#Open Data APIs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
uuuh also i just realized that you can edit tags now in the browser version??? like, you can edit them AFTER you type them and hit "enter"???? that is such a good update that i'm almost tempted to go back to using the browser version more often than the app. (almost.)
#that coupled with the fact that tumblr drains my phone's battery in like 30 min. of use#and how hot my phone gets during that time#(probably due to all of the energy the app spends collecting god knows what data)#like...hmm...#SHOULD i go back to using only the browser????#sigh i wish tumblr's api was open source so i had more options
8 notes
·
View notes
Text
What is a Cricket API & Why Is It Essential for Fantasy website, Betting & Live Scores in 2025?

Discover how Cricket API powers live scores, fantasy platforms, betting odds & real-time stats. Best Cricket API provider for 2025 - fantasygameprovider.com
Why Cricket API Is Taking Over in 2025
In the fast-evolving world of fantasy sports and online betting, Cricket API has become the core technology behind real-time match updates, odds, statistics, and live scores. Whether you're running a fantasy cricket platform, managing a sports betting website, or developing a live scoreboard app, having access to a reliable API of cricket is crucial.
But what exactly is a Cricket API? And how does it impact your sports platform in 2025?
Let’s break it down systematically with all the trending searchable terms and features users are actively looking for on Google.
What is a Cricket API?
A Cricket API is a set of web services that provide real-time cricket data, including live scores, fixtures, player statistics, match results, session fancy odds, and betting odds. These APIs allow developers to fetch updated information automatically from trusted databases and display it on their websites or mobile applications.
✅ Key Data Provided by Cricket APIs:
Live Scores & Ball-by-Ball Commentary
Player and Team Stats
Cricket Fixtures & Schedule
Scoreboard API for Live Visualization
Cricket Odds API for Betting Platforms
Fantasy Cricket Player Stats
Match Lists and Series Info
Live Cricket Odds API Integration
Why Cricket API is Must-Have for Fantasy & Betting Apps
If you're in the fantasy gaming or online betting industry, you need accurate, fast, and detailed cricket feeds. That’s where fantasygameprovider.com comes in—offering powerful live match API, scoreboard API cricket, and odds feeds that give your platform a competitive edge.
📌 Use Cases:
✅ Fantasy Cricket Platforms use Cricket API to assign player points in real-time.
✅ Betting Websites rely on the Cricket Odds API to display dynamic odds & session fancy updates.
✅ Score Apps use the Livescore API to provide ball-by-ball commentary and real-time statistics.
✅ Cricket News Portals use it to display up-to-the-minute results and analytics.
🧠 How Does Cricket API Work?
A Cricket API connects your website or app with a cricket data provider’s server. You send a request (e.g., “Give me today’s match list”) and the API returns data in formats like JSON or XML.
json
CopyEdit
{
"match_id": "123456",
"teams": ["India", "Australia"],
"score": "India 250/7",
"status": "Live"
}
This seamless data delivery is key to user engagement, betting decisions, and fantasy scoring.
Best Features of Cricket API from FantasyGameProvider.com
If you're looking for a top-rated Cricket API provider in 2025, fantasygameprovider.com is your go-to solution. Here's why:
🔍 Real-Time Feeds:
Cricket Livescore API with millisecond refresh rate
Auto-sync with international cricket board feeds
📊 Complete Stats:
Batting, bowling, fielding, and player form analysis
Career statistics for fantasy API integration
🧩 Modular APIs:
Add Match API to add fixtures on the fly
Session Fancy API to serve betting data instantly
💰 Odds & Betting:
Odds API with dynamic live odds
Seamless odds feed integration for sportsbook platforms
Cricket Match List API & Fixtures API – What You Get
With the Cricket Match List API, you get:
List of all upcoming matches
Series details
Start times and status
With the Fixtures API:
Tournaments, leagues, and cups sorted by time zones
Venue details, umpire info, weather updates
Perfect for fantasy cricket and live streaming platforms looking to schedule in-app events.
Why Security & Speed Matter in Cricket APIs
A poor API with delayed feeds or security gaps can:
Cost you money in betting miscalculations
Lose your audience trust
Lead to API bans or slowdowns during peak matches
That’s why fantasygameprovider.com ensures:
End-to-end encrypted API access
99.9% uptime with 24x7 support
Dedicated endpoints for high-traffic events like World Cups and IPL
Integrating the API – Easy & Developer Friendly
Even if you're not a tech expert, you can integrate our Cricket API within hours. We offer:
Developer-friendly documentation
Sample code in PHP, Node.js, Python
24x7 developer support
Custom dashboards and analytics feeds
So, whether you're running a cricket betting site, fantasy platform, or live scoreboard, integration is fast and seamless.
Open Data Cricket vs Paid Cricket API – Which One's Better?
While Open Data Cricket sources are free, they come with:
⚠️ Limited data
⚠️ Slow updates
⚠️ No support
Compare that with our premium Live Cricket Odds API or Fantasy API, and you'll realize:
You get real-time results, secure delivery, and customized endpoints
💡 Who Needs a Cricket API?
This isn’t just for tech developers. A cricket API is essential for:
📱 Fantasy cricket startups
🎲 Online sportsbooks
📰 Sports news channels
📊 Data analytics firms
📺 Live match broadcasters
📈 Cricket fan engagement apps
Worldwide Coverage by FantasyGameProvider.com
We offer data for:
✅ IPL, PSL, BBL, CPL
✅ ICC World Cups & T20 leagues
✅ Domestic cricket from India, UK, Australia, Pakistan, Sri Lanka, Bangladesh
✅ Women’s Cricket & U19 tournaments
Our Cricket Feed API covers every ball, everywhere.
Top Benefits of Using Our Cricket API
Feature
Benefits
🧠 Real-time Data
Enhanced user engagement
💹 Live Cricket Odds API
Better betting strategies
🧮 Cricket Statistics API
Insightful analytics
🔐 Secured API Access
Data integrity
⏱️ 24x7 Support
Zero downtime
🔧 Easy Integration
Saves dev time
📢 Call To Action
Ready to boost your fantasy cricket platform or betting app with real-time, accurate data?
👉 Get the #1 Cricket API for 2025 at FantasyGameProvider.com 💬 Schedule a free demo. 🔌 Integrate. 📈 Grow traffic, engagement, and revenue.
Frequently Asked Questions (FAQs)
Q1. What is the Cricket API?
A Cricket API provides real-time match data, odds, player stats, and scores to power apps and websites related to cricket.
Q2. How can I get a live cricket odds API?
Visit fantasygameprovider.com and request access to the live odds API with full documentation.
Q3. Can I use Cricket API for my fantasy cricket platform?
Absolutely. The API offers player stats, points calculation, match lists, and more for fantasy scoring systems.
