#LLM open-source
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Le Tendenze dell’Intelligenza Artificiale Oggi L’intelligenza artificiale (AI) sta trasformando il mondo: l’89% dei tool AI aziendali è fuori controllo (LayerX Security), esponendo a data breach e violazioni di compliance, mentre Nello Cristianini prevede un’AI sovrumana con AGI e ASI (il Mulino). La programmazione potrebbe sparire entro un anno, dice Anthropic (Anthropic), ma NextGenAI di OpenAI e il Work Trend Index di Microsoft vedono nuove opportunità. I dati sintetici, generati con GAN e SMOTE, rivoluzionano machine learning e privacy, mentre il quantum computing di D-Wave supera i limiti classici (Science). OpenEuroLLM (Cineca) punta sulla sovranità digitale con LLM open-source, ma i chatbot come Grok-3 mostrano hallucination (Tow Center). Tra bias, shadow AI e data center, serve un equilibrio: l’AI è un alleato, se guidata da CISO, auditing e strategie umane.
#AGI#AI#AI generativa#AI sovrumana#ASI#auditing#bias#chatbot#CISO#compliance#data breach#data center#dati sintetici#GAN#hallucination#Intelligenza Artificiale#LLM open-source#machine learning#NextGenAI#OpenEuroLLM#privacy#programmazione#quantum computing#ricerca accademica#shadow AI#sicurezza dei dati#SMOTE#sovranità digitale
1 note
·
View note
Text
still confused how to make any of these LLMs useful to me.
while my daughter was napping, i downloaded lm studio and got a dozen of the most popular open source LLMs running on my PC, and they work great with very low latency, but i can't come up with anything to do with them but make boring toy scripts to do stupid shit.
as a test, i fed deepseek r1, llama 3.2, and mistral-small a big spreadsheet of data we've been collecting about my newborn daughter (all of this locally, not transmitting anything off my computer, because i don't want anybody with that data except, y'know, doctors) to see how it compared with several real doctors' advice and prognoses. all of the LLMs suggestions were between generically correct and hilariously wrong. alarmingly wrong in some cases, but usually ending with the suggestion to "consult a medical professional" -- yeah, duh. pretty much no better than old school unreliable WebMD.
then i tried doing some prompt engineering to punch up some of my writing, and everything ended up sounding like it was written by an LLM. i don't get why anybody wants this. i can tell that LLM feel, and i think a lot of people can now, given the horrible sales emails i get every day that sound like they were "punched up" by an LLM. it's got a stink to it. maybe we'll all get used to it; i bet most non-tech people have no clue.
i may write a small script to try to tag some of my blogs' posts for me, because i'm really bad at doing so, but i have very little faith in the open source vision LLMs' ability to classify images. it'll probably not work how i hope. that still feels like something you gotta pay for to get good results.
all of this keeps making me think of ffmpeg. a super cool, tiny, useful program that is very extensible and great at performing a certain task: transcoding media. it used to be horribly annoying to transcode media, and then ffmpeg came along and made it all stupidly simple overnight, but nobody noticed. there was no industry bubble around it.
LLMs feel like they're competing for a space that ubiquitous and useful that we'll take for granted today like ffmpeg. they just haven't fully grasped and appreciated that smallness yet. there isn't money to be made here.
#machine learning#parenting#ai critique#data privacy#medical advice#writing enhancement#blogging tools#ffmpeg#open source software#llm limitations#ai generated tags
61 notes
·
View notes

