
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by blackcatblog-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
9 days
Number of Posts By Type
Text
6
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Tute 8
PERSISTENT DATA
The opposite of dynamic—it doesn’t change and is not accessed very frequently.
Core information, also known as dimensional information in data warehousing. Demographics of entities—customers, suppliers,orders.
Master data that’s stable.
Data that exists from one instance to another. Data that exists across time independent of the systems that created it. Now there’s always a secondary use for data, so there’s more persistent data. A persistent copy may be made or it may be aggregated. The idea of persistence is becoming more fluid.
Stored in actual format and stays there versus in-memory where you have it once, close the file and it’s gone. You can retrieve persistent data again and again. Data that’s written to the disc; however, the speed of the discs is a bottleneck for the database. Trying to move to memory because it’s 16X faster.
Every client has their own threshold for criticality (e.g. financial services don’t want to lose any debits or credits). Now, with much more data from machines and sensors, there is greater transactionality. The meta-data is as important as Now, with much more data from machines and sensors, there is greater transactionality. The meta-data is as important as the data itself. Meta-data must be transactional.
Non-volatile. Persists in the face of a power outage.
Any data stored in a way that it stays stored for an extended period versus in-memory data. Stored in the system modeled and structured to endure power outages. Data doesn’t change at all.
Data considered durable at rest with the coming and going of hardware and devices. There’s a persistence layer at which you hold your data at risk.Data that is set and recoverable whether in flash or memory backed.
With persistent data, there is reasonable confidence that changes will not be lostand the data will be available later. Depending on the requirements, in-cloud or in-memory systems can qualify. We care most about the “data” part. If it’s data, we want to enable customers to read, query, transform, write, add-value, etc.
A way to persist data to disk or storage. Multiple options to do so with one replica across data centers in any combination with and without persistence. Snapshot data to disk or snapshot changes. Write to disk every one second or every write. Users can choose between all options. Persistence is part of a high availability suite which provides replication and instant failover. Registered over multiple clouds. Host thousands of instances over multiple data centers with only two node failures per day. Users can choose between multiple data centers and multiple geographies. We are the company behind Redis. Others treat as a cache and not a database. Multiple nodes – data written to disks. You can’t do that with regular open source. If you don’t do high availability, like recommended, you can lose your data.
Anything that goes to a relational or NoSQL database in between.
DATA
All information systems require the input of data in order to perform organizational activities. Data, as described by Stair and Reynolds (2006), is made up of raw facts such as employee information, wages, and hours worked, barcode numbers, tracking numbers or sale numbers.
The scope of data collected depends on what information needs to be extrapolated for maximum efficiency. Kumar and Palvia (2001) state that: “ Data plays a vital role in organizations, and in recent years companies have recognized the significance of corporate data as an organizational asset” (¶ 4). Raw data on it’s own however, has no representational value (Stair and Reynolds, 2006). Data is collected in order to create information and knowledge about particular subjects that interest any given organization in order for that organization to make better management decisions.
DATABASE
A database (DB), in the most general sense, is an organized collection of data. More specifically, a database is an electronic system that allows data to be easily accessed, manipulated and updated.
In other words, a database is used by an organization as a method of storing, managing and retrieving information.
Modern databases are managed using a database management system (DBMS).
DATABASE SERVER
The term database server may refer to both hardware and software used to run a database, according to the context. As software, a database server is the back-end portion of a database application, following the traditional client-server model. This back-end portion is sometimes called the instance. It may also refer to the physical computer used to host the database. When mentioned in this context, the database server is typically a dedicated higher-end computer that hosts the database.
Note that the database server is independent of the database architecture. Relational databases, flat files, non-relational databases: all these architectures can be accommodated on database servers.
DATABASE MANAGEMENT SYSTEM
Database Management System (also known as DBMS) is a software for storing and retrieving users’ data by considering appropriate security measures. It allows users to create their own databases as per their requirement.
It consists of a group of programs which manipulate the database and provide an interface between the database. It includes the user of the database and other application programs.
The DBMS accepts the request for data from an application and instructs the operating system to provide the specific data.
In large systems, a DBMS helps users and other third-party software to store and retrieve data.
DBMS vs FILES
Multi-user access-It does not support multi-user access
Design to fulfill the need for small and large businesses-It is only limited to smaller DBMS system.
Remove redundancy and Integrity-Redundancy and Integrity issues
Expensive. But in the long term Total Cost of Ownership is cheap-It’s cheaper
Easy to implement complicated transactions-No support for complicated transactions
Pros of the File System
Performance can be better than when you do it in a database. To justify this, if you store large files in DB, then it may slow down the performance because a simple query to retrieve the list of files or filename will also load the file data if you used Select * in your query. In a files ystem, accessing a file is quite simple and light weight.
Saving the files and downloading them in the file system is much simpler than it is in a database since a simple “Save As” function will help you out. Downloading can be done by addressing a URL with the location of the saved file.
Migrating the data is an easy process. You can just copy and paste the folder to your desired destination while ensuring that write permissions are provided to your destination.
It’s cost effective in most cases to expand your web server rather than pay for certain databases.
It’s easy to migrate it to cloud storage i.e. Amazon S3, CDNs, etc. in the future.
Cons of the File System
Loosely packed. There are no ACID (Atomicity, Consistency, Isolation, Durability) operations in relational mapping, which means there is no guarantee. Consider a scenario in which your files are deleted from the location manually or by some hacking dudes. You might not know whether the file exists or not. Painful, right?
Low security. Since your files can be saved in a folder where you should have provided write permissions, it is prone to safety issues and invites trouble, like hacking. It’s best to avoid saving in the file system if you cannot afford to compromise in terms of security.
Pros of Database
ACID consistency, which includes a rollback of an update that is complicated when files are stored outside the database.
Files will be in sync with the database and cannot be orphaned, which gives you the upper hand in tracking transactions.
Backups automatically include file binaries.
It’s more secure than saving in a file system.
Cons of Database
You may have to convert the files to blob in order to store them in the database.
Database backups will be more hefty and heavy.
Memory is ineffective. Often, RDBMSs are RAM-driven, so all data has to go to RAM first. Yeah, that’s right. Have you ever thought about what happens when an RDBMS has to find and sort data? RDBMS tracks each data page — even the lowest amount of data read and written — and it has to track if it’s in-memory or if it’s on-disk, if it’s indexed or if it’s sorted physically etc.
TYPES OF DATABASE
Depending upon the usage requirements, there are following types of databases available in the market:
Centralised database.
Distributed database.
Personal database.
End-user database.
Commercial database.
NoSQL database.
Operational database.
Relational database.
Cloud database.
Object-oriented database.
Graph database.
But we ca conseder the following databases as main databases.
1.Relational Database
The relational database is the most common and widely used database out of all. A relational database stores different
data in the form of a data table.
2.Operational Database
Operational database, which has garnered huge popularity from different organizations, generally includes customer database, inventory database, and personal database.
3.Data Warehouse
There are many organizations that need to keep all their important data for a long span of time. This is where the importance of the data warehouse comes into play.
4.Distributed Database
As its name suggests, the distributed databases are meant for those organizations that have different workplace venues and need to have different databases for each location.
5.End-user Database
To meet the needs of the end-users of an organization, the end-user database is used.
key terms of different types of database users
application programmer: user who implements specific application programs to access the stored data
application user: accesses an existing application program to perform daily tasks.
database administrator (DBA): responsible for authorizing access to the database, monitoring its use and managing all the resources to support the use of the entire database system
end user: people whose jobs require access to a database for querying, updating and generating reports
sophisticated user: those who use other methods, other than the application program, to access the database
STATEMENT VS PREPARED STATEMENT VS CALLABLE STATEMENT IN JAVA
JDBC API provides 3 different interfaces to execute different SQL Queries. They are:
Statement: Statement interface is used to execute normal SQL Queries.
PreparedStatement: It is used to execute dynamic or parametrized SQL Queries.
CallableStatement: It is used to execute the Stored Procedure.
STATEMENT
In JDBC Statement is an Interface. By using Statement object we can send our SQL Query to Database. At the time of creating a Statement object, we are not required to provide any Query. Statement object can work only for static query.
PREPARED STATEMENT
PreparedStatement is an interface, which is available in java.mysql package. It extends the Statement interface.
Benefits of Prepared Statement:
It can be used to execute dynamic and parametrized SQL Query.
Prepared Statement is faster then Statement interface. Because in Statement Query will be compiled and execute every time, while in case of Prepared Statement Query won’t be compiled every time just executed.
It can be used for both static and dynamic query.
In case of Prepared Statement no chance of SQL Injection attack. It is some kind of problem in database programming.
CALLABLE STATEMENT
CallableStatement in JDBC is an interface present in a java.sql package and it is the child interface of Prepared Statement. Callable Statement is used to execute the Stored procedure and functions. Similarly to method stored procedure has its own parameters. Stored Procedure has 3 types of parameters.
IN PARAMETER : IN parameter is used to provide input values.
OUT PARAMETER : OUT parameter is used to collect output values.
IN OUT PARAMETER : It is used to provide input and to collect output values.
The driver software vendor is responsible for providing the implementations for Callable statement interface. If Stored Procedure has OUT parameter then to hold that output value we should register every OUT parameter by using registerOutParameter() method of CallableStatement. CallableStatement interface is better then Statement and PreparedStatement because its call the stored procedure which is already compiled and stored in the database.
ORM
ORMs have some nice features. They can handle much of the dog-work of copying database columns to object fields. They usually handle converting the language’s date and time types to the appropriate database type. They generally handle one-to-many relationships pretty elegantly as well by instantiating nested objects. I’ve found if you design your database with the strengths and weaknesses of the ORM in mind, it saves a lot of work in getting data in and out of the database. (You’ll want to know how it handles polymorphism and many-to-many relationships if you need to map those. It’s these two domains that provide most of the ‘impedance mismatch’ that makes some call ORM the ‘vietnam of computer science’.)
For applications that are transactional, i.e. you make a request, get some objects, traverse them to get some data and render it on a Web page, the performance tax is small, and in many cases ORM can be faster because it will cache objects it’s seen before, that otherwise would have queried the database multiple times.
For applications that are reporting-heavy, or deal with a large number of database rows per request, the ORM tax is much heavier, and the caching that they do turns into a big, useless memory-hogging burden. In that case, simple SQL mapping (LinQ or iBatis) or hand-coded SQL queries in a thin DAL is the way to go.
Pros of ORM:
Portable: ORM is used so that you write your structure once and ORM layer will handle the final statement that is suitable for the configured DBMS. This is an excellent advantage as simple operation like limit is added as ‘limit 0,100’ at the end of select statement in MySQL, while it is ‘select top 100 from table’ in MS SQL.
Nesting of data: in case of relationships, the ORM layer will pull the data automatically for you.
Single language: you don’t to know SQL language to deal the database only your development language.
Adding is like modifying: most ORM layers treat adding new data (SQL insert) and updating data (SQL Update) in the same way, these makes writing and maintaining code a piece of cake.
Cons of ORM
Slow: if you compare the performance between writing raw SQL or using ORM, you will find raw much faster as there is no translation layer.
Tuning: if you know SQL language and your default DBMS well, then you can use your knowledge to make queries faster but this is not the same when using ORM.
Complex Queries: some ORM layers have limitations especially when executing queries so sometimes you will find yourself writing raw SQL.
Studying: in case you are working in a big data project and you are not happy with the performance, you will find yourself studying the ORM layer so that you can minimize the DBMS hits.
JAVA ORM TOOLSHibernate
Hibernate is an object-relational mapping (ORM) library for the Java language, providing a framework for mapping an object-oriented domain model to a traditional relational database. Hibernate solves object-relational impedance mismatch problems by replacing direct persistence-related database accesses with high-level object handling functions.
Hibernate’s primary feature is mapping from Java classes to database tables (and from Java data types to SQL data types). Hibernate also provides data query and retrieval facilities. Hibernate generates the SQL calls and attempts to relieve the developer from manual result set handling and object conversion and keep the application portable to all supported SQL databases with little performance overhead.
IBatis / MyBatis
iBATIS is a persistence framework which automates the mapping between SQL databases and objects in Java, .NET, and Ruby on Rails. In Java, the objects are POJOs (Plain Old Java Objects). The mappings are decoupled from the application logic by packaging the SQL statements in XML configuration files. The result is a significant reduction in the amount of code that a developer needs to access a relational database using lower level APIs like JDBC and ODBC.
Other persistence frameworks such as Hibernate allow the creation of an object model (in Java, say) by the user, and create and maintain the relational database automatically. iBATIS takes the reverse approach: the developer starts with an SQL database and iBATIS automates the creation of the Java objects. Both approaches have advantages, and iBATIS is a good choice when the developer does not have full control over the SQL database schema.
For example, an application may need to access an existing SQL database used by other software, or access a new database whose schema is not fully under the application developer’s control, such as when a specialized database design team has created the schema and carefully optimized it for high performance.
Toplink
In computing, TopLink is an object-relational mapping (ORM) package for Java developers. It provides a framework for storing Java objects in a relational database or for converting Java objects to XML documents.
TopLink Essentials is the reference implementation of the EJB 3.0 Java Persistence API (JPA) and the open-source community edition of Oracle’s TopLink product. TopLink Essentials is a limited version of the proprietary product. For example, TopLink Essentials doesn’t provide cache synchronization between clustered applications, some cache invalidation policy, and query Cache.
.NET ORM TOOLSLinqConnect
LinqConnect is a fast, lightweight, and easy to use LINQ to SQL compatible ORM solution, supporting SQL Server, Oracle, MySQL, PostgreSQL, and SQLite. It allows you to use efficient and powerful data access for your .NET Framework, Metro, Silverlight, or Windows Phone applications supporting Code-First, Model-First, Database-First or mixed approaches.
NHibernate
Entity Developer for NHibernate, being the best NHibernate designer to-date, allows you to create NHibernate models fastly in a convenient GUI environment.
Devart has almost ten-year experience of developing visual ORM model designers for LINQ to SQL and Entity Framework and there is a number of satisfied LINQ to SQL and Entity Framework developers that use Entity Developer. Our extensive experience and skills have become the soundest cornerstone of our NHibernate designer.
Entity Framework 6
Entity Framework 6 (EF6) is a tried and tested object-relational mapper (O/RM) for .NET with many years of feature development and stabilization.
As an O/RM, EF6 reduces the impedance mismatch between the relational and object-oriented worlds, enabling developers to write applications that interact with data stored in relational databases using strongly-typed .NET objects that represent the application’s domain, and eliminating the need for a large portion of the data access “plumbing” code that they usually need to write.
NOSQL
NoSql solves the problem of scalability and availability against that of atomicity or consistency. So According to CAP(Consistency, Availability and Tolerance to network partitions) theorem for shared-data systems, only two can be achieved at any time. NoSql approach to store data and querying is quite better :
Schemaless data representation:Most of them offer schemaless data representation & allow storing semi-structured data.Can continue to evolve over time— including adding new fields or even nesting the data, for example, in case of JSON representation.
Development time: No complex SQL queries. No JOIN statements.
Speed:Very High speed delivery & Mostly in-built entity-level caching
Plan ahead for scalability:Avoiding rework
Why do we need NoSQL
NoSQL offers a simpler data model in other words, it motivates to use the concepts of embedding and indexing your data rather than using the concept of joining the data.
If a developer wants to do rapid development of the application then NoSQL will be useful.
NoSQL provides high scaling out capability.
NoSQL allows you to add any kind of data in your database because it is flexible.
It also provides distributed storage and high availability of the data.
Streaming is also accepted by NoSQL because it can handle a high volume of data which is stored in your database.
It offers real-time analysis, and redundancy so as to replicate your data on more than one servers.
As mentioned earlier, it is highly scalable therefore it can be implemented with a very low budget.
Types of NoSQL databases
There are 4 basic types of NoSQL databases:
Key-Value Store – It has a Big Hash Table of keys & values {Example- Riak, Amazon S3 (Dynamo)}
Document-based Store- It stores documents made up of tagged elements. {Example- CouchDB}
Column-based Store- Each storage block contains data from only one column, {Example- HBase, Cassandra}
Graph-based-A network database that uses edges and nodes to represent and store data. {Example- Neo4J}
HADOOPWhat is Hadoop:
Hadoop is an open-source tool from theApache Software Foundation.
It provides an efficient framework for running jobs on multiple nodes of clusters.
Hadoop consists of three key parts :
HADOOP Distributed file system (HDFS) – It is the storage layer of Hadoop.
Map Reduce – It is the data processing layer of Hadoop.
YARN – It is the resource management layer of Hadoop.
Why Hadoop
Hadoop is still the backbone of all the Big Data Applications, following characteristics of Hadoop make it a unique platform:
Open Source
Distributed Processing
Fault Tolerance
Reliability
High Availability
Scalability
Economic
Easy to use
Data Locality
HDFS Key Features
HDFS is a fault-tolerant and self-healing distributed filesystem designed to turn a cluster of industry-standard servers into a massively scalable pool of storage. Developed specifically for large-scale data processing workloads where scalability, flexibility, and throughput are critical, HDFS accepts data in any format regardless of schema, optimizes for high-bandwidth streaming, and scales to proven deployments of 100PB and beyond.
Hadoop Scalable:
HDFS is designed for massive scalability, so you can store unlimited amounts of data in a single platform. As your data needs grow, you can simply add more servers to linearly scale with your business.
Flexibility:
Store data of any type — structured, semi-structured, unstructured — without any upfront modeling. Flexible storage means you always have access to full-fidelity data for a wide range of analytics and use cases.
Reliability:
Automatic, tunable replication means multiple copies of your data are always available for access and protection from data loss. Built-in fault tolerance means servers can fail but your system will remain available for all workloads.
MapReduce Key FeaturesAccessibility:
Supports a wide range of languages for developers, including C++, Java, or Python, as well as high-level language through Apache Hive and Apache Pig.
Flexibility:
Process any and all data, regardless of type or format — whether structured, semi-structured, or unstructured. Original data remains available even after batch processing for further analytics, all in the same platform.
Reliability:
Built-in job and task trackers allows processes to fail and restart without affecting other processes or workloads. Additional scheduling allows you to prioritize processes based on needs such as SLAs.
Hadoop Scalable:
MapReduce is designed to match the massive scale of HDFS and Hadoop, so you can process unlimited amounts of data, fast, all within the same platform where it’s stored.
While MapReduce continues to be a popular batch-processing tool, Apache Spark’s flexibility and in-memory performance make it a much more powerful batch execution engine. Cloudera has been working with the community to bring the frameworks currently running on MapReduce onto Spark for faster, more robust processing.
MapReduce is designed to process unlimited amounts of data of any type that’s stored in HDFS by dividing workloads into multiple tasks across servers that are run in parallel.
YARN Key Features
YARN provides open source resource management for Hadoop, so you can move beyond batch processing and open up your data to a diverse set of workloads, including interactive SQL, advanced modeling, and real-time streaming.
Hadoop Scalable:
YARN is designed to handle scheduling for the massive scale of Hadoop so you can continue to add new and larger workloads, all within the same platform.
Dynamic Multi-tenancy:
Dynamic resource management provided by YARN supports multiple engines and workloads all sharing the same cluster resources. Open up your data to users across the entire business environment through batch, interactive, advanced, or real-time processing, all within the same platform so you can get the most value from your Hadoop platform.
0 notes
Text
Tute 5
Web Service
W3C (World Wide Web Consortium) describes web service as a system of software allowing different machines to interact with each other through network. Web services achieve this task with the help of XML, SOAP, WSDL and UDDI open standards.
XML: The full form of XML is ‘Extensible Markup Language’ which is used to share data on the web and in universal format.
SOAP: Standing for ‘Simple Object Access Protocol’ which is an application communication protocol that sends and receives messages through XML format. It is one of the best ways to communicate between applications over HTTP which is supported by all browsers and servers.
WSDL: Written in XML, WSDL stands for Web Services Description Language and is used to describe web service. WSDL comprises three parts such as Definitions (usually expressed in XML including both data type definitions), Operations and Service bindings. Operations denote actions for the messages supported by a Web service.
There are three types of operations:
One way
Request response
Notification
Service bindings: Service bindings is a connecting to the port.
UDDI: Universal Description, Discovery, and Integration (UDDI) provides the description of a set of services supporting the depiction and discovery of businesses, organizations, and other Web Services providers. It is based on common set of industry standards, including HTTP, XML, XML Schema, and SOAP.
Web Application
An application that the users access over the internet is called a web application. Generally, any software that is accessed through a client web browser could be called a web application.
What is client?
So what is a client? A ‘client’ can be referred to the program that the person use to run the application in the client-server environment. The client-server environment refers to multiple computers sharing information such as entering info into a database. Here the “client” is the application that is used to enter the info, while the “server” is the application that is used to store the information.
Web Services vs Web Applications
Web Services can be used to transfer data between Web Applications.
Web Services can be accessed from any languages or platform.
A Web Application is meant for humans to read, while a Web Service is meant for computers to read.
Web Application is a complete Application with a Graphical User Interface (GUI), however, web services do not necessarily have a user interface since it is used as a component in an application.
Web Application can be access through browsers.
Our expertise lies in our in-depth knowledge, vast experience and exposure in automating business processes, offering effective web services and web applications solutions to transform them into your business objectives. We have an adept team with best of breed technologies to change the growth story of your business.
Carmatec brings together multifaceted skill-set from the areas of design, behavioral science, usability, analytics, marketing and brand creation to provide businesses with holistic solutions for Web Design, Web & Mobile Development,
Remote IT infrastructure management, Software Development, Managed IT services, Cloud Consulting, Internet Marketing and Branding.
WSDL
WSDL stands for Web Services Description Language. It is the standard format for describing a web service. WSDL was developed jointly by Microsoft and IBM.
Features of WSDL
WSDL is an XML-based protocol for information exchange in decentralized and distributed environments.
WSDL definitions describe how to access a web service and what operations it will perform.
WSDL is a language for describing how to interface with XML-based services.
WSDL is an integral part of Universal Description, Discovery, and Integration (UDDI), an XML-based worldwide business
registry.
WSDL is the language that UDDI uses.
WSDL is pronounced as 'wiz-dull' and spelled out as 'W-S-D-L'.
WSDL Usage
WSDL is often used in combination with SOAP and XML Schema to provide web services over the Internet. A client program connecting to a web service can read the WSDL to determine what functions are available on the server. Any special datatypes used are embedded in the WSDL file in the form of XML Schema. The client can then use SOAP to actually call one of the functions listed in the WSDL.
History of WSDL
WSDL 1.1 was submitted as a W3C Note by Ariba, IBM, and Microsoft for describing services for the W3C XML Activity on XML Protocols in March 2001. WSDL 1.1 has not been endorsed by the World Wide Web Consortium (W3C), however it has just released a draft for version 2.0 that will be a recommendation (an official standard), and thus endorsed by the W3C.
WSDL Elements
The WSDL file contains the following main parts
The <types> tag is used to define all the complex datatypes, which will be used in the message exchanged between the client application and the web service. This is an important aspect of the client application, because if the web service works with a complex data type, then the client application should know how to process the complex data type. Data types such as float, numbers, and strings are all simple data types, but there could be structured data types which may be provided by the web service.
For example, there could be a data type called EmployeeDataType which could have 2 elements called "EmployeeName" of type string and "EmployeeID" of type number or integer. Together they form a data structure which then becomes a complex data type.
The <message> tag is used to define the message which is exchanged between the client application and the web server. These messages will explain the input and output operations which can be performed by the web service. An example of a message can be a message which accepts the EmployeeID of an employee, and the output message can be the name of the employee based on the EmpoyeeID provided.
The <portType> tag is used to encapsulate every input and output message into one logical operation. So there could be an operation called "GetEmployee" which combines the input message of accepting the EmployeeID from a client application and then sending the EmployeeName as the output message.
The <binding> tag is used to bind the operation to the particular port type. This is so that when the client application calls the relevant port type, it will then be able to access the operations which are bound to this port type. Port types are just like interfaces. So if a client application needs to use a web service they need to use the binding information to ensure that they can connect to the interface provided by that web service.
The <service> tag is a name given to the web service itself. Initially, when a client application makes a call to the web service, it will do by calling the name of the web service. For example, a web service can be located at an address. The service tag will actually have the URL which will actually tell the client application that there is a web service available at this location.
SOAP
SOAP is a messaging protocol and in a nutshell is just another XML language. Its purpose is the data exchange over networks. Its concern is the encapsulation of these data and the rules for transmitting and receiving them.
HTTP is an application protocol and SOAP messages are placed as the HTTP payload. Although there is the overhead of HTTP, it has the advantage that it is a protocol that is open to firewalls, well-understood and widely-supported. Thus, web services can be accessed and exposed via technology already in-place.
SOAP messages are usually exchanged via HTTP. Although it is possible to use other (application) protocols, e.g. SMTP or FTP, the non-HTTP bindings are not specified by SOAP specs and are not supported by WS-BP (interoperability spec). You could exchange SOAP messages over raw TCP but then you would have web services that are not interoperable (not compliant to WS-BP).
Nowadays the debate is why have the SOAP overhead at all and not send data over HTTP (RESTful WS).
Why use HTTP for SOAP?
I will try to address in more detail the question in the OP, asking why use HTTP for SOAP:
First of all SOAP defines a data encapsulation format and that's that. Now the majority of traffic in the web is via HTTP. HTTP is literary EVERYWHERE and supported by a well-established infrastructure of servers and clients(namely browsers). Additionally it is a very well understood protocol.
The people who created SOAP wanted to use this ready infrastructure and SOAP messages were designed so that they can be tunneled over HTTP In the specs they do not refer to any other non-HTTP binding but specifically refer to HTTP as an example for transfer. The tunneling over HTTP would and did help in it's rapid adoption. Because the infrastructure of HTTP is already in-place, companies would not have to spend extra money for another kind of implementation. Instead they can expose and access web services using technology already deployed.
Specifically in Java a web service can be deployed either as a servlet endpoint or as an EJB endpoint. So all the underlying network sockets, threads, streams, HTTP transactions etc. are handled by the container and the developer focuses only on the XML payload. So a company has Tomcat or JBoss running in port 80 and the web service is deployed and accessible as well. There is no effort to do programming at the transport layer and the robust container handles everything else. Finally the fact that firewalls are configured not to restrict HTTP traffic is a third reason to prefer HTTP.
Since HTTP traffic is usually allowed, the communication of clients/servers is much easier and web services can function without network security blockers issues as a result of the HTTP tunneling.
SOAP is XML=plain text so firewalls could inspect the content of HTTP body and block accordingly. But in this case they could also be enhanced to reject or accept SOAP depending on the contents.This part which seems to trouble you is not related to web services or SOAP, and perhaps you should start a new thread concerning how firewalls work.
Having said that, the fact that HTTP traffic is unrestricted often causes security issues since firewalls are essentially by-passed, and that is why application-gateways come in. But this is not related to this post.
Summary
So to sum up the reasons for using HTTP:
HTTP is popular and successful.
HTTP infrastructure is in place so no extra cost to deploy web services.
HTTP traffic is open to firewalls, so there are no problems during web service functioning as a result of network security.
0 notes
Text
PAF04 – Distributed systems
1. Explain the term “distributed systems”, contrasting it from “distributed computing”
A distributed system is the collection of autonomous computers that are connected using a communication network and they communicate with each other by passing messages. The different processors have their own local memory. They use a distribution middleware. They help in sharing different resources and capabilities to provide users with a single and integrated coherent network.
Distributed computing is a field of computer science that studies distributed systems and the computer program that runs in a distributed system is called a distributed program.
A distributed system requires concurrent Components, communication network and a synchronization mechanism. A distributed system allows resource sharing, including software by systems connected to the network.
Examples of distributed systems / applications of distributed computing :
Intranets, Internet, WWW, email.
Telecommunication networks: Telephone networks and Cellular networks.
Network of branch office computers -Information system to handle automatic processing of orders,
Real-time process control: Aircraft control systems,
Electronic banking,
Airline reservation systems,
Sensor networks,
2. Compare and contrast the standalone systems with distributed systems, providing examples for advantageous use of both
Operating system is developed to ease people daily life. For user benefits and needs the operating system may be single user or distributed. In distributed systems, many computers connected to each other and share their resources with each other. There are some advantages and disadvantages of distributed operating system that we will discuss.
Advantages of distributed operating systems:-
Give more performance than single system
If one pc in distributed system malfunction or corrupts then other node or pc will take care of
More resources can be added easily
Resources like printers can be shared on multiple pc’s
Disadvantages of distributed operating systems:-
Security problem due to sharing
Some messages can be lost in the network system
Bandwidth is another problem if there is large data then all network wires to be replaced which tends to become expensive
Overloading is another problem in distributed operating systems
If there is a database connected on local system and many users accessing that database through remote or distributed way then performance become slow
The databases in network operating is difficult to administrate then single user system
A standalone computer is exactly what its name implies: a computer that stands on its own. Any tasks or data associated with that computer stay inside it and are not accessible from anywhere else. Any peripherals, such as printers, must be directly connected to it in order to work.
Standalone Advantages
One advantage of a standalone computer is damage control. For example, if something goes wrong, only the standalone will be affected. Simplicity is another advantage, because it takes a lot less expertise to manage one computer than it does to setup or troubleshoot several. Standalone computers can also be more convenient. For example, printing on a network may require you to walk some distance from the computer to the printer. Inversely, any peripherals on a standalone have to be in arm's reach. Finally, a standalone does not affect other computer users. With a network, one user may waste space by watching movies or listening to music. In turn, everyone else using the network may see slower computer performance.
Standalone Disadvantages
Standalone computers have drawbacks. First of all, users are restricted to a single computer. On a network, users can access their files from any connected computer. Second, the same software cannot be installed simultaneously. While a network allows everything to be changed at once, a standalone requires that any new programs must be set up one-by-one, which is much more time-consuming. Third, it is much cheaper to connect every computer to one printer than to buy a printer for each standalone computer. Finally, standalones are harder to monitor. On a network, certain software can be used to simultaneously view each user's activity.
3. Discuss the elements of distributed systems
There are a certain major characteristics of distributed system as:
RESOURCE SHARING: It is the ability of the system to use any hardware, software or data anywhere in the system. The resource manager controls access, provides naming scheme and controls concurrency among the system tools. The resource sharing model depicts the correct resources provided and how they are used for interaction among each other
OPENNESS: It is concerned with extensi
on and improvement of distributed system and how new components are integrated to existing ones.
CONCURRENCY: Components in distributed system are executed in concurrent processes. Moreover, the integrity of the system is violated if concurrent updates are not coordinated.
SCALABILITY: It is the adaption of distributed system to accommodate more users and respond faster. This is usually done by adding faster processors. In a distributed system, components are not required to be changed when scale of the system increased.
FAULT TOLERANCE: Fault tolerance in distributed system is achieved by recovery and redundancy processes and is quite competitive.
TRANSPARENCY: Distributed system should be perceived by users and application programmers as a whole rather than a collection of cooperative components. This is transparency of a distributed system.
9. Explain the MVC style, indicating the limitations of it in the context of web-based systems
Components of MVC
1) Model: It specifies the logical structure of data in a software application and the high-level class associated with it. It is the domain-specific representation of the data which describes the working of an application. When a model changes its state, domain notifies its associated views, so they can refresh.
2) View: View component is used for all the UI logic of the application and these are the components that display the application’s user interface (UI). It renders the model into a form suitable for interaction. Multiple views can exist for a single model for different purposes.
3) Controller: Controllers act as an interface between Model and View components. It processes all the business logic and incoming requests, manipulate data using the Model component, and interact with the Views to render the final output. It receives input and initiates a response by making calls on model objects.
Advantages of MVC
1) Faster development process: MVC supports rapid and parallel development. With MVC, one programmer can work on the view while other can work on the controller to create business logic of the web application. The application developed using MVC can be three times faster than application developed using other development patterns.
2) Ability to provide multiple views: In the MVC Model, you can create multiple views for a model. Code duplication is very limited in MVC because it separates data and business logic from the display.
3) Support for asynchronous technique: MVC also supports asynchronous technique, which helps developers to develop an application that loads very fast.
4) Modification does not affect the entire model: Modification does not affect the entire model because model part does not depend on the views part. Therefore, any changes in the Model will not affect the entire architecture.
5) MVC model returns the data without formatting: MVC pattern returns data without applying any formatting so the same components can be used and called for use with any interface.
6) SEO friendly Development platform: Using this platform, it is very easy to develop SEO-friendly URLs to generate more visits from a specific application.
Disadvantages of MVC
1) Increased complexity
2) Inefficiency of data access in view
3) Difficulty of using MVC with modern user interface.
4) Need multiple programmers
5) Knowledge on multiple technologies is required.
6) Developer have knowledge of client side code and html code.
10. Identify different approaches of use of MVC for web-based systems and discuss their strengths and weaknesses
11. Discuss the need for very specific type of communication technologies/techniques for the distributed/web-based systems
12. Compare and contrast RPC with RMI
RPC is C based, and as such it has structured programming semantics, on the other side, RMI is a Java based technology and it's object oriented.
With RPC you can just call remote functions exported into a server, in RMI you can have references to remote objects and invoke their methods, and also pass and return more remote object references that can be distributed among many JVM instances, so it's much more powerful.
RMI stands out when the need to develop something more complex than a pure client-server architecture arises. It's very easy to spread out objects over a network enabling all the clients to communicate without having to stablish individual connections explicitly.
13. Explain the need for CORBA, indicating it’s use in web-based systems
The Common Object Request Broker Architecture (CORBA) is a standard developed by the Object Management Group (OMG) to provide interoperability among distributed objects. CORBA is the world's leading middleware solution enabling the exchange of information, independent of hardware platforms, programming languages, and operating systems. CORBA is essentially a design specification for an Object Request Broker (ORB), where an ORB provides the mechanism required for distributed objects to communicate with one another, whether locally or on remote devices, written in different languages, or at different locations on a network.
