#data_collection
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Link
The Scrutiny of Worldcoin: Privacy Concerns and Government Investigations In recent months, Worldcoin, the ambitious crypto project co-founded by OpenAI CEO Sam Altman, has been under the spotlight. With its promise of a digital ID and free cryptocurrency in exchange for iris scans, the project has attracted almost 2.3 million users worldwide. However, this innovative venture has not escaped the watchful eyes of governments and privacy advocates, raising concerns about data collection and security. Privacy Concerns Surrounding Worldcoin Privacy Advocates' Perspective Privacy campaigners have raised questions about Worldcoin's data collection practices, emphasizing the need for stringent safeguards. The Scrutiny of Worldcoin Data Encryption and Regulatory Commitments Worldcoin claims to either delete or encrypt the biometric data it collects and expresses its commitment to working closely with regulators to ensure compliance. Government Investigations Across the Globe Argentina - Scrutiny by AAIP The Argentinian data regulator, Agencia de Acceso an Informacion Publica (AAIP), is investigating Worldcoin over its collection, storage, and use of personal data. Questions revolve around risk mitigation and the legal basis for processing personal data. Britain - Inquiry by the ICO The Information Commissioner's Office (ICO) in the UK has initiated inquiries into Worldcoin's operations, focusing on data collection practices. France - CNIL's Checks France's data watchdog, CNIL, conducted "checks" at Worldcoin's Paris office and expressed doubts about the legality of biometric data collection. Germany - Ongoing Investigations German authorities, including a data watchdog and the financial regulator Bafin, have been investigating Worldcoin since late last year, citing concerns about the handling of sensitive biometric data. Kenya - Suspension of Local Activities Kenya suspended Worldcoin's local activities in August to assess potential risks to public safety, including concerns about consumer consent and inducement. Portugal - CNPD's Inspection Portugal's data regulator, CNPD, has inspected Worldcoin's local data collection operation and collaborated with Bavarian data protection authorities in Germany. FAQs for the Scrutiny of Worldcoin Q1: Is Worldcoin's biometric data collection legal? A1: The legality of Worldcoin's biometric data collection is currently under scrutiny in several countries, with privacy advocates and government regulators examining the project's practices. Q2: What is Worldcoin's response to privacy concerns? A2: Worldcoin claims to either delete or encrypt the biometric data it collects and has expressed a commitment to working closely with regulators to ensure compliance. Q3: How many people have signed up for Worldcoin's offerings? A3: Approximately 2.3 million individuals worldwide have signed up for Worldcoin, agreeing to have their irises scanned in exchange for a digital ID and free cryptocurrency.
#Bafin#biometric_data#CNIL#data_collection#data_encryption#digital_ID.#government_investigations#ICO#Kenya#openai#Portugal#privacy_concerns#regulatory_compliance#Sam_Altman#Worldcoin
1 note
·
View note
Text
DATA_Collective, Interconexiones, Francisco Guerra Trujillo-Patricio Alvarez Aragon
Francisco GuerraPatricio Àlvarez Aragón Este mes de mayo llega a Sineu un colectivo de Chile. Data_C es un colectivo de investigadores chilenos interesados en la Memoria histórica popular de Chile y su intrahistória, así cómo de los lugares en que ejecutan sus investigaciones y la implementación de datos digitales y científicos para la creación de sus proyectos artísticos y conectivos. Data_ C…

View On WordPress
#art#artistinresidence#chile#contemporaryart#datacolletive#espai sant marc#espaisantmarc#franciscoguerra#interconexiones#mallorca#patricioalvarezaragon#sant marc air#santiago#santmarcair#sineu#spain
36 notes
·
View notes
Text
Overcoming Node.js Limits: Efficient XML Streaming to MongoDB

In the realm of big data processing, efficiently handling large XML files is a common challenge faced by software developers and solution architects. This blog post delves into the intricacies of streaming large XML files into MongoDB using Node.js, emphasizing memory management, batch processing, handling duplicate entries, and synchronizing asynchronous operations. Streamlining to Avoid Memory Heap Errors When dealing with sizable XML files, trying to load the entire file into memory can spell trouble in Node.js. This is because Node.js has a memory limit (usually 512MB or 1GB, depending on the version and system). Large files can quickly surpass this limit, leading to application crashes. The remedy here lies in streaming. By employing a streaming XML parser like SAX, we can read and process the file in smaller, more manageable portions, substantially reducing memory consumption. Streaming operates by triggering events (e.g., opentag, text, and