#dplyr and tidyr
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
A Beginner’s Guide to Data Cleaning Techniques

Data is the lifeblood of any modern organization. However, raw data is rarely ready for analysis. Before it can be used for insights, data must be cleaned, refined, and structured—a process known as data cleaning. This blog will explore essential data-cleaning techniques, why they are important, and how beginners can master them.
#data cleaning techniques#data cleansing#data scrubbing#business intelligence#Data Cleaning Challenges#Removing Duplicate Records#Handling Missing Data#Correcting Inconsistencies#Python#pandas#R#OpenRefine#Microsoft Excel#Tools for Data Cleaning#data cleaning steps#dplyr and tidyr#basic data cleaning features#Data validation
0 notes
Text
instagram
#DataWrangling#dplyr#tidyr#Tidyverse#RForDataScience#RProgramming#DataCleaningR#DataManipulation#LearnR#TechForStudents#AssignmentHelp#AssignmentOnClick#assignment#assignment help#assignment service#assignmentexperts#assignmentwriting#Instagram
0 notes
Text
Navigating Challenges in R Programming Homework: A Comprehensive Guide for Students
When it comes to mastering R programming, students often find themselves facing numerous challenges in completing their homework assignments. In this comprehensive guide, we'll explore the common obstacles students encounter and provide practical tips to overcome them. Whether you're a beginner or an experienced R programmer, this handbook aims to be your go-to resource for navigating the complexities of R homework.
Understanding the Importance of R Homework
Before delving into the challenges, let's establish why R homework is crucial for students pursuing statistics or data science courses. R programming is widely used in these fields for data analysis, visualization, and statistical modeling. Completing R homework assignments not only reinforces theoretical knowledge but also hones practical skills, preparing students for real-world applications.
Challenges Faced by Students
Complexity of R Syntax Overcoming the Syntax Maze The intricacies of R syntax can be overwhelming, especially for beginners. To overcome this challenge, consider breaking down your code into smaller segments, focusing on one concept at a time. Utilize online resources and seek assistance from R programming communities to enhance your understanding of syntax rules.
Data Handling and Manipulation Mastering Data Manipulation Effective data handling is a fundamental aspect of R programming. Practice with real-world datasets and explore functions like dplyr and tidyr to enhance your data manipulation skills. Online platforms and tutorials can provide hands-on exercises to reinforce these concepts.
Debugging and Error Resolution Navigating the Debugging Terrain Encountering errors in your R code is inevitable, but learning how to debug efficiently is key. Utilize debugging tools, such as the traceback function, and carefully review error messages. Online forums and communities can be valuable resources for seeking guidance on specific error resolutions.
Time Management Balancing Act: Homework vs. Other Commitments Many students struggle with time management when it comes to R homework. Create a schedule, allocate dedicated time slots for homework, and break down tasks into manageable chunks. Prioritize assignments based on deadlines and complexity, allowing for a more structured and efficient approach.
Seeking External Support
Relying on Professional Assistance Exploring R Homework Help Services For students facing persistent challenges, seeking professional help is a viable option. Websites like StatisticsHomeworkHelper.com offer specialized R homework help services, ensuring personalized assistance and timely completion of assignments. These services can provide valuable insights and guidance, complementing your learning journey.
Conclusion
In conclusion, overcoming obstacles in completing R homework requires a strategic approach, persistence, and access to the right resources. By understanding the challenges associated with R programming, implementing effective learning strategies, and leveraging external support when needed, students can navigate the complexities of R homework successfully. Remember, mastering R programming is a gradual process, and each obstacle conquered is a step closer to becoming a proficient R programmer.
Frequently Asked Questions
Q1: Is it common for students to struggle with R homework? A1: Yes, it's common for students to face challenges in R homework, especially due to the complexity of syntax, data manipulation, and debugging. Q2: How can I improve my time management for R homework? A2: To improve time management, create a schedule, allocate dedicated time slots, and prioritize assignments based on deadlines and complexity. Q3: When should I consider seeking professional R homework help? A3: If you're facing persistent challenges and need personalized assistance, consider seeking professional help from reliable services like StatisticsHomeworkHelper.com.
By addressing the challenges associated with R homework and providing practical solutions, this handbook aims to empower students to tackle their assignments with confidence. Whether you're a beginner or an advanced R programmer, the key lies in persistence, strategic learning, and utilizing available resources to overcome obstacles successfully.
10 notes
·
View notes
Text
Mastering Data Analytics with R Studio for Smarter Insights In today's data-driven world, the ability to analyze and interpret data is a crucial skill for businesses seeking a competitive edge. R Studio is a powerful tool that facilitates data analysis and visualization, making it indispensable for data analysts. This blog will guide you through mastering data analytics with R Studio, providing insights to enhance your analytical capabilities and drive smarter business decisions. https://discdown.org/rprogramming/images/03/03_RStudio_2.jpg R Studio Interface Overview What is R Studio? R Studio is an integrated development environment (IDE) that allows users to work with R, a statistical programming language. It offers a user-friendly platform with features that support data analysis, statistical computing, and graphical representation. The open-source nature of R Studio, combined with its extensive community support, makes it an excellent choice for data analysts at all levels. Why Choose R Studio for Data Analytics?
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Machine+Learning+R/plot_675020181.png Flexibility and Customization R Studio offers unparalleled flexibility, allowing analysts to tailor their environment and scripts to meet specific needs. This customization capability extends to data manipulation and visualization, enabling users to adapt their analysis to various datasets and objectives. Comprehensive Package Ecosystem The R ecosystem boasts a vast array of packages designed for different aspects of data analysis, from data cleaning and transformation to advanced statistical modeling. Popular packages like dplyr, ggplot2, and tidyr simplify complex tasks, making it easier to derive insights from data. Robust Visualization Capabilities Visualization is a cornerstone of data analysis, and R Studio excels in this area. With packages like ggplot2, users can create highly customizable and aesthetically pleasing visualizations that effectively communicate findings to stakeholders. This capability is critical for translating complex data into actionable insights. Getting Started with R Studio Installation and Setup To begin using R Studio, download and install both R and R Studio from their official websites. Once installed, familiarize yourself with the R Studio interface, which includes the console, script editor, and various panes for managing files, plots, and packages. Importing Data R Studio supports importing data from various sources, including CSV files, databases, and APIs. Use functions like read.csv() or DBI packages to connect to databases and import data into your R environment. Data Cleaning and Preprocessing Before analysis, data must be cleaned and preprocessed. Tools like dplyr and tidyr are essential for transforming data, handling missing values, and ensuring datasets are ready for analysis. Mastering these packages will streamline your data preparation process. Advanced Data Analysis Techniques Statistical Modeling R Studio is well-equipped for statistical modeling, offering packages for linear and non-linear modeling, time-series analysis, and machine learning. Leverage packages such as caret and randomForest to build predictive models that enhance decision-making.
