#microservices observability
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Struggling with Microservices Monitoring?
Struggling with Microservices Monitoring?
Microservices architectures bring agility but also complexity. From Microservices application Monitoring to tackling real-time challenges in Microservices Monitoring, the right APM tool makes all the difference.
🔍 Discover how Application Performance Monitoring (APM) boosts microservices observability, performance, and reliability.
✅ Ensure seamless APM for Microservices ✅ Resolve bottlenecks faster ✅ Achieve end-to-end visibility
📖 Read now: https://www.atatus.com/blog/importance-of-apm-in-microservices
#APM#MicroservicesMonitoring#Observability#DevOps#APMTool#Application Performance monitoring#apm tool#apm for microservices#microservices observability#Microservices architectures#Microservices application Monitoring#Challenges in Microservices Monitoring
0 notes
Text
🚀 Istio Service Mesh Essentials: What You Need to Know
In today’s cloud-native world, managing microservices at scale requires more than just containers and Kubernetes. That’s where Istio, a powerful open-source service mesh, steps in — offering observability, security, and traffic control for your applications without changing your code.
🔍 What Is Istio?
Istio is a service mesh that provides a uniform way to secure, connect, and observe microservices. It works by injecting lightweight proxies (Envoy) alongside services (a pattern known as the sidecar pattern), allowing developers to offload network-level concerns like:
Service discovery
Load balancing
Traffic routing
Metrics collection
Security policies
⚙️ Key Components of Istio
Envoy Proxy A high-performance proxy that intercepts all incoming and outgoing traffic for the service it’s attached to.
Pilot Manages service discovery and traffic management.
Citadel Handles strong identity and certificate management for mutual TLS.
Mixer (Deprecated in recent versions) Was used for policy enforcement and telemetry collection. Now replaced by extensions and telemetry APIs.
Istiod A simplified control plane that consolidates the roles of Pilot, Citadel, and others in recent Istio releases.
🔐 Why Use Istio?
✅ Security: Enforce mutual TLS, fine-grained access policies, and encrypt service-to-service communication.
✅ Traffic Management: Split traffic between service versions for canary deployments, A/B testing, or blue-green releases.
✅ Observability: Automatically generate metrics, logs, and distributed traces for all services using tools like Prometheus, Grafana, and Jaeger.
✅ Resilience: Implement retries, timeouts, and circuit breakers without touching application code.
🌐 Istio in the Real World
Imagine a microservices app running on Kubernetes. Instead of each service implementing its own security and logging, Istio takes care of these concerns at the infrastructure layer, freeing developers to focus on core functionality.
Getting Started
You can install Istio on Kubernetes using the istioctl CLI or Helm charts. Once installed:
Label your namespace for Istio injection
Deploy services
Use VirtualServices and DestinationRules to control traffic
Monitor traffic using Prometheus and Kiali dashboards
🔚 Conclusion
Istio is an essential tool for organizations operating microservices in production. It reduces complexity, enhances security, and brings deep insights into service behavior — all without requiring code changes.
Whether you’re just getting started or scaling a mature environment, Istio Service Mesh brings enterprise-grade networking and observability to your cloud-native stack.
#Istio#ServiceMesh#IstioServiceMesh#CloudNative#Microservices#Kubernetes#DevOps#CloudSecurity#KubernetesNetworking#EnvoyProxy#ZeroTrust#ServiceDiscovery#TrafficManagement#Observability#DevSecOps#IstioMesh#K8sTools#OpenSourceTools#IstioTutorial#PlatformEngineering#CloudArchitecture#ApplicationSecurity#SiteReliabilityEngineering
0 notes
Text
How to Handle Failure Gracefully in Cloud Native Applications

Building modern software requires more than just writing clean code or deploying fast features. It also demands resilience—the ability to continue functioning under stress, errors, or system breakdowns. That’s why cloud native application development has become the gold standard for creating fault-tolerant, scalable systems. Cloud-native approaches empower teams to build distributed applications that can recover quickly and handle unexpected failures gracefully.
Failure is inevitable in large-scale cloud systems. Services crash, networks drop, and dependencies fail. But how your application responds to failure determines whether users experience a hiccup or a total breakdown.
Understand the Nature of Failures in Cloud Native Systems
Before you can handle failures gracefully, it’s essential to understand what kinds of failures occur in cloud-native environments:
Service crashes or downtime
Latency and timeouts in microservices communication
Database unavailability
Network outages
Resource exhaustion (memory, CPU, etc.)
Third-party API failures
Because cloud-native systems are distributed, they naturally introduce new failure points. Your goal is not to eliminate failure completely—but to detect it quickly and minimize its impact.
Design for Failure from the Start
One of the core principles of cloud native design is to assume failure. When teams bake resilience into the architecture from day one, they make systems more robust and maintainable.
Here are a few proactive design strategies:
Decouple services: Break down monolithic applications into loosely coupled microservices so that the failure of one service doesn’t crash the entire application.
Use retries with backoff: When a service is temporarily unavailable, automatic retries with exponential backoff can give it time to recover.
Implement circuit breakers: Circuit breakers prevent cascading failures by temporarily stopping requests to a failing service and allowing it time to recover.
Graceful degradation: Prioritize core features and allow non-critical components (e.g., recommendations, animations) to fail silently or provide fallback behavior.
Monitor Continuously and Detect Early
You can't fix what you can’t see. That’s why observability is crucial in cloud native environments.
Logging: Capture structured logs across services to trace issues and gather context.
Metrics: Monitor CPU usage, memory, request latency, and error rates using tools like Prometheus and Grafana.
Tracing: Use distributed tracing tools like Jaeger or OpenTelemetry to monitor the flow of requests between services.
Alerts: Configure alerts to notify teams immediately when anomalies or failures occur.
Proactive monitoring allows teams to fix problems before users are impacted—or at least respond swiftly when they are.
Automate Recovery and Scaling
Automation is a critical pillar of cloud native systems. Use tools that can self-heal and scale your applications:
Kubernetes: Automatically reschedules failed pods, manages load balancing, and ensures desired state configuration.
Auto-scaling: Adjust resources dynamically based on demand to avoid outages caused by spikes in traffic.
Self-healing workflows: Design pipelines or jobs that restart failed components automatically without manual intervention.
By automating recovery, you reduce downtime and improve the user experience even when systems misbehave.
Test for Failure Before It Happens
You can only prepare for failure if you test how your systems behave under pressure. Techniques like chaos engineering help ensure your applications can withstand real-world problems.
Chaos Monkey: Randomly terminates services in production to test the system’s fault tolerance.
Failure injection: Simulate API failures, network delays, or server crashes during testing.
Load testing: Validate performance under stress to ensure your systems scale and fail predictably.
Regular testing ensures your teams understand how the system reacts and how to contain or recover from those situations.
Communicate During Failure
How you handle external communication during a failure is just as important as your internal mitigation strategy.
Status pages: Keep users informed with real-time updates about known issues.
Incident response protocols: Ensure teams have predefined roles and steps to follow during downtime.
Postmortems: After recovery, conduct transparent postmortems that focus on learning, not blaming.
Clear, timely communication builds trust and minimizes user frustration during outages.
Embrace Continuous Improvement
Failure is never final—it’s an opportunity to learn and improve. After every incident, analyze what went wrong, what worked well, and what could be done better.
Update monitoring and alerting rules
Improve documentation and runbooks
Refine retry or fallback logic
Train teams through simulations and incident drills
By continuously refining your practices, you build a culture that values resilience as much as innovation.
Conclusion
In cloud native application development, failure isn’t the enemy—it’s a reality that well-designed systems are built to handle. By planning for failure, monitoring intelligently, automating recovery, and learning from each incident, your applications can offer high availability and user trust—even when things go wrong.
Remember, graceful failure handling is not just a technical challenge—it’s a mindset that prioritizes resilience, transparency, and continuous improvement. That’s what separates good systems from great ones in today’s cloud-native world.
#CloudNative#DevOps#Azure#Kubernetes#Microservices#CloudComputing#SiteReliability#ResilienceEngineering#FailureHandling#Observability#CloudZone
0 notes
Text
Exploring the Azure Technology Stack: A Solution Architect’s Journey
Kavin
As a solution architect, my career revolves around solving complex problems and designing systems that are scalable, secure, and efficient. The rise of cloud computing has transformed the way we think about technology, and Microsoft Azure has been at the forefront of this evolution. With its diverse and powerful technology stack, Azure offers endless possibilities for businesses and developers alike. My journey with Azure began with Microsoft Azure training online, which not only deepened my understanding of cloud concepts but also helped me unlock the potential of Azure’s ecosystem.
