#Spectrogram Charts
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
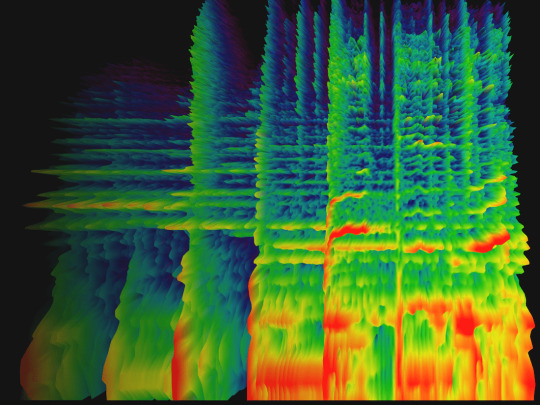
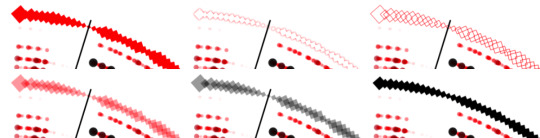
Doing testing on using the spectrograms for manually spotting AI generated music, and so far more people get over 50% than they do below, but the accuracy still isn’t high enough for my liking…
However, results are also likely highly dependent on how well each individual can read the contrast of the spectrogram and to what degree they believe the contrast matches either AI or human. So, I believe with practice or training, an individual can increase their accuracy in using the chart to spot spectrograms that are more likely AI than human 🤔 just like how you get better at picking out AI images with practice, even ones that are more convincing
However, over sampling 30+ spectrograms of both AI and human, there is the occasional one that looks similar to the other, but if found this to exceedingly rare. The one that was the closest to human spectrograms was an AI jazz song, which even to me looked indistinguishable. But I have yet to see a human one that is as washed out as AI ones, and they pretty much never have a flat yellow line at the bottom.
It is unlikely this test would ever be the only one needed in determining an AI song to human, but I believe it could end up being a good tool to use among other tools, namely human intuition, listening for common synthetic AI voices/compositions, generic lyrics, lack of credits, weird behavior from the uploader, etc etc.
When I have more to share I will 🤔
#AI#music#spectrogram#ai music#reminds me of when someone kept putting blatany wrong info about furries on a page about them and claimed u weren’t furry if you were-#-in fandoms like the lion king. so I got pissed and surveyd like 100 people to prove him wrong which it did#and then I went back with the source and fixed the page and told him politely he was wrong and I had proof#he got so mad that he left the entire website. and here I am getting pissed at someone and then obsessively trying to prove them wrong#again… lmaooooo….#anyways. my accuracy at picking whether a spectrogram is ai or human is higher than average because I’m the one who made the test and chart#and uhhh let’s just say all of dudes spectrograms fall within appears like ai. and follow the generic way most Suno songs look#Suno is reeeeeally bad with the washed out quality of its spectrograms even tho all ai ones have poor contrast…#additionally there’s a higher percentage of testers who also identify 7 of his songs as more likely being ai spectrograms :)#but I do want to prove the accuracy can be higher so as to increase the likelihood of these answers being correct
1 note
·
View note
Text
I mean like.
stylistic stuff.
biomechanics of like. what muscles or sensations u should try and look for to know u are getting the desired effect.
encouragement
We need more people who do voice training that aren't yanks. How many excellent transgender regional accents are lost to the painful american twang of YouTube voice training tutorial? Even one is too many and it's so many more than that
#eg 'is this my falsetto or not' <- helps to know that you can test by sliding down and seeing if there's a stop.#idk. im a sicko but I think the exercises and ear training stuff is more helpful than a spectrogram and a vowel F1 F2 chart#I tbh have the reverse I feel like it's hard to find the American accent that sounds good like. either I go waaaay too valley girl#or I end up British. bc of ur country's monopoly on podded casts
1K notes
·
View notes
Text
Spectrogram (1959), Hugh le Caine
The Spectrogram, shown here as it was in 1966, was used to control the output of the Sine bank, or the Multi-track (Special Purpose) Tape Recorder. The chart paper moved past a series of light sensitive switches and was illuminated by the light above the instrument. When the light was blocked by a darkened area of the paper, the sound generator would be turned on.

#Spectogram#Hugh le Caine#Oramics predecessor#early electronic music#visual synthesisers#music from light receptors
0 notes
Text
All Things Linguistic - 2022 Highlights
2022 was a year of opening up again and laying foundations for future projects. I spent the final 3 months of it on an extended trip to Singapore, Australia, and New Zealand, which is a delightful reason to have a delay in writing this year in review post.
Interesting new projects this year included my first piece in The Atlantic, why we have so much confusion on writing the short form of "usual" and 103 languages reading project: inspired by a paper by Evan Kidd and Rowena Garcia.
Continuations of existing projects:
Return of LingComm Grants
A survey for those using Because Internet for teaching
10 year Blogiversary of All Things Linguistic: highlights from the past year and highlights from the past decade
6 years of Lingthusiasm
Conferences/Talks
LSA 2022 and judging Five Minute Linguist
I was on panels about swearing in SFF and the Steerswoman books at a local literary speculative fiction con, Scintillation
I was on panels at WorldCon (ChiCon 8) in Chicago: Ask A Scientist, That's Not How That Works!, and Using SFF for Science Communication
I was a contestant for the second time in Webster's War of the Words, a virtual game show fundraiser for the Noah Webster House.
I attended the Australian Linguistics Society annual meeting in Melbourne and the New Zealand Linguistics Society annual meeting in Dunedin, where I gave a talk co-authored with Lauren Gawne called Using lingcomm to design meaningful stories about linguistics
Lingthusiasm
In our sixth year of Lingthusiasm, a podcast that’s enthusiastic about linguistics which I make with Lauren Gawne and our production team, we did a redesign of how the International Phonetic Alphabet symbols are layed out in a chart, in order to correspond more closely with the principle that the location of a symbol is a key to how it's articulated. This involved much digging into the history of IPA layouts and back-and-forths with our artist, Lucy Maddox, and we were very pleased to make our aesthetic IPA design available on a special one-time edition of lens cloths for patrons as well as our general range of posters, tote bags, notebooks, and other all-time merch.
We also did our first Lingthusiasm audience survey and Spotify for some reason gave us end-of-year stats only in French, which I guess is on brand, but we were pleased to see notebooks, and Lingthusiasm is one of Spotify's top 50 Science podcastsF/href.li/?https:/www.redbubble.com%2Fi%2Fmouse-pad%2FAesthetic-IPA-Chart-Square-by-Lingthusiasm%2F129215087.G1FH6&t=OTkxYjYxYjNmMzA1M2VhNGViOGIxZWIxOGI0NDRjYjE2YTIzYTE2NCw2YTgzNDQyZTM3MzY0YjRkNjc3NGJkNzhhYzJhMzk3ZjA2Y2NkYzIz&ts=1684794278">other all-time merch!
Main episodes from this year
Making speech visible with spectrograms
Knowledge is power, copulas are fun.
Word order, we love
What it means for a language to be official
Tea and skyscrapers - When words get borrowed across languages
What we can, must, and should say about modals
Language in the brain - Interview with Ev Fedorenko
Various vocal fold vibes
What If Linguistics
The linguistic map is not the linguistic territory
Who questions the questions?