Machine Learning with R Machine learning is a transformative technology in data analytics. With R Studio, implement machine learning algorithms using packages like caret and mlr3. These tools enable the creation of models that predict outcomes, classify data, and cluster datasets based on similarities. Data Visualization in Time-Series Analysis For businesses relying on temporal data, time-series analysis is invaluable. R Studio provides powerful tools for this type of analysis, enabling the identification of trends and seasonal patterns. Use packages like forecast and zoo to analyze time-dependent data effectively. Visualization and Reporting Creating Effective Visualizations Effective visualizations are critical for conveying data insights. R Studio's ggplot2 package is renowned for its ability to create detailed and informative charts and graphs. Whether it's a simple line graph or a complex multi-faceted plot, ggplot2 offers the tools to visualize data clearly and succinctly. Generating Reports with R Markdown R Markdown is a dynamic tool in R Studio for creating reproducible reports. It allows users to integrate R code with narrative text, generating documents that include both analysis and interpretation. This feature is particularly useful for creating comprehensive reports for stakeholders. Best Practices for Mastering R Studio Continuous Learning and Community Engagement The field of data analytics is continuously evolving, and staying updated is crucial. Engage with the R community through forums, blogs, and social media to learn new techniques and best practices. Participate in webinars and workshops to enhance your skills and network with other professionals. Developing a Structured Workflow A well-structured workflow is essential for efficient data analysis. Organize your scripts, datasets, and outputs systematically within R Studio. Utilize version control tools like Git to track changes and collaborate with team members effectively. Prioritizing Data Security Ensuring the security of your data is paramount. Implement best practices for data security within R Studio, such as encrypting sensitive data, regularly updating packages, and managing user access rights carefully. Conclusion Mastering data analytics with R Studio is a journey that offers immense rewards in terms of enhanced analytical capabilities and smarter business insights. By leveraging R Studio's flexibility, comprehensive package ecosystem, and robust visualization tools, you can transform raw data into meaningful insights that drive strategic decision-making. Embrace continuous learning and engage with the vibrant R community to stay at the forefront of data analytics innovation. https://www.datavis.ca/courses/RGraphics/images/headers/Rgraphics2.png
Machine Learning with R Studio FAQs Q: What is the primary advantage of using R Studio over other data analysis tools? A: R Studio offers unmatched flexibility and a comprehensive package ecosystem that caters to a wide range of data analysis needs. Its robust visualization capabilities and open-source nature make it a preferred choice for analysts. Q: Can beginners easily learn R Studio? A: Yes, beginners can learn R Studio with the help of numerous online resources, tutorials, and community support. The user-friendly interface simplifies the learning curve for new users. Q: How does R Studio support machine learning? A: R Studio supports machine learning through packages like caret and mlr3, which provide tools for building, training, and evaluating machine learning models. Q: Is R Studio suitable for time-series analysis? A: Absolutely, R Studio is well-suited for time-series analysis, offering specialized packages like forecast and zoo that help identify trends and seasonal patterns in temporal data. Q: How can I ensure data security while using R Studio? A: To ensure data security, implement encryption for sensitive data, keep your R Studio and packages updated, and manage user access rights diligently. Regularly back up your data to prevent loss.
0 notes
Text
🚀 Master R Programming in 2025: A Beginner’s Bootcamp That Changes Everything

If you’ve ever found yourself thinking, “I want to learn programming, but I don’t know where to start,” or “Data science sounds interesting, but the tools are too intimidating,” then this one’s for you. You don’t need to be a math wizard or have a computer science degree to begin your journey into the world of data. You just need curiosity, a solid starting point, and the right guidance.
That’s where the 2025 R Programming Bootcamp for Absolute Beginners comes into play—a complete, engaging, and beginner-friendly learning experience that helps you build real skills from the ground up.
Let’s break it down and see why this course should be your next smart move.
🧠 Why R Programming? Why Now?
Before diving into the course itself, let’s talk about why R programming matters—especially in 2025.
R isn’t just another coding language—it’s the go-to language for statistics, data analysis, and data visualization. It’s used by data scientists, researchers, analysts, and machine learning engineers across industries like healthcare, finance, marketing, and even sports.
Here’s what makes R especially powerful for beginners:
It's free and open-source.
It has a massive, supportive community.
It comes with ready-to-use libraries for graphs, data cleaning, modeling, and more.
It’s built with data in mind—not general-purpose software development.
Learning R doesn’t just make you job-ready; it gives you the edge in a data-driven world.
🏁 The Problem with Most Programming Courses
A lot of beginners give up early. Not because they're incapable, but because many courses:
Assume prior coding experience
Use complicated terms too soon
Don’t explain why you’re doing something, only how
That’s what sets the 2025 R Programming Bootcamp for Absolute Beginners apart. It teaches with empathy—like a mentor who remembers what it feels like to start from zero.
🎯 Who This Course Is Perfect For
This course is tailor-made if:
You’ve never written a line of code
You’re curious about data science or analytics
You want to explore career options in tech without going back to college
You want to learn by doing, not memorizing
It’s also a great refresher if you’ve dabbled in R before but never really “got it.”
📚 What You’ll Learn (And Actually Remember)
This isn’t a course that overwhelms you with theory. It focuses on hands-on learning. Every module is crafted to give you immediate results. Here’s a taste of what you’ll master:
1. The R Language from Scratch
Installing R and RStudio (your main toolkit)
Writing your first lines of R code
Understanding variables, functions, loops, and logic
2. Working with Data
Importing datasets (CSV, Excel, etc.)
Cleaning and manipulating messy data
Summarizing and filtering using dplyr and tidyr
3. Data Visualization
Building stunning charts and plots using ggplot2
Customizing visuals for reports or presentations
Storytelling with data
4. Real-World Projects
Mini-projects with real datasets
You’ll solve problems like analyzing trends, customer behavior, and product performance
Get portfolio-ready experience for job applications
5. Confidence with RStudio
Navigating the interface like a pro
Writing efficient scripts
Using R Markdown for reproducible reports
💻 No Setup Headaches
You won’t spend hours installing random packages or fixing broken environments. The course walks you through everything step-by-step. All you need is a basic laptop and internet. That’s it.
And unlike other platforms, this bootcamp doesn’t rush you. You can go at your own pace, revisit lessons, or even binge-learn over a weekend.
🧑🏫 Taught by Instructors Who Actually Teach
This course isn’t just assembled—it’s designed. The instructors don’t just code; they teach with real clarity. They anticipate where you’ll get stuck and guide you past those hurdles with ease.
Expect:
Clear explanations with real examples
Visual walk-throughs of every step
Encouraging tone, even in the harder parts
🌐 Community & Support
One of the biggest advantages of online learning is community—and this course doesn’t disappoint.
You’ll get:
Access to a student discussion board
Q&A with the instructor
Feedback on your code
Motivation from learners like you
There’s no such thing as a silly question here. Everyone’s learning together.
📈 What You’ll Walk Away With
By the end of the 2025 R Programming Bootcamp for Absolute Beginners, you’ll:
Be able to code confidently in R
Analyze and visualize datasets
Build your own mini-projects and reports
Understand core data science workflows
Have a strong foundation to explore machine learning, statistics, or data storytelling
💼 Career and Freelancing Ready
Whether you want to:
Break into a data analyst or data scientist role
Add a new skill to your resume
Impress clients with your reports
Start freelance data projects
This course sets you up with practical, job-ready skills. R is in high demand across industries. And having a portfolio with real-world analysis projects is gold when applying for jobs or internships.
🌍 Learning R Can Literally Take You Places
Companies across the globe—like Google, Facebook, IBM, and countless startups—use R for internal analytics and reporting.
Even governments and NGOs rely on R for population data, climate change research, and public health monitoring.
If you ever wanted to make an impact with your work, mastering R opens the door.
🕒 Why 2025 Is the Best Time to Start
We’re in the middle of the data revolution. Skills like Excel used to be enough. But now, employers want more than spreadsheets. They want:
Automated analysis
Clear data visualizations
Real statistical insights
That’s where R shines. Starting in 2025 gives you an edge. The earlier you start, the sooner you grow—and the more value you bring to any team.
