
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by edinb19-blog and here's what we found interesting.
Average Info
Notes Per Post
7K
Likes Per Post
3K
Reblog Per Post
4K
Reply Per Post
7
Time Between Posts
7 days
Number of Posts By Type
Photo
3
Video
1
Note
1
Link
2
Text
1
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Photo
Cloud computing present a lot of advantages. However, an important risk to take into consideration is to define who is responsable for data protection compliance and what measures should be implemented to safeguard data subjects rights and freedoms.
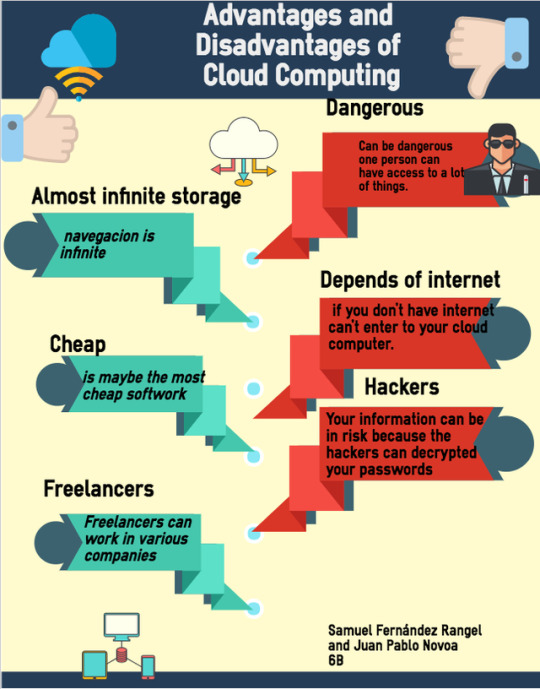
Advantages and disadvantages of Cloud Computing
1 note
·
View note
Video
We are experimenting what some decades ago it was just thought to be science fiction. Smart cities and internet of things are revolutionizing the way people live in their communities, as they have the potential to solve different public and individual issues without human oversight (environmental, governance, infrastructure, connectivity, food supply, medical assistance, monitoring of children and the older, smart door bells, lighting, thermostats, remote controllability, constant cloud connectivity, security, energy, etc.).
But this is not the panacea, as it comes with its own problems. One of them is privacy.
In order to relay and trust on the efficiency of the system, people need to give something in turn. Hence, unprecedented amount of sensors and cameras will collect and process the information of every single person. Think about being tracked though your web browsing, financial conduct, preferences in all sort of matters, health condition, travels and movement habits, work performance or your conversations. Moreover, the surveillance will not occur just in public places, but in what we usually consider as private areas, such as our very own homes or vehicles.
The inherent problem then, as intrusive technologies continue to develop, is the privacy and transparency in the use of the individual’s information. It could be understood that it represents the price to be paid for the next step towards an interconnected and digital world, or on the contrary, active efforts should be taken to regulate the processing before it is too late. We strongly believe in the latter option.
Facebook is a good example of how individuals can become digital dependents. This company has been found guilty of using people’s data for unauthorized purposes, making out of it a very lucrative business. However, users find it difficult to close their accounts as Facebook has become essential for social relationships. Now think on the challenge that would represent the decision to disconnect from a smart city, with the consequence of not just losing social events and relationships, but with the risk of being isolated from society.
Alternatively, and without adequate regulation, the only private space we will be authorized to keep will be our own minds. But who knows, maybe in the future even this last refuge could be intervened for the sake of a “greater good”.
instagram
This Chinese city’s traffic is controlled by an AI brain. Stay up to date with AI companies in your industry at Welcome.AI ⠀ ⠀ #china #ai #brain #smartcity #traffic #imagerecognition #society #tracking #futuretech #technology #artificialintelligence https://www.instagram.com/p/BtADZTWnT–/?utm_source=ig_tumblr_share&igshid=1dr8c15ixr3du
6 notes
·
View notes
Photo
Have you considered privacy issues regarding targeted advertising? Do you really know who is collecting your data as you browse the web and how they use it?
This picture represents a caricature of the people’s unawareness regarding the way in which companies use their personal data for their own benefit.

1 note
·
View note
Note
In April 2019 the UK government released the Online Harms White Paper (available here), which is a regulatory framework for companies that allow users to share or upload contents. Its purpose is to tackle illegal and unacceptable online activities as described by the re-blogged comment above.
