
Last Seen Blogs

highly-enlightened
༎ຶ༽higher enlightenment❀


ebanglatrick
Untitled

thehungryllamaa
The Llamaa

allthingsmpreg
Mpreg’s Anonymous
Text
Business Transformation: Driving Success in the Modern Age
Introduction
In today's fast-paced business landscape, staying relevant and competitive requires organizations to adapt, evolve, and innovate. This article delves into the concept of business transformation, guiding you through its fundamental principles and the key factors that drive success. Explore the power of change, the importance of embracing technology, and how to lead your company into a thriving future.
Business Transformation: Defining the Vision
Understanding Business Transformation: Unlocking its Essence
Exploring the Core Purpose of Business Transformation
Embracing Change: The Pathway to Success
Leveraging LSI Keywords: Driving Organic Growth
Navigating the Challenges
Identifying the Roadblocks to Transformation
Overcoming Resistance to Change
Addressing Cultural Shifts within the Organization
Building Agile and Resilient Teams
The Role of Leadership
Empowering Transformational Leadership
The Art of Visionary Thinking
Fostering Innovation and Creativity
Leading by Example: Embracing Change as a Leader
Embracing Technological Advancements
Digital Transformation: Key to Future Success
Harnessing the Potential of Artificial Intelligence (AI)
Leveraging Big Data Analytics for Informed Decision-making
Integrating Automation for Enhanced Efficiency
Transforming Customer Experience
Understanding Customer-Centric Transformation
Unleashing the Power of Personalization
Embracing Omni-Channel Experiences
Utilizing Customer Feedback for Continuous Improvement
Data-Driven Decision Making
Making Decisions with Data Insights
Establishing KPIs for Measuring Transformation Success
Data Visualization: Simplifying Complex Information
The Role of Predictive Analytics in Strategic Planning
Cultivating a Culture of Innovation
Creating an Innovative Ecosystem
Encouraging a Growth Mindset Among Employees
Fostering Collaboration and Knowledge Sharing
Celebrating and Learning from Failure
Sustainability and Responsibility
Transforming for a Better World
Integrating Sustainable Practices into Business Operations
Social Responsibility and Corporate Ethics
The Role of ESG in Modern Business Transformation
Nurturing Talent and Skill Development
Investing in the Workforce of Tomorrow
Identifying Skill Gaps and Bridging Them
Embracing Lifelong Learning Initiatives
Diversity and Inclusion: Empowering Diverse Perspectives
Adapting to Market Disruptions
Navigating Disruptive Technologies and Trends
Seizing Opportunities in the Face of Uncertainty
Preparing for Industry Disruptions
The Art of Pivoting: Turning Challenges into Opportunities
Human-Centric Approach
Understanding the Human Element of Transformation
Empathy in Business Leadership
Employee Well-being and Work-Life Balance
The Role of Emotional Intelligence in Transformational Leadership
Building Resilience
Strengthening the Organization's Ability to Bounce Back
Crisis Management and Preparedness
Anticipating and Mitigating Risks
Learning from Adversities and Continuous Improvement
Measuring Transformation Success
Defining Metrics for Progress Evaluation
ROI and Financial Indicators
Customer Satisfaction and Retention Rates
Employee Engagement and Retention Metrics
Collaboration and Partnerships
Driving Transformation through Collaboration
Establishing Strategic Partnerships
Exploring Mergers and Acquisitions
The Power of Collective Intelligence
Customer-Centric Innovation
Creating Products and Services that Wow Customers
Design Thinking and User-Centered Development
Customer Journey Mapping: Enhancing Customer Experience
Iterative Prototyping: Learning from User Feedback
Leveraging Industry Best Practices
Benchmarks for Transformation Success
Learning from Success Stories of Top Performers
Adopting Lean and Six Sigma Principles
Continuous Improvement: Kaizen Philosophy
Communication and Change Management
The Art of Effective Communication
Transparent and Authentic Communication with Stakeholders
Change Management Strategies for Smooth Transformation
Engaging Employees during the Transformation Journey
The Power of Reskilling and Upskilling
Preparing the Workforce for the Future
Identifying Emerging Skills in the Industry
Investing in Training and Development Programs
Nurturing a Learning Culture within the Organization
Integrating Sustainability into Strategy
Strategies for Sustainable Business Practices
Implementing Circular Economy Principles
Eco-Friendly Supply Chain Management
Climate Change Adaptation and Mitigation
Building a Transformation Roadmap
Creating a Comprehensive Transformation Plan
Setting Clear Objectives and Milestones
Allocating Resources and Budgeting
Monitoring and Reviewing Progress Regularly
Business Transformation: The FAQs
FAQ 1: What is the primary goal of business transformation? Answer: The primary goal of business transformation is to enable organizations to adapt to changing market conditions, leverage new opportunities, and achieve sustainable growth.
