
Statistics
We looked inside some of the posts by apecode-blog and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
24 hours
Number of Posts By Type
Text
7
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
什么样的工具,让马蜂窝能完成1800万次抄袭?
这篇题为《独家|估值175亿的旅游独角兽,是一座僵尸和水军构成的鬼城?》的文章,爆了一个大猛料。
估值约175亿人民币的独角兽公司马蜂窝21,000,000(别数了,两千一百万条)点评,其中有1800万条是从别的网站搬运而来的。抄袭来源包括且不限于携程、艺龙(都是友商)、穷游(这是直接竞品)、AGENDA(这也是竞品)、美团、大众点评(无辜躺枪)、Yelp(国外点评无辜躺枪)等多家点评与OTA网站。
不仅如此,文章中还提到,马蜂窝不仅抄袭,并且还造假。
许多官方抽奖活动,最终获奖者几乎都是马蜂窝内部员工或虚假账号,一个长期搬运内容的账号,竟然连续中奖12次。 本来说好的大奖,最后全变成了内部福利。这个操作实在是让人佩服~
而今早,马蜂窝官方也正式回应称,此事是有组织的进攻。
如果文章内容属实,那么这家成立八年之久,在无数驴友中颇具影响力的旅行攻略内容社区,也算是践行了自己的slogan——
自己办不到的,拿来就好。
不过,我在看完这篇文章的时候,比起文章的内容,更让我好奇的是:马蜂窝究竟是如何把这么多内容搬运到自己这里的?
毕竟,按照作者的说法,马蜂窝抄袭了1800万条点评,那么意味着,平均每天要搬运6600多条记录,这还不算问答和攻略,而且是在全年无休的情况下才能实现。全靠人力的话,马蜂窝整个公司啥都不用干了,天天Ctrl C+V就好了。
所以,这肯定是工具化解决。
三节课作为一家倡导“行胜于言”、“少空谈扯淡、多动手实操”的互联网人在线大学,一向喜欢基于具体的业务实践来对一些产品的新动向进行调研和分析,给从业者提供借鉴与参考。
今天,我们也立足于真实的业务场景,和大家谈一个互联网中非常重要,但又引发无数争议的工具——爬虫。
一、什么是爬虫?
你有没有用过抢票软件?
每当春运或者节假日期间,我们总能看到各种抢票软件在微信群中疯转。大家求爷爷告奶奶一般,希望你能帮忙点个加速,好能够早一��买到归家或旅行的车票。
但无论你如何努力,往往总是直到最后千钧一发之刻,才能拿到前往远方的车票。
这个让你可能又爱又恨的抢票软件,它的技术原理就是爬虫。
所谓爬虫,如果从技术原理上讲,它就是一个高效的下载工具,能够批量将网页下载到本地,留作备份。如果结合一些其他工具和算法,就能够实现,收集同一类型的网页,重复执行同一动作等行为。
简单讲,就是通过技术和算法模拟一个人在网络上的行为,像人一样点网页,像人一样下订单,只不过,相比起真人,他的效率高的异常。
它的工作状态有些像蚁群,每个蚂蚁的工作任务都非常简单,但是,当一大群蚂蚁重复相同的工作的时候,就能产生超乎寻常的效果。
比如说,如果你需要把全网关于某个关键词的网站全部收集汇总到一起(比如:三节课),这时,就是爬虫挨个查找所有关于三节课的信息,呈现到你的面前。
再比如说,当你想要找到12306中,某天所有北京到上海的余票,爬虫就可以帮助你不停地刷新网页,直到出现那张可以带你出发的车票。
在互联网世界,所有收集信息的过程,都离不开爬虫的参与。可以这样说,没有爬虫,就没有互联网。
▲ 图片来源网络
二、爬虫的善与恶
爬虫也分善恶。
爬虫最为广泛,也使人受益最大的应用就是搜索引擎。
现在,几乎所有有一定体量的app,都会有一个搜索框,通过搜索框,你可以查找到各种你需要的信息和内容,这是爬虫对人最大的价值。同时,也是支撑起谷歌近万亿美元市值的工具之一。
但是,并不会是所有的爬虫都像谷歌这样你好我好大家好,反而真的会像虫子一样惹人烦恼。
▲ 图片来源网络
上面这张图,显示了爬虫流量的主要去向,每个色块背后,都是一个真实而又强大的利益链条。这些流量的去向,就不再充满善意,更多情况下,是生长在灰色地带。
这些爬虫,或是为了一己私利,或是出于某些商业利益,对某一款app疯狂的骚扰,甚至影响了正常业务发展。这些爬虫,就是恶意的爬虫(虽然恶意,对于消费者来说可能并不是坏事,这里的恶意主要是指对被爬网站的恶意)。
接下来,我们��展示一下那些恶意爬虫应用,以及这些应用都是怎么赚钱的?
▌ 刷票软件
12306常年饱受爬虫软件的骚扰。
许多刷票软件,通过加价,或者要求分享转发的方式,帮助你买票,进而实现收入或者用户的增长。
这个看起来并不复杂的行为,其实带给12306巨大的压力。
你知道每年过年之前,12306 被点成什么样了吗?公开数据是这么说的——
“最高峰时1天内页面浏览量达813.4亿次,1小时最高点击量59.3亿次,平均每秒164.8万次。”
在每秒164.8万次点击背后,不仅是全国人民急切的回家之心,还有无数刷票软件带来的天量点击。
你可能还记得,前两年12306上线了奇葩的验证码,需要我们在一堆图片中,找到符合要求的一种。图片清晰度感人,要求奇葩,时不时会闹出各种各样的笑话。还有许多人在网上吐槽12306是不是故意刁难我们?
▲ 为推广传统文化,12306不遗余力
说实话,这真不是12306故意刁难我们,实在是饱受爬虫骚扰之后的无奈之举。许多人利用爬虫技术反复登录刷新,力求在新的余票出现之时,第一时间抢到票。
为了尽可能避免这种情况,尽可能让真人买到票,12306才不得不上线这些奇葩的验证码。许多爬虫只有最简单的点击和收集数据的能力,并不能识别图片,绝大多数爬虫都会被拦截。
但是,还是会有少部分的高阶玩家,攻破这道防线。
有一种东西叫做“打码平台”,你可以了解一下。
打码平台雇佣了很多叔叔阿姨,他们在电脑屏幕前不做别的事情,专门帮人识别验证码。
那边抢票软件遇到了验证码,系统就会自动把这些验证码传到叔叔阿姨面前,他们手工选好之后,然后再把结果传回去。总共的过程用不了几秒时间。
而且,这样的打码平台还有记忆功能。如果叔叔阿姨已经标记了某张图,那么下次这张图片再出现的时候,系统就直接判断。
时间一长,12306 系统里的图片就被标记完了,机器自己都能认识,叔叔阿姨都可以坐在一边斗地主了。
即使如此,还是做到了每秒164.8万次点击,如果没有这层防火墙,数量更是难以想象。
你可能会问,就算用了刷票软件又如何,抢到票不就好了?
且不说刷票软件带来的巨大的流量压力,需要为此多付出的服务器成本。为了防范刷票,不得不将注册和验证流程越搞越烦琐,平���无数烦恼。
而且,你用抢票软件买到了票,那么,不会使用抢票软件的叔叔阿姨们又该怎么办呐?
所以,这事不是你方便了就好。
▌ 僵尸粉大军
在微博上有一类粉丝,叫做“僵尸粉”。
我们经常能够看到一些微博名称中带着一长串数字,没有头像,却疯狂的转发一些热门评论,或者疯狂对着一个微博点赞转发,点开主页却一条微博都没有。这些没有头像,以数字命名的微博粉丝,就是僵尸粉。
它们按时上班,找到某个人的微博,疯狂的点赞留言转发关注,造成一种火热的幻觉。
僵尸粉的兴起,与爬虫也离不开关系。
就像我们说的,爬虫是模仿真人的行为,但是,只能模仿最简单的行为,比如说,按照事先安排好的文案和进行评论,再比如说,点赞转发加关注。所以,如果只看数据,不仔细分辨,往往能够瞒天过海。
许多僵尸粉每天日夜辛劳,刷赞刷评论刷关注,为微博的活跃数据添砖加瓦,贡献一份力量。
可是,微博不像是12306,可以靠买票赚钱,刷量又有什么用呐?
用处大了。
你是一个萌新用户,用爬虫伪造出10万粉丝,按时按点互动点赞留言。
广告主看到数据很开心,在你这里投放广告,提升注册数。可是你这都是爬虫的假账号,没有真人该咋办呐?
