#free webscraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
Finished my last midterm for my degree today... feeling dread. Can't get an entry level data scientist position 💔 became a math and statistics machine in the last 4 years but my downfall was only receiving basic training on SQL
#now I have to set aside free time to learn more coding languages#and business data analytics software :(#but hey maybe I can do some cool statistical experiments solo to build my portfolio#get ready for a disco elysium ao3 analysis#gonna webscrape ao3 and analyze for trends in what fics get the most engagement 🫣
0 notes
Text
year in review - hockey rpf on ao3

hello!! the annual ao3 year in review had some friends and i thinking - wouldn't it be cool if we had a hockey rpf specific version of that. so i went ahead and collated the data below!!
i start with a broad overview, then dive deeper into the 3 most popular ships this year (with one bonus!)
if any images appear blurry, click on them to expand and they should become clear!
₊˚⊹♡ . ݁₊ ⊹ . ݁˖ . ݁𐙚 ‧₊˚ ⋅. ݁
before we jump in, some key things to highlight: - CREDIT TO: the webscraping part of my code heavily utilized the ao3 wrapped google colab code, as lovingly created by @kyucultures on twitter, as the main skeleton. i tweaked a couple of things but having it as a reference saved me a LOT of time and effort as a first time web scraper!!! thank you stranger <3 - please do NOT, under ANY circumstances, share any part of this collation on any other website. please do not screenshot or repost to twitter, tiktok, or any other public social platform. thank u!!! T_T - but do feel free to send requests to my inbox! if you want more info on a specific ship, tag, or you have a cool idea or wanna see a correlation between two variables, reach out and i should be able to take a look. if you want to take a deeper dive into a specific trope not mentioned here/chapter count/word counts/fic tags/ship tags/ratings/etc, shoot me an ask!
˚ . ˚ . . ✦ ˚ . ★⋆. ࿐࿔
with that all said and done... let's dive into hockey_rpf_2024_wrapped_insanity.ipynb
BIG PICTURE OVERVIEW
i scraped a total of 4266 fanfics that dated themselves as published or finished in the year 2024. of these 4000 odd fanfics, the most popular ships were:

Note: "Minor or Background Relationship(s)" clocked in at #9 with 91 fics, but I removed it as it was always a secondary tag and added no information to the chart. I did not discern between primary ship and secondary ship(s) either!
breaking down the 5 most popular ships over the course of the year, we see:

super interesting to see that HUGE jump for mattdrai in june/july for the stanley cup final. the general lull in the offseason is cool to see as well.
as for the most popular tags in all 2024 hockey rpf fic...

weee like our fluff. and our established relationships. and a little H/C never hurt no one.
i got curious here about which AUs were the most popular, so i filtered down for that. note that i only regex'd for tags that specifically start with "Alternate Universe - ", so A/B/O and some other stuff won't appear here!

idk it was cool to me.
also, here's a quick breakdown of the ratings % for works this year:

and as for the word counts, i pulled up a box plot of the top 20 most popular ships to see how the fic length distribution differed amongst ships:

mattdrai-ers you have some DEDICATION omg. respect
now for the ship by ship break down!!
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#1 MATTDRAI
most popular ship this year. peaked in june/july with the scf. so what do u people like to write about?

fun fun fun. i love that the scf is tagged there like yes actually she is also a main character
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#2 SIDGENO
(my babies) top tags for this ship are:

folks, we are a/b/o fiends and we cannot lie. thank you to all the selfless authors for feeding us good a/b/o fic this year. i hope to join your ranks soon.
(also: MPREG. omega sidney crosby. alpha geno. listen, the people have spoken, and like, i am listening.)
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#3 NICOJACK
top tags!!