FAQ 2: How can leaders overcome resistance to change during transformation? Answer: Leaders can overcome resistance to change by communicating the vision effectively, involving employees in decision-making, and fostering a culture of trust and open communication.
FAQ 3: What role does technology play in business transformation? Answer: Technology plays a pivotal role in business transformation by enabling automation, data-driven decision-making, and improving overall efficiency and productivity.
FAQ 4: How can organizations measure the success of their transformation efforts? Answer: Organizations can measure transformation success through key performance indicators (KPIs), such as financial indicators, customer satisfaction rates, and employee engagement metrics.
FAQ 5: What is the importance of a customer-centric approach in transformation? Answer: A customer-centric approach ensures that transformation efforts align with customer needs and preferences, ultimately driving better customer experiences and loyalty.
FAQ 6: How can organizations build a culture of innovation during transformation? Answer: Organizations can foster innovation by encouraging a growth mindset, promoting collaboration, and embracing failures as learning opportunities.
Conclusion
In conclusion, business transformation is not just a buzzword; it's a critical process for any organization looking to stay competitive in the modern age. Embracing change, leveraging technology, and putting people at the center of transformation efforts are the keys to success. By following industry best practices, nurturing a culture of innovation, and being open to collaborations, businesses can thrive and flourish in the face of ever-changing market dynamics.
0 notes
Text
CoffeeBeans is a technology company that helps businesses create great products using cutting-edge technology. We’re also a product company, and we create products for various domains primarily built on AI. Our core powerhouse lies in the people who make CoffeeBeans. We value a positive attitude, a sense of ownership, and a can-do spirit. Our mission is to use technology to help businesses achieve their goals and dreams.
URL:- https://coffeebeans.io/
Email:- [email protected]
#automation testing#security testing#test automation services#performance consultancy#test strategy#it security service#CoffeeBeans#it consulting
0 notes
Text
Discovering the Innovations in Apache Kafka 3.3: From Zookeeper to KRaft
Apache Kafka, the open-source, distributed event streaming platform, has been a game-changer in the world of data processing and integration. It has been continuously evolving over the years, offering new features and improvements that make it more scalable, secure, and efficient. The latest release of Apache Kafka, version 3.3, brings a number of exciting changes, including the replacement of Zookeeper and the introduction of a new consensus mechanism called KRaft.
The Evolution of Apache Kafka’s Consensus Mechanism
One of the main changes in Apache Kafka 3.3 is the replacement of Zookeeper with a new consensus mechanism called KRaft. Zookeeper has been a critical component of Apache Kafka for many years, providing a centralized configuration service for the platform. However, Zookeeper has been a bottleneck for large-scale, high-throughput deployments, leading to limitations in scalability and reliability.
KRaft is a distributed consensus algorithm that provides strong consistency guarantees while also being highly scalable. Unlike Zookeeper, which operates in a leader-based fashion, KRaft operates in a leaderless fashion, meaning there is no central point of failure. This provides faster and more efficient leader elections and lower latencies, making it a more reliable and scalable solution for Apache Kafka.
