#midjourney tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text



Spaceknights:
Skera the Scanner and Vola the Trapper




Scanner and Trapper got the closest to my Tokusatsu-Spaceknight dreams in relation to my Live-Action ROM Spaceknight video project.

All the SpaceKnights are at least a bit toyetic, and you can see Marvel trying to throw Parker Bros a bone that they never snatched with everyone from Firefall onward. Scanner and Trapper are two of my favorites.
Full tutorializing under the fold.
Overpainting was the most effective way to get the designs to where I wanted them, and this is going to be the main breakdown of that (later posts about other knights will likely focus on other aspects).
I used Midjourney's edit feature to do this. The first step is getting the image high-enough res to work with. MJ's edit feature can be used as a very effective image upscaler, and that's the first step.

It's also useful for removing word balloons and other obstructions that the AI will later misinterpret and getting a view of an entire character if parts are cropped off. You will need to often extract backgrounds manually, especially with comic art where AI background removal tools usually fail.



Once the image is upscaled you're going to get better results using the overpainting/retexture feature. Which you're going to have to use a lot because anytime you're using overpainting to shift a character in art style, its going to involve compositing.
No single version of Vola or Sekra had all the right parts, so photoshopped the bits I liked together before re-loading it into MJ's editor for some touchups. Sometimes you have to make a mockup and use that as a character reference or fully retexture over it.
You'll notice that I removed Vola's net. Accessories, if on the character model, will always be on the character when used with Vidu's system, and often glitch because of it. You can always put them back in with a second image reference or with a specific reference that still has them.
Once you have the reference image, you can use the character. Though if you want to use them a lot, you'll want a full model sheet with multiple views.
More to come.
#AI tutorial#midjourney tutorial#the process#unreality#rom#rom spaceknight#spaceknights#dire wraiths#marvel#fauxstalgia#nostalgia#ai art#ai assisted art#ai video#vidu#vidu ai#fanart#fan casting
13 notes
·
View notes
Note
Q what prompts did you use to get you that uncanny nostalgia cartoon aesthetic with midjourney?
Changed up a lot over time.
The thing that worked best most recently was building a moodboard of screencaps from a potluck of shows, but for straight prompting I tended to have a format along the lines of:
(description of scene), vintage cartoon screencap, 1985 (series real or imaginary), by (pick two or more of Filmation, TOEI, AKOM, TMS, Sunbow Productions, Toei, etc, etc.), vhscore. vintage cel animation still.
Usually at --ar 4:3, under niji if you want it to look high budget, under the standard model if you want it to be a low budget ep. But moodboards and style prompting are your friends.
Sure would be nice to not be unjustly banned from there, mumblegrumble.
7 notes
·
View notes
Text
Dream Up ist da - ohne Zusatzkosten!
Direkt in DeviantArt verwendbar, keine Zusatzkosten zu deiner bestehenden DeviantArt Membership. Einfachste Bedienung, schau einfach mal direkt rein: https://www.deviantart.com/dreamup Weiters gibt es von meiner Weihnachtsaktion noch ein XXL-Archiv zum Sonderpreis das zwar bestellt aber nie bezahlt wurden, wer also hier zuschlagen möchte, für nur 200 Euro (inkl. HDD und Postversand) inkl. dem…

View On WordPress
#art#bildbearbeitung#brownz#brownzart#composing#darkart#Dreamup#midjourney#photoshop#schulungen#synthography#tutorial#workshop
2 notes
·
View notes
Text
A lot of this is spot on, but I think the choice of tools has skewed the data here, however, and may give an incorrect impression of how AI art tools on the whole work, because Dall-E 3 isn't representative of the options at large.
Dall-E 3 is pretty (if you make it be) and has good coherency and works with more naturally written prompts, but it is wholly uncooperative and has almost zero workflow accommodations for artistic applications, heck, It can't even do non-square aspect ratios (at least through Bing).
Playground AI beats it out on those fronts, and Midjourney and Stable Diffusion piledrive it into the concrete.
The only reason to ever use Dall-E 3's chat GPT interface is if you want to run up to three jobs simultaneously on a free bing account. It routinely misinterprets input, even direct "replace this word in the prompt with this other word" requests. It's essentially playing whisper-telephone with two hallucinating robots instead of one.
Here's how the process would go down in Midjourney:
Gonna be making a 90s fighting game version of my DeinoSteve character. Goal is to keep him largely on-model, minus changes that work for the style change from 70s comic/80s cartoon to 90s fighting game.
Prompt: fullbody character design, a velociraptor-anthro fighting game character, in the style of 1996 Capcom (Darkstalkers 3/Street Fighter Alpha 3) promotional art, fullbody on white background. Red scales, yellow shirt, black leather jacket, long tail, clawed feet, long tail, retrosaur asthetics, vector art inks with flat anime shading
Aspect ratio 3:4, Niji model v6, style 50:


