
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by maphyorg and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
27 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
WordPress REST API: An Introduction
WP REST API: What is it and how to get started?

If you’ve spent any time in the WordPress community over the past few years, chances are you’ve heard reference made to the new REST API. However, unless you’re an experienced developer, you may not have any idea what the WordPress REST API actually is.
While the technical details are a bit complex, the basic concepts behind this feature are easy enough to grasp. The new API helps expand what WordPress as a platform can do. What’s more, the REST API makes it simpler than ever for developers to connect WordPress with other sites and applications.
In this comprehensive guide, we’ll walk you through all the basics you need to know. We’ll explain what APIs are in general, and what REST APIs (and the WordPress-specific version) are in particular. Then, we’ll talk about how to start using the WordPress REST API yourself. Let’s jump right in!
An introduction to Application Programming Interfaces (APIs)
Before we delve into the REST API specifically, let’s back up a little. To understand this concept, it’s key to first have a basic idea of what APIs are in general.
At its most fundamental level, an API – or Application Programming Interface – enables two applications to communicate with one another. For instance, when you visit a website, your browser sends a request to the server where that site is located. That server’s API is what receives your browser’s request, interprets it, and sends back all the data required to display your site.
There’s a lot more to the way APIs work in a technical sense, of course. However, we’re going to focus on what probably matters most to you – the practical applications. APIs have been getting lots of attention and visibility, because many companies have begun to package them up and provide them as products you can use.
In other words, developers at a company like Google will collect some parts of their application’s code together, and make it publicly available. That way, other developers can use the API as a tool to help their own sites connect to Google and take advantage of its features:

For instance, you could use the Google Maps API to place a fully-functioning map on your site that benefits from all of Google’s relevant data and features. This saves you from having to code up a map and collect all that data yourself. The same applies to a wide range of sites and applications.
As websites and the functionality they rely on get more complex, tools like APIs become crucial. They enable developers to build on existing functionality, making it possible to simply ‘plug in’ new features to your website. In turn, the site that owns the API benefits from the increased exposure and traffic.
The fundamental rules of a REST (Representational State Transfer) API
There are many ways to create an API. A REST (Representational State Transfer) API is a particular type that is developed following specific rules. In other words, REST presents a set of guidelines developers can use when building APIs. This ensures that the APIs function effectively.
To understand how REST APIs work, you therefore need to know what rules (or ‘constraints’) they function under. There are five basic elements that make an API ‘RESTful’. Keep in mind that the ‘server’ is the platform the API belongs to, and the ‘client’ is the site, application, or software connecting to that platform:

Client-server architecture. The API should be built so that the client and the server remain separate from one another. That way they can continue to develop on their own, and can be used independently.
Statelessness. REST APIs must follow a ‘stateless’ protocol. In other words, they can’t store any information about the client on the server. The client’s request should include all the necessary data upfront, and the response should provide everything the client needs. This makes each interaction a ‘one and done’ deal, and reduces both memory requirements and the potential for errors.
Cacheability. A ‘cache’ is the temporary storage of specific data, so it can be retrieved and sent faster. RESTful APIs make use of cacheable data whenever possible, to improve speed and efficiency. In addition, the API needs to let the client know if each piece of data can and should be cached.
Layered system. Well-designed REST APIs are built using layers, each one with its own designated functionality. These layers interact, but remain separate. This makes the API easier to modify and update over time, and also improves its security.
Uniform interface. All parts of a REST API need to function via the same interface, and communicate using the same languages. This interface should be designed specifically for the API and able to evolve on its own. It should not be dependent on the server or client to function.
Any API that follows these principles can be considered RESTful. There is also a sixth constraint, referred to as ‘code on demand’. When followed, this technique lets the API instruct the server to transmit code to a client, in order to extend its functionality. However, this constraint is optional, and not adopted by all REST APIs.
The WordPress REST API
At this point, you may be wondering how all of this affects you. APIs are excellent tools, but are they relevant to your day-to-day work? If you’re a WordPress user, the answer is unequivocally “yes”.
The WordPress REST API has been under development for a couple of years now. For quite a while, it was worked on as an independent plugin, which developers could contribute to over time was available for anyone to experiment with.
In fact, there were two separate versions of the REST API plugin. Elements of the API were added into the core platform as early as update 4.4. This was followed by it becoming fully integrated as of WordPress 4.7 (in 2016). This means that today, WordPress has its own fully-functional REST API.
Why did the platform make this move? According to the project site itself, it’s because WordPress is moving towards becoming a “fully-fledged application framework”. In other words, the REST API enables the platform to interact with just about any site and web application. Plus, it can communicate and exchange data regardless of what languages an external program uses.

This opens up numerous possibilities for developers. It also makes WordPress as a platform more flexible and universal than ever. As Katie Keith, the Operations Director at Barn2 Media puts it:
By understanding the REST API, WordPress developers can choose the most effective way to implement each task, without being confined to specific technologies or platforms such as PHP or the WordPress back end. Used effectively, the REST API makes third party integrations much easier…It even opens up new opportunities, for example to create your own WordPress-based mobile apps, or explore new and unique ways to communicate with WordPress.
It’s also important to note that you may hear this feature sometimes referred to as the WordPress JSON REST API. The ‘JSON’ part, which stands for JavaScript Object Notation, describes the format this API uses to exchange data. That format is based on JavaScript, and is a popular way of developing APIs thanks to how well it interfaces with many common programming languages. In other words, a JSON API is able to more easily facilitate communications between applications that utilize different languages.
The anatomy of a WordPress REST API request
You should now understand the overall purpose and direction of the WordPress REST API. As such, let’s get into a few specifics about how it works. There are some basic concepts you’ll need to understand if you want to get hands-on and start experimenting with the API yourself.
As we’ve explained, every API processes requests and returns responses. In other words, a client asks it to perform a certain action, and the API carries out that action. Exactly how APIs do this can vary. REST APIs are specifically designed to receive and respond to particular type of requests, using simple HTML commands (or ‘methods’).
To illustrate, here are the most basic and important HTML methods a client may send:

GET: This command retrieves a resource from the server (such as a particular piece of data).
POST: With this, the client adds a resource to the server.
PUT: You can use this to edit or update a resource that’s already on the server.
DELETE: As the name suggests, this removes a resource from the server.
Along with these commands, the client will send one or more lines that communicate exactly which resource is desired and what should be done with it. For example, a request to upload a PHP file into a particular folder on a server might look like this:
POST /foldername/my_file.php
The /foldername/my_file.php part is called the ‘route’, since it tells the API where to go and what data to interact with. When you combine it with the HTTP method (POST in this case), the entire function is referred to as an ‘endpoint’.
Most REST APIs and the clients that interact with them get a lot more complicated than this – WordPress’ version included. However, these basic elements form the basis for how the WordPress REST API works.
How to start using the WordPress REST API
As long as you have a WordPress site set up, you can start experimenting with the REST API right away. You can perform various GET requests to retrieve data directly, simply by using your browser.
To access the WordPress REST API, you’ll need to start with the following route:
yoursite.com/wp-json/wp/v2
Then, you can add onto this URL to access various types of data. For instance, you could look up a specific user profile via a route like this:
yoursite.com/wp-json/wp/v2/users/4567
In this scenario, “4567” is the unique user ID for the profile you want to see. If you left out that ID, you would instead see a list of all the users on your site:

You can use the same basic route to view other types of data, such as your posts or pages. You can even search for subsets of the data that meet certain criteria. For example, you could retrieve all posts that include a specific term using this URL:
yoursite.com/wp-json/wp/v2/posts?=search[keyword]
This is just a simple illustration, of course. There’s almost no limit to what you can actually do using the WordPress REST API. If you want to learn more about how it works, we recommend starting with the following resources:
The REST API Handbook. This is an official WordPress resource that documents all sorts of information about the REST API. Among other things, you’ll find a list of endpoints you can use, as well as details on some of the REST API’s structural aspects that we haven’t touched on here.
W3Schools tutorials. While this resource isn’t REST API-specific, it offers handy tutorials that can help you brush up on key concepts, such as HTTP methods and JSON.
The Ultimate Guide to the WordPress REST API. This free e-book from WP Engine contains lots of practical information and examples. Plus, it will walk you through how to accomplish several basic (and more advanced) tasks.
While we’re at it, also check out this list of the top 10 plugins for WordPress developers. They will surely come in handy as you’re exploring the world of REST API.
The WordPress REST API is no doubt a complex topic. Even for non-developers, however, it’s worthwhile to understand the basics of how this technology works, and what it makes possible. What’s more, it may even enable you to start dabbling in development yourself!
Conclusion
There’s no better time to learn about the WordPress REST API than now. Since it’s been fully merged into WordPress core, it’s going to play an important role in the platform’s future. Developers of all stripes will be using this API to connect WordPress to the broader web in ways that were previously difficult or impossible.
Understanding this concept for yourself can be a bit challenging. At a basic level, however, the concepts are easy enough to grasp. A REST API is an interface that enables two programs to ‘talk’ to one another, and is created following guidelines that ensure it’s flexible, extensible, and secure. If you want to delve deeper into how all of this works and how it can be used, there are lots of helpful resources out there, such as the official handbook.
from WordPress https://maphyorg.wpcomstaging.com/3281.html
0 notes
Text
论工科线性代数的现代化与大众化
作者:陈怀琛 教授
数学与工程的结合在本世纪中最明显的特色就是计算机广泛应用于科学计算。但是在大学的数学教育中,并没有得到充分的体现,学生学习的主要仍是笔算,与未来的工作严重脱节。在线性代数课程中,这一点表现尤其明显。实践证明,线性代数课程的现代化改革将是提高大学数学教育应用水平的一个有效的切入点,本文将对此进行论述。
关于线性代数课程目标的争论和演变
从上世纪起,线性代数从一门较抽象的理论学科发展成为所有专业科学计算的技术基础,从少数数学家的象牙之塔进入到每个大学生的手头工具库。这一转换可以概括为“现代化”和“大众化”两个方面,没有任何一门其他课程会在短期内经历这样的巨变。如何认识和应对这个变化,并在有限的时间内,把最需要的内容教给具有不同需求的学生,使课程的改造能够以更自觉的方式,更明确的目标,在更广泛的领域向前推进,这是本文的主题。在本文中所说的“工科”,只是为了简短顺口,论述的内容也适用于理、经、管等非数学专业。
虽然线性代数已经列为大学的公共数学基础课,但要记住这个角色还相当新,其目标还非常模糊,它远未起到应有的作用。微积分已经在大学教学计划中存在了两百年,它和工科后续课已进行了无数次磨合。而线性代数的第一本研究生教材出现在1940年代,第一本本科教材出现在1959年,第一个CPMU(美国本科数学大纲委员会)建议大纲于1965年制订。由于课程当初主要用于数学系,因此其着重点是抽象的“N维向量空间”,目标是为更抽象的高年级数学课程作铺垫。“矩阵应用”的这个侧面则受到相当程度的忽视,与后续课的需要存在着巨大鸿沟。
20世纪后50年计算技术的高速发展,推动了大规模工程和经济系统问题的解决。使人们看到,线性代数和相关的矩阵模型是如微积分那样的数学工具。无所不在的线性代数问题,等待着各层次的工程技术人员快速精确地去解,修这门课程的学生绝大多数已是非数学系的。然而,这门课程却仍然沿用了为数学系设计的以抽象的N维向量空间为主线的大纲,对矩阵模型及相关的计算极度地忽视。大多数学生对这门课的反映是抽象、冗繁、枯燥、无用。他们在毕业并工作多年后仍普遍批评这门课“有用的不教,教了的没用”,提出了强烈的改革要求。
对这种要求的答复集中表现为1990年美国LACSG(线性代数大纲研究组)提出的五条改革建议。其要点是:要满足非数学专业面向应用的需要;要强调以矩阵运算为基础(不是向量空间);要从学生的实际水平出发(低年级);要采用最新的软件工具(用计算机).这四条强调的都是课程的实用性,降低其抽象性。为了适应少数学生深化理论的需求,加了第五条:对想读数学学位的学生应另开一门高年级课程。这些建议在美国的线性代数界得到了广泛的支持,1992年起,又由国家科学基金会(NSF)资助了为期六年的ATLAST计划,对教师进行数学软件的培训。美国当前的教学内容和教材,已经与20年前大不相同了。概括起来,一是现代化,普遍用计算机解决问题;二是大众化,使理论基础不高的普通学生都能听懂,并会用矩阵解题。MIT的G.Strang教授提出了“让线性代数向世界开放”的口号,听他视频课的已超过100万人。
中国的线性代数在1980年代开始进入大学,1995年,教育部数学教指委正式发布了对它的“教学基本要求”,它所用的恰恰是美国改革前的大纲,而且理论更深,实践为零。针对理论和实践严重失衡的现象,2005年起,西安电子科技大学开展了“用MATLAB提高线性代数教学水平”的研究试点。主要抓了“有用的不教”、“实践为零”的问题,先利用补丁教材《线性代数实践及MATLAB入门》,组织了全校的教师培训班。又编写了理论与实践结合的教材《工程线性代数(MATLAB版)》,在学生中进行了试点教学。目的就是强调矩阵建模和计算机应用那个侧面,这些工作得到了数学基础课程分教指委的赞同和高教司的支持。2009年,高教司设立了“利用信息技术工具改造课程”的项目,其中由西安电子科技大学牵头,18所大学参与,实施了“用MATLAB及建模实践改造工科线性代数”子项。两年多来,共有200多名教师、45000名学生参加了这项改革,由于利用了概念形象化的手段、算题简捷化的工具和丰富多彩的应用实例,受到参试师生普遍的欢迎。在2011年项目评审时得到了教育部高等学校数学与统计学教指委数学基础课程分教指委的高度评价。参试师生提出的主要诉求是增加上机实践的时数。
要补充实践内容,只要证明旧内容的不足,容易得到认可。但学时会有所增加,而且解决不了理论过难过深、数学系味道太重的问题。全面的改革,应该删掉部分工科当前不用的东西,这就容易引起争议,弄不好影响改革进程。因此这两年中,我们对理论简化的问题没有付诸试验。主要进行调查,只动口,不动手。现在机算的问题已经解决,我认为应该进入对理论教学内容作改革的攻坚阶段。这里最重要的出发点是“需求牵引”,因为后续课和毕业后工作的需求是客观存在并与时俱进的,按照客观需要决定教学大纲是课程磨合的好方法。这里特别要强调两点.
其一是把学生的近期需求与远期需求相区别。对于大学一年级来说,本科的后续课要用的内容,属于近期需求,必须尽力满足,而且应该列为必修的内容;远期需求是指未来工作或考研等可能用到的内容,不应列为公共基础课内容,可以到高年级时由少数学生选修。
其二是数学系学生要“搞数学”,非数学系学生则是要会“用数学”,这两者是很不同的。同样是“用数学”,层次差别也很大。再就是‘需要’和‘可能’往往难于兼顾,为达到最主要的目标,必须要忍痛割爱。所以选择课程内容和方法时要在这些方面下功夫。
工科对线性代数的需求及要增补的内容
我们主要以机械类、电子信息类、和控制类的教学计划为对象进行调查,研究它们的后续课程中有哪些地方用到线性代数。从调查的结果中可以发现,各专业都有十门以上的后续课要用线性代数。在文献中可以还找出类似的几十个例子.比如三坐标测量仪的数据分析要用矩阵,测量卫星轨道数据要解超定矩阵方程.频谱分析要用1024阶复数矩阵乘法,根据k点幅谱要求设计N阶最佳滤波器遇到的是N阶超定方程;数值方法课中N点的曲线拟合要解N—1阶超定方程;解偏微分方程的有限元法要解几十万阶的矩阵方程;…。可以说,凡是要用计算机解题的地方都要用矩阵。但后续课需要解的是高阶、复数的线性方程组,而我们的线性代数课程没有教学生矩阵求解的软件工具,包括数百万现在已是各行业骨干的教师及工程师都没学过。矩阵模型若不用软件工具.其效率还不如初等代数。而复杂些的,十个小时也算不出来。这些题目若按矩阵模型用计算机算,几分钟就解出来了。这不是在国际科学技术竞争中自甘落后吗?
说到底,工科机、电、控制专业所需要的数学,无非是代数和微积分.代数问题比微积分还多。毕业的学生遇到微积分还可以去查查书.找解答;碰到代数问题就一筹莫展。代数问题的特点是“繁”,“矩阵+软件”是针对这个特点的杀手锏。现在的线性代数只教前一半.那就是丢掉了这个杀手锏的精髓。稍复杂些的代数问题就不会解.而它占到了工程中数学问题的一多半。这种教学中的偏颇已经造成我国一代人才在数学能力上的畸形,严重影响了工科学生的培养质量。
除了解高阶方程这一头的缺失之外,在向量空间这一头也有问题。传统的线性代数总强调N维抽象向量空间的重要性。我们也在本科课程中进行了调查.可是到现在还没有找到一个有说服力的需求实例。有人指出.将一个函数展开为N阶傅里叶级数,可以看成是N维向量的叠加��是的,专门搞代数的人可以这样去理解,但绝大多数搞工的老师和本科教材都不会从这个角度去思考,而是用波形叠加来理解,这更加符合工科形象思维习惯。
对工科大学生来说,最重要的是看得见、摸得着的欧几里得空间,后续课中就有很多实际应用问题,有些是在现代化机械车间中就会遇到的。
例1 三坐标测量仪测得工件截面上五点的三维坐标,问这些点是否在一个平面上?求该平面的方程及各点误差;它们是否构成一个圆?求该拟合圆的方程。
例2 给出三角形刚体在平面上的初位置和终位置.问这个位移如何用矩阵乘法来表示?从初位置到终位置,如何分成十步来实现连续动画?
例3 任何刚体的空间转动能否及怎样用矩阵乘法表示?
例4 3D动画需要把三维物体的形象投影到二维的屏幕上,怎样用矩阵运算来实现投影?
这些都是很直观的“线性代数和空间解析几何”的问题,但按现在的不用计算机的教材教课,这些问题都是解不出来的。也就是说,在向量空间的教学内容上,喊的是N维向量空间,其实连二、三维的问题都没搞懂,而后者才真正是工科大学本科的迫切需求。当把上述问题用计算机软件来解时,空间解析几何又进入了新的层次。并且为学生理解和掌握三坐标测量、机器人和机械手、计算机图形学、2D,3D动漫技术、三维空间六自由度航行器运动学等广泛的现代化新课程作了准备。
线性代数花了很大篇幅讨论N维向量空间,这在当时也许是合理的。因为教学对象是数学系的研究生,强调的是推导和证明,那时还没有计算机,不能指望线性代数有多少工程应用价值。现在时代发生了巨大的变化,线性代数已成为科学计算的基础,教学对象是立体概念尚待建立的低年级学生(我教过制图,知道让有些人建立空间概念是多么困难,何况N维),计算机已普及到人手���台,强调的是面向现代化工程应用。目标、对象、条件都不同了,大纲怎么能一成不变呢?50多年来,线性代数的发展都是围绕着计算技术实现的,它的教学内容当然应该体现出时代的精神。
由于线性代数内容非常丰富,各类学生的需求在理论和应用两个领域又有很大的差异,可以设想,改革的大方案应该是把线性代数分成两门课。第一门是低年级公共课,强调矩阵方程的解和欧氏空间,强调形象教学和感性认识,强调计算机软件应用,以满足本科四年中各后续课程的科学计算需求为必达的起码目标;第二门是高年级选修课,它可以为数学系的后续课程做铺垫,也为可为考研做准备,其内容可有更高的抽象性。不过学第二门课也要有第一门课作为基础,因为任何高级的抽象思维必须建立在大量的感性知识之上。这样,第一门课就会变得较为形象而易学,全体理工科本科和大专学生都要修,所以要特别强调它的大众化方向。
解决好线性代数课的大众化问题
要解决好这个问题,首先要弄清楚工科毕业生究竟是如何使用数学的。开发Mathematica软件的数学家Wolfram在2010年指出,即使是美国,在学校内的许多课程仍然在用手算,而到企业和社会上,他们所用的都是CAD软件,即机算。如果仍然只会手算,他们将被解雇。“School Math(学校数学)”不向“Real World Math(真实世界数学)”靠拢,会造成巨大的鸿沟,浪费大量的社会资源,影响国民经济的发展,这段话对线性代数尤其适用。
工科学生学数学是为了“用数学”,数学系学生是“搞数学”(指研究数学),其实大多数数学系学生毕业后是做大、中学数学老师,也还是用数学,搞数学的是极少数。这两者有很大的不同,培养的方法也应该完全不同。举学车为例吧,在几十年前,当汽车还没有大批量生产时,车的质量不稳定,开车的人要不断地调整修理它的各种部件,开车的必须懂汽车的详细结构,培养一个司机和培养一个技术员差不多,要花很多时间;到了今天,由于汽车质量的提高和各种自动化装置的应用,学开车可以完全不了解车的结构,他们只要知道驾驶座周围的仪表和操纵杆会对车的运动产生何种影响,又认路,就能熟练驾驶了。学开车只要几天,开车大众化很容易实现。
“用数学”和“搞数学”的差别也类似,由于数学软件已经高度自动化,“用数学”者对于数学理论的推理和证明的要求可以大大降低,对计算的细节也无需深究,主要要知道所做计算的目标和物理意义,知道达到目标的多种途径及其优劣,能做出比较选择。还要知道数学软件中各种命令的用途,以及计算机可能作出的反应。正如钱学森指出的:“数学课不是为了学生学会自己去求解,而是为了学生学会让电子计算机去求解,学会理解电子计算机给出的答案,知其所以然。”
拿行列式作为例子。中国大部分线性代数书都从数序起讲,光N阶行列式的定义和它的性质就要花几个学时,但大部分的师生连二、三阶行列式的几何意义都不知道,对四阶以上行列式则从来没有算过,更没有用过。人们都知道行列式的用途是判解的存在性,再问一下,判解和求解哪个容易?多数人是答不出来的!其实,用高斯消元法解方程比按定义计算行列式快得多,即求解比判解的计算复杂度小很多(5阶差10倍,25阶差1023倍),与其费力判解,不如直接求解。用计算机算题都是直接求解,如果无解,计算机会告诉你:“行列式接近于零,解不可靠”。这时工程师要做的是从物理上找原因,决不必去重算行列式的。只有书呆子才会先算行列式判解,再去求解。如果有人按克拉默法则算N+1个行列式去求N个解,更是N重的书呆子了。老师教了学生所有算行列式的方法,不结合应用,貌似内容多、水平高,其结果很可能培养出来“不会用数学”的书呆子!舍简就繁的根源在于“搞数学”的人看来,最重要的是解的“存在和唯一性”,要从源头就有严格的证明,这就必须从严格定义出发,所以行列式便被奉为圣灵,放在线性代数的第一章第一节开讲。因为要笔算行列式,所以要引出并证明它的许多性质。而从“用数学”的人看来,既然行列式计算根本无助于求方程解,那么为了计算它而推导的性质都没有工程价值,完全可以不讲。只要以二、三阶行列式为例弄清它的几何意义,知道它等于零为什么意味着无解或向量组线性相关就够了,真正计算必须得靠计算机。
有些老师会认为这样讲行列式水平太低了。我建议您们看看Strang在教材中是怎么讲的。他特意把行列式列为第五章,并在序中写明了这样布局的意义,就是为了贬低行列式计算,避免误导学生真去算它。在这章中,他讲了行列式的十个性质、代数余子式以及克拉默法则,采用的方法都是举二、三阶行列式的例题来说明(不是证明)。几句话带过,就是只要你知道有这么回事,他的这本书就这样完全避开了任何N维空间的推导,同时他的���却得到了一百万的听众,在中国这样的书该被嗤之以鼻了。所以要想出版大众化的教材,评价的标准必须把易懂实用(而不是证明严密)放在第一位。大众化的线性代数不仅要能为普通大学的新生所接受,最好也能为高职高专的学生所掌握和使用,那就必须删去一切人为的“拦路虎”,把线性代数变得浅显易懂。
再来看线性方程组解的特性的讨论,其实难点就是研究欠定方程组的解空间,那是一个占学时很多,师生都感到摸不到头脑的主题,它在工程上的用途却几乎为零。任何一个正确建立的工程问题,必须存在确定的解,故其数学模型只可能是适定或超定,不可能是具有无数庸解的欠定方程组。欠定方程是条件欠缺造成的,工程师可以用“条件不足”为理由而拒绝欠定命题,超定命题则是工程师必须会解的,现在却不教。“大讲欠定,不讲超定”是线性代数“教了的没用,有用的不教”的典型。其实,数学界从来强调命题的“存在和唯一”,也就是说,如果解不满足唯一性,这个命题就没必要研究下去了!不知线性代数为什么例外,明明已由行列式为零判为庸解的命题,却还要花时间去研究这些庸解组成的空间?这绝不是工科的需求!目前知道,它的唯一的需求是来自线性代数自身的求特征向量,因为求的解不是一个点,而是一根过原点的线(即一维子空间),才出现欠定方程组求解的问题。
特征向量的计算实际上涉及三个串接的难关,第一个是求特征方程,它涉及到繁琐的行列式计算;第二个是特征根的计算,涉及一元高次多项式求根;第三个才是解欠定方程组。想用手算矩阵的特征向量必须过这三关,其中最难是第二关,因为手工只能求到二阶,到了三阶,这一关就过不去,在第三关上下再大功夫也是白搭。可见,即使是三阶(非老师凑好的)实系数方阵,特征向量就不可能靠手算求出,更无必要拉扯出更抽象的N维向量子空间。要想对学生有用,主要是讲清特征向量的概念,要计算必须得靠计算机。
上面举了两个例子,都是占学时很多的难点,却都不是工科本科所需要的重点,可以大大精简。其他的内容也可以用类似的方法(即按它对工科有无用处来判断取舍)来处理,在这个过程中,我们才能真正吃透线性代数的全部内容,并用各专业需求的胃液对它进行消化,创造出适合于相应专业的浓缩营养品,培养出真正会用数学的人才。不做这个消化工作,像反刍动物一样,把吃进去的素材全部照样吐出来喂学生,那是很不可取的。要做好消化工作,数学和专业教师的结合是必不可少的条件。靠清一色的同行教师来搞改革,很不利于创新思维的出现。作为工科出身的教师,我愿意同有志于斯的数学家合作,共同编写大众化的线性代数教材。
有些老师会反对,说你要删去的这些理论对培养学生思维能力多么重要。这要看学时约束条件,争论的焦点是:对非数学系低年级,在有限的学时内,什么是学生最需要并能够接受的内容。有些争论可能会持续较长的时间,为了不影响公共课教学大纲的制订,我们建议设置一门高级选修课,它可收容这些有争议的高深内容,而保证必修课程中内容的实用和精炼。公共线性代数的大众化每年将使几百万学生和技术人员受益,他们将接受概念简洁、目的明确的理论,并且会用计算机方便地解决遇到的代数问题,使数学用于现实世界,对我同的现代化事业作出巨大贡献。高级线性代数课程是为拟深造理论的高年级工科及数学系学生进行铺垫的。在大四开这门选修课,学生的理论和实践的基础都打好了,接受能力大大提高,而且选课的必是学生中的尖子,任课教师人数减少了,执教者必是教师中的精华。可以放手讲他们擅长的内容,教学质量必有很大的提高。学生学完后很快参加考研,效果肯定好得多(现在的考研题也该改,要理论与实践结合),何必要在低年级上那些太抽象的课,让90%以上的师生陪绑受罪、吃力不讨好呢。把线性代数分成两门课可以防止基本学时的膨胀,确实会是领导、各类教师、各类学生皆大欢喜的事,我们应该促成它的实现。
结语
对工科学生而言,数学课应该使他们有宏观的用数学的思想,要使工程师了解工程中可能遇到的各种数学问题的类别,并且知道应该用什么样的数学理论和软件工具来解决,这是一种高水平的抽象,由于计算机软件的高度发展和自动化,他人和前人的经验都已经集成在软件中,不必自己都懂,不一定要求掌握其编程、推导的细节。用了软件,后续课和工程中大量的线性代数以及其他数学问题,就有了多快好省的解决办法。所以“现代化”是“大众化”的基础。现在“现代化”的客观条件已经完全具备,主要是掌握软件工具的老师太少,需要形成一个学习和培训的环境,像美国在1992—1997年实行的ATLAST计划那样;“大众化”应该是我们奋斗的当前和长期的目标,需要各方面的专家权威进行更多的分析和论证,希望教育部的学术指导部门能予以足够的关注,能参照美国LACSG那样,组织各方面专家进行有充分准备的讨论,形成有权威的改革建议。
from WordPress https://maphyorg.wpcomstaging.com/3249.html
0 notes
Text
涌现论综述
概观
涌现是系统和复杂性理论中的核心概念之一,因为它描述了一个成为或创造的普遍过程,当我们将基本部件相互作用并自组织起来创造新的组织模式时,新的特征和特性就会出现。从宇宙的演变到交通堵塞的形成,从社会运动的发展到鸟类的成群结队,从数万亿细胞的合作导致人体死亡,到飓风和金融危机的形成,涌现是一个非常抽象的概念。
虽然涌现的概念几千年来一直受到许多人的关注,但它经常被视为一种病态。随着复杂性理论的发展,我们可以使用越来越多的计算和概念工具以结构化的科学方式来理解它。在这本书中,我们将借鉴复杂性和系统理论中的不同观点,以连贯的方式构建理解涌现的框架。更具体地说,我们对涌现的探索将从非线性模式形成的角度展开。在这种情况下,基础部分之间的协同作用产生了自组织,形成了一种独特的模式,这种模式由演化动力学驱动,创造出了新的组织层次。
本文由四个主要部分组成。
在第一部分中,我们首先讨论一般的关联模式,然后再看协同互动,这是涌现的基础。
下一节集中讨论模式的形成,即零件如何自组织的问题;将他们的状态同步化,形成一个新的组织层次。在这里,我们将讨论经常使用的两种主要不同类型的涌现;所谓的强势和弱势涌现。
在第三部分中,我们将研究整合层次的概念,协同作用如何导致模式形成,以及被称为整合层次的新的组织层次的出现。我们将讨论这些不同的层次是如何形成自己不可简化的内部结构和过程,从而在微观和宏观组织层次之间产生复杂的动态。
最后一部分,我们将看看在某个过程中,涌现是如何随着时间的推移而出现的。我们将讨论混沌边缘假说;为什么自组织的、涌现的系统从未完全锁定到位,而是通过秩序和无序之间的动态相互作用来进化,以创造新的复杂度。
本文不需要任何具体的科学背景就可以阅读,它与许多不同的领域相关,特别是计算机科学、生物学和生态学、哲学、认知科学领域的领域,它适合任何对用复杂性和系统理论框架更好地理解涌现这一核心概念感兴趣的人。
涌现
涌现是哲学、艺术和科学中的一个术语,用来描述当我们将事物组合在一起时,新的属性和特征是如何产生的。涌现描述了一个过程,通过这一过程,组成部分相互作用形成协同效应,这些协同效应随后增加了组合组织的价值,从而产生了一个新的宏观组织层次,这是部分之间协同效应的产物,而不仅仅是部分本身的属性。
因为涌现属性是部件之间协同作用的产物,所以它们不能在子系统中局部观察到,而只能作为全局结构或集成网络观察到。以这种方式,出现创造了一个具有两种或两种以上不同的、不可简化的组织模式的系统,称为一体化层次。
因此,当提到涉及涌现的现象时,新的描述词汇对于不同的层次是必要的。因为宏观涌现现象不能在适用于零件的词汇中描述;这些新出现的特征需要新的术语和新概念来对它们进行分类。从某种意义上来说,由于涌现现象被认为是不可减少的,从其基本组成部分来看,预测涌现现象的最佳手段是计算机模拟。
涌现包括创造一些新的东西,这些东西是在创造之前从对零件的描述中无法预料的。这些新产生的东西具有一个强度谱。它解释了不同类型的涌现,这些涌现被描述为强或弱。在强度谱的最弱端,这些新奇的现象可能只是看起来不同,而在它们出现之后,我们仍然可以理解清楚它们是如何从一些基本部分中衍生出来的。在强度谱的最强端,一件事是由另一件事引起的,但决不能还原成那件事。
涌现的经典例子可以在群居昆虫如蚂蚁和蜜蜂在创造蚁群和巢穴的集体行为中找到。在人类社会组织和人类意识中还发现了许多其他例子。水的溶剂特性是经常被引用的涌现例子,因为氢原子和氧原子都不具备这种特性,也不具备这种特性的缩小版。溶剂作用似乎来自氢和氧的非线性组合。
涌现哲学研究中存在一个主要区隔,即所谓的本体论和认识论的涌现。认识论指的是知识以及一个人如何认识世界。认识论的出现是这样一种观点,即由于我们知识的限制,一些系统在实践中无法用它们的组成单位来描述,也就是说,我们无法获得所有相关信息和进行计算。
本体论是指存在的本质,它关注我们认为我们周围世界中事物的客观存在。随着本体论的出现,我们不仅仅是在陈述我们对世界的认识,我们也在陈述世界的真实情况。当我们谈论本体论的出现时,不管我们对世界的理解如何,我们都在陈述世界是怎样的。如果本体论的出现被识别,这意味着理论上不可能完全理解一个系统的组成部分,这不仅仅是因为实际的限制,而是因为新的和基本上不可约的组织层次出现在更高的层次。
涌现属性归属于元素的整个结构化集合,其中涌现属性不是单独获取的集合元素属性的加法函数。例如,人体的质量是孤立的所有部分的简单总和,因此不是一个涌现的特征。然而,人类意识似乎是一种涌现现象,因为我们不能把它作为基本认知部分的总和来描述。系统的行为更多地是由组件之间的交互而不是组件本身的行为造成的。整体的附加值——存在于零件及其特性之上和之外——是相互作用的产物。这些从整体上增加或减少价值的部分之间的特定互动称为协同作用。然后,涌现是系统各部分之间协同互动的产物。
当两个或两个以上的要素相互区别并协调它们的状态和活动时,就会产生积极的协同作用。差异化使部件专业化,而集成使它们能够协调不同的能力以实现整体结果,通过这样做,协同互动增加了整个系统的价值,我们得到了一些比其部件之和更大的组合组织:涌现。从传粉昆虫和植物的相互作用来看,这些协同作用在我们的世界中是一种普遍现象:微生物及其宿主、不同药物之间的相互作用、以及各种社会组织,如企业、家庭和朋友。
因为协同作用中的各个部分是相互区别和协调的,这意味着它们具有特定类型的交互作用,如果我们通过移动各个部分或者以不同的方式重组它们来改变交互作用,那么附加值可能会很大。例如,如果我们有一把锁和一组钥匙,这些钥匙中只有一把能够打开锁,尽管在质量和其他物理属性上,这些钥匙几乎完全相同,如果我们拿走除了正确的一把以外的任何一把钥匙,并将其与锁组合起来,这个组合将几乎为零,因为锁不会打开,因此这个组合将不起作用。但是,当我们把正确的钥匙和锁结合起来时,我们会得到一个有价值的整体运行系统。这种附加值来自钥匙和锁之间的协同作用,这种特定的钥匙和锁被设计成相互区别和协调,从而实现它们的组合功能。无论是锁还是钥匙都无法实现隔离保护某物的综合功能。因此,我们需要两个不同的部分,但它们也需要以某种方式共同工作,以获得整体运行的系统。其他钥匙不同于这个锁,但是它们没有和这个锁协调,因此当我们组合它们时,没有增加价值或功能。
协同互动产生了新的组织层次,这些层次有自己的内部属性、特征和动态。这些新出现的层次被称为整合层级。尽管这些新的层次并不直接依赖于其组成部分的性质,但已经出现的组织模式取决于其组成部分之间协同作用的完整性。如果我们消除协同效应,整合层级将会瓦解和消失。因此,不像简单的线性系统可以简化为单一层次的组织,涌现导致了不止一个层次的组织的发展,这些不同的层次代表了不同的环境和管理零件的规则集。
有了整合层级,我们就有了一种动态,其中更高的层次依赖于更低的层次,然而,更高的层次也创造了自己的组织模式,这种模式反馈给微观层次的基本部分来进行互动。所有涌现系统都由一组微观层次的构建块组成,这些构建块对系统设置了一组向上的物理约束,但是宏观层次定义了一种组织模式,然后通过为部件的操作创建上下文来对其施加向下的影响。例如,移动通过微处理器的电子是使计算成为可能的物理构件。处理器是对正在运行的宏级软件程序的物理限制之一。
然而,宏观层面上的程序正在执行一些与部件组织无关的过程——比如一个人用它来创建网站——所有人都认为软件的宏观层面操作完全依赖于处理器中移动的物理电子的微观层面,这个人在构建网站时正在执行的宏观层面过程的结构与计算机中正在进行的底层微观层面物理处理无关。这种软件活动可以在许多不同类型的计算机上以相同的方式进行,这些计算机在硬件中具有非常不同的底层模式,软件的上层是通过创造向下的效果来调节电子在微观层面上的移动。
由于在一个整体系统中不同层次的组织发展,涌现在不同层次之间产生了复杂的动态;最明显的是在系统的宏观和微观层次之间。产生某种形式出现的系统具有特定的微观-宏观反馈动态,这对于理解它们的整体行为变得重要。高层影响低层的动态是涌现的关键部分,它被称为向下因果关系。向下因果关系是指,在一个展现出涌现的系统中,作为涌现现象轨迹的更高或更宏观的层次会对最初涌现的系统中的更低层次的基底产生某种向下的因果影响。
这种相互作用可以在生物有机体中看到,因为个体器官和组织创造了整个有机体,但是有机体作为一个整体,反馈来调节这些部分。在社会中,个人创建机构,但这些机构会反馈,将个人约束到整个机构的目标。同样,经济和金融市场涉及宏观结构(如市场价格)和个人行为之间的持续互动。
在所有情况下,当我们从微观层面进入宏观层面时,涌现涉及对正在使用的系统的新描述,这可以在许多科学领域看到。例如,经济学分为微观经济学和宏观经济学,不同领域使用不同的术语。同样,理论物理仍然被分为微观层面的量子力学描述和宏观层面的广义相对论描述。在社会研究中,微观和宏观被分成两个不同的领域,有各自的词汇;谈论个人的心理学和谈论社会系统中宏观模式的社会学。这是因为,像社会运动一样,现象只出现在许多个体的同步活动中,因此不会成为个体研究的一部分,而只会成为整个社会群体研究的一部分。
然而,仍然存在的问题是,我们是出于权宜之计和缺乏知识而在每一个层面上形成不同的描述,还是我们这样做是因为从根本上来说,不可能从微观层面全面推导出宏观层面的描述?这种差异体现在强涌现和弱涌现两个方面。
弱涌现描述了任何涌现过程,给定足够的信息,理论上可以由计算机模拟。随着微弱涌现的过程,新的特征和特性可能会出现在一个无法事先预测的系统中。然而,一旦它们出现,至少从理论上来说,可以从下面的组成部分中得到它们;即使实际上这通常在计算上不可行。强烈涌现的过程是那些即使在理论上也无法从对底层组成部分的性质和相互作用的充分理解中导出的过程。然后,必须从宏观动力学的角度来理解更高层次的涌现特性和特征,而不涉及微观力学。