The CORBA Interface Definition Language, or IDL, allows the development of language and location-independent interfaces to distributed objects. Using CORBA, application components can communicate with one another no matter where they are located, or who has designed them. CORBA provides the location transparency to be able to execute these applications.
CORBA is often described as a "software bus" because it is a software-based communications interface through which objects are located and accessed. The illustration below identifies the primary components seen within a CORBA implementation.
Data communication from client to server is accomplished through a well-defined object-oriented interface. The Object Request Broker (ORB) determines the location of the target object, sends a request to that object, and returns any response back to the caller. Through this object-oriented technology, developers can take advantage of features such as inheritance, encapsulation, polymorphism, and runtime dynamic binding. These features allow applications to be changed, modified and re-used with minimal changes to the parent interface. The illustration below identifies how a client sends a request to a server through the ORB:
Interface Definition Language (IDL) A cornerstone of the CORBA standards is the Interface Definition Language. IDL is the OMG standard for defining language-neutral APIs and provides the platform-independent delineation of the interfaces of distributed objects. The ability of the CORBA environments to provide consistency between clients and servers in heterogeneous environments begins with a standardized definition of the data and operations constituting the client/server interface. This standardization mechanism is the IDL, and is used by CORBA to describe the interfaces of objects.
IDL defines the modules, interfaces and operations for the applications and is not considered a programming language. The various programming languages, such as Ada, C++, or Java, supply the implementation of the interface via standardized IDL mappings.
Application Development Using ORBexpress The basic steps for CORBA development can be seen in the illustration below. This illustration provides an overview of how the IDL is translated to the corresponding language (in this example, C++), mapped to the source code, compiled, and then linked with the ORB library, resulting in the client and server implementation.
The basic steps for CORBA development include:
Create the IDL to Define the Application Interfaces The IDL provides the operating system and programming language independent interfaces to all services and components that are linked to the ORB. The IDL specifies a description of any services a server component exposes to the client. The term "IDL Compiler" is often used, but the IDL is actually translated into a programming language.
Translate the IDL An IDL translator typically generates two cooperative parts for the client and server implementation, stub code and skeleton code. The stub code generated for the interface classes is associated with a client application and provides the user with a well-defined Application Programming Interface (API). In this example, the IDL is translated into C++.
Compile the Interface Files Once the IDL is translated into the appropriate language, C++ in this example, these interface files are compiled and prepared for the object implementation.
Complete the Implementation If the implementation classes are incomplete, the spec and header files and complete bodies and definitions need to be modified before passing through to be compiled. The output is a complete client/server implementation.
Compile the Implementation Once the implementation class is complete, the client interfaces are ready to be used in the client application and can be immediately incorporated into the client process. This client process is responsible for obtaining an object reference to a specific object, allowing the client to make requests to that object in the form of a method call on its generated API.
Link the Application Once all the object code from steps three and five have been compiled, the object implementation classes need to be linked to the C++ linker. Once linked to the ORB library, in this example, ORBexpress, two executable operations are created, one for the client and one for the server.
Run the Client and Server The development process is now complete and the client will now communicate with the server. The server uses the object implementation classes allowing it to communicate with the objects created by the client requests.
In its simplest form, the server must perform the following:
Create the required objects.
Notify the CORBA environment that it is ready to receive client requests.
Process client requests by dispatching the appropriate servant.
CORBA Programming Definitions Within a CORBA development process, there are a number of unique terms specific to a CORBA implementation. Developers may find our Glossary of Terms helpful in understanding a full CORBA implementation.
14. Discuss the XML specification, highlighting the important sections such as element naming conventions
XML stands for Extensible Markup Language. It is a text-based markup language derived from Standard Generalized Markup Language (SGML).
XML tags identify the data and are used to store and organize the data, rather than specifying how to display it like HTML tags, which are used to display the data. XML is not going to replace HTML in the near future, but it introduces new possibilities by adopting many successful features of HTML.
There are three important characteristics of XML that make it useful in a variety of systems and solutions −
XML is extensible − XML allows you to create your own self-descriptive tags, or language, that suits your application.
XML carries the data, does not present it − XML allows you to store the data irrespective of how it will be presented.
XML is a public standard − XML was developed by an organization called the World Wide Web Consortium (W3C) and is available as an open standard.
XML Usage
A short list of XML usage says it all −
XML can work behind the scene to simplify the creation of HTML documents for large web sites.
XML can be used to exchange the information between organizations and systems.
XML can be used for offloading and reloading of databases.
XML can be used to store and arrange the data, which can customize your data handling needs.
XML can easily be merged with style sheets to create almost any desired output.
Virtually, any type of data can be expressed as an XML document.
What is Markup?
XML is a markup language that defines set of rules for encoding documents in a format that is both human-readable and machine-readable. So what exactly is a markup language? Markup is information added to a document that enhances its meaning in certain ways, in that it identifies the parts and how they relate to each other. More specifically, a markup language is a set of symbols that can be placed in the text of a document to demarcate and label the parts of that document.
Following example shows how XML markup looks, when embedded in a piece of text −
<message> <text>Hello, world!</text> </message>
This snippet includes the markup symbols, or the tags such as <message>...</message> and <text>... </text>. The tags <message> and </message> mark the start and the end of the XML code fragment. The tags <text> and </text> surround the text Hello, world!.
Is XML a Programming Language?
A programming language consists of grammar rules and its own vocabulary which is used to create computer programs. These programs instruct the computer to perform specific tasks. XML does not qualify to be a programming language as it does not perform any computation or algorithms. It is usually stored in a simple text file and is processed by special software that is capable of interpreting XML.
15. Compare and contrast XML and JSON, indicating the pros and cons of both
JSON
Pro:
Simple syntax, which results in less "markup" overhead compared to XML.
Easy to use with JavaScript as the markup is a subset of JS object literal notation and has the same basic data types as JavaScript.
JSON Schema for description and datatype and structure validation
JsonPath for extracting information in deeply nested structures
Con:
Simple syntax, only a handful of different data types are supported.
No support for comments.
XML
Pro:
Generalized markup; it is possible to create "dialects" for any kind of purpose
XML Schema for datatype, structure validation. Makes it also possible to create new datatypes
XSLT for transformation into different output formats
XPath/XQuery for extracting information in deeply nested structures
built in support for namespaces
Con:
Relatively wordy compared to JSON (results in more data for the same amount of information).
16. Identify other data formatting/structuring techniques available for the communication of web-based systems
1. HTML ● HTML stands for Hyper Text Markup Language. ● With HTML you can create your own Website.
2. CSS ● CSS stands for Cascading Style Sheets. ● CSS describes how HTML elements are to be displayed on screen, paper, or in other media. ● CSS saves a lot of work. It can control the layout of multiple web pages all at once.
3. JavaScript ● JavaScript is the programming language that control the behavior of web pages.
4. jQuery ● jQuery is a lightweight and "write less, do more", JavaScript library. ● The purpose of jQuery is to make it much easier to use JavaScript on your website. ● Before you start studying jQuery, you should have a basic knowledge of HTML, CSS & JavaScript.
5. AJAX ● AJAX stands for Asynchronous JavaScript And XML. ● AJAX is not a programming language. ● AJAX allows update parts of a web page, without reloading the whole page.
6. XML ● XML stands for eXtensible Markup Language. ● XML was designed to store and transport data. ● XML was designed to be both human- and machine-readable. XML is a W3C Recommendation.
7. JSON ● JSON stands for JavaScript Object Notation. ● JSON is a syntax for storing and exchanging data(same like XML). ● JSON is better than XML in all the ways.
8. Bootstrap ● Bootstrap is the most popular front-end(HTML, CSS, and JavaScript) framework for developing responsive, mobile-first websites. ● Responsive web design is about creating web sites which automatically adjust themselves to look good on all devices, from small phones to large desktops.
9. PHP ● PHP stands for Hypertext Preprocessor. ● PHP is a server scripting language, and a powerful tool for making dynamic and interactive Web pages. ● PHP is a widely-used, free, and efficient server- side scripting language.
10. ASP ● ASP stands for Active Server Pages. ● ASP is a development framework for building web pages. ● ASP is a Microsoft's first server side scripting language.
11. SQL ● SQL stands for Structured Query Language. ● SQL is a standard language for accessing and manipulating databases. ● SQL is an ANSI (American National Standards Institute) standard.
12. AngularJS ● AngularJS is a JavaScript framework. ● AngularJS is perfect for Single Page Applications (SPAs). ● Before you study AngularJS, you should have a basic understanding of HTML, CSS & JavaScript.
13. Node.js ● Node.js is an open source server framework. ● Node.js allows you to run JavaScript on the server. ● Node.js is free and runs on various platforms(Windows, Linux, Unix, Mac OS X, etc.)
14. BackboneJS ● BackboneJS is a lightweight JavaScript library that allows to develop and structure client side applications that run in a web browser. It offers MVC framework which abstracts data into models, DOM (Document Object Model) into views and bind these two using events.
15. ExpressJS ● Express is a minimal and flexible Node.js web application framework that provides a robust set of features for web and mobile applications. It is an open source framework developed and maintained by the Node.js foundation.
16. KnockoutJS ● KnockoutJS is basically a library written in JavaScript, based on MVVM pattern that helps developers in building rich and responsive websites. ● KnockoutJS library provides an easy and clean way to handle complex data-driven interfaces. It is independent of any other framework.
17. ReactJS ● React is a front-end library developed by Facebook. It is used for handling the view layer for web and mobile apps. ● ReactJS allows us to create reusable UI components. It is currently one of the most popular JavaScript libraries and has a strong foundation and large community behind it.
18. AWS ● AWS stands for Amazon Web Services. ● AWS is Amazon’s cloud web hosting platform that offers flexible, reliable, scalable, easy-to- use, and cost-effective solutions.
19. Firebase ● Firebase is a backend platform for building Web, Android and IOS applications. It offers real time database, different APIs, multiple authentication types and hosting platform.
20. CakePHP ● CakePHP is an open-source framework for PHP. It is intended to make developing, deploying and maintaining applications much easier. It is based on an MVC architecture that is both powerful and easy to grasp. It guarantee a strict but natural separation of business logic from data and presentation layers.
21. CodeIgnitor ● CodeIgniter is a powerful PHP framework built for developers who need a simple and elegant toolkit to create full-featured web applications. ● It is an Open Source framework. It has a very rich set of functionality, which will increase the speed of website development work.
22. Laravel ● Laravel is a powerful MVC PHP framework, designed for developers who need a simple and elegant toolkit to create full-featured web applications. ● It offers a robust set of tools and an application architecture that incorporates many of the best features of frameworks like CodeIgniter, Yii, ASP.NET MVC, Ruby on Rails, Sinatra, & others.
23. Zend ● Zend is an open source PHP framework. It is pure object-oriented and built around the MVC design pattern. ● Zend framework contains collection of PHP packages which can be used to develop web applications and services.
24. Yii ● The Yii framework is an open-source PHP framework for rapidly-developing, modern Web applications. It is built around the Model-View- Controller composite pattern. Yii provides secure and professional features to create robust projects rapidly.
25. Symfony ● Symfony is an open-source PHP web application framework, designed for developers who need a simple and elegant toolkit to create full-featured web applications.
26. Magento ● Magento is an open source E-commerce software, created by Varien Inc., which is useful for online business. It has a flexible modular architecture and is scalable with many control options that is helpful for users. Magento uses E-commerce platform which offers organizations ultimate E-commerce solutions and extensive support network.
27. WordPress ● WordPress is an open source Content Management System (CMS), which allows the users to build dynamic websites and blog. ● WordPress is the most popular blogging system on the web and allows updating, customizing and managing the website from its back-end CMS and components.
28. Joomla ● Joomla is an open source CMS, which is used to build websites and online applications. It is free and extendable which is separated into front- end templates and back-end templates (administrator). ● Joomla is developed using PHP, Object Oriented Programming, software design patterns and MySQL (used for storing the data).
29. Drupal ● Drupal is a free and open source Content Management System (CMS) that allows organizing, managing and publishing your content. This reliable and secure CMS is built on PHP based environment and powers millions of applications and websites. ● WhiteHouse.gov, World Economic Forum, Stanford University, Examiner.com etc...
0 notes
Text
PAF 03
1. Discuss the importance of maintaining the quality of the code, explaining the different aspects of the code quality
Code quality is a vague definition. What do we consider high quality and what’s low quality?
Code quality is rather a group of different attributes and requirements, determined and prioritized by your business.
These requirements have to be defined with your offshore team in advance to make sure you’re on the same side.
Here are the main attributes that can be used to determine code quality:
Clarity: Easy to read and oversee for anyone who isn’t the creator of the code. If it’s easy to understand, it’s much easier to maintain and extend the code. Not just computers, but also humans need to understand it.
Maintainable: A high-quality code isn’t overcomplicated. Anyone working with the code has to understand the whole context of the code if they want to make any changes.
Documented: The best thing is when the code is self-explaining, but it’s always recommended to add comments to the code to explain its role and functions. It makes it much easier for anyone who didn’t take part in writing the code to understand and maintain it.
Refactored: Code formatting needs to be consistent and follow the language’s coding conventions.
Well-tested: The less bugs the code has the higher its quality is. Thorough testing filters out critical bugs ensuring that the software works the way it’s intended.
Extendible: The code you receive has to be extendible. It’s not really great when you have to throw it away after a few weeks.
Efficiency: High-quality code doesn’t use unnecessary resources to perform a desired action
https://bit.ly/2BWiWJM
2. Explain different approaches and measurements used to measure the quality of code
Following things can be done to measure code quality,
The code works correctly in the normal case.
The performance is acceptable, even for large data.
The code is clear, using descriptive variable names and method names.
Comments should be in place for things that are unusual, such as a fairly novel method of doing something that makes the code less clear but more performant (to work around a bottleneck), or a workaround for a bug in a framework.
The code is broken down so that when things change, you have to change a fairly small amount of code. (Responsibilities should be well defined, and each piece of code should be trusted to do its job.)
The code handles unexpected cases correctly.
Code is not repeated. A bug in properly factored code is a bug. A bug in copy/paste code can be 20 bugs.
Consts are used in the code instead of constant values. Their usage should be semantic. That is, if you have 20 columns and 20 rows, you could have columnCount = 20 and rowCount = 20, and use those correctly. You should never have twenty = 20 (yes, sadly I've seen this).
The UI should feel natural: you should be able to click the things it feels like you should click, and type where it feels like you should type.
The code should do what it says without side effects.
https://bit.ly/2IKDJ95
3. Identify and compare some available tools to maintain the code quality
Best Code Review Tools in the Market
Collaborator
Review Assistant
Codebrag
Gerrit
Codestriker
Rhodecode
Phabricator
Crucible
Veracode
Review Board
Here we go with a brief review of the individual tool.
1) Collaborator
Collaborator is the most comprehensive peer code review tool, built for teams working on projects where code quality is critical.
See code changes, identify defects, and make comments on specific lines. Set review rules and automatic notifications to ensure that reviews are completed on time.
Custom review templates are unique to Collaborator. Set custom fields, checklists, and participant groups to tailor peer reviews to your team’s ideal workflow.
Easily integrate with 11 different SCMs, as well as IDEs like Eclipse & Visual Studio
Build custom review reports to drive process improvement and make auditing easy.
Conduct peer document reviews in the same tool so that teams can easily align on requirements, design changes, and compliance burdens.
2) Review Assistant
Review Assistant is a code review tool. This code review plug-in helps you to create review requests and respond to them without leaving Visual Studio. Review Assistant supports TFS, Subversion, Git, Mercurial, and Perforce. Simple setup: up and running in 5 minutes.
Key features:
Flexible code reviews
Discussions in code
Iterative review with defect fixing
Team Foundation Server integration
Flexible email notifications
Rich integration features
Reporting and Statistics
Drop-in Replacement for Visual Studio Code Review Feature and much more
3) Codebrag
Codebrag is a simple, light-weight, free and open source code review tool which makes the review entertaining and structured.
Codebrag is used to solve issues like non-blocking code review, inline comments & likes, smart email notifications etc.
With Codebrag one can focus on workflow to find out and eliminate issues along with joint learning and teamwork.
Codebrag helps in delivering enhanced software using its agile code review.
License for Codebrag open source is maintained by AGPL.
https://bit.ly/2Tbhf62
4. Discuss the need for dependency/package management tools in software development?
A package manager or package management system is a collection of software tools that automates the process of installing, upgrading, configuring, and removing computer programs for a computer's operating system in a consistent manner.[1]
A package manager deals with packages, distributions of software and data in archive files. Packages contain metadata, such as the software's name, description of its purpose, version number, vendor, checksum, and a list of dependencies necessary for the software to run properly. Upon installation, metadata is stored in a local package database. Package managers typically maintain a database of software dependencies and version information to prevent software mismatches and missing prerequisites. They work closely with software repositories, binary repository managers, and app stores.
Package managers are designed to eliminate the need for manual installs and updates. This can be particularly useful for large enterprises whose operating systems are based on Linux and other Unix-like systems, typically consisting of hundreds or even tens of thousands of distinct software packages.[2]
https://bit.ly/2SCng6q
5. Explain the role of dependency/package management tools in software development
A dependency is something you rely upon to achieve a goal but that is not under your control. Project dependencies come in many shapes and sizes. They include hardware, software, resources, and people. Your software project will rely on a large number of dependencies, regardless of the size of the your technology stack, or the available human and financial resources.
A functional dependency entails the components, assets, or resources required for a project to function. Functional dependencies are the result of the tasks and activities required by a business to achieve a desired outcome. The best way to resolve issues caused by this type of dependency is to identify them. Next, build a list and organize the list in order of importance. Then, decide which dependencies are redundant or no longer needed. Remove these from the project.
If you need a dependency that is still in development or unavailable, you can use mocking techniques. For example, if your component depends on an external API, you can simulate the API calls and responses. Continue to develop and test your component, until the component is available. You can also rewrite your project requirements to remove the dependency and any related issues.
These dependencies are components, assets, or resources required to build or test a project. Development and testing could be viewed as separate processes, but modern approaches of agile, shift left, andcontinuous testing view them as a single unit. Development and testing processes are subject to functional dependencies. They are also heavily reliant on the quality of available human resources.
Different team members have different levels of skills and experience. Teams often depend on the expertise of individual people. This works as long as each person remains a member of the team. Team members who are absent for an extended period or leave the organization, leave a void that can be hard to fill.
You can resolve these dependencies via training. Ensure all team members can handle the roles and responsibilities of other team members. Remove any risk of your teams becoming reliant on key individuals to handle critical tasks.
6. Compare and contrast different dependency/package management tools used in industry
The apt family
Actually, apt should be capitalized, since it's an acronym that stands for Advanced Packaging Tool, but since the actual utilities are lowercase-only, we will refer to them like that. The apt family is a frontend to dpkg in the Debian family of Linux operating systems, and also used in some OpenSolaris offshoots. Some of these applications are apt-get, apt-cache, apt-cdrom or apt-file. This is not a comprehensive list, but all the more often used utilities are there. There's also aptitude, which, when invoked without arguments, presents a nice menu , either curses-based or GTK-based, but can be used with commands/arguments like the apt-* commands to manage software on your computer. It might be worth noting that various Debian-derivatives might have changed some things in these applications, but this part will treat the tools that are to be found in a standard Debian system.
apt vs aptitude
Since it's Debian vanilla we're talking about, I would recommend aptitude instead of apt-*. But there would be others that would recommend the opposite. We suggest you try them both and see what you like most. There aren't many differences between the two if you're a beginner with Debian or derivatives, but in time you will notice you will prefer one of them.We will show you how to use both, however, so you'll find it easier to choose.
pacman
Arch Linux's own package manager is a relative newcomer, since the distribution is also newer, but that doesn't mean it lacks features one can find in yum or zypper, to take two random examples.One difference between pacman and the above-mentioned package manager is that it doesn't offer commands like update or remove. Instead one uses single-letter arguments to get various functions offered by pacman (but you can use long, double-dash options as well, however the short ones are more popular). Another difference would be, and there is no subjectivity involved, that pacman is faster. Actually this is one of the reasons why I use Arch for my older, weaker computers.
https://bit.ly/2Tn3ZKN
7. What is a build tool? Indicate the significance of using a build tool in large scale software development, distinguishing it from small scale software development
Build Process is a Process of compiling your source code for any errors using somebuild tools and creating builds(which are executable versions of the project). ... Continuous integration build etc. Build tools help and automates the process of creating builds.
https://bit.ly/2Eph24Y
8. Explain the role of build automation in build tools indicating the need for build automation
Build automation is the process of automating the creation of a software build and the associated processes including: compiling computer source code into binary code, packaging binary code, and running automated tests.
To save time and money and to reduce human mistakes that are possible during manual building, software developers usually try to automate this process.Automated builds are very important during software development and the use ofautomated tests during the build process is also important.
9. Compare and contrast different build tools used in industry
1. Gradle
Your DevOps tool stack will need a reliable build tool. Apache Ant and Maven dominated the automated build tools market for many years, but Gradle showed up on the scene in 2009, and its popularity has steadily grown since then. Gradle is an incredibly versatile tool which allows you to write your code in Java, C++, Python, or other languages. Gradle is also supported by popular IDEs such as Netbeans, Eclipse, and IntelliJ IDEA. If that doesn’t convince you, it might help to know that Google also chose it as the official build tool for Android Studio.
While Maven and Ant use XML for configuration, Gradle introduces a Groovy-based DSL for describing builds. In 2016, the Gradle team also released a Kotlin-based DSL, so now you can write your build scripts in Kotlin as well. This means that Gradle does have some learning curves, so it can help a lot if you have used Groovy, Kotlin or another JVM language before. Besides, Gradle uses Maven’s repository format, so dependency management will be familiar if you have prior experience with Maven. You can also import your Ant builds into Gradle.
The best thing about Gradle is incremental builds, as they save a nice amount of compile time. According to Gradle’s performance measurements, it’s up to 100 times faster than Maven. This is in part because of incrementality, but also due to Gradle’s build cache and daemon. The build cache reuses task outputs, while the Gradle Daemon keeps build information hot in memory in-between builds.
All in all, Gradle allows faster shipping and comes with a lot of configuration possibilities.
2. Git
Git is one of the most popular DevOps tools, widely used across the software industry. It’s a distributed SCM (source code management) tool, loved by remote teams and open source contributors. Git allows you to track the progress of your development work. You can save different versions of your source code and return to a previous version when necessary. It’s also great for experimenting, as you can create separate branches and merge new features only when they’re ready to go.
To integrate Git with your DevOps workflow, you also need to host repositories where your team members can push their work. Currently, the two best online Git repo hosting services are GitHuband Bitbucket. GitHub is more well-known, but Bitbucket comes with free unlimited private repos for small teams (up to five team members). With GitHub, you get access only to public repos for free—which is still a great solution for many projects.
Both GitHub and Bitbucket have fantastic integrations. For example, you can integrate them with Slack, so everyone on your team gets notified whenever someone makes a new commit.
3. Docker
Docker has been the number one container platform since its launch in 2013 and continues to improve. It’s also thought of as one of the most important DevOps tools out there. Docker has made containerization popular in the tech world, mainly because it makes distributed development possible and automates the deployment of your apps. It isolates applications into separate containers, so they become portable and more secure. Docker apps are also OS and platform independent. You can use Docker containers instead of virtual machines such as VirtualBox.
What I like the most about Docker is that you don’t have to worry about dependency management. You can package all dependencies within the app’s container and ship the whole thing as an independent unit. Then, you can run the app on any machine or platform without a headache.
Docker integrates with Jenkins and Bamboo, too. If you use it together with one of these automation servers, you can further improve your delivery workflow. Besides, Docker is also great for cloud computing. In recent years, all major cloud providers such as AWS and Google Cloud added support for Docker. So, if you are planning a cloud migration, Docker can ease the process for you.
https://bit.ly/2E4glPL
10. Explain the build life cycle, using an example (java, .net, etc…)
Build Lifecycle Basics
Maven is based around the central concept of a build lifecycle. What this means is that the process for building and distributing a particular artifact (project) is clearly defined.
For the person building a project, this means that it is only necessary to learn a small set of commands to build any Maven project, and the POM will ensure they get the results they desired.
There are three built-in build lifecycles: default, clean and site. The default lifecycle handles your project deployment, the clean lifecycle handles project cleaning, while the site lifecycle handles the creation of your project's site documentation.
A Build Lifecycle is Made Up of Phases
Each of these build lifecycles is defined by a different list of build phases, wherein a build phase represents a stage in the lifecycle.
For example, the default lifecycle comprises of the following phases (for a complete list of the lifecycle phases, refer to the Lifecycle Reference):
validate - validate the project is correct and all necessary information is available
compile - compile the source code of the project
test - test the compiled source code using a suitable unit testing framework. These tests should not require the code be packaged or deployed
package - take the compiled code and package it in its distributable format, such as a JAR.
verify - run any checks on results of integration tests to ensure quality criteria are met
install - install the package into the local repository, for use as a dependency in other projects locally
deploy - done in the build environment, copies the final package to the remote repository for sharing with other developers and projects.
These lifecycle phases (plus the other lifecycle phases not shown here) are executed sequentially to complete the default lifecycle. Given the lifecycle phases above, this means that when the default lifecycle is used, Maven will first validate the project, then will try to compile the sources, run those against the tests, package the binaries (e.g. jar), run integration tests against that package, verify the integration tests, install the verified package to the local repository, then deploy the installed package to a remote repository.
https://bit.ly/29DPIol
11. What is Maven, a dependency/package management tool or a build tool or something more?
What is a Build Tool?
A build tool is a tool that automates everything related to building the software project. Building a software project typically includes one or more of these activities:
Generating source code (if auto-generated code is used in the project).
Generating documentation from the source code.
Compiling source code.
Packaging compiled code into JAR files or ZIP files.
Installing the packaged code on a server, in a repository or somewhere else.
Any given software project may have more activities than these needed to build the finished software. Such activities can normally be plugged into a build tool, so these activities can be automated too.
The advantage of automating the build process is that you minimize the risk of humans making errors while building the software manually. Additionally, an automated build tool is typically faster than a human performing the same steps manually.
Maven, a Yiddish word meaning accumulator of knowledge, was originally started as an attempt to simplify the build processes in the Jakarta Turbine project. There were several projects each with their own Ant build files that were all slightly different and JARs were checked into CVS
I hope now you have a clear idea about dependency management and build automation tools. I’ll directly come to the point by providing the list of objectives that maven attempts to achieve( these are mentioned in its official website)
Make the build process easy — The programmers doesn’t need to know much about the process of how maven works or provide every configuration settings manually
Provide a uniform build system — Working on a one project with maven is sufficient to work on other maven projects
Provide quality project information — Maven provides user to specify the project information using the POM and make them available to use whenever needed. Some information are generated from the source of the project
Provide guidelines for development best practices
Allowing transparent migration to new features — Provide the ability to take advantage of updated versions of the dependencies and plugins for the same project (programmer can use updated or newly added Plugins)
https://bit.ly/2NCyKG9
12. Discuss how Maven uses conventions over configurations, explaining Maven’s approach to manage the configurations
Convention over Configuration
Maven uses Convention over Configuration, which means developers are not required to create build process themselves.
Developers do not have to mention each and every configuration detail. Maven provides sensible default behavior for projects. When a Maven project is created, Maven creates default project structure. Developer is only required to place files accordingly and he/she need not to define any configuration in pom.xml.
As an example, following table shows the default values for project source code files, resource files and other configurations. Assuming, ${basedir}denotes the project location −
Item Default
1.source code ${basedir}/src/main/java
2.Resources ${basedir}/src/main/resources
In order to build the project, Maven provides developers with options to mention life-cycle goals and project dependencies (that rely on Maven plugin capabilities and on its default conventions). Much of the project management and build related tasks are maintained by Maven plugins.
Developers can build any given Maven project without the need to understand how the individual plugins work. We will discuss Maven Plugins in detail in the later chapters.
https://bit.ly/2EqqIfp
13. Discuss the terms build phases, build life cycle, build profile, and build goal in Maven
A Maven phase represents a stage in the Maven build lifecycle. Each phase is responsible for a specific task.
Here are some of the most important phases in the default build lifecycle:
validate: check if all information necessary for the build is available
compile: compile the source code
test-compile: compile the test source code
test: run unit tests
package: package compiled source code into the distributable format (jar, war, …)
integration-test: process and deploy the package if needed to run integration tests
install: install the package to a local repository
deploy: copy the package to the remote repository
Phases are executed in a specific order. This means that if we run a specific phase using the comma
A Build Lifecycle is a well-defined sequence of phases, which define the order in which the goals are to be executed. Here phase represents a stage in life cycle. As an example, a typical Maven Build Lifecycle consists of the following sequence of phases.
Apache Maven 2.0 goes to great lengths to ensure that builds are portable. Among other things, this means allowing build configuration inside the POM, avoiding all filesystem references (in inheritance, dependencies, and other places), and leaning much more heavily on the local repository to store the metadata needed to make this possible.
However, sometimes portability is not entirely possible. Under certain conditions, plugins may need to be configured with local filesystem paths. Under other circumstances, a slightly different dependency set will be required, and the project's artifact name may need to be adjusted slightly. And at still other times, you may even need to include a whole plugin in the build lifecycle depending on the detected build environment.
To address these circumstances, Maven 2.0 introduces the concept of a build profile. Profiles are specified using a subset of the elements available in the POM itself (plus one extra section), and are triggered in any of a variety of ways. They modify the POM at build time, and are meant to be used in complementary sets to give equivalent-but-different parameters for a set of target environments (providing, for example, the path of the appserver root in the development, testing, and production environments). As such, profiles can easily lead to differing build results from different members of your team. However, used properly, profiles can be used while still preserving project portability. This will also minimize the use of -f option of maven which allows user to create another POM with different parameters or configuration to build which makes it more maintainable since it is runnning with one POM only.
Default (or Build) Lifecycle
This is the primary life cycle of Maven and is used to build the application. It has the following 21 phases.
Maven Goal
Each phase is a sequence of goals, and each goal is responsible for a specific task.
When we run a phase – all goals bound to this phase are executed in order.
Here are some of the phases and default goals bound to them:
compiler:compile – the compile goal from the compiler plugin is bound to the compile phase
compiler:testCompile is bound to the test-compile phase
surefire:test is bound to test phase
install:install is bound to install phase
jar:jar and war:war is bound to package phase
We can list all goals bound to a specific phase and their plugins using the command:
validate
Validates whether project is correct and all necessary information is available to complete the build process.
initialize
Initializes build state, for example set properties.
generate-sources
Generate any source code to be included in compilation phase.
process-sources
Process the source code, for example, filter any value.
generate-resources
Generate resources to be included in the package.
process-resources
Copy and process the resources into the destination directory, ready for packaging phase.
compile
Compile the source code of the project.
process-classes
Post-process the generated files from compilation, for example to do bytecode enhancement/optimization on Java classes.
generate-test-sources
Generate any test source code to be included in compilation phase.
process-test-sources
Process the test source code, for example, filter any values.
test-compile
Compile the test source code into the test destination directory.
process-test-classes
Process the generated files from test code file compilation.
test
Run tests using a suitable unit testing framework (Junit is one).
prepare-package
Perform any operations necessary to prepare a package before the actual packaging.
package
Take the compiled code and package it in its distributable format, such as a JAR, WAR, or EAR file.
pre-integration-test
Perform actions required before integration tests are executed. For example, setting up the required environment.
integration-test
Process and deploy the package if necessary into an environment where integration tests can be run.
post-integration-test
Perform actions required after integration tests have been executed. For example, cleaning up the environment.
verify
Run any check-ups to verify the package is valid and meets quality criteria.
install
Install the package into the local repository, which can be used as a dependency in other projects locally.
deploy
Copies the final package to the remote repository for sharing with other developers and projects.
https://bit.ly/2T9UfnJ
14. Discuss with examples, how Maven manages dependency/packages and build life cycle
Maven Life Cycle
"Maven is based around the central concept of a build lifecycle. What this means is that the process for building and distributing a particular artifact (project) is clearly defined."
" For the person building a project, this means that it is only necessary to learn a small set of commands to build any Maven project, and the POM will ensure they get the results they desired."
Apache Maven Project - Introduction
There are three built-in build lifecycles:
default lifecycle handles project deployment.
clean lifecycle handles project cleaning.
site lifecycle handles the creation of project's site documentation.
Default lifecycle
The default lifecycle has the following build phases:
validate: validate the project is correct and all necessary information is available.
compile: compile the source code of the project.
test: test the compiled source code using a suitable unit testing framework. These tests should not require the code be packaged or deployed.
package: take the compiled code and package it in its distributable format, such as a JAR.
integration-test: process and deploy the package if necessary into an environment where integration tests can be run.
verify: run any checks to verify the package is valid and meets quality criteria.
install: install the package into the local repository, for use as a dependency in other projects locally.
deploy: done in an integration or release environment, copies the final package to the remote repository for sharing with other developers and projects.
These lifecycle phases (plus the other lifecycle phases not shown here) are executed sequentially to complete the default lifecycle.
https://bit.ly/2VtNOZx
15. Identify and discuss some other contemporary tools and practices widely used in the software industry
0 notes
Text
PAF tute 02
Question-1
What is the need for VCS ( Version Control System ) ?