没事,你找不来人没关系,有爬虫啊。你有十万个爬虫账号,可以匀出一万来,点击注册账户,刷刷刷把数据刷上去,躺着就把钱赚了。。
再不济,有一个看起来火热的号,还可以乘着机会早日卖掉,这也换来一波不菲的收入。
最后,你还能靠买清粉工具再赚一波。
别人只是一石二鸟,你可能是一鱼三吃,实在是佩服。
而且,微博官方对这事其实心知肚明,只不过睁一只眼,闭一只眼罢了,毕竟,有了僵尸粉,数据还好看很多,何乐而不为呐?
▌ 返利电商刷低价
不知道你还记不记得有一���网站叫“聚合电商”“返利平台”等等等等。
这些网站,也是爬虫工具的受益者,它的基本原理和搜索引擎类似。
搜索引擎是将网页爬取过来,聚合在一起展示出来。
返利网站是将商品爬取出来, 聚合在一起展示出来,顺道把不同网站的商品做一个比价。
当然,无论是淘宝还是京东,对于这件事都是拒绝的,毕竟,谁也没法保证自己的每件商品就是全网最低价。如果都被返利网站展示出来,岂不就亏了。
不过,对于店铺来说,可能就不一样了,毕竟,多一个渠道就多一份销售额,在哪卖不是卖啊。
这类网站,原理和搜索引擎接近,盈利模式也差不多。
一方面,他们经常会设置竞价排名,通过花更多钱,获得更好的广告位,提升销售额。
如果觉得竞价排名良心过意不去,你还可以设置独立广告位,点击一次转一次的钱。
不过,最大头的收入还是做中间商,店铺每成交一单,店家适当给平台一些返利。
对于消费者来说,这可能不算什么坏事,不过,对于电商平台来说,可能不算好事,毕竟这些店铺能来网上卖货都是靠他们的努力,平白无故就被你抓取了,最后钱还让你赚走了,心情肯定不好。
▌ 社区批量抓取数据和内容
再有一类,就是文章开头提到的马蜂窝一类的网站。
其实,许多社区产品中的内容,大多数都是爬虫爬取而来,除了像马蜂窝,许多问答、文库或招聘网站都会通过爬虫获取内容。
毕竟,好内容自带流量,当你有了足够多的优质内容,也就有了足够大的流量,变现就很轻松了。
对此,被爬网站有时候也是睁一只眼,闭一只眼,管不管,全在于自己有没有这项业务。
最典型的例子就是领英,领英在2017年曾经将一家名为HiQ的数据分析企业告上法庭,原因是认定这家企业抓取领英用户的就职状态信息,提供给另外两家利用机器学习分析员工跳槽倾向和职业技能的企业。
结果却是即使打着保护用户隐私的旗号,领英仍然败诉并且被联邦法庭要求开放数据接口。
原因是HiQ已经这样爬取领英的数据长达五年,领英一直知情并且曾经去参加过HiQ组织的论坛峰会。如今领英自己开展了和HiQ类似的业务,就要断了HiQ的生路。
这和大多数网站对待爬虫的态度都很接近,当你规模不大,或者我还不准备做你这块的生意时,可以纵容你爬取我的信息,一定程度上,这个爬取过程还能提高我的受益。
但是,一旦超出我的承受范围,就要采取必要手段反击。
以上,就是爬虫常见的一些骚操作,说实话,这也只是窥其一角,爬虫在整个互联网中的应用,远超你的想象。
政务网站、搜索引擎、地图、自媒体等等等等一系列火热的应用,背后都有爬虫的身影,这也是为什么我们说,没有爬虫,就没有互联网。
三、爬虫二三问
说了关于爬虫的应用,关于爬虫,你可能还有些问题需要讨论一下。
▌ 这事违法吗?
大多数并不会。
目前尚没有任何法律明确规定,类似爬虫这样的行为违法。
即使是马蜂窝,你可以说他侵权,但是,如果他将自己定位以为平台的话,那些将其它网站内容放在马蜂窝的行为,其实也是用户自发,与平台无关。
毕竟,���像我们说的,爬虫毕竟也只是模仿人的行为,难道,你要因为一个人或一群人点击次数过于密集而惩罚他吗?
所以,爬虫本身并不违法。但是,你如何使用爬虫获取的数据和信息,大多数情况都是有明确的规定的。
比如说,你将别人有明确版权的文章或者图片爬取出来,作为商用,这无疑是侵权行为,我当然可以告你。
再比如说,你爬取一些个人隐私数据,公开买卖,也是违法行为,我也是可以处理的。
所以——
▌ 我究竟应该如何看待爬虫?
对于个人而言,爬虫作为高效的信息和数据获取工具,一定是互联网人的必备技巧,他将大幅节省你的时间,极大程度提高你的工作效率。
举个最简单的例子,作为一个新媒体从业者,我会把一些我喜欢的公众号文章通过爬虫爬取下来,进行分析对比,这要比我一篇一篇的看效率高多了。
比如说竞品分析、行业研究、人群画像等工作,通过爬虫,你可以只需要几分钟的时间,就能够将某一类数据全部爬取下来,然后有针对性的进行数据分析,优化你的行文。
对于公司来说,爬虫的应用空间就更为巨大了。
这两年火热的今日头条就是典型案例,不太严谨的说,今日头条核心就是做了三件事—— 1. 把网络上所有的资讯文章,以及用户在社交网站上的数据爬取下来。
把这些数据进行分类打标签,进行一一对应。 1. 2. 将拥有同类标签的文章和用户进行匹配。
通过高效的应用搜索引擎和个性化推荐功能,将传统的人找信息的分发模式,转变为信息找人的分发模式,帮助其成为一家独角兽。
你或许做不成下一个今日头条,但是,拥有更多的数据能够帮助你做成的事情,超过你的想象。
但是,技术虽然有价值,如何使用技术就成为新的问题。
马蜂窝这次的事件发生,给我们提了个醒,很多创业公司早期,都难免会在灰色地带做一些事情。
毕竟当初整个互联网世界还是一片蛮荒,大家都在跑马圈地,你不干,就有别人干,生存第一,虽然原则上不能原谅,但是情感上也能理解。
但是,当你已经成为一家成熟的大公司时,就必须承担必要的责任和底线。
在很多时候,应用爬虫其实是一个零和游戏,一方受益就代表着另一方受损,会使用抢票软件的人就会使不使用抢票软件的人受损;使用僵尸粉刷量的人,抢夺的是那些辛辛苦苦做内容的媒体人的空间;返利平台则是直接截了电商的胡。
很难说在这场竞争中究竟孰是孰非,孰优孰劣。但是,一旦我们的竞争,并没有让大家变得更好,或者是以一方付出更高的代价来实现的,这件事真的��合理吗?
在三节课内部,我们一直有这样一种看法—— 对于在互联网行业做产品还是做运营的所有人来说,我们工作的最大意义,正是在于“我们在运用着自己力所能及的一些方法和工具,一点点在让这个世界变得更加完整和美好”的可能性。
而爬虫也应该是在这个过程中可以运用到一种工具和方法,用这个能量巨大的工具,让我们自己,也让我们所处的环境变得更好,不也更有意义吗?
按照马蜂窝的回应,网站存有抄袭,但也只是小范围存在,并没有达到1800万条的规模。
无论如何,我们都希望这次马蜂窝能够从中吸取教训,真正能够培植起自己独有的内容生产体系和架构,成为一家更让人热爱的旅游攻略平台。
毕竟,不忘初心,也算是互联网人的必备技巧了。
0 notes
Text
Adobe秀出十大PS新神技,个个惊艳炸裂!
真的,说到P图,Adobe不是针对谁……
这家已经发展成全家桶的公司,未来可能依然王旗不倒。
不信��他们刚刚秀出了基于人工智能、机器学习等前沿技术的十大神技。
个个炸裂,招招惊艳。
自动剪片,画面跟着主角跑
剪辑师经常遇到一个问题:把视频剪成不同的长宽比,比如把横向的视频剪成纵向,通常很灾难。
截取框不动的话,主角汽车只要随便动一动,几秒就出圈了;
如果每一帧都要手动调整截取框的位置,又很麻烦。
不过,这个名叫Project Smooth Operator的功能,可以利用Adobe Sensei人工智能和机器学习框架,自动追踪视频里主角的位置。
驾车穿越大漠,用纵向视频也感受得到浩瀚的气象。
如果,主角的移动方式再狂野一些呢:
△ 这是最终效果
运动场景也能驾驭,就算滑雪选手动作幅度再大,都可以收在狭窄的截取框里。 如果主角不止一位呢?当然是根据各自的动作,自动锁定每一帧的重点:
比如,一人,一狗,一段闲在的时光。
还有三人跳伞,身体互相交叠,依然不在话下。
自动抠图,不管背景多复杂
这项叫做Fast Mask的功能,可以自动分割视频的主角和背景,速度迅猛。而且操作简单。
只要在任意一帧里,手动标记几个点,就能自动选中主角:
再点击“Propagation”,其他帧的主角,就��键抠成了:
这样,主角和背景就轻松分开。
然后,背景部分想要怎么改,都没问题。比如,变成黑白,再加上字:
那么,复杂背景表现如何?
