#mlops engineer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
MLOps Engineer (12 Better Roles And Killer Responsibilities)

Bridge the Gap: MLOps engineers bridge the gap between data science and operations, ensuring smooth transitions of machine learning models from development to real-world use.
Deployment and Management: They handle deploying models in production environments, managing their performance, and ensuring version control.
Automation Champions: Automating the machine learning workflow is a core responsibility. They build pipelines to automate tasks like data cleaning, model training, and deployment.
Collaboration is Key: MLOps engineers collaborate with data scientists, DevOps, and IT teams to ensure successful deployments, infrastructure management, and efficient resource allocation.
Monitoring and Optimization: They monitor deployed models for accuracy, drift (performance degradation), and resource utilization. They troubleshoot issues and work to optimize model performance and efficiency.
Continuous Learning: Staying up-to-date on the latest MLOps tools, frameworks, and best practices is crucial. They continuously evaluate and improve the MLOps pipeline to stay ahead of the curve.
https://aitech.studio/ai-career-options/mlops-engineer-roles/
0 notes
Text
Core Principles of MLOps
0 notes
Text
How Does MLOps Differ from DevOps?
For more details, you can read this blog. Think of DevOps as the manager of a software development factory. They oversee the entire production process, from design and development to testing and deployment, ensuring the factory runs smoothly and efficiently and consistently delivers high-quality software products.
MLOps is a specialized department in this software factory focused on producing machine learning models. MLOps engineers manage the entire lifecycle of these models, from data preparation and model training to deployment and monitoring. They collaborate closely with data scientists and developers to ensure models are built, tested, and deployed in a reliable, scalable, and maintainable manner.
While DevOps ensures the overall software development process is streamlined and efficient, MLOps specifically addresses the unique challenges and requirements of developing and deploying machine learning models. Just as a factory has different departments for producing various products, MLOps is a specialized unit within the larger DevOps ecosystem, ensuring machine learning models are built and deployed with the same rigor and reliability as other software components.
MLOps tools are designed to address the unique challenges of managing machine learning models. They include model versioning, data versioning, model registry, and model serving.
MLOps tools also provide specialized support for popular machine learning frameworks and libraries, such as TensorFlow, PyTorch, and scikit-learn. This can simplify the deployment of models in production for data scientists, as they won’t have to worry about the underlying infrastructure and deployment mechanisms. Additionally, these tools can streamline the entire process within a single platform, eliminating the need for multiple tools and systems for different parts of the workflow.
Therefore, although DevOps and MLOps share conceptual similarities, such as automation and collaboration, they differ in their scope and the tools and techniques they use.
1 note
·
View note
Text
What is MLOps? - Machine Learning Operations explained
Download our concise whitepaper on the transformative potential of Machine Learning Operations (MLOps) and how businesses can implement it in a seamless manner.
0 notes
Text
Learn Docker and kubernetes in 50+ hrs from Professionals. Join Docker Training @Bitaacademy and get your placement.

#dockers#Course#career#education#technology#engineering#itjobs#engineeringjobs#dockercontainer#dockerhub#dockerfile#dockerproducts#mlops#kubernetes#programmings#webdevelopment
0 notes
Text
Harness power to deploy and fine-tune Large Language Models on your own Infrastructure.
TrueFoundry LLMOps platform allows you to deploy the best LLMs like Llama2 and Falcon-40B to quickly drive innovation and achieve your business
1 note
·
View note
Text
Tech Skill For Computer Science Students
Technical Skills for Computer Science Students
Software Development
MERN Stack
Python-Django Stack
Ruby on Rails ( RoR )
LAMP ( Linux, Apache Server, MySql, PHP )
.Net Stack
Flutter Stack ( For mobile app )
React Native Stack ( Cross Platform mobile app development )
Java Enterprise Edition
Serverless stack - "Cloud computing service"
Blockchain Developer
Cyber Security
DevOps
MLOps
AL Engineer
Data Science
9 notes
·
View notes
Text
February Goals
1. Reading Goals (Books & Authors)
LLM Twin → Paul Iusztin
Hands-On Large Language Models → Jay Alammar
LLM from Scratch → Sebastian Raschka
Implementing MLOps → Mark Treveil
MLOps Engineering at Scale → Carl Osipov
CUDA Handbook → Nicholas Wilt
Adventures of a Bystander → Peter Drucker
Who Moved My Cheese? → Spencer Johnson
AWS SageMaker documentation
2. GitHub Implementations
Quantization
Reinforcement Learning with Human Feedback (RLHF)
Retrieval-Augmented Generation (RAG)
Pruning
Profile intro
Update most-used repos
3. Projects
Add all three projects (TweetGen, TweetClass, LLMTwin) to the resume.
