiFi Router via /r/technology --… https://t.co/c3U4eC1F7K
Чт, 07:34: "Capturing What’s Online in China Before It Vanishes" Check out via NYT https://t.co/Psvqj7rF1i The New York Times
Чт, 07:36: "Capturing What’s Online in China Before It Vanishes" by RAYMOND ZHONG via NYT https://t.co/Psvqj7rF1i https://t.co/EPNZSADyk3
Чт, 11:43: OCULUS RIFT S ПОЛНЫЙ ОБЗОР https://t.co/Zqp8kKyvGD
Чт, 12:04: "Amazon Flunks Children’s Privacy, Advocacy Groups Charge" Check out via NYT https://t.co/OyGuLNscS3 The New York Times
Чт, 12:07: "Amazon Flunks Children’s Privacy, Advocacy Groups Charge" by NATASHA SINGER via NYT https://t.co/OyGuLNscS3 https://t.co/CsA1fUtLcm
source https://karelin-vlad.livejournal.com/70912.html
0 notes
Text
Биржевые курсы криптовалют 21.07.18 (в 08:00 МСК)
За последние сутки только 10% монет из первой сотни по объёму торгов выросли в цене, остальные 90% показывают нисходящий тренд и теряют стоимость. Максимальный рост за эти 24 часа показала криптовалюта KickCoin $0.1174 (+16.00%). Наибольшее падение произошло у криптовалюты CoinBene $0.09255 (-17.36%). Смотрите наш отчёт ниже. Биткоин отступает назад: $7 295.46 (-2.14%) (см. прогноз) 🔽 Эфириум корректируется по цене: $455.91 (-1.53%) (см. прогноз) 🔽 Рипл уходит вниз: $0.4499 (-3.26%) (см. прогноз) 🔽 Удивительно, но ни одна криптовалюта из ТОП-10 не показала за эти сутки положительную динамику цены. Куда катится этот мир? Наибольшее падение в ТОП-10 показала криптовалюта ADA $0.1627 (-9.30%). 📊 ТОП-10 криптовалют с наибольшим объёмом торгов за 24 часа: 1. Bitcoin $7 295.46 (-2.14%) 2. Ethereum $455.91 (-1.53%) 3. Bitcoin Cash $765.11 (-5.81%) 4. EOS $7.87 (-3.67%) 5. XRP $0.4499 (-3.26%) 6. CoinEx token $0.1037 (-6.15%) 7. Litecoin $81.19 (-4.79%) 8. Tronix $0.03519 (-3.72%) 9. Ethereum Classic $16.11 (-7.41%) 10. Cardano $0.1627 (-9.30%) 📈 ТОП-10 криптовалют с наибольшим ростом за 24 часа: 1. KickCoin $0.1174 (+16.00%) 2. Vechain $1.77 (+6.62%) 3. SelfKey $0.0115 (+6.38%) 4. Pundi X $0.003347 (+4.39%) 5. Metaverse $1.93 (+4.32%) 6. Decentraland $0.123 (+3.62%) 7. Mithril $0.6319 (+1.47%) 8. Waves $2.98 (+0.33%) 9. Tether $0.9994 (+0.06%) 10. True USD $0.998 (+0.05%) 📉 ТОП-10 криптовалют с наибольшим падением за 24 часа: 1. CoinBene $0.09255 (-17.36%) 2. Project Pai $0.7901 (-16.47%) 3. IoT Chain $0.4375 (-13.50%) 4. ZenCash $26.64 (-13.28%) 5. 0x $1.05 (-13.22%) 6. Bluzelle $0.3011 (-12.62%) 7. Reddcoin $0.004074 (-11.85%) 8. Ignis $0.07457 (-11.40%) 9. Golem Network Token $0.295 (-11.38%) 10. Steem $1.37 (-11.03%) 📋 Следите за новостями на нашем сайте, чтобы иметь возможность предсказывать поведение рынка: Аналитика тут: https://cryptolot.ru/tag_analitika_20 Прогнозы тут: https://cryptolot.ru/tag_prognozy_21 💰 Играй бесплатно. Сейчас! https://cryptolot.ru/active 👍 – поиграй на бирже бесплатно, прежде чем вкладывать реальные деньги в криптовалюты. © КРИПТОLOT
https://cryptolot.ru/top10?1532207401
0 notes
Text
Что ждет Big Data в 2020: итоги ушедшего десятилетия и будущие перспективы

