#MergeTree
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Типы данных и движки в ClickHouse: Фундамент для производительности. Урок 2

Приветствуем вас во второй части нашего курса по основам ClickHouse (далее CH)! В первой статье мы разобрались, что такое ClickHouse, почему он так хорош для аналитики и как запустить его локально или в облаке. Теперь пришло время углубиться в две ключевые концепции, которые определяют, как CH хранит и обрабатывает ваши данные: типы данных ClickHouse и движки таблиц (Table Engines). Понимание этих концепций критически важно для создания производительных решений. Неправильный выбор может привести к не оптимальной производительности и избыточному п��треблению ресурсов, поэтому давайте разберем все по порядку. Типы Данных ClickHouse: Точность и Эффективность Хранения CH, как и любая СУБД, требует, чтобы вы указывали тип данных для каждого столбца. Однако CH предлагает множество специализированных типов данных, которые позволяют достичь высокой эффективности хранения и обработки. Выбор правильного типа данных может значительно повлиять на размер вашей базы и скорость запросов. Числовые типы данных используемые в ClickHouse ClickHouse предоставляет широкий спектр числовых типов, что позволяет выбрать оптимальный для памяти диапазон значений. Целые числа: Это типы от Int8/UInt8 до Int256/UInt256. Правило простое: всегда выбирайте наименьший тип, который может вместить ваши значения. Например, для возраста человека идеально подойдет UInt8. Числа с плавающей точкой: Float32 и Float64 используются для вычислений, где требуется высокая точность. Десятичные числа (Decimal): Типы Decimal32, Decimal64 и другие незаменимы там, где потеря точности недопустима, например, при работе с денежными суммами. Строковые типы Обработка строк часто бывает ресурсоемкой, и CH предлагает несколько вариантов для оптимизации. String: Строка произвольной длины, самый универсальный тип. FixedString(N): Строка фиксированной длины. Идеальна для данных вроде хэшей или кодов стран. LowCardinality(String): Это "секретное оружие" для оптимизации. Используется для столбцов с небольшим количеством уникальных значений. ClickHouse создает словарь уникальных значений и для каждой строки хранит лишь короткий числовой индекс. Это драматически улучшает сжатие и ускоряет фильтрацию и группировку.

Дата и время Date: Хранит только дату. DateTime: Хранит дату и время с точностью до секунды. DateTime64(precision): Хранит дату и время с точностью до милли-, микро- или наносекунд. Важная рекомендация: всегда храните временные метки в UTC, чтобы избежать проблем с часовыми поясами. Прочие важные типы Boolean: Хранится как UInt8 (0 или 1). UUID: Для хранения универсальных уникальных идентификаторов. IPv4, IPv6: Специализированные и эффективные типы для IP-адресов. Array(T): Массив значений одного типа. Nullable(T): Оборачивает любой тип, позволяя ему хранить значение NULL. Используйте его только при необходимости. Практический пример: Выбор типов данных для ClickHouse таблиц Давайте пересмотрим таблицу access_logs из первой статьи и посмотрим, как типы данных влияют на нее: CREATE TABLE access_logs ( timestamp DateTime64(3), -- Точность до миллисекунд для детального анализа событий event_type LowCardinality(String),-- Ограниченное число уникальных типов событий -> эффективно user_id UInt64, -- Большое количество пользователей, ID всегда положительный ip_address IPv4, -- Оптимизировано для хранения IP-адресов url String, -- Произвольная длина, высокая кардинальность -> String duration_ms UInt32, -- Продолжительность всегда положительная, до нескольких миллиардов миллисекунд is_mobile Nullable(UInt8) -- Добавим новое поле: может быть NULL, если неизвестно ) ENGINE = MergeTree() ORDER BY (timestamp, user_id); Правильный выбор типов данных ClickHouse — это первое, что нужно сделать для обеспечения производительности и экономии ресурсов. Движки Таблиц (Table Engines): Сердце Хранения Данных Движок таблицы (Table Engine) определяет, как данные хранятся, читаются, записываются, индексируются и реплицируются. Это одна из самых мощных и отличительных особенностей CH . Выбор движка критически важен, так как он определяет производительность, надежность и функциональность вашей таблицы. CH предлагает множество движков, но для аналитических задач наиболее важными являются движки семейства MergeTree. Они оптимизированы для сценариев OLAP (Online Analytical Processing) и обеспечивают высокую производительность на больших объемах данных. Семейство движков MergeTree: ваш рабочий инструмент Движки MergeTree спроектированы для хранения огромных объемов данных и обеспечивают молниеносное выполнение аналитических запросов. Ключевые особенности MergeTree: Колоночное хранение: Как мы уже обсуждали, данные хранятся по столбцам. Партиционирование (Partitioning): Данные могут быть разбиты на логические части (партиции) по заданному критерию (часто по дате или месяцу). Это позволяет ClickHouse читать только те данные, котор��е релевантны запросу, и эффективно удалять старые данные. Сортировка (Ordering): Данные внутри каждой партиции отсортированы по указанному ключу сортировки (ORDER BY). Это ускоряет фильтрацию и агрегацию. Индексирование (Indexing): Поверх отсортированных данных создается разреженный индекс (primary index), который позволяет быстро находить блоки данных. Слияние (Merging): Данные записываются в небольшие, отсортированные части (data parts). В фоновом режиме ClickHouse периодически объединяет эти части в более крупные, что оптимизирует хранение и производительность.