Some pretty good stables at DeinoSteve (left image), but nobody's quite right. I've got several ways to get him kitted out right, but we'll use the same techniques CGPT was trying to use: inpainting and variations.
Upper right is closer to the character concept, but I like upper left's pose better, so we'll start by doing some variations on the subtle setting (right image)
You'll notice the variation problem from Dall-E 3 isn't there. Using Chat-GPT to change the prompt means you're at the mercy of two hallucinating robots instead of one, and it's probably been altering the prompt wildly with each revision, thus the slow degradation of mural-jesus.

Now, I'm just demonstrating in-system tools here, but on a piece that I was doing for finalization, I'd be upscaling all the ones that had features I liked, for later composition.
Steve looks... okay here, but he's off model in several major ways. Pants wrong color, no full-t-shirt, the spines on the tail, etc.

So here we'll do some inpainting. Unlike the GPT setup, I'm laying out what areas I specifically want changed at each go. Starting with the pants, I forgot to mention in the first prompt he wears blue jeans, so I add that to the prompt as well. If you're out to do your own post-editing, you can hit more parts at once and just composite from fewer gens.


I like #4 (left)'s swagger, so we'll repeat the process to get him full sleeves on his jacket, and to remove the spiked wrist cuffs. #4, again, is my winner. Now, I can keep varying individual bits, but I can also return to doing general variations, and the influence from the current version will carry over.


Now, it will me re-doing some bits, but #2 is pretty sweet, so he'll be where I tinker next. Note how a bit of his tail and claws are cropped out. I can fix that with outpainting.
If I were instead going for an edit in post, I'd probably have taken the best 5-6 chunks, merged, dropped to line art, then recolored by this point.

Now, I can keep tinkering on him bit by bit, put part of using the AI system is knowing when you're going to have to go manual. I know from experience that my chance of getting him to have his raptor-foot claws is going to require me to go in and do 'em manually.
If its not the horns and claws on dinosaurs, its hairstyles and clothing details on humans, the nature of using a randomized system is that you're going to get random hiccups.

But there are ways to mitigate that, depending on your toolset. Stable Diffusion has controlnet, different versions of which let you control things like poses, character details, and composition more directly, (as I understand it. I haven't messed with it myself, don't have that kind of beastly graphics card)
MJ's answer is presently in alpha: character reference. It's an extension of their image-prompting system (which isn't the same as image-to-image), wherein an image is examined by the AI's image-identification/checking processes and the results are used as part of the prompt. For Character reference, it tries to drop everything that isn't connected to character design.
A quickie iteration using a handful of previous DeinoSteve pics made the image on the left, while re-running the prompt with the semi-final DeinoSteve above as a character prompt produced the images on the right.


Of course, even with the additional workflow tools you get with non-DallE generators, doing anything with long-term consistency is going to require manual editing.
Anything with narrative? Well, this panel has over 20 individual gens in it, from across two generators (MJ and Dall-E 3)

The AI systems will get better over time, but there's an inherent paradox that I don't think they'll escape. To get to complex results you need complex control, and to gain complex control you need, well, complex controls
The more stuff an AI generator can do, the more literal and figurative buttons and/or menus you need to use those features. The more complex the features, the more knowledge and practice it takes to utilize them. Essentially: Any tool capable of (heavy air quotes) "replacing" an artist will wind up requiring an artist to operate it at that level.
As with other force-multipliers for art (photography, digital image manipulation, automated image touchup/filtering, etc) the skill gradient never goes away.
Among the many downsides of AI-generated art: it's bad at revising. You know, the biggest part of the process when working on commissioned art.
Original "deer in a grocery store" request from chatgpt (which calls on dalle3 for image generation):

revision 5 (trying to give the fawn spots, trying to fix the shadows that were making it appear to hover):

I had it restore its own Jesus fresco.
Original:

Erased the face, asked it to restore the image to as good as when it was first painted:
Wait tumblr makes the image really low-res, let me zoom in on Jesus's face.
Original:

Restored:

One revision later:

Here's the full "restored" face in context:

Every time AI is asked to revise an image, it either wipes it and starts over or makes it more and more of a disaster. People who work with AI-generated imagery have to adapt their creative vision to what comes out of the system - or go in with a mentality that anything that fits the brief is good enough.
I'm not surprised that there are some places looking for cheap filler images that don't mind the problems with AI-generated imagery. But for everyone else I think it's quickly becoming clear that you need a real artist, not a knockoff.
more
3K notes
·
View notes
Text
youtube
#ai product photography#chatgpt product design#ai product photography - chatgpt product design#product photography ai#product photography#ai product design generator#ai product design#ai product design free#ai product design tools#ai image generator#ai product design software#chatgpt product image#best ai for product design#ai tutorial#ai product photos#ai tools#artificial intelligence#ai product photography midjourney#aman agrawal#Youtube
0 notes
Text
Batalha Legal pelo Nome 'iPhone' no Brasil Pode Redefinir o Mercado de Smartphones
A disputa judicial entre a Gradiente e a Apple pelo uso da marca ‘iPhone’ no Brasil chegou a um ponto crucial, com a recente decisão do Superior Tribunal de Justiça (STJ), que pode alterar o mercado de smartphones e o reconhecimento de marcas nacionais. Contexto da Disputa pelo Nome ‘iPhone’ Desde o início da disputa legal entre a Gradiente e a Apple, o Brasil tem sido palco de uma batalha…
#Algoritmo#Análise#Automação#Case de Sucesso#ChatGPT#copywriting#Criadores de Conteúdo#Google#IA Generativa#Instagram#Lista#Marketing#Midjourney#Notícia#OpenAI#Programação#SEO#Startups#TikTok#Tutorial#Vídeos
0 notes
Photo

How to Make Your Own Peanut Butter
#peanut butter#peanut butters#homemade peanut butter#how to make peanut butter#recipes#nut butter#healthy snacks#cooking tips#food tutorial#midjourney#ai
0 notes
Text
Some quick tips for peeps using MJ that don't want it to look like everyone else using MJ.
1. The Ultra Stylish All Dress Alike
First, adjust your style setting (--s (number)). This is how much of the Midjourney 'secret sauce' is added. The lower this number, the closer to your prompt the style will be, at a cost of coherence and 'prettiness'.


Same prompt, same seed, style 500 on the left, style 25 (my preferred setting) on the right. The differences in lighting, pose, skin reflectivity, etc are apparent. You can think of it as a "de-instagram" setting.
3. Use your Variations



"A dinosaur astronaut", original gen, vary (subtle) and Vary (strong) results
If you get something you like for an initial result, the first thing I tend to do is immediately to a Vary (Strong) on it. The results are usually better than the original one because you're essentially re-running the initial prompt with the first result as an additional image prompt, reinforcing the subject.
Using subtle variations to get closer to what you want is one of the big features of MJ, and it's sorely underused.
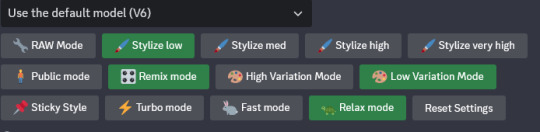
I recommend setting to low variation mode so your normal variations are subtle ones, and putting on remix mode. Remix mode prompts you to change the prompt every time you do a variation. If you're close but something's not right, that's an easy way to go.



Changing prompts is especially useful if combined with Vary (Region). Basically, if you like everything about a pic but some select details, you can highlight an area and have the system produce new variations just changing that region. It's obvious use is fixing generation errors, but by changing the prompt, you can get results that the robot can't imagine as a solo prompt.
3. Get Weird With It
--weird is a highly unused setting. It's also very powerful, while it goes up to 1000, I tend to not go above 1-5.
A cartoon penguin made of knives at 0 weird, 1 weird, and 50 weird:



Near as I can tell, weird restricts the 'does this make sense' checks, allowing for more out-there results, both in terms of style and subject matter. At the very low levels (1-5) it increases prompt adherence, at higher levels it reduces it substantially.
4. Prompt Big and Blend your Concepts
MJ deals with short prompts by filling in its own leanings where there's gaps, so short prompts look the most midjourney-esq while longer ones (especially when combined with --weird or a low --s value) fight back against it more.
When prompting for art styles, prompting for multiple art styles/artists at once produces weird hybrids. Prompting an artist with the wrong medium (A painting by a sculptor, a drawing by a cinematographer, etc) also can produce new, strange results.