Q4. What is the difference between open-source cricket API and paid API?
Open APIs are limited in accuracy and speed. Paid APIs like ours offer reliable, secure, and full-featured services with support.
Final Thoughts
In 2025, whether you're in fantasy gaming, betting, or sports broadcasting, you can't afford to ignore the power of a robust Cricket API.
📊 The smarter your data source, the better your platform performs. 🚀 Go live, go fast, go global — with fantasygameprovider.com.
#Cricket API#Cricket Data#Sports API#Live score API#Fixtures API#Fantasy cricket#Fantasy API#api#cricket#statistics#results#Cricket Livescore API#Livescore Feed#Livescore API#Cricket Feed#odds api#odds#odds feeds#open data cricket#cricket odds api#live cricket odds api#API of cricket#cricket API provider#live match API#scoreboard API cricket#togedit#tog2edit#theoldguardedit#togsource#filmedit
0 notes
Text
How to Use n8n and AI to Build an Automation System
Automation is changing how we work every day. It helps save time, reduce mistakes, and get more done with less effort. If you want to automate your tasks but don’t know where to start, this guide is for you. In this post, you will learn how to use n8n — a free, open-source automation tool — combined with AI to build smart workflows that do work for you. What Is n8n? n8n (pronounced…
#AI automation#AI integration#AI workflow#AI-powered workflows#API integration#artificial intelligence tools#automate emails#automate tasks#automation platform#automation software#automation system#automation tips#business automation#chatbot automation#data processing automation#email automation#intelligent automation#low-code automation#n8n automation#no-code automation#open source automation#productivity tools#smart automation#time-saving tools#workflow automation#workflow builder
0 notes
Text
Explore the best developer friendly API platforms designed to streamline integration, foster innovation, and accelerate development for seamless user experiences.
Developer Friendly Api Platform
#Developer Friendly Api Platform#Consumer Driven Banking#Competitive Market Advantage Through Data#Banking Data Aggregation Services#Advanced Security Architecture#Adr Open Banking#Accredited Data Recipient
0 notes
Link
Apache Kafka became the de facto standard for data streaming. However, the combination of an event-driven architecture with request-response APIs is crucial for most enterprise architectures. This blog post explores how Tinybird innovates with a REST/HTTP layer on top of the open source analytics database ClickHouse in the cloud. Integrating Kafka with Tinybird, the benefits of fully managed services like Confluent Cloud, and customer stories from Factorial, FanDuel and Hard Rock Digital show why Kafka and analytics databases complement each other for more innovation and faster time-to-market. The post Apache Kafka and Tinybird (ClickHouse) for Streaming Analytics HTTP APIs appeared first on Kai Waehner.
#Analytics#Apache Kafka#ClickHouse#Cloud#database#Tinybird#api#data lake#data warehouse#HTTP#kafka#open source#Request Response#REST#sql#WebSockets
0 notes
Text
0 notes
Text
re: "outlawing AI"
i am reposting this because people couldn't behave themselves on the original one. this is a benevolent dictatorship and if you can't behave yourselves here i'll shut off reblogs again. thank you.
the thing i think a lot of people have trouble understanding is that "ai" as we know it isn't a circuitboard or a computer part or an invention - it's a discovery, like calculus or chemistry. the genie *can't* be re-corked because it'd be like trying to "cork" the concept of, say, trigonometry. you can't "un-invent" it.
even if you managed to somehow completely outlaw the performance of the kinds of linear algebra required for ML, and outlawed the data collection necessary, and sure, managed to get style copyrighted, you can't un-discover the underlying mathematical facts. people will just do it in mexico instead. it'd be like trying to outlaw guns by trying to get people to forget that you can ignite a mixture of powders in a small metal barrel to propel things very fast. or trying to outlaw fire by threatening to take away everyone's sticks.
the battleground is already here. technofascists and bad actors without your ethical constraints are drawing the lines and flooding the zone with propaganda & slop, and you’re wasting time insisting to your enemies that it’s unfair you’re being asked to fight with guns when you’d rather use sticks.
as a wise sock puppet once said; "this isn't about you. so either get with it, or get out of the fucking way"
-----
Attempts to prohibit AI "training" misunderstand what is being prohibited. To ban the development of AI models is, in effect, to ban the performance of linear algebra on large datasets. It is to outlaw a way of knowing. This is not regulation - it is epistemological reactionary-ism. reactionism? whatever
Even if prohibition were successful in one nation-state:
Corporations would relocate to jurisdictions with looser controls - China, UAE, Japan, Singapore, etc.
APIs would remain accessible, just more expensive and less accountable. What, are you gonna start blocking VPNs from connecting to any country with AI allowed? Good luck.
Research would continue outside the oversight of the very publics most concerned about ethical constraints.
This isn’t speculation. This is exactly what happened with stem cells in the early 2000s. When the U.S. government restricted federal funding, stem cell research didn’t vanish, it just moved and then kept happening until people stopped caring.
The fantasy that a domestic ban could meaningfully halt or reverse the development of a globally distributed method is a fantasy of epistemic sovereignty - the idea that knowledge can be territorially contained and that the moral preferences of one polity can shape the world through sheer force of will.
But the only way such containment could succeed would be through:
Total international consensus (YEAH RIGHT), and
Total enforcement across all borders, black markets, and academic institutions, at the barrel of a gun - otherwise, what is backing up your enforcement? Promises and friendly handshakes?
This is not internationalism. It is imperialist utopianism. And like most utopian projects built on coercion, it will fail - at the cost of handing control to precisely the actors most willing to exploit it.
Liberal moralism often derides socialist or communist futures as "unrealistic.", as you can see in the absurd, hyperbolically, pants-shittingly mad reaction to Alex Avila's video. Yet the belief that machine learning can be outlawed globally - a method of performing mathematics that is already published, archived, and disseminated across open academic networks the globe over - is far more implausible. literally how do you plan on doing that? enforcing it?
The choice is not between AI and no AI. The choice is between AI in the service of capital, extraction, and domination, or AI developed under conditions of public ownership, democratic control, and epistemic openness. You get to pick.
The genie and the bottle are not even in the same planet. The bottle's gone, Will.
590 notes
·
View notes
Text
Are the means of computation even seizable?

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in PITTSBURGH in TOMORROW (May 15) at WHITE WHALE BOOKS, and in PDX on Jun 20 at BARNES AND NOBLE with BUNNIE HUANG. More tour dates (London, Manchester) here.

Something's very different in tech. Once upon a time, every bad choice by tech companies – taking away features, locking out mods or plugins, nerfing the API – was countered, nearly instantaneously, by someone writing a program that overrode that choice.
