#Unauthorized Data Scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
In response to the latest unauthorized scraping of Ao3, I’m not going to private any of my fics.
Why?
Because control is both an illusion and addictive. At the end of the day, privating fics provides very limited protection. All a scraper needs to get past is an Ao3 account, which has actually happened in the past.
I want my writing to be available to everyone and I’m not going to let some lazy-ass little fucker ruin that.
Besides. My writing will always be superior to whatever GenAI can produce. So is everyone else’s. And you, lazy-ass fucker (who is probably not reading this, but just in case), know it too. Cry about it 😛
#I respect the decision of everyone who wants to private their fics#It is your work; your choice to make#I’m just here to offer my perspective#Ao3#AI#Generative AI#Fuck GenAI#Fuck AI#Data Scraping#Unauthorized Data Scraping#Writing#Currantlee here
3 notes
·
View notes
Text
AO3 Data Scraped for AI Training Dataset
What is happening, and what you can do. Check for potential edits with additions at the end of the post!
What is happening? What do we know?
A user going by "nyuuzyou" on the HuggingFace platform uploaded a dataset a few days ago - containing scraped content from AO3. HuggingFace is a very popular platform and widely used for sharing machine learning and AI models/datasets. The scraped dataset includes fics, fanart, and other fanworks - all taken without permission and intended for use in training gen AI models. You can find more information in this Reddit post.
This dataset is one of several compiled from various websites—at least seven in total. While two datasets have been removed, the AO3 one was only disabled on HuggingFace. This means that it’s not downloadable at the moment but still visible. It may also return if takedown efforts end up being challenged/reversed by that user.
Key Details
Scope: On AO3, all content with work IDs between 1 and 63,200,000 has been targeted. The work ID is the number at the end of a work's URL — for example, in https://archiveofourown.org/works/12345678, 12345678 is the work ID. You can find it by simply opening the work and checking the URL in your browser’s address bar. So, if your work falls in that range and is publicly accessible (i.e., not locked and open to everyone, including guests), it’s mostly likely included in the dataset. This dataset is currently disabled on HuggingFace, but that doesn't mean it's gone. It's only a temporary takedown as of now.
Takedown notices have been issued, but this user has also uploaded the dataset to other sites after backlash and partial removal.
There are talks in the discussion forums of potentially moving this dataset to Telegram, torrents, and/or other private channels.
HuggingFace AO3 dataset page
Other distributed sites listed here (as per a Reddit comment)
Currently deleted from ModelScope
What can you do?
Should the dataset return again and you see that your work was affected: file your own DMCA or copyright takedown notice. The uploader, in their own words, "has not agreed to take down the entire repo. At this time, the scraper has agreed with taking down art from the person who owns the copyright. That means each of you will need to request a takedown."
Instructions and a sample CSV template to list your work IDs for removal are provided in this guide. You can find more details in this announcement by PaperDemon.
Lock your works! It would limit visibility to registered users only, and is a very good step to prevent scraping or unauthorized use. To lock all your works on AO3, go to “My Works,” click “Edit Works,” and select all. Then click “Edit” and check the box labeled “Only show to registered users.” Scroll down and click “Update All Works” to apply the change.
⚠️ | Final Notes:
This user has so far shown no signs of stopping and is continuing to redistribute the data across multiple sites, even after numerous takedown requests (read more here). So, we can only recommend to be cautious and beware, lock your works, feel free to make use of takedown notices if you're unfortunately affected, and spread the word to fellow creators.
Follow up on this and get the latest updated in the Fanfic Communities Network (FCN) Discord Server!
If you have more information regarding this - e.g. if works from other sites are affected too - please reach out to us in the FCN!!
Edit (2025-04-26):
The user who has scraped the works has, upon request by another person, posted a way to convert ao3 json to markdown:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/170
https://gist.github.com/nyuuzyou/b2f83669ad80a22e435728245ebcdf9f
This shows us that nyuuzyou continues to show no signs of taking down the scraped works.
Edit (2025-04-28):
A user warned that even archive-locked AO3 fics were included in a scraped dataset (most likely taken while the scraper was logged in, before they were banned or switched to public-only access). Some public works were missed as well:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/213#680fcdb76d9e022324a70cf1
Edit (2025-05-03):
Hey everybody, this is a bit late, but the AO3 dataset has been permanently removed from HuggingFace: https://huggingface.co/datasets/nyuuzyou/archiveofourown. While this unfortunately doesn’t prevent it from being shared elsewhere (like torrents) nor does it guarantee any deletion of past downloads and whatnot, having it taken down from a major platform like HF is still a significant step forward. (There is more info about other sites on PaperDemon.)
So please don’t be disheartened—every action counts, and this shows that pushing back and filing DMCAs and copyright notices as appropriate does make a difference. We’ll certainly keep an eye out for more info and post updates here, but thank you again to everyone who helped report, spread the word, or supported the effort. Keep reading, keep writing. ♥️
#fanfiction#community#discordserver#fanfiction community#theft#ao3 works being stolen#fanfic theft#fanfiction stealing#ao3
159 notes
·
View notes
Text
AI Scraping Response from r/AO3 mods
AO3’s Data Was Scraped For AI: What To Know
News/Updates
Hi all—as you may be aware, there’s been an incident regarding the Archive’s data being used to potentially train generative AI.
It seems that a user by the name of nyuuzyou conducted an unauthorized scrape of the Archive, both artwork and writing (as well as at least seven other websites) and uploaded the dataset to the machine-learning website Huggingface. This only scraped publicly available works—archive-locked works do not appear to be a part of that dataset. The works in the set are from as recent as March of this year, and comprise all publicly available works before then.
