#SQL query tuning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Enhancing Query Performance through Cardinality Estimation in SQL Server 2022
You’ve just stumbled upon a guide that’s all about making your SQL Server 2022 dance to the rhythm of your queries, smoother and faster than ever. Picture this: You’re tuning your SQL queries, and something feels off. The server’s taking its sweet time, and you can’t help but wonder, “Could this get any better?” Enter the world of Cardinality Estimation (CE) – SQL Server’s crystal…
View On WordPress
#Cardinality Estimation optimization#Query execution plans optimization#SQL query tuning#SQL Server 2022 performance#Update SQL statistics
0 notes
Text
SQL Query Optimization | SQL Query Optimization and performance tuning
SQL Query Optimization | SQL Query Optimization and performance tuning In this video we have discussed tips and tricks by … source
0 notes
Text
SQL for Hadoop: Mastering Hive and SparkSQL
In the ever-evolving world of big data, having the ability to efficiently query and analyze data is crucial. SQL, or Structured Query Language, has been the backbone of data manipulation for decades. But how does SQL adapt to the massive datasets found in Hadoop environments? Enter Hive and SparkSQL—two powerful tools that bring SQL capabilities to Hadoop. In this blog, we'll explore how you can master these query languages to unlock the full potential of your data.
Hive Architecture and Data Warehouse Concept
Apache Hive is a data warehouse software built on top of Hadoop. It provides an SQL-like interface to query and manage large datasets residing in distributed storage. Hive's architecture is designed to facilitate the reading, writing, and managing of large datasets with ease. It consists of three main components: the Hive Metastore, which stores metadata about tables and schemas; the Hive Driver, which compiles, optimizes, and executes queries; and the Hive Query Engine, which processes the execution of queries.
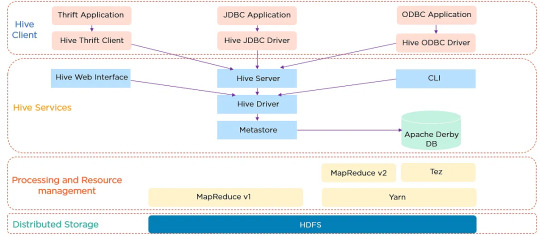
Hive Architecture
Hive's data warehouse concept revolves around the idea of abstracting the complexity of distributed storage and processing, allowing users to focus on the data itself. This abstraction makes it easier for users to write queries without needing to know the intricacies of Hadoop.
Writing HiveQL Queries
HiveQL, or Hive Query Language, is a SQL-like query language that allows users to query data stored in Hadoop. While similar to SQL, HiveQL is specifically designed to handle the complexities of big data. Here are some basic HiveQL queries to get you started:
Creating a Table:
CREATE TABLE employees ( id INT, name STRING, salary FLOAT );
Loading Data:
LOAD DATA INPATH '/user/hive/data/employees.csv' INTO TABLE employees;
Querying Data:
SELECT name, salary FROM employees WHERE salary > 50000;
HiveQL supports a wide range of functions and features, including joins, group by, and aggregations, making it a versatile tool for data analysis.
HiveQL Queries
SparkSQL vs HiveQL: Similarities & Differences
Both SparkSQL and HiveQL offer SQL-like querying capabilities, but they have distinct differences:
Execution Engine: HiveQL relies on Hadoop's MapReduce engine, which can be slower due to its batch processing nature. SparkSQL, on the other hand, leverages Apache Spark's in-memory computing, resulting in faster query execution.
Ease of Use: HiveQL is easier for those familiar with traditional SQL syntax, while SparkSQL requires understanding Spark's APIs and dataframes.
Integration: SparkSQL integrates well with Spark's ecosystem, allowing for seamless data processing and machine learning tasks. HiveQL is more focused on data warehousing and batch processing.
Despite these differences, both languages provide powerful tools for interacting with big data, and knowing when to use each is key to mastering them.

SparkSQL vs HiveQL
Running SQL Queries on Massive Distributed Data
Running SQL queries on massive datasets requires careful consideration of performance and efficiency. Hive and SparkSQL both offer powerful mechanisms to optimize query execution, such as partitioning and bucketing.
Partitioning, Bucketing, and Performance Tuning
Partitioning and bucketing are techniques used to optimize query performance in Hive and SparkSQL:
Partitioning: Divides data into distinct subsets, allowing queries to skip irrelevant partitions and reduce the amount of data scanned. For example, partitioning by date can significantly speed up queries that filter by specific time ranges.
Bucketing: Further subdivides data within partitions into buckets based on a hash function. This can improve join performance by aligning data in a way that allows for more efficient processing.
Performance tuning in Hive and SparkSQL involves understanding and leveraging these techniques, along with optimizing query logic and resource allocation.

Hive and SparkSQL Partitioning & Bucketing
FAQ
1. What is the primary use of Hive in a Hadoop environment? Hive is primarily used as a data warehousing solution, enabling users to query and manage large datasets with an SQL-like interface.
2. Can HiveQL and SparkSQL be used interchangeably? While both offer SQL-like querying capabilities, they have different execution engines and integration capabilities. HiveQL is suited for batch processing, while SparkSQL excels in in-memory data processing.
3. How do partitioning and bucketing improve query performance? Partitioning reduces the data scanned by dividing it into subsets, while bucketing organizes data within partitions, optimizing joins and aggregations.
4. Is it necessary to know Java or Scala to use SparkSQL? No, SparkSQL can be used with Python, R, and SQL, though understanding Spark's APIs in Java or Scala can provide additional flexibility.
5. How does SparkSQL achieve faster query execution compared to HiveQL? SparkSQL utilizes Apache Spark's in-memory computation, reducing the latency associated with disk I/O and providing faster query execution times.
Home
instagram
#Hive#SparkSQL#DistributedComputing#BigDataProcessing#SQLOnBigData#ApacheSpark#HadoopEcosystem#DataAnalytics#SunshineDigitalServices#TechForAnalysts#Instagram
2 notes
·
View notes
Text
SQL Fundamentals #2: SQL Data Manipulation
In our previous database exploration journey, SQL Fundamentals #1: SQL Data Definition, we set the stage by introducing the "books" table nestled within our bookstore database. Currently, our table is empty, Looking like :
books
| title | author | genre | publishedYear | price |
Data manipulation

