
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by quan-chau-blog and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
13 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Senior Seminar Reflective Post
My experiences in the Senior Seminar course have been rewarding in terms of what I have learned and how I have improved myself to be prepared for my post-graduation life. By participating in ethical discussions and working on my research project, I have learned how to think critically, look at social and technical problems from different angles, and apply analytical skills to my research topic.
What I value the most in this course are the class discussions. Not only did I get to know more about the technology world (e.g. self-driving cars, virtual reality, ethics in technology), but also I get to think about the social issues related to modern technology critically. When discussing these issues with other members in the class, I am encouraged to support my opinions, but at the same time, I learn to listen to others and adjust my perception as I see fit. Because technology can be applied to everyone, I also need to put myself in others’ shoes. For example, I may not consider privacy violations in social media a serious issue in my life, but for other people, personal information is important to them. Being a liberal arts student, I learn not to evaluate ethics using my personal experience, but instead, I evaluate ethics based on the rights and the benefits of the involved parties. There were several discussion topics that I was completely unfamiliar with, which made me pay extra attention to the readings so I can understand the questions and share my ideas. At the same time, there were topics related to software development that I was familiar with thanks to my work experience. These were the chances for me to share my knowledge and compare my understanding with others’. Moreover, for global issues such as government surveillance and algorithm bias, I tried to analyze how these issues would affect people from different countries instead of focusing on the US alone. These discussions allowed me to think about ethical problems locally and globally, which sometimes made me realize the significant differences between the society I live in and the world around me.
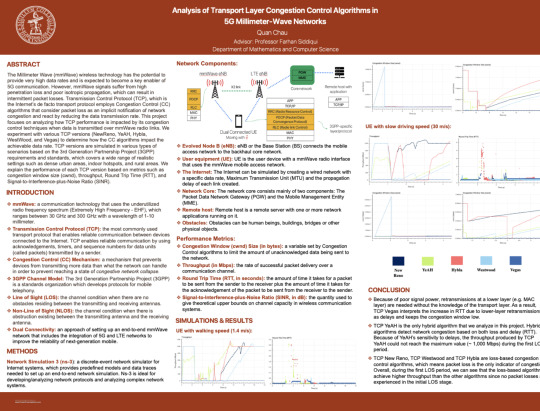
Image 1: The poster of my research project
Moreover, the work I have been putting into my research project has taught me tremendously about the importance of contributing to a pool of knowledge on a topic that is new to the technology world. When I started this project, it was mostly about my personal gain of knowledge and experience. However, after working on 5G mmWave for almost a year, my personal gain is still important, but I am more proud of myself because hopefully in the near future when these results get published, it will be the basis for further research and development, similar to how I relied on other research papers to get started on mine. One of the motivations that have led me to this project was how the development of 5G mmWave would help people’s everyday lives by improving the performance of several operations and enabling faster communication. While I did not have a chance to work on an HFOSS project, I am aware of the importance of my research topic to the general public and my responsibility to provide accurate results and analysis for future research. Sharing the knowledge I have gained and the materials I have collected about this topic to the class was also a rewarding experience for me, as I could contribute to the class members' learning experience in this course. Last but not least, as a Computer Science student who used to not know much about wireless networks and mobile technology, I hope that my experiences with this research project will motivate me to get out of my comfort zone in the future as a software engineer and a member of the society.
0 notes
Text
H/FOSS projects, Algorithm Bias and Inclusive Coding (InCoding)
How I'm fighting bias in algorithms | Joy BuolamwiniThere are various reasons why companies struggle to fight algorithm bias. Although it is true that bias in algorithms can never be eradicated (the same for bias in society), there are ways to mitigate biases and make technology work for everyone. One problem we are facing is that most algorithms are made within companies, in their offices, and by their people. There are many layers of filtering and privacy, and the more “proprietary” an algorithm is, the more biased it can become. When discussing algorithm bias, people rarely mention the role of the open-source movement and how it could become one of the best solutions to make algorithms and technology fairer. In fact, there have been many successful artificial intelligence open-source projects such as TensorFlow and IBM Watson, which have been rigorously tested for anti-bias (Read more in https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias). Also, the nature of open source communities is ideal for the development of machine-learning debugging tools that identify data bias in large sets of data.
In Joy Buolamwini’s TED talk about bias in algorithms (https://youtu.be/UG_X_7g63rY), she introduced an interesting example of bias in facial recognition algorithms. The facial recognition technology she used only recognized a white person’s face as a human face, and it constantly had problems with identifying faces of people of color. However, when she put on a white mask, her “face” was recognized immediately. This is a very simple and straightforward demonstration of algorithm bias, but from this example, we can imagine how uneasy technology users would feel if they encountered these issues in their everyday life.

