
This blog focuses on Health IT and technologies used in my current position such as SQL Server, SSIS, SSRS, etc... I have been with Northwestern's Medical EDW since early 2009 and in health care IT since 2002.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by jontav-blog and here's what we found interesting.
Average Info
Notes Per Post
32
Likes Per Post
28
Reblog Per Post
3
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Give Yourself Time
Time is precious! It passes us by without any regard for what may be occurring in our day. How rude. This is, arguably, a technology blog so what’s this post mean in the context of data loading processes particularly those that build data warehouses and similar data products?
Consider delaying the filtering of data when the presence of data causes no harm yet the absence of data causes harm (i.e. pulling people away from normal work to fix the problem).
Example:
Let’s say you whitelist identifiers used in the process of building a table such as in this pseudocode:
begin transaction; delete from my_table; insert into my_table(cols) select * from staging join whitelist on staging.id = whitelist.id; commit transaction;
What happens when an identifier drops off that whitelist? You get contacted immediately about someone asking where their data went!
You may want to implement something along the lines of the following provided data sticking around for a bit causes no harm:
The user takes an action to delete an identifier from the whitelist.
Soft-delete that identifier and mark it with a deletion timestamp.
Continue loading data for identifiers with a deletion timestamp within the last N days (let's say 14 days).
Warn people when identifiers are about to expire for data loading purposes. They then have time to take action to prevent that from occurring if it should not occur.
3 notes
·
View notes
Text
SSIS 2008 R2 Configuration Files - Order of Precedence
When creating a variable in an SSIS package, there are a number of locations where its value can be specified at design time. Here's a 2008 R2 test showing a few of those locations and which wins when the ETL actually runs.
A variable named "subject" was created in an SSIS package. A Send Mail Task component was added to simply email me the value of this variable when the package is run.
This package was then scheduled in a SQL Server Agent job and the variable's value was then specified in four places:
Package: Variable Value
Package: Configuration File A
Job Step: Configuration File B
Job Step: Set Values
Each location has a different value. Given that different values exist in all four locations, what location trumps the others?
Here's what my testing showed as the order of precedence:
Package: Configuration File
Job Step: Set Values
Job Step: Configuration File
Package: Variable Value
In other words, a value found in the package's config file wins. If no value is found there, then the job step's Set Values configuration is used and so on.
I did not test SSIS 2005 or 2012. Results may differ for those versions and 2012 has new functionality to consider altogether.
3 notes
·
View notes
Text
The Best Simpsons Episode Ever
Lisa the Vegetarian is the best Simpsons episode ever.
Here's how it was decided....
Six fellow Simpsons fans and I determined this important fact over many work lunches. Each of us submitted a ranked list of our 30 favorite Simpsons episodes from most to least favorite. The episode I ranked highest was Homer's Enemy for instance.
The highest ranked episode on each person's list earned 30 points, the next highest 29 points all the way down to the thirtieth episode which earned 1 point.
All seven lists were combined to determine the 64 episodes that earned the most number of points. These 64 episodes then populated a four-region bracket similar to how the NCAA March Madness bracket is setup. In other words, we identified the 64 Best Simpsons Episodes ever and now that the bracket was set, the big dance could begin!
Each week or two, we'd pick a match-up to watch and progress our way through the rounds: 64 episode round, 32 episode round, etc... All who watched a match voted for the episode they thought was best. The episode with the most votes advanced to the next round.
Some numbers:
108 total episodes were represented on the seven lists. The top 64 were chosen for the tournament.
A surprising 56 episodes appeared only on one list, respectively.
No episode appeared on all seven lists. One episode, You Only Move Twice, appeared on six lists and made it to the championship match.
Lisa the Vegetarian, a two seed appearing on four lists, was the overall winner.
Homer & Apu, a 15 seed, advanced to the Final Four.
The contest took 500 days to finish. We watched the first match on October 17, 2011 and the last on February 28, 2013. Some weeks were skipped due to works and holidays of course.
You can view a PDF of the episode bracket.
3 notes
·
View notes
Text
Books I've Recently Read
As it turns out, the holidays and a honeymoon are a great time to fire up the Kindle for some relaxing reading. Non-fiction books that I've enjoyed recently and are helpful to working in data are:
To Sell Is Human: The Surprising Truth About Moving Others
The Power of Habit: Why We Do What We Do in Life and Business
The Signal and the Noise: Why So Many Predictions Fail-but Some Don't
Data Driven: Profiting from Your Most Important Business Asset
I've found each of these helpful in formalizing definitions for issues we are beginning to tackle and how to practically move forward with fixing those issues.
0 notes
Text
Fixing Tumblr Connection Reset Issue
Is Tumblr your blog hosting platform that visitors reach through your custom domain (e.g. blog.jontav.com) and you're plagued by "connection reset" errors? Revisit Tumblr's instructions for using a custom domain.
Previously, the instructions stated to setup an alias to a specific IP address. Now (10/26/2012), the instructions provided are different depending on how you want surface your Tumblr blog on your domain.
After using the new instructions, I no longer receive "connection reset" errors. I must have missed the notification from Tumblr as these updated instructions were new to me!
0 notes
Text
SSIS 2008 R2 Logging - Recommended Options
Within a SQL Server Integration Services (SSIS) ETL, tasks are being performed around data being moved from A to B with transformations occurring in between. Detailed logging options can be configured.
In our environment, logging when tasks occur along with any errors, warnings, and failures works best. Logging all possible events is rarely needed and often leads to performance degradation. The mere act of logging requires resources after all (CPU, disk, memory).
Example Package
I setup a sample 2008 R2 ETL with four Control Flow items executed sequentially. Artificial delays have been coded into most of the components. The first component, for example, is an Execute SQL Task that is setup to delay two seconds.
Since each delay is controlled, the goal is to enable configuration to confirm those delays in our logging table.
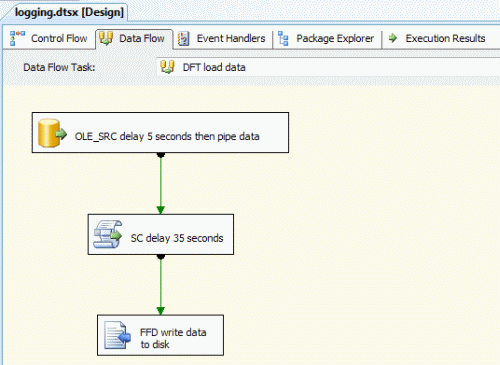
Control Flow
Here are the four Control Flow items. The last item emails the execution instance GUID to me, which is used to look-up the logging that has occurred.

