
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by mmm-plts and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
8 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Proyecto Minería de datos Tabla de agua
El proyecto consiste en analizar los datos del estado de las válvulas de agua en Tanzania, para que mediante el código se pueda establecer cuales requieren mantenimiento y de que tipo. Los datos los proporciona el gobierno de Tanzania, a través de la plataforma Drivendata.
Las variables y objetivos se pueden consultar en el enlace
Pregunta de investigación: https://www.drivendata.org/competitions/7/pump-it-up-data-mining-the-water-table/
¿Cuántas válvulas de agua necesitan mantenimiento?
¿Qué mantenimiento se debe realizar a las válvulas?
Métodos
Los datos los proporciona el Ministerio de agua de Tanzania y la plataforma Drivendata, la cual facilita las observaciones (n=14851) a parte de los datos de entrenamiento(n =5941) para el código.
El análisis lo voy a realizar con la regresión linear de Pearson, para determinar el comportamiento de las válvulas del sistema de agua
Cantidades
El objetivo es predecir el estado de funcionamiento de un punto de agua para cada registro del conjunto de datos. Proporcionan la siguiente información sobre los puntos de agua:
amount_tsh - Altura estática total (cantidad de agua disponible para el punto de agua) date_recorded - Fecha en que se introdujo la fila funder - Quién financió el pozo gps_height - Altitud del pozo installer - Organización que instaló el pozo longitude - Coordenada GPS latitude - Coordenada GPS wpt_name - Nombre del punto de agua, si lo hay num_private - basin - Cuenca hidrográfica geográfica subvillage - Ubicación geográfica region - Ubicación geográfica region_code - Ubicación geográfica (codificada) district_code - Ubicación geográfica (codificada) lga - Ubicación geográfica ward - Ubicación geográfica population - Población alrededor del pozo public_meeting - Verdadero/Falso recorded_by - Grupo que introduce esta fila de datos scheme_management - Quién gestiona el punto de agua scheme_name - Quién gestiona el punto de agua permit - Si el punto de agua está autorizado construction_year - Año de construcción del punto de agua extraction_type - Tipo de extracción que utiliza el punto de agua extraction_type_group - Tipo de extracción que utiliza el punto de agua extraction_type_class - Tipo de extracción que utiliza el punto de agua management - Cómo se gestiona el punto de agua management_group - Cómo se gestiona el punto de agua payment - Cuánto cuesta el agua payment_type - Cuánto cuesta el agua water_quality - Calidad del agua quality_group - Calidad del agua quantity - Cantidad de agua quantity_group - Cantidad de agua source - Origen del agua source_type - Origen del agua source_class - Origen del agua waterpoint_type - Tipo de punto de agua waterpoint_type_group - Tipo de punto de agua
0 notes
Text
Código K- means craters of mars
-- coding: utf-8 --
""" Created on Fri Jun 16 19:08:39 2023
@author: ANGELA """ from pandas import Series, DataFrame import pandas import numpy as np import matplotlib.pylab as plt from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.cluster import KMeans
"""Data management"""
data = pandas.read_csv('marscrater_pds.csv', low_memory=False) data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE'],errors='coerce') data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE'],errors='coerce') data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE'],errors='coerce') data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS'],errors='coerce') data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'],errors='coerce')
upper-case all DataFrame column names
data.columns = map(str.upper, data.columns) data_clean =data.dropna()
target = data_clean.DEPTH_RIMFLOOR_TOPOG
select predictor variables and target variable as separate data sets
cluster= data_clean[['LATITUDE_CIRCLE_IMAGE','LONGITUDE_CIRCLE_IMAGE','DIAM_CIRCLE_IMAGE']] cluster.describe()
standardize clustering variables to have mean=0 and sd=1
clustervar=cluster.copy() clustervar['LATITUDE_CIRCLE_IMAGE']=preprocessing.scale(clustervar['LATITUDE_CIRCLE_IMAGE'].astype('float64')) clustervar['LONGITUDE_CIRCLE_IMAGE']=preprocessing.scale(clustervar['LONGITUDE_CIRCLE_IMAGE'].astype('float64')) clustervar['DIAM_CIRCLE_IMAGE']=preprocessing.scale(clustervar['DIAM_CIRCLE_IMAGE'].astype('float64'))
clustervar['DEPTH_RIMFLOOR_TOPOG']=preprocessing.scale(clustervar['DEPTH_RIMFLOOR_TOPOG'].astype('float64'))
split data into train and test sets
clus_train, clus_test = train_test_split(clustervar, test_size=.3, random_state=200)
k-means cluster analysis for 1-9 clusters
from scipy.spatial.distance import cdist clusters=range(1,10) meandist=[]
Calculate cluster
for k in clusters: model=KMeans(n_clusters=k) model.fit(clus_train) clusassign=model.predict(clus_train) meandist.append(sum(np.min(cdist(clus_train, model.cluster_centers_, 'euclidean'), axis=1)) / clus_train.shape[0])
""" Plot average distance from observations from the cluster centroid to use the Elbow Method to identify number of clusters to choose """
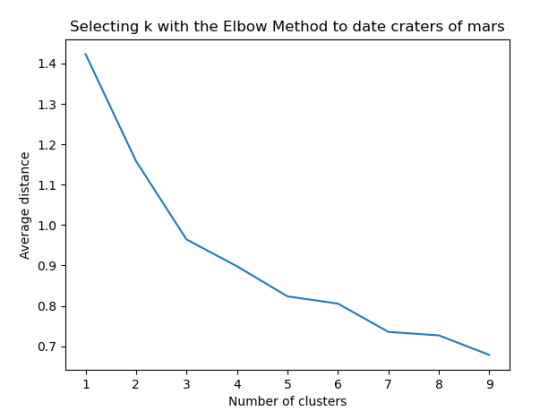
plt.plot(clusters, meandist) plt.xlabel('Number of clusters') plt.ylabel('Average distance') plt.title('Selecting k with the Elbow Method to date craters of mars')
Interpret 3 cluster solution
model3=KMeans(n_clusters=3) model3.fit(clus_train) clusassign=model3.predict(clus_train)
plot clusters
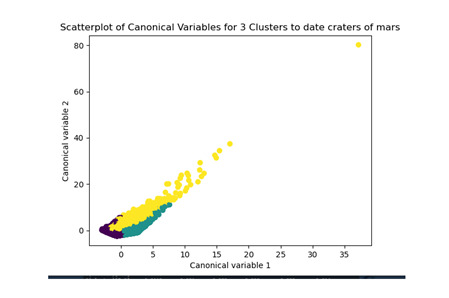
from sklearn.decomposition import PCA pca_2 = PCA(2) plot_columns = pca_2.fit_transform(clus_train) plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1], c=model3.labels_,) plt.xlabel('Canonical variable 1') plt.ylabel('Canonical variable 2') plt.title('Scatterplot of Canonical Variables for 3 Clusters to date craters of mars') plt.show()
""" BEGIN multiple steps to merge cluster assignment with clustering variables to examine cluster variable means by cluster """
create a unique identifier variable from the index for the
cluster training data to merge with the cluster assignment variable
clus_train.reset_index(level=0, inplace=True)
create a list that has the new index variable
cluslist=list(clus_train['index'])
create a list of cluster assignments
labels=list(model3.labels_)
combine index variable list with cluster assignment list into a dictionary
newlist=dict(zip(cluslist, labels)) newlist
convert newlist dictionary to a dataframe
newclus=DataFrame.from_dict(newlist, orient='index') newclus
rename the cluster assignment column
newclus.columns = ['cluster']
now do the same for the cluster assignment variable
create a unique identifier variable from the index for the
cluster assignment dataframe
to merge with cluster training data
newclus.reset_index(level=0, inplace=True)
merge the cluster assignment dataframe with the cluster training variable dataframe
by the index variable
merged_train=pandas.merge(clus_train, newclus, on='index') merged_train.head(n=100)
cluster frequencies
merged_train.cluster.value_counts()
""" END multiple steps to merge cluster assignment with clustering variables to examine cluster variable means by cluster """
FINALLY calculate clustering variable means by cluster
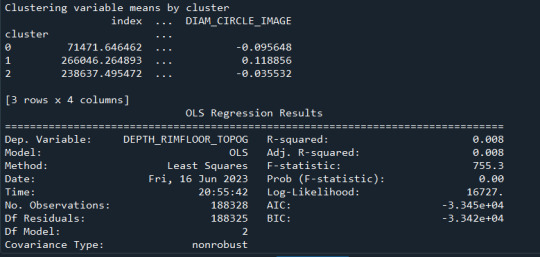