In this blog, I will share my experience working with a specific Azure technology stack that has proven to be transformative in various projects. This stack primarily focuses on serverless computing, container orchestration, DevOps integration, and globally distributed data management. Let’s dive into how these components come together to create robust solutions for modern business challenges.

Understanding the Azure Ecosystem
Azure’s ecosystem is vast, encompassing services that cater to infrastructure, application development, analytics, machine learning, and more. For this blog, I will focus on a specific stack that includes:
Azure Functions for serverless computing.
Azure Kubernetes Service (AKS) for container orchestration.
Azure DevOps for streamlined development and deployment.
Azure Cosmos DB for globally distributed, scalable data storage.
Each of these services has unique strengths, and when used together, they form a powerful foundation for building modern, cloud-native applications.
1. Azure Functions: Embracing Serverless Architecture
Serverless computing has redefined how we build and deploy applications. With Azure Functions, developers can focus on writing code without worrying about managing infrastructure. Azure Functions supports multiple programming languages and offers seamless integration with other Azure services.
Real-World Application
In one of my projects, we needed to process real-time data from IoT devices deployed across multiple locations. Azure Functions was the perfect choice for this task. By integrating Azure Functions with Azure Event Hubs, we were able to create an event-driven architecture that processed millions of events daily. The serverless nature of Azure Functions allowed us to scale dynamically based on workload, ensuring cost-efficiency and high performance.
Key Benefits:
Auto-scaling: Automatically adjusts to handle workload variations.
Cost-effective: Pay only for the resources consumed during function execution.
Integration-ready: Easily connects with services like Logic Apps, Event Grid, and API Management.
2. Azure Kubernetes Service (AKS): The Power of Containers
Containers have become the backbone of modern application development, and Azure Kubernetes Service (AKS) simplifies container orchestration. AKS provides a managed Kubernetes environment, making it easier to deploy, manage, and scale containerized applications.
Real-World Application
In a project for a healthcare client, we built a microservices architecture using AKS. Each service—such as patient records, appointment scheduling, and billing—was containerized and deployed on AKS. This approach provided several advantages:
Isolation: Each service operated independently, improving fault tolerance.
Scalability: AKS scaled specific services based on demand, optimizing resource usage.
Observability: Using Azure Monitor, we gained deep insights into application performance and quickly resolved issues.
The integration of AKS with Azure DevOps further streamlined our CI/CD pipelines, enabling rapid deployment and updates without downtime.
Key Benefits:
Managed Kubernetes: Reduces operational overhead with automated updates and patching.
Multi-region support: Enables global application deployments.
Built-in security: Integrates with Azure Active Directory and offers role-based access control (RBAC).
3. Azure DevOps: Streamlining Development Workflows
Azure DevOps is an all-in-one platform for managing development workflows, from planning to deployment. It includes tools like Azure Repos, Azure Pipelines, and Azure Artifacts, which support collaboration and automation.
Real-World Application
For an e-commerce client, we used Azure DevOps to establish an efficient CI/CD pipeline. The project involved multiple teams working on front-end, back-end, and database components. Azure DevOps provided:
Version control: Using Azure Repos for centralized code management.
Automated pipelines: Azure Pipelines for building, testing, and deploying code.
Artifact management: Storing dependencies in Azure Artifacts for seamless integration.
The result? Deployment cycles that previously took weeks were reduced to just a few hours, enabling faster time-to-market and improved customer satisfaction.
Key Benefits:
End-to-end integration: Unifies tools for seamless development and deployment.
Scalability: Supports projects of all sizes, from startups to enterprises.
Collaboration: Facilitates team communication with built-in dashboards and tracking.

4. Azure Cosmos DB: Global Data at Scale
Azure Cosmos DB is a globally distributed, multi-model database service designed for mission-critical applications. It guarantees low latency, high availability, and scalability, making it ideal for applications requiring real-time data access across multiple regions.
Real-World Application
In a project for a financial services company, we used Azure Cosmos DB to manage transaction data across multiple continents. The database’s multi-region replication ensure data consistency and availability, even during regional outages. Additionally, Cosmos DB’s support for multiple APIs (SQL, MongoDB, Cassandra, etc.) allowed us to integrate seamlessly with existing systems.
Key Benefits:
Global distribution: Data is replicated across regions with minimal latency.
Flexibility: Supports various data models, including key-value, document, and graph.
SLAs: Offers industry-leading SLAs for availability, throughput, and latency.
Building a Cohesive Solution
Combining these Azure services creates a technology stack that is flexible, scalable, and efficient. Here’s how they work together in a hypothetical solution:
Data Ingestion: IoT devices send data to Azure Event Hubs.
Processing: Azure Functions processes the data in real-time.
Storage: Processed data is stored in Azure Cosmos DB for global access.
Application Logic: Containerized microservices run on AKS, providing APIs for accessing and manipulating data.
Deployment: Azure DevOps manages the CI/CD pipeline, ensuring seamless updates to the application.
This architecture demonstrates how Azure’s technology stack can address modern business challenges while maintaining high performance and reliability.
Final Thoughts
My journey with Azure has been both rewarding and transformative. The training I received at ACTE Institute provided me with a strong foundation to explore Azure’s capabilities and apply them effectively in real-world scenarios. For those new to cloud computing, I recommend starting with a solid training program that offers hands-on experience and practical insights.
As the demand for cloud professionals continues to grow, specializing in Azure’s technology stack can open doors to exciting opportunities. If you’re based in Hyderabad or prefer online learning, consider enrolling in Microsoft Azure training in Hyderabad to kickstart your journey.
Azure’s ecosystem is continuously evolving, offering new tools and features to address emerging challenges. By staying committed to learning and experimenting, we can harness the full potential of this powerful platform and drive innovation in every project we undertake.
#cybersecurity#database#marketingstrategy#digitalmarketing#adtech#artificialintelligence#machinelearning#ai
2 notes
·
View notes
Text
Open Platform For Enterprise AI Avatar Chatbot Creation

How may an AI avatar chatbot be created using the Open Platform For Enterprise AI framework?
I. Flow Diagram
The graph displays the application’s overall flow. The Open Platform For Enterprise AI GenAIExamples repository’s “Avatar Chatbot” serves as the code sample. The “AvatarChatbot” megaservice, the application’s central component, is highlighted in the flowchart diagram. Four distinct microservices Automatic Speech Recognition (ASR), Large Language Model (LLM), Text-to-Speech (TTS), and Animation are coordinated by the megaservice and linked into a Directed Acyclic Graph (DAG).
Every microservice manages a specific avatar chatbot function. For instance:
Software for voice recognition that translates spoken words into text is called Automatic Speech Recognition (ASR).
By comprehending the user’s query, the Large Language Model (LLM) analyzes the transcribed text from ASR and produces the relevant text response.
The text response produced by the LLM is converted into audible speech by a text-to-speech (TTS) service.
The animation service makes sure that the lip movements of the avatar figure correspond with the synchronized speech by combining the audio response from TTS with the user-defined AI avatar picture or video. After then, a video of the avatar conversing with the user is produced.
An audio question and a visual input of an image or video are among the user inputs. A face-animated avatar video is the result. By hearing the audible response and observing the chatbot’s natural speech, users will be able to receive input from the avatar chatbot that is nearly real-time.
Create the “Animation” microservice in the GenAIComps repository
We would need to register a new microservice, such “Animation,” under comps/animation in order to add it:
Register the microservice
@register_microservice( name=”opea_service@animation”, service_type=ServiceType.ANIMATION, endpoint=”/v1/animation”, host=”0.0.0.0″, port=9066, input_datatype=Base64ByteStrDoc, output_datatype=VideoPath, ) @register_statistics(names=[“opea_service@animation”])
It specify the callback function that will be used when this microservice is run following the registration procedure. The “animate” function, which accepts a “Base64ByteStrDoc” object as input audio and creates a “VideoPath” object with the path to the generated avatar video, will be used in the “Animation” case. It send an API request to the “wav2lip” FastAPI’s endpoint from “animation.py” and retrieve the response in JSON format.