Security Enhancements in Apache Kafka 3.3
In addition to the replacement of Zookeeper, Apache Kafka 3.3 also brings a number of security enhancements. This includes support for Mutual TLS (Transport Layer Security), which provides an additional layer of encryption for communication between Kafka clients and brokers. This enhances the overall security of the platform, making it a better choice for sensitive and regulated environments.
Apache Kafka 3.3 also includes improved support for Kerberos authentication, which is a widely used security protocol for secure communication over networks. These enhancements make Apache Kafka even more secure, ensuring that data transmitted through the platform is protected against unauthorized access and tampering.
API Enhancements in Apache Kafka 3.3
Apache Kafka 3.3 brings a number of API enhancements that make it easier for developers to build and integrate the platform into their applications. This includes new APIs for managing topics and partitions, as well as improvements to the existing APIs for producing and consuming messages. These enhancements make the platform more user-friendly and accessible, providing developers with more options for customizing and integrating Apache Kafka into their applications.
The Power of Apache Kafka Connector APIs
Another major feature of Apache Kafka 3.3 is the addition of new connector APIs. These APIs make it easier to integrate Apache Kafka with other systems and data sources, such as databases and data lakes. This opens up a whole new world of possibilities for data ingestion, processing, and analysis, making Apache Kafka an even more powerful tool for building modern data-driven applications.
Conclusion
In conclusion, Apache Kafka 3.3 is a major milestone for the platform, offering a number of exciting new features and enhancements that make it even more scalable, secure, and efficient. From the replacement of Zookeeper with KRaft, to the new security and API enhancements, this release makes Apache Kafka an even better choice for event streaming and data integration. Whether you’re a developer looking to build a new application, or an IT professional looking to modernize your data architecture, Apache Kafka 3.3 is the perfect solution for your needs.
Keywords: Apache Kafka, Zookeeper, KRaft, event streaming, data integration, security, API enhancements, connector APIs, Mutual TLS, Kerberos authentication, distributed consensus algorithm.
Read more
0 notes
Text
When to use serverless computing?
Serverless computing has been gaining popularity as a powerful and efficient solution for building and deploying applications. With serverless computing, developers can focus on writing code without worrying about managing servers or infrastructure. In this blog post, we’ll take a deep dive into the architecture and capabilities of serverless computing, exploring how it works, its benefits and drawbacks, and its potential applications.
What is Serverless Computing?
Serverless computing is a cloud computing model where the cloud provider manages the infrastructure and automatically provisions resources as needed to execute code. This means that developers don’t have to worry about managing servers, scaling, or infrastructure maintenance. Instead, they can focus on writing code and building applications. Serverless computing is often used for building event-driven applications or microservices, where functions are triggered by events and execute specific tasks.
How Serverless Computing Works
In serverless computing, applications are broken down into small, independent functions that are triggered by specific events. These functions are stateless, meaning they don’t retain information between executions. When an event occurs, the cloud provider automatically provisions the necessary resources and executes the function. Once the function is complete, the resources are de-provisioned, making serverless computing highly scalable and cost-efficient.
Serverless Computing Architecture
The architecture of serverless computing typically involves four components: the client, the API Gateway, the compute service, and the data store. The client sends requests to the API Gateway, which acts as a front-end to the compute service. The compute service executes the functions in response to events and may interact with the data store to retrieve or store data. The API Gateway then returns the results to the client.
Benefits of Serverless Computing
Serverless computing offers several benefits over traditional server-based computing, including:
Reduced costs: Serverless computing allows organizations to pay only for the resources they use, rather than paying for dedicated servers or infrastructure.
Improved scalability: Serverless computing can automatically scale up or down depending on demand, making it highly scalable and efficient.
Reduced maintenance: Since the cloud provider manages the infrastructure, organizations don’t need to worry about maintaining servers or infrastructure.
Faster time to market: Serverless computing allows developers to focus on writing code and building applications, reducing the time to market new products and services.
Drawbacks of Serverless Computing
While serverless computing has several benefits, it also has some drawbacks, including:
Limited control: Since the cloud provider manages the infrastructure, developers have limited control over the environment and resources.