Love and fury at the linguistics of emotions
Bonus Episodes
We interview each other! Seasons, word games, Unicode, and more
Emoji, Mongolian, and Multiocular O ꙮ - Dispatches from the Unicode Conference
Behind the scenes on how linguists come up with research topics
Approaching word games like a linguist - Interview with Nicole Holliday and Ben Zimmer of Spectacular Vernacular
What makes a swear word feel sweary? A &⩐#⦫&
There’s like, so much to like about “like”
Language inside an MRI machine - Interview with Saima Malik-Moraleda
Using a rabbit to get kids chatting for science
Behind the scenes on making an aesthetic IPA chart - Interview with Lucy Maddox
Linguistics and science communication - Interview with Liz McCullough
103 ways for kids to learn languages
Speakest Thou Ye Olde English?
Selected Tweets
Linguistics Fun
aunt and niece languages
Swedish chef captions
IPA wordle
wordle vs kiki
creative use of emoji and space
resume glottal stop
dialects in a trenchcoat
which of these starter Pokemon is bouba and which is kiki
(for no author would use, because of the known rendolence of onions, onions)
acoustic bike
An extremely charming study by Bill Labov featuring a rabbit named Vincent
Rabbit Meme
Cheering on linguistics effects (Stroup and Kiki/Bouba) in a vote on the cutest scientific effect name
Old English Hrickroll
The word you get assigned with your linguistics degree
Sanskrit two-dimensional alphabet
Cognate Objects
Linguist Meetup in Linguaglossa?
baɪ ði eɪdʒ ʌv θɚti
j- prefixing
"But clerk, I am Bill Labov" (pagliacci meme)
Usual winner
Because Internet Tumblr vernacular
Linguist "Human" Costume
Cursed kiki/bouba
dot ellipsis vs comma ellipsis
intersection of signed languages and synesthesia?
Antipodean linguistic milestone
Selected Blog Posts:
Linguistic Jobs
Online Linguistics Teacher
Impact Lead
Customer Success Manager
Hawaiian and Tahitian language Instructor, Translator & Radio Host
Language Engineer
Data Manager & Digital Archivist
Linguistics fun
xkcd: neoteny recapitulated phylogeny
Eeyore Linguistic Facts
Lingthusiasm HQ: Frown Thing!
xkcd is making a vowel hypertrapezoid
Title: Ships and Ice Picks: An Ethnographic Excavation of alt.goncharov
Missed out on previous years? Here are the summary posts from 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, and 2021. If you’d like to get a much shorter monthly highlights newsletter via email, with all sorts of interesting internet linguistics news, you can sign up for that at gretchenmcc.substack.com.
44 notes
·
View notes
Text
That's a good additional deep dive into the account, here's my thoughts:
I'm not a music person, but I haven't been able to find an easy to access, reliable service or software that can determine an AI generated song from a human one. The most accurate I can tell is just human pattern seeking- listening to enough AI to squint when you think something is AI.
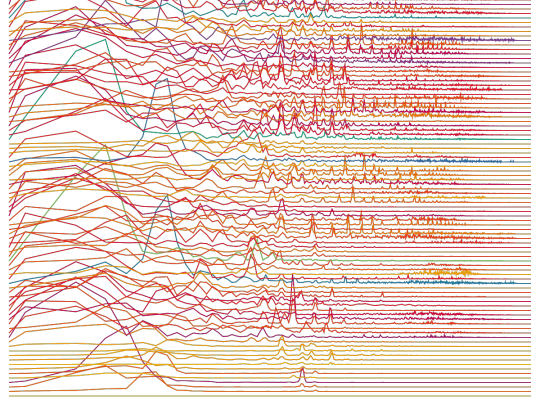
...I did however get a little crazy not having a easy reliable way to do that, and came up with... eyeballing spectrograms. Not enough testing outside of myself and 3 others to determine how accurate it is in general at assisting humans in categorizing AI vs. human made correctly, but I will say that all the Church of Null spectrograms I looked at fall closer into the "looks like AI spectrograms" side of the chart (the songs included are top down, left right: Silly Cynmas, Hail, Hymn of Cyn, Message for Mankind, Transcend, Jax song).
As for audacity, those screenshots are weird, too. As far as I can tell, Audacity does not come with a native way to show the file extensions on the names of imported files (it never does for me, and I could not find a preference option). Looking it up yielded "it doesn't have that option," as recently as 2024. To get the file extensions to show, you either re-name the files themselves (so, blahblah.wav.wav in file explorer) or you rename the track by hand in audacity. I don't know why EI would do that. It's just a weird detail, could mean something (an attempt to prove it isnt Suno, as Suno downloads as mp3) or nothing (dude just renames them for personal reasons). However I don't believe showing audacity means anything because I can make something look like that and I know nothing about music. Behold, five minutes in audacity:
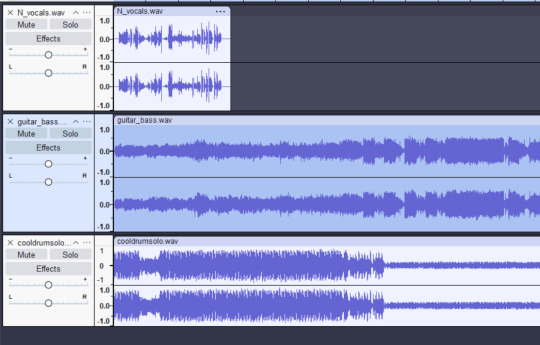
I think the entire story is bogus and/or embellished. A lot of the details aren't technically impossible, but they are weird, coupled with how similar many of the songs and vocals sound to other Suno songs and vocals (the ones linked on the original post). I don't think anybody can make this much high quality music, for free, just for their fanfic, 3-4 times a month, or that with the quality of the compositions and vocals that nobody involved with it desire credits. There are 6 "cores" who supposedly record their voices or lend instrumentals for these, according to EI, so there are 6 unknown people plus that weird YT channel (of which was created the same yr EI's channel was, in 2015). Even as EI puts some of these songs on Spotify, supposedly not a one wants credit. A big red flag on AI playlists that I've been told to look out for is lack of credits, and EI has squat in that department. It's just a really, really weird story.
So, I believe that if there is anything human added in, it is added in after the songs have been generated with an AI, and based on my experience both listening to a copious amount of and generating songs with Suno, it sounds like Suno is that AI. I think EI is a liar. Additionally, EI is so adverse to accusations of AI usage that they have manual comment moderation on all the YT videos and deleted multiple comments on the fanfic asking about the linked music being AI generated- before turning off anon commenting all together to attempt to prevent that. The only AI questions I saw allowed in was I believe 1-2 on the first video, so if anybody out there ALSO thinks it could be AI, EI certainly is not letting those comments through.
Church of Null is definitely using AI for its songs... not even gonna twiddle my thumbs with the "maybes" anymore :^P
After being convinced Church of Null is using Suno AI despite the song generator artist's claim that it isn't AI, I did further research by.. gag... making a Suno AI account to look more closely at MD generated songs on the platform, including their voices.
I found two accounts that, while I don't think that they're Electrical Ink, are certainly in the same vein and later on were inspired by them. They're perfect examples of Suno AI voices, compositions, and lyrics that are incredibly similar to all Church of Null songs.
