#Real-Time Data Pipeline with Spark
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
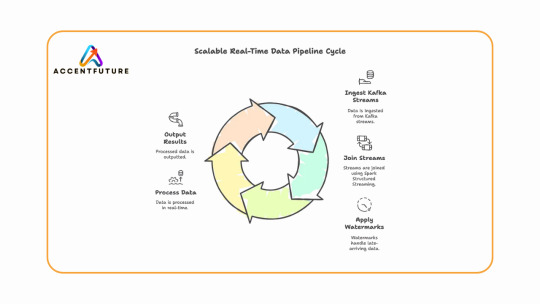
Learn how to build real-time data pipelines using Databricks Stream-Stream Join with Apache Spark Structured Streaming. At AccentFuture, master streaming with Kafka, watermarks, and hands-on projects through expert Databricks online training.
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes
Text
#Databricks interview questions#Scenario based Databricks questions#Databricks data engineer interview questions#Spark Databricks interview questions#Real-time Databricks interview scenarios#Databricks ETL pipeline design#Delta Lake interview questions#Databricks course online
0 notes
Text
Unveiling the Power of Delta Lake in Microsoft Fabric
Discover how Microsoft Fabric and Delta Lake can revolutionize your data management and analytics. Learn to optimize data ingestion with Spark and unlock the full potential of your data for smarter decision-making.
In today’s digital era, data is the new gold. Companies are constantly searching for ways to efficiently manage and analyze vast amounts of information to drive decision-making and innovation. However, with the growing volume and variety of data, traditional data processing methods often fall short. This is where Microsoft Fabric, Apache Spark and Delta Lake come into play. These powerful…
#ACID Transactions#Apache Spark#Big Data#Data Analytics#data engineering#Data Governance#Data Ingestion#Data Integration#Data Lakehouse#Data management#Data Pipelines#Data Processing#Data Science#Data Warehousing#Delta Lake#machine learning#Microsoft Fabric#Real-Time Analytics#Unified Data Platform
0 notes
Text
i love mashing my interests together in my fists and im learning a new process today so here's what types of welding i think the bridge team (+some extras) from tng would do/enjoy
🩶picard does not care for welding, NEEEEXT (but if he did he would enjoy acetylene welding)(because he was born old) i think he should give it a shot anyways bc chipping the slag off a stick weld feels very much like archaeology.
❤️rikers dad made him weld i bet. mig. i don't think he liked it either but he was probably fine at it. like if he had to mig something together it wouldnt fall apart. immediately.
🧡geordi welds for surely, and he's good as fuck at it. mig, tig, arc, and beyond. HOWEVER, he seems like the type to prefer more advanced methods like stir welding and EBW. anything requiring some level of interfacing through a machine rather than stinger to steel. when i write fic i headcanon that since its the future there's cool new ✨futuristic✨ post-advent-of-space-travel welding methods that involve cold welding, and i think he'd like that, too. he is an engineer, after all, and there's overlap between these fields.
💛data would be fantastic at any kind of welding as long as he's studied up on it first, but i don't think he'd find any value in it beyond its function. you wouldn't find him on weld forums ogling any crisp weaves. the only reason he'd find a personal interest in it would be because his friends like it.
🤍tasha welds most definitely, and i think she's pretty good at it. her knowledge starts at mig, thru flux core and ends at arc -- i can't imagine the colony she came from had much use for tig or any of the more advanced methods. to her, i bet welding is just a useful repair skill everyone should know at least a little about, like sewing.
🤎worf has never tried welding but i think he would love arc welding. pipe. in the late summer. for nine hours. it's a real test of strength you can pride yourself on if you don't sweat yourself to death in your leathers. need to know what a klingon welding hood would look like. GET THIS GUY ON A PIPELINE NOW!!!!!
🩵iiiiiii think deanna would be really good at tig if she applied herself but i don't think she'd like welding at all. i don't think she'd like the smells, sounds, wearing the ppe, any of it. the fumes probably give her a headache. and that is ok 🙏
💙beverly can mig weld, i bet. it's neither here nor there for her, just something she can do in a pinch. it comes in handy when you're helping out around a colony, but as a doctor, she finds she's plenty of help without it anyways.
🩷i feel like wesley can hella tig weld. i think he's in the boat with geordi where they don't really care for the 'dirtier' types but overall he's more into the technical bits of engineering rather than the fabrication end of it. honestly, i think more than anything he'd be really into soldering. but anyways, tig welding is hard and impressive and he should be VERY PROUD of himself 🫶✨
💚q can weld stuff together with his mind. whatever. cheater. but if he was stripped of his q powers and made to weld he would hhhhhHHAAAATE it i promise. screaming and jumping at the sparks, touching the hot metal on accident and whinging about it, upset cuz he's too hot to be wearing leathers, etc. he would wilt. womp womp.
💜i bet guinan is secretly a master welder and she anonymously runs a welding forum and posts the most picturesque woven beads you've ever seen in your life. she's secretly the talk of all the techs at every docking station -- like banksy for people who chew dip. its art when she does it.
🖤lore hates welding he can and will bitch about it the entire time if he's made to. the only kind he can tolerate is mig but even then, he finds it all tedious. i think if you ever sat him down to arc weld for an hour and came back to check on him, all you'd find left would be a plate covered in errant strikes, 50 partially coated, bent-up rods all over the floor, and a broken stinger. he also seems like the type to not wear his leathers and then complain when he gets holes burnt into his arms.
6 notes
·
View notes
Text
NVIDIA AI Workflows Detect False Credit Card Transactions

A Novel AI Workflow from NVIDIA Identifies False Credit Card Transactions.
The process, which is powered by the NVIDIA AI platform on AWS, may reduce risk and save money for financial services companies.
By 2026, global credit card transaction fraud is predicted to cause $43 billion in damages.
Using rapid data processing and sophisticated algorithms, a new fraud detection NVIDIA AI workflows on Amazon Web Services (AWS) will assist fight this growing pandemic by enhancing AI’s capacity to identify and stop credit card transaction fraud.