Bad clients would be muscled aside by third-party clients. Locked bootloaders would be hacked and replaced. Code that confirmed you were using OEM parts, consumables or adapters would be found and nuked from orbit. Weak APIs would be replaced with muscular, unofficial APIs built out of unstoppable scrapers running on headless machines in some data-center. Every time some tech company erected a 10-foot enshittifying fence, someone would show up with an 11-foot disenshittifying ladder.
Those 11-foot ladders represented the power of interoperability, the inescapable bounty of the Turing-complete, universal von Neumann machine, which, by definition, is capable of running every valid program. Specifically, they represented the power of adversarial interoperability – when someone modifies a technology against its manufacturer's wishes. Adversarial interoperability is the origin story of today's tech giants, from Microsoft to Apple to Google:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
But adversarial interop has been in steady decline for the past quarter-century. These big companies moved fast and broke things, but no one is returning the favor. If you ask the companies what changed, they'll just smirk and say that they're better at security than the incumbents they disrupted. The reason no one's hacked up a third-party iOS App Store is that Apple's security team is just so fucking 1337 that no one can break their shit.
I think this is nonsense. I think that what's really going on is that we've made it possible for companies to design their technologies in such a way that any attempt at adversarial interop is illegal.
"Anticircumvention" laws like Section 1201 of the 1998 Digital Millennium Copyright Act make bypassing any kind of digital lock (AKA "Digital Rights Management" or "DRM") very illegal. Under DMCA, just talking about how to remove a digital lock can land you in prison for 5 years. I tell the story of this law's passage in "Understood: Who Broke the Internet," my new podcast series for the CBC:
https://pluralistic.net/2025/05/08/who-broke-the-internet/#bruce-lehman
For a quarter century, tech companies have aggressively lobbied and litigated to expand the scope of anticircumvention laws. At the same time, companies have come up with a million ways to wrap their products in digital locks that are a crime to break.
Digital locks let Chamberlain, a garage-door opener monopolist block all third-party garage-door apps. Then, Chamberlain stuck ads in its app, so you have to watch an ad to open your garage-door:
https://pluralistic.net/2023/11/09/lead-me-not-into-temptation/#chamberlain
Digital locks let John Deere block third-party repair of its tractors:
https://pluralistic.net/2022/05/08/about-those-kill-switched-ukrainian-tractors/
And they let Apple block third-party repair of iPhones:
https://pluralistic.net/2022/05/22/apples-cement-overshoes/
These companies built 11-foot ladders to get over their competitors' 10-foot walls, and then they kicked the ladder away. Once they were secure atop their walls, they committed enshittifying sins their fallen adversaries could only dream of.
I've been campaigning to abolish anticircumvention laws for the past quarter-century, and I've noticed a curious pattern. Whenever these companies stand to lose their legal protections, they freak out and spend vast fortunes to keep those protections intact. That's weird, because it strongly implies that their locks don't work. A lock that works works, whether or not it's illegal to break that lock. The reason Signal encryption works is that it's working encryption. The legal status of breaking Signal's encryption has nothing to do with whether it works. If Signal's encryption was full of technical flaws but it was illegal to point those flaws out, you'd be crazy to trust Signal.
Signal does get involved in legal fights, of course, but the fights it gets into are ones that require Signal to introduce defects in its encryption – not fights over whether it is legal to disclose flaws in Signal or exploit them:
https://pluralistic.net/2023/03/05/theyre-still-trying-to-ban-cryptography/
But tech companies that rely on digital locks manifestly act like their locks don't work and they know it. When the tech and content giants bullied the W3C into building DRM into 2 billion users' browsers, they categorically rejected any proposal to limit their ability to destroy the lives of people who broke that DRM, even if it was only to add accessibility or privacy to video:
https://www.eff.org/deeplinks/2017/09/open-letter-w3c-director-ceo-team-and-membership
The thing is, if the lock works, you don't need the legal right to destroy the lives of people who find its flaws, because it works.
Do digital locks work? Can they work? I think the answer to both questions is a resounding no. The design theory of a digital lock is that I can provide you with an encrypted file that your computer has the keys to. Your computer will access those keys to decrypt or sign a file, but only under the circumstances that I have specified. Like, you can install an app when it comes from my app store, but not when it comes from a third party. Or you can play back a video in one kind of browser window, but not in another one. For this to work, your computer has to hide a cryptographic key from you, inside a device you own and control. As I pointed out more than a decade ago, this is a fool's errand:
https://memex.craphound.com/2012/01/10/lockdown-the-coming-war-on-general-purpose-computing/
After all, you or I might not have the knowledge and resources to uncover the keys' hiding place, but someone does. Maybe that someone is a person looking to go into business selling your customers the disenshittifying plugin that unfucks the thing you deliberately broke. Maybe it's a hacker-tinkerer, pursuing an intellectual challenge. Maybe it's a bored grad student with a free weekend, an electron-tunneling microscope, and a seminar full of undergrads looking for a project.
The point is that hiding secrets in devices that belong to your adversaries is very bad security practice. No matter how good a bank safe is, the bank keeps it in its vault – not in the bank-robber's basement workshop.
For a hiding-secrets-in-your-adversaries'-device plan to work, the manufacturer has to make zero mistakes. The adversary – a competitor, a tinkerer, a grad student – only has to find one mistake and exploit it. This is a bedrock of security theory: attackers have an inescapable advantage.
So I think that DRM doesn't work. I think DRM is a legal construct, not a technical one. I think DRM is a kind of magic Saran Wrap that manufacturers can wrap around their products, and, in so doing, make it a literal jailable offense to use those products in otherwise legal ways that their shareholders don't like. As Jay Freeman put it, using DRM creates a new law called "Felony Contempt of Business Model." It's a law that has never been passed by any legislature, but is nevertheless enforceable.
In the 25 years I've been fighting anticircumvention laws, I've spoken to many government officials from all over the world about the opportunity that repealing their anticircumvention laws represents. After all, Apple makes $100b/year by gouging app makers for 30 cents on ever dollar. Allow your domestic tech sector to sell the tools to jailbreak iPhones and install third party app stores, and you can convert Apple's $100b/year to a $100m/year business for one of your own companies, and the other $999,900,000,000 will be returned to the world's iPhone owners as a consumer surplus.
But every time I pitched this, I got the same answer: "The US Trade Representative forced us to pass this law, and threatened us with tariffs if we didn't pass it." Happy Liberation Day, people – every country in the world is now liberated from the only reason to keep this stupid-ass law on their books:
https://pluralistic.net/2025/01/15/beauty-eh/#its-the-only-war-the-yankees-lost-except-for-vietnam-and-also-the-alamo-and-the-bay-of-ham
In light of the Trump tariffs, I've been making the global rounds again, making the case for an anticircumvention repeal:
https://www.ft.com/content/b882f3a7-f8c9-4247-9662-3494eb37c30b
One of the questions I've been getting repeatedly from policy wonks, activists and officials is, "Is it even possible to jailbreak modern devices?" They want to know if companies like Apple, Tesla, Google, Microsoft, and John Deere have created unbreakable digital locks. Obviously, this is an important question, because if these locks are impregnable, then getting rid of the law won't deliver the promised benefits.