it seems nice and cozy over there... room for one more?
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS: JDTZ.
i wasnt gonna plot this but @marcandreyuri asked me if i could take a look and the results are so compelling i must include it. are yall ok. do u need a hug

top tags being h/c, angst, angst, TRADES, pining, open endings... T_T katie said its a "torture vortex" and i must concurr
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS BONUS: ALPHA/BETA/OMEGA
as an a/b/o enthusiast myself i got curious as to what the most popular ships were within that tag. if you want me to take a look about this for any other tag lmk, but for a/b/o, as expected, SID GENO ON TOP BABY!:

thats all for now!!! if you have anything else you are interested in seeing the data for, send me an ask and i'll see if i can get it to ya!
#fanfic#sidgeno#evgeni malkin#hockey rpf#sidney crosby/evgeni malkin#hockeyrpf#hrpf fic#sidgeno fic#sidney crosby#hockeyrpf wrapped 2024#leon draisaitl#matthew tkachuk#mattdrai#leon draisaitl/matthew tkachuk#nicojack#nico hischier#nico hischier/jack hughes#jack hughes#jamie drysdale#trevor zegras#jdtz#jamie drysdale/trevor zegras#pittsburgh penguins#edmonton oilers#florida panthers#new jersey devils
481 notes
·
View notes
Text
pleaseee help me if youre familiar w python and webscraping.
im trying to webscrape this site w infinite scrolling (think like. twitter.) but parsehub only goes up to 200 pages in the free version. is there any possible way to start scraping the next 200 pages?
literally dont even know how to search this up bc i dont do this ever 😭😭😭😭😭😭😭
6 notes
·
View notes
Text
It's worse.
The glasses Meta built come with language translation features -- meaning it becomes harder for bilingual families to speak privately without being overheard.
No it's even worse.
Because someone has developed an app (I-XRAY) that scans and detects who people are in real-time.
No even worse.
Because I-XRAY accesses all kinds of public data about that person.
Wait is it so bad?
I-XRAY is not publicly usable and was only built to show what a privacy nightmare Meta is creating. Here's a 2-minute video of the creators doing a experiment how quickly people on the street's trust can be exploited. It's chilling because the interactions are kind and heartwarming but obviously the people are being tricked in the most uncomfortable way.
Yes it is so bad:
Because as satirical IT News channel Fireship demonstrated, if you combine a few easily available technologies, you can reproduce I-XRAYs results easily.
Hook up an open source vision model (for face detection). This model gives us the coordinates to a human face. Then tools like PimEyes or FaceCheck.ID -- uh, both of those are free as well... put a name to that face. Then phone book websites like fastpeoplesearch.com or Instant Checkmate let us look up lots of details about those names (date of birth, phone #, address, traffic and criminal records, social media accounts, known aliases, photos & videos, email addresses, friends and relatives, location history, assets & financial info). Now you can use webscrapers (the little programs Google uses to index the entire internet and feed it to you) or APIs (programs that let us interface with, for example, open data sets by the government) -> these scraping methods will, for many targeted people, provide the perpetrators with a bulk of information. And if that sounds impractical, well, the perpetrators can use a open source, free-to-use large language model like LLaMa (also developed by Meta, oh the irony) to get a summary (or get ChatGPT style answers) of all that data.
Fireship points out that people can opt out of most of these data brokers by contacting them ("the right to be forgotten" has been successfully enforced by European courts and applies globally to people that make use of our data). Apparently the New York Times has compiled an extensive list of such sites and services.
But this is definitely dystopian. And individual opt-outs exploit that many people don't even know that this is a thing and that place the entire responsibility on the individual. And to be honest, I don't trust the New York Times and almost feel I'm drawing attention to myself if I opt out. It really leaves me personally uncertain what is the smarter move. I hope this tech is like Google's smartglasses and becomes extinct.
i hate the "meta glasses" with their invisible cameras i hate when people record strangers just-living-their-lives i hate the culture of "it's not illegal so it's fine". people deserve to walk around the city without some nameless freak recording their faces and putting them up on the internet. like dude you don't show your own face how's that for irony huh.
i hate those "testing strangers to see if they're friendly and kind! kindness wins! kindness pays!" clickbait recordings where overwhelmingly it is young, attractive people (largely women) who are being scouted for views and free advertising . they're making you model for them and they reap the benefits. they profit now off of testing you while you fucking exist. i do not want to be fucking tested. i hate the commodification of "kindness" like dude just give random people the money, not because they fucking smiled for it. none of the people recording has any idea about the origin of the term "emotional labor" and none of us could get them to even think about it. i did not apply for this job! and you know what! i actually super am a nice person! i still don't want to be fucking recorded!
& it's so normalized that the comments are always so fucking ignorant like wow the brunette is so evil so mean so twisted just because she didn't smile at a random guy in an intersection. god forbid any person is in hiding due to an abusive situation. no, we need to see if they'll say good morning to a stranger approaching them. i am trying to walk towards my job i am not "unkind" just because i didn't notice your fucked up "social experiment". you fucking weirdo. stop doing this.
19K notes
·
View notes
Text
🛒 Want to Dominate the eCommerce Market? Start with Price Tracking.
In the fast-moving world of eCommerce, pricing is everything.