Now, let's embark on database interaction—data manipulation. This is where the magic happens, where our "books" table comes to life, and we finish our mission of data storage.
Inserting Data
Our initial task revolves around adding a collection of books into our "books" table. we want to add the book "The Great Gatsby" to our collection, authored F. Scott Fitzgerald. Here's how we express this in SQL:
INSERT INTO books(title, author, genre, publishedYear, price) VALUES('The Great Gatsby', 'F. Scott Fitzgerald', 'Classic', 1925, 10.99);
Alternatively, you can use a shorter form for inserting values, but be cautious as it relies on the order of columns in your table:
INSERT INTO books VALUES('The Great Gatsby', 'F. Scott Fitzgerald', 'Classic', 1925, 10.99);
Updating data
As time goes on, you might find the need to modify existing data in our "books" table. To accomplish this, we use the UPDATE command.For example :
UPDATE books SET price = 12.99 WHERE title = 'The Great Gatsby';
This SQL statement will locate the row with the title "The Great Gatsby" and modify its price to $12.99.
We'll discuss the where clause in (SQL fundamentals #3)
Deleting data
Sometimes, data becomes obsolete or irrelevant, and it's essential to remove it from our table. The DELETE FROM command allows us to delete entire rows from our table.For example :
DELETE FROM books WHERE title = 'Moby-Dick';
This SQL statement will find the row with the title "Moby-Dick" and remove it entirely from your "books" table.
To maintain a reader-friendly and approachable tone, I'll save the discussion on the third part of SQL, which focuses on data querying, for the upcoming post. Stay tuned ...
#studyblr#code#codeblr#javascript#java development company#study#progblr#programming#studying#comp sci#web design#web developers#web development#website design#webdev#website#tech#sql#sql course#mysql#datascience#data#backend
45 notes
·
View notes
Text
The Skills I Acquired on My Path to Becoming a Data Scientist
Data science has emerged as one of the most sought-after fields in recent years, and my journey into this exciting discipline has been nothing short of transformative. As someone with a deep curiosity for extracting insights from data, I was naturally drawn to the world of data science. In this blog post, I will share the skills I acquired on my path to becoming a data scientist, highlighting the importance of a diverse skill set in this field.
The Foundation — Mathematics and Statistics
At the core of data science lies a strong foundation in mathematics and statistics. Concepts such as probability, linear algebra, and statistical inference form the building blocks of data analysis and modeling. Understanding these principles is crucial for making informed decisions and drawing meaningful conclusions from data. Throughout my learning journey, I immersed myself in these mathematical concepts, applying them to real-world problems and honing my analytical skills.
Programming Proficiency
Proficiency in programming languages like Python or R is indispensable for a data scientist. These languages provide the tools and frameworks necessary for data manipulation, analysis, and modeling. I embarked on a journey to learn these languages, starting with the basics and gradually advancing to more complex concepts. Writing efficient and elegant code became second nature to me, enabling me to tackle large datasets and build sophisticated models.
Data Handling and Preprocessing
Working with real-world data is often messy and requires careful handling and preprocessing. This involves techniques such as data cleaning, transformation, and feature engineering. I gained valuable experience in navigating the intricacies of data preprocessing, learning how to deal with missing values, outliers, and inconsistent data formats. These skills allowed me to extract valuable insights from raw data and lay the groundwork for subsequent analysis.
Data Visualization and Communication
Data visualization plays a pivotal role in conveying insights to stakeholders and decision-makers. I realized the power of effective visualizations in telling compelling stories and making complex information accessible. I explored various tools and libraries, such as Matplotlib and Tableau, to create visually appealing and informative visualizations. Sharing these visualizations with others enhanced my ability to communicate data-driven insights effectively.

Machine Learning and Predictive Modeling
Machine learning is a cornerstone of data science, enabling us to build predictive models and make data-driven predictions. I delved into the realm of supervised and unsupervised learning, exploring algorithms such as linear regression, decision trees, and clustering techniques. Through hands-on projects, I gained practical experience in building models, fine-tuning their parameters, and evaluating their performance.
Database Management and SQL
Data science often involves working with large datasets stored in databases. Understanding database management and SQL (Structured Query Language) is essential for extracting valuable information from these repositories. I embarked on a journey to learn SQL, mastering the art of querying databases, joining tables, and aggregating data. These skills allowed me to harness the power of databases and efficiently retrieve the data required for analysis.

Domain Knowledge and Specialization
While technical skills are crucial, domain knowledge adds a unique dimension to data science projects. By specializing in specific industries or domains, data scientists can better understand the context and nuances of the problems they are solving. I explored various domains and acquired specialized knowledge, whether it be healthcare, finance, or marketing. This expertise complemented my technical skills, enabling me to provide insights that were not only data-driven but also tailored to the specific industry.
Soft Skills — Communication and Problem-Solving
In addition to technical skills, soft skills play a vital role in the success of a data scientist. Effective communication allows us to articulate complex ideas and findings to non-technical stakeholders, bridging the gap between data science and business. Problem-solving skills help us navigate challenges and find innovative solutions in a rapidly evolving field. Throughout my journey, I honed these skills, collaborating with teams, presenting findings, and adapting my approach to different audiences.
Continuous Learning and Adaptation
Data science is a field that is constantly evolving, with new tools, technologies, and trends emerging regularly. To stay at the forefront of this ever-changing landscape, continuous learning is essential. I dedicated myself to staying updated by following industry blogs, attending conferences, and participating in courses. This commitment to lifelong learning allowed me to adapt to new challenges, acquire new skills, and remain competitive in the field.
In conclusion, the journey to becoming a data scientist is an exciting and dynamic one, requiring a diverse set of skills. From mathematics and programming to data handling and communication, each skill plays a crucial role in unlocking the potential of data. Aspiring data scientists should embrace this multidimensional nature of the field and embark on their own learning journey. If you want to learn more about Data science, I highly recommend that you contact ACTE Technologies because they offer Data Science courses and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested. By acquiring these skills and continuously adapting to new developments, they can make a meaningful impact in the world of data science.
#data science#data visualization#education#information#technology#machine learning#database#sql#predictive analytics#r programming#python#big data#statistics
15 notes
·
View notes
Text
What It’s Like to Be a Full Stack Developer: A Day in My Life
Have you ever wondered what it’s like to be a full stack developer? The world of full stack development is a thrilling and dynamic one, filled with challenges and opportunities to create end-to-end solutions. In this blog post, I’m going to take you through a day in my life as a full stack developer, sharing the ins and outs of my daily routine, the exciting projects I work on, and the skills that keep me at the forefront of technology.