На пороге 3-го десятилетия 21 века пришло время подвести итог прошедшим годам и cделать прогнозы на будущее. В этой статье мы поговорим о ключевых событиях минувших лет, помечтаем о том, что ждет Big Data и чего нам принесет эта ИТ-область. Также поделимся с вами своими планами на 2020 год: расскажем о новых обучающих курсах и обра��овательных направлениях.
Главные ИТ-тренды последних 10 лет в России и за рубежом
В первое 10-летие 21 века облачные вычисления (Cloud Computing) и основанные на них SaaS/PaaS/IaaS-решения успешно заняли свое место в ландшафте корпоративной инфраструктуры. NoSQL-СУБД, BI-системы и технологии контейнеризации (виртуализации) перестали быть игрушкой для гиков и активно используются как крупными игроками, так и малым бизнесом. IP-телефония, онлайн ERP- и CRM-продукты с модулями предиктивной аналитики – это must-have любого предприятия. На место локальных решений приходят облачные сервисы, а ИТ-гиганты открывают исходные коды своих программ, поддерживая свободное ПО и получая прибыль с коммерческих консультаций и заказных разработок. 2010-е можно по праву назвать эпохой Больших Данных (Big Data), как наиболее обсуждаемой темой в мире ИТ. Вместе с интернетом вещей (Internet of Things), цифровизацией, искусственным интеллектом и машинным обучением (Machine Learning, ML), технологии Big Data считаются основой 4-ой промышленной революции (Industry 4.0, I4.0). Напомним, суть I4.0 состоит в объединении данных, инструментов и процессов из разных прикладных областей с целью сокращения общих затрат, снижения рисков и повышения эффективности производства и других сфер человеческой жизни с помощью киберфизических систем. Однако, любые технологии, в т.ч. Big Data (Hadoop, Kafka, Spark, Cassandra, NiFi, HBase и пр.) – это всего лишь инструменты оптимизации прикладной деятельности. Сегодня, когда искусственный интеллект активно внедряется в жизнь, заменяя людей в выполнении рутинных операций и быстрой обработке огромных объемов информации, выигрывает не тот, кто быстро решает типовые задачи, а тот, кто придумывает новые. Проанализировав популярность наиболее известных технологий I4.0 с помощью Google Trends, можно сделать выводы, что во всем мире за последние 10 лет сформировался устойчивый интерес к следующим ИТ-понятиям: Большие данные, как на уровне технологий (Apache Hadoop, Kafka, Spark, HBase, Cassandra и другие NoSQL-СУБД, Java, R, Python и другие языки программирования для разработки Big Data приложений), так и практические примеры использования всех этих инструментов в прикладных областях (от маркетинга до нефтегазовой промышленности). Data Science, включая анализ данных, машинное обучение (Machine Learning) и другие методы искусственного интеллекта, направленные на извлечение полезных для бизнеса сведений из огромных объемов информации, распознавание образов и прогнозирование событий. Agile-подходы к организации совместной работы, перешедшие из ИТ-сферы в разряд лучших практик управления проектами для любой области деятельности. Интернет вещей (Internet Of Things, IoT), в т.ч. промышленный (Industrial IoT, IIoT), в рамках которого все больше устройств оснащаются Wi-Fi-модулями, запускаются 5G-сети, дроны летают все быстрее, дома и города становятся умнее, а каждое производственное предприятие стремится стать data-driven компанией.
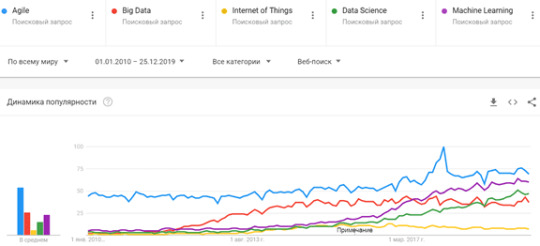
Главные ИТ-тренды мира 2019-2020 Россия не отстает от мировых тенденций, однако, наряду к вышеуказанным терминам, в нашей стране также существенно возрос интерес к цифровизации. Сегодня тема цифровой трансформации захватила почти все отечественные индустрии, от банков до рекламы. Однако, чтобы цифровизация не стала очередным модным словом (buzzword), за фасадом которого старые проблемы так и останутся нерешенными, необходимо четко понимать, чем именно она выгодна бизнесу. Эффективное применение Big Data, Machine Learning, IoT и других технологий Industry 4.0 реализуемо только при условии адекватного понимания возможностей этих инструментов у руководителей предприятий, менеджеров и прочих лиц, принимающих решения. Вероятнее всего, демистификация терминов Big Data, Data Science, Machine Learning, IoT и станет главным трендом наступившего года.
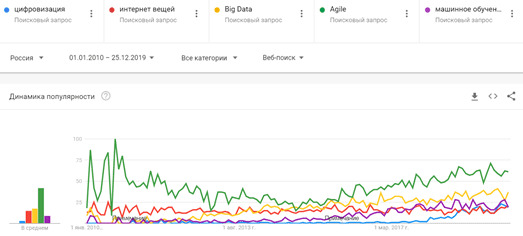
Самые популярные ИТ-тренды в России 2019-2020
Чего ждать от Big Data в будущем: прогнозы и планы на 2020 год
В 2020 году нас ждет еще больше интересных достижений Data Science: системы автоматического машинного обучения (AutoML), DevOps- и DataOps-инженерия, виртуальная и дополненная реальности (VR/AR), а также синергетический эффект сочетания этих и других технологий I4.0. Например, камеры уличного наблюдения будут в режиме реального времени идентифицировать преступников, а банки собираются оценивать платежеспособность потенциального заемщика на основании его пользовательского поведения в сети (история запросов в браузере, показатели соцсетей, просмотры веб-страниц, покупки в интернет-магазинах и т.д.). В связи с этими и другими подобными кейсами использования личной информации граждан в бизнес-целях стоит ожидать новую лавину инцидентов с персональными данными: от утечек до огромных штрафов из-за несоблюдения требований GDPR и отечественных регуляторов. Чтобы не упустить критический момент потери рынка или провала внутренних показателей, руководитель должен быть в курсе текущих тенденций и своевременно осознавать потребность корпоративных изменений. Именно потребность в изменениях обусловливает появление стратегических бизнес-целей, которые трассируются в конкретные тактические инициативы, операционные процессы, программные продукты и прочие технические решения. В частности, BABOK (Business Analysis Body Of Knowledge, свод знаний по бизнес-анализу), профессиональны�� стандарт бизнес-аналитика от международного института бизнес-анализа (IIBA, International Institute of Business Analysis), позиционирует потребность как движущую силу изменений по улучшению корпоративной деятельности, что принесет дополнительную ценность всем заинтересованным лицам. Клиенты, конкуренты, поставщики, партнеры, регуляторы и прочие факторы внешней среды (экономика, политика, экология и т.д.) влияют на любой бизнес, определяя его существование наравне с внутренними показателями. Сбор, агрегация и аналитическое сопоставление внешних и внутренних данных позволят своевременно осознать потребность в изменениях, выявив перспективные направления по устранению текущих дефектов и достижению будущих возможностей. Далее стратегии воплощаются в проектах, которые поставляют решения, приносящие ценность для бизнеса. Технологии Big Data и Agile-подходы являются лишь инструментами реализации поставленных целей, а ключевую роль задает грамотная постановка задачи. И именно этот этап – самый трудоемкий и сложный в любом проекте. К примеру, Хадуп, Спарк, Кафка и прочие технологии больших данных не решат все проблемы с падением прибыли в гипермаркете, но основанные на них аналитические системы помогут сократить отток клиентов (Churn Rate) и сократить воровство.
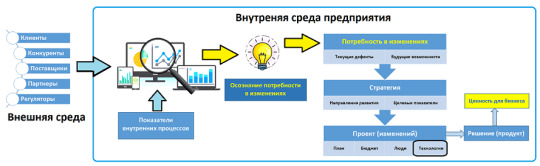
Big Data и бизнес-анализ для управления изменениями В новом году мы представим множество познавательных примеров и сценариев использования (use cases) технологий Big Data (Apache Hadoop, Kafka, Spark, NiFi, HBase и пр.), чтобы большие данные принесли вам еще большую пользу. В дополнение к новым курсам по Cassandra и Kubernetes, а также статьям инструментального характера, Школа Больших Данных запускает серию публикаций и образовательных программ по системному и бизнес-анализу для менеджеров и аналитиков. Ведь руководителя интересует не столько «Что такое хадуп?», сколько то, чем именно эта технология будет полезна бизнесу в качественном и количественном выражении. Эти и другие вопросы по аналитике больших данных, внедрению интернета вещей, проектам цифровизации и оптимизации корпоративной деятельности мы будем рассматривать в нашем блоге, а также на образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве: BDAM: Аналитика больших данных для руководителей AOPB: Анализ и оптимизация бизнес-процессов