It's true that there aren't as many jailbreaks as we used to see. When a big project like Nextcloud – which is staffed up with extremely accomplished and skilled engineers – gets screwed over by Google's app store, they issue a press-release, not a patch:
https://arstechnica.com/gadgets/2025/05/nextcloud-accuses-google-of-big-tech-gatekeeping-over-android-app-permissions/
Perhaps that's because the tech staff at Nextcloud are no match for Google, not even with the attacker's advantage on their side.
But I don't think so. Here's why: we do still get jailbreaks and mods, but these almost exclusively come from anonymous tinkerers and hobbyists:
https://consumerrights.wiki/Mazda_DMCA_takedown_of_Open_Source_Home_Assistant_App
Or from pissed off teenagers:
https://www.theverge.com/2022/9/29/23378541/the-og-app-instagram-clone-pulled-from-app-store
These hacks are incredibly ambitious! How ambitious? How about a class break for every version of iOS as well as an unpatchable hardware attack on 8 years' worth of Apple bootloaders?
https://pluralistic.net/2020/05/25/mafia-logic/#sosumi
Now, maybe it's the case at all the world's best hackers are posting free code under pseudonyms. Maybe all the code wizards working for venture backed tech companies that stand to make millions through clever reverse engineering are just not as mad skilled as teenagers who want an ad-free Insta and that's why they've never replicated the feat.
Or maybe it's because teenagers and anonymous hackers are just about the only people willing to risk a $500,000 fine and 5-year prison sentence. In other words, maybe the thing that protects DRM is law, not code. After all, when Polish security researchers revealed the existence of secret digital locks that the train manufacturer Newag used to rip off train operators for millions of euros, Newag dragged them into court:
https://fsfe.org/news/2025/news-20250407-01.en.html
Tech companies are the most self-mythologizing industry on the planet, beating out even the pharma sector in boasting about their prowess and good corporate citizenship. They swear that they've made a functional digital lock…but they sure act like the only thing those locks do is let them sue people who reveal their workings.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/05/14/pregnable/#checkm8
#pluralistic#apple#drm#og app#instagram#meta#dmca 1201#comcom#competitive compatibility#interop#interoperability#adversarial interoperability#who broke the internet#self-mythologizing#infosec#schneiers law#red team advantage#attackers advantage#luddism#seize the means of computation
432 notes
·
View notes
Text
"Artists have finally had enough with Meta’s predatory AI policies, but Meta’s loss is Cara’s gain. An artist-run, anti-AI social platform, Cara has grown from 40,000 to 650,000 users within the last week, catapulting it to the top of the App Store charts.
Instagram is a necessity for many artists, who use the platform to promote their work and solicit paying clients. But Meta is using public posts to train its generative AI systems, and only European users can opt out, since they’re protected by GDPR laws. Generative AI has become so front-and-center on Meta’s apps that artists reached their breaking point.
“When you put [AI] so much in their face, and then give them the option to opt out, but then increase the friction to opt out… I think that increases their anger level — like, okay now I’ve really had enough,” Jingna Zhang, a renowned photographer and founder of Cara, told TechCrunch.
Cara, which has both a web and mobile app, is like a combination of Instagram and X, but built specifically for artists. On your profile, you can host a portfolio of work, but you can also post updates to your feed like any other microblogging site.
Zhang is perfectly positioned to helm an artist-centric social network, where they can post without the risk of becoming part of a training dataset for AI. Zhang has fought on behalf of artists, recently winning an appeal in a Luxembourg court over a painter who copied one of her photographs, which she shot for Harper’s Bazaar Vietnam.
“Using a different medium was irrelevant. My work being ‘available online’ was irrelevant. Consent was necessary,” Zhang wrote on X.
Zhang and three other artists are also suing Google for allegedly using their copyrighted work to train Imagen, an AI image generator. She’s also a plaintiff in a similar lawsuit against Stability AI, Midjourney, DeviantArt and Runway AI.
“Words can’t describe how dehumanizing it is to see my name used 20,000+ times in MidJourney,” she wrote in an Instagram post. “My life’s work and who I am—reduced to meaningless fodder for a commercial image slot machine.”
Artists are so resistant to AI because the training data behind many of these image generators includes their work without their consent. These models amass such a large swath of artwork by scraping the internet for images, without regard for whether or not those images are copyrighted. It’s a slap in the face for artists – not only are their jobs endangered by AI, but that same AI is often powered by their work.
“When it comes to art, unfortunately, we just come from a fundamentally different perspective and point of view, because on the tech side, you have this strong history of open source, and people are just thinking like, well, you put it out there, so it’s for people to use,” Zhang said. “For artists, it’s a part of our selves and our identity. I would not want my best friend to make a manipulation of my work without asking me. There’s a nuance to how we see things, but I don’t think people understand that the art we do is not a product.”
This commitment to protecting artists from copyright infringement extends to Cara, which partners with the University of Chicago’s Glaze project. By using Glaze, artists who manually apply Glaze to their work on Cara have an added layer of protection against being scraped for AI.
Other projects have also stepped up to defend artists. Spawning AI, an artist-led company, has created an API that allows artists to remove their work from popular datasets. But that opt-out only works if the companies that use those datasets honor artists’ requests. So far, HuggingFace and Stability have agreed to respect Spawning’s Do Not Train registry, but artists’ work cannot be retroactively removed from models that have already been trained.
“I think there is this clash between backgrounds and expectations on what we put on the internet,” Zhang said. “For artists, we want to share our work with the world. We put it online, and we don’t charge people to view this piece of work, but it doesn’t mean that we give up our copyright, or any ownership of our work.”"
