
Statistics
We looked inside some of the posts by iain-coding and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
1 day
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Evaluation
This is the video I put together to explain the function library I wrote
What went well: Over the course of this project, I've hit a lot of problems with systems not working together properly, but I've always managed to find a way to overcome those issues, even if they seemed insurmountable at times. I think I've really been able to push myself in terms of determination and focus, and become a better programmer as a result. I'm definitely proud of how hard I've worked on this project and the fact that I've managed to do something a little different.
What could have gone better: I think that I had a tendency to stick to ideas for too long. I found that I would cling to a problem because I kept thinking I could find a solution for it, rather than just going another layer up and finding a different way of doing that thing which was causing the problem. I definitely think I could have done more research for different methods of storing data on an external server, as I went through several iterations before eventually landing on using AWS. Unfortunately, there's no real way I could have known I'd encounter the issues I did, so in many ways I'm glad I went through all these different iterations of the problem. While it was frustrating, and would have been much nicer to get it right in the first couple of attempts, I still learned a lot about what could go wrong in any given situation, especially when working with external servers and asynchronous operations.
What will I do differently next time: I think that for the next project, I'm going to put more effort into finding various solutions to problems so that I can make a more informed decision about what I'm doing before I start trying to implement solutions. I think this way I can avoid crashing into potentially predictable issues if I just take things a little slower and don't rush into problems. I've developed a bad habit of examining a problem and jumping on the first solution I come up with, so next time I think I'd like to make more of an effort to record my problems and then make a list of potential solutions, so that I can weigh up pros and cons to each.
Conclusion: Overall, I think I learned a lot from this project. It's been a good opportunity to practice writing C++, and I've definitely improved at problem solving and working with external API's, which is a very important skill when working on complex systems involving external servers. I'm looking forward to using these skills to build on the next project, and really get into working with underlying systems and to build more complex programs.
0 notes
Text
Get value function update and returning multiple values from unreal engine
One of the things I still needed to do was return values from the "get" function out into unreal engine. This was challenging for a couple of reasons. In c++, you can add return types to your functions. However, you can't add multiple return values in the same way you can have multiple inputs to a function. My first thought to solve this was to return a struct, however because that has to cross boundaries into Unreal Engine, that relies on Unreal supporting structs as return types, which I guess it doesn't because that didn't work and actually broke everything quite dramatically. However, one cursory google search revealed this forum post which outlines a way you can return multiple values if you define them as pointers in the input space. This means they are pointers to values in the code. If you want them to not be changed, you can assign them as const(ant) but we want to assign to the values, so I don't do that. The complete code appears as follows:

This defines in and out values and does all the setup as before.

Then, the code initialises a couple of values: "x" - which is just a translation buffer for data types between values, and "count" which is how the logic of this function flows. You see, querying an item in the table will cause it to return out all the different values for that item. What this means it's if we query a level, it's going to give us 3 values in this order: Level No Yes
However, we only want yes and no, and we want them to just be the values rather than "Yes: 7" which is how the default output would format them. In fact, you can see the default output on lines 229 and 236, if slightly modified for my output log, as this is how I tested this. Then we've got a switch case, and this next bit is why I specify the order the values came in, because our "count" variable is going to count where we're up to in the list and make sure logic goes through accordingly. I initialised the variable to 1, so first time around it just has to break out, as we don't need the level - we have it already. However, this won't just break out completely because this is in a for loop. It's going through all the values that were returned out. So it's checked one, now it's going through for 2, so before breaking out of 1, we increment the count, so when the switch goes around again, it finds value 2, which tells it to record that value to x as an integer. No is then given the value of x, newly converted into an integer. The first thing I did when setting this up was wonder why I can't just set no as the result of stoi(i.second.GetN()) as that would make much more sense, however it turns out you can't assign a pointer value with a function call, so this ends up being the easier way of getting it working. It then increments the count and does it again for the third item, which is yes.

Here's the unreal engine implementation, which will get a couple of values and then calculate a percentage from them. Here is that in action:
0 notes
Text
Presenting the data in an understandable format
Compared to everything else, this was pleasantly effortless to set up. All I had to do was create a progress bar and bind it to a float variable, seen here:

I apply some string formatting to it in order to split the number at the "." and give it a slightly neater look. This way there's no decimal point. Then I started constructing the logic. First, you can see the two events that call the bar to be filled. First is begin play, which creates the widget and selects a random percent. Then, if I press the "r" key, for random, it sets the current percent to 0 and generates a new max percent. Ignore the "pitch" value. I was using that, but am not any more. Then, both of these cause the "fill bar" custom event to be called.
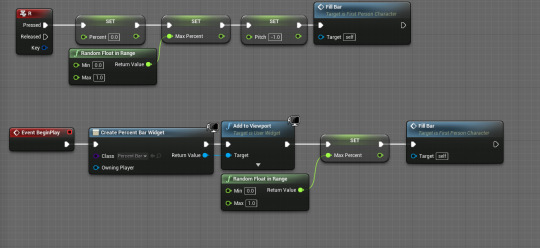
The actual fill bar function works by checking to see if the current percent is greater than or equal to the max percentage which was set by the random number generation. If it is, the function stops, but if it's not, the function continues through. It increases the percent to a maximum of the max percent, increasing it by 0.01 each time. This value is then doubled to be passed into the pitch multiplier on a beep, which is played each cycle, creating a simple rising audio effect. There's a small delay to let the engine catch up with everything, then the cycle begins anew.
Here is a demonstration of it all working:
Of course, this isn't all of it. This is just using random numbers, rather than the values from the server, but the idea is that once I've got the separate discrete parts, I can combine them together to create something presentable.
0 notes
Text
Getting items from AWS with unreal engine
This is the aws function I'm most worried about setting up, as getting something from a server is what's called an asynchronous function. This means that a CPU thread sends off the "get request" to the server, and then has to wait for a response. This response time is really quite fast, in human terms at least, usually being less than a second (depending on how far away you are from the server you're interfacing with), but in computer terms, half a second is glacially slow, and while that's going on, the CPU thread just has to sit there and wait. This can lead to something called thread blocking, especially in applications which heavily rely on multithreading to achieve good performance, such as game engines. I'm writing all of this before setting up the get function with unreal, so perhaps it'll work out ok, but I'm nonetheless anxious about it.
Pleasingly, it appears my anxiousness was unfounded, as it actually works just fine. Here you can see the Unreal Engine integration

And here you can see the underlying C++. I feel like I've explained most of this before, but just for completeness' sake, it initialises the API, constructs the client options and adds all the necessary information like access keys and region to that object. Then it constructs the information needed to query everything, then calls the query function. For the moment, the way it outputs everything is just writing it to the output log, which you can see in the little for loop on line 191/192. Obviously this doesn't help us in Unreal engine, so the next step for this is function specifically is to get it returning values. However, we have the slight problem that we want to return multiple values, but you can't tell c++ that you want to return 4 integers. At least not 4 separate integers. So what I'm going to have to do is set up an array or struct as a return type.
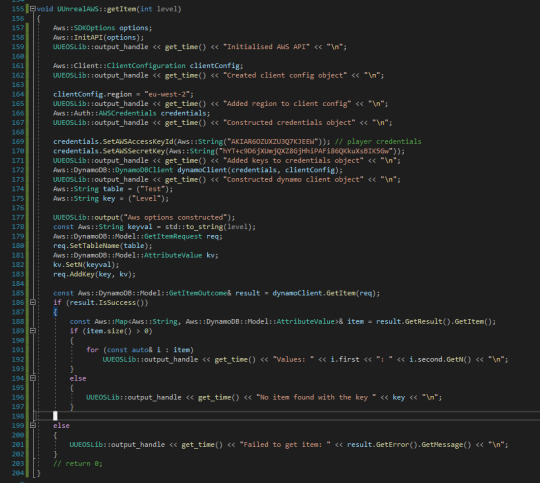
Here you can see the values that are returned by the "get" function. You can also see that I called the add function. This was to initialise the numbers to 6 and 4 so that I could confirm it was returning the correct numbers. If it was just returning 0 I wouldn't know if that was correct or it was just returning null.
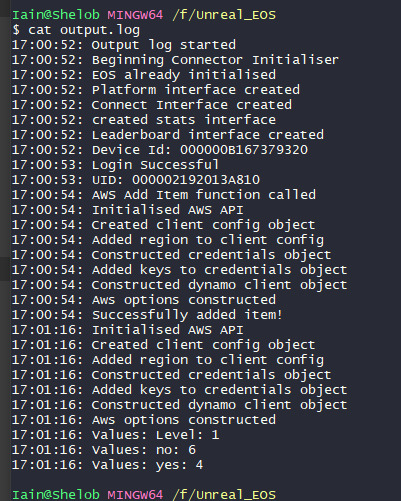
Here's the web portal just to show that those are the values we're expecting to see.

0 notes
Text
Updating items on AWS with unreal engine
This, much like the add item function, is pretty similar to the original command line application, though I have made one significant change, and that's how it determines which to update. Formerly I had an if else which took a number input, and the user would have to choose whether they wanted to update yes or no. Here I've simplified that down using Unreal Engine because I'm no longer bound by the shortcomings of command line applications (though overall I do think them to be superior). Now, the function takes two arguments: an integer for the level, and a boolean for the choice. This works seeing as all this well ever be doing is incrementing the value. This way I can simplify the amount the person actually using the library has to think about. This is especially important given what I'm going to do to simultaneously complicate and simplify things later on. But more on that when we come to it. For now, here's the unreal implementation:
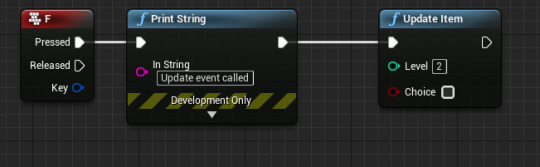
Pretty simple you can see. The boolean takes true to mean yes and false as no. Here, of course, is the actual underlying C++.