Version control is the ability to manage the change and configuration of an application. Versioning is a priceless process, especially when you have multiple developers working on a single application, because it allows them to easily share files. Without version control, developers will eventually step on each other’s toes and overwrite code changes that someone else may have completed without even realizing it. Using these systems allows you to check files out for modifications, then, during check-in, if the files have been changed by another user, you will be alerted and allowed to merge them.
Version control systems allow you to compare files, identify differences, and merge the changes if needed prior to committing any code. Versioning is also a great way to keep track of application builds by being able to identify which version is currently in development, QA, and production. Also, when new developers join the team, they can easily download the current version of the application to their local environment using the version control system and are able to keep track of the version they’re currently running. During development, you can also have entirely independent code versions if you prefer to keep different development efforts separate. When ready, you can merge the files to create a final working version.
Another great use for versioning is when troubleshooting an issue, you are able to easily compare different versions of files to track differences. You can compare the last working file with the faulty file, decreasing the time spent identifying the cause of an issue. If the user decides to roll back the changes, you can implement the last working file by using the correct version.
https://bit.ly/2T6MH4s
Question-2
Differentiate the three models of VCSs, stating their pros and cons
Local Data Model:
This is the simplest variations of version control, and it requires that all developers have access to the same file system.
Client-Server Model:
Using this model, developers use a single shared repository of files. It does require that all developers have access to the repository via the internet of a local network. This is the model used by Subversion (SVN).
Distributed Model:
In this model, each developer works directly with their own local repository, and changes are shared between repositories as a separate step. This is the model used by Git, an open source software used by many of the largest software development projects.
https://bit.ly/2EoBc01
Question-3
Git and GitHub, are they same or different? Discuss with facts.
"Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency"
Git is a distributed peer-peer version control system. Each node in the network is a peer, storing entire repositories which can also act as a multi-node distributed back-ups. There is no specific concept of a central server although nodes can be head-less or 'bare', taking on a role similar to the central server in centralised version control systems.
What is GitHub:
"GitHub is a web-based Git repository hosting service, which offers all of the distributed revision control and source code management (SCM) functionality of Git as well as adding its own features."
Github provides access control and several collaboration features such as wikis, task management, and bug tracking and feature requests for every project.
You do not need GitHub to use Git.
GitHub (and any other local, remote or hosted system) can all be peers in the same distributed versioned repositories within a single project.
Github allows you to:
Share your repositories with others.
Access other user's repositories.
Store remote copies of your repositories (github servers) as backup of your local copies.