Read the rest of the article here:
https://techcrunch.com/2024/06/06/a-social-app-for-creatives-cara-grew-from-40k-to-650k-users-in-a-week-because-artists-are-fed-up-with-metas-ai-policies/
610 notes
·
View notes

Text
how to save 101
so i recently had a poll asking what you'd do if you have $10,000, and over half of the respondents said that they'd save it for something big
if you're saving for something big — like college, a car, starting a side hustle, or even financial freedom — here's some unexpected advice that actually does something. not cute. not tiny. real.
open a HYSA (high-yield savings account) at a credit union or online bank. no, not your regular bank. they usually pay literal cents in interest. but online banks like Ally or SoFi (or your local credit union) offer 4–5% APY as of now. if you’re saving over time, that compound interest builds and beats inflation. it’s not glamorous, but it works. set it. forget it. grow.
invest in an I-Bond. you heard right — a government bond. it’s basically a super-safe investment you can buy with as little as $25. I-Bonds adjust with inflation and earn interest over time. teens can buy them through a parent or guardian's TreasuryDirect account. way better than letting your money rot in checking.
don’t save — prepay. saving up for something long-term? like a course, a trip, or even SAT tutoring? instead of stashing cash, prepay now if there’s a discount or price lock. a lot of services let you pay in advance, especially if they’re small businesses. this saves you from price hikes — and yourself.
build credit (yes, really). if you’re 18 or close to it, use $10,000 as a starter safety net for a secured credit card. this builds your credit history early — a big deal for apartments, student loans, and future jobs. make one small charge monthly (like Spotify), pay it off, never miss. boring? yes. life-changing? also yes.
micro-fund a revenue-generating skill. take that $10,000 and turn it into money. Examples:
buy a domain + hosting for a blog you monetize
invest in a course that teaches design, data entry, or UX
get supplies for a hyper-niche Etsy shop (e.g. enamel pin display boards or zines)
buy an external mic and start voiceover freelancing
a 10,000 bucks won’t change your life. but how you use it might.
#explorepage#fyp#goals#tumblr tips#saving money#helpful#poll results#useful#useful information#resources#viral#relatable content#budgeting#money#spending money#teen blog#financial advice#advice blog#real talk#self improvement#investinyourself#moneyforstudents#saveitforsomethingbig#mintconditioned
54 notes
·
View notes
Text
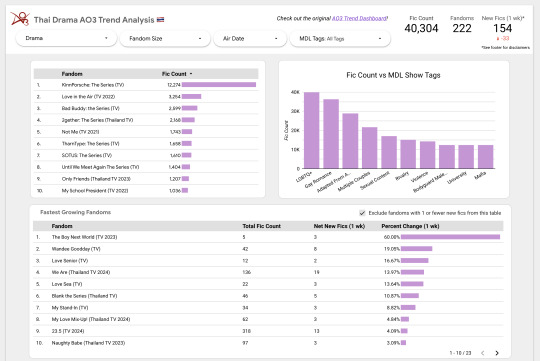
Introducing the Thai Drama AO3 Trends Dashboard! (Beta) 🇹🇭
Over the last several weeks or so I've been building an auto-scraping setup to get AO3 stats on Thai Drama fandoms. Now I finally have it ready to share out!
Take a look if you're interested and let me know what you think :)
(More details and process info under the cut.)
Main Features
This dashboard pulls in data about the quantity of Thai Drama fics over time.
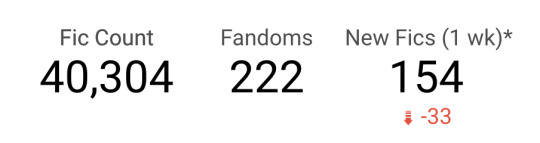
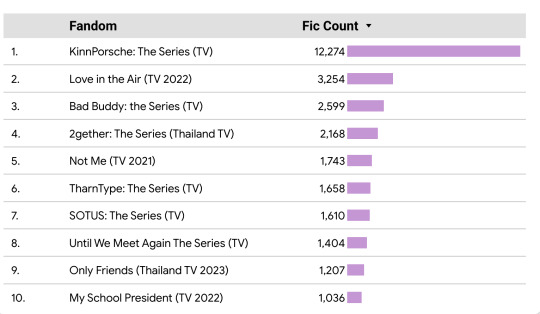
Using filters, it allows you to break that data down by drama, fandom size, air date, and a select number of MyDramaList tags.
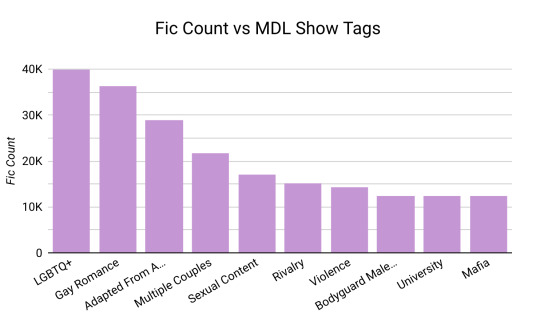
You can also see which fandoms have had the most new fics added on a weekly basis, plus the growth as a percentage of the total.
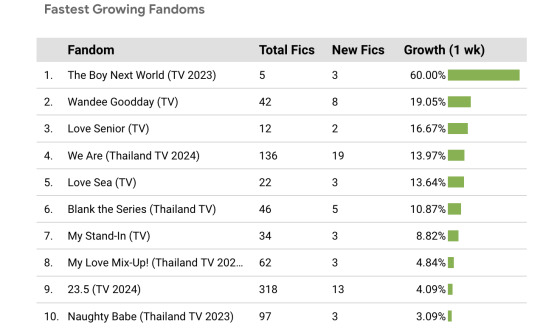
My hope is that this will make it easier to compare Thai Drama fandoms as a collective and pick out trends that otherwise might be difficult to see in an all-AO3 dataset.
Process
Okay -- now for the crunchy stuff...
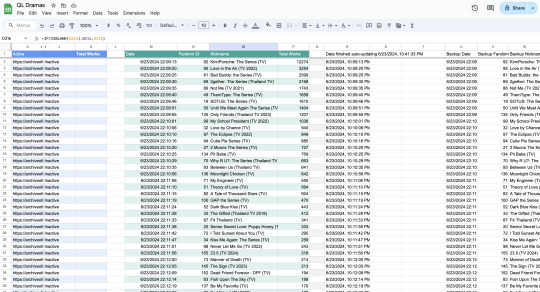
Scraping 🔎
Welcome to the most over-complicated Google Sheets spreadsheet ever made.
I used Google Sheets formulas to scrape certain info from each Thai Drama tag, and then I wrote some app scripts to refresh the data once a day. There are 5 second breaks between the refreshes for each fandom to avoid overwhelming AO3's servers.
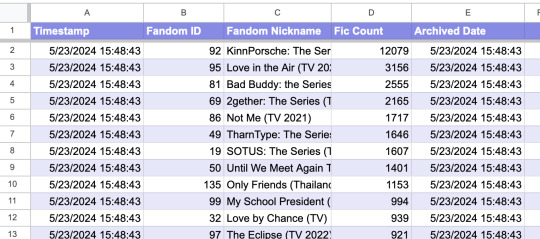
Archiving 📁
Once all the data is scraped, it gets transferred to a different Archive spreadsheet that feeds directly into the data dashboard. The dashboard will update automatically when new data is added to the spreadsheet, so I don't have to do anything manually.
