
Dieser Blog enthält meine (Theresa Siefert) Erfahrungen und Notizen zur Vorlesung "Bibliotheks- und Archivinformatik" der Fachhochschule Graubünden.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by bainlerntagebuch and here's what we found interesting.
Average Info
Notes Per Post
2
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 minutes
Number of Posts By Type
Text
11
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Abschluss - Was ich gelernt habe und der Serendipity-Effekt
In diesem letzen Blogeintrag teile ich nun meine Gedanken dazu, was ich in der Vorlesung gelernt habe, was ich nicht gelernt habe und was mir bleiben wird.

Zu jeder Stunde hatten wir dieses Schaubild und tatsächlich – am Ende wusste ich sogar, was alles bedeutet! Ich meine damit, am Anfang wurde zwar erklärt, was es mit allem auf sich hat, aber am Ende konnte ich mir unter allem etwas vorstellen.
Ich muss zugeben, dass der Kurs für mich eher schwierig war. Zur allerersten Sitzung war ich krank, danach konnte ich zweimal an den Vorlesungen teilnehmen. Danach hat mir meine Gesundheit einen Strich durch die Rechnung gemacht und ich konnte die Vorlesungen nur noch als Videoaufzeichnungen Tage danach geniessen. Dies hatte sowohl Vor- als auch Nachteile – ich muss zugeben, dass ich während dem Nachschauen durch das Googlen der Inhalte oft in diversen Nebenspalten und ähnlichen Themen verschwunden bin – lang lebe der Serendipity-Effekt. Jedoch hat es mir auch ermöglicht, alles ganz in Ruhe und in meinem Tempo durchzugehen.
Gelernt habe ich vor allem, dass ich oftmals „oberflächlich“ wusste, worum es geht, als ich mir dann jedoch Gedanken über die Inhalte der Blogeinträge gemacht habe, so habe ich gemerkt, dass einige der wichtigsten Begriffe doch nicht so klar waren, wie ich dachte. Hier war es wirklich spannend zu sehen, was ich alles noch lernen konnte. Auch war es wirklich toll zu sehen, was hinter all den Programmen, welche ich täglich nutze und mir nie Gedanken dazu mache, steht. Dadurch ist mir auch klar geworden, warum manche Dinge so sind wie sie sind.
Es machte mitunter verwirrend, all die verschiedenen Programme, Abkürzungen und Funktionen auseinanderzuhalten. Das war auch der Grund, wieso ich meistens nur eine kurze Zusammenfassung der Systeme mit Hintergrundinformationen in meinen Blogeinträgen gemacht habe. Dies hat mir geholfen, später wieder dort nachzuschauen, um herauszufinden, was was war. Jedoch bliebt mein Wissen sehr oberflächlich, da viele Dinge angesprochen wurden und dann direkt zum nächsten Thema übergegangen ist. Durch das viele Installieren von verschiedenen Programmen und ausprobieren mehrerer Möglichkeiten hat man hier manchmal den Überblick verloren. Ich denke es hätte mir mehr Spaß gemacht, etwas länger bei den einzelnen Optionen zu vermeiden (aber mir ist natürlich bewusst, dass dafür nicht unbedingt die Zeit blieb).
Auch mein Verhältnis mit meinem Lerntagebuch war mitunter schwierig - und ich denke das merkt man auch, wenn man alle Einträge liest. Ich konnte mich nie so ganz entscheiden, wie ich nun mit meinem Lerntagebuch "reden" sollte. So wurde es letzten endes ein Mix aus Literaturarbeit, Aufsatz und Gedanken.
Am meisten Mühe hat mir tatsächlich die Arbeit auf GitHub mit MarkUp bereitet – dass hätte ich nicht gedacht. Schließlich konnte ich meinen Blog auf GitHub nicht zum laufen bringen (leider weiss ich bis heute nicht, was ich falsch gemacht habe) und musste in letzter Minute auf ein anderes Format umsteigen. Ich hoffe jedoch, dass ich alle Import/Exportfehler beheben konnte.
Zum Schluss möchte ich nur sagen: das Modul hat mir Spass gemacht und ich habe viel gelernt.
0 notes
Text
Vorlesung 10 - Linked Data
Ablauf der Stunde:
Übung ChatGPT ( Suchanfragen in natürlicher Sprache vergleichen mit Bing und PerplexityAI)
Aktuelle Datenmodelle (Bibframe etc.)
Metadaten anreichern mit OpenRefine und Wikidata
Was ist Linked Data?
Linked Data kommen aus dem Semantic Web und sind Kernelemente des Linked Open Data. Sie sind verlinkte Daten unterschiedlicher Herkunft. Durch ihre automatisierte Verknüpfung soll ein Mehrwert gewonnen werden und neue Zusammenhänge erkannt werden. Sie sollen dabei eindeutig identifiziert werden und referenzierbar sein. Kernidee ist es, dass die Daten sowohl Maschinen- als auch menschenlesbar sind. Die Daten werden in RDF-Formaten dargestellt und lassen sich dadurch referenzieren (so lassen sich Daten auch konvertieren).

Quelle Bild: https://www.researchgate.net/figure/The-Web-of-Data-structured-and-interlinked-data-in-RDF_fig1_242700809
Die vier Designprinzipien von Linked Data:
Benutzen von Uniform Resource Identifiers (URIs) als Namen für Dinge
http URIs müssen als Namen nachgeschlagen werden können
URIs müssen nützliche Informationen in RDF oder SPARQL Standards liefern
Links zu anderen URIs einfügen, damit User weitere Dinge entdecken können
Aktuelle Datenmodelle
BIBFRAME
Die „Bibliographic Framework Initiative“ ist von der Library of Congress ins Leben gerufen worden, um alle bisherigen Formate abzulösen. Ziel ist es, auch die Möglichkeiten, welche das Semantic-Web- und Linked-Data Technologien mit sich bringen, einzubeziehen (1). Die Initiative soll dazu führen, dass bibliographische Informationen nützlicher werden (innerhalb und ausserhalb der Bibliothek-Community) und MARC21 abzulösen. Die aktuellste Version ist BIBFRAME 2.0 von 2016. Es gibt auch eine deutsche Arbeitsgruppe von der Deutschen Nationalbibliothek.