作为一种认识论,涌现反映了某种看待世界的方式,这可能与还原论形成对比。涌现的概念可以被认为是系统思维和整体范式背后为数不多的核心概念之一。整体论和还原论都导致了看待世界的截然不同的方式和进行科学研究的根本不同的方式。
划分这两种范式的核心问题是,我们的世界是否仅仅由几条基本法则来表达,这些法则直接支配着自然界最基本的部分,通过它们,它们构成了更复杂的系统?这将是还原论者所持的立场,自然会导致对更基本的基础部分的研究。或者涌现是否是我们宇宙的一个基本部分?在这种情况下,理论上甚至不可能将一切都简化为只涉及基本基本部分的账户,因此,我们应该集中精力研究如何理解不同层次上出现的组织模式的抽象原则。这将是更全面的方法所持的立场。
基本的还原论直觉是,世俗事件和过程只受几个基本属性的支配,通过几个基本物理定律联系起来,这导致了所谓的物理学的完整性。一切都是物理的,每一个事件、现象或过程都是由一些低级的物理交互作用引起的。
奥本海默和普特南在1958年为科学事业提供了经典的结构简化概念,他们明确地将科学视为一种等级结构,更高层次的科学领域显示为由更低层次的科学实体构成的复合物。这种等级可以被认为是一个金字塔,以减少为手段上下移动它的等级。在底层,我们有基础物理,在这些之上,我们有其他物理领域,然后是化学、生物学、心理学、经济学和其他社会科学领域。
其结果是一种有点疏远的世界观,以基本物理粒子为中心,以人类活动为某种形式的外围活动,从而形成了一个与我们日常世界经历相去甚远的知识库。涌现的想法导致了科学事业的一个非常不同的概念,这种概念并不试图分解事物,而是着眼于许多不同的层次来寻找所有人都共有的模式和过程。这种方法基于抽象,通过识别所有级别上所有类型系统共有的模式。整体论试图理解综合、协同和变化动态的基本过程,这在所有类型的系统中都可以看到。它不是将事物简化为物理元素和定律的有限子集,而是积极寻求多样性,以获得所有层次上出现的所有系统共有的抽象模式。在这里,科学的统一不是在基本部分寻找,而是在抽象的抽象模型中寻找,这些模型适用于所有系统,包括社会、物理、生物、工程。
from WordPress https://maphyorg.wpcomstaging.com/3229.html
0 notes
Text
在WordPress博客中插入Jupyter Notebook
如何将两个强大工具结合
WordPress是世界上使用最为广泛的博客系统,也是本站所使用的博客系统。笔者创立本站的一大初衷在于,能够在网络上自由的发布技术类文章,这类文章经常包含代码、公式和图表。一些常见的公共博客平台对这些元素或者仅有有限的支持,或者在撰写和自动化操作上极为不便。因此,笔者希望在这个网站上获得功能、自由与便捷的平衡。
目前,本站发表的博文在代码、公式与图表的展示上仍然不尽完美。近期,笔者关注到Jupyter Notebook这一工具。这一工具在程序员中使用广泛,其功能也十分强大。几乎是目前科学计算和写作的最佳解决方案。那么能否将Jupyter的笔记本快捷地发表在Wordpress上呢?
经过一番探索,我发现了两个方案。
方案一
使用这个开源工具,其使用步骤在这个网页上有更为详细的说明,其效果如下。该工具的优点在于只需使用一行短代码,即可直接将存储在Github上的ipynb格式的Jupyter Notebook展示在Wordpress中,具有非常接近原生文件的排版样式,并且它可以自动检测Github上源文件的更新,并作出同步更改。美中不足之处在于:即使安装Latex插件,数学公式也无法显示,这一问题需要进一步修复。另外一个缺点在于,文件需要上传到Github上公开,对于敏感代码不太方便。
[nbconvert url="https://github.com/spatialaudio/digital-signal-processing-lecture/blob/master/recursive_filters/cascaded_structures.ipynb"]
方案二
如何能够渲染出公式呢?这个网页介绍了另外一个办法。这个方法使用Jupyter官方的nbconvert工具将本地的Jupyter笔记本转换为Html文件,然后将其复制到Wordpress自带的html编辑器,同时添加自定义的CSS文件。在安装了QuickLatex插件后,公式可以得到正常显示。然而,美中不足的是,无法像第一种方法那样自动连接Github文件进行更新,另外其样式也不如原生样式美观。
from WordPress https://maphyorg.wpcomstaging.com/3185.html
0 notes
Text
Multiparadigm Data Science «多范式数据科学»
本文翻译自此网站
Multiparadigm Data Science is a new approach of using modern analytical techniques, automation and human-data interfaces to arrive at better answers with flexibility and scale. «多范式数据科学是一种利用现代分析技术、自动化和人-数据接口以具有灵活性和规模化的方式获得更好答案的新方法。»
Many organizations are still doing traditional data science—confining themselves to problems that are answerable with traditional statistical methods—rather than utilizing the broad range of interfaces and techniques available today. «许多组织仍在进行传统的数据科学研究,将自己局限于可以用传统统计方法解决的问题,而不是利用当今广泛的新界面和新技术。» Whether it’s automated machine learning, interactive notebooks and report generation, natural language queries of data for instant visualizations or implementing neural networks with ease and efficiency, modern problem solving requires access to the right technology at every stage. «无论是自动机器学习、交互式笔记本和报告生成、用于即时可视化的自然语言数据查询或轻松高效地实现神经网络,现代问题的解决都需要在每个阶段使用正确的技术。»
With a flexible, integrated multiparadigm workflow, problems too complex for traditional methods can get real, quantifiable answers. «通过灵活、集成的多范式工作流,对于传统方法来说过于复杂的问题可以得到真实、可量化的答案。»
Interfacing with Your Data «与你的数据连接»
Having the right interface to get answers from data is crucial; «拥有从数据中获得答案的正确界面至关重要;» different interfaces are suited to different tasks. «不同的交互界面适用于不同的任务。» A multiparadigm system combines a broad range of intuitive options for interacting with data every step of the way. «多范式系统结合了一系列直观的选项,可以在每一步与数据交互。»
Interactive Notebooks «交互式笔记本»
Streamline your daily workflow using high-level notebook documents that combine text, images, code and interactive examples—editable and runnable on any platform for fast, easy collaboration. «使用可在任何平台上编辑和运行的文本、图像、代码和交互式示例相结合的高级笔记本文档简化您的日常工作流程,实现快速、轻松的协作。»
Natural Language «自然语言»
Query your data instantly with natural language and get conversational answers for an intuitive, low-effort process that leads to more insights and better decisions. «使用自然语言即时查询数据,并获得对话式答案,以获得直观、低工作量的过程,获得更多的洞察力和更好的决策。»
Triggered Reporting «触发的报告»
Automatically receive alerts and updated reports based on custom criteria, tracking trends in real time for critically timed decisions. «根据自定义标准自动接收警报和更新的报告,实时跟踪趋势,以便进行关键的即时决策。»
Presentations with Live Modeling «带实时建模的演示文稿»
Run your meetings interactively, adjusting parameters to compute instant what-if scenarios for deeper discussions and stronger results. «以交互方式运行会议,调整参数以即时计算假设情景,以便进行更深入的讨论并获得更强大的结果。»
Programmatic Access «程序访问»
Store your models as platform-independent packages and APIs, providing a centralized framework for computation and automation to power human-data interfaces across your enterprise. «将您的模型存储为独立于平台的包和API,为计算和自动化提供一个集中的框架,以支持整个企业中的人-数据接口。»
Classic Interfaces with Modern Integration «经典界面与现代集成»
Seamlessly connect existing spreadsheets, databases and applications into higher-level computation, stepping up speed and accuracy with additional back end power. «无缝地将现有的电子表格、数据库和应用程序连接到更高级别的计算中,通过额外的后端功能提高速度和准确性。»
Know Your Data Science Areas «了解您的数据科学领域»
The field of data science is constantly growing and changing. «数据科学领域不断发展变化。» A multiparadigm workflow requires a broad algorithmic toolkit with the full suite of processing, analysis and visualization for ever-increasing computational needs. «一个多范式工作流需要一个广泛的算法工具箱,它具有全套处理、分析和可视化功能,以满足日益增长的计算需求。»
Machine Learning «机器学习»
Generate adaptive models directly from complex datasets for object classification and predictive analytics, such as identifying which new advertising markets to enter. «直接从复杂的数据集中生成自适应模型,用于对象分类和预测分析,例如确定要进入的新广告市场。»
Neural Networks «神经网络»
Create and train layered processing networks for deep analysis and processing tasks, such as recognizing defective items coming off a production line. «创建并培训分层处理网络,用于深入分析和处理任务,例如识别生产线中出现的缺陷项目。»
Dynamic Visualization «动态可视化»
Display data in styled plots, charts and infographics, making it human-readable and interactive for quick analysis and decision making. «以样式图、图表和信息图形显示数据,使其具有可读性和交互性,以便快速分析和决策。»
Data Semantics «数据感知»
Standardize various incoming datasets into a unified framework for easier analysis, such as consolidating data with different unit systems. «将各种输入数据集标准化为统一的框架,以便于分析,例如使用不同的单元系统整合数据。»
Systems Modeling «系统建模»
Model physical, electrical and other systems to inform design decisions, like the most effective heating installation for a building. «对物理、电气和其他系统进行建模,以告知设计决策,如建筑物最有效的加热装置。»
Optimization «优化»
Use high-level mathematics to discover the “best values” for your data in relation to key criteria, such as the ideal allocation of portfolio assets. «使用高级数学来发现与关键标准相关的数据的“最佳值”,例如投资组合资产的理想分配。»
Signal Processing «信号处理»
Process and filter images, audio and other collected data to analyze underlying patterns, such as detecting an irregular heartbeat from an ECG. «处理和过滤图像、音频和其他收集到的数据,以分析潜在模式,例如检测心电图中的不规则心跳。»
Geocomputation «地理计算学»
Use precise geolocation data and powerful geodetic computations to accurately examine real-world situations, such as visualizing optimal routes for a bus service. «使用精确的地理位置数据和强大的大地测量计算来精确地检查现实情况,例如可视化公交服务的最佳路线。»
Graph/Network Analysis «图/网络分析»
Explore and visualize systems of discrete relationships to analyze correlations and patterns, such as modeling demographics in a social network. «探索和可视化离散关系系统以分析相关性和模式,例如在社会网络中建模人口统计学。»
Cluster Analysis «聚类分析»
Group and analyze data based on similarity measures to extract underlying patterns and relationships, such as which customers are most similar to your top 100. «根据相似性度量对数据进行分组和分析,以提取基础模式和关系,例如哪些客户与您的前100名最相似。»
Survival Analysis «生存分析»
Compute survival functions and lifetime distributions to analyze time-to-event data, such as the expected lifetime of a piece of industrial equipment. «计算生存函数和生存期分布,以分析时间到事件数据,例如一件工业设备的预期寿命。»
Queueing Theory «排队论»
Model and simulate systems of queues to analyze waiting times and resource allocation, such as the optimal number of tellers at a bank branch. «对排队系统进行建模和模拟,以分析等待时间和资源分���,例如银行分支机构出纳员的最佳数量。»
Statistical Distributions «统计分布»
Fit historic data to parametric distributions to make inferences about the underlying events, such as the likelihood of a customer clicking through an ad. «将历史数据与参数分布相匹配,以对基础事件进行推断,例如客户点击广告的可能性。»
Morphological Analysis «形态分析»
Use geometric transformations on images and higher-dimensional data to analyze spatial properties, such as counting particles in a microscopic image. «对图像和更高维度的数据使用几何变换来分析空间属性,例如计算微观图像中的粒子数。»
Custom Interface Construction «自定义接口构造»
Make interactive onscreen controls for real-time adjustment of parameters in analyses and visualizations, allowing deeper exploration of data. «在屏幕上进行交互式控制,以便实时调整分析和可视化中的参数,从而更深入地探索数据。»
Mathematical Modeling «数学建模»
Drive systems of differential equations, recurrence relations and symbolic formulas with your data to test and refine models, such as computing the recovery rate of an epidemic. «驱动微分方程、递推关系和符号公式系统与您的数据一起测试和完善模型,例如计算一个流行病的恢复率。»
Time Series «时间序列»
Model, simulate and forecast sequences of events over time to track long-term trends and make predictions, such as expected sales for the next holiday season. «对一段时间内的事件序列进行建模、模拟和预测,以跟踪长期趋势并做出预测,例如下一个假日季的预期销售额。»
Semantic Text Analysis «语义文本分析»
Analyze underlying structures in linguistic data to clean up data and extract meaning, such as determining sentiment in customer comments. «分析语言数据中的底层结构,以清理数据并提取含义,例如确定客户评论中的情绪。»
Report Generation «报告生成»
Display conclusions and insights in a styled, formatted document for meetings, ongoing projects or public information, like a quarterly earnings report. «在样式化、格式化的文档中显示结论和见解,用于会议、正在进行的项目或公共信息,如季度收益报告。»
Wavelets «小波»
Deconstruct data signals into constituent parts for advanced manipulation and filtering of specific features, such as eliminating background noise from sensor data. «将数据信号分解为组成部分,以便对特定功能进行高级操作和过滤,例如从传感器数据中消除背景噪声。»
Random Processes «随机过程»
Model the progression of a system over time to make observations and predictions about its behavior, such as analyzing peak hours at a particular store location. «对系统随时间的发展进行建模,以对其行为进行观察和预测,例如分析特定商店位置的高峰时间。»
Computer Vision «计算机视觉»
Process visual data with machine learning and other sophisticated algorithms for analysis of features and patterns, such as identifying road hazards from a video feed. «使用机器学习和其他复杂算法处理视觉数据,以分析特征和模式,例如从视频源识别道路危险。»
Parallel Computing «并行计算»
Distribute parallel tasks to available computation units for large-scale scientific computing and other high-performance applications. «将并行任务分配给可用的计算单元,用于大规模科学计算和其他高性能应用。»
Thirty years of building the ultimate computation environment make the Wolfram technology stack ideal for Multiparadigm Data Science (MPDS)—a multitude of interfaces, language types, computational approaches and ready-to-use data all woven into one ecosystem. «30年的终极计算环境建设使Wolfram技术栈成为多范式数据科学(MPDS)的理想之选——许多接口、语言类型、计算方法和随时可用的数据都交织在一个生态系统中。»
A multiparadigm approach requires a broad, flexible computational toolkit that incorporates all aspects of a project into one start-to-finish workflow. «多范式方法需要一个广泛的、灵活的计算工具箱,它将项目的所有方面整合到一个从开始直到最终完成的完整工作流中。» The Wolfram technology stack does exactly this, enabling you to take data from hundreds of formats, carry out a full spectrum of analysis and visualization and immediately share or publish your results—all using the world’s largest collection of algorithms and computable knowledge. «Wolfram技术栈正是这样做的,使您能够从数百种格式中获取数据,进行全谱的分析和可视化,并立即使用世界上最大的算法和可计算知识集合共享或发布您的结果。»
from WordPress https://maphyorg.wpcomstaging.com/3177.html
0 notes
Text
大数据时代的网络分析
这是Science杂志对其发表的Benson等人所著论文“ Higher-order organization of complex networks ”的评述。
我们如何全面挖掘大数据?
“为了挖掘网络数据的布线模式并揭示功能组织,仅仅考虑简单的描述符是不够的……,对我们相互关联的世界的整体分析需要概念和方法学范式的转变“
我们生活在一个由相互关联的实体组成的复杂世界中。在人类努力的所有领域,从生物学到医学、经济学和气候科学,我们都充斥着大量的数据集。这些数据集从不同和互补的角度描述复杂的现实世界系统,将实体建模为节点,将它们的连接建模为边,组成大型网络。这些网络数据是领域特定信息的新的丰富来源,但是这些信息目前大部分隐藏在复杂的布线模式中。破译这些模式是至关重要的,因为大型网络的计算分析常常是难以解决的,所以我们对这个世界提出的许多问题都无法得到准确的回答,即使有无限的计算能力和时间。因此,唯一的希望是近似地(也就是启发式地)回答这些问题,并证明在最坏的情况下,近似的答案离确切的未知答案有多远。Benson等人朝这个方向迈出重要的一步,提供一个可扩展的启发式框架,根据实体的布线模式对实体进行分组,并使用发现的模式揭示几个现实世界网络系统的高阶组织原则。
为了挖掘网络数据的布线模式并揭示功能组织,仅仅考虑简单的描述符是不够的,例如每个实体(节点)与其他实体的交互次数(称为节点度),因为两个网络在这种简单的描述符中可能是相同的,但是具有非常不同的连接结构(见图)。
因而,Benson等人使用称为graphlets的高阶描述符(例如,三角形),他是基于在数据中的节点子集上获得的小子网,该子集包含数据中出现的所有交互(3)。他们识别网络区域,这些区域富含特定graphlet类型的实例,很少有特定小图的实例跨越这些区域的边界。如果预先指定了graphlet类型,该方法可以发现通过它互连的节点,这使得Benson等人得以。将线虫神经网络中已知控制特定类型运动的20个神经元聚集在一起,该方法将局部布线图案与由其引入的高阶结构模块化相结合,揭示了网络数据中的高阶功能区域。
这一结果的重要性在于它适用于广泛的网络数据,我们必须理解这些数据才能回答当今人类面临的基本问题,从气候变化和转基因生物的影响,到环境,到粮食安全、人类迁徙、经济和社会危机,理解疾病、衰老和个性化医疗。例如,细胞是一个复杂的相互作用分子系统,其中基因被转录成RNA并翻译成蛋白质,这些蛋白质采用各种三维结构来实现特定的细胞功能。分子相互作用被不同的高通量生物技术捕获,并用不同类型的网络建模。分子网络的个体分析显示,参与类似功能的分子倾向于在一个网络中聚集在一起,并且有类似的连线(13),这使得我们能够更好地理解基因功能和细胞的分子组织,并改进治疗方法。
然而,每一种网络类型都提供了有限的关于正在研究的现象的信息。例如,疾病很少是单个突变基因或单个断裂分子相互作用的结果。相反,它是细胞内和细胞间复杂相互作用的多重扰动的产物。网络医学将网络分析与数据集成结合起来,挖掘大量互补数据,揭示看似无关疾病之间的共同分子机制。相比之下,看似相同疾病的患者可能有非常不同的疾病分子机制和对治疗的反应(例如,癌症异质性)。因此,个性化医疗旨在根据个体患者的基因和分子特征提供个性化治疗,这可能涉及将已知药物重新用于不同的患者群体,从而有助于缓解与开发新药所需的成本和时间相关的制药行业瓶颈。网络数据分析和集成的方法对于这些新生领域至关重要,因为全面理解只能来自于全面挖掘所有可用的基因、分子和临床数据。
对我们相互关联的世界进行整体分析,需要概念和方法学范式的转变。与其孤立地分析单一数据源,比如比对基因序列(这已经彻底改变了我们对生物学的理解),更深入的见解将来自于在单一框架内比对所有类型的数据——“数据比对”例如,关于一个细胞的所有遗传和分子相互作用数据可以整合到同一计算框架中,并且需要开发方法来对齐这些在“细胞排列”的新范例中“整合的细胞”同样,世界经济体系包括贸易、金融交易和投资网络,目前,这些网络已经被单独研究过。但是,要完全理解财富、危机和经济复苏的根源,只能通过整合和集体分析所有这些网络化的经济和地缘政治数据。类似地,气候测量由编码了跨地理区域的气候元素(例如,风速、大气压力和温度)的各种网络所捕获,而整体的、数据一致的分析可能有助于解释这个复杂的动态系统,并更好地预测人为改变的影响。应该开发和应用能够捕捉数据高阶组织复杂性的数学形式,以及从这些形式中计算和提取信息的算法。扩展Benson等人的框架,在这些集成和对齐的数据系统中找到更高阶的结构可能是一种前进的方式。由于数据的大规模、复杂性、异构性、噪声以及不同的时间和空间尺度,计算问题仍有待解决。
from WordPress https://maphyorg.wpcomstaging.com/3174.html
0 notes
Text
社交网络分析与机器学习
谈到数据科学,你会想到机器学习和数据挖掘,但是你应该考虑将社交网络分析作为数据科学工具包的一部分。社交网络分析通过使用图和网络来映射和测量关系,提供了从你的数据集中捕获特征的新方法,并且它是对传统机器学习技术,如聚类分析,的补充。
让我们用一个例子来展示它是如何工作的。这篇文章解释了Facebook是如何知道你什么时候离婚的(甚至在你之前)。不幸的是,我们无法访问Facebook拥有的数据集,但是我们可以使用公开的数据集进行类似的分析。
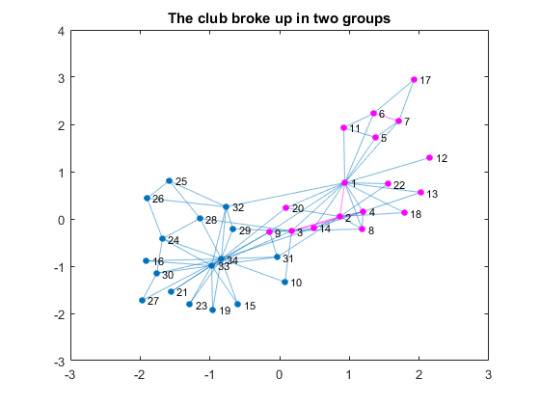
Zachary’s的空手道俱乐部数据集
Zachary的空手道俱乐部数据集包含了20世纪70年代美国大学空手道俱乐部34名成员之间的社交网络。我们不知道细节,但是这个俱乐部爆发的一场争端最终导致了它分成两组。我们能通过观察类似Facebook的社交关系结构来准确预测俱乐部会如何分裂吗?
让我们加载数据集
您可以在此下载数据集,但它是一种不熟悉的非表格文本格式。我创建了一个加载数据的脚本来解析这个文本文件,但是你可以直接加载MAT文件。
load karate.mat
创建图对象
单个成员表示为节点,连接两个节点的边表示他们的友谊。因此,边只是一对节点。边表示成78×2矩阵中的行。节点只是代表节点的数字数组。友谊是相互的,因此没有方向。我们可以用无向图来表示这个社交网络。您可以通过提供形成边的节点列表来创建图。
G = graph(edges(:,1), edges(:,2)); % create a graph from edges G.Nodes = table(name); % name the nodes figure % visualize the graph plot(G); title('Zachary''s Karate Club')