Data Flow
The Data Flow Task delays for five seconds before piping one row of data to a Script Component Transformation, which delays for 35 seconds. That row is then written to a flat file on my laptop.
Default Logging Options
An "SSIS log provider for SQL Server" has been configured to write its information to a database on our development server. The package events that will be logged are:
Bad stuff happening: OnError, OnTaskFailed, OnWarning
Timing of stuff happening: OnPreExecute, OnPostExecute
First Run Instance
I executed the ETL and got an email with its execution instance GUID upon completion:

Using that, here's the raw data in the execution log...

...and the query used to find it:
-- Execution Log: select l.id, l.event, l.source, l.sourceid, l.message, l.starttime, l.endtime, datediff(second, l.starttime, l.endtime) as row_duration -- not helpful from ETLExecutionLog.dbo.sysdtslog90 l where l.executionid = '4BD3B61F-AFD3-4A6A-9F89-D9845A695CBF' order by l.starttime
The result set is kinda useful and even better when aggregated using only the OnPreExecute and OnPostExecute events...
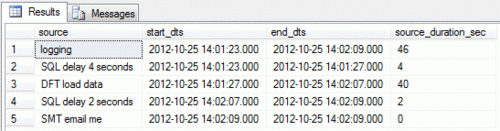
...as generated with this query:
-- Timing of Control Flow items: select l.source, min(l.starttime) as start_dts, max(l.endtime) as end_dts, datediff(second, min(l.starttime), max(l.endtime)) as source_duration_sec from ETLExecutionLog.dbo.sysdtslog90 l where l.executionid = '4BD3B61F-AFD3-4A6A-9F89-D9845A695CBF' and l.event in ('OnPreExecute','OnPostExecute') -- comment out if these events don't exist group by l.source order by 2
Much better! I can now identify how long each Control Flow item took to run. The entire package took 46 seconds and the expected amount of each delay I setup is actually what's being captured.
This is showing that the Data Flow Task, which took 40 seconds to finish its work, is the bottleneck. Knowing this fact is typically enough to continue investigation (e.g. manually open the ETL and play around with what happens in the DFT). Nearly all of our data flows are as simple as possible. Data is selected, transformed just a bit, and stored in a table.
Let's say you're ETL is typically more complicated than that. You may want to enable an additional level of logging for the DFT level.
More Logging, Second Run Instance
I've modified the package's logging configuration to capture the OnPipelineComponent time event for the DFT in question. The package has run and once again I've been emailed the execution instance GUID: 6664EBC7-3DF8-461E-AB81-2E2F20F67D14.
The logging data isn't as clean as before, but it's enough to identify that the Script Component transformation is the bottleneck taking 35 seconds to finish:

That result set was generated with a query similar to the first one given above:
select l.id, l.event, l.source, l.sourceid, l.message, l.starttime, l.endtime from ETLExecutionLog.dbo.sysdtslog90 l where l.executionid = '6664EBC7-3DF8-461E-AB81-2E2F20F67D14' and l.event like '%PipelineComponentTime%' order by l.message, l.starttime
Summary
In my environment at work, we've found it beneficial to enable package level logging for these and only these events:
Bad stuff happening: OnError, OnTaskFailed, OnWarning
Timing of stuff happening: OnPreExecute, OnPostExecute
Having information on these events is typically all that is needed to narrow your investigation efforts when addressing errors or bottlenecks. Basically, it points you in the right direction for where to go next.
1 note
·
View note
Text
Parallel Processing Options in SSIS 2008 R2
SQL Server Integration Services (SSIS) is a flexible ETL tool. Not all parallel processing options are well understood so I thought I'd quickly cover a few in this post:
Built-in Control Flow and Data Flow settings
Standard Microsoft components
Custom CozyRoc component
While many of the built-in settings and standard components enable the parallel processing of data, it's done in such a way that code and error handling configuration must be duplicated.
My computer has eight CPUs available for work as seen in the Windows Task Manager:

Control Flow: MaxConcurrentExecutables Setting
The MaxConcurrentExecutables property controls the "threads that a package can create." To me, that means it'll determine how many Control Flow items will run at the same time.
The example ETL below has 32 Execute SQL Tasks. Each task simply runs a two-second query. Microsoft's documentation states that the default setting, -1, will execute items "equal (to) the number of processors plus two." My laptop has 8 CPUs so as expected 10 Control Flow items run in parallel as seen below:

Shown below is an example of the property set to a value of 3. Three SQL tasks have already completed and three more are being run. The tasks chosen to run are selected randomly.

If the computer can handle it, the property can be increased to run more items in parallel than the default permits as seen below:

Parallel processing of Control Flow items is great when each item performs different tasks. If the same task is performed, then code is being repeated and any configuration for event handlers.
Read Microsoft's documentation on this setting.
Data Flow: EngineThreads Setting
The EngineThreads property, according to Microsoft's documentation, provides a suggestion on the number threads used for pulling data from source components and transforming & storing data in destination components. For example, setting this property's value to 2 provides the suggestion that 2 threads start for sourcing data and 2 for transforming and storing data.
The screenshot below shows an ETL with the EngineThreads property set to a value of 2. The Data Flow Task itself contains 40 sequential flows of data. Each flow selects some data then copies some columns. Since the EngineThreads property is only a suggestion, SSIS has opted to spin up more threads to accomplish the work. No limitation has been enforced based on the property's value of 2.