AO3 is aware of this, and they have filed a DCMA takedown to Huggingface, where the data has been made temporarily unavailable (aka nobody is currently able to use it for training). In response, the uploader filed a counterclaim to try to get it reinstated—though as Huggingface’s Terms of Service don’t allow uploads of any content the uploader doesn’t own the rights to, it’s unlikely that their counterclaim will succeed. However, the user also uploaded the dataset to two more websites after the Huggingface takedown: modelscope and datafish. These two sites are based in China and Russia respectively, places that do not always respond to DCMA takedowns—however, the upload to modelscope does appear to have been taken down/deleted as of writing this. (We also cannot link to these websites as Reddit has them shadowbanned).
The website Paperdemon has more information about the timelines, other websites affected, and how to request a DCMA takedown to Huggingface (which will hopefully not be necessary, but a good resource in case the counterclaim succeeds.)
As scraping like this is unfortunately hard to control, the best option we can recommend as a subreddit is to lock your works to only be available to registered archive users (as they are less likely to be scraped, though this is not foolproof). For readers, if you do not have an account, you will need to make one to be able to view archive-locked works. You can find a link to our most recent invite request thread here, or add your email to the signup waitlist on AO3 to get an invite directly in a few days.
~Cthulu (and the rest of the mod team)
Original post is here.
114 notes
·
View notes
Text
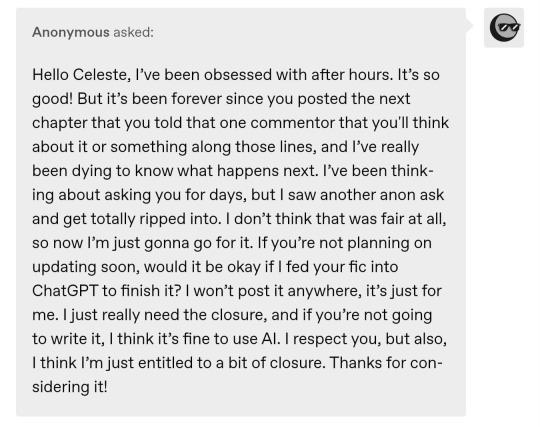
Anon.
Are you fucking serious right now?
I saw your message and I had to take a full-ass walk around my block because I was genuinely afraid I’d punch my goddamn wall.

Let me break this down for you very clearly, so even your AI-smooth-brained moral compass can process it:
You are not entitled to shit.
Not my writing. Not the ending. Not a single fucking word I typed out with my own fucking bleeding fingers.
You think you “need” closure?
Cool. I “need” eight hours of sleep, a functioning spine, and respect from strangers online. Guess what?
None of us are getting what we want today.
Fanfiction is a gift.
Not a product, not a service, not a series finale you paid for on HBO Max.
A gift.
You don’t throw a tantrum because the gift didn’t come with a bonus epilogue and a director’s cut.
Your entire ask is a monument to entitlement. You say “if you're not going to write it, I think it's fine to use Al?”
I did NOT write it for AI. I wrote it for human readers. For emotion. For narrative voice. For soul.
AI doesn’t have that. You want a soulless machine to mock my style and feed you a bootleg version of my work?? Which is, not to say but, the equivalent of a a knock-off Louis Vuitton sold from the back of a van?
Then don’t ask me. Just go to your shameful little corner and live with the fact that you’re the kind of person who disrespects art to feed your own dopamine addiction.
You wanted permission, so now you get the wrath.
I see in your other little asks, “AI is there to make things easier.”
At whose fucking expense? The thousands of fanfic writers whose fics are being scraped, harvested, mimicked and tossed into machine-learning hell so you don’t have to wait for an update?
Do you have any idea how many of us have had our fics [both in our caratblr and other fandom spaces] show up on AI mirror sites or been plagiarized by bots? Do you know how many real authors are losing book deals, commissions, or livelihoods because of this exact entitled logic?
Let me give you a basic fucking rundown since you clearly didn’t do the homework:
AI is not ethical – Generative AI is trained off data sets that include unauthorized, uncredited, scraped work from unpaid artists, writers, poets, journalists, bloggers, fanfic writers—fuck, even therapy forums.
Authors are suing OpenAI for ingesting copyrighted novels without permission.
Fanfic is already vulnerable – We exist in a legal gray area protected only by community ethics and mutual respect. You're breaking both.
You say “I won't post it anywhere, it's just for me.”
Oh, wow, thanks. So you only want to steal quietly. Like that makes it better.
You think the damage only happens when it’s public? WRONG.
Every time you plug an artist’s work into a machine, it gets processed, stored, used for training, forever.
You have no control over where it goes or how it’s repurposed later. You are feeding the beast and killing the creators in the process.
Don’t give me “I respect you but—”
If you respected me, this message wouldn’t exist.
You get your AI-stitched ending, it doesn’t scratch the itch, and you feed it another one.
And another.
And another.
Until the entire fucking archive is turned into a graveyard of replicas and you’re the ghoulish little shit dancing on the corpses of every writer you leeched dry.
And you say “I think I’m just entitled to a bit of closure”?
Entitled. You actually used the word.
Thank you for confirming what we already knew:
That you don’t see us as people.
You see us as content machines that owe you something because you liked our work. You don’t want closure, you want control, and you will NOT get it from me.
You’re entitled to a bath, a glass of water, and the air you breathe—not my writing, not my thoughts, and definitely not a fucking auto-generated Frankenstein mockery of my style you can jerk off your emotions to.
So here's your closure:
No, you may not touch my fic.
No, you may not feed it to a bot.
No, you may not engage with my writing, my blog, my friend's blog, or my community ever again.