谁是联系最多的人?
该图显示了一个典型的“中心和辐条”结构,其中有几个中心,这些中心是具有大量连接的节点。如果你有很多朋友,你会很受欢迎,所以这代表受欢迎度。量化受欢迎程度的一种方法是一种称为度的度量,即连接到每个节点的边数。让我们找到这个社交网络的度分布。
D = degree(G); % get degrees per node mu = mean(D); % average degrees figure histogram(D); % plot histogram hold on line([mu, mu],[0, 10], 'Color', 'r') % average degrees line title('Karate Club Degree Distribution') xlabel('degrees (# of connections)'); ylabel('# of nodes'); text(mu + 0.1, 10, sprintf('Average %.2f Degrees', mu)) text(14.5, 1.5, 'Node 1') text(11, 2, 'Node 33') text(16, 2, 'Node 34')

你可以看到两个人(节点1和34)的度数远高于平均度数。节点33有很多朋友,但没有这两个朋友多。让我们给这两个人的边(连接)上色。
N1 = neighbors(G, 1); % get 1's friends N1 = [N1; 1]; % add 1 N34 = neighbors(G, 34); % get 34's friends N34 = [N34; 34]; % add 34 c1 = [1,0,1]; % 1's group color c2 = [0,1,0.5]; % 34's group color figure P = plot(G); % plot the graph highlight(P, N1, 'NodeColor', c1, 'EdgeColor', c1); % highlight 1's friends highlight(P, N34, 'NodeColor', c2, 'EdgeColor', c2);% highlight 34's friends title('Friends of Nodes 1 and 34')

分裂
通过给这两者的连接着色,你可以看到俱乐部已经有了基于社会关系的两个小群。让我们根据上述链接的教科书中的信息,将之前的可视化与实际分手的可视化进行比较。
G1nodes = [1, 2, 3, 4, 5, 6, 7, 8, 9,... % Node 1's group 11, 12, 13, 14, 17, 18, 20, 22]; figure P = plot(G); % plot the graph highlight(P, G1nodes, 'NodeColor', c1,'EdgeColor', c1); % highlight group title('The club broke up in two groups')
预测分裂
现在我们已经熟悉了这个数据集,让我们看看是否有办法检测这个数据集中的两个组。这是这个网络的邻接矩阵。每一行和每一列都是节点标识,如果两个节点有关系,则交集变为1,否则为0。对角线元素代表自我连接,因此在这个社交网络中它们是0。
A = adjacency(G); % create adjacency matrix A = full(A); % convert the sparse matrix to full matrix figure imagesc(A) % plot the matrix axis square title('Adjacency Matrix')

分层聚类方法
在机器学习中,这可以作为聚类问题来处理。让我们尝试使用共享连接数作为距离度量的分层聚类——共享的连接数越多,距离越近。由于我们有二进制数据,我们将使用Jaccard距离。
dist = pdist(A, 'jaccard'); % use Jaccard distance to score connections Z = linkage(dist); % create tree figure dendrogram(Z) % plot dendrogram title('Dendrogram Plot') xlabel('Node Id'); ylabel('Distance')

这看起来不太对,因为它完全忽略了网络中的连接结构。这是一个很好的例子,传统的机器学习方法无法单独解决这个问题。
图划分方法
根据图论,我们可以用什么来划分图?PatQuillen建议的一种方法是使用代数连通性根据创建两个子集所需的最小切割次数对节点进行加权,FielderVector用于此目的。在典型的使用中,我们希望将节点划分成两组大小相等的节点。让我们用中值来划分节点。值低于中值的节点与值较高的节点相比,连接性较差。
现在让我们使用FielderVector来识别图形分区,并将结果与实际分割进行比较。
L = laplacian(G); % get Laplacian Matrix of G [V, ~] = eig(full(L),'vector'); % get eigenvectors from L w = V(:,2); % the Fiedler Vector P1nodes = find(w < median(w)); % select nodes below median value errors = setdiff(G1nodes, P1nodes) % any diff from the actual split? errors = Empty matrix: 1-by-0
你可以看到FielderVector在识别这个图的分区方面做得非常好。如果你按FielderVector对邻接矩阵排序,你也可以看到这种分割。
[~, order] = sort(w); % sort the weights by value sortedA = A(order, order); % apply the sort order to A figure imagesc(sortedA) title('Sorted Adjacency Matrix')

总结——这与Facebook的例子相比如何?
在这种情况下,我们只需要FielderVector来划分图。但是在更复杂的情况下,你可以用它作为聚类分析的距离度量,代替上面例子中的Jaccard距离。社交网络分析和机器学习应该是数据科学工具包中的补充工具。
这如何适用于Facebook预测夫妻分手的情况?将节点1和节点34视为一对夫妇,将图视为他们的Facebook好友。它看起来与上面引用的文章中的图惊人地相似,只是它有两个以上的集群。如果你仔细想想,你有老同学、同事、家庭成员和其他社交活动,他们通常会形成不同的群体。
有趣的是,这篇文章说,夫妻共有的共同朋友的总数并不是浪漫关系的好指标。如果他们共同的朋友连接较少,那更好一点。显然,浪漫关系和空手道俱乐部并不共享同样的社会动态。
from WordPress https://maphyorg.wpcomstaging.com/3165.html
0 notes
Text
数学公式处理的便捷工具
背景
在阅读专业文献的时候,我们经常遇到复杂的数学公式,理解公式的内涵自然是阅读文献的一大难点。然而,有一个更为基础的问题:我们该如何记录并输入这些公式呢?
通常情况下,数学公式受限于其复杂的版式,我们无法直接选中再复制,直接截图是一个比较简单的办法,但是当我们需要查找公式,再次录入或者需要对公式稍作修改的时候,又变得十分不便。为此,本文将会介绍几个解决这一问题的软件工具,并简单介绍如何利用Matlab写一个识别并处理数学公式的工具。
公式录入
毫无疑问,录入数学公式最为方便的方式是使用Latex语言,但是Latex语言对初学者不同友好,一方面需要安装和设置庞大的软件环境,另一方面也需要记忆一些语法。个人认为,最为实用和便捷的公式记录工具是Typora编辑器,它是一个Markdown语言文本编辑器,支持公式实时预览,安装即用,还可以导出为Word文件,十分强大。

Typora文本编辑器界面,简洁却又不失强大
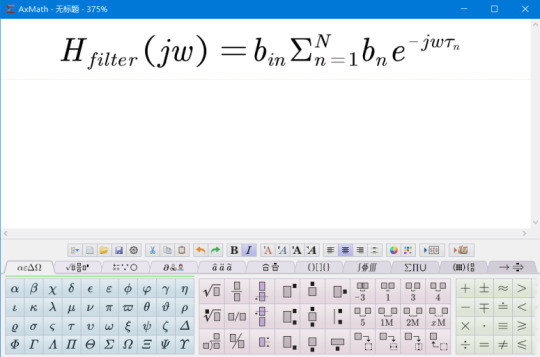
如果我们需要在熟悉的Word中录入公式的话,推荐一个优秀的国产软件AxMath,它虽然收费,但是仅需20多元即可终身使用,对于需要经常输入公式的人来说,绝对物有所值。AxMath最大的特点在于,它既支持使用Latex语法输入公式,也支持直接点击符号面板输入,另外还有公式记录本功能。它的Word插件功能完善,可以直接在Word中插入公式图片,给公式自动编号以及直接将Latex代码转换为公式。可以说,有了这个软件,公式的录入问题基本就解决了。

AxMath支持Latex代码的双向转换
可以使用内置的种类繁多的符号面板输入公式,还有Latex代码自动提示和补全功能

AxMath的Word插件提供了丰富的功能
公式自动识别
公式录入再方便,遇到复杂的公式,手动输入的话仍然十分耗费精力。有没有什么工具可以自动识别公式图片并将其转换为代码呢?这是一个十分复杂的问题,几年前仍然是无解的,但是,托深度学习技术的福,现在这个问题几经基本解决并且商业化了。Mathpix就是专门提供公式图片转Latex代码服务的公司。如果你对其背后的技术感兴趣,你可以到这个网站查看一个类似的实现。这里我仅仅介绍如何使用它们的服务。
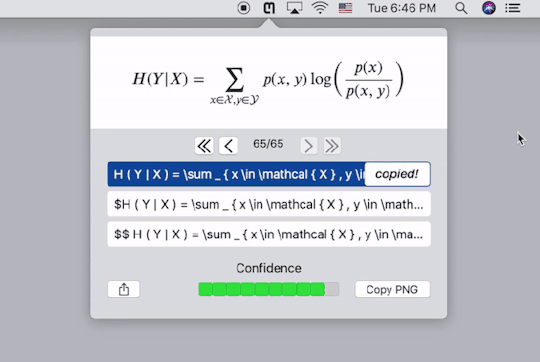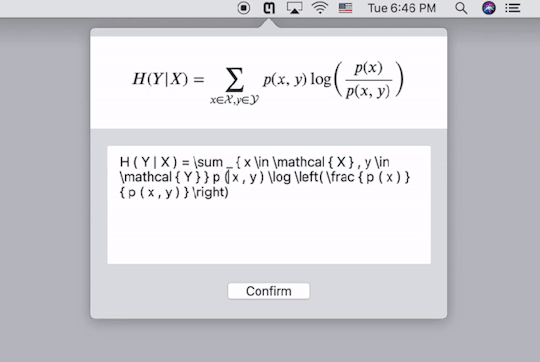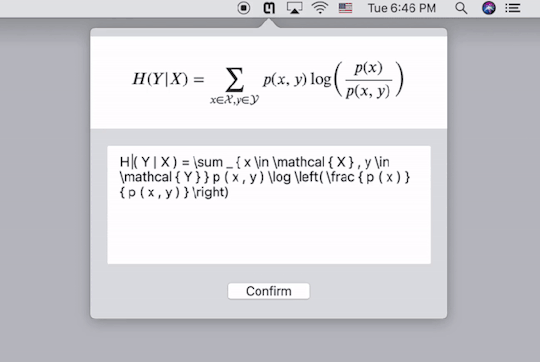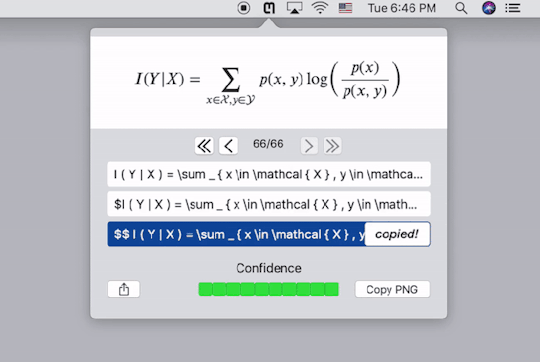
Mathpix提供了跨平台的客户端,下载安装以后,按快捷键截图要识别的公式的图片,它就会自动给出Latex代码,同时直接复制到剪贴板。下图中的三行代码都是一样的,只不过在代码两端加了$号,便于我们直接黏贴到Latex编辑器里去。个人实测,识别的精度相当高。这样,我们就能更方便的录入公式了。
需要注意的是,Mathpix返回的Latex代码语法较为严格,会添加很多空格,并将sin,cos之类的数学名进行单独标注,有的编辑器可能会不支持,需要自己稍作修改。
Mathpix的Mac客户端使用界面
使用Matlab编写一个公式识别小工具
Mathpix公司同时提供了API接口,可以使用visa信用卡注册账户,每月有1000次的免费识别额度。虽然其官方客户端已经能够满足日常使用,但是如果我们需要对公式进行更复杂的处理,还是需要自己编写客户端。事实上,国内外常见的搜题软件,比如小猿搜题,使用的正是Mathpix公司的技术。
这里,我将简单介绍一下如何使用Matlab编写一个公式识别app。完整的app界面如下,它除了可以从本地或者剪贴板中打开不同格式的图片,并进行识别之外,还可以将公式代码进行修改并重新渲染成不同格式和字体大小的公式图片。后期还可以再添加其它自动处理功能。

App打开时的界面(请忽略单词拼写错误)
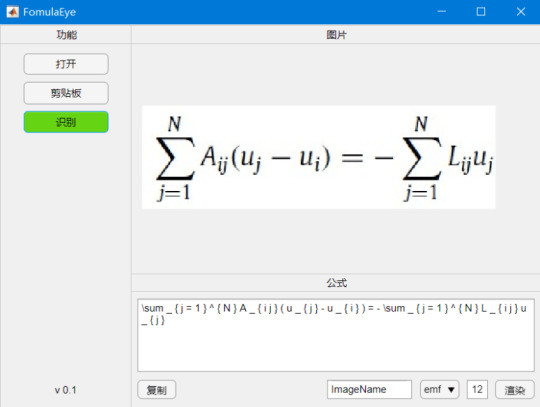
打开并识别公式图片之后的界面
渲染Latex代码
Matlab的绘图功能其实本身就支持Latex代码,我们可以直接使用Latex代码在标题和标签中插入公式,因此我们只需要从现有的代码生成一个只有标题的图片就行了。在渲染之前,我们需要注意将返回代码中的“\operatorname”删除,因为这不是通用的latex代码。
function outputPath = RenderTex(app) equationText=join(['$$',string(app.TextArea.Value),'$$']); fontSize=app.FontSize.Value; format=string(app.OutputFormat.Value); fileName=string(app.RenderImgName.Value); % Create a figure for rendering the equation. hFigure = figure('handlevisibility','off', ... 'integerhandle','off', ... 'visible','off', ... 'paperpositionmode', 'auto', ... 'color','w'); hAxes = axes('position',[0 0 1 1], ... 'parent',hFigure, ... 'xtick',[],'ytick',[], ... 'xlim',[0 1],'ylim',[0 1], ... 'visible','off'); hText = text('parent',hAxes,'position',[.5 .5], ... 'horizontalalignment','center','fontSize',fontSize, ... 'interpreter','latex'); % Render and snap! [lastMsg,lastId] = lastwarn(''); set(hText,'string',equationText); if ispc % The font metrics are not set properly unless the figure is visible. set(hFigure,'Visible','on'); end % We adapt the figure size to the equation size, in order to crop it % properly when printing. The following lines allow to respect the font % size. textDimension = get(hText,'Extent'); figureDimension = get(hFigure,'Position'); newWidth=textDimension(3)*figureDimension(3); newHeight=textDimension(4)*figureDimension(4); set(hFigure,'Position',[figureDimension(1) figureDimension(2) newWidth newHeight]); % Draw the figure drawnow; texWarning = lastwarn; lastwarn(lastMsg,lastId) % and save it saveas(hFigure,fileName,format); outputPath=regexprep(join([pwd,'\',fileName,'.',format]),' ',''); %close(hFigure); end
查询Mathpix API
Mathpix没有提供使用Matlab查询其API的代码,并且查询之前我们需要将图片转换为base64格式,因此实现起来还是颇费一番周折。查询功能主要使用webwrite函数来实现。
function MathpixQuery(app) base_url = 'https://api.mathpix.com/v3/latex'; app_id = '你自己的id'; app_key = '你自己的key'; fid = fopen(app.fullpath,'rb'); bytes = fread(fid); fclose(fid); encoder = org.apache.commons.codec.binary.Base64; imgstring = char(encoder.encode(bytes))'; body = ['{ "src": "data:image/jpeg;base64,', imgstring, '" }']; options = weboptions('HeaderFields', {'app_id', app_id; 'app_key', app_key; 'Content-Type', 'application/json'}, 'RequestMethod', 'post','Timeout',12); app.response = webwrite(base_url, body, options); end
from WordPress https://maphyorg.wpcomstaging.com/3149.html
0 notes
Text
Cheatsheets for AI, Neural Networks, Machine Learning, Big Data, etc.
Neural Networks

Neural Networks Cheat Sheet
Neural Networks Graphs
Neural Networks Graphs Cheat Sheet


Neural Network Cheat Sheet
Machine Learning Overview

Machine Learning Cheat Sheet
Machine Learning: Scikit-learn algorithm
This machine learning cheat sheet will help you find the right estimator for the job which is the most difficult part. The flowchart will help you check the documentation and rough guide of each estimator that will help you to know more about the problems and how to solve it.