One easy CUDA project.
One more project (RAG/Flash Attn/RL).
4. YouTube Videos
Complete AWS dump: 2 playlists.
Complete two SageMaker tutorials.
Watch something from YouTube “Watch Later” (2-hour videos).
Two CUDA tutorials.
One Azure tutorial playlist.
AWS tutorial playlist 2.
5. Quizzes/Games
Complete AWS quiz
2 notes
·
View notes
Text
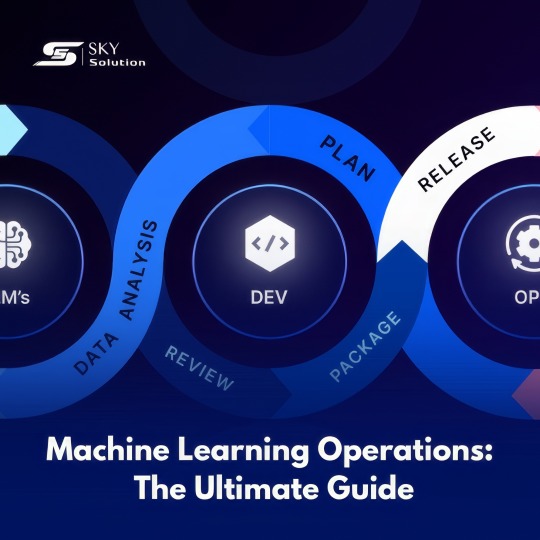
🚀 Machine Learning Operations (MLOps): The Ultimate Guide! 🚀
MLOps combines Machine Learning (ML) and IT Operations (Ops) to streamline the end-to-end ML lifecycle, ensuring efficient deployment and management of ML models in production. It bridges the gap between data scientists, engineers, and IT teams for smoother collaboration!
2 notes
·
View notes
Text
Autonomous AI Agents in the Enterprise: Tools, Tactics, and Transformation in 2025
The integration of autonomous AI agents into enterprise operations marks a significant shift in how businesses approach automation and decision-making. These agents, capable of planning, adapting, and acting with minimal human intervention, are revolutionizing industries from finance to healthcare. As organizations seek to scale these systems, understanding the practical realities of deployment, control, and governance is crucial. This article explores the evolution of autonomous AI agents, examines recent frameworks and best practices, and provides actionable insights for AI practitioners and technology leaders.
Evolution of Agentic and Generative AI in Software
Autonomous AI agents, also known as agentic AI, have evolved from experimental tools to critical components of enterprise technology. Initially, AI systems were narrowly programmed with limited adaptability. The advent of large language models (LLMs) and generative AI transformed this landscape, enabling agents to generate content, reason contextually, and interact dynamically. By 2025, autonomous AI agents have moved beyond pilots and prototypes into enterprise-critical roles. They operate with goal-driven autonomy across multiple systems and workflows, integrating with real-time structured data to reduce errors and deliver consistent outputs. Enterprises are now architecting AI agent ecosystems rather than isolated deployments, reflecting a maturity that blends AI dynamism with software engineering rigor. Developing an effective agentic AI program is central to this transformation, enabling organizations to design agents that can autonomously coordinate complex tasks across departments and systems.
Role of Generative AI
Generative AI plays a pivotal role in enhancing the capabilities of autonomous AI agents. It enables agents to generate content, improve decision-making, and adapt to new information more effectively. For instance, in creative industries, generative AI is used to create customized music tracks and art pieces, opening new revenue streams for artists and businesses. The synergy between generative AI and agentic AI programs is driving new levels of autonomy and creativity in AI workflows.
Latest Frameworks, Tools, and Deployment Strategies
LLM Orchestration and Multi-Agent Systems
Recent frameworks emphasize orchestrating multiple specialized agents rather than relying on single monolithic entities. Multi-agent system architectures enable agents to collaborate, each designed for distinct roles such as data gathering, analysis, execution, or monitoring. Hierarchical management structures with "super-agents" allow complex tasks to be decomposed and coordinated seamlessly, a key element in advanced agentic AI programs.