(Lisa Frank/H.R. Giger style mashup using :: technique (below))
But the real trick is in "prompt smashing" or multi-prompting. Basically, midjourney uses :: to split prompts. Intended function is to allow you to add individual weights to each section, if you want something strongly emphasized.



But in practice, it blends the concepts of the two prompts to create a new, third thing.
As above with "an illustration of an armored dinosaur in the woods, in the style of vibrant comics, toycore, ps1 graphics, national geographic photo, majestic elephants, exotic, action painter" then "daft punk & particle party daft punk world tour, in the style of romina ressia, polished craftsmanship, minimalistic metal sculptures, ultra hd, mark seliger, installation-based, quadratura" and then the two prompts run together separated by ::.
Each one was also iterated to produce a better result than the initial gen.
5. Just edit the darn thing.
Learning to edit your works outside of the AI system will always improve your work beyond what the machine itself can do. Whether it's just the simple matter of doing color adjustment/correction:

Or more heavy compositing and re-editing combined with other techniques:








Editing and compositing your gens is always superior to just posting them raw, even if its just a little cropping to get the figure slightly off-center or compiling 20ish individual gens into a single comic-style battle scene before recoloring it from scratch.
But at the very least, before you post, go over the image and make sure there's nothing glaring.
I don't think that making or using AI art/image generation is morally wrong, as you guys know, but I have to admit that slotting a wibbly-lined low effort image selected from the first result set from Midjourney in your content is incredibly tacky. At least select something that looks good. Maybe something without the boring AI "sheen" look either.
You see this a lot in clickbaity content like web spam and youtube shorts attempting to algorithm game.
1K notes
·
View notes
Text
youtube
18 outils d’IA que vous devez ABSOLUMENT connaître en 2025 ! 🧠🔥
🤖 L’intelligence artificielle évolue à une vitesse folle… et si vous pouviez en tirer profit dès maintenant ? Dans cette vidéo, découvrez 18 outils d’IA incontournables (+ 2 bonus) qui vont révolutionner votre façon de travailler et booster votre productivité !
📌 Au programme :
✅ Des outils IA pour automatiser vos tâches 📊
✅ Des assistants intelligents pour optimiser votre workflow 💡
✅ Des solutions pour rédiger, créer et analyser plus vite que jamais
🚀 Que vous soyez entrepreneur, créateur de contenu ou étudiant, ces 18 outils IA vous feront gagner un temps précieux et amélioreront votre efficacité au quotidien !
🔥 Ne passez pas à côté des meilleures innovations IA ! Regardez la vidéo maintenant et adoptez ces outils dès aujourd’hui !
#gemini ai#intelligence artificielle#ai studio#google ai studio#google ai studio tutorial#live trading#bitcoin#ai studio google#use ai studio google#how use ai studio google#how to use google ai studio#google ai studio for beginners#gemini advanced#kling#midjourney#outils IA#productivité#outils d’intelligence artificielle#booster sa productivité#AI tools#outils pour entrepreneurs#automatiser son travail#IA et futur du travail#bolt ai#ai video generator#Youtube
0 notes
Text
Master Midjourney | Create Stunning AI Art with This Step-by-Step Guide | My AI Mastery
youtube
Discover the power of Midjourney, the leading AI art generator! Learn how to navigate the Discord interface, craft effective prompts, and create mind-blowing images. See real-world examples and compare Midjourney to other AI tools like Dall-E and Stable Diffusion. Unleash your creativity today!
#Midjourney#AIArt#GenerativeAI#Tutorial#Art#DigitalArt#Creative#AI#StepByStep#HowTo#Discord#PromptEngineering#DallE#StableDiffusion#ArtTutorial#AIArtist#Youtube
0 notes
Text
Here Comes the Hotstepper

Mur-da-rah!
Prompt: Nah, na-na-na-nah Na-na-na-na, na-na-na, na-na-na Na-na-na-nah
The prompt is the na-na chorus pattern from this classic.
youtube
Process under the fold (How to move gens to v6 without major changes).
I actually prompted this back in 2022, when Midjourney was under version 3. I've been reorganizing my images lately and also cataloging things like old prompts, and I came across the above image in its original grid:

Since I'm playing Fear & Hunger right now, this is all very on-brand.
I have recently found a trick in Midjourney for getting access to the old school aesthetics with more of the current control and coherence (and speed), for at least some of the old models, the region-vary works, so you can select a section of background, change the version on the prompt, and run it, and it will move the image to the new model more or less unchanged.
From there, you can use the iteration, outpainting, and upscaler functions as you desire, with different combinations allowing for varying levels of madness/coherence to your taste.
The initial image was a "creative" upscale, which reinterpreted the OG splorts through the new engine's tastes to create that interesting combination of texture and shadow. But it wound up reinterpreting the top of the column of heads into a massive one, rather than the taper you get with the subtle upscale:

Which has a very different feel.
The image(s) above in this post were made using a dumb as hell prompt and have not been modified/iterated extensively. As such, they do not meet the minimum expression threshold, and are in the public domain.
I was inspired to start experimenting along these lines by this:
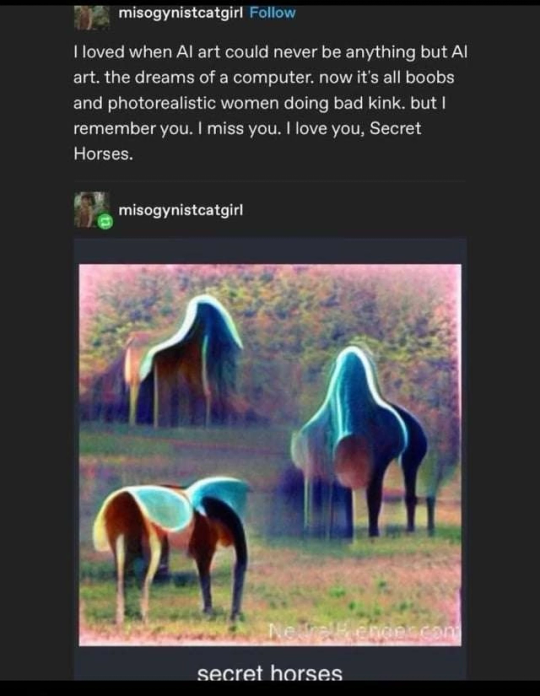
So I'm calling this trick "secret horsing"
#midjourney#midjourney v3#midjourney v6#secret horsing#secret horses#Ini Kamoze#Here Comes The Hotstepper#ai art#midjourney tutorial#unreality#generative art#ai artwork#public domain art#public domain#free art#Youtube
8 notes
·
View notes
Text
Time to offer an actual breakdown of what's going on here for those who are are anti or disinterested in AI, and aren't familiar with how they work, because the replies are filled with discussions on how this is somehow a down-step in the engine or that this is a sign of model collapse.
And the situation is, as always, not so simple.
Different versions of the same generator always prompt differently. This has nothing to do with their specific capabilities, and everything to do with the way the technology works. New dataset means new weights, and as the text parser AI improves (and with it prompt understanding) you will get wildly different results from the same prompt.
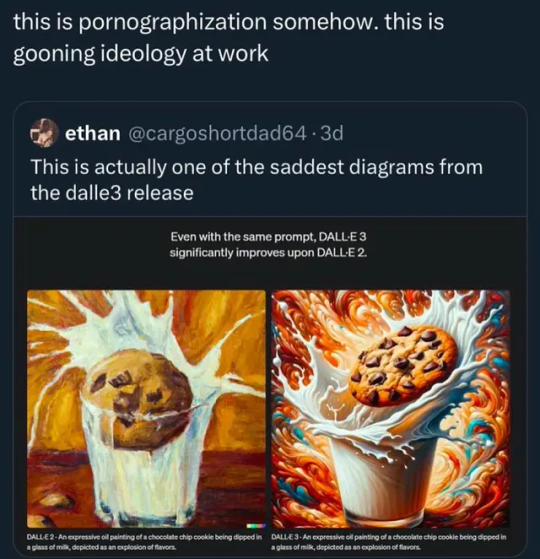
The screencap was in .webp (ew) so I had to download it for my old man eyes to zoom in close enough to see the prompt, which is:
An expressive oil painting of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors.
Now, the first thing we do when people make a claim about prompting, is we try it ourselves, so here's what I got with the most basic version of dall-e 3, the one I can access free thru bing:

Huh, that's weird. Minus a problem with the rim of the glass melting a bit, this certainly seems to be much more painterly than the example for #3 shown, and seems to be a wildly different style.