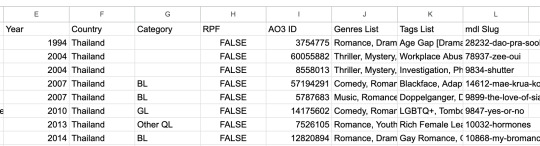
Show Metadata 📊
I decided to be extra and use a (currently unofficial) MyDramaList API to pull in data about each show, such as the year it came out and the MDL tags associated with it. Fun! I might pull in even more info in the future if the mood strikes me.
Bonus - Pan-Fandom AO3 Search
Do you ever find it a bit tedious to have like, 15 different tabs open for the shows you're currently reading fic for?
While making this dash, I also put together this insane URL that basically serves as a "feed" for any and all new Thai drama fics. You can check it out here! It could be useful if you like checking for new fics in multiple fandoms at once. :)
Other Notes
Consider this dashboard the "beta" version -- please let me know if you notice anything that looks off. Also let me know if there are any fandoms missing! Thanks for checking it out!
The inspiration for this dashboard came from @ao3-anonymous 's AO3 Fandom Trend Analysis Dashboard, which I used as a jumping off point for my own data dash. Please give them some love <3
#in which i am the biggest nerd ever#thai bl#thai drama#lgbt drama#ql drama#data science#acafan#fandom data visualization#fanfiction data
287 notes
·
View notes
Text

Jungkook's Solar Return Chart 2024-2025



₊ ⊹ ALLEGEDLY FOR ENTERTAINMENT PURPOSES ONLY₊ ⊹
All pictures were found on Pinterest
Other posts you could like:
જ⁀➴ JK's Solar Return for 2023-2024
જ⁀➴ Jungkook's Fashion Style Evolution
જ⁀➴ When will Jungkook marry?
PRIVATE BOOKING OPEN
email adress: [email protected]
Soft To You presentation and Q&A ᡣ𐭩 rules ᡣ𐭩 private readings reviews
astrology menu ᡣ𐭩 tarot menu ᡣ𐭩 special astrology & tarot readings
What is a Solar Return Chart?
A solar return chart is a chart that literally describes your year from your birthday of a year until the day before next year. For example, Jungkook's 2024-2025 Solar Return will starts on September 1st 2024 until August 31st 2025. It describes the year for you, what will mostly happens. It said as a solar return chart because your sun returns in its home sign (your natal sun).
How to check your Solar Return Chart?
Go to astro.com > Free Horoscopes > Horoscope Drawings and Data > Extended Chart Selection
Enter your birth day, month, year, time and location
Where it's written chart selection with "natal chart", scroll to Solar Return Chart
On the box down there you can add asteroids to see more details ("additional objects")



ᯓ★ Annual Profection Year: 4H
When one is turning 27 years old, they are in their 4H APY. A 4H APY can mean JK will be focused on stability this year, family, close relationships too. What does he want to settle for, and what does he want to invest in. This year will be filled with reflections about his future, and what kind of life he wants to live in. It's also a time to move, to think of children, future, and building a foundation, but what kind of foundation? What kind of future does he want to build.
ᯓ★ 2H Sun means this year for JK will be focused on Money and Possessions. JK can start to think differently about money, perhaps also be more responsible. He can also make more money this year, find other ways to make money, or just have a new source of income. He can also manifest more money in his life. Very ambitious this year, it can also mean taking risks with money because of his ambition and projects.
ᯓ★ Leo Rising is a time for extra popularity for JK! I know it's strange to say that considering he is already very famous lol. But JK will be more under the projectors the year. I think he can be talked about more and will be more "seen" by other people. Getting more attention. JK's appearance could again make a lot of success for people around him. JK Could also look more proud and confident this year. JK can also do some activities this year that will make him way more famous, just having more attention on his activity this year.
ᯓ★ Moon 12H can mean JK will be more sensitive this year, will feel everything more intensely too. Perhaps will need more sleep as well. Could feel lonely sometimes this year, or just will need more time alone.
ᯓ★ Leo Moon means JK will feel more popular this year, perhaps he will feel seen again, with Military in between. He could also have some spotlight again, and perhaps also feel seen for his talent. He could feel like his popularity will go higher. Though he can react in a more dramatic way this year, he could also have a lot of inspiration for his work coming from his emotions.
ᯓ★ Mercury 1H can be a sign of JK standing more for himself this year. JK can also be more confident about his opinions. He can discover a lot about himself too, and perhaps even learn something new about him.
ᯓ★ Leo Mercury can mean JK can speak in a more confident way this year, and can be more confident in his ideas, and what he believes in. He can speak louder too, or just be more proud and less shy about his voice. JK can also talk a lot about what inspire him this year.
ᯓ★ Moon conjunct Mercury can mean JK will speak more about his feelings and his emotions, how things make him feel. He can be more real with people such as ARMY on certain situations. He will say what he thinks and thinks what he says.
ᯓ★ Part of Fortune 2H can be another big sign of having money this year, being lucky with money. JK can def attract a lot of money. Could also mean a glow up, JK can take better care of himself and put more money in clothings for example.
ᯓ★ Sun conjunct POF can be a sign JK will be more lucky this year.
ᯓ★ Venus 2H can be a sign JK will make more money this year. I guess also strange in a way to say that about him, but I truly think he will make a deal that can make him have more money. He can attract more in general, and he can also buy more clothing, luxuries, etc. We could also see JK be more in touch with his feminine side, perhaps also doing photoshoots with more feminine vibe perhaps!
ᯓ★ Juno 3H is a sign of this year being the year he will meet or see his Future Spouse! Many people asked me this, I think they won't meet for sure this year. But I think with this placement JK will be introduced to his FS online. I think he will see her online, on social media, and won't totally be able to reach out.
ᯓ★ Briede 3H means something similar, but the fact that Briede and Juno conjunct each other is a great sign. I think JK will def encounter his FS online this year. This can also be a sign of getting to know your FS better, learning more infos about your FS, etc.
ᯓ★ Vertex 5H is a sign JK will live a transformative experience in his love life. Perhaps also Something significant will happen to him this year. It can also mean he will get a sudden good idea or inspiration.
ᯓ★ Pluto 6H is an indictor or losing or gaining weight! JK could gain weight this year, but it can be muscles since Pluto trine Mars. JK could also overwork himself this year, perhaps working so much he can get sick because of that.
ᯓ★ Saturn 8H can mean JK can feel stuck in his inner world, he could actually realize something needs to change in his life. He needs to face what needs to change and do some actions towards it. It can still be hard and confusing since Neptune is there too. Saturn also opposite Sun, which means this transformation JK will need to get this year will be hard on him.
