#Watermarking in Apache Spark
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
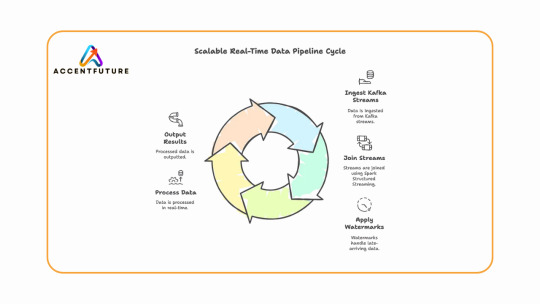
Learn how to build real-time data pipelines using Databricks Stream-Stream Join with Apache Spark Structured Streaming. At AccentFuture, master streaming with Kafka, watermarks, and hands-on projects through expert Databricks online training.
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes
Text
How to Optimize ETL Pipelines for Performance and Scalability

As data continues to grow in volume, velocity, and variety, the importance of optimizing your ETL pipeline for performance and scalability cannot be overstated. An ETL (Extract, Transform, Load) pipeline is the backbone of any modern data architecture, responsible for moving and transforming raw data into valuable insights. However, without proper optimization, even a well-designed ETL pipeline can become a bottleneck, leading to slow processing, increased costs, and data inconsistencies.
Whether you're building your first pipeline or scaling existing workflows, this guide will walk you through the key strategies to improve the performance and scalability of your ETL pipeline.
1. Design with Modularity in Mind
The first step toward a scalable ETL pipeline is designing it with modular components. Break down your pipeline into independent stages — extraction, transformation, and loading — each responsible for a distinct task. Modular architecture allows for easier debugging, scaling individual components, and replacing specific stages without affecting the entire workflow.
For example:
Keep extraction scripts isolated from transformation logic
Use separate environments or containers for each stage
Implement well-defined interfaces for data flow between stages
2. Use Incremental Loads Over Full Loads
One of the biggest performance drains in ETL processes is loading the entire dataset every time. Instead, use incremental loads — only extract and process new or updated records since the last run. This reduces data volume, speeds up processing, and decreases strain on source systems.
Techniques to implement incremental loads include:
Using timestamps or change data capture (CDC)
Maintaining checkpoints or watermark tables
Leveraging database triggers or logs for change tracking
3. Leverage Parallel Processing
Modern data tools and cloud platforms support parallel processing, where multiple operations are executed simultaneously. By breaking large datasets into smaller chunks and processing them in parallel threads or workers, you can significantly reduce ETL run times.
Best practices for parallelism:
Partition data by time, geography, or IDs
Use multiprocessing in Python or distributed systems like Apache Spark
Optimize resource allocation in cloud-based ETL services
4. Push Down Processing to the Source System
Whenever possible, push computation to the database or source system rather than pulling data into your ETL tool for processing. Databases are optimized for query execution and can filter, sort, and aggregate data more efficiently.
Examples include:
Using SQL queries for filtering data before extraction
Aggregating large datasets within the database
Using stored procedures to perform heavy transformations
This minimizes data movement and improves pipeline efficiency.
5. Monitor, Log, and Profile Your ETL Pipeline
Optimization is not a one-time activity — it's an ongoing process. Use monitoring tools to track pipeline performance, identify bottlenecks, and collect error logs.
What to monitor:
Data throughput (rows/records per second)
CPU and memory usage
Job duration and frequency of failures
Time spent at each ETL stage
Popular tools include Apache Airflow for orchestration, Prometheus for metrics, and custom dashboards built on Grafana or Kibana.
6. Use Scalable Storage and Compute Resources
Cloud-native ETL tools like AWS Glue, Google Dataflow, and Azure Data Factory offer auto-scaling capabilities that adjust resources based on workload. Leveraging these platforms ensures you’re only using (and paying for) what you need.
Additionally:
Store intermediate files in cloud storage (e.g., Amazon S3)
Use distributed compute engines like Spark or Dask
Separate compute and storage to scale each independently
Conclusion
A fast, reliable, and scalable ETL pipeline is crucial to building robust data infrastructure in 2025 and beyond. By designing modular systems, embracing incremental and parallel processing, offloading tasks to the database, and continuously monitoring performance, data teams can optimize their pipelines for both current and future needs.
In the era of big data and real-time analytics, even small performance improvements in your ETL workflow can lead to major gains in efficiency and insight delivery. Start optimizing today to unlock the full potential of your data pipeline.
0 notes
Link
0 notes
Text
[100% OFF] Apache Spark 3 - Real-time Stream Processing using Scala
[100% OFF] Apache Spark 3 – Real-time Stream Processing using Scala
What you Will learn ? Real-time Stream Processing Concepts Spark Structured Streaming APIs and Architecture Working with File Streams Working With Kafka Source and Integrating Spark with Kafka State-less and State-full Streaming Transformations Windowing Aggregates using Spark Stream Watermarking and State Cleanup Streaming Joins and Aggregation Handling Memory Problems with Streaming…