Block me. Report me. Cry about it.
But know this:
Every time you open an AI generator to finish a story you didn’t write, you are choosing to destroy the very creators you claim to admire.
You should be ashamed, but you won’t be. Because parasites don’t feel guilt, they just suck and suck and suck until there’s nothing left.
I'll never forget this time and date.
I hope it was worth it.
Let this be your final fucking warning.
— Celeste.
#please get the fuck off my and my friend's and other writers blog#you're NOT welcomed#you deadass came into MY inbox with a digital scalpel asking to butcher my fic#and expected me to say “yes queen go ahead”???#feed my blood sweat and tears into the algorithm grinder bc YOU can’t wait???#go gnaw on drywall#the entitlement is fucking radioactive#“i won’t share it” oh wow babe THANK YOU for promising to keep your theft private. like that makes you less of a digital robber#cry me a river build a bridge and then jump off it#you don’t “need closure” you need a damn hobby and some fucking boundaries#go knit or scream into a jar or idk read a newspaper#don’t treat writers like vending machines and throw tantrums when the candy doesn’t drop#AI is not your little storytelling fairy godmother. it’s a grave-digging industry leech#go sit in a corner and think about why no one wants you in fandom spaces anymore#and don’t come back unless it’s with a goddamn apology and a clue#mylovesstuffs asks
78 notes
·
View notes
Note
Unfortunate as it is, copyright law is the only practical leverage most people have to fight against tech companies scraping their work for commercial usage without their permission, especially people who also don't have union power to leverage either. Even people who prefer to upload their work for free online shouldn't be taken advantage of; Just because something is available for free online doesn't mean that it's freely available for someone to profit from in any way, especially if the author did not authorize it.
Okay Nonny. Bear with me, you’re not gonna like how I start this and probably not how I finish it either, but I do have a point in the middle. So.
There is in fact long established precedent for people being allowed to profit off of various uses of others’ work without permission, in ways that creative types in general and fandom specifically tend to wholeheartedly approve of. Parody, collage, fanart commissions, unauthorized merch, monetized reaction or analysis videos on youtube, these are significantly clearer cut examples of actually *using* copyrighted material in your own work than the generative ai case. And except for fanart commissions and unauthorized merch, which mostly live off of copyright holders staying cool about it, these are all explicitly permitted under copyright law.
Now, the generative ai case has some conflicting factors around it. On the one hand, it’s not only blatantly transformative to the point where the dataset cannot be recognized in the end result (and when it overfits and comes out with something not sufficiently transformative, that’s covered by preexisting copyright law), it also doesn’t exactly *use* the copyrighted work the way other transformative uses do. A parody riffs off a particular other work, or a few particular other works. A collage or a reaction video uses individual pieces of other works. Generative AI doesn’t do that, it comes up with patterns based on having looked at what a huge number of other works have in common. Like if a formulaic writing/art advice book were instead a robot artist. But on the other hand, the AI that was trained is potentially being used to compete in the same market as the work it was trained on. That “competition in the same market” element is why fan merch and fanart commissions rely on sufferance, rather than legality. That’s part of fair use too. So perhaps there’s some case to be made against AI from that perspective. *But*… the genAI creations, while competing in the same market as some of their training data, are *a lot more different from that training data* than a fanart is from an official art. To a significant degree the most similar comparison here isn’t other types of transformative work it’s… a person who learns to write by reading a lot. They’ll end up competing in the same market as some of *their* training data too. But of course that doesn’t *feel* the same. For starters, that’s *one person* adding themselves to the competition pool. An AI is adding *everyone who uses the AI* to the competition pool. It may be a similar process, but the end result is much more disruptive. Generative AI is going to make making a living off art even harder - and even finding cool *free* art harder - by flooding the market with crap at a whole new scale. That sucks! It’s shitty, and it feels hideously unfair that it uses artists’ work to do it, and people have decided to label this unfairness “theft”. Now, I do not think that is an accurate label and I’ve reached the point of being really frustrated and annoyed about it, on a personal level. Not all things that are unfair are theft and just saying “theft” louder each time is not actually an argument for why something should be considered theft. An analogy I like here: If someone used art you made to make a collage campaigning against your right to make that art (I can picture some assholes doing this with, say, selfies of drag queens), that would feel violating. It would feel unfair. It would suck! But it wouldn’t be theft or plagiarism.
…*And* on whatever hand we’re on now, my own first thought *was* “Okay well, on the one hand when you look at the mechanics this is pretty obviously less infringing than collage or parody, which I don’t think should be banned, but… maybe we can make a special extra strict copyright that applies only to AI? Just because of how this sucks.” And you know, maybe I’m wrong about my current stance and that’s still a good idea! But there seems to be a lack of caution regarding what sorts of rulings are being invited. It seems like some people are running towards any interpretation of copyright that slows down AI, regardless of what *else* it implies. Maybe I’m wrong! I’m no expert. Maybe it’ll be fine and maybe I’m just too pissed at anti-ai shit to see this clearly. I really wish the AI people had done open calls requesting people to add their work to the datasets, for which I think they would have gotten a lot of uptake before the public turned against AI. Maybe if we do end up with copyright protections against AI training that’ll happen and everything’ll be drastically improved. I dunno.
But I get fucking nervous and freaked out at OTW sending DMCA takedowns as a form of agitation for increased copyright protection and I think that’s a reasonable emotional response.
59 notes
·
View notes
Text
I’ve kept my ao3 completely open and public through targeted harassment campaigns, fandom faction wars, plagiarism/stolen fic incidents (fuck you very much 3 specific wattpad users!), but as of today, every fic on my account is now locked to registered users only. Because for the nth time someone has scraped ao3, and I’ve found my works stolen in a genAI dataset.