Morning Ritual: Coffee, Code, and Planning
My day typically begins with a strong cup of coffee and some quiet time for reflection. It’s during this peaceful morning routine that I gather my thoughts, review my task list, and plan the day ahead. Full stack development demands a strategic approach, so having a clear plan is essential.
Once I’m geared up, I dive into code. Mornings are often the most productive time for me, so I use this period to tackle complex tasks that require deep concentration. Whether it’s optimizing database queries or fine-tuning the user interface, the morning is when I make significant progress.
The Balancing Act: Frontend and Backend Work
One of the defining aspects of being a full stack developer is the constant juggling between frontend and backend development. I seamlessly switch between crafting elegant user interfaces and building robust server-side logic.

In the frontend world, I work with HTML, CSS, and JavaScript to create responsive and visually appealing web applications. I make sure that the user experience is smooth, intuitive, and visually appealing. From designing layouts to implementing user interactions, frontend development keeps me creatively engaged.
On the backend, I manage server-side scripting languages like Python and Node.js, ensuring that the data and logic behind the scenes are rock-solid. Databases, both SQL and NoSQL, play a central role in the backend, and I optimize them for performance and scalability. Building APIs, handling authentication, and managing server infrastructure are all part of the backend responsibilities.
Collaboration and Teamwork
Full stack development often involves collaborating with a diverse team of developers, designers, and project managers. Teamwork is a cornerstone of success in our field, and communication is key. I engage in daily stand-up meetings to sync up with the team, share progress, and discuss roadblocks.

Collaborative tools like Git and platforms like GitHub facilitate seamless code collaboration. Code reviews are a regular part of our workflow, ensuring that the codebase remains clean, maintainable, and secure. It’s in these collaborative moments that we learn from each other, refine our skills, and collectively push the boundaries of what’s possible.
Continuous Learning and Staying Updated
Technology evolves at a rapid pace, and staying updated is paramount for a full stack developer. In the afternoon, I set aside time for learning and exploration. Whether it’s delving into a new framework, exploring emerging technologies like serverless computing, or simply catching up on industry news, this dedicated learning time keeps me ahead of the curve. The ACTE Institute offers numerous Full stack developer courses, bootcamps, and communities that can provide you with the necessary resources and support to succeed in this field. Best of luck on your exciting journey!
The Thrill of Problem Solving
As the day progresses, I often find myself tackling unforeseen challenges. Full stack development is, at its core, problem-solving. Debugging issues, optimizing code, and finding efficient solutions are all part of the job. These challenges keep me on my toes and are a source of constant learning.
Evening Reflection: Wrapping Up and Looking Ahead
As the day winds down, I wrap up my work, conduct final code reviews, and prepare for the next day. Full stack development is a fulfilling journey, but it’s important to strike a balance between work and personal life.
Reflecting on the day’s accomplishments and challenges, I’m reminded of the rewarding nature of being a full stack developer. It’s a role that demands versatility, creativity, and adaptability, but it’s also a role that offers endless opportunities for growth and innovation.
Being a full stack developer is not just a job; it’s a way of life. Each day is a new adventure filled with code, collaboration, and the excitement of building end-to-end solutions. While the challenges are real, the satisfaction of creating something meaningful is immeasurable. If you’ve ever wondered what it’s like to be a full stack developer, I hope this glimpse into my daily life has shed some light on the dynamic and rewarding world of full stack development.
#full stack developer#frameworks#web development#web design#education#learning#information#technology
3 notes
·
View notes
Text
Enhancing Business Intelligence with Query Optimisation – How Efficient Data Retrieval Improves Decision-Making
In the fast-paced world of modern business, timely and data-driven decisions are essential. Business Intelligence (BI) tools have become the cornerstone of strategic planning and performance monitoring, allowing organisations to make sense of vast volumes of data. However, the value of BI is heavily dependent on the efficiency of data retrieval processes behind the scenes. Query optimisation, the process of enhancing SQL queries to reduce execution time and resource usage, is pivotal in ensuring that decision-makers have access to accurate insights when they need them. Mastering these optimisation techniques is a vital component of any comprehensive data science course, where industry demand for real-time analytics and performance tuning is on the rise.
The Link Between Query Performance and Business Intelligence
Business Intelligence platforms rely on retrieving structured data from relational databases, transforming it into actionable dashboards, KPIs, and reports. These systems are only as effective as the speed and reliability of the underlying queries. When queries are inefficient—scanning unnecessary rows, failing to use indexes, or performing costly joins—response times lag, dashboards stall, and users lose trust in the system.
Efficient query design ensures:
Faster loading of reports and visualisations
Real-time insights for operational and strategic decisions
Reduced load on servers and infrastructure
Scalability of analytics solutions as data volume grows
These benefits highlight why query optimisation isn’t just a technical concern—it’s central to business performance.
Key Query Optimisation Techniques
Students in a well-structured data science course are trained to identify and implement common optimisation strategies that lead to significant performance gains. These include:
1. Indexing Critical Columns
Indexes are like a table of contents in a book, helping the database quickly find rows that match specific criteria. Creating indexes on columns frequently used in WHERE, JOIN, and ORDER BY clauses can drastically reduce query time.
2. Using SELECT Wisely
Avoid using SELECT *, which retrieves all columns, many of which may not be needed. Selecting only relevant fields minimises data transfer and improves processing speed.
3. Applying Proper Filtering
Well-constructed WHERE clauses narrow down data early in the execution plan, reducing the amount of data processed. Using functions in filters can slow down queries, so it’s better to avoid wrapping columns in functions where possible.
4. Optimising Joins
When combining data from multiple tables, ensure that joined columns are indexed and choose the correct join type (e.g., INNER JOIN over LEFT JOIN if nulls aren’t needed). Also, filter data before joining when possible.
5. Limiting Result Sets
Using LIMIT or TOP clauses is especially useful for queries that support dashboards or previews. It prevents excessive data loading, which can degrade performance.
6. Materialised Views and Caching
For queries that are computationally expensive but frequently accessed, storing pre-computed results in materialised views or caching layers can dramatically improve response times.
Real-World Business Scenarios
In sectors like finance, retail, and logistics, real-time dashboards help leaders make decisions such as reallocating inventory, adjusting marketing campaigns, or monitoring risk. Without optimised queries, a BI dashboard monitoring warehouse inventory might take minutes to load, making it ineffective for time-sensitive adjustments.
A data science course in Mumbai might task students with building a sales performance dashboard using a sample retail database. Through exercises, they learn how to use EXPLAIN plans to understand query performance, apply indexes, and restructure inefficient queries. This hands-on practice ensures they can support the BI needs of real-world organisations.
Integration with BI Tools
Query optimisation directly affects how well tools like Tableau, Power BI, and Looker perform. These platforms send queries to databases and rely on fast responses to populate visuals. Understanding how these tools interact with underlying SQL queries enables data professionals to write more efficient backend logic.
Courses often include modules on:
Writing optimised queries for embedded dashboards
Reducing API latency with better data source structuring
Automating report generation through scheduled, optimised scripts
Conclusion
Efficient query optimisation is the backbone of powerful Business Intelligence. It transforms slow, clunky dashboards into responsive, real-time decision-making tools. For aspiring data professionals, learning how to fine-tune queries is a non-negotiable skill. A strong data science course in Mumbai provides the foundation and hands-on experience needed to support data-driven business environments. With these skills, students are prepared to turn data into insights—faster, smarter, and at scale.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text
Becoming a Full-Stack Data Scientist: Bridging the Gap between Research and Production