In contrast to conventional techniques, the process, which was introduced this week at the Money20/20 fintech conference, helps financial institutions spot minute trends and irregularities in transaction data by analyzing user behavior. This increases accuracy and lowers false positives.
Users may use the NVIDIA AI Enterprise software platform and NVIDIA GPU instances to expedite the transition of their fraud detection operations from conventional computation to accelerated compute.
Companies that use complete machine learning tools and methods may see an estimated 40% increase in the accuracy of fraud detection, which will help them find and stop criminals more quickly and lessen damage.
As a result, top financial institutions like Capital One and American Express have started using AI to develop exclusive solutions that improve client safety and reduce fraud.
With the help of NVIDIA AI, the new NVIDIA workflow speeds up data processing, model training, and inference while showcasing how these elements can be combined into a single, user-friendly software package.
The procedure, which is now geared for credit card transaction fraud, might be modified for use cases including money laundering, account takeover, and new account fraud.
Enhanced Processing for Fraud Identification
It is more crucial than ever for businesses in all sectors, including financial services, to use computational capacity that is economical and energy-efficient as AI models grow in complexity, size, and variety.
Conventional data science pipelines don’t have the compute acceleration needed to process the enormous amounts of data needed to combat fraud in the face of the industry’s continually increasing losses. Payment organizations may be able to save money and time on data processing by using NVIDIA RAPIDS Accelerator for Apache Spark.
Financial institutions are using NVIDIA’s AI and accelerated computing solutions to effectively handle massive datasets and provide real-time AI performance with intricate AI models.
The industry standard for detecting fraud has long been the use of gradient-boosted decision trees, a kind of machine learning technique that uses libraries like XGBoost.
Utilizing the NVIDIA RAPIDS suite of AI libraries, the new NVIDIA AI workflows for fraud detection improves XGBoost by adding graph neural network (GNN) embeddings as extra features to assist lower false positives.
In order to generate and train a model that can be coordinated with the NVIDIA Triton Inference Server and the NVIDIA Morpheus Runtime Core library for real-time inferencing, the GNN embeddings are fed into XGBoost.
All incoming data is safely inspected and categorized by the NVIDIA Morpheus framework, which also flags potentially suspicious behavior and tags it with patterns. The NVIDIA Triton Inference Server optimizes throughput, latency, and utilization while making it easier to infer all kinds of AI model deployments in production.
NVIDIA AI Enterprise provides Morpheus, RAPIDS, and Triton Inference Server.
Leading Financial Services Companies Use AI
AI is assisting in the fight against the growing trend of online or mobile fraud losses, which are being reported by several major financial institutions in North America.
American Express started using artificial intelligence (AI) to combat fraud in 2010. The company uses fraud detection algorithms to track all client transactions worldwide in real time, producing fraud determinations in a matter of milliseconds. American Express improved model accuracy by using a variety of sophisticated algorithms, one of which used the NVIDIA AI platform, therefore strengthening the organization’s capacity to combat fraud.
Large language models and generative AI are used by the European digital bank Bunq to assist in the detection of fraud and money laundering. With NVIDIA accelerated processing, its AI-powered transaction-monitoring system was able to train models at over 100 times quicker rates.
In March, BNY said that it was the first big bank to implement an NVIDIA DGX SuperPOD with DGX H100 systems. This would aid in the development of solutions that enable use cases such as fraud detection.
In order to improve their financial services apps and help protect their clients’ funds, identities, and digital accounts, systems integrators, software suppliers, and cloud service providers may now include the new NVIDIA AI workflows for fraud detection. NVIDIA Technical Blog post on enhancing fraud detection with GNNs and investigate the NVIDIA AI workflows for fraud detection.
Read more on Govindhtech.com
#NVIDIAAI#AWS#FraudDetection#AI#GenerativeAI#LLM#AImodels#News#Technews#Technology#Technologytrends#govindhtech#Technologynews
2 notes
·
View notes
Text
Data Engineering Syllabus | IABAC
Data Engineering courses cover database management, ETL processes, big data technologies (Hadoop, Spark), cloud platforms (AWS, GCP), data modeling, and pipeline automation. It specializes in planning, developing, and maintaining scalable data systems for efficient storage, processing, and real-time analytics. https://iabac.org/blog/what-is-the-syllabus-for-data-engineering

1 note
·
View note
Text
Data Engineering and AI: What You Need to Know

In today’s digital-first world, Artificial Intelligence (AI) is driving innovation across every industry. From personalized product recommendations to intelligent chatbots and self-driving cars, AI is everywhere. But behind every smart system lies something critical — data. And that’s where data engineering comes in.
If you're considering a career in tech, understanding how Data Engineering and AI work together is essential. Let’s explore their connection, why this pairing matters, and how a BCA in Data Engineering from Edubex can prepare you for this exciting future.
What is Data Engineering?
Data engineering involves designing, building, and maintaining systems that collect, store, and process large volumes of data. Data engineers make it possible for data scientists and AI systems to access clean, reliable, and scalable data.
Their core responsibilities include:
Developing data pipelines
Working with databases and cloud platforms
Ensuring data integrity and security
Automating data workflows
Without data engineers, AI algorithms would have no reliable data to work with.
How AI Relies on Data Engineering
AI needs vast amounts of high-quality data to learn and make accurate predictions. Here’s how data engineers support AI:
✅ Data Collection: Gathering raw data from multiple sources
✅ Data Cleaning: Removing errors, duplicates, and inconsistencies
✅ Data Structuring: Organizing data into usable formats
✅ Real-Time Data Flow: Providing continuous data streams for AI applications like fraud detection or recommendation systems
In short, AI is only as good as the data it receives, and that data is managed by engineers.
Key Tools and Technologies You’ll Learn
A BCA in Data Engineering from Edubex will help you master the tools that power modern AI systems:
Programming Languages: Python, SQL, Java
Big Data Platforms: Hadoop, Apache Spark
Cloud Computing: AWS, Google Cloud, Microsoft Azure
Data Warehousing: Snowflake, Redshift, BigQuery
AI/ML Basics: Understanding models and how they consume data
This skill set forms the backbone of both data engineering and AI development.