Leading cloud providers and platforms have introduced tools to facilitate this:
Salesforce Agentforce 2.0: Automates CRM workflows by deploying agents integrated tightly with customer data.
Microsoft Copilot Agents: Embed AI agents across Office applications, orchestrating tasks from email triage to report generation.
Google Cloud Agentspace: Provides unified orchestration for distributed AI agents across cloud environments.
These platforms also support no-code approaches, allowing business users to deploy AI agents using no-code interfaces that democratize automation and accelerate adoption without deep programming expertise.
MLOps for Generative Models
Scaling generative AI agents demands robust MLOps practices tailored for continuous training, model versioning, and deployment monitoring. Enterprises invest in pipelines that support:
Data curation optimized for inference accuracy.
Policy-driven governance to ensure compliance and auditability.
Infrastructure compatible with multi-agent coordination protocols (MCP), enabling context sharing among agents.
Implementing an agentic AI program with integrated MLOps ensures seamless updates and reliability in production environments, especially when deploying AI agents using no-code tools that require automated governance and monitoring.
Deployment Strategies
Successful deployment strategies often start with high-volume, rule-based processes such as customer service or data entry, where outcomes are measurable and risks manageable. From there, enterprises expand into more complex decision-making scenarios, layering autonomy incrementally while maintaining human oversight where necessary. Leveraging generative AI professional courses in Mumbai and other global hubs can help upskill teams to handle these sophisticated deployments effectively.
Advanced Tactics for Scalable, Reliable AI Systems
Designing for Modularity and Resilience
Large-scale autonomous agent systems require modular designs to isolate failures and enable independent updates. Microservices architectures combined with container orchestration (e.g., Kubernetes) provide elasticity and fault tolerance. This architectural approach is integral to a mature agentic AI program that supports continuous evolution and scaling.
Real-Time Data Integration
Autonomous agents depend on a unified data foundation that delivers curated, consistent, and real-time data streams across systems. Without this, agents suffer from disconnected context and hallucinations, undermining reliability. Deploying AI agents using no-code platforms benefits from underlying robust data pipelines that ensure real-time synchronization and governance.
Policy-Based Governance and Compliance
Embedding governance as code ensures that AI agents operate within defined ethical, legal, and operational boundaries. This includes lineage tracking, access controls, and automated compliance checks integrated into deployment pipelines. Incorporating these policies early in an agentic AI program reduces risks and ensures regulatory adherence.
Continuous Learning and Feedback Loops
Agents must evolve with changing business conditions. Establishing feedback loops from production results back to model retraining pipelines is essential for sustained accuracy and relevance. Generative AI professional courses in Mumbai often emphasize these feedback mechanisms to train practitioners in best practices for continuous improvement.
Ethical Considerations in Autonomous AI Deployment
As autonomous AI agents become more pervasive, ethical considerations become increasingly important. These include:
Bias Mitigation: Ensuring that AI models are free from bias and discrimination is critical. This involves diverse data sets and regular model audits.
Privacy and Security: Protecting user data and ensuring the security of AI systems against adversarial attacks is paramount.
Transparency and Explainability: Providing clear explanations for AI-driven decisions helps build trust and accountability.
An agentic AI program must embed these ethical principles into design and deployment phases to foster responsible AI use.
The Role of Software Engineering Best Practices
Scaling autonomous AI agents is as much a software engineering challenge as an AI one. Best practices that underpin reliability, security, and maintainability include:
Version Control and CI/CD: Managing AI models, configurations, and code with robust versioning and automated deployment pipelines.
Observability: Implementing comprehensive logging, tracing, and metrics to monitor agent behavior and performance.
Security Hardening: Protecting data pipelines and agent execution environments against adversarial inputs and unauthorized access.
Testing and Validation: Beyond unit tests, employing simulation environments and adversarial testing to validate agent decision-making under diverse scenarios.
Scalability Engineering: Leveraging cloud-native patterns such as autoscaling, load balancing, and distributed caching to handle variable workloads.
These practices ensure that AI agents integrate seamlessly with existing enterprise systems and meet organizational standards for quality and risk management, a core focus in any agentic AI program.
Cross-Functional Collaboration for AI Success
Deploying autonomous AI agents at scale requires collaboration across multiple disciplines:
Data Scientists and ML Engineers develop and fine-tune models.