Cold start times: When a function is executed for the first time, it may take longer to start up, leading to slower response times.
Vendor lock-in: Organizations may be tied to a specific cloud provider, making it difficult to switch providers or migrate to a different environment.
Some facts about serverless computing
Serverless computing is often referred to as Functions-as-a-Service (FaaS) because it allows developers to write and deploy individual functions rather than entire applications.
Serverless computing is often used in microservices architectures, where applications are broken down into smaller, independent components that can be developed, deployed, and scaled independently.
Serverless computing can result in significant cost savings for organizations because they only pay for the resources they use. This can be especially beneficial for applications with unpredictable traffic patterns or occasional bursts of computing power.
One of the biggest drawbacks of serverless computing is the “cold start” problem, where a function may take several seconds to start up if it hasn’t been used recently. However, this problem can be mitigated through various optimization techniques.
Serverless computing is often used in event-driven architectures, where functions are triggered by specific events such as user interactions, changes to a database, or changes to a file system. This can make it easier to build highly scalable and efficient applications.
Now, let’s explore some other serverless computing frameworks that can be used in addition to Google Cloud Functions.
AWS Lambda: AWS Lambda is a serverless compute service from Amazon Web Services (AWS). It allows developers to run code in response to events without worrying about managing servers or infrastructure.
Microsoft Azure Functions: Microsoft Azure Functions is a serverless compute service from Microsoft Azure. It allows developers to run code in response to events and supports a wide range of programming languages.
IBM Cloud Functions: IBM Cloud Functions is a serverless compute service from IBM Cloud. It allows developers to run code in response to events and supports a wide range of programming languages.
OpenFaaS: OpenFaaS is an open-source serverless framework that allows developers to run functions on any cloud or on-premises infrastructure.
Apache OpenWhisk: Apache OpenWhisk is an open-source serverless platform that allows developers to run functions in response to events. It supports a wide range of programming languages and can be deployed on any cloud or on-premises infrastructure.
Kubeless: Kubeless is a Kubernetes-native serverless framework that allows developers to run functions on Kubernetes clusters. It supports a wide range of programming languages and can be deployed on any Kubernetes cluster.
IronFunctions: IronFunctions is an open-source serverless platform that allows developers to run functions on any cloud or on-premises infrastructure. It supports a wide range of programming languages and can be deployed on any container orchestrator.
These serverless computing frameworks offer developers a range of options for building and deploying serverless applications. Each framework has its own strengths and weaknesses, so developers should choose the one that best fits their needs.
Real-time examples
Coca-Cola: Coca-Cola uses serverless computing to power its Freestyle soda machines, which allow customers to mix and match different soda flavors. The machines use AWS Lambda functions to process customer requests and make recommendations based on their preferences.
iRobot: iRobot uses serverless computing to power its Roomba robot vacuums, which use computer vision and machine learning to navigate homes and clean floors. The Roomba vacuums use AWS Lambda functions to process data from their sensors and decide where to go next.
Capital One: Capital One uses serverless computing to power its mobile banking app, which allows customers to manage their accounts, transfer money, and pay bills. The app uses AWS Lambda functions to process requests and deliver real-time information to users.
Fender: Fender uses serverless computing to power its Fender Play platform, which provides online guitar lessons to users around the world. The platform uses AWS Lambda functions to process user data and generate personalized lesson plans.
Netflix: Netflix uses serverless computing to power its video encoding and transcoding workflows, which are used to prepare video content for streaming on various devices. The workflows use AWS Lambda functions to process video files and convert them into the appropriate format for each device.
Conclusion
Serverless computing is a powerful and efficient solution for building and deploying applications. It offers several benefits, including reduced costs, improved scalability, reduced maintenance, and faster time to market. However, it also has some drawbacks, including limited control, cold start times, and vendor lock-in. Despite these drawbacks, serverless computing will likely become an increasingly popular solution for building event-driven applications and microservices.