For years, the ideal data scientist was often portrayed as a brilliant researcher, adept at statistics, machine learning algorithms, and deep analytical dives within the comfortable confines of a Jupyter notebook. While these core skills remain invaluable, the landscape of data science has dramatically shifted by mid-2025. Companies are no longer content with insightful reports or impressive model prototypes; they demand operationalized AI solutions that deliver tangible business value.
This shift has given rise to the concept of the "Full-Stack Data Scientist" – an individual capable of not just building models, but also taking them from the initial research phase all the way to production, monitoring, and maintenance. This role bridges the historically distinct worlds of data science (research) and software/ML engineering (production), making it one of the most in-demand and impactful positions in the modern data-driven organization.
Why the "Full-Stack" Evolution?
The demand for full-stack data scientists stems from several critical needs:
Accelerated Time-to-Value: The longer a model remains a "research artifact," the less value it generates. Full-stack data scientists streamline the transition from experimentation to deployment, ensuring insights are quickly converted into actionable products or services.
Reduced Silos and Improved Collaboration: When data scientists can speak the language of engineering and understand deployment challenges, collaboration with MLOps and software engineering teams becomes far more efficient. This reduces friction and miscommunication.
End-to-End Ownership & Accountability: A full-stack data scientist can take ownership of a project from inception to ongoing operation, fostering a deeper understanding of its impact and facilitating quicker iterations.
Operational Excellence: Understanding how models behave in a production environment (e.g., data drift, model decay, latency requirements) allows for more robust model design and proactive maintenance.
Cost Efficiency: In smaller teams or startups, a full-stack data scientist can cover multiple roles, optimizing resource allocation.
The Full-Stack Data Scientist's Skillset: Beyond the Notebook
To bridge the gap between research and production, a full-stack data scientist needs a diverse and expanded skillset:
1. Core Data Science Prowess: (The Foundation)
Advanced ML & Deep Learning: Proficiency in various algorithms, model selection, hyperparameter tuning, and understanding the nuances of different model architectures (e.g., Transformers, Diffusion Models for GenAI applications).
Statistics & Mathematics: A solid grasp of statistical inference, probability, linear algebra, and calculus to understand model assumptions and interpret results.
Data Analysis & Visualization: Expert-level exploratory data analysis (EDA), data cleaning, feature engineering, and compelling data storytelling.
Programming Languages: Mastery of Python (with libraries like Pandas, NumPy, Scikit-learn, TensorFlow/PyTorch) and often R, for data manipulation, modeling, and scripting.
2. Data Engineering Fundamentals: (Getting the Data Right)
SQL & Database Management: Expert-level SQL for querying, manipulating, and optimizing data from relational databases. Familiarity with NoSQL databases (e.g., MongoDB, Cassandra) is also valuable.
Data Pipelines (ETL/ELT): Understanding how to build, maintain, and monitor data pipelines using tools like Apache Airflow, Prefect, or Dagster to ensure data quality and timely delivery for models.
Big Data Technologies: Experience with distributed computing frameworks like Apache Spark for processing and transforming large datasets.
Data Warehousing/Lakes: Knowledge of data warehousing concepts and working with data lake solutions (e.g., Databricks, Snowflake, Delta Lake) for scalable data storage.
3. MLOps & Software Engineering: (Bringing Models to Life)
Version Control (Git): Non-negotiable for collaborative code development, model versioning, and reproducibility.
Containerization (Docker): Packaging models and their dependencies into portable, isolated containers for consistent deployment across environments.
Orchestration (Kubernetes): Understanding how to manage and scale containerized applications in production environments.
Cloud Platforms: Proficiency in at least one major cloud provider (AWS, Azure, Google Cloud) for deploying, managing, and scaling ML workloads and data infrastructure. This includes services like SageMaker, Azure ML, Vertex AI.
Model Serving Frameworks: Knowledge of tools like FastAPI, Flask, or TensorFlow Serving/TorchServe to expose models as APIs for inference.
Monitoring & Alerting: Setting up systems (e.g., Prometheus, Grafana, MLflow Tracking, Weights & Biases) to monitor model performance, data drift, concept drift, and system health in production.
CI/CD (Continuous Integration/Continuous Deployment): Automating the process of building, testing, and deploying ML models to ensure rapid and reliable updates.
Basic Software Engineering Principles: Writing clean, modular, testable, and maintainable code; understanding design patterns and software development best practices.
4. Communication & Business Acumen: (Driving Impact)
Problem-Solving: The ability to translate ambiguous business challenges into well-defined data science problems.
Communication & Storytelling: Effectively conveying complex technical findings and model limitations to non-technical stakeholders, influencing business decisions.
Business Domain Knowledge: Understanding the specific industry or business area to build relevant and impactful models.
Product Thinking: Considering the end-user experience and how the AI solution will integrate into existing products or workflows.
How to Become a Full-Stack Data Scientist
The path to full-stack data science is continuous learning and hands-on experience:
Solidify Core Data Science: Ensure your foundational skills in ML, statistics, and Python/R are robust.
Learn SQL Deeply: It's the lingua franca of data.
Dive into Data Engineering: Start by learning to build simple data pipelines and explore distributed processing with Spark.
Embrace MLOps Tools: Get hands-on with Docker, Kubernetes, Git, and MLOps platforms like MLflow. Cloud certifications are a huge plus.
Build End-to-End Projects: Don't just stop at model training. Take a project from raw data to a deployed, monitored API. Use frameworks like Streamlit or Flask to build simple UIs around your models.
Collaborate Actively: Work closely with software engineers, DevOps specialists, and product managers. Learn from their expertise and understand their challenges.
Stay Curious & Adaptable: The field is constantly evolving. Keep learning about new tools, frameworks, and methodologies.
Conclusion
The "Full-Stack Data Scientist" is not just a buzzword; it's the natural evolution of a profession that seeks to deliver real-world impact. While the journey requires a significant commitment to continuous learning and skill expansion, the rewards are immense. By bridging the gap between research and production, data scientists can elevate their influence, accelerate innovation, and truly become architects of intelligent systems that drive tangible value for businesses and society alike. It's a challenging but incredibly exciting time to be a data professional.
#technology#artificial intelligence#ai#online course#xaltius#data science#gen ai#data science course#Full-Stack Data Scientist
0 notes
Text
LAMP Application Development Services: Guide for Digital Product Teams
1. Snapshot: Why This Guide Matters
Linux + Apache + MySQL + PHP (the classic LAMP stack) remains one of the most proven ways to deliver secure, scalable, and cost‑effective web applications. Even in a cloud‑native, container‑heavy world, LAMP continues to power content platforms, SaaS dashboards, B2B portals, eCommerce sites, and customer self‑service tools. If you’re evaluating vendors or trying to decide whether to modernize, re‑platform, or extend an existing LAMP solution, this guide breaks down exactly what to expect from professional LAMP Application Development Services—and when partnering with a Custom Software Development Company USA makes strategic sense.