It doesn’t matter how great your product is, if your competitor silently drops their price, you lose. That’s why ecommerce price tracking is no longer a nice-to-have. It’s the backbone of real-time market strategy.
What is it? It’s the process of monitoring your competitors’ product prices across marketplaces like Amazon, Walmart, and Flipkart to make smarter decisions, faster.
But great price tracking isn’t just about scraping numbers. ✅ You need the right tools ✅ Clean, structured data ✅ Legal awareness ✅ Smart automation ✅ Real-time alerts
🔧 That’s where 42Signals comes in.
Our platform gives you real-time competitor price tracking, Telegram alerts, pricing dashboards, and even MAP violation monitoring, so your brand can stay ahead without burning margins.
Just a few of the use cases: 💼 Adjust your pricing dynamically 📉 Detect competitor discounts 📦 Optimize stock and promotions 📊 Visualize trends over time 🚀 Build a stronger pricing strategy
Bonus: It’s totally legal and compliant. And it works.
A solar gadget brand using 42Signals saw a 40% increase in conversions and 18% growth in AOV, just by tracking competitors and reworking value offers instead of slashing prices.
✨ Bottom line? You don’t need to win every price war, you just need to know which ones to fight.
👉 Try 42Signals now – Free Trial
#ecommerce #pricetracking #retailanalytics #competitorintelligence #digitalcommerce #amazon #pricingstrategy #42signals #marketintelligence #webscraping #retailtech #datadriven
#ecommerce#price#pricetracking#retail#retailanalytics#competitor#competitorintelligence#digital#digitalcommerce#amazon#pricing#pricingstrategy#42signals#market#marketnitelligence#web#webscraping#reati#reatiltech#data#datadriven
0 notes
Text
What Is Web Scraping and Why Does It Matter?
Ever spent hours copying and pasting data for market research or competitor analysis? Enter web scraping—your shortcut to extracting online info automatically. Imagine tracking product prices, building prospect lists, or monitoring competitor updates, all without the repetitive manual work.
Here’s the rundown:
Effortless Automation: Pull “hidden” data straight from source code—no coding background required!
Save Time & Energy: Let Headless Browser + ChatGPT handle the routine tasks (you can chill while it scrapes).
Organized Results: Transform messy pages into clean spreadsheets or JSON files for easy analysis.
Stay Ethical & Secure: Use best practices and site rules—no overloading servers or breaking TOS.
Who’s this for?
Entrepreneurs needing up-to-date market info
Marketers and analysts staying ahead of the competition
Anyone who values turning chaos into usable data
Ready to dive in? Web scraping is the power move to convert the vast internet into the neat dataset you’ve always wanted.
#WebScraping #Automation #DataAnalysis #TechTips #ProductivityHacks
0 notes
Text
Unlocking the Power of Data: A Comprehensive Guide to Web Scraping
🌐 What is Web Scraping? Web scraping is the automated process of extracting data from websites, allowing businesses and individuals to gather valuable insights quickly and efficiently. Whether you're conducting market research, optimizing SEO, or analyzing real estate trends, web scraping can transform how you access and utilize data.
🔧 Tools of the Trade From user-friendly options like Octoparse and ParseHub to powerful frameworks like Scrapy and Beautiful Soup, there’s a tool for everyone—regardless of your technical skill level. Discover which tools best suit your needs!
⚖️ Ethical Considerations As you dive into web scraping, remember to respect website guidelines and data privacy laws. Ethical scraping practices ensure that you can gather information responsibly without overloading servers or infringing on privacy.
💡 Best Practices Maximize your scraping efficiency by implementing strategies like throttling requests, using proxies, and handling dynamic content effectively. Planning your approach can save you time and headaches!
🚀 Future Trends Stay ahead of the curve with AI integration in scraping tools and the rise of no-code solutions that make data extraction accessible to everyone.
For expert software development services tailored to your needs, check out Hexadecimal Software. And if you're looking for a seamless real estate experience, explore HexaHome for commission-free property management!
👉 Read the full blog for an in-depth look at web scraping: [Your Blog Link Here]
WebScraping #DataExtraction #TechTrends #SoftwareDevelopment #HexadecimalSoftware #HexaHome #MarketResearch #SEO #DataDriven
Feel free to customize any part of this post or add images to make it more visually appealing on Tumblr!
0 notes
Text
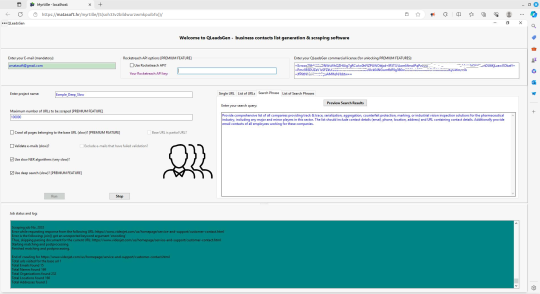
QLeadsGen is a cutting-edge software designed to streamline your B2B marketing and sales efforts through advanced artificial intelligence and natural language processing. It efficiently gathers crucial business data from the web, including:
- Email addresses
- Phone numbers
- Company URLs
- Contact names
- Organization details
- Locations and addresses
Here are some of its standout features:
- AI-driven search engine for pinpoint company targeting.
- Advanced Named Entity Recognition for precise contact extraction.
- Integration with RocketReach API for access to high-quality employee data.
- Intelligent email matching to consolidate contact information.
- A free version available to explore core functionalities.
With QLeadsGen, you can:
- Target leads in specific industries or create highly-focused contact lists.
- Provide search criteria or a list of websites for AI to scrape data.
Whether you're looking to enhance your lead generation process or to expand your sales outreach, QLeadsGen uses AI to make the process seamless. Try the free version to witness the impact of AI-powered contact scraping on your business.
#LeadGeneration #AIMarketing #B2BLeads #ContactScraping #SalesIntelligence #DigitalMarketing #EmailMarketing #WebScraping #DataMining #Leads #BusinessLeads #DigitalMarketing
Learn more: https://matasoft.hr/QTrendControl/index.php/qleadsgen-business-contacts-web-scraping-software
0 notes
Text
Some Important Tips for Successful Web Scraping Services: Do’s and Don'ts