This time it was 144 out of 145 of my works stolen and included in an unauthorized data set being disseminated to multiple sites.
144 works comprising well over 2.5 *million* words and a decade of my creative labor.
Fuck that.
I hope every single person profiting off these “tools” gets exactly what’s coming to them.
24 notes
·
View notes
Note
Is there even a site left to post art? Seriously here i really like posting my artwork and creating a safe community why this app decides to follow down the rabbit hole of A! and ruin everything?
I want to be more hopeful that it won't last and get sued those who illegally use our pieces. :/
i think anything being posted publicly (bar perhaps on very niche places no one else will find u either) is probably getting scraped, which is supported by the kind of weak 'We Will Try To Stop Unauthorized Data Trawlers' lines we get fed - even sites that have explicit anti-AI stances like Pillowfort can't promise that ur images are fully protected
i'd assume paywalled sites like patreon/subscribestar offer a smidge of protection just bc the ai people don't want income to flow anywhere else than their own pockets? as for lawsuits, ye, i hope they tread on the toes of some other shitty corporation with an interest in protecting their intellectual property since they have the $ to throw at this problem
when all the platforms we post to are owned by corporations that are only interested in shortsighted financial gain/dont need to respect their userbase, this type of behaviour is to be expected... as i mentioned previously though, i have hope that the bubble will burst like it did w/ nfts, that people will realize theyre swallowing shit and it turns out not to be as profitable as the profiteers hoped (at which point theyll turn to the next exploitative grift)
#cleo talks#margaretkart#the whole ai debacle unfortunately contributes to a general downward arc in quality of media#but tbh.. im fortunate to not have to rely on financially motivated corporations for my livelihood#(private clients are often more generous than say wotc lol)#so im sad about the state of the world but at least theres that#look to individuals and smaller communities#and Begging ppl to put their money where their mouth is#just bc boring ass Marvel is using AI doesnt mean there isn't still incredible creative work to find elsewhere
148 notes
·
View notes
Text
Hey guys! Just found out that AO3 has been put into an unauthorized data scrape for GenAI purposes from this post I saw just now.
I also read that fics that are only accessible to registered users are not affected by this data scrape. So it looks like I'll be changing Metallic Figment's settings for the time being. If you've been reading it without an account, then I'm sorry for the inconveniences. There is no work around other than making an account sadly.
#xiaolin showdown#chroxia#metallic figment#fic update#also just to clarify#this is not a safe space for AI users#you WILL be hit by a car if you defile my work with your grubby little ai hands
12 notes
·
View notes
Text
Cloudflare AI Bot Blocker: A Game-Changer for Web Publishers
Introduction The digital publishing world is fighting back against unauthorized AI data scraping. With the launch of the Cloudflare AI bot blocker, over a million websites—including media giants like Sky News and Buzzfeed—can now block AI bots from collecting content without consent. This transformative tool gives creators the control they’ve long demanded over their digital work. Why Is…
#AI bot blocker#AI content scraping#AI copyright#AI paywall model#BBC AI legal threats#Cloudflare#Cloudflare AI bot blocker#content scraping defense#digital publishing#how to block AI crawlers#Matthew Prince#online publishers#Perplexity AI#web crawler protection
5 notes
·
View notes
Text
"...Nightshade, a project from the University of Chicago, gives artists some recourse by 'poisoning' image data, rendering it useless or disruptive to AI model training. Ben Zhao, a computer science professor who led the project, compared Nightshade to 'putting hot sauce in your lunch so it doesn’t get stolen from the workplace fridge.'
"...Zhao and his team aren’t trying to take down Big AI — they’re just trying to force tech giants to pay for licensed work, instead of training AI models on scraped images.
"'There is a right way of doing this,' he continued. 'The real issue here is about consent, is about compensation. We are just giving content creators a way to push back against unauthorized training.'"
#AI#AI generated art#Nightshade#training AI#protecting artists' work#gosh sure would be a shame if someone used this and a company wouldn't be able to train its AI off of your scraped art without having to pa#artists
24 notes
·
View notes
Text
Trump's second term is only three and a half weeks old. The press, politicians, and many Americans seem to have forgotten what happened two weeks ago. Here is a quick refresher of what Trump or his minions have done in 25 days:
Pardoned 1,500 insurrectionists who assisted Trump in his first attempted coup.
Converted the DOJ into his political hit squad by opening investigations into members of the DOJ, FBI, Congress, and state prosecutors’ offices who attempted to hold Trump to account for his crimes.
Fired a dozen inspectors general, whose job it is to identify fraud and corruption and to serve as a check on abuses of power by the president.
Fired dozens of prosecutors and FBI agents who worked on criminal cases relating to Trump
Fired dozens of prosecutors who worked on criminal cases against January 6 insurrectionists
Opened investigations into thousands of FBI agents who worked on cases against January 6 insurrectionists
Disbanded the FBI the group of agents designed to prevent foreign election interference in the US
Disbanded the DOJ group of prosecutors targeting Russian oligarchs’ criminal activity affecting the US
Fired the chairs and members of the National Labor Relations Board, the Equal Opportunity Employment Commission, and the Federal Election Commission and refused to replace them, effectively shutting down those independent boards in violation of statute
Shut down and defunded the Consumer Financial Protection Bureau
Shut down and defunded USAID by placing virtually the entire staff of the agency on leave
Impounded billions of dollars of grants appropriated by Congress to USAID, National Institutes of Health, Department of Education, and the EPA, all in violation of Article I of the Constitution, which grants Congress the power to make appropriations
Allowed a group of hackers to seize control of large swaths of the federal government’s computer network by attaching unauthorized servers, changing and creating new computer code outside of federal security protocols, creating “backdoors” in secure systems, installing unsanctioned “AI” software to scrape federal data (including personal identification information), and installing “spyware” to monitor email of federal employees
Disobeyed multiple court orders to release frozen federal funds (an ongoing violation; see the NYTimes on Wednesday)
Granted a corrupt pardon to the Mayor of New York in exchange for his promise to cooperate in Trump's immigration crackdown
The above is a partial list, each item of which is illegal (at least) and unconstitutional (at worst). Taken together, they compel the conclusion that Trump has not only violated his oath in every conceivable way but that he is actively working to overthrow the Constitution. That is the very definition of a coup.