Die (Bibliografischen-)Daten werden über RDF in drei Instanzen organisiert: Work, Instance und Item. Weiter gibt es mit Agent, Subject und Event drei Klassen.

Quelle Bild: Library of Congress
RiC
Records of Contexts basieren ebenfalls auf dem Linked Data Konzept. Das Ziel hier ist es Metadatenstandards für Archive so wie ISAD(G) und ISDF in einem Standard zu verknüpfen. Auch hier sollen die kontextuellen Umstände besser erkennbar gemacht werden und für ein tieferes Verständnis der Daten sorgen (erweitertes Prozenienzprinzip) (Quelle). Das Model wurde 2016 publiziert und 2021 wurde RiC-CM 2.0 veröffentlicht. Es wurde eine OWL-Ontologie für RiC unter dem Name RiC-O im Jahr 2019 herausgebracht.

Ein sehr guter Link, welcher das Prinzip erklärt: https://archivwelt.hypotheses.org/1982
Metadaten anreichern mit OpenRefine
Ich muss zugeben, dass ich mittlerweile OpenRefine wieder gelöscht hatte (zu wenig Speicherplatz) und beinahe vergessen hatte, was das war. Zum Glück hatte ich meine Aufzeichnungen noch. Für das anreichern der Metadaten wurde Reconciling genutzt. Hierbei werden Datensätze mit externen Quellen gematcht. Dies wird gemacht um beispielsweise Wikidata hinzuzufügen (wie in der Übung) oder Varianten zusammenzuführen. Man benötigt dazu eine API, daher müssen die Daten den API Standards entsprechen.
0 notes
Text
Vorlesung 9 - Suchmaschinen und Discovery-Systeme
Ablauf der heutigen Einheit:
Funktion von Suchmaschinen
Daten Integration
Marktübersicht Discovery-Systeme
Was sind Discovery-Systeme?
Immer geht es um Discovery-Systeme, jedoch habe ich mir ehrlich gesagt nie Gedanken darüber gemacht, was diese eigentlich sind. Sie sind bibliothekarische Suchsysteme, welche auf Suchmaschienentechnologie beruhen und (ältere) OPAC-Systeme ergänzen. Sie bestehen aus Suchoberflächen und Datenbanken mit durchsuchbarem Datenbankindex und können auch eine Mischung davon sein.
Solr und VuFind
Solr
Solr ist eine Open-Source-Plattform mit REST-API, mit welchem die Suche auf Webseiten durchgeführt werden kann. Es ist ein sehr weit verbreitetes Tool. Die aktuelle Version welche heruntergeladen werden kann ist Apache SOLR 9.2.1. Es erlaubt das Durchsuchen der Webseite, das Indizieren, Monitoring und Verwalten.
VuFind
VuFind ist ein open source „library resource portal” welches entwickelt und gewartet wird von der Villanova University. Es ermöglicht das Suchen der Bibliotheksressourcen und durchsucht dabei den Katalog, institutionelle Repositorien und Bibliographien. Es ist modular aufgebaut und lässt sich den eigenen Wünschen nach anpassen und integrieren. VuFind selbst basiert auf dem Discovery-System Solr, d.h.
Solr vs. VuFind
Beide Systeme sollten miteinander verglichen werden. Hierbei stellte sich schnell heraus, dass die Benutzeroberfläche von VuFind viel Benutzerfreundlicher ist. Bei Solr benötigt es einiges an Hintergrundwissen, wie beispielsweise welche Felder für was genutzt werden sollen. Gerade die Sucheingabe wirkt unter „q“ auf den ersten Blick versteckt. Daher ist es ein muss, das Benutzerhandbuch zu konsultieren. Die Suchoberfläche von VuFind wirkt hier viel „gewohnter“ mit einer klassischen Suchmaske inklusive einfacher und erweiterter Suche. Jedoch ist die Oberfläche von Solr – so wie ich es verstanden habe – nicht für den direkten Einsatz gedacht, sondern für die die hintergründige Implementierung. Daher ist es nicht verwunderlich, dass Solr bei einem Vergleich der Benutzeroberfläche nicht so gut abschneidet.
Marktübersicht
Es gibt einige bekannte Discovery-Systeme, beispielsweise (komerzielle Produkte wie) Primo (ExLibris), EBSCO und wie oben bereits beschrieben VuFind (OpenSource).
Swisscovery
Mit Discovery-Systemen habe ich selbst Erfahrung durch „Swisscovery“ – sowohl aus Perspektive eines Nutzers als auch eines Mitarbeiters, da mein Arbeitsplatz Swisscovery Basel nutzt. Dieses System wird bereitgestellt von SLSP (Swisss Library Service Plattform) und basiert auf Pimo. Zur Nutzung und Zufriedenheit kann ich hier sagen, dass es ein sehr mühsames tool ist, welches leider nicht immer so funktioniert wie es sollte. Gerade meine Bibliothek – die Bibliothek der Juristischen Fakultät Basel – hatte enorme Probleme mit der Suchfunktion. Dies hatte mehrere Gründe – da wir eine Präsenzbibliothek sind, sollten alle unsere Bücher als nicht entleihbar sein, anfangs wurde dies jedoch oftmals nicht angezeigt. Auch gab es Schwierigkeiten mit der Anzeige von Holdings vs. Exemplardaten. Bei uns existiert oft eine „Gundsignatur“ welche bei dem Übergeordneten Holding angezeigt wird, danach eine spezifische Signatur für das Exemplar. Auch dies wurde den Nutzern anfangs nicht immer richtig angezeigt und führte zu einigen Problemen.