Remember to import it in comps/init.py and add the “Base64ByteStrDoc” and “VideoPath” classes in comps/cores/proto/docarray.py!
This link contains the code for the “wav2lip” server API. Incoming audio Base64Str and user-specified avatar picture or video are processed by the post function of this FastAPI, which then outputs an animated video and returns its path.
The functional block for its microservice is created with the aid of the aforementioned procedures. It must create a Dockerfile for the “wav2lip” server API and another for “Animation” to enable the user to launch the “Animation” microservice and build the required dependencies. For instance, the Dockerfile.intel_hpu begins with the PyTorch* installer Docker image for Intel Gaudi and concludes with the execution of a bash script called “entrypoint.”
Create the “AvatarChatbot” Megaservice in GenAIExamples
The megaservice class AvatarChatbotService will be defined initially in the Python file “AvatarChatbot/docker/avatarchatbot.py.” Add “asr,” “llm,” “tts,” and “animation” microservices as nodes in a Directed Acyclic Graph (DAG) using the megaservice orchestrator’s “add” function in the “add_remote_service” function. Then, use the flow_to function to join the edges.
Specify megaservice’s gateway
An interface through which users can access the Megaservice is called a gateway. The Python file GenAIComps/comps/cores/mega/gateway.py contains the definition of the AvatarChatbotGateway class. The host, port, endpoint, input and output datatypes, and megaservice orchestrator are all contained in the AvatarChatbotGateway. Additionally, it provides a handle_request function that plans to send the first microservice the initial input together with parameters and gathers the response from the last microservice.
In order for users to quickly build the AvatarChatbot backend Docker image and launch the “AvatarChatbot” examples, we must lastly create a Dockerfile. Scripts to install required GenAI dependencies and components are included in the Dockerfile.
II. Face Animation Models and Lip Synchronization
GFPGAN + Wav2Lip
A state-of-the-art lip-synchronization method that uses deep learning to precisely match audio and video is Wav2Lip. Included in Wav2Lip are:
A skilled lip-sync discriminator that has been trained and can accurately identify sync in actual videos
A modified LipGAN model to produce a frame-by-frame talking face video
An expert lip-sync discriminator is trained using the LRS2 dataset as part of the pretraining phase. To determine the likelihood that the input video-audio pair is in sync, the lip-sync expert is pre-trained.
A LipGAN-like architecture is employed during Wav2Lip training. A face decoder, a visual encoder, and a speech encoder are all included in the generator. Convolutional layer stacks make up all three. Convolutional blocks also serve as the discriminator. The modified LipGAN is taught similarly to previous GANs: the discriminator is trained to discriminate between frames produced by the generator and the ground-truth frames, and the generator is trained to minimize the adversarial loss depending on the discriminator’s score. In total, a weighted sum of the following loss components is minimized in order to train the generator:
A loss of L1 reconstruction between the ground-truth and produced frames
A breach of synchronization between the lip-sync expert’s input audio and the output video frames
Depending on the discriminator score, an adversarial loss between the generated and ground-truth frames
After inference, it provide the audio speech from the previous TTS block and the video frames with the avatar figure to the Wav2Lip model. The avatar speaks the speech in a lip-synced video that is produced by the trained Wav2Lip model.
Lip synchronization is present in the Wav2Lip-generated movie, although the resolution around the mouth region is reduced. To enhance the face quality in the produced video frames, it might optionally add a GFPGAN model after Wav2Lip. The GFPGAN model uses face restoration to predict a high-quality image from an input facial image that has unknown deterioration. A pretrained face GAN (like Style-GAN2) is used as a prior in this U-Net degradation removal module. A more vibrant and lifelike avatar representation results from prettraining the GFPGAN model to recover high-quality facial information in its output frames.
SadTalker
It provides another cutting-edge model option for facial animation in addition to Wav2Lip. The 3D motion coefficients (head, stance, and expression) of a 3D Morphable Model (3DMM) are produced from audio by SadTalker, a stylized audio-driven talking-head video creation tool. The input image is then sent through a 3D-aware face renderer using these coefficients, which are mapped to 3D key points. A lifelike talking head video is the result.
Intel made it possible to use the Wav2Lip model on Intel Gaudi Al accelerators and the SadTalker and Wav2Lip models on Intel Xeon Scalable processors.
Read more on Govindhtech.com
#AIavatar#OPE#Chatbot#microservice#LLM#GenAI#API#News#Technews#Technology#TechnologyNews#Technologytrends#govindhtech
3 notes
·
View notes
Text
Cloud-Native Development in the USA: A Comprehensive Guide
Introduction
Cloud-native development is transforming how businesses in the USA build, deploy, and scale applications. By leveraging cloud infrastructure, microservices, containers, and DevOps, organizations can enhance agility, improve scalability, and drive innovation.
As cloud computing adoption grows, cloud-native development has become a crucial strategy for enterprises looking to optimize performance and reduce infrastructure costs. In this guide, we’ll explore the fundamentals, benefits, key technologies, best practices, top service providers, industry impact, and future trends of cloud-native development in the USA.
What is Cloud-Native Development?
Cloud-native development refers to designing, building, and deploying applications optimized for cloud environments. Unlike traditional monolithic applications, cloud-native solutions utilize a microservices architecture, containerization, and continuous integration/continuous deployment (CI/CD) pipelines for faster and more efficient software delivery.
Key Benefits of Cloud-Native Development
1. Scalability
Cloud-native applications can dynamically scale based on demand, ensuring optimal performance without unnecessary resource consumption.
2. Agility & Faster Deployment
By leveraging DevOps and CI/CD pipelines, cloud-native development accelerates application releases, reducing time-to-market.
3. Cost Efficiency
Organizations only pay for the cloud resources they use, eliminating the need for expensive on-premise infrastructure.
4. Resilience & High Availability
Cloud-native applications are designed for fault tolerance, ensuring minimal downtime and automatic recovery.
5. Improved Security
Built-in cloud security features, automated compliance checks, and container isolation enhance application security.
Key Technologies in Cloud-Native Development
1. Microservices Architecture
Microservices break applications into smaller, independent services that communicate via APIs, improving maintainability and scalability.
2. Containers & Kubernetes
Technologies like Docker and Kubernetes allow for efficient container orchestration, making application deployment seamless across cloud environments.
3. Serverless Computing
Platforms like AWS Lambda, Azure Functions, and Google Cloud Functions eliminate the need for managing infrastructure by running code in response to events.
4. DevOps & CI/CD
Automated build, test, and deployment processes streamline software development, ensuring rapid and reliable releases.
5. API-First Development
APIs enable seamless integration between services, facilitating interoperability across cloud environments.
Best Practices for Cloud-Native Development
1. Adopt a DevOps Culture
Encourage collaboration between development and operations teams to ensure efficient workflows.
2. Implement Infrastructure as Code (IaC)
Tools like Terraform and AWS CloudFormation help automate infrastructure provisioning and management.
3. Use Observability & Monitoring
Employ logging, monitoring, and tracing solutions like Prometheus, Grafana, and ELK Stack to gain insights into application performance.
4. Optimize for Security
Embed security best practices in the development lifecycle, using tools like Snyk, Aqua Security, and Prisma Cloud.
5. Focus on Automation
Automate testing, deployments, and scaling to improve efficiency and reduce human error.
Top Cloud-Native Development Service Providers in the USA
1. AWS Cloud-Native Services
Amazon Web Services offers a comprehensive suite of cloud-native tools, including AWS Lambda, ECS, EKS, and API Gateway.
2. Microsoft Azure
Azure’s cloud-native services include Azure Kubernetes Service (AKS), Azure Functions, and DevOps tools.
3. Google Cloud Platform (GCP)
GCP provides Kubernetes Engine (GKE), Cloud Run, and Anthos for cloud-native development.
4. IBM Cloud & Red Hat OpenShift
IBM Cloud and OpenShift focus on hybrid cloud-native solutions for enterprises.
5. Accenture Cloud-First
Accenture helps businesses adopt cloud-native strategies with AI-driven automation.
6. ThoughtWorks
ThoughtWorks specializes in agile cloud-native transformation and DevOps consulting.