5 notes
·
View notes
Text
Thai Drama Stats Special Edition:
The Great Archive Lockdown 🔒
Hi folks! In case you weren't aware, there are various scraping bots that trawl through AO3 and use the data for AI training, content mill sites, or other vaguely nefarious purposes. One site, "Fanfic Books", is essentially creating an unauthorized mirror of AO3. Here are some posts about it.
To combat this, many users have recently chosen to "Archive Lock" their fics.
What is Archive Locking?
An archive locked work, or "restricted" work, is only visible to users who are logged into AO3. This prevents anonymous users (and bots that aren't using login credentials) from reading your fic or finding your fic in searches. This doesn't block all scraping bots, but it should keep most of them out.
What does this have to do with fandom stats?
The AO3 scraping I do doesn't use login credentials, so I can't count archive locked fics. That's totally fine! I am in no way telling you to stop archive locking! Lock or unlock to your hearts content!
It does, however, mean that the data I pulled from my Thai Drama AO3 Trends Dashboard this week (July 1 - July 7, 2024) are looking especially strange.
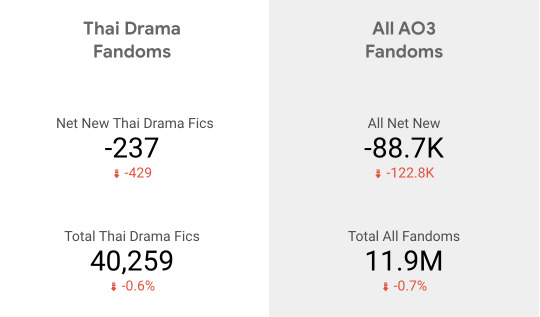
Holy moly! We actually have negative growth. More fics were locked than posted, which is why the Net New is negative. I'd estimate that about 1% of all previously public Thai Drama fics were archive locked this week.
This matches trends on all of AO3. This week, the total number of publicly available fics actually decreased by 0.7% -- and that's including all the new fics being posted!
When did this happen?
The timing for both Thai Drama fandom and all of AO3 is pretty consistent.
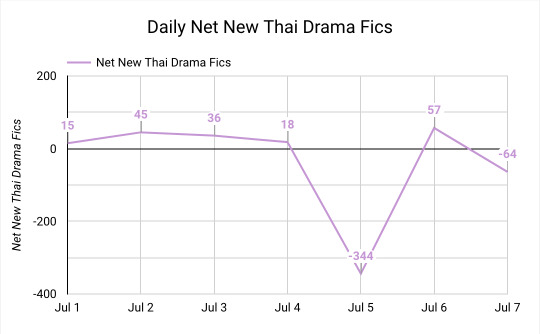
For Thai Drama fandom, most of the locking happened on Friday, July 5, but there was also some locking on Sunday.
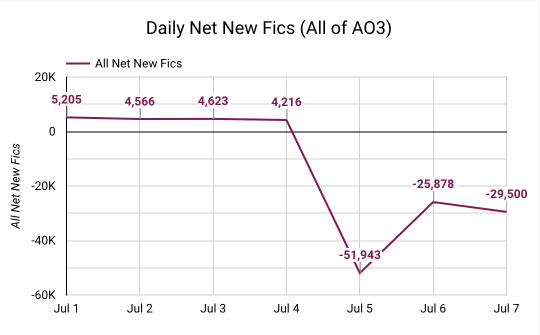
When we look at all of AO3, it seems like most of the mass-locking happened on July 5th as well, with additional locking happening all throughout the weekend.
Which Thai Drama fandoms were most affected?
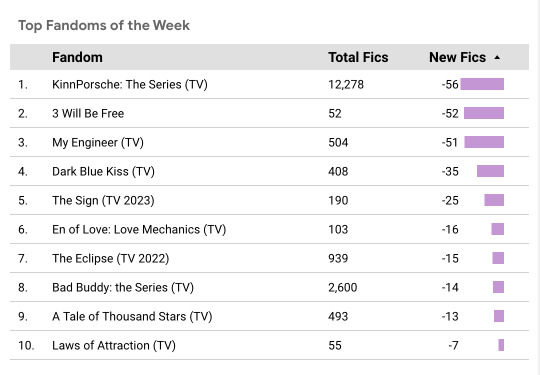
When we look at sheer numbers, KinnPorsche, of course, has a lot of newly-locked fics. 3 Will Be Free, My Engineer, and Dark Blue Kiss were locked down a lot as well.
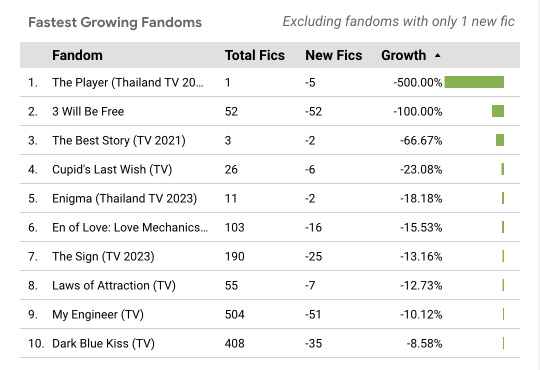
When we look at the top fandoms by negative growth, The Player saw almost all of its fics vanish overnight. 3 Will Be Free was cut neatly in half.