Why Choose a BCA in Data Engineering at Edubex?
Industry-Aligned Curriculum: Learn what's relevant in today’s job market
Hands-on Learning: Work on real-world data sets and projects
Career-Focused: Prepare for roles like Data Engineer, AI Engineer, and Data Analyst
Flexible Learning: 100% online learning options to fit your schedule
Global Recognition: Programs aligned with international standards
Careers at the Intersection of Data Engineering and AI
Completing a BCA in Data Engineering opens doors to a variety of AI-related careers:
Machine Learning Data Engineer
Data Pipeline Developer
Big Data Engineer
AI Infrastructure Engineer
Cloud Data Engineer
These roles are in high demand across industries like finance, healthcare, e-commerce, and more.
Final Thoughts
As AI continues to reshape our world, data engineers are becoming the unsung heroes of this transformation. By enrolling in a BCA in Data Engineering at Edubex, you're not just learning how to handle data — you’re preparing to power the intelligent systems of tomorrow.
Ready to take your place in the future of AI and data?
0 notes
Text

🚀 Master Databricks for a Future-Proof Data Engineering Career!
Looking to accelerate your career in data engineering? Our latest blog dives deep into expert strategies for mastering Databricks—focusing purely on data engineering, not data science!
✅ Build real-time & batch data pipelines ✅ Work with Apache Spark & Delta Lake ✅ Automate workflows with Airflow & Databricks Jobs ✅ Learn performance tuning, CI/CD, and cloud integrations
Start your journey with AccentFuture’s expert-led Databricks Online Training and get hands-on with tools used by top data teams.
📖 Read the full article now and take your engineering skills to the next level! 👉 www.accentfuture.com
#Databricks#DataEngineering#ApacheSpark#DeltaLake#BigData#ETL#DatabricksTraining#AccentFuture#CareerGrowth
0 notes
Text
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes
Text
The Future of Recruitment: Trends and Technologies Transforming Hiring
In the ever-evolving world of talent acquisition, recruitment agencies are no longer just middlemen between employers and job seekers. From AI-driven sourcing to remote-first hiring strategies, the industry is undergoing a major transformation. Whether you're an employer in Canberra or a job seeker in Melbourne, staying updated on the latest recruitment trends and technologies is essential. This article explores how the recruitment landscape is shifting and what it means for both employers and recruitment agencies in Canberra and Melbourne.
The Evolving Role of Recruitment Agencies
The traditional model of recruitment is being redefined. No longer just resume filters, recruitment agencies are now strategic talent partners. Especially in cities like Canberra and Melbourne, where niche skills and competitive job markets demand smarter hiring solutions, recruitment agencies are embracing innovation to offer value-added services such as:
Workforce planning
Employer branding
Talent mapping
Diversity and inclusion consulting
For businesses in Canberra and Melbourne, partnering with modern recruitment agencies means access to deeper candidate insights, faster hiring cycles, and more robust compliance with local labor laws.
Top Recruitment Trends Shaping the Industry
1. AI and Automation in Hiring
Artificial Intelligence (AI) is arguably the most impactful trend in recruitment today. From intelligent resume parsing to candidate matching, AI tools are reducing time-to-hire and enhancing accuracy.
Recruitment agencies in Canberra, for instance, are using AI to:
Pre-screen candidates using behavioral data
Automate communication via chatbots
Predict candidate success based on historical data
Similarly, recruitment agencies in Melbourne have started leveraging predictive analytics to match candidates to roles based on cultural fit and long-term potential, not just experience.
2. Rise of Remote and Hybrid Workforces
The COVID-19 pandemic changed the world of work forever. Remote and hybrid work is now standard practice in many sectors. This has created new challenges—and opportunities—for recruitment agencies.
Melbourne-based agencies are now:
Sourcing candidates nationally and internationally
Using virtual interviewing tools
Helping employers craft remote work policies
Canberra, as a city with a strong government presence, is also seeing a shift toward hybrid public service roles. Agencies must adapt to these changes by understanding remote workforce dynamics and related compliance needs.
3. Data-Driven Recruitment
Gone are the days when gut instinct alone drove hiring decisions. Data is now a key component of smart recruitment. Advanced analytics help agencies understand:
Candidate engagement metrics
Time-to-fill and cost-per-hire
Diversity and inclusion performance
Recruitment agencies in Canberra use these data points to refine strategies for public sector hiring, which often involves rigorous selection processes. Melbourne agencies, on the other hand, are using data to help fast-growth tech startups scale their teams quickly and efficiently.
Emerging Technologies in Recruitment
1. Applicant Tracking Systems (ATS)
Modern recruitment agencies rely on cloud-based ATS platforms to:
Streamline candidate pipelines
Collaborate with hiring managers in real time
Maintain GDPR and Fair Work compliance
In both Canberra and Melbourne, the demand for agencies using advanced ATS tools is growing, especially among employers who want transparency in the hiring process.
2. Video Interviewing Platforms
With the rise of remote hiring, video interviewing software has become essential. Tools like HireVue, Spark Hire, and Zoom-integrated platforms are helping recruiters:
Conduct asynchronous interviews
Use facial recognition and speech analysis for deeper evaluation
Reduce interview scheduling conflicts
Recruitment agencies in Melbourne are increasingly using these tools for high-volume retail and hospitality hiring. Canberra agencies, focused on professional services, use video interviews to improve candidate accessibility and convenience.
3. Talent Intelligence Platforms
These platforms provide insights into global talent availability, compensation benchmarks, and competitor hiring strategies. They are helping recruitment agencies in Canberra and Melbourne offer strategic advice to clients and enhance workforce planning capabilities.
Focus on Diversity, Equity & Inclusion (DEI)
Recruitment agencies across Australia are making DEI a top priority. This means:
Removing bias from job descriptions
Implementing blind hiring practices
Expanding outreach to underrepresented communities
Agencies in Canberra, with its multicultural population, are building inclusive talent pipelines for both public and private sectors. Meanwhile, recruitment agencies in Melbourne are working with start-ups and enterprises to create equitable hiring frameworks, especially for leadership roles.