View On WordPress
0 notes
Text
Impetus Technologies Announces New StreamAnalytix Enhancements
Los Gatos, Calif: Impetus Technologies, a big data software products, and services company, today unveiled a number of enhancements to StreamAnalytix, a powerful visual platform for unified streaming and batch data processing based on best-of-breed open source technologies. Numerous Fortune 500 companies are making their real-time enterprise architecture a reality with StreamAnalytix.
StreamAnalytix simplifies the use of Apache Spark and is designed to help organizations address the rising demand for Spark development talent. With an intuitive visual integrated development environment (IDE), StreamAnalytix enables even those with limited development experience to build and operationalize Spark applications end to end.
“Apache Spark is already the de facto standard for stream processing. Advancements like Structured Streaming have made Spark-streaming even more powerful,” said Anand Venugopal, head of StreamAnalytix at Impetus. “Now all of these capabilities are included in, and supported by, StreamAnalytix along with a visual drag-and-drop interface, an exhaustive set of pre-built Spark operators, and full application lifecycle support - enabling developers to realize the full potential of enhancements to Apache Spark with unprecedented ease.”
The most recent enhancements to StreamAnalytix, include:
Full support for Spark Structured Streaming: With Structured Streaming, StreamAnalytix now enables continuous applications by exposing a single API to write streaming as well as batch queries. It handles streaming complexities by ensuring exactly-once-semantics, doing incremental aggregations, and providing data consistency across sources and sinks.
Late data handling and watermarking: Allows handling of delayed data by maintaining intermediate calculations; as new data arrives aggregates are updated based on the time windows specified. These time windows can be defined by watermarking specific time intervals.
5X faster performance: Enables significantly faster processing with Spark Structured Streaming as the underlying technology.
Auto Schema Detection: Automates the creation of schema within pre-built operators. Data can be accessed from a data storage system, or configured from a source such as Kafka, JDBC and more. StreamAnalytix then automatically examines each field and assigns a data type to that field based on the values within the data to enable the identification of columns.
Auto pipeline inspect: Allows the use of a data inspect feature during pipeline development, and before and after the use of every individual operator for an end-to-end view of data transformation at every step.
Real-time event monitoring: Users now receive all performance metrics in real-time, and can keep a continuous watch on their application data pipelines, as well as the cluster infrastructure on both local and cloud-based environments.
Support for Apache Spark 2.2 and Hadoop 2.7.3
Impetus also announced that it will present a tech talk titled “Leveraging Spark Machine Learning for Real-time Credit Card Approvals” at the Spark + AI Summit. The session will describe how StreamAnalytix leveraged Spark Streaming and Spark Machine Learning (ML) models to build and operationalize real-time credit card approvals for a major bank. It will include a deep dive into the Spark-based ML capabilities used, as well as how a typical ML pipeline looks.
Impetus’ experts will showcase how users with very little Spark development experience can utilize the visual IDE and drag-and-drop features of StreamAnalytix to build and operationalize a Spark pipeline in minutes.
This article was first appeared on MarTech Advisor
0 notes
Text
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes
Text
Stateful-проблемы JOIN-операций в Apache Spark Structured Streaming и их решения

Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join используют водяные знаки (watermark).
Соединение потоков в Apache Spark Structured Streaming
Соединение (Join) считается достаточно сложной операцией в SQL. А соединение потоков данных усложняется задержками поступления информаций. Для ограниченного источника данных, такого, как статичная СУБД, все данные для соединения имеются в наличии, тогда как в случае потокового источника данные непрерывно перемещаются, причем с непостоянной скоростью. Это может быть связано с техническими причинами, такими как проблемы с конвейером приема, или из-за функциональных требований, когда связанные события не всегда генерируются в течение аналогичного периода времени. К примеру, процесс заказа в интернет-магазине, который обычно длится долго. Поэтому операция соединения должна управлять набором связанных, но асинхронных событий.

Кроме того, при соединении потоков необходимо обеспечить управление состоянием, т.к. данные для конкретного события могут поступить в любой момент (рано или поздно), а количество места, зарезервированного для их хранения, ограничено. Поэтому следует понимать, что делать с накопленным состоянием и когда его можно сбросить, что соответствует моменту, в который не ожидается получение какого-либо нового события для данного ключа соединения. Начиная с версии Apache Spark 2.3.0, библиотека Structured Streaming решает обе эти проблемы, позволяя соединять 2 или более потоков следующим образом [1]: семантика соединения потоков аналогична работе с пакетами; вывод генерируется, как только будет найден соответствующий элемент при внутреннем соединении (Inner Join); водяной знак (watermark) и запрос временного диапазона используются для соединения поздних данных и принятия решения о сбросе состояния, когда более не ожидается событий для данного ключа; поддерживаются разные типы соединения: внутреннее и внешнее (Outer Join); соединения могут быть каскадными, т.е. применяться более чем к 2 потокам данных.
Join-операции и watermark: особенности потоковой обработки Big Data
В случае внутреннего соединения Apache Spark Structured Streaming, результатом которого являются только совпавшие по условию объединенные записи из входных наборов данных, строка без соответствия не генерируется. Поэтому не требуется никаких временных ограничений для соединенных столбцов. Однако, каждая потенциально присоединяемая строка буферизуется в хранилище состояний. Соединение и выдача результата выполняются каждый раз, когда найдена соответствующая строка. При этом строки, даже без совпадений, могут оставаться в хранилище состояний в течение очень долгого времени. Поэтому рекомендуется иметь условие, указывающее, как долго должно сохраняться состояние конкретного ключа. Для этого Apache Spark Structured Streaming использует механизм водяных знаков – watermark [2], о котором мы рассказывали здесь. Можно рассматривать водяной знак как отметку, которая «дискретизирует» поток данных по аналогии с переводом сигнала из аналоговой формы в цифровую.

Отслеживание водяных знаков актуально и для внешних соединений. Outer Join дает все строки с одной стороны, даже если некоторые из них не имеют совпадений в соединяемом наборе данных. Для ограниченных источников данных, таких как СУБД, такие несоответствия возвращаются напрямую с нулевым значением, представляющим строку на другой стороне. Однако, в случае неограниченных источников, т.е. потоков данных, нужно учитывать влияние задержки сети или временное выпадение из онлайн устройства, генерирующего события. Из-за таких ситуаций в какой-то момент времени не все соединяемые данные могут быть в наличии. Поэтому следует иметь возможность отложить физическое соединение до того момента, когда придет большая часть строк для Join-операции. Для этого требуется где-то сохранить строки с одной стороны [3].

