
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by botvisions-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
3
Photo
8
Video
2
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Hyperreal Identity
The focus of this post is to discuss the way in which personal identity become increasingly more fluid, indeterminate, manipulable, and hyperreal in the context of digital networks. On April 7, 2017, French artists Raphael Fabre applied for an identity card using a 3d rending is his official image. As he notes “The document validating my identity most formally is an image of me that is virtually virtual, a video game version, a fiction.”



Raphael Fabre ‘CNI’ - 2017 The work reflects the way in which our identity in the digital age is constructed through digital artefacts ie data: instagram photos, fit-bit biometrics, internet browsing cookies etc etc, all combine to construct our data bodies which eradicate any notion of the self as a fixed singular entity. As Fabre notes: “Since it is a representation, the idea of the identity itself becomes a sham ... a reflection of the world of digital retouching, big data and social media in which we live.”

The render the Fabre created, was however, based on images of the artist which where then overlaid onto a 3d mesh. However, with the aid of new machine learning techniques we can now render photorealistic images of faces from scratch. NVIDIA recently unveiled a Generative Adversarial Neural Network that has been trained on images of celebrities, using this data it can interpolate a new face by applying several filters to an image of random noise. Eventually this process produces an image that the network itself cannot distinguish from the training data.



All of the people above, do not exist, they are merely representations - floating signifiers untethered to any referent in reality. They are the ultimate icons for what we are becoming.
Perhaps we find ourselves arriving at a fundamental reality, that as technology become increasing able to simulate the world, the world itself is increasingly cast in doubt. The following video is a demonstration of a neural network that can capture facial movements from one source and map it onto another source video. In this way, Barak Obama can be controlled like a meet puppet, and potentially used to spread lies and propaganda.


https://www.youtube.com/watch?v=ohmajJTcpNk
The doubt towards the very validity of images themselves is brilliantly demonstrated by the blog hyperrealcg.tumblr.com started by 3D Software artist Kim Laughton. The blog post miscellaneous banal imagery taken by digital cameras as displays it as though it is a state-of-the-art CG render, with captions such as: “software: Autodesk Softimage renderer: Arnold render time: 4h 24min” “Used way too much shaders, it came out too dark but I kind of like it this way” Nedless to say, many people, and click-baity news publications were fooled by the elaborate in-joke.

“The End of the Day” Artist: artbyjake Software: Octane Render Render time: 15 hours, DOF added in post

Artist: Logic Software: Cinema 4D Mograph test

Title: Lounge scene Artist: David OReilly Render time: 7 hours
0 notes
Photo









Experiments in neural style transfer using https://deepart.io
0 notes
Photo









Experiments in neural style transfer using https://deepart.io
0 notes
Text
Corporate Animism

The focus of this post is the notion raise in Hito Steyerl’s essay: ‘corporate animism’. The concept is inspired by Google’s Deep Dream Image Inceptionism discussed previously. It is the “optical unconscious” of the neural networks, the images or visions produced autonomously through the process of deep learning. Steyeral notes: “In a feat of genius, inceptionism manages to visualize the unconscious of prosumer networks: images surveilling users, constantly registering their eye movements, behavior, preferences, aesthetically helplessly adrift between Hundertwasser mug knockoffs and Art Deco friezes gone ballistic. Walter Benjamin’s “optical unconscious” has been upgraded to the unconscious of computational image divination.” This concept of the unconscious mind of computers ties into a much larger discourse surrounding generative art and the creative autonomy of machines. Algorithmically generated art has a history as long as computers themselves. An early example of computer based generative art is Michael Noll’s works of the early 60s

Michael Noll - Frames of a Randomly Changing Object, 1962-63 While the prospect of autonomous computer creativity in early computer art had a certain utopian tone in the 60s and 70s, today, it is no longer a speculative fiction but a reality of our digitally augmented world, and has a far more sinister implications. I wish to discuss two recent, very concrete examples of corporate animism from digital media culture. Two cases in which automated processes, feeding back onto each other, have autonomously created data objects that then leak into the physical world. The first is the phenomenon of automatically generated videos for babies on Youtube also known as ‘kidbait’. There are several channels of this nature on Youtube uploading several videos a day featuring bright colours, recognisable characters and extremely poor, slap-dash animations. Two channels of note are Toys in Japan and Rhymes for Super Kids. Both of these channels have thousands of videos, each featuring slight variation on a few set templates:

Screenshot from Rhymes for Super Kids

Screenshot from Toys in Japan
These videos appear in such high quantities that it seems incredibly likely they are being automatically generated in a deliberate strategy to game Youtube recommendation algorithms in order to generate ad revenue from children idly click on the thumbnails. This accounts for the fact that many of the video have a large number of gibberish comments, seemingly left by babies, mashing the keypad:

As VanDeGraph notes, writing on the subject for Medium: “Social systems like youtube generally follow a power law, and so most of the attention in the form of views goes to the top videos, this allows the videos to snowball, which makes the considerable advantage the toy videos have in obtaining views appear to be even larger when we only look at the top videos.” It has been suggested that these videos base their content on trending search terms in order to boost its prominence. This would account for the fact the videos often feature characters that are eerily unsuitable for babies:

Even weirder is the fact that many of the videos on Youtube aimed for children feature syringes, simply because viewer data confirms that babies gravitate toward videos that feature them: “These channels are successful because they use kidbait, which includes having colorful thumbnails, popular characters, and syringes…apparently.”

The videos are so effective at gaming the algorithms, that clicking on a few of these video will saturate the recommended videos with near identical versions:

This would mean that a baby idly clicking on thumbnails could finds themselves in an endless cycle of near identical videos, which, being a baby, they would have no way of navigating out of. These videos are extremely uncanny as there is almost no creative intention behind them, they merely reflect the preferences of Youtube’s recommendation algorithms. The videos are an unintended consequence of the neural systems that deliver the content which are themselves optimised to perform in certain ways. These videos reveal the underlying scripts and biases of the algorithm, and reveal to us the networked unconscious. But if AI generated videos for kids isn’t sinister enough, Youtube is also host to, In Jonathan Albright’s words what amounts to “a large-scale “fake news” video content farm.” There are approximately 80,000 videos each titled “A tease: ...” For example:
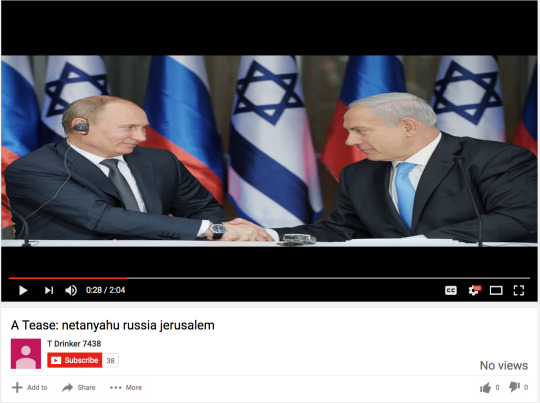
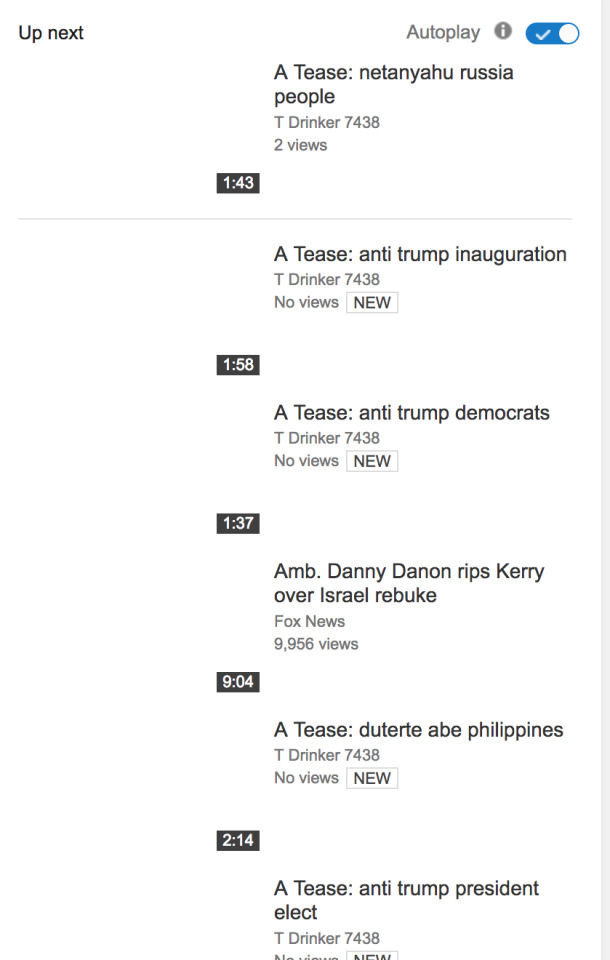
These videos are automatically compiled and edited together by a programme known as “T”. Each “T” AI-generated video consists of a progressive “slideshow” of still images related to the title of the video, which originate from various websites, Wordpress blogs, and content delivery networks across the internet.” “Everything about these “A Tease…” videos suggests SEO, social politcs amplification, and YouTube AI-playlist placement: In addition to the video titles being keyword-packed and URLs pasted all over the video descriptions, the spoken text that’s already published on news sites should help to boost the overall relevance of these videos and any associated news-related “channels” on YouTube.” This large-scale fake news farm is not an isolated incident but as Albright notes is part of a larger ‘micro-propaganda network’, a network of thousands of websites connected through hyperlinks which has been weaponised as part of an a extreme right propaganda strategy.