Software Engineers and DevOps build scalable, secure infrastructure and deployment pipelines.
Business Stakeholders define objectives, constraints, and success metrics.
Compliance and Security Teams embed governance frameworks.
A shared language and aligned goals are critical. Regular cross-functional syncs and integrated tooling help break down silos, ensuring that AI agents deliver measurable business value while adhering to operational constraints. Training through generative AI professional courses in Mumbai can strengthen these collaborative capabilities.
Measuring Success: Analytics and Monitoring
Effective scaling mandates comprehensive analytics and monitoring to track:
Agent Performance: Accuracy, latency, and success rates in task completion.
Operational Metrics: Resource utilization, error rates, and throughput.
Business Impact: Productivity gains, cost reductions, and customer satisfaction improvements.
Advanced dashboards integrate telemetry from agent orchestration platforms and business systems, enabling real-time insights and proactive troubleshooting. Continuous measurement supports iterative improvement and justifies further investment, a critical aspect of any agentic AI program.
Case Study: Autonomous AI Agents at a Leading Financial Services Firm
Background
A top-tier financial services company sought to automate its accounts payable and receivable operations, a process historically prone to delays and errors. Their goal was to reduce manual effort, accelerate payment cycles, and enhance compliance.
Implementation
The firm adopted a multi-agent system architecture as part of its agentic AI program:
Invoice Processing Agent: Extracted and validated invoice data using generative AI models.
Payment Approval Agent: Assessed payment legitimacy against policy rules and flagged exceptions.
Reconciliation Agent: Matched payments with accounting records and generated audit trails.
These agents operated on a unified data platform integrating ERP systems, banking APIs, and compliance databases. Policy-based governance ensured auditability and regulatory adherence. Deployment leveraged containerized microservices orchestrated via Kubernetes, with automated CI/CD pipelines for model updates. Real-time monitoring dashboards tracked agent accuracy and cycle times. The firm also empowered business users to deploy AI agents using no-code tools, accelerating adoption and iterative enhancements.
Challenges
Initial models struggled with diverse invoice formats and unstructured data, requiring iterative data augmentation and fine-tuning.
Cross-system data latency caused occasional synchronization issues, resolved by implementing event-driven data pipelines.
Governance workflows needed refinement to balance automation speed with human oversight in high-risk scenarios.
Outcomes
Invoice processing accuracy exceeded 90%, reducing manual reviews by 75%.
Payment cycle time dropped by 50%, improving vendor relations.
Compliance incidents decreased due to automated audit trails and policy enforcement.
The project scaled from a pilot in one region to enterprise-wide adoption within 18 months, inspiring similar autonomous agent initiatives in HR and procurement.
Additional Case Studies and Applications
Education Sector
Autonomous AI agents are revolutionizing education through adaptive learning systems. These systems personalize learning experiences for students, enhancing engagement and outcomes. The global adaptive learning market is projected to reach $4.6 billion by 2027, growing at a CAGR of 22.2%. These educational platforms often incorporate agentic AI programs to tailor content dynamically and improve student outcomes.
Public Services
In public services, autonomous AI is used to improve government operations. For instance, AI-powered chatbots provide citizens with personalized support, reducing response times and increasing citizen satisfaction. Deploying AI agents using no-code solutions accelerates implementation in resource-constrained environments.
Creative Industries
The creative industries benefit from autonomous AI in content creation. Companies like Amper Music use AI to generate customized music tracks, opening new revenue streams for musicians and enabling businesses to produce high-quality music content efficiently. These innovations stem from integrating generative AI capabilities within agentic AI programs.
Healthcare
In healthcare, autonomous AI agents are transforming operations by reducing administrative burdens and improving diagnostics. For example, AI agents automate clinical documentation, freeing physicians to focus on patient care. Healthcare organizations increasingly utilize generative AI professional courses in Mumbai and worldwide to train staff on these technologies.
Actionable Tips and Lessons Learned
Start Small, Scale Gradually: Begin with well-defined, high-volume tasks before expanding agent autonomy to complex decisions.
Invest in Data Foundations: Unified, high-quality, real-time data is the bedrock of reliable agent operation.
Embrace Multi-Agent Architectures: Decompose workflows into specialized agents to improve maintainability and performance.
Integrate Governance Early: Build compliance and auditability into agent design, not as an afterthought.