https://bit.ly/2H1oaHN
Question-4
Compare and contrast the Git commands, commit and push
git commit. The "commit" command is used to save your changes to the local repository. Note that you have to explicitly tell Git which changes you want to include in a commit before running the "git commit" command. This means that a file won't be automatically included in the next commit just because it was changed.
The git push command is used to upload local repository content to a remote repository. Pushing is how you transfer commits from your local repository to a remote repo. ... Remote branches are configured using the git remote command.Pushing has the potential to overwrite changes, caution should be taken when pushing.
https://bit.ly/2EBUPAl
Question-5
Discuss the use of staging area and Git directory
To stage a file is simply to prepare it finely for a commit. Git, with its index allows you to commit only certain parts of the changes you've done since the last commit. Say you're working on two features - one is finished, and one still needs some work done. You'd like to make a commit and go home (5 o'clock, finally!) but wouldn't like to commit the parts of the second feature, which is not done yet. You stage the parts you know belong to the first feature, and commit. Now your commit is your project with the first feature done, while the second is still in work-in-progress in your working directory.

So the staging area is like:
a cache of files that you want to commit
not a series of tubes but actually a dump truck, ready to move the work you load it with, in to the repository
a magical place where selected files will be turned into stone with your wizardry and can be magically transported to the repository at your whim
the yellow brick road for the files to go happily to the repository (or fall off if you want to revert)
the fictional place at the sea port where files are received a pair of cement shoes and then thrown into the repository sea
the receptions desk at the library, you put the files there for the librarian to prepare for filing into the library
a box where you put things in before shoving it under your bed, where your bed is a repository of boxes you've previously have shoved in
the loading bay of files before it goes into the repository warehouse with the power loader
the filter of an electric drip coffee maker, if the files are like the coffee powder, then the committed files are the brewed coffee
the Scrooge McDuck's office next to the vault, the files are like the coins before they go into the vault of his massive Money Bin
the pet store, once you bring a pet home you're committed
https://bit.ly/2tyZIpd
Question-6
Explain the collaboration workflow of Git, with example
Question-7
Discuss the benefits of CDNs
Content Delivery Network and its Business BenefitsContent Delivery Networks (CDN) accounts for large share of delivering content across websites users and networks across the globe. The content found in the websites of today contain a variety of formats such as text, scripts, documents, images, software, media files, live streaming media and on-demand streaming media and so on. In order to deliver such diverse content to users across the globe efficiently, CDNs are deployed in datacenters. CDNs accelerate website performance and provide a numerous benefits for users and also for the network infrastructure.
The internet is a collection of numerous networks or datacenters. The growth of the world-wide-web and related technologies along with proliferation of wireless technologies, cloud computing, etc. is leveraging users to access the internet with multiple devices in addition to computers. Web servers deployed in networks on the internet cater to most of the user requests on the internet. But, when web servers are located in one single location it becomes increasingly difficult to handle multiple workloads. This has an effect on website performance and efficiency is reduced significantly. Further, users access a variety of applications such as interactive multimedia apps, streaming audio and video along with static and dynamic web pages across millions of websites which require efficient and robust network infrastructures and systems. In order to balance the load on infrastructures and to provide content quickly to end users CDNs are deployed in data centers.
Content Delivery Networks (CDN) is a system of servers deployed in different geographical locations to handle increased traffic loads and reduce the time of content delivery for the user from servers. The main objective of CDN is to deliver content at top speed to users in different geographic locations and this is done by a process of replication. CDNs provide web content services by duplicating content from other servers and directing it to users from the nearest data center. The shortest possible route between a user and the web server is determined by the CDN based on factors such as speed, latency, proximity, availability and so on. CDNs are deployed in data centers to handle challenges with user requests and content routing.
CDNs are used extensively by social networks, media and entertainment websites, e-commerce websites, educational institutions, etc. to serve content quickly to users in different locations. Organizations by implementing CDN solutions stand to gain in many ways that include,
Faster content load / response time in delivering content to end users.
Availability and scalability, because CDNs can be integrated with cloud models
Redundancy in content, thus minimizing errors and there is no need for additional expensive hardware
Enhanced user experience with CDNs as they can handle peak time loads
Data integrity and privacy concerns are addressed
The benefits of CDNs are more emphasized by examining its usage in a few real time application areas. Some common application areas include,
E-Commerce: E-commerce companies make use of CDNs to improve their site performance and making their products available online. According to Computer World, CDN provides 100% uptime of e-commerce sites and this leads to improved global website performance. With continuous uptime companies are able to retain existing customers, leverage new customers with their products and explore new markets, to maximize their business outcomes.
Media and Advertising: In media, CDNs enhance the performance of streaming content to a large degree by delivering latest content to end users quickly. We can easily see today, there is a growing demand for online video, and real time audio/video and other media streaming applications. This demand is leveraged by media, advertising and digital content service providers by delivering high quality content efficiently for users. CDNs accelerate streaming media content such as breaking news, movies, music, online games and multimedia games in different formats. The content is made available from the datacenter which is nearest to users’ location.
Business Websites: CDNs accelerate the interaction between users and websites, this acceleration is highly essential for corporate businesses. In websites speed is one important metric and a ranking factor. If a user is far away from a website the web pages will load slowly. Content delivery networks overcome this problem by sending requested content to the user from the nearest server in CDN to give the best possible load times, thus speeding the delivery process.
Education: In the area of online education CDNs offer many advantages. Many educational institutes offer online courses that require streaming video/audio lectures, presentations, images and distribution systems. In online courses students from around the world can participate in the same course. CDN ensures that when a student logs into a course, the content is served from the nearest datacenter to the student’s location. CDNs support educational institutes by steering content to regions where most of the students reside.
In the internet, closer is always better to overcome problems in latency and performance, CDNs are seen as an ideal solution in such situations. Since CDNs share digital assets between nodes and servers in different geographical locations, this significantly improves client response times for content delivery. CDN nodes or servers deployed at multiple locations in data centers also take care of optimizing the delivery process with users. However, the CDN services and the cost are worked out in SLAs with the data center service provider.
https://bit.ly/1KoxNs2
Question-8
How CDNs differ from web hosting servers?