2. What Is the LAMP Stack (Modern View)
Classic definition still stands—but today’s implementations are more flexible:
Linux – Often Ubuntu, Amazon Linux, or containerized base images.
Apache (or Nginx swap‑in) – Many shops run Apache behind an Nginx reverse proxy, or go all‑Nginx.
MySQL / MariaDB – Managed cloud DBs (RDS, Cloud SQL) reduce ops load.
PHP – Frequently PHP 8.x with Composer, frameworks like Laravel, Symfony, or legacy codebases.
Modern LAMP ≠ legacy only. Your services partner should support containers, CI/CD, caching, and API integration.
3. When You Should Explore LAMP Application Development Services
Consider professional LAMP help if you face any of the following:
Legacy App Drag: Older PHP 5/7 code that needs PHP 8 migration.
Scaling Traffic Spikes: Marketing campaigns, seasonal commerce, or SaaS growth.
Security & Compliance Pressure: Patch levels, encrypted data, access policies.
Multi‑App Consolidation: Merging several microsites into one managed platform.
Custom API Extensions: Exposing internal systems to partners, apps, or BI tools.
Cloud Cost Optimization: Refactor to use managed DBs, auto‑scaling compute, and caching layers.
4. Core Capabilities to Expect from a LAMP Services Partner
A mature provider of LAMP Application Development Services should deliver:
Architecture & Code Audits – Identify upgrade blockers, vulnerabilities, and performance bottlenecks.
Custom Application Development – New modules, dashboards, data entry flows, and user roles.
Framework Upgrades / Refactors – Modernize to Laravel/Symfony or harden legacy PHP.
Database Design & Optimization – Schema refactoring, indexing, query tuning, read replicas.
API & Integration Engineering – REST/GraphQL, auth tokens, SSO, ERP/CRM connectors.
Performance & Caching Strategy – Opcode caching, Redis, CDN, asset compression.
DevOps & CI/CD Automation – Git pipelines, container builds, staging → prod promotion.
Monitoring, Support & SLA Maintenance – Uptime, security patches, capacity planning.
5. Why Work with a Custom Software Development Company USA
If your market, data residency, compliance audits, procurement teams, or funding stakeholders are US‑based, aligning with a Custom Software Development Company USA can accelerate approvals and reduce risk.
Advantages:
US Contracts & IP Governance – Simplifies enterprise onboarding.
Timezone Alignment for Stakeholder Demos – Faster acceptance cycles.
Regulatory Familiarity – HIPAA, SOC 2, PCI���DSS, accessibility (Section 508 / WCAG).
Multi‑Stack Depth – LAMP + mobile apps + cloud + analytics under one umbrella.
Hybrid Delivery Models – Onshore strategy, offshore development for cost control.
8. Key Cost Drivers (Budget With Eyes Open)
Code complexity & legacy debt.
Framework modernization scope (plain PHP → Laravel).
Database scale, sharding, or replication needs.
Security compliance (pen tests, logging, audit trails).
Third‑party integrations (payments, analytics, SSO, ERP).
24/7 vs business‑hours support.
Onshore vs blended resource model (USA + global).
Request role‑based rate cards and a phased estimate: stabilize → optimize → extend.
9. Due Diligence Questions for LAMP Vendors
Technical
What PHP versions do you actively support? Any PHP 8 upgrade case studies?
How do you manage zero‑downtime DB migrations?
What caching layers do you recommend for high‑read workloads?
Security & Compliance
Patch cadence? Dependency scanning?
Experience with HIPAA / PCI hosting?
Process & Delivery
CI/CD tooling? Rollback strategy?
Communication rhythm (standups, demos, reports)?
Commercial
Do you offer fixed, T&M, or dedicated team pricing? Hybrid?
SLA tiers for uptime & response time?
10. SEO Implementation Tips for Your LAMP Services Page
To rank without keyword stuffing:
Use LAMP Application Development Services in the H1 or intro.
Reference geographic trust with Custom Software Development Company USA in a credibility or compliance section.
Add semantic variants: Linux hosting experts, PHP MySQL development, open‑source stack engineering.
Include structured data (Organization + Service schema).
Publish case studies with metrics: load speed, conversion lift, scaling stats.
Link internally to related stacks (PHP, Laravel, DevOps, Cloud Migration).
11. 10‑Step Implementation Roadmap (Copy + Adapt)
Business goals + technical baseline review.
Code & infrastructure audit (security, versioning, DB health).
Prioritize fixes vs new features.
Define hosting / cloud strategy (managed DB? containers?).
Upgrade PHP & dependencies (where needed).
Implement CI/CD + staging environments.
Add caching + performance instrumentation.
Build/refactor priority modules.
Security hardening + load validation.
Launch, monitor, iterate; move to managed support or dedicated team.
12. Final Takeaway & Call to Action
You don’t have to abandon proven systems to innovate. With the right LAMP Application Development Services partner—and especially when backed by a full‑spectrum Custom Software Development Company USA capable of compliance, scaling, and multi‑stack delivery—you can extend the life of existing assets and modernize for future growth.
Ready to evaluate vendors? Share your current stack (Linux distro, PHP version, DB size), performance pain points, and launch goals—I’ll help you outline a shortlist and next steps.
#LAMP Application Development Services#lamp development services#lamp stack development#lamp web development company
0 notes
Text
Identifying Memory Grant Contributors in SQL Server Query Plans
Introduction When optimizing SQL Server performance, it’s crucial to understand how memory grants are allocated to query plan operators. Excessive memory grants can lead to inefficient resource utilization and impact overall system performance. In this article, we’ll explore practical T-SQL code examples and techniques to determine which operators are contributing the most to memory grants in…