Industry Impact of Cloud-Native Development in the USA
1. Financial Services
Banks and fintech companies use cloud-native applications to enhance security, compliance, and real-time data processing.
2. Healthcare
Cloud-native solutions improve patient data accessibility, enable telemedicine, and support AI-driven diagnostics.
3. E-commerce & Retail
Retailers leverage cloud-native technologies to optimize supply chain management and enhance customer experiences.
4. Media & Entertainment
Streaming services utilize cloud-native development for scalable content delivery and personalization.
Future Trends in Cloud-Native Development
1. Multi-Cloud & Hybrid Cloud Adoption
Businesses will increasingly adopt multi-cloud and hybrid cloud strategies for flexibility and risk mitigation.
2. AI & Machine Learning Integration
AI-driven automation will enhance DevOps workflows and predictive analytics in cloud-native applications.
3. Edge Computing
Processing data closer to the source will improve performance and reduce latency for cloud-native applications.
4. Enhanced Security Measures
Zero-trust security models and AI-driven threat detection will become integral to cloud-native architectures.
Conclusion
Cloud-native development is reshaping how businesses in the USA innovate, scale, and optimize operations. By leveraging microservices, containers, DevOps, and automation, organizations can achieve agility, cost-efficiency, and resilience. As the cloud-native ecosystem continues to evolve, staying ahead of trends and adopting best practices will be essential for businesses aiming to thrive in the digital era.
1 note
·
View note
Text
This Week in Rust 545
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Newsletters
Motion Blur, Visualizations, and beautiful renders
Project/Tooling Updates
r3bl_trerminal_async v0.5.1 released
minbpe-rs v0.1.0: Port of Andrej Karpathy's minbpe to Rust
Message retention and replay with Selium
Observations/Thoughts
Leaving Rust gamedev after 3 years
Tasks are the wrong abstraction
Go or Rust? Just Listen to the Bots
Cracking the Cryptic (with Z3 and Rust)
So, you want to write an unsafe crate
Designing an efficient memory layout in Rust with unsafe & unions, or, an overlong guide in avoiding dynamic dispatch
Event driven Microservices using Kafka and Rust
Writing ergonomic async assertions in Rust
Making an HTML parsing script a hundred times faster with Rayon
Rust binaries stability
[audio] Ratatui with Orhun Parmaksiz :: Rustacean Station
The Mediocre Programmer's Guide to Rust
Rust Walkthroughs
Boosting Dev Experience with Serverless Rust in RustRover
developerlife.com - Rust Polymorphism, dyn, impl, using existing traits, trait objects for testing and extensibility
Performance optimization with flamegraph and Divan
Research
Rust Digger: There are 4,907 interesting Crate homepages
Miscellaneous
Writing A Wasm Runtime In Rust
GitHub Sponsor Rust developer Andrew Gallant (BurntSushi)
Giving Rust a chance for in-kernel codecs
Zed Decoded: Rope & SumTree
An almost infinite Fibonacci Iterator
[video] From C to Rust: Bringing Rust Abstractions to Embedded Linux
Crate of the Week
This week's crate is efs, a no-std ext2 filesystem implementation with plans to add other file systems in the future.
Another week completely devoid of suggestions, but llogiq stays hopeful he won't have to dig for next week's crate all by himself.
Please submit your suggestions and votes for next week!
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No Calls for papers or presentations were submitted this week.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
EuroRust 2024| Closes 2024-06-03 | Vienna, Austria & online | Event date: 2024-10-10
Scientific Computing in Rust 2024| Closes 2024-06-14 | online | Event date: 2024-07-17 - 2024-07-19
Conf42 Rustlang 2024 | Closes 2024-07-22 | online | Event date: 2024-08-22
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
409 pull requests were merged in the last week
abort a process when FD ownership is violated
add support for run-make-support unit tests to be run with bootstrap
ast: generalize item kind visiting
coverage: avoid hard-coded values when visiting logical ops
coverage: replace boolean options with a CoverageLevel enum
debuginfo: stabilize -Z debug-macros, -Z collapse-macro-debuginfo and #[collapse_debuginfo]
delegation: support renaming, and async, const, extern "ABI" and C-variadic functions
deny gen keyword in edition_2024_compat lints
deref patterns: lower deref patterns to MIR
detect borrow error involving sub-slices and suggest split_at_mut
disallow ambiguous attributes on expressions
do not ICE on invalid consts when walking mono-reachable blocks
don't ICE when codegen_select_candidate returns ambiguity in new solver
don't fatal when calling expect_one_of when recovering arg in parse_seq
enforce closure args + return type are WF
fix ICE on invalid const param types
fix ICE when ADT tail has type error
fix weak memory bug in TLS on Windows
improve diagnostic for unknown --print request
improve handling of expr→field errors
mark unions non-const-propagatable in KnownPanicsLint without calling layout
pretty-print parenthesis around binary in postfix match
provide more context and suggestions in borrowck errors involving closures
record certainty of evaluate_added_goals_and_make_canonical_response call in candidate
remove special-casing for SimplifiedType for next solver
rename inhibit_union_abi_opt() to inhibits_union_abi_opt()
renamed DerivedObligation to WellFormedDeriveObligation
require explicitly marking closures as coroutines
restrict promotion of const fn calls
set writable and dead_on_unwind attributes for sret arguments
strengthen tracking issue policy with consequences
suggest ref mut for pattern matching assignment
suggest using type args directly instead of equality constraint
use fulfillment in method probe, not evaluation
use probes more aggressively in new solver
weak lang items are not allowed to be #[track_caller]
miri: detect wrong vtables in wide pointers
miri: unix_sigpipe: don't inline DEFAULT, just use it from rustc
miri: add -Zmiri-env-set to set environment variables without modifying the host environment
miri env: split up Windows and Unix environment variable handling
miri: file descriptors: make write take &mut self
miri: implement LLVM x86 AVX2 intrinsics
miri: make miri-script a workspace root
miri: use the interpreted program's TZ variable in localtime_r
miri: windows: basic support for GetUserProfileDirectoryW
stabilise inline_const
stabilize Utf8Chunks
stabilize non_null_convenience
stabilize std::path::absolute
stabilize io_error_downcast
deLLVMize some intrinsics (use u32 instead of Self in some integer intrinsics)
stop using LLVM struct types for alloca
thread_local: be excruciatingly explicit in dtor code
fix offset_of! returning a temporary
relax A: Clone bound for rc::Weak::into_raw_and_alloc
PathBuf: replace transmuting by accessor functions
codegen_gcc: some fixes for aarch64
codegen_gcc: some more fixes and workarounds for Aarch64
cargo: alias: Aliases without subcommands should not panic
cargo: lints: Don't always inherit workspace lints
cargo install: Don't respect MSRV for non-local installs
cargo toml: Be more forceful with underscore/dash redundancy
cargo toml: Don't double-warn when underscore is used in workspace dep
cargo toml: Remove underscore field support in 2024
cargo toml: Warn, rather than fail publish, if a target is excluded
cargo toml: remove support for inheriting badges
cargo: note where lint was set
cargo: cleanup linting system
cargo: fix target entry in .gitignore
cargo: fix warning suppression for config.toml vs config compat symlinks
bindgen: add dynamic loading of variable
bindgen: remove which dependency
bindgen: simplify Rust to Clang target conversion
clippy: single_match(_else) may be machine applicable
clippy: non_canonical_partial_ord_impl: Fix emitting warnings which conflict with needless_return
clippy: type_complexity: Fix duplicate errors
clippy: check if closure as method arg has read access in collection_is_never_read
clippy: configurably allow useless_vec in tests
clippy: fix large_stack_arrays linting in vec macro
clippy: fix false positive in cast_possible_truncation
clippy: suppress readonly_write_lock for underscore-prefixed bindings
rust-analyzer: different error code of "no such field" error based on variant type
rust-analyzer: don't retry position relient requests and version resolve data
rust-analyzer: fix attributes on generic parameters colliding in item tree
rust-analyzer: fix doc comment desugaring for proc-macros
rust-analyzer: fix expression scopes not being calculated for inline consts
rust-analyzer: fix source roots not always being created when necessary
rust-analyzer: make cargo run always available for binaries
rust-analyzer: manual: remove suggestion of rust-project.json example
rust-analyzer: support hovering limits for adts
rustfmt: fix wrong indentation on inner attribute
Rust Compiler Performance Triage
Several non-noise changes this week, with both improvements and regresions coming as a result. Overall compiler performance is roughly neutral across the week.