Since most biases are caused by technical aspects of algorithms (e.g. initial datasets, implementation of the algorithm), bringing these technologies to open-source communities can lead to significant changes:
The datasets being fed to the algorithms can be evaluated and contributed to by a larger community than a company’s engineering team. Moreover, these contributors are from various places in the world who have different races and hold different beliefs.
Sometimes, technical errors and improper coding practices can accidentally bring out biased results. Having more developers looking at and make changes to the core of an algorithm can help avoid these scenarios.
The definition of bias is varying. Therefore, limiting the bias-tackling tasks to a small group of people can never solve the problems completely. Open source communities play an important role here because we can hardly find such a large pool of software engineers and developers in any other place. The more members contribute to the development of an algorithm, the more objective it becomes and as a result, the outcomes of the algorithm will be more likely to be accepted by the vast majority of technology users.

In Joy Buolamwini’s talk, she also introduced a notion of Incoding, which stands for Inclusive Coding. In my opinion, this is a more subtle approach to tackle algorithm bias, which is gradually changing the way people code and make technical decisions. There are three important messages that developers should keep in mind: Who Codes Matters, How We Code Matters, and Why We Code Matters. It is hard to prove whether this movement will ever change the state of algorithm bias, but I think it is always a good practice to pay attention to the impact of the code we write and the software we produce.
AI and machine learning bias has dangerous implications: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
How I'm fighting bias in algorithms | Joy Buolamwini: https://youtu.be/UG_X_7g63rY
0 notes
Text
Facial Recognition is not only about unlocking your phone
I am generally positive when it comes to new and sophisticated technologies. Therefore, I am not a fan of utilitarianism. I do not see a point in “calculating” benefits and drawbacks to evaluate if one use of technology trumps the other. I care about what new technology can do to a specific field and how it can improve the quality of life.
In this post, I want to focus specifically on the potentials of facial recognition technologies on the improvement of healthcare and diagnostics. These applications are not well-known among the discussions about facial recognition, but for me, they are among the most important reasons why I think facial recognition is the future.
1. Diagnostics

Image 1: Using facial recognition to detect early warning signs of stroke (Retrieved from https://lbbonline.com/news/fatal-recognition-is-an-app-that-uses-facial-recognition-to-detect-warning-signs-of-a-stroke/)
The amount of information we can retrieve from the observation of one’s face is incredible. For example, there are many signs of stroke that can be spotted on a person’s face such as face drooping (according to [1]). With the use of facial recognition, we can identify strokes from phones and cameras promptly since the devices have a thorough knowledge of the signs and symptoms. As an example, article [4] discusses a mobile application that detects early warning signs of a stroke .
Facial recognition technologies can also indicate many different health parameters such as body fat, BMI and blood pressure. These parameters can be sent to doctors to track a patient’s health, especially for elders under scrutiny. More information about how facial recognition can change the future of diagnostics can be found in [2].
2. Healthcare
One application of facial recognition related to healthcare is to assessing one’s genetic information. For example, we can detect rare genetic conditions such as the Cornelia de Lange syndrome, which can be easily overlooked by physicians [3]. Aside from precision, this is also a much more economical solution than ordering a genetic test from an institution. It has also been proven that facial technologies have outperformed clinicians in identifying specific syndromes (read [3] for more details).

Image 2: The use of medical AI using face recognition (Retrieved from https://healthcare-in-europe.com/en/news/china-pushes-the-use-of-medical-ai.html)
From the basic idea of facial recognition, new technologies are invented to improve our quality of life. Basic furniture and wearables have been replaced with those with facial recognition features such as smart glasses and smart mirrors to improve the amount of information provided to people in their daily lives. Indeed, what I find important about the use of facial recognition is not how it helps diagnose “big and rare” symptoms, but how it can spot little things in my daily life. I want to see how my face changes compared to yesterday (or last week) and if there are any new bruises and redness so I can change my moisturizers and skincare routine before it gets worse.
I acknowledge that the use of facial recognition in healthcare may cause controversy, as the analysis of one’s medical conditions can raise a lot of concerns about privacy. However, I think these concerns are common among new technologies (e.g. self-driving cars, fingerprint scanning, and advanced blood testing) and there are (or will be) solutions to make the technologies safer and better for medical use. In my opinion, it is always better to think of ways to improve than to think of reasons to avoid new technology.
[1] https://www.stroke.org/en/about-stroke/stroke-symptoms
[2] https://www.medicalnewstoday.com/articles/320316#Model-predicts-body-fat,-BMI,-blood-pressure
[3] https://medicalfuturist.com/your-guide-to-facial-recognition-technology-in-healthcare/
[4] https://lbbonline.com/news/fatal-recognition-is-an-app-that-uses-facial-recognition-to-detect-warning-signs-of-a-stroke/
0 notes
Text
How should we think of Autonomous Vehicle
I have had several discussions about autonomous vehicles (AV) and self-driving cars in the past few years with fellow students, professors and software engineers I met during internships. In Silicon Valley, at least from my perspective, engineers and “tech” people do not talk about the trolley problem and how self-driving cars can change the world. We always give new technologies doubts since they are new and unfamiliar. At the same time, we are all excited about it and hold miraculous assumptions about our future (e.g. an extremely low chance of accidents, the ability to take people anywhere without any human control). Because of these assumptions, we expect too much in the AVs. We will gradually consider safety as a certainty, and people will no longer be responsible for their own safety while in autonomous vehicles.