Read more
0 notes
Text
Embedded Databases Decoded: Choosing the Right Type for Your Application’s Success
An embedded database is a database management system that is integrated within an application rather than being a standalone system. This means that the application has direct control over the database, and the database runs within the same process as the application. Embedded databases are often used in applications where data needs to be stored and accessed locally, without the need for a separate database server.
Embedded databases are typically used when an application needs to store data locally and the data is not shared with other applications or users. They are often used in desktop and mobile applications, as well as in embedded systems such as IoT devices, where network connectivity may be limited or unreliable.
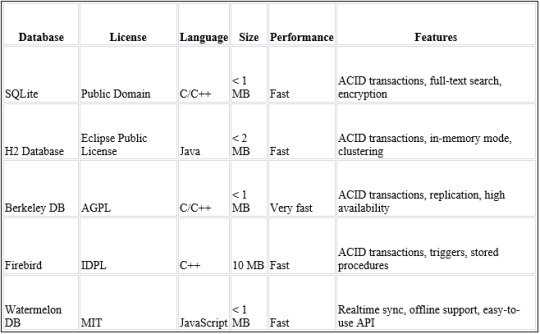
Some common examples of embedded databases include SQLite, H2 Database, Berkeley DB, and Firebird. These databases are often lightweight, fast, and efficient, making them ideal for use in applications with limited resources. They may also include features such as ACID transactions, replication, or full-text search, depending on the specific needs of the application.
When to use one?
Embedded databases are typically used when an application needs to store data locally and the data is not shared with other applications or users. They are often used in desktop and mobile applications, as well as in embedded systems such as IoT devices, where network connectivity may be limited or unreliable.
One popular embedded database that deserves special mention is Watermelon DB. Watermelon DB is an open-source, reactive database that is designed specifically for use in client-side applications. It provides a fast and reliable way to store data locally, with built-in support for offline data synchronization.
Watermelon DB is ideal for use in mobile and web applications that need to work offline. It uses a data synchronization protocol called Differential Synchronization, which allows the database to synchronize with a remote server while minimizing bandwidth usage and reducing conflicts. Watermelon DB is also highly scalable, making it suitable for use in applications with large and complex data models.
Some common use cases for embedded databases include:
● Desktop and mobile applications that need to store data locally.
● IoT devices that need to store sensor data locally.
● Point-of-sale systems that need to store transaction data locally.
● Gaming applications that need to store game data locally.
● Medical devices that need to store patient data locally.
Popular Embedded databases:
● SQLite: A lightweight, open-source database that is widely used in mobile and desktop applications.
● H2 Database: A Java-based database that is designed to be fast and efficient.
● Berkley DB: A high-performance, embeddable database that is used in a wide range of applications.
How to choose the correct embedded database?
Choosing the correct embedded database for your application depends on a number of factors, such as the size and complexity of the application, the performance requirements, and the desired features. Here are some steps you can follow to choose the right embedded database for your needs:
· Identify the requirements of your application: Determine what kind of data needs to be stored and how it will be accessed, as well as any performance or scalability requirements.
· Consider the size of the database: Depending on the size of your application and the amount of data you need to store, you may need to choose a database that is lightweight and efficient. Look for databases that have a small footprint and use minimal system resources.
· Evaluate the performance: Consider the performance characteristics of the database, such as query times and transaction processing speeds, to ensure that it meets your requirements.
· Look for required features: Determine which features are essential for your application, such as support for ACID transactions, replication, or full-text search. Make sure the database you choose includes these features.
· Check the licensing: Some embedded databases have more restrictive licenses than others. Make sure the license of the database you choose is compatible with your application’s requirements and licensing model.
Embedded databases are an important component in many desktop and mobile applications, as well as in embedded systems such as IoT devices. These databases provide a lightweight and efficient way to store data locally without the need for a separate database server.