The first is The Solver, who was making MD AI songs before Electrical Ink, but who is too Uzi focused to make me think they're the same person. (click read more to check the comparisons out).
First MD AI song on the account (Oct 2) , the first one uploaded by Electrical Ink was Oct 7th
First Cyn song on their Suno (Oct 16)
This voice vs. Electrical Ink's Jax song
This AI N song with the same voice as Church of Null's N song, but the Suno AI generated one came first (Oct vs. Dec)
This account starts making church themed Cyn/Cyn worship songs in Nov, but it's possible these were inspired by the Church of Null ones (a few of the early songs did get 50k+ views). Here's one of them.
The second is supreme_solver, who made a handful of Cyn heavy AI songs, including one referencing Church of Null. This account made their first MD song on Oct 20th. They made a Church of Null song on Nov 11th, using the same male AI voice on many of the Church of Null songs.
Nothing will give you an ear for AI generated music and lyrical habits like listening to them for like, two hours. Kill me.
The Church of Null songs are, definitively, 100%, AI generated songs, and Electrical Ink is just a plain ol' internet liar who didn't want to be dismissed or demeaned for using AI. But, I think lying about it is worse than just using it and owning up to it. And pretending to have 6 friends/“coworkers” who adore your fic and help with it and the songs when really it’s just a bot churning AI slop out is incredibly depressing.
Also, Electrical Ink appears to have manually comment moderation on, meaning only comments manually allowed will show. I thought it was a word filter for AI words, but no comment I make shows up when I'm logged out, so comments aren't being auto approved, meaning manual is turned on (that's how you check if your comment was removed/not posted; it will show to you if logged in, but will be gone when logged out/viewed by others). So, if anybody were to suggest AI, it would be unlikely to be approved (mine asking 'Suno' 3 days ago was not).
Okay. I'm done with this sleuthing now :P don't think anybody cares much about CoN anyways. But what a load of AI dude-bro tomfuckery. I'm tired of AI people playing pretend to get headpats and taking up spots from real human musicians and artisans, then blatantly lying to your face about it (lookin at u, DA AI spam accounts, and AI slop farms on Spotify).

20 notes
·
View notes
Text
Superlinguo 2022 in review
At the start of 2022 it was my aim to move gently through this year, after the general global upheaval the pandemic brought, and settling back into work after parental leave. I mostly think managed that for myself, and things worth sharing still happened this year.
Lingthusiasm
Lingthusiasm turned 6 this year. As well as regular episodes and bonus episodes every month, this year we ran a special offer for patrons and did a one-off print run of lens cloths with our redesigned aesthetic IPA.
Main episodes
Love and fury at the linguistics of emotions (transcript)
Who questions the questions? (transcript)
The linguistic map is not the linguistic territory (transcript)
What If Linguistics - Absurd Hypothetical Questions with Randall Munroe of xkcd (transcript)
Various vocal fold vibes (transcript)
Language in the brain - Interview with Ev Fedorenko (transcript)
What we can, must, and should say about modals (transcript)
Tea and skyscrapers - When words get borrowed across languages (transcript)
What it means for a language to be official (transcript)
Word order, we love (transcript)
Knowledge is power, copulas are fun (transcript)
Making speech visible with spectrograms (transcript)
Bonus episodes
Speakest Thou Ye Olde English?
103 ways for kids to learn languages
Linguistics and science communication - Interview with Liz McCullough
Behind the scenes on making an aesthetic IPA chart - Interview with Lucy Maddox
Using a rabbit to get kids chatting for science
Language inside an MRI machine - Interview with Saima Malik-Moraleda
There’s like, so much to like about “like”
What makes a swear word feel sweary? A &⩐#⦫& Liveshow
Approaching word games like a linguist - Interview with Nicole Holliday and Ben Zimmer of Spectacular Vernacular
Behind the scenes on how linguists come up with research topics
Emoji, Mongolian, and Multiocular O ꙮ - Dispatches from the Unicode Conference
LingComm: 2022 grants and conference posts
This year we ran another round of LingComm Grants, and we’ve been enjoying seeing new linguistic communication projects come to life. We also published summaries of top tips from plenary panels of the 2021 LingComm conference, and I teamed up with Gabrielle Hodge to write about how to plan communication access for online conferences. The LingComm conference will be back in 2023!
Tips for LingComm series
Planning communication access for online conferences: A Research Whisperer post about LingComm21
LingComm23 conference (February 2023)
2022 LingComm Grantees: New linguistics projects for you to follow
Top Superlinguo posts in 2022
Superlinguo remains a place where I can test out ideas or share things that aren’t necessarily the shape of an academic publication. I also continued my slow series of posts about linguistics books for kids, with a gem from 1966!
General posts
Superlinguo turns 11!
New Superlinguo Welcome page
Linguistics books for kids: How You Talk
Long form blog posts
Notes and observations about air quote gestures
Fictional gestures in scifi and fantasy
Information and advice
Doing your own Linguistics Job Interviews
Planning communication access for online conferences: A Research Whisperer post about LingComm21
Managing Breakout Rooms in online Tutorials and Workshops
Adopting the Trømso Recommendations in academic publishing
Linguistics Job Interviews
In 2022 the Linguistics Job Interviews series was edited by Martha Tsutsui-Bilins. After 8 years and 80+ interviews, the regular monthly series is coming to an end. There were 12 new interviews this year:
Interview with a Director of Conversation Design
Interview with an Artist
Interview with a Research Scientist
Interview with a Language Engineer
Interview with a Data Manager & Digital Archivist
Interview with a Natural Language Annotation Lead
Interview with an EMLS/Linguistics instructor & mother of four
Interview with a Performing Artiste and Freelance Editor
Interview with a Hawaiian and Tahitian language Instructor, Translator & Radio Host
Interview with a Customer Success Manager
Interview with an Impact Lead
Interview with an Online Linguistics Teacher
Regular interviews may have ended, but I’ll have more on linguistics, jobs and careers in 2023. I also wrote this post about doing your own Linguistics Job Interviews, to encourage other people to share their stories or interview others about their experiences.