Image 1: An example of media sensationalism on autonomous vehicles (Retrieved from https://innovationatwork.ieee.org/autonomous-vehicles-for-today-and-for-the-future/)
I think we should all be informed about the current state of autonomous vehicles. The safe and ubiquitous deployment of autonomous vehicles should be at least a decade away (read articles [1] and [2] as examples). Although we already have “autopilot” in Tesla vehicles, it is still required that the drivers must focus on the road to be able to react to any emergencies. Specifically, in the description of the Autopilot feature on Tesla official website, it is explicitly stated that “current Autopilot features require active driver supervision and do not make the vehicle autonomous.” There are promises about a “full self-driving experience”, but it does not mean anything until we see it working in real life.
Therefore, we must change our mindset: We must control the autonomous vehicles instead of letting them control us. People “driving” an AV should not have different attitudes than people driving a non-autonomous car. This means that the act of driving (in any vehicles) should require the same level of attention, carefulness and responsibility. Here are some arguments that, in my opinion, convey misleading expectations on autonomous vehicles:
1. AVs should not be human tunable because it would put too much pressure on the drivers
Anyone who thinks this is the right idea should answer one question: Is it usual or unusual for a driver to be put into pressure when driving? As I mentioned above, drivers should expect in AVs no more than what they expect in cars nowadays. If someone is afraid of being responsible, or being put into pressure when they drive for the sake of safety, perhaps they should not drive a car at all.
2. If an AV is human tunable, there will be issues related to racism, sexism, etc:
My response to this argument is similar to what I shared in my last blog post. Technology is not, in any ways, racist or sexist by itself. It portrays these ideas because people discriminate against each other in the society. If an AV is human tunable, it will be expected to react the same way its owner would react. Therefore, an AV car will behave the same way as cars nowadays in some very rare occasions that involve accidents. Then why do people drive cars and make decisions, but disagree with the fact that a car drives them and makes the same decisions? Note that I avoid discussing the ability of technology to always make similar decisions to a person since this argument does not focus on that aspect.
I acknowledge that my opinions above may be extreme for some readers, but I think it is important to point out the reality instead of what the future is imagined to be.
[1] 1 in 10 vehicles will be autonomous by 2030: https://www.techrepublic.com/article/1-in-10-vehicles-will-be-autonomous-by-2030/
[2] BlackBerry CEO says autonomous cars are at least a decade away: https://www.siliconrepublic.com/machines/autonomous-vehicles-decade-away-blackberry-chief-john-chen
0 notes
Text
Is it morally correct to hide the truth?
This post discusses the article ‘Black teenagers’ vs. ‘white teenagers’: Why Google’s algorithm displays racist results (https://splinternews.com/black-teenagers-vs-white-teenagers-why-googles-algori-1793857436 ) in the context of ethics. The question implied in the article is whether or not Google should alter their algorithm to hide racist content. However, in this post, I want to discuss an even broader question: Is it morally right to hide the truth, especially on online platforms like Google?

There are several workable ethical theories, each of which provides a different answer to this question. For example, using Rule Utilitarianism, some may argue that a change in Google’s algorithm would lead to a greater total increase in happiness. However, setting aside the ethical theories, I believe a more important factor to be considered is what users consider online platforms such as Google and Facebook to be and the roles online platforms play in their lives. It is worth noting that Google, Facebook or Snapchat are not initially built to be an educational platform. Instead, their initial goal was to bring what is happening in real life to the Internet and make it accessible to everyone. With this point of view, the most important criterion for these online platforms should be that they have to truly reflect the society in real life. We do not go to Facebook to see a movie or read fiction, but we log in to see how our friends are doing, what they care about the most and their opinion on different matters. These actions should reflect exactly how we meet our friends and talk about various topics in daily conversations.