Смотреть расписание занятий

Зарегистрироваться на курс Read the full article
#BigData#IIoT#InternetofThings#IoT#MachineLearning#Большиеданные#интернетвещей#МашинноеОбучение#предиктивнаяаналитика#Цифроваятрансформация
1 note
·
View note
Link
0 notes
Text
CDC для потоковой аналитики Big Data с Apache Kafka и Spark: 3 практических примера

Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых транзакций.
Зачем нужны потоковые конвейеры транзакционной обработки Big Data на Apache Kafka и Spark
Напомним, благодаря вычислениям в оперативной памяти Apache Spark намного ускоряет процессы обработки данных в таких Big Data хранилищах, как AWS S3 и Hadoop HDFS. А в рамках потокового конвейера Spark Streaming API позволяет обрабатывать данные в течение нескольких секунд по мере их поступления от источника, в качестве которого может выступать Kafka. Однако, разговор о аналитике больших данных в режиме реального времени не имеет смысла, если исходные данные, поступающие в конвейер Kafka-Spark, имеют возраст в несколько часов или дней. Решить эту проблему поможет подход сбора измененных данных (CDC, Change Data Capture), что особенно актуально для транзакций. CDC получает оперативные транзакции СУБД-источника и отправляет копии в конвейер с практически нулевой задержкой вместо медленных пакетных заданий. Это также снижает накладные расходы на вычисления и требования к пропускной способности сети. Чтобы наглядно показать, насколько такое решение выгодно бизнесу, далее ы рассмотрим пару практических примеров, а сейчас отметим лучшие практики реализации CDC-подхода с помощью Apache Kafka и Spark [1]: Kafka обеспечивает потоковый примем и агрегацию данных от множества источников, позволяя буферизовать входящие сообщения в течение настраиваемых периодов времени. Такое поведение (много источников, большие объемы данных и разные временные интервалы с целевым приемником) типичны для транзакций СУБД, которые генерируются непрерывно, а анализируются периодически. CDC-данные могут требовать дополнительной логики для установки точной согласованности транзакций и обеспечения ACID-соответствия на основе схем исходной СУБД и ��араметров записи. Эти накладные расходы на обработку быстро возрастают в случае нескольких потребителей и производителей, которые используют данные из разных топиков. Поэтому рекомендуется ограничивать количество целей и потоков Kafka. Упростить развертывание и управление сложным Big Data решением помогут облачные провайдеры. AWS, Azure и Google Cloud включают Apache Spark в свои IaaS/SaaS-решения, такие как Amazon EMR, Azure Data Lake Store (ADLS) и Google Dataproc. Кроме того, Databricks предоставляет платформу на основе Apache Spark как услугу, где можно настроить собственный конвейер и систему аналитики больших данных. Как все эти и другие лучшие практики реализуются в бизнесе, рассмотрим далее.
3 примера CDC-конвейеров потоковой аналитики больших данных
Оперативная отчетность из ERP вместо ночных ETL-заданий
Крупному производителю пищевых продуктов требовалось оперативная аналитика и непрерывная интеграция данных о производственных мощностях, заказах клиентов и заказах на закупку. Сперва компания пыталась объединить различные большие наборы данных, распределенные по нескольким разрозненным хранилищам, в нескольких приложениях SAP ERP. Однако, ночная пакетная репликация не позволяла быстро сопоставлять заказы и данные о производственных линиях. Эти задержки замедляли график работы завода и снижали точность ежедневных отчетов о продажах. Поэтому предприятие решило изменить подход к хранению и интеграции корпоративных данных, перейдя на Apache Hadoop. Было построено новое озеро данных (Data Lake) на Hadoop Hortonworks, включая Spark и CDC. CDC обеспечивает эффективное копирование изменений записей SAP каждые 5 секунд, извлекая эти данные из исходного пула ERP-системы и таблиц кластера. Далее CDC внедряет эти обновления источников данных вместе с обновлениями метаданных в очередь сообщений Kafka, которая буферизует эти большие объемы информации и отправляет их по запросу потребителям HDFS и HBase в Data Lake. Чтобы сократить накладные расходы на обработку и пересылку данных по сети, количество топиков Apache Kafka было ограничено до 10, по одной на исходную таблицу. После того, как данные поступают в HDFS и HBase, быстрые Spark-приложения сопоставляют заказы с производством в реальном времени, поддерживая ссылочную целостность для таблиц заказов на закупку. Таким образом, в результате замены пакетных ETL-процессов на потоковую CDC-передачу, компания ускорила продажи и доставку своей продукции за счет точной оперативной отчетности в реальном времени, чтобы работать более эффективно и прибыльно [1].
CDC с Kafka и Spark на MS Azure и Databricks
Другой интересный пример использования CDC-похода в построении Big Data конвейеров на Kafka и Spark - оперативная отчетность по финансовым показателям в реальном времени. Для этого американская компания, за��имающаяся частным и венчурным капиталом, создала озеро данных для консолидации и анализа операционных показателей своих портфельных компаний. Чтобы не заниматься развертыванием и администрированием локальной Big Data инфраструктуры, предприятие разместило свое озеро данных в облаке Microsoft Azure. Далее процесс real-time консолидации больших данных построен следующим образом [1]: CDC удаленно собирает обновления и изменения из исходных СУБД (Oracle, SQL Server, MySQL и DB2) в четырех разных местах по всем США; далее эти данные отправляются через зашифрованное соединение на репликацию в облако MS Azure; механизм репликации MS Azure по запросу публикует обновления данных в Apache Kafka и в файловой системе Databricks, сохраняя сообщения в формате JSON; приложения Apache Spark подготавливают данные в микро-пакетах для озера данных HDInsight, SQL-хранилища и других внутренних и внешних подписчиков топиков Kafka, классифицированных по исходным таблицам. Такая CDC-архитектура позволяет финансовой корпорации эффективно получать аналитику больших данных в реальном времени без ущерба текущим бизнес-процессам.
Change Data Capture в решениях Informatica
Благодаря преимуществам и относительной простоте CDC-подхода его активно используют вендоры корпоративных Big Data решений. В частности, компания Informatica выделяет следующие кейсы применения своего продукта Cloud Mass Ingestion Service, построенного на основе CDC с использованием Apache Kafka и Spark [2]: прием данных из различных источников (озера и корпоративные хранилища, файлы, потоковые данные, IoT, локальные СУБД) в облачное Data WareHouse и Data Lake с синхронизацией исходных и целевых данных; модернизация или миграция КХД: массовое извлечение данных из локальных СУБД (Oracle, IBM DB2, Microsoft SQL и пр.) в облачное хранилище данных. CDC обеспечивает синхронизацию источника и цели ускорение обмена сообщениями для потоковой аналитики больших данных и генерации комплексных отчетов в реальном времени.