The other three generated with that prompt are closer to what the initial post shows, only with much more stability about the glass. See, most AI generators generate results in sets, usually four, and, as always:
Everything you see AI-wise online is curated, both positive and negative.*
You have no idea how many times the OP ran each prompt before getting the samples they used.
Earlier I had mentioned that the text parser improvements are an influence here, and here's why-
The original prompt reads:
An expressive oil painting of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors.
V2 (at least in the sample) seems to have emphasized the bolded section, and seems to have interpreted "expressive" as "expressionist"


On the left, Dall-E2's cookie, on the right, Emil Nolde, Autumn Sea XII (Blue Water, Orange Clouds), 1910. Oil on canvas.
Expressionism being a specific school of art most people know from artists like Evard Munch. But "expressive" does not mean "expressionist" in art, there's lots of art that's very expressive but is not expressionist.
V3 still makes this error, but less so, because it's understanding of English is better.
V3 seems to have focused more on the section of the prompt I underlined, attempting to represent an explosion of flavors, and that language is going to point it toward advertising aesthetics because that's where the term 'explosion of flavor' is going to come up the most.
And because sex and food use the same advertising techniques, and are used as visual metaphors for one another, there's bound to be crossover.
But when we update the prompt to ask specifically for something more like the v2 image, things change fast:
An oil painting in the expressionist style of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors, impasto, impressionism, detail from a larger work, amateur
We've moved the most important part (oil painting) to the front, put that it is in an expressionist style, added 'impasto' to tell it we want visible brush strokes, I added impressionism because the original gen had some picassoish touches and there's a lot of blurring between impressionism and expressionism, and then added "detail from a larger work" so it would be of a similar zoom-in quality, and 'amateur' because the original had a sort of rough learners' vibe.




Shown here with all four gens for full disclosure.
Boy howdy, that's a lot closer to the original image. Still higher detail, stronger light/dark balance, better textbook composition, and a much stronger attempt to look like an oil painting.
TL:DR The robot got smarter and stopped mistaking adjectives for art styles.
Also, this is just Dall-E 3, and Dall-E is not a measure for what AI image generators are capable of.
I've made this point before in this thread about actual AI workflows, and in many, many other places, but OpenAI makes tech demos, not products. They have powerful datasets because they have a lot of investor money and can train by raw brute force, but they don't really make any efforts to turn those demos into useful programs.
Midjourney and other services staying afloat on actual user subscriptions, on the other hand, may not have as powerful of a core dataset, but you can do a lot more with it because they have tools and workflows for those applications.
The "AI look" is really just the "basic settings" look.
It exists because of user image rating feedback that's used to refine the model. It tends to emphasize a strong light/dark contrast, shininess, and gloss, because those are appealing to a wide swath of users who just want to play with the fancy etch-a-sketch and make some pretty pictures.
Thing is, it's a numerical setting, one you can adjust on any generator worth its salt. And you can get out of it with prompting and with a half dozen style reference and personalization options the other generators have come up with.
As a demonstration, I set midjourney's --s (style) setting to 25 (which is my favored "what I ask for but not too unstable" preferred level when I'm not using moodboards or my personalization profile) and ran the original prompt:

3/4 are believably paintings at first glance, albeit a highly detailed one on #4, and any one could be iterated or inpainted to get even more painterly, something MJ's upscaler can also add in its 'creative' setting.
And with the revised prompt:

Couple of double cookies, but nothing remotely similar to what the original screencap showed for DE3.
*Unless you're looking at both the prompt and raw output.
original character designs vs sakimichan fanart
#ai tutorial#ai discourse#model collapse#dall-e 3#midjourney#chocolate chip cookie#impressionism#expressionism#art history#art#ai art#ai assisted art#ai myths
1K notes
·
View notes
Text
BROWNZ#1: Faszinierende digitale Bilderwelten von Peter "Brownz" Braunschmid - Jetzt erhältlich!
BROWNZ#1 Profirezepte für Kreative inkl. Rohdaten & Extras – das brandneue Videotraining von Peter Brownz Braunschmid ist nun erhältlich.Das komplette Inhaltsverzeichnis befindet sich weiter unten. Folgende Bestellmöglichkeiten gibt es:1.: Digital – Per „DropBox“ Zugang zu meinem Online Ordner mit allen Videos und Zusatzdaten für 49 Euro.2.: Klassisch auf 2 DVDs oder einem USB-Stick mit…