Network graph of 6,902 related videos from “A Tease…” search on YouTube (API) (red = trump-leaning / blue = Clinton-leaning) The full extent of the micro-propaganda network is approximated below:

“Micro-propaganda” network of 117 “fake news,” viral, anti-science, hoax, and misinformation websites. The algorithms that filter our news are increasingly also determining the news. Reality itself becomes inflected by the subconscious mind of the network. This is indeed a form of corporate animism, Google, Youtube, Amazon, et al, having long since gained omniscience are now slowly developing omnipotence and the world they have created for us, is uncanny and fundamentally uncertain.
0 notes











Photo





Ap0phen1a - Artwork Proposal
The primary inspiration for the piece was taken from an article by Hito Steyerl entitled: A Sea of Data: Apophenia and Pattern (Mis-)Recognition. Steyerl describes apophenia as “the perception of patterns within random data.7” Common examples of apophenia include: seeing faces in clouds, seeing constellations in stars, palm reading, tarot card reading, and other forms of divination. According to Benjamin Bratton apophenia is characterised by the “drawing connections and conclusions from sources with no direct connection other than their indissoluble perceptual simultaneity,”
Apophenia often plays out within the field of machine learning and data mining. This phenomenon is known as ‘overfitting’, defined as: a modeling error which occurs when a function is too closely fit to a limited set of data points. Overfitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study.” We can think of online conspiracy theories as being overly complicated models for explaining random artefacts from large archives of images and text. In other words apophenia, and overfitting can be understood as a failure in the filtering of signal and noise, specifically when noise slips through the filter and is presented as signal. For Ranciere the separating of signal from noise has a distinct political dimension as it is the process by which political subjects are constructed - those who ‘have a voice’ and those who don’t: “The politics of these categories … has consisted in making what was unseen visible; in getting what was only audible as noise to be heard as speech.” For Steyerl: “The distinction between speech and noise served as a kind of political spam filter.” and has particular relevance today in the age of ubiquitous digital surveillance. Machine learning is currently being used by Google search engines, Youtube and Netflix’s recommendation algorithms, Paypal’s fraud detection, translation services, insurance companies, market analysis, stock trading, medical diagnosis, etc, etc, etc. Thus we find ourselves in what Steyerl calls the data neolithic, a return to a more pagan, pre-modern epistemology where machines act as soothsayers and fortune tellers. Steyerl asks: “Are we to assume that machinic perception has entered its own phase of magical thinking?... How does the world of pattern recognition and big-data divination relate to the contemporary jumble of oligocracies, troll farms, mercenary hackers, and data robber barons supporting and enabling bot governance, Khelifah clickbait and polymorphous proxy warfare? Is the state in the age of Deep Mind, Deep Learning, and Deep Dreaming a Deep State™? One in which there is no appeal nor due process against algorithmic decrees and divination?”
0 notes
Photo