Triage done by @simulacrum. Revision range: a77f76e2..c65b2dc9
2 Regressions, 2 Improvements, 3 Mixed; 1 of them in rollups 51 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
experimental project goal program for 2024 H2
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: merge] Precise capturing
[disposition: merge] Unsafe Extern Blocks
[disposition: merge] MaybeDangling
Tracking Issues & PRs
Rust
[disposition: merge] Add Option::take_if
[disposition: merge] elaborate obligations in coherence
[disposition: merge] Allow coercing functions whose signature differs in opaque types in their defining scope into a shared function pointer type
[disposition: merge] Let's #[expect] some lints: Stabilize lint_reasons (RFC 2383)
[disposition: merge] Tracking Issue for ASCII trim functions on byte slices
[disposition: merge] Add IntoIterator for Box<[T]> + edition 2024-specific lints
[disposition: merge] Add Box<[T; N]>: IntoIterator without any method dispatch hacks
[disposition: merge] rustdoc-search: search for references
[disposition: close] Extra trait bound makes function body fail to typecheck
[disposition: merge] Make casts of pointers to trait objects stricter
[disposition: merge] Tracking Issue for split_at_checked
New and Updated RFCs
[new] Precise capturing
Upcoming Events
Rusty Events between 2024-05-01 - 2024-05-29 🦀
Virtual
2024-05-01 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 5 - Project Structure
2024-05-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-05-02 | Virtual (Aarhus, DK) | Rust Aarhus Organizers
Rust Aarhus Organizers: Status
2024-05-02 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-05-02 | Virtual (London, UK) | Women in Rust
Women in Rust: Lunch & Learn! (Virtual)
2024-05-07 | Virtual (Buffalo, NY) | Buffalo Rust Meetup
Buffalo Rust User Group
2024-05-09 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-05-09 | Virtual (Israel) | Rust in Israel
Rust at Microsoft, Tel Aviv - Are we embedded yet?
2024-05-09 | Virtual (Nuremberg/Nürnberg, DE) | Rust Nuremberg
Rust Nürnberg online
2024-05-14 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-05-14 | Virtual (Halifax, NS, CA) | Rust Halifax
Rust&Tell - Halifax
2024-05-14 | Virtual + In-Person (München/Munich, DE) | Rust Munich
Rust Munich 2024 / 1 - hybrid (Rescheduled)
2024-05-15 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-05-16 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-05-21 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful—forensic parsing via Artemis
2024-05-23 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-05-28 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
Africa
2024-05-04 | Kampala, UG | Rust Circle Kampala
Rust Circle Meetup
Asia
2024-05-11 | Bangalore, IN | Rust Bangalore
May 2024 Rustacean meetup
Europe
2024-05-01 | Köln/Cologne, DE | Rust Cologne
This Month in Rust, May
2024-05-01 | Utrecht, NL | NL-RSE Community
NL-RSE RUST meetup
2024-05-06 | Delft, NL | GOSIM
GOSIM Europe 2024
2024-05-07 & 2024-05-08 | Delft, NL | RustNL
RustNL 2024
2024-05-07 | Oxford, UK | Oxfrod Rust Meetup Group
More Rust - Generics, constraints, safety.
2024-05-08 | Cambridge, UK | Cambridge Rust Meetup
Monthly Rust Meetup
2024-05-09 | Gdańsk, PL | Rust Gdansk
Rust Gdansk Meetup #2
2024-05-14 | London, UK | Rust London User Group
Rust Hack & Learn May 2024
2024-05-14 | Virtual + In-Person (München/Munich, DE) | Rust Munich
Rust Munich 2024 / 1 - hybrid (Rescheduled)
2024-05-14 | Prague, CZ | Rust Prague
Rust Meetup Prague (May 2024)
2024-05-14 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup
2024-05-16 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #7
2024-05-16 | Paris, FR | Rust Paris
Paris Rust Meetup #68
2024-05-21 | Aarhus, DK | Rust Aarhus
Hack Night
2024-05-21 | Zurich, CH | Rust Zurich
Save the date - Mai Meetup
2024-05-22 | Leiden, NL | Future-proof Software Development by FreshMinds
Coding Dojo Session
2024-05-23 | Bern, CH | Rust Bern
2024 Rust Talks Bern #2
2024-05-24 | Bordeaux, FR | Rust Bordeaux
Rust Bordeaux #3: Discussions
2024-05-28 - 2024-05-30 | Berlin, DE | Oxidize
Oxidize Conf 2024
North America
2024-05-04 | Cambridge, MA, US | Boston Rust Meetup
Kendall Rust Lunch, May 4
2024-05-08 | Detroit, MI, US | Detroit Rust
Rust Social - Ann Arbor
2024-05-09 | Spokane, WA, US | Spokane Rust
Monthly Meetup: Topic TBD!
2024-05-12 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, May 12
2024-05-14 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2024-05-16 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-05-20 | Somerville, MA, US | Boston Rust Meetup
Ball Square Rust Lunch, May 20
2024-05-21 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-05-22 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2024-05-25 | Chicago, IL, US | Deep Dish Rust
Rust Talk Double Feature
Oceania
2024-05-02 | Brisbane City, QL, AU | Rust Brisbane
May Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
"I'll never!" "No, never is in the 2024 Edition." "But never can't be this year, it's never!" "Well we're trying to make it happen now!" "But never isn't now?" "I mean technically, now never is the unit." "But how do you have an entire unit if it never happens?"
– Jubilee on Zulip
Thanks to Jacob Pratt for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
1 note
·
View note
Text
Unlocking Agility and Innovation Through Cloud Native Application Development
In today’s hyper-connected digital world, agility is the key to competitive advantage. Enterprises can no longer afford the slow pace of traditional software development and deployment. What they need is a modern, scalable, and resilient approach to building applications—this is where Cloud Native Application Development takes center stage.
By utilizing the full potential of cloud computing, organizations can accelerate digital innovation, deliver superior user experiences, and respond to changes with unmatched speed. Cloud native is not merely a buzzword; it is a complete paradigm shift in how software is created, delivered, and managed.
Understanding Cloud Native: A New Way to Build Applications
Cloud native application development is about designing software specifically for cloud environments. Unlike legacy systems that are simply hosted on the cloud, cloud native apps are built in and for the cloud from day one.
Key characteristics include:
Distributed Microservices: Each component is independently deployable and scalable.
Containerization: Applications run in lightweight containers that ensure portability and consistency.
Dynamic Orchestration: Automated scaling and recovery using platforms like Kubernetes.
DevOps Integration: Continuous integration and continuous deployment pipelines for rapid iteration.
This approach enables development teams to build flexible, fault-tolerant systems that can evolve with the needs of the business.
The Building Blocks of Cloud Native Applications
🌐 Microservices Architecture
Cloud native applications are composed of small, autonomous services. Each service handles a specific function, like user authentication, payment processing, or notifications. This modularity allows updates to be made independently, without affecting the entire system.
📦 Containers
Containers bundle an application and all its dependencies into a single, self-sufficient unit. This ensures that the application runs the same way across different environments, from development to production.
⚙️ Orchestration with Kubernetes
Kubernetes automates the deployment, scaling, and management of containers. It ensures that applications are always running in the desired state and can handle unexpected failures gracefully.
🔄 DevOps and CI/CD
Automation is at the heart of cloud native development. Continuous Integration (CI) and Continuous Delivery (CD) allow teams to ship updates faster and with fewer errors. DevOps practices promote collaboration between developers and operations teams, leading to more reliable releases.
🔍 Observability and Monitoring
With distributed systems, visibility is critical. Cloud native applications include tools for logging, monitoring, and tracing, helping teams detect and fix issues before they affect users.
Why Cloud Native Matters for Modern Enterprises
1. Rapid Innovation
The ability to release features quickly gives businesses a major edge. Cloud native enables faster development cycles, allowing companies to experiment, gather feedback, and improve continuously.
2. Resilience and High Availability
Cloud native systems are designed to withstand failures. If one service fails, others continue to function. Auto-healing and failover mechanisms ensure uptime and reliability.