Prioritize Observability: Implement end-to-end monitoring to detect failures early and understand agent behavior.
Foster Cross-Functional Teams: Align data scientists, engineers, and business leaders around shared goals and metrics.
Plan for Continuous Learning: Establish feedback mechanisms that feed production insights back into model improvements.
Leverage Cloud-Native Tools: Use container orchestration, scalable storage, and serverless compute to handle dynamic workloads.
Utilize No-Code Deployment: Deploy AI agents using no-code platforms to accelerate innovation and democratize access.
Engage in Professional Training: Enroll in generative AI professional courses in Mumbai or other centers to build expertise in agentic AI programs.
Conclusion
2025 marks a pivotal year for autonomous AI agents as they transition from experimental to enterprise-critical technology. Scaling these systems requires rigorous software engineering, robust data infrastructure, and strategic governance. By adopting multi-agent architectures, investing in unified data pipelines, and fostering cross-disciplinary collaboration, organizations can unlock substantial productivity gains and operational efficiencies. The path is complex but navigable, as evidenced by real-world successes in finance, HR, and beyond. For AI practitioners and technology leaders, the imperative is clear: build scalable, reliable, and governed autonomous AI agent ecosystems now to stay competitive in this new era of intelligent automation. Embedding an agentic AI program, leveraging no-code deployment, and investing in generative AI professional courses in Mumbai are key strategic moves to lead this transformation.
0 notes
Text
IT Operations: A Landscape Shaped By Innovative AIOps Tools

AIOps Overview: AIOps, a novel strategy harnessing AI and machine learning, is reshaping the IT landscape by automating processes and enhancing system performance13.
Role in IT Operations: AIOps plays a fundamental role in managing IT systems efficiently, offering automation and improved supervision to enhance operations13.
Benefits of AIOps: The horizon of AIOps is filled with benefits like increased effectiveness, speed, and innovation in IT operations, signaling a transformative shift in managing IT ecosystems13.
Machine Learning Integration: AIOps leverages machine learning and data science to enhance IT procedures, automate processes, and provide proactive solutions for potential issues13.
Future Prospects: The future of AIOps looks promising with advancements in machine learning routines, integration with technologies like IoT and cloud computing, and the ability to predict and prevent complex IT malfunctions13.
Use Cases: AIOps showcases its worth through streamlined incident administration, continuous monitoring, anomaly detection, predictive analytics, root cause analysis, and more across various industries23.
Market Growth: The adoption of AIOps is on the rise, with significant investments expected in the coming years as organizations aim to enhance their digital experiences and streamline IT operations3.
Implementation Challenges: Implementing AIOps requires overcoming common barriers, creating a business case, selecting suitable tools, developing rollout plans, and engaging employees for successful integration
https://aitech.studio/aih/aii/aitool/it-operations/
0 notes
Text
Components of MLOps
0 notes
Text
From ETL to AI Agents: How AI Is Transforming Data Engineering

For decades, the core of data engineering revolved around ETL (Extract, Transform, Load). Data engineers were the master builders of complex pipelines, meticulously crafting code and configurations to pull data from disparate sources, clean and reshape it, and load it into data warehouses or lakes for analysis. This was a critical, yet often manual and maintenance-heavy, endeavor.
But as of 2025, the data landscape is exploding in complexity, volume, and velocity. Traditional ETL, while still foundational, is no longer enough. Enter Artificial Intelligence, particularly the burgeoning field of AI Agents. These are not just algorithms that automate tasks; they are autonomous programs that can understand context, reason, make decisions, and execute complex operations without constant human intervention, fundamentally transforming the very essence of data engineering.
The Era of Manual ETL: Necessary, but Challenging
Traditional data engineering faced several inherent challenges:
Manual Overhead: Building and maintaining pipelines for every new data source or transformation was a laborious, code-intensive process.
Scalability Issues: Adapting pipelines to handle ever-increasing data volumes and velocities often meant significant re-engineering.
Error Proneness: Manual coding and rule-based systems were susceptible to human error, leading to data quality issues.
Rigidity: Responding to schema changes or new business requirements meant significant rework, slowing down time-to-insight.
Bottlenecks: Data engineers often became bottlenecks, with other data professionals waiting for their support to access or prepare data.