Machine Learning Cheat Sheet
Scikit-Learn
Scikit-learn (formerly scikits.learn) is a free software machine learninglibrary for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.

Scikit-Learn Cheat Sheet
MACHINE LEARNING : ALGORITHM CHEAT SHEET
This machine learning cheat sheet from Microsoft Azure will help you choose the appropriate machine learning algorithms for your predictive analytics solution. First, the cheat sheet will asks you about the data nature and then suggests the best algorithm for the job.

MACHINE LEARNING ALGORITHM CHEAT SHEET
Python for Data Science

Python Data Science Cheat Sheet

Big Data Cheat Sheet
TensorFlow
In May 2017 Google announced the second-generation of the TPU, as well as the availability of the TPUs in Google Compute Engine.[12] The second-generation TPUs deliver up to 180 teraflops of performance, and when organized into clusters of 64 TPUs provide up to 11.5 petaflops.

TesorFlow Cheat Sheet
Keras
In 2017, Google’s TensorFlow team decided to support Keras in TensorFlow’s core library. Chollet explained that Keras was conceived to be an interface rather than an end-to-end machine-learning framework. It presents a higher-level, more intuitive set of abstractions that make it easy to configure neural networks regardless of the backend scientific computing library.

Keras Cheat Sheet
Numpy
NumPy targets the CPython reference implementation of Python, which is a non-optimizing bytecode interpreter. Mathematical algorithms written for this version of Python often run much slower than compiled equivalents. NumPy address the slowness problem partly by providing multidimensional arrays and functions and operators that operate efficiently on arrays, requiring rewriting some code, mostly inner loops using NumPy.

Numpy Cheat Sheet
Pandas
The name ‘Pandas’ is derived from the term “panel data”, an econometricsterm for multidimensional structured data sets.

Pandas Cheat Sheet
Data Wrangling
The term “data wrangler” is starting to infiltrate pop culture. In the 2017 movie Kong: Skull Island, one of the characters, played by actor Marc Evan Jackson is introduced as “Steve Woodward, our data wrangler”.

Data Wrangling Cheat Sheet

Pandas Data Wrangling Cheat Sheet
Data Wrangling with dplyr and tidyr

Data Wrangling with dplyr and tidyr Cheat Sheet

Data Wrangling with dplyr and tidyr Cheat Sheet
Scipy
SciPy builds on the NumPy array object and is part of the NumPy stack which includes tools like Matplotlib, pandas and SymPy, and an expanding set of scientific computing libraries. This NumPy stack has similar users to other applications such as MATLAB, GNU Octave, and Scilab. The NumPy stack is also sometimes referred to as the SciPy stack.[3]

Scipy Cheat Sheet
Matplotlib
matplotlib is a plotting library for the Python programming language and its numerical mathematics extension NumPy. It provides an object-orientedAPI for embedding plots into applications using general-purpose GUI toolkits like Tkinter, wxPython, Qt, or GTK+. There is also a procedural“pylab” interface based on a state machine (like OpenGL), designed to closely resemble that of MATLAB, though its use is discouraged.[2] SciPymakes use of matplotlib.
pyplot is a matplotlib module which provides a MATLAB-like interface.[6]matplotlib is designed to be as usable as MATLAB, with the ability to use Python, with the advantage that it is free.

Matplotlib Cheat Sheet
Data Visualization

Data Visualization Cheat Sheet

ggplot cheat sheet
PySpark

Pyspark Cheat Sheet
Big-O
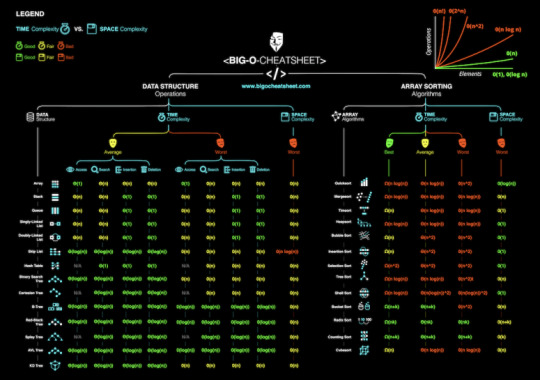
Big-O Algorithm Cheat Sheet
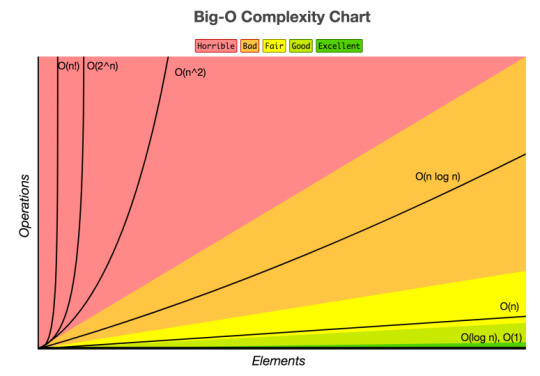
Big-O Algorithm Complexity Chart
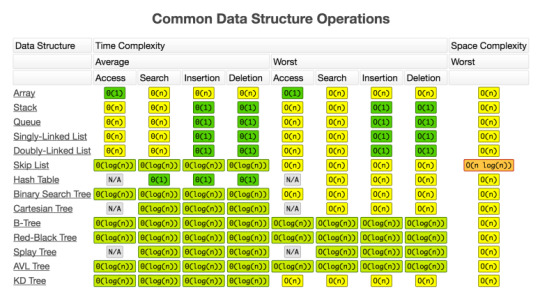
BIG-O Algorithm Data Structure Operations
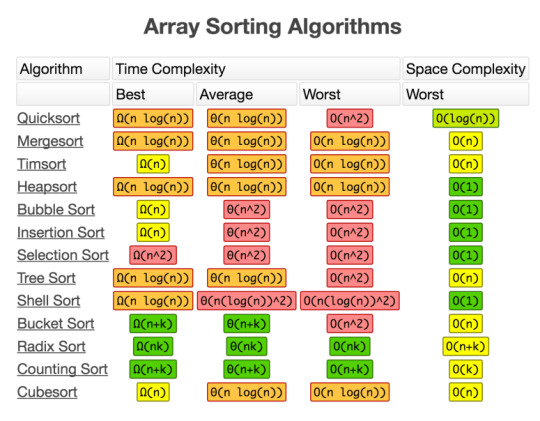
Big-O Array Sorting Algorithms
from WordPress https://maphyorg.wpcomstaging.com/3118.html
0 notes
Text
神经网络实践指南
神经网络是近年来非常热门的技术,给很多领域带来了技术革新,然而,学习并在实践中应用神经网络技术并非易事,它既涉及复杂的数学概念和公式,也牵涉到计算机编程方面的知识,同时还需要一定的软硬件环境支持。本文综合各方资料,旨在提供一种最具可行性的实践神经网络的思路。
在Mathematica中学习神经网络
热门的神经网络框架有很多,比如Tensorflow、MXNet、Torch等,它们大多使用Python语言。然而这里,我们另辟蹊径,使用Wolfram公司的商业软件Mathematica来进行入门学习和实践,原因如下:
Mathematica提供了集成的软件环境,无需安装其它软件,甚至数据和预训练好的模型都可以直接在软件内下载,大大节省了我们的时间。
Mathematica的语法非常简单,很接近我们日常使用的自然语言,大多数时候我们都可以直接通过函数名知道其作用,而交互式的执行方式可以让我们实时查看计算结果。
Mathematica提供了非常完善的中文文档和案例支持,对输出结果可以提供智能联想,方便我们随时学习新的函数的使用方法。
在Mathematica中用上一个神经网络有多简单呢?我们来看经典的MNIST手写数字识别问题。【参考软件内置的教程“神经网络简介”】
直接使用预训练的模型
第一步,获取预训练神经网络模型
在搭建自己的神经网络模型之前,我们先使用现有的模型。我们可以通过如下代码直接从Wolfram Neural Net Repository中下载预训练的LeNet模型:
lenetModel=NetModel["LeNet Trained on MNIST Data"]
第二步,使用模型
获取的模型可以像MMA中的任意函数一样,直接作用于新的图片。
这样,我们就像“把大象放进冰箱”,完成了最基本的使用神经网络这一任务。对于初学者来说,在其它语言环境中,完成这一任务可能都是一个艰巨的挑战,搭建各种语言环境就像造一台新的冰箱一样会耗费我们很多经历。
自然,我们想知道这里面发生了什么,让我们深入最为关键的NetModel一探究竟。
深入NetModel
收起状态下,一个NetModel图标会显示输入、输出接口的类型及对应层数,点击NetModel图标上的加号,我们可以看到其具体内部组成。
我们可以看到,一个Net是由众多Layer以及Input和Output组成。每一层都有对应的类型(class, vector, tensor)和尺寸。我们来一一理清其组成成分的含义。
层-Layer
毫无疑问,层是神经网络最核心同时也是最复杂的部分,Input和Output可以看作连接层的接口,其上会分别挂载编码器和解码器,用于将文件格式与数学编码相互转换。那么什么是层?
层是作用在数值张量上的运算,它会产生另一个张量(向量、矩阵可看作张量的特殊情况)。
大多数层只有一个输入和输出,少数层会有多个输入和输出。
层与层可以连接成一条链(对应NetChain函数)或者有向无环图(对应NetGraph函数)。
层中含有可学习的参数,用于在训练过程中调整。
上图展示了一个ConvolutionLayer的内部参数。每一类层根据它们对张量所进行的操作,所需的参数都不尽相同。红色的参数名表示该参数需要进行初始化之后,该层才能执行运算。
上图展示了另外一种常见的层,ElementwiseLayer。这一名称表明它将函数作用于每一个元素。这一层通常被用来应用激活函数。
MMA中目前支持的层类型如下:
层是网络的组成单元,要组成NeuralNet,可以通过NetChain或者NetGraph连接起来。二者的区别在于,NetChain只能有一个输入和输出,而NetGraph可以指定多个。
训练
一个未经训练的NetModel无法作用于实际数据。我们可以将神经网络看作一个灵活的万能模具,而待解决的实际问题可以抽象成一个具体的函数。训练的目的就是用数据微调模具,直至其接近所需的函数。用于训练的数据往往由输入、输出对组成。如果是具有多个输入和输出的模型,可以使用Association或者Dataset数据类型。
训练一个神经网络的基本目标是找到损失函数的最优值所对应的参数。使用的具体算法包含两个核心思想:反向传播和梯度下降。
反向传播的含义是在神经网络中反方向传播误差,并在每一个参数上计算梯度。
然后按照公式更新参数,这被称为梯度下降,而r叫做学习率。
在实际应用中可能会使用更复杂的参数优化算法,比如Adam等。
不同的噪声或者问题类型倾向于使用特定的损失函数层,而在Mathematica中,损失函数由NetTrain函数自动选择。
更多关于使用Mathematica进行机器学习的文章请参考该知识库页面。
from WordPress https://maphyorg.wpcomstaging.com/3082.html
0 notes
Text
Maphy: Unauthorized Post Attempt from [email protected]
An unauthorized message has been sent to Maphy. Sender: [email protected] Subject: 154389 is Mailgun login passcode If you wish to allow posts from this address, please add [email protected] to the registered users list and manually add the content of the email found below. Otherwise, the email has already been deleted from the server and you can ignore this message. If you would like to prevent postie from forwarding mail in the future, please change the FORWARD_REJECTED_MAIL setting in the Postie settings panel The original content of the email has been attached.