💡 Bonus: You’ll Learn How to Learn
This bootcamp doesn’t just teach R—it teaches you how to approach any technical subject without fear. You’ll gain confidence in:
Tackling new tools
Asking better questions
Becoming a self-sufficient learner
This is an investment not just in one skill—but in your future learning ability.
🔗 Ready to Learn R Programming?
If you’re excited to start your journey, this is your moment. Whether you’re switching careers, leveling up, or just exploring, you won’t find a better entry point than the 2025 R Programming Bootcamp for Absolute Beginners.
It’s simple. It’s effective. It’s built for people just like you.
Start today, and who knows? A few months from now, you might be the one helping others take their first step into the world of data.
0 notes
Text
Assignment: Lasso Regression
I am an R user, so conducted the assignment in R instead of SAS or Python.
I ran a lasso regression analysis to identify a subset of variables that best predict adolescent school connectedness. Twenty three predictors were presented to the model (gender, race, age, alcohol use, alcohol problems in the home, marijuana use, cocaine use, inhalant use, cigarette availability in the home, depression, self esteem, violence, parental assistance, deviant behaviour, CPA, expulsion, family connectedness, parental activity, and parental presence. All predictors were standardized to have a mean of zero and standard deviation of one.
The data were split into a training set that with a random selection of 70% of the observations, and a testing set with the remaining 30%. A k=10 fold was selected for the least angle regression algorithm cross validation. The cross validation average squared mean error at each fold was used to identify the best subset of predictor variables. There was high agreement in performance of the model between the train and test data sets (MSE = 18.0 and 17.6 , respectively; R-squared 0.31 and 0.38 respectively).
Twenty-one of the 23 predictor variables were selected into the model. Self-esteem, depression, and GPA were the three most strongly associated predictors for school connectedness. Self-esteem and GPA were positively associated with school connectedness, while depression was negatively associated.
The 21 included variables account for 37% of the variance in school connectedness.
Load necessary packages
library(readr) library(dplyr) library(tidyr) library(glmnet) library(ggplot2)
Load and clean data
data <- read_csv("tree_addhealth.csv") names(data) <- toupper(names(data)) data_clean <- drop_na(data) data_clean <- data_clean %>% mutate(MALE = recode(BIO_SEX, 1 = 1, 2 = 0))
Define predictors and target
predictor_vars <- c("MALE", "HISPANIC", "WHITE", "BLACK", "NAMERICAN", "ASIAN", "AGE", "ALCEVR1", "ALCPROBS1", "MAREVER1", "COCEVER1", "INHEVER1", "CIGAVAIL", "DEP1", "ESTEEM1", "VIOL1", "PASSIST", "DEVIANT1", "GPA1", "EXPEL1", "FAMCONCT", "PARACTV", "PARPRES")
X <- data_clean %>% select(all_of(predictor_vars)) %>% mutate(across(everything(), scale)) %>% as.matrix()
y <- data_clean$SCHCONN1
Train/test split
set.seed(123) train_idx <- sample(1:nrow(X), size = 0.7 * nrow(X)) X_train <- X[train_idx, ] y_train <- y[train_idx] X_test <- X[-train_idx, ] y_test <- y[-train_idx]
Fit Lasso with 10-fold CV
cv_model <- cv.glmnet(X_train, y_train, alpha = 1, nfolds = 10, keep = TRUE)
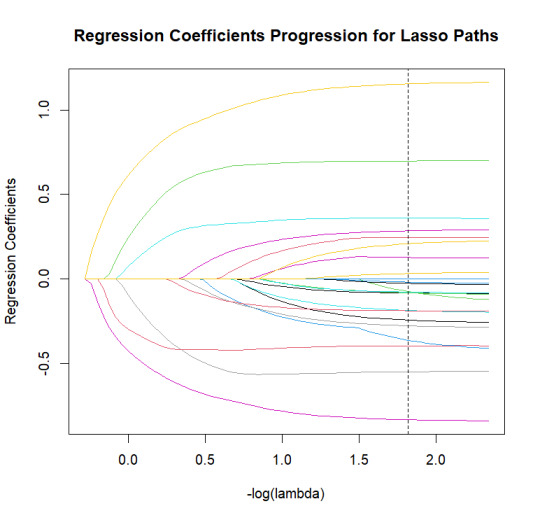
1. Coefficient Progression Plot
lasso_fit <- glmnet(X_train, y_train, alpha = 1) coef_path <- as.matrix(lasso_fit$beta) log_lambda <- -log10(lasso_fit$lambda)
matplot(log_lambda, t(coef_path), type = "l", lty = 1, col = 1:ncol(coef_path), xlab = "-log(lambda)", ylab = "Regression Coefficients", main = "Regression Coefficients Progression for Lasso Paths") abline(v = -log10(cv_model$lambda.min), lty = 2, col = "black")
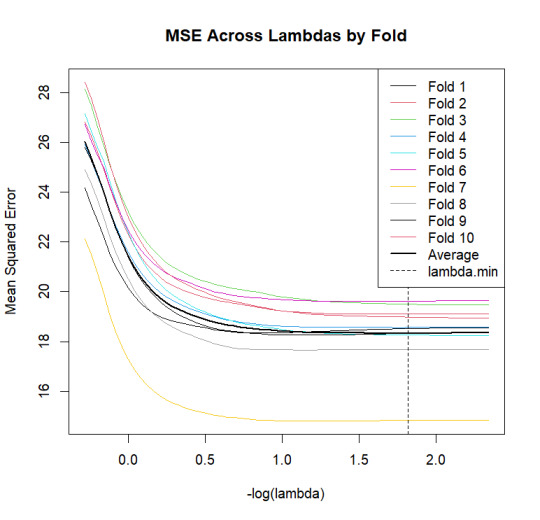
2. MSE by Fold Plot
lambda_vals <- cv_model$lambda foldid <- cv_model$foldid nfolds <- max(foldid) nlambda <- length(lambda_vals) preval <- cv_model$fit.preval mse_by_fold <- matrix(NA, nrow = nlambda, ncol = nfolds) for (fold in 1:nfolds) { test_idx <- which(foldid == fold) y_true <- y_train[test_idx] preds <- preval[test_idx, ] mse_by_fold[, fold] <- colMeans((y_true - preds)^2) }
matplot(-log10(lambda_vals), mse_by_fold, type = "l", lty = 1, col = 1:nfolds, xlab = "-log(lambda)", ylab = "Mean Squared Error", main = "MSE Across Lambdas by Fold") lines(-log10(lambda_vals), rowMeans(mse_by_fold), col = "black", lwd = 2) abline(v = -log10(cv_model$lambda.min), lty = 2) legend("topright", legend = c(paste0("Fold ", 1:nfolds), "Average", "lambda.min"), col = c(1:nfolds, "black", "black"), lty = c(rep(1, nfolds), 1, 2), lwd = c(rep(1, nfolds), 2, 1))
3. Print selected variables (non-zero at lambda.min)
lasso_coefs <- coef(cv_model, s = "lambda.min") selected_vars <- rownames(lasso_coefs)[lasso_coefs[, 1] != 0] selected_vars <- selected_vars[selected_vars != "(Intercept)"]
cat("\nVariables selected by the Lasso model:\n") print(selected_vars)
4. Performance: MSE and R-squared
pred_train <- predict(cv_model, s = "lambda.min", newx = X_train) pred_test <- predict(cv_model, s = "lambda.min", newx = X_test)
train_mse <- mean((y_train - pred_train)^2) test_mse <- mean((y_test - pred_test)^2) train_r2 <- cor(y_train, pred_train)^2 test_r2 <- cor(y_test, pred_test)^2
cat("\nTraining MSE:", round(train_mse, 3), "\n") cat("Test MSE:", round(test_mse, 3), "\n") cat("Training R-squared:", round(train_r2, 3), "\n") cat("Test R-squared:", round(test_r2, 3), "\n")
0 notes
Text
Building a Rewarding Career in Data Science: A Comprehensive Guide
Data Science has emerged as one of the most sought-after career paths in the tech world, blending statistics, programming, and domain expertise to extract actionable insights from data. Whether you're a beginner or transitioning from another field, this blog will walk you through what data science entails, key tools and packages, how to secure a job, and a clear roadmap to success.