Read Microsoft's documentation on this setting.
Data Flow: Conditional Split Transformation
In cases where transforming data is the bottleneck, the data flow can be split into multiple transformations for parallel processing. One way to accomplish that task is assigning each row into a bucket then using a Conditional Split transformation to pipe each bucket to its own path.
Let's say each record as an integer ID. A bucket ID could be created using the mod operator, which returns the remainder in a division operation. 103 / 4 = 25 r 3 for example as seen in the example below for record 102 through 110. Without a numeric value on each row, a derived value could be used such as the result of the NTILE ranking function.

The Conditional Split transformation can be setup to direct all records in bucket 1 down a path while all records in bucket 2 are directed to another path. A default path should be specified to ensure all records are processed. The screenshot below show ~75,000 records being split between three paths. The default path has more work to do because only two of the buckets are purposely split into their own paths.

If each transformation is doing the same work, a drawback to this approach is repeating code in each path as well as any handling of rows that error.
Data Flow: Balanced Data Distributor Transformation
Microsoft released the Balanced Data Distributor as an SSIS add-on (you don't get it out-of-the-box). It's incredibly simple to use and performs the same function as the Conditional Split approach described above. Simply drop the BDD transformation into your data flow then pipe its output to multiple transformations and destinations. That's it. The BDD automatically splits the flow. Much less painful than the Conditional Split approach.

If each transformation is doing the same work, a drawback to this approach is repeating code in each path as well as any handling of rows that error.
Control Flow: CozyRoc Parallel Loop Task
CozyRoc develops a fantastic suite of custom SSIS components for an equally fantastic price (seriously, they could charge double at least). One of these components is the Parallel Loop Task. This component permits a Foreach Loop Container to be run many times in parallel.
For example, if your normal ETL flow grabs 100 IDs then processes those IDs sequentially in a Foreach Loop container, the Parallel Loop Task component can be used to spin up multiple instances of that Foreach Loop container. Any code or event handlers that exist are also respected so you need not worry about code duplication. One of my co-worker's has used this and other CozyRoc components to develop a slick method of loading dynamic data sources in parallel.

The image above shows CozyRoc's component in action. Multiple instances of the Foreach Loop are being executed in parallel.
0 notes
Text
Storing IDs from Identity Management Solutions
For enterprises with many applications, identity management solutions prove useful in matching records across these systems using common characteristics. Algorithms to perform this matching can become complicated, but a simple example would be matching patient records in different systems should those records share the same last name, date of birth, and SSN.
Information could of course be updated so two records that may have been matched together previously may shift and be matched with different records. In other words, the enterprise ID is useful at a specific point in time (i.e. now) to identify similar records across applications. It is not a permanent identifier that can always be used to identify a specific record across enterprise applications.
Let's look at an example.
Sample Data
Our identity management solution has matched records coming from various systems resulting in three patients as seen in the image below: Jon Doe, Sally Doe, and John Doe.

The patient Sally Doe for instance has an enterprise ID of 543 used to group her records found in Cerner and Epic.
The important concept to note is that the enterprise ID simply buckets these records together at a specific point in time. It is not a permanent identifier that can always be used to identify Sally Doe's records across enterprise applications.
List of IDs to Track
Let's say someone is analyzing data from Cerner, finds what they need, and stores the enterprise IDs of these patients to track them going forward:

The context in which these enterprise IDs has NOT been stored. No information exists to note that the enterprise ID was found based on records identified in Cerner. Since enterprise IDs serve to group records as of "now," storing them for future use can prove problematic.
Enterprise ID Shift
Now, let's assume that information was corrected in the source systems and a couple records move from enterprise ID 100 to the other buckets. The Athena record from enterprise ID 100 is corrected in the source system and now matches to enterprise ID 543. The Cerner record from enterprise ID 100 is corrected in the source system and now matches to enterprise ID 850.