小朋友在草地上轻快地跑跳,依然只要操作一帧,后面就都可以近乎完美地分割。
就算,猫咪的身体被柱子遮挡,Adobe还是很聪明。
戏精3D虚拟相机
3D模型要在2D表面上观察,一点也不友好。转角度、调位置都是分开进行:
△ Adobe Dimension是传统软件
但如果把PC工具和手机摄像头结合起来呢?就是Adobe的华尔兹计划(Project Waltz)。
只要随意移动手机,镜头里的模型就会跟着动了:
当然,还可以走远一点,发现飞船上面还有一只红色的飞行器:
当然,作为视频内容创作者,你也可以假装走进这台红色的飞机。��演驾驶员,模仿气流袭来、飞机振动的感觉。
戏精的事业道路,可能真的会越走越宽。
多角度包装盒设计,图形完美拼接
你知道纸盒上的图案设计出来有多难吗?
我们用的盒子,在设计师的电脑里,只是一个平面。
于是,设计师不只要设想出完成的图案什么样,还要脑补它摊开到一个平面上的样子。
你可以想象下这个过程,是不是脑细胞瞬间死了几个亿?关键,有时候还会这样:
但在Adobe的这个“神奇纸盒”功能里,一切都变得非常so easy。
duang~图案就出现在平面图上了,神奇不神奇?
包装设计师们看到这,估计都馋哭了吧~
花式字体自动生成
你们知道那种芝士字体么?
就是这种,长得像芝士一样的字体,许多海报装饰文字中,经常用到类似的花式字体。
设计资源网站中会有许多这种类似的字体包。这样的字体包设计非常复杂,每一种样式都需要26个字母大小写单独设计,如果是中文……那可能就得设计几千个汉字。
即使不买字体包,单独做几个汉字的海报标题,也需要设计师耗上大半天的时间。
Fontphoria这个功能就是用来拯救设计师于水火的。
上台演示的是一位小伙,拿着一张图就开整。
首先开始在下面的字母C上画圈。
再镂空,“C”就变成了带有芝士孔洞的C。
当他把这个字母C挪到上面的单词CHEESE上时,精彩的一幕发生了。
这个单词中的所有字母都变成了带有孔洞的芝士样子,完全复刻了字母C的风格。
即使换成别的字母,也是一样的芝士风。
而且,不只有这种手段。
海报上的字体,也能识别学习。比如这个海报。
这个工具可以自动识别字体。
很快,它就学会了这个字体,并保存下来,小伙当场就是一个T。
而且还不止一个T字,其他的字母都有。
最后,小伙掏出了纸巾,还有点紧张,难倒是要当众…….别误会。
纸巾上面画了一个独角兽,还有几行字。小伙把它放在摄像头前面,施展“挪移大法”,把上面海报上的字体用到了纸巾上。
非常完美!
这背后使用的,是一种深度学习技术,能够自动识别文本的风格,然后学习保存,字体再用起来的时候,就非常方便了。
馋不馋?反正我口水都止不住了……
添加骨架,静图变动图
这个工具名为GoodBones,首先在静态图上,标记出一个骨架。
然后,拖动骨架,就能���静态图片中的元素动起来。
还有更多精彩的用法,比如让恐龙张嘴:
帮情侣秀恩爱:
先加“骨头”,然后让他们慢慢靠近……慢慢靠近……
看完之后的第一感觉是啥?你是不是有了一个大胆的想法?
祈雨神刷
把晴天改成雨天有多难?
设计师需要绘制雨滴的效果,一滴一滴描绘雨水落下来的路径,做出雨滴飘过的动效……估计做完之后,他们会去HR那里排队辞职。
但是有Brush Bounty这个功能,就足够拯救设计师(以及HR)了。
设计师只要选中雨刷,在画面上刷上几下,动态、飘零的雨滴就出现在了画面上!
一张静态图分分钟变成了gif。
而且,还可以把下雨改成“暴雨”或是“小雨”,再也不怕甲方给奇葩需求了。
除了当“雨刷”用,Brush Bounty还可以当吹风机用,只要刷一下,就可以把画面女主角的头发吹得随风而动,调整摆动的方向:
甚至给女主角的头发染色:
这效果、这速度,戴森卷发棒看了想找个地缝钻进去。
除了“染发”,还能“变天”,只要拿刷子一刷,就可以自动把蓝天变成星空。
照片变视频
出去旅游的时候,拍了风景照片固然很棒,不过,如果你的照片会动呢?是不是听起来更鹅妹子嘤了?
Moving Stills这个功能就可以实现把静态的照片3D化,然后变成视频。
话不多说,看图。
△ 夕阳下的妹子.jpg
△ 悄咪咪走近夕阳下的妹子.mp4
△ 房间.jpg
△ 从上往下看房间.gif
还有风景照片,看起来像是桂林山水的样子。
△ 桂林山水.jpg
△ 从左到右坐船看桂林山水.mp4
△ 从下到上用无人机拍桂林山水.mp4
事实上,可以从8个不同的方向生成“航拍视频”,角度随意选择。
3D编辑器
Project Model Morph是一个3D模型编辑器。
在这个编辑器中,把一张普通的图片拖进来,丢到3D模型上,pia~
就像贴海报一样,图片被“贴”到了3D模型上。
还可以自带对称的拖动模型上的任何一个部件。
拉长
加粗
缩短
拖拽
看起来就像在陶吧玩泥巴。
制作完之后,效果依然闪闪发光,毫无PS痕迹。
人声变琴声
前面都是处理图像、视频的技术,Project kazoo不一样,这是本场唯一一个可以P声音的功能。
只要哼几句曲调录下来,就可以自动变成小提琴或是大提琴的声音,还可以调节提琴的音调高低。
不只���变成提琴的声音,还可以“变性”,演示的小哥就把自己哼的一段男中音乐曲变成了女高音。
最魔性的是,变声的同时还可以保留语音,也就是说,你可以把你的“哈哈哈哈哈”让小提琴“笑出来”。
上面这十大功能,是不是每个看起来都非常强大?
据说,Adobe未来会陆续放出这些功能,可能是作为PhotoShop等软件的新增功能,也可能会推出新的产品。
期待~
— 完 —
0 notes
Text
日志级别如何划分?
