
artificialimages-blog
Fake it till you make it
SFW adventures with the Faceswap Github project
5 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

girlysweetcravings
Girlysweetcravings

stevencanavan
Steven Canavan

incorrect-nmhe-quotes
NMHE quotes

nma-nekro
𝐍𝐌𝐀 🔹 𝐍𝐄𝐊𝐑𝐎

mrujaa
michelle
Text
Finding out total iterations for training across Faceswap sessions
Today a small change was made to Faceswap’s Github repo which stops the cumulative lifetime total training time for the project being shown in the GUI. The developers considered this a ‘bug’. Personally I can see no sense in it - it was good to have the total displayed without any further effort.
Anyway they told me that if you go into the Analysis tab and hit ‘Refresh’ button, you get the cumulative total at the bottom - and so you do:
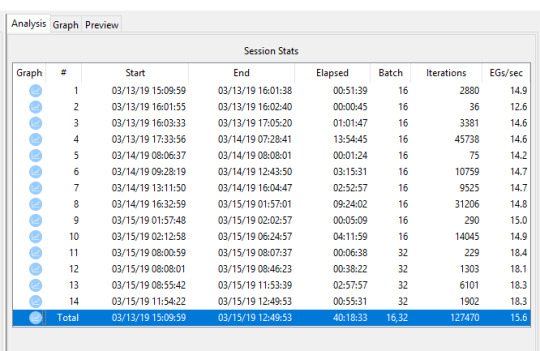
I was a bit glum when I saw this, considering how many iterations this model has truly been through, and how far it has to go yet!
Still, it is useful to know there is a way to at least hunt out the stats in the GUI.
0 notes
Text
Semi-official: subpixel upscaling is probably pointless
One of the Faceswap devs at the Discord server said today:
‘I would just leave [subpixel upscaling] off. As far as I can tell it does exactly the same as the pixel shufflers already do, and may get removed in a future update.’
SU has been handed round the forums as some kind of potential holy grail since the refactor, mainly because of the non-existent documentation. This kind of puts an end to that.
0 notes
Text
Adding data partway through training
It’s always good to add better data to your training set, and better late than never - but it does skew the curve - literally.
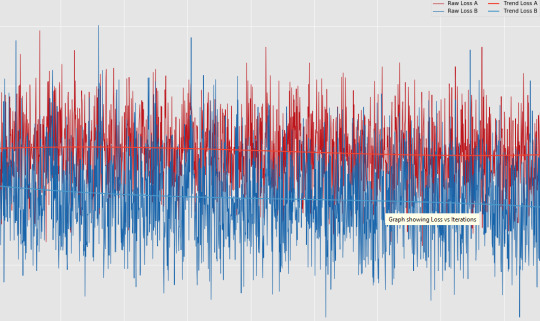
Some of the images being processed are mature within the model, others brand new, so the preview window becomes a very mixed bag indeed when you update the source data!
0 notes
Text
15% loss if using JPG instead of PNG
Basically another ‘Doh’ moment. When extracting from a video to frames, advice I’ve read in recent days (from those who would know) is to use PNG all the way through the data gathering process for Faceswap, since JPG artefacts will impact the accuracy of the model, costing maybe 15% accuracy.
Makes sense, but the model I am currently training, I have already disposed of the high GB source material, and it would be an endless pain to recreate it all. Next time I’ll use PNG. Of course, PNG is going to take up a lot more space.
Faceswap’s Effmpeg module is supposed to handle this, but I’m damned if I can get it to extract without crashing, so have been using Free Video To Jpg Converter.
Anyway, the forums suggest that VirtualDub 32 bit is the best way to extract PNG without errors, so I tried it today. It’s good but very slow!
0 notes
Text
Doh
It’s amazing how long it took me to find this option in the March refactor of Faceswap:
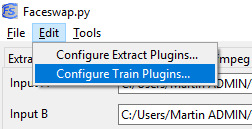
Like a lot of people, I thought that the Lowmem model had been dumped. In fact it was just split up over the interface. To get it back, you need to choose ‘Original’ as your model setting and to go to Configure Train Plugins > Model > Original ... and then tick Lowmem:
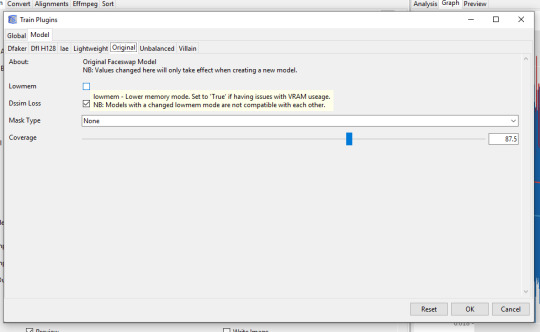
On my 4gb 1050ti, I am limited to Original (not lowmem) and Dfl-H128, which was ported over from DeepFaceLab to Faceswap about three weeks ago. Before the refactor, the only extra option I had was Gan128, which was psychedelic but totally non-functional, and was removed in the 2019 refactor.
I would have RTFM, but there is no FM to read! It is all spread over Discord servers and chat windows and random posts, in archives which often have to be read in reverse.
This is an arcane pursuit, for sure.
1 note
·
View note