Upon breaking this down, you'll notice that it actually contains much the same code as the add item function, and you may now be realising why I so badly want to optimise and tidy this up. However, aside from that, it has a neat little if/else statement which sets the name of the string to be updated based on the boolean which was passed in, it constructs an update expression which writes a little bit of "aws-non-sql" in order to tell the function to increment the given value. All of this comes, of course, with output logging for debugging purposes. If I was to present this professionally in a products, I wouldn't include this kind of debugging because it wouldn't be of use to the average end user.
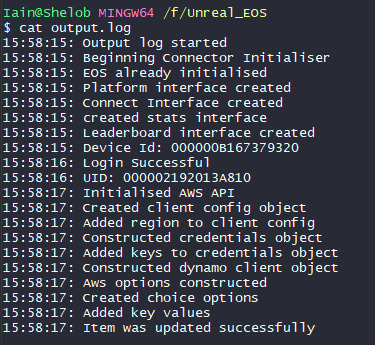
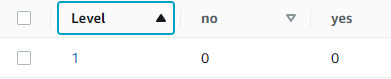
Here you can see the terminal output. For testing purposes, I updated both a yes and no on different levels.

And here you can see the updated values on the aws web portal. Which seems like pretty definitive working to me.
0 notes
Text
Adding Items to AWS from unreal engine
This is slightly different to updating or getting items, and those will be covered in their own blog posts, along with another blog posts outlining how I've refactored the code to look nicer. For the time being though, at the end of the last blog post, I noted that it seemed like the add item function wasn't working and I was going to have to debug it. Luckily, it seems this was an edge case, as the next few times I tested it, it worked fine. I had level 1 set to yes 2, no 0 and level 2 set to no 2, yes 0. Using my unreal engine project, I have set them both to 0 (over two separate runs)
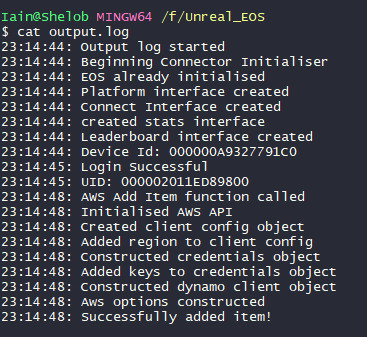
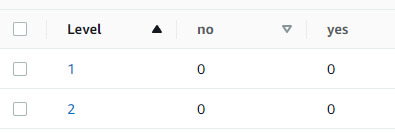
Here is the C++ function: (It's largely the same as in the command line application, but it's important to record these things for posterity.)
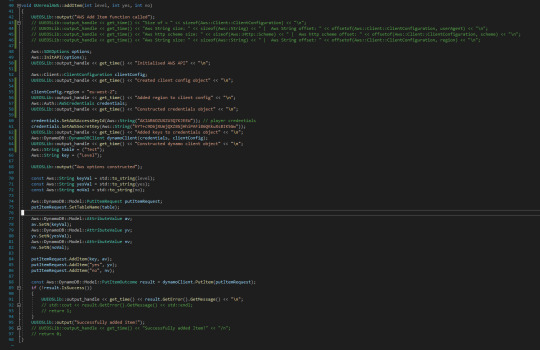
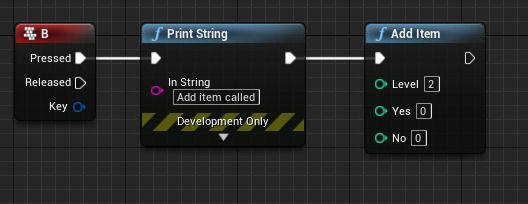
While a small proportion of the function is commented out, those are just debugging things. You can see that it works just the same as before, initialising the objects and adding the necessary information to them, constructing the push objects and then sending them all off to the server. Last but not least, here is the Unreal implementation of this system.
0 notes
Text
Integrating AWS with unreal engine Part 3: anguish
So while the results of my previous blog post seem pretty positive, this does present us with a wider problem. Turning on debug iterator support could fix the problem, but there's no telling how it'll affect a release build without testing it. This is a bit of an annoying problem, but I'll take it one step at a time.
The final solution ended up being to recompile the AWS SDK with the iterator debug level arguments built into it, so that when the dll files are called, they have that as an intrinsic property. This is also good because it allows me to record the process by which I compiled the sdk. First, I added line 65 to CmakeLists.txt, which contains the different options called when invoking cmake.

Then, I wrote this short batch file which just runs all the commands with the necessary arguments. Doing it this way rather than manually typing it out is nice because it meant that during debugging, I could recompile the SDK multiple times easily, and also I didn't have to fight with command prompt's terrible tab completion. Trying to type anything in cmd is like pulling teeth.