Now, given the enterprise IDs that were previously stored...
...it is impossible to know whether removing ID 100 is appropriate here.
Food for Thought
Storing just an enterprise ID is problematic as records shift between buckets. Some buckets may disappear altogether depending on what records survive the matching logic.
Storing key pieces of information used in the matching algorithm may be better than storing the enterprise ID itself.
Consider flagging the records that need to be tracked in a source system itself. When performing analysis, identify records that have been flagged then look up its enterprise ID to find its records in other systems.
0 notes
Text
Coldplay Wristbands
File this post under fun with technology! Earlier this week, Nikki and I went to Coldplay's Tuesday night concert at the United Center here in Chicago. Coldplay puts on an excellent show. They're all around entertainers and one particularly impressive item in this show was the light-up wristbands given to every guest.
When entering the venue, each guest was given a green, white, orange, pink, or blue wristband to wear during the concert. These wristbands are made by Xylobands. Each color could be controlled while the music was playing. For instance, all the blue wristbands would flash while all the orange wristbands stayed on. 20,000+ people all had lights synced to the music. Very cool. Here's a great video from YouTube:
Naturally, I brought my home and took it apart to see how this pulled off. The exit we used did not have any collection bins. Here's a picture of the cover taken off my green wristband:

That's a 3V CR2032 battery sitting on top of the circuit board and here's a shot of the bottom:

Two more 3V batteries are on the bottom of the device (CR2016s) and the wires to the LEDs can clearly be seen. So, there are a total of 9V powering the wristband, which should be good for days. Does it still work and how's they pull off controlling the wristbands?
Taking out and putting the batteries back into the device caused the lights to flash. That's smart. The microcontroller flashes the lights to let the person know the band is ready for action.

Two components are largely responsible for this device working:
A computer chip to read instructions and tell the lights what to do (blink, flash, turn off, stay on, etc...)
A wireless receiver to get those instructions.
Here's a picture showing those two components:

Each chip has text written on it and a bit of Googling shows that they're both from Silicon Labs:
C8051F980 Microcontroller: this holds the brains of the operations. Based on the instructions it gets, it'll control the lights. It'll also flash the lights when it first turns on (i.e. gets power) and then probably starts communicating with the RF receiver. I imagine the device also enters a low power consumption mode after not receiving a signal for a period of time.
Si4313 RF Receiver: these are the ears of the device. This component is used to wirelessly receive instructions. You can see its oscillator just to the left of it in the image.
Hats off to Coldplay for turning the entire venue into the inside of a Christmas tree and to Xylobands for inventing such a neat device!
8 notes
·
View notes
Text
Hiring Data Architects with SQL and RDBMS Experience
The Northwestern Medical EDW (where I work) is hiring! Specifically, we're looking for folks who can interact with professional staff (business analysts, clinicians, etc...) and are familiar with:
SQL
Database modeling and architecture
ETL process (extract, transform, load)
Northwestern is a great place to work and the EDW is a fun team filled with talented individuals who get along really well. As an example, we're currently working our way through a 64 Simpsons episodes bracket to determine the best episode of all time. We use proven technology to solve problems and at the same time, never shy away from exploring new technologies.
Interested? View more details on the team's blog.
5 notes
·
View notes
Text
CMS Incentive Programs
As a techy who has worked on CMS Incentive Programs the past three years, I often get asked by business and clinical users to provide an overview of the programs. Included below is my understanding of the programs as of now (July 2012). As always, check with Uncle Sam at CMS for specifics.
CMS Programs
The Centers for Medicare & Medicaid Services (CMS) offers voluntary programs that provide organizations with a financial incentive for their participation. This incentive is often millions of dollars. In future years, the programs transition to penalties. Organizations who do not participate will be penalized a percentage of their Medicare reimbursements, which again is millions of dollars.
The four programs in question are:
EHR Incentive Program (aka Meaningful Use): Does your organization make good use of its EMR software?
PQRS Incentive Program: Can your organization calculate and submit quality data to CMS?
eRx Incentive Program: Has your organization implemented e-prescribing and made regular use of the functionality?
eRx Penalty: Has your organization implemented e-prescribing and made regular use of the functionality?
Important points regarding those programs:
Each program is separate and as of now, each has almost no influence on any other program unfortunately. Future CMS legislation may change that (e.g. reporting PQRS incentive satisfies the CQM component of Meaningful use).
Programs pay for participation, not performance. That will hopefully change in the future as well.
The eRx Penalty is part of the eRx Incentive Program, but it must be reported separately so I consider it a different program.
With each program, data must be sent to CMS. There are different ways how that submission can be done.
Reporting Data to CMS
Each program requires organizations to report data to CMS. Sending that data to CMS can be accomplished in a number of ways depending on the program. The list below shows the methods that I know about.
EHR Incentive Program aka Meaningful Use
Manual Attestation
Manually type numbers into a CMS web application.
For a hospital, these numbers are entered once for the entire organization.
For an outpatient organization, these numbers are entered once for each provider attesting.
A key part of MU attestation is calculating and reporting Clinical Quality Measures (CQMs), which is the intent of the PQRS Incentive Program.
PQRS Incentive Program
Individual Provider Reporting
Submit an XML file to CMS through a third-party such as a CMS qualified Registry or Data Submission Vendor.
Claims
Submit data directly to CMS on Medicare claims.