clustergrp = merged_train.groupby('cluster').mean() print ("Clustering variable means by cluster") print(clustergrp)
validate clusters in training data by examining cluster differences in DEPTH_RIMFLOOR_TOPOG using ANOVA
first have to merge DEPTH_RIMFLOOR_TOPOG with clustering variables and cluster assignment data
DRT_data=data_clean['DEPTH_RIMFLOOR_TOPOG']
split DEPTH_RIMFLOOR_TOPOG data into train and test sets
DRT_train, DRT_test = train_test_split(DRT_data, test_size=.3, random_state=123) DRT_train1=pandas.DataFrame(DRT_train) DRT_train1.reset_index(level=0, inplace=True) merged_train_all=pandas.merge(DRT_train1, merged_train, on='index') sub1 = merged_train_all[['DEPTH_RIMFLOOR_TOPOG', 'cluster']].dropna()
import statsmodels.formula.api as smf import statsmodels.stats.multicomp as multi
DTRmod = smf.ols(formula='DEPTH_RIMFLOOR_TOPOG ~ C(cluster)', data=sub1).fit() print (DTRmod.summary())
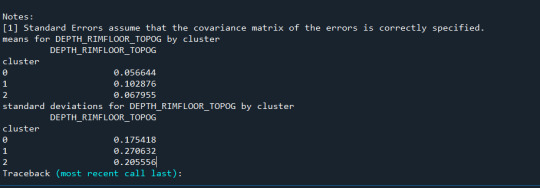
print ('means for DEPTH_RIMFLOOR_TOPOG by cluster') m1= sub1.groupby('cluster').mean() print (m1)
print ('standard deviations for DEPTH_RIMFLOOR_TOPOG by cluster') m2= sub1.groupby('cluster').std() print (m2)
mc1 = multi.MultiComparison(sub1['GPA1'], sub1['cluster']) res1 = mc1.tukeyhsd() print(res1.summary())
Resultados
Los cluster posibles son 3, 5, 7 y 8 donde se evidencia un punto de quiebre en la ilustración, por lo que se realizó la prueba con 3 clusters y se evidencia que puede presentarse un overfiting al esta muy cerca y cobre puestos los clusters

0 notes
Text
Lasso Regresion Crater of Mars
-- coding: utf-8 --
""" Created on Tue Jun 13 19:40:50 2023
@author: ANGELA """
import pandas import numpy as np from pandas import Series, DataFrame import matplotlib.pylab as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LassoLarsCV
data = pandas.read_csv('marscrater_pds.csv', low_memory=False) data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE'],errors='coerce') data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE'],errors='coerce') data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE'],errors='coerce') data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS'],errors='coerce') data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'],errors='coerce')
data_clean =data.dropna() target = data_clean.DEPTH_RIMFLOOR_TOPOG
select predictor variables and target variable as separate data sets
predvar= data_clean[['LATITUDE_CIRCLE_IMAGE','LONGITUDE_CIRCLE_IMAGE','DIAM_CIRCLE_IMAGE']] predictors=predvar.copy() print(predictors)
from sklearn import preprocessing predictors['LATITUDE_CIRCLE_IMAGE']=preprocessing.scale(predictors['LATITUDE_CIRCLE_IMAGE'].astype('float64')) predictors['LONGITUDE_CIRCLE_IMAGE']=preprocessing.scale(predictors['LONGITUDE_CIRCLE_IMAGE'].astype('float64')) predictors['DIAM_CIRCLE_IMAGE']=preprocessing.scale(predictors['DIAM_CIRCLE_IMAGE'].astype('float64')) pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, target, test_size=.3, random_state=20)
specify the lasso regression model
Cv = 10 representa la validación cruzada con 10 k-fold,
la opcción precomputer es para no utilizar modelos de matriz pecalculados de la función, sirve en casos de modelos grandes
.fit(predictores, data sets )
model=LassoLarsCV(cv=10, precompute=True).fit(pred_train,tar_train)
print variable names and regression coefficients
dict(zip(predictors.columns, model.coef_))
plot coefficient progression
m_log_alphas = -np.log10(model.alphas_) ax = plt.gca() plt.plot(m_log_alphas, model.coef_path_.T) plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.ylabel('Regression Coefficients') plt.xlabel('-log(alpha)') plt.title('Regression Coefficients Progression for Lasso Paths')
plot mean square error for each fold
m_log_alphascv = -np.log10(model.cv_alphas_) plt.figure() plt.plot(m_log_alphascv, model.cv_mse_path_, ':') plt.plot(m_log_alphascv, model.cv_mse_path_.mean(axis=-1), 'k', label='Average across the folds', linewidth=2) plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.legend() plt.xlabel('-log(alpha)') plt.ylabel('Mean squared error') plt.title('Mean squared error on each fold')
MSE from training and test data
from sklearn.metrics import mean_squared_error train_error = mean_squared_error(tar_train, model.predict(pred_train)) test_error = mean_squared_error(tar_test, model.predict(pred_test)) print ('training data MSE') print(train_error) print ('test data MSE') print(test_error)
R-square from training and test data
rsquared_train=model.score(pred_train,tar_train) rsquared_test=model.score(pred_test,tar_test) print ('training data R-square') print(rsquared_train) print ('test data R-square') print(rsquared_test)
Result
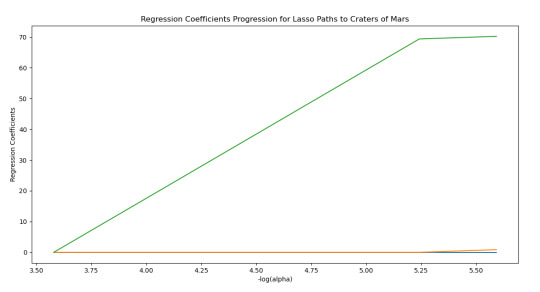
Los resultados muestran que una variable esta fuertemente relacionada con la predicción de la profundidad del cráter
0 notes
Text
Cráteres en marte árbol
from pandas import Series, DataFrame import pandas as pd import numpy as np import os import matplotlib.pylab as plt from sklearn import tree from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report import sklearn.metrics # Feature Importance from sklearn import datasets from sklearn.ensemble import ExtraTreesClassifier
os.chdir("C:\TREES")
Load the dataset
AH_data = pd.read_csv("tree_addhealth.csv") data_clean = AH_data.dropna()
data_clean.dtypes data_clean.describe()
Split into training and testing sets
predictors = data_clean[['BIO_SEX','HISPANIC','WHITE','BLACK','NAMERICAN','ASIAN','age', 'ALCEVR1','ALCPROBS1','marever1','cocever1','inhever1','cigavail','DEP1','ESTEEM1','VIOL1', 'PASSIST','DEVIANT1','SCHCONN1','GPA1','EXPEL1','FAMCONCT','PARACTV','PARPRES']]
targets = data_clean.TREG1
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4)
pred_train.shape pred_test.shape tar_train.shape tar_test.shape
Build model on training data
from sklearn.ensemble import RandomForestClassifier
classifier=RandomForestClassifier(n_estimators=25) classifier=classifier.fit(pred_train,tar_train)
predictions=classifier.predict(pred_test)
sklearn.metrics.confusion_matrix(tar_test,predictions) sklearn.metrics.accuracy_score(tar_test, predictions)
fit an Extra Trees model to the data
model = ExtraTreesClassifier() model.fit(pred_train,tar_train)
display the relative importance of each attribute
print(model.feature_importances_)
""" Running a different number of trees and see the effect of that on the accuracy of the prediction """
trees=range(25) accuracy=np.zeros(25)
for idx in range(len(trees)): classifier=RandomForestClassifier(n_estimators=idx + 1) classifier=classifier.fit(pred_train,tar_train) predictions=classifier.predict(pred_test) accuracy[idx]=sklearn.metrics.accuracy_score(tar_test, predictions)
plt.cla() plt.plot(trees, accuracy)
0 notes
Text
Árbol de decisión
Código
""" Created on Sun May 7 19:00:21 2023
@author: ANGELA """
import pandas import numpy as np import os from pandas import Series, DataFrame import matplotlib.pylab as plt from sklearn.model_selection import train_test_split from sklearn import tree from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report import sklearn.metrics
Feature Importance
from sklearn import datasets from sklearn.ensemble import ExtraTreesClassifier