The next step was to test that this had actually taken effect. So I copied the new .dll files into the necessary places in the AWS-Test command line application, compiled and ran it.
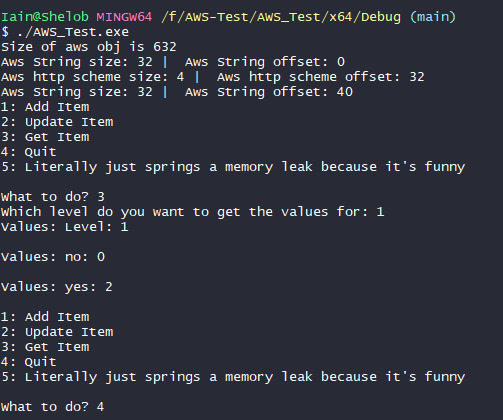
And you can see here that the sizing has scaled down, as it was in the Unreal project previously, but I can still do things like make queries without the entire system exploding.
So I copied the recompiled SDK into the unreal project directories, did a full rebuild and called a function which should query a number.
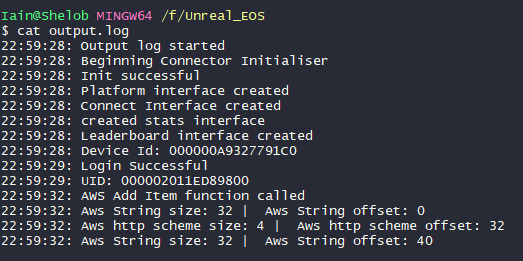
You can see here that it stopped about halfway through, but what's important is that it didn't crash. I think that means it's safe to say the integration is, for the time being, complete. I can now move onto debugging this new problem and actually getting some working functions, and good code implemented.
0 notes
Text
Integrating AWS with Unreal Engine Part 2: Electric Boogaloo
In a move which, I thought, should solve the memory issue (blatant foreshadowing) I added the pragma pack lines to the #include sections of the C++ file, as they allocate buffers around memory for those specific items
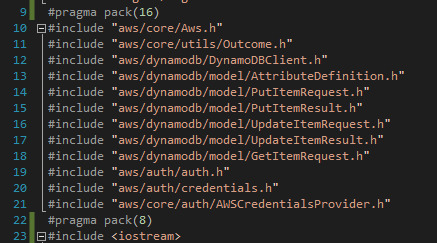
I then clean built, called the function, and the sizeof command returned the same 632 when we really wanted the 744 from the Aws_test. This is a less than ideal solution.

I did the inverse of this in the AWS-TEST project and learned that the sizeof didn't change there either. Setting #pragma pack(8) still returns a size of 744
Ok, after a good night's sleep, I've decided that a good step going forward would be to drop the #pragma pack's and all that, and instead try and get a side by side comparison of how each compiler interprets the different objects within the client configuration object, as that way I might be able to see where the issue is arising. I will also pair this with an offset reading, as that way I can see if any objects have unexpectedly different offset. The results are... interesting to say the least. Compare and contrast: AWS_Test (command line)

Unreal EOS (unreal build tool)

You can see here that for some reason, the different compile methods are allocating different amounts of space to the Aws String object. This is, needless to say, less than ideal, and seems to be quite a pain to fix. This stack overflow post suggests that the debug iterator level might have an impact on how memory is allocated for "some reason." Basically when you're in debug mode, it has an additional pointer on the front of strings for some reason. This was confirmed by setting the iterator debug level to 0 in my aws_test script and checking the outputs again

You can clearly see here that it's now expecting the Aws string to be several bytes smaller, and this is now in line with unreal EOS. So I've got two things to do. First, I need to check to see if my AWS Test now also crashes when initialising a client credentials object. Second, I need to see what the iterator debug level is set to in the compile options for the unreal build tool, and then maybe figure out how to change them.
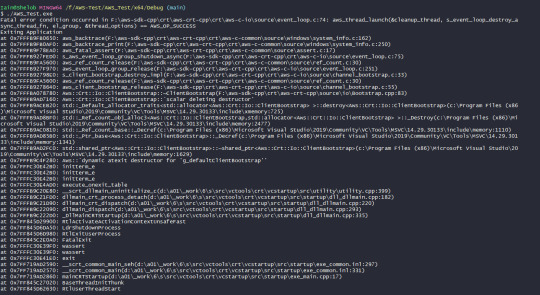
Well what do you know? That is quite the dramatic explosion if I've ever seen one. (For context, I moved the return to just after it created the client configuration options.) So I think I'm happy to call that reproduceable behaviour. Now I have to figure out how to stop unreal engine from doing it.
[Continued in part 3]
0 notes
Text
Integrating AWS with unreal engine
Getting AWS integrated with unreal engine has been a rather tricky task, as the compiler has been distinctly unhelpful with build errors. However, with some research into unhelpful error messages, and a considerable amount of bashing my head against a seemingly brick wall I've finally managed to break through and figure out how to get these things talking to each other.
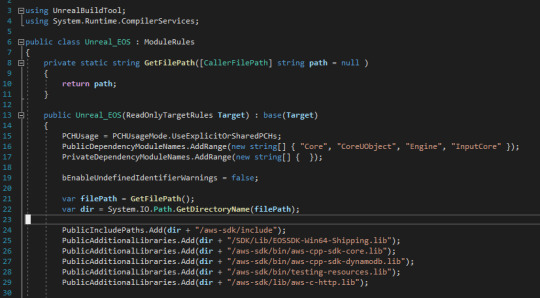
First things first, there's the tidy up in build.cs with the paths. I got really bored of constantly swapping drive flags every time I switch systems, so I wrote this little C# function which gets the current directory name from the build.cs file path and then path to the lib files I need relative to that. The other thing I added in here was the "bEnableUndefinedIdentifierWarnings = false" which is a line that basically tells the compiler to shut up about some weird errors it was generating relating to undefined macros. In reality, they're just warnings which don't affect what we're doing (I think) but they were being interpreted by the compiler as errors.