This data is cool I guess, but... so what?
If these numbers are accurate, it represents another sudden and massive shift towards archive locking on AO3.
According to @star-grazing's stats about archive locking in December 2022, the total number of archive locked works on AO3 increased by 70% in just a couple weeks after a reddit post went viral about AI bots scraping AO3 for machine learning material.
Those stats show that in December 2022, 5.79% of AO3 fics were archive locked. When I checked the numbers again today, 9.37% of all works were archive locked.
Using rough estimates, from the last few days of AO3 data, I'd say that the total number of archive locked works increased by 8% since last Thursday (7/4). And trends seem to indicate that the great lockdown is still going!
Anyway...
Thanks for sticking with me! This is a really fun time to be collecting AO3 stats :) If you have more questions, feel free to reach out. I also put some more details under the cut! Thanks y'all!
Are we sure it was archive locking, and not some other data issue?
Er, good question. It's my best guess, and I've tried to rule out other potentially culprits. The AO3 Fandom Trend Analysis Dashboard, which has data about all fandoms on AO3, doesn't seem to show anything amiss. Their data uses login credentials, meaning they can count archive locked fics.
I also went through several tags manually while logged in and logged out to compare numbers from this week to previous weeks. It doesn't seem like there was a mass deletion or retag that I could see.
I also used the "restricted:true" search operator to search for archive locked fics while logged in. A lot of those missing fics pop back up!
I absolutely welcome other theories though, if you think of one!
Is this still happening?
Seemingly yes, for Thai Dramas at least! When I checked the "All Thai Dramas" AO3 search this morning, the total number of Thai Drama fics had dropped below the 40K mark - lower than when I first started keeping track a month ago!

We probably have a lot more archive locking in our future!
How do I archive lock my own fics?
There's a really good tutorial over here.
Help! I don't have an AO3 account, so I can't read all these archive locked fics anymore.
Please message me! I have some spare invites.
Which fandoms are the most "locked down"?
I'm not sure, but there is a Fanlore article about Hockey RPF and the Fourth Wall which provides some comparison stats. Hockey fandom has traditionally been one of the most locked down fandoms; less than half of hockey rpf fics are publicly available.
You can also peruse this AO3 search to see all archive locked fics.
#fandom stats#ao3 psa#archive locking#restricted works#archive of our own#special edition#thai drama fanfic stats#i should probably try to figure out a way to count archive locked fics eventually but...#sigh... i would have to stop scraping with google sheets which took uhh#SOOO long to figure out#it's fine. such is the nature of data scraping
15 notes
·
View notes
Note
Hi! I’ve been following you for a while especially because I followed and loved your detective Conan shinran fanfictions that you wrote. There’s a specific one I tried to go back to for a re-read word play but it looks like the link isn’t working. Do you have a copy of this that you can share with me?
It's still there. Either get or log into an ao3 account. Like many other authors currently, I've restricted my ao3 works to users only to prevent unauthorized data scraping from for-profit companies using fic as free training for their large language models. I would also advise you download every work you even tangentially like because you never know when it will disappear.
It doesn't stop people that are determined to do it (some of my fic ended up in the huggingface crawl that I had only ever posted locked) but it remains a significant enough deterrent.
edit: oh wait, was it from my deleted blog? I don't know if i have the sfw version anymore but I'll try to find it
2 notes
·
View notes
Text
Over 170 images and personal details of children from Brazil have been scraped by an open-source dataset without their knowledge or consent, and used to train AI, claims a new report from Human Rights Watch released Monday.
The images have been scraped from content posted as recently as 2023 and as far back as the mid-1990s, according to the report, long before any internet user might anticipate that their content might be used to train AI. Human Rights Watch claims that personal details of these children, alongside URL links to their photographs, were included in LAION-5B, a dataset that has been a popular source of training data for AI startups.
“Their privacy is violated in the first instance when their photo is scraped and swept into these datasets. And then these AI tools are trained on this data and therefore can create realistic imagery of children,” says Hye Jung Han, children’s rights and technology researcher at Human Rights Watch and the researcher who found these images. “The technology is developed in such a way that any child who has any photo or video of themselves online is now at risk because any malicious actor could take that photo, and then use these tools to manipulate them however they want.”
LAION-5B is based on Common Crawl—a repository of data that was created by scraping the web and made available to researchers—and has been used to train several AI models, including Stability AI’s Stable Diffusion image generation tool. Created by the German nonprofit organization LAION, the dataset is openly accessible and now includes more than 5.85 billion pairs of images and captions, according to its website.
The images of children that researchers found came from mommy blogs and other personal, maternity, or parenting blogs, as well as stills from YouTube videos with small view counts, seemingly uploaded to be shared with family and friends.
“Just looking at the context of where they were posted, they enjoyed an expectation and a measure of privacy,” Hye says. “Most of these images were not possible to find online through a reverse image search.”
LAION spokesperson Nate Tyler says the organization has already taken action. “LAION-5B were taken down in response to a Stanford report that found links in the dataset pointing to illegal content on the public web,” he says, adding that the organization is currently working with “Internet Watch Foundation, the Canadian Centre for Child Protection, Stanford, and Human Rights Watch to remove all known references to illegal content.”