5cc16c9723895-z7VwPl.tmp_.txt
5cc16c97239c2-Gs5KDF.tmp_.htm
from WordPress https://maphy.org/3314.html
0 notes
Text
APIs for Scholarly Resources
APIs for Scholarly Resources
An API, short for application programming interface, is a tool used to share content and data between software applications. APIs are used in a variety of contexts, but some examples include embedding content from one website into another, dynamically posting content from one application to display in another application, or extracting data from a database in a more programmatic way than a regular user interface might allow.
Many scholarly publishers, databases, and products offer APIs to allow users with programming skills to more powerfully extract data to serve a variety of research purposes. With an API, users might create programmatic searches of a citation database, extract statistical data, or dynamically query and post blog content.
Below is a list of commonly used scholarly resources at MIT that make their APIs available for use. If you have programming skills and would like to use APIs in your research, use the information below to get an overview of some available APIs.
If you have any questions or know of an API you would like to see include in this list, please contact [email protected].
arXiv API
What it does: Gives programmatic access to all of the arXiv data, search and linking facilities
How it’s accessed: API calls are made using any web-enabled client (e.g. a web browser) to make an HTTP GET or POST request to an appropriate URL. API users can use the programming language of their choice
Result format: Atom
How to register: Free to use, no registration or API key required
Limitations: No stated limitations, but high-volume users should contact arXiv at http://arxiv.org/help/contact
Contact for technical questions: arXiv Google Group
For more information: http://arxiv.org/help/api/index
SAO/NASA Astrophysics Data System (ADS) API
What it does: Provides access to ADS database of bibliographic data on astronomy and physics publications
How it’s accessed: HTTP GET requests, or via an unofficial Python client
Result format: varies
How to register: Free to register, API key required
Limitations: Rate limits apply
Contact for technical questions: [email protected]
For more information: http://adsabs.github.io/help/api/, terms of use available here: http://adsabs.github.io/help/terms/
BioMed Central API
What it does: Retrieves: 1) BMC Latest Articles; 2) BMC Editors picks; 3) Data on article subscription and access; 4) Bibliographic search data
How it’s accessed: RESTful interface, queries are made as HTTP GET requests
Result format: JSON and Prism Aggregate (PAM)
How to register: Free to access, no registration required
Limitations: No stated limitations
Contact for technical questions: [email protected]
For more information: https://www.biomedcentral.com/getpublished/indexing-archiving-and-access-to-data/api
Caselaw Access Project API
CORE API
What it does: gives programmatic access to metadata and full-text of millions of OA research papers
How it’s accessed: RESTful interface, queries are made as HTTP GET requests
Result format: JSON
How to register: Free to use, API key required, register for API key at https://core.ac.uk/api-keys/register
Limitations: Quota applied for query volume, details at https://core.ac.uk/services#api
Contact for technical questions: [email protected]
For more information: https://core.ac.uk/services#api
CrossRef REST API
What it does: Allows access to metadata records for over 75 million scholarly works that have CrossRef DOIs, covering around 5000 publishers. Can be used for text- and data-mining, checking against funder mandates, and to obtain metadata in a variety of representations.
How it’s accessed: RESTful interface
Result format: JSON
How to register: No registration required
Limitations: No stated limitations
Contact for technical questions: [email protected]
For more information: https://www.crossref.org/services/metadata-delivery/rest-api/
DVN (Dataverse Network) APIs for Data Sharing
What they do: Multiple APIs available to allow programmatic access to data and metadata in the Dataverse Network, which includes the Harvard Dataverse Network, MIT Libraries-purchased data, and data deposited in other Dataverse Network repositories
How they’re accessed: HTTPS. A Dataverse community-written software program can also be used to access the APIs via an RCurl package
Result format: XML; Byte Stream for Data Access requests
How to register: Access to restricted data sets requires approval by data owners. To access MIT Libraries-purchased data, login to Dataverse by selecting Massachusetts Institute of Technology and using your certificates or touchstone. More information available at: http://guides.dataverse.org/en/4.6/api/dataaccess.html#authentication-and-authorization
Limitations: No limitations on public data set downloads after agreeing to terms of use. No limitations on restricted data set downloads after access is granted by data owners
Contact for technical questions: [email protected]; Questions can also be posted in https://groups.google.com/forum/#!forum/dataverse-community
For more information: http://guides.dataverse.org/en/4.6/api/
Digital Public Library of America (DPLA) API
What it does: Allows programmatic access to metadata in DPLA collections, including partner data from Harvard, New York Public Library, ARTstor, and others
How it’s accessed: RESTful interface
Result format: Structured JSON-LD objects
How to register: Free to use; API key must be requested with information here: https://dp.la/info/developers/codex/policies/#get-a-key
Limitations: No stated limitations
Contact for technical questions: [email protected]; Users can also submit issues to DPLA’s Issue Tracker
For more information: http://dp.la/info/developers/codex/
Europeana APIs
What they do: Four APIs available to allow access to metadata, annotation, and download of Europeana data
How they’re accessed: API details here
Result format: Varies by API
How to register: http://labs.europeana.eu/api/registration
Limitations: Free to register, no stated limitations
Contact for technical questions: API Google groups page
For more information: http://labs.europeana.eu/api
HathiTrust Data API
What it does: Can be used to retrieve content (page images, OCR, and in some cases whole volume packages), and metadata for HathiTrust Digital Library volumes
How it’s accessed: RESTful interface
Result format: XML, JSON or binary depending on the resource queried
How to register: Two methods of access: via a Web client, requiring authentication (users who are not members of a HathiTrust partner institution must sign up for a University of Michigan “Friend” Account), or programmatically using an access key that can be obtained at http://babel.hathitrust.org/cgi/kgs/request
Limitations: No stated limitations but is not meant for large-scale retrieval of data
Contact for technical questions: [email protected], https://www.hathitrust.org/feedback
For more information: https://www.hathitrust.org/data_api
IEEE Xplore API
What it does: Provides flexible query and retrieval of metadata records for more then 4 million documents comprising IEEE journals, conference proceedings, and technical standards
How it’s accessed: HTTP requests using structured URL queries
Result format: JSON, XML
How to register: Follow the steps at https://developer.ieee.org/getting_started
Limitations: Maximum of 200 results may be retrieved in a single query. A query term can only contain a maximum of 10 words
Contact for technical questions: [email protected]
For more information: https://developer.ieee.org/
JSTOR Data for Research
What it does: Not a true API, but allows computational analysis and selection of JSTOR’s scholarly journal and primary resource collections. Includes tools for faceted searching and filtering, text analysis, topic modeling, data extraction, and visualization
How it’s accessed: Web interface
Result format: CSV, varies depending on tool used
How to register: Free to access, registration is required to obtain results; no institutional affiliation required
Limitations: Datasets are capped by default at 1,000 articles; users seeking larger results are asked to contact JSTOR Data for Research
Contact for technical questions: [email protected], http://about.jstor.org/contact
For more information: http://about.jstor.org/service/data-for-research
Library of Congress APIs
What they do: Multiple APIs available to download bibliographic data and search Library of Congress digital collections, including images, public radio and television, and historic newspapers
How they’re accessed: Varies by API used, more information available here
Result format: Varies by API used
How to register: Free to use, most APIs do not require an API key
Limitations: Not specified, varies by API used
Contact for technical questions: https://labs.loc.gov/lc-for-robots/
For more information: https://labs.loc.gov/lc-for-robots/
Nature Blogs API
What it does: Blog tracking and indexing service; tracks Nature blogs and other third-party science blogs
How it’s accessed: RESTful interface, queries are made as HTTP GET requests
Result format: Default is JSON, some queries return Atom/RSS
How to register: Free to register, API key no longer required as of 2013
Limitations: 2 calls per second; 5,000 calls per day; RSS results are limited to 100 items maximum
Contact for technical questions: [email protected]
For more information: http://www.nature.com/developers/documentation/api-references/blogs-api/
Nature OpenSearch API
What it does: Bibliographic search service for Nature content
How it’s accessed: RSS, JSON, ATOM, SRU XML, TURTLE, depending on interface used
Result format: REST API with two interfaces: 1) OpenSearch standard interface using keyword searches; 2) SRU search interface using CQL structed queries
How to register: Free to register, API key no longer required as of 2013
Limitations: Results served in pages of 25 records. Additional records can be retrieved by paging through the result set. The page size can be varied and is capped at 100 records
Contact for technical questions: [email protected]
For more information: http://www.nature.com/developers/documentation/api-references/opensearch-api/
NLM APIs
What it does: multiple APIs and other data tools for accessing various NLM databases.
For more information: https://wwwcf.nlm.nih.gov/nlm_eresources/eresources/search_database.cfm
Notable included APIs:
Entrez Programming Utilities
What it does: Set of 9 server-side programs for searching 38 NCBI Entrez databases of biomedical literature and data
How it’s accessed: To access data, a piece of software posts an URL using a fixed sytax to NCBI’s E-Utilities server, then retrieves and processes data. Users can use any programming language that can send the URL and interpret the XML response (e.g. Perl, Python, Java, C++, etc.)
Result format: XML
How to register: Free to register; registration is not necessary but strongly encouraged
Limitations: 3 URL requests per second; large jobs should be limited to weekends or business hours
Contact for technical questions: [email protected]
For more information: https://www.ncbi.nlm.nih.gov/books/NBK25500
Digital Collections Web Service
What it does: Provides access to metadata and full-text OCR of all resources in the Digital Collections repository
How it’s accessed: HTTP requests using structured URL queries
Result format: XML
How to register: No registration required
Limitations: 85 requests per minute per IP address; contact NLM for larger projects
Contact for technical questions: https://support.nlm.nih.gov/ics/support/ticketnewwizard.asp?style=classic&deptID=28054
For more information: https://collections.nlm.nih.gov/web_service.html
Open-i Open Access Image Search
What it does: search and retrieval of abstracts and images (including charts, graphs, clinical images, etc.) from the open source literature, and biomedical image collections
How it’s accessed: RESTful interface or web interface
Result format: JSON through API, image results through web interface
How to register: No registration required
Limitations: maximum 30 results per API query
Contact for technical questions: https://openi.nlm.nih.gov/contactus.php
For more information: https://openi.nlm.nih.gov/; https://openi.nlm.nih.gov/services.php?it=xg
PMC Open Access Web Service
What it does: Allows discovery of downloadable fulltext resources from the PMC Open Access Subset
How it’s accessed: API calls are made using any web-enabled client (e.g. a web browser) to make an HTTP GET or POST request to an appropriate URL
Result format: XML results showing articles available in tgz or PDF format
How to register: Registration not required
Limitations: result set limited to 1000 records at a time
Contact for technical questions: [email protected]
For more information: https://www.ncbi.nlm.nih.gov/pmc/tools/oa-service/
OECD Data APIs
What they do: Allows programmatic access to a selection of OECD datasets
How they’re accessed: two RESTful APIs available for queries in SDMX-JSON or SDMX-ML formats
Result format: JSON, XML
How to register: No registration required
Limitations: 1 million data points; not all OECD datasets are covered
Contact for technical questions: [email protected]
For more information: https://data.oecd.org/api/
ORCID API
What it does: Queries and searches the ORCID researcher identifier system and obtain researcher profile data
How it’s accessed: RESTful interface
Result format: HTML, XML, or JSON
How to register: Two options: 1) Users can access the Public API, which only returns data marked as “public”; 2) Become an ORCID member to receive API credentials: see here
Limitations: Data retrieved through Public API is limited
Contact for technical questions: https://orcid.org/help/contact-us
For more information: https://orcid.org/organizations/integrators/API
PLoS Article-Level Metrics API
What it does: Retrieves article-level metrics (including usage statistics, citation counts, and social networking activity) for articles published in PLOS journals and articles added to PLOS Hubs: Biodiversity
How it’s accessed: queries made as HTTP GET requests through a RESTful interface, or via web interface
Result format: XML, JSON, CSV
How to register: Free to register; API key needed; Go to http://api.plos.org/registration/
Limitations: Results limited to batches of 50 at a time
Contact for technical questions: [email protected]; Questions can also be posted in PLoS API Google Group
For more information: http://alm.plos.org/; http://almreports.plos.org/; http://alm.plos.org/docs/api
PLoS Search API
What it does: Allows PLoS content to be queried for integration into web, desktop, or mobile applications
How it’s accessed: RESTful interface, queries are made as HTTP GET requests
Result format: XML
How to register: Free to register; API key needed; go to http://api.plos.org/registration/.
Limitations: Max is 7200 requests a day, 300 per hour, 10 per minute; users should wait 5 seconds for each query to return results; requests should not return more than 100 rows; high-volume users should contact [email protected]; API users are limited to no more than five concurrent connections from a single IP address
Contact for technical questions: [email protected]; Questions can also be posted in PLoS API Google Group
For more information: http://api.plos.org/solr/faq/
ScienceDirect APIs
What they do: Multiple APIs available for different use cases, including text mining of full-text content, search widgets, displaying journal or book level data, federated searching, and indexing
How they’re accessed: varies, depending on use case
Result format: varies, depending on use case
How to register: Free to register. MIT users should contact [email protected] to receive an API key
Limitations: varies, depending on use case
Contact for technical questions: [email protected]
For more information: https://dev.elsevier.com/; https://dev.elsevier.com/sd_apis.html
Scopus APIs
What they do: Multiple APIs available for different use cases, including displaying publications on a website, showing cited-by counts on a website, federated searching, populating repositories with metadata, populating VIVO profiles, and others
How they’re accessed: varies, depending on use case
Result format: varies, depending on use case
How to register: Free to register; some functionality requires MIT affiliation
Limitations: varies, depending on use case
Contact for technical questions: [email protected]
For more information: https://dev.elsevier.com/; https://dev.elsevier.com/sc_apis.html
Springer APIs
What they do: Multiple APIs providing access to Springer metadata and open access content
How they’re accessed: RESTful interface, using structured URL requests
Result format: XML, JSON, PRISM, A++ depending on query specifications
How to register: Free to register, API key required
Limitations: maximum results for a single query is 100 results for metadata queries, or 20 results for open access queries
Contact for technical questions: [email protected]
For more information: https://dev.springer.com/; https://dev.springer.com/docs; https://dev.springer.com/restfuloperations
STAT!Ref OpenSearch API
What it does: Bibliographic search service for displaying STAT!Ref results on a website.
How it’s accessed: OpenSearch specifications
Result format: RSS, ATOM, HTML
How to register: Free to register for users at a subscribing institution
Limitations: Limits exist but are not specified; high-volume users should contact STAT!Ref
Contact for technical questions: [email protected]
For more information: http://online.statref.com/Resources/StatRefOpenSearch.aspx
Web of Science Web Services
What it does: Bibliographic search service; allows automatic, real-time querying of records; primarily for populating an institutional repository
How it’s accessed: Uses SOAP protocol to access
Result format: XML
How to register: Free to register if you are affiliated with a host institution that subscribes to Web of Science
Limitations: Extractable data is limited to particular fields, databases, and file depths, also depends on host institution’s subscription
Contact for technical questions: http://ip-science.thomsonreuters.com/techsupport
For more information: http://wokinfo.com/products_tools/products/related/webservices/
World Bank APIs
What they do: Provide access to World Bank statistical databases, indicators, projects, and loans, credits, financial statements and other data related to financial operations
How they’re accessed: Three RESTful APIs available to provide access to different datasets: Indicators (time series data), Projects (data on the World Bank’s operations), Finances (World Bank financial data)
Result format: XML, JSON, RDF, and Atom, depending on specific API used
How to register: Free to use, no registration or API key required
Limitations: Request volume limits are unspecified, but should be “reasonable”
Contact for technical questions: [email protected] or “Contact support” link here
For more information: https://datahelpdesk.worldbank.org/knowledgebase/topics/125589
UN Comtrade APIs
What they do: Allow access to data on International Merchandise Trade Statistics (IMTS) and the work of the International Merchandise Trade Statistics Section (IMTSS) of the United Nations Statistics Division
How they’re accessed: Some services in REST, some in SOAP
Result format: XML or CSV, depending on service
How to register: Comtrade Web Services requires IP authentication, users must have site license account, however, access to metadata and data availability is not restricted
Limitations: Depending on access rights, the following data can be obtained: Comtrade Data, Tariff Line Data, Total Trade, Annual Totals, Processed Data or Original Data. The latest three are restricted for data exchange between UN and OECD.
Contact for technical questions: [email protected]
For more information: https://comtrade.un.org/ws/
Wiley Text and Data Mining
What it does: Allows text- and data-mining access to content in the Wiley Online Library
How it’s accessed: Accessible via CrossRef’s TDM service; RESTful interface
Result format: JSON
How to register: Must be part of a subscribing institution to have full text access. Users will encounter a click-through agreement and will receive a Client API Token, which is needed when requesting full text of articles
Limitations: rate-limits implemented through CrossRef rate-limiting headers, exact limitations not specified
Contact for technical questions: [email protected]; [email protected] for support using the CrossRef TDM service
For more information: http://olabout.wiley.com/WileyCDA/Section/id-826542.html
from WordPress https://maphy.org/3293.html
0 notes
Text
WordPress REST API: An Introduction

If you’ve spent any time in the WordPress community over the past few years, chances are you’ve heard reference made to the new REST API. However, unless you’re an experienced developer, you may not have any idea what the WordPress REST API actually is.
While the technical details are a bit complex, the basic concepts behind this feature are easy enough to grasp. The new API helps expand what WordPress as a platform can do. What’s more, the REST API makes it simpler than ever for developers to connect WordPress with other sites and applications.
In this comprehensive guide, we’ll walk you through all the basics you need to know. We’ll explain what APIs are in general, and what REST APIs (and the WordPress-specific version) are in particular. Then, we’ll talk about how to start using the WordPress REST API yourself. Let’s jump right in!
An introduction to Application Programming Interfaces (APIs)
Before we delve into the REST API specifically, let’s back up a little. To understand this concept, it’s key to first have a basic idea of what APIs are in general.
At its most fundamental level, an API – or Application Programming Interface – enables two applications to communicate with one another. For instance, when you visit a website, your browser sends a request to the server where that site is located. That server’s API is what receives your browser’s request, interprets it, and sends back all the data required to display your site.
There’s a lot more to the way APIs work in a technical sense, of course. However, we’re going to focus on what probably matters most to you – the practical applications. APIs have been getting lots of attention and visibility, because many companies have begun to package them up and provide them as products you can use.
In other words, developers at a company like Google will collect some parts of their application’s code together, and make it publicly available. That way, other developers can use the API as a tool to help their own sites connect to Google and take advantage of its features:

For instance, you could use the Google Maps API to place a fully-functioning map on your site that benefits from all of Google’s relevant data and features. This saves you from having to code up a map and collect all that data yourself. The same applies to a wide range of sites and applications.
As websites and the functionality they rely on get more complex, tools like APIs become crucial. They enable developers to build on existing functionality, making it possible to simply ‘plug in’ new features to your website. In turn, the site that owns the API benefits from the increased exposure and traffic.
The fundamental rules of a REST (Representational State Transfer) API
There are many ways to create an API. A REST (Representational State Transfer) API is a particular type that is developed following specific rules. In other words, REST presents a set of guidelines developers can use when building APIs. This ensures that the APIs function effectively.
To understand how REST APIs work, you therefore need to know what rules (or ‘constraints’) they function under. There are five basic elements that make an API ‘RESTful’. Keep in mind that the ‘server’ is the platform the API belongs to, and the ‘client’ is the site, application, or software connecting to that platform:

Client-server architecture. The API should be built so that the client and the server remain separate from one another. That way they can continue to develop on their own, and can be used independently.
Statelessness. REST APIs must follow a ‘stateless’ protocol. In other words, they can’t store any information about the client on the server. The client’s request should include all the necessary data upfront, and the response should provide everything the client needs. This makes each interaction a ‘one and done’ deal, and reduces both memory requirements and the potential for errors.
Cacheability. A ‘cache’ is the temporary storage of specific data, so it can be retrieved and sent faster. RESTful APIs make use of cacheable data whenever possible, to improve speed and efficiency. In addition, the API needs to let the client know if each piece of data can and should be cached.
Layered system. Well-designed REST APIs are built using layers, each one with its own designated functionality. These layers interact, but remain separate. This makes the API easier to modify and update over time, and also improves its security.
Uniform interface. All parts of a REST API need to function via the same interface, and communicate using the same languages. This interface should be designed specifically for the API and able to evolve on its own. It should not be dependent on the server or client to function.
Any API that follows these principles can be considered RESTful. There is also a sixth constraint, referred to as ‘code on demand’. When followed, this technique lets the API instruct the server to transmit code to a client, in order to extend its functionality. However, this constraint is optional, and not adopted by all REST APIs.
The WordPress REST API
At this point, you may be wondering how all of this affects you. APIs are excellent tools, but are they relevant to your day-to-day work? If you’re a WordPress user, the answer is unequivocally “yes”.
The WordPress REST API has been under development for a couple of years now. For quite a while, it was worked on as an independent plugin, which developers could contribute to over time was available for anyone to experiment with.
In fact, there were two separate versions of the REST API plugin. Elements of the API were added into the core platform as early as update 4.4. This was followed by it becoming fully integrated as of WordPress 4.7 (in 2016). This means that today, WordPress has its own fully-functional REST API.
Why did the platform make this move? According to the project site itself, it’s because WordPress is moving towards becoming a “fully-fledged application framework”. In other words, the REST API enables the platform to interact with just about any site and web application. Plus, it can communicate and exchange data regardless of what languages an external program uses.