I also moved all of the dynamically loaded libraries, or .dll files into the binaries folder in the project source so it's easier for unreal engine to find them because otherwise the .uproject file simply wouldn't open.
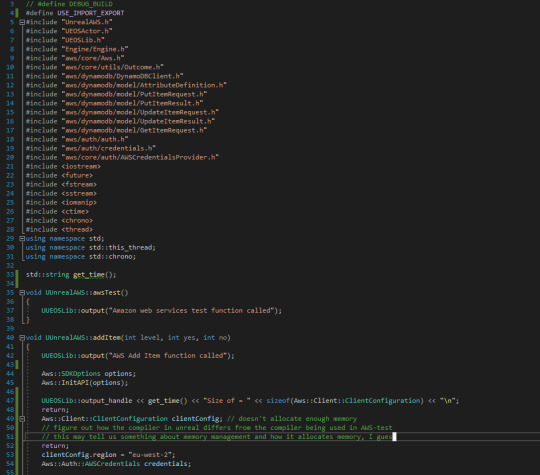
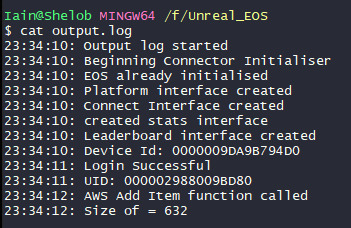
So then I put all the necessary header files in the source and started building a simple add item function. However, you can see at the bottom there things start to get a little bit messy, and also that's not the complete function. You see, the first time I tested this, unreal engine crashed, which was entertaining. This was a weird problem to debug. I used the return statement to break out of the code at different points, and learned that thing that causes the crash is actually the initialisation of the client configuration object, which isn't what I was expecting. I was expecting it to simply be the API initialisation for some simple reason. However, it's a little more fun than that. Here's the output log from this code, alongside the command line application. What I've done is I've used a command called "sizeof" to check how big the compiler expects something to be in memory. You can see in the command line application that it expects the client config object to be 744 bytes, whereas in the unreal engine version, it's expecting it to be 632 bytes. What this means practically is that when this is run, the compiler isn't allocating enough memory, and as a result, we're getting a buffer overflow error, which means it's trying to write data beyond outside the allocated bounds.
However apparently stack corruption is also possible, and I don't even want to think about half of these, so for the time being lets assume it's the compiler's fault and try to debug that.

In order to debug this, I started by trying to figure out what flags were being passed to the base C++ compiler, but for this I needed to circumvent unreal build tool, which is a tad challenging. However, invoking the build tool manually and passing the "Very Verbose" flag allowed me to get a lot of output in the command line. It was then with the help of a pair of very venerable, yet nonetheless keen eyes, I had this line:

That line of generated output has led me to this file, which contains all of the flags which have been passed to the cl compiler. Now I just have to sort through all this and see if I can find what I'm looking for, and more importantly, why it's screwing up my memory allocation
And here is a line in the 4546 line output log I generated for my command line program AWS_Test.
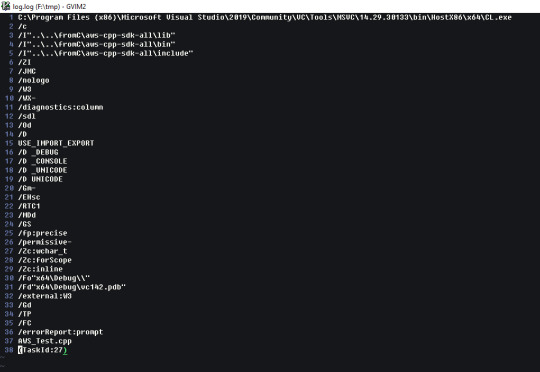
Upon closer investigation, along with cross-referencing some docs, we can discover that in the UnrealEOS Aws library I've been writing is built with the option "/Zp8" which means, according to the docs, that it builds object structures with 8 byte boundaries of memory around it in the stack, which is most likely the cause of the out of bounds exception we're getting. What we (probably) want is a 16 byte boundary, or to use something more useful, such as pack pragma (which is linked just below this table of information.)
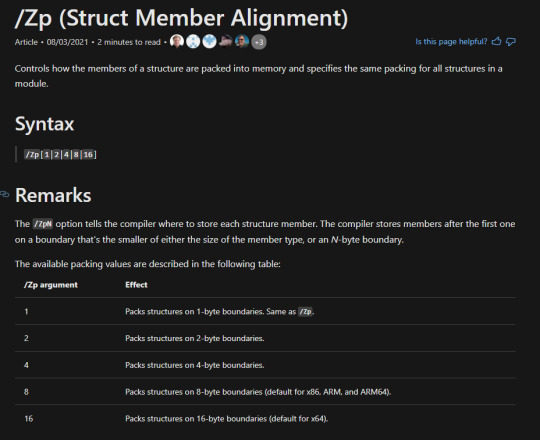
0 notes
Text
How to present code
There are a number of different ways to present code, especially in a job interview setting. The first thing I found in my research was this stack overflow thread: Job interview thread This gave me some interesting ideas, but the first thing which I really felt I could apply was including links to a github project, which I can definitely do because I version control most of my stuff on github. Although it does mean I need to start recording my work more diligently, so that I've got a more accurate record of what I've been doing.
0 notes
Text
Restructuring code for efficacy
I have a firm belief that it's is our job, as programmers, to write the best, most efficient code that we possibly can for a number of reasons. It's important for our code to be neat, tidy and readable so that if someone else has to maintain our work, or we have to come back to it after a long break, we have to be able to understand what it does. Of course code comments can help with this, but the idea is to write code sufficiently readable that it doesn't need comments. Then there's the separate, but equally important, idea that code should be lightweight. This is where I start to have problems with lots of modern software such as Microsoft products, and lots of Apple products, but I'll refrain from going on a tangent about that for the time being. It is with this in mind that I refactored some code this afternoon to prevent overuse of system resources repeatedly making, destroying and remaking things which are used more than once.
Here's the information on the client configuration. This is what tells the API what permissions the user trying to make any given request has. Formerly, I would have to remake these credentials at the beginning of every function call. I have now moved it into the main function, and simply pass it into other functions as a pointer to the actual object. I have, accordingly, changed the calls to it in code such that it redirects through the pointer to the actual object it's referencing. Highlighted below.