Text
Regarding the DeepSeek AI Hysteria:
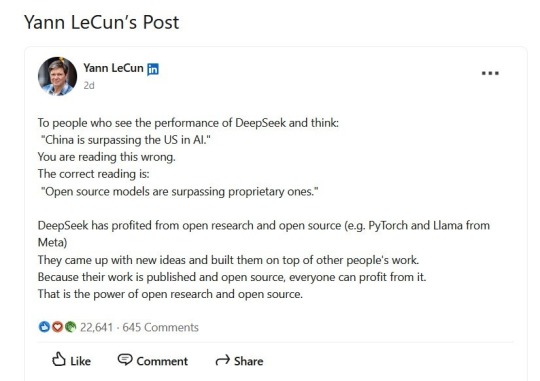
Text of posting:
To people who see the performance of DeepSeek and think: "'China is surpassing the US in AI." You are reading this wrong. The correct reading is: "Open source models are surpassing proprietary ones." DeepSeek has profited from open research and open source (e.g. PyTorch and Llama from Meta). They came up with new ideas and built them on top of other people's work. Because their work is published and open source, everyone can profit from it. That is the power of open research and open source.
Also recommended reading:
#ai bubble#proprietary software#nvidia#openai#llm#open source development#software development#ai industry#chinese software#chinese ai#ai hype#ai bullshit#yann lecun#american ai#ars technica#signal boost
4 notes
·
View notes
Text
Learn how Open-FinLLMs is setting new benchmarks in financial applications with its multimodal capabilities and comprehensive financial knowledge. Finetuned from a 52 billion token financial corpus and powered by 573K financial instructions, this open-source model outperforms LLaMA3-8B and BloombergGPT. Discover how it can transform your financial data analysis.
#OpenFinLLMs#FinancialAI#LLMs#MultimodalAI#MachineLearning#ArtificialIntelligence#AIModels#artificial intelligence#open source#machine learning#software engineering#programming#ai#python
2 notes
·
View notes
Text
*sees this post pop up in my notes*
*twitches*
I’d made some generalizations in that (which I standby, they’re just coming from an opposite direction) but had to break out the sources and numbers when someone told me I was making generalizations in the same way as the people who “””uncovered””” that AO3 was scraped for AI (no) did and anyways I get tempted to post those notes here sometimes before I have to bonk myself on the head and remind myself no one cares
#in doing some digging on this specifically in relationship to fandom#I’d accidentally set it so that I’m seeing this a lot more than normal#@ me deep breaths and remember it’s artificially loud!!!!!!#i have a doc that’s just me yelling into a rabbit hole#no clue if it’s helping but#i keep seeing wild takes and I’m just yelling into the void CITE. YOUR. SOURCES.#genuinely a bit miffed about being accused of making a sweeping generalization in the same way as the people who claim ao3’s scraped for ai#meh#idk if person is ignoring me or verifying info for themselves rn but i gotta remember i don’t actually care#and really just need to go drink some water#anyways cookie is annoyed on the internet news at 11#sighs#*yes ik I didn’t originally cite mine either but#1) my mission statement is just to explain to some friends how LLMs work and give notes on things to look up/consider re: gen AI#2) I’m not telling people that they were deliberately targeted and are now open to LITIGATION FOR COPYRIGHT INFRINGEMENT#(also I’m sorry but??????? what???????????????)#SIGHS 🤦♂️
4 notes
·
View notes
Text
Or, to look at the situation from another angle:

Text of posting:
To people who see the performance of DeepSeek and think:
"'China is surpassing the US in AI."
You are reading this wrong. The correct reading is:
"Open source models are surpassing proprietary ones."
DeepSeek has profited from open research and open source (e.g. PyTorch and Llama from Meta). They came up with new ideas and built them on top of other people's work.
Because their work is published and open source, everyone can profit from it. That is the power of open research and open source.
I am very wary of people going "China does it better than America" because most of it is just reactionary rejection of your overlord in favor of his rival, but this story is 1. absolutely legit and 2. way too funny.

US wants to build an AI advantage over China, uses their part in the chip supply chain to cut off China from the high-end chip market.
China's chip manufacturing is famously a decade behind, so they can't advance, right?

They did see it as a problem, but what they then did is get a bunch of Computer Scientists and Junior Programmers fresh out of college and funded their research in DeepSeek. Instead of trying to improve output by buying thousands of Nvidia graphics cards, they tried to build a different kind of model, that allowed them to do what OpenAI does at a tenth of the cost.