3. Scalability on Demand
Applications can scale horizontally to handle increased loads. Whether it’s handling traffic spikes during promotions or growing user bases over time, cloud native apps scale effortlessly.
4. Operational Efficiency
Containerization and orchestration reduce resource waste. Teams can optimize infrastructure usage, cut operational costs, and avoid overprovisioning.
5. Vendor Independence
Thanks to container portability, cloud native applications are not tied to a specific cloud provider. Organizations can move workloads freely across platforms or opt for hybrid and multi-cloud strategies.
Ideal Use Cases for Cloud Native Development
Cloud native is a powerful solution across industries:
Retail & E-commerce: Deliver seamless shopping experiences, handle flash sales, and roll out features like recommendations and live chat rapidly.
Banking & Finance: Build secure and scalable digital banking apps, real-time analytics engines, and fraud detection systems.
Healthcare: Create compliant, scalable platforms for managing patient data, telehealth, and appointment scheduling.
Media & Entertainment: Stream content reliably at scale, deliver personalized user experiences, and support global audiences.
Transitioning to Cloud Native: A Step-by-Step Journey
Assess and Plan Evaluate the current application landscape, identify bottlenecks, and prioritize cloud-native transformation areas.
Design and Architect Create a blueprint using microservices, containerization, and DevOps principles to ensure flexibility and future scalability.
Modernize and Build Refactor legacy applications or build new ones using cloud-native technologies. Embrace modularity, automation, and testing.
Automate and Deploy Set up CI/CD pipelines for faster releases. Deploy to container orchestration platforms for better resource management.
Monitor and Improve Continuously monitor performance, user behavior, and system health. Use insights to optimize and evolve applications.
The Future of Software is Cloud Native
As digital disruption accelerates, the demand for applications that are fast, secure, scalable, and reliable continues to grow. Cloud native application development is the foundation for achieving this digital future. It’s not just about technology—it’s about changing how businesses operate, innovate, and deliver value.
Enterprises that adopt cloud native principles can build better software faster, reduce operational risks, and meet the ever-changing expectations of their customers. Whether starting from scratch or transforming existing systems, the journey to cloud native is a strategic move toward sustained growth and innovation.
Embrace the future with Cloud Native Application Development Services.
0 notes
Text
United States of America – The Insight Partners is delighted to release its new extensive market report, "Serverless Computing Market: A Detailed Analysis of Trends, Challenges, and Opportunities." This report provides a detailed and comprehensive view of the dynamic market, reporting existing dynamics, and predicting growth.
Overview
The Serverless Computing industry is in the midst of major change. Spurred by technological upheaval at a breakneck speed, changing regulatory landscapes, and evolving consumer behaviors, this market segment is becoming an instrumental facilitator of digital transformation. This report probes what is driving market momentum and what roadblocks must be overcome to achieve enduring growth.
Key Findings and Insights
Market Size and Growth
Historical Data and Forecast: The Serverless Computing Market is anticipated to register a CAGR of 18.2% during the forecast period.
Key Factors Affecting Growth:
Growing demand for scalable and economical cloud services
Growing use of microservices architecture
Less complex operations and infrastructure management
Booming DevOps and automation trends
Get Sample Report: https://www.theinsightpartners.com/sample/TIPRE00039622
Market Segmentation
By Service Type
Compute
Serverless Storage
Serverless Database< Application Integration
Monitoring & Security
Other Service Types
By Service Model
Function-as-a-service
Backend-as-a-service
By Deployment
Public Cloud
Private Cloud
Hybrid Cloud
By Organization Size
SMEs
Large Enterprises
Identifying Emerging Trends
Technological Advancements
Integration with AI and ML as part of serverless platforms
Improved observability and monitoring capabilities
Execution with containers along with serverless functions (hybrid architecture)
Support for real-time edge computing
Shifting Consumer Preferences
Shift in favor of pay-as-you-go pricing models
Increasing need for vendor-agnostic platforms
Greater emphasis on performance, latency minimization, and flexibility
Moving away from monolithic towards event-driven architectures
Regulatory Shifts
Regulatory compliance requirements under GDPR, HIPAA, and CCPA impacting data processing
Policies for data residency and sovereignty impacting cloud strategy
Increased third-party API and data sharing practices scrutiny
Growth Opportunities
Cloud-first strategies expanding into emerging markets
Hyperscaler and startup collaborations for developing serverless tools
Higher demand for IoT use cases propelling edge-serverless models
Adoption by non-traditional verticals such as education and agriculture
Vendor innovations in reducing cold start times and improving developer experiences
Conclusion
The Serverless Computing Industry Market: Global Trends, Share, Size, Growth, Opportunity, and Forecast Period report offers valuable information for companies and investors interested in entering this emerging market. By examining the competitive space, regulatory setting, and technological advancements, this report enables evidence-based decision-making to unlock new business prospects.
About The Insight Partners
The Insight Partners is among the leading market research and consulting firms in the world. We take pride in delivering exclusive reports along with sophisticated strategic and tactical insights into the industry. Reports are generated through a combination of primary and secondary research, solely aimed at giving our clientele a knowledge-based insight into the market and domain. This is done to assist clients in making wiser business decisions. A holistic perspective in every study undertaken forms an integral part of our research methodology and makes the report unique and reliable.
0 notes
Text
Master Infra Monitoring & Alerting with This Prometheus MasterClass

In today’s fast-paced tech world, keeping an eye on your systems is not optional — it's critical. Whether you're managing a handful of microservices or scaling a complex infrastructure, one tool continues to shine: Prometheus. And if you’re serious about learning it the right way, the Prometheus MasterClass: Infra Monitoring & Alerting is exactly what you need.
Why Prometheus Is the Gold Standard in Monitoring
Prometheus isn’t just another monitoring tool — it’s the backbone of modern cloud-native monitoring. It gives you deep insights, alerting capabilities, and real-time observability over your infrastructure. From Kubernetes clusters to legacy systems, Prometheus tracks everything through powerful time-series data collection.
But here’s the catch: it’s incredibly powerful, if you know how to use it.
That’s where the Prometheus MasterClass steps in.
What Makes This Prometheus MasterClass Stand Out?
Let’s be honest. There are tons of tutorials online. Some are free, some outdated, and most barely scratch the surface. This MasterClass is different. It’s built for real-world engineers — people who want to build, deploy, and monitor robust systems without guessing their way through half-baked guides.
Here’s what you’ll gain:
✅ Hands-On Learning: Dive into live projects that simulate actual infrastructure environments. You won’t just watch — you’ll do.
✅ Alerting Systems That Work: Learn to build smart alerting systems that tell you what you need to know before things go south.
✅ Scalable Monitoring Techniques: Whether it’s a single server or a Kubernetes cluster, you’ll master scalable Prometheus setups.
✅ Grafana Integration: Turn raw metrics into meaningful dashboards with beautiful visualizations.
✅ Zero to Advanced: Start from scratch or sharpen your existing skills — this course fits both beginners and experienced professionals.
Who Is This Course For?
This isn’t just for DevOps engineers. If you're a:
Software Developer looking to understand what’s happening behind the scenes…
System Admin who wants smarter monitoring tools…
Cloud Engineer managing scalable infrastructures…
SRE or DevOps Pro looking for an edge…
…then this course is tailor-made for you.
And if you're someone preparing for a real-world DevOps job or a career upgrade? Even better.
Monitoring Isn’t Just a “Nice to Have”
Too many teams treat monitoring as an afterthought — until something breaks. Then it’s chaos.
With Prometheus, you shift from being reactive to proactive. And when you take the Prometheus MasterClass, you’ll understand how to:
Set up automatic alerts before outages hit
Collect real-time performance metrics
Detect slowdowns and performance bottlenecks
Reduce MTTR (Mean Time to Recovery)
This isn’t just knowledge — it’s job-saving, career-accelerating expertise.
Real-World Monitoring, Real-World Tools
The Prometheus MasterClass is packed with tools and integrations professionals use every day. You'll not only learn Prometheus but also how it connects with:
Grafana: Create real-time dashboards with precision.
Alertmanager: Manage all your alerts with control and visibility.
Docker & Kubernetes: Learn how Prometheus works in containerized environments.
Blackbox Exporter, Node Exporter & Custom Exporters: Monitor everything from hardware metrics to custom applications.
Whether it’s latency, memory usage, server health, or request failures — you’ll learn how to monitor it all.