0 notes
Text
Vorlesung 8 - Daten modellieren und Schnittstellen nutzen
Ablauf der heutigen Einheit:
Austauschprotokolle
Metadaten harvesten
Crosswalks
MarcEdit
Tools zur Metadatentransformation
Austauschprotokolle
Viele der bisher genannten Metadatenstandards sind international und für den Austausch konzipiert. Daher muss es auch Austauschprotokolle geben, um die Daten zu übertragen. Dafür gibt es eine Bandbreite an Möglichkeiten, über Harvesting, APIS oder Python.
Z39.50
Ein sehr altes Austauschprogramm, welches von der Library of Congress zur Verfügung gestellt wurde.
Search/Retrive via URL
Ebenfalls von der Library of Congress bereitgestellt und oft in Verbindung zu Z39.50 genutzt. Eignet sich besonders für Live-Abfragen
OAI-PMH
Open Archives Initiative Protocol for Metadata Harvesting (Open Archives Initiative). Unterstützt das automatisierte Harvesting („Einsammeln“ od. „ernten“) von Metadaten. Das Ganze geschieht über Data Provider und Service Provider. Das Protokoll basiert auf XML und erleichtert den Zugang zu Daten in Repositorien. Man kann in Verbindung mit VuFindHarvest in den bisher kennengelernten Systemen Metadaten harvesten.
Koha
ArchivesSpace
DSpace
Crosswalks und XSLT
Wenn Metadaten von einem in den anderen Standard konvertiert werden nennt man das Crosswalks. Dafür gibt es dann bestimmte Regeln, welche eingehalten werden sollen (Mapping) um die Werte und Felder zuzuordnen. Versucht wird, dass ganze so genau wie möglich zu machen, aber nicht immer ist eine 1:1 Übersetzung möglich, da nicht alle Elemente perfekt zugeordnet werden können.
XSLT steht für XSL-Transformation und wird verwendet um ein XSL-Dokument in ein anderes zu konvertieren. Für Alma gibt es ebenfalls die Möglichkeit einen solchen „Crosswalk“ für die Konvertierung von MARC21 zu Dublin Core Dokumenten (Link)
Zusammenfassung der Schritte:
Harvester Installieren
Daten formatieren über Crosswalks
Fazit:
Ich fand diese Einheit recht schwierig und musste einige Male Pausieren oder zurückspulen. Auch finde ich den ganzen Prozess der Schnittstellen recht mühsam und verwirrend.
Im Verlaufe der Vorlesung ist mir eingefallen, dass auf meiner letzen Arbeitsstelle ein Tool zur Verfügung stand, mit welchem wir MARC21-Daten kopieren konnten. Das ganze ging über eine Webseite (diese war von einer Person ehrenamtlich erstellt worden), auf welcher man über den Titel, ISBN oder Auto die entsprechenden Katalogisate suchen konnte. Außerdem konnte man auswählen, in welchen Verbünden man nach Datensätzen suchen wollte. Danach konnte man in der Ergebnisleiste das passende Katalogisat in der gewünschten Form auswählen – jedoch musste man es kopieren und dann in Bibliotheca in der Katalogisierungsmaske nach MARK21 einfügen. Also alles in allem recht unelegant. Jedoch hat es uns in unserer kleinen Bibliothek viel Zeit gespart. Hätte ich die Tools von hier bereits gekannt, wäre es vielleicht noch schneller gegangen. (Leider konnte ich die Webseite nicht mehr finden um sie hier zu verknüpfen).
0 notes
Text
Vorlesung 7 - Repository-Software für Publikationen und Forschungsdaten
Zu beginn der Vorlesung wurden noch einige Nachträge bezüglich der letzten Stunde gemacht. Dabei wurden auch Übungen zum Thema Import/Export durchgeführt. Da mir jedoch wenige Zeichen bleiben, gehe ich nicht mehr weiter darauf ein.
Repositorium
Was ist eigentlich ein Repository bzw. Repositorium? Es ist ein verwalteter Speicherort für digitale Objekte. Häufig ist es öffentlich oder einem eingeschränkten Benutzerkreis zugänglich.
Ziel ist die Langzeitverfügbarkeit von digitalen Ressourcen. Sie können unterschieden werden nach:
Art der zu speichernden Objekte
der Domäne der enthaltenen Daten
Speicherfrist der Daten
Policies, mit denen die Daten genutzt und abgerufen werden dürfen.
Repositorien bestehen aus einer (Repositoriums-)Software und einer Datenbank.
Open Access und Open Data
Unter „Open Access“ versteht man wissenschaftliche Publikationen, welche frei zugänglich sind. Es erlaubt somit das kostenlose Lesen, Downloaden, Speichern und Verlinken von publizierten Dokumenten. Auf der Suche nach einem Schaubild, welches ich hier einfügen kann, hat sich gezeigt, dass dies nicht so einfach ist, da es ein unterschiedliches Verständnis für „Open Access“ und was es beinhaltet gibt. Es wird unter anderem unterschieden zwischen goldenen und grünen Open Access. Golden bedeutet Open Access-Erstveröffentlichung mit gleichen Standards wie bei Closed-Access-Veröffentlichungen. Grüner Weg ist die Zweitveröffentlichung auf institutionellen od. disziplinären Repositorien.