View On WordPress
#art#bildbearbeitung#brownz#brownzart#composing#ki#midjourney#photoshop#schulungen#tutorial#workshop
0 notes
Text
Magen David
פינת החדשות******פוליטיקה ש�� גזענות ולמה ג’ימיני, הצאצא של בארד, לא מייצג דמויות עכשיו;השבוע ג’ימיני, הבינה של גוגל, הפסיקה לייצר דימויים בגלל מחלוקת שהיא יותר מדי גזענית.ציטוט מתוך “גלובוס“שערורייה חובקת עולם ההייטק פרצה השבוע, כאשר רובוט הבינה המלאכותית של גוגל הפיק, על פי הזמנה, דמויות של שחורים במדי הצבא הנאצי במלחמת העולם השנייה.ה’ניו יורק טיימס’ דיווח, אחרים העתיקו, מנכ”ל גוגל התנצל, ותפוקת…

View On WordPress
0 notes
Text
What are some of your Midjourney tips for beginners?
This is great for learning the basics!
0 notes
Text
First off, thank you!
I can generally put together a page and a half a day this way, depending on how tricky the composition is and how devoted to it I am at the moment. Basically even-stevens with a lot of hand-drawn work, but with a mix of advantages and disadvantages.


I tend to make the process harder on myself than it needs to be.
This is partially because the datasets trend to the modern and my insistence on the look of the 60s, 70s or 80s for any given project means I'm doing a lot of reworks and tinkering. The dinosaur and battle-animal-style furry characters are harder to keep consistent than human characters, etc.
Part of it is I'm always trying to squeeze maximum results out of the tech, so every time there's a new version, my ambitions seem to inflate to match, keeping my general time-investment steady.




Human characters and more modern styles come easier to the generators, so if you're dealing with easily promptable set of character features, or ones that MJ's character reference system can make sense of, you'd probably have a much faster time producing usable raws for compositing. And fixing hairstyles and shirt-cuffs tends to be easier than fixing tusks and horns.
The areas that are difficult are things like fighting (less of a problem with stable diffusion, there's a little Cotton Mather in the major service-driven ones that imposes rules stricter than Y-7 cartoons). For Mrs. Nice kicking Wally into the time hole (as an example):



Mrs. Nice is kicking a punching bag, and Wally is slipping on the floor. The background was cobbled together from several chunks so the cave environment would be consistent.
Sometimes you have to prompt indirectly or use placeholder props to get the kinds of actions you want. It might not understand a sci-fi brainwashing chair, but it can do an electric chair made of futuristic metal. "Octopus tentacles for hair" makes hairy tentacles, so you put "tentacles coming out of her head." They aren't frozen in a block of ice, they're in a glass box that is covered in frost. That sort of thing.
It doesn't make a huge difference for my workflow, because I tend to composite characters from multiple gens in most situations. I find it, counterintuitively, makes for less stiff compositions.
The fauxtalgia-comics look, however, is just one option in hojillions. Because my techniques work on any style of art you want to use. The photoshoppery just gets more complicated for stuff that's painterly, pseudo-photocomic-y, or other.

I consider myself a nostalgia-artist (not a nostalgic artist, though I am often that. I try to make nostalgia my medium). I've got a whole deal about it, I'll get into it on its own post sometime.
But experimental and hybrid styles can produce some wild stuff, and I'm certain experimental forms are going to benefit from it.









I don't think that making or using AI art/image generation is morally wrong, as you guys know, but I have to admit that slotting a wibbly-lined low effort image selected from the first result set from Midjourney in your content is incredibly tacky. At least select something that looks good. Maybe something without the boring AI "sheen" look either.
You see this a lot in clickbaity content like web spam and youtube shorts attempting to algorithm game.
#art tutorial#ai tutorial#ai assisted art#ai comics#tyrannomax#dr. underfang#Mrs. Nice#Mrs Naultius#midjourney#Dall-e 3
1K notes
·
View notes