#cloudfront
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
CloudFront Now Supports gRPC Calls For Your Applications

Your applications’ gRPC calls are now accepted by Amazon CloudFront.
You may now set up global content delivery network (CDN), Amazon CloudFront, in front of your gRPC API endpoints.
An Overview of gRPC
You may construct distributed apps and services more easily with gRPC since a client program can call a method on a server application on a separate machine as if it were a local object. The foundation of gRPC, like that of many RPC systems, is the concept of establishing a service, including the methods that may be called remotely along with their parameters and return types. This interface is implemented by the server, which also uses a gRPC server to manage client requests. The same methods as the server are provided by the client’s stub, which is sometimes referred to as just a client.
Any of the supported languages can be used to write gRPC clients and servers, which can operate and communicate with one another in a range of settings, including your desktop computer and servers within Google. For instance, a gRPC server in Java with clients in Go, Python, or Ruby can be readily created. Furthermore, the most recent Google APIs will include gRPC interfaces, making it simple to incorporate Google functionality into your apps.
Using Protocol Buffers
Although it can be used with other data formats like JSON, gRPC by default serializes structured data using Protocol Buffers, Google’s well-established open source method.
Establishing the structure for the data you wish to serialize in a proto file a regular text file with a.proto extension is the first step in dealing with protocol buffers. Protocol buffer data is organized as messages, each of which is a brief logical record of data made up of a number of fields, or name-value pairs.
After defining your data structures, you can use the protocol buffer compiler protoc to create data access classes from your proto specification in the language or languages of your choice. These offer methods to serialize and parse the entire structure to and from raw bytes, along with basic accessors for each field, such as name() and set_name(). For example, executing the compiler on the aforementioned example will produce a class named Person if you have selected C++ as your language. This class can then be used to serialize, retrieve, and populate Person protocol buffer messages in your application.
You specify RPC method parameters and return types as protocol buffer messages when defining gRPC services in standard proto files:
Protoc is used by gRPC with a specific gRPC plugin to generate code from your proto file. This includes the standard protocol buffer code for populating, serializing, and retrieving your message types, as well as generated gRPC client and server code.
Versions of protocol buffers
Although open source users have had access to protocol buffers for a while, the majority of the examples on this website use protocol buffers version 3 (proto3), which supports more languages, has a little simplified syntax, and several helpful new capabilities. In addition to a Go language generator from the golang/protobuf official package, Proto3 is presently available in Java, C++, Dart, Python, Objective-C, C#, a lite-runtime (Android Java), Ruby, and JavaScript from the protocol buffers GitHub repository. Additional languages are being developed.
Although proto2 (the current default protocol buffers version) can be used, it advises using proto3 with gRPC instead because it allows you to use all of the languages that gRPC supports and prevents incompatibilities between proto2 clients and proto3 servers.
What is gRPC?
A contemporary, open-source, high-performance Remote Procedure Call (RPC) framework that works in any setting is called gRPC. By supporting pluggable load balancing, tracing, health checking, and authentication, it may effectively connect services both within and between data centers. It can also be used to link devices, browsers, and mobile apps to backend services in the last mile of distributed computing.
A basic definition of a service
Describe your service using Protocol Buffers, a robust language and toolkit for binary serialization.
Launch swiftly and grow
Use the framework to grow to millions of RPCs per second and install the runtime and development environments with only one line.
Works on a variety of platforms and languages
For your service, automatically create idiomatic client and server stubs in several languages and platforms.
Both-way streaming and integrated authentication
Fully integrated pluggable authentication and bi-directional streaming with HTTP/2-based transport
For creating APIs, gRPC is a cutting-edge, effective, and language-neutral framework. Platform-independent service and message type design is made possible by its interface defining language (IDL), Protocol Buffers (protobuf). With gRPC, remote procedure calls (RPCs) over HTTP/2 are lightweight and highly performant, facilitating communication between services. Microservices designs benefit greatly from this since it facilitates effective and low-latency communication between services.
Features like flow control, bidirectional streaming, and automatic code generation for multiple programming languages are all provided by gRPC. When you need real-time data streaming, effective communication, and great performance, this is a good fit. gRPC may be an excellent option if your application must manage a lot of data or the client and server must communicate with low latency. However, compared to REST, it could be harder to master. Developers must specify their data structures and service methods in.proto files since gRPC uses the protobuf serialization standard.