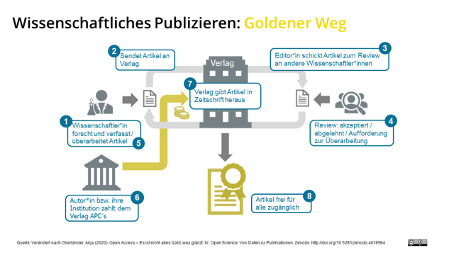
Quelle: http://doi.org/10.5281/zenodo.4018594 (CC BY 4.0 International)
Weiterführender Link: https://forschungsdaten.info/themen/finden-und-nachnutzen/open-data-open-access-und-nachnutzung/
DSpace
DSpace ist eine Software, welche sich für Publikationen und Forschungsdaten eignet. Dabei können auch Erweiterungen für Forschungsinformationen verwendet werden. Entwickelt wurde die Open-Source-Software vom MIT und wird von einigen Hochschulen wie beispielsweise der ETH oder dem MIT genutzt. Es wurde entwickelt angelehnt an das OAIS-Referenzmodell. Als Metadatenstandard wird eine abgeänderte Form von Dublin Core verwendet (besprochen in Vorlesung 4).
Es gibt drei Schichten:
Anwendungsschicht: hier ist auch die OAI-PHM Schnittstelle verankert
Geschäftslogik: Benutzer, Gruppen, Rechte etc.
Speicherung: physikalische Speicherung Metadaten & Inhalt
Es wurde im Unterricht Übungen zu Communitys und Collections / Einreichung und Review / Import und Export durchgeführt. Dafür wurde ein Zugang mit der Demo verwendet. Leider ist es mir schwergefallen die Übungen durchzuführen, da ich die Oberfläche recht verwirrend fand. Beim Nachschauen der Vorlesung stellte sich heraus, dass ich nicht die einzige Person war, der es so ging. Daher habe ich noch ein paar Videos über die Software angeschaut, um ein besseres Verständnis zu bekommen.
Repositroy-Software
Es gibt verschiedene Repository-Softwares, welche verwendet werden können. In der Vorlesung wurden einige der wichtigen für den deutschsprachigen Raum angesprochen. Bisher kannte ich ehrlich gesagt keine Repository-Software, mir war nur das Repository der Uni Basel bekannt, welches edoc heisst.
0 notes
Text
Vorlesung 6 Funktion und Aufbau Archivsystemen & Übung
Ablauf der Einheit:
Metadatenstandards in Archiven
ArchivesSpace
Archivsysteme
Auf den Sinn und Zweck von Metadatenstandards muss nicht mehr eingegangen werden, da dies schon in den letzten beiden Vorlesungen besprochen wurde
Metadatenstandards in Archiven – ISAD(G) und EDA
Es war interessant wieder einmal über ISAD(G) zu hören. In meiner Ausbildung in Deutschland zur Fachangestellten für Medien- und Informationsdienste wurde das katalogisieren von Archivgut nach ISAD(G) unterrichtet und wir mussten die Felder auswendig lernen. Es war spannend zu sehen, wie viel davon mir noch im Gedächtnis verblieben ist, im Studium wurde es in vergangenen Vorlesungen auch kurz angesprochen, jedoch nur oberflächlich. Aufgrund der Neugierde habe ich nach der Vorlesung auch meine alten Unterlagen aus der Berufsschule nach meinen Aufzeichnungen davon durchsucht.
ISAG(G) – das Archivregelwerk
Die Abkürzung steht für* International Standard Archival Description (General)* und ist ein internationaler Standard zur Verzeichnung von Archivalien. Die erste Fassung wurde 1993/94 veröffentlicht, die zweite Fassung 2000. Die zweite Fassung ist auch heute noch in Verwendung. ISAD(G) kann, ähnlich wie RDA, auch in Verbindung mit anderen Standards genutzt werden. Da es ein Internationaler Standard ist, dient er auch zum internationalen Austausch von Verzeichnungsinformationen. Ein weiterer Vorteil ist, dass er ungeachtet der Form und des Mediums angewendet werden kann. Die Datenstruktur orientiert sich an den früheren analogen Findmitteln wie Findbücher und Zettelkästen. ISAD(G) nutzt das Provienienzprinzip, das heisst es wird abgebildet nach Entstehungszusammenhang. Dabei wird auf mehreren Ebenen verzeichnet.
Kurzer Ausflug da ich es immer wieder vergesse: Provenienzprinzip: Archivalien werden nach ihrer Entstehung und ihrer Herkunft geordnet. Pertinenzprinzip: Archivalien werden nach Themenfeldern (Sachverhalten/Ereignissen/Personen) geordnet.
Bereiche und Verzeichnungselemente:
Es gibt 7 Verzeichnungselementgruppen:
Identifikation (Signatur etc.)
Kontext (Herkunft, Geschichte etc.)
Inhalt und Ordnung (Form und Inhalt, Bewertung etc.)
Zugangs- und Benutzungsbedingungen (Sprache, Schrift, Findmittel)
Sachverwandte Unterlagen (Aufbewahrungsort Originale, Kopien etc.)
Anmerkungen
Kontrolle (Bearbeiter etc.)
Weiter existieren sechs Pflichtfelder, welche bei der Verzeichnung ausgefüllt werden müssen:
Signatur
Titel
Provenienz
Entstehungszeitraum
Umfang
Verzeichnungsstufe
Ob und wie etwas verzeichnet werden muss ist immer auch abhängig von der Stufe, folgende Stufen gibt es (vom Großen ins Kleine):
Archiv
Bestand
Serie
Akte/Dossier
Dokument
Weitere Informationen hierzu sind unter der Schweizerischen Richtlinie für die Umsetzung von ISAD(G) zu finden unter folgendem Link.
ISAAR(CPF)
Beim International Standard Archival Authority Record for Corporate Bodies, Persons and Families handelt es sich um einen Standard für Normdateien. Da hier der Verzeichnisaufwand relativ hoch ist, wird dieser Standard nur selten verwendet. Er soll die Verbindung zwischen Urhebern und Unterlagen schaffen. Dabei ist er international verwendbar und schafft die Möglichkeit, Kontext und Inhalt von Archivgut getrennt zu verwalten[1].