closetag) as the file is read, allowing for incremental data processing. This approach ensures that only a fraction of the file resides in memory at any given time, effectively avoiding heap memory limitations. Enhancing Efficiency with Batch Processing Inserting each parsed object into MongoDB one at a time can be quite inefficient, especially with substantial datasets. This approach multiplies the number of database operations, resulting in reduced throughput and prolonged processing times. The solution to this conundrum is batch processing. It involves grouping multiple documents into a single insert operation. This method significantly reduces the number of database write operations, optimizing the data import process. Developers can fine-tune the batch size (e.g., 100 documents per batch) to strike a balance between memory usage and operational efficiency. Larger batches excel in efficiency but consume more memory, while smaller ones are lighter on memory but may lead to an increased number of database operations. Tackling Duplicate Entry Errors Even when using UUIDs for document _ids to ensure uniqueness, duplicate entry errors can still crop up. These issues are particularly noticeable with smaller batch sizes, hinting at a problem with asynchronous batch processing. The key insight here is Node.js' asynchronous nature, combined with the streaming XML parser. It leads to a situation where one batch is being processed and inserted into MongoDB, while the SAX parser continues reading and queuing up another batch. If the second batch begins processing before the first one completes, it results in duplicate _id errors. Introducing Synchronization for Asynchronous Batching To tackle the challenge of synchronizing batch processing, we introduced a control mechanism called isBatchProcessing. This simple boolean flag indicates whether a batch is currently being processed. In practice, before initiating a new batch insertion, the script checks if isBatchProcessing is set to false. If it is, the insertion proceeds, and the flag is set to true. After the batch is successfully inserted, the flag is reset to false. This ensures that each batch is fully processed before the next one starts, effectively preventing overlapping operations and eliminating duplicate entry errors. A Technical Consideration This solution elegantly synchronizes the asynchronous events triggered by the SAX parser with MongoDB operations. It's a straightforward yet powerful approach to managing concurrency in Node.js applications, ensuring both data integrity and operational efficiency. Final Script const fs = require('fs'); const sax = require('sax'); const { MongoClient } = require('mongodb'); const { v4: uuidv4 } = require('uuid'); // Importing the UUID v4 function // MongoDB setup const uri = "your_mogo_uri"; const client = new MongoClient(uri); const dbName = 'db_name'; const collectionName = 'data_collection'; const BATCH_SIZE = 100; let isBatchProcessing = false; // Flag to control batch processing async function main() { try { await client.connect(); console.log("Connected successfully to MongoDB"); const db = client.db(dbName); const collection = db.collection(collectionName); // XML file setup const stream = fs.createReadStream('lorem200000.tmx'); const xmlParser = sax.createStream(true); let documents = ; let currentElement = {}; xmlParser.on('opentag', (node) => { currentElement = { _id: uuidv4() }; for (let attr in node.attributes) { currentElement = node.attributes; } }); xmlParser.on('text', (text) => { if (text.trim()) { currentElement = text.trim(); } }); xmlParser.on('closetag', async (tagName) => { if (Object.keys(currentElement).length > 1) { documents.push(currentElement); currentElement = {}; if (documents.length >= BATCH_SIZE && !isBatchProcessing) { isBatchProcessing = true; await insertDocuments(collection, documents); documents = ; isBatchProcessing = false; } } }); xmlParser.on('end', async () => { if (documents.length > 0) { await insertDocuments(collection, documents); } console.log('XML parsing completed.'); await client.close(); }); async function insertDocuments(collection, docs) { try { await collection.insertMany(docs, { ordered: false }); } catch (err) { if (err.writeErrors) { err.writeErrors.forEach((writeError) => { console.error('Write Error:', writeError.err); }); } else { console.error('Error inserting documents:', err); } } } stream.pipe(xmlParser); } catch (err) { console.error("An error occurred:", err); await client.close(); } } main().catch(console.error); Read the full article
0 notes
Conversation
Hassan:We need to do data collection based on what Madam Mary guided the class on. We shall have to pick a letter from the networks department head.
0 notes
Link
Are you want to grow your business by generating lead. I Will Do Targeted/B2B Lead Generation & Web Research.
3 notes
·
View notes
Link
Are you want to grow your business by generating lead. I Will Do Targeted/B2B Lead Generation & Web Research.