Future Challenges and Opportunities
1. Talent Shortages in Key Sectors
Sectors such as healthcare, engineering, IT, and construction are facing persistent talent shortages in Australia. Recruitment agencies must:
Build passive talent pools
Upskill candidates through training partnerships
Offer flexible work solutions
2. Employer Branding as a Differentiator
Candidates today care about company culture, values, and social impact. Recruitment agencies in Melbourne and Canberra are helping employers:
Develop compelling employer value propositions (EVPs)
Promote their brand across job boards and social media
Create consistent candidate experiences
3. Regulatory Compliance
With frequent updates to labour laws, especially around visa sponsorships and remote employment, staying compliant is crucial. Trusted recruitment agencies in Canberra, given its political ecosystem, are well-positioned to guide clients through complex HR regulations.
What Employers Should Look for in a Modern Recruitment Agency
Whether you're hiring in Canberra or Melbourne, the right recruitment partner should offer:
✅ Deep industry knowledge ✅ Advanced recruitment technologies ✅ Transparent processes and communication ✅ DEI-integrated hiring approaches ✅ Flexibility to scale hiring based on business needs
Conclusion
The future of recruitment is intelligent, inclusive, and tech-driven. Employers who align with forward-thinking recruitment agencies—especially those based in evolving markets like Canberra and Melbourne—will gain a competitive edge in attracting and retaining top talent.
As technology continues to advance and workforce expectations shift, the best recruitment agencies won’t just fill jobs—they’ll build the future of work.
0 notes
Text
How Social Media Experts in Gurgaon Drive Results Beyond Just Likes and Shares

Social Media Experts in Gurgaon: In today’s fast-scrolling world, social media experts in Gurgaon do much more than just posting and using hashtags. They help brands start real conversations, guide people towards becoming customers, and make sure the time and money spent online bring real business results.
1. Beyond Vanity Metrics
Likes and shares look good in reports, but they rarely pay the bills. The best social media management company in Gurgaon will track deeper signals, comment sentiment, click‑through rates, cost per lead, and repeat engagement. These metrics show whether content sparks curiosity, moves visitors to your site, and nudges them toward purchase.
2. Strategy First, Content Second
Great feeds begin with clear intent. Who are we talking to? What keeps them up at night? Which platform feels like home to them at 8 p.m.? A data‑driven roadmap answers these questions before the first creative concept leaves the brainstorming board. At Providence Adworks, every campaign kicks off with audience mapping, competitive audits, and platform research because social media experts in Gurgaon win only when insights guide ideas.
3. Design + Storytelling = Scroll Stoppers
Your audience is bombarded by visuals every second. To stand out, clever design must pair with storytelling that mirrors local humour, culture, and business nuances. A smart social media optimization company in Gurgaon layers thumb‑stopping graphics with copy that addresses real pain points. Think festival‑themed reels, snackable LinkedIn carousels, or short‑form videos featuring local influencers whose credibility can’t be bought, only earned.
4. Platform Mastery in Real Time
Algorithms evolve overnight. What worked yesterday on Instagram Stories might flop today. A nimble social media marketing company in Gurgaon never sets campaigns on autopilot. Real‑time dashboards flag dips in reach, spikes in comments, or unusual CPCs so teams can tweak everything from creative to ad spend on the fly. Each optimization builds a tighter feedback loop and a more efficient budget.
5. Local Context, Global Ambition
Knowing the pulse of Gurgaon and Delhi NCR is half the battle: timing a post around traffic, referencing hyper‑local events, or tapping business forums where decision‑makers hang out. The other half? Scaling that knowledge to resonate nationally (or globally) as your brand grows. The best social media management company in Gurgaon combines grassroots relevance with big-picture thinking, ensuring campaigns feel personal yet future-proof.
6. Providence Adworks: The Conversion‑Driven Difference
Brands partner with Providence Adworks not for likes but for outcomes, qualified leads, stronger recall, and sales conversations that finish with a “yes.” Our team recognized among social media experts in Gurgaon, deploys:
Intent-driven content calendars that balance evergreen thought leadership with real-time trend-jacking.
Creative labs where strategists and designers co‑build series tailored to each platform’s strengths.
Full‑funnel analytics that map every rupee to its return, proving social isn’t just a brand exercise but a revenue engine.
7. Results That Speak Louder Than Metrics
Clients have slashed cost‑per‑lead by up to 40 percent, doubled qualified traffic in under a quarter, and booked pipeline opportunities that once required expensive on‑ground events. When a campaign hits these numbers, the likes and shares become nice bonuses, not the goal.
Final Word
Social media is your brand’s first handshake with many potential customers. To make it firm and memorable, you need more than templates or trendy sounds you need strategic partners who treat your KPIs like their own. So, if you’re ready to align every post with a purpose, consider collaborating with a team that Gurgaon’s most ambitious brands already trust: Providence Adworks, the social media marketing company in Gurgaon that turns conversations into conversions.
Ready to see what purposeful social can do? Let’s talk.
0 notes
Text
Leveraging Apache Spark for Large-Scale Feature Engineering and Data Preprocessing

In today’s data-driven world, the success of machine learning models hinges significantly on the quality of data they consume. As data grows within organisation, performing feature engineering and preprocessing at scale has become a complex challenge. Enter Apache Spark—a powerful open-source unified analytics engine designed for big data processing. Its in-memory computation capabilities, fault tolerance, and distributed architecture make it an ideal tool for handling large datasets efficiently.
Whether you're building predictive models in a multinational enterprise or taking up a data scientist course in Pune, understanding how to leverage Apache Spark for preprocessing tasks is essential. This blog explores how Spark revolutionises large-scale data preparation and why it's a go-to choice for data scientists across industries.
Understanding Apache Spark’s Role in Data Preparation
Apache Spark is not just a distributed processing engine—it’s a complete ecosystem that supports SQL queries, streaming data, machine learning, and graph processing. Its strength lies in its ability to process data in parallel across clusters of machines, drastically reducing the time required for tasks like cleaning, transforming, and encoding large volumes of data.