Übung zu AtoM und ArchivesSpace
Es sollte nun auch ein Eintrag zur Übung zum Vergleich von AtoM und ArchiveSpace gemacht werden. Verglichen werden sollten die Verwaltungs- und Veröffentlichungsfunktionen.
AtOM
Atom ist ein webbasiertes und quelloffenes System. Das System ist von dem Metadatenstandard auf ISAD(G) aufgebaut. Es gibt leider leider keine deutsche Übersetzung.
Es gibt eine Demo-Version, welche für den Vergleich genutzt wurde.
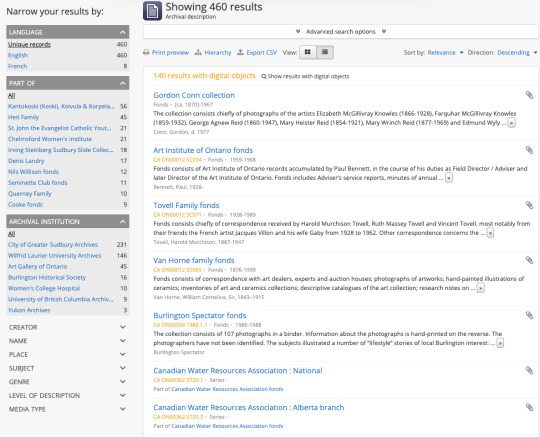
Suche
Wenn man sich eingeloggt hat, kann man über das Suchfeld in der Mitte suchen. Dabei kann man nach Sprachen, Instituten etc. suchen. Weiter gibt es eine erweiterte Suche. Ich finde alles sehr intuitiv zu bedienen.
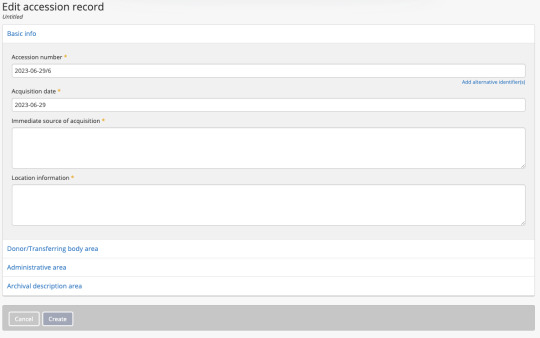
Katalogisieren
Für das Erfassen bzw. katalogisieren war ich für einen Moment ein wenig unsicher, was ich machen muss. Klickt man über das + in der Ecke auf "Accession Record", so kann man einen neuen Datensatz erfassen. Pflichtfelder sind mit Sternchen markiert. Wenn man weiter möchte, muss man auf die eingeklappten Abschnitte klicken.
ArchivesSpace
ArchivesSpace ist eine Open-Source-Software, bei welcher man auch bezahlen kann, um mehr Funktionen und Vorteile zu haben. Wie auch AtoM basiert ArchivesSpace auf den Standards ISAD(G), DACS und ISAAR(CPF). Das System hat leider noch keine deutsche Übersetzung.
Ich habe für den Vergleich die Sandbox-Version genutzt.
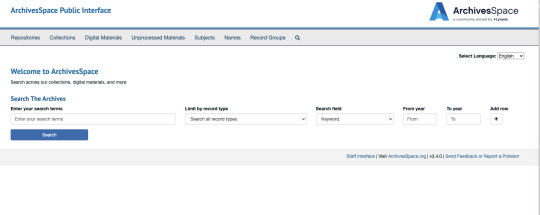
Suche
Für die Suche hat man etwas weniger Möglichkeiten wie bei Atom. Toll ist aber, dass man die Sprache auf Deutsch einstellen kann. Man kann zwischen Suchbegriffen, Art, Schlagworten und Jahr auswählen. Man kann auch weitere Zeilen mit und/oder Verknüpfungen hinzufügen. Die Anzeige der Suchergebnisse ist sehr ähnlich wie bei AtoM

Katalogisieren
Zum Katalogisieren klickt man bei ArchivesSpace auf "Select Create" und fügt dann ein neues Katalogisat hinzu. Auch hier werden Pflichtfelder mit Sternchen gekennzeichnet. Im Gegensatz zu AtoM, wo die einzelnen Felder aufgeklappt werden müssen, hat man hier auf der linken Seite ein Menü, bei welchem man die Kategorien auswählen kann. Die Möglichkeiten beim katalogisieren ist sehr gross, d.h. man kann es sehr ausführlich machen.

Quelle Foto: https://rs4.reuther.wayne.edu/SuperManual/01_accessioning/01_02_archivesspace_accessions/
Fazit:
Mir gefallen beide Systeme in grossen und ganzen gut. Ich finde auch wenn sie teilweise andere Funktionen/Workflows haben, ähneln sie sich.
0 notes
Text
Vorlesung 5: Funktionen und Aufbau von Bibliothekssystemen Teil 2 - Bibliothekssysteme in der Praxis
Ablauf der Vorlesung:
Übung zu Datenimport
Datenexport und Schnittstellen
Marktübersicht Bibliothekssysteme
Übung
Im zweiten Teil des Themas "Funktionen und Aufbau von Bibliothekssystemen ging es explizit um Bibliothekssysteme in der Praxiss und es wurden weitere Aufgaben zu Koha durchgeführt. Dabei sollte ein Datenimport mit dem Z39.50-Server durchgeführt werden um einen Datensatz zu importieren. Dafür musste auch ein SRU Server eingerichtet werden. Sobald die Schnittstelle hergestellt wurde, konnte man über die Suche MARC21 Daten in das Bibliothekssystem importieren. Nachdem man die Daten importiert hatte, konnte man die Daten über die gewohnte Katalogisierungsmaske bearbeiten. Ich fand, dass es zwar auf den ersten Blick kompliziert klang, aber eigentlich sehr einfach auszuführen war - vielleicht auch, weil wir auf der Arbeit auch über Schnittstellen importieren und ich es bereits gewohnt war.