0 notes
Text
Survey Analysis Software for Better User Research
Widely accepted as an appreciable strategy by the marketers, online surveys are too familiar now for the strategists for gathering the feedbacks. The pattern of the survey is increasingly becoming an accepted tool for the UX practitioners and with this aspect, the use of Survey Data Analysis Software is becoming widespread.
Talking about the digital space, there are many aspects in which the Survey Analysis Software is becoming popular, which have been worked upon by Q-Fi Solutions.
Acquiring the genuine feedbacks for a product gone live.
Gathering the reasons due to which people visit a website and assess the experience in each visit.
Acquiring the quantifying results from the qualitative researches with includes the interviews and contextual inquiry.
To properly evaluate the usability, including g the system usability scale.
Benefits to be focused
The Survey Data Analysis Software can be a benefit in acquiring the mindset and perceptions of the customers and market status and is useful to inform the design process by the information like:
1. Knowledge about the end users which will be a help to understand them in a better way and acquiring an idea to design the products accordingly.
2. It mitigates the risk of taking the step to design any wrong or poor solution for the end users.

3. Software analysis software used by Q-Fi Solutions also helps in providing the stakeholders with a confidence that the design approach they are following will be useful. The idea to gather large sample sizes, considering in the comparison to qualitative research often supports in speaking the language of the business stakeholders.
4. Not just this, but the information which is acquired through the survey also offers a framework to widen the research scope. If there would be no such information then the research will be an exercise, working on the guesswork which is likely to miss out the perceptions and demands of the stakeholders.
Everything needed for a better survey is known by Q-Fi Solutions which will be your helping hand in acquiring genuine information through successful surveys.
0 notes
Audio
YaleGlobal Podcast; Global Data for Sale by YaleUniversity https://ift.tt/2HM8CEw
0 notes
Text
Sensu Metrics Collection - #Ankaa
Sensu Metrics Collection This is a guest post to the Sensu Blog by Michael Eves, member to the Sensu community. He offered to share his experience as a user in his own words, which you can do too by emailing . Learn all about the community at sensuapp.org/community . Considering Sensu When people look for metrics... https://ankaa-pmo.com/sensu-metrics-collection/ #Data_Collection #Graphite #Metrics #Monitoring #Open_Source #Sensu #Tutorial
#data collection#graphite#metrics#monitoring#Open Source#sensu#tutorial#Actualités#Méthodes et organisation des process IT
4 notes
·
View notes
Text
Essentials of Data Analysis

Data Analysis is an integral part of every business.There are various data analysis technique which can be applied with all kinds of data in order to find patterns, discover insights and making data-driven decisions. The following gives a brief idea of the process and the techniques undertaken during data analysis:
Process followed in Data Analysis
Define your goals clearly
Collect the required data
Data Cleaning by removing unnecessary rows and columns and redundant data
Analyze data using various tools
Visualizing Data
Drawing an inference and conclusion
Methods of Data Analysis (for both Quantitative and Qualitative Data)
Sentimental Analysis
Regression Analysis
Time Series Analysis
Cluster Analysis
Predictive Analysis
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#Sentimental Analysis#Regression Analysis#Time Series Analysis#Cluster Analysis#Predictive Analysis#inference#Visualizing Data#Analyze data#Data Cleaning#Data_Collection
1 note
·
View note
Link
Meta Considers Offering Ad-Free Facebook and Instagram in Europe to Address Regulatory Scrutiny Meta Platforms, the parent company of Facebook and Instagram, is exploring the introduction of paid versions of these social media platforms for European Union (EU) users. This move is seen as a response to increasing scrutiny from EU regulators, aiming to provide an ad-free experience to paying subscribers while continuing to offer free versions supported by ads within the EU. Why is Meta Considering Paid Versions? In an effort to address privacy concerns and regulatory pressure from the EU, Meta is contemplating the introduction of paid versions of Facebook and Instagram. These paid versions would serve as an alternative to Meta's existing ad-based services, which heavily rely on data analysis. Balancing Advertisements and User Privacy The proposed paid versions of Facebook and Instagram would be ad-free, offering users a more private and uninterrupted experience. However, Meta intends to maintain free versions of these apps, featuring ads, to cater