Although this argument may already fall into one of the ethical theory, I want to justify a point based on the nature of the tools being used (Google - an online platform), not on the consequences or the motivations. We can see that most social tech companies stick to this “goal” by refusing to completely alter the truth. Let’s take Facebook as an example. After the US election in 2016, lots of people criticized Facebook for portraying fake news, which detrimentally affected the election results. While this is not a false statement, we should trace the root of the problem. Let’s now consider this question: Does Facebook show fake news because the CEO and the board members favor one candidate over another, or is it because the people in the society want to show fake news to each other for their own good? Apparently, we all know that there are non-Facebook people who pay for ads to show fake news to favor a specific candidate. Although these ads are not facts, they reflect the propaganda being broadcast in real life. In my opinion, it is Facebook’s job to reflect the opinion of society, but it is not their job to fact-check and provide the most up-to-date verified information. There are knowledge-focused platforms such as Wikipedia that are already taking care of that.
To sum up, I do think technology is ethical, but the notion of ethics varies based on culture and backgrounds. There are many cultures in the world, but there is only one Google and Facebook. In the end, technology can never reflect every point of view, so it is “good enough” to reflect the majority of them. It should be mainly the user’s job to decide which information they want to believe and to act on.
0 notes
Text
Reflection on discussion about Open Source Community
I have always wanted to work on an open-source project on Github, but I never had a chance to do so. In this course, although I did not contribute directly to any open source community, I have learned how these communities work and what it takes for an open-source project to be successful from both the participants and the project owners. Also, thanks to the class discussion and the group presentations, I have realized the importance of contributing to and engaging with a community.
One of the biggest problems of me and many developers in joining an open-source community is “engaging with the unfamiliar”. When we join a Slack channel, it is hard to know who to ask questions, and what questions we should ask. Some people are afraid of asking too many questions, and it is not unusual to be shy in a community of 10,000 people who we have never met or talked to before. However, there will be a time when we get comfortable, and we realize that we have become a member of a community. Engaging with a completely new community can push me out of my comfort zone to explore new skills, meet new people and bring positive changes to the community. During the class discussion, I also learn to actively raise my voice to address problems, ideas and ask questions so I can understand a topic in depth. I believe that everyone has something to learn from, and people grow by learning from each other’s mistakes and successes. Therefore, being an active member of a community is the best way for me to improve myself and help others.
Discussing Open Source Community has also cultivated in me the initiative to implement changes. There are two types of changes I want to reflect on: the changes contributors make to a project, and the changes the project makes to the society. Participating in an open-source project includes correcting what is going wrong in that project. We fix bugs, make recommendations and look for a better way to implement a feature. Because of the “free” nature of open source projects, I realize the importance of being proactive in making changes. Furthermore, learning about the statuses of HFOSS projects makes me believe more in the fact that there are lots of developers who contribute to a project to achieve goals for common good. This will be a huge motivation for me to choose HFOSS when I look for new projects to work on in the future.
Before this course, I had mixed feelings about H/FOSS projects as I did not think that people could learn much from working on these projects. However, I realize that what is more important than an open-source project is its open-source community. Besides technical skills, the community allows contributors, including me, to practice their soft skills and prepare them for a life of civic engagement.
0 notes
Text
How important are HFOSS projects in tech interviews?
I have been describing H/FOSS as a side activity for software developers and a learning activity for students. However, experiences with H/FOSS projects can also be a huge factor in one’s career path. When choosing a software project to work on, many programmers consider between joining an open-source community and starting their own software from scratch. In this post, I want to discuss what interviewers can see from a candidate through her commitment to HFOSS projects.
In most interviews, the interviewers do not ask explicitly about a candidate’s commitment to open-source projects. The most important parts about a project experience are the challenges, the thought process and how well a candidate deals with her problems. In my opinion, the fact that the project being HFOSS does not add direct values to the candidate’s experience or the project itself, but it tells a lot about the candidate.

First, it possibly implies that the candidate is passionate and that she does not enter the field just because of its reputation and high salaries. Involving in an HFOSS project is doing voluntary work for the community and self-development. It is easy to join an open-source project, but being motivated enough to commit to the same project for a long time is a big deal.
Secondly, it might imply that the candidate is an exceptional team player. Not everyone has the skills to work effectively in a team on a software project, let alone working in a remote team of developers of different levels and expertise. In an interview, senior developers do not only look for candidates with outstanding technical skills, but they also see if the candidate can fit in the current team in the long run.
Sometimes, contributing to a company’s project increases a candidate’s chance of getting an offer from that company. Most large-sized companies open source some of their projects, which are managed by their employees. Telling stories to the interviewer about your work towards their company’s projects can be a big plus in a technical interview. Also, in some companies, the project managers actively look for outstanding contributors to pull into their companies. However, being noticed by the project managers in a large company’s project is certainly not an easy task.
0 notes
Text
What motivates and what demotivates programmers to join an Open Source community?
As mentioned in one of my earlier posts, open source projects are getting more popular as they provide a “geeky” playground for developers of any level to have fun while improving their skills. Although there are lots of ways developers can get attracted to an open source project, these projects are not always approachable. In this post, I discuss some reasons why programmers/developers are motivated and discouraged to join an open source community.
The Motivations