In traditional setups, such processes can be both time-consuming and memory-intensive. Spark addresses these challenges through its Resilient Distributed Datasets (RDDs) and high-level APIs like DataFrames and Datasets, which are well-optimised for performance.
The Importance of Feature Engineering
Before diving into Spark’s capabilities, it’s crucial to understand the role of feature engineering in machine learning. It involves selecting, modifying, or creating newfeature from data for enhancing predictive power of models. These tasks might include:
Handling missing values
Encoding categorical variables
Normalising numerical features
Generating interaction terms
Performing dimensionality reduction
When datasets scale to terabytes or more, these steps need a framework that can handle volume, variety, and velocity. Spark fits this requirement perfectly.
Distributed Feature Engineering with Spark MLlib
Spark MLlib, the machine learning library within Spark, provides a robust set of tools for feature engineering. It includes:
VectorAssembler: Combines multiple feature columns into a single vector column, which is a required format for ML models.
StringIndexer: Converts categorical variables into numeric indices.
OneHotEncoder: Applies one-hot encoding for classification algorithms.
Imputer: Handles missing values by replacing them with mean, median, or other statistical values.
StandardScaler: Normalises features to bring them to a common scale.
These transformations are encapsulated within a Pipeline in Spark, ensuring consistency and reusability across different stages of data processing and model training.
Handling Large-Scale Data Efficiently
The distributed nature of Spark allows it to handle petabytes of data across multiple nodes without crashing or slowing down. Key features that support this include:
Lazy Evaluation: Spark doesn’t execute transformations until an action is called, allowing it to optimise the entire data flow.
In-Memory Computation: Spark stores intermediate results in memory rather than disk, significantly speeding up iterative algorithms.
Fault Tolerance: If a node fails, Spark recovers lost data using lineage information without requiring manual intervention.
This makes Spark particularly useful in real-time environments, such as fraud detection systems or recommendation engines, where performance and reliability are critical.
Real-World Use Cases of Apache Spark in Feature Engineering
Numerous industries employ Spark for preprocessing and feature engineering tasks:
Finance: For risk modelling and fraud detection, Spark helps process transaction data in real-time and create predictive features.
Healthcare: Patient data, often stored in varied formats, can be standardised and transformed using Spark before feeding it into ML models.
E-commerce: Customer behaviour data is preprocessed at scale to personalise recommendations and optimise marketing strategies.
Telecom: Call data records are analysed for churn prediction and network optimisation using Spark’s scalable capabilities.
These examples highlight Spark’s versatility in tackling different data preparation challenges across domains.
Integrating Spark with Other Tools
Apache Spark integrates seamlessly with various big data and cloud platforms. You can run Spark jobs on Hadoop YARN, Apache Mesos, or Kubernetes. It also supports multiple programming languages including Python (through PySpark), Scala, Java, and R.
Moreover, Spark can work with data stored in HDFS, Amazon S3, Apache Cassandra, and many other storage systems, offering unparalleled flexibility. This interoperability makes it an essential skill taught in any modern data scientist course, where learners gain hands-on experience in deploying scalable data workflows.
Challenges and Best Practices
Despite its advantages, using Spark for feature engineering comes with certain challenges:
Complexity: Spark’s steep learning curve can be a barrier for beginners.
Resource Management: Improper configuration of cluster resources may lead to inefficient performance.
Debugging: Distributed systems are inherently harder to debug compared to local processing.
To mitigate these issues, it’s best to:
Start with smaller data samples during development.
Use Spark’s built-in UI for monitoring and debugging.
Follow modular coding practices with well-structured pipelines.
Conclusion
Apache Spark has emerged as a cornerstone for data preprocessing and feature engineering in the era of big data. Its scalability, flexibility, and integration with machine learning workflows make it indispensable for organisations aiming to build efficient and intelligent systems. Whether you’re working on real-time analytics or developing batch processing pipelines, Spark provides the robustness needed to prepare data at scale.For aspiring data professionals, gaining practical exposure to Spark is no longer optional. Enrolling in a reputable data scientist course in Pune can be a strategic move towards mastering this vital tool and positioning yourself for success in a competitive job market.
0 notes
Text
Unlock the Power of Data with Our Big Data Fundamentals Course in the UAE
In today’s digital-first world, data is the new oil — and those who know how to manage and analyze it hold the key to innovation, business intelligence, and career advancement. The Big Data Fundamentals course at Go Learning is expertly designed to introduce learners to the core principles of Big Data, preparing them for success in one of the fastest-growing fields in tech.
Why Big Data Matters
Big Data is more than just a buzzword — it’s a driving force behind strategic decisions, consumer insights, and technological advancement. From healthcare and retail to finance and artificial intelligence, industries across the globe rely on Big Data to optimize operations and predict future trends. Understanding the fundamentals of Big Data gives you the ability to contribute meaningfully to data-driven environments.
What You’ll Learn in Our Big Data Fundamentals course
Our Big Data Fundamentals course provides a comprehensive introduction to the key concepts, tools, and techniques that define Big Data systems and architectures. By the end of the program, learners will have a strong grasp of:
Big Data concepts and evolution Understand how Big Data differs from traditional data and the 5Vs — Volume, Velocity, Variety, Veracity, and Value.
Big Data architecture Explore the components of modern Big Data systems including storage, processing, and analysis frameworks.
Technologies like Hadoop and Spark Learn how open-source technologies enable distributed computing and real-time data processing.
Data processing pipelines Get hands-on experience in creating end-to-end data workflows and understand ETL (Extract, Transform, Load) processes.
Use cases across industries Examine real-world Big Data applications in marketing, healthcare, finance, and logistics.
Who Should Take This Course?
Whether you’re a beginner exploring a new career path or a professional looking to upskill, our Big Data Fundamentals course is ideal for:
IT professionals transitioning into data science roles
Business analysts looking to understand data infrastructure
Students and graduates aiming to build a career in data and AI
Entrepreneurs who want to use data for strategic decisions
Course Features at Go Learning
At Go Learning, we prioritize a learner-focused approach. Our Big Data Fundamentals course offers:
Interactive Learning Modules — Clear, easy-to-understand lessons developed by industry experts Flexible Learning — Study online at your own pace Practical Exercises — Work on real datasets to apply your learning Certification — Earn a recognized certificate to boost your resume Career Guidance — Access mentorship and job support in the data science ecosystem
Why Choose Go Learning?