Group Practice Reporting Option (GPRO)
Submit data directly to CMS using the GPRO web application.
Direct from EHR
Submit data directly to CMS directly from your EMR application.
eRx Incentive Program
Individual Provider Reporting
Submit an XML file to CMS through a third-party such as a CMS qualified Registry or Data Submission Vendor.
Claims
Submit data directly to CMS on Medicare claims.
Group Practice Reporting Option (GPRO)
Submit an XML file to CMS through a third-party such as a CMS qualified Registry or Data Submission Vendor.
Organizations cannot submit eRx directly to CMS under GPRO.
Direct from EHR
Submit data directly to CMS directly from your EMR application.
eRx Penalty
Claims
Submit data directly to CMS on Medicare claims.
Additional Notes
In addition to crunching data and submitting numbers to CMS, there are other tasks required for participating in a program. Tasks such as going through a vetting process, attending weekly/monthly meetings, submitting letters, identifying and arranging access to resources, etc… should not be discounted.
Large medical campuses with multiple organizations participating in all programs under different reporting options will need to carve out a lot of time/resources to support simply submitting data.
CMS should eliminate separate reporting for avoiding the eRx penalty and earning the eRx incentive.
CMS should eliminate the PQRS incentive program and fold it into the EHR incentive program or let organizations satisfy the CQM component of MU by PQRS participation.
This is perhaps the nerdiest post ever published on Tumblr.
0 notes
Text
Orbitz and Mac Users
Orbitz has been catching a lot of negative press lately for WSJ's discovery that Mac users are offered pricier hotel options than PC users. Mac users are not charged a different price for the same option, just shown different options that cost more because as the article notes, Apple consumers typically have a higher household income.
I say kudos to Orbitz for making a business decision after analyzing data and knowing its customers!
1 note
·
View note
Text
Amazon AWS: S3 and CloudFront
I finally had some free time to play around with Amazon's S3 and CloudFront services (commercial cloud services are not used at my work currently). Within 10 minutes, I was able to upload an image into an S3 bucket then create a global distribution network in CloudFront. The ease of use is simply amazing.
For this post, let's pretend that my website is insanely popular with a global audience. I will be uploading an image that can be viewed from my website. I want my site to be fast no matter where the visitor is located.
Image Uploaded
I uploaded an image of me and four friends rafting to an Amazon S3 bucket. Creating an S3 Bucket and uploading objects to it is a snap using Amazon's AWS console. They also publish libraries in a number of languages should you choose to interact with their services programmatically.
S3 Bucket
My image was uploaded to Amazon's servers located in Oregon. That is to say, whenever the rafting image is displayed on my website, the image is transferred from Oregon to your computer. This is true if you live in Chicago, USA or Berlin, Germany.
S3 bucket name: cf.jontav.com
Region: Oregon, USA
Image URL: http://cf.jontav.com.s3-us-west-2.amazonaws.com/cloudfront.jpg
S3 Image
Here is the actual image as coming from Amazon's servers in Oregon, USA:
A Global Problem
For visitors in Germany, my rafting picture hosted in Oregon must travel a long way to reach them. Too long! Physical distances impact even the internet. The more distance between my image and visitors, the slower my website will be. Imagine a business hosting thousands of products, images and selling globally. A slow site means lots of money lost.
For my German visitors, wouldn't it be better to host the image in Europe itself? That would put my image physically closer to them (my site would load faster). Fortunately, Amazon has another dead-simple service to solve this problem called CloudFront.
CloudFront