View On WordPress
#execution plan operators#memory grant troubleshooting#performance tuning in SQL Server#query plan analysis#SQL Server memory optimization
0 notes
Text
SQL Query Optimization and performance tuning | SQL Tutorial for Beginners in Hindi
In this video we have discussed tips and tricks by which we can optimize any SQL query and improve performance. LinkedIn: … source
0 notes
Text
How can SAP HANA performance be tracked and improved?
SAP HANA performance can be tracked using tools such as the SAP HANA Cockpit, SQL Plan Cache, Performance Trace, and the SAP HANA Studio. These tools help monitor memory usage, CPU load, expensive SQL statements, and disk I/O. Regularly analyzing SQL statements using the SQL Analyzer and identifying long-running or high-resource queries is key. Indexes, partitioning, and data modeling practices—like using column store over row store and minimizing joins—can significantly improve performance. Data aging and archiving strategies also help by reducing the in-memory data footprint.
To improve performance, developers should optimize data models, avoid unnecessary data replication, and use appropriate compression. Monitoring alerts and logs can help identify and troubleshoot performance bottlenecks in real-time. System updates and patching should also be kept up-to-date to benefit from SAP’s latest performance improvements.
As a student of Anubhav Oberoy’s SAP HANA training, I found his sessions incredibly insightful.