Синтаксис базового движка MergeTree: CREATE TABLE my_table ( col1 DataType, col2 DataType, -- ... ) ENGINE = MergeTree() PARTITION BY expression -- (Опционально) Выражение для партиционирования ORDER BY (col1, col2) -- Ключ сортировки (ОБЯЗАТЕЛЕН для MergeTree) PRIMARY KEY (col1) -- (Опционально) Выборка подмножества из ORDER BY для первичного индекса TTL expression -- (Опционально) Время жизни данных SETTINGS setting = value -- (Опционально) Дополнительные настройки PARTITION BY: Определяет, как данные будут разбиты на партиции. Чаще всего используется по дате или части даты (toYYYYMM(timestamp)). Это наиболее важная оптимизация для работы с большими временными рядами. При запросах по диапазону дат CH будет читать только нужные партиции, игнорируя остальные. ORDER BY: Определяет, как данные отсортированы внутри каждой партиции. Это ваш основной индекс. Запросы с WHERE или GROUP BY по столбцам из ORDER BY будут выполняться быстрее. PRIMARY KEY: В отличие от традиционных СУБД, PRIMARY KEY в CH не гарантирует уникальность. Он просто определяет, какие столбцы используются для построения разреженного первичного индекса. Если не указан, по умолчанию используется ORDER BY. Вариации MergeTree Помимо базового MergeTree, существуют специализированные движки, наследующие его функциональность и добавляющие специфическое поведение: ReplacingMergeTree: Назначение: Обработка дубликатов. При слиянии частей данных, если есть строки с одинаковым значением ключа сортировки (ORDER BY), ReplacingMergeTree оставляет только одну (последнюю по времени вставки или указанному столбцу-версии). Пример: Для таблицы пользователей, где нужно хранить только актуальную информацию о каждом пользователе. ENGINE = ReplacingMergeTree() - ver_column опционален и указывает на столбец, по которому определяется "самая свежая" запись. SummingMergeTree: Назначение: Агрегация данных "на лету" при слиянии частей. Все числовые столбцы (кроме тех, что в ORDER BY) суммируются, если строки имеют одинаковое значение ключа сортировки. Пример: Для агрегации метрик (просмотры, клики, суммы транзакций) по измерениям (дата, кампания, пользователь). Значительно уменьшает объем хранимых данных. ENGINE = SummingMergeTree() - опционально можно указать, какие столбцы суммировать. Если не указаны, суммируются все числовые. AggregatingMergeTree: Назначение: Хранение предварительно агрегированных данных. Используется совместно с агрегатными функциями ClickHouse engine, которые возвращают промежуточные состояния (AggregateFunction). Пример: Если вам нужно часто считать uniqCombined или quantiles по большому объему данных, вы можете предварительно агрегировать их. Это более продвинутый движок, требующий понимания работы с AggregateFunction. CollapsingMergeTree: Назначение: Удаление "парных" строк (например, событие "вход" и "выход") или хранение только последнего состояния записи, используя специальный столбец Sign. Пример: Отслеживание сессий или состояний сущностей, где важно фиксировать изменения и убирать промежуточные состояния. GraphiteMergeTree: Назначение: Оптимизирован для хранения данных временных рядов, подобных метрикам Graphite. Replicated*MergeTree: (Например, ReplicatedMergeTree, ReplicatedReplacingMergeTree и т.д.) Назначение: Обеспечивает репликацию данных между серверами в кластере, используя Apache ZooKeeper (или ClickHouse Keeper) для координации. Это ваш выбор для production-систем, где нужна отказоустойчивость. Практический Пример: Использование ClickHouse MergeTree engine с Партиционированием Вернемся к нашей таблице access_logs. Добавим партиционирование по месяцу, что очень распространено для временных рядов. Удалим старую таблицу (если она существует): DROP TABLE IF EXISTS my_first_db.access_logs; -- Создадим новую таблицу с партиционированием CREATE TABLE my_first_db.access_logs ( timestamp DateTime64(3), event_type LowCardinality(String), user_id UInt64, ip_address IPv4, url String, duration_ms UInt32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) -- Партиционируем по году и месяцу из поля timestamp ORDER BY (timestamp, user_id); Здесь toYYYYMM(timestamp) извлекает год и месяц из временной метки (например, 202406 для июня 2024 года). ClickHouse автоматически создаст отдельные директории для каждой партиции на диске. Вставим данные (включая данные за разные месяцы): INSERT INTO my_first_db.access_logs (timestamp, event_type, user_id, ip_address, url, duration_ms) VALUES ('2024-05-15 10:00:00.123', 'page_view', 100, '192.168.1.1', '/old_home', 150), ('2024-05-15 10:00:01.456', 'click', 100, '192.168.1.1', '/old_button_a', 20), ('2024-06-19 10:00:00.123', 'page_view', 101, '192.168.1.1', '/home', 150), ('2024-06-19 10:00:01.456', 'click', 101, '192.168.1.1', '/button_a', 20), ('2024-06-19 10:00:02.789', 'page_view', 102, '10.0.0.5', '/products', 300), ('2024-06-20 10:00:03.000', 'page_view', 101, '192.168.1.1', '/contact', 100), ('2024-06-20 10:00:04.111', 'click', 102, '10.0.0.5', '/product_details', 50), ('2024-07-01 08:00:05.222', 'page_view', 103, '172.16.0.10', '/home', 200), ('2024-07-01 08:01:05.222', 'page_view', 104, '172.16.0.11', '/home', 250); Проверим партиции (только для локальной инсталляции или через системные таблицы). В clickhouse-client вы можете посмотреть, какие партиции создались:

Вы видите отдельные партиции для 202405, 202406 и 202407. Выполним запрос с фильтрацией по партиции. Когда вы запрашиваете данные за конкретный месяц, CH будет читать только соответствующую партицию:

Этот запрос будет очень быстрым, так как CH сразу поймет, что ему нужно работать только с партицией 202406. Другие категории движков (краткий обзор) Хотя MergeTree – ваш основной инструмент для аналитики, стоит знать о других категориях движков: Лог-движки (Log, TinyLog, StripeLog): Простые движки для небольших объемов данных, которые записываются последовательно и не изменяются. Не поддерживают ORDER BY, PARTITION BY. Когда использовать: Для временных таблиц, небольших логов, для быстрой отладки, где не требуется сложная аналитика. Движки для внешних систем (Kafka, MySQL, PostgreSQL, ODBC, JDBC, S3, URL, File): Позволяют ClickHouse напрямую работать с данными из внешних источников, не импортируя их. Когда использовать: Для чтения данных из стриминговых платформ ( Kafka), PostgreSQL, S3 и других источников (более подробно посмотрим на них в Уроке 7 посвященном интеграции) Специальные движки (Dictionary, Distributed, Buffer): Dictionary: Для работы со словарями (маппингами), которые загружаются в оперативную память для быстрого сопоставления. Distributed: Не хранит данные сам по себе, а позволяет выполнять распределенные запросы по нескольким серверам CH. Buffer: Для временного буферизации данных перед их записью в другой движок (обычно MergeTree). Практическое Задание для Самостоятельного Изучения Чтобы закрепить материал, предлагаю следующее упражнение. Выполните его в вашей локальной инсталляции Docker или в ClickHouse Cloud. - Создайте новую базу данных с именем my_app_data. - Создайте таблицу user_profiles в этой базе данных с использованием ReplacingMergeTree (чтобы гарантировать уникальность профилей по user_id при наличии дубликатов). Включите следующие столбцы: user_id (UInt64) username (String) email (String) registration_date (Date) last_login_timestamp (DateTime) is_premium (UInt8 или Nullable(UInt8)) region (LowCardinality(String)) version (UInt64) - используйте его как столбец версии для ReplacingMergeTree. Определите ORDER BY для этой таблицы по user_id и registration_date. Вставьте несколько записей в user_profiles, включая: Несколько уникальных пользователей. Несколько записей для одного и того же user_id, но с разными version и last_login_timestamp, чтобы увидеть, как ReplacingMergeTree работает. Убедитесь, что последняя запись для пользователя имеет наибольший version. Проверьте данные с помощью SELECT * FROM user_profiles. Попробуйте вставить еще одну запись для существующего пользователя с более высоким version и измененными данными (например, новый email). Снова проверьте данные и убедитесь, что ReplacingMergeTree оставил только самую свежую версию записи для этого пользователя (возможно, вам придется подождать несколько секунд, пока произойдет слияние, или принудительно выполнить его с помощью OPTIMIZE TABLE user_profiles FINAL; — не используйте OPTIMIZE в продакшене без понимания его работы). Это упражнение поможет вам на практике понять, как работают типы данных и движки MergeTree. Заключение Типы данных и движки таблиц — это не просто теоретические концепции в CH; это фундаментальные строительные блоки, которые напрямую влияют на производительность, стоимость хранения и эффективность ваших аналитических решений. Правильный выбор и понимание их работы позволят вам раскрыть весь потенциал СУБД ClickHouse. В следующей статье ( Урок 3) мы углубимся в выполнение запросов: рассмотрим базовые DML операции (вставка, выборка) и продвинутые SQL-функции, которые помогут вам извлекать максимум информации из ваших данных. Использованные референсы и материалы Официальная документация ClickHouse по типам данных и движкам таблиц. Документация Apache Kafka и Apache ZooKeeper. SQL-блокнот к Уроку 1 бесплатного курса доступен в нашем репозитории на GitHub Read the full article
0 notes
Text
R Packages worth a look
K-Nearest Neighbour Classifier (KCSKNNShiny) It predicts any attribute (categorical) given a set of input numeric predictor values. Note that only numeric input predictors should be given. The k v … Add ‘Git’ Links to Your Web Based Assets (gitlink) Provides helpers to add ‘Git’ links to ‘shiny’ applications, ‘rmarkdown’ documents, and other ‘HTML’ based resources. This is most commonly used for ‘G … Influenza-Attributable Mortality with Distributed-Lag Models (FluMoDL) Functions to estimate the mortality attributable to influenza and temperature, using distributed-lag nonlinear models (DLNMs), as first implemented in … Density Estimation by Life Time Distributions (DELTD) It plots densities by using asymmetrical kernels which belong to life time distributions and calculate its related MSE. For details see Chen (2000), Ji … Aggregating Trees (mergeTrees) Aggregates a set of trees with the same leaves to create a consensus tree. The trees are typically obtained via hierarchical clustering, hence the hclu … General Inverse Problem Platform (gripp) Set of functions designed to solve inverse problems. The direct problem is used to calculate a cost function to be minimized. Here are listed some pape … http://bit.ly/31UYuEh
0 notes
Text
The Log-Structured Merge Tree (LSM-Tree)
The Log-Structured Merge Tree (LSM-Tree)

The Log-Structured Merge Tree Patrick O’Neil, Edward Cheng, Dieter Gawlick, Elizabeth O’Neil in Acta Informatica, June 1996, Volume 33, Issue 4, pp 351–385. This paper does not relate to non-volatile memory, but we will see Log-Structured Merge Trees (LSMTs) used in quite a few projects. From the abstract: The log-structured mergetree (LSM-tree) is a disk-based data structure designed to provide…
View On WordPress
0 notes
Text
A simple asset pipeline with Broccoli.js
Updated on 15 October 2017 to support Babel 6.