Learn to Set Up Monitoring in Hours, Not Weeks
One of the biggest challenges in learning a complex tool like Prometheus is the time investment. This course respects your time. Each module is focused, practical, and designed to help you get results fast.
By the end of the Prometheus MasterClass, you’ll be able to:
Set up Prometheus in any environment
Monitor distributed systems with ease
Handle alerts and incidents with confidence
Visualize data and performance metrics clearly
And the best part? You’ll actually enjoy the learning journey.
Why Now Is the Right Time to Learn Prometheus
Infrastructure and DevOps skills are in huge demand. Prometheus is used by some of the biggest companies — from startups to giants like Google and SoundCloud.
As more companies embrace cloud-native infrastructure, tools like Prometheus are no longer optional — they’re essential. If you're not adding these skills to your toolbox, you're falling behind.
This MasterClass helps you stay ahead.
You’ll build in-demand monitoring skills, backed by one of the most powerful tools in the DevOps ecosystem. Whether you're aiming for a promotion, a new job, or leveling up your tech stack — this course is your launchpad.
Course Highlights Recap:
🚀 Full Prometheus setup from scratch
📡 Create powerful alerts using Alertmanager
📊 Build interactive dashboards with Grafana
🐳 Monitor Docker & Kubernetes environments
⚙️ Collect metrics using exporters
🛠️ Build real-world monitoring pipelines
All of this, bundled into the Prometheus MasterClass: Infra Monitoring & Alerting that’s designed to empower, not overwhelm.
Start Your Monitoring Journey Today
You don’t need to be a Prometheus expert to start. You just need the right guidance — and this course gives it to you.
Whether you’re monitoring your first server or managing an enterprise-grade cluster, the Prometheus MasterClass gives you everything you need to succeed.
👉 Ready to take control of your infrastructure monitoring?
Click here to enroll in Prometheus MasterClass: Infra Monitoring & Alerting and take the first step toward mastering system visibility.
0 notes
Text
Ensuring Seamless Service During Product Deployments for SaaS Platforms
In the dynamic world of Software as a Service (SaaS), ensuring uninterrupted service during production deployments is not just an operational goal—it’s a vital component of customer trust and satisfaction. As developers and operations teams push out new features and updates, the challenge lies in deploying these changes without impacting the user experience. Here’s how industry leaders manage to maintain this delicate balance.
Continuous integration and continuous deployment (CI/CD)
The heart of minimizing disruption lies in automating the deployment pipeline. CI/CD practices enable teams to integrate code changes more frequently and reliably. By automating builds, tests, and deployments, teams can detect and resolve issues early, ensuring a smooth transition to production.
Blue-green deployments: A safety net for rollouts
Blue-green deployments offer a robust strategy for reducing downtime and mitigating risk. This involves maintaining two identical environments; as one serves live traffic, the other hosts the new release. This setup not only facilitates instant rollbacks in case of issues but also allows for testing in a live environment without affecting the user experience.
Canary releases: The gradual rollout approach
Canary releasing is a technique where new features are rolled out to a small segment of users before a wider release. This method helps in identifying unforeseen issues early, minimizing potential impacts on the broader user base.
Feature toggling: Flexibility in feature deployment
Feature toggles offer an excellent way to control the availability of features without redeploying. This approach allows teams to enable or disable features on the fly, providing a flexible way to test new functionality and manage rollouts.
Microservices: Independence in deployment
Embracing a microservices architecture can significantly reduce deployment risks. By breaking down the application into smaller, independently deployable services, teams can update parts of the system without affecting others, enhancing overall stability.
Thoughtful database migrations
Changes to databases can be particularly risky. Employing non-destructive database migration strategies ensures that application operations are not disrupted, allowing for safer schema changes and data transformations.
Monitoring and observability: The watchful eyes
With comprehensive monitoring and observability tools, teams can quickly detect and address issues as they arise. Real-time insights into application performance and user experience are crucial for maintaining service quality during and after deployments.
Preparing for automated rollbacks
Despite all precautions, the need to rollback a deployment can still arise. Automating this process ensures that operations can quickly revert to a stable state if the new release encounters significant issues.
Load testing: The dress rehearsal
Load testing in a staging environment that closely mirrors production is critical. This step helps uncover any performance issues that could degrade the user experience, ensuring the new release is fully vetted for load handling.
Final thoughts
Deploying new features and updates is a hallmark of the SaaS model, but doing so without impacting user experience is what sets apart the best in the business. By adopting these industry-standard practices, SaaS platforms can ensure that their services remain seamless, secure, and stable, irrespective of the changes being deployed. Embrace these strategies to not just meet but exceed your users’ expectations, solidifying your place in the competitive landscape of SaaS providers.
Explore Centizen Inc’s comprehensive staffing solutions and innovative software offerings, including ZenBasket and Zenyo, to elevate your business operations and growth.
0 notes
Text
Still Running Legacy Software in 2025? These 6 Cloud-Native Strategies Will Change Everything
Legacy tech doesn’t just slow you down—it costs you real money, blocks innovation, and frustrates your dev team.
If you’re thinking about modernization, don’t just migrate—rethink everything with cloud-native principles.
In our latest blog at Skywinds, we break down 6 practical strategies to cut costs and boost agility in 2025:
✅ Audit the true cost of your legacy stack ✅ Use microservices (not just rewrites) ✅ Automate releases with CI/CD ✅ Go serverless and use scalable cloud-native databases ✅ Bake in full observability ✅ Build a smart, phased roadmap
These aren’t just buzzwords—they’re what high-performing teams are actually using right now.
Read the full breakdown here → https://medium.com/@skywinds.tech/modernizing-software-in-2025-6-cloud-native-strategies-that-cut-costs-and-boost-agility-
#cloudnative#softwaremodernization#devops#techstrategy#microservices#serverless#programming#skywinds
0 notes
Text
OpenShift + AWS Observability: Track Logs & Metrics Without Code
In a cloud-native world, observability means more than just monitoring. It's about understanding your application behavior—in real time. If you’re using Red Hat OpenShift Service on AWS (ROSA), you’re in a great position to combine enterprise-grade Kubernetes with powerful AWS tools.
In this blog, we’ll explore how OpenShift applications can be connected to:
Amazon CloudWatch for application logs
Amazon Managed Service for Prometheus for performance metrics
No deep tech knowledge or coding needed — just a clear concept of how they work together.
☁️ What Is ROSA?
ROSA (Red Hat OpenShift Service on AWS) is a fully managed OpenShift platform built on AWS infrastructure. It allows you to deploy containerized apps easily without worrying about the backend setup.
👁️ Why Is Observability Important?
Think of observability like a fitness tracker — but for your application.
🔹 Logs = “What just happened?” 🔹 Metrics = “How well is it running?” 🔹 Dashboards & Alerts = “What do I need to fix or optimize?”
Together, these help your team detect issues early, fix them fast, and make smarter decisions.
🧰 Tools That Work Together
Here’s how ROSA integrates with AWS tools: PurposeToolWhat It DoesApplication LogsAmazon CloudWatchCollects and stores logs from your OpenShift appsMetricsAmazon Managed Service for PrometheusTracks performance data like CPU, memory, and networkVisualizationAmazon Managed GrafanaShows dashboards using logs & metrics from the above
⚙️ How It All Connects (Simplified Flow)
✅ Your application runs inside OpenShift (ROSA).
📤 ROSA forwards logs (like errors, activity) to Amazon CloudWatch.
📊 ROSA sends metrics (like performance stats) to Amazon Managed Prometheus.
📈 Grafana connects to both and gives you beautiful dashboards.
No code needed — this setup is supported through configuration and integration provided by AWS & Red Hat.
🔒 Is It Secure?
Yes. ROSA uses IAM roles and secure endpoints to make sure your logs and data are only visible to your team. You don’t have to worry about setting up security from scratch — AWS manages that for you.
🌟 Key Benefits of This Integration
✅ Real-time visibility into how your applications behave ✅ Centralized monitoring with AWS-native tools ✅ No additional tools to install — works right within ROSA and AWS ✅ Better incident response and proactive issue detection
💡 Use Cases
Monitor microservices in real time
Set alerts for traffic spikes or memory usage
View errors as they happen — without logging into containers
Improve app performance with data-driven insights
🚀 Final Thoughts
If you’re using ROSA and want a smooth, scalable, and secure way to monitor your apps, AWS observability tools are the answer. No complex coding. No third-party services. Just native integration and clear visibility.