When Wikipedia was first released, hardly anyone would think that one day, it will be a nightmare for Microsoft’s Encarta. At that time, people did not believe in the notion of voluntary contribution, and the society was functioning based on a carrot-and-stick system. This means that people work hard to earn rewards. When I introduced the book Drive last time, I wanted to introduce a more up-to-date meaning of motivation, in which what “drives” people also includes self-improvement, joy, and satisfaction.
Similarly, what “drives” developers to contribute to open source communities is not about the physical rewards. Their motivations are generated by these factors:
It is fun to code along with other people and learn from them.
Open source communities create great opportunities to work with large scale projects
Working on open source projects is mostly low-stress.
It is great to know that they are contributing to the society, especially in HFOSS projects.
The Bad
In my early years of college, I found it hard to join any open source projects. I did not know what steps to take, who I should talk to and whether or not a project is worth my time. Most of the time, we take the first steps ourselves. There is no one guiding us through the process, and we are easily discouraged by the amount of time it takes to start and get familiar with a project. Although there are communication channels, not everyone is comfortable with talking to strangers and asking lots of questions.

For some programmers, contributing to a software project without any compensation is unacceptable. This is not a wrong attitude. Indeed, I do think open source contributors should be paid or rewarded in one way or another. The reason why people still contribute to open source projects is that, besides the above reasons, the system does not work this way (yet!). If we look deeper into any project, we can see that there is an implicit reward system, which, for example, gives developers more control and power over the project.
The last point I want to make is about the project’s ownership. When a developer starts a project from scratch, they will definitely have more ownership over the project than when they jump into an open source one. For me, attaining ownership is a very legit reason for a programmer to leave an open source community and start an independent software project, because having more ownership means having more freedom and credits.
If you want to read about an example of a reward system in open source communities, this is a good example: https://www.wired.com/story/github-sponsors-lets-users-back-open-source-projects/
0 notes
Text
How to optimize sprint planning?
What is Sprint Planning?
Sprint planning is a process in the Scrum framework where the team meets to discuss which tasks from the backlog will be worked on in the next sprint. This happens at the start of every sprint (typically 1-4 weeks) and the length of the meeting varies based on the scale of each sprint (typically more than 1 hour).

Preparation
For the sprint planning meeting to be productive, the Scrum Master and the team members have to be prepared and ensure the followings:
The product backlog is clean and easy to follow. This includes prioritizing tasks, separating different types of tasks, and removing/adding tasks if necessary.
The current sprint has been cleaned up by the team members. This means that any finished tasks have to be marked “Done” so they will not be transferred to the next sprint, and any unfinished tasks have to be reviewed and broken up if necessary.
An updated burn-down chart for the current sprint on which the team can rely and make decisions for the next sprint.
Team members should have an idea of what they are going to work on in the next sprint. This helps the discussion move faster and reduces the amount of work of the Scrum Master.

During the meeting
The most important requirement of a sprint planning meeting is that all members need to be present. Although the Scrum Master and other team members may know what each other is working on, we want to minimize any incorrect assumptions and miscommunications that may cause team conflicts later on.
One of the approaches during the meeting, which I found effective in my experience was:
1. Go through the current sprint and discuss the finished and unfinished tasks. During this step, the team may discuss these questions:
What are the blockers of the unfinished tasks? And what has to be fulfilled/worked on to remove those blockers?
Do the finished tasks need any follow-ups or do they lead to new tasks that have to be done in the next sprint?
Should we move these tasks to the next sprint, or should we move them to the backlog for further considerations?
2. Next, go through the backlog in order of highest priority to lowest priority. For each task in the backlog, the Scrum Master should already have in mind who he/she will assign the task to. Certainly, there will be disagreements and the team have to discuss the workload and the specialization of each member to decide who will take the task.
3. Review the tasks in the next sprint to ensure the followings:
Every team member has a relatively equal workload to the others. This does not always have to be the case, but this should be a goal.
The amount of work is finish-able within the sprint. This can be measured by the metrics from the burndown chart and the story point of each task. The Scrum Master should be able to estimate the amount of work that can be done during a sprint, and have his/her criteria to increase/reduce workload.
Although it seems that there are not a lot of steps before and during a sprint planning meeting, it can take longer than expected because team members do not always agree with the Scrum Master’s decisions. The preparation steps are important as it helps clear up any potential confusion and disagreement before the meeting.
0 notes
Text
Flyweight… or Lightweight?
Software design patterns are the solution to commonly occurring problems in software development. These problems can be structural, behavioral, or concurrency problems. Using the right design patterns eases potentially major mistakes in the future, which may force the developers to re-architect the entire product. In this post, I want to introduce a design pattern called Flyweight. I picked this design pattern initially because of its interesting name, but it also has many applications and advantages related to memory usage and performance.