日志记录是软件开发的一个概念,几乎所有(可能并不是所有)软件都能从日志记录中获得很多好处。在开始一个大项目时,日志记录通常是我第一个要搭建的子系统。关于它的好处,我可以说出一大堆,但我想把这个机会留给其他人(或者哪一天我想说了再说)。现在,我想说一说日志级别。
日志级别是对基本的“滚动文本”式日志记录的一个重要补充。每条日志消息都会基于其重要性或严重程度分配到一个日志级别。例如,“你的电脑着火了”是一个非常重要的消息,而“无法找到配置文件”的重要等级可能就低一些。
很多应用程序和库会根据自己或用户的需求定义自己的日志级别(参考文末的“外部例子”了解这方面的内容)。当然,并没有一种约定俗成的方法来做这件事,想怎么做都是可以的,但我想要说说我认为的最重要的五个(或者六个,或者四个)日志级别,它们应该是你自定义日志级别的基础。
我还将讨论给这些级别分配的颜色(或者说风格),因为带有不同颜色(或风格)的日志更容易追踪。如果采用了这样的系统,就可以很容易检查你的程序状态,就算没有受过训练的人也可以轻易分辨。谁知道呢,你可能留下电脑跑去吃午饭了,如果出现问题只能找别人来查看日志。
E r r o r
错误已经发生了,这是毫无疑问的。错误的来源可能是在外部���但不管怎样都需要看一下是怎么回事。
可以用这个级别来表示需要引起人们注意(大多数时候需要采取行动)的错误。大多数难以优雅处理的异常都属于 Error 范畴。
风格:能引起人们注意的东西。我使用红色文本来表示(我的终端背景是黑色的)。 例子: * 无法找到"crucial.dat"文件 * 错误的处理数据:[堆栈追踪或后续的调试消息] * 在连接数据库时 * 在连接数据库时
W a r n
错误有可能已经发生了。我只是一条日志消息,无法分析到底发生了什么,或许需要其他人来看看是不是有问题。
这可能是一个平行空间里的错误。它可能是当前或未来潜在问题(比如响应速度慢、连接断开、内存吃紧等等)的预兆,也可能是程序在处理某些任务时出现错误(但可能不一会再发生类似的情况)。
风格:能引起人们注意但又不会让人感到厌烦的风格,以免你在解决其他问题时没空来处理这些错误。与 Error 的风格不同,我使用黄色的文本来表示 Warn。
例子: * 连接关闭,在 2 秒后重新连接 * 无法找到"logging.conf"[在配置文件中指定的],回到默认配置 * 30 秒后尝试连接超时 * 出现 FileVersionTooOldException 异常,回到 Version12Parser
I n f o
通知用户一个操作或状态发生了变化。别紧张,继续手头的活。
Info 可以说是(一般的非技术)用户可以接触到的最“啰嗦”的日志级别。如果有人把它们大声念给你听,你也不会介意,这是你最乐于见到的日志记录。它不会包含很多技术细节,可能只包含普通用户会关注的信息(比如文件名等)。
风格:可以和背景颜色区分开来,我使用白色文本。
例子: * 代理初始化完毕 * 加载存档"yeti02" * 进入高速模式 * 当前目录是"/tmp" * 上行线路已建立 * 渲染完成,耗时 42.999 秒
Debug
如果你能读懂这个级别的日志,那么你离程序已经很近了。
这就是为什么你需要保存日志文件,在修复 bug 时需要这些日志。这是开发人员最关心的内容。
在转储程序运行流程和其他技术问题时,应该使用 Debug 级别的日志。除非日志太多了(在这种情况下使用 Trace 级别更合适)或者更适合使用更高级别的日志,否则 Debug 日志是非常值得保留的,毕竟是你自己在代码中记录这些日志的。如果和其他的Debug 或更高级别的消息重叠,而且没有包含更多的信息,那么可以考虑将其删除。
风格:可以很容易就忽略的风格。我使用浅灰色或米黄色文本,也就是我的终端的默认文本颜色。
例子: * 从"/etc/octarine/octarine.conf"读取配置 * 使用"/home/aib/.octarinerc"覆盖配置 * 分析完成,创建图… * 作为”user”连接到服务器:4242 * 发送两条消息 * 渲染时故障: * Foo 0.990 秒 * Bar 42.009 秒
Trace
这些技术细节可能与程序不是很相干,除非你正好需要它们。
Trace 的信息是更加具体的调试信息,你可能并不想看到它(除非你向保存日志的人卖硬盘的时候需要)。它会包含比如说调用了什么函数(函数名),或是和客户端交换了什么网络包等内容。它善于找到一些低级错误,但通常你可以在调试消息中缩小范围,找到问题。
大多数 Trace 消息包含了你已经知道的信息(Debug消息中说了是“登录”,所以这肯定是登录相关的数据包),所以可能对你不是很有用,除非你的假设是错误的。(”它会不会是登出消息?!“、”这里应该调用 foo。为什么 foo 的 Trace 信息没有打印出来呢?”)
风格:使用比 Debug
消息更加不显眼的风格。我使用深灰色,通常用来表示禁用的颜色。 例子:
调用参数 ("baz", "bar", 42) 函数”foo”
->GET / HTTP/1.1\nHost: localhost\n\n
收到: \n\n [...]
F a t a l
发生了一个致命错误,我们要退出了。祝你好运!
它应该比 Error 更严重,但使用它的频率比 Trace 还少,所以我把它放在文章的最后。顾名思义,致命错误表示这种情况的发生将导致程序无法继续运行。因此,给它们专门设置一个级别没什么意义。但是致命的错误也可能是常见和可恢复的(比如重启就能解决),因此仍然值得一提。
风格:如果你想不出其他样式的话,可以选择比 Error 更显眼的风格。我使用紫色文本,从远处看的话和 Error 的红色文本相近,但近看就不一样。
例子: * 内存不足 * 无法分配 65536 字节的磁盘空间 * 许可过期,切换到免费软件模式
外部例子
任何成熟的日志记录 API 或库都应该有自己的日志级别(可能支持用户自定义)。以下是广泛使用的库,仅供参考:
Linux 的 printk * https://en.wikipedia.org/wiki/Printk#Logging_Levels
Python 的 logging * https://docs.python.org/library/logging.html#logging-levels
Java 的java.util.logging.Level https://docs.oracle.com/javase/6/docs/api/java/util/logging/Level.html log4j 的 org.apache.log4j.Level * https://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html * JavaScript 的 console.level 调用 WHATWG 或 Node.js 的 Console API 规范
NLog 的日志级别 * https://github.com/nlog/nlog/wiki/Log-levels
0 notes
Text
Android Studio 3.2 都有哪些更新?这些关键点不要错过
Android Studio 3.2 是应用开发者切入最新的 Android 9 Pie 发布版和构建新的Android App Bundle的最佳途径。自从 2018 年 Google I/O 大会 Android Studio 宣布更新后,我们精炼和完善了 20 多项新功能,并集中力量提升 Android Studio 3.2 稳定版的质量。
每一位开发者都应该使用 Android Studio 3.2 来过渡到使用新应用发布格式 Android App Bundle。只需极少的工作,就能用 Android Studio 生成一个 App Bundle。将 App Bundle 上传到 Google Play 后即可向用户分发更小的优化后应用。早期采用者已证实 App Bundle 比旧的 APK 应用尺寸减少了 11% - 64%。
另一个您不想错过的功能是 Energy Profiler (电量分析器)。新分析器提供一套工具帮助诊断和改善应用的能耗。更长的设备电池寿命一直是用户最关心的一方面,而利用 Android Studio 3.2 中的电量监测器,您可以通过确保应用在正确的时间使用适当的电量,帮助改善设备电池寿命。
您还应该试试新的 Android 模拟器 Snapshots 快照功能。利用这个功能,您可以将模拟器的当前状态快速生成一张快照,包括屏幕、应用和设置的当前状态。您能够在 2 秒内恢复或引导到您的模拟器快照。对于任何一位寻求超快引导时间或寻求在一个预期的 Android 环境中运行测试的应用开发者而言,Android 模拟器快照都是应用开发的一项革命性功能。
除了这些重磅功能外,Android Studio 3.2 中有 20 项新功能以及许多内部的质量改进。利用 Android Studio 3.2,您还可以通过 Android Slices 针对最新技术进行开发,从Android Jetpack,到与 Google AI 无缝整合。
Android Slices
https://developer.android.google.cn/guide/slices/
感谢为 canary 和 beta 版提供早期反馈的开发者们。您们的反馈帮我们改进了 Android Studio 3.2 的质量和功能。如果您已经准备好迎接下一个稳定版,并希望使用各种新的生产力特性,Android Studio 3.2 已经准备就绪可以下载了。
下面是 Android Studio 3.2 新特性完整列表,按关键开发者流程组织。
开发
Slices 支持 - Slices 是一种接入内置 Android AI 功能的新方式,能够在 Google 搜索和 Google 智能助理中呈现应用内容。Android Studio 3.2 有一个内置模板可以帮您用新的 Slice Provider API 来扩展您的应用,以及新的 Lint 检查来确保您在构建 Slice 时遵循最佳实践。如需使用,在项目文件夹上右键,依次选择 “New→ Other→ Slice Provider”。
△ Slices Provider 模板
样本数据 - 这个特性允许您使用占位符数据协助设计应用。这将帮助您根据运行时环境数据将布局可视化。通过 “布局编辑器” 中的一个弹出窗口,您可以为各种视图添加内置样本数据,如 RecyclerView、ImageView 和 TextView。