Clearly the Online Harms White Paper has been created with good and understandable intentions. It approaches the difficult task of striking the right balance between the freedom of speech and online security.
However, the concrete tools and measures to implement the controls are at the very least controversial, having in mind the technological means available in our days and the ambiguous concepts used by such framework.
It is important to stay aware of the development of this matter, as an incorrect, inappropriate or disproportionate application may directly affect the rights and freedoms of all online users.
How are you guys going to prevent the spread of misinformation, like Deep Fakes and fake news? Perhaps there could be some kind of feature in which users could to label their posts as "news", and then if a post gets popular enough other users could start rating that post based on the accuracy of its source?
First off, this is an absolutely fantastic question and I’ve half a mind to write a full paper on the subject, so thank you for sending this, it’s my favourite question for quite some time (which means everyone else gets an apology because this touches on some of my special interests, so you’re getting a long post).
So, the UK Government produced something a little while ago called the Online Harms White Paper, setting out what the government considers to be harmful content online. Personally I hate it since it basically threatens to create a regulatory body for social media companies, but also because I disagree with some of the categorisations in there. The summary table is on page 31, screenshotted here for convenience:

You may disagree with some of them as I do (FGM should quite clearly be in clear definition and I don’t know what logic they’re using to say intimidation is separate from harassment), but we do see that disinformation is on there as a Harm.
In my view, there’s a scale of disinformation, and it gets a little fuzzy and overlaps with the other harms a bit in some cases. On a wider scale, we have fake news proper - climate deniers, Murdoch-owned newspapers in general, that “vaccines cause autism” paper. On a narrower scale, we have callout posts (both manufactured and selective evidence variants) and deepfakes of nudes, etc etc.
In both ends of the scale, there’s an agenda - whether that’s to protect corporate interests, political goals, or just trying to get revenge on and ruin someone’s day, there’s an agenda behind all misinformation.
Of all of this, deepfakes are probably the easiest to tackle - and even then, it’s still nearly impossible. In fact, from my own research, it seems to be taken as a national security threat almost - I’ve only been able to find a handful of papers on the subject, and some of them have notifications on them that they’ve been declassified or were produced intentionally as unclassified for interested parties. One of them is this, which notes that almost immediately upon a flaw being discovered which let AI go “yes, this is a deepfake”, the AI that produces deepfakes was improved to correct that flaw. Last week, Google released thousands of videos for engineers to try and come up with something, but even then, they acknowledged that any techniques were unlikely to work for very long and they expected the technology to improve beyond detection capabilities.
One way around it is to loosen the criteria and have it basically do the shotgun approach under the assumption that eventually it’ll hit something accurately, but then we end up with Tumblr’s porn filter.
With fake news, luckily, it’s a bit easier - there’s actually AI already that can detect it with an >95% accuracy. Unfortunately, that costs a lot of money to use, and we don’t have the budget for that.
To get back to the suggestion in the question though, there’s an inherent problem with the human factor: bias. It’s what created the fake news in the first place, and people will inherently just mark anything they disagree with, or even just don’t like as fake news. It’s also not really the focus of the site - news will be shared and of course, people are encouraged to do so, but for now, with the (relatively) low user count and the fact that it’s not posted often, implementing anything beyond manual review when it’s seen isn’t really worth it.
