
She/her, digital artist, elder millenial and reluctant social media participant.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by katdbee and here's what we found interesting.
Average Info
Notes Per Post
22
Likes Per Post
22
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
24 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.


Text

Workflow variations of tile sampling, open pose, and soft edge control nets. Set out to make some half-orc polearm bearers.






















Enough for a whole little tribe <3




As always, feel free to use these for whatever.



#ai generated images#automatic1111#stable diffusion#ai generated#ai rpg character portrait#ai art#ai generated rpg characters#half orc#polearm
1 note
·
View note
Text
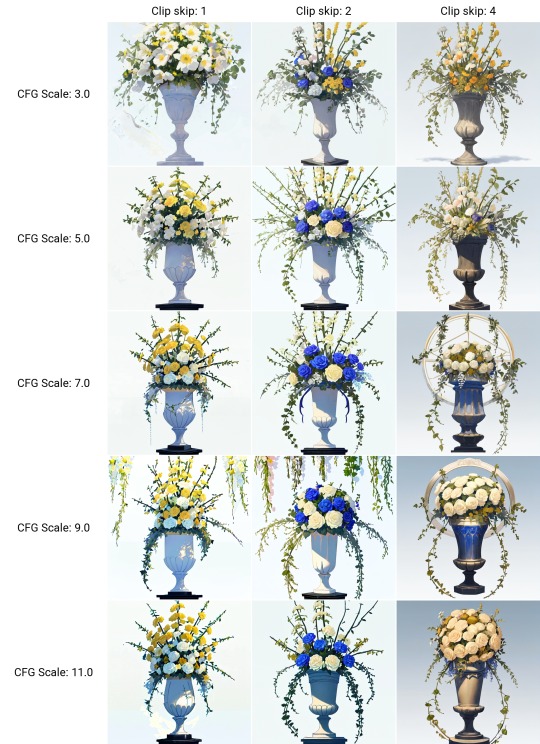
AI flower arrangements. Generated a large batch to get a feel for some of the variation in the models I have.

Automatic1111 text2img XYZ grid generation prompted as:
floral arrangement of yellow white and pink acacia flowers with ivy in a tall white vase on a black pedestal against a blue background






DPM++SDE Karras sampler @ 20 steps 512x512


1 note
·
View note
Text


Workflow for generating 25 images of a character concept using Automatic1111 and Control Net image diffusion method with txt2img;
Enable Control Net , Low VRAM, and Preview checkboxes on.
Select the Open Pose setting and choose the openpose_hand preprocessor. Feed it a good clean source image such as this render of figure I made in Design Doll. Click the explodey button to preprocess the image, and you'll get a spooky rave skeleton like this.


Low VRAM user (me, I am low VRAM) tip: Save that preprocessed image and then replace the source image with it. Change the preprocessor to none, and it saves a bit of time.
Lower the steps from 20 if you like. Choose the DPM++SDE Karras sampler if you like.
Choose X/Y/Z plot from the script drop down and pick the settings you like for the character chart about to be generated. in the top one posted I used X Nothing Y CFG scale 3-7 Z Clipskip 1,2,3,7,12




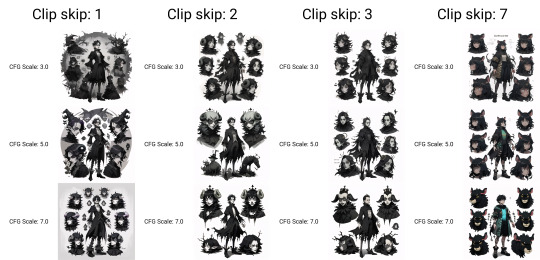


Thanks for reading.
#automatic1111#stable diffusion#synthography#ai generated images#ai art generation#diffusion workflow#ai horror
3 notes
·
View notes
Text






















ControlNet softedge used with render of 3D model of hands holding an icosphere. Assorted models and LORAs used.
4 notes
·
View notes
Text

For me the fascinating thing about image diffusion (Synthography ?) is that concepts exist within the models and they're accessed as easily as knowing the words for it.

As someone who struggles to find the visual language for the thing I want to experience, this is mind blowing.


For these images I took a certain creation myth that I've always loved to daydream about and then narrowed it to key visual concepts.


I then generated xyz grids for multiple 512x512 images at various cfg and clip skip settings, creating multiple iterations of the visual concepts given to it.













And then I enjoyed the results. Hopefully you have too.

1 note
·
View note
Text


3 notes
·
View notes
Text
Embrace series, continued 3
Continuing to document the process as I recall, I had managed to get some constrained results using the dolls which did evoke some pretty cool images however it was getting away from where I wanted to go.



So I changed up the dolls a bit, moved the camera around and set to false perspective to create a super deformation and really push around the results.


It went to some abstract places sometimes


Which I loved on one level but I wanted to rein it back in to more literal human figures embracing.

for the record higher cfg = more abstraction cfg 3 above, cfg 7 below

cfg 9 below

Going back through previous generations is such a treat for me because I miss so many gems the first time.