There was a time when traditional web hosting had lorded over everything else that happened over the World Wide Web. There were several hosting companies that housed basic as well as corporate websites, which were purely static and comprised of small files that could be viewed and downloaded by users on the internet. But, these days are long gone. Now, the internet has earned the reputation of being the central repository and delivery of personal, corporate and home multimedia content that has revolutionized education and entertainment. However, current technology and traditional web hosting is no longer capable of meeting the demands of websites.
CDN Hosting
Today, content delivery networks or CDNs have gained prominence. These are simply networked systems that are in cooperative mode and peak with neural networks. Powerful servers known as edge servers are located in various locations for serving large corporations and they provide numerous services to the users seamlessly, without letting them know the location of the server from where data is sent. These networked hosts, which are deployed in different parts of the world, now play a significant role in surpassing the computing resources of traditional web hosting in order to deliver rich and high-quality multimedia content in a reliable and cost-effective way, particularly when content delivery networks such as KeyCDN are used.
Differences Between CDNs and Web Hosting
Web Hosting is used to host your website on a server and let users access it over the internet. A content delivery network is about speeding up the access/delivery of your website’s assets to those users.
Traditional web hosting would deliver 100% of your content to the user. If they are located across the world, the user still must wait for the data to be retrieved from where your web server is located. A CDN takes a majority of your static and dynamic content and serves it from across the globe, decreasing download times. Most times, the closer the CDN server is to the web visitor, the faster assets will load for them.
Web Hosting normally refers to one server. A content delivery network refers to a global network of edge servers which distributes your content from a multi-host environment.
https://bit.ly/2DZXcgn
Question-9
Identify free and commercial CDNs
Free CDNs
Given that you’ve landed on this page for “free CDN for WordPress”, let’s dive down into the article.
1. CloudFlare
CloudFlare is popularly known as the best free CDN for WordPress users. It is one of the few industry-leading players that actually offer a free plan. Powered by its 115 datacenters, CloudFlare delivers speed, reliability, and protection from basic DDoS attacks. And it’s WordPress plugin is used in over 100,000 active websites.
2. Incapsula
Incapsula provides Application Delivery from the cloud: Global CDN, Website Security, DDoS Protection, Load Balancing & Failover. It takes 5 minutes to activate the service, and they have a great free plan and a WordPress plugin to get correct IP Address information for comments posted to your site.
Features offered by both CloudFlare and Incapsula:
In a nutshell, this is what Incapsula and CloudFlare does:
Routes your entire website’s traffic through their globally distributed network of high end servers (This is achieved by a small DNS change)
Real-time threat analysis of incoming traffic and blocking the latest web threats including multi-Gigabit DDoS attacks
Outgoing traffic is accelerated through their globally powered content delivery network
3. Photon by Jetpack
To all WordPress users – Jetpack needs no introduction. In their recent improvement of awesomeness, they’ve included a free CDN service (called Photon) that serves your site’s images through their globally powered WordPress.com grid. To get this service activated, all you have to do is download and install Jetpack and activate its Photon module.
WordPress users need no introduction to Jetpack. One of the coolest features Jetpack has to offer is their free CDN service called Photon. The best part? You don’t need to configure a thing! Simply install the plugin, login with your WordPress.com account and activate the photon module. That’s it. All you images will be offloaded to the WordPress grid that powers over hundreds of thousands of website across the globe.
Commercial CDNs
1.EdgeCast/Verizon
The Edgecast Content Delivery Network from Verizon Digital Media Services is a media-optimized CDN built to meet the demands of the modern Internet. With centralized SuperPop architecture, Anycast based routing and proprietary caching technologies, Edgecast CDN is one of the highest performing and most reliable CDNs in the world. Leading sites like Quora, Lenovo, Novica and CafePress rely on Verizon Digital Media Services to deliver optimal viewing experiences to every screen globally. Specific services include: PCI-Compliant dynamic acceleration, Application delivery, HTTP/HTTPs caching, Streaming, Storage, DNS, Web Application Firewall and DDoS mitigation.
2. Fastly
Fastly is a Content Delivery Network provider, founded in 2011 in San Francisco. Fastly’s global network is built with 10Gb Ethernet, multi-core CPUs, and all Solid State Drives (SSDs). They also offer access to real-time performance analytics, and the ability to cache frequently changing content at the edge.
3. Hibernia
Hibernia Networks is a privately held, US-owned, provider of global capacity telecommunication services. Hibernia Networks owns and operates a global network connecting North America, Europe and Asia. Hibernia offers over 120 network Points of Presence (PoPs) on over 24,000 kilometers of fiber. Hibernia’s network provides service, from 2.5 Gbit/s to 100 Gbit/s wavelengths and Ethernet from 10 Mbit/s to 100 Gbit/s. They are currently headquartered in Dublin, Ireland.
https://bit.ly/2GGHBG8
https://bit.ly/2SVcOvS
Question-10
Discuss the requirements for virtualization
Meeting hardware requirements for virtualization remains something of an art form. It is important to give each virtual machine the hardware it needs, but it is also important not to waste resources by over provisioning virtual machines. This decreases the total number of virtual machines that can simultaneously run on a host server, which increases costs. This article examines various techniques to ensure that you assign the proper hardware resources for virtual machines.
To meet hardware requirements for virtualization, heed application needs, guest machine limitations
Almost every application vendor publishes a list of hardware requirements for its applications. These requirements do not change just because an application runs on a virtual server. If an application requires 4 GB of memory, then you need to make sure the virtual machine on which you plan to run the application is provisioned with at least 4 GB of memory.
Some organizations prefer to give each virtual machine as much memory as it is ever likely to use, rather than taking the time to figure out how much memory each virtual machine really needs. Although this technique might waste memory, it does improve virtual machine performance, since the machine has been allocated plenty of memory.
If your organization uses this technique, one way to avoid wasting memory is to know the upper memory limits that each operating system supports. For example, 32-bit operating systems can address a maximum of 4 GB of memory. Assigning anything over 4 GB to a virtual machine running a 32-bit operating system would be a waste, since the operating system won’t even see the extra memory. (There are exceptions for servers using a Physical Address Extension).
To better identify your hardware requirements for virtualization of applications, the chart below illustrates the maximum amount of memory supported by various Windows Server operating systems.
Operating SystemMaximum Memory Supported
Windows Server 2008 R2 Datacenter 2 TB
Windows Server 2008 R2 Enterprise 2 TB
Windows Server 2008 R2 Foundation 8 GB
Windows Server 208 R2 Standard 32 GB
Assuming that you base virtual server memory allocations around how much memory the virtual servers actually need, as opposed to how much they can support, you can simplify the memory planning process by using single-purpose virtual machines.
Memory planning can become complicated when you try to host multiple applications on a single virtual machine. Since each application vendor specifies the amount of memory required by its applications, let's pretend that one application requires 4 GB of RAM and that the other application requires 2 GB. Does that mean that hardware requirements for a virtual machine hosting both applications would be 6 GB of RAM?
The answer is probably not. When an application vendor specifies the amount of memory required for their application, the estimate usually takes into account the memory required by the operating system. If you are hosting two separate applications, then you usually won't be able to simply add the memory requirements together to determine the total memory needed. Both sets of memory requirements probably take the operating systems memory requirements into account.
To give you a more concrete example, suppose the applications were running on Windows Server 2008, which requires at least 512 MB of memory. However, Microsoft recommends equipping servers with at least 2 GB of memory. In that case, then the first application (the one requiring 4 GB) probably requires 2 GB for itself and 2 GB for the operating system. The second application (the one requiring 2 GB) probably does not use any more memory than some of the optional Windows system services, and, therefore, works fine with 2 GB of memory, assuming that nothing else is running on the server.
he two applications used in this example would probably work fine with a little over 4 GB of RAM. The problem is that we don’t really know that for sure. To address the hardware requirements for virtualization, it is a lot easier to run each application in its own virtual machine rather than guess how much memory is required.
Of course, using a dedicated virtual machine for each application can consume more memory than would be used running multiple applications on a single virtual machine. The tradeoff, however, is that using a separate virtual machine for each application increases security and it makes it possible to shut down a virtual machine without affecting multiple applications. For health care organizations virtualizing mission-critical applications, this piece of mind is probably worth the extra memory consumption.
Performance Monitor not best choice for gauging hardware requirements for virtualization
In the past, the tool of choice for determining a system's hardware usage has always been the Performance Monitor. In a virtual environment, however, the Performance Monitor is of limited use. It works well for tracking memory usage and can be helpful for virtual machine capacity planning, but it does not work so well for tracking CPU or disk I/O consumption.
When you run the Performance Monitor inside a virtual machine, the Performance Monitor can only look at the resources that have been allocated to that virtual machine, not the resources available on the system as a whole. As such, if you use the Performance Monitor to measure the impact that the virtual machine is having on the physical hardware, the measurements will be skewed.
https://bit.ly/2XiPgzF
Question-11 Discuss and compare the pros and cons of different virtualization techniques in different levels
Advantages of Virtualization
Following are some of the most recognized advantages of Virtualization, which are explained in detail.
Using Virtualization for Efficient Hardware Utilization
Virtualization decreases costs by reducing the need for physical hardware systems. Virtual machines use efficient hardware, which lowers the quantities of hardware, associated maintenance costs and reduces the power along with cooling the demand. You can allocate memory, space and CPU in just a second, making you more self-independent from hardware vendors.
Using Virtualization to Increase Availability
Virtualization platforms offer a number of advanced features that are not found on physical servers, which increase uptime and availability. Although the vendor feature names may be different, they usually offer capabilities such as live migration, storage migration, fault tolerance, high availability and distributed resource scheduling. These technologies keep virtual machines chugging along or give them the ability to recover from unplanned outages.
The ability to move a virtual machine from one server to another is perhaps one of the greatest single benefits of virtualization with far reaching uses. As the technology continues to mature to the point where it can do long-distance migrations, such as being able to move a virtual machine from one data center to another no matter the network latency involved.
Disaster Recovery
Disaster recovery is very easy when your servers are virtualized. With up-to-date snapshots of your virtual machines, you can quickly get back up and running. An organization can more easily create an affordable replication site. If a disaster strikes in the data center or server room itself, you can always move those virtual machines elsewhere into a cloud provider. Having that level of flexibility means your disaster recovery plan will be easier to enact and will have a 99% success rate.
Save Energy
Moving physical servers to virtual machines and consolidating them onto far fewer physical servers’ means lowering monthly power and cooling costs in the data center. It reduces carbon footprint and helps to clean up the air we breathe. Consumers want to see companies reducing their output of pollution and taking responsibility.
Deploying Servers too fast
You can quickly clone an image, master template or existing virtual machine to get a server up and running within minutes. You do not have to fill out purchase orders, wait for shipping and receiving and then rack, stack, and cable a physical machine only to spend additional hours waiting for the operating system and applications to complete their installations. With virtual backup tools like Veeam, redeploying images will be so fast that your end users will hardly notice there was an issue.
Save Space in your Server Room or Datacenter
Imagine a simple example: you have two racks with 30 physical servers and 4 switches. By virtualizing your servers, it will help you to reduce half the space used by the physical servers. The result can be two physical servers in a rack with one switch, where each physical server holds 15 virtualized servers.
Testing and setting up Lab Environment
While you are testing or installing something on your servers and it crashes, do not panic, as there is no data loss. Just revert to a previous snapshot and you can move forward as if the mistake did not even happen. You can also isolate these testing environments from end users while still keeping them online. When you have completely done your work, deploy it in live.
Shifting all your Local Infrastructure to Cloud in a day
If you decide to shift your entire virtualized infrastructure into a cloud provider, you can do it in a day. All the hypervisors offer you tools to export your virtual servers.
Possibility to Divide Services
If you have a single server, holding different applications this can increase the possibility of the services to crash with each other and increasing the fail rate of the server. If you virtualize this server, you can put applications in separated environments from each other as we have discussed previously.
Disadvantages of Virtualization
Although you cannot find many disadvantages for virtualization, we will discuss a few prominent ones as follows −
Extra Costs
Maybe you have to invest in the virtualization software and possibly additional hardware might be required to make the virtualization possible. This depends on your existing network. Many businesses have sufficient capacity to accommodate the virtualization without requiring much cash. If you have an infrastructure that is more than five years old, you have to consider an initial renewal budget.
Software Licensing
This is becoming less of a problem as more software vendors adapt to the increased adoption of virtualization. However, it is important to check with your vendors to understand how they view software use in a virtualized environment.
Learn the new Infrastructure
Implementing and managing a virtualized environment will require IT staff with expertise in virtualization. On the user side, a typical virtual environment will operate similarly to the non-virtual environment. There are some applications that do not adapt well to the virtualized environment.
https://bit.ly/2EnIl0B
Question-12
Identify popular implementations and available tools for each level of visualization
Big Data and the ever-growing access we have to more information is the driving force behind artificial intelligence and the wave of technological change sweeping across all industries.
But all the data in the world is useless – in fact it can become a liability – if you can’t understand it. Data visualization is about how to present your data, to the right people, at the right time, in order to enable them to gain insights most effectively.
Shutterstock
Luckily visualization solutions are evolving as rapidly as the rest of the tech stack. Charts, videos, infographics and at the cutting edge even virtual reality and augmented reality (VR & AR) presentations offer increasingly engaging and intuitive channels of communication.
Here’s my run-down of some of the best, most popular or most innovative data visualization tools available today. These are all paid-for (although they all offer free trials or personal-use licences). Look out for another post soon on completely free and open source alternatives.
Tableau
Tableau is often regarded as the grand master of data visualization software and for good reason. Tableau has a very large customer base of 57,000+ accounts across many industries due to its simplicity of use and ability to produce interactive visualizations far beyond those provided by general BI solutions. It is particularly well suited to handling the huge and very fast-changing datasets which are used in Big Data operations, including artificial intelligence and machine learning applications, thanks to integration with a large number of advanced database solutions including Hadoop, Amazon AWS, My SQL, SAP and Teradata. Extensive research and testing has gone into enabling Tableau to create graphics and visualizations as efficiently as possible, and to make them easy for humans to understand.
Qlikview
Qlik with their Qlikview tool is the other major player in this space and Tableau’s biggest competitor. The vendor has over 40,000 customer accounts across over 100 countries, and those that use it frequently cite its highly customizable setup and wide feature range as a key advantage. This however can mean that it takes more time to get to grips with and use it to its full potential. In addition to its data visualization capabilities Qlikview offers powerful business intelligence, analytics and enterprise reporting capabilities and I particularly like the clean and clutter-free user interface. Qlikview is commonly used alongside its sister package, Qliksense, which handles data exploration and discovery. There is also a strong community and there are plenty of third-party resources available online to help new users understand how to integrate it in their projects.
FusionCharts
This is a very widely-used, JavaScript-based charting and visualization package that has established itself as one of the leaders in the paid-for market. It can produce 90 different chart types and integrates with a large number of platforms and frameworks giving a great deal of flexibility. One feature that has helped make FusionCharts very popular is that rather than having to start each new visualization from scratch, users can pick from a range of “live” example templates, simply plugging in their own data sources as needed.
Question-13
What is the hypervisor and what is the role of it?
A hypervisor is one of two main ways to virtualize a computing environment. By ‘virtualize’, we mean to divide the resources (CPU, RAM etc.) of the physical computing environment (known as a host) into several smaller independent ‘virtual machines’ known as guests. Each guest can run its own operating system, to which it appears the virtual machine has its own CPU and RAM, i.e. it appears as if it has its own physical machine even though it does not. To do this efficiently, it requires support from the underlying processor (a feature called VT-x on Intel, and AMD-V on AMD).
One of the key functions a hypervisor provides is isolation, meaning that a guest cannot affect the operation of the host or any other guest, even if it crashes. As such, the hypervisor must carefully emulate the hardware of a physical machine, and (except under carefully controlled circumstances), prevent access by a guest to the real hardware. How the hypervisor does this is a key determinant of virtual machine performance. But because emulating real hardware can be slow, hypervisors often provide special drivers, so called ‘paravirtualized drivers’ or ‘PV drivers’, such that virtual disks and network cards can be represented to the guest as if they were a new piece of hardware, using an interface optimized for the hypervisor. These PV drivers are operating system and (often) hypervisor specific. Use of PV drivers can speed up performance by an order of magnitude, and are also a key determinant to performance.
Type 1 and Type 2 hypervisors
Hypervisors are often divided between Type 1 and Type 2 hypervisors.
A Type 1 hypervisor (sometimes called a ‘Bare Metal’ hypervisor) runs directly on top of the physical hardware. Each guest operating system runs atop the hypervisor. Xen is perhaps the canonical example.
One or more guests may be designated as special in some way (in Xen this is called ‘dom-0’) and afforded privileged control over the hypervisor.
A Type 2 hypervisor (sometimes called a ‘Hosted’ hypervisor) runs inside an operating system which in turn runs on the physical hardware. Each guest operating system then runs atop the hypervisor. Desktop virtualization systems often work in this manner.
A common perception is that Type 1 hypervisors will perform better than Type 2 hypervisors because a Type 1 hypervisor avoids the overhead of the host operating system when accessing physical resources. This is too simplistic an analysis. For instance, at first glance, KVM is launched as a process on a host Linux operating system, so appears to be a Type 2 hypervisor. In fact, the process launched merely gives access to a limited number of resources through the host operating system, and most performance sensitive tasks are performed by a kernel module which has direct access to the hardware. Hyper-V is often thought of as a Type 2 hypervisor because of its management through the Windows GUI; however, in reality, a hypervisor layer is loaded beneath the host operating system.
Another wrinkle is that the term ‘bare metal’ (often used to signify a Type 1 hypervisor) is often used to refer to a hypervisor that loads (with or without a small embedded host operating system, and whether or not technically a Type 1 hypervisor) without installation on an existing platform, rather like an appliance. VMware describes ESXi as a ‘bare metal’ hypervisor in this context. Flexiant Cloud Orchestrator’s deployment of both Xen and KVM also fit into this category: we PXEboot a tiny operating system image dedicated to the running of the hypervisor. However, both hypervisors could be installed in a conventional server environment.
https://bit.ly/2tR4LV1
Question-14
How does the emulation is different from VMs?
The purpose of a virtual machine is to create an isolated environment.
The purpose of an emulator is to accurately reproduce the behavior of some hardware.
Emulation or virtualization: What’s the difference?
Emulation and virtualization carry many similarities, yet they have distinct operational differences. If you’re looking to access an older operating system within a newer architecture, emulation would be your preferred route. Conversely, virtualized systems act independent of the underlying hardware. We’ll look to separate these often confused terms, and describe what each of them mean for business IT operations.
What’s the difference?
Emulation, in short, involves making one system imitate another. For example, if a piece of software runs on system A and not on system B, we make system B “emulate” the working of system A. The software then runs on an emulation of system A.
In this same example, virtualization would involve taking system A and splitting it into two servers, B and C. Both of these “virtual” servers are independent software containers, having their own access to software based resources – CPU, RAM, storage and networking – and can be rebooted independently. They behave exactly like real hardware, and an application or another computer would not be able to tell the difference.
Each of these technologies have their own uses, benefits and shortcomings.
Emulation
In our emulation example, software fills in for hardware – creating an environment that behaves in a hardware-like manner. This takes a toll on the processor by allocating cycles to the emulation process – cycles that would instead be utilized executing calculations. Thus, a large part of the CPU muscle is expended in creating this environment.
Interestingly enough, you can run a virtual server in an emulated environment. So, if emulation is such a waste of resources, why consider it?
Emulation can be effectively utilized in the following scenarios:
• Running an operating system meant for other hardware (e.g., Mac software on a PC; console-based games on a computer)
• Running software meant for another operating system (running Mac-specific software on a PC and vice versa)
• Running legacy software after comparable hardware become obsolete
Emulation is also useful when designing software for multiple systems. The coding can be done on a single machine, and the application can be run in emulations of multiple operating systems, all running simultaneously in their own windows.
Virtualization
In our virtualization example, we can safely say that it utilizes computing resources in an efficient, functional manner – independent of their physical location or layout. A fast machine with ample RAM and sufficient storage can be split into multiple servers, each with a pool of resources. That single machine, ordinarily deployed as a single server, could then host a company’s web and email server. Computing resources that were previously underutilized can now be used to full potential. This can help drastically cut down costs.
While emulated environments require a software bridge to interact with the hardware, virtualization accesses hardware directly. However, despite being the overall faster option, virtualization is limited to running software that was already capable of running on the underlying hardware. The clearest benefits of virtualization include:
•Wide compatibility with existing x86 CPU architecture
•Ability to appear as physical devices to all hardware and software
•Self-contained in each instance
Between emulation and virtualization, your business can perform most virtual systems functions. While both services sound alike, it all revolves around how you utilize the software. If you want the software to get out of the way, virtualization allows guest code to run directly on the CPU. Conversely, emulators will run the guest code themselves, saving the CPU for other tasks.
https://bit.ly/2DUBDxy
Question-15
Compare and contrast the VMs and containers/dockers, indicating their advantages and disadvantages