At CoffeeBeans, we have experience and expertise in using embedded databases to build reliable and efficient solutions for our clients’ offline data storage and synchronization needs. If you’re looking for a partner to help you implement offline capabilities in your mobile or web application, we can help. Our team of experts can help you design and implement a solution that meets your needs and provides a seamless offline user
Read more
0 notes
Text
Integrating and Synchronizing Algolia with Strapi (v4)
In today’s fast-paced digital world, providing efficient search functionality is crucial for delivering a seamless user experience. Algolia, a powerful search and discovery API, offers developers a way to implement robust search capabilities into their applications. In this blog post, we will explore how to integrate and synchronize Algolia with Strapi (v4) to enhance search functionality for a “Product” collection
Setting Up Algolia and Strapi Integration:
To begin, we need to set up Algolia and Strapi integration. We assume you already have a Strapi project and have installed Algolia. Now, let’s create a helper function that will initialize the Algolia index.const algoliasearch = require("algoliasearch");
const client = algoliasearch(
process.env.ALGOLIA_APP_ID,
process.env.ALGOLIA_API_KEY
);
const getAlgoliaIndex = (name) => {
const index = client.initIndex(`${name}(${process.env.NODE_ENV})`);
return index;
};
module.exports = getAlgoliaIndex;
This code sets up the Algolia client using your Algolia app ID and API key. The getAlgoliaIndex function initializes the index with the provided name and environment variables. Note that we have also used the current environment with the index name to differ between the indices of different environments.
Synchronizing Strapi Product Collection with Algolia:
Now, let’s proceed to add and synchronize the “Product” collection in Strapi with Algolia. We will utilize Strapi’s lifecycle hooks to achieve this. Specifically, we will use the afterCreate lifecycle method.
Navigate to the product content type in your Strapi project and locate the lifecycles.js file. If it doesn’t exist, create one in the same directory. Add the following code to the lifecycles.js file:const getAlgoliaIndex = require("./path/to/getAlgoliaIndex");
const index = getAlgoliaIndex("product");
module.exports = {
async afterCreate(entry, data) {
const { id } = data.result;
// Query product added to database
const product = await strapi.db.query('api::product.product').findOne({
where: {
id
}
})
try {
// Save the object to Algolia
await index.saveObject({ ObjectID: id , ...product });
console.log("Object saved to Algolia");
} catch (error) {
console.error("Error saving object to Algolia", error);
}
},
};
In this code snippet we import the getAlgoliaIndex function we created and then initialize the Algolia index by calling the function and passing a name for the index.
In the afterCreate lifecycle method we query the data which is added to the database.
Finally we use index.saveObject method to save the new entry to Algolia. We wrap this operation in a try-catch block to handle any potential errors.
Conclusion:
By integrating and synchronizing Algolia with Strapi, we have empowered our application with advanced search capabilities. Leveraging Algolia’s powerful search API, we can deliver fast and relevant search results to our users. This integration enables real-time updates to the Algolia index whenever a new product is created in Strapi. Implementing Algolia within Strapi not only enhances search functionality but also provides a scalable solution for managing search operations in your application.
Read more
0 notes
Text
Enhancing Security with Threat Modeling Using the Security Burrito Approach and STRIDE
In today’s rapidly evolving threat landscape, organizations need robust security measures to protect their systems and data. Threat modeling is an essential process that helps identify and address potential vulnerabilities early in the software development life cycle. By combining the Security Burrito approach and the STRIDE model, organizations can enhance their threat modeling practices and strengthen their overall security posture. In this blog, we will explore how these two approaches work together to mitigate threats effectively.
Threat Modeling with the Security Burrito Approach
The Security Burrito approach, emphasizing continuous security throughout the project life cycle, provides a solid foundation for threat modeling. Here’s how it can be applied:
Incorporate Security from the Start: By integrating security considerations from the initial stages of design and development, organizations ensure that security is a fundamental aspect of the project. This includes identifying potential threats and considering countermeasures early on.
Continuous Security Assessment: Adopting a continuous security mindset allows for ongoing assessment of potential threats. Regular security reviews and risk assessments help identify and address vulnerabilities in real-time, reducing the likelihood of security breaches.