Eventually I do hope (and optimistically, anticipate) we’ll get to a point that we do need to start thinking about this, and I’m kind of excited to tackle the challenge, but for now there’s just more important things for us to focus on, let alone the budget requirements - this is something that we’ll need AI to handle. Unfortunately, the costs for that are insane - the hardware to train a model isn’t optimised for actually USING the model and vice versa. From scan.co.uk:
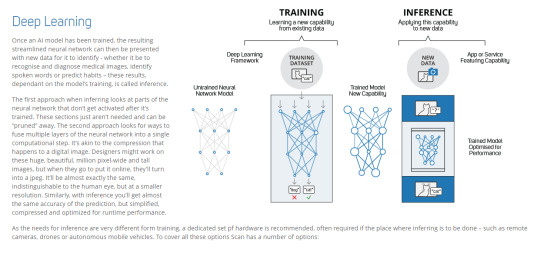
For extremely slow training, we’re looking at around $10,000 for a server capable of it. $200,000 for one that’ll get the job done fast enough that adding more material to the training queue is actually worth it. The prices for inference servers are about the same. We just straight up don’t have that kind of money right now - including my personal hardware pool (because lets face it, it was going to end up being used for WF eventually), the GPUs I have on hand are 4 Quadro GVS 295s (effectively useless, they’re from 2005), two Quadro K600s, a GT 710, a GT 730, and a GTX 1080 Ti. Of these, the K600s can be made to run Tensorflow with some modifications, but the only one really worth a damn for anything AI wise is the 1080 Ti, which is currently earmarked for our video transcoding server. If I can find some more money from somewhere for a second one, we might be able to get a basic model going that goes “Aye, this looks a bit dodgy” to point stuff out to us to review, but as with the rest of moderation, it’d only be AI-assisted rather than AI-enforced (that is; everything involving deleting, hiding, or removing something from the site has a human as the actual instigator of the action - any bots simply point us in the direction of stuff we might want to look at). This is, basically, a roundabout way of saying: Even though it’s something we want to work on eventually and that I’m actually looking forward to, we currently do not have the budget or hardware to do it.
So, to summarise: Policy wise that stuff can absolutely fuck off. Implementation wise, we’re basically stuck doing manual review because even multi-billion dollar companies can’t pull this off, let alone a site that’s still more or less running out of the garage it started in.
41 notes
·
View notes
Link
File sharing has raised a lot of legal and policy issues. In particular, copyright holders have had to deal with online piracy, affecting directly the revenues of their products and services. Just remember the experience of Napster (one of the first important peer-to-peer file sharing programs), that made it possible for users all around the world to download music and other materials for free.
Copyright owners have two possibilities to face this reality.
One option is to intimidate individual file-sharers, intermediaries/online providers and third parties thought legal actions, claiming damages and injunctions. The other option is to adapt and reinvent their businesses, offering a better and more persuasive service to consumers.
Experience has proven that technology will allow users to find alternative ways to obtain a cheaper and more efficient solution to their problems. In other words, online platforms challenge and revolutionize traditional models of businesses, not only regarding copyrights, but in all sort of matters.
Good examples are Uber (regarding the private transportation business) and Airbnb (with regard to the hotel business). In fact, Uber is aiming beyond, exploring the idea to provide financial services that may challenge the bank business (click here for more information). Furthermore, Netflix and Spotify have demonstrated that an immense number of users prefer to subscribe and pay reasonable prices for a good product, compatible with copyright laws, rather than downloading the same material online.
All of these online platforms do not have the potential to eliminated online piracy by their own, but indeed they have prevented that more people become new illegal file-sharing subjects, or even, may have converted online pirates into traditional and regulated consumers.
The real problem is that internet may be used to create infinite ways to evade restrictions on files sharing, especially considering that the new generations of consumers are much more familiarized and experts with online tools than their predecessors.
So why don’t rethink the strategy. It seems reasonable that if the world is changing, so must the companies and their online business. Attracting consumers rather than intimidate them should be the premise to approach the problem.
What alternatives may be develop to capture users’ attention and persuade them to become permanent consumers? If copyright holders can figure this out, online piracy and unlawful sharing should eventually decrease and as a medium-long term policy, probably it will become their best economical-reputational option.
As the common saying goes, “if you cannot beat them, join them”, or in this case, persuade them with innovation and creativeness.
0 notes
Photo
Do you agree with the “meme bann”?
Article 13 of the Copyright Directive states: “Online content sharing service providers and right holders shall cooperate in good faith in order to ensure that unauthorised protected works or other subject matter are not available on their services”.
Think about it. Usually memes are artistic/humor works based on copyright material. This provision will limit or forbid their creation and sharing.
Article 13 has been voted and accepted by the European Parliament, but now the EU's member states must interpret its wording and enact such article.
Get involved and informed on how this may affect you and the freedom of expression in internet.