When you put CloudFront in front of your gRPC API endpoints, we see two advantages.
Initially, it permits the decrease of latency between your API implementation and the client application. A global network of more than 600 edge locations is provided by CloudFront, with intelligent routing to the nearest edge. TLS termination and optional caching for your static content are offered by edge locations. Client application requests are sent to your gRPC origin by CloudFront via the fully managed, high-bandwidth, low-latency private AWS network.
Second, your apps gain from extra security services that are set up on edge locations, like traffic encryption, AWS Web Application Firewall’s HTTP header validation, and AWS Shield Standard defense against distributed denial of service (DDoS) assaults.
Cost and Accessibility
All of the more than 600 CloudFront edge locations offer gRPC origins at no extra cost. There are the standard requests and data transfer costs.
Read more on govindhtech.com
#CloudFront#SupportsgRPC#Applications#Google#AmazonCloudFront#distributeddenialservice#DDoS#Accessibility#ProtocolBuffers#gRPC#technology#technews#news#govindhtech
0 notes
Text
Choosing the right CDN can make or break your website's performance. Our latest blog compares Cloudflare and AWS Cloudfront, diving into their features, costs, and speed to help you pick the best option for your needs. Don't miss out!
0 notes
Text
#AWS#AWS Cloudformation#Cloudformation#AWS Lambda#Lambda#AWS Certificate Manager#Certificate Manager#ACM#Lambda@Edge#AWS WAF#WAF#AWS Secrets Manager#Secrets Manager#Amazon S3#S3#Amazon CloudFront#CloudFront#Custom Resources#Custom Resource#Cross-Region#Cross Region#CI/CD#DevOps
0 notes
Text
How to Choose the Right CDN — AWS CloudFront Vs Cloudflare
Cloudflare vs CloudFront
Cloudflare and CloudFront are services that can help reduce your website’s load time. In addition to speeding up your content delivery and load times, they can provide many advantages to your organization. They both work similarly by distributing server loads across multiple servers, but they have fundamental differences. Cloudflare is a service that provides other application services such as DNS, load balancing, video streaming, DDoS attacks protection, web application firewall (WAF), analytics, domain registry, and more. At the same time, Cloudfront is just a CDN provider with the sole purpose of accelerating content delivery.
What is a CDN?
“Content Delivery Network,” or “CDN,” is a network of computers, servers, and nodes worldwide. You upload your website files to the ‘cloud,’ and then this content will be delivered via dedicated servers/nodes that are geographically closer to your end customers than the original hosting server.
What is Cloudflare?
Cloudflare is a buzzing brand in the CDN industry for its ability to provide cutting-edge performance capabilities and robust security features. It functions essentially as a reverse proxy, and its infrastructure is built from scratch, without any legacy system. It was originally intended to keep fraudsters off your website and stop them from harvesting emails. Their global infrastructure and algorithm provide advanced security systems along with performance enhancement. The incorporation of machine learning into the Cloudflare infrastructure enables it to continuously learn, adapt, and integrate to meet the complex needs of the ever-evolving technical environment.
What is CloudFront?
A relatively different or conventional CDN tool does not require you to change nameservers as you did in Cloudflare. Amazon Cloudfront is entirely different from the “Reverse Proxy” approach of Cloudflare.
Cloudfront is another well-known global CDN (Content Delivery Network) that retrieves data from the Amazon S3 bucket and distributes it to multiple data centers it acquires. It uses a network of data centers, often referred to as Edge Locations, to deliver the data centers, often referred to as Edge Locations. When a user requests data on the internet, the nearest edge location is routed, resulting in the lowest latency, low network traffic, faster access to content, and an overall better web experience.