to users who opt not to subscribe to the paid service. EU Regulatory Scrutiny Meta's decision to explore ad-free paid versions comes as a response to mounting regulatory challenges in the EU. The company has faced antitrust investigations and lost legal battles related to data collection without user consent. Pricing Details Remain Unclear While the company is considering these ad-free versions, the cost of subscription remains undisclosed. Meta has not yet confirmed how much users in the EU would need to pay for the ad-free experience. Meta's Ongoing Battle in Norway In addition to EU challenges, Meta has been fined heavily by Norway's data protection authority for privacy breaches, with daily fines amounting to NOK 1 million. The company is currently seeking a temporary injunction against this order. Possible FAQs: 1. Why is Meta considering ad-free paid versions of Facebook and Instagram in the EU? Meta is exploring this option in response to increasing scrutiny from EU regulators and to provide an ad-free experience to users concerned about privacy. 2. Will free versions of Facebook and Instagram still be available in the EU? Yes, Meta plans to continue offering free versions of these apps with ads to users in the EU alongside the paid ad-free versions. 3. How much will the paid versions cost? The pricing for the ad-free versions has not been confirmed yet. Meta has not provided details about subscription costs. 4. Why is Meta facing fines in Norway, and what is the company doing about it? Meta has been fined by Norway's data protection authority for privacy breaches. The company is currently seeking a temporary injunction to contest the fines. 5. Is this move by Meta related to the recent antitrust investigations in the EU? Yes, Meta's decision to explore ad-free paid versions is partly a response to regulatory challenges, including antitrust investigations, in the EU.
#ad_free#antitrust#data_collection#data_protection_authority#EU#facebook#Instagram#Keywords_Meta#Norway#paid_versions#privacy_concerns#regulatory_scrutiny#subscription_pricing
0 notes
Photo

RetailGraph and #AIOCD_AWACS_Integration feature help pharma business in easy #data_collection that ensures better visibility.
Let's use RetailGraph & get an easy process to know about #AIOCD_AWACS integration. 👉https://zurl.co/CUti
0 notes
Link
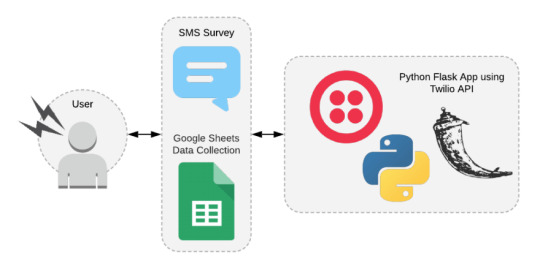
Happy Wednesday evening and last day of the Twilio x Dev Hackathon! I hope you are all doing well. It has been great to spend the month of April working with Twilio and Google sheets on this project in order to capture SMS data from a survey.
For those who may not have seen the other posts in this series, you can view them above. The first post began as the initial start of the project in Tracking Migraines with SMS which is just an introductory post.
The setup of Google Sheets is discussed in Setting up Python to Connect to Google Sheets where I talked about API Errors due to scope along with path issues with PyTest.
My first experience with Flask is talked about in the post What I Learned using Flask for the First Time in which I discussed port issues, data types, casting data types, and Flask sessions. This section also details issues with getting to the next question in the survey.
The final integration of Google Sheets and Twilio is discussed in Integrating Twilio with Google Sheets. This post discusses clearing results in a list, and data import issues with Google Sheets appending single quotes at the start of numbers and dates.
With all of that said, todays post will focus on the wrap up of the Twilio x Dev Hackathon, along with a walk through and discussion of the application flow through the functions in app.py.
Quick Recap
For a quick recap on the project concept, I spend time logging migraines for the doctors office but don't remember the format she wanted, or the details she found important. This application was created as a way to request a survey for a migraine, quickly fill out the details, and log the data for later use at the doctors appointment.
Commonly Asked Questions for Migraines
Below is a list of commonly asked questions relating to migraines:
In a scale of 1-10, how would you rate your migraine?
Where is your migraine located today?
How long did your migraine last (in hours)?
What medication did you take to treat the migraine?
Has anything changed? Is anything out of the ordinary? Do you have any other notes to add?
Category - Engaging Engagements and Interesting Integrations
During this hackathon, I focused on two categories: Engaging Engagements and Interesting Integrations.
Engaging Engagements looked at developing applications that a company could implement to better engage with their customers or to manage their business. An application of this type could be utilized by doctors offices in order to collect data commonly needed during patient visits or to have patients collect their own data for use in their visits.