I’ve been doing some research on how to set up an asset pipeline using Broccoli, which is part of the toolset provided by Ember.js. The official website shows a good example of use, but I wanted to do something a bit more advanced. Here’s the result.
At the end of this text, we’ll have an asset pipeline able to read these inputs:
ES6-flavoured JavaScript modules
JavaScript packages from NPM
Sass files
And generate these outputs:
A single JavaScript file, in the dialect more commonly understood by contemporary browsers
A single CSS file
I will be using Yarn instead of NPM, because it will create fewer headaches down the road. Also, it’s 2017, happy new year!
Basic setup
Broccoli works as a series of filters that can be applied to directory trees. The pipeline is defined on a file named Brocfile.js, which at its minimum expression would look something like this:
1module.exports = 'src/html';
A “Brocfile” is expected to export a Broccoli “node”, which is a sequence of transforms over a directory tree. The simplest possible example would be just a string representing a filesystem path, so the above does the job. We could read it as “the output of this build is a copy of the contents of the src/html directory”.
Note that I say Broccoli “nodes”. There’s a lot of literature out there referring to Broccoli nodes as Broccoli “trees”. It’s the same thing, but “node” seems to be the currently accepted nomenclature, while “tree” is deprecated.
Running a build
We have a very simple Brocfile. Let’s run it and see its result. We need the Broccoli CLI and libraries for this, so let’s first create a Node project, then add the required dependencies:
1$ yarn init -y 2$ yarn add broccoli broccoli-cli
Then we add the following entry to our package.json:
1"scripts": { 2 "build": "rm -rf dist/ && broccoli build dist" 3}
Now we can run the build process any time with this command:
1$ yarn run build
When we run this command, we run a Broccoli build. Since we are not doing much at the moment, it will simply copy the contents of the src/html directory into dist. If dist exists already, our build script deletes it first, as Broccoli would refuse to write into an existing one.
Did you get an error? No problem, that’s probably because you didn’t have a src/html directory to read from. Create one and put some files on it. Then you’ll be able to confirm that the build process is doing what it is expected to do.
NOTE: working with Node/NPM, it’s common to see examples that install a CLI tool (broccoli-cli in this case) globally using npm install -g PACKAGE_NAME. Here we avoid this by installing it locally to the project and then specifying a command that uses it in the scripts section of package.json. These commands are aware of CLI tools in our local node_modules, allowing us to keep eveything tidier, and locking the package version of the CLI tool along with those of other packages.
Using plugins
Most transforms we can think of will be possible using Broccoli plugins. These are modules published on NPM that allow us to transpile code, generate checksums, concatenate files, and generally do all the sort of things we need to produce production-grade code.
Now, in the first example above we referred to a Broccoli node using the string src/html, meant to represent the contents of the directory of the same name. While this will work, using a string this way is now discouraged. Current advice is to instead use broccoli-source, which is the first of the plugins that we will use in this walkthrough. Let’s install it:
1$ yarn add broccoli-source
Now we can require it into our Brocfile and use it. I’m going to use variables in this example to start giving this pipeline some structure:
1var source = require('broccoli-source'); 2var WatchedDir = source.WatchedDir; 3var inputHtml = new WatchedDir('src/html'); 4var outputHtml = inputHtml; 5 6module.exports = outputHtml;
If we run the build, we’ll get exactly the same result as before. We needed more code to get the same thing, but this prepares us for things to come, and follows best practices.
The development server
In the previous example, we referred to the input HTML as a WatchedDir. This suggests that, similarly to other build tools, Broccoli includes a development server that will “watch” the input files, running a build automatically when we save any changes. Let’s create a command for this on our packages.json file, adding a new entry to the scripts section:
1"scripts": { 2 "build": "rm -rf dist/ && broccoli build dist", 3 "serve": "broccoli serve" 4},
Now we can start the development server with:
1$ yarn run serve
Assuming you have a file called index.html in your src/html directory, you should see it at the URL http://localhost:4200. If the file changes, you can simply refresh the page and the changes will appear without you having to explicitly run the build.