YouTube’s terms of service do not allow scraping except under certain circumstances; these instances seem to run afoul of those policies. “We've been clear that the unauthorized scraping of YouTube content is a violation of our Terms of Service,” says YouTube spokesperson Jack Maon, “and we continue to take action against this type of abuse.”
In December, researchers at Stanford University found that AI training data collected by LAION-5B contained child sexual abuse material. The problem of explicit deepfakes is on the rise even among students in US schools, where they are being used to bully classmates, especially girls. Hye worries that, beyond using children’s photos to generate CSAM, that the database could reveal potentially sensitive information, such as locations or medical data. In 2022, a US-based artist found her own image in the LAION dataset, and realized it was from her private medical records.
“Children should not have to live in fear that their photos might be stolen and weaponized against them,” says Hye. She worries that what she was able to find is just the beginning. It was a “tiny slice” of the data that her team was looking at, she says—less than .0001 percent of all the data in LAION-5B. She suspects it is likely that similar images may have found their way into the dataset from all over the world.
Last year, a German ad campaign used an AI-generated deepfake to caution parents against posting photos of children online, warning that their children’s images could be used to bully them or create CSAM. But this does not address the issue of images that are already published, or are decades old but still in existence online.
“Removing links from a LAION dataset does not remove this content from the web,” says Tyler. These images can still be found and used, even if it’s not through LAION. “This is a larger and very concerning issue, and as a nonprofit, volunteer organization, we will do our part to help.”
Hye says that the responsibility to protect children and their parents from this type of abuse falls on governments and regulators. The Brazilian legislature is currently considering laws to regulate deepfake creation, and in the US, representative Alexandria Ocasio-Cortez of New York has proposed the DEFIANCE Act, which would allow people to sue if they can prove a deepfake in their likeness had been made nonconsensually.
“I think that children and their parents shouldn't be made to shoulder responsibility for protecting kids against a technology that's fundamentally impossible to protect against,” Hye says. “It's not their fault.”
5 notes
·
View notes
Text
How to Bypass ISP Whitelists with Dynamic Proxies in 2025
In 2025, more digital platforms and AI content services have quietly adopted ISP whitelist systems to control who gets access to their data, media, and tools. If you’ve ever tried reaching an AI-powered streaming platform or research database only to see your connection denied, chances are you’ve bumped into one of these. Over the past year, we’ve seen businesses struggle with this growing trend, and at IPFLY, we’ve focused on solving it with our Dynamic Residential Proxies. Today, I want to share how our proxies help companies navigate these restrictions safely, efficiently, and at scale.

What Is an ISP Whitelist and Why It's Growing in 2025
At its core, an ISP whitelist is a list of approved internet service providers or specific IP ranges that a website or platform allows through its firewall. Anyone outside those ranges is automatically blocked. While this technique isn’t new, its use has exploded this year, especially in industries like:
1. AI-generated content services
2. Regionalized streaming platforms
3. Secure fintech APIs
4. Research archives behind government restrictions
As AI media tools became a major business asset in 2025, many providers turned to ISP whitelists to prevent abuse, scraping, and unauthorized use. The catch? Legitimate businesses often get caught in the crossfire.
The Real-World Challenges ISP Whitelists Cause
Our clients constantly share their frustrations with us, because navigating these restrictions is no easy task.
1. Blocked Access to AI Tools
AI-generated video platforms, image banks, and localization APIs now check your connection’s originating ISP. If your IP isn’t on the whitelist, you’re denied access.
2. Streaming Content Limits
Many media companies running content A/B tests or global campaign checks can’t view international platform variations anymore, thanks to strict ISP restrictions.
3. Proxy Detection Crackdowns
Free VPNs, shared proxies, and even datacenter proxies are now easily flagged and blocked, leaving users unable to pass these ISP whitelists.
The result? Valuable opportunities are lost and productivity bottlenecks you can’t afford in a competitive AI-driven market.
How Dynamic Residential Proxies Easily Bypass ISP Whitelists
Here’s where our solution makes a real difference. Unlike static or datacenter proxies, our Dynamic Residential Proxies source real residential IP addresses from everyday ISPs worldwide. That means when you connect to a whitelisted platform, it looks like a regular home internet user, exactly what those lists permit.
Why It Works:
Trusted Residential ISPs: Our proxy IPs originate from authentic residential networks, helping your traffic blend naturally with allowed users.
Smart IP Rotation: For sensitive platforms, you can schedule IP rotations or keep the same connection when session persistence is needed.
Precise Geotargeting: Choose from thousands of IPs across specific cities and countries to pass both ISP and regional restrictions in one go.
Leak Prevention Features: We’ve built DNS, WebRTC, and IP leak checks directly into our management dashboard so your activity stays airtight.
This isn’t just how to sneak past filters — it’s how to do it securely, without risking bans or connection drops mid-task.
Real Use Cases from Teams We Support

The advantages become obvious when you see what businesses achieve with this setup:
Ad Tech Firms Checking Global Campaign Placements
One of our clients runs targeted ads across Asia and Europe. By pairing dynamic residential proxies with their tools, they verify how their ads render locally, bypassing regional ISP blocks and maintaining campaign integrity.
AI Startups Accessing Regional Data Sources
An AI developer we work with scrapes localized news feeds and public datasets for model training. With our residential proxies, they safely access whitelisted AI resources without their IP pool getting flagged.
Market Research Teams Monitoring AI Tools
When new AI services launch, research analysts need to track performance, content variations, and pricing across regions. Our proxy pool lets them view region-restricted content and platforms that enforce ISP whitelist policies.
These cases all share a need for stable, scalable, and undetectable proxy connections — exactly what our infrastructure is built for.