James Bridle - Cloud Index (2016)
http://cloudindx.com/
“Since the beginning of time, humans have looked to the sky to determine the future; today we look to the Cloud. The technologies we are developing today are capable of analysing the world at a scale never before imagined. Satellites scour the earth's surface from orbit; sensors in our devices record our every move, and every mood. By processing this data, we attempt to predict, and thus control, future outcomes.
At the same time, and over many years, we have developed technologies for predicting, and altering, the weather. We can seed and disperse clouds, change the reflectivity of the atmosphere, and alter the global climate. For centuries, we have done so unintentionally; now we must consider the question of whether we should do so intentionally.
The Cloud Index is a series of simulations: a weather forecast for possible futures. The simulations depict proposed cloud structures which correspond to measured electoral scenarios. These are dreams of the weather, hallucinated by machines. If we wish to change the future, we must change the weather.”
Cloud Index is a work by James Bridle that combines neural networks in order to predict voting results in the 2016 EU Referendum based on the weather. By training these networks on UK satellite imagery and polling data from the past 6 years it is able to ‘learn’ the correlations between cloud patterns and political moods. This work comments on the ‘data neolithic’ that Hito Steyerl has identified. The idea that data can reveal some mystical truth, that algorithms possess a magical ability to predict/determine the future.
In fact, as Bridle notes: “What is revealed by the network is... the quantum nature of knowledge itself: an abstract truth in superposition which is collapsed by our description of it.”
0 notes
Video
youtube
Simim Winiger - Generating Stories about Images (2015) https://medium.com/@samim/generating-stories-about-images-d163ba41e4ed
“Stories are a fundamental human tool that we use to communicate thought. Creating a stories about a image is a difficult task that many struggle with. New machine-learning experiments are enabling us to generate stories based on the content of images. This experiment explores how to generate little romantic stories about images
neural-storyteller is a recently published experiment by Ryan Kiros(University of Toronto). It combines recurrent neural networks (RNN), skip-thoughts vectors and other techniques to generate little story about images. Neural-storyteller’s outputs are creative and often comedic. It is open-source.
This experiment started by running 5000 randomly selected web-images through neural-storyteller and experimenting with hyper-parameters. neural-storyteller comes with 2 pre-trained models: One trained on 14 million passages of romance novels, the other trained on Taylor Swift Lyrics. Inputs and outputs were manually filtered and recombined into two videos.”




0 notes
Photo




onformative - Google Faces (2015) Production: Julia Laub Creative Direction & Design: Cedric Kiefer Code: Christian Loclair

“An algorithmic robot hovering over the world to spot portraits hidden in the topography on planet earth. The custom application works autonomously to process vast amounts of satellite images through Google Maps by using a face detection algorithm. This endless cycle produces interesting results for reflection on the natural world.
Objective investigations and subjective imagination collide into one inseparable process in the human desire to detect patterns. The tendency to detect meaning in vague visual stimuli is a psychological phenomenon called pareidolia.
Google Faces explores how the cognitive experience of pareidolia can be generated by a machine. By developing an algorithm to simulate this occurrence, a face tracker continuously searches for figure-like shapes while hovering above landscapes of the earth.
A video of the software in action can be found here: https://vimeo.com/66055499 The “Face on Mars” image taken by the Viking 1 spacecraft on July 25th, 1976, was a primary source of inspiration:

1 note
·
View note
Photo





Images from the ‘The New Inquirer’s Conspiracy Bot’ https://conspiracy.thenewinquiry.com/
“Machine learning algorithms, which are used by computers to identify relationships in large sets of data, echo our pattern-seeking tendencies, since pattern recognition is what they’re designed for. When seeking to program learning algorithms with human intelligence, we inevitably include our peculiarities and paranoias. Like the human brain, machine learning algorithms arrive at shallow, inappropriate conclusions from ingesting sprawls of data.
But when it comes to machines, paranoid assumptions about the world are mutually reinforcing: When they see the false patterns we see, they validate the faults of our own pattern-seeking tendency through the illusion of computational rigor. Seeing our own judgments reflected in the algorithm, we feel more confident in its decisions.
The New Inquiry’s Conspiracy Bot condenses this recursive symbiosis. Just like us, our bot produces conspiracies by drawing connections between news and archival images—sourced from Wikimedia Commons and publications such as the New York Times—where it is likely none exist. The bot’s computer vision software is sensitive to even the slightest variations in light, color, and positioning, and frequently misidentifies disparate faces and objects as one and of the same. If two faces or objects appear sufficiently similar, the bot links them. These perceptual missteps are presented not as errors, but as significant discoveries, encouraging humans to read layers of meaning from randomness.”
This project is a perfect embodiment of the kind of paranoia engendered by the ‘total noise’ of the internet. I particularly love the visual style used which has been coined as “chart brut”. The style constitutes a kind of visual language for paranoid apophenia: http://gawker.com/chart-brut-how-the-ms-paint-graphics-of-conspiracy-too-1651851261
“It's a digital middle-ground between the string-and-thumbtack cork-board flowcharts favored by premium-cable obsessives like Rust Cohle and Carrie Mathison, and the meaningless tangles of agency responsibilities beloved by security-apparatus bureaucrats... the crude style of Chart Brut at large is a perfectly realized embodiment of the confused and confusing conspiracy-curious internet. The academic Kathleen Stewart once wrote about the web's love of conspiracy: "The internet was made for conspiracy theory: it is a conspiracy theory: one thing leads to another, always another link leading you deeper into no thing and no place." Conspiracy charts—literal webs of interconnected institutions, people, and ideas—are the visual manifestation of the de-centered, endlessly deferred internet.”
0 notes
Text
Hito Steyerl - A Sea of Data: Apophenia and Pattern (Mis-)Recognition
http://www.e-flux.com/journal/72/60480/a-sea-of-data-apophenia-and-pattern-mis-recognition/ For my project I want to focus on machine learning as the general overarching subject. I recently read this article by Hito Steyerl which provides some very unique perspectives machine-learning as a form of ‘automated apophenia’.
Apophenia is a term that describes the act of recognising meaningful patterns in arbitrary data. This process can be described as one of extracting signal from noise, the question of how to do this is complicated a) by big data and the practice of ubiquitous dataveillance, and b) by machine learning and automated processes that filter, analyse and model this data.
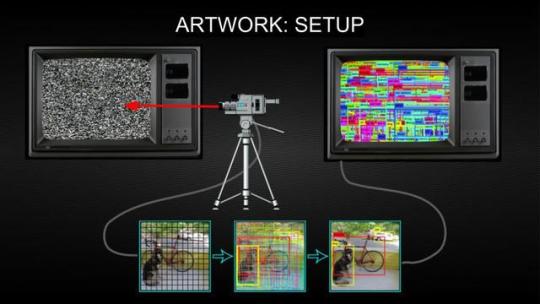
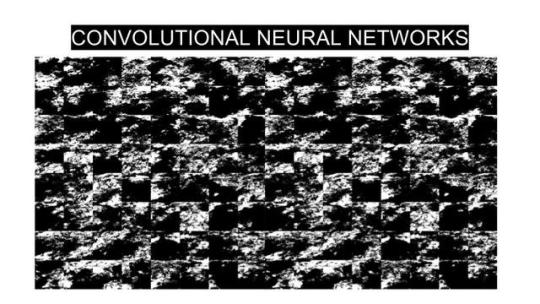
Machine learning can be described as an advanced form of automated pattern recognition - for instance - Convolutional Neural Networks, such as those used in Google Image searches, face recognition, or Deep Dreaming / Inceptionism, work by scanning image data for various statistical features, the presence of these features then produce a certain probability that image falls into a particular image category: a face, a tree, etc.

(example of a image dataset used to ‘train’ image recognition software) Google’s Deep Dream engine provides a extreme example of automated apophenia, as Steyerl notes “They reveal the networked operations of computational image creation, certain presets of machinic vision, its hardwired ideologies and preferences.” The engine is trained on extremely large datasets of images that collectively produce a worldview based on object categories:

The above image is an example of an image created with Google Inceptionism. The original image’s features are analysed and the probabilities of particular object classifications are determined, the deep dream engine then recursively alters the image in order to maximize these probabilities creating an image that is ‘hyper-interpretable’ by the net-work, so to speak. The engine is trained on extremely large datasets of images that collectively produce a algorithmic worldview based on object categories:

The above image shows a collection of flower images clustered by a neural network to show similarities - the extraction semiotic information from the noise of the dataset. However, this automated process of signal extraction has profound political consequences. The question must be raised as to what biases or ideologies are being unknowingly encoded into these networks by these massive datasets. For example, in 2015 a user noticed that Google Photos’ image recognition software was identifying black people as ‘gorillas’.
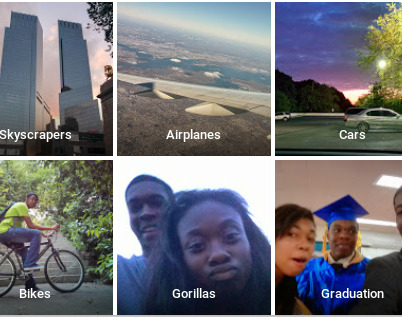
The nature of the neural network means that it is impossible to know definitively how a particular determination of an image has been made - the neural network is like a prophet reading tea-leaves.
Steyerl sees our reliance on big-data analysis and machine learning software as a return to a more archaic and superstitious way of understanding reality which she terms the ‘Data Neolithic’. I believe this framework can help describe the age of digital hyperreality, post-truth, and speculative algo-trading in which we find ourselves.
0 notes