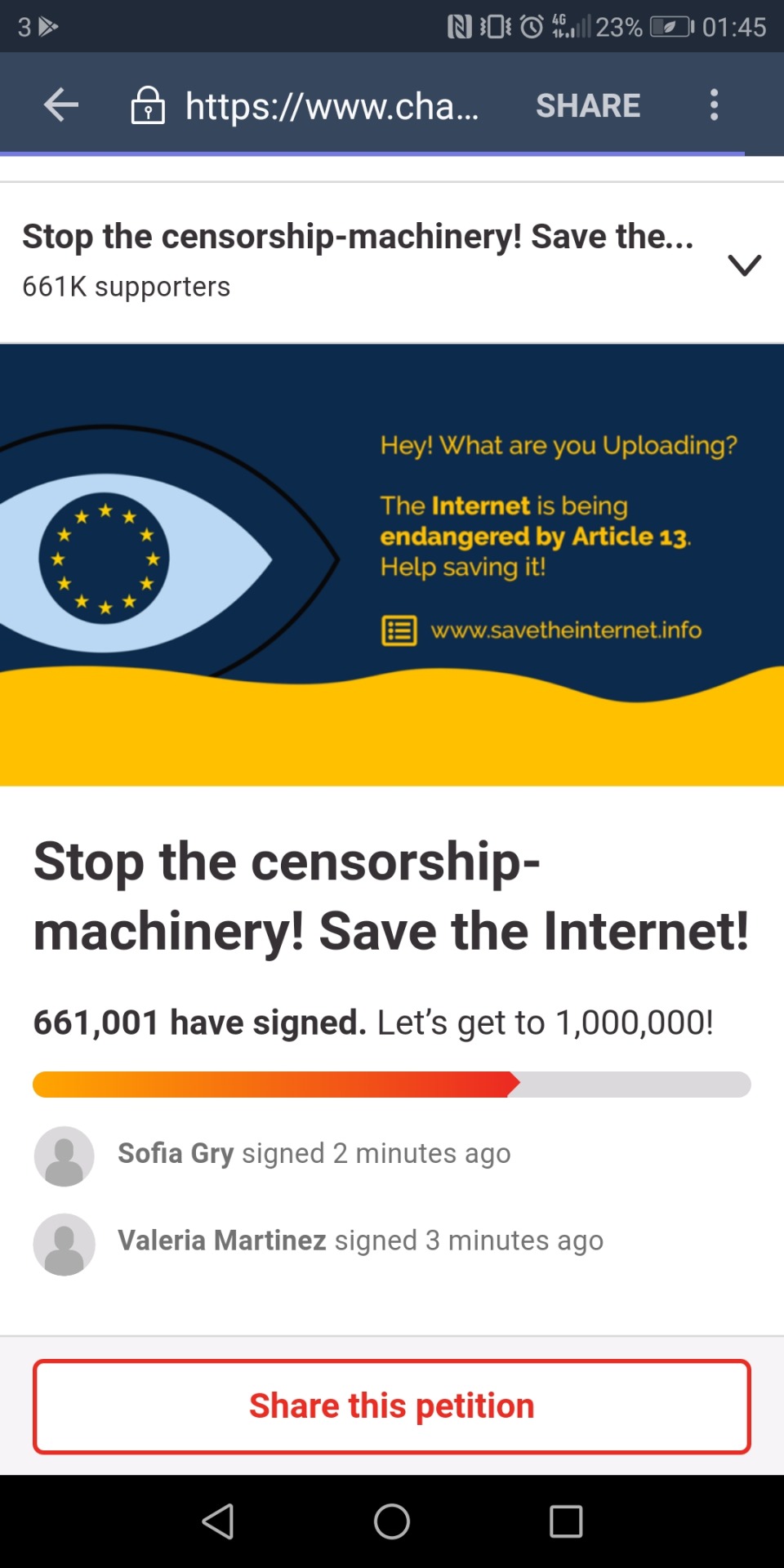
Please don’t let this happen, it’ll ruin lives and jobs and take away peoples freedom in Europe. Even if you don’t live in Europe please sign the petition, it affects everyone. Europe helped the US out with Net Neutrality, so please help us out with Article 13 https://www.change.org/p/european-parliament-stop-the-censorship-machinery-save-the-internet

7K notes
·
View notes
Link
Copyright can protect a large variety of elements, such as literary, dramatic and musical works, databases, sound recordings, films, broadcasts, etc. Especially when thinking about photographs, different questions may arise. In order to review some of them, it is interesting to remember the case of Naruto’s “selfie”. The “selfie” of this macaque was captured by equipment installed by photographer David Slater in the natural environment of Naruto, at Indonesia (see a previous blog on this iconic issue here).