Interesting Integrations focused on the integration of the Twilio API with at least one other API. This application integrated Twilio with the Google Sheets API in order to log data in an easy to access format.
Filled out Twilio CodeExchange Agreement: ✔️ Agreed to the Competition's Terms: ✔️
Link to Code
To clone the code, please visit the GitHub project Migraine Tracking.
Demo Link
In the repository is also a GIF showing a brief demo of the code. There is also a README available for those who would like to run the code locally and try it out.
Application Flow
The first route that is reached when the application receives an SMS is the /sms route that calls the function sms_survey(). This function looks to see if a question ID comes in and in the session, the function will redirect to the /answer route.
Before a question ID will come in, the function will first default to collecting the Twilio number, the users number, and the date. Note: These were hidden in the demo data output in Google Sheets. These values are appended to the collected data list and then the a welcome message will be displayed to the user through the welcome_user() function. After displaying the welcome message, the user is redirected to the first question in the survey.
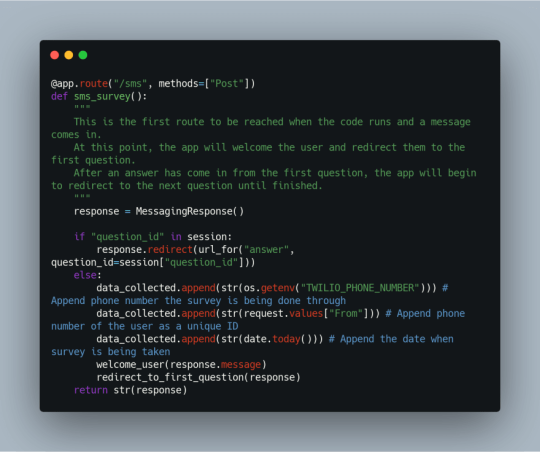
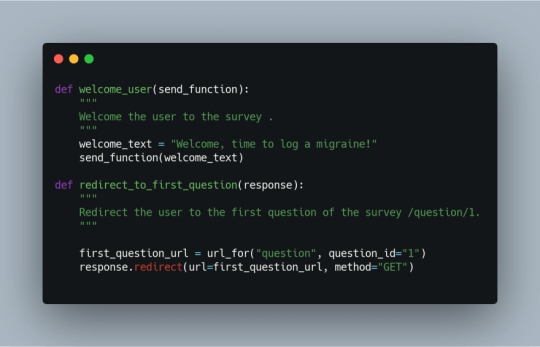
welcome_user(), seen below, will return a brief message to the user. Then the user is directed to the /question/<question_id> route.
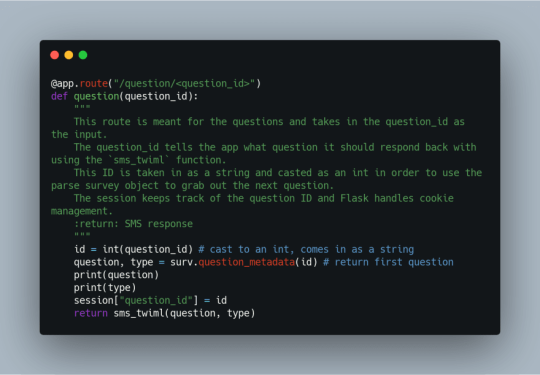
The /question/<question_id> route takes in the question ID and tells the application which question it should respond back to the user with. Using the question ID, we pass the ID into the parseJson pulls out the first question and its type. The question ID is stored into a session variable called question_id to be used as the application looks for the next question or the end of the survey. Once that has been captured, the sms_twiml() function is called with question and type.
This function responds with the message and type of data to ask the user for. The three types of data asked for in this survey are text, hours, or a numeric number from 1 to 10.

After the user has answered the question, the application will redirect to the /answer/<question_id> route. This route first iterates to the next question ID which is used to grab data collected from the parseJson object. Then, the user entered data for the previous question is extracted and appended to the data_collected list. extract_content() returns either text for text elements or numeric digits for hours and numeric answers. If data is available for the next question, the survey will continue by redirecting to the /question/<question_id> route, otherwise the survey will end and display a goodbye message through the use of the goodbye_twiml() function.