Как это работает на практике, мы рассмотрим завтра, заглянув под капот Big Data системы потоковой аналитики больших данных на базе Informatica, Databricks c CDC-реализацией в конвейере Kafka-Spark. А научиться самостоятельно строить эффективные конвейеры аналитики больших данных с Apache Kafka и Spark вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: Apache Kafka для разработчиков Основы Apache Spark для разработчиков Потоковая обработка в Apache Spark Анализ данных с Apache Spark Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop Источники 1. https://www.eckerson.com/articles/best-practices-for-real-time-data-pipelines-with-change-data-capture-and-spark 2. https://www.informatica.com/content/dam/informatica-com/en/collateral/white-paper/change-data-capture-for-real-time-data-ingestion-and-streaming-analytics_white-paper_3914en.pdf Read the full article
0 notes
Text
Как связать Greenplum и Kafka: 2 способа интеграции и коннектор Arenadata DB

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB.
IoT и не только или зачем интегрировать Greenplum с Apache Kafka
Прежде всего поясним, почему вообще возникает задача интеграции MPP-СУБД Greenplum с брокером сообщений Apache Kafka. Представьте, что есть множество входящих потоков данных, например, от устройств интернета вещей (Internet of Things, IoT), которые необходимо проанализировать в реальном времени. Или нужна оперативная аналитика биржевых показателей на платформе онлайн-трейдинга, где миллионы клиентов со всего мира торгуют валютой и ценными бумагами в режиме онлайн. Технология массивно-параллельной обработки данных (Massive Parallel Processing, MPP), реализованная в Greenplum, позволяет быстро и надежно решить подобные проблемы событийно-потоковой обработки (event streaming). Однако, загрузка этой информации происходит в Greenplum не напрямую, а опосредовано, через надежную Big Data систему сбора и агрегации потоковых данных – распределенную стриминговую платформу Apache Kafka. 6-я версия Greenplum, выпущенная осенью 2019 года, включает 2 следующих способа интеграции с Apache Kafka [1]: · Greenplum Stream Server (GPSS) – средство ETL-процессов, которое принимает потоковые данные от одного или нескольких клиентов, используя механизм внешних таблиц базы Гринплам для преобразования и вставки данных в целевую таблицу этой СУБД; · PXF (Platform eXtension Framework) – специализированный Java-фреймворк параллельного обмена данными со сторонними системами, который обеспечивает одновременное взаимодействие всех сегментов кластера Гринплам с внешним источником данных. Также интересен способ интеграции Arenadata DB, основанно�� на Greenplum, и Кафка с помощью специализированного коннектора. Каждый из перечисленных способов мы подробнее рассмотрим далее.
Что такое Greenplum Stream Server и как он работает
Greenplum Stream Server – это потоковый сервер gRPC, система удаленного вызова процедур с открытым исходным кодом, изначально разработанная в Google в 2015 году. Он включает операции и сообщения, необходимые для подключения к Greenplum и для записи данных от внешней системы в таблицу MPP-СУБД [2]: · утилита командной строки gpss, которая позволяет запустить экземпляр GPSS, бесконечно ожидающий данных клиента; · утилита командной строки gpsscli для отправки заданий загрузки данных из Kafka в экземпляр GPSS и управления этими заданиями. Типичная последовательность выполнения ETL-задачи с использованием GPSS выглядит следующим образом [2]: · пользователь инициирует одно или несколько ETL-заданий через клиентское приложение; · клиентское приложение использует gRPC-протокол для отправки и запуска заданий на загрузку данных в работающий экземпляр службы GPSS; · Экземпляр службы GPSS передает каждую транзакцию запроса на загрузку в главный экземпляр кластера Greenplum, с помощью протокола gpfdist для хранения данных во внешних таблицах, которые создаются вновь или используются повторно. · Экземпляр службы GPSS записывает данные, полученные от клиента, непосредственно в сегменты кластера базы данных Greenplum. Важным ограничением этого способа является то, что Greenplum Stream Server не поддерживает загрузку данных из нескольких топиков Kafka в одну и ту же таблицу СУБД Гринплам. В этом случае все задания будут зависать [3].

Интеграция Гринплам и Кафка с помощью Greenplum Stream Server
Как устроен PXF-фреймворк
PXF появился еще в 5-ой версии Greenplum в 2017 году. Этот Java-фреймворк реализован в виде отдельного процесса на сервере, который общается с сегментами Greenplum через REST API с одной стороны, а с другой – использует сторонние Java-клиенты и библиотеки, чтобы через JDBC связать Гринплам с Apache HDFS, Hbase и Hive, а также внешними СУБД. Например, именно так X5 Retail Group в 2019 году построила собственную аналитическую платформу на базе Arenadata DB с кластером Hadoop, о чем мы подробно рассказывали здесь. PXF предоставляет коннекторы для доступа к данным, хранящимся во внешних источниках. Коннекторы сопоставляют внешний источник данных с определением внешней таблицы базы данных Greenplum. Один процесс PXF-агента на каждом хосте сегмента Greenplum выделяет рабочий поток для каждого экземпляра СУБД, который участвует в запросе к внешней таблице. Агенты PXF на хостах с несколькими сегментами взаимодействуют с внешним хранилищем данных параллельно. PXF содержит встроенные коннекторы для Hadoop (HDFS, Hive, HBase), хранилищ объектов (Azure, Google Cloud Storage, Minio, S3) и баз данных SQL (через JDBC), а также поддерживает форматы данных text, Avro, JSON, RCFile, Parquet, SequenceFile и ORC [4]. Именно PXF-коннекторы лежат в основе интеграции Arenadata DB c Apache Kafka, которую мы рассмотрим далее.