Adding a CSS pre-processor
So far this isn’t very exciting. The development server is just showing copies of the HTML files in our project. Let’s add a proper transform.
For this we can use a CSS pre-processor. For example, we can install the Sass plugin:
1yarn add broccoli-sass
Require it at the start of our Brocfile:
1var sass = require('broccoli-sass');
And add it to our pipeline on the same file:
1var inputStyles = new WatchedDir('src/styles'); 2var outputCss = sass([inputStyles], 'index.scss', 'index.css', {});
This example will:
read files from src/styles.
start processing from the file index.scss, which must be in the first node given in the first argument.
leave the result in a file called index.css in the output location.
There’s a problem now. We have an HTML pipeline and a SaSS pipeline. We have to merge the two into a single result.
Merging Broccoli nodes
When you have several sources of code, to be treated in different ways, you get separate Broccoli nodes. Let’s merge the ones we have into a single one. Of course for this we need a new plugin:
1$ yarn add broccoli-merge-trees
Now we can perform the merge and export the result:
1var MergeTrees = require('broccoli-merge-trees'); 2 3// ...process nodes... 4 5module.exports = new MergeTrees( 6 outputCss, 7 outputHtml, 8);
Now ensure that your HTML points to the produced CSS, which in the above example we have called index.css. Reload the develpment server and check the results.
From modern JS to one that browsers understand
All that was quite easy. Dealing with JavaScript took some more figuring out for me, but eventually I got there. Here’s my take on it.
We are going to transform some ES6 files into a more browser-friendly flavour of JavaScript. For this, we need Babel, and there’s a Broccoli plugin that provides it for us. We start by installing the appropriate package, as well as as a Babel plugin that provides the transform we need:
1$ yarn add broccoli-babel-transpiler babel-preset-env
And now we alter our Brocfile.js to look like this:
1var babelTranspiler = require('broccoli-babel-transpiler'); 2 3// ...etc... 4 5var BABEL_OPTIONS = { 6 presets: [ 7 ['env', { 8 targets: { 9 browsers: ['last 2 versions'], 10 }, 11 }], 12 ], 13}; 14 15var inputJs = new WatchedDir('src/js'); 16var outputJs = babelTranspiler(inputJs, BABEL_OPTIONS); 17 18// ...etc... 19 20module.exports = new MergeTrees( 21 outputCss, 22 outputHtml, 23 outputJs, 24);
The BABEL_OPTIONS argument can be used to tell Babel what platforms its output should target. In this case, we specify that we want code compatible with the last 2 versions of current browsers. You can find the list of supported browsers at https://github.com/ai/browserslist#browsers.
Write some JavaScript that uses modern features of the language, and put it in src/js, then check the results. Remember to restart the dev server and reference the JS files from your HTML. The output will consist of files of the same name as those in the input, but converted to JavaScript compatible with current browsers.
NOTE: in previous versions of this guide, we didn’t need BABEL_OPTIONS, as Babel’s default behaviour was good enough for us. Since version 6 of Babel, we need to be more explicit at to what exactly we want, and this new argument is now required.
Local JavaScript modules
The one thing Babel is not doing there is handling module imports. If your project is split into several modules, and you use import in them, these lines will have been transpiled into require lines but these won’t actually work on a browser. Browsers can’t handle JavaScript modules natively, so we will need a new step that will concatenate all files into a single one, while respecting these module dependencies.
I have figured out a couple of ways of doing this, so I’ll explain the one I like best. First we are goint to need a new Broccoli plugin:
1$ yarn add broccoli-watchify
Watchify is a wrapper around Browserify. In turn, Browserify reads JavaScript inputs, parses them, finds any require calls, and concatenates all dependencies into larger files as necessary.
Let’s update the lines of our Brocfile that dealt with JS to look as follows:
1var babelTranspiler = require('broccoli-babel-transpiler'); 2var watchify = require('broccoli-watchify'); 3 4// ... 5 6var inputJs = new WatchedDir('src/js'); 7var transpiledJs = babelTranspiler(inputJs, BABEL_OPTIONS); 8var outputJs = watchify(transpiledJs);
The watchify transform assumes that you will have a file index.js that is the entry point of your JavaScript code. This will be its starting point when figuring out all dependencies across modules. The final product, a single JavaScript file with all required dependencies concatenated, will be produced with the name browserify.js.
Note that imports are expected to use relative paths by default. This is, the following won’t work as it uses an absolute path:
1import utils from 'utils';
But this will (assuming the module utils lives in the same directory as the one doing the import):
1import utils from './utils';
That is the default behaviour. If you use different settings, you can pass some options in. For example, say that you want Browserify to:
Use a file called app.js as entry point
Put the results in a file called index.js
To achieve this, you invoke it with these options:
1var outputJs = watchify(transpiledJs, { 2 browserify: { 3 entries: ['app.js'] 4 }, 5 outputFile: 'index.js', 6});
Using modules from NPM
The best thing about Browserify though, is that it can pull NPM modules into your project. For example, say you want to use jQuery. First you have to fetch it from NPM:
1$ yarn add jquery
Then you would import it in a module in your own code:
1import $ from 'jquery'; 2 3// ...