Material Design 更新 - 当您从 Android Design 支持库迁移到新的 MaterialComponents 应用主题和库时,Android Studio 3.2 将为您提供新的和更新的小部件,如:BottomAppBar、按钮、卡片、文本域、新字体样式等。
CMakeList 编辑支持 - 对于在应用中使用 C/C++ 的开发者,Android Studio 优化了对 Cmake 的支持。在 Android Studio 3.2 里,代码补全和语法高亮现在都对一般 CMakeList 构建脚本命令有效。
更新助理 - Android Studio 3.2 有一个新的助理面板,每次更新后会自动打开来通知您关于 IDE 的最新变化。您也可以通过依次选择 “Help → What's New in Android Studio” 来打开这个面板。
AndroidX 重构支持 - Android Jetpack 的组件之一是引入了 Android 扩展库(AndroidX)替换了 Android 支持库。如需添加 AndroidX 到一个新项目,需要添加 android.useAndroidX=true 到 gradle.properties 文件。此外,Android Studio 3.2 有一个新的内置重构动作以帮助您将项目迁移到新的命名空间和依赖。而且如果您有任何 Maven 依赖尚未迁移到 AndroidX 命名空间,Android Studio 构建系统将自动转换这些项目依赖。
IntelliJ 平台更新 - Android Studio 3.2 包含了 IntelliJ 2018.1.6 平台发布。这个 IntelliJ 版本大幅改进了数据流分析、调试、新检测、行内外部注释、Git 部分提交等等。
Kotlin 更新 - Android Studio 3.2 捆绑了 Kotlin 1.2.61,支持 Kotlin 友好的 Android 9 Pie SDK。
构建 * Android App Bundle - Android App Bundle 是新的应用发布格式,旨在帮您向用户提供更小的 APK 并降低应用的下载大小。Google Play 名为 Dynamic Delivery “动态交付” 的新应用服务模式会处理您的 App Bundle,针对每个用户的设备配置生成并服务优化后的 APK,从而让用户只需下载其需要的代码和资源就能运行您的应用。利用 Android Studio 3.2 或通过 命令行可以轻松将您的代码构建为一个 App Bundle,并根据语言、屏幕密度和 ABI 缩减 APK 大小,且应用代码不会改变。
△ 构建 Android App Bundle
D8 Desugaring - 某些情况下,新的 Java 语言特性要求新的字节码和语言 API。但较旧的 Android 设备可能不支持这些特性。Desugaring允许您通过在构建过程中将新字节码和语言 API 替换为旧版,从而在较旧的设备上使用这些特性。D8 Desugaring 在 Android Studio 3.2 中默认启用,现在您可以使用大多数最新的语言变更,同时针对较旧的目标设备。
R8 优化器 - 从 Android Studio 3.2 开始,我们将逐渐使用 R8 替代 ProGuard 来优化和缩减 Java 语言字节码。R8 仍处于实验阶段,因此我们尚不推荐您使用 R8 发布您的应用,但现在很适合向 Android Studio 团队提交早期反馈,以便我们在 R8 正式取代 ProGuard 前进行调整。
测试
模拟器 Snapshots - 最新版的 Android 模拟器允许您将模拟器的当前状态创建一份快照,并在 2 秒内引导和切换到任何快照。基于 Android 模拟器 Quickboot 特性构建的 Android 快照稳定版能够更快保存和加载,这主要得益于内部的速度改进优化。 在测试和开发应用时,Android 快照允许您预配置一个拥有您想要的预设、应用、数据和设置的 Android 虚拟设备(AVD)快照,并反复回到同样的快照。
△ Android 模拟器 Snapshots
Microsoft® Hyper-V™ 支持 - 现在您可以在 Windows® 10 启用了 Hyper-V 的电脑上运行 Android 模拟器。Intel HAXM 仍是默认的 hypervisor,能够提供最快的 Android 模拟器体验。但得益于微软近年的开源贡献,以及新 Windows Hypervisor Platform (WHPX) API 的加入,Android 模拟器能够与其他使用 Hyper-V 的应用共存,如:使用新 Hyper-V 支持的本地虚拟机。
AMD® 处理器支持 - 现在 Windows 10 上的 Android 模拟器支持 AMD 处理器。以前 AMD 处理器运行 Windows 时,Android 模拟器只能进行缓慢的软件模拟,但现在使用 AMD 处理器的开发者拥有了硬件加速性能。
Android 模拟器中的录屏 - 现在您可以使用 Android 模拟器中新增的录屏功能在任何 Android API Level 录制屏幕和音频。过去,受 Android 模拟器支持的限制,物理 Android 设备上的录屏只能在 Android 4.4 KitKat (API 19) 及以上进行,且没有音频。利用最新的 Android 模拟器 (v28.0.+) 您将不再受此限制。此外,还内置了转换器,支持输出为 GIF 和 WebM。您可以通过 Android 模拟器扩展控制面板、命令行和从 Android Studio 中触发新的录屏特性。
Android 模拟器的虚拟场景摄像头 - Android 模拟器的新虚拟场景摄像头,能够帮您为 Google 构建虚拟现实体验的平台 ARCore 进行开发。模拟器经���准,可使用 ARCore API 用于 AR 应用,还允许您注入虚拟场景位图图像。该虚拟场景摄像头还可以用作兼容 HAL3 的摄像头。
ADB 连接助手 - Android Studio 3.2 有一个新的助手系统,能帮助解决 Android ADB 设备连接问题。ADB 连接助手会引导您进行一般的解决步骤,以将您的 Android 设备连接到您的开发机。您可以通过 “运行” 对话框或依次选择 “Tools → Connect Assistant” 来触发助手。
优化
Energy 分析器 - 许多手机用户都十分关心电池寿命,而您的应用对电池寿命的影响可能超出您的预期。Android Studio 性能监测器套件中的电量监测器能够帮您了解您的应用对 Android 设备电量的影响。现在您能够以可视化的方式估计系统组件的用电情况,还能检查可能耗尽电池的后台事件。要使用电量监测器,请确保您已经连接到一部运行 Android 8.0 Oreo (API 26)或更高级系统的 Android 设备或模拟器。
△ 电量监测器
System Trace 系统跟踪 - CPU 监测器中的新 “系统跟踪” 特性允许您查看您的应用与系统资源交互的详情。查看您的线程状态的精确时序和持续时间,以可视化方式查看您的 CPU 各核心的瓶颈,以及添加定制跟踪事件以供分析。要使用系统跟踪,开始监测您的应用,点击进入 CPU 监测器,然后选择 “系统跟踪” 记录配置。
Profiler Sessions - 现在我们能够自动将监测器数据保存为 “会话” 以便之后打开 Android Studio 时再次访问和查看。我们还新增了导入和导出 CPU 记录和堆转储的功能,以便之后用其他工具分析或查看。
自动 CPU 记录 - 现在您可以使用调试 API 自动记录 CPU 活动。在您将您的应用部署到一部设备之后,当您的应用调用 startMethodTracing(String tracePath) 时监测器会自动开始记录 CPU 活动,而当您的应用调用 stopMethodTracing() 时会停止记录。类似地,现在您还可以通过在您的运行配置里启用 “启动时开始记录方法跟踪” 选项,在应用启动时自动开始记录 CPU 活动。
JNI 引用追踪 - 如果您的 Android 应用中有 C/C++ 代码,现在 Android Studio 3.2 允许您在内存监测器中查看您的 JNI 代码的内存分配。只要您将您的应用部署到一部运行 Android 8.0 Oreo(API 26)或更高级系统的设备上,您就可以从您的 JNI 引用中下钻查询分配调用堆栈。要使用该功能,启动一个内存监测器会话,并从 Live Allocation 下拉菜单中选择 JNI 堆。
新版本重点特性总结
最新版 Android Studio 3.2 Canary 包含: 开发 * AndroidX 重构 * 样本数据 * Material Design 更新 * Android Slices * CMakeList 编辑 * 新助理 * 新 Lint 检查 * Intellij 平台更新 * Kotlin 更新
构建 * Android App Bundle * D8 Desugaring * R8 优化器
测试 * Android 模拟器截图 * Android 模拟器中的录屏 * 虚拟场景 Android 模拟器摄像头 * AMD 处理器支持 * Hyper-V 支持 * ADB 连接助手
优化 * 电量分析器 * 系统跟踪 * 监测器会话 * 自动 CPU 记录 * JNI 引用追踪
0 notes
Text
如何获得更小的应用文件尺寸?来了解下 Android App Bundle
对于手机用户来说,“存储空间不足” 警告有时会显得非常烦人。时至今日,手机存储容量仍然是有限的。虽然存储容量多年来一直在增长,但是填充在我们手机里的东西:音乐、应用、游戏、照片等也同样在增长。
如何针对不同的用户给出最优的安装体验,正是 Android App Bundle 所要解决的问题。本文将阐述 App Bundle 可以带来的好处,并演示如何使用这种全新的分发功能。 传统的 Android Package Kit (APK) 包含应用支持的所有设备的代码和资源 (布局文件、图像等)。因此,您在安装 APK 时可能装上了一些您永远不会用到的资源。您的屏幕尺寸不会改变,您的 CPU 也不会; 您通常不会说应用所支持的所有语言。很明显,APK 里的内容的比您要求的更多,占用的空间也比实际需要的更多。
如果因为上述原因带来的臃肿的 APK 让您颇为困扰,现在解决方案就在眼前 —— 今年在谷歌 I/O 上发布的 Android App Bundle,可以帮助开发者用更小尺寸的 APK 交付出同样卓越的应用。下面,我们将解释 Android App Bundles 可以为您提供何种帮助,并演示其使用方式。
Android App Bundle 是什么?