I kind of wish I could post them all, or at least all the ones that give me that little pause to go 'ooh', but the more there is the less special it gets yeah?

I picked this one to upscale and attempt to refine
#automatic1111#stable diffusion#ai art#ai art generation#ai generated#digital art#ai artwork#ai art gallery#ai artist
0 notes
Text

Embrace series, continued.
I like this piece because the strange anatomy reads as action, contrasted with the larger figures stability.
continuing to document the creative process from my last post, another method that saw a lot of use was text2img with control nets. It struggles mightily sometimes with which way to face body parts but does offer creative compromises in the process.












what I really love is that there's so many stylistic variations being produced all from the same seed, model, and usually prompt, this is mostly coming from altering clipskip and cfg values with control net keeping certain aspects in shape.


Of course I cherry pick my favorites as pieces I can come back to and iterate on differently and that's part of why I post them here.
//more posts will continue to outline my progress with the Embrace series. It's hard to take a break from generating and to recall what's been done to get there, although I know I should really be taking better notes.
#automatic1111#stable diffusion#ai art generation#ai art#ai generated#ai artwork#ai art gallery#ai artist#aiartists#digital art
1 note
·
View note
Text

I call this series Embrace
this result came about by accident and yet I like it the most of the others from this series. This one is my second favorite.

the entire creative process, for posterity, began with generating a grid with a wide range of clip skip and cfg values and the simple prompt 'a ball'. Which yielded many spherical shapes of course but also some completely unexpected ideas as well.



I liked this one, it gave me the idea of a couple embracing and a happy wholesome fluffy kind of thing. Hence, Embrace.
I iterated on it in a few ways such as inpainting.


then decided to make a Design Doll file and render out some inputs for Stable Diffusion control net and img2img and so on. Though that didn't always turn out.
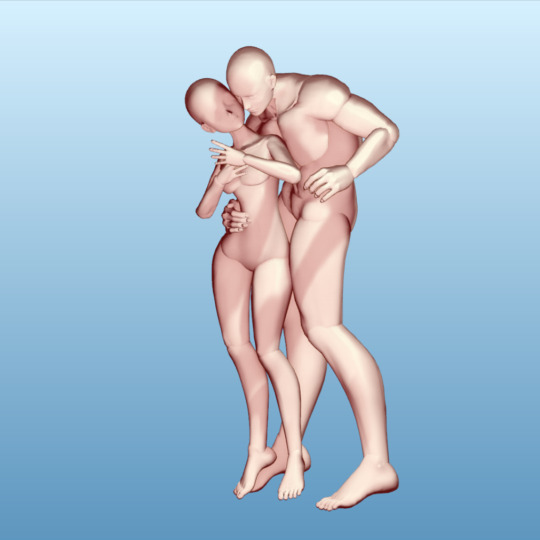
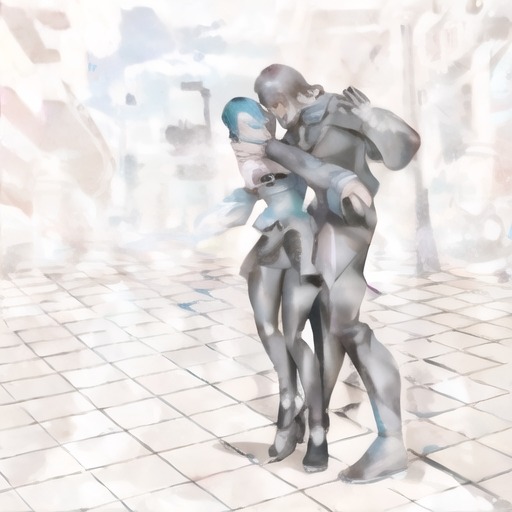


I even tried this crude mashup as img2img and got some mixed results. Still very much leaning into the unpredictable of what happens when the concept is rendered.




that still manage to be lovely in variously abstract sort of way
//the text2img results with controlNet go next.
1 note
·
View note
Text



practice using controlNet tile resample upscaling to add details to an image and inpainting to fix up faces I could take it farther now or I can come back to it another time
#ai generated images#ai art#ai art generation#automatic1111#stable diffusion#ai artwork#ai digital art#digital art
1 note
·
View note
Text






I think I was playing with the control net Reference processor. I think. I go through bursts of not wanting to do work. Some of my earlier inputs/results for Art Nouveau: Flame got plugged in.
0 notes
Text
























Character portraits, free for use as always.
More of the same from me, it's character portraits as practice on generating good hands.
Gonna talk process for a minute There's a few ways to do it, but I get the best results out of setting the openpose controlnet to 'controlnet is more important' and a canny or lineart model that defines the figure further (always make sure it's on for at least the first half of the steps if not the whole way). It absolutely will struggle with open shapes such as where the top of the nagitata is cropped from the input image so the machine does it best to make something up. I got more weird weapons than I did mutant hands, and the mutant hands I did get were from turning on the lineart at the last half of the steps. The depth model is great for creating a lush painterly effect in the generation. The more nets you stack the longer the generation takes so keep that in mind.
Also turn your sampling steps DOWN. What you get in 10 steps will be enough to have a good idea of the generation and demonstrate hand consistency.
A good way to save time while figuring this out is to preprocess the image, save it with the little download icon in the preview window (click allow preview checkbox if you don't see it), and then put that preprocessed image into the controlnet and set the preprocessor to none. That way it won't be re-preprocessing that image over and over which cuts generation time down considerably.
This is the doll I put into the preprocessor and the the openpose that comes out. By preprocessing at a 2048 resolution and generating at 512x768 the details are kept much better than if pixel perfect is used, however if it needed to preprocess and generate this openpose image every single time it would still be cooking right now.