Platform eXtension Framework Greenplum для интеграции с внешними системами
Big Data интеграция: коннектор к Кафка в Arenadata DB
Установка коннектора выполняется с помощью специального пакета adb_kafka_external_connector-.rpm на все сервера-сегменты кластера Greenplum. Этот пакет добавляет на каждый сервер Гринплам исполняемые файлы [5]: · /usr/lib/adbkafka/adb-kafka-consumer; · /usr/lib/adbkafka/adb-kafka-producer. С архитектурной точки зрения коннектор Arenadata DB (ADB) к Apache Kafka – это кластер из отдельных синхронизированных процессов, запущеных в Docker, которые, с одной стороны, являются потребителями Кафка (consumer), а с другой — вставляют данные из топиков напрямую в сегменты Greenplum. Коннектор может работать с Kafka Registry и обеспечивает полную консистентность переносимых данных даже в случае аппаратных сбоев [6]. При использовании этого решения необходимо учитывать следующую специфику: ·· число разделов (partition) в топике Kafka должно быть больше или равно числу сегментов ADB, которые запрашивают данные. Иначе нужно корректировать число сегментов при создании внешней таблицы [7]; · все сегменты-хосты кластера ADB должны иметь сетевой доступ до всех брокеров и Zookeeper-узлов кластера Kafka, а также иметь о них записи (hostname и IP-адрес) в своих директориях /etc/hosts [8]; · создание внешних таблиц коннектора доступно только суперпользователям СУБД, при том использование таблиц не ограничено [7]. Больше подробностей по настройке и эксплуатации Greenplum на примере Arenadata DB рассматривается на специализированном курсе Эксплуатация Arenadata DB в нашем лицензированном учебном центре повышения квалификации «Школа Больших Данных», который является единственным авторизованным партнером компании Arenadata по сертификации специалистов и обучению в Москве. А особенности интеграции Apache Kafka с другими внешними источниками для потоковой обработки Big Data вы узнаете на практических курсах по Кафка для программистов, архитекторов, инженеров и аналитиков больших данных: Kafka интеграция для разработчиков Kafka Streams для разработчиков

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. http://docs.greenplum.org/6-4/analytics/overview.html 2. https://gpdb.docs.pivotal.io/streaming-server/1-3-6/overview.html 3. https://medium.com/@yaniv.bhemo/how-to-integrate-greenplum-db-with-apache-kafka-5bada63400b3 4. https://gpdb.docs.pivotal.io/6-1/pxf/intro_pxf.html 5. https://docs.arenadata.io/adb/adbkafka/Installation.html 6. https://habr.com/ru/post/474008/ 7. https://docs.arenadata.io/adb/adbkafka/Restrictions.html 8. https://docs.arenadata.io/adb/adbkafka/Requirements.html Read the full article
#ArenaData#BigData#Docker#Greenplum#IIoT#InternetofThings#IoT#Kafka#SQL#архитектура#Большиеданные#интернетвещей#обработкаданных
0 notes
Text
Big Data, Machine Learning и Internet of Things в складской логистике: 7 FMCG-кейсов

Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний, а также крупных FMCG-компаний.
5 направлений использования Big Data, Machine Learning и Internet of Things в логистике
Сначала перечислим наиболее перспективные приложения технологий Big Data, Machine Learning и Internet of Things в логистике: · складская роботизация – от «умных» погрузчиков до дронов. Например, в Amazon маленькие роботы KIVA самостоятельно перемещают предметы внутри склада, сокращая расходы на 20%. В этой же компании летающие дроны успешно доставляют заказы удаленностью до 30 минут [1]. Здесь же отметим еще 1 пример складской цифровизации с использованием квадрокоптеров, когда они в конце рабочего дня сканируют штрих-коды на товарах, автоматически передавая данные в систему учета. Это повышает эффективность процессов инвентаризации на 20% [2]. В частности, компания DroneScan заявляет, что их дроны всего за 2 дня проведут инвентаризацию качественнее, чем 80 человек за 3 дня [3]. · оптимизация финального этапа доставки товара к потребителю, так называемой «последней мили». Стоимость этой задачи может составлять до 28% от общей цен доставки. Это происходит из-за особенностей городской инфраструктуры, например, отсутствия подъездных путей, ремонта дорог, пробок и других внешних факторов. Постоянный сбор и аналитика таких данных позволяет оперативно перестроить маршрут и подобрать подходящую для конкретного заказа технику [3]. Вышеупомянутый пример Amazon с дронами показывает, что их использование снижает стоимость последней мили до $1 при доставки малогабаритных грузов (менее 2,25 кг) [1]. · трекинг грузов с помощью RFID-меток, которые позволяют следить за перемещением товара на протяжении всей цепочки поставок. Такой непрерывный мониторинг сокращает убытки из-за нарушения условий хранения и транспортировки скоропортящейся продукции или товаров с особенностями перевозки. Экономия может составить до 30%. Например, транспортная компания DHL устанавливает на свои грузы IoT-датчики Smart Sensor. А другой крупный перевозчик, Cerasis внедряет Big Data решения для оптимизации маршрутов, сокращения расхода топлива и снижения негативного влияния на окружающую среду. Также компания планирует использовать IoT-датчики для непрерывного мониторинга состояния своих машин, чтобы снижать затраты на ремонт и уменьшать время простоя [1]. · обязательная маркировка продукции с помощью уже упомянутых RFID-меток или DataMatrix-кодов. Напомним, в России с января 2019 года введена обязательная цифровая маркировка ряда товаров: лекарства, табачная продукция, духи и туалетная вод, шины и покрышки, обувь, некоторые виды одежды и текстиля, фотографическое оборудование и молочная продукция [4]. Такая маркировка делает уникальной каждую единицу продукции, поэтому ритейлерам нужно менять ранее устоявшиеся процедуры оптовой отгрузки и приемки товаров. В частности, агрегировать коды в паллетных этикетках и встраивать эти решения в уже существующую ИТ-инфраструктуру, а также организуя их интеграцию с надзорными органами [5]. · сокращение операций, не добавляющих ценности по методологии Lean. Например, трудозатраты комплектовщика заказов на чтение бумажных листов подбора или инструкций с экрана планшета. Чтобы устранить это, распределительный центр сети супермаркетов «Верный» внедрил систему голосового отбора Vocollect. Она позволила увеличить производительность на 35% и довести до 99,97% точность операций по сбору заказов, радикально сократив ошибки в комплектации по причине человеческого фактора. Теперь все взаимодействие с системой управления складом идет через голос: комплектовщик просто слушает команды и выполняет задания, задавая вопросы или сообщая о готовности. Это отличный пример практического использования алгоритмов Machine Learning для распознавания речи [6].