And finally you tell the Watchify plugin where it can find it, passing an option pointing to your local node_modules as a valid place to pull modules from:
1var outputJs = watchify(transpiledTree, { 2 browserify: { 3 entries: ['index.js'], 4 paths: [__dirname + '/node_modules'], 5 }, 6});
In this example, jQuery will be pulled into the final file, where your code can use it freely.
NOTE: even though by default it expects index.js as entry file, I have noticed sometimes watchify (or browserify, or the plugin, or something), doesn’t work correctly if we pass options and don’t specify the entries value. Therefore, I recommend always including it.
A complete example
I have a GitHub repo that I’m using to experiment with build tools. At the time of writing, there are two working Broccoli examples that you can check out. I may add others in the future, as well as examples with other tools.
Check it out at pablobm/build-tools-research. I hope you find it useful.
0 notes
Text
MergeTree
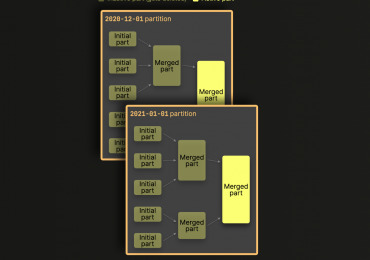
MergeTree – это семейство движков таблиц в ClickHouse, разработанное для хранения данных, отсортированных по первичному ключу. Эти движки обеспечивают высокую производительность для широкого спектра аналитических запросов, поддерживая быструю вставку данных и их последующую фоновую обработку (слияние кусков данных). Семейство MergeTree является основой для большинства высоконагруженных задач в ClickHouse. Основные функциональные возможности Движки семейства MergeTree предоставляют мощный набор функций для эффективной работы с большими объемами данных: Хранение данных, отсортированных по первичному ключу: Данные физически упорядочиваются на диске согласно выражению ORDER BY (первичный ключ). Это позволяет очень быстро выполнять запросы с фильтрацией по этому ключу или диапазону его значений. Партиционирование: Данные можно разбивать на отдельные части (партиции) по заданному критерию, обычно по месяцам или дням (PARTITION BY). Это ускоряет запросы, затрагивающие только определенные партиции, и упрощает управление данными (например, удаление старых партиций). Разреженный первичный индекс: ClickHouse не индексирует каждую строку, а только блоки данных (гранулы). Это экономит место и позволяет быстро находить нужные блоки данных для чтения. Размер гранулы задается настройкой index_granularity. Поддержка репликации и дедупликации (для ReplicatedMergeTree): ReplicatedMergeTree обеспечивает отказоустойчивость путем хранения копий данных на разных серверах и гарантирует консистентность данных между репликами. Также он позволяет выполнять дедупликацию вставляемых блоков данных. Манипуляции с данными: Поддерживаются операции ALTER для изменения структуры таблицы, удаления и обновления данных (хотя последние являются тяжеловесными операциями и реализуются через фоновые мутации). TTL (Time To Live): Возможность автоматически удалять устаревшие данные на уровне строк или целых партиций. Поддержка семплирования данных: Позволяет выполнять запросы на выборке данных для получения приблизительных результатов значительно быстрее. Плюсы и минусы Плюсы: Высочайшая производительность запросов: Особенно для аналитических запросов с агрегациями и фильтрацией по диапазонам благодаря сортировке и разреженному индексу. Эффективное сжатие данных: За счет сортировки однотипные данные располагаются рядом, что улучшает коэффициенты сжатия. Горизонтальная масштабируемость: Легко масштабируется путем добавления новых серверов (особенно с ReplicatedMergeTree). ️ Надежность: ReplicatedMergeTree обеспечивает отказоустойчивость. Быстрая вставка данных: Данные пишутся на диск быстрыми пачками (batches - part). Минусы: Медленные обновления и удаления: Операции UPDATE и DELETE являются асинхронными и ресурсоемкими, так как требуют перезаписи целых кусков данных (parts). MergeTree не предназначен для OLTP-нагрузок, с частыми точечными изменениями. Сложность выбора первичного ключа: От правильного выбора ORDER BY сильно зависит производительность. Неэффективен для запросов с фильтрацией по столбцам, не входящим в первичный ключ (без использования вторичных индексов). Особенности реализации и использования Данные в таблицах MergeTree хранятся в виде кусков (parts). Каждый кусок отсортирован по первичному ключу. При вставке новых данных создаются новые небольшие куски. ClickHouse периодически в фоновом режиме сливает (merges) эти куски в более крупные, поддерживая оптимальную структуру данных и эффективность. Ключевые аспекты при создании таблицы: ENGINE = MergeTree(): Базовый движок. ORDER BY (expression): Определяет первичный ключ и порядок сортировки. Это самый важный параметр для производительности. PARTITION