Neben dem Datenimport sollte auch der Datenexport geübt werden. Dafür wurde wieder die OAI-PMH Schnittstelle genutzt. Diese ermöglicht das regelmässige automatisierte Abrufen von Änderungen. So können die Daten zur Weiterverarbeitung oder bei der Aggregation von Verbundrecherchen genutzt werden. Leider hat diese Übung bei mir nicht geklappt. Dennoch war es durch die Videoaufzeichnung interessant zu sehen, welche Vorteile eine solche Schnittstelle bringt.
Marktübersicht Bibliothekssysteme
In den öffentlichen Bibliotheken sind kostenpflichtige Systeme wie BIBLIOTHECAPlus (OCLC) sehr weit verbreitet. Im Bereich der wissenschaftlichen Bibliotheken wurde früher oft Aleph genutzt, was in den letzen Jahren jedoch von Alma abgelöst wurde.
Alma
Alma ist ein Bibliothekssystem mit welchem ich selbst in meinem Arbeitsalltag arbeite. Es ist ein browserbasiertes/cloudbasiertes Bibliothekssystem welches gedruckte, elektronische und digitale Medien in der selben Oberfläche verwaltet. Meine Arbeitsstelle ist die Bibliothek der Juristischen Fakultät in Basel und Alma hat uns eine enorme Arbeitserleichterung gebracht. Denn wir besitzen quasi hochspezialisierte Bücher, bei denen das Katalogisieren oftmals sehr Zeitaufwendig ist. Durch die Zusammenlegung (fast) aller Schweizer Hochschulbibliotheken, ist die Wahrscheinlichkeit, dass jemand anderes das Buch bereits katalogisiert hat, viel höher - das spart Zeit und Nerven.
Kooperatives Netzwerk - Network Zone
Die Network Zone ist der gemeinsame Katalog der Bibliotheken, welche gemeinsam Metadaten austauschen. Was hier der besondere Vorteil ist, ist der, dass eine Verbesserung oder Aktualisierung direkt für alle gilt. Wenn man also ein Katalogisat bereits in der Network Zone findet, kann man sein eigenes Exemplar direkt an das Holding hängen.

Community Zone
Findet man ein Katalogisat (noch) nicht in der Network Zone, so kann man nun in der Community-Zone nachschauen, ob es hier bereits Katalogisiert wurde und die Datensätze einfach in die eigene Institution importieren.

ERM - Electroinc Resource Management
Bietet die Möglichkeiten elektronische Ressourcen direkt zu verwalten und führt zu einer höheren Effektivität und Bewirtschaftung bei elektronischen Informationsressourcen und der Lizenzierung.
0 notes
Text
Vorlesung 4 Funktion und Aufbau von Bibliothekssystemen Teil 1
Ablauf der Einheit:
Metadatenstandards
Koha
Metadatenstandards:
Was sind Metadatenstandards?
Metadatenstandards sind verpflichtende Regelungen für Metadaten. Sie werden genutzt, um ein gemeinsames Verständnis für die Bedeutung und Semantik der Daten sicherzustellen, sowie die richtige Verwendung und Interpretation, sowohl seitens der Ersteller*innen, als auch seitens der Nutzer*innen. Dafür werden gewisse Kriterien festgelegt, welche die Daten definieren – diese werden dann Metadaten genannt. Es gibt drei Arten von Metadatenstandards : - Beschreibende Metadaten - Strukturelle Metadaten - Administrative Metadaten Metadaten werden sehr häufig in SGML (Standard Gerneralized Markup Language) oder XML beschrieben.
In Bibliotheken werden ebenfalls Metadaten bzw. Metadatenstandards für die Katalogisierung verwendet. Besonders bekannt sind MARC21, GND (Gemeinsame Normdatei) sowie der Dublin Core (DCMI - Dublin Core Metadata Initiative). Die GND wird verwendet um Normdaten kooperativ nutzen und verwalten zu können - dabei beschränkt sie sich nicht nur auf Bibliotheken sondern schliesst auch Archive, Museen sowie Kultur- und Wissenschaftseinrichtungen mit ein [2].
MARC21
Was ist MARC21?
MARC21 (Machine-Readable Cataloging) ist ein Medataten-Standard, welcher 1999 in der Library of Congress unter dem Namen „ MARC21 Format for bibliographic Data“ erstellt wurde. Ziel des Standards ist die Repräsentation und der Austausch von bibliografischen Informationsdaten in einem maschienenlesbaren Format [^3] . Dabei besteht ein Datensatz aus drei Elementen:

[^4] Es ermöglicht die Beschreibung von diversen Trägerdateien, wie Bücher, Periodika, Karten, Musik, Videos und Computerdateien. Das Schema, mit welchem die Daten beschrieben werden ist das XML-Schema MARCXML. Es ist ein einfaches Schema, dass flexibel und leicht erweiterbar ist [^5].
Was ist der Vorteil? Vorteile liegen darin, dass sich eine vielzahl von katalogisierungsregelungen abbildenlassen (Flexibilität). Ein weiterer grosser Vorteil ist, dass es sich für Dokumente aller Art eignet. Ausserdem ist durch seine grosse Verbreitung ein (leichterer) internationaler Austausch möglich.
Wie und wo wird es eingesetzt?
Wie bereits etwas weiter oben erwähnt ist das Format International, und wid auch international genutzt. Jedoch ist hier anzumerken, dass in vielen Ländern und Communitys abgeänderte Versionen verwendet werden. MaRC21 wird zum Katalogisieren sowie zum Austausch verwendet.