The legal dispute initiated when Wikimedia Fundation refused to remove the picture from its website arguing that as it had been taken by Naruto, the picture was not subject to copyrights, and therefore it was of public domain. On the contrary, photographer David Slater claimed that he was the author and that the refusal of Wikipedia Fundation caused him financial damages.
A Court in the United States ruled in 2014 that animals could not be holders of copyrights under the local law. Latter, “People for the Ethical Treatment of Animals” (PETA) filed another lawsuit arguing that the macaque should be recognized as holder of copyrights. In April 2018, a United States’ Appeal Court rejected such claim (click here for more facts on the case).
A short summary done by the BBC news (including the photograph claims) can be seen here.
The issue about whether an animal can be holder of copyrights is an interesting matter. However, another relevant question to analyze is if the pictures taken by the photographer had enough merits to be protected by copyrights. It is important to mention that section 4 of Copyright, Designs and Patents Act 1988 (CDPA) define originality as a key factor to decide if a photograph may be protected by copyrights.
Based on Naruto’s experience, it seems relevant the rulings in case Antiquesportfolio.com pic v Rodney Fitch & Co Ltd [2001]” and case “C 145/10 Painer v Standard Verlags GmbH [2012]” (Charlotte Waelde; Abbe E. L Brown; Smita Kheria; Jane Cornwell, (2016) Contemporary intellectual property: law and policy Oxford University Press, p. 55 and p. 73). To see other applicable cases in the UK click here.
Considering the aforementioned rulings, it could be stated that the photographer is lawfully the copyright holder as the picture constitutes an original work due to the way he installed and manage to adapt the lighting, focus and angle of the camera in order to obtain such a clear picture of Naruto.
The lessons learned from Naruto’s case may well be examined in the light of the new information technologies. At this time, copyrights of photographs taken by autonomous robots or AI may only be attribute to their human owners. But, what would happen if machines eventually develop capacity to create original work on its own. Would the present copyright rules still apply or such futuristic (but probable) case would challenge said paradigm? What do you think?
0 notes
Text
One possible issue with online collaborative work
Evolution of information technology and the internet has promoted several issues that challenge the traditional areas of law. A very sensitive and relevant one has to do with intellectual property rights (IPR) and the way it may respond and protect innovations or creativeness in relation to software, Artificial Intelligence (AI) or collaborative work. Such protection is vital for promoting and protecting the work and investment of individual or joint developers who naturally may trust that the legal system will guarantee exclusive rights to exploit and obtain financial revenue for their effort.
The aim of this post is to comment a legal issue that the IPR may face when trying to protect the rights of people participating in an online collaborative work. Internet has made easier for people to collaborate in a common work, regardless of their physical location. Hence, restrictions of distance and number of participants have been moderated in the digital environment.
A good example of online collaboration is the free online encyclopedia Wikipedia. A more complex example may be patent pools in the pharmaceutical business. Probably in these two cases, the collaborative projects have settled clearly the rights of each participant, and consequently, property debates should not arise over the finalized work.
But what could happen if such conditions are not settled beforehand? Could participants claim to be lawful owners or authors of collective work? And in this case, how should the property rights be distributed among them and how could each one of them exploit (financially) the concluded work?
On one hand, the patents Act 1977 seems to provide that any person claiming proprietary interest could ask the comptroller about who the true proprietor(s) are, and if applicable, obtain rights for or under the patent (section 37). Moreover, if there are two or more proprietors, each of them will be entitled to equal undivided share in the patent, subject that there is no contrary agreement (section 36). On the other hand, the Designs and Patents Act 1988, describes the concepts of “unknown authorship” and “work of joint authorship” (articles 9 and 10), but -apparently- it does not resolve the issue when the identity of multiple authors are known and where the contribution of each one of them is distinct from the others. Moreover, the Software Directive (Directive 2009/24/EC of the European Parliament and of the Council) states that the exclusive rights of software shall be jointly owned by all the natural persons who participated in its creation (article 2).
As this preliminar review of regulations evidence, an online collaborative work (whether patentable or subject to copyrights) could give rise to ownership or authorship issues, and subsequently end up in judicial disputes. In order to prevent such misunderstandings, it seems advisable to be aware and resolve this issue before starting an online collaborative work, by means of a formal agreement or by having binding online conditions.
1 note
·
View note