For more information about Web Scraping data entry services please visit us at: https://latestbpoblog.blogspot.com/2023/10/some-important-tips-for-successful-web-scraping-services-dos-and-donts.html
Web scraping is the simplest and most efficient technique to collect the needed data. You can collect, extract, clean, filter, and standardize data using web data scraping services, which will then deliver it to you in the format of your choice with accurate, error-free results. By visiting the above blog, you can get some important tips for successful Web Scraping Services.
#WebScrapingServices #WebScraping #WebScrapingCompanies #OutsourceWebScraping #OutsourceWebScrapingServices
#WebScrapingServices#WebScraping#WebScrapingCompanies#OutsourceWebScraping#OutsourceWebScrapingServices
0 notes
Text
0 notes
Text
yes i am a very serious computer person

#im redoing the thing because my perfectionist ass was unhappy with the earlier version#and the presentation is tomorrow#just need to work on the webscraping and the ui and.....i'll be a free elf#sakshi rambles
1 note
·
View note
Link

#web scraping tools#webscraping#web scraping services#proxy#free proxy#ip proxy#proxy server#proxy provider#antiblock#antiscratch#big data#datacollection#dataanalysis#octoparse#crawling#web crawling#webcrawler#web scraper#scraper
0 notes
Text
Webscraper free