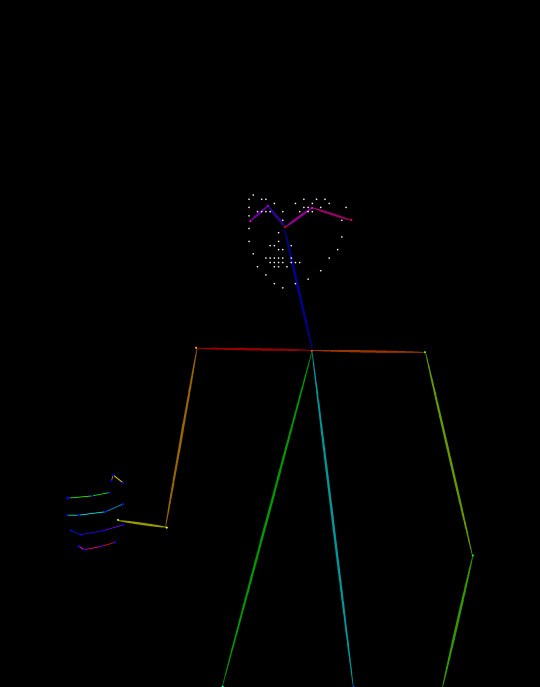
Then this is aaaaaa I don't remember, one of the lineart or canny or whatever preps that makes a rough invert sketch of the input. That got saved and then plugged in again and processed one more time to keep the most relevant edges.
This is also how I came to realize the machines struggle with open shapes. I'm not sure how I'll try to get around that yet.


#automatic1111#stable diffusion#ai art#ai generated images#ai art generation#ai workflow#ai hands#aiartcommunity#ai generated#AIssisted#ai rpg character portrait#rpg character#character art
3 notes
·
View notes
Text
painting over a generated image


left original -> right modified
I had a very soft painterly generated image so I layered the image over itself selectively and painted in a few details.
As someone who gets stuck in detail hell, having the machine produce something that's a soft starting point is amazing. It's giving me a lot more opportunities to practice at blending modes and using mixing brushes. And as someone who procrastinates with 'reference gathering', the method of cludging together Design Dolls and image diffusion takes away so many excuses. Maybe I'll have to make a later post on how I smash these tools together for consistently posed characters.
0 notes
Text

fixing attempts
so this one guy has cool armor, but the weapon in his hand was so disappointing I had to make it my first attempts at fixing with Inpainting.


still a long road to go
1 note
·
View note
Text

hands up



some outcomes of practicing img2img using a 'hands-up' posed input image with the vague prompt of high contrast blue hair character making a face, and a familiar seed



hands splayed is not a complicated pose, however the machine would sometimes struggle on which direction to face the elbows and the hands maybe a quarter of the time.







Because I chose to use an input with a radial gradient background, the machine interprets it by rendering shapes behind the figure.








---- These ones below are some of what happens when mixing an input image with the arms down and a control net with hands up get smashed together. I find them creatively evocative, however the hands went crazy for more than half.



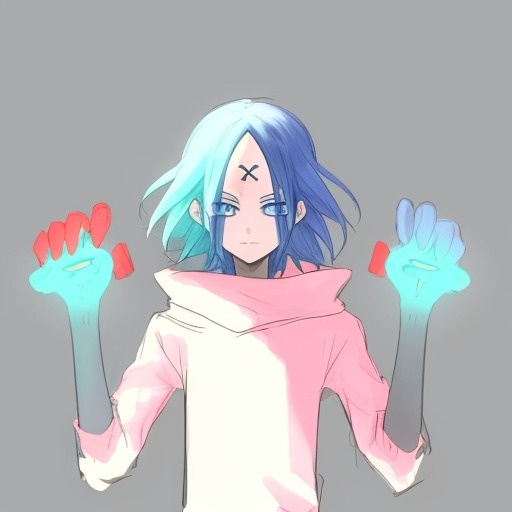




obviously you get way more mutant hands when the input image and control net pose are way different. The all black background was from using an input image in img2img with a transparent background
#automatic1111#stable diffusion#ai art#ai generated images#ai generated#controlnet#hands up pose#img2img#aiartcommunity#aigeneratedart#ai character#ai generated references
0 notes
Text


More RPG character portraits along the same lines as the earlier posted naginata guys.
















#automatic1111#stable diffusion#ai character portraits#ai generated images#ai rpg character portrait#rpg character
2 notes
·
View notes