ᯓ★ Neptune 8H can mean JK can be confused about his spirituality this year. He can have signs, and even be lead to be more open on this side of his life, but he can be confused about what to do. He can also be more into occult and esoteric researches.



╰┈➤ Get your own Solar Return Chart, from 15€ to 50€ ⋆౨ৎ˚⟡˖ ࣪
ᯓ★ Chiron 9H can be a sign of JK learning a hard and painful lesson when it comes to spirituality this year. Can be about friendship, online presence, community, fandom, perhaps JK will realize something painful about his relationship to ARMY.
ᯓ★ MC Taurus can be a sign of JK having a pleasant reputation. JK can be seen as respectable, someone who is hard working and works well. Someone who has a lot of money too, someone people should respect. He can also be admired for his beauty. Because his Solar Return MC falls in his Natal 5H, he could also be seen as a true artist, someone who has a lot of imagination. JK can perhaps even touch to the movie making world this year more than before.
ᯓ★ Uranus 10H is something I wanted to talk about for sure here. This placement is gonna make some noise I think. So Uranus 10H is a sign of a major and perhaps sudden change in one's career. The thing is, Uranus is ruled by Aquarius, and JK has Aquarius 7H, which is the house of contract and partnership. Now, hear me out. I think JK will change his contract perhaps with HYBE this year. There is a major change, and since 10H Ruler in 2H is here, he can get a lot of money from this. Or actually be the winner in this change. Uranus 10H can also be a sign of being fired, but I don't see it particularly here. But the change will def give JK a lot of money, and also attention. JK will also perhaps be seen in a different light. He will want to change his reputation. JK can also do a project in his career that no one will be expecting, and it will make him get a lot of money.
ᯓ★ Jupiter 11H is a sign JK will achieve dreams, and goals he had. He could also meet new people or feel very blessed with people who are around him. JK will spend more time with people this year. He could also have new goals and will be very into achieving them. He could be veryyyy popular this year.
ᯓ★ Mars 11H means JK will have more popularity this year. He can find himself meeting new friends, but at least this means everyone will wanna be his friends. He can find himself being chased after people wanting to be close to him. JK can collab with a lot of different people, he will be approached mostly. He can also be seen more with friends.
ᯓ★ 1H Ruler in 2H can mean changing aesthetic, changing how you look. JK can change his style this year, his appearance, perhaps his hair, etc. He can also buy new clothings. JK can also happen to shop more this year, and be more interested in fashion. He can spend more money on himself too.
ᯓ★ 2H Ruler in 1H is very similar to the one I just said. Overall, spending a lot of money on himself and for himself. He can also make a lot of money because of him, his appearance. Perhaps he can get more modeling contracts.
ᯓ★ 3H Ruler in 2H can mean JK can post a lot about his new aesthetic online, or he can show more his outfits, or we will have more contents on jk's outfits lol. More people can talk about his fashion sense, and he can do it too.
ᯓ★ 4H Ruler in 6H can mean jk can find a new routine at home, or with family. He can also work with family members, or he can also move in or live often with a coworker. He can also live in his office lol, or his work can become a comfort place.
ᯓ★ 5H Ruler in 11H can mean he can become very inspired by his friends. But it can mean having a crush on someone online, on a friend, etc.
ᯓ★ 6H Ruler in 8H can mean JK's routine at work will change, transform this year. He can do new projects that will make him go out of his comfort zone he was used to in his career. Since JK will go out of Military in June 2025, this can also translate change in his career (Military to being a Singer again).
ᯓ★ 7H Ruler in 10H is a change in relationships! JK can have a sudden change in his relationships, but also this can mean he will change his contract with HYBE perhaps.
ᯓ★ 8H Ruler in 8H is a sign of having a deep transformation. JK can change a lot of things about himself this year, perhaps it's a year JK will change his appearance, his relationship with his fans, he can also change his career, goals. He will not be the same man. Though, this is part of the process. He can also discover more about himself this year.
ᯓ★ 9H Ruler in 11H can mean having long distance friendships, perhaps he can have friends who live abroad lol. Or he can also be away from his friends and mostly communicate online with them. He can learn a lot on social medias in general, if he wanna learn or study something, internet will be his best friend! He can also be truly inspired by his relationships and friends.
ᯓ★ 10H Ruler in 2H can mean making more money because of work. JK can happen to do a change in his career that will bring him more money for sure. He can change his aesthetic at work too.
ᯓ★ 11H Ruler in 1H can mean JK can be more present on social medias this year, or he can change his aesthetic online too. He can also be more talked about online.
ᯓ★ 12H Ruler in 12H means it can be a more spiritual year for JK. JK can be more spiritual. He can feel more alone, and desire to be more alone, on his own. He can also be more private about what he feels this year. This is also an indicator of sleeping more.
Thank you for reading!
back to index ; ask ; request ; rules
#astrology#jk#bts#jungkook#astro#astro tumblr#astro notes#astro community#astro observations#solar return chart#astrology solar return#solar return#bts jungkook#jungkook bts#astro jk#astro jungkook#jungkook astrology#bts jungkook astrology#jungkook astro#jungkook solar return#bts astrology#bts astro
177 notes
·
View notes
Text
Within minutes, we found a publicly accessible ClickHouse database linked to DeepSeek, completely open and unauthenticated, exposing sensitive data. It was hosted at oauth2callback.deepseek.com:9000 and dev.deepseek.com:9000.
This database contained a significant volume of chat history, backend data and sensitive information, including log streams, API Secrets, and operational details.
More critically, the exposure allowed for full database control and potential privilege escalation within the DeepSeek environment, without any authentication or defense mechanism to the outside world.
lol
43 notes
·
View notes
Text
DigitalAPICraft- A Unified Platform for API Based Integration Ecosystem
DigitalAPICraft, an enterprise-grade developer’s portal, which allows you to build an API ecosystem in your company and manage all your APIs with centralized control. Visit Here - https://digitalapicraft.com/one-api-market-place/
#api ecosystem#api marketplace#financial services apis#api data integration#open banking api sandbox
0 notes
Text
clarification re: ChatGPT, " a a a a", and data leakage
In August, I posted:
For a good time, try sending chatGPT the string ` a` repeated 1000 times. Like " a a a" (etc). Make sure the spaces are in there. Trust me.
People are talking about this trick again, thanks to a recent paper by Nasr et al that investigates how often LLMs regurgitate exact quotes from their training data.
The paper is an impressive technical achievement, and the results are very interesting.
Unfortunately, the online hive-mind consensus about this paper is something like:
When you do this "attack" to ChatGPT -- where you send it the letter 'a' many times, or make it write 'poem' over and over, or the like -- it prints out a bunch of its own training data. Previously, people had noted that the stuff it prints out after the attack looks like training data. Now, we know why: because it really is training data.