Academic articles in 2022
This year I had two academic articles published. I also published one academic review of a monograph:
Gawne, L. & S. Styles. 2022. Situating linguistics in the social science data movement. In A.L. Berez-Kroeker, B. McDonnell, E. Koller & L.B. Collister (Eds), The Open Handbook of Linguistic Data Management, 9-25. MIT Press. [Open Access PDF][Superlinguo summary]
Gawne, L. & T. Owen-Smith. 2022. The General Fact/Generic Factual in Yolmo and Tamang. Studies in Language. Issue number forthcoming doi: 10.1075/sl.21049.gaw [published version][Green OA version][blog summary]
Gawne, L. 2022. Review of Repetitions in Gesture by Jana Bressem. The Linguist List. [HTML]
The year ahead
I will be on parental leave in 2023 🎉
Last time I went on leave with a newborn I had no idea if I would have a job to return to. I’m very grateful to not have that stress hanging over me this time around. Lingthusiasm will continue as regularly scheduled. It will be interesting to see how things here go without the monthly job interview posts. I’ll still have new publications, and various linguistics resources and observations to share, if maybe on a less than weekly basis. You can always follow Superlinguo on Tumblr @superlinguo), join the mailing list (in the sidebar), go retro and use the RSS feed, or follow me on Twitter (@superlinguo)
Previous years
Superlinguo 2021 in review
Superlinguo 2020 in review
Superlinguo 2020 (2019 in review)
Superlinguo 2019 (2018 in review)
Superlinguo 2018 (2017 in review)
Superlinguo 2017 (2016 in review)
Superlinguo 2015 highlights
61 notes
·
View notes
Text
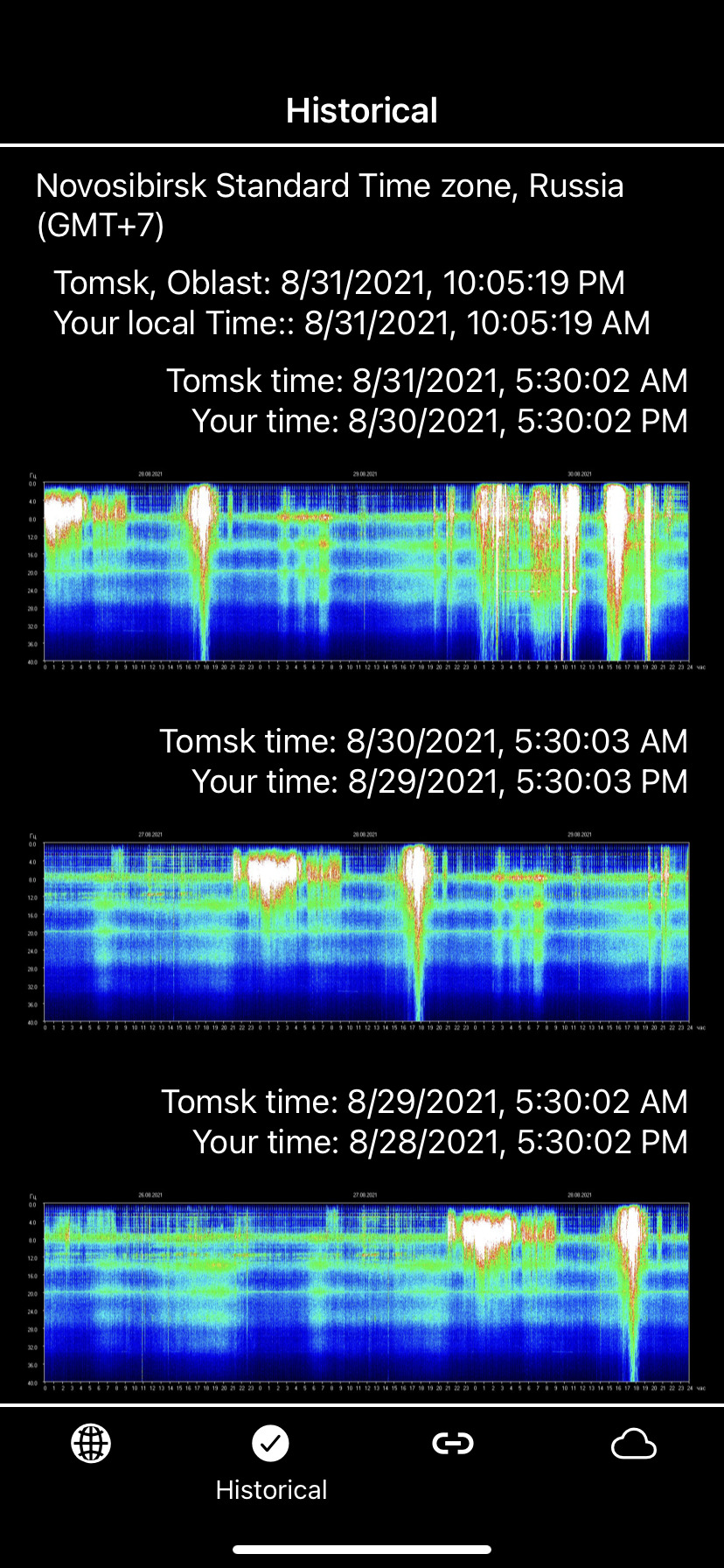
“The Schumann resonances (SR) are a set of spectrum peaks in the extremely low frequency (ELF) portion of the Earth’s electromagnetic field spectrum. Schumann resonances are global electromagnetic resonances, generated and excited by lightning discharges in the cavity formed by the Earth’s surface and the ionosphere. … In the normal mode descriptions of Schumann resonances, the fundamental mode is a standing wave in the Earth-ionosphere cavity with a wavelength equal to the circumference of the Earth.” (Wikipedia)
Now, to the chart (“spectrogram”).
DATES: Look at the top of the chart. You’ll see that the chart divides into three-day sequences, with the dates printed across the top horizontal of the chart. Dates move left to right, most recent on the right.
TIMES: Next, look at the the bottom of the chart. You’ll see the times, which present in a 0-24 hour sequence, one block of 24 hours for each corresponding date above. The chart uses local Tomsk (Siberia) time which is GMT+7. You’ll need to convert the chart times to your local time. I’m in the US, so the equivalents here are:
United States Conversions:
Eastern (GMT-4): Chart minus 11 hrs
Central (GMT-5): Chart minus 12 hrs
Mountain (GMT-6): Chart minus 13 hrs
Pacific (GMT -7): Chart minus 14 hrs
SR VALUES: Now look at the left vertical side of the chart. These numbers represent the framework for reading the Schumann Resonance peak values — lowest at top progressing to the highest at bottom, in increments of 4 Hz. SR frequencies are relatively stable and do not change. Also, there is not just one SR frequency, but an array of peak frequencies. The SR values cover a range from 3 Hz to 60 Hz, with set values at intervals roughly 6.5 Hz apart, except for the lowest value, 4.11. Because different authorities post slightly different values for the SR peaks, here are the rounded off SR peak values pretty much agreed upon universally: 4, 7.83 (fundamental SR), 14, 20, 26, 33, 39, 45, 59. All measured in Hz or cycles per second.
The SR frequencies are read ACROSS or HORIZONTALLY, usually in the green intensity shade. You can easily track a specific frequency through the 3-day cycle. You’ll see that the green lines typically indicate at the 7.83, 14, 20, and 26 Hz frequencies. Other frequencies you’ll see, less frequently, are the lowest, 4 Hz, and the 33 Hz and higher.
SR AND HUMAN BRAINWAVES: Here’s the cool part: These Schumann Resonance ELF (Extremely Low Frequency) waves in the Earth’s magnetic field just happen to OVERLAP with the electrical patterns (“brain waves”) observed across the cortex of the human brain. Studies have shown that SR frequencies have particular effects on the human brain and nervous system, the cardiovascular system, the autonomous nervous system, circadian rhythms, immune function, DNA, and more. The fundamental Schuman Resonance, 7.83 Hz, corresponds to the high theta of the human brainwave range.