Both VMs and containers can help get the most out of available computer hardware and software resources. Containers are the new kids on the block, but VMs have been, and continue to be, tremendously popular in data centers of all sizes.
If you’re looking for the best solution for running your own services in the cloud, you need to understand these virtualization technologies, how they compare to each other, and what are the best uses for each. Here’s our quick introduction.
Basic Definitions — VMs and Containers
What are VMs?
A virtual machine (VM) is an emulation of a computer system. Put simply, it makes it possible to run what appear to be many separate computers on hardware that is actually one computer.
The operating systems (“OS”) and their applications share hardware resources from a single host server, or from a pool of host servers. Each VM requires its own underlying OS, and the hardware is virtualized. A hypervisor, or a virtual machine monitor, is software, firmware, or hardware that creates and runs VMs. It sits between the hardware and the virtual machine and is necessary to virtualize the server.
Since the advent of affordable virtualization technology and cloud computing services, IT departments large and small have embraced virtual machines (VMs) as a way to lower costs and increase efficiencies.
VMs, however, can take up a lot of system resources. Each VM runs not just a full copy of an operating system, but a virtual copy of all the hardware that the operating system needs to run. This quickly adds up to a lot of RAM and CPU cycles. That’s still economical compared to running separate actual computers, but for some applications it can be overkill, which led to the development of containers.
Benefits of VMs
All OS resources available to apps
Established management tools
Established security tools
Better known security controls
Popular VM Providers
VMware vSphere
VirtualBox
Xen
Hyper-V
KVM
What are Containers?
With containers, instead of virtualizing the underlying computer like a virtual machine (VM), just the OS is virtualized.
Containers sit on top of a physical server and its host OS — typically Linux or Windows. Each container shares the host OS kernel and, usually, the binaries and libraries, too. Shared components are read-only. Sharing OS resources such as libraries significantly reduces the need to reproduce the operating system code, and means that a server can run multiple workloads with a single operating system installation. Containers are thus exceptionally light — they are only megabytes in size and take just seconds to start. Compared to containers, VMs take minutes to run and are an order of magnitude larger than an equivalent container.
In contrast to VMs, all that a container requires is enough of an operating system, supporting programs and libraries, and system resources to run a specific program. What this means in practice is you can put two to three times as many as applications on a single server with containers than you can with a VM. In addition, with containers you can create a portable, consistent operating environment for development, testing, and deployment.
Types of Containers
Linux Containers (LXC) — The original Linux container technology is Linux Containers, commonly known as LXC. LXC is a Linux operating system level virtualization method for running multiple isolated Linux systems on a single host.
Docker — Docker started as a project to build single-application LXC containers, introducing several changes to LXC that make containers more portable and flexible to use. It later morphed into its own container runtime environment. At a high level, Docker is a Linux utility that can efficiently create, ship, and run containers.
Benefits of Containers
Reduced IT management resources
Reduced size of snapshots
Quicker spinning up apps
Reduced & simplified security updates
Less code to transfer, migrate, upload workloads
Popular Container Providers
Linux Containers
Docker
Windows Server Containers
LXC
LXD
CGManager
Uses for VMs vs Uses for Containers
Both containers and VMs have benefits and drawbacks, and the ultimate decision will depend on your specific needs, but there are some general rules of thumb.
VMs are a better choice for running apps that require all of the operating system’s resources and functionality, when you need to run multiple applications on servers, or have a wide variety of operating systems to manage.
Containers are a better choice when your biggest priority is maximizing the number of applications running on a minimal number of servers.
What’s the Diff: VMs vs Containers
VMs Containers
Heavy weight Lightweight Limited performance Native performance Each VM runs in its own OSAll Containers share the host OS Hardware-level virtualization OS virtualization Startup time in minutes Startup time in milliseconds Allocates required memory Requires less memory space
For most, the ideal setup is likely to include both. With the current state of virtualization technology, the flexibility of VMs and the minimal resource requirements of containers work together to provide environments with maximum functionality.
https://bit.ly/2NjXp26
0 notes
Text
PAF TUTORIAL 1
Question 1
What is the difference between declarative and imperative programming paradigms?