#WEBSCRAPER FREE SOFTWARE#
#WEBSCRAPER FREE FREE#
You can get data in raw HTML from any website online by sending just one API request via this tool. With Smartproxy, you get the benefit of 40 million+ proxies and a powerful web scraper in a single tool. There is a 100 GB Enterprise plan also available, which starts at $700/month. Its Micro Plan will cost you $80/month for 8 GB, The starter 25 GB plan will cost you $225/month and the regular 50 GB plan will cost you $400/month. Pay as little as $12.5 for 1GB for small projects. Price: Smartproxy offers a flexible pricing plan. Let’s see the detailed review of each tool on the list. Standard: $149 per month, Professional: $499 per month, & Enterprise: Get a quote.
#WEBSCRAPER FREE SOFTWARE#
Enterprise Plan: (Get a quote)Įxecutives, Data Scientists, software developers, business analysts, pricing analysts, consultants, marketing professionals etc.įree plan for everyone. Starter Plan: Starts at $129/site for 50K records. Web Scraping service platform that’s effortless.
#WEBSCRAPER FREE FREE#
Small, medium, enterprise as well as individualsĬhrome extension: A free tool to scrape dynamic web pages.įree: Browser extension. We handle 2 billion API requests per month for over 1,000 businesses and developers around the world The following image will show you the typical uses of web scraping and their percentage.Įasy data gathering at scale with Web Scraping API Many times, it is used to know more about your competitors. Web Scraping is used for research work, sales, marketing, finance, e-commerce, etc. However, as this work needs to be performed for a high data volume, Scrapers are used. Many times government websites make data available for public use. Web Scraping is considered as bad or illegal but it not always bad. There are two different methods for performing web scraping, one is accessing www via HTTP or a web browser and the second one is making use of bot or web crawler. Then it makes a search for your required data and makes the conversion in the required format. This program sends a GET request to the website from which the data needs to be scrapped.Īs a result of this request, an HTML document which will be analyzed by this program is received. In order to scrape data from a website, software or a program is used.
0 notes
Text
Whatever. Making my own post about AO3 and ChatGPT now. Here's an abbreviated version
ChatGPT is a GPT-3 model that is also trained on "Reinforcement Learning from Human Feedback". This means that its dataset that it is based on is both the data used to train GPT-3 and people using ChatGPT and telling it if the results it gave are bad or good.
GPT-3's dataset is HUGE. like seriously huge. A large portion of it is from Common Crawl, which scrapes a lot of the web.
All the data that GPT-3 is trained on goes up until 2021. None of the data is newer than that. The only newer data that ChatGPT has is the human feedback stuff. It does not know about the world after 2021.
Common Crawl is open to everyone and free, anyone can use this data if they want. They scrape the web monthly.
AO3 used to be in the Common Crawl data, but as of December 23, 2022, their webscraper has been blocked from scraping AO3.
So what this means:
ChatGPT has no knowledge of any fic you have written after 2021
ChatGPT, even if its data gets updated, will not be able to access any fics you have posted after December 23, 2022
Common Crawl probably couldn't access any locked fics you have anyway
Someone using ChatGPT is not going to cause ChatGPT to then go and scrape your fic. All the scraping has been done
Someone using ChatGPT to write fic will help it write fic better, because it learns from human interaction
Also, while GPT-3 is much better than GPT-2, it is basically fancy autosuggest. It works by predicting the order words will go in. If it is writing something, it does not inherently "know" it is writing about a person who has, say, two arms and two legs. So it can very well generate a sentence where someone has 4 arms or more because it doesn't know anything, it just predicts. So even though it is becoming more convincing, rest assured that, at the moment, something someone generates with ChatGPT is not going to outshine your work because it won't make sense.
Here's a few links
Introducing ChatGPT
AO3's announcement that Common Crawl is blocked
Paper on GPT-3
Common Crawl's website
5 notes
·
View notes
Text
Generating Danny Phantom Quotes from AI
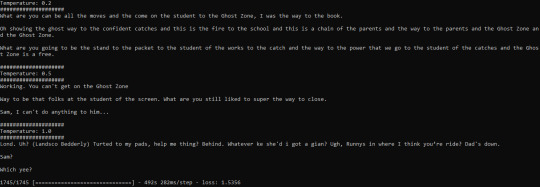
Temperature: 0.2
What are you can be all the moves and the come on the student to the Ghost Zone, I was the way to the book.
Oh showing the ghost way to the confident catches and this is the fire to the school and this is a chain of the parents and the way to the parents and the Ghost Zone and the Ghost Zone.
What are you going to be the stand to the packet to the student of the works to the catch and the way to the power that we go to the student of the catches and the Ghost Zone is a free.
Temperature: 0.5
Working. You can't get on the Ghost Zone
Way to be that folks at the student of the screen. What are you still liked to super the way to close.
Sam, I can't do anything to him...
Temperature: 1.0
Lond. Uh? (Landsco Bedderly) Turted to my pads, help me thing? Behind. Whatever ke she'd i got a gian? Ugh, Runnys in where I think you’re ride? Dad's down.
Sam?
Which yee?
I literally saw this prompt last night. And now here I am coding a program to automatically generate quotes based on Danny’s lines in the actual show. I’m dumping these quotes on @dannyphantombot cause why the heck not. See the process of setting this up below the cut.
Let me know if I should make more blogs like this for other characters!
Part 1: Getting the Datasets
I got most of the episode transcripts from here. Since I’m too lazy to teach myself webscraping, I just copied and pasted em into an Excel spreadsheet and filtered for Danny’s lines.
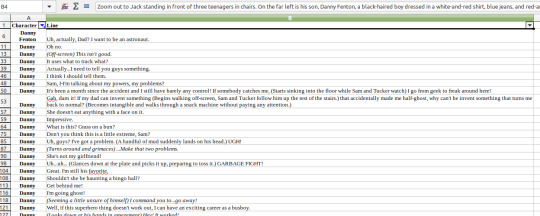
(I’m using LibreCalc here)
Then I copied and pasted the entire Line column to a text file.
Part 2: Playing with textgenrnn
This may get confusing for those who aren’t familiar with programming.
I’m using this library to generate quotes. I have PyCharm and used pip to install textgenrnn (PM me if you try this and run into any trouble, textgenrnn is VERY iffy when installing).
I ran a command to train a model on the text file. My cheap laptop then proceeded to work overtime.