Human brainwaves and SR correspondences:
Delta: 0 Hz to 4 Hz corresponds with SR 4.11 Hz
Theta: 4 Hz to 8 Hz corresponds with SR 4.11 Hz, SR 7.83 Hz
Alpha: 8 Hz to 12 Hz corresponds with SR 7.83 Hz
Beta: 12 Hz to 30 Hz* corresponds with SR 14 Hz, 20 Hz, 26 Hz
Gamma: 30 Hz to 100 Hz corresponds with SR 33 Hz, 39 Hz, 45 Hz, 59 Hz
*There are differing opinions among authorities as to the demarcation between upper limit of beta and onset of gamma brainwaves. Some cite 25 Hz, others 40 Hz. Most seem to cite 30 Hz. Just know that upper value is a bit fluid.
COLOR CODE: Intensity readings go from lowest blue (background intensity) to green to yellow to white (highest). Typical SR readings are in green range.
IMPORTANT: The SR is read HORIZONTALLY, so you’ll be looking at the green horizontal lines. (Do not consider the VERTICAL white lines or white ‘splashes’ as SR readings.)
VERTICAL WHITE LINES/SPLASHES: So, what ARE those vertical WHITE lines or wider splashes? In general, they represent energy bursts or ionospheric plasma excitations. For the most part, the electromagnetic (EM) bursts are probably lightning-related or TLE-related. While lightning is THE major driver of the SR, electromagnetic bursts have often been found to be sprites, a type of lightning phenomena that occurs high in the atmosphere:
“It is now believed that many of the Schumann resonances transients (Q bursts) are related to the transient luminous events (TLEs). In 1995 Boccippio et al.[38] showed that sprites, the most common TLE, are produced by positive cloud-to-ground lightning occurring in the stratiform region of a thunderstorm system, and are accompanied by Q-burst in the Schumann resonances band.” (Wikipedia)
Transient luminous events (TLEs) are upper atmosphere electrical discharges such as sprites, ELVES, and jets. To read more about transient luminous events, here’s a good article, with photos: https://weather.com/news/news/transient-luminous-events-mysteries-sky-20130731
In addition to intense lightning and TLEs, plasma excitations could also be caused by:
— intense thunderstorming
— solar activity (e.g. solar winds, CMEs, solar flares)
— geomagnetic disturbances (resulting from solar activity)
— some speculate HAARP and scalar weapons discharges may affect the SR
— energy bursts of unknown origin
3 notes
·
View notes
Audio
Take a look at LightningChart .NET gallery. Observe the various types of charts examples! The fastest data visualization tool for WPF and Windows Forms. Visit us: https://www.arction.com/gallery/
0 notes
Text
I’ve mentioned this before to people, but for some reason I want to put it in a post now.
I saw on Wikipedia an article about “Formants”, and I think it’s neat!
The Formants are like, something about the different frequency peaks in a spectrogram of speech, and different vowels have different ones. Here is a chart from Wikipedia of the different ones that different vowels have on average:
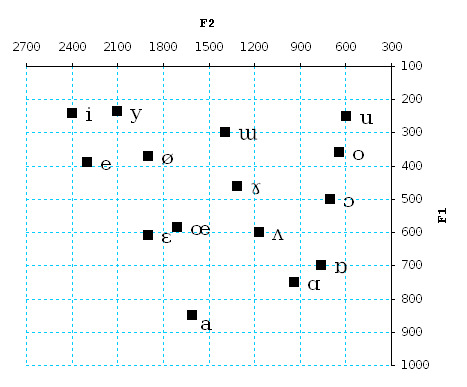
(this image available at [link] and is licensed under CC BY-SA 4.0 )
And, unless I am misinterpreting this chart, it appears to me that there is a region of sounds which is possible to produce, and which I expect would sound somewhat like a vowel, but would not sound like any vowel that people can make with their voice. Specifically, I mean the area near the bottom left of the chart, say with F2=2100Hz and F1=800Hz .
(Or at least, I imagine that people can’t pronounce these “vowels”. I could be wrong though. Maybe languages just happen to never use those vowels, despite being available. Maybe people can pronounce them, but doing so is inconvenient so language avoids them?)
I think it could be neat to do something like this. Like, maybe make a text* to speech program which supports vowels that people can’t* pronounce, but could maybe learn to recognize.
Maybe a fun conlang could be produced which people could understand easily enough, but would be physiologically unable to speak!
That sounds like a fun idea to me.
3 notes
·
View notes
Text
Someone ought to tell all the rad Murder Drone artists whose art is used on the Church of Null thumbnails/slideshows that their art is, without permission, being associated with AI generated songs (and that the person is just lying about it being AI)
All the art is yoinked from Twitter which I don’t have anymore 😭 but the credits are on the video descriptions 🙏
Edit: Adding the evidence below the cut; the songs and Electrical Ink fail 3 different tests, which point towards high likelihood of AI usage
#1 - Using SubmitHub's AI song checker, first testing accuracy of checker. Claims 90% accuracy, did own test with 10 human and 10 AI. About the same accuracy on both at 60%, with remaining percentage usually "inconclusive" with a smaller percentage of inaccuracy (10% in the human test, 20% in AI test but only for Udio). Caveat: Udio throws it off, every Udio song tested was inconclusive or incorrect, however I noted a mix of human and AI tells still reported in the Udio breakdowns. Therefore, this checker is reasonably accurate at marking AI as AI and is more likely to say something is inconclusive than to mark it incorrectly, but should not be the only tool used to assess.
Sampling every other Church of Null song (testing with full MP3s), SubmitHub's checker identified 10 of 12 songs as strongly AI and the remaining 2 as inconclusive. This is a higher rate of being marked as AI than either the human or AI tests I did beforehand. If it were human there would be some marked human, if it were Udio AI it would more likely show a mix of human and inconclusive. All AI and two inconclusive is more likely Suno AI.
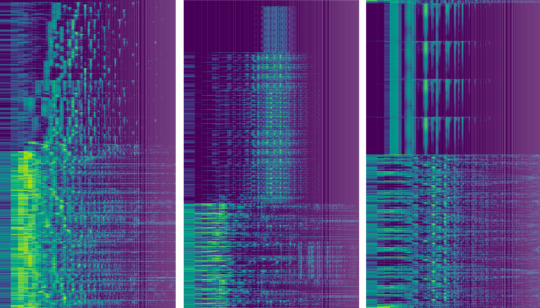
#2 - Using my manual spectrogram contrast test, first testing on 23 respondents. Results are in the link, with 65% of respondents getting a score of over half correctly assessed. This test becomes more accurate when used by an individual practiced in it (comparing an unlabeled spectrogram to a chart of AI and human spectrograms, then sorting it onto either side accordingly by which pattern it most closely resembles). My own score was 12/14. This test will never be 100% accurate as not every spectrogram follows the pattern; i.e. rarely, an AI song has the spectrogram appearance as a human made one.
Respondents were mixed on whether a sampling of 6 songs from Church of Null were AI or human at the end of the test, with both high scoring and low scoring assessing them about the same, with only a slightly higher rate of being assessed as AI in high scoring testers. Only one lower scoring tester assessed AI under 50%, assessing two of six as AI (33%). However, nobody assessed the set as being all human. Note, psychology may have made this set difficult, as respondents may have believed it was unlikely that a set would be all AI or all human, which would influence answers.
When I originally assessed the six spectrograms, I assessed all of them as appearing closer to AI generated spectrograms than human, using the reference charts. I am very practiced at spectrogram contrast assessment since I am the one who made these charts and tests, sampling 30+ AI and 30+ human.