🎯 Whether you’re a DevOps engineer or a product manager, understanding your application’s health has never been easier.
For more info, Kindly follow: Hawkstack Technologies
0 notes
Text
Scaling Machine Learning Operations with Modern MLOps Frameworks
The rise of business-critical AI demands sophisticated operational frameworks. Modern end to end machine learning pipeline frameworks combine ML best practices with DevOps, enabling scalable, reliable, and collaborative operations.
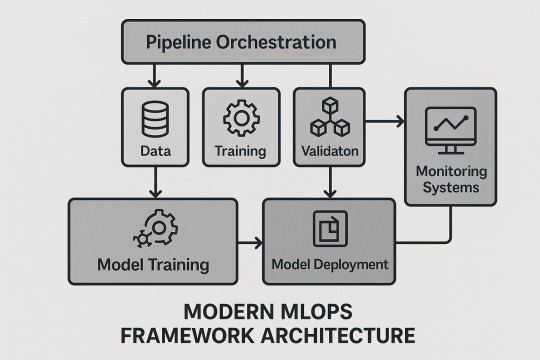
MLOps Framework Architecture
Experiment management and artifact tracking
Model registry and approval workflows
Pipeline orchestration and workflow management
Advanced Automation Strategies
Continuous integration and testing for ML
Automated retraining and rollback capabilities
Multi-stage validation and environment consistency
Enterprise-Scale Infrastructure
Kubernetes-based and serverless ML platforms
Distributed training and inference systems
Multi-cloud and hybrid cloud orchestration
Monitoring and Observability
Multi-dimensional monitoring and predictive alerting
Root cause analysis and distributed tracing
Advanced drift and business impact analytics
Collaboration and Governance
Role-based collaboration and cross-functional workflows
Automated compliance and audit trails
Policy enforcement and risk management
Technology Stack Integration
Kubeflow, MLflow, Weights & Biases, Apache Airflow
API-first and microservices architectures
AutoML, edge computing, federated learning
Conclusion
Comprehensive end to end machine learning pipeline frameworks are the foundation for sustainable, scalable AI. Investing in MLOps capabilities ensures your organization can innovate, deploy, and scale machine learning with confidence and agility.
0 notes
Text
The Growing Role of DevOps in Cloud-Native Development

In today’s fast-paced digital ecosystem, businesses are rapidly shifting towards cloud-native architectures to enhance scalability, resilience, and agility. At the heart of this transformation lies a game-changer: DevOps. At VGD Technologies, we believe that integrating DevOps into cloud-native development is not just a trend—it's a competitive necessity.
What is Cloud-Native Development?
Cloud-native is more than just a buzzword. It's an approach to building and running applications that fully exploit the benefits of the cloud computing model. It focuses on:
Microservices architecture
Containerization (like Docker & Kubernetes)
Scalability and resilience
Automated CI/CD pipelines
But without DevOps, cloud-native is incomplete.
DevOps + Cloud-Native = Continuous Innovation//Game-Changing Synergy
DevOps, the synergy of development and operations, plays a pivotal role in automating workflows, fostering collaboration, and reducing time-to-market. When paired with cloud-native practices—like microservices, containers, and serverless computing—it becomes the engine of continuous delivery and innovation. The integration of DevOps practices in cloud-native environments empowers teams to:
Automate deployments and reduce manual errors
Speed up release cycles using CI/CD pipelines
Ensure reliability and uptime through monitoring and feedback loops
Enable seamless collaboration between development and operations
Together, they create a self-sustaining ecosystem that accelerates innovation and minimizes downtime.
Why It Matters More Than Ever
With the rise of platforms like Kubernetes, Docker, and multi-cloud strategies, enterprises are prioritizing infrastructure as code (IaC), automated CI/CD pipelines, and real-time observability. DevOps ensures seamless integration of these tools into your cloud-native stack, eliminating bottlenecks and improving reliability.
AI-powered DevOps is on the rise
Infrastructure as Code (IaC) is the norm
Security automation is embedded from Day 1
Serverless computing is reshaping how we deploy logic
Observability is now a must-have, not a nice-to-have
At VGD Technologies, we harness these trends to deliver cloud-native solutions that scale, secure, and simplify business operations across industries.
Real-World Impact
Companies adopting DevOps in their cloud-native journey report:
30–50% faster time-to-market
Significant cost reduction in operations
Improved user experience & satisfaction From startups to enterprise-level businesses, this approach is transforming the way software delivers value.
VGD Technologies’ Cloud-Native DevOps Expertise
At VGD Technologies, we help enterprises build cloud-native applications powered by DevOps best practices. Our solutions are designed to:
Faster delivery
Automate infrastructure provisioning
Enable zero-downtime deployments
Implement proactive monitoring and alerts
Enhance scalability through container orchestration
Stronger security posture
Reduced operational overhead
From startups to large-scale enterprises, our clients trust us to deliver robust, scalable, and future-ready applications that accelerate digital transformation.
What’s Next?
As businesses continue to adopt AI/ML, IoT, and edge computing, the fusion of DevOps and cloud-native development will become even more vital. Investing in DevOps today means you're building a foundation for tomorrow’s innovation.
Let’s Talk DevOps-Driven Digital Transformation
Looking to future-proof your applications with a cloud-native DevOps strategy?
Discover how we can help your business grow at: www.vgdtechnologies.com
#DevOps#CloudNative#DigitalTransformation#Kubernetes#Microservices#Serverless#CloudComputing#CICD#InfrastructureAsCode#TechInnovation#VGDTechnologies#FutureOfTech#EnterpriseIT#DevOpsCulture#SoftwareEngineering#ModernDevelopment#AgileDevelopment#AutomationInTech#FullStackDev#CloudSolutions
1 note
·
View note
Text
How Can You Monitor and Optimize AI Applications in Production?

Deploying AI applications in production environments requires robust monitoring and optimization strategies to ensure reliable performance and cost-effectiveness. Modern businesses increasingly rely on sophisticated monitoring frameworks to maintain their AI systems, whether they're building traditional web applications through ASP.NET development services or implementing cutting-edge machine learning solutions. The complexity of AI workloads demands comprehensive observability solutions that go beyond traditional application monitoring.
Using Telemetry: Logging, Tracing, and Metrics via OpenTelemetry
OpenTelemetry provides a standardized approach to collecting telemetry data from AI applications. This framework enables comprehensive visibility into your AI systems through three key pillars:
Logging: Capture detailed information about model predictions, input data quality, and system events. Structured logging helps identify patterns in model behavior and track decision-making processes.
Tracing: Monitor the complete request flow through your AI pipeline, from data preprocessing to model inference and post-processing. Distributed tracing reveals bottlenecks and dependencies across microservices.
Metrics: Collect quantitative data about model performance, latency, throughput, and resource utilization. Custom metrics can track business-specific KPIs like prediction accuracy and data drift.
Setting Up Alerts and Dashboards for AI Workloads
Effective monitoring requires proactive alerting systems that notify teams of potential issues before they impact users. Key alerting strategies include:
Performance Alerts: Set thresholds for response times, error rates, and model accuracy degradation. Configure alerts for anomalous prediction patterns or sudden changes in model behavior.
Resource Alerts: Monitor CPU, memory, and GPU utilization to prevent resource exhaustion. Set up alerts for cost spikes or unexpected scaling events.
Data Quality Alerts: Implement checks for data drift, missing features, or outliers in input data that could affect model performance.
Maintaining Performance and Cost Efficiency
Optimization strategies focus on balancing performance with operational costs:
Model Optimization: Implement techniques like quantization, pruning, and knowledge distillation to reduce model size and inference time while maintaining accuracy.
Infrastructure Scaling: Use auto-scaling policies based on demand patterns and implement spot instances for cost-effective training workloads.
Caching Strategies: Implement intelligent caching for frequently requested predictions and preprocessed data to reduce computational overhead.
The landscape of AI applications development continues evolving rapidly, making monitoring and optimization critical for success. Organizations must adopt comprehensive observability practices that encompass telemetry collection, proactive alerting, and continuous optimization to maintain competitive advantage in production environments.
0 notes