Flyweight is the solution to two problems:
An excessive number of object initialization can significantly increase memory usage, and most of the time, objects are relatively identical.
Object initialization is typically fast, but performing many of them can increase the execution time of a program, which leads to poor performance.
The most important component in a Flyweight architecture is the factory, which stores all objects created. The objects are stored in a key-value manner so that when we want to retrieve an object, we can refer to its unique key to pull it out from the factory. Whenever a program needs to create a new object, it first checks the factory. If the factory already contains an object with the intended attributes, that object will be reused. Otherwise, the program creates a new object and send it to the factory for future usage.
Intrinsic and Extrinsic state
There are two types of state in a flyweight object. Intrinsic states are attributes that can be shared among objects, and extrinsic states are attributes that are unique to each object created, or at least unique to most objects. For example, we have a class called TShirt, which represents t-shirts being sold at a clothing store. Every time we have a new t-shirt of size ‘M’, we do not need to create a new object. Instead, we pull an object that represents a t-shirt of size ‘M’ to reuse it. In this case, size is an intrinsic state of the class TShirt. However, since each t-shirt has a unique barcode, barcode is an extrinsic state.
In gaming, Flyweight is important because we need to allow the program to react to any action as fast as possible. Let’s look into a soccer game where we have two teams, A and B. It is clear that all players in team A have the same mission, getting the ball to team B’s goal, and similarly for all players in team B. Also, every player in team A and every player in team B has the same t-shirt color. Therefore, to simulate a soccer game, we only need two classes (TeamAPlayer, TeamBPlayer) and two objects, one for each team’s players.
The intrinsic states in this example are mission and color, which are similar for all players in a team.
The extrinsic states can be the player’s name, age, and position. For each of the extrinsic state, there is an assignment function in each class so that when we want to reuse an object, we can override the extrinsic states and assign new values to them.
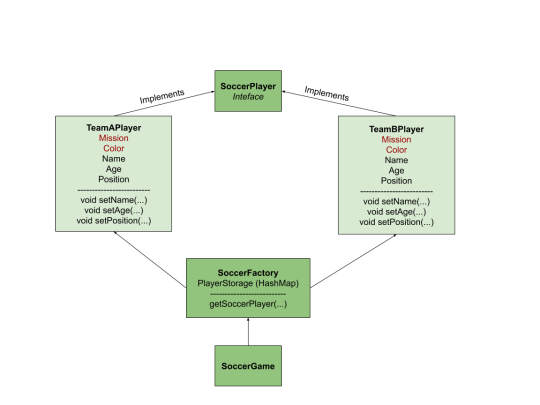
Diagram of an example architecture of a soccer game
Although this design pattern seems lightweight and effective, there are some questions that the developers need to answer before using Flyweight:
In terms of performance, we reduce the amount of time initializing objects, but at the same time, do we also have some latency retrieving the object from the factory and mutate its state?
Does multithreading work when we reuse the same object over and over again by mutating its state?
Since we keep changing the state of an object, what should we do if we want to reserve a state of an object for a period of time?
0 notes
Text
Proof of Conception, Prototype or Minimum Viable Product?
It is controversial how much time programmers and solution architects should spend on designing and planning a software product before implementing it. Theoretically, some people would agree that it takes approximately 50% of the entire development lifecycle. But practically, designing, planning and implementing are not necessarily independent tasks, but in fact, most programmers rely on “implementation” to make important design decisions such as technologies, feature priority, and hardware resources.
In this context, “implementation” has different meanings. During the software planning process, there are three types of implementation: Proof of Concept (PoC), Prototype, Minimum Viable Product (MVP).
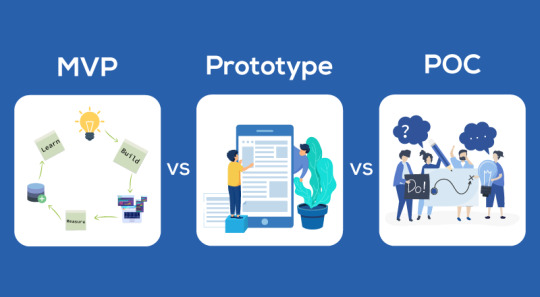
Proof of Conception (PoC): Can this product/feature be developed?
This is usually the first out of three types of implementation during a software design process. Proof of Concept is a small and simple piece of software that demonstrates the functionalities and proves that the assumptions made about the feature or product are achievable. Typically, PoC represents ideas that allow people to have a clear picture of what a feature does (instead of interpreting it from a written description). Here are some examples that demonstrate the simplicity of a PoC:
Instead of implementing data communication, the values are usually hard-coded to replicate realistic scenarios.
A PoC does not comprehensively use the intended technologies, but it can imitate what the technologies will do to a project (e.g. API calls can be replaced with function calls, …)
If a product has a user interface, its PoC does not necessarily need one. The software can be functional through some developer’s portal or the machine’s terminal.
Prototype: How will this product/feature be developed?
After we confirm that the product or feature is feasible, we need to validate our development plan by creating a prototype. A prototype should focus on users, meaning that it should be simple but detailed enough for the users to be able to use and for the development team to observe user experience. A prototype should have a simplistic interface and basic features that give a general idea of the final product.
Prototypes are important as they help detect critical design issues before further development is made. Most of the time, a prototype will not be used in the final product, as it is not built to be deployed, and therefore does not have the required production quality.
Minimum Viable Product (MVP): What are the core functionalities and value proposition?