Amazon CloudFront vs. Cloudflare: The Key Differences
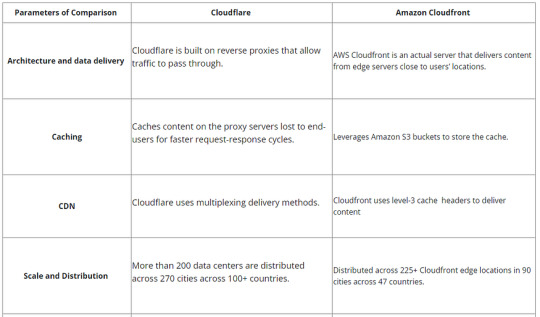
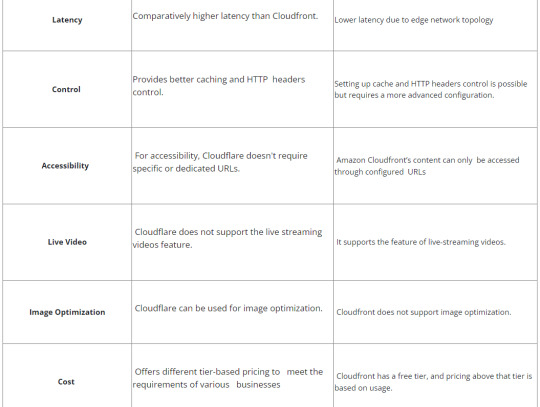
Cloudflare and AWS Cloudfront are both well-established names in the CDN industry. They both provide a wide range of features, which is why it can be confusing when choosing one of them. Amazon Cloudfront and Cloudflare are both highly recommended & suited Delivery Networks to users and can be used as per your requirements. Ultimately, the best choice depends on your specific business requirements. As you’ve seen, there are essential differences between the two services. So, to select the CDN service that best suits your business model, you’ll want to accurately and thoroughly understand the benefits and capabilities of both choices.
Still confused? KnackForge experts can help you choose the best option for your business! Contact our Cloud technical consultants today for a free consultation.
0 notes
Text

AWS CloudFront helps you to perform various tasks including retrieving data. To do that, you need a Python library named boto3. This library allows you to interact with resources in AWS with the help of Python code. One more thing to consider while using boto3 to connect to AWS resources is selecting the right AWS resource explore.
0 notes
Text
Create a static website using Amazon S3 and deliver it seamlessly through an Amazon CloudFront distribution.
0 notes
Text
let me tell you a story
there once was a little fish who loved to scrape website's API endpoints to gather information for their apps
then cloudfront blocked their vps and ruined their day
the end
0 notes
Text
0 notes
Text
This blog post dives into the world of Round-Trip Time (RTT) and its impact on network performance. It explains how RTT affects user experience and outlines actionable strategies to optimize your network for faster data transfer and smoother operation. You'll learn about the factors that contribute to latency, along with effective techniques to reduce RTT and improve overall network efficiency. Additionally, the post explores how Amazon CloudFront can be leveraged to achieve significant performance gains.
0 notes
Text
Exploring Live Streaming Capabilities with AWS Elemental Link

Experience Secure and High-Speed Live Streaming with AWS Elemental Link: Connect with Top Certified AWS Partners for Immediate Service
#aws live streaming#aws elemental link#aws live streaming architecture#live streaming with aws#aws live audio streaming#aws Cloudfront live streaming#aws live streaming pricing
0 notes
Text
Deliver your content worldwide at a high data transfer speed and avoid DDoS attacks with AWS CloudFront to boost the video viewing experience of users.
0 notes
Text
Boosting Performance: CloudFront KeyValueStore Optimization

You may safely distribute both static and dynamic content with fast transfer speeds and minimal latency by using Amazon CloudFront. You can handle millions of requests per second and latency-sensitive customizations with CloudFront Functions. CloudFront Functions, for example, can be used to rewrite URLs, authorize requests, normalize cache keys, and change headers.
AWS are pleased to present CloudFront KeyValueStore, a safe, low-latency global key value datastore that can be accessed readly from within CloudFront Functions. This feature enables highly customized logic to be implemented at CloudFront edge locations.
In the past, configuration data had to be included directly into the function code. For instance, information for choosing which URL to send the viewer to when a URL needs to be redirected. Every tiny change in configuration when embedding it with the function code necessitates a code change and a redeployment of the function code. There is a chance that code will be accidentally altered when new lookup additions need updating and deploying code. Additionally, since the maximum function size is 10 KB, many use cases will struggle to fit all of the data within the code.
You can now update the function code and the data associated with it separately using CloudFront KeyValueStore. As a result, function code is made simpler and data updates are made simple without requiring code modifications to be deployed.
Let’s examine how this functions in real life.
Building a key value store for CloudFront
You select Functions from the navigation pane in the CloudFront dashboard. Then now you select Create KeyValueStore under the KeyValueStores menu.
This allows you to import key-value pairs into an Amazon Simple Storage Service (Amazon S3) bucket from a JSON file. If you want to start with no keys, therefore you not doing that right now. You finish the key value store creation by entering a name and description.