The AI Revolution: Beyond Automated ETL to Autonomous Data
AI's role in data engineering is evolving rapidly. It's no longer just about using AI for data analysis; it's about leveraging AI as an agent to actively manage and optimize the data infrastructure itself. These AI agents are imbued with capabilities that elevate data engineering from a purely operational function to a strategic, self-optimizing discipline.
How AI Agents are Reshaping Data Engineering Operations:
Intelligent ETL/ELT Orchestration & Optimization: AI agents can dynamically analyze data workloads, predict peak times, and adjust resource allocation in real-time. They can optimize query execution plans, identify inefficient transformations, and even rewrite parts of a pipeline to improve performance. This leads to truly self-optimizing data flows, ensuring efficiency and reducing cloud costs.
Automated Data Quality & Cleansing: One of the most tedious tasks is data quality. AI agents continuously monitor incoming data streams, automatically detecting anomalies, inconsistencies, missing values, and data drift. They can suggest, and in many cases, automatically apply cleansing rules, resolve data conflicts, and flag critical issues for human review, significantly enhancing data reliability.
Smart Schema Evolution & Management: Data schemas are rarely static. AI agents can intelligently detect schema changes in source systems, analyze their impact on downstream pipelines, and automatically propose or even implement schema adjustments in data lakes and warehouses. This proactive adaptation minimizes disruptions and ensures data compatibility across the ecosystem.
Enhanced Data Governance & Security: AI agents can act as vigilant guardians of your data. They monitor data access patterns, identify unusual or unauthorized data usage, and automatically enforce granular access controls and compliance policies (e.g., masking sensitive PII in real-time). This significantly bolsters data security and simplifies regulatory adherence.
MLOps Integration & Feature Engineering Automation: For data engineers supporting Machine Learning Operations (MLOps), AI agents are a game-changer. They can monitor the health of data pipelines feeding ML models, detect data drift (where incoming data deviates from training data), and automatically trigger model retraining or alert data scientists. Furthermore, AI can assist in automated feature engineering, exploring and suggesting new features from raw data that could improve model performance.
Proactive Anomaly Detection & Self-Healing Pipelines: Imagine a pipeline that can fix itself. AI agents can analyze logs, performance metrics, and historical patterns to predict potential pipeline failures or performance degradation before they occur. In many instances, they can even initiate self-healing mechanisms, rerouting data, restarting failed components, or escalating issues with detailed diagnostics to human engineers.
The Benefits: A New Era of Data Agility
This transformation delivers tangible benefits:
Unprecedented Efficiency & Speed: Faster data delivery to analysts and business users, enabling quicker insights and more agile decision-making.
Higher Data Quality & Reliability: Automated, continuous monitoring and remediation lead to more trustworthy data.
Greater Agility & Adaptability: Data infrastructure becomes resilient and responsive to evolving business needs and data sources.
Significant Cost Reduction: Optimized resource usage and reduced manual intervention translate to lower operational expenditures.
Empowered Data Professionals: Data engineers are freed from repetitive, low-value tasks, allowing them to focus on complex architectural challenges, strategic planning, and innovation.
The Evolving Role of the Data Engineer
This shift doesn't diminish the role of the data engineer; it elevates it. The focus moves from purely building pipes to designing, overseeing, and fine-tuning intelligent data ecosystems. Future-ready data engineers will need:
An understanding of AI/ML fundamentals and MLOps.
Skills in evaluating, integrating, and even "prompting" AI agents.
A strong grasp of data governance and ethical AI principles.
An architectural mindset, thinking about scalable, autonomous data platforms.
Enhanced collaboration skills to work seamlessly with AI agents and data scientists.
The transition from traditional ETL to AI-powered data management is one of the most exciting shifts in the technology landscape. AI agents are not replacing data engineers; they are augmenting their capabilities, making data engineering more intelligent, efficient, and strategic. For organizations and professionals alike, embracing this AI-driven evolution is key to unlocking the full potential of data in the years to come.
0 notes
Text
MLOps and DevOps: Why Data Makes It Different
In today’s fast-evolving tech ecosystem, DevOps has become a proven methodology to streamline software delivery, ensure collaboration across teams, and enable continuous deployment. However, when machine learning enters the picture, traditional DevOps processes need a significant shift—this is where MLOps comes into play. While DevOps is focused on code, automation, and systems, MLOps introduces one critical variable: data. And that data changes everything.