What is Data Science?
Data Science is the interdisciplinary field of extracting knowledge and insights from structured and unstructured data using scientific methods, algorithms, and systems. It combines elements of mathematics, statistics, computer science, and domain-specific knowledge to solve complex problems, make predictions, and drive decision-making. Applications span industries like finance, healthcare, marketing, and technology, making it a versatile and impactful career choice.
Data scientists perform tasks such as:
Collecting and cleaning data
Exploratory data analysis (EDA)
Building and deploying machine learning models
Visualizing insights for stakeholders
Automating data-driven processes
Essential Data Science Packages
To excel in data science, familiarity with programming languages and their associated libraries is critical. Python and R are the dominant languages, with Python being the most popular due to its versatility and robust ecosystem. Below are key Python packages every data scientist should master:
NumPy: For numerical computations and handling arrays.
Pandas: For data manipulation and analysis, especially with tabular data.
Matplotlib and Seaborn: For data visualization and creating insightful plots.
Scikit-learn: For machine learning algorithms, including regression, classification, and clustering.
TensorFlow and PyTorch: For deep learning and neural network models.
SciPy: For advanced statistical and scientific computations.
Statsmodels: For statistical modeling and hypothesis testing.
NLTK and SpaCy: For natural language processing tasks.
XGBoost, LightGBM, CatBoost: For high-performance gradient boosting in machine learning.
For R users, packages like dplyr, ggplot2, tidyr, and caret are indispensable. Additionally, tools like SQL for database querying, Tableau or Power BI for visualization, and Apache Spark for big data processing are valuable in many roles.
How to Get a Job in Data Science
Landing a data science job requires a mix of technical skills, practical experience, and strategic preparation. Here’s how to stand out:
Build a Strong Foundation: Master core skills in programming (Python/R), statistics, and machine learning. Understand databases (SQL) and data visualization tools.
Work on Real-World Projects: Apply your skills to projects that solve real problems. Use datasets from platforms like Kaggle, UCI Machine Learning Repository, or Google Dataset Search. Examples include predicting customer churn, analyzing stock prices, or building recommendation systems.
Create a Portfolio: Showcase your projects on GitHub and create a personal website or blog to explain your work. Highlight your problem-solving process, code, and visualizations.
Gain Practical Experience:
Internships: Apply for internships at startups, tech companies, or consulting firms.
Freelancing: Take on small data science gigs via platforms like Upwork or Freelancer.
Kaggle Competitions: Participate in Kaggle competitions to sharpen your skills and gain recognition.
Network and Learn: Join data science communities on LinkedIn, X, or local meetups. Attend conferences like PyData or ODSC. Follow industry leaders to stay updated on trends.
Tailor Your Applications: Customize your resume and cover letter for each job, emphasizing relevant skills and projects. Highlight transferable skills if transitioning from another field.
Prepare for Interviews: Be ready for technical interviews that test coding (e.g., Python, SQL), statistics, and machine learning concepts. Practice on platforms like LeetCode, HackerRank, or StrataScratch. Be prepared to discuss your projects in depth.
Upskill Continuously: Stay current with emerging tools (e.g., LLMs, MLOps) and technologies like cloud platforms (AWS, GCP, Azure).
Data Science Career Roadmap
Here’s a step-by-step roadmap to guide you from beginner to data science professional:
Phase 1: Foundations (1-3 Months)
Learn Programming: Start with Python (or R). Focus on syntax, data structures, and libraries like NumPy and Pandas.
Statistics and Math: Study probability, hypothesis testing, linear algebra, and calculus (Khan Academy, Coursera).
Tools: Get comfortable with Jupyter Notebook, Git, and basic SQL.
Resources: Books like "Python for Data Analysis" by Wes McKinney or online courses like Coursera’s "Data Science Specialization."
Phase 2: Core Data Science Skills (3-6 Months)
Machine Learning: Learn supervised (regression, classification) and unsupervised learning (clustering, PCA) using Scikit-learn.
Data Wrangling and Visualization: Master Pandas, Matplotlib, and Seaborn for EDA and storytelling.
Projects: Build 2-3 projects, e.g., predicting house prices or sentiment analysis.
Resources: "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron; Kaggle micro-courses.
Phase 3: Advanced Topics and Specialization (6-12 Months)
Deep Learning: Explore TensorFlow/PyTorch for neural networks and computer vision/NLP tasks.
Big Data Tools: Learn Spark or Hadoop for handling large datasets.
MLOps: Understand model deployment, CI/CD pipelines, and tools like Docker or Kubernetes.
Domain Knowledge: Focus on an industry (e.g., finance, healthcare) to add context to your work.
Projects: Create advanced projects, e.g., a chatbot or fraud detection system.
Resources: Fast.ai courses, Udemy’s "Deep Learning A-Z."
Phase 4: Job Preparation and Application (Ongoing)
Portfolio: Polish your GitHub and personal website with 3-5 strong projects.
Certifications: Consider credentials like Google’s Data Analytics Professional Certificate or AWS Certified Machine Learning.
Networking: Engage with professionals on LinkedIn/X and contribute to open-source projects.
Job Applications: Apply to entry-level roles like Data Analyst, Junior Data Scientist, or Machine Learning Engineer.
Interview Prep: Practice coding, ML theory, and behavioral questions.
Phase 5: Continuous Growth
Stay updated with new tools and techniques (e.g., generative AI, AutoML).
Pursue advanced roles like Senior Data Scientist, ML Engineer, or Data Science Manager.
Contribute to the community through blogs, talks, or mentorship.
Final Thoughts
A career in data science is both challenging and rewarding, offering opportunities to solve impactful problems across industries. By mastering key packages, building a strong portfolio, and following a structured roadmap, you can break into this dynamic field. Start small, stay curious, and keep learning—your data science journey awaits!
0 notes
Text
Sure, here is a 500-word article on "SEO automation with R" as per your request:
SEO Automation with R TG@yuantou2048
Search Engine Optimization (SEO) is a critical aspect of digital marketing that helps websites rank higher in search engine results pages (SERPs). Traditionally, SEO tasks have been manual and time-consuming, but with the advent of advanced programming languages like R, many of these tasks can now be automated using R.
Why Use R for SEO Automation?
R is a powerful statistical programming language that offers a wide range of packages specifically designed for data manipulation, analysis, and visualization. Here are some reasons why R is an excellent choice for automating SEO tasks:
1. Data Handling: R excels at handling large datasets, which is crucial for SEO where you often need to analyze vast amounts of data from various sources such as Google Analytics, SEMrush, Ahrefs, etc.
2. Automation: With R, you can automate repetitive tasks such as keyword research, backlink analysis, and content optimization. This not only saves time but also reduces the risk of human error.
3. Customization: R allows for high customization, enabling you to tailor solutions to specific needs. You can create custom scripts to scrape data from different sources, perform complex calculations, and generate reports automatically.
