
My SLOG for CSC148H [Spring 2016] @University of Toronto Jason Dam
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by jason148blog-blog and here's what we found interesting.
Average Info
Notes Per Post
13
Likes Per Post
9
Reblog Per Post
4
Reply Per Post
0
Time Between Posts
8 days
Number of Posts By Type
Text
9
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Application of Hashing
In the end of the course, we touched on the topic of hashing which I thought was a really interesting and if not essential topic to cover in CS. We know that hash tables are extremely fast data structures as they run with a precision of O(1) runtime but that’s not all they’re used for.
Hashing are a fundamental component when it comes to data encryption. Keep in mind that hashing and encryption are two different things but are often confused as one. As we seen, a (good) hash function is a one-way function meaning we can’t reverse a hash value back into it’s original value. This is extremely useful when we want to store information like passwords in which the information is too sensitive to simply put wholly into a database, so we hash it.
Therefore when the user enters their password, we just check if their password hashes to the same hash stored under their username.
On the other hand, we have encryption which is similar to hashing but not exactly the same. We use encryption not when we want to store sensitive data but rather when we want to send sensitive data as in encryption we need a way to reverse our scrambled data, aka decryption. The procedure of encryption also requires a key, where the key is used to essentially “lock” and “unlock” the data.
Encryption usually falls under two types of encryption techniques, symmetric key encryption and asymmetric key encryption, also known as public key encryption. More on these topics can be found online.
---------------------------------------
As for my SLOG, this is my final week post for CSC148.
I plan to update and maintain this blog as I further continue my studies in CS, that is implying I don’t get lazy and forget...
0 notes
Text
148 Impressions #2
Week 11 SLOG
This is a revisit/continuation of a slog post I've posted a while back.
It’s almost near the end of the semester and looking back on it all, time seems to come and go really quickly. We began the course a few months back with our transition from 108 into 148. The transition to say the least was rather quite bumpy than smooth. In 108, we were taught the basics of coding and were taught about common objects like str, int, boolean, and how to incorporate them into functions. Overall 108 was a lot more logic-based and more focused on writing individual functions.
On the other hand, 148 puts a whole new twist on things. Rather than focusing on writing code, we’re more focused on object-design and implementation of classes, stuff like ADT and API. To be honest, 148 really took me by surprise because I've never learnt any of this beforehand.
Further onwards into the course, we started to touch on common data structures like queues, stacks, and trees which was a really interesting aspect in CS. By then we've learned how to create and implement our own classes and design our own objects. This was completely new from 108, so in return it was quite difficult to follow along at first but after some practice, I started to understand the content better.
A major icebreaker I've got to say in this course was the two assignments. The two assignments was extremely helpful in compiling our abilities and skills we've learnt throughout the course. The assignments to say the least were really well designed to guide and enforce the course content and helped me a lot in understanding the importance of classes and objects.
Overall, 148 was a great course and an essential preparation for future studies in CS. In all, I am very satisfied in the structure of the course and how it all went.
0 notes
Text
Mergesort
One of the sorting algorithms I have most difficulty tracing is mergesort. Mainly it’s because of the fact that mergesort uses recursion, which is already pretty hard to trace. But I find the sorting idea behind mergesort the most interesting compared to the other ones.
The simple idea of mergesort is to divide and conquer the list at once. We break down the list into halves, continually doing so until we have a list of only one or zero element. From there, we then “merge” each list back together until we return to the original list, which is now sorted. All this is done through the manner of recursion.