This opens up numerous possibilities for developers. It also makes WordPress as a platform more flexible and universal than ever. As Katie Keith, the Operations Director at Barn2 Media puts it:
By understanding the REST API, WordPress developers can choose the most effective way to implement each task, without being confined to specific technologies or platforms such as PHP or the WordPress back end. Used effectively, the REST API makes third party integrations much easier…It even opens up new opportunities, for example to create your own WordPress-based mobile apps, or explore new and unique ways to communicate with WordPress.
It’s also important to note that you may hear this feature sometimes referred to as the WordPress JSON REST API. The ‘JSON’ part, which stands for JavaScript Object Notation, describes the format this API uses to exchange data. That format is based on JavaScript, and is a popular way of developing APIs thanks to how well it interfaces with many common programming languages. In other words, a JSON API is able to more easily facilitate communications between applications that utilize different languages.
The anatomy of a WordPress REST API request
You should now understand the overall purpose and direction of the WordPress REST API. As such, let’s get into a few specifics about how it works. There are some basic concepts you’ll need to understand if you want to get hands-on and start experimenting with the API yourself.
As we’ve explained, every API processes requests and returns responses. In other words, a client asks it to perform a certain action, and the API carries out that action. Exactly how APIs do this can vary. REST APIs are specifically designed to receive and respond to particular type of requests, using simple HTML commands (or ‘methods’).
To illustrate, here are the most basic and important HTML methods a client may send:

GET: This command retrieves a resource from the server (such as a particular piece of data).
POST: With this, the client adds a resource to the server.
PUT: You can use this to edit or update a resource that’s already on the server.
DELETE: As the name suggests, this removes a resource from the server.
Along with these commands, the client will send one or more lines that communicate exactly which resource is desired and what should be done with it. For example, a request to upload a PHP file into a particular folder on a server might look like this:
POST /foldername/my_file.php
The /foldername/my_file.php part is called the ‘route’, since it tells the API where to go and what data to interact with. When you combine it with the HTTP method (POST in this case), the entire function is referred to as an ‘endpoint’.
Most REST APIs and the clients that interact with them get a lot more complicated than this – WordPress’ version included. However, these basic elements form the basis for how the WordPress REST API works.
How to start using the WordPress REST API
As long as you have a WordPress site set up, you can start experimenting with the REST API right away. You can perform various GET requests to retrieve data directly, simply by using your browser.
To access the WordPress REST API, you’ll need to start with the following route:
yoursite.com/wp-json/wp/v2
Then, you can add onto this URL to access various types of data. For instance, you could look up a specific user profile via a route like this:
yoursite.com/wp-json/wp/v2/users/4567
In this scenario, “4567” is the unique user ID for the profile you want to see. If you left out that ID, you would instead see a list of all the users on your site:

You can use the same basic route to view other types of data, such as your posts or pages. You can even search for subsets of the data that meet certain criteria. For example, you could retrieve all posts that include a specific term using this URL:
yoursite.com/wp-json/wp/v2/posts?=search[keyword]
This is just a simple illustration, of course. There’s almost no limit to what you can actually do using the WordPress REST API. If you want to learn more about how it works, we recommend starting with the following resources:
The REST API Handbook. This is an official WordPress resource that documents all sorts of information about the REST API. Among other things, you’ll find a list of endpoints you can use, as well as details on some of the REST API’s structural aspects that we haven’t touched on here.
W3Schools tutorials. While this resource isn’t REST API-specific, it offers handy tutorials that can help you brush up on key concepts, such as HTTP methods and JSON.
The Ultimate Guide to the WordPress REST API. This free e-book from WP Engine contains lots of practical information and examples. Plus, it will walk you through how to accomplish several basic (and more advanced) tasks.
While we’re at it, also check out this list of the top 10 plugins for WordPress developers. They will surely come in handy as you’re exploring the world of REST API.
The WordPress REST API is no doubt a complex topic. Even for non-developers, however, it’s worthwhile to understand the basics of how this technology works, and what it makes possible. What’s more, it may even enable you to start dabbling in development yourself!
Conclusion
There’s no better time to learn about the WordPress REST API than now. Since it’s been fully merged into WordPress core, it’s going to play an important role in the platform’s future. Developers of all stripes will be using this API to connect WordPress to the broader web in ways that were previously difficult or impossible.
Understanding this concept for yourself can be a bit challenging. At a basic level, however, the concepts are easy enough to grasp. A REST API is an interface that enables two programs to ‘talk’ to one another, and is created following guidelines that ensure it’s flexible, extensible, and secure. If you want to delve deeper into how all of this works and how it can be used, there are lots of helpful resources out there, such as the official handbook.
from WordPress https://maphy.org/3281.html
0 notes
Text
邮件模板网站
随着移动设备上的消费者越来越多,你需要确保你的电子邮件广告使用的是适合在任何屏幕上展示的响应式设计。
以下这些响应式邮件模板已经在各种大小的屏幕和邮件客户端上进行了测试。
其中既有单一的邮件模板,也有具有多种布局方案的模板集合。所有的这些模板都是免费的。(有些网站可能国内访问不了)
Cerberus (3种)

Cerberus是一个HTML电子邮件布局模式的小集合,其中包括流体、响应式和混合模板。
Slate(5种)

Slate是五种响应式邮件模板的集合。这些模板是为商务需求而设计的���例如:新闻邮件、产品更新、收据、简单的声明或书信邮件等。
Sendwithus开源邮件模板(14种)

Sendwithus开源模板是由Sendwithus社区(邮件营销公司)创建和管理的免费邮件模板集合。任何人都可以贡献新的主题和模板,或者对现有的模板进行更新。
Responsive Email Patterns(36种)

Responsive Email Patterns 集合了大量响应式邮件的模式和模块。你可以先预览一个布局,然后获取代码。
MailChimp Email Blueprints(6种)

Email Blueprints是一组HTML电子邮件模板,这些模板包括了模板语言元素,只要导入到MailChimp的帐户时,这些元素就可以对模板进行自定义。
Zurb响应式邮件模板(5种)

这里提供了Zurb的5个免费电子邮件模板,其中包括了新闻通讯、侧边栏和主图式布局。每个模板都有单独的CSS和HTML,以适用于你的邮件营销工具。
Antwort(3种)

Antwort 提供了单、双、三列式的电子邮件响应式布局模板,以适合不同用户的屏幕宽度。Antwort的目的是要教你如何为邮件做出响应式布局,这就是它为什么要提供开源的HTML。
Free Newsletter Template

这是PSD2HTML在GraphicsFuel 上提供的一个免费多用途邮件模板。完全兼容34个邮件客户端和浏览器,并在7种实际设备上进行了测试。
Passion

Passion 是DynamicXX在Pixel Buddha上提供的响应式多用途邮件模板。
MailPortfolio

MailPortfolio是一个响应式的邮件模板,具有简单而干净的设计。
Respmail

Respmail使用MailChimp的Email Blueprint作为基础,这是一个经改进的版本,具有更多的编辑行选项、重新定义的结构以及针对Outlook、Yahoo、Hotmail、Gmail等平台的修复。
Mosaico(2种)