Regelwerk vs. Datenformat
Regelwerk ist die theoretische Grundlage und legt fest wie etwas zu beschreiben ist (RDA oder RAK-WB). Das Dateiformat legt fest auf welche Art es zu beschreiben ist d.h. wie die praktische Repräsentation aussehen soll. Dies geschieht durch Datentypen und Strukturen(MARC21).
Bibliothekssoftware Koha
Koha ist ein Open-Source-Projekt des Horowhenua Library Trust, welches kostenlos nutzbar ist. Das Projekt bzw. das System ist community-basiert und wurde 1999 in Neuseeland gestartet. Ein Jahr später wurde die Koha 1.00 Version zum Download zur Verfügung gestellt ^6. Die Software bietet grundlegende Funktionen wie Verwaltung, Katalogisierung und Ausleihe.
Übung im Unterricht
Die untenstehenden Screenshots beschreiben die im Unterricht durchgeführten Übungen zum erstellen und bearbeiten von Benutzern/Büchern.



[^1]: Metadaten Wikipedia [^2]: DNB - GND [^4]: Quelle Bild [^5]: DDBinfo für Daten [^6] Koha
0 notes
Text
Vorlesung 3 - Open Refine
Ablauf der Einheit:
Kurze Besprechung wegen des ausgefallenen Termins
TimeOut Codespace
Einführung in OpenRefine
Was ist OpenRefine?
Eine kostenlose open source Software, die das Arbeiten mit schlechten bzw. chaotischen Daten erleichtern soll. Es gibt neben den eigenen Möglichkeiten und Features auch Erweiterungen der Community. Main Features sind (laut eigenen Angaben):
Facetten
Clustering
Recualition
Infinite undo/redo
Privatsphäre
Wikibase
Die Software kann heruntergeladen werden und über den Browser bedient werden.
Herunterladen und Oberfläche:
Wenn man die Software heruntergeladen hat, so öffnet sich diese im Browser. Die Startseite sieht aus wie im Oberen Bild. Hier kann man nun ein neues Projekt erstellen, ein Projekt öffnen oder Importieren. Ausserdem lässt sich die Sprache ändern. Die Software unterstützt eine Vielzahl von Formaten, vor allem auch die gängigen Formate wie CSV, xls, JSON und XML. Die Handhabung ist recht einfach und die Beschreibungen selbsterklärend.

Übung an den Beispieldaten:
Um mit der Software und ihren Funktionen bekannt zu werden, wurden Beispieldaten heruntergeladen und mit diesen gearbeitet. Der Zweck der Übung war es, die Basisfunktionen kennenzulernen. Nach dem Importieren der Daten wurde in der rechten Ecke auf „Create project“ geklickt. (Foto: Einfügen der Daten über den angegebenen Link)
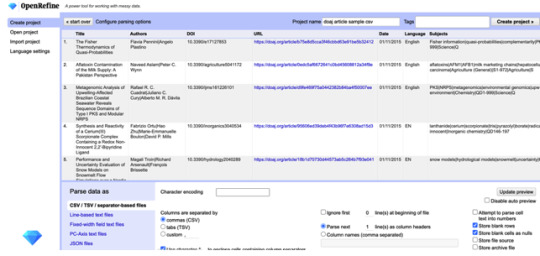
Zum Einstieg gab es die Übung mit den Baisfunktionen der Software. Hier sollten zunächst die Sprachen als Facetten ausgewählt werden. Außerdem sollten bei der Spalte „Authors“ ein Seperator (I) eingefügt werden, sowie doppelte Nennungen geclustert werden und die Zellen mit mehreren Values mit I zusammengeführt werden. Durch das Einfügen der „Text facet“ öffnet sich auf der linken Seite der Filter hierzu und man erkennt zugleich auch die Häufigkeit der Angezeigten Texte, was einen Überblick erleichtert. Die Handhabung der Übung war sehr intuitiv und führte zu keinen Problemen. Durch das Klicken auf das nach unten gedrehte Dreiecke öffnete sich das Menü und von dort aus konnte die Auswahl getroffen werden.

Folgendes sind die Basisfunktionen:
Facetten und Filter hinzufügen
Informationen ergänzen
Durchsuchen der Daten
Einfügen neuer Spalten inkl. Verknüpfen mit Daten und Überprüfen
Fazit der Stunde:
Die Übung sowie das Programm haben sehr viel Spaß gemacht. Es gibt keine offenen Fragen zur Zeit.
Quellen für diese Stunde:
https://openrefine.org/https://librarycarpentry.org/lc-open-refine/
0 notes
Text
Vorlesung 1 - Technische Grundlagen
Kurze Info: Leider war es mir bisher aufgrund meiner Krankheit noch nicht möglich, die gesamte Vorlesung des 15.2.2023 nachzuholen. Daher wird dies noch in den nächsten Tagen folgen.
Generelle Inhalte der 1. Vorlesung:
Einführung in die Lernumgebung inkl. HedgeDoc, Github
Markdown
Einführung in die Grundlagen von UnixShell
Übung zum Dateisystem mit UnixShell
Versionskontrolle mit Git
Beitreten und Beenden von Code Spaces
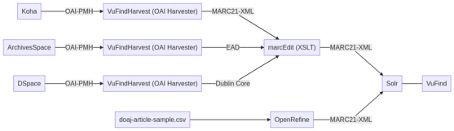
Zunächst einmal wurde das Schaubild, welches durch diesen Kurs führen soll erklärt. Hier werden die wichtigsten technischen Zusammenhänge dargestellt und erklärt.