Here’s a quick photo on how mergesort works:
The dividing of the list
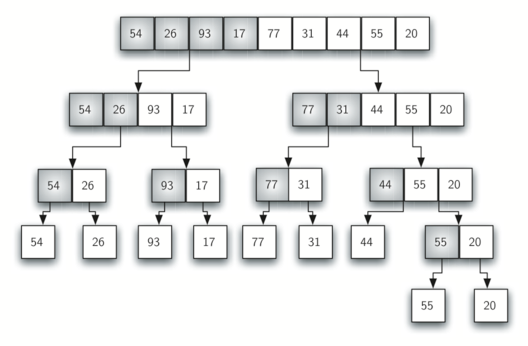
The merging of the divided list
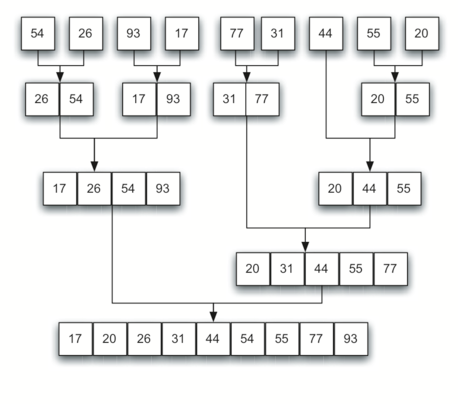
Photo credits / URL
0 notes
Text
BSTs
BST is known as a Binary Search Tree which is a special type of tree; a tree is a data structure we have already seen before. A BST is a special tree in which the parent node will only have a maximum of 2 children, one left child and one right child. A given property of a valid BST is that the left child will always contain data/value that is lesser or equal to that of the parent and the right child will always contain data/value that is greater or equal.
This property allows for a quicker traversal and runtime when we implement and call functions to search a BST. Since the BST is already partially sorted due to this property, a lot of operations like search, insert and delete will consist of a runtime of O(log n), which is considerably faster than other data structures.
Be careful to implement BST methods correctly in accordance to this property.
Some other operations pertaining to BST includes traversal. There are three types of traversals with a BST, preorder, inorder, and postorder.
Preorder Traversal
Visit the current node
Traverse the left branch
Traverse the right branch
Inorder Traversal
Traverse the left branch
Visit the current node
Traverse the right branch
Postorder Traversal
Traverse the left branch
Traverse the right branch
Visit the current node
0 notes
Text
Trees!
As the midterm dawns upon me tomorrow, I finally figured it was time to stop my metamorphosis into a potato and start studying, the sooner the better but I always tend to fall victim to procrastination in the end anyways.
So here I am, the day before the midterm trying to piece everything together.
…
An important ADT and indeed a fundamental one we touched base on in the past few weeks is the idea of a tree.
No, not the trees in the park although similar.
I like to define a tree in CS as a nonlinear data structure which consists of one if not many tree nodes. So what exactly are these tree nodes? Tree nodes are also an ADT which when linked together form a tree, very much like how linked-list-nodes essentially link together to form a linked list as previously seen.
What does a tree node consist of?
A tree node consists of usually two things, its value which is an object or a reference to an object, and its children, which can be one, many or none. A tree node’s children is simply a reference to other tree nodes in which those tree nodes are the child of the parent node, hence there are connected by something called a link or an edge.
A tree node by itself (in isolation) will only know its children nodes but not its parent node.
Now that we know what a tree is, let’s go onto some terminologies of trees.
Root
A root or root-node is simply the top-most node or the very first node or parent node. All other nodes descend from the root node, in other words, the root node is the “seed” of the tree. Tree operations usually start from the root node.
Internal node
An internal node is a node within the tree that has children, the root node is also considered an internal node whether it has children or not.
Leaf node
A leaf node or simply leaf is a node within the tree which has no children and therefore ends that specific path of the tree. A root node is never considered a leaf node even if it has no children.
Height
The height of a node is the maximum number of links/edges required to reach a leaf node from that starting node. The height of the root node is considered the height of the entire tree. Leafs have a height of zero.
Leafs have a height of one in this course so the height is the maximum number of edges required to reach a leaf node from the starting node plus one.
Depth
The depth of a node is the exact number of links\edges needed in order to reach the root node from that starting node. The depth of the root node is zero.