The term programming paradigm refers to the style or way of thinking and addressing problems. Simply, it's a programming style. There may be more than one type programming paradigm...
Never use the phrase “programming language paradigm.”
A paradigm is a way of doing something (like programming), not a concrete thing (like a language). Now, it’s true that if a programming language L happens to make a particular programming paradigm P easy to express, then we often say “L is a P language” (e.g. “Haskell is a functional programming language”) but that does not mean there is any such thing as a “functional language paradigm”.
Some Common Paradigms
Following are few examples for programming paradigms.
Imperative: Programming with an explicit sequence of commands that update state.
Declarative: Programming by specifying the result you want, not how to get it.
Structured: Programming with clean, goto-free, nested control structures.
Procedural: Imperative programming with procedure calls.
Functional (Applicative): Programming with function calls that avoid any global state.
Function-Level (Combinator): Programming with no variables at all.
Object-Oriented: Programming by defining objects that send messages to each other. Objects have their own internal (encapsulated) state and public interfaces. Object orientation can be.
In this article we are not going to discuss about above all. Here we are going to talk about declarative programming and imperative programming. declarative programming and imperative programming are two different approaches that offer a different way of working on a given project or application. But what is the difference between declarative and imperative programming? And when should you use one over the other?
What is imperative programming?
Let's start with imperative programming first. It's the form and style of programming in which we care about how we get a response, step by step. We want the same result at the end of the day, but we ask the registrant to do things in a certain way in order to get the right answer we are looking for.
Your code focuses on creating statements that change program states by creating algorithms that tell the computer how to do things. It closely relates to how hardware works. Typically your code will make use of conditinal statements, loops and class inheritence.
Procedural and object-oriented programming belongs to the imperative paradigm that you know about languages such as C, C ++, C #, PHP, Java and of course Assembly.
Problems with an Imperative Approach
You may already be seeing some issues with the imperative approach. First, our code is pretty messy. The script does a bunch of things, and we don’t know which part of the script is dedicated to which functionality. Second, it’s not easily reusable. If we try to do another analysis, we’ll be changing variables or copy and pasting code, which violates the programming principle of DRY—don’t repeat yourself. Third, if we need to change the program, there are many parts that are dependent on other parts, which means that one change is likely to require a bunch of other changes to accommodate it.
Advantage:
Very simple to implement
It contains loops, variables etc.
Disadvantage:
Complex problem cannot be solved
Less efficient and less productive
Parallel programming is not possible
What is declarative programming?
Next, let’s take a look at declarative programming This is the form or style of programming where we are most concerned with what we want as the answer, or what would be returned. Here, we as developers are not concerned with how we get there, simply concerned with the answer that is received.
Control flow in declarative programming is implicit: the programmer states only what the result should look like,not how to obtain it.
No loops, no assignments, etc. Whatever engine that interprets this code is just supposed go get the desired information, and can use whatever approach it wants. (The logic and constraint paradigms are generally declarative as well.)
In computer science the declarative programming is a style of building programs that expresses logic of computation without talking about its control flow. It often considers programs as theories of some logic.It may simplify writing parallel programs. The focus is on what needs to be done rather how it should be done basically emphasize on what code code is actually doing. It just declare the result we want rather how it has be produced. This is the only difference between imperative (how to do) and declarative (what to do) programming paradigms. Getting into deeper we would see logic, functional and database.
Imperative: C, C++, Java Declarative: SQL, HTML (Can Be) Mix: JavaScript, C#, Python
Think about your typical SQL or HTML example,
SELECT * FROM Users WHERE Country=’Mexico’;
<article> <header> <h1>Declarative Programming</h1> <p>Sprinkle Declarative in your verbiage to sound smart</p> </header> </article>
By glancing at both examples, you have a very clear understanding of what is going on. They’re both declarative. They’re concerned with WHAT you want done, rather than HOW you want it done.
commonly listed advantages of declarative programming?
Reuse: it is easier to create code that can be used for different purposes; something that’s notoriously hard when using imperative constructs.
Idempotence: you can work with end states and let the program figure it out for you. For example, through an upsert operation, you can either insert a row if it is not there, or modify it if it is already there, instead of writing code to deal with both cases.
Error recovery: it is easy to specify a construct that will stop at the first error instead of having to add error listeners for every possible error. (If you’ve ever written three nested callbacks in node.js, you know what I mean.)
Commutativity: the possibility of expressing an end state without having to specify the actual order in which it will be implemented.
Disadvantages of declarative programming?
Thre is not much but as a user of a declarative language, you have limited or no control over how your inputs are dealt with and therefore have no option but to mitigate the impact of any imperfections/bugs in the underlying language and rely on the providers of the declarative language to address the issues.
Summary
Declarative programming is when you say what you want
Imperative language is when you say how to get what you want.
A simple example in Python:
Declarative
small_nums = [x for x in range(20) if x < 5]
Imperative
small_nums = [] for i in range(20): if i < 5: small_nums.append(i)
The first example is declarative because we do not specify any "implementation details" of building the list.you aren't saying how to obtain what you want; you are only saying what you want.
So finally I hope that you got an idea about what is declarative and Imperative programming.

References
Images
https://bit.ly/2UWZO5r
https://bit.ly/2IcV7TO
Other
https://bit.ly/2DLHl4O
https://bit.ly/2k405RO
https://bit.ly/2SSNfHV
https://bit.ly/2NI8QmQ
https://bit.ly/2DGDQN9
https://bit.ly/2TAZold
Question2
What is the difference between procedural programming and functional programming.
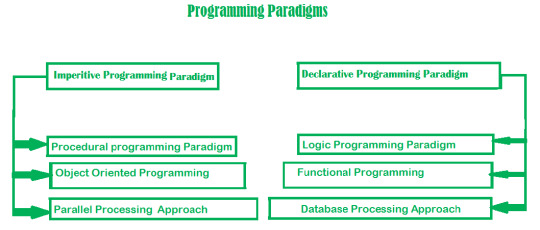
In a previous letter we have talked about imperative and declarative progamming. So now we are going to discuss about the difference between procedural programming and functional programming.
Functional Programming Paradigm
A functional language (ideally) allows you to write a mathematical function, i.e. a function that takes “n” arguments and returns a value. If the program is executed, this function is logically evaluated as needed.
The functional programming paradigms has its roots in mathematics and it is language independent. The key principal of this paradigms is the execution of series of mathematical functions. The central model for the abstraction is the function which are meant for some specific computation and not the data structure. Data are loosely coupled to functions.The function hide their implementation. Function can be replaced with their values without changing the meaning of the program. Some of the languages like perl, javascript mostly uses this paradigm.
Functional Programming is,
Often recursive.
Always returns the same output for a given input.
Order of evaluation is usually undefined.
Must be stateless. i.e. No operation can have side effects.
Good fit for parallel execution
Tends to emphasize a divide and conquer approach.
May have the feature of Lazy Evaluation.
Examples of Functional programming paradigm:
JavaScript : developed by Brendan Eich Haskwell : developed by Lennart Augustsson, Dave Barton
Scala : developed by Martin Odersky
Erlang : developed by Joe Armstrong, Robert Virding
Lisp : developed by John Mccarthy
ML : developed by Robin Milner Clojure : developed by Rich Hickey
Procedural Programming Paradigm
A procedural language performs a series of sequential steps. (There’s a way of transforming sequential logic into functional logic called continuation passing style.) This paradigm emphasizes on procedure in terms of under lying machine model. There is no difference in between procedural and imperative approach. It has the ability to reuse the code and it was boon at that time when it was in use because of its reusability.
Procedural Programming is,
The output of a routine does not always have a direct correlation with the input.
Everything is done in a specific order.
Execution of a routine may have side effects.
Tends to emphasize implementing solutions in a linear fashion.
Examples of Procedural programming paradigm:
C : developed by Dennis Ritchie and Ken Thompson
C++ : developed by Bjarne Stroustrup
Java : developed by James Gosling at Sun Microsystems
ColdFusion : developed by J J Allaire
Pascal : developed by Niklaus Wirth
Summary
More simply the difference between these two is like this,
Functional programming focuses on expressions
Procedural programming focuses on statements
Expressions have values. A functional program is an expression who’s value is a sequence of instructions for the computer to carry out.
Statements don’t have values and instead modify the state of some conceptual machine.
In a purely functional language there would be no statements, in the sense that there’s no way to manipulate state (they might still have a syntactic construct named “statement”, but unless it manipulates state I wouldn’t call it a statement in this sense). In a purely procedural language there would be no expressions, everything would be an instruction which manipulates the state of the machine.
Haskell would be an example of a purely functional language because there is no way to manipulate state. Machine code would be an example of a purely procedural language because everything in a program is a statement which manipulates the state of the registers and memory of the machine.
The confusing part is that the vast majority of programming languages contain both expressions and statements, allowing you to mix paradigms. Languages can be classified as more functional or more procedural based on how much they encourage the use of statements vs expressions
In procedural, I’d ask:
Go to the kitchen.
Open the fridge.
Look for beer.
If you find beer, grab it.
Close the fridge.
Walk back here.
In functional, I’d tell you:
Here’s how to walk.
Here’s how to access the fridge.
Here’s how to look for something.
Here’s how to grab something.
That’s all about the difference between procedural programming and functional programming. I hope now you have an idea about the difference.
References
Images
https://bit.ly/2Eb7Dip
Other
https://bit.ly/2X2vd8m
https://bit.ly/2SzoF2y
https://bit.ly/2SSNfHV
Question 3
Lambda calculus and Lambda expressions in functional programming.

Alonzo Church (1903–1995 ) Professor at Princeton (1929–1967) and UCLA (1967–1990) Invented the Lambda Calculus. It was developed to to study computations with functions.
Imperative programming concerned with “how.” Functional programming concerned with “what.”
Based on the mathematics of the lambda calculus (Church as opposed to Turing). “Programming without variables” It is elegant and a difficult setting in which to create subtle bugs. It’s a cult: once you catch the functional bug, you never escape.
The lambda calculus has three basic components, or lambda terms: expressions, variables and abstractions. The word expression refers to a superset of all those things: an expression that can be a variable name, an abstraction or a combination of those things.
An abstraction is a function. It is a lambda term that has a head and a body and is applied to an argument. An argument is an input value. The head of a function is a 𝜆(lambda) followed by a variable name.The body of the function is another expression. So a simple function might look like: 𝜆x.x . It’s an identity function because it just return the argument passed to it. In the previous example of f(x) = x + 1 we were talking about a function called f, but the lambda abstraction 𝜆x.x has no name. It’s an anonymous function (we all are familiar with this term, because it’s a very powerful idea and almost all imperative languages have some sort of implementation of it too). In the definition the dot separates the parameters of the lambda function from the body.
earlier Functional programming languages are based on Lambda Calculus, as we have learned a bit more about lambdas we can relate more about how they are connected. We might have heard the phrase Functions are first class citizens in functional languages. Lets explain that a bit. Imperative languages usually treat functions differently than other values(variables, objects and other inhabitants of a program) in the program though that is changing with omnipresence of lambdas(anonymous) function everywhere.
But in functional languages functions are just like any other value. You can toss function around, return another function from a function body, compose functions to build complex functionalities from simple functions and all sorts of cool things.
And if the function is a pure( like mathematical one) which always return the same output for the same input you don’t even need to care where the function is being evaluated, be it in another core of the same machine or in the cloud because you don’t need to care. All you want is the result of applying the function to an input.
Building Software is a complex task and Composability is a(or is the) way to handle complexity. You start with simple building blocks and compose them to build complex program to solve complex problems. Pure functions are such building blocks.
In a way, programs in functional languages are like reducing expressions(remember beta reduction from last paragraph). The compilers continue evaluating expressions until it reaches a point when it can’t reduce the expression anymore and the execution is complete.
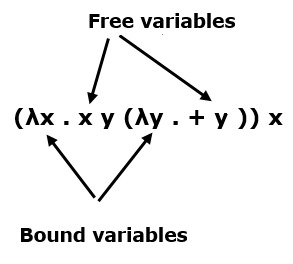
x -(Variable)
A character or string representing a parameter or mathematical/logical value
(λx.M) -(AbstractionFunction)
definition (M is a lambda term). The variable x becomes bound in the expression.
(M N) -(ApplicationApplying)
a function to an argument. M and N are lambda terms.
References
Images
https://bit.ly/2UU9AVY
https://bit.ly/2ByXvhK
Other
https://bit.ly/2EdUSE1
https://bit.ly/1TsPkGn
https://bit.ly/2Szi3RP
Question 4
What is meant by “no side-effects” and “referential transparency” in functional programming?
Referential Transparency
Referential transparency is a property of a specific part of a program or a programming language, especially functional programming languages like Haskell and R. An expression in a program is said to be referentially transparent if it can be replaced with its value and the resulting behavior is the same as before the change. This means that the program's behavior is not changed whether the input used is a reference or an actual value that the reference is pointing to.
As programs are composed of subprograms, which are programs themselves, it applies to those subprograms, too. Subprograms may be represented, among other things, by methods. That means method can be referentially transparent, which is the case if a call to this method may be replaced by its return value:
int add(int a, int b) { return a + b } int mult(int a, int b) { return a * b; } int x = add(2, mult(3, 4));
In this example, the mult method is referentially transparent because any call to it may be replaced with the corresponding return value. This may be observed by replacing mult(3, 4) with 12:
int x = add(2, 12)
In the same way, add(2, 12) may be replaced with the corresponding return value, 14:
int x = 14;
None of these replacements will change the result of the program, whatever it does.
side effect
Functional programming is based on the simple premise that your functions should not have side effects; they are considered evil in this paradigm. If a function has side effects we call it a procedure, so functions do not have side effects. We consider that a function has a side effect if it modifies a mutable data structure or variable, uses IO, throws an exception or halts an error; all of these things are considered side effects. The reason why side effects are bad is because, if you had them, a function can be unpredictable depending on the state of the system; when a function has no side effects we can execute it anytime, it will always return the same result, given the same input.
Simply side effect refers simply to the modification of some kind of state - for instance:
Changing the value of a variable;
Writing some data to disk;
Enabling or disabling a button in the User Interface.
References
https://bit.ly/2GsOFGv
https://bit.ly/2X5qYsP
https://bit.ly/2UYMLR9
https://bit.ly/2BA9Li4
https://bit.ly/2nG5zHG
Question 5
Key features of Object Oriented Programming