data = pandas.read_csv('marscrater_pds.csv', low_memory=False) data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE'],errors='coerce') data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE'],errors='coerce') data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE'],errors='coerce') data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS'],errors='coerce') data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'],errors='coerce')
data_clean =data.dropna() pr1=data_clean.get('LATITUDE_CIRCLE_IMAGE').reshape(data_clean('LATITUDE_CIRCLE_IMAGE')[1:]) pr2=data_clean.get('LONGITUDE_CIRCLE_IMAGE').reshape(data_clean('LONGITUDE_CIRCLE_IMAGE')[1:]) pr3=data_clean.get('NUMBER_LAYERS').reshape(data_clean('NUMBER_LAYERS')[1:]) pr4=data_clean.get('DEPTH_RIMFLOOR_TOPOG').reshape(data_clean('DEPTH_RIMFLOOR_TOPOG')[1:]) data_clean.describe predictors = pr1,pr2,pr3,pr4 print(predictors) targets= data_clean.DIAM_CIRCLE_IMAGE
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets)
pred_train.shape pred_test.shape tar_train.shape tar_test.shape
Build model on training data
classifier=DecisionTreeClassifier() classifier=classifier.fit(pred_train,tar_train)
predictions=classifier.predict(pred_test)
imagen1=sklearn.metrics.confusion_matrix(tar_test,predictions) sklearn.metrics.accuracy_score(tar_test, predictions) print(imagen1)
Displaying the decision tree
from sklearn import tree
from StringIO import StringIO
from io import StringIO
from StringIO import StringIO
from IPython.display import Image out = StringIO() tree.export_graphviz(classifier, out_file=out) import pydotplus graph=pydotplus.graph_from_dot_data(out.getvalue()) Image(graph.create_png()) graph.write_png ("Treee_marscrater.png")
0 notes
Text
Regresión logística cráteres en marte
import numpy import pandas import statsmodels.api as sm import seaborn import statsmodels.formula.api as smf
bug fix for display formats to avoid run time errors
pandas.set_option('display.float_format', lambda x:'%.2f'%x)
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'])
recode layer numbers into 2 groups: 0:{0,1}, 1:{2,3,4,5}
recode = {0: 0, 1: 0, 2:1, 3:1, 4:1, 5:1} data['lay_new'] = data['NUMBER_LAYERS'].map(recode)
recode depth into 2 groups: 0: <= 0 , 1: > 0
def depth(x): if x['DEPTH_RIMFLOOR_TOPOG'] <= 0: return 0 else: return 1 data['depth_new'] = data.apply(lambda x: depth(x), axis=1)
recode diameter into 2 groups: 0: < 2 , 1: >= 2
def diameter(x): if x['DIAM_CIRCLE_IMAGE'] < 2: return 0 else: return 1 data['diam_new'] = data.apply(lambda x: diameter(x), axis=1)
logistic regression for depth+diameter -> number of layers
print ("Logistic regression model for the association between crater's depth&diameter and number of layers") model1 = smf.logit(formula="lay_new ~ depth_new + diam_new", data=data) results1 = model1.fit() print(results1.summary())
odds ratios with 95% confidence intervals
print("\nConfidence intervals") conf = results1.conf_int() conf['Odds ratio'] = results1.params conf.columns = ['Lower conf.int.', 'Upper conf.int.', 'Odds ratio'] print(numpy.exp(conf))
Resultados
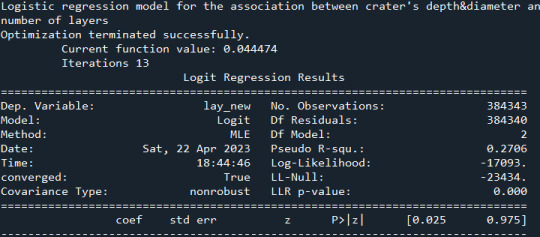
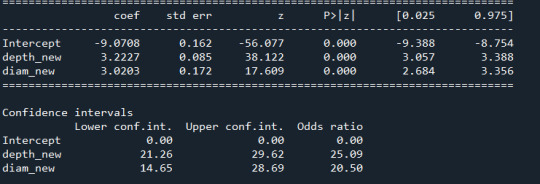
0 notes
Text
Regresión lineal Cráteres en Marte
Comparto mi código
-- coding: utf-8 --
""" Created on Thu Apr 20 19:10:44 2023
@author: ANGELA """
import numpy import pandas import matplotlib.pyplot as plt import statsmodels.api as sm import statsmodels.formula.api as smf import seaborn
Configuración matplotlib
plt.style.use('ggplot')
def funtion_plot(val_x,val_y, title): # relación entre diametro del crater cob la profundidad plt = seaborn.regplot(x=val_x, y =val_y, fit_reg = True, data = data) plt.xlabel("km") plt.ylabel (" km") plt.title(title) plt.show()
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE'], errors='coerce') data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE'], errors='coerce') data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE'], errors='coerce') data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS'], errors='coerce') data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'], errors='coerce')
Relaciono por cantidad de cortes
sub1=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)].dropna() cut0 =data[(data['NUMBER_LAYERS']==0)].dropna() cut1 =data[(data['NUMBER_LAYERS']==1)].dropna() cut2 =data[(data['NUMBER_LAYERS']==2)].dropna() cut3 =data[(data['NUMBER_LAYERS']==3)].dropna() cut4 =data[(data['NUMBER_LAYERS']==4)].dropna() cut5 =data[(data['NUMBER_LAYERS']==5)].dropna()
#
Regresión
#
Orden 1
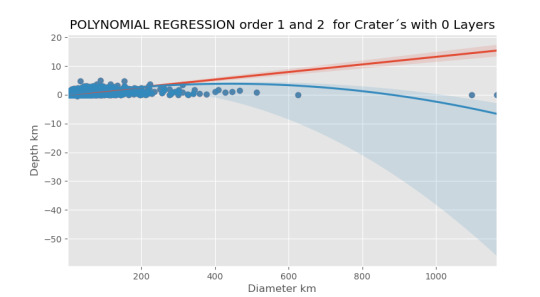
imagen0=seaborn.regplot(x=cut0['DIAM_CIRCLE_IMAGE'], y =cut0['DEPTH_RIMFLOOR_TOPOG'], scatter=True, data = sub1) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("POLYNOMIAL REGRESSION order 1 and 2 for Crater´s with 0 Layers"") plt.show()
orden 2
imagen0=seaborn.regplot(x=cut0['DIAM_CIRCLE_IMAGE'], y =cut0['DEPTH_RIMFLOOR_TOPOG'], scatter=True, order=2, data = sub1) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 0 Layers") plt.show()
Centro
sub1['DIAM_CIRCLE_IMAGE_c']=(sub1['DIAM_CIRCLE_IMAGE']-sub1['DIAM_CIRCLE_IMAGE'].mean()) sub1['DEPTH_RIMFLOOR_TOPOG_c'] =(sub1['DEPTH_RIMFLOOR_TOPOG']-sub1['DEPTH_RIMFLOOR_TOPOG'].mean()) sub1[['DIAM_CIRCLE_IMAGE_c', 'DEPTH_RIMFLOOR_TOPOG_c']].describe()
analisis de función cuadratica
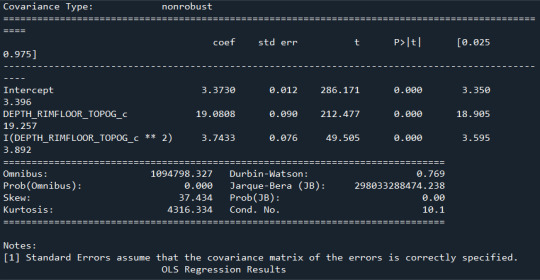
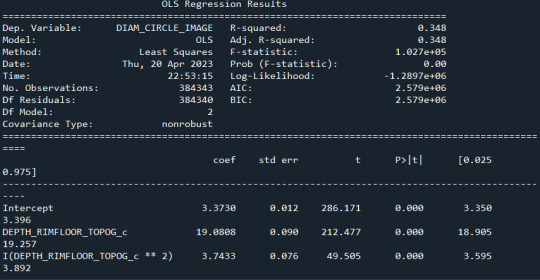
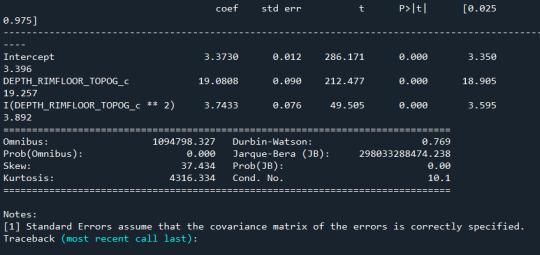
model1 = smf.ols('DIAM_CIRCLE_IMAGE ~ DEPTH_RIMFLOOR_TOPOG_c +I(DEPTH_RIMFLOOR_TOPOG_c**2)', data=sub1) results1 = model1.fit() print (results1.summary())
model2=smf.ols('DIAM_CIRCLE_IMAGE ~ DEPTH_RIMFLOOR_TOPOG_c +I(DEPTH_RIMFLOOR_TOPOG_c**2)', data=sub1) results2 = model2.fit() print (results2.summary())
Q-Q plot
model3= smf.ols('DIAM_CIRCLE_IMAGE ~ DEPTH_RIMFLOOR_TOPOG_c +I(DEPTH_RIMFLOOR_TOPOG_c**2)', data=sub1) results3 = model3.fit() print (results2.summary())
Los resultados:
Se observa que en ningún caso el valor P es significativo
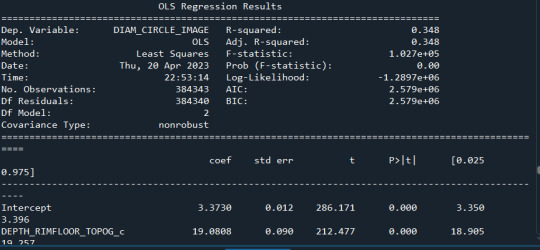
0 notes
Text
Regresión lineal Cráteres en marte
Comparto mi código
-- coding: utf-8 --
""" Created on Mon Apr 17 22:46:27 2023
@author: ANGELA """
import numpy as np import pandas import statsmodels.formula.api as smf import scipy from scipy import stats from scipy.stats import pearsonr import seaborn import matplotlib.pyplot as plt
data = pandas.read_csv('marscrater_pds.csv', low_memory=False) data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'])
sub1=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)] cut0 =data[(data['NUMBER_LAYERS']==0)] cut1 =data[(data['NUMBER_LAYERS']==1)] cut2 =data[(data['NUMBER_LAYERS']==2)] cut3 =data[(data['NUMBER_LAYERS']==3)] cut4 =data[(data['NUMBER_LAYERS']==4)] cut5 =data[(data['NUMBER_LAYERS']==5)]
imagen5=seaborn.regplot(x=cut5['DIAM_CIRCLE_IMAGE'], y =cut5['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut5) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 5 Layers")
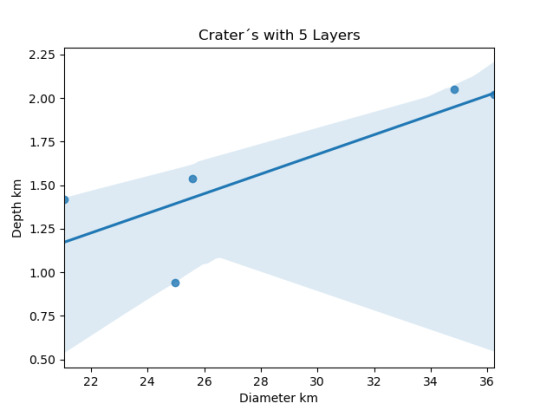
0 notes
Text
Descripción de datos
Muestra
La muestra de datos se toma del estudio de Stuart Robbins sobre la descripción estadística de los Cráteres en la Marte, el cual caracteriza los datos con base en el análisis de imágenes captadas por satélites de la superficie del planeta. Son de mi interés los datos sobre: diámetro, profundidad, ubicación (longitud y latitud) y número de capaz que de la imagen.