Go Learning is a leading educational platform in the UAE, trusted by thousands of learners for upskilling in the tech and business domains. With certified instructors, practical content, and a focus on employability, we help students move from learning to earning.
Career Prospects After the Big Data Fundamentals course
Big Data is at the heart of modern decision-making, and skilled professionals are in high demand. After completing this course, you can explore roles like:
Junior Data Analyst
Big Data Developer
Business Intelligence Associate
Data Engineer (Entry-level)
AI/ML Support Roles
The foundational knowledge from this course also paves the way for advanced study in data science, artificial intelligence, and cloud computing.
Enroll Today and Start Your Big Data Journey
Don’t miss out on the opportunity to future-proof your career. Whether you’re planning a move into data science or enhancing your current tech skills, the Big Data Fundamentals course at Go Learning is the perfect starting point.
FAQs
Q1: Do I need prior experience in coding to join this course? No. This course is designed for beginners. Basic familiarity with computers is helpful but not mandatory.
Q2: Is the course available online? Yes. You can access all modules online and learn at your convenience.
Q3: Will I receive a certificate? Yes. You will receive a certificate upon successful completion of the course.
Q4: Can this course help me get a job? Absolutely. While this is a fundamentals course, it builds the right base for data-related roles and further specialization.
Q5: Is there any support available after the course? Yes. Go Learning offers mentorship and career guidance even after you complete the course.
0 notes
Text
AI Development Companies: Building the Foundations of Intelligent Systems
AI Development Companies: Building the Foundations of Intelligent Systems
In recent years, artificial intelligence has moved from academic research labs to boardrooms, factory floors, and cloud platforms. Behind this evolution are AI development companies — specialized firms that don’t just write code but architect intelligence into machines, processes, and decision systems. These companies don’t follow trends; they shape them.
This article delves deep into what AI development companies actually do, how they build intelligent systems, the technologies they work with, the challenges they solve, and why their work has become indispensable in shaping the digital ecosystem.
1. What Defines an AI Development Company?
An AI development company is not simply a software agency offering machine learning as a feature. It’s a multidisciplinary team that combines expertise in data science, algorithm engineering, cloud computing, statistics, and domain-specific knowledge to craft solutions that can learn from data and make decisions.
At its core, an AI development company:
Designs learning algorithms (supervised, unsupervised, reinforcement learning)
Implements neural networks and deep learning architectures
Processes structured and unstructured data (text, images, audio, video)
Integrates intelligent systems into real-time environments
Manages lifecycle from data ingestion → model training → deployment → continuous monitoring
But unlike traditional software, AI solutions are non-deterministic — meaning they adapt and evolve over time. That nuance changes everything — from how systems are built to how they’re maintained.
2. The Architecture of AI Solutions
A high-quality AI system is rarely built in a straight line. Instead, it’s the outcome of layered thinking and iterations. Here’s a simplified breakdown of how an AI solution typically comes to life:
a. Problem Formalization
Not every business problem can be solved with AI — and not all AI solutions are useful. The first step involves abstracting a real-world problem into a machine-learnable format. For instance:
“Predict machine failure” becomes a time-series classification problem.
“Understand customer feedback” becomes a sentiment analysis task.
b. Data Strategy and Engineering
The backbone of AI is data. Noisy, incomplete, or biased data leads to faulty predictions — the classic “garbage in, garbage out” scenario.
Data engineers in AI firms:
Set up data pipelines (ETL/ELT)
Structure databases for high-performance querying
Implement real-time data ingestion using Kafka, Flink, or Spark
Normalize and enrich datasets using feature engineering
c. Model Selection and Training
Once clean data is available, data scientists and ML engineers begin the experimental phase:
Testing different models: decision trees, random forests, CNNs, RNNs, transformers
Evaluating with metrics like accuracy, recall, F1-score, AUC-ROC
Handling overfitting, class imbalance, and data leakage
Using frameworks like TensorFlow, PyTorch, Scikit-learn, Hugging Face, and ONNX
The goal isn’t just performance — it’s robustness, explainability, and reproducibility.
d. Model Deployment and Integration
AI that lives in a Jupyter notebook is of no value unless deployed at scale. AI development companies handle:
Containerization (Docker, Kubernetes)
RESTful APIs and gRPC endpoints
CI/CD for ML (MLOps) pipelines
Real-time model serving using TorchServe or TensorFlow Serving
Monitoring tools for model drift, latency, and accuracy
This step transforms a model into a living, breathing system.
3. Core Technical Capabilities
Let’s dive deeper into the capabilities most AI development firms provide — beyond just buzzwords.
i. Custom Machine Learning
Custom ML models are trained on client-specific datasets. These aren't pre-trained models from public repositories. They're tailored to context — medical diagnostics, fraud detection, recommendation systems, etc.
ii. Natural Language Processing (NLP)
Understanding human language isn’t trivial. NLP requires:
Tokenization and lemmatization
Named Entity Recognition (NER)
Sentiment analysis
Topic modeling (LDA, BERT embeddings)
Text summarization and question answering
Modern NLP relies heavily on transformer-based models (BERT, RoBERTa, GPT variants) and fine-tuning on domain-specific corpora.
iii. Computer Vision
From analyzing CT scans to identifying defective components on a conveyor belt, computer vision is vital. AI firms use:
CNN architectures (ResNet, EfficientNet, YOLO)
Image segmentation (U-Net, Mask R-CNN)
Object tracking and OCR (Tesseract, OpenCV)
Augmentation techniques (rotation, flipping, noise injection)
iv. AI for Edge Devices
Not all intelligence runs in the cloud. AI companies also build models optimized for edge deployment — lightweight neural nets that run on microcontrollers or mobile chips (e.g., TensorFlow Lite, ONNX Runtime Mobile).
v. Conversational AI and Speech Recognition
Custom AI chatbots today use:
Dialogue management systems (Rasa, Dialogflow)
ASR (Automatic Speech Recognition) using wav2vec, DeepSpeech
TTS (Text-to-Speech) using Tacotron, WaveNet
Context-aware conversations with memory modules
These aren’t static bots—they learn from interactions.