Collaboration and Communication: Encouraging collaboration between developers, security professionals, and other stakeholders fosters a proactive security culture. Effective communication ensures that threat modeling activities align with project goals and that potential threats are properly understood and addressed.
Applying the STRIDE Model in Threat Modeling
The STRIDE model is a useful framework for identifying potential threats in software systems. It stands for the following threat categories:
Spoofing Identity: This includes threats such as impersonation or unauthorized access. Countermeasures may involve implementing strong authentication mechanisms, multi-factor authentication, and robust user identity management.
Tampering with Data: Threats in this category involve unauthorized modification or manipulation of data. Countermeasures can include data validation, input sanitization, and encryption to protect data integrity.
Repudiation: This category focuses on threats related to denying or disputing actions or events. Implementing audit logs, digital signatures, and secure timestamps helps establish non-repudiation and traceability.
Information Disclosure: Threats in this category pertain to unauthorized access or exposure of sensitive information. Countermeasures may involve data encryption, access controls, and secure transmission protocols.
Denial of Service: These threats aim to disrupt or disable system functionality. Countermeasures may include implementing rate limiting, traffic monitoring, and employing mitigation strategies against DoS attacks.
Elevation of Privilege: This category deals with unauthorized access to elevated privileges. Countermeasures may involve implementing strong access controls, privilege separation, and least privilege principles.
Combining the Security Burrito approach with the STRIDE model enhances threat modeling practices:
Continuous threat identification and mitigation: By continuously assessing threats and vulnerabilities, organizations can promptly identify and address security issues using the appropriate STRIDE categories.
Proactive security measures: By integrating security from the early stages and fostering a security-first mindset, organizations can proactively implement countermeasures to mitigate identified threats effectively.
Collaboration and knowledge sharing: The Security Burrito approach promotes collaboration between stakeholders, allowing for collective understanding and action against identified threats based on the STRIDE model.
Conclusion
Threat modeling is a critical component of effective security practices. By combining the Security Burrito approach with the STRIDE model, organizations can strengthen their threat modeling efforts and enhance their overall security posture. This integrated approach ensures that potential threats are identified and mitigated throughout the project life cycle, enabling organizations to build more secure and resilient software systems.
Read more
0 notes
Text
What is Serverless Computing?
Serverless computing is a cloud computing model where the cloud provider manages the infrastructure and automatically provisions resources as needed to execute code. This means that developers don’t have to worry about managing servers, scaling, or infrastructure maintenance. Instead, they can focus on writing code and building applications. Serverless computing is often used for building event-driven applications or microservices, where functions are triggered by events and execute specific tasks.
How Serverless Computing Works
In serverless computing, applications are broken down into small, independent functions that are triggered by specific events. These functions are stateless, meaning they don’t retain information between executions. When an event occurs, the cloud provider automatically provisions the necessary resources and executes the function. Once the function is complete, the resources are de-provisioned, making serverless computing highly scalable and cost-efficient.
Serverless Computing Architecture
The architecture of serverless computing typically involves four components: the client, the API Gateway, the compute service, and the data store. The client sends requests to the API Gateway, which acts as a front-end to the compute service. The compute service executes the functions in response to events and may interact with the data store to retrieve or store data. The API Gateway then returns the results to the client.
Benefits of Serverless Computing
Serverless computing offers several benefits over traditional server-based computing, including:
Reduced costs: Serverless computing allows organizations to pay only for the resources they use, rather than paying for dedicated servers or infrastructure.
Improved scalability: Serverless computing can automatically scale up or down depending on demand, making it highly scalable and efficient.
Reduced maintenance: Since the cloud provider manages the infrastructure, organizations don’t need to worry about maintaining servers or infrastructure.
Faster time to market: Serverless computing allows developers to focus on writing code and building applications, reducing the time to market new products and services.
Drawbacks of Serverless Computing
While serverless computing has several benefits, it also has some drawbacks, including:
Limited control: Since the cloud provider manages the infrastructure, developers have limited control over the environment and resources.