Как и в случае внутреннего соединения с водяным знаком, при Outer Join строки буферизуются в хранилище состояний. И внешнее соединение также использует идею водяных знаков и условий запроса диапазона, чтобы решить, когда данная строка не должна получать никаких новых совпадений во втором потоке. Поэтому внешнее соединение без водяного знака просто невозможно. Интересно, что результаты соединения обусловлены сопоставлением: совпавшие строки возвращаются, как только это возможно, а несоответствующие – только по достижении времени водяного знака [3].
2 стратегии управления водяными знаками в Apache Spark
Таким образом, без концепции «просроченного состояния» сохранение соответствия строк будет длиться неограниченно долго, а, поскольку источник данных неограничен, рано или поздно он неизбежно выйдет из строя (закончится место). Поэтому Apache Spark предоставляет 2 различных стратегии для управления истечением срока действия (водяным знаком): ключ состояния, которая применяется к запросу, когда столбец watermark’а определен по крайней мере в одном из соединяемых потоков, например, столбец с отметкой времени (timestamp) или столбец временного окна (window). Если водяной знак определен только для одной стороны, Apache Spark может определить его и для другой. Также эта стратегия применяется, если имеется определение условия диапазона для столбца водяного знака в условии JOIN, который ��олжен соединяться иначе, чем при равенстве значений. Название этой стратегии «ключ состояния» происходит от использования водяного знака непосредственно в условии JOIN. значения состояния, когда условие JOIN не содержит равенства в поле водяного знака, а указывает на диапазон, выраженный как неравенство. Таким образом, название этой стратегии - водяной знак со значением состояния. Условие диапазона, определенное в условии JOIN, автоматически влияет на водяной знак одной из соединенных сторон. Когда это условие выражается как leftTimeWatermark> rightTimeWatermark + 10 минут, это означает, что левая сторона будет принимать только события, произошедшие позже, чем водяной знак правой стороны + 10 минут. При этом, если водяной знак правой стороны равен 10:00, то водяной знак левой стороны автоматически становится 10:10. Это работает и наоборот, то есть левый водяной знак влияет на правый. Такая стратегия также будет работать, если определены 2 разных значения водяных знаков с обеих сторон. Apache Spark Structured Streaming будет использовать одно общее значение водяного знака, минимальное для соединяемых потоков. Наличие двух разных watermark’ов не будет работать в случае водяного знака с ключом состояния, т.к. потоки соединяются по равенству водяных знаков. Водяной знак состояния также может применяться к кейсам с временными окнами, но, как и в случае столбцов с отметками времени, он должен быть выражен как неравенство в условии JOIN. Также возможно совместное использование этих 2-х стратегий, однако движок Apache Spark Structured отдает предпочтение водяному знаку с ключом состояния из-за его более строгого характера. Это довольно четко показано в методе getOneSideStateWatermarkPredicate (oneSideInputAttributes: Seq [Attribute], oneSideJoinKeys: Seq [Expression], otherSideInputAttributes: Seq [Attribute]), который находит, какие атрибуты использовались для определения атрибута водяного знака и создает JoinStateWatermarkPredicate - абстракцию предикатов водяных знаков состояния соединения, описываемых выражением SQL-оптимизатора Catalyst, следующим образом [4]: JoinStateKeyWatermarkPredicate, если водяной знак был определен для ключа соединения с выражением водяного знака для индекса выражения ключа соединения; JoinStateValueWatermarkPredicate, если водяной знак был определен среди атрибутов oneSideInputAttributes (с водяным знаком значения состояния на основе заданных атрибутов oneSideInputAttributes и otherSideInputAttributes). Таким образом, все стратегии управления «сроком годности» соединяемых потоков в Apache Spar Streaming используют концепцию водяного знака, чтобы обнаруживать опоздавшие строки, которые будут отброшены в следующем цикле обработки [2].

Узнайте больше про особенности Apache Spark Structured Streaming для аналитики больших данных и разработки распределенных приложений на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: Core Spark – Основы Apache Spark для разработчиков Потоковая обработка в Apache Spark Анализ данных с Apache Spark Источники https://www.waitingforcode.com/apache-spark-structured-streaming/inner-joins-streams-apache-spark-structured-streaming/read https://www.waitingforcode.com/apache-spark-structured-streaming/stream-to-stream-state-management/read https://www.waitingforcode.com/apache-spark-structured-streaming/outer-joins-apache-spark-structured-streaming/read https://jaceklaskowski.gitbooks.io/spark-structured-streaming/content/spark-sql-streaming-StreamingSymmetricHashJoinHelper.html Read the full article
0 notes