4. Real-World Applications and Use Cases
AI development companies work across sectors. Here are some deeply technical use cases:
Predictive Maintenance in Manufacturing: Sensor data is processed in real-time using anomaly detection models to predict equipment failures.
Dynamic Pricing in eCommerce: Reinforcement learning optimizes pricing strategies based on demand elasticity, competitor actions, and inventory.
Autonomous Drones in Agriculture: Computer vision identifies crop health using NDVI maps and deep segmentation.
Medical Imaging: AI models analyze radiology images with 95%+ accuracy, outperforming baseline human diagnosis in certain conditions.
Financial Risk Modeling: Graph neural networks are used to detect collusion and fraud in transactional networks.
These solutions are not “plug and play.” They’re complex, highly customized systems involving multi-disciplinary collaboration.
5. Challenges That AI Developers Tackle Head-On
AI development is not glamorous — it’s gritty, iterative, and nuanced. Here are some of the challenges seasoned firms navigate:
a. Data Scarcity
In niche domains, labeled datasets are rare. Developers use:
Transfer learning
Semi-supervised learning
Synthetic data generation using GANs or simulators
b. Model Interpretability
AI is often a black box. But for sectors like healthcare or law, explainability is non-negotiable.
Tools like LIME, SHAP, Eli5, and Captum help visualize why a model made a decision.
c. Bias and Fairness
Biases in training data can lead to discriminatory AI. Ethical AI teams run bias audits, adversarial testing, and ensure demographic parity.
d. Model Drift
Real-world data evolves. AI models degrade over time. Firms set up continuous monitoring and retraining pipelines — a concept known as MLOps.
e. Security and Privacy
AI systems are susceptible to adversarial attacks and data poisoning. Encryption, differential privacy, and federated learning are becoming standard protocols.
6. What Makes a Good AI Development Company?
It’s not just about code. The best AI firms:
Focus on research-backed development (often publishing papers or contributing to open-source)
Maintain a cross-functional team (data scientists, ML engineers, DevOps, domain experts)
Use version control for data and models (DVC, MLflow)
Engage in responsible AI practices (bias testing, energy efficiency)
Follow agile and reproducible experimentation workflows
Moreover, a good AI partner doesn’t overpromise — they explain the limitations clearly, define metrics transparently, and test rigorously.
Final Reflections
AI is not a monolithic solution — it's a continuously evolving field grounded in mathematics, computing, and human context. AI development companies are the silent architects building the systems we now rely on — from the voice that answers your customer query to the model that flags a disease before symptoms arise.
These companies aren’t magicians — they’re deeply technical teams who understand that AI is both an art and a science. In their world, every model is an experiment, every dataset a story, and every deployment a responsibility.
As organizations move deeper into data-driven decision-making, the role of AI development firms will only become more integral. But success lies not in chasing trends — it lies in choosing partners who understand the terrain, ask the right questions, and build with rigor.
0 notes
Text
Data Science Career Paths
Looking to start or grow your career in data science? You’re in the right place. This guide will walk you through what data science career paths look like, why they matter in Hyderabad, and how you can build a strong future with the right skills.
Whether you’re a student, a working professional, or someone switching careers, this page will help you understand what to learn, what jobs to aim for, and how Varniktech can support you — 100% online.
What is a Data Science Career Path?
A data science career path is the journey you take as you grow your skills and move through roles in the world of data. Think of it like a map. You start with the basics, like Excel or Python, and move into bigger roles like Data Analyst, Machine Learning Engineer, or even a Chief Data Officer.
Let’s say you love solving puzzles. In data science, your puzzle pieces are numbers, facts, and patterns. Your job is to put those pieces together to solve real-world business problems — from predicting sales to preventing fraud.
Why Data Science Career Paths Matter in Hyderabad
Hyderabad is one of India’s biggest IT hubs. From global MNCs to fast-growing startups, every company is generating tons of data. And they all need skilled people to make sense of it.
Local Trends You Should Know:
Hyderabad is home to top firms hiring for data roles: Deloitte, Amazon, TCS, Infosys, Accenture.
Over 35% of IT job listings in Hyderabad now mention data skills (Source: Naukri Jobs Report 2025).
The Telangana state is pushing AI, machine learning, and analytics as part of its digital economy.
If you live in or around Hyderabad — or want a remote job with top Hyderabad-based firms — learning data science gives you a huge advantage.
Key Benefits of Learning Data Science
Here’s why more and more people are choosing the data science career path in India:
High Salaries: Entry-level roles start at ₹6 LPA, and can go beyond ₹25 LPA with experience.
Job Demand: 1.5 lakh+ open roles across India (LinkedIn, 2025).
Career Flexibility: You can work in IT, healthcare, banking, e-commerce, or even sports analytics.
Remote Opportunities: Most data jobs can be done from anywhere — even from your home in Hyderabad.
Future-Proof Career: Data skills are needed in AI, robotics, and automation.
What You’ll Learn in a Data Science Course
A good data science course doesn’t just teach you theory — it gives you the real tools used by professionals. At Varniktech, here’s what we cover:
Core Modules:
Python for Data Science
Statistics & Probability Basics
SQL & Databases
Data Wrangling & Cleaning
Data Visualization with Power BI & Tableau
Machine Learning with Scikit-learn
Deep Learning with TensorFlow
Big Data Tools like Spark & Hadoop
Real-time Projects using Live Datasets
Capstone Projects for Portfolio Building
All modules are taught by experts working in the industry, and the pace is beginner-friendly.