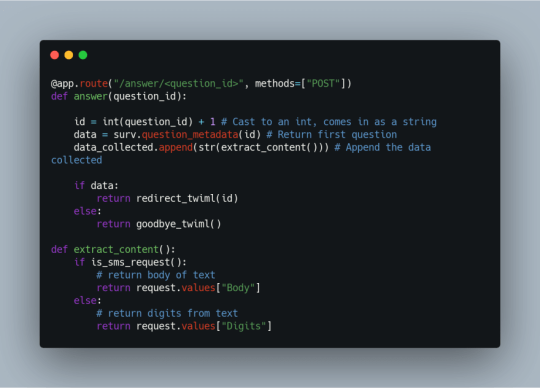
The redirect_twiml() redirects the survey to the /question/<question_id> route to allow the user to view and answer the next question, repeating the process until all questions have been answered.

The goodbye_twiml() function ends the survey, appending all the data collected into the Google Sheet using the spreadsheet object. After a goodbye message is displayed to the user, the data collected is cleared from the data_collected list and the session variable for question_id is cleared.

And that is the overall flow of the code from first question to last.
Development Stack
Thank you for following along this past month as all of the pieces have come together to log the data into the Google sheet from the SMS survey.
Thank you to all those who put together this hackathon and participated in it. Have a Happy May!
0 notes
Text
Ways In Which Choosing Contractors Safety Data Sheets Can Benefit You

As long as you ensure that your contractors complete the contractor safety data sheet there is no doubt that they are going to be fully compliant to the regulations by OSHA. There is an opportunity to make your employees comprehensive about the usage of materials in a way that can minimize hazards as long as you use a safety data sheets. The only way you can boost the level of communication between Juniors and the managers is to ensure that a fill a contractor safety data sheet. Learn more about the contractor safety data sheet on this page.
As a result of the fact that filling the safety data sheet requires constant communication in order to discuss the types of hazards there is no way this can be accomplished without having people discuss. You have a chance to obtain relevant details from the juniors in this is not something you can obtain if you do not use a safety data sheet.
Choosing a contractor safety data sheet also guarantees that you save money. If your project is not safety compliant this is something that can cause you a lot of problems with the state. Since you can also receive huge penalties from the government on the basis of non-compliance you are going to realize that this amount of money will it be wasted at the detriment of the completion of your project. Taking into account the fact that every contractor is going to be aware of the safety standards there is no way they can end up injuring themselves on the site. It is also possible to save yourself from there hassle catering for the medical bills of the contractors especially when they injure themselves while working on your site. It is not possible for the project to delay since there are minimal injuries on the contractors. Find out more about safety data sheet at shop.msdscatalogservice.com.
There is no other great opportunity to save time during the orientation of new workers like when you choose to use a contractor safety data sheet. Before any contractors can be hired for your project they are more likely to be green on the safety standards of your organization and they are less likely to uphold them. It is usually a very time-consuming process to keep training each and every contractor that is hired and it can also mean the waste of resources.
It is worth noting that when contractors have a look at the contractor safety data sheet it becomes easier for them to learn about all the hazards and this means that they are going to uphold safety all the time. Provided you have a contractor safety data sheet you are less likely to be worried about the regular inspections that are carried out by the enforcing agents and this is very relieving. Follow this link for more information: https://en.wikipedia.org/wiki/Data_collection.
0 notes
Link
Are you want to grow your business by generating lead. I Will Do Targeted/B2B Lead Generation & Web Research.
check me on fiverr: https://bit.ly/3NQbFxE
0 notes
Photo

Series & Systems://Data_Collection
28/09/17
I think our data collection for this project went really well. I collected my data from the Upper Gardens in Bournemouth, while Connor collected them from the seafront and Stew collected them from the high street. From the upper gardens this was the data I collected: Time: 18:00 - 19:00 Place: Upper Gardens Time : Gender 18:01 – M 18:19 – M 18:22 – M 18:23 – M 18:24 – M 18:25 – M 18:31 – M 18:38 – M 18:40 – M 18:42 – F 18:43 – M 18:43 – M 18:43 – M 18:43 – F 18:43 – M 18:43 – F 18:50 – M 18:52 – M
If I were to collect the data again, I might have gone further from the others. Each of our data came out very different so I don’t think we collected the same runners, but it would have been more valid if we were further apart. We recorded when a runner passed us directly, so the actual process of recording was really effective I think.
1 note
·
View note