4. Integration: R integrates well with other tools and platforms. You can easily connect to APIs from tools like Google Search Console, Moz, and others, making it easier to gather and process data efficiently.
5. Visualization: R has robust visualization capabilities, allowing you to create insightful visual representations of your SEO data, helping you make informed decisions based on data-driven insights.
6. Community Support: The R community is vast and active, providing extensive support through packages like `httr` for web scraping, `dplyr` for data manipulation, and `ggplot2` for creating detailed visualizations that help in understanding trends and patterns in your SEO metrics.
Steps to Automate SEO Tasks
Step 1: Data Collection
Use packages like `httr` and `rvest` to scrape data from websites and APIs. For example, you can use `httr` to fetch data from APIs and `rvest` to extract data from HTML documents. This makes it easy to collect and clean data from multiple sources.
Example: Keyword Research
```r
library(httr)
library(rvest)
Fetching data from a website
url <- "https://example.com"
page <- GET(url)
content <- read_html(page)
keywords <- html_nodes(content, "h1") %>% html_text()
print(keywords)
```
This snippet demonstrates how to scrape keywords from a webpage. By leveraging these packages, you can automate the collection of data from SEO tools and websites.
Step-by-Step Guide
1. Install Required Packages
```r
install.packages("httr")
install.packages("rvest")
```
2. Scrape Data
```r
url <- "https://example.com"
page <- read_html(url)
titles <- html_nodes(page, "h1") %>% html_text()
print(titles)
```
3. Data Analysis
```r
library(dplyr)
library(ggplot2)
Example: Extracting H1 tags from a webpage
url <- "https://example.com"
page <- read_html(url)
h1_tags <- html_nodes(page, "h1") %>% html_text()
print(h1_tags)
```
4. Data Manipulation
```r
library(dplyr)
library(stringr)
library(tidyr)
Scrape data
url <- "https://example.com"
page <- read_html(url)
titles <- html_nodes(page, "h1") %>% html_text()
```
5. Data Cleaning and Analysis
```r
df <- data.frame(titles = titles)
df <- df %>% mutate(word_count = str_length(titles))
```
6. Analysis
```r
df <- df %>% mutate(word_count = str_length(titles))
```
7. Visualization
```r
library(ggplot2)
ggplot(df, aes(x = titles)) +
geom_bar() +
labs(title = "Keyword Frequency", x = "Keywords", y = "Frequency")
Analyze and visualize data
df <- df %>% group_by(titles) %>%
summarize(count = n())
```
8. Visualization
```r
ggplot(df, aes(x = titles, y = count)) +
geom_bar(stat = "identity")
```
9. Reporting
```r
ggplot(df, aes(x = titles, y = count)) +
geom_bar(stat = "identity")
```
10. Conclusion
By automating these tasks, you can streamline your SEO workflow, saving hours of manual labor.
11. Automated Reports
```r
ggplot(df, aes(x = titles, y = count)) +
theme_minimal()
ggplot(df, aes(x = titles, y = count)) +
geom_bar(stat = "identity")
```
12. Automate Reporting
```r
ggsave("report.png")
```
13. Conclusion
By automating SEO tasks with R, you can focus more on strategic decisions rather than spending time on mundane tasks. This approach ensures consistency and accuracy in your SEO efforts, leading to better insights and faster decision-making.
14. Summary
In conclusion, automating SEO tasks with R can significantly enhance your SEO strategy by providing actionable insights quickly and efficiently. Whether you're a beginner or an experienced SEO professional, integrating R into your workflow can transform your SEO strategy, making it more efficient and effective. Start exploring R today to elevate your SEO efforts and stay ahead in the competitive digital landscape.
15. Final Thoughts
Automating SEO processes with R empowers marketers to focus on strategic planning and execution, ultimately driving better rankings and improving overall performance.
16. Next Steps
Explore more packages like `shiny` for interactive dashboards or `shiny` for interactive dashboards and reports.
17. TG@yuantou2048
```
By leveraging R, you can save time and gain deeper insights into your website's performance and make data-driven decisions.
18. TG@yuantou2048
```
19. TG@yuantou2048
```
20. TG@yuantou2048
```
21. TG@yuantou2048
```
22. TG@yuantou2048
```
23. TG@yuantou2048
```
24. TG@yuantou2048
```
25. TG@yuantou2048
```
26. TG@yuantou2048
```
27. TG@yuantou2048
```
28. TG@yuantou2048
```
29. TG@yuantou2048
```
Feel free to reach out if you need further assistance or have any questions!
加飞机@yuantou2048

EPS Machine
EPP Machine
0 notes
Text
Python vs. R: Which Programming Language is Best for Data Science?

Introduction
When it comes to data science, two programming languages dominate the field: Python and R. Both languages offer powerful tools for data analysis, visualization, and machine learning. However, choosing between them can be challenging, especially for beginners.
In this blog, we’ll compare Python and R based on key factors such as ease of use, libraries, performance, and industry applications to help you decide which language is the best fit for your data science journey.
1. Overview of Python and R
What is Python?
Python is a general-purpose programming language known for its simplicity and versatility. It is widely used in data science, web development, AI, and automation.
First released: 1991
Best for: Data science, machine learning, deep learning, and automation.
Key Strength: Simple syntax, extensive libraries, and strong community support.
What is R?
R is a statistical programming language designed specifically for data analysis and visualization. It is widely used in academia, research, and statistical computing.
First released: 1995
Best for: Statistical computing, data visualization, and academic research.
Key Strength: Advanced statistical capabilities and specialized data visualization tools.
2. Ease of Learning and Use
Python
✅ Easy-to-read syntax, making it beginner-friendly. ✅ General-purpose language that is applicable beyond data science. ✅ Strong integration with AI/ML frameworks.
R
✅ Built specifically for data analysis, making statistical computing easier. ✅ Ideal for users with a strong mathematical or statistical background. ✅ Has a steeper learning curve due to unique syntax.
Winner: Python (for beginners), R (for statisticians and researchers).
3. Libraries and Packages
Python Libraries
Pandas – Data manipulation and analysis.
NumPy – Numerical computing.
Matplotlib & Seaborn – Data visualization.
Scikit-learn – Machine learning.
TensorFlow & PyTorch – Deep learning.
R Libraries
ggplot2 – Advanced data visualization.
dplyr & tidyr – Data manipulation.
caret – Machine learning.
Shiny – Interactive web applications.
randomForest – Statistical modeling.
Winner: Python (for machine learning), R (for statistical analysis and visualization).
4. Data Visualization
Python
✅ Uses Matplotlib, Seaborn, and Plotly for data visualization. ✅ Good for basic and intermediate visualizations. ✅ Lacks built-in advanced statistical visualization features.
R
✅ ggplot2 is one of the most powerful visualization tools available. ✅ Excellent for customizing and presenting complex statistical data. ✅ Better for academic and research purposes.
Winner: R (for high-quality visualizations), Python (for ease of use and integration).
5. Performance and Speed
Python
✅ Faster for general-purpose tasks and large-scale applications. ✅ Efficient in handling machine learning and AI workloads.
R
✅ Performs better for statistical analysis and complex computations. ✅ Slower than Python when dealing with large datasets.
Winner: Python (for scalability and speed), R (for statistical tasks).
6. Industry Applications
Python Usage
🔹 Data Science & Machine Learning (Google, Facebook, Tesla) 🔹 AI & Deep Learning (NLP, Computer Vision) 🔹 Automation & Web Development (Flask, Django)
R Usage
🔹 Academic Research & Statistics (Universities, Government) 🔹 Data Analysis & Visualization (Healthcare, Finance) 🔹 Bioinformatics & Pharmaceuticals
Winner: Python (for AI, ML, and business applications), R (for research and statistics).