Wir haben somit drei Katalogisierungssysteme. Durch eine Schnittstelle (OAI-PMH) wird es dem Harvester möglich gemacht Datensätze aus den Systemen herunterzuladen. Wenn die Daten heruntergeladen werden, können sie über diverse Programme (Open Refine und marcEdit) konvertiert werden. Diese Daten wiederum können über Suchsysteme wie Solr durchsucht werden und über eine Suchmaske bzw. Oberfläche gesucht werden (VuFind).
Der Unterricht wurde gemeinsam in einem Dokument durchgeführt, was eine neue Art des Unterrichts für mich war, mir aber gut gefallen hat.
Übung zu der Auszeichnungssprache Markdown
Markdown war etwas, von dem ich zwar schon viel gehört hatte, mich aber nie wirklich auseinandersetzt habe. Das Tutorial, welches verlinkt war, war eine sehr hilfreiche Übung. Durch den langsamen Aufbau der Schwierigkeit und das repetitieren eine klare und verständliche Einführung war.
Markdown
Die Idee hinter Marktdown ist, so schnell lesbar und schreibbar zu sein wie möglich. Die Quelle dafür ist die Formatierung von Nur-Text-Emails und bietet daher nur wenige formatierungs Möglichkeiten an. Diese Formatierungen sind HTML-Tags. Es ist im Unterschied zu HTML, was ein Publikations-Format ist, ein Schreibformat.
Von Bedeutung sind:
Überschriften: werden mit # dargestellt, je mehr Rauten, desto kleiner die Überschrift
Zitate: können über > gemacht werden. Wie bei den Überschriften gilt hier - je mehr, desto verschachtelter.
Listen: können über mehrere Zeichen erstellt werden: - , + und * (oder über Nummerierungen)
Fusszeilen: bzw. Quellenangaben gehen über [^1] erstellt werden. An einer anderen Stelle muss dann: [^1] (Quellenangabe) stehen.
Kursiv: *in Sternchen*
Fett: _mit Unterstrich_
Weitere Infos unter: Markdown
Die Unix Shell
Die Shell wurde bereits in einigen Vorlesungen wie beispielsweise Wirtschaftsinformatik und ARIS eingeführt und verwendet. Dennoch fällt mir der Umgang mit der Shell zugegebenermaßen immer noch nicht leicht. Daher war es ganz gut, dass diese nochmals besprochen wurde.
Was ist die Shell?
Sie ist der Mittler zwischen dem Benutzer und dem Betriebssystemkern. Ihr Ziel ist es, Kommandos entgegenzunehmen und das Betriebssystem um die Ausführung dieser zu bitten. Diese Kommandos sind festgelegt und laufen nach einem bestimmten Schema ab. Es gibt zwei Arten von Kommandos:
Kommandos in der Shell
Kommandos die im Dateisystem gesucht und gestartet werden.
Wichtige Kommandos: cat, -b, -n, -s, ln (link), cp (Copy), mv (move/verschieben), rm (remove /löschen), cd (wechseln des aktuellen Arbeitsverzeichnisses), pwd (Print Working Directory - Name des aktuellen Verzeichnisses).
Weitere Kommandos
Links: https://de.wikipedia.org/wiki/Unix-Shell
0 notes
Text
Einführung
title: "Semesterstart"
date: 2023-02-15
Im nachfolgenden Blogeintrag werde ich Bezug auf den Einstieg in den Kurs sowie meine bisherigen Erfahrungen und Erwartungen an die Vorlesung teilen.
Der Einstieg oder „Wo bin ich gestartet?“
Leider konnte ich den ersten Termin dieses Kurses nicht wahrnehmen, da ich krank war. Dies führte dazu, dass auch dieser Blog ein wenig später entstanden ist und ich die Inhalte der ersten Vorlesung über die Videoaufzeichnungen nachholen muss(te). Für den Kurs „Bibliotheks- und Archivinformatik“ soll im Laufe des Semesters ein sogenanntes Lerntagebuch geführt werden, welches die Erfahrungen und Inhalte der Vorlesung wiedergibt.
Bisherige Erfahrungen
Seit Beginn meiner Ausbildung als Fachangestellte für Medien- und Informationsdienste in der Fachrichtung Bibliothek habe ich beruflich mit Bibliothekssoftware zu tun. In meiner ersten Arbeitsstelle habe ich mit "Bibliothecaplus" gearbeitet. Dies ist eine Software von OCLC und wird vorrangig von öffentlichen Bibliotheken genutzt. Die genauen Abläufe des Systems waren mir jedoch ungekannt, da wir bei Problemen einen externen Support hatten, welcher sich um diese gekümmert hat. Bei meiner aktuellen Arbeitsstelle in einer wissenschaftlichen Bibliothek wurde zunächst mit der Software "Aleph" gearbeitet, im Jahr 2021 wurde dann auf die Online-Bibliothekssoftware "Alma" gewechselt. Diese beiden Softwaren unterschieden sich vom Aufbau in den Funktionen sowohl voneinander als auch von der Software der öffentlichen Bibliothek. Jedoch hat es mir die Möglichkeit gegeben, verschiedene Softwares inklusiver unterschiedlichem Aufbau und Möglichkeiten kennenzulernen. Innerhalb der Bibliothekssysteme hatte ich vor allem mit den Katalogisierungsmodulen sowie den Benutzerdatenmodulen zu tun.
Erwartungen
Wie bei den Erfahrungen aufgeführt, kannte ich Bibliothekssysteme bisher lediglich aus Sicht der Anwender und habe mir um ehrlich zu sein, nie große Gedanken über den Aufbau und die dahintersteckende Technik gemacht. Daher ist es meine Erwartung an diesen Kurs, den Aufbau und die Hintergründe der Abläufe und Zusammenhänge zu erfahren sowie mögliche Fehlerquellen etwas besser zu verstehen.
2 notes
·
View notes