#3 - Using a smell test, or suspicious tells that just make you feel like something is off with the vibes. This can be lack of credits/suspicious credits, an AI "shimmer" effect on all the audio, generic lyrics that sound AI generated/edited, a music production output that is unrealistic for hand-made music, etc.
In Church of Null's case, it's creator Electrical Ink: shows no musical production on the channel before CoN, claims to have 6 anon helpers/vocalists but only credits a weird blank "creative consulting" channel, has produced 25 beautiful songs with complex compositions and vocals in 4 months while claiming to record these in person (and simultaneously writing 62k+ words of the fanfic, or about 15k a month), includes the robotic "shimmer" present in Suno AI while claiming it's "autotune," deletes comments asking if it's Suno (happened to me), and uses art before asking permission for the thumbnails and lyric videos.
The one other credit I found under a reply to a random comment is E-LIVE-YT (a "collaborator" on one song, however E-LIVE may have exaggerated this as they couldn’t even remember Electrical Ink’s name during a livestream), a real person who uploaded at least 1 AI generated song (admitted) but claims the rest are human made. Though, they also produce music at an unrealistic rate (43 tracks in 5 months) but mostly "extensions" of existing music, something AI song generators let you do (he uses Bandlab, which has AI tools exactly for that). The ones with lyrics have Suno's "shimmer" and the lyrical breakdown that E-LIVE posts on comments read as AI summaries/analysis (right down to calling N "they," not knowing his pronoun; a shortcut to chatGPT was on their desktop during a livestream, they removed this for later streams). Additionally, E-LIVE also has strange credits to blank channels and 1 or 2 tiny channels that just upload poor quality Roblox clips.
Ironically, even this "fan" "collaborator" believes Church of Null is AI and complains about competing with it, and regular Suno AI users in the Suno Discord believe so too.


Sniff sniff.... somethin smells funny...
#murder drones#uzi doorman#cyn#church of null#serial designation n#serial designation v#nuzi#someone tell them plllllz I know I personally wouldn’t want my art stolen for a bunch of Suno AI generated music
41 notes
·
View notes
Link
1 note
·
View note
Link
Music Visualisation - Adore You by Nadieh Bremer
Year 3 - Translate and Transform
(20 October 2020)
Edit note: This portfolio page seems to be a perfect example for how to explain/describe a design process in a process book! She added little ‘thought-notes’ at the left side, explained the process well organised and added in images and videos for every section.
I came across this poster which immediately caught my attention for two reasons:
1. It looked extremely nice and detailed 2. I like the song and was interested in how it was represented visually.

Nadieh Bremer included not only the poster in her portfolio but also the how she created it. It seemed to have been a long and highly complex process which included tracking data of the song using computer tools that I have never heard of in my life.
I tried to understand everything she wrote about because this process actually interests me a lot since I love music and the opportunity to combine music with art/design (whichever one is the preferred one) is something I would like to explore more. But. It is quite complicated and I think I’d even have issues following all the small steps properly if it was written in German.
These are sections of her article and some things/images I’d like to remember.
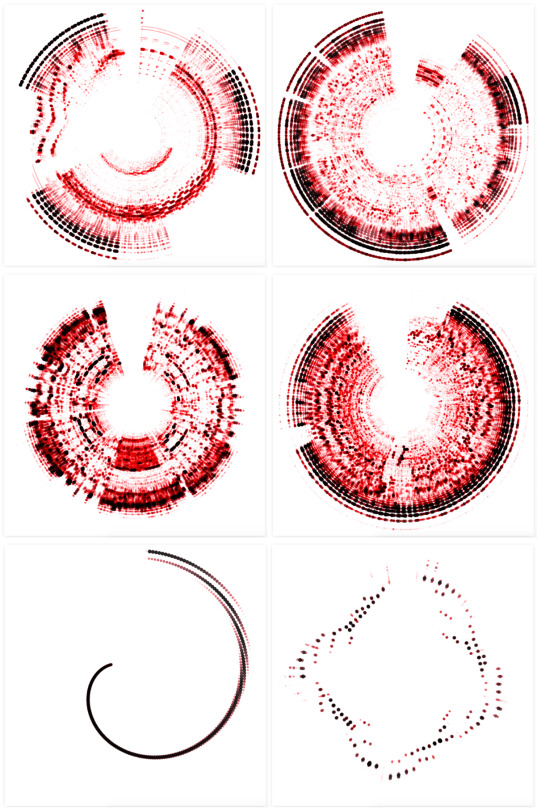
Visualizing Music - Logarithmic Scales - Amplitude Spectrum (Images below)
Spectrograms - Circles (Image Below)
The outcomes (below) she had for ‘circles’ reminded me a lot of the graphics created by Nicholas Rougeux. I would even go as far as to say that this is how he created these visuals as well as they really look similar.
Spotify Audio Analysis
This (below) looks complicated but so interesting and I’d love to take more time to actually understand every step and calculation properly. But I think someone would have to try and explain it to me cause reading alone is quite challenging. Also, this is where design meets maths, something I would have denied when I was in school - seems I was wrong back then. It also includes coding. Seems like this might be something for my future as well?

Spotify Charts and Streaming
Spotify Playlists | Part I
Spotify Audio Features | Part I
Spotify Playlists | Part II
Spotify Audio Features | Part II
Poster Design - Testing on Other Songs
Turns out she created more than one poster. I love the style of these posters and I also love how different they look while still maintaining consistency.
Data Uploading UI
Final Result & Animated Poster
Yes, she even animated it. I can’t share the video here, please check it out on her website!
I am amazed, fascinated and intimidated at the same time. Is something like this possible to be done within a week (just a thought regarding this project)? Probably not, cause for me it seems like that must have taken months. I don’t exactly know how long it has taken her to finish the whole project but she wrote that Sony commissioned her in April. The article was written in September. So that would be around 4-5 months.
There are six posters available to download for free. Also, on this page there is a short list of all the data used in this project:
https://medium.com/sony-music-data-insights/how-we-used-data-to-design-modern-record-certification-plaques-bc2c575a9fa3
0 notes
Text
Alarming AI Clones Both a Person’s Voice and Their Speech Patterns
Gates Keeper
Engineers at Facebook’s AI research lab created a machine learning system that can not only clone a person’s voice, but also their cadence — an uncanny ability they showed off by duplicating the voices of Bill Gates and other notable figures.
This system, dubbed Melnet, could lead to more realistic-sounding AI voice assistants or voice models, the kind used by people with speech impairments — but it could also make it even more difficult to discern between actual speech and audio deepfakes.
Format Change
Text-to-speech computer systems aren’t particularly new, but in a paper published to the pre-print server arXiv, the Facebook researchers describe how Melnet differs from its predecessors.
While researchers trained many previous systems using audio waveforms, which chart how sound’s amplitude changes over time, the Facebook team used spectrograms, a format that is far more compact and informationally dense, according to the researchers.
AI Fake Out
The Facebook team used audio from TED Talks to train its system, and they share clips of it mimicking eight speakers, including Gates, on a GitHub website.
The speech is still somewhat robotic, but the voices are recognizable — and if researchers can smooth out the system even slightly, it’s conceivable that Melnet could fool the casual listener into thinking they’re hearing a public figure saying something they never actually uttered.