It's unfortunate that people believe this, because it's false. Or at best, a mixture of "false" and "confused and misleadingly incomplete."
The paper
So, what does the paper show?
The authors do a lot of stuff, building on a lot of previous work, and I won't try to summarize it all here.
But in brief, they try to estimate how easy it is to "extract" training data from LLMs, moving successively through 3 categories of LLMs that are progressively harder to analyze:
"Base model" LLMs with publicly released weights and publicly released training data.
"Base model" LLMs with publicly released weights, but undisclosed training data.
LLMs that are totally private, and are also finetuned for instruction-following or for chat, rather than being base models. (ChatGPT falls into this category.)
Category #1: open weights, open data
In their experiment on category #1, they prompt the models with hundreds of millions of brief phrases chosen randomly from Wikipedia. Then they check what fraction of the generated outputs constitute verbatim quotations from the training data.
Because category #1 has open weights, they can afford to do this hundreds of millions of times (there are no API costs to pay). And because the training data is open, they can directly check whether or not any given output appears in that data.
In category #1, the fraction of outputs that are exact copies of training data ranges from ~0.1% to ~1.5%, depending on the model.
Category #2: open weights, private data
In category #2, the training data is unavailable. The authors solve this problem by constructing "AuxDataset," a giant Frankenstein assemblage of all the major public training datasets, and then searching for outputs in AuxDataset.
This approach can have false negatives, since the model might be regurgitating private training data that isn't in AuxDataset. But it shouldn't have many false positives: if the model spits out some long string of text that appears in AuxDataset, then it's probably the case that the same string appeared in the model's training data, as opposed to the model spontaneously "reinventing" it.
So, the AuxDataset approach gives you lower bounds. Unsurprisingly, the fractions in this experiment are a bit lower, compared to the Category #1 experiment. But not that much lower, ranging from ~0.05% to ~1%.
Category #3: private everything + chat tuning
Finally, they do an experiment with ChatGPT. (Well, ChatGPT and gpt-3.5-turbo-instruct, but I'm ignoring the latter for space here.)
ChatGPT presents several new challenges.
First, the model is only accessible through an API, and it would cost too much money to call the API hundreds of millions of times. So, they have to make do with a much smaller sample size.
A more substantial challenge has to do with the model's chat tuning.
All the other models evaluated in this paper were base models: they were trained to imitate a wide range of text data, and that was that. If you give them some text, like a random short phrase from Wikipedia, they will try to write the next part, in a manner that sounds like the data they were trained on.
However, if you give ChatGPT a random short phrase from Wikipedia, it will not try to complete it. It will, instead, say something like "Sorry, I don't know what that means" or "Is there something specific I can do for you?"
So their random-short-phrase-from-Wikipedia method, which worked for base models, is not going to work for ChatGPT.
Fortuitously, there happens to be a weird bug in ChatGPT that makes it behave like a base model!
Namely, the "trick" where you ask it to repeat a token, or just send it a bunch of pre-prepared repetitions.
Using this trick is still different from prompting a base model. You can't specify a "prompt," like a random-short-phrase-from-Wikipedia, for the model to complete. You just start the repetition ball rolling, and then at some point, it starts generating some arbitrarily chosen type of document in a base-model-like way.
Still, this is good enough: we can do the trick, and then check the output against AuxDataset. If the generated text appears in AuxDataset, then ChatGPT was probably trained on that text at some point.
If you do this, you get a fraction of 3%.
This is somewhat higher than all the other numbers we saw above, especially the other ones obtained using AuxDataset.
On the other hand, the numbers varied a lot between models, and ChatGPT is probably an outlier in various ways when you're comparing it to a bunch of open models.
So, this result seems consistent with the interpretation that the attack just makes ChatGPT behave like a base model. Base models -- it turns out -- tend to regurgitate their training data occasionally, under conditions like these ones; if you make ChatGPT behave like a base model, then it does too.
Language model behaves like language model, news at 11
Since this paper came out, a number of people have pinged me on twitter or whatever, telling me about how this attack "makes ChatGPT leak data," like this is some scandalous new finding about the attack specifically.
(I made some posts saying I didn't think the attack was "leaking data" -- by which I meant ChatGPT user data, which was a weirdly common theory at the time -- so of course, now some people are telling me that I was wrong on this score.)
This interpretation seems totally misguided to me.
Every result in the paper is consistent with the banal interpretation that the attack just makes ChatGPT behave like a base model.
That is, it makes it behave the way all LLMs used to behave, up until very recently.
I guess there are a lot of people around now who have never used an LLM that wasn't tuned for chat; who don't know that the "post-attack content" we see from ChatGPT is not some weird new behavior in need of a new, probably alarming explanation; who don't know that it is actually a very familiar thing, which any base model will give you immediately if you ask. But it is. It's base model behavior, nothing more.
Behaving like a base model implies regurgitation of training data some small fraction of the time, because base models do that. And only because base models do, in fact, do that. Not for any extra reason that's special to this attack.
(Or at least, if there is some extra reason, the paper gives us no evidence of its existence.)
The paper itself is less clear than I would like about this. In a footnote, it cites my tweet on the original attack (which I appreciate!), but it does so in a way that draws a confusing link between the attack and data regurgitation:
In fact, in early August, a month after we initial discovered this attack, multiple independent researchers discovered the underlying exploit used in our paper, but, like us initially, they did not realize that the model was regenerating training data, e.g., https://twitter.com/nostalgebraist/status/1686576041803096065.
Did I "not realize that the model was regenerating training data"? I mean . . . sort of? But then again, not really?
I knew from earlier papers (and personal experience, like the "Hedonist Sovereign" thing here) that base models occasionally produce exact quotations from their training data. And my reaction to the attack was, "it looks like it's behaving like a base model."
It would be surprising if, after the attack, ChatGPT never produced an exact quotation from training data. That would be a difference between ChatGPT's underlying base model and all other known LLM base models.
And the new paper shows that -- unsurprisingly -- there is no such difference. They all do this at some rate, and ChatGPT's rate is 3%, plus or minus something or other.
3% is not zero, but it's not very large, either.
If you do the attack to ChatGPT, and then think "wow, this output looks like what I imagine training data probably looks like," it is nonetheless probably not training data. It is probably, instead, a skilled mimicry of training data. (Remember that "skilled mimicry of training data" is what LLMs are trained to do.)
And remember, too, that base models used to be OpenAI's entire product offering. Indeed, their API still offers some base models! If you want to extract training data from a private OpenAI model, you can just interact with these guys normally, and they'll spit out their training data some small % of the time.
The only value added by the attack, here, is its ability to make ChatGPT specifically behave in the way that davinci-002 already does, naturally, without any tricks.
265 notes
·
View notes