CloudFront is a global distribution network with its servers existing all over the world. It'll automatically handle the distribution of your content to those servers. For example, my picture hosted in Oregon will be copied to Europe for visitors in that part of the world. Visitors in Germany will then see the image hosted in Europe, which is much closer to them physically than Oregon USA.
Setting up and configuring CloudFront is incredibly easy. When setting up a new distribution, you simply configure it with where to find your original content. A CloudFront domain is then provided. Accessing that domain will serve your content.
For instance, I created a new CloudFront that points to my S3 Bucket configured above (cf.jontav.com). Accessing my rafting image stored in that S3 bucket is done through this URL:
http://cf.jontav.com.s3-us-west-2.amazonaws.com/cloudfront.jpg
After setting up a CloudFront distribution, that rafting image is now referenced here:
http://dz56qmnx8h00u.cloudfront.net/cloudfront.jpg
CloudFront Image
Shown below is the same image as served through CloudFront. Depending on where you live in the world, the image you see may be coming from the USA, Europe, South America, or Asia. If you live in Germany, chances are the image below is being served from Amazon's Frankfurt servers.
Cost
I have all 3,353 of my photographs copied into an Amazon S3 bucket. These pictures take up 6.02 GB of storage space. Let's assume that last month, 1,000 of those pictures were viewed with 80% of the traffic coming from the United States, 10% from Europe, 5% from Japan, and 5% from South America.
For that level of use, how much would my monthly cost be for the S3 storage and the CloudFront global distribution network? $1.16. One Dollar and Sixteen Cents. That's the estimate provided by Amazon's AWS calculator.
Thoughts
It was that easy to setup a global distribution network for my pictures and with the usage levels I'm seeing, it'll cost less than a freakin' candybar?! Amazing.
If you are at all remotely interested in information technology, you'll want an Amazon AWS account. The services are simply too fun not to play with. Bonus: new AWS users typically get one year free of service!
Well done, Amazon AWS team. I tip my hat to you.
4 notes
·
View notes
Text
Bad IT Architecture
InfoWorld's Advice Line blog is new to me and already, I'm very impressed with the articles written by Bob Lewis. Case in point, I couldn't agree more with the "Bad IT architecture: The symptoms" in his How to Avoid Bad IT Architecture article.
0 notes
Text
Yahoo Mail on Windows Phone 7
When setting up a Yahoo mail account on my Windows Phone 7 Samsung Focus, the default outgoing email server is: winmo.smtp.mail.yahoo.com. This stopped working randomly one day. The phone began prompting for my credentials when attempting to send an email. The user name and password were never accepted so I was no longer able to send email from my phone.
These solutions I found online did not work for me:
Change password
Delete account and add again
Type in short username (e.g. jontav) then try long username (e.g. [email protected])
Use password without special characters
This solution did work for me:
Change the outgoing server to: smtp.mail.yahoo.com
Huzzah! I can once again send email from my phone. The Google does not turn up a cause for this problem. It just randomly started occurring for me one day.
0 notes
Text
SSRS Lookup
In the 2008 R2 version, Microsoft introduced the lookup function in SQL Server Reporting Services. This function proves useful when joining data across multiple data sets coming from different servers.
Let's assume you had these two tables to work with:
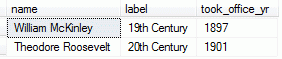
presidents table
name took_office_yr William McKinley 1897 Theodore Roosevelt 1901
century_labels table
century label roman_label 18 19th Century XIX 19 20th Century XX 20 21st Century XXI
The final result set in the report I want to display matches a president with the label column:
If both tables are available on the same server, you're better off performing that join in SQL. However, if these tables exist in entirely different data sources, you can get the century's label using the SSRS lookup function.
Our SSRS report has these two data sets:

The "year_century" field in the presidents dataset is populated with the following expression: =Left(Fields!took_office_yr.Value,2). This will make performing the lookup easier as it takes a full year (e.g. 1897) and returns just the first two digits (e.g. 18).
The actual lookup expression is:
=Lookup(Fields!year_century.Value, Fields!century.Value, Fields!label.Value, "century_labels")
The parameter values are:
The value to lookup from the presidents dataset.
The value to find in the century_labels dataset.
The value to display from the century_labels dataset.
The dataset to use in the lookup, century_labels.
Here's the SSRS table while in design view:

And here's the table when the report is run:

Nothing earth-shattering here. The key takeaway is that the lookup function is a useful tool for joining datasets coming from different sources. If all data exists from one source, you're better off performing the join on the server itself.
0 notes
Text
SQL Server Management Studio Templates
In the SQL Server 2008 R2 environment at work, ten or so databases exist on the same server with the main enterprise data warehouse database hosting scores of schemas containing thousands of tables and tens of thousands of columns. These schemas and tables contain data from the many clinical applications used on Northwestern's medical campus. I often need to search through table and column names to discover where data might be living, but get tired of typing queries similar to the following over and over again:
use r2; select s.name as schema_nm, t.name as table_nm from sys.schemas s inner join sys.tables t on s.schema_id = t.schema_id where s.name = 'dbo' and t.name like '%acc%'
This is where SSMS templates come in handy. A template can be created to prompt the database, schema, and table name to be searched.

First, open the Template Explorer:

Then, in the Template Explorer pane, create a new folder than a new template within that folder. I created a "My Custom Templates" folder and "Table Search" template:
Edit the template to contain the following SQL:
use <Database Name, sysname, r2>; select s.name as schema_nm, t.name as table_nm from sys.schemas s inner join sys.tables t on s.schema_id = t.schema_id where s.name = '<Schema Name, sysname, dbo>' and t.name like '%<Table Name, sysname, acc>%'

Save then close the template. It's now ready for use. Double-click the template's name a new query window will open with the text stored in the template. From the Query menu, select "Specify Values for Template Parameters" or alternatively just press Ctrl+Shift+M:

SSMS will then prompt to fill in the parameter values. The parameters I created in this example are for the database name, schema name, and table name:
I'm going to accept the default parameters and click OK. The query itself will change to whatever values were given for the parameters.
use r2; select s.name as schema_nm, t.name as table_nm from sys.schemas s inner join sys.tables t on s.schema_id = t.schema_id where s.name = 'dbo' and t.name like '%acc%'
Hoozah! With a few keystrokes, I'm able to quickly search object metadata. The syntax for creating a parameter is simply:
<Parameter Name, Data Type, Default Value>
I love easy-to-use functionality that saves tons of time! Not a lot of folks are aware of SSMS templates so that's what prompted this post.
4 notes
·
View notes