Para más información consultar CRATER_ID o el siguiente enlace
https://d3c33hcgiwev3.cloudfront.net/a89f644116bccca879c14b59b603165b_C3W1-Assignment-Example---Writing-About-Your-Data.pdf?Expires=1681257600&Signature=IyvSwwP3x4LqH1lKQ4fS1yXQdxav0L9u7KBmBOAf9nGGs4CzBg90NpaJYjDNEVnLhrAgLgtjM8xXKxoPSKKZTc8ACIhbO-9Mhdd38Ffzy1GIcMqTAIZnXyXSzrcLqQy8wvdFUyY0n-k8ZD2~GBzkPv9ImeTYnI9IL17RrEJEo4M&Key-Pair-Id=APKAJLTNE6QMUY6HBC5A
Procedimiento
La información se caracterizó en una escala de kilómetros (km) tomando los cráteres con un diámetro mayor a km, el objetivo fue determinar la causa de formación, es decir, si fue por erosión, erupción de volcanes, deterioritos entre otros. Se tiene aproximadamente 378 600 datos.
Medidas
Diámetro = kilómetros (km)
Profundidad = kilómetros (km)
Longitud = Grados decimales (norte)
Latitud = Grados decimales (este)
Número de capaz = unidades
0 notes
Text
Variable moderadora Cráteres en Marte
Luego del análisis de los datos de los Cráter en Marte una variable moderadora puede ser la ubicación (Latitud, Longitud) en relación con la profundidad y el diámetro. Les comparto mi código y los resultados:
Código
import numpy as np import pandas import statsmodels.formula.api as smf import scipy from scipy import stats from scipy.stats import pearsonr import seaborn import matplotlib.pyplot as plt
data = pandas.read_csv('marscrater_pds.csv', low_memory=False) data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'])
#Se escribe de la siguiente manera el código
# modelname =smf.ols(formula='QUANT_RESPONSE ~ C(CAT_EXPLANATORY)', data=dataframe.fit())
# print(modelname.symary())
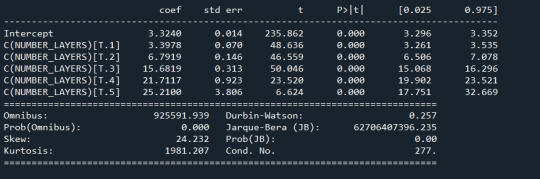
model1=smf.ols(formula='NUMBER_LAYERS ~ C(LATITUDE_CIRCLE_IMAGE)',data=data).fit()
print(model1.sumary())
Relaciono por cantidad de cortes
sub1=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)] cut0 =data[(data['NUMBER_LAYERS']==0)] cut1 =data[(data['NUMBER_LAYERS']==1)] cut2 =data[(data['NUMBER_LAYERS']==2)] cut3 =data[(data['NUMBER_LAYERS']==3)] cut4 =data[(data['NUMBER_LAYERS']==4)] cut5 =data[(data['NUMBER_LAYERS']==5)]
using ols function for calculating the F-statistic and associated p value
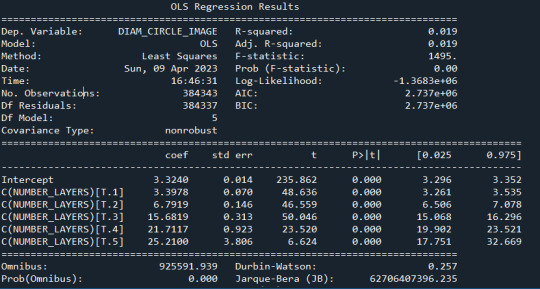
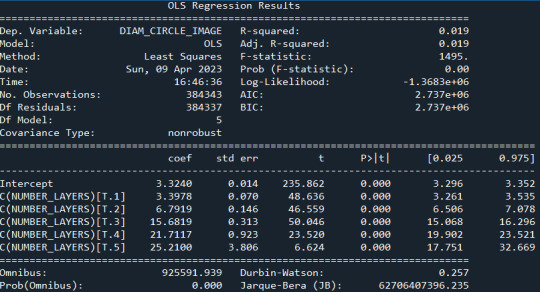
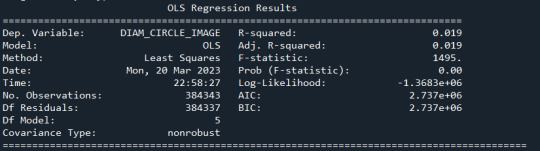
model1 = smf.ols(formula='DIAM_CIRCLE_IMAGE ~ C(NUMBER_LAYERS)', data=sub1) results1 = model1.fit() print ("Modelo OLS de Diámetro y Número de capas \n" , results1.summary())
Con los cortes hice nuevos dataframe por cada capa, análizo los resultados
de cada capa y comaparó la capa uno con la cero
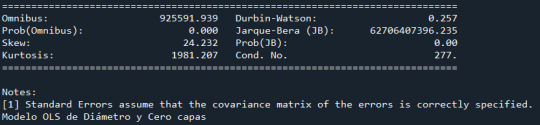
model2 = smf.ols(formula='DIAM_CIRCLE_IMAGE ~ C(NUMBER_LAYERS)', data=cut0) results2 = model2.fit() print ("Modelo OLS de Diámetro y Cero capas \n", results2.summary())
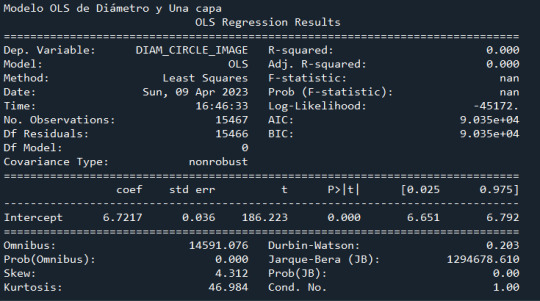
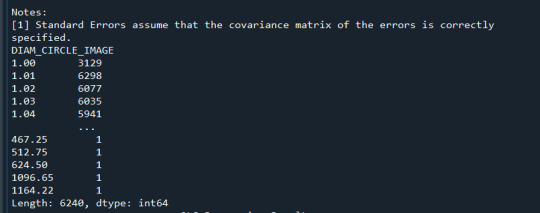
model3 = smf.ols(formula='DIAM_CIRCLE_IMAGE ~ C(NUMBER_LAYERS)', data=cut1) results3 = model3.fit() print ("Modelo OLS de Diámetro y Una capa \n", results3.summary())
ct1 = sub1.groupby('DIAM_CIRCLE_IMAGE').size() print (ct1)
using ols function for calculating the F-statistic and associated p value