Object-oriented programming (OOP) is a programming paradigm based on the concept of “objects”, which may contain data, in the form of fields, often known as attributes; and code, in the form of procedures, often known as methods. A feature of objects is that an object’s procedures can access and often modify the data fields of the object with which they are associated (objects have a notion of “this” or “self”). In OOP, computer programs are designed by making them out of objects that interact with one another.[1][2]There is significant diversity of OOP languages, but the most popular ones are class-based, meaning that objects are instances of classes, which typically also determine their type.
Many of the most widely used programming languages (such as C++, Object Pascal, Java, Python etc.) are multi-paradigm programming languages that support object-oriented programming to a greater or lesser degree, typically in combination with imperative, procedural programming. Significant object-oriented languages include Java, C++, C#, Python, PHP, JavaScript, Ruby, Perl, Object Pascal, Objective-C, Dart, Swift, Scala, Common Lisp, and Smalltalk.
OOP Characteristics:
Objects
Classes
Data Abstraction
Encapsulation
Inheritance
Polymorphism
Objects:
In other words object is an instance of a class.
Classes:
These contain data and functions bundled together under a unit. In other words class is a collection of similar objects. When we define a class it just creates template or Skelton. So no memory is created when class is created. Memory is occupied only by object. In other words classes acts as data types for objects.
Data Hiding:
This concept is the main heart of an Object oriented programming. The data is hidden inside the class by declaring it as private inside the class. When data or functions are defined as private it can be accessed only by the class in which it is defined. When data or functions are defined as public then it can be accessed anywhere outside the class. Object Oriented programming gives importance to protecting data which in any system. This is done by declaring data as private and making it accessible only to the class in which it is defined. This concept is called data hiding. But one can keep member functions as public.
Encapsulation:
The technical term for combining data and functions together as a bundle is encapsulation.
Inheritance:
Inheritance as the name suggests is the concept of inheriting or deriving properties of an exiting class to get new class or classes. In other words we may have common features or characteristics that may be needed by number of classes. So those features can be placed in a common tree class called base class and the other classes which have these charaterisics can take the tree class and define only the new things that they have on their own in their classes. These classes are called derived class. The main advantage of using this concept of inheritance in Object oriented programming is it helps in reducing the code size since the common characteristic is placed separately called as base class and it is just referred in the derived class. This provide the users the important usage of terminology called as reusability
Polymorphism and Overloading:
Poly refers many. So Polymorphism as the name suggests is a certain item appearing in different forms or ways. That is making a function or operator to act in different forms depending on the place they are present is called Polymorphism.
And due to this all future object oriented programming language like c++, java are more popular in use .
References
Images
https://bit.ly/2tpi5g9
Other
https://bit.ly/2zV49xn
https://bit.ly/20Rx76M
Question 6
How the event-driven programming is different from other programming paradigms?
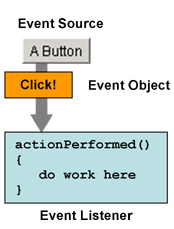
Event-driven programming is a programming paradigm in which the flow of program execution is determined by events - for example a user action such as a mouse click, key press, or a message from the operating system or another program. An event-driven application is designed to detect events as they occur, and then deal with them using an appropriate event-handling procedure. The idea is an extension of interrupt-driven programming of the kind found in early command-line environments such as DOS, and in embedded systems (where the application is implemented as firmware).

References
https://bit.ly/2X60aJ5
https://che.gg/2SSmxCj
https://bit.ly/2ylqy6S
Question 7
Compiled languages, Scripting languages, and Markup languages.

Programming Languages
A programming language is simply a set of rules that tells a computer system what to do and how to do it. It gives the computer instructions for performing a particular task. A programming language consists of a series of well-defined steps which the computer must strictly follow in order to produce the desired output. Failure to follow the steps as it has been defined will result in an error and sometimes the computer system won’t perform as intended.These instructions are usually written by programmers who have an in-depth knowledge about a particular programming language. They are not only knowledgeable about the syntax of that language but also they have mastered the data structures and algorithms used for that language. This is because the basic function of a programming language is to translate the input data into meaningful output.
Markup languages
From the name, we can easily tell that a markup language is all about visuals and looks. Basically, this is the primary role of markup languages. They are used for the presentation of data. They determine the final outlook or appearance of the data that needs to be displayed on the software. Two of the most powerful markup languages are HTML and XML. If you have used both of these two languages, you should be aware of the impact that they can have on a website in terms of the aesthetics.
A properly utilized HTML with the help of CSS will result in a beautiful or stunning website. Markup languages are characterized by tags which are used for defining elements in the document. They are human-readable because they contain normal texts.
There are different types of markup languages and each one of them is designed to perform a specific role. For instance, the primary role of HTML is to give a structure to the website and its component. On the other hand, XML was designed to store and transport structured data. If you are planning to be a front-end developer, consider sharpening your knowledge on markup languages.
Scripting language
A scripting language is a type of language that is designed to integrate and communicate with other programming languages. Examples of commonly used scripting languages include JavaScript, VBScript, PHP among others. There are mostly used in conjunction with other languages, either programming or markup languages. For example, PHP which is a scripting language is mostly used in conjunction with HTML. It is safe to say that all scripting languages are programming languages, but not all programming languages are scripting languages.
One of the differences between scripting languages and programming languages is in terms of compilation. While it is a must for a programming to be compiled, scripting languages are interpreted without being compiled. It is important to note that scripting languages are interpreted directly from the source code.
Due to the absence of the compilation process, scripting languages are a bit faster than the programming languages. In recent years, we have seen a widespread use of scripting languages in developing the client side of web applications.
References
Images
https://bit.ly/2V1FGiM
Other
https://bit.ly/2V1FGiM
Question 8
Role of the virtual runtime machines.
A runtime system, also called run-time system, runtime environment or run-time environment, primarily implements portions of an execution model. This is not to be confused with the runtime lifecycle phase of a program, during which the runtime system is in operation. Most languages have some form of runtime system that provides an environment in which programs run. This environment may address a number of issues including the layout of application memory, how the program accesses variables, mechanisms for passing parameters between procedures, interfacing with the operating system, and otherwise. The compiler makes assumptions depending on the specific runtime system to generate correct code. Typically the runtime system will have some responsibility for setting up and managing the stack and heap, and may include features such as garbage collection, threads or other dynamic features built into the language.
Example: Java virtual machine
A Java virtual machine (JVM) is a virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. The JVM is detailed by a specification that formally describes what is required of a JVM implementation. Having a specification ensures interoperability of Java programs across different implementations so that program authors using the Java Development Kit (JDK) need not worry about idiosyncrasies of the underlying hardware platform.
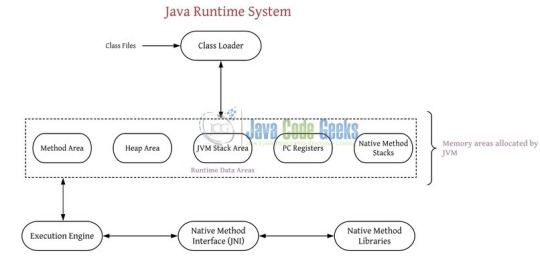
References
https://bit.ly/2TLEH61
https://bit.ly/2V2lkpz
Question 9
How the JS code is executed (What is the runtime? where do you find the interpreter?)

What is JavaScript? JavaScript is primarily a client-side language. JavaScript started at Netscape, a web browser developed in the 1990s. A webpage can contain embedded JavaScript, which executes when a user visits the page. The language was created to allow web developers to embed executable code on their webpages, so that they could make their webpages interactive, or perform simple tasks. Today, browser scripting remains the main use-case of JavaScript.
The runtime environment provides the built-in libraries that are available to the program at runtime (during execution). So, if you're going to use the Window object or the DOM API in the browser, those would be included in the browser's JS runtime environment. A Node.js runtime includes different libraries, say, the Cluster and FileSystem APIs. Both runtimes include the built-in data types and common facilities such as the Console object.
Chrome and Node.js therefore share the same engine (Google's V8), but they have different runtime (execution) environments.
In a way, the runtime is to the engine what the linker is to the compiler in a traditional compiled language.
Unlike C and other compiled languages, Javascript runs in a container - a program that reads your js codes and runs them. This program must do two things
parse your code and convert it to runnable commands
provide some objects to javascript so that it can interact with the outside world.
The first part is called Engine and the second is Runtime.
For example, the Chrome Browser and node.js use the same Engine - V8, but their Runtimes are different: in Chrome you have the window, DOM objects etc, while node gives you require, Buffers and processes.
A JavaScript interpreter is a program or an engine which executes JavaScript code. A JavaScript engine can be implemented as a standard interpreter, or just-in-time compiler that compiles JavaScript to bytecode in some form.
JavaScript is an interpreted language, not a compiled language. A program such as C++ or Java needs to be compiled before it is run. The source code is passed through a program called a compiler, which translates it into bytecode that the machine understands and can execute. In contrast, JavaScript has no compilation step. Instead, an interpreter in the browser reads over the JavaScript code, interprets each line, and runs it. More modern browsers use a technology known as Just-In-Time (JIT) compilation, which compiles JavaScript to executable bytecode just as it is about to run.
References
https://bit.ly/2SH1eR1
https://bit.ly/2SS7g4n
https://bit.ly/2UVp9g0
https://bit.ly/2wqRanM
https://stanford.io/2J5Rev1
Question 10
How the output of an HTML document is rendered, indicating the tools used to display the output.

A web browser is a piece of software that loads files from a remote server (or perhaps a local disk) and displays them to you — allowing for user interaction.
However, within a browser there exists a piece of software called the browser engine.
Within different browsers, there’s a part of the browser that figures out what to display to you based on the files it receives. This is called the browser engine.
The browser engine is a core software component of every major browser, and different browser manufacturers call their engines by different names.
The browser engine for Firefox is called Gecko, and that of Chrome is called Blink, which happens to be a fork of Webkit. Don’t let the names confuse you. They are just names. Nothing serious.
Browser engine is the key software responsible for what we’re discussing.
Sending & receiving information
This is not supposed to be a computer science networks class, but you may remember that data is sent over the internet as “packets” sized in bytes.
The point I’m trying to make is that when you write some HTML, CSS and JS, and attempt to open the HTML file in your browser, the browser reads the raw bytes of HTML from your hard disk (or network).
The browser reads the raw bytes of data, and not the actual characters of code you have written.
The browser receives the bytes of data but it can’t really do anything with it.
The raw bytes of data must be converted to a form it understands.
This is the first step.
From raw bytes of HTML to DOM
What the browser object needs to work with is a Document Object Model (DOM) object.
So, how is the DOM object derived?
Well, pretty simple.
Firstly, the raw bytes of data are converted into characters.
You may see this with the characters of code you have written. This conversion is done based on the character encoding of the html file.
At this point, the browser’s gone from raw bytes of data to the actual characters in the file.
Characters are great, but they aren’t the final result.
These characters are further parsed into something called tokens.
So, what are these tokens?
A bunch of characters in a text file does not do the browser engine a lot of good.
Without this tokenization process, the bunch of characters will just result in a bunch of meaningless text i.e html code — that doesn’t produce an actual website.
When you save a file with the .html extension, you signal to the browser engine to interpret the file as an html document. The way the browser “interprets” this file is by first parsing it.
In the parsing process, and particularly during tokenization, every start and end html tags in the file are accounted for.
The parser understands each string in angle brackets e.g "<html>", "<p>", and understands the set of rules that apply to each of them. For example, a token that represents an anchor tag will have different properties from one that represents a paragraph token.
Conceptually, you may see a token as some sort of data structure that contains information about a certain html tag. Essentially, an html file is broken down into small units of parsing called tokens. This is how the browser begins to understand what you’ve written.
Tokens are great, but they are also not our final result.
After the tokenization is done, the tokens are then converted into nodes.
You may think of nodes as distinct objects with specific properties. In fact, a better way to explain this is to see a node as a separate entity within the document object tree.
Nodes are great, but they still aren’t the final results.
Now, here’s the final bit.
Upon creating these nodes, the nodes are then linked in a tree data structure known as the DOM.
The DOM establishes the parent-child relationships, adjacent sibling relationships etc.
The relationship between every node is established in this DOM object.
Now, this is something we can work with.
If you remember from web design 101, you don’t open the CSS or JS file in the browser to view a webpage. No. You open the HTML file, most times in the form index.html
This is exactly why you do so: the browser must go through transforming the raw bytes of html data into the DOM before anything can happen.
Depending on how large the html file is, the DOM construction process may take some time. No matter how small, it does take some time (no matter how minute) regardless of the file size.
References
https://bit.ly/2E4iehe
Question 11
Different types of CASE tools, Workbenches, and Environments for different types of software systems (web-based systems, mobile systems, IoT systems, etc.)

Types of CASE tools
Classic CASE tools - established software development support tools (e.g. interactive debuggers, compilers, etc.)
Real CASE tools - can be separated into three different categories, depending on where in the development process they are most involved in:
Upper - support analysis and design phases
Lower - support coding phase
Integrated - also known as I-CASE support analysis, design and coding phases
Upper and lower CASE tools are named as such because of where the phases they support are in the Waterfall Model (see below)


References
https://fla.st/2N98YsT
https://bit.ly/2tmwXvF
Question 12
Difference between framework, library, and plugin, giving some examples.
Library vs framework
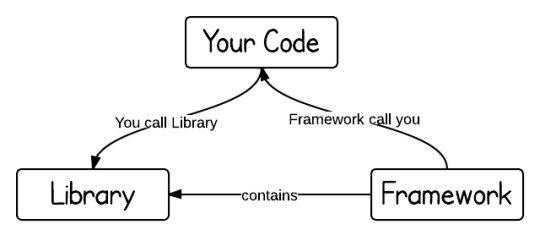
The key difference between a library and a framework is "Inversion of Control". When you call a method from a library, you are in control. But with a framework, the control is inverted: the framework calls you.
A library is just a collection of class definitions. The reason behind is simply code reuse, i.e. get the code that has already been written by other developers. The classes and methods normally define specific operations in a domain specific area. For example, there are some libraries of mathematics which can let developer just call the function without redo the implementation of how an algorithm works.
In framework, all the control flow is already there, and there's a bunch of predefined white spots that you should fill out with your code. A framework is normally more complex. It defines a skeleton where the application defines its own features to fill out the skeleton. In this way, your code will be called by the framework when appropriately. The benefit is that developers do not need to worry about if a design is good or not, but just about implementing domain specific functions.
Frameworks vs plugins
Frameworks provide functionality, which programs must be written to use; plugins extend something else's functionality, usually in a way that doesn't require rewriting existing programs to use. You may well use both, with a framework that provides a basic interface and plugins that add functionality to the interface.
Library vs plugins
The main difference between plugin and library is that a plugin is an extension that improves the capabilities of an application while a library is a collection of classes and functions that helps to develop a software.
EXAMPLES:
Framework.
Popular examples include ActiveX and .NET for Windows development, Cocoa for Mac OS X, Cocoa Touch for iOS, and the Android Application Framework forAndroid. Software development kits (SDKs) are available for each of these frameworks and include programming tools designed specifically for the corresponding framework.
Plugins
Web browsers have historically allowed executables as plug-ins, though they are now mostly deprecated. (These are a different type of software module than browser extensions.) Two plug-in examples are the Adobe Flash Player for playing videos and a Java virtual machine for running applets.
library
library is a collection of non-volatile resources used by computer programs, often for software development. These may include configuration data, documentation, help data, message templates, pre-written code and subroutines, classes, values or type specifications. In IBM's OS/360 and its successors they are referred to as partitioned data sets.
References
https://bit.ly/2eL9dI8
https://bit.ly/2TLVFkG
https://bit.ly/2BF8LJo
https://bit.ly/2GGkACF
https://bit.ly/2X6AQlW
https://bit.ly/2T07G9f
1 note
·
View note