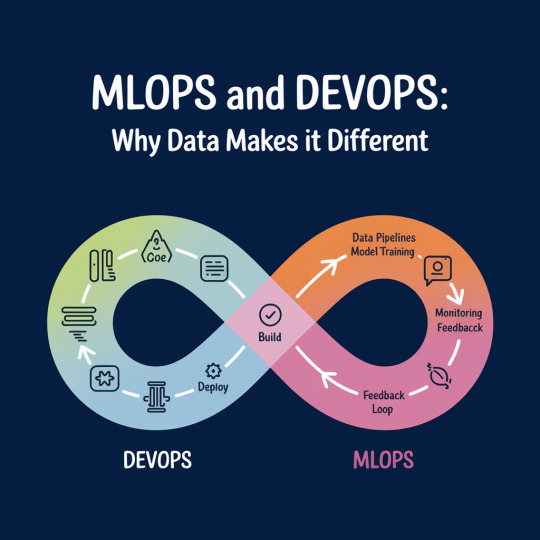
To understand this difference, it's essential to explore how DevOps and MLOps operate. DevOps aims to automate the software development lifecycle—from development and testing to deployment and monitoring. It empowers teams to release reliable software faster. Many enterprises today rely on expert DevOps consulting and managed cloud services to help them build resilient, scalable infrastructure and accelerate time to market.
MLOps, on the other hand, integrates data engineering and model operations into this lifecycle. It extends DevOps principles by focusing not just on code, but also on managing datasets, model training, retraining, versioning, and monitoring performance in production. The machine learning pipeline is inherently more experimental and dynamic, which means MLOps needs to accommodate constant changes in data, model behavior, and real-time feedback.
What Makes MLOps Different?
The primary differentiator between DevOps and MLOps is the role of data. In traditional DevOps, code is predictable; once tested, it behaves consistently in production. In MLOps, data drives outcomes—and data is anything but predictable. Shifts in user behavior, noise in incoming data, or even minor feature drift can degrade a model’s performance. Therefore, MLOps must be equipped to detect these changes and retrain models automatically when needed.
Another key difference is model validation. In DevOps, automated tests validate software correctness. In MLOps, validation involves metrics like accuracy, precision, recall, and more, which can evolve as data changes. Hence, while DevOps teams rely heavily on tools like Jenkins or Kubernetes, MLOps professionals use additional tools such as MLflow, TensorFlow Extended (TFX), or Kubeflow to handle the complexities of model deployment and monitoring.
As quoted by Andrej Karpathy, former Director of AI at Tesla: “Training a deep neural network is much more like an art than a science. It requires insight, intuition, and a lot of trial and error.” This trial-and-error nature makes MLOps inherently more iterative and experimental.
Example: Real-World Application
Imagine a financial institution using ML models to detect fraudulent transactions. A traditional DevOps pipeline could deploy the detection software. But as fraud patterns change weekly or daily, the ML model must learn from new patterns constantly. This demands a robust MLOps system that can fetch fresh data, retrain the model, validate its accuracy, and redeploy—automatically.
This dynamic nature is why integrating agilix DevOps practices is crucial. These practices ensure agility and adaptability, allowing teams to respond faster to data drift or model degradation. For organizations striving to innovate through machine learning, combining agile methodologies with MLOps is a game-changer.
The Need for DevOps Transformation in MLOps Adoption
As companies mature digitally, they often undergo a DevOps transformation consulting journey. In this process, incorporating MLOps becomes inevitable for teams building AI-powered products. It's not enough to deploy software—businesses must ensure that their models remain accurate, ethical, and relevant over time.
MLOps also emphasizes collaboration between data scientists, ML engineers, and operations teams, which can be a cultural challenge. Thus, successful adoption of MLOps often requires not just tools and workflows, but also mindset shifts—similar to what organizations go through during a DevOps transformation.
As Google’s ML Engineer D. Sculley stated: “Machine Learning is the high-interest credit card of technical debt.” This means that without solid MLOps practices, technical debt builds up quickly, making systems fragile and unsustainable.
Conclusion
In summary, while DevOps and MLOps share common goals—automation, reliability, and scalability—data makes MLOps inherently more complex and dynamic. Organizations looking to build and maintain ML-driven products must embrace both DevOps discipline and MLOps flexibility.
To support this journey, many enterprises are now relying on proven DevOps consulting services that evolve with MLOps capabilities. These services provide the expertise and frameworks needed to build, deploy, and monitor intelligent systems at scale.