Android App Bundle 是一种发布格式 —— 精确地说,是一个带有 .aab 扩展名的 zip 文件。它包含应用支持的所有设备的代码和资源,例如 DEX 文件、本地代码库、清单文件、各种资源文件等。一旦上传用于发布,Google Play 就会处理 APK 的签名和生成,这个过程称为动态交付 (Dynamic Delivery)。动态交付的用途是,根据用户的设备配置为用户生成优化的 APK。那么这究竟是怎么做到的? 分拆 APK (在 Lollipop 中引入) 是从给定的 Android App Bundle 生成的,其行为与单个 APK 无异。一个典型的应用可以获得一个基础 APK 和多个配置 APK。而且,如果应用具有动态功能,用户也可以获得动态功能 APK 及其配置 APK。基本 APK 包含所有设备配置共有的文件,如清单文件。配置 APK 是为您生成的,每个之中都包含有特定设备配置的相关资源:语言、CPU 架构或屏幕像素密度。因此,用户将获得标准的基本 APK (与所有其他设备一样) 以及仅包含用户设备相关资源的配置 APK。
这意味着,如果我使用的是一台 Android One 手机 (小米 A1) 而且我设置的主要语言是英文,则这台手机将获得基础 APK 以及支持英文、arm64 CPU 架构和 xhdpi 屏幕分辨率的配置 APK。更棒的是,当设备配置 (如语言) 发生变化时,Google Play 会检测到它,并下载该语言的配置 APK。为了进一步降低 APK 大小,我们正计划推出基于纹理压缩格式、图形 API 和新平台功能的分发方案。
动态功能 APK 包含用户首次安装应用时不需要的应用功能代码和资源。开发者可以把这些用途或功能添加到他们的应用中,Google Play 会按需提供这些动态功能模块,而不是在安装时统一添加,从而进一步减少应用下载体积。这也很好理解:我们有必要将那些消耗空间且在安装时根本用不着的功能,以及那些很少用得着的功能,都打包进动态功能模块中,这将显著减少用户安装时的文件下载量。
安装早于 Android Lollipop 版本的设备也可以享受安装文件体积缩小的福利,但其 APK 中将包含所有语言。
在如今,很显然构建一个统一的臃肿的 APK 的做法已经过时了。Android App Bundle 代表着 Android 应用交付的未来,接下来我们就可以看到如何构建这样的一个安装包。
Android App Bundle != APK
Android App Bundle 与 APK 有一些相似之处,但它们是截然不同的,且用于不同的目的。首先,App Bundle (应用束)纯粹是为了上传设计的文件,用户无法直接安装和使用它。它是一个 zip 文件,Google Play 从中生成优化的 APK 并将其提供给设备进行安装。应用束包含用于帮助工具生成 APK 的元数据文件 (这些元数据文件最终不会出现在 APK 中)。此外,应用束拥有严格的验证标准。
从 APK 切换到应用束是一个无缝过程。如果您使用 Android Studio 3.2 及更高版本,那么您只需点击几下即可生成已签名的应用束,将其上传到 Play Store,即可让用户开始享受更小尺寸 APK 所带来的便利。由于您的代码库没有重大变化,因此您无需担心会有什么问题发生。Android App Bundle 的早期采用者已经发现,动态交付显著减小了他们的应用体积。一些开发者甚至可以将他们的 APK 大小减半。 △ 一些知名 app 使用 App Bundle 减小应用体积的数据
Android App Bundle 的好处都有哪些?
Android App Bundle 为应用开发者和用户带来了诸多好处。这里我们来看看其中的几条: 较小的应用意味着更多用户可以安装您的应用,而无需考虑删除什么以腾出空间。 较小的应用意味着用户不太可能卸载您的应用以在其设备上腾出空间。 Android App Bundle 是单一工件,因此无需构建、签名或管理多个 APK。 * 您可以为特定用例和受众添加动态功能,而无需增加安装时的应用体积。
这个列表还会越来越长,许多有趣的功能很快就会提供给开发者,例如应用束即将支持免安装应用。
构建 App Bundle
大多数应用项目都不需要花费太多精力来构建支持动态交付的应用束。实际上,如果您已根据既定惯例组织应用代码和资源,只需在 Android Studio 中点击几下,就可以构建已签名的 Android 应用束。但首先,我们需要获得 Android Studio Canary。另外值得注意的是 Android Studio 3.2 稳定版最近已经发布。
获得 3.2 版本的 Android Studio:
https://developer.android.google.cn/studio/
在 Android Studio 中打开项目后,转到菜单栏并选择 Build > Build Bundle(s)/ APKs > Build Bundle(s)。等待生成应用束。您可以在生成应用束后的弹出窗口中点击选项来找到生成的 .aab 文件,并进行分析。 △ 通过菜单构建 App Bundle
△ 构建完成后可以查看或者分析生成的 App Bundle
这个 Android App Bundle 无法上传到 Play Console,因为它未被签名。想要生成签名版本的话,请选择Build > Generate Signed Bundle/APK… > Android App Bundle > Select Base Module > Enter Signing Credentials & Check any other options (和您操作 APK 所做的事情一样)。 您也可以通过命令行使用 Gradle 的打包任务生成相同的 Android App Bundle。要生成已签名的应用束,就必须在模块的 build.gradle 文件中配置签名信息。
想要更好地控制从 Android App Bundle 进行拆分的方式的话,您可以从应用束的设置区块中进行精确设置:
方便强大的 bundletool
Bundletool 是一个用于处理 Android App Bundle 的命令行工具。使用 bundletool,您可以构建 Android App Bundle,提取连接的设备配置,生成 APK Set 文件 (.apks),从 APK Set 文件中提取或安装 APK,以及验证应用束。由于 Android App Bundle 仅是一种发布格式,因此 bundletool 用于生成和测试 APK。Google Play 和 IDE 使用的也是相同的工具,而且它是开源的。
Bundletool 的 GitHub 地址:
https://github.com/google/bundletool
使用 bundletool 这是 bundletool 接受的所有命令:build-bundle,build-apks,extract-apks,get-device-spec,install-apks,validate 和 version。使用 bundletool help 获取有关命令的详细信息,例如标识符和其他选项。
在以下示例中,我们将找到已连接设备的配置,构建 APK,并为连接的设备安装 APK。
动态功能模块
动态功能模块让您可以将特定的功能移动到单独的模块中。我们使用了动态交付技术,根据需要向用户提供这些功能。动态功能模块需要您的仔细考量,以及付出一些工作量进行实际的拆分。
有关创建和配置动态功能模块的详细文档:
https://developer.android.google.cn/guide/app-bundle/configure#dynamic_feature_modules
上传到 Play Store
拥有已签名的 Android App Bundle 后,您可以将其上传到 Play Store,让 Google Play 动态地为您的用户提供优化后的 APK。您还需要开通使用 Google Play 进行应用签名的功能,这样才能上传应用束。
使用 Google Play 进行应用签名提供了一种管理应用签名密钥的安全方式。Google Play 会管理您的应用签名密钥,您只使用上传密钥,用于验证您的身份。自己管理应用签名密钥存在风险,因为在丢失密钥后,您将无法更新已发布的应用; 同样,您的密钥很容易被盗。将签名过程委派给 Google Play 可以让您的密钥更加安全,您还可以请求重置上传密钥。所以,您永远不必担心被自己的应用拒之门外。开通应用签名后,Google Play 会自动生成��签署发送给用户设备的 APK。 上传后,单击应用束并选择 Explore App Bundle 即可查询节省空间的大小。在这里,您可以搜索和下载针对特定设备的 APK。对于列出的配置,您可以选择 VIEW DEVICES 以查看将获得该特定 APK 的设备列表。 好消息是,Android App Bundle 可以通过 Publishing API 发布。
小结
正如我们所见,Android App Bundle 代表着 Android 应用交付的未来,提供单一的 APK 的做法已经过时。应用体积可以减小,而且还可以提供定制功能,为每个用户提供度身定制的体验。
更棒的是,开发者并不需要花费太大力气就可以尽享这些收益。一些开发者已经发现应用体积大幅减少。用户也可以获得极大的好处,因为他们的设备可以为音乐、电影、应用等其他内容提供更多的可用空间。开发者还可以通过使用 Android Vitals 进一步提高其应用在用户设备上的性能和稳定性。
"我们期待着您用更小的文件体积,为用户带来优良的、个性化的体验,并因此促进您的应用获得更多的安装和更大的成功。"
0 notes
Text
手把手 | 两种数据科学编程中的思维模式(附代码)
数据科学的完整流程一般包含以下几个组成部分: * 数据收集 * 数据清洗 * 数据探索和可视化 * 统计或预测建模
虽然这些组成部分有助于我们理解数据科学的不同阶段,但对于编程工作流并无助益。
通常而言,在同一个文件中覆盖完整的流程将会导致Jupyter Notebook、脚本变成一团乱麻。此外,大多数的数据科学问题都要求我们在数据收集、数据清洗、数据探索、数据可视化和统计/预测建模中切换。
但是还存在更好的方法来组织我们的代码!在这篇博客中,我将介绍大多数人在做数据科学编程工作的时候切换的两套思维模式:原型思维模式和生产流思维模式。
原型思维模式强调 生产流思维模式强调 某部分代码的迭代速度 整体工作流程的迭代速度 更少的抽象 (直接修改代码和数据类型) 更多的抽象 (修改参数) 代码更松散 (模块化程度低) 代码更结构化 (模块化程度高) 帮助人们更了解代码和数据 帮助电脑更自动地运行代码
我个人使用JupyteLab来进行整个流程的操作(包括写原型代码和生产流代码)。我建议至少使用JupyteLab来写原型代码:
JupyteLab: http://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html
借贷俱乐部数据
为了更好地理解原型和生产流两种思维模式,我们来处理一些真实的数据。我们将使用个人对个人的借贷网站——借贷俱乐部上面的借贷数据。跟银行不同,借贷俱乐部自身并不借钱,而是为贷款人提供一个市场以贷款给因不同的原因(比如维修、婚礼)需要借款的个人。
借贷俱乐部网站: https://www.dataquest.io/blog/programming-best-practices-for-data-science/www.lendingclub.com
我们可以使用这个数据来建立一个模型,判断一个给定的贷款申请是否会成功。这篇博客中,我们不会深入到建立机器学习模型工作流。
借贷俱乐部提供关于成功的贷款(被借贷俱乐部和联合贷款人通过的贷款)和失败的贷款(被借贷俱乐部和联合贷款人拒绝的贷款,款项并没有转手)的详尽历史数据。打开他们的数据下载页,选择2007-2011年,并下载数据:
数据下载页: https://www.lendingclub.com/info/download-data.action
原型思维模式
在原型思维模式中,我们比较关心快速迭代,并尝试了解数据中包含的特征和事实。创建一个Jupyter Notebook,并增加一个Cell来解释: 你为了更好地了解借贷俱乐部而做的所有调查 * 有关你下载的数据集的所有信息
首先,让我们将csv文件读入pandas:
import pandas as pd loans_2007 = pd.read_csv('LoanStats3a.csv') loans_2007.head(2)
我们得到两部分输出,首先是一条警告信息:
/home/srinify/anaconda3/envs/dq2/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (0,1,2,3,4,7,13,18,24,25,27,28,29,30,31,32,34,36,37,38,39,40,41,42,43,44,46,47,49,50,51,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,123,124,125,126,127,128,129,130,131,132,133,134,135,136,142,143,144) have mixed types. Specify dtype option on import or set low_memory=False. interactivity=interactivity, compiler=compiler, result=result)
然后是数据框的前5行,这里我们就不展示了(太长了)。
警告信息让我们了解到如果我们在使用pandas.read_csv()的时候将low_memory参数设为False的话,数据框里的每一列的类型将会被更好地记录。
第二个输出的问题就更大了,因为数据框记录数据的方式存在着问题。JupyterLab有一个内建的终端,所以我们可以打开终端并使用bash命令head来查看原始文件的头两行数据。
head -2 LoanStats3a.csv
原始的csv文件第二行包含了我们所期望的列名,看起来像是第一行数据导致了数据框的格式问题:
Notes offered by Prospectus https://www.lendingclub.com/info/prospectus.action
增加一个Cell来说明你的观察,并增加一个code cell来处理观察到的问题。
import pandas as pd loans_2007 = pd.read_csv('LoanStats3a.csv', skiprows=1, low_memory=False)
在借贷俱乐部下载页查看数据字典以了解哪些列没有包含对特征有用的信息。Desc和url列很明显就没有太大的用处。
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
然后就是将超过一半以上都缺失值的列去掉,使用一个cell来探索哪一列符合这个标准,再使用另一个cell来删除这些列。
loans_2007.isnull().sum()/len(loans_2007) loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
因为我们使用Jupyter Notebook来记录我们的想法和代码,所以实际上我们是依赖于环境(通过IPython内核)来记录状态的变化。这让我们能够自由地移动cell,重复运行同一段代码,等等。
通常而言,原型思维模式专注于: 可理解性: 使用Markdown cell来记录我们的观察和假设 使用一小段代码来进行真实的逻辑操作 * 使用大量的可视化和计数
抽象最小化: * 大部分的代码都不在函数中(更为面向对象)
我们会花时间来探索数据并且写下我们采取哪些步骤来清洗数据,然后就切换到工作流模式,并且将代码写得更强壮一些。
生产流模式
在生产流模式,我们会专注于写代码来统一处理更多的情况。比如,我们想要可以清洗来自借贷俱乐部的所有数据集的代码,那么最好的办法就是概括我们的代码,并且将它转化为数据管道。数据管道是采用函数式编程的原则来设计的,数据在函数中被修改,并在不同的函数之间传递:
函数式编程教程: https://www.dataquest.io/blog/introduction-functional-programming-python/
这里是数据管道的第一个版本,使用一个单独的函数来封装数据清洗代码。
import pandas as pd def import_clean(file_list): frames = [] for file in file_list: loans = pd.read_csv(file, skiprows=1, low_memory=False) loans = loans.drop(['desc', 'url'], axis=1) half_count = len(loans)/2 loans = loans.dropna(thresh=half_count, axis=1) loans = loans.drop_duplicates() # Drop first group of features loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1) # Drop second group of features loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1) # Drop third group of features loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1) frames.append(loans) return frames frames = import_clean(['LoanStats3a.csv'])
在上面的代码中,我们将之前的代码抽象为一个函数。函数的输入是一个文件名的列表,输出是一个数据框的列表。
普遍来说,生产流思维模式专注于: 适合的抽象程度 代码应该被泛化以匹配的类似的数据源 * 代码不应该太过泛化以至于难以理解
管道稳定性 * 可依赖程度应该和代码运行的频率相匹配(每天?每周?每月?)
在不同的思维模式中切换
假设我们在运行函数处理所有来自借贷俱乐部的数据集的时候报错了,部分潜在的原因如下: 不同的文件当中列名存在差异 超过50%缺失值的列存在差异 * 数据框读入文件时,列的类型存在差异
在这种情况下,我们就要切换回原型模式并且探索更多。如果我们确定我们的数据管道需要更为弹性化并且能够处理数据特定的变体时,我们可以将我们的探索和管道的逻辑再结合到一起。
以下是我们调整函数以适应不同的删除阈值的示例:
import pandas as pd def import_clean(file_list, threshold=0.5): frames = [] for file in file_list: loans = pd.read_csv(file, skiprows=1, low_memory=False) loans = loans.drop(['desc', 'url'], axis=1) threshold_count = len(loans)*threshold loans = loans.dropna(thresh=half_count, axis=1) loans = loans.drop_duplicates() # Drop first group of features loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1) # Drop second group of features loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1) # Drop third group of features loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1) frames.append(loans) return frames frames = import_clean(['LoanStats3a.csv'], threshold=0.7)
默认值是0.5,如果需要的话,我们也可以改为0.7。
这是一些将管道改得更为弹性的方式,按推荐程度降序排列: 使用可选参数、位置参数和必需参数 在函数中使用if / then语句以及使用布尔输入值作为函数的输入 * 使用新的数据结构(字典,列表等)来表示特定数据集的自定义操作
这个管道可以扩展到数据科学工作流程的所有阶段。这是一些伪代码,可以总揽它的结构。
import pandas as pd def import_clean(file_list, threshold=0.5): ## Code def visualize(df_list): # Find the most important features and generate pairwise scatter plots # Display visualizations and write to file. plt.savefig("scatter_plots.png") def combine(df_list): # Combine dataframes and generate train and test sets # Drop features all dataframes don't share # Return both train and test dataframes return train,test def train(train_df): # Train model return model def validate(train_df, test-df): # K-fold cross validation # Return metrics dictionary return metrics_dict frames = import_clean(['LoanStats3a.csv', 'LoanStats2012.csv'], threshold=0.7) visualize(frames) train_df, test_df = combine(frames) model = train(train_df) metrics = test(train_df, test_df) print(metrics)
下一步
如果你对加深理解和练习感兴趣的话,我推荐: 了解如何将你的管道转化为作为一个模块或者从命令行中单独运行的脚本: * https://docs.python.org/3/library/main.html
了解如何使用Luigi来构建更复杂的、能够在云上面运行的管道 * https://marcobonzanini.com/2015/10/24/building-data-pipelines-with-python-and-luigi/
了解更多有关数据工程的信息: * https://www.dataquest.io/blog/tag/data-engineering/
0 notes
Text
What-If 工具:无需写代码,即可测试机器学习模型
构建有效的机器学习 (ML) 系统需要提出许多问题。仅仅训练一个模型,然后放任不管,是远远不够的。而优秀的开发者就像侦探一样,总是不断探索,试图更好地理解自己的模型:数据点的变化对模型的预测结果有何影响?对于不同的群体,例如在历史上被边缘化的人群,模型的表现是否有所不同?用于测试模型的数据集的多样化程度如何?