model1 = smf.ols(formula='DIAM_CIRCLE_IMAGE ~ C(NUMBER_LAYERS)', data=sub1) results1 = model1.fit() print (results1.summary())
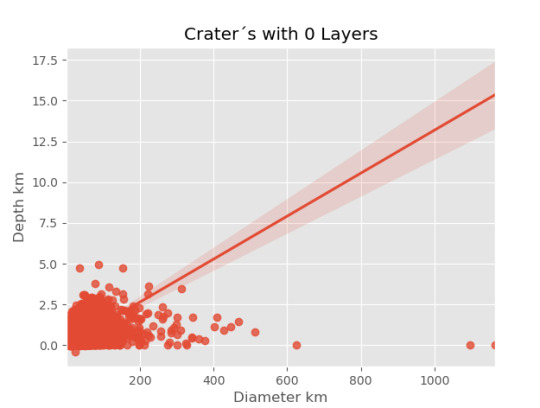
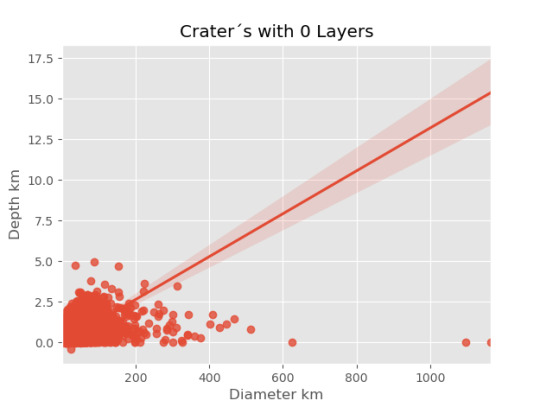
imagen0=seaborn.regplot(x=cut0['DIAM_CIRCLE_IMAGE'], y =cut0['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut0) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 0 Layers") plt.show()
imagen1=seaborn.regplot(x=cut1['DIAM_CIRCLE_IMAGE'], y =cut1['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut1) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 1 Layers")
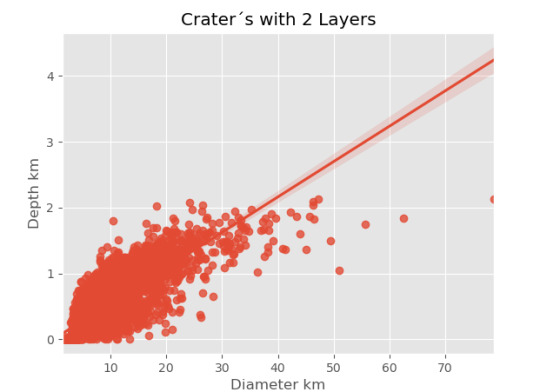
imagen2=seaborn.regplot(x=cut2['DIAM_CIRCLE_IMAGE'], y =cut2['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut2) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 2 Layers")
imagen3=seaborn.regplot(x=cut3['DIAM_CIRCLE_IMAGE'], y =cut3['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut3) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 3 Layers")
imagen4=seaborn.regplot(x=cut4['DIAM_CIRCLE_IMAGE'], y =cut4['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut4) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 4 Layers")
imagen5=seaborn.regplot(x=cut5['DIAM_CIRCLE_IMAGE'], y =cut5['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut5) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 5 Layers")
Resultados

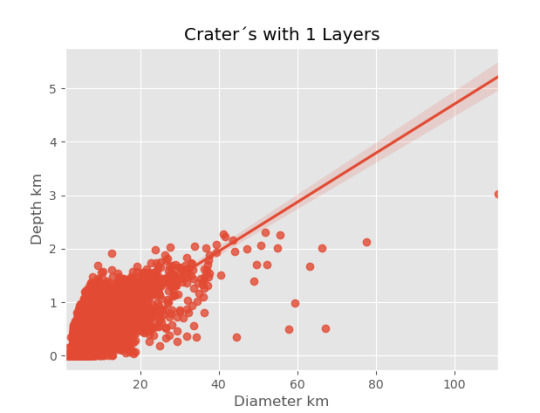
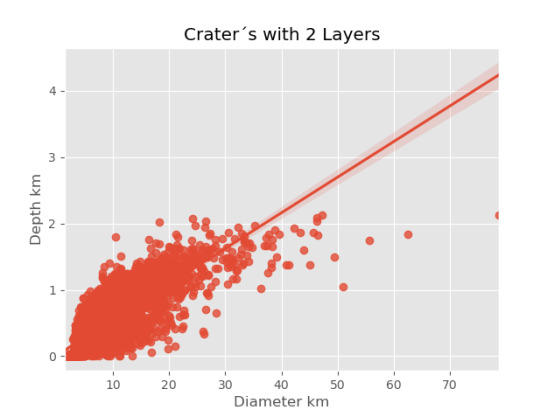
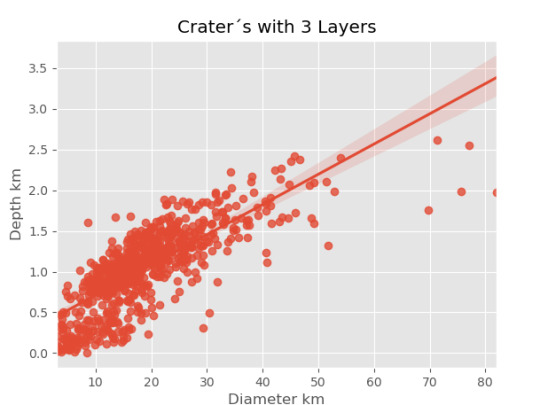
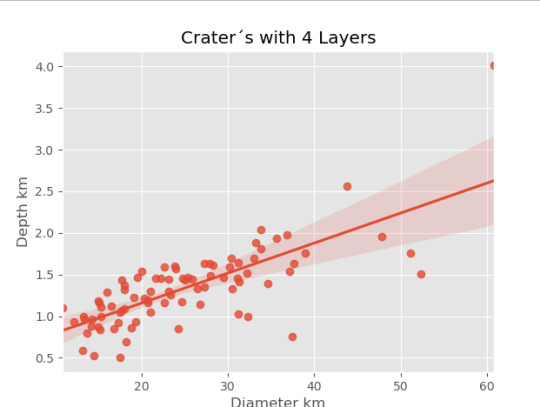
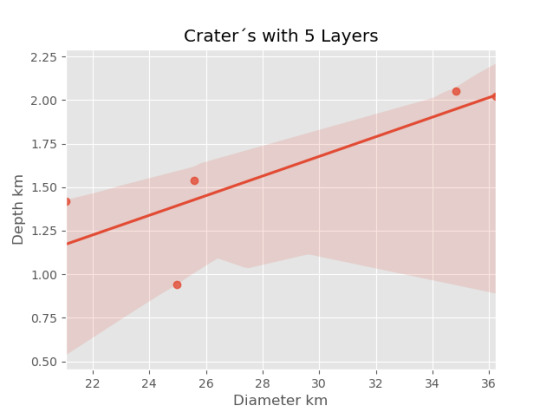
0 notes
Text
Correlación Cráteres en Marte
Comparto los resultados del análisis que realice de la correlación de los de cráteres en Marte con la profundidad, el número de capas, la longitud y la latitud.
-- coding: utf-8 --
""" Created on Sun Apr 9 10:55:58 2023
@author: ANGELA """
import pandas import seaborn import scipy import matplotlib.pyplot as plt
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'])
sub1=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)] cut0 =data[(data['NUMBER_LAYERS']==0)]
print("Relación diámetro y profundidad") print(scipy.stats.pearsonr(cut0['DIAM_CIRCLE_IMAGE'], cut0['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 0 layer')
imagen0=seaborn.regplot(x=cut0['DIAM_CIRCLE_IMAGE'], y =cut0['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut0) plt.xlabel("Diámetro km") plt.ylabel("Profundidad km") plt.title("Cráter con 0 capas ") plt.show()
data_clean=data.dropna()
print (" \n Correlación entre diámetro del cráter y Número de capas") print (scipy.stats.pearsonr(data_clean['DIAM_CIRCLE_IMAGE'], data_clean['NUMBER_LAYERS']))
print ( "\n Correlación entre diámetro del cráter y latitud") print (scipy.stats.pearsonr(data_clean['DIAM_CIRCLE_IMAGE'], data_clean['LATITUDE_CIRCLE_IMAGE']))
print ("\n Correlación entre diámetro del cráter y longitud") print (scipy.stats.pearsonr(data_clean['DIAM_CIRCLE_IMAGE'], data_clean['LONGITUDE_CIRCLE_IMAGE']))
Los resultados son:
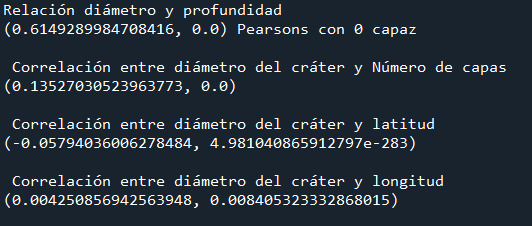
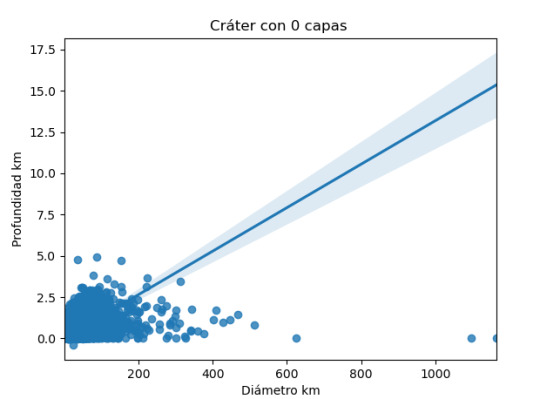
Se evidencia que la relación es positiva en tanto en el resultado de correlación de Pearson como en la imagen obtenida.