His real-time examples and performance tuning strategies helped me understand not just the "how" but the "why" behind optimization techniques. His approach makes complex topics simple and applicable in real-world scenarios, which significantly enhanced my confidence and skillset in SAP HANA.
#online sap training#online free sap training#sap ui5 training#online sap ui5 training#free sap training#ui5 fiori training#sap abap training
0 notes
Text
Database Design & Development Services India | Empowering Businesses with NRS Infoways
In today's digital era, data is the lifeblood of any successful organization. Managing this data efficiently requires robust database systems that are secure, scalable, and tailored to unique business needs. NRS Infoways, a leading IT company, offers comprehensive Database Design & Development Services in India to help businesses streamline operations, improve decision-making, and achieve long-term growth.
Why Database Design & Development Matters
A well-structured database is essential for businesses of all sizes. Whether it's managing customer records, handling inventory, or analyzing sales trends, a reliable database system ensures data accuracy, fast access, and high security. Poor database design can lead to data inconsistencies, performance issues, and costly downtime.
This is where NRS Infoways steps in—with years of experience and a skilled team of database architects and developers, we provide top-tier Database Design & Development Services in India that align with your business goals.
What We Offer at NRS Infoways
At NRS Infoways, we believe every business is unique, and so are its data management needs. Our services cover a wide spectrum of database solutions designed to cater to both simple and complex business environments.
1. Custom Database Design
We begin with an in-depth understanding of your business processes and data flow. Our experts create custom database architectures that ensure optimal performance, scalability, and security. We handle everything from ER modeling and schema design to normalization and indexing strategies.
2. Database Development
Our team uses cutting-edge technologies to build secure and robust databases that integrate seamlessly with your existing systems. Whether you require relational databases like MySQL, PostgreSQL, MS SQL Server, or NoSQL solutions like MongoDB or Cassandra, we've got you covered.
3. Migration & Integration
Need to move your data from an outdated system to a modern one? Our seamless data migration and integration services ensure zero data loss and minimal downtime. We also offer legacy system modernization to improve efficiency.
4. Performance Optimization
An efficient database should be fast and responsive. We regularly monitor and fine-tune databases for performance, ensuring quick query response times and reduced system load.
5. Data Security & Backup
At NRS Infoways, data security is a top priority. We implement multi-layered security measures, including access control, encryption, and regular backups, to protect your business data from breaches or loss.
6. Support & Maintenance
Our job doesn't end with deployment. We provide ongoing support and maintenance services to ensure your database operates smoothly and continues to meet evolving business needs.
Industries We Serve
Our Database Design & Development Services in India are tailored for various industries, including:
E-commerce
Healthcare
Banking & Finance
Logistics & Supply Chain
Education
Real Estate
Travel & Hospitality
No matter your industry, we design and develop database systems that enhance productivity and deliver insights for better decision-making.
Why Choose NRS Infoways?
Expert Team: Our certified database developers and architects bring deep technical expertise and industry knowledge.
Custom Solutions: We build solutions specifically tailored to your business requirements.
Affordable Pricing: High-quality services at competitive rates.
Client-Centric Approach: Transparent communication, timely delivery, and dedicated support.
Latest Technologies: We stay up to date with the latest database platforms and development frameworks.
Let’s Build Your Data Backbone
With NRS Infoways’ Database Design & Development Services in India, you gain a trusted partner who understands the critical role of data in driving business success. Whether you're building a new system from scratch or upgrading an existing one, we ensure your data works as hard as you do.
Ready to optimize your data infrastructure? Connect with NRS Infoways today and let us turn your data into a strategic business asset.
0 notes
Text
Top 10 Database Formulas Every Beginner Should Know

Databases are the foundation of nearly every application you use — from banking apps to Instagram feeds. But behind the scenes, they rely on powerful (yet simple) logic to store, retrieve, and process data.
In this post, we break down 10 essential formulas and concepts that power SQL and database systems. Whether you're a student, aspiring backend developer, or just curious — these are the must-knows.
Why These Formulas Matter Understanding these basics helps you:
Write better SQL queries
Design efficient schemas
Scale large databases
Tune performance and avoid bugs
Let’s get into it.
1. SELECT + WHERE Clause Formula: SELECT column_name FROM table_name WHERE condition;
Explanation: Retrieves only the data you want — filtering rows based on criteria.
2. JOINs (INNER, LEFT, RIGHT) Formula: SELECT * FROM A INNER JOIN B ON A.id = B.id;
Explanation: Combines data from two or more tables based on relationships.
3. Aggregation Functions Formula: SELECT COUNT(*), SUM(sales), AVG(price) FROM products;
Explanation: Summarizes your data with totals, averages, and more.
4. Normalization Rules Concept: 1NF → 2NF → 3NF
Explanation: Breaks complex tables into smaller ones to eliminate redundancy.
5. ACID Properties Formula:
Atomicity
Consistency
Isolation
Durability
Explanation: Ensures your database transactions are reliable and safe.
6. Index Search Time (B-Tree) Formula: Search time ≈ O(log n)
Explanation: Why indexes speed up queries — like a binary search tree.
7. CAP Theorem Concept: Pick 2 of 3: Consistency, Availability, Partition Tolerance
Explanation: No distributed system can guarantee all three simultaneously.
8. Sharding Function Formula: shard_id = user_id % number_of_shards
Explanation: Evenly distributes data across multiple servers to scale large systems.
9. Hash Partitioning Formula: partition = hash(key) % num_partitions
Explanation: Maps data to specific storage buckets for faster access.
10. Query Cost Estimation Conceptual Formula: Total Cost = CPU + I/O + Network Latency
Explanation: Helps the database decide the fastest way to run your query (used in EXPLAIN plans).
Final Thoughts These formulas power nearly every modern web or mobile app. Understanding them makes you a better developer, architect, or analyst.
Bookmark this list or turn it into a personal cheat sheet.
Coming next in the series:
Top 10 Statistics Formulas
Top 10 Cybersecurity Formulas
Top 10 Cloud & Big Data Formulas
Follow Uplatz for more hands-on guides and cheat sheets.
1 note
·
View note
Text
SQL Server Courses Online Free: Start Learning & Get Job-Ready