Image from https://clevertap.com/blog/minimum-viable-product/
The biggest difference between an MVP and the previous two types of implementation is that an MVP will be released and properly tested. An MVP is the early version of the product that satisfies three conditions: usable, deployable and maintainable. Additional features of the product are built on top of the MVP based on business requirements and real user feedback. Unlike PoC and Prototypes, which can be considered as part of planning and designing, an MVP is the first phase of the implementation process.
It is important to know when and whether or not we should apply any of these implementation types to developing a new software product. Although this practice is widely applied by software companies, not every software product can be developed this way. Furthermore, there is no right or wrong answer to the question of how much time we should spend on planning and designing. However, I believe there are always templates and practices that work best with each type of product.
Note: The descriptions of each implementation type above are based on my own experience and some online research. They may not be generally accepted since different programmers use PoC, Prototypes and MVP for different purposes.
0 notes
Text
How does software dual-licensing work?
When we start a project, licensing seems to be one of the many trivial tasks we have to do, and not many programmers would want to spend time working on licenses. In this post, I will briefly describe the importance of licensing in an open-source community. However, I want to focus on “dual licensing”, a licensing model that allows a project to be both “free” and proprietary.
Why is software licensing important?

Photo retrieved from https://www.technotification.com/2018/04/types-of-open-source-licenses.html
Licenses are regulations in a software community. They regulate how software can be used, modified and redistributed. Although there is no official paperwork or registration involved, including the license within a software project allows the software to be legally available under the licenses’ terms and conditions. Some examples of software licenses are the MIT license, the GNU General Public License, and proprietary licenses created by the project owners.
Dual licensing

Photo retrieved from https://medium.com/deconet/how-to-get-paid-for-open-source-6e13bb238a7f
As mentioned above, dual licensing provides a mean for companies to release software in both a free and proprietary manner. Usually, there will be two versions of the software:
Under proprietary license: This version allows companies to commercially distribute the software with added features, technical support, and plugins that work with other software products of the company.
Under open-source (or copyleft) license: This version allows companies to share the source code with the general public, and allows the public to contribute to the source code. Under most open source licenses, the end-user will be able to redistribute the software, but probably not commercially.
There are several reasons for which a project owner would choose to use dual-licensing.
Firstly, even if a project is a free software, we still need fundings to maintain consistent development. In many cases, companies usually use the funds provided by the proprietary version to cover the cost of the open-source version. Now you may wonder why someone would choose to pay for something available for free. When an end-user wants to deploy the software on a large scale, they need more than just the code. They also require constant technical support, hardware resources, or additional features that are customizable to their cases. And since that end-user is also using the software to support their commercial software products, they are willing to pay for these benefits.
Another reason for dual licensing is when companies want to expand the development of a software project while they do not want to put more resources into it. In this case, companies usually keep their version for proprietary purposes, but they will also open-source the project to the community.
Dual licensing is ideal for software products that start as proprietary software, although it can also be applied to free software as well. The biggest advantage of dual licensing is that it provides flexibility for companies and project owners to distribute their projects and for the end-users to choose which version they want to use.
0 notes
Text
Microservice architecture and event-driven architecture are pecfect together
Technology companies always look for scalable solutions, which gradually replace monolithic and vertically-scaled applications. If we discuss scalability in software development 20 years ago, most engineers would go with building more advanced servers, processors and computers to accomplish more tasks. This would work if we take into account Moore’s Law, which states that the number of transistors on a chip doubles every year. Although Moore’s Law has been true since 1965, it is expected to end in 2025. This leads to the findings for solutions that allow engineers to horizontally scale, which means adding more machines to a system instead of expanding a single machine.