Оператор склада с системой голосового отбора Vocollect Наконец, еще одним популярным кейсом применения Big Data и Machine Learning является прогнозирование спроса с целью выстраивания оптимальной логистики. Некоторые примеры этого мы рассмотрим далее.
Предиктивная аналитика больших данных: 3 кейса от FMCG-гигантов и транспортной компании
С мая 2018 года «Магнит» применяет машинное обучение для прогнозирования спроса в своих магазинах. Нейросети обрабатывают большие данные о продажах, покупательских предпочтениях, погоде, календарных и религиозных праздниках, социальных событиях и прочих внешних факторах. Такая аналитика Big Data позволяет выявить нелинейные зависимости, прогнозируя увеличение спроса на товары. По результатам использования этой системы предиктивной аналитики выручка ритейлера выросла на 4 миллиарда рублей в год [7]. Другой отечественный FMCG-гигант, X5 Retail Group, в октябре 2019 года запустил для своих поставщиков онлайн-платформу аналитики больших данных, которая позволит партнерам компании формировать отчёты по истории покупок их товаров в торговых сетях ритейлера. Таким образом, поставщики анализировать продажи, выявлять источники изменения спроса, узнавать о переключении потребителей на конкурирующие бренды, определять ротацию покупателей и изменение их потребностей. На основе истории покупок и информации о потребительском поведении сформирована база аналитических модулей, которые позволяют получить бизнес-инсайты. На октябрь 2019 года партнёры Х5 могли формировать только 3 отчета: диагностика категории, источники продаж и миграция покупателей. В 2020 году ритейлер планирует реализовать еще 8 аналитических модулей для исследования промоакций и трекинга новинок, анализа покупательской корзины, дерева принятия решений, профиля потребителя, а также тестирования и кластеризации магазинов [8]. Интересен также опыт транспортной компании ПЭК, которая в 2019 году запустила собственный Центр управления перевозками (ЦУП) на базе Big Data. Это значительно повысило точность прогнозирования и планирования грузоперевозок, а также улучшило мониторинга остатков на складах. ЦУП позволяет в режиме реального времени прогнозировать загрузку 189 складов по всей России на месяц вперед, обрабатывая каждую секунду более 500 операций. Эта Big Data система аккумулирует все сведения для построения прогнозов загрузки складов и эффективного управления операционной деятельностью. Технологически ЦУП компании ПЭК основан на наиболее популярных технологиях Big Data [9]: · Akka Framework для разработки параллельных и распределенных микросервисов на JVM; · Spark Streaming для потоковой обработки больших данных; · Apache Kafka для обмена сообщениями между сервисами; · Apache Hadoop для хранения исторических данных; · PostgreSQL для срочной отчетности; · оперативные данные хранятся в памяти (IMDB, In-memory Database).

Модель ЦУП транспортной компании ПЭК В следующей статье мы продолжим рассматривать большие данные и машинное обучение в ритейле, разобрав еще несколько примеров использования роботов и систем видеоаналитики в магазинах и на складах. А как еще применять Big Data и Machine Learning в цифровизации FMCG-бизнеса, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, аналитиков и Data Scientist’ов) в Москве: Аналитика больших данных для руководителей

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://retailer.ru/cifrovizacija-i-ja-kak-logtech-menjaet-rossijskuju-logistiku/ 2. https://www.fesco.ru/blog/34774/ 3. https://e-pepper.ru/news/roboty-bigdata-drony-kak-tekhnologii-izmenili-skladskuyu-i-transportnuyu-logistiku.html 4. https://www.moedelo.org/club/article-knowledge/obyazatelnaya-markirovka-tovarov-2020 5. https://www.retail.ru/cases/id-logistics-skvoznaya-markirovka-pilotnyy-proekt-stanovitsya-realnostyu/ 6. https://www.retail.ru/cases/vernyy-innovatsii-skladskoy-logistiki/ 7. https://new-retail.ru/business/keysy/keysy_i_perspektivy_prognoznoy_analitiki_v_logistike_kak_ee_ispolzuet_rossiyskiy_riteyl7755/ 8. https://retail-loyalty.org/news/big-data-x5-zapustila-analiticheskiy-servis-dlya-proizvoditeley/?id=2909164 9. https://news.myseldon.com/ru/news/index/211402190 Read the full article
#BigData#Hadoop#IIoT#InternetofThings#IoT#Kafka#MachineLearning#RFID#Spark#беспилотник#Большиеданные#дрон#интернетвещей#логистика#МашинноеОбучение#обработкаданных#предиктивнаяаналитика#ритейл
0 notes
Text
Всегда Coca-Cola: 5 Big Data кейсов от FMCG-гиганта