And here you can see it still works with this updated system. (although I did obviously have to move the API initialiser before the client configuration, seeing as it makes API calls - but once I'd made that change, it worked perfectly.)
0 notes
Text
Updating items on AWS
The "put item" function, helpful though it is, isn't quite right for what I'm trying to achieve, because it overwrites any existing data. Theoretically, if I could query the data, I could then increment the necessary thing and then push it back, but that's sort of inefficient, dumb and all around not a good idea. Luckily for me, there is an "update item" method, which should do what I need. I just need to get it working.
Ok so I got it working (it took me 3 days to get working) and there was a little bit of hassle in this department. I forgot to get proper screenshots of the first working iteration, but it wasn't too different from the second. Just a little less complex. In short, it worked when pushing values to "yes", but it got upset about pushing values to "no" because it's apparently a "reserved keyword" which is crap, but ok.



Anyway, the solution wasn't too hard. Apparently AWS has it's own fancy SQL language data types. I don't understand it properly, but here's some stuff:
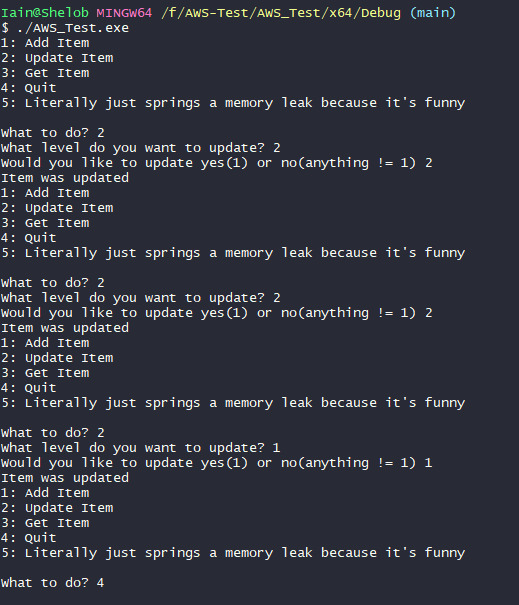
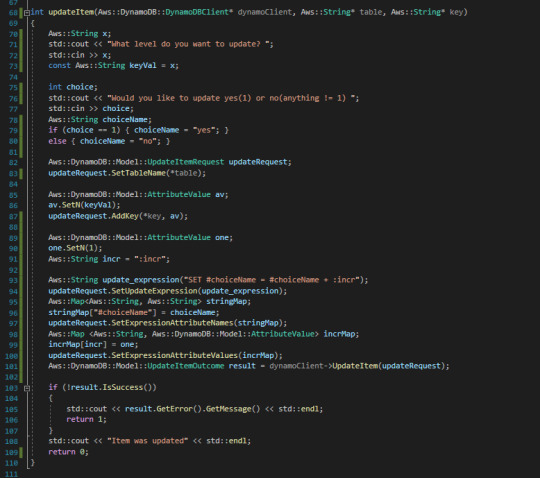
So there we go, it works. For a quick breakdown of the code, it takes some user input to decide which level to update and which value to update. Then it constructs an update request, gives it the table name, puts a couple of values in there too, but not too many because the rest is handled by the update expressions. Update expressions are fancy stuff that I don't 100% understand, but is sort of like AWS SQL injection. and then it calls the function.
0 notes
Text
Getting items from AWS
Being able to retrieve values from the server is an important part of being able to use this system, as I need to fetch values and then manipulate them. That in mind, I copied out the example code from the documentation and set about deciphering it.
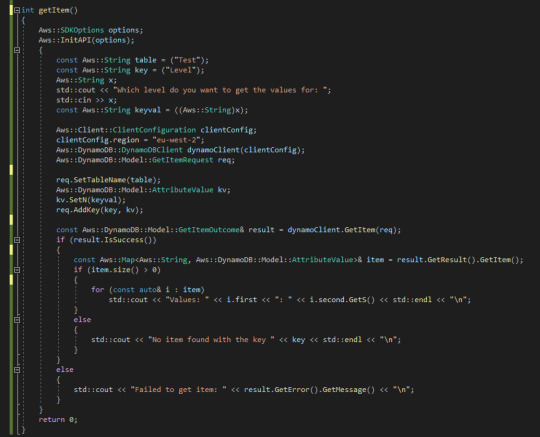
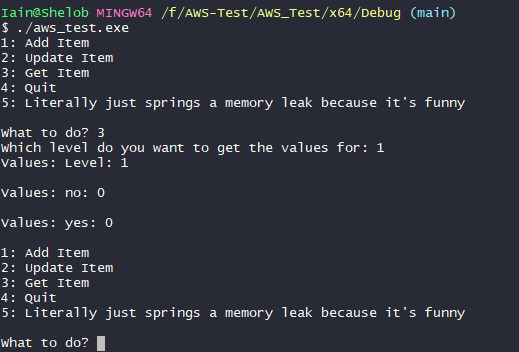
What you're seeing here is a relatively simple function which sets some variables, then prompts for input so we can query a specific level. Next it sets up the client configuration. For efficiencies sake, later I'd like to set this up with a proper object so I don't have to keep creating it in every function, but this works for the time being. It then passes the values into the request and returns the values being requested. This seemed simple enough, so I put it to the test:


apparently amazon have a sense of humour about what qualifies as "getting" something.
Ok it turns out this was a really easy thing to fix. If you take a look at the first screenshot, specifically the line where I do "std::cout << "Values: " << (etc)" and then compare it to this:

I promise, it's different. The thing is, the values I'm trying to query are numbers. If you look again at the first screenshot (assuming you haven't noticed it yet) you might see the bit that goes: "<< i.second.GetS() <<" What that means is "get me a string from the returned value", but the thing is, we're not querying strings. So in the second screenshot you may notice I've changed it from GetS to GetN. From Get String to Get Number.
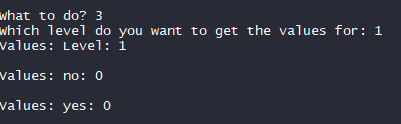
Anyhow, it works now.
0 notes
Text
Adding items to AWS
So before I get into any of this, I have a little confession to make - It's not quite this easy to get started. There was a bit of a learning process as I got everything set up and compiled the SDK. However, I'm skipping over that because it's (relatively) well documented on the github page. Long story short, there are a couple of magic runes you have to type into a command prompt to make it go, but now that I've got some compiled binaries, I can get started.

First of all, this is how you can add an item to a table on the AWS main page:
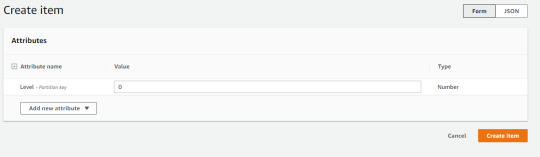
As you can see, it's really quite simple. However, asking players to record the decisions they made after every chapter of a game seems like a really tedious thing to do, so instead we need to find a way of doing this through code such that it can be called from inside a program in the background. To do this, we need to make an API call from their SDK. Luckily for us, there's some sample code for this exact thing. I made a couple of tweaks for it to support the table I've made, and that looks like this:
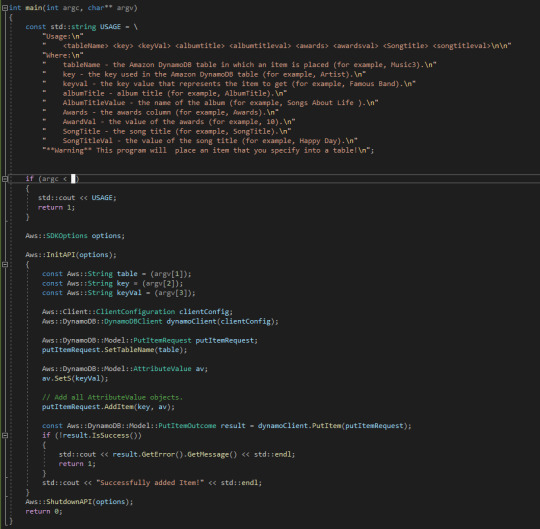
Now, this program is supposed to be run from the command line, so we have to pass it arguments. The first thing is just a print statement explaining how to use it. Ignore that. The first thing is an if statement which just checks the number of arguments. The number hidden by my cursor is 3. We need to pass in three arguments: a table, a "key" (basically the thing we want to change) and the value. If I invoke that command, we get this error message:
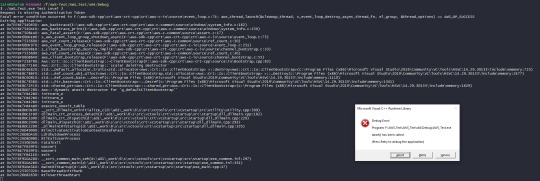
All this is saying is that it's missing the authentication token. Now, I've got a little file which I generated from the AWS called new_user_credentials.csv which I've added to the project as an environment variable.
Ok so a little bit of debugging later I figured out a couple of issues. First, the environment variable I was setting was pointing to a .csv file, but that's the wrong format. So I created a new file which has information in it in the following format: (this is for admin permissions, but I'll create a user permissions one too)

This is then set as a variable in "bash" like so: (this basically just says "hey look this name means this file")

There were a couple of additions to make to the code as well:


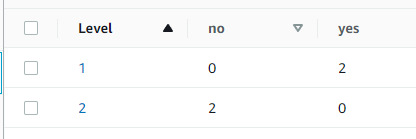
Here you can see I've added a few more arguments to the script. This is because this table works as a kind of headers and values system, where, for example "Key" is the table header and "Key Val" is the value that goes in that column. Here, I've done two headers, "Level" and "yes" and the corresponding values of 3 and 6. You can see this represented on the webpage like so:
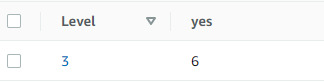
The last main thing I need to test about this before I start work on integrating it into Unreal Engine is how it reacts to adding things to an existing row. Either it can create a new row with identical values, or it can append to the existing row. If it's the latter, excellent! If it's the former, some logic tweaking may be required.
0 notes
Text
Interfacing with AWS from code
This isn't exactly going to be a comprehensive guide seeing as I'm just gonna live blog this as I figure it out.
If we want access to the C++ API for AWS (why is everything an acronym?) we're going to need to clone the github repo for all of the API calls down so that we can select the ones we want to use. So clone the repo down with the following command:

This will take a while because, as github repos go, this one is C H O N K Y

Out of curiosity, I ran "du -h" (print the disk usage in a human readable format) on the directory, and this reminded me how slow windows' file system is. When I got back with my coffee, the total file size came to just under a gigabyte. (This did partly take a while because I was cloning it to an external drive, so it's not entirely Windows' fault, but the file system is still excruciatingly slow)
I then had to follow the instructions in the github readme to compile everything with the correct arguments, which was an arduous and difficult process that I probably should have recorded, but I really just wanted to be done with it. So anyway, now I have a compiled SDK to write code with.
0 notes
Text
Setting up the AWS
The first step to getting started with this system was to set up an AWS account. This was a surprisingly arduous task, and infuriated me greatly, after entering more captchas than I have seen in my entire life, 3 text messages and 3 emails, I was finally allowed to log in. I also had to enter my bank details to that they could take a dollar off me for a week to confirm I'm a real person. This isn't a big deal, it's just a minor annoyance, but it was very annoying given I only want to access the free tier of things.
Complaints about the system aside, I'm now ready to get started with integrating the SDK into the unreal project, and setting up the table I need. I'm going to be using DynamoDB because of it allows concurrent access to multiple users without merge conflicts, allows users to read and write data. Time to get set up. The first page I'm met with on opening it up is this:
I clicked the "create table" button and started to go through the process of setting up a table - this just being a test table, there's no real risk with sharing this information. When setting something up on AWS, there seems to be a degree of expected technical prowess, which is interesting because I don't know what half of this stuff does and it isn't really explained. That being said, I created a table name and a partition key (whatever that is) but omitted the sort key because it's optional, and I also don't know what that is.

However, while exploring some of the advanced options, I came across this little table, which gave me considerable cause for concern given this is the free tier of storage, and is supposed to stay free. A little bit of research revealed this stack overflow post which explains that this is how much it would cost if you used up the free storage. You see, this tier gives you 25 gigabytes of storage for free (should be plenty for what I'm doing, although if this was more than a proof of concept, I might go for a little more than 25? maybe? It's hard to say) and if you use more than 25 gig, this is the pricing things will be at, however, as long as I stay under 25 gig, we'll be just fine.

With all of this in mind, I'm going to elect to not change anything and just use the default settings for this project. So I hit confirm to create the table and wait for Amazon to actually create it.
Next up, we open the table we just created, and are met with a scary looking page:
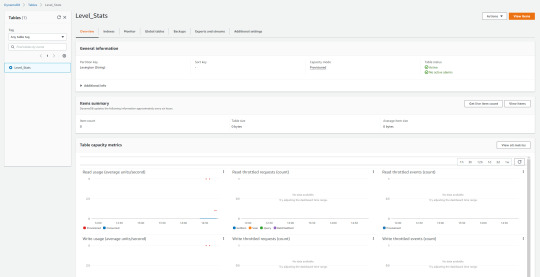
However, we don't really need to worry about most of this information for the time being, though it may become important later on. For now, we just need to figure out how to interface with this table.
0 notes
Text
Making the choice to move to AWS
I spent a portion of today setting up the leaderboards interface for the EOS. The original idea was to use the leaderboards to try and pull each users data from the corresponding stats. The problem with this is that as soon as I got it set up, it returned error code 18 again, meaning that it couldn't find the requested data. At this point, I've got a choice to make. Either I can keep pursuing this idea simply because it's what I've been working on for the last 5 months, even though I don't think it can supply the data handling I need from it, or I can try something else.
I think it should be obvious from that what I'm going to do.
It's frustrating that this isn't working because of how much time I've put into the systems, but I'll keep all the records I've got of setting everything up so that my learning experience with this system can be recorded for posterity on my blogs. I'll do the same with AWS too. However, I'm not going to be completely getting rid of the EOS functionality, because I do think that this will be the way to go if I want to set up multiplayer matchmaking, and keeping the existing functionality around will make learning how to do that much easier when I do decide to take the plunge.
For the time being though, I'm going to work on trying to use an AWS system to set up what I want. Namely I'm going to use DynamoDB primarily because of it's ability to process multiple requests to edit one single thing without merge errors. This is a huge requirement for me, as the idea is that multiple people can be updating this at any one time, and this solution is considerably easier than me having to write the code myself, which then runs on an AWS server, and I have to worry about maintaining it and making sure it can handle multiple requests and things like that. My job for tomorrow is to finish this research and set up the C++ SDK in Unreal so that I can demo the functionality.
0 notes