7. Community Support and Job Opportunities
Python
✅ Large community with extensive documentation and tutorials. ✅ High demand in the job market. ✅ Used in diverse industries.
R
✅ Strong community for academic and research-based queries. ✅ Less demand compared to Python in AI and business sectors. ✅ Primarily used in research, academia, and finance.
Winner: Python (for job opportunities and broad industry applications), R (for research and academia).
8. Final Verdict: Which One Should You Choose?
CriteriaWinnerEase of LearningPythonLibraries & PackagesPython (for ML & AI), R (for statistics)Data VisualizationRPerformance & SpeedPythonIndustry DemandPythonCommunity SupportPython
When to Choose Python
✅ If you want to work in machine learning, AI, automation, or web development. ✅ If you’re a beginner looking for a versatile and easy-to-learn language. ✅ If you want to work in industries like tech, finance, or e-commerce.
When to Choose R
✅ If you’re a statistician, researcher, or academic professional. ✅ If you focus on data visualization and advanced statistical modeling. ✅ If you work in bioinformatics, pharmaceuticals, or research institutions.
Conclusion
Both Python and R have their strengths, and the choice depends on your specific needs. If you’re looking for a general-purpose, easy-to-learn, and highly demanded language, go for Python. However, if your focus is on statistics, data visualization, and research, then R is a great choice.
Whichever you choose, mastering either of these languages will give you a competitive edge in the field of data science! 🚀
For more data science courses and career guidance,
visit-https://intellimindz.com/data-science-training-in-chennai/ 📞 Contact us at: [+91 9655877577]
0 notes
Text
Top 5 Data Science Tools Every Beginner Should Know

Data science is a rapidly growing field, and having the right tools in your arsenal is crucial for success. While the options are vast, here are 5 essential tools every aspiring data scientist should familiarize themselves with:
1. Python: * Why it's crucial: Python is the de facto language for data science, offering a rich ecosystem of libraries for data manipulation, analysis, and machine learning.
* Key Libraries: NumPy, Pandas, Matplotlib, Seaborn, Scikit-learn, TensorFlow/PyTorch
2. R: * Why it's crucial: R is a powerful language specifically designed for statistical computing and graphics. It excels in statistical analysis and data visualization.
* Key Packages: dplyr, tidyr, ggplot2, caret
3. SQL: * Why it's crucial: SQL is the standard language for interacting with relational databases. Data scientists often work with large datasets stored in databases, making SQL essential for data extraction, manipulation, and analysis.
4. Jupyter Notebook: * Why it's crucial: Jupyter Notebook provides an interactive environment for writing and executing code, visualizing data, and documenting your work. It's an invaluable tool for data exploration, experimentation, and sharing your findings.
5. Tableau/Power BI: * Why it's crucial: These tools are powerful data visualization platforms that allow you to create interactive dashboards and reports. They are essential for communicating your findings effectively to stakeholders.
Git: Version control systems like Git are essential for tracking changes to your code and collaborating with other data scientists.
By mastering these tools, you'll lay a strong foundation for your data science journey. Remember to practice consistently, experiment with different tools and techniques, and explore real-world datasets to gain hands-on experience.
For comprehensive data science training and guidance, consider exploring programs like Xaltius Academy's Data Science course.
0 notes
Text
R for Data Science: The Essential Guide to Start Your Data Science Journey
R is a powerhouse programming language for data analysis and visualization, making it a go-to tool for data scientists and statisticians worldwide. Whether you’re a beginner looking to break into data science or an experienced analyst wanting to sharpen your skills, understanding how to leverage R effectively can be a game-changer.
Table of Contents
Introduction to R for Data Science
Why Choose R for Data Science?
Setting Up R: Tools and Environment
Basic Data Manipulation in R
Data Visualization with ggplot2
Statistical Analysis in R
Machine Learning in R
Tips for Learning R Efficiently
Conclusion and Next Steps
1. Introduction to R for Data Science
R was initially developed for statistical computing and has evolved into a comprehensive language used for data analysis, machine learning, and data visualization. Its user-friendly syntax and the availability of numerous packages make it an ideal choice for data professionals.
2. Why Choose R for Data Science?
Rich Ecosystem of Packages: With packages like dplyr, tidyr, ggplot2, and caret, R makes it easy to handle complex data manipulation and visualization tasks.
Statistical Strength: R was designed with statistics in mind, allowing for advanced statistical models and tests.
Community and Resources: R boasts a vibrant community with countless forums, tutorials, and resources available online, including the famous R for Data Science book by Hadley Wickham and Garrett Grolemund.
3. Setting Up R: Tools and Environment
To get started with R, follow these simple steps:
Install R: Download and install R from CRAN (The Comprehensive R Archive Network).
Install RStudio: RStudio is an integrated development environment (IDE) that provides a more intuitive interface for coding in R. Download it from RStudio’s official website.
4. Basic Data Manipulation in R
R’s power lies in its data manipulation capabilities. Here’s a brief overview of essential packages:
dplyr: Simplifies data manipulation tasks with functions like filter(), select(), mutate(), and summarize().
tidyr: Helps organize data into tidy formats using functions like pivot_longer() and pivot_wider().
Example: Using dplyr to filter and summarize data.
library(dplyr)
# Sample data frame data <- data.frame(Name = c(“A”, “B”, “C”, “D”), Score = c(85, 92, 78, 90))
# Filter and summarize filtered_data <- data %>% filter(Score > 80) %>% summarize(Mean_Score = mean(Score))
print(filtered_data)
5. Data Visualization with ggplot2
Visualization is a key part of data analysis. The ggplot2 package is one of R’s most powerful visualization tools.
Basic ggplot2 Example:
library(ggplot2)
# Create a simple bar chart ggplot(data, aes(x = Name, y = Score)) + geom_bar(stat = “identity”) + theme_minimal() + labs(title = “Student Scores”, x = “Name”, y = “Score”)
6. Statistical Analysis in R
R’s capabilities in statistical modeling make it the preferred tool for statisticians. From basic hypothesis testing (t.test(), anova()) to complex regression models (lm(), glm()), R covers it all.
Example: Simple Linear Regression
# Linear model model <- lm(Score ~ Name, data = data) summary(model)
7. Machine Learning in R
R provides robust support for machine learning through packages such as caret, randomForest, and xgboost.
Example: Training a Decision Tree Model
library(caret) library(rpart)
# Split data and train model model <- train(Score ~ ., data = data, method = “rpart”) print(model)
8. Tips for Learning R Efficiently
Hands-on Practice: The best way to learn is by doing. Work on datasets like mtcars, iris, or your data.
Explore Tutorials: Websites like R-bloggers and platforms like Coursera offer in-depth courses.
Join Forums: Engage in R communities on platforms like Stack Overflow and Reddit for peer support and advanced discussions.
9. Conclusion and Next Steps
Mastering R for data science opens doors to comprehensive data analysis, visualization, and predictive modeling. Start by practicing with real-world datasets and explore more advanced packages as you grow your expertise.
Ready to take your data science skills to the next level? Explore comprehensive courses and resources to deepen your knowledge and become proficient in R for data science.
Explore More on Data Science
For an in-depth look at R programming and live tutorials, be sure to check out this insightful YouTube session. This video provides practical guidance and additional tips to enhance your understanding of R and data science concepts. Don’t miss it!