По запросу одного из наших клиентов, этой статьей мы открываем серию публикаций про применение технологий Big Data и Machine Learning в торговле быстрооборачиваемых товаров повседневного спроса (FMCG, Fast moving consumer goods). Сегодня рассмотрим, как большие данные, машинное обучение и прочие методы искусственного интеллекта используются в производстве и продаже газированных напитков на примере компании Coca-Cola.
Big Data, Machine Learning и Internet of Things: все будет Coca-Cola
Ежедневно в мире потребляется около 2-х миллиардов прохладительных напитков, из которых более 500 брендов принадлежат компании Coca-Cola – крупнейшему производителю газированной воды. Предприятие генерирует множество данных: показатели технологических процессов, бизнес-метрики, информация о пользовательских предпочтениях и множество других разнообразных данных. Разумеется, для этого активно используются современные ИТ-инструменты, в т.ч. технологии Big Data и Machine Learning. Примеры их реального внедрения можно сгруппировать по следующим категориям [1]: · разработка новых продуктов; · маркетинговые исследования и персонализация рекламных кампаний; · автоматическое интерактивное взаимодействие с покупателем; · оптимизация производства с помощью интернета вещей (Internet of Things, IoT) и дополненной реальности (Augmented Reality, AR); · комплексная цифровизация бизнеса. Далее рассмотрим, как все это реализуется на практике.
Машинное обучение для создания новых вкусов
В 2017 году компания запустила новый напиток со вкусом вишни – Cherry Sprite, идея для которого была определена на основе данных из автоматов самообслуживания. Эти машины предлагают покупателям самостоятельно выбирать вкусовые добавки к своим напиткам. Проанализировав клиентские предпочтения с помощью ML-алгоритмов кластеризации, Coca-Cola выбрала наиболее популярную комбинацию вкусов и превратила ее в готовый напиток для широкой аудитории [2]. Подобным образом, анализируя большие данные о потребностях локальных покупателей в более чем 200 странах мира, компания выявляет потребительские ожидания относительно тренда на ЗОЖ. Таким образом Кока-Кола компенсировала падение спроса на сладкие газированные напитки с помощью производства натуральных соков, продавая их под брендами Minute Maid и Simply Orange. При этом предприятие анализирует данные о погоде, спутниковые снимки, информацию об урожайности, показателях кислотности и сладости, а также ценообразовании, чтобы обеспечить оптимальное выращивание апельсиновых культур и сохранить оригинальный вкус [1].
Персонализация маркетинга
Чтобы лучше понять свою целевую аудиторию, таргетировать рекламные кампании и повысить их конверсию, Coca-Cola активно применяет технологии интеллектуального анализа данных (Data Mining). Так, еще в 2016 году корпорация продвигала свою марку холодного чая Gold Peak, ориентируя рекламные объявления на людей на основе анализа их фото в социальных сетях. С помощью ML-алгоритмов распознавания изображений, компания определяла фотографии людей со стаканами, банками и бутылками, в которых находился продукт Кока-Колы или ее конкурентов. Выявив таким образом любителей чая, компания таргетировала на них рекламные объявления на 40 различных мобильных сайтах, включая соцсети Instagram, Facebook и Twitter. В результате такой точечной рекламы конверсия продаж выросла более чем на 2%, что в 3-4 раза больше лучших показателей в FMCG-сектора. Дополнительным эффектом этого применения технологий Big Data стало множество детальных потребительских портретов (пол, возраст, регион, занятость, интересы, платежеспособность, семейное положение и прочие характеристики клиента). После такого успеха собранная таким образом информация используется и в других маркетинговых задачах [3].
Искусственный интеллект в вендинговом автомате
Современный торговый автомат – это не просто немая витрина с продуктами, а полноценное средство общения с покупателем. Для интерактивного взаимодействия с клиентами Кока-Кола внедрила в свои вендинговые машины программные модули, которые меняют цвет сенсорного экрана в зависимости от предпочтений пользователя и окружающей обстановки. Это входит в программу персонализации продажи напитков, когда пользователь заказывает свою любимую смесь из любого торгового автомата. При этом вендинговая машина учитывает вкусы клиента при смешивании напитка, например, предлагая ему определенный ассортимент добавок. Также искусственный интеллект меняет поведение автомата в зависимости от его местоположения, добавляя больше интерактива в оживленных местах (торгово-развлекательные центры и пр.) или строгости в официальных учреждениях, таких как больницы, центры оказания госуслуг и т.д. [4].
Интернет вещей и дополненная реальность на производстве
Комплексная цифровизация производства предполагает непрерывную онлайн-интеграцию технологических показателей с бизнес-метриками за счет промышленного интернета вещей (Industrial Internet of Things, IIoT). В Coca-Cola эти технологии сопровождаются устройствами дополненной реальности, когда специальные очки позволяют наложить компьютерную графику на предметы реального мира. Благодаря этому специалисты по обслуживанию технологического оборудования получают дополнительные сведения о технике в процессе ее профилактического осмотра или ремонта. Также AR используется для решения проблем с вендинговыми автоматами в удаленных или труднодоступных местах, таких как круизные лайнеры, когда они находятся в море [1].
Тотальная цифровизация
Кока-Кола также использует Big Data и Machine Learning для оптимизации расходов, управление цепочками поставок, сканирование промо-кодов с использованием OCR-технологии для распознавания образов и множества других бизнес-задач [5]. Для этого в компании внедрено современное корпоративное хранилище данных, которое аккумулирует всю многоканальную информацию о розничной торговле, чтобы быстро и точно реагировать на изменения рынка. Еще предприятие поддерживает процессы управления основными данными, чтобы стандартизовать все процедуры Data Governence для эффективного производства и продвижения продукции, а также для повышения качества обслуживания потребителей [6]. Как адаптировать эти примеры использования Big Data и Machine Learning в цифровизацию своего бизнеса, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, аналитиков и Data Scientist’ов) в Москве: Аналитика больших данных для руководителей