Mientras que, el diámetro de los cráteres con la latitud es negativa y con la longitud es positiva, acá se debe realizar un análisis más detallado para establecer de como influye la comparación de la latitud con las variables de posición
0 notes
Text
Chi Square Test of independence mars cráter
Los resultados del análisis de la relación de los Cráter en Marte por localización:
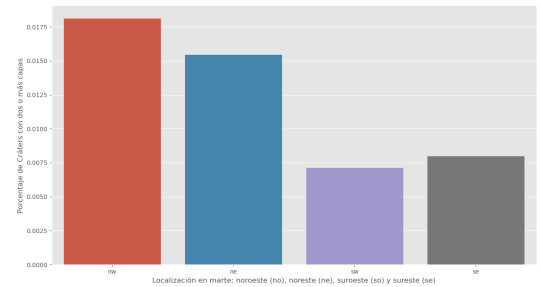
HEMISPH ne nw se sw NUMBER_LAYERS 0 83077 58145 116963 106427 1 3816 3352 4210 4089 2 1139 928 733 635 3 210 177 218 134 4 14 29 20 22 5 1 1 2 1 HEMISPH ne nw se sw NUMBER_LAYERS 0 0.941308 0.928359 0.957567 0.956149 1 0.043237 0.053519 0.034467 0.036736 2 0.012905 0.014817 0.006001 0.005705 3 0.002379 0.002826 0.001785 0.001204 4 0.000159 0.000463 0.000164 0.000198 5 0.000011 0.000016 0.000016 0.000009 (1211.8051983648297, 4.764380687163198e-249, 15, array([[8.37261542e+04, 5.94166637e+04, 1.15875396e+05, 1.05593786e+05], [3.55169996e+03, 2.52048078e+03, 4.91548482e+03, 4.47933444e+03], [7.88781882e+02, 5.59762816e+02, 1.09165904e+03, 9.94796263e+02], [1.69697179e+02, 1.20426411e+02, 2.34857651e+02, 2.14018759e+02], [1.95186201e+01, 1.38514816e+01, 2.70133969e+01, 2.46165014e+01], [1.14815412e+00, 8.14793036e-01, 1.58902335e+00, 1.44802949e+00]]))
-------------We recoded the layers` numbers into 2 groups: {0,1} and {2,3,4,5}------------ HEMISPH ne nw se sw lay 0 86893 61497 121173 110516 1 1364 1135 973 792 HEMISPH ne nw se sw lay 0 0.984545 0.981878 0.992034 0.992885 1 0.015455 0.018122 0.007966 0.007115 (704.4708220575237, 2.252119348843716e-152, 3, array([[ 87277.85416412, 61937.14449853, 120790.88089025, 110073.1204471 ], [ 979.14583588, 694.85550147, 1355.11910975, 1234.8795529 ]]))
-------------Post hoc test for nw-vs-ne quadrant------------ q ne nw lay 0 86893 61497 1 1364 1135 q ne nw lay 0 0.984545 0.981878 1 0.015455 0.018122 (15.833488192885673, 6.916745222155225e-05, 1, array([[86795.30138048, 61594.69861952], [ 1461.69861952, 1037.30138048]]))
-------------Post hoc test for nw-vs-se quadrant------------ q nw se lay 0 61497 121173 1 1135 973 q nw se lay 0 0.981878 0.992034 1 0.018122 0.007966 (377.7348327804021, 3.8737141718946335e-84, 1, array([[ 61917.47632294, 120752.52367706], [ 714.52367706, 1393.47632294]]))
-------------Post hoc test for nw-vs-sw quadrant------------ q nw sw lay 0 61497 110516 1 1135 792 q nw sw lay 0 0.981878 0.992885 1 0.018122 0.007115 (442.16011137363716, 3.667121665472413e-98, 1, array([[ 61938.12933195, 110074.87066805], [ 693.87066805, 1233.12933195]]))
-------------Post hoc test for ne-vs-se quadrant------------ q ne se lay 0 86893 121173 1 1364 973 q ne se lay 0 0.984545 0.992034 1 0.015455 0.007966 (260.9361105986223, 1.0726740385377792e-58, 1, array([[ 87276.70690057, 120789.29309943], [ 980.29309943, 1356.70690057]]))
-------------Post hoc test for ne-vs-sw quadrant------------ q ne sw lay 0 86893 110516 1 1364 792 q ne sw lay 0 0.984545 0.992885 1 0.015455 0.007115 (319.5677037387337, 1.7991398424026695e-71, 1, array([[ 87303.51571167, 110105.48428833], [ 953.48428833, 1202.51571167]]))
-------------Post hoc test for se-vs-sw quadrant------------ q se sw lay 0 121173 110516 1 973 792 q se sw lay 0 0.992034 0.992885 1 0.007966 0.007115 (5.501456858593796, 0.019000637530707735, 1, array([[121222.53032289, 110466.46967711], [ 923.46967711, 841.53032289]]))
0 notes
Text
ANOVA Cráteres en Marte
Comparto los resultados de mi análisis con ANOVA, donde obtengo la correlación de Pearson , para la relación de diámetro y profundidad según la cantidad de capaz captadas en los datos.
El código es:
-- coding: utf-8 --
""" Created on Mon Mar 13 09:32:30 2023
@author: ANGELA """
import numpy import pandas import statsmodels.formula.api as smf import statsmodels.stats.multicomp as multi import seaborn import scipy from scipy import stats from scipy.stats import pearsonr import matplotlib.pyplot as plt
Configuración matplotlib
plt.style.use('ggplot')
def funtion_plot(val_x,val_y, title): # relación entre diametro del crater cob la profundidad plt = seaborn.regplot(x=val_x, y =val_y, fit_reg = True, data = data) plt.xlabel("km") plt.ylabel (" km") plt.title(title) plt.show()
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'])
funtion_plot(data['DIAM_CIRCLE_IMAGE'], data['DEPTH_RIMFLOOR_TOPOG'])
Relaciono por cantidad de cortes
Sub1=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)]
cut0 =data[(data['NUMBER_LAYERS']==0)] cut1 =data[(data['NUMBER_LAYERS']==1)] cut2 =data[(data['NUMBER_LAYERS']==2)] cut3 =data[(data['NUMBER_LAYERS']==3)] cut4 =data[(data['NUMBER_LAYERS']==4)] cut5 =data[(data['NUMBER_LAYERS']==5)]
print("Relation depth and diameter") print(scipy.stats.pearsonr(cut0['DIAM_CIRCLE_IMAGE'], cut0['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 0 layer') print(scipy.stats.pearsonr(cut1['DIAM_CIRCLE_IMAGE'], cut1['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 1 layer') print(scipy.stats.pearsonr(cut2['DIAM_CIRCLE_IMAGE'], cut2['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 2 layer') print(scipy.stats.pearsonr(cut3['DIAM_CIRCLE_IMAGE'], cut3['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 3 layer') print(scipy.stats.pearsonr(cut4['DIAM_CIRCLE_IMAGE'], cut4['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 4 layer') print(scipy.stats.pearsonr(cut5['DIAM_CIRCLE_IMAGE'], cut5['DEPTH_RIMFLOOR_TOPOG']), 'Pearsons with 5 layer')