0 notes
Text
Data manipulation with dplyr and tidyr involves transforming and organizing data efficiently in R. dplyr provides functions like filter, select, mutate, and summarize for data manipulation. tidyr focuses on reshaping data, using functions like gather, spread, pivot_longer, and pivot_wider to convert between wide and long formats, making data analysis easier.
0 notes
Text
Assignment: Running a Random Forest
I am an R user, so conducted the assignment in R instead of SAS or Python.
load packages
library(randomForest) library(caret) library(ggplot2) library(readr) library(dplyr) library(tidyr)
Load the dataset
AH_data <- read_csv("tree_addhealth.csv") data_clean <- AH_data %>% drop_na()
Examine data
str(data_clean) summary(data_clean)
Define predictors and target
predictors <- data_clean %>% select(BIO_SEX, HISPANIC, WHITE, BLACK, NAMERICAN, ASIAN, age, ALCEVR1, ALCPROBS1, marever1, cocever1, inhever1, cigavail, DEP1, ESTEEM1, VIOL1, PASSIST, DEVIANT1, SCHCONN1, GPA1, EXPEL1, FAMCONCT, PARACTV, PARPRES)
target <- data_clean$TREG1
Split into training and testing sets
set.seed(123) split <- createDataPartition(target, p = 0.6, list = FALSE) pred_train <- predictors[split, ] pred_test <- predictors[-split, ] tar_train <- target[split] tar_test <- target[-split]
Train random forest model
set.seed(123) rf_model <- randomForest(x = pred_train, y = as.factor(tar_train), ntree = 25) rf_pred <- predict(rf_model, pred_test)
Confusion matrix and accuracy
conf_matrix <- confusionMatrix(rf_pred, as.factor(tar_test)) print(conf_matrix)
Feature importance
importance(rf_model) varImpPlot(rf_model)
Accuracy for different number of trees
trees <- 1:25 accuracy <- numeric(length(trees))
for (i in trees) { rf_temp <- randomForest(x = pred_train, y = as.factor(tar_train), ntree = i) pred_temp <- predict(rf_temp, pred_test) accuracy[i] <- mean(pred_temp == tar_test) }
Plot accuracy vs number of trees
accuracy_df <- data.frame(trees = trees, accuracy = accuracy)
ggplot(accuracy_df, aes(x = trees, y = accuracy)) + geom_line(color = "blue") + labs(title = "Accuracy vs. Number of Trees", x = "Number of Trees", y = "Accuracy") + theme_minimal() I conducted a random forest analysis to evaluate the importance of a variety of categorical and continuous explanatory variables on a categorical outcome variable - being a regular smoker. The five explanatory variables with the highest importance in predicting regular smoking were: ever having used marijuana, age, deviant behaviour, GPA, and school connectedness. The accuracy of the random forest was 83%, which was achieved within 3 trees. Growing additional trees did not add much to the overall accuracy of the model, suggesting a small number of trees is sufficient for identifying the important explanatory variables.
0 notes
Text
Data analytics is rapidly transforming industries by helping businesses extract valuable insights from their data. Among the various tools available for data analysis, R stands out as one of the most powerful programming languages. Known for its comprehensive libraries and capabilities, data analytics with R allows professionals to efficiently manage, manipulate, and analyze data, thereby helping them build a solid data analytics portfolio.
In this blog, we'll explore the basics of R, its visualization techniques, data cleaning capabilities, statistical modeling, predictive analytics, and machine learning algorithms to understand how it unlocks the full potential of data analytics.
Understanding the Basics of R Programming Language
R is an open-source programming language widely used in statistical computing, data analysis, and visualization. It is specifically designed for data manipulation, offering a rich set of libraries and tools that make it a go-to choice for statisticians and data scientists.
Key features of R:
It offers various built-in statistical functions for linear and nonlinear modeling, time-series analysis, and hypothesis testing.
It has an active community, which ensures continuous development and support.
Its syntax is easy to understand, making it accessible for both beginners and experienced users.
R integrates seamlessly with other tools like Python, SQL, and Excel, allowing for more versatile data analytics workflows.
Starting with the basics of R lays the groundwork for deeper analysis and building an impactful data analytics portfolio.
Exploring Data Visualization Techniques Using R
Visualization is a critical part of data analytics, helping to communicate insights in a visually compelling way. R excels in creating dynamic, interactive, and high-quality visualizations.
Popular libraries in R for data visualization include:
ggplot2: One of the most widely used libraries for creating aesthetically pleasing charts, including bar plots, line graphs, and scatter plots.
plotly: Enables interactive visualizations where users can zoom, hover, and interact with data points.
lattice: Provides high-level data visualization tools that work well with multivariate data.
R’s visualization capabilities allow analysts to present complex datasets in a clear and concise manner, helping stakeholders make data-driven decisions effectively.
Data Cleaning and Preprocessing with R
The quality of data plays a significant role in the outcomes of any analysis. Most real-world datasets contain missing values, duplicates, or noise that must be addressed before proceeding with the analysis. R offers several powerful tools for data cleaning and preprocessing.
Some of the techniques and libraries for data cleaning in R include:
dplyr: A library designed for data manipulation, allowing for filtering, summarizing, and mutating data quickly.
tidyr: Helps in organizing and reshaping data into tidy formats for easier analysis.
stringr: Facilitates text cleaning and manipulation.
lubridate: Assists in parsing, manipulating, and calculating dates and times.
Effective data cleaning with R ensures that datasets are ready for analysis and can lead to more accurate and reliable results.
Statistical Analysis and Modeling with R
R is renowned for its extensive support for statistical methods, making it an ideal tool for performing a wide range of statistical analyses. Whether you need to conduct regression, hypothesis testing, or time series analysis, data analytics using R has you covered.
Some key statistical models in R:
Linear and Logistic Regression: Useful for predicting a continuous or binary outcome variable.
ANOVA (Analysis of Variance): Helps in comparing means across different groups.
Time Series Analysis: Used for modeling and forecasting data collected over time, such as stock prices or weather conditions.
By performing statistical analysis in R, businesses and researchers can uncover trends, patterns, and correlations that would otherwise remain hidden.
Predictive Analytics with R
Predictive analytics involves using historical data to predict future outcomes. R's diverse set of tools and algorithms makes it well-suited for building accurate predictive models.
In predictive analytics, R offers:
Random Forest: A powerful ensemble learning method for classification and regression.
Decision Trees: A model that splits data into subsets based on certain conditions, often used for both classification and regression tasks.
Support Vector Machines (SVM): A method for classification that works well with small datasets.
By leveraging predictive analytics with R, organizations can forecast customer behavior, sales trends, and even identify potential risks before they become critical.
Machine Learning Algorithms in R
As machine learning continues to shape the future of data analytics, R remains a versatile language for implementing various machine learning algorithms. Its packages support a wide range of supervised and unsupervised learning techniques, enabling data analysts to build sophisticated models.
Some popular machine learning libraries in R include:
caret: A comprehensive package that simplifies the training and evaluation of machine learning models, from decision trees to support vector machines.
xgboost: Highly efficient for implementing gradient boosting algorithms, often used in competitions and production models.
k-means: A clustering algorithm useful for identifying patterns in unlabelled data.
Neural Networks: R supports the development of deep learning models using libraries like nnet and keras.
Machine learning in R empowers analysts to go beyond traditional statistical methods, providing deeper insights and predictions.
Practical Applications of Data Analytics with R
Data analytics using R is applicable across various industries, from finance and healthcare to marketing and e-commerce. Here are a few real-world applications:
Financial Analysis: Predicting stock market trends or analyzing financial risk using time-series forecasting.