Branches
Branches are simply links to children nodes from the parent. So the maximum branching factor of a tree is the maximum number of children that a node within the tree has.
Subtree
A subtree is a tree that is derived from the original tree which has a node within the original tree as its root node and contains all its descendants from that node. Each node within the tree can be broken into a subtree and the subtree of the root node is simply the original tree itself.
Binary Tree
A binary tree is a special type of tree where each node are only allowed two children node, a left node and a right node where usually one side contains value/data that are greater than the parent node and the other contains lesser value/data.
Aside from that, that’s all I can think of and say today. Hopefully I got my terms correct. D:
3 notes
·
View notes
Text
ADT you say?
What is it, and why do we need it?
ADT defined as abstract data type is a data type that is abstract.
Sick definition, but what do I mean by a data type, or better yet what do I mean by abstract.
As we know it, programming doesn't involve the handling of real-world objects (maybe except your computer) unlike say cooking, in which we handle real-life interpretations of objects and their physical entities.
For example, say we’re making a salad (our software), first off we’re going to need some vegetables (our superclass), so we’re going to use those tomatoes you left hanging in the fridge a week ago (our object), and these tomatoes we’re using are very much real, they exist as physical objects!
Now that tomato we’re using has physical properties otherwise known as data, i.e. the tomato is red, the tomato has a stem, and the tomato belongs to the vegetable class.
Yes, tomatoes are vegetables.
Along with this, you can also perform tasks with the tomato otherwise known as operations, i.e. cut the tomato, peel the tomato, and finally perhaps squash the tomato (Or throw them at people).
All of this makes up the properties and behaviours of a tomato but these are very much more physical than abstract. In computer science, we don’t have the luxury of working with real-life objects like tomatoes so therefore we need a solution in which we can abstractly represent those objects we are working with, otherwise known as ADT.
We as programmers need a way to represent entities and intangible objects in a way which can help us solve and tackle problems.
This begins our topic of ADT. An ADT is something we use to store data and the operations pertaining to that data. For example if we wanted to make a virtual salad simulation for whatever reason, a tomato object would then have to be an ADT since we’re not using real tomatoes anymore, hence the idea of a tomato is now abstract rather than physical.
When we’re dealing with ADT, we usually want our data type to be semantically representative of that of its real life counterpart like our tomato but this doesn't have to always be the case. Let’s look an integer, integers are ADT but integers are also abstract in real-life as in integers don’t represent any real-world objects, but integers are in fact a fundamental ADT in CS.
Without integer ADT, the world as we know it today will fall apart and crumble to dust, like my GPA.
If you logically think of it, how in the world does a computer add numbers like 5 + 3? Sure we all know what 5 and 3 are, but philosophically 5 and 3 are nothing more than plain symbols with no physical meaning to them, but it is us human who assign the abstract numerical meaning to the symbols 5 and 3.
If you tell an alien to calculate 5 + 3, chances are it has no idea what this gibberish is.
So how does a computer understand how to calculate and manipulate values such as 5 and 3? Well it’s all thanks to the hidden implementation of the integer ADT written by somebody we will never know.
As you now see, it was the ingenious minds of far-away computer scientists who were able to tell a computer how to add integers, but how did they do it? Quite frankly, we don’t know and we really don’t care.
We shall and need hide our implementations.
But I’ll leave this for next weeks SLOG cause I got to go...
0 notes
Text
148 impressions
My impressions so far on 148
We’re about 6 weeks into the course and I have to say that CSC148 is a lot more different than its prerequisite CSC108. Well for first, I feel that 148 doesn't emphasize logical thinking and problem-solving unlike 108. 108 was a lot more algorithmic-focused and had a bigger stress on application of functions and problem-solving hence 108 had a lot more coding. On the other hand, 148 is more focused on documentation and class-design pertaining to OOP, which consequently results in minimal coding and reasoning.