Career Paths & Real-World Use Cases
There’s no one way to succeed in data science — you can choose a path based on your interest and strengths. Here are some of the most popular job roles in India right now:
Popular Career Roles:
Data Analyst – Clean, visualize, and interpret data
Business Intelligence (BI) Analyst – Help teams make smart business decisions
Data Scientist – Build models to predict and automate decisions
ML Engineer – Deploy machine learning systems in production
Data Engineer – Manage large datasets and pipelines
AI/Deep Learning Specialist – Work on advanced AI systems
Product Analyst – Analyze user data to improve products
Fraud Analyst / Risk Analyst – Popular in fintech and banking
Real-World Use Cases in Hyderabad:
E-commerce: Flipkart and Amazon use data science to recommend products.
Healthcare: Startups in HITEC City are using AI to predict patient risks.
Finance: Banks like ICICI and SBI need data experts to detect fraud.
Startups: Analytics-driven hiring is booming in unicorn startups based in Hyderabad.
Tools, Tips & Best Practices
To grow in your data science career, mastering the right tools and following smart learning tips is key.
Must-Know Tools:
Python – for coding and automation
Jupyter Notebooks – for sharing and explaining code
Tableau / Power BI – for dashboards and reports
SQL – for pulling data from databases
Scikit-learn – for machine learning
Git & GitHub – for version control
Google Colab – for online, no-install coding
Quick Learning Tips:
Practice every day on Kaggle or GitHub
Work on real datasets (not just theory)
Break projects into small tasks
Watch how professionals solve problems on YouTube
Join data science forums or Telegram groups for doubt clearing
How Varniktech Supports Your Learning
Varniktech is an online-only training platform — so you learn from anywhere, at your own pace, without giving up your job or studies. But we still give you full support like any top institute in Hyderabad.
What Makes Us Different:
Expert Trainers: Learn from professionals working at TCS, Cognizant, and Deloitte
Live Classes + Recordings: Never miss a session
Real Projects: You’ll build a data science portfolio to show recruiters
Interview Prep: Resume building, mock interviews, and placement guidance
Certifications: Industry-recognized credentials
Placement Assistance: We help connect you with companies hiring for remote and Hyderabad-based roles
Student Success Stories: Many of our students have landed jobs in Capgemini, Wipro, and startups after completing the course
You also get access to peer learning, Telegram study groups, and lifetime course access.
Final Thoughts — Start Your Data Science Journey Today
A career in data science isn’t just a trend. It’s the future of work — and Hyderabad is at the center of this tech shift. Whether you’re a beginner or someone switching from IT support or testing, learning data science can change your career trajectory.
At Varniktech, we make that journey smooth and accessible — through expert teaching, project-based learning, and complete job support.
Ready to start your data science career path? [Join Varniktech’s Data Science Program Now] [Download Course Syllabus] [Talk to a Career Counselor]
0 notes
Text
Revolutionising UK Businesses with AI & Machine Learning Solutions: Why It’s Time to Act Now
Embracing AI & Machine Learning: A Business Imperative in the UK
Artificial intelligence (AI) and machine learning (ML) are no longer just buzzwords – they’re business-critical technologies reshaping how UK companies innovate, operate, and grow. Whether you're a fintech startup in London or a retail chain in Manchester, adopting AI & Machine Learning solutions can unlock hidden potential, streamline processes, and give you a competitive edge in today's fast-moving market.
Why UK Businesses Are Investing in AI & ML
The demand for AI consultants and data scientists in the UK is on the rise, and for good reason. With the right machine learning algorithms, companies can automate repetitive tasks, forecast market trends, detect fraud, and even personalize customer experiences in real-time.
At Statswork, we help businesses go beyond the basics. We provide full-spectrum AI services and ML solutions tailored to your specific challenges—from data collection and data annotation to model integration & deployment.
Building the Right Foundation: Data Architecture and Management
No AI system can work without clean, well-structured data. That’s where data architecture planning and data dictionary mapping come in. We work with your teams to design reliable pipelines for data validation & management, ensuring that your models are trained on consistent, high-quality datasets.
Need help labeling raw data? Our data annotation & labeling services are perfect for businesses working with training data across audio, image, video, and text formats.
From Raw Data to Real Intelligence: Advanced Model Development
Using frameworks like Python, R, TensorFlow, PyTorch, and scikit-learn, our experts build powerful machine learning algorithms tailored to your goals. Whether you're interested in supervised learning techniques or looking to explore deep learning with neural networks, our ML consulting & project delivery approach ensures results-driven implementation.
Our AI experts also specialize in convolutional neural networks (CNNs) for image and video analytics, and natural language processing (NLP) for understanding text and speech.
Agile Planning Meets Real-Time Insights
AI doesn't operate in isolation—it thrives on agility. We adopt agile planning methods to ensure our solutions evolve with your needs. Whether it's a financial forecast model or a recommendation engine for your e-commerce site, we stay flexible and outcome-focused.
Visualising your data is equally important. That’s why we use tools like Tableau and Power BI to build dashboards that make insights easy to understand and act on.
Scalable, Smart, and Secure Deployment
After building your model, our team handles model integration & deployment across platforms, including Azure Machine Learning and Apache Spark. Whether on the cloud or on-premises, your AI systems are made to scale securely and seamlessly.
We also monitor algorithmic model performance over time, ensuring your systems stay accurate and relevant as your data evolves.
What Sets Statswork Apart?
At Statswork, we combine deep technical expertise with business acumen. Our AI consultants work closely with stakeholders to align solutions with business logic modeling, ensuring that every model serves a strategic purpose.
Here’s a glimpse of what we offer:
AI & ML Strategy Consultation
Custom Algorithm Design
Data Sourcing, Annotation & Data Management
Image, Text, Audio, and Video Analytics
Ongoing Model Maintenance & Monitoring
We don't believe in one-size-fits-all. Every UK business is different—and so is every AI solution we build.
The Future is Now—Don’t Get Left Behind
In today’s data-driven economy, failing to adopt AI & ML can leave your business lagging behind. From smarter automation to actionable insights, the benefits are enormous—and the time to start is now.
Whether you're building your first predictive model or looking to optimize existing processes, Statswork is here to guide you every step of the way.
Ready to Transform Your Business with AI & Machine Learning? Reach out to Statswork—your trusted partner in AI-powered innovation for UK enterprises.
0 notes