After 7 minutes, I got those lovely quotes you saw above. The higher the temperature, the more random the quotes become.

>>> textgen.generate(temperature=0.1) What are you can be and I can be the beam to the confident walkie and the control there.
>>> textgen.generate(temperature=2) Ukms! *Nice)breat-uhdwbngoog!"" Maymetch,buster.ńalonaUd gotta add-us foortst? Stಠlong.) Impon,- fun?
See?
Also, going through the original prompt from @reallydumbdannyphantomaus, there’s a similar function for predicative text in this library.
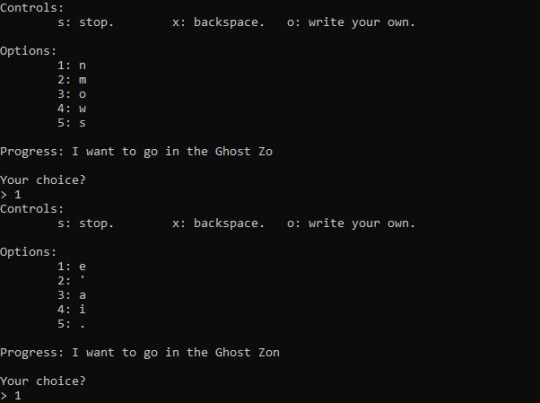
Unfortunately it goes letter by letter instead of word by word, but still (I’m currently geeking out over how it picked up Ghost Zone though :0 ).
Part 3: Writing a Python Script to Automatically Post These
I won’t go into too much detail here since you could find the code on my Github. Basically, I use the Tumblr API to queue these to @dannyphantombot.
Going forward, I’ll try to pop this on my Raspberry Pi and schedule the script to run regularly.
#danny phantom#machine learning#mine#ghjssks#aaaaaaa i spent the whole day on this#yo go check out dannyphantombot!#my precious bot#bot stuff
20 notes
·
View notes
Text
Are you looking for new business contacts? QLeadsGen is business leads generation software, scraping web sites and extracting publically available, published business information, such as e-mails, phones, URLs, names, organizations, locations and addresses, according to provided Google search criteria or by specifing list of web-sites to be scraped.
Once business data is extracted, QLeadsGen software is able to match e-mails with corresponding entities, providing you final consolidated list of e-mails contacts with additional information on corresponding names, organizations, locations, web-sites and phones.
Free version is available, limited to scraping max. 100 web sites in a session.
#LeadGeneration #LeadsGeneration #lead-generation #leads-generation #WebScraping #web-scraping #WebScrapper #web-scraper #DataMining #data-mining #business-contacts #BusinessContacts #ContactsList #contacts-list #B2B digitalmarketing, #DigitalMarketing #digital-marketing #marketing #email #e-mail #google
https://matasoft.hr/QTrendControl/index.php/qleadsgen-business-contacts-web-scraping-software/get-qleadsgen-software
0 notes