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://www.forbes.com/sites/bernardmarr/2017/09/18/the-amazing-ways-coca-cola-uses-artificial-intelligence-ai-and-big-data-to-drive-success/ 2. https://www.bernardmarr.com/default.asp?contentID=1280 3. https://www.mobilemarketer.com/news/coca-cola-targets-users-based-on-photos-they-share-on-social-media/442927/ 4. https://venturebeat.com/2017/07/11/coca-cola-reveals-ai-powered-vending-machine-app/ 5. https://analyticsindiamag.com/coca-cola-leans-on-data-analytics-ai-for-deeper-industry-insights/ 6. https://www.researchgate.net/publication/309520280_Innovation_business_model_of_Big_Data------_Taking_Coca-Cola_as_an_example Read the full article
#BigData#IIoT#InternetofThings#IoT#MachineLearning#Большиеданные#интернетвещей#Искусственныйинтеллект#МашинноеОбучение#обработкаданных#предиктивнаяаналитика#ритейл
0 notes
Text
Как найти узкое место рабочего процесса: строим VSM и разбираемся с ценностями
Вчера мы рассмотрели, что такое функционально-стоимостный анализ (ФСА) и как этот метод позволяет оценить бизнес-процессы в денежном выражении. Однако, результаты ФСА, в первую очередь, ориентированы на оптимизацию с точки зрения финансов, а не организации и технологий. Исправить ситуацию помогут принципы бережливого производства (Lean). Сегодня мы расскажем об одном из них – картировании потоков создания ценностей (VSM), а также поговорим как DevOps воплощает идеи Lean и при чем здесь расширенная аналитика больших данных (Big Data).
Цифровизация потоков создания ценности: что такое VSM
Цифровизация предполагает не просто внедрение Big Data, Machine Learning и прочих методов искусственного интеллекта для оптимизации деятельности. Прежде всего, цифровая трансформация направлена на изменение бизнес-процессов, чтобы ускорить их, а также снизить затраты и ошибки, повысив результативность. Для построения новых моделей деятельности используется не только расширенная аналитика Big Data, но и уже давно существующие и успешно применяемые методы системного анализа и менеджмента качества. В частности, идеи бережливого производства, которые помогли японской автомобильной компании «Тойота» выйти из послевоенного кризиса [1]. Напомним, основная философия Lean состоит в устранении потерь – действий, которые не производят ценности для конечного потребителя. Одним из наиболее понятных и широко применяемых на практике методов Lean является картирование потоков создания ценностей (VSM, Value Stream Mapping). VSM - это простая и наглядная графическая схема, показывающая движение процессов, материалов и информации для предоставления продукта или услуги конечному потребителю. VSM не просто визуализирует производственную деятельность, а позволяет определить ее узкие места за счет анализа основных показателей каждого процесса. Выявить потери и оценить качество процесса помогут следующие метрики [2]: · время выпуска (Lead Time, LT) – общее время выполнения процесса, включая согласование, процедуры возврата, а также ожидание данных, материалов и прочих ресурсов; · время обработки (Process Time, PT) – время непосредственного выполнения работы, дающей результат процесса (ценность); · доля работ, выполненных без ошибок (Percent Complete and Accurate, %C/A) – в идеале должна быть равной 100%, но на практике может не измеряться вовсе. Отношение PT к LT показывает, сколько времени выполняется непосредственная работа по созданию ценности от всего времени процесса. В идеальном случае (PT/LT)->1. Таким образом, можно выявить потери ресурсов (времени, финансов и человеческого труда) на непродуктивные операции: согласование, поиск или ожидание данных, перемещение, копирование, перепроизводство, дополнительная обработка, создание запасов и возникновение дефектов. К примеру, DevOps-подход стремится увеличить скорость создания ПО, снижая LT за счет ускорения процессов развертывания и тестирования. В частности, быстрое развертывание тестовых и production-сред с помощью технологий контейнеризации (Docker, Kubernetes и т.д.) позволяет устранить временные потери на ожидание результатов работы администраторов [2]. Чтобы понять, почему фактические показатели отличаются от их плановых значений, можно использовать метод диаграммы Исикавы (Fishbone), о котором мы писали в этой статье. VSM наглядно показывает, какие этапы создания ценности стоит улучшить. Продолжая пример из вчерашней статьи про функционально-стоимостный анализ, определим непосредственную ценность процессов проектирования новой Big Data системы. Поскольку цель настоящей статьи – познакомить с основными принципами Value Stream Mapping, мы представим процесс работы с требованиями к программному продукту упрощенно, а не так подробно, как это рекомендует профессиональное руководство по бизнес-анализу BABOK. Итак, пусть рассматриваемая деятельность состоит из следующих этапов: · определение бизнес-потребностей и выявление требований к решению, включая разработку вспомогательных планов (по бизнес-анализу, коммуникациям и пр.), взаимодействие со стейкхолдерами, поиск информации, анализ текущих процессов, информационных систем, потоков данных, документации и архитектуры предприятия, оформление и согласование результатов. 75% времени всей этой деятельности уходит на вспомогательную работу, которая, хоть и помогает аналитику, не создает конечной ценности. Показатель %C/A здесь сложно оценить, поэтому оставим его не заданным. · разработка технического задания на новую систему, включая консультации со стейкхолдерами, согласование и исправление документов. Здесь также работа по непосредственному созданию технического задания занимает лишь 25% от всего времени процесса. Будем считать, что результат на 90% отражает реальные бизнес-потребности и особенности применения будущего продукта. · создание подробного технического проекта будущей системы с описанием всех функциональных и нефункциональных требований, вариантов и сценариев использования, а также архитектуры решения с учетом корпоративного ИТ-ландшафта. Как и в предыдущих этапах, большая часть времени (60%) уходит на поиск и ожидание данных, консультации и согласование. При этом созданный технический проект описывает лишь 80% реальных бизнес-потребностей. Таким образом, все процессы можно оптимизировать, сократив LT за счет устранения задач поиска информации с помощью корпоративной базы знаний и продвинутого управления данными (Augmented Data Management). Как это реализуется на базе технологий Big Data и Machine Learning, мы рассказывали здесь. Простой пример карты потока создания ценности в бизнес-процессе анализа
Как построить карту потоков ценностей с помощью Big Data и Internet of Things
Разумеется, на практике картирование потока ценности является более трудоемким процессом, чем в рассмотренном примере. Помимо хронометража рабочего времени каждой задачи и детальной фиксации всех ее операций и их участников, на карту этапов создания продукта также наносятся материальные и информационные потоки, а также периодичность, способы и направления движения результатов [3]. Создание подобной карты вручную – достаточно сложный и длительный процесс, поскольку бизнес-аналитику необходимо самостоятельно собрать множество разных данных и потратить время на детальный хронометраж каждого этапа создания ценности. Как правило, промышленные предприятия с отлаженным конвейером работ частично содержат нужные данные в виде карт производственных процессов. Но такие VSM содержат далеко не все данные для комплексной бизнес-аналитики и не всегда на 100% точно отражают реальность. Исправить это несоответствие поможет цифровизация. Информация о фактических показателях любого производственного процесса может быть собрана и обработана автоматически с помощью технологий Big Data, IoT/IIoT-устройств и алгоритмов Machine Learning. Такая система расширенной аналитики сама подскажет менеджеру или аналитику, что можно оптимизировать и как. Например, помечать материальные ресурсы RFID-метками или QR-кодами, чтобы автоматически отслеживать их перемещение, не тратя время на ручной поиск в корпоративных базах. Именно так было поступили некоторые отечественные и зарубежные логистические компании, о чем мы писали здесь. Сегодня некоторые варианты такой оптимизации предлагают модули CRM-, ERP-, SCM- и других профильных корпоративных информационных систем, а также BI-решения. Однако пока это можно назвать локальной оптимизацией, а не комплексным улучшением деятельности всего предприятия. Кроме того, готовое бизнес-решение не генерируется системой, а предлагается аналитиком на основе данных. Поэтому доля человеческого труда по рутинной обработке даже проанализированных данных здесь еще высока. В отличие от лоскутной автоматизации, цифровизация всех бизнес-процессов с интеграцией каждого потока данных в единую ИТ-инфраструктуру повысит общую эффективность компании, воплощая идеи Lean [4]. Подводя итог описанию VSM, отметим, что данный метод бережливого производства достаточно прост, но понятен и полезен. Неслучайно профессиональный стандарт бизнес-аналитика, руководство BABOK включило Value Stream Mapping в состав наиболее часто используемых техник процессного анализа. Другие техники BABOK и особенности их применения в аналитике больших данных, а также при внедрении технологий Big Data мы рассмотрим в следующий раз. Пример карты потоков создания ценностей в разработке программного обеспечения - Lean для DevOps-инженеров Другие практические кейсы прикладного системного анализа, цифровизации бизнеса и аналитики больших данных вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве: Аналитика больших данных для руководителей Анализ и оптимизация бизнес-процессов

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://ru.wikipedia.org/wiki/Производственная_система_«Тойоты» 2. https://www.litres.ru/oleg-skrynnik/devops-dlya-it-menedzherov-48411311/ 3. https://en.wikipedia.org/wiki/Value-stream_mapping 4. https://realitsm.ru/2019/11/gajd-po-value-stream-mapping-vsm-vygody-procedury-cennost/ Read the full article
#BigData#DevOps#InternetofThings#Большиеданные#интернетвещей#предиктивнаяаналитика#системныйанализ#Цифроваятрансформация#цифровизация
0 notes