imagen0=seaborn.regplot(x=cut0['DIAM_CIRCLE_IMAGE'], y =cut0['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut0) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 0 Layers") plt.show()
imagen1=seaborn.regplot(x=cut1['DIAM_CIRCLE_IMAGE'], y =cut1['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut1) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 1 Layers")
imagen2=seaborn.regplot(x=cut2['DIAM_CIRCLE_IMAGE'], y =cut2['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut2) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 2 Layers")
imagen3=seaborn.regplot(x=cut3['DIAM_CIRCLE_IMAGE'], y =cut3['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut3) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 3 Layers")
imagen4=seaborn.regplot(x=cut4['DIAM_CIRCLE_IMAGE'], y =cut4['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut4) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 4 Layers")
imagen5=seaborn.regplot(x=cut5['DIAM_CIRCLE_IMAGE'], y =cut5['DEPTH_RIMFLOOR_TOPOG'], fit_reg = True, data = cut5) plt.xlabel("Diameter km") plt.ylabel("Depth km") plt.title("Crater´s with 5 Layers")
Los resultados son:
El calculo de la relación de Pearson por la cantidad de capaz es

Los resultados gráficos son:

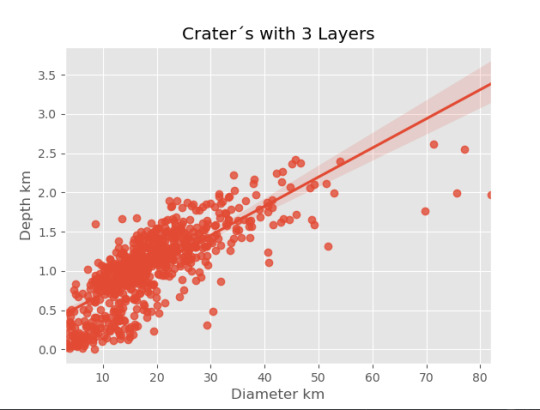
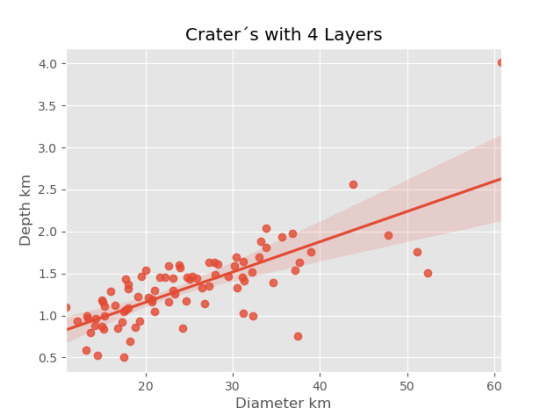
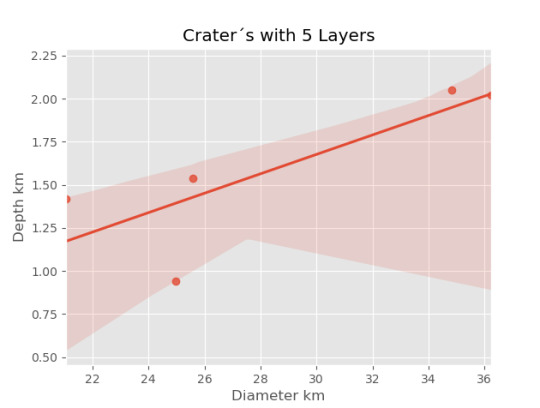
0 notes
Text
Análisis tamaño Cráter en Marte
Les comparto mi código
import seaborn import pandas import matplotlib.pyplot as plt
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) fre_DIAM_CIRCLE_IMAGE=data["DIAM_CIRCLE_IMAGE"].value_counts(sort=False,dropna=False)
Sub1_DIAM_CIRCLE_IMAGE=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)] print(Sub1_DIAM_CIRCLE_IMAGE," Layers 1")
Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'] = pandas.cut(Sub1_DIAM_CIRCLE_IMAGE.NUMBER_LAYERS,[0, 1, 2, 3, 4]) Cut_x_num_layers = Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'].value_counts(sort=False, dropna=True) print(Cut_x_num_layers)
Clasifico los grupos por nombre del crater
print (pandas.crosstab(Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'],Sub1_DIAM_CIRCLE_IMAGE['CRATER_NAME']))
Definicón de variables categoricas para plotear en python
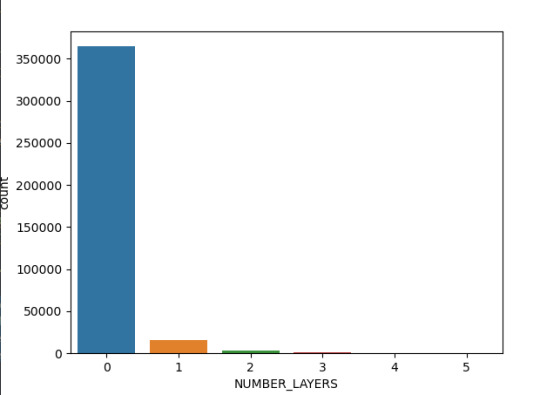
Sub1_DIAM_CIRCLE_IMAGE['CRATER_NAME'] =Sub1_DIAM_CIRCLE_IMAGE['CRATER_NAME'].astype('category') #Definición de la variable categoría plot1=seaborn.countplot(x="NUMBER_LAYERS", data=Sub1_DIAM_CIRCLE_IMAGE) plot1.plt.title ('Cantidad de Capas registradas') plot1.plt.xlabel('Layer') plot1.plt.ylabel('Cantidad layers')
Relación de las variables con la categoria establecida
plot2=seaborn.regplot(x='DIAM_CIRCLE_IMAGE', y = 'LATITUDE_CIRCLE_IMAGE', fit_reg = False, data=data) plot2.plt.title ('Relación de diametro del crater con la latitud de marte') plot2.plt.xlabel('Diametro del crater') plot2.plt.ylabel('Latitud')
plot3=seaborn.regplot(x='DIAM_CIRCLE_IMAGE', y = 'LONGITUDE_CIRCLE_IMAGE', fit_reg = False, data=data) plot3.plt.title ('Relación de diametro del crater con la longitud de marte') plot3.plt.xlabel('Diametro del crater') plot3.plt.ylabel('Longitud')
plot4=seaborn.regplot(x='DIAM_CIRCLE_IMAGE', y = 'NUMBER_LAYERS', fit_reg = False, data=data) plot4.title ('Diametro por número de capaz') plot4.plt.xlabel('Diametro del crater') plot4.plt.ylabel('Número de capaz')
En este caso se relacionan dos varaibles categoricas por lo tanto se utiliza el método catplot
plot5=seaborn.catplot(x='DIAM_CIRCLE_IMAGE', y = 'CRATER_NAME', data=Sub1_DIAM_CIRCLE_IMAGE) plot5.plt.title ('Diametro del crater') plot5.plt.xlabel('Crater') plot5.plt.ylabel('Diametro en mm')
Los resultados:
La toma de datos del diámetro del Cráter se realizó hasta 4 capaz de cada, en la siguiente imagen se denota que la mayoría (más de 35000 observaciones) no tiene capaz lo que hace que el detalle de la imagen e información sea menor respecto a las que tienen 3 capaz (alrededor de 1000 observaciones).
Ahora bien, la relación de la latitud respecto al diámetro registrado del Cráter, el cual esta hasta en 200 km se concentra principalmente en las latitudes de - 75 a - 25, mientras que el cráter de mayor tamaño se ubica en - 75 °. En ese sentido se puede establecer interrogantes cómo ¿Sucedió algún evento geológico que implico la concentración de Cráter en estas latitudes ?, ¿El planeta marte tuvo choques con asteroides en la latitud de -75 que generaran un crater de casi 1200 km ?
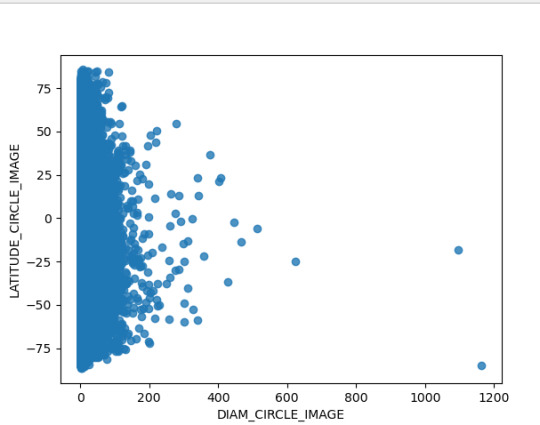
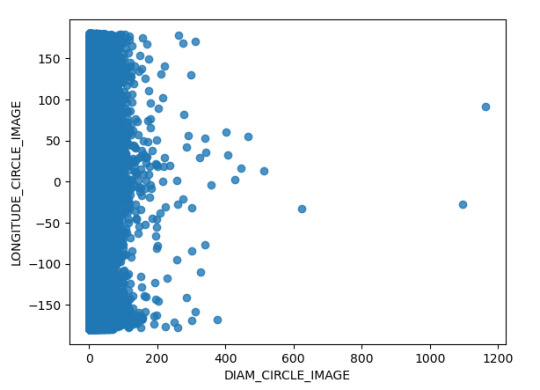
Así mimo, en el análisis se hizo el análisis mediante la siguiente grafica de la dispersión del Diámetro del Cráter y la ubicación longitudinal del mismo; encontrando que el Cráter de mayo tamaño se ubica en 100 y la mayor concentración de longitudinal esta en entorno de la longitud 0. A continuación, presentó la grafica obtenida
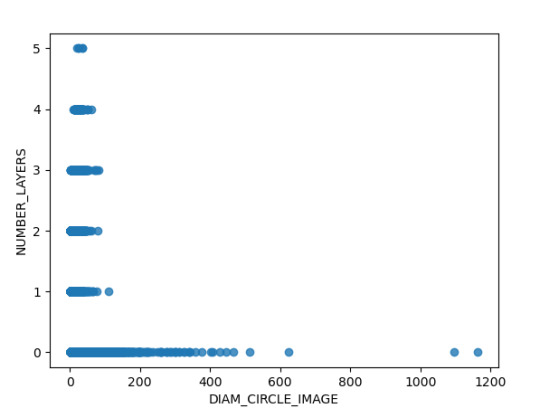
Finalmente se analizaron la relación de dos variables cuantitativas como lo son el diámetro y la cantidad de capaz de los cráteres, en donde identifica que existen observaciones de hasta 5 capaz que no se evidenciaron en grafica anterior, posiblemente por el método de regplot de Pandas es más adecuado para evidenciar el detalle de la dispersión de los datos.
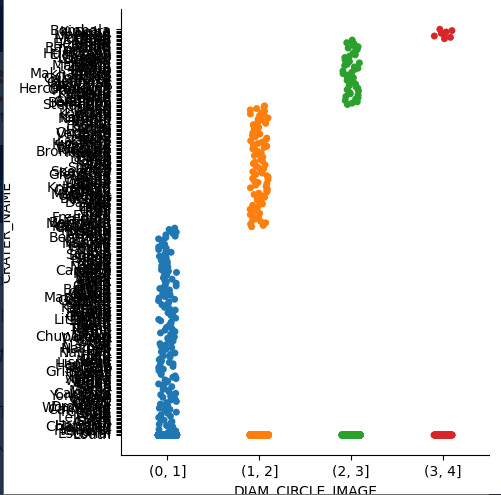
Otro par de variables cuantitativas relacionadas corresponde al diámetro respecto al nombre del Cráter, no obstante como se evidencia a continuación, por la cantidad de datos no es posible identificar fácilmente el nombre del cráter.