Photo retrieved from https://docs.bmc.com/docs/TSLogAnalytics/110/sizing-and-scalability-considerations-721194160.html
One of the biggest movements to horizontal scaling is the migration to microservice architecture. This architecture breaks up a complicated system into smaller services (microservices) and these services can be developed in isolation. The reason why microservice architecture is scalable is that each service does not need to run in the same data center or be managed by the same organization, which allows us to use hardware resources more efficiently. For example, if we need additional service, we just need to add a computing unit to our data center to ensure sufficient resources. However, since we keep accumulating services and resources, this architecture has a hard requirement, which is a scalable communication system between services.
This is when event-driven architecture (EDA) comes in handy. This post aims to explain this architecture in the most basic way to explain why it is widely used in software development. In EDA, there is a central channel, which is subscribed to by some microservices. This central channel can be a broker (e.g. Kafka broker) or a mediator whose responsibility is to publish messages to its subscribers. These messages can be events triggered by an external service, a message sent by one of the microservices, or a response to a request between two microservices. Once the subscribers get the notification that there is a message, they will react to it and complete their tasks without knowing whether or not other microservices also react to the same message. Let’s think about it like a fire alarm system. When there is an excessive amount of smoke, the smoke detector will publish a signal. This signal will trigger all of the subscribed fire alarms in an area, and when the fire alarms go off, they also “publish” a message to everyone within the area and the security team which might not be in the area. Each person with their role will react differently to the fire alarm, and they might or might not know what others do (if their role does not involve communication with others).

A simple representation of an event-driven system
EDA is ideal for scalability, and that is what tech-companies prioritize these days. However, arguments are stating that EDA does not provide high QoS (Quality of Service) as a microservice may not know if another microservice reacts to its message or not. Although this is true if we only consider the pure implementation of EDA, some tools and practices provide secure communication between microservices. For example, the requesting service can check if the receiving service has received the message and updated a piece of information by periodically checking from mutual resources.
0 notes
Text
Introduction to Git: Cherrypicking
Git is a distributed version control system that enables software developers to track changes and maintain their source code history. Among the features of Git, “cherrypick” is an extremely powerful tool, although its concept is not widely understood by entry-level developers.
What is cherry-picking?
The term cherry-picking is used in many scientific branches such as medicine, climate research, and computer science. In version control, cherry-picking means merging a specific commit from another branch to the current branch. When we do a “git merge some_feature”, the head (latest commit) of some_feature is merged into the current branch we are on. This forces all of the changes in some_feature to be available in the current branch. However, sometimes, we do not want all the changes to be checked in, or more specifically, we just want a specific commit to be available in the master/release branch. This is when git cherry-pick comes in handy.
As an example, consider the current state of some_feature and master as follows:

First, let’s check out the master branch with
git checkout master
If we do a
git merge some_feature
successfully, the commit tree will look like this:
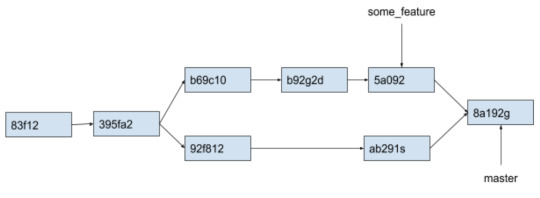
With a “git merge”, the history of the master branch includes all commits within the some_feature branch. However, let’s assume the commit “b92g2d” is a very important commit that we want to release immediately, while we have not tested the changes in commit “5a092” yet. In this case, we have to do “
git cherrypick b92g2
The commit tree will now look like this:

The way “git cherrypick” merges the commit to master branch is very similar to how “git merge” merges the head of some_feature to master. This means that there can still be a merge conflict, but this merge conflict is only specific to the commit “b92g2d”.
When should we cherry-pick?
When there is a healthy and ripe cherry that we want to harvest right away! Software developers often use “git cherrypick” when they want to release hotfixes to a bug, or when there is a requirement that needs to be checked in immediately for their customers.
Let’s go back to the example above and assume that each of the three new commits in some_feature implements a different bug fix or a unique part of a complex feature. Also, the commit with commit hash “b92g2d” contains a change in system configuration, which is required by the Quality Assurance (QA) team so they can test the system stability as soon as possible. In this case, although other parts of the feature are not ready yet, we can still have the commit available in the master branch by doing a cherrypick.
Cherrypicking is not a popular and frequently used command as it is only needed in a few scenarios in the software development process. However, it is a powerful and convenient command in preserving the git history and applying hotfixes.
0 notes
Text
Why should open-source projects be more “proprietary”?
I have mentioned free, open-source software and proprietary software under the context where either they are entirely two different directions of software development or they compete with each other to gain popularity. However, for both types of software to grow, the project organizers of each type should also learn from each other to change the way their organizations currently work and attract talented contributors to support their projects.
There are two things in which open-source software can hardly catch up with proprietary software:
Help newcomers getting started with the software: Most proprietary software products have good documentation, detailed guides for beginners and organized design documents. These documents are revised and updated frequently by company employees. Whenever someone wants to explore a project, they always have the most up-to-date information and tutorials.

Provide points of contact: In a proprietary community, most of the case there are people available to answer questions, and users know who to contact for any section of a project.
With open-source projects, the hardest part to get a user (or a developer) to join a community is to help them understand the project in a short amount of time. In fact, an open-source project’s documentation should be even better than a proprietary one, as the work being done is voluntary and good documentation is the first