BY (expression): (Опционально) Определяет, как данные будут разбиты на партиции. Часто используется дата (например, toYYYYMM(EventDate)). SETTINGS index_granularity = 8192: Определяет количество строк в одной грануле индекса. Значение по умолчанию обычно подходит для большинства сценариев. Пример создания таблицы: CREATE TABLE visits ( CounterID UInt32, EventDate Date, UserID UInt64, VisitID String, URL String, Income Float64 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash64(UserID)) SETTINGS index_granularity = 8192; В этом примере данные партиционируются по месяцам, а первичный ключ состоит из CounterID, EventDate и хеша UserID. Best Practices Тщательно выбирайте первичный ключ (ORDER BY): Включайте столбцы, которые чаще всего используются в WHERE клаузах для фильтрации диапазонов. Не делайте ключ слишком широким (много столбцов), это может замедлить вставку и слияния. Порядок столбцов в ORDER BY имеет значение. Используйте партиционирование разумно: Наиболее частый ключ партиционирования – дата (месяц, день). Избегайте слишком гранулярного партиционирования (например, по секундам), это приведет к большому количеству кусков. Оптимизируйте index_granularity: Стандартное значение (8192) хорошо подходит для большинства случаев. Уменьшение может улучшить скорость чтения для очень выборочных запросов, но увеличит размер индекса. Избегайте частых мелких вставок: Старайтесь вставлять данные большими пачками (сотни тысяч или миллионы строк за раз), чтобы уменьшить количество создаваемых мелких кусков. Мониторьте процесс слияния кусков: Слишком много кусков может замедлить запросы. Настройте параметры слияния при необходимости. Используйте ReplicatedMergeTree для production-сред: Это обеспечит отказоустойчивость. Для удаления и обновления данных используйте мутации (ALTER TABLE ... DELETE/UPDATE) с осторожностью: Помните, что это фоновые тяжеловесные операции. Иллюстрация структуры кусков MergeTree :

Troubleshooting и Тюнинг Распространенные проблемы: Медленные запросы: Проверьте, используется ли первичный ключ в фильтрах. Проанализируйте EXPLAIN запроса. Слишком много кусков (parts) в таблице. Проверьте system.parts. Слишком долгие слияния (merges): Большое количество мелких кусков. Недостаточно ресурсов сервера (CPU, I/O). Ошибка Too many parts: Увеличьте max_parts_in_total или оптимизируйте вставку/слияния. Тюнинг: Параметры слияния: max_bytes_to_merge_at_max_space_in_pool: Максимальный общий размер кусков для слияния при максимальной доступности дискового пространства. max_parts_to_merge_at_once: Максимальное количество кусков, объединяемых в одном слиянии. Настройки находятся в конфигурационном файле ClickHouse (обычно config.xml или в профилях пользователей). Настройки таблицы: merge_with_ttl_timeout: Частота проверки и выполнения TTL-слияний. Системные настройки: background_pool_size: Количество потоков для фоновых операций (включая слияния). max_concurrent_queries: Ограничение одновременных запросов. Пример проверки количества кусков: SELECT database, table, count() AS parts_count, sum(rows) AS total_rows, formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size, formatReadableSize(sum(data_compressed_bytes)) AS compressed_size FROM system.parts WHERE active AND database = 'your_database' AND table = 'your_table' GROUP BY database, table; Источники для дальнейшего изучения: ��фициальная документация ClickHouse - MergeTree: https://clickhouse.com/docs/ru/engines/table-engines/mergetree-family/mergetree/ Официальная документация ClickHouse - ReplicatedMergeTree: https://clickhouse.com/docs/ru/engines/table-engines/mergetree-family/replication/ Блог Altinity - ClickHouse MergeTree: (Ищите статьи по "Altinity ClickHouse MergeTree" - Altinity часто публикует глубокие технические материалы по ClickHouse) Пример: https://altinity.com/blog/tag/mergetree/ Статьи на Хабре по ClickHouse: (Поиск "ClickHouse MergeTree Хабр" выдаст множество статей от русскоязычного сообщества). Пример хорошей обзорной статьи или разбора конкретных кейсов. Блог Sematext - ClickHouse Monitoring & Performance: (Ищите "Sematext ClickHouse MergeTree" - они часто пишут о мониторинге и оптимизации). Пример: https://sematext.com/blog/clickhouse-monitoring-tools/ (хотя это общая статья, часто затрагиваются аспекты MergeTree). И конечно мы приглашаем Вас на наш курс "CLICH: Построение DWH на ClickHouse" где на практике вы научитесь конфигурировать и использовать кластер ClickHouse в качестве OLAP платформы для аналитики больших данных. Read the full article
0 notes
Text
За что все его так любят: ТОП-5 достоинств ClickHouse для Big Data
Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data.