0 notes
Text
Clasificación diámetros de cráteres
Compartó el código que realice en python:
-- coding: utf-8 --
""" Created on Thu Feb 16 17:06:12 2023
@author: ANGELA """
import pandas
lectura del archivo csv
data = pandas.read_csv('marscrater_pds.csv', low_memory=False)
Variables de interés convertidas en númericas
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE'])
Distribución de las variables
fr_LATITUDE_CIRCLE_IMAGE=data["LATITUDE_CIRCLE_IMAGE"].value_counts(sort=False,dropna=False)
fre_LONGITUDE_CIRCLE_IMAGE=data["LONGITUDE_CIRCLE_IMAGE"].value_counts(sort=False,dropna=False)
fre_DIAM_CIRCLE_IMAGE=data["DIAM_CIRCLE_IMAGE"].value_counts(sort=False,dropna=False)
print(fr_LATITUDE_CIRCLE_IMAGE)
print(fre_LONGITUDE_CIRCLE_IMAGE)
print(fre_DIAM_CIRCLE_IMAGE)
Sub grupos de intereés son los diametros hasta 30000 con 1, 2 ,3 y cuatro capaz reportada
Sub1_DIAM_CIRCLE_IMAGE=data[(data['DIAM_CIRCLE_IMAGE']>=0) & (data['DIAM_CIRCLE_IMAGE']<=70000)] print(Sub1_DIAM_CIRCLE_IMAGE," Layers 1")
Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'] = pandas.cut(Sub1_DIAM_CIRCLE_IMAGE.NUMBER_LAYERS,[1, 2, 3, 4]) Cut_x_num_layers = Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'].value_counts(sort=False, dropna=True) print(Cut_x_num_layers)
Clasifico los grupos por nombre del crater
print (pandas.crosstab(Sub1_DIAM_CIRCLE_IMAGE['DIAM_CIRCLE_IMAGE'],Sub1_DIAM_CIRCLE_IMAGE['CRATER_NAME']))
Tuve los siguientes resultados:
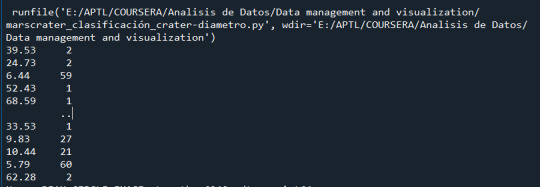
Conteo de los valores de la variable DIAM_CIRCLE_IMAGE
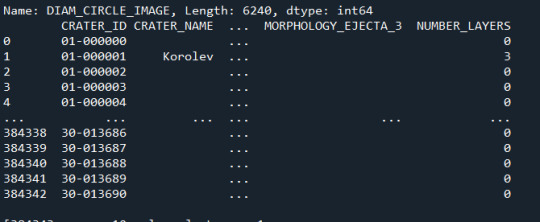
Sub grupo realizado de la variable DIAM_CIRCLE_IMAGE

Corte de el Sub grupo realizado de la variable DIAM_CIRCLE_IMAGE
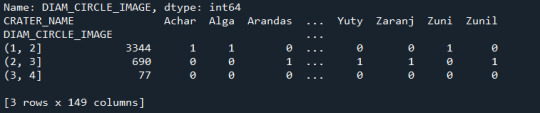
Recorrido por variable CRATER_NAME del Sub grupo realizado de la variable DIAM_CIRCLE_IMAGE
0 notes
Text
Programa de lectura datos csv
Comparto con ustedes el programa de lectura de datos del archivo CSV para el proyecto del curso de Gestión y visualización de datos
-- coding: utf-8 --
""" Created on Fri Feb 10 09:04:40 2023
@author: ANGELA """ import pandas import numpy
data=pandas.read_csv('marscrater_pds.csv',low_memory=False)
el comando low_mwmory=False indica que cada columna esta dividida por comas',', aumenta la eficiencia del programa
print(len(data), ' Filas de data') #imprime el número de filas de data print(len(data.columns), 'Columnas de data')#imprime el número de columnas de data data['CRATER_ID'].dtype # indica el tipo de variable que es CRATER_ID pandas.set_option('display.float_format', lambda x:'%f'%x) #esta línea de alguna manera ayuda a gestionar los errores print("=============")
El cambio a tipo numerico de los datos de las variables se hace con los siguientes comandos
data['LATITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LATITUDE_CIRCLE_IMAGE']) data['LONGITUDE_CIRCLE_IMAGE']=pandas.to_numeric(data['LONGITUDE_CIRCLE_IMAGE']) data['DIAM_CIRCLE_IMAGE']=pandas.to_numeric(data['DIAM_CIRCLE_IMAGE']) data['DEPTH_RIMFLOOR_TOPOG']=pandas.to_numeric(data['DEPTH_RIMFLOOR_TOPOG']) data['NUMBER_LAYERS']=pandas.to_numeric(data['NUMBER_LAYERS']) print(data['LATITUDE_CIRCLE_IMAGE'].dtype)#imprime el tipo de dato que de la varaible LATITUDE_CIRCLE_IMAGE print("=============")
Se tiene que identificar la distribución de las variables, es decir contar la frecuencia de las varaibles
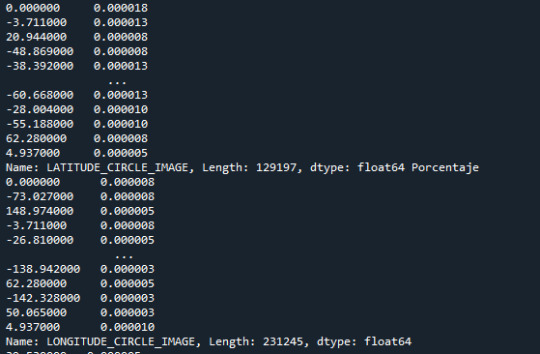
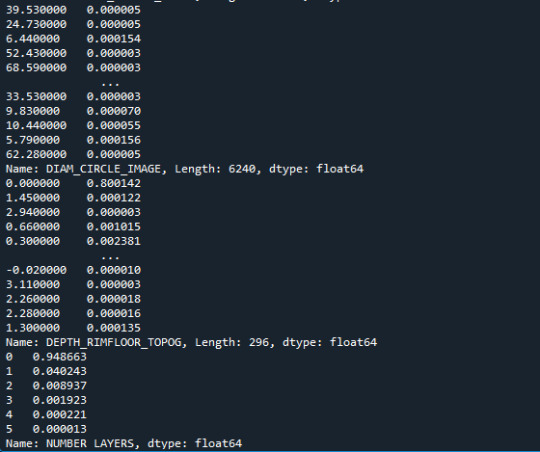
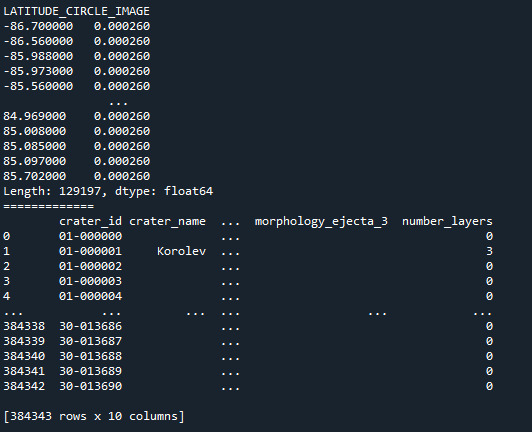
fr1_LATITUDE_CIRCLE_IMAGE=data["LATITUDE_CIRCLE_IMAGE"].value_counts(sort=False) #último comando es para no organizar los datos, así presenta datos sin normalizar print(fr1_LATITUDE_CIRCLE_IMAGE,"Valores de conteo") fr2_LATITUDE_CIRCLE_IMAGE=data["LATITUDE_CIRCLE_IMAGE"].value_counts(sort=False,normalize=True) fre_LONGITUDE_CIRCLE_IMAGE=data["LONGITUDE_CIRCLE_IMAGE"].value_counts(sort=False,normalize=True)#obtengo los porcentajes de la varaible fre_DIAM_CIRCLE_IMAGE=data["DIAM_CIRCLE_IMAGE"].value_counts(sort=False,normalize=True) fre_DEPTH_RIMFLOOR_TOPOG=data["DEPTH_RIMFLOOR_TOPOG"].value_counts(sort=False,normalize=True) fre_NUMBER_LAYERS=data["NUMBER_LAYERS"].value_counts(sort=False,normalize=True)
print(fr2_LATITUDE_CIRCLE_IMAGE, "Porcentaje") print(fre_LONGITUDE_CIRCLE_IMAGE) print(fre_DIAM_CIRCLE_IMAGE) print(fre_DEPTH_RIMFLOOR_TOPOG) print(fre_NUMBER_LAYERS)
print("=============") ct_fre_LATITUDE_CIRCLE_IMAGE=data.groupby('LATITUDE_CIRCLE_IMAGE').size()*100/len(data) print(ct_fre_LATITUDE_CIRCLE_IMAGE)
print("=============")
Con el fin de mantener una estructura en la escritura del código se recomienda dejar todas las variables en mayúscula o en minúscula con los siguientes líneas
data.columns=map(str.lower,data.columns)# todo minúscula print(data)
La salida
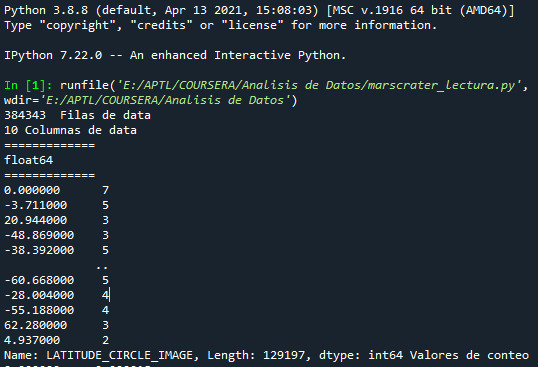
0 notes
Text
Primer proyecto Análisis Datos python
Hola, decidí trabajar el grupo de datos sobre los cráteres en Marte. Pienso utilizar las variables de Latitud. Longitud y Diámetro. El segundo tema que me interesa es sobre la tendencia política según la religión y el genero de los entrevistados.
1 note
·
View note