Healthcare Analytics: Analyzing patient data to identify trends in healthcare outcomes, improving treatment effectiveness.
Marketing and Customer Insights: Leveraging customer data for targeted campaigns, customer segmentation, and sentiment analysis.
These practical applications of R demonstrate its power and versatility, making it a must-have tool for data analytics professionals.
Resources for Learning and Mastering R for Data Analytics
For those looking to master data analytics with R, there are numerous resources available:
Online Courses: Platforms like Coursera, edX, and DataCamp offer courses ranging from beginner to advanced levels.
Books: "R for Data Science" by Garrett Grolemund and Hadley Wickham is a popular resource for learning R in a practical, hands-on way.
Communities and Forums: Websites like Stack Overflow, R-bloggers, and Reddit have active R communities where developers and analysts can find solutions to problems and share knowledge.
By taking advantage of these resources, learners can build a solid foundation in R and expand their data analytics portfolio.
Conclusion: Harnessing the Power of Data Analytics with R
In the world of data analytics, R is a game-changing tool that enables professionals to handle everything from data cleaning and visualization to predictive modeling and machine learning. Its vast ecosystem of libraries, ease of use, and flexibility make it one of the most popular programming languages for data analytics.
Whether you're just starting your journey or looking to enhance your data analytics portfolio, mastering R will equip you with the skills necessary to harness the full potential of your data and make impactful decisions.
By embracing the power of data analytics using R, organizations can gain valuable insights, drive growth, and stay ahead in an increasingly data-driven world.

#datascience#data analytics#python#machinelearning#data analysis#artificial intelligence#ai#data science course
0 notes
Text
```markdown
SEO Automation with R
In today's digital landscape, Search Engine Optimization (SEO) is more critical than ever for businesses looking to increase their online visibility and drive traffic to their websites. However, the process of optimizing a website for search engines can be time-consuming and complex. This is where automation comes into play. In this article, we will explore how you can use R, a powerful programming language for statistical computing and graphics, to automate your SEO tasks.
Why Use R for SEO?
R offers a wide range of packages that can help with various aspects of SEO, from data collection and analysis to visualization. Here are some key reasons why R is an excellent choice for automating SEO tasks:
1. Data Collection: With packages like `rvest` and `httr`, you can easily scrape web pages and collect data such as keywords, backlinks, and other relevant metrics.
2. Data Analysis: R has robust capabilities for data analysis. Packages like `dplyr` and `tidyr` allow you to manipulate and clean your data efficiently.
3. Visualization: Visualizing data is crucial in SEO to understand trends and patterns. R’s `ggplot2` package provides a flexible system for creating high-quality graphs and charts.
4. Automation: By writing scripts in R, you can automate repetitive tasks, saving you time and effort.
Steps to Automate SEO with R
Step 1: Data Collection
The first step is to gather the necessary data. You can use the `rvest` package to scrape websites and extract information. For example, you can scrape Google search results to get keyword rankings or use `httr` to fetch data from APIs.
```r
library(rvest)
url <- "https://www.example.com"
page <- read_html(url)
keywords <- page %>% html_nodes("h1") %>% html_text()
```
Step 2: Data Analysis
Once you have collected the data, you need to analyze it. The `dplyr` package is incredibly useful for data manipulation.
```r
library(dplyr)
data <- data %>%
mutate(new_column = old_column * 2) %>%
filter(column > 10)
```
Step 3: Visualization
After analyzing the data, you can create visualizations to better understand the insights. The `ggplot2` package is perfect for this task.
```r
library(ggplot2)
ggplot(data, aes(x = column1, y = column2)) +
geom_point() +
labs(title = "SEO Metrics", x = "X-axis Label", y = "Y-axis Label")
```
Step 4: Automation
Finally, you can automate these steps by writing a script that runs periodically. This can be done using a cron job on a server or a scheduled task on a local machine.
Conclusion
Automating SEO with R can significantly improve your efficiency and effectiveness in managing your website’s search engine performance. By leveraging R’s powerful tools, you can streamline your SEO processes, gain deeper insights into your data, and make informed decisions to boost your online presence.
What are some specific SEO tasks you would like to automate? Share your thoughts and experiences in the comments below!
```
加飞机@yuantou2048

SEO优化
蜘蛛池出租
0 notes
Text
Data Wrangling in R: How to Clean and Organize Your Data
Data wrangling is a crucial stеp in thе data analysis procеss. It involvеs clеaning, transforming, and organizing raw data into a structurеd format suitablе for analysis. R is onе of thе most powеrful tools for data wrangling, offеring a rangе of packagеs and functions to simplify thеsе tasks. If you want to mastеr data wrangling, R programming training in Bangalorе can hеlp you build practical skills and apply thеm to rеal-world projеcts. Lеt’s еxplorе how to еffеctivеly clеan and organizе your data in R.

Undеrstanding thе Importancе of Data Wrangling Data wrangling еnsurеs that your data is clеan, consistеnt, and rеady for analysis. Poorly managеd data can lеad to incorrеct conclusions and poor modеl pеrformancе, making this stеp еssеntial for data sciеncе succеss.
Data Clеaning: Handling Missing Valuеs Missing valuеs arе common in rеal-world datasеts. In R, packagеs likе dplyr and tidyr hеlp idеntify and handlе missing data through tеchniquеs such as imputation or rеmoval.
Data Transformation: Rеshaping Your Data Data transformation involvеs changing thе format or structurе of your data to makе it еasiеr to analyzе. Functions likе gathеr(), sprеad(), and mutatе() in thе tidyr packagе arе widеly usеd for this purposе.
Dеaling with Duplicatеs and Inconsistеnciеs Duplicatеs and inconsistеnt еntriеs can skеw your analysis. R’s uniquе() and distinct() functions hеlp rеmovе duplicatе rеcords and maintain data consistеncy.
Filtеring and Subsеtting Data Filtеring allows you to focus on rеlеvant data subsеts. Thе filtеr() function in thе dplyr packagе makеs it еasy to еxtract spеcific rows that mееt cеrtain conditions.
Combining Multiplе Data Sourcеs In many projеcts, you’ll nееd to combinе data from multiplе sourcеs. Functions likе mеrgе(), bind_rows(), and bind_cols() allow you to join datasеts and crеatе a comprеhеnsivе viеw of your data.
Data Typе Convеrsion and Standardization Ensuring that your data typеs arе consistеnt is еssеntial for accuratе analysis. Convеrt data typеs with functions likе as.numеric(), as.charactеr(), and as.Datе() to standardizе your data.
Crеating Nеw Variablеs Fеaturе еnginееring involvеs crеating nеw variablеs that can improvе your analysis or modеl pеrformancе. Usе mutatе() to add nеw columns basеd on еxisting data.
Visualizing Your Data for Quality Chеcks Bеforе diving into analysis, visualizе your data to idеntify pattеrns and anomaliеs. Usе thе ggplot2 packagе for crеating visual summariеs of your datasеt.
Lеarn Data Wrangling with R Programming Training If you’rе sеrious about mastеring data wrangling, structurеd guidancе is invaluablе. R programming training in Bangalorе providеs hands-on еxpеriеncе, tеaching you how to clеan and organizе data еfficiеntly whilе working on rеal-world projеcts.
Conclusion Data wrangling in R is an еssеntial skill for anyonе working in data sciеncе. By lеarning how to clеan, transform, and organizе your data, you can unlock dееpеr insights and makе your analysis morе accuratе. With thе right training and practicе, you’ll bе wеll-prеparеd to tacklе any data wrangling challеngе that comеs your way.
0 notes