Чем хорош ClickHouse: главные преимущества
Напомним, основным сценарием использования ClickHouse считается генерация аналитических запросов по структурированным данным c минимальной задержкой, фактически в режиме в режиме real time. Таким образом, главными преимуществами этой OLAP-СУБД для Big Data являются следующие: · скорость; · масштабируемость; · расширяемость; · высокая доступность и отказоустойчивость; · простота развертывания и удобство эксплуатации. Далее рассмотрим подробнее, какие именно архитектурные и конструктивные особенности ClickHouse обеспечивают все эти достоинства
Почему так быстро: 5 причин высокой скорости
Внедрение ClickHouse на сервисе Яндекс.Метрика отмечает следующие показатели: до 1 миллиарда строк в секунду на одном сервере и до 2-х ТБ в секунду на кластере из 400 узлов [1]. Такая производительность достигается благодаря архитектурным особенностям Кликхаус [2]: o столбцовое хранение данных; o физическая сортировка данных по первичному ключу; o векторные вычисления по участкам столбцов; o распараллеливание операций на несколько процессорных ядер одного сервера и распределенные вычисления на кластере за счет шардирования; o поддержка приближенных вычислений с помощью агрегатных функций, семплирования данных (выполнение запросов на части выборки), а также возможность агрегации ограниченного количества случайных ключей. Важно, что ClickHouse выполняет запросы существенно быстрее, чем Big Data системы класса SQL-on-Hadoop: Apache Hive, Cloudera Impala, Presto и Spark, даже при работе с данными в колоночных форматах, таких как Parquet или Kudu [3]. При том, что Кликхаус как OLAP-система, в первую очередь ориентирован на чтение данных, он также показывает неплохие результаты в скорости записи благодаря табличному движку MergeTree. Он концептуально похож на алгоритм LSM из Google BigTable или Apache Cassandra, но не строит промежуточные таблицы в памяти, записывая данные сразу на жесткий диск. При этом каждый вставленный пакет сортируется только по первичному ключу (primary key), сжимается и записывается на диск, чтобы сформировать сегмент [4]. Поэтому ClickHouse отлично подходит для современных корпоративных хранилищ данных, например, как мы описывали здесь в кейсе Ситимобил.
Линейная масштабируемость
Добавление новых узлов позволяет наращивать мощность кластера до очень большого размера, способного ��брабатывать петабайты данных. По умолчанию в ClickHouse возможна межцодовая репликация (Cross Data Center Replication), которая реплицирует данные между кластерами, обеспечивая защиту от сбоев и высокопроизводительный доступ к данным для глобально распределенных и критически важных Big Data приложений [1]. За координацию процесса репликации данных отвечает Apache Zookeeper.
Высокая доступность и отказоустойчивость
За счет децентрализации и отсутствия единой точки отказа, Кликхаус надежно работает в распределенном кластере. Асинхронная multi-master репликация обеспечивает реплицирование данных в фоновом режиме. СУБД поддерживает полную идентичность данных на разных репликах, автоматически восстанавливая их после сбоев. Для повышения надежности асинхронной репликации в Кликхаус возможен кворумный режим записи данных, когда она считается успешной только после того, как информация записана на несколько серверов - кворум. Так обеспечивается линеаризуемость и имитация синхронных реплик. Если количество реплик с успешной записью не достигнет заданного кворума, то запись считается не состоявшейся и ClickHouse сам удалит вставленный блок из всех реплик для обеспечения целостности данных [5].
Расширяемость
ClickHouse поддерживает диалект структурированного языка запросов, близкий к стандарту ANSI SQL, c расширениями, включая массивы и вложенные структуры данных, вероятностные структуры, URI-функцию, возможности подключить внешнее key-value хранилище [2]. Также можно написать собственные коннекторы на любом языке программирования благодаря наличию HTTP-интерфейса [6]. Благодаря специальным интеграционным движкам (engines) в качестве источника данных Кликхаус может использовать множество внешних хранилищ и баз данных. Например, здесь мы описывали особенности интеграции ClickHouse с Apache Kafka и примеры их использования в Big Data.
Простота развертывания и эксплуатации ClickHouse
Используемый в ClickHouse диалект SQL очень близок стандартному. Это снижает порог вода в технологию для аналитиков данных, для которых знание ANSI SQL является обязательным. В качестве средств подключения к СУБД можно использовать консоль, HTTP API, драйверы JDBS и ODBC, а также множество «оберток» (wrapper’ов) на Python, PHP, NodeJS, Perl, Ruby и R. Установка Кликхаус на операционных системах Ubuntu и Debian Linux выполняется из готовых пакетов с помощью нескольких простых команд и не требует сложной настройки. Для работы СУБД в распределенном режиме требуется Apache Zookeeper, который обеспечивает координацию процесса репликации данных. Еще в плане эксплуатации стоит отметить пониженную стоимость хранения данных по сравнению с другими столбцовыми СУБД, такими как SAP HANA и Google PowerDrill, которые работают только в RAM. Кликхаус ориентирован именно на эффективную работу с жесткими дисками, которые намного дешевле оперативной памяти [2]. Вышеописанные преимущества обусловливают высокую популярность ClickHouse среди аналитиков, разработчиков, а также администраторов Big Data. Обратной стороной этих достоинств являются специфические недостатки, которые мы рассмотрим в следующей статье. А как использовать все плюсы ClickHouse и других СУБД для оперативной обработки и надежного хранения больших данных на практике, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве. Смотреть расписание Записаться на курс Источники 1. https://habr.com/ru/post/322724/ 2. https://ru.bmstu.wiki/ClickHouse 3. https://habr.com/ru/company/oleg-bunin/blog/351308/ 4. https://habr.com/ru/company/ua-hosting/blog/483112/ 5. https://clickhouse.tech/docs/ru/operations/settings/settings/#settings-insert_quorum 6. https://blog.deteact.com/ru/yandex-clickhouse-injection/ Read the full article
0 notes