Them being young and at a Hedgefund AI research branch and not at established Chinese techgiants seems to be important because chinese corporate culture is apparently full of internal sabotage, so newbies fresh from college being told they have to solve the hardest problems in computing was way more efficient than what usually is done. The result:

American AIs are shook. Nvidia, the only company who actually is making profit cause they are supplying hardware, took a hit. This is just the market being stupid, Nvidia also sells to China. And the worst part for OpenAI. DeepSeek is Open Source.

Anybody can implement deepseek's model, provided they have the hardware. They are totally independent from DeepSeek, as you can run it from your own network. I think you will soon have many more AI companies sprouting out of the ground using this as its base.

What does this mean? AI still costs too much energy to be worth using. The head of the project says so much himself: "there is no commercial use, this is research."

What this does mean is that OpenAI's position is severely challenged: there will soon be a lot more competitors using the DeepSeek model, more people can improve the code, OpenAI will have to ask for much lower prices if it eventually does want to make a profit because a 10 times more efficient opensource rival of equal capability is there.
And with OpenAI or anybody else having lost the ability to get the monopoly on the "market" (if you didn't know, no AI company has ever made a single cent in profit, they all are begging for investment), they probably won't be so attractive for investors anymore. There is a cheaper and equally good alternative now.
AI is still bad for the environment. Dumb companies will still want to push AI on everything. Lazy hacks trying to push AI art and writing to replace real artists will still be around and AI slop will not go away. But one of the main drivers of the AI boom is going to be severely compromised because there is a competitor who isn't in it for immediate commercialization. Instead you will have a more decentralized open source AI field.
Or in short:

#ai bubble#llm bubble#nvidia crash#chinese ai#open source development#open source#deepseek#us ai#proprietary software#yann lecun#llm
3K notes
·
View notes
Text
There is something deliciously funny about AI getting replaced by AI.
tl;dr: China yeeted a cheaper, faster, less environmental impact making, open source LLM model onto the market and US AI companies lost nearly 600 billions in value since yesterday.
Silicone Valley is having a meltdown.
And ChatGTP just lost its job to AI~.
27K notes
·
View notes
Text
Penguin Woes
It's early summer and if you know me, you know summer's my IT Spring Cleaning season. I usually format all my personal devices once a year and considering my job, that always comes with an associated symptom the veterans call distro-hopping.
Being a Sysadmin of a fairly small company, we've gotten away with getting our agents set up on Linux Mint, seeing as we don't directly interface with dealership CRM tools. However, we do keep Windows systems for most of the front-end stuff, when dealing with our clients, seeing as Joe McCarSalesman isn't very likely to know his sudo from his dir.
On my end, though, once I've accounted for the one laptop that has to remain a Windows rig and for my main machine that I use for multiplayer gaming with Walt and Sarah, all bets are off. When enough of the workforce is off on vacation, I usually take one or two days off to get my pen-testing dummy out of the closet and poke around with a few operating systems. Wanting to test out ChatGPT's advice regarding Fedora Workstation 42 after years of being married to various Ubuntu forks (primarily Mint, because Mint fucking works), I slapped it onto my Ventoy stick, plugged a sacrificial SSD in and unplugged everything else - and got to testing.
First big oopsie from Fedora's boys: a hard crash at the Date and Time selection, with disgruntled users on Reddit specifying that the only way to move past it was to restart the installer and to click on your desired location, as opposed to using a drop-down menu to reliably select a locale.
Second big oopsie: even if you set a second SSD to be a separate mount point for a Steam Library, Fedora 42 refuses to let said SSD be displayed as an option in Steam. Actually hot-plugged drives like USB sticks show up - but separate drives connected to the PC apparently don't, unless you're ready to spend forty-five minutes wrangling the Terminal.
And a point of contention: the absence of any GUI support for officially-supported NVIDIA drivers. You'd think that a platform that's as mature as Fedora's would have figured out that a certain percentage of its user base is going to use hardware that hasn't quite jumped onboard the Open-Source train as much as AMD.
One of my Helpdesk employees scoffed. "Come on, Grem - you use the Terminal all the time! Who cares if you need to bring up RPM Fusion manually!"
To which I replied that from what I've seen, the Linux community tends to mistakenly assume that video servers (Wayland/Xorg) and GUI design matters more than making the core experience comfortable. If updating your GPU isn't a basic aspect of a computer's maintenance, then I don't know what is. This is where Mint scores a substantial point. In a few clicks, a freshly-installed Mint instance can have all its drivers - video drivers included - and be ready for the more granular aspects of the setup process.
As ever, I tend to think that Linux will only ever mature when the Terminal is only as necessary as Windows' Command Prompt can be - which is not much at all.
Basic setup shouldn't involve the Terminal or the Command Prompt - on any level.
Oh - and ChatGPT's advice for the best distros for specific hardware configs is definitely suspect.
#IT Post#Linux#Fedora Workstation 42#Linux Mint#Computing#Open-Source Software#Distro-Hopping#ChatGPT#Shitty Advice from an LLM
0 notes
Text
A worthwhile use for ChatGPT
I admit that discovering software bugs is a worthwhile use for large language models (LLMs).
However, it's easy to imagine how a tool that discovers zero-day vulnerabilities in Linux could be abused. For instance, if someone wished to exploit or sell zero-days instead of reporting them ...
#chatgpt#generative ai#open source#linux#zero day#gpt#software engineering#software bugs#llm ai#kernel
1 note
·
View note
Text
rasbt/llama-3.2-from-scratch · Hugging Face
0 notes
Text
🚀 DeepSeek is revolutionizing AI, competing with OpenAI’s ChatGPT, Google’s Gemini & xAI’s Grok! 🤖🔥 💡 Its DeepSeek LLM (67B parameters) outperforms LLaMA-2 70B in math & coding! 📊🔢 🖥️ DeepSeek Coder, trained on 2T tokens, excels in multi-language coding! 💻🚀 📅 In March 2025, DeepSeek-V3-0324 launched, boosting reasoning & coding! 📈⚡ ��� With a research-first, open-source approach, can DeepSeek lead global AI? 🤔🔍 #AI #DeepSeek
#AGI#AI#AI competition#AI Innovation#Artificial Intelligence#DeepSeek#DeepSeek LLM#Google Gemini#open-source AI#OpenAI competitor#xAI Grok
0 notes
Text
So LLM companies are killing FOSS projects by scraping every diff of every file and by making bullshit bug reports devs have to inspect just to find the issues reported don't actually exist, and standing between at least some of them and oblivion is an anime-girlified Egyptian god.
0 notes
Text
Learn how Kimi K2 distinguishes itself as a premier open-weight coding model. We dive into its one-trillion-parameter Mixture-of-Experts (MoE) architecture, which efficiently uses only 32 billion active parameters. Find out how its unique approach—applying reinforcement learning directly to tool use—enables its impressive single-attempt accuracy on SWE-bench and allows it to outperform proprietary models in agentic coding tasks.
#KimiK2#MoonshotAI#MixtureOfExperts#MoE#LLM#AI#ArtificialIntelligence#OpenWeight#CodingAI#AICoding#AgenticAI#artificial intelligence#machine learning#software engineering#programming#python#open source#nlp
0 notes
Text
SuperGPQA: Bytedance open source benchmark for LLM
The new SuperGPQA benchmark, developed by experts and the open-source community, offers an assessment of the capabilities of LLMs in 285 disciplines through multiple-choice questions, collaborative filtering and specialized annotations. Key points: Multidisciplinary benchmark with 26,529 multiple-choice questions In-depth assessment in 285 graduate-level disciplines Human-LLM collaborative filtering mechanism supported by expert feedback Methodological directions for future improvement of LLMs ByteDance’s Doubao Large Model Team, in synergy with the open-source M-A-P community,... read more: https://www.turtlesai.com/en/pages-2425/supergpqa-bytedance-open-source-benchmark-for-llm
0 notes
Text
youtube
L'IA française est au top :)
0 notes