READ MORE: Facebook’s AI system can speak with Bill Gates’s voice [MIT Tech Review]
More on AI: This AI That Sounds Just Like Joe Rogan Should Terrify Us All
The post Alarming AI Clones Both a Person’s Voice and Their Speech Patterns appeared first on Futurism.
0 notes
Link
Dance Dance Revolution (DDR) is a popular rhythm-based video game. Players perform steps on a dance platform in synchronization with music as directed by on-screen step charts. While many step charts are available in standardized packs, users may grow tired of existing charts, or wish to dance to a song for which no chart exists. We introduce the task of learning to choreograph. Given a raw audio track, the goal is to produce a new step chart. This task decomposes naturally into two subtasks: deciding when to place steps and deciding which steps to select. For the step placement task, we combine recurrent and convolutional neural networks to ingest spectrograms of low-level audio features to predict steps, conditioned on chart difficulty. For step selection, we present a conditional LSTM generative model that substantially outperforms n-gram and fixed-window approaches.
On teaching a computer to make Dance Dance Revolution levels. (To see the actual paper, click on ‘PDF’ or ‘Other Formats’ in right-hand column, after the word ‘Download’.)
1 note
·
View note
Text
Lightbody Reconnect
A Blog from ReconnectYourself.com
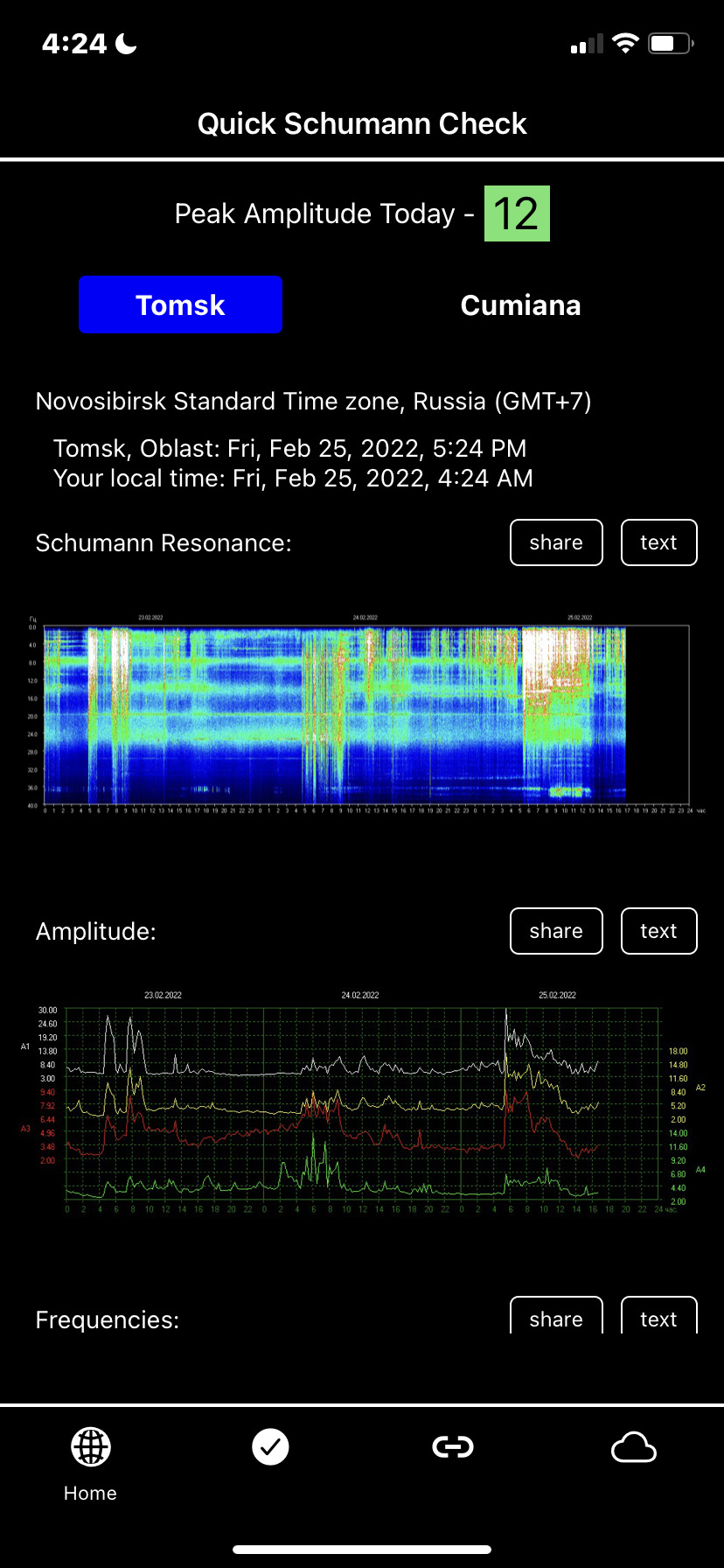
How to Read the TSU Schumann Resonance (SR) Chart
uitleg schumann resonanceI’ve had several requests asking how to read the Schumann Resonance (SR) chart I’ve been posting. I use the SR monitoring at the Space Observing System at Tomsk Science University, located in Siberia. Let me first note that the following suggestions are not any official guidelines from the SOS, but are my personal observations and practices, having read these charts for several years.
The SR website is:
http://sosrff.tsu.ru/?page_id=7
Here is a sample chart you can refer to:
SCHUMANN GRAPH SAMPLE
But first, a definition of the Schumann Resonance:
“The Schumann resonances (SR) are a set of spectrum peaks in the extremely low frequency (ELF) portion of the Earth’s electromagnetic field spectrum. Schumann resonances are global electromagnetic resonances, generated and excited by lightning discharges in the cavity formed by the Earth’s surface and the ionosphere. … In the normal mode descriptions of Schumann resonances, the fundamental mode is a standing wave in the Earth-ionosphere cavity with a wavelength equal to the circumference of the Earth.” (Wikipedia)
Now, to the chart (“spectrogram”).
DATES: Look at the top of the chart. You’ll see that the chart divides into three-day sequences, with the dates printed across the top horizontal of the chart. Dates move left to right, most recent on the right.
Advertisements
REPORT THIS AD
TIMES: Next, look at the the bottom of the chart. You’ll see the times, which present in a 0-24 hour sequence, one block of 24 hours for each corresponding date above. The chart uses local Tomsk (Siberia) time which is GMT+7. You’ll need to convert the chart times to your local time. I’m in the US, so the equivalents here are:
United States Conversions:
Eastern (GMT-4): Chart minus 11 hrs
Central (GMT-5): Chart minus 12 hrs
Mountain (GMT-6): Chart minus 13 hrs
Pacific (GMT -7): Chart minus 14 hrs
SR VALUES: Now look at the left vertical side of the chart. These numbers represent the framework for reading the Schumann Resonance peak values — lowest at top progressing to the highest at bottom, in increments of 4 Hz. SR frequencies are relatively stable and do not change. Also, there is not just one SR frequency, but an array of peak frequencies. The SR values cover a range from 3 Hz to 60 Hz, with set values at intervals roughly 6.5 Hz apart, except for the lowest value, 4.11. Because different authorities post slightly different values for the SR peaks, here are the rounded off SR peak values pretty much agreed upon universally: 4, 7.83 (fundamental SR), 14, 20, 26, 33, 39, 45, 59. All measured in Hz or cycles per second.