Pro Tips for Managing ISP Whitelist Challenges
If you’re facing these restrictions in your own workflows, here’s what we’ve learned works best:
1. Always choose residential IPs from verified ISPs to avoid instant detection.
2. Organize your proxy IPs by region and ISP — many platforms whitelist both together.
3. Monitor your IP reputation and connection logs to stay ahead of issues.
4. Use real-time health checks to swap out proxies before connection quality drops.
We routinely help clients set up custom IP pools and automate these monitoring tasks via our dashboard and proxy management API.
Future Trends: Tighter Controls and Smarter Bypasses
The trend toward ISP-based access control is only going to intensify as AI content services grow. In response, we’re expanding our offerings in:
New regions with stricter ISP whitelists
API-based proxy rotation for automated workflows
Deeper reporting and alert systems for connection health and proxy performance
By investing early in infrastructure upgrades and proactive support, we’re making sure businesses can stay ahead of these digital roadblocks.
A Smarter Way to Bypass ISP Whitelists with IPFLY
Getting blocked by an ISP whitelist isn’t just an inconvenience anymore — it’s a productivity killer for AI developers, digital marketers, and research firms alike. That’s why we built our Dynamic Residential Proxy solution with these exact challenges in mind.

With trusted residential IPs, global coverage, smart rotation, and dedicated technical support, our proxy network helps businesses navigate tough restrictions safely and reliably. If you’re looking for a proven way to access AI tools, streaming services, or region-specific content in a whitelist-heavy digital world, our team at IPFLY is ready to help you build the perfect proxy stack.
0 notes
Text
How a NY Brand Reduced MAP Violations by 34% with Actowiz Metrics

Introduction
In the hyper-competitive online retail space, Minimum Advertised Price (MAP) enforcement has become a cornerstone for protecting brand equity and distributor relationships. This case study explores how a well-known New York-based consumer electronics brand partnered with Actowiz Metrics to monitor, detect, and reduce MAP violations across platforms like Amazon, Walmart, eBay, and Newegg, achieving a 34% reduction in violations within three months.
The Client
The client is a mid-size electronics brand based in New York City, distributing through a network of resellers, affiliates, and third-party marketplaces. Their products include:
Bluetooth speakers
Smart home devices
Charging stations
Wireless headphones
Despite having MAP agreements in place, the brand noticed frequent underpricing by unauthorized sellers, hurting authorized dealer sales and customer trust.
Challenges Faced
Lack of Visibility Across Marketplaces: The client was blind to who was undercutting prices on third-party marketplaces.
High Volume of Violations: With 300+ SKUs, manual checks were impossible. Sellers changed prices frequently.
Delayed Detection: By the time they noticed a violation, the damage was already done.
Brand Erosion: Retail partners complained about unequal pricing and pulled out of MAP compliance.
Objectives

Achieve real-time monitoring of MAP violations.
Track seller identities and pricing trends.
Generate automated violation reports.
Improve enforcement by backing communication with data.
Solution by Actowiz Metrics
Actowiz Metrics deployed an AI-enabled eCommerce Price Monitoring System that:
Scraped product pricing data every 2 hours from:
Amazon US (Seller Central + Buy Box + 3P)
Walmart.com
eBay.com
Newegg.com
Mapped SKUs, GTINs, ASINs with real-time price tracking.
Identified unauthorized sellers via reverse lookup.
Triggered violation alerts based on a defined MAP price threshold.
Delivered reports via dashboard and daily email exports.
Implementation Timeline
Week 1:
SKU database integrated
Custom MAP thresholds uploaded
Scraper setup for 4 platforms
Week 2:
Alerting system activated
First MAP violation report delivered
Week 3-4:
Seller identities enriched using Actowiz reverse engineering methods
Monthly summary dashboard configured
Month 2:
Action taken on 187 violating listings
4 unauthorized sellers blacklisted
Month 3:
Weekly violations dropped from 122 to 81
Brand restored compliance confidence with retailers
Key Benefits
Automated Monitoring: 24/7 price checks reduced dependency on manual checks.
Accurate Seller Detection: Identified both seller name and potential warehouse locations.
Increased Enforcement: Legal and compliance teams used Actowiz’s visual reports in takedown notices.
Improved Trust: Retailers rejoined MAP compliance once uniform pricing was restored.
Feedback from Client
“Actowiz Metrics helped us bring discipline to our entire reseller ecosystem. For the first time, we had data to confront MAP violators. The reports and seller profiles gave our compliance team the edge we needed.”
— VP of Channel Sales, New York-Based Electronics Brand
Future Roadmap
Integrating EU and Canada sellers into the same MAP monitoring.
Adding coupon discount monitoring and hidden-price scraping.
Creating an automated violation takedown workflow with legal teams.
Why Actowiz Metrics Was Chosen
Scalable scraping infrastructure across Amazon, Walmart, and niche marketplaces
AI-powered seller name de-duplication and identification
Custom alerting rules per product line
Dedicated account manager for weekly support
Conclusion
This case study proves that automated MAP monitoring backed by intelligent scraping can make a significant difference in brand compliance, partner relationships, and revenue retention. Actowiz Metrics offers a seamless and scalable way to eliminate MAP pricing chaos.
For brands struggling with unauthorized discounting and price wars, Actowiz provides not just data—but decisive action tools that restore control. Learn More
#MapViolationMonitoringTools#EcommercePriceMonitoringUSA#AmazonMAPEnforcementUSA#RealTimeSellerTrackingSolution#UnauthorizedSellerDetectionSoftware#RetailPriceScrapingNewYork#ActowizMAPMonitoringService
0 notes