You select Edit under the Key value pairs area and then Add pair once the key value store has been established. You enter Hello World for the value and hello for the key before saving the adjustments. For now, one key is sufficient, but you can add more keys and values.
Changes made to a key value store propagate quickly to all CloudFront edge locations, allowing functions connected with the key value store to use it with little latency.
Utilizing CloudFront Functions’ CloudFront KeyValueStore
You select Functions from the navigation pane in the CloudFront console, followed by Create function. You give the function a name, choose the cloudfront-js-2.0 runtime, and finish the function’s creation. Then you correlate this function with the key value store using the newly available option.
You can use the console’s key value store ID, which you copy, in the function code that follows:
This function answers with the name of the key and its value, using the first segment of the request path as the key.
Now you publish the function and save the modifications. You can link the function to a CloudFront distribution which you previously made in the Publish tab of the function. You can intercept all requests to the distribution using the Default (*) cache action and the Viewer Request event type.
You return to the functions list in the console and watch for the function to be deployed. Next, you download content from the distribution using curl from the command line and verify the function’s outcome.
Initially, you can test a few pathways that call the method and checkup the previous key you made (hello): Success! Next, you experiment with a different approach to observe that, in the event that the key cannot be retrieved, the code returns the default value.
Now that we have this basic example working, let’s try a more sophisticated and practical one.
Using CloudFront KeyValueStore configuration data, rewrite the URL
Let’s create a function that looks up the custom path that CloudFront should use to send the actual request in a key-value store using the content of the URL in the HTTP request. This feature can assist in managing the various services that make up a website.
Things to consider
Today, CloudFront KeyValueStore is accessible in every edge location across the world. Pay just for the read/write operations from the public API and the read operations from within CloudFront Functions when using CloudFront KeyValueStore. View the CloudFront pricing page for additional details.
The AWS Management Console, AWS Command Line Interface (AWS CLI), and AWS SDKs can all be used to manage a key value store. Support for AWS CloudFormation is on the horizon. You can link a single key value store to every function, and key value stores have a maximum capacity of 5 MB. A key can have a maximum size of 512 bytes. Values may have a maximum value of 1KB. Using a source file on Amazon S3, you can import key/value data while building a key-value store. This file has the following JSON structure:
Key/value data imports during creation provide easy configuration replication between environments (e.g., preproduction and production) and can automate the setup of a new environment (e.g., test or dev).
Read more on Govindhtech.com
#CloudFront#AWS#amazon#API#data#keyvaluestore#AWSManagementConsole#AWSCommandLineInterface#technews#technology#govindhtech
0 notes
Text

Cloudfront
#applecross#Applecross peninsula#sky#clouds#skyline#horizon#cloudy#scotland#great britain#uk#landscape photography#nature photography#landscape#nature#original photography on tumblr#scottish highlands#mountainscape#mountain scenery#mountains
11 notes
·
View notes
Text
#AWS#AWS Amplify#AWS Amplify Hosting#AWS Amplify CLI#Amazon S3#Amazon CloudFront#AWS CloudFormation#AWS CodeCommit#Git#GitHub#CI/CD#Serverless#Static Website#Static Website Hosting#Architecture as Code#AaC
0 notes
Text
🎬 Entertainment App Development Services: Build the Future of Digital Entertainment
In a digital-first world where users stream, binge, listen, and share content 24/7, the demand for entertainment app development services is skyrocketing. Whether you're launching the next Netflix, Spotify, or a regional OTT platform, a powerful entertainment app can place your content at the fingertips of millions.
This blog explores everything you need to know about building a successful entertainment mobile app—features, tech stack, monetization models, and how the right development partner can turn your vision into a captivating, scalable reality.

📱 Why You Need an Entertainment App in 2025
The entertainment industry is undergoing a massive digital shift. With over 6.5 billion smartphone users globally, streaming content—whether video, music, or live performances—has become the new normal. Audiences demand convenience, personalization, and immersive experiences, all of which can be delivered through a well-developed mobile application.
From OTT platform development to podcast and music streaming apps, custom solutions are now essential for media brands, production houses, indie artists, and entertainment startups.
📈 Market Stats Worth Noting:
The global video streaming market is expected to surpass $920 billion by 2030.
Time spent on entertainment and media apps increased by 40% post-pandemic.
Subscription-based platforms like Netflix, Hotstar, and Gaana have seen record-breaking growth.
If you're in the business of content creation or distribution, now is the time to invest in expert entertainment app development services.