要回答这些类型的问题并不容易。探索 “What-If” 场景通常意味着编写一次性的自定义代码来分析特定模型。此过程不仅效率低下,而且非编程人员很难参与塑造和改进 ML 模型的过程。Google AI PAIR 计划的一个重点就是让广大用户能够更轻松地检查、评估和调试 ML 系统。
我们发布了 What-If 工具(https://pair-code.github.io/what-if-tool/),这是开源 TensorBoard 网络应用的一个新功能,可以让用户在无需编写代码的情况下分析 ML 模型。在给定 TensorFlow 模型和数据集指针的前提下,What-If 工具可为模型结果探索提供交互式可视界面。

What-If 工具:展示了一组面部图片(共 250 张),以及微笑检测模型得出的结果
What-If 工具拥有各种功能,包括使用 Facets 自动可视化数据集、手动编辑数据集示例并查看相关更改的影响,以及自动生成局部依赖图(显示模型的预测结果如何随任何单个功能的更改而变化)。下面详细探索其中两项功能。
探索数据点上的 What-If 场景
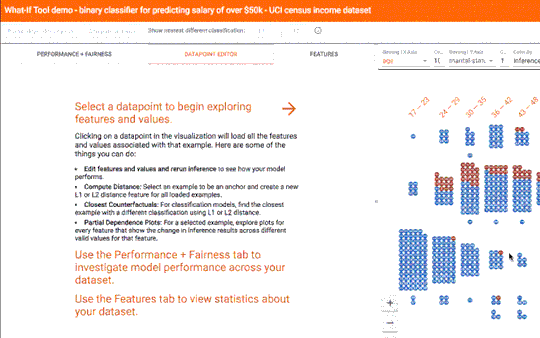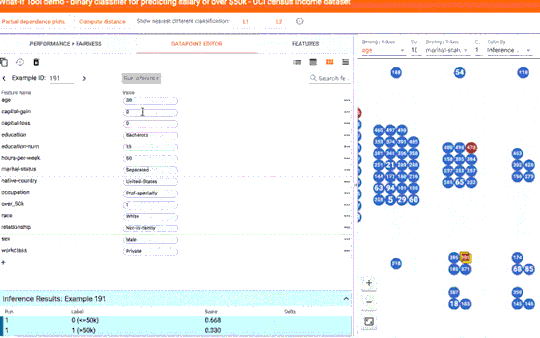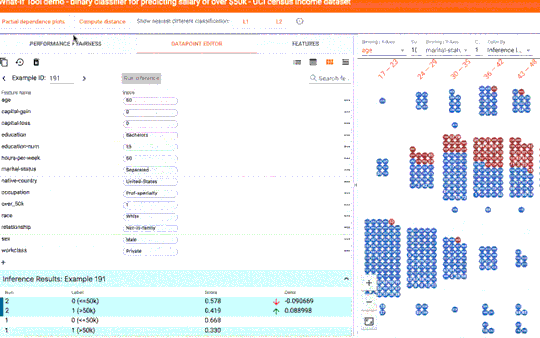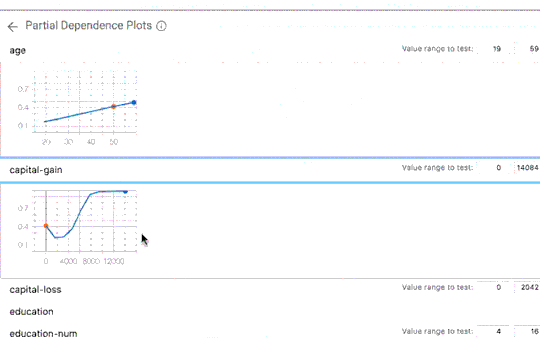
▌反事实
只需点击一下按钮,即可将某个数据点与模型预测不同结果的最相似点进行比较。我们将这些点称为 “反事实”,它们可以清楚显示出模型的决策边界。或者,您也可以手动编辑一个数据点,然后探索模型预测的变化情况。在下方的屏幕截图中,我们将该工具用于二进制分类模型。此模型根据 UCI 人口普查数据集的公开人口普查数据来预测某个人的收入是否超过 5 万美元。这是 ML 研究人员常用的基准预测任务,特别适用于分析算法公平性的情况,我们很快会谈及这个话题。在这个案例中,对于选定的数据点,模型预测此人收入超过 5 万美元的置信度为 73%。该工具自动找出数据集中与此最相似的人(模型预测其收入少于 5 万美元),并将二者进行并排比较。在此案例中,只需对年龄和职业作出微小的改变,模型的预测就会出现大幅变化。

反事实对比
▌表现和算法公平性分析
您也可以探索不同分类阈值的影响,并考虑不同数值公平性标准等限制条件。下方的屏幕截图展示了微笑检测模型的结果,该模型使用开源 CelebA 数据集(由带注解的名人面部图像组成)进行训练。在下图中,我们根据头发是否为棕色,将数据集中的面部图像分成两组,并为其中每组绘制一条 ROC 曲线和预测结果的混淆矩阵,同时提供滑块,设定模型必须在达到一定的置信度,才会判定是否为微笑的面部图像。在此案例中,该工具自动为两组设置了置信度阈值,以优化模型,从而实现机会均等。

比较两组数据在微笑检测模型上的表现,并将其分类阈值设置为满足 “机会均等” 限制条件
▌演示
为了说明 What-If 工具的功能,我们发布了一组使用预训练模型的演示:
检测错误分类:这是一种多分类模型,通过对植物花朵的四次测量来预测植物种类。该工具有助于显示模型的决策边界和导致错误分类的原因。该模型使用 UCI 鸢尾花数据集进行训练。
评估二进制分类模型的公平性:这是上文提及的微笑检测图像分类模型。该工具有助于评估不同子组的算法公平性。在训练模型的过程中,为了展示该工具如何帮助揭示模型中的此类偏见,我们特意没有提供来自特定人群子集的任何示例。评估公平性需要谨慎考虑整体环境,但这是很有用的量化起点。
研究不同子组的模型表现:这是根据人口普查信息预测对象年龄的回归模型。该工具有助于展示模型在不同子组的相对表现,以及不同特点如何分别影响预测结果。该模型使用 UCI 人口普查数据集进行训练。
▌What-If 的实际应用
我们与 Google 内部团队一起测试了 What-If 工具的表现,从中看到这个工具的直接价值。有一个团队很快发现,他们的模型错误地忽略了数据集的一个整体特点,进而修复了之前并未发现的代码错误。另一个团队使用该工具将其示例按表现最佳到最差进行直观排列,进而发现表现不佳的模型示例类型有何模式。
我们希望 Google 内部和外部的人士都能使用此工具,以更好地理解 ML 模型,并开始评估其公平性。此外,由于此代码是开源的,我们欢迎大家为该工具的发展添砖加瓦。
▌致谢
What-If 是众人合作的成果,其成功离不开 Mahima Pushkarna 设计的用户体验,Jimbo Wilson 对 Facets 作出的更新,还有许多其他人提供的意见。我们想感谢测试此工具并提供宝贵反馈的 Google 团队,还要感谢 TensorBoard 团队的一切帮助。
【完】
0 notes