Cold start times: When a function is executed for the first time, it may take longer to start up, leading to slower response times.
Vendor lock-in: Organizations may be tied to a specific cloud provider, making it difficult to switch providers or migrate to a different environment.
Some facts about serverless computing
Serverless computing is often referred to as Functions-as-a-Service (FaaS) because it allows developers to write and deploy individual functions rather than entire applications.
Serverless computing is often used in microservices architectures, where applications are broken down into smaller, independent components that can be developed, deployed, and scaled independently.
Serverless computing can result in significant cost savings for organizations because they only pay for the resources they use. This can be especially beneficial for applications with unpredictable traffic patterns or occasional bursts of computing power.
One of the biggest drawbacks of serverless computing is the “cold start” problem, where a function may take several seconds to start up if it hasn’t been used recently. However, this problem can be mitigated through various optimization techniques.
Serverless computing is often used in event-driven architectures, where functions are triggered by specific events such as user interactions, changes to a database, or changes to a file system. This can make it easier to build highly scalable and efficient applications.
Now, let’s explore some other serverless computing frameworks that can be used in addition to Google Cloud Functions.
AWS Lambda: AWS Lambda is a serverless compute service from Amazon Web Services (AWS). It allows developers to run code in response to events without worrying about managing servers or infrastructure.
Microsoft Azure Functions: Microsoft Azure Functions is a serverless compute service from Microsoft Azure. It allows developers to run code in response to events and supports a wide range of programming languages.
IBM Cloud Functions: IBM Cloud Functions is a serverless compute service from IBM Cloud. It allows developers to run code in response to events and supports a wide range of programming languages.
OpenFaaS: OpenFaaS is an open-source serverless framework that allows developers to run functions on any cloud or on-premises infrastructure.
Apache OpenWhisk: Apache OpenWhisk is an open-source serverless platform that allows developers to run functions in response to events. It supports a wide range of programming languages and can be deployed on any cloud or on-premises infrastructure.
Kubeless: Kubeless is a Kubernetes-native serverless framework that allows developers to run functions on Kubernetes clusters. It supports a wide range of programming languages and can be deployed on any Kubernetes cluster.
IronFunctions: IronFunctions is an open-source serverless platform that allows developers to run functions on any cloud or on-premises infrastructure. It supports a wide range of programming languages and can be deployed on any container orchestrator.
These serverless computing frameworks offer developers a range of options for building and deploying serverless applications. Each framework has its own strengths and weaknesses, so developers should choose the one that best fits their needs.
Real-time examples
Coca-Cola: Coca-Cola uses serverless computing to power its Freestyle soda machines, which allow customers to mix and match different soda flavors. The machines use AWS Lambda functions to process customer requests and make recommendations based on their preferences.
iRobot: iRobot uses serverless computing to power its Roomba robot vacuums, which use computer vision and machine learning to navigate homes and clean floors. The Roomba vacuums use AWS Lambda functions to process data from their sensors and decide where to go next.
Capital One: Capital One uses serverless computing to power its mobile banking app, which allows customers to manage their accounts, transfer money, and pay bills. The app uses AWS Lambda functions to process requests and deliver real-time information to users.
Fender: Fender uses serverless computing to power its Fender Play platform, which provides online guitar lessons to users around the world. The platform uses AWS Lambda functions to process user data and generate personalized lesson plans.
Netflix: Netflix uses serverless computing to power its video encoding and transcoding workflows, which are used to prepare video content for streaming on various devices. The workflows use AWS Lambda functions to process video files and convert them into the appropriate format for each device.
Conclusion
Serverless computing is a powerful and efficient solution for building and deploying applications. It offers several benefits, including reduced costs, improved scalability, reduced maintenance, and faster time to market. However, it also has some drawbacks, including limited control, cold start times, and vendor lock-in. Despite these drawbacks, serverless computing will likely become an increasingly popular solution for building event-driven applications and microservices.
Read more
4 notes
·
View notes