🛠️ Core Features of a Winning Entertainment App
To compete with giants like Netflix, Spotify, or Amazon Prime, your app must go beyond basic functionality. Here's what users expect from a top-tier entertainment mobile app:
1. Content Streaming (Video/Audio)
High-quality streaming with adaptive bitrate, low buffering, and seamless playback across devices.
2. User Profiles & Personalization
Smart algorithms that recommend content based on watch history, preferences, or listening habits.
3. Subscription & Monetization Models
Support for freemium access, in-app purchases, advertisements, and recurring subscriptions.
4. Search & Filter
Powerful content discovery with keyword search, genres, languages, trending content, and more.
5. Multi-Platform Access
Cross-platform compatibility (Android, iOS, smart TVs, tablets, etc.) with a unified user experience.
6. Offline Downloads
Let users enjoy content without internet access by enabling secure offline downloads.
7. Live Streaming
Incorporate live shows, concerts, or podcasts with real-time chat and engagement.
8. Push Notifications
Keep users engaged by notifying them about new releases, trending content, and personalized suggestions.
9. Social Sharing & Integration
Let users share what they watch or listen to on social media, enhancing app visibility and virality.
🧠 Choosing the Right Technology Stack
Behind every great entertainment app is a powerful and scalable tech architecture. Here's what a reliable entertainment app development company should offer:
➤ Frontend (Mobile App Development)
React Native / Flutter for cross-platform development
Swift (iOS) and Kotlin (Android) for native apps
Custom UI/UX based on Figma, XD, or Sketch
➤ Backend
Node.js, Laravel, or Django for scalable API architecture
MongoDB or PostgreSQL for content and user data
Real-time databases like Firebase for chat, notifications, and analytics
➤ Streaming & CDN
Integration with AWS CloudFront, Vimeo OTT, or Wowza
DRM support to prevent piracy
Adaptive Bitrate Streaming (HLS, MPEG-DASH)
➤ Analytics & Recommendation Engine
Firebase, Mixpanel, or Google Analytics for user behavior
AI-powered recommendation engine to boost engagement and retention
💰 Monetization Strategies for Entertainment Apps
Monetization is crucial. Your entertainment app can generate recurring revenue through several models:
🔒 Subscription (SVOD)
Offer access to premium content on a weekly, monthly, or annual basis.
🎯 Advertisement (AVOD)
Free content monetized through banner ads, interstitials, or video ads using Google AdMob or Facebook Audience Network.
📥 Pay-per-view
Ideal for exclusive concerts, movie releases, or premium shows.
💼 Freemium
Provide basic content for free while charging for access to premium features or shows.
🤝 Why Hire Expert Entertainment App Developers?
Entertainment apps are high-stakes projects. Performance issues, bugs, or poor user experience can lead to instant churn. Here’s why hiring a team with domain expertise in entertainment mobile app development is critical:
They understand media licensing, content management, and user behavior.
They can optimize infrastructure for millions of concurrent users.
They’re familiar with UI/UX best practices that align with binge-watching or continuous listening behaviors.
They offer post-launch support for updates, bug fixes, and user feedback handling.
A team like Kickass Developers, with expertise in custom mobile app development, OTT app development, and audio/video streaming, ensures your idea is executed with precision and long-term scalability.
🚀 Final Thoughts: Your Entertainment App Is the Future of Engagement
Whether you’re building a regional OTT app, a music discovery platform, or a niche video streaming service, your success hinges on the right blend of technology, UX, scalability, and speed to market.
Investing in experienced entertainment app development services is your first step toward captivating your audience, building loyalty, and driving recurring revenue.
📞 Ready to Build Your Entertainment App?
Looking for a team that understands the entertainment industry inside and out?
Kickass Developers specializes in designing custom, high-performance entertainment applications tailored to your audience, brand, and growth goals.
📧 Contact us today at [email protected] 🌐 Or visit us at kickassdevelopers.com
#Entertainment App Developers#OTT App Development#Video Streaming App Services#Music App Development#Android Entertainment App#iOS Video App#Podcast App Developers#Live Streaming App Development#Subscription App Development
2 notes
·
View notes
Text
The AWS CloudFront helps you to perform various tasks including retrieving data. To do that, you need a Python library named boto3. This library allows you to interact with resources in AWS with the help of Python code. One more thing to consider while using boto3 to connect to AWS resources is selecting the right AWS profile.
0 notes