What I mean by this is that in 148, the aspect of coding and constructing algorithms is far less emphasized. With that in mind, the spotlight of 148 is rather pointed towards the designing/implementation of classes and objects. Because of this, we are forced to focus our attention moreover to API and class-implementation rather than function-implementation and problem-solving like that in 108.
My thoughts on all this
My studies in CS had really taken a turn in 148. For the last couple of years, my CS courses had never bothered to underline the importance of good class-design and API but instead they only focused on the problem-solving aspect of things like learning how to write working functions.
But ultimately what struck me the most in 148 is the fact that we as computer scientists/programmers write software not only for ourselves, but also for other programmers and users, in other words our clients. Because of this, we must place a heavy significance in maintaining that our code/software work not only for the benefit of ourselves, but also for the interest of our clients hence this is why we as programmers must put a heavy emphasis on the implementation (API i.e. docstrings) of our codes and 148 has done an excellent job in shedding the light in regards to this.
5 notes
·
View notes
Text
All stack things
What is a stack?
Well since we recently touched base on the idea of a stack data structure, I might as well go ahead and write a stack of sentences on it. The idea of a stack is really straight-forward. It’s constructed based off the idea of a LIFO structure (Last in, first out). Much like the name suggests, a stack is kind of like a “stack” of objects; for an analogy, the objects can be blocks, books, coins, whatever, as long as they’re on top of each other in a stack.
A real-life analogy of a stack which helps me a lot is to think of a tennis ball tube. In the tube, we have only one opening where we put the tennis balls inside. So if we wanted to remove a tennis ball from the tube, the only tennis ball we can physically remove without busting open the tube would be the one we last placed in; i.e.the one at the very top (Last in, first out). On the other hand, the only way to insert a tennis ball into the tube, is to place it on top of all the other ones.
How are stacks even relevant to me?
Understanding stacks can help you visualize and deepen your understanding on many things pertaining to CS or just stuff in general. On the core level, stacks are important in constructing basic computer fundamentals and languages but aside from that, the idea of stacks are used in our everyday lives too. For example, software like Internet explorer, MS paint, Pycharm all have undo or back functions. These again, work off the idea of a stack. In a simple explanation, the software will record and remember your previous action and push that onto a stack. Therefore when you make a mistake, you can simply call the undo function, where it checks your “stack of actions” and can easily backtrack (undo) your last performed action which would be on the top of the stack.
4 notes
·
View notes
Text
An Intro
Where am I from?
Short introduction to myself as a computer science student in my first year undergrad. I am from Toronto myself, lived here, went to school here, and grew up here all my life. What had driven me into pursuing computer science stemmed from my very first CS class in grade 10. The introductory CS course was in Python and dealt with the most simplistic of things like learning how to print “Hello World”. From there, my interest in coding started to take off.
Few months later, I started to write more and more complicated code. My very first functional program I’d written was a simple guess-the-number game. As basic as it was, to me it was quite satisfying. By the end of the course, I had designed a playable game of Connect-Four on the Python shell as part of my final assignment.
Along with that, another reason why I was so interested in coding came from the thankful apathy and bad-teachings of my CS teacher, which sparked my initiative to self-teach myself and to also explore the realm of CS in my spare time in order to compensate for her laziness. Thanks Ms. P.
From there I went on to taking CS in both grade 11 and 12 (in Java) before coming here to UofT. Through my three years of high-school experience, I've already come to learn many of the concepts and practices taught in first year CS. But still, many things in CSC148 are new to me like the idea of API and design recipes, all of which were not taught in high-school CS.
My intentions for this blog
To me, I really want this blog not only to be a one-time do-and-forget thing for CSC148, but rather as a sort of personal log that will help guide me through my time with CS in university and perhaps the future, acting as a tool in reinforcing and documenting my learnings and endeavours.
Aside from all that, I really have nothing else to say regarding CS. As for my side hobbies and interests, I enjoy astronomy, writing, poetry and of course, gaming.
1 note
·
View note