Mosaico是一款开放源代码编辑器,你可以通过简单的拖放界面创建出响应式邮件。它提供了两个��板,分别是Versafix-1和Versafluid。
from WordPress https://maphy.org/3267.html
0 notes
Text
论工科线性代数的现代化与大众化
作者:陈怀琛 教授
数学与工程的结合在本世纪中最明显的特色就是计算机广泛应用于科学计算。但是在大学的数学教育中,并没有得到充分的体现,学生学习的主要仍是笔算,与未来的工作严重脱节。在线性代数课程中,这一点表现尤其明显。实践证明,线性代数课程的现代化改革将是提高大学数学教育应用水平的一个有效的切入点,本文将对此进行论述。
关于线性代数课程目标的争论和演变
从上世纪起,线性代数从一门较抽象的理论学科发展成为所有专业科学计算的技术基础,从少数数学家的象牙之塔进入到每个大学生的手头工具库。这一转换可以概括为“现代化”和“大众化”两个方面,没有任何一门其他课程会在短期内经历这样的巨变。如何认识和应对这个变化,并在有限的时间内,把最需要的内容教给具有不同需求的学生,使课程的改造能够以更自觉的方式,更明确的目标,在更广泛的领域向前推进,这是本文的主题。在本文中所说的“工科”,只是为了简短顺口,论述的内容也适用于理、经、管等非数学专业。
虽然线性代数已经列为大学的公共数学基础课,但要记住这个角色还相当新,其目标还非常模糊,它远未起到应有的作用。微积分已经在大学教学计划中存在了两百年,它和工科后续课已进行了无数次磨合。而线性代数的第一本研究生教材出现在1940年代,第一本本科教材出现在1959年,第一个CPMU(美国本科数学大纲委员会)建议大纲于1965年制订。由于课程当初主要用于数学系,因此其着重点是抽象的“N维向量空间”,目标是为更抽象的高年级数学课程作铺垫。“矩阵应用”的这个侧面则受到相当程度的忽视,与后续课的需要存在着巨大鸿沟。
20世纪后50年计算技术的高速发展,推动了大规模工程和经济系统问题的解决。使人们看到,线性代数和相关的矩阵模型是如微积分那样的数学工具。无所不在的线性代数问题,等待着各层次的工程技术人员快速精确地去解,修这门课程的学生绝大多数已是非数学系的。然而,这门课程却仍然沿用了为数学系设计的以抽象的N维向量空间为主线的大纲,对矩阵模型及相关的计算极度地忽视。大多数学生对这门课的反映是抽象、冗繁、枯燥、无用。他们在毕业并工作多年后仍普遍批评这门课“有用的不教,教了的没用”,提出了强烈的改革要求。
对这种要求的答复集中表现为1990年美国LACSG(线性代数大纲研究组)提出的五条改革建议。其要点是:要满足非数学专业面向应用的需要;要强调以矩阵运算为基础(不是向量空间);要从学生的实际水平出发(低年级);要采用最新的软件工具(用计算机).这四条强调的都是课程的实用性,降低其抽象性。为了适应少数学生深化理论的需求,加了第五条:对想读数学学位的学生应另开一门高年级课程。这些建议在美国的线性代数界得到了广泛的支持,1992年起,又由国家科学基金会(NSF)资助了为期六年的ATLAST计划,对教师进行数学软件的培训。美国当前的教学内容和教材,已经与20年前大不相同了。概括起来,一是现代化,普遍用计算机解决问题;二是大众化,使理论基础不高的普通学生都能听懂,并会用矩阵解题。MIT的G.Strang教授提出了“让线性代数向世界开放”的口号,听他视频课的已超过100万人。
中国的线性代数在1980年代开始进入大学,1995年,教育部数学教指委正式发布了对它的“教学基本要求”,它所用的恰恰是美国改革前的大纲,而且理论更深,实践为零。针对理论和实践严重失衡的现象,2005年起,西安电子科技大学开展了“用MATLAB提高线性代数教学水平”的研究试点。主要抓了“有用的不教”、“实践为零”的问题,先利用补丁教材《线性代数实践及MATLAB入门》,组织了全校的教师培训班。又编写了理论与实践结合的教材《工程线性代数(MATLAB版)》,在学生中进行了试点教学。目的就是强调矩阵建模和计算机应用那个侧面,这些工作得到了数学基础课程分教指委的赞同和高教司的支持。2009年,高教司设立了“利用信息技术工具改造课程”的项目,其中由西安电子科技大学牵头,18所大学参与,实施了“用MATLAB及建模实践改造工科线性代数”子项。两年多来,共有200多名教师、45000名学生参加了这项改革,由于利用了概念形象化的手段、算题简捷化的工具和丰富多彩的应用实例,受到参试师生普遍的欢迎。在2011年项目评审时得到了教育部高等学校数学与统计学教指委数学基础课程分教指委的高度评价。参试师生提出的主要诉求是增加上机实践的时数。
要补充实践内容,只要证明旧内容的不足,容易得到认可。但学时会有所增加,而且解决不了理论过难过深、数学系味道太重的问题。全面的改革,应该删掉部分工科当前不用的东西,这就容易引起争议,弄不好影响改革进程。因此这两年中,我们对理论简化的问题没有付诸试验。主要进行调查,只动口,不动手。现在机算的问题已经解决,我认为应该进入对理论教学内容作改革的攻坚阶段。这里最重要的出发点是“需求牵引”,因为后续课和毕业后工作的需求是客观存在并与时俱进的,按照客观需要决定教学大纲是课程磨合的好方法。这里特别要强调两点.
其一是把学生的近期需求与远期需求相区别。对于大学一年级来说,本科的后续课要用的内容,属于近期需求,必须尽力满足,而且应该列为必修的内容;远期需求是指未来工作或考研等可能用到的内容,不应列为公共基础课内容,可以到高年级时由少数学生选修。
其二是数学系学生要“搞数学”,非数学系学生则是要会“用数学”,这两者是很不同的。同样是“用数学”,层次差别也很大。再就是‘需要’和‘可能’往往难于兼顾,为达到最主要的目标,必须要忍痛割爱。所以选择课程内容和方法时要在这些方面下功夫。
工科对线性代数的需求及要增补的内容
我们主要以机械类、电子信息类、和控制类的教学计划为对象进行调查,研究它们的后续课程中有哪些地方用到线性代数。从调查的结果中可以发现,各专业都有十门以上的后续课要用线性代数。在文献中可以还找出类似的几十个例子.比如三坐标测量仪的数据分析要用矩阵,测量卫星轨道数据要解超定矩阵方程.频谱分析要用1024阶复数矩阵乘法,根据k点幅谱要求设计N阶最佳滤波器遇到的是N阶超定方程;数值方法课中N点的曲线拟合要解N—1阶超定方程;解偏微分方程的有限元法要解几十万阶的矩阵方程;…。可以说,凡是要用计算机解题的地方都要用矩阵。但后续课需要解的是高阶、复数的线性方程组,而我们的线性代数课程没有教学生矩阵求解的软件工具,包括数百万现在已是各行业骨干的教师及工程师都没学过。矩阵模型若不用软件工具.其效率还不如初等代数。而复杂些的,十个小时也算不出来。这些题目若按矩阵模型用计算机算,几分钟就解出来了。这不是在国际科学技术竞争中自甘落后吗?
说到底,工科机、电、控制专业所需要的数学,无非是代数和微积分.代数问题比微积分还多。毕业的学生遇到微积分还可以去查查书.找解答;碰到代数问题就一筹莫展。代数问题的特点是“繁”,“矩阵+软件”是针对这个特点的杀手锏。现在的线性代数只教前一半.那就是丢掉了这个杀手锏的精髓。稍复杂些的代数问题就不会解.而它占到了工程中数学问题的一多半。这种教学中的偏颇已经造成我国一代人才在数学能力上的畸形,严重影响了工科学生的培养质量。
除了解高阶方程这一头的缺失之外,在向量空间这一头也有问题。传统的线性代数总强调N维抽象向量空间的重要性。我们也在本科课程中进行了调查.可是到现在还没有找到一个有说服力的需求实例。有人指出.将一个函数展开为N阶傅里叶级数,可以看成是N维向量的叠加。是的,专门搞代数的人可以这样去理解,但绝大多数搞工的老师和本科教材都不会从这个角度去思考,而是用波形叠加来理解,这更加符合工科形象思维习惯。
对工科大学生来说,最重要的是看得见、摸得着的欧几里得空间,后续课中就有很多实际应用问题,有些是在现代化机械车间中就会遇到的。
例1 三坐标测量仪测得工件截面上五点的三维坐标,问这些点是否在一个平面上?求该平面的方程及各点误差;它们是否构成一个圆?求该拟合圆的方程。
例2 给出三角形刚体在平面上的初位置和终位置.问这个位移如何用矩阵乘法来表示?从初位置到终位置,如何分成十步来实现连续动画?
例3 任何刚体的空间转动能否及怎样用矩阵乘法表示?
例4 3D动画需要把三维物体的形象投影到二维的屏幕上,怎样用矩阵运算来实现投影?
这些都是很直观的“线性代数和空间解析几何”的问题,但按现在的不用计算机的教材教课,这些问题都是解不出来的。也就是说,在向量空间的教学内容上,喊的是N维向量空间,其实连二、三维的问题都没搞懂,而后者才真正是工科大学本科的迫切需求。当把上述问题用计算机软件来解时,空间解析几何又进入了新的层次。并且为学生理解和掌握三坐标测量、机器人和机械手、计算机图形学、2D,3D动漫技术、三维空间六自由度航行器运动学等广泛的现代化新课程作了准备。
线性代数花了很大篇幅讨论N维向量空间,这在当时也许是合理的。因为教学对象是数学系的研究生,强调的是推导和证明,那时还没有计算机,不能指望线性代数有多少工程应用价值。现在时代发生了巨大的变化,线性代数已成为科学计算的基础,教学对象是立体概念尚待建立的低年级学生(我教过制图,知道让有些人建立空间概念是多么困难,何况N维),计算机已普及到人手一台,强调的是面向现代化工程应用。目标、对象、条件都不同了,大纲怎么能一成不变呢?50多年来,线性代数的发展都是围绕着计算技术实现的,它的教学内容当然应该体现出时代的精神。
由于线性代数内容非常丰富,各类学生的需求在理论和应用两个领域又有很大的差异,可以设想,改革的大方案应该是把线性代数分成两门课。第一门是低年级公共课,强调矩阵方程的解和欧氏空间,强调形象教学和感性认识,强调计算机软件应用,以满足本科四年中各后续课程的科学计算需求为必达的起码目标;第二门是高年级选修课,它可以为数学系的后续课程做铺垫,也为可为考研做准备,其内容可有更高的抽象性。不过学第二门课也要有第一门课作为基础,因为任何高级的抽象思维必须建立在大量的感性知识之上。这样,第一门课就会变得较为形象而易学,全体理工科本科和大专学生都要修,所以要特别强调它的大众化方向。
解决好线性代数课的大众化问题
要解决好这个问题,首先要弄清楚工科毕业生究竟是如何使用数学的。开发Mathematica软件的数学家Wolfram在2010年指出,即使是美国,在学校内的许多课程仍然在用手算,而到企业和社会上,他们所用的都是CAD软件,即机算。如果仍然只会手算,他们将被解雇。“School Math(学校数学)”不向“Real World Math(真实世界数学)”靠拢,会造成巨大的鸿沟,浪费大量的社会资源,影响国民经济的发展,这段话对线性代数尤其适用。
工科学生学数学是为了“用数学”,数学系学生是“搞数学”(指研究数学),其实大多数数学系学生毕业后是做大、中学数学老师,也还是用数学,搞数学的是极少数。这两者有很大的不同,培养的方法也应该完全不同。举学车为例吧,在几十年前,当汽车还没有大批量生产时,车的质量不稳定,开车的人要不断地调整修理它的各种部件,开车的必须懂汽车的详细结构,培养一个司机和培养一个技术员差不多,要花很多时间;到了今天,由于汽车质量的提高和各种自动化装置的应用,学开车可以完全不了解车的结构,他们只要知道驾驶座周围的仪表和操纵杆会对车的运动产生何种影响,又认路,就能熟练驾驶了。学开车只要几天,开车大众化很容易实现。
“用数学”和“搞数学”的差别也类似,由于数学软件已经高度自动化,“用数学”者对于数学理论的推理和证明的要求可以大大降低,对计算的细节也无需深究,主要要知道所做计算的目标和物理意义,知道达到目标的多种途径及其优劣,能做出比较选择。还要知道数学软件中各种命令的用途,以及计算机可能作出的反应。正如钱学森指出的:“数学课不是为了学生学会自己去求解,而是为了学生学会让电子计算机去求解,学会理解电子计算机给出的答案,知其所以然。”
拿行列式作为例子。中国大部分线性代数书都从数序起讲,光N阶行列式的定义和它的性质就要花几个学时,但大部分的师生连二、三阶行列式的几何意义都不知道,对四阶以上行列式则从来没有算过,更没有用过。人们都知道行列式的用途是判解的存在性,再问一下,判解和求解哪个容易?多数人是答不出来的!其实,用高斯消元法解方程比按定义计算行列式快得多,即求解比判解的计算复杂度小很多(5阶差10倍,25阶差1023倍),与其费力判解,不如直接求解。用计算机算题都是直接求解,如果无解,计算机会告诉你:“行列式接近于零,解不可靠”。这时工程师要做的是从物理上找原因,决不必去重算行列式的。只有书呆子才会先算行列式判解,再去求解。如果有人按克拉默法则算N+1个行列式去求N个解,更是N重的书呆子了。老师教了学生所有算行列式的方法,不结合应用,貌似内容多、水平高,其结果很可能培养出来“不会用数学”的书呆子!舍简就繁的根源在于“搞数学”的人看来,最重要的是解的“存在和唯一性”,要从源头就有严格的证明,这就必须从严格定义出发,所以行列式便被奉为圣灵,放在线性代数的第一章第一节开讲。因为要笔算行列式,所以要引出并证明它的许多性质。而从“用数学”的人看来,既然行列式计算根本无助于求方程解,那么为了计算它而推导的性质都没有工程价值,完全可以不讲。只要以二、三阶行列式为例弄清它的几何意义,知道它等于零为什么意味着无解或向量组线性相关就够了,真正计算必须得靠计算机。
有些老师会认为这样讲行列式水平太低了。我建议您们看看Strang在教材中是怎么讲的。他特意把行列式列为第五章,并在序中写明了这样布局的意义,就是为了贬低行列式计算,避免误导学生真去算它。在这章中,他讲了行列式的十个性质、代数余子式以及克拉默法则,采用的方法都是举二、三阶行列式的例题来说明(不是证明)。几句话带过,就是只要你知道有这么回事,他的这本书就这样完全避开了任何N维空间的推导,同时他的课却得到了一百万的听众,在中国这样的书该被嗤之以鼻了。所以要想出版大众化的教材,评价的标准必须把易懂实用(而不是证明严密)放在第一位。大众化的线性代数不仅要能为普通大学的新生所接受,最好也能为高职高专的学生所掌握和使用,那就必须删去一切人为的“拦路虎”,把线性代数变得浅显易懂。
再来看线性方程组解的特性的讨论,其实难点就是研究欠定方程组的解空间,那是一个占学时很多,师生都感到摸不到头脑的主题,它在工程上的用途却几乎为零。任何一个正确建立的工程问题,必须存在确定的解,故其数学模型只可能是适定或超定,不可能是具有无数庸解的欠定方程组。欠定方程是条件欠缺造成的,工程师可以用“条件不足”为理由而拒绝欠定命题,超定命题则是工程师必须会解的,现在却不教。“大讲欠定,不讲超定”是线性代数“教了的没用,有用的不教”的典型。其实,数学界从来强调命题的“存在和唯一”,也就是说,如果解不满足唯一性,这个命题就没必要研究下去了!不知线性代数为什么例外,明明已由行列式为零判为庸解的命题,却还要花时间去研究这些庸解组成的空间?这绝不是工科的需求!目前知道,它的唯一的需求是来自线性代数自身的求特征向量,因为求的解不是一个点,而是一根过原点的线(即一维子空间),才出现欠定方程组求解的问题。
特征向量的计算实际上涉及三个串接的难关,第一个是求特征方程,它涉及到繁琐的行列式计算;第二个是特征根的计算,涉及一元高次多项式求根;第三个才是解欠定方程组。想用手算矩阵的特征向量必须过这三关,其中最难是第二关,因为手工只能求到二阶,到了三阶,这一关就过不去,在第三关上下再大功夫也是白搭。可见,即使是三阶(非老师凑好的)实系数方阵,特征向量就不可能靠手算求出,更无必要拉扯出更抽象的N维向量子空间。要想对学生有用,主要是讲清特征向量的概念,要计算必须得靠计算机。
上面举了两个例子,都是占学时很多的难点,却都不是工科本科所需要的重点,可以大大精简。其他的内容也可以用类似的方法(即按它对工科有无用处来判断取舍)来处理,在这个过程中,我们才能真正吃透线性代数的全部内容,并用各专业需求的胃液对它进行消化,创造出适合于相应专业的浓缩营养品,培养出真正会用数学的人才。不做这个消化工作,像反刍动物一样,把吃进去的素材全部照样吐出来喂学生,那是很不可取的。要做好消化工作,数学和专业教师的结合是必不可少的条件。靠清一色的同行教师来搞改革,很不利于创新思维的出现。作为工科出身的教师,我愿意同有志于斯的数学家合作,共同编写大众化的线性代数教材。
有些老师会反对,说你要删去的这些理论对培养学生思维能力多么重要。这要看学时约束条件,争论的焦点是:对非数学系低年级,在有限的学时内,什么是学生最需要并能够接受的内容。有些争论可能会持续较长的时间,为了不影响公共课教学大纲的制订,我们建议设置一门高级选修课,它可收容这些有争议的高深内容,而保证必修课程中内容的实用和精炼。公共线性代数的大众化每年将使几百万学生和技术人员受益,他们将接受概念简洁、目的明确的理论,并且会用计算机方便地解决遇到的代数问题,使数学用于现实世界,对我同的现代化事业作出巨大贡献。高级线性代数课程是为拟深造理论的高年级工科及数学系学生进行铺垫的。在大四开这门选修课,学生的理论和实践的基础都打好了,接受能力大大提高,而且选课的必是学生中的尖子,任课教师人数减少了,执教者必是教师中的精华。可以放手讲他们擅长的内容,教学质量必有很大的提高。学生学完后很快参加考研,效果肯定好得多(现在的考研题也该改,要理论与实践结合),何必要在低年级上那些太抽象的课,让90%以上的师生陪绑受罪、吃力不讨好呢。把线性代数分成两门课可以防止基本学时的膨胀,确实会是领导、各类教师、各类学生皆大欢喜的事,我们应该促成它的实现。
结语
对工科学生而言,数学课应该使他们有宏观的用数学的思想,要使工程师了解工程中可能遇到的各种数学问题的类别,并且知道应该用什么样的数学理论和软件工具来解决,这是一种高水平的抽象,由于计算机软件的高度发展和自动化,他人和前人的经验都已经集成在软件中,不必自己都懂,不一定要求掌握其编程、推导的细节。用了软件,后续课和工程中大量的线性代数以及其他数学问题,就有了多快好省的解决办法。所以“现代化”是“大众化”的基础。现在“现代化”的客观条件已经完全具备,主要是掌握软件工具的老师太少,需要形成一个学习和培训的环境,像美国在1992—1997年实行的ATLAST计划那样;“大众化”应该是我们奋斗的当前和长期的目标,需要各方面的专家权威进行更多的分析和论证,希望教育部的学术指导部门能予以足够的关注,能参照美国LACSG那样,组织各方面专家进行有充分准备的讨论,形成有权威的改革建议。
from WordPress https://maphy.org/3249.html
0 notes
Text
涌现论综述
概观
涌现是系统和复杂性理论中的核心概念之一,因为它描述了一个成为或创造的普遍过程,当我们将基本部件相互作用并自组织起来创造新的组织模式时,新的特征和特性就会出现。从宇宙的演变到交通堵塞的形成,从社会运动的发展到鸟类的成群结队,从数万亿细胞的合作导致人体死亡,到飓风和金融危机的形成,涌现是一个非常抽象的概念。
虽然涌现的概念几千年来一直受到许多人的关注,但它经常被视为一种病态。随着复杂性理论的发展,我们可以使用越来越多的计算和概念工具以结构化的科学方式来理解它。在这本书中,我们将借鉴复杂性和系统理论中的不同观点,以连贯的方式构建理解涌现的框架。更具体地说,我们对涌现的探索将从非线性模式形成的角度展开。在这种情况下,基础部分之间的协同作用产生了自组织,形成了一种独特的模式,这种模式由演化动力学驱动,创造出了新的组织层次。
本文由四个主要部分组成。
在第一部分中,我们首先讨论一般的关联模式,然后再看协同互动,这是涌现的基础。
下一节集中讨论模式的形成,即零件如何自组织的问题;将他们的状态同步化,形成一个新的组织层次。在这里,我们将讨论经常使用的两种主要不同类型的涌现;所谓的强势和弱势涌现。
在第三部分中,我们将研究整合层次的概念,协同作用如何导致模式形成,以及被称为整合层次的新的组织层次的出现。我们将讨论这些不同的层次是如何形成自己不可简化的内部结构和过程,从而在微观和宏观组织层次之间产生复杂的动态。
最后一部分,我们将看看在某个过程中,涌现是如何随着时间的推移而出现的。我们将讨论混沌边缘假说;为什么自组织的、涌现的系统从未完全锁定到位,而是通过秩序和无序之间的动态相互作用来进化,以创造新的复杂度。
本文不需要任何具体的科学背景就可以阅读,它与许多不同的领域相关,特别是计算机科学、生物学和生态学、哲学、认知科学领域的领域,它适合任何对用复杂性和系统理论框架更好地理解涌现这一核心概念感兴趣的人。
涌现
涌现是哲学、艺术和科学中的一个术语,用来描述当我们将事物组合在一起时,新的属性和特征是如何产生的。涌现描述了一个过程,通过这一过程,组成部分相互作用形成协同效应,这些协同效应随后增加了组合组织的价值,从而产生了一个新的宏观组织层次,这是部分之间协同效应的产物,而不仅仅是部分本身的属性。
因为涌现属性是部件之间协同作用的产物,所以它们不能在子系统中局部观察到,而只能作���全局结构或集成网络观察到。以这种方式,出现创造了一个具有两种或两种以上不同的、不可简化的组织模式的系统,称为一体化层次。
因此,当提到涉及涌现的现象时,新的描述词汇对于不同的层次是必要的。因为宏观涌现现象不能在适用于零件的词汇中描述;这些新出现的特征需要新的术语和新概念来对它们进行分类。从某种意义上来说,由于涌现现象被认为是不可减少的,从其基本组成部分来看,预测涌现现象的最佳手段是计算机模拟。
涌现包括创造一些新的东西,这些东西是在创造之前从对零件的描述中无法预料的。这些新产生的东西具有一个强度谱。它解释了不同类型的涌现,这些涌现被描述为强或弱。在强度谱的最弱端,这些新奇的现象可能只是看起来不同,而在它们出现之后,我们仍然可以理解清楚它们是如何从一些基本部分中衍生出来的。在强度谱的最强端,一件事是由另一件事引起的,但决不能还原成那件事。
涌现的经典例子可以在群居昆虫如蚂蚁和蜜蜂在创造蚁群和巢穴的集体行为中找到。在人类社会组织和人类意识中还发现了许多其他例子。水的溶剂特性是经常被引用的涌现例子,因为氢原子和氧原子都不具备这种特性,也不具备这种特性的缩小版。溶剂作用似乎来自氢和氧的非线性组合。
涌现哲学研究中存在一个主要区隔,即所谓的本体论和认识论的涌现。认识论指的是知识以及一个人如何认识世界。认识论的出现是这样一种观点,即由于我们知识的限制,一些系统在实践中无法用它们的组成单位来描述,也就是说,我们无法获得所有相关信息和进行计算。
本体论是指存在的本质,它关注我们认为我们周围世界中事物的客观存在。随着本体论的出现,我们不仅仅是在陈述我们对世界的认识,我们也在陈述世界的真实情况。当我们谈论本体论的出现时,不管我们对世界的理解如何,我们都在陈述世界是怎样的。如果本体论的出现被识别,这意味着理论上不可能完全理解一个系统的组成部分,这不仅仅是因为实际的限制,而是因为新的和基本上不可约的组织层次出现在更高的层次。
涌现属性归属于元素的整个结构化集合,其中涌现属性不是单独获取的集合元素属性的加法函数。例如,人体的质量是孤立的所有部分的简单总和,因此不是一个涌现的特征。然而,人类意识似乎是一种涌现现象,因为我们不能把它作为基本认知部分的总和来描述。系统的行为更多地是由组件之间的交互而不是组件本身的行为造成的。整体的附加值——存在于零件及其特性之上和之外——是相互作用的产物。这些从整体上增加或减少价值的部分之间的特定互动称为协同作用。然后,涌现是系统各部分之间协同互动的产物。
当两个或两个以上的要素相互区别并协调它们的状态和活动时,就会产生积极的协同作用。差异化使部件专业化,而集成使它们能够协调不同的能力以实现整体结果,通过这样做,协同互动增加了整个系统的价值,我们得到了一些比其部件之和更大的组合组织:涌现。从传粉昆虫和植物的相互作用来看,这些协同作用在我们的世界中是一种普遍现象:微生物及其宿主、不同药物之间的相互作用、以及各种社会组织,如企业、家庭和朋友。
因为协同作用中的各个部分是相互区别和协调的,这意味着它们具有特定类型的交互作用,如果我们通过移动各个部分或者以不同的方式重组它们来改变交互作用,那么附加值可能会很大。例如,如果我们有一把锁和一组钥匙,这些钥匙中只有一把能够打开锁,尽管在质量和其他物理属性上,这些钥匙几乎完全相同,如果我们拿走除了正确的一把以外的任何一把钥匙,并将其与锁组合起来,这个组合将几乎为零,因为锁不会打开,因此这个组合将不起作用。但是,当我们把正确的钥匙和锁结合起来时,我们会得到一个有价值的整体运行系统。这种附加值来自钥匙和锁之间的协同作用,这种特定的钥匙和锁被设计成相互区别和协调,从而实现它们的组合功能。无论是锁还是钥匙都无法实现隔离保护某物的综合功能。因此,我们需要两个不同的部分,但它们也需要以某种方式共同工作,以获得整体运行的系统。其他钥匙不同于这个锁,但是它们没有和这个锁协调,因此当我们组合它们时,没有增加价值或功能。
协同互动产生了新的组织层次,这些层次有自己的内部属性、特征和动态。这些新出现的层次被称为整合层级。尽管这些新的层次并不直接依赖于其组成部分的性质,但已经出现的组织模式取决于其组成部分之间协同作用的完整性。如果我们消除协同效应,整合层级将会瓦解和消失。因此,不像简单的线性系统可以简化为单一层次的组织,涌现导致了不止一个层次的组织的发展,这些不同的层次代表了不同的环境和管理零件的规则集。
有了整合层级,我们就有了一种动态,其中更高的层次依赖于更低的层次,然而,更高的层次也创造了自己的组织模式,这种模式反馈给微观层次的基本部分来进行互动。所有涌现系统都由一组微观层次的构建块组成,这些构建块对系统设置了一组向上的物理约束,但是宏观层次定义了一种组织模式,然后通过为部件的操作创建上下文来对其施加向下的影响。例如,移动通过微处理器的电子是使计算成为可能的物理构件。处理器是对正在运行的宏级软件程序的物理限制之一。
然而,宏观层面上的程序正在执行一些与部件组织无关的过程——比如一个人用它来创建网站——所有人都认为软件的宏观层面操作完全依赖于处理器中移动的物理电子的微观层面,这个人在构建网站时正在执行的宏观层面过程的结构与计算机中正在进行的底层微观层面物理处理无关。这种软件活动可以在许多不同类型的计算机上以相同的方式进行,这些计算机在硬件中具有非常不同的底层模式,软件的上层是通过创造向下的效果来调节电子在微观层面上的移动。
由于在一个整体系统中不同层次的组织发展,涌现在不同层次之间产生了复杂的动态;最明显的是在系统的宏观和微观层次之间。产生某种形式出现的系统具有特定的微观-宏观反馈动态,这对于理解它们的整体行为变得重要。高层影响低层的动态是涌现的关键部分,它被称为向下因果关系。向下因果关系是指,在一个展现出涌现的系统中,作为涌现现象轨迹的更高或更宏观的层次会对最初涌现的系统中的更低层次的基底产生某种向下的因果影响。
这种相互作用可以在生物有机体中看到,因为个体器官和组织创造了整个有机体,但是有机体作为一个整体,反馈来调节这些部分。在社会中,个人创建机构,但这些机构会反馈,将个人约束到整个机构的目标。同样,经济和金融市场涉及宏观结构(如市场价格)和个人行为之间的持续互动。
在所有情况下,当我们从微观层面进入宏观层面时,涌现涉及对正在使用的系统的新描述,这可以在许多科学领域看到。例如,经济学分为微观经济学和宏观经济学,不同领域使用不同的术语。同样,理论物理仍然被分为微观层面的量子力学描述和宏观层面的广义相对论描述。在社会研究中,微观和宏观被分成两个不同的领域,有各自的词汇;谈论个人的心理学和谈论社会系统中宏观模式的社会学。这是因为,像社会运动一样,现象只出现在许多个体的同步活动中,因此不会成为个体研究的一部分,而只会成为整个社会群体研究的一部分。
然而,仍然存在的问题是,我们是出于权宜之计和缺乏知识而在每一个层面上形成不同的描述,还是我们这样做是因为从根本上来说,不可能从微观层面全面推导出宏观层面的描述?这种差异体现在强涌现和弱涌现两个方面。
弱涌现描述了任何涌现过程,给定足够的信息,理论上可以由计算机模拟。随着微弱涌现的过程,新的特征和特性可能会出现在一个无法事先预测的系统中。然而,一旦它们出现,至少从理论上来说,可以从下面的组成部分中得到它们;即使实际上这通常在计算上不可行。强烈涌现的过程是那些即使在理论上也无法从对底层组成部分的性质和相互作用的充分理解中导出的过程。然后,必须从宏观动力学的角度来理解更高层次的涌现特性和特征,而不涉及微观力学。
作为一种认识论,涌现反映了某种看待世界的方式,这可能与还原论形成对比。涌现的概念可以被认为是系统思维和整体范式背后为数不多的核心概念之一。整体论和还原论都导致了看待世界的截然不同的方式和进行科学研究的根本不同的方式。
划分这两种范式的核心问题是,我们的世界是否仅仅由几条基本法则来表达,这些法则直接支配着自然界最基本的部分,通过它们,它们构成了更复杂的系统?这将是还原论者所持的立场,自然会导致对更基本的基础部分的研究。或者涌现是否是我们宇宙的一个基本部分?在这种情况下,理论上甚至不可能将一切都简化为只涉及基本基本部分的账户,因此,我们应该集中精力研究如何理解不同层次上出现的组织模式的抽象原则。这将是更全面的方法所持的立场。
基本的还原论直觉是,世俗事件和过程只受几个基本属性的支配,通过几个基本物理定律联系起来,这导致了所谓的物理学的完整性。一切都是物理的,每一个事件、现象或过程都是由一些低级的物理交互作用引起的。
奥本海默和普特南在1958年为科学事业提供了经典的结构简化概念,他们明确地将科学视为一种等级结构,更高层次的科学领域显示为由更低层次的科学实体构成的复合物。这种等级可以被认为是一个金字塔,以减少为手段上下移动它的等级。在底层,我们有基础物理,在这些之上,我们有其他物理领域,然后是化学、生物学、心理学、经济学和其他社会科学领域。
其结果是一种有点疏远的世界观,以基本物理粒子为中心,以人类活动为某种形式的外围活动,从而形成了一个与我们日常世界经历相去甚远的知识库。涌现的想法导致了科学事业的一个非常不同的概念,这种概念并不试图分解事物,而是着眼于许多不同的层次来寻找所有人都共有的模式和过程。这种方法基于抽象,通过识别所有级别上所有类型系统共有的模式。整体论试图理解综合、协同和变化动态的基本过程,这在所有类型的系统中都可以看到。它不是将事物简化为物理元素和定律的有限子集,而是积极寻求多样性,以获得所有层次上出现的所有系统共有的抽象模式。在这里,科学的统一不是在基本部分寻找,而是在抽象的抽象模型中寻找,这些模型适用于所有系统,包括社会、物理、生物、工程。
from WordPress https://maphy.org/3229.html
0 notes