SQL Server Courses Online Free: Start Learning & Get Job-Ready
In today’s competitive tech world, data drives everything. Companies are increasingly leaning on databases to manage, analyze, and extract value from massive datasets. If you're looking to kickstart a high-paying tech career, learning SQL Server can be your golden ticket—especially when you can access SQL Server courses online free and gain job-ready skills without spending a penny.
Before diving deep into this opportunity, it’s also worth checking out our guide to SQL Server interview questions to prepare yourself for your next role in database administration or backend development.
Let’s explore how the right free SQL Server course can shape your career path, and even how it fits into the roadmap of becoming a .NET Solution Architect.
Why SQL Server Skills Are a Game-Changer in 2025
Microsoft SQL Server continues to dominate as a powerful, scalable, and versatile relational database management system (RDBMS). Whether you're managing databases for large enterprises or developing applications that rely on structured data, proficiency in SQL Server is a must-have.
In 2025, employers are no longer just hiring based on degrees—they're hiring based on demonstrable skills. And what better way to prove your value than by completing SQL Server courses online free?
Benefits of Choosing SQL Server for Your Career
1. High Demand Across Industries
From healthcare to finance, retail to tech startups, SQL Server is used everywhere. The demand for SQL experts is steadily growing, and free online courses help eliminate the barrier to entry.
2. Complements Your .NET Development Journey
If you’re eyeing a future as a .NET Solution Architect, learning SQL Server is essential. Back-end development with .NET often involves SQL Server for database design, querying, and performance tuning.
3. Opportunity to Work with Real-World Tools
Many SQL Server courses online free offer training in tools like SSMS (SQL Server Management Studio), Azure SQL Database, and more. These are the very tools used in production environments.
What You’ll Learn in SQL Server Online Free Courses
1. SQL Basics and Syntax
Start from the fundamentals: writing SELECT, INSERT, UPDATE, and DELETE queries, and understanding how databases are structured.
2. Database Design and Normalization
Learn how to design robust databases using normalization techniques, keys, and constraints to ensure data integrity.
3. Stored Procedures and Functions
Create stored procedures to encapsulate business logic inside your database. Learn about triggers, views, and functions.
4. Performance Tuning
Discover indexing strategies, execution plans, and query optimization—critical skills for enterprise-scale databases.
5. Security and Backup Strategies
Understand user authentication, roles, and backup strategies to keep your data safe and reliable.
Top Free Online Platforms Offering SQL Server Training
Microsoft Learn
Microsoft’s official platform offers detailed, structured courses ranging from beginner to advanced SQL Server concepts.
Coursera (Audit Mode)
Many courses offer free access if you opt-out of the certificate. Institutions like Stanford and the University of Michigan offer SQL learning through this mode.
Udemy Free Courses
Several free SQL Server courses are available on Udemy that cover database fundamentals and advanced queries.
Khan Academy & Codecademy
While not SQL Server-specific, they offer a great starting point in SQL which transitions well into SQL Server.
From Learning SQL to Becoming a .NET Solution Architect
Once you've completed SQL Server courses online free, the next step could be expanding your backend development knowledge into the .NET ecosystem.
Here’s a quick roadmap:
Master C#: Core programming language for .NET development
Understand ASP.NET Core: For building web APIs and backend services
Dive into Entity Framework: For ORM-based interaction with SQL Server
Architectural Patterns: Learn about MVC, microservices, and clean architecture
Cloud Integration: Azure DevOps, Azure SQL, and CI/CD pipelines
Completing this roadmap prepares you for one of the most in-demand positions today: .NET Solution Architect.
SQL Server Certification: Should You Go for It?
After mastering the concepts through free courses, you might consider official certification. Certifications like “Microsoft Certified: Azure Database Administrator Associate” can add more weight to your resume.
However, don’t rush. Build your foundational skills first, then decide if the investment in certification aligns with your goals.
Real-World Applications of SQL Server Skills
Backend Development: Manage application data in scalable ways.
Business Intelligence: Use SSRS and SSIS for reporting and data transformation.
Data Analysis: Write complex queries to derive actionable insights.
Cloud Data Solutions: Work with Azure SQL Database to manage cloud-native applications.
Common Mistakes to Avoid While Learning
1. Ignoring Schema Design
A poorly designed schema leads to slow queries and data inconsistencies.
2. Memorizing Instead of Practicing
SQL is best learned by doing. Use sandboxes and real datasets for practice.
3. Skipping Performance Optimization
In large-scale applications, performance tuning can make or break the user experience.
Community Support & Career Opportunities
SQL Server has a vibrant global community. From Stack Overflow to Reddit and specialized forums, you'll never feel alone in your learning journey.
As for jobs, SQL Server expertise is a must-have for roles such as:
Database Administrator (DBA)
Backend Developer
Data Analyst
DevOps Engineer
.NET Solution Architect
In the middle of your learning journey, completing SQL Server courses online free gives you both theoretical and practical knowledge that puts you ahead of other candidates in interviews and promotions.
Final Thoughts: Your Career Starts Here
Whether you're a student, career switcher, or IT professional looking to upgrade your skillset, there’s no better time than now to begin. By leveraging SQL Server courses online free, you're equipping yourself with real-world skills that are in high demand.
So don’t wait for an opportunity—create one. Start learning today and lay the foundation for a career in backend development or even a transition into a .NET Solution Architect role. Your future begins with a simple query—quite literally.
FAQs
What is the difference between SQL and SQL Server?
Answer: SQL is a language used to query databases. SQL Server is Microsoft’s relational database management system that uses SQL to manage data.
How long does it take to learn SQL Server?
Answer: With consistent effort, you can grasp the basics in 2-4 weeks. Advanced concepts may take 2-3 months of regular practice.
Can I get a job just by learning SQL Server?
Answer: Yes, many roles like data analyst, support engineer, and junior DBA require SQL Server skills. Pair it with another skill like C# or Power BI to increase your opportunities.
Do I need to install SQL Server on my machine?
Answer: You can, but many online courses provide browser-based environments or use cloud services like Azure SQL to practice.
Is SQL Server suitable for freelancers?
Answer: Absolutely. Many small to medium businesses use SQL Server and need part-time or contract-based support.
Is SQL Server harder than MySQL or PostgreSQL?
Answer: Not necessarily. The core SQL is the same. SQL Server has some enterprise features that take time to learn, but the basics are easy to pick up.
What roles can I apply for after learning SQL Server?
Answer: Database Developer, SQL Analyst, Business Intelligence Developer, and even DevOps Engineer roles require SQL Server skills.
Can I learn SQL Server without prior programming knowledge?
Answer: Yes. SQL is declarative and simpler to understand than most programming languages. You can start as a complete beginner.
Will learning SQL Server help in Data Science?
Answer: Definitely. SQL is foundational for data querying and transformation in data science pipelines.
What software do I need to practice SQL Server?
Answer: You can use SQL Server Express (free), SSMS (SQL Server Management Studio), or cloud platforms like Azure SQL Database.
1 note
·
View note
Text
Aaron Bertrand : More showplan improvements? Yes, please!

Aaron Bertrand (@AaronBertrand) highlights a handful of Connect items aimed at improving SQL Server showplan diagnostics and query tuning in general. Continue reading… SQLPerformance.com SQLPerformance.com is about providing innovative and practical solutions for improving SQL Server performance. Whether you are running a 3rd party application database where very little can be changed, or you are a DBA at a site where getting the application developers to change anything is next to impossible, industry experts including Paul Randal, Jonathan Kehayias, Erin Stellato and Paul White will cover both the “how” and the “why.”
0 notes