Ready to enable intelligent automation in your organization? Visit Cloudastra Technology: Cloudastra DevOps as a Services and discover how our expertise in DevOps and MLOps can help future-proof your technology stack.
0 notes
Text
youtube
ML Workflow: Define, Train, Deploy - Your Complete Guide Our guide covers the essential steps: Define a clear problem, gather & clean data, engineer features, train & evaluate models, and deploy for real-world impact. We'll show you how to build your first demo! Download the sample notebook. #MachineLearning #MLWorkflow #DataScience #ModelTraining #DataCleaning #FeatureEngineering #DeepLearning #MLOps #PythonTutorial #AI https://www.youtube.com/shorts/SxULwWgXZhw via Tech AI Vision https://www.youtube.com/channel/UCgvOxOf6TcKuCx5gZcuTyVg June 26, 2025 at 09:01PM
#ai#aitechnology#innovation#generativeai#aiinengineering#aiandrobots#automation#futureoftech#echaivision#Youtube
0 notes
Text
Developing and Deploying AI/ML Applications on Red Hat OpenShift AI (AI268)
As artificial intelligence and machine learning (AI/ML) become integral to digital transformation strategies, organizations are looking for scalable platforms that can streamline the development, deployment, and lifecycle management of intelligent applications. Red Hat OpenShift AI (formerly Red Hat OpenShift Data Science) is designed to meet this exact need—providing a powerful foundation for operationalizing AI/ML workloads in hybrid cloud environments.
The AI268 course from Red Hat offers a hands-on, practitioner-level learning experience that empowers data scientists, developers, and DevOps engineers to work collaboratively on AI/ML solutions using Red Hat OpenShift AI.
🎯 Course Overview: What is AI268?
Developing and Deploying AI/ML Applications on Red Hat OpenShift AI (AI268) is an intermediate-level training course that teaches participants how to:
Develop machine learning models in collaborative environments using tools like Jupyter Notebooks.
Train, test, and refine models using OpenShift-native resources.
Automate ML workflows using pipelines and GitOps.
Deploy models into production using model serving frameworks like KFServing or OpenVINO.
Monitor model performance and retrain based on new data.
🔧 Key Learning Outcomes
✅ Familiarity with OpenShift AI Tools Get hands-on experience with integrated tools like JupyterHub, TensorFlow, Scikit-learn, PyTorch, and Seldon.
✅ Building End-to-End Pipelines Learn to create CI/CD-style pipelines tailored to machine learning, supporting repeatable and scalable workflows.
✅ Model Deployment Strategies Understand how to deploy ML models as microservices using OpenShift AI’s built-in serving capabilities and expose them via APIs.
✅ Version Control and Collaboration Use Git and GitOps to track code, data, and model changes for collaborative, production-grade AI development.
✅ Monitoring & Governance Explore tools for observability, drift detection, and automated retraining, enabling responsible AI practices.
🧑💻 Who Should Take AI268?
This course is ideal for:
Data Scientists looking to move their models into production environments.
Machine Learning Engineers working with Kubernetes and OpenShift.
DevOps/SRE Teams supporting AI/ML workloads in hybrid or cloud-native infrastructures.
AI Developers seeking to learn how to build scalable ML applications with modern MLOps practices.
🏗️ Why Choose Red Hat OpenShift AI?
OpenShift AI blends the flexibility of Kubernetes with the power of AI/ML toolchains. With built-in support for GPU acceleration, data versioning, and reproducibility, it empowers teams to:
Shorten the path from experimentation to production.
Manage lifecycle and compliance for ML models.
Collaborate across teams with secure, role-based access.
Whether you're building recommendation systems, computer vision models, or NLP pipelines—OpenShift AI gives you the enterprise tools to deploy and scale.
🧠 Final Thoughts
AI/ML in production is no longer a luxury—it's a necessity. Red Hat OpenShift AI, backed by Red Hat’s enterprise-grade OpenShift platform, is a powerful toolset for organizations that want to scale AI responsibly. By enrolling in AI268, you gain the practical skills and confidence to deliver intelligent solutions that perform reliably in real-world environments.
🔗 Ready to take your AI/ML skills to the next level? Explore Red Hat AI268 training and become an integral part of the enterprise AI revolution.
For more details www.hawkstack.com
0 notes