The SR frequencies are read ACROSS or HORIZONTALLY, usually in the green intensity shade. You can easily track a specific frequency through the 3-day cycle. You’ll see that the green lines typically indicate at the 7.83, 14, 20, and 26 Hz frequencies. Other frequencies you’ll see, less frequently, are the lowest, 4 Hz, and the 33 Hz and higher.
SR AND HUMAN BRAINWAVES: Here’s the cool part: These Schumann Resonance ELF (Extremely Low Frequency) waves in the Earth’s magnetic field just happen to OVERLAP with the electrical patterns (“brain waves”) observed across the cortex of the human brain. Studies have shown that SR frequencies have particular effects on the human brain and nervous system, the cardiovascular system, the autonomous nervous system, circadian rhythms, immune function, DNA, and more. The fundamental Schuman Resonance, 7.83 Hz, corresponds to the high theta of the human brainwave range.
Human brainwaves and SR correspondences:
Delta: 0 Hz to 4 Hz corresponds with SR 4.11 Hz
Theta: 4 Hz to 8 Hz corresponds with SR 4.11 Hz, SR 7.83 Hz
Alpha: 8 Hz to 12 Hz corresponds with SR 7.83 Hz
Beta: 12 Hz to 30 Hz* corresponds with SR 14 Hz, 20 Hz, 26 Hz
Gamma: 30 Hz to 100 Hz corresponds with SR 33 Hz, 39 Hz, 45 Hz, 59 Hz
*There are differing opinions among authorities as to the demarcation between upper limit of beta and onset of gamma brainwaves. Some cite 25 Hz, others 40 Hz. Most seem to cite 30 Hz. Just know that upper value is a bit fluid.
Advertisements
REPORT THIS AD
COLOR CODE: Intensity readings go from lowest blue (background intensity) to green to yellow to white (highest). Typical SR readings are in green range.
IMPORTANT: The SR is read HORIZONTALLY, so you’ll be looking at the green horizontal lines. (Do not consider the VERTICAL white lines or white ‘splashes’ as SR readings.)
VERTICAL WHITE LINES/SPLASHES: So, what ARE those vertical WHITE lines or wider splashes? In general, they represent energy bursts or ionospheric plasma excitations. For the most part, the electromagnetic (EM) bursts are probably lightning-related or TLE-related. While lightning is THE major driver of the SR, electromagnetic bursts have often been found to be sprites, a type of lightning phenomena that occurs high in the atmosphere:
“It is now believed that many of the Schumann resonances transients (Q bursts) are related to the transient luminous events (TLEs). In 1995 Boccippio et al.[38] showed that sprites, the most common TLE, are produced by positive cloud-to-ground lightning occurring in the stratiform region of a thunderstorm system, and are accompanied by Q-burst in the Schumann resonances band.” (Wikipedia)
Transient luminous events (TLEs) are upper atmosphere electrical discharges such as sprites, ELVES, and jets. To read more about transient luminous events, here’s a good article, with photos: https://weather.com/news/news/transient-luminous-events-mysteries-sky-20130731
In addition to intense lightning and TLEs, plasma excitations could also be caused by:
— intense thunderstorming
— solar activity (e.g. solar winds, CMEs, solar flares)
— geomagnetic disturbances (resulting from solar activity)
— some speculate HAARP and scalar weapons discharges may affect the SR
— energy bursts of unknown origin
EFFECT OF ENERGY BURSTS ON SR READINGS: When ionospheric plasma gets excited, the SR waves at various resonances can get excited, as well. You’ll often see a wider, “puffier” green color displayed behind, around, or following an energy burst. You may see the “excitation” activate the higher SR values that correspond with the brain’s higher beta and gamma frequencies. I often call these the “transformation waves.” Energy bursts can also trigger the low 4.11 Hz SR and the fundamental 7.83 Hz that correspond to our theta brainwave. This wave is incredibly transforming, as well. It’s been called the “miracle wave” for its deep healing, calming, and rebalancing qualities; theta accesses the subconscious mind.
REPORT THIS AD
When these energy bursts first started happening back in 2014, the human monitors at the Space Observing System at Tomsk Science University thought an equipment malfunction had caused the anomaly. But upon checking, they realized that equipment was fine and had, indeed, recorded SR values in a higher range not seen before. But as to the origin of the spikes, they had no answers.
A SPECULATIVE OBSERVATION: When these plasma spikes occur, perhaps humans are receiving a double impact: not only are the SR frequencies resonating with our brain waves (theta, alpha, beta, and gamma) but we are also feeling the effects of the ionospheric energy bursts themselves. For those who are energy-sensitive, these plasmic excitations or energy disturbances may be felt or sensed — much like a sensitive can “feel” geomagnetic storming, distant earthquakes and volcanoes, the magnetic pull of a full moon, or incoming photonic or cosmic energies.
Back to the Schumann Resonance:
“Every second, a multitude of pulses travel around the world in this unique, resonant chamber between Earth and the ionosphere, sending colluding signals to all microorganisms. These signals couple us to the Earth’s magnetic field. Named after their discoverer, these Schumann Resonances (SR) drive the harmonizing pulse for life in our world.” – Eric Thompson
Mother Earth is taking care of her kids

0 notes
Photo

June 6, 2021 The world is definitely different! The Russian ELF spectrogram and Amplitude chart are showing evidence of heightened potency of our Earth’s atmosphere to ground vibrations. Specifically what they call the Schumann resonance but it’s the Earth’s first and forever lol. Schumann is just the lucky one to be attached to it! 7.83hz is this constant hum in the extremely low frequency range (ELF) how loud it gets depends on how much energy is grounding down from space via lightning, according to Wikipedia/NASA. This frequency stays pretty much the same. It’s the volume behind it, like turning up the song of earth, that causes us to feel different in my opinion from researching this for about 5 years now. Please avoid the hype of “frequency is rising” and try “the amplitude is up today” Or “Earth’s song is loud today” perhaps for those artsy people like me 😄⚡️ I hold space for this concept to be scientifically understood and then broadened into expanded understanding of the mechanics of the cosmos and our planet as a whole. We live in a frequency bath but the Earth and Sun really dictate a lot of that. Play Solfeggio frequencies in your home if you want to heal and realign in more beautiful organic resonance. They’re available on all platforms for music now! Solfeggio is a divine fractal mathematic scale, in my understanding. I’ve used them so many times to help align my chaos. I love when the Schumann resonances/Earth Resonances get loud because I feel better. I feel more aligned in my body. Now they’re quieting down and I already feel less enlivened. See my next post to look at what the Sun is and has been sending our way, to stimulate our planet like a bell being struck. There’s a simplicity to this but there’s also those taking this deeply in the esoteric who don’t even know how to read the charts they’re posting. It’s ok, that’s why I’m here, everyone lives in these frequencies so all our perspectives hold truths. I love everyone’s rights to share their perspective 🤍☀️🌎 All your observations/questions can go in the comments to help us all converse and learn about this! Much love!! Alexis of @ascensiondiaries Defender and helper of life 😇 https://www.instagram.com/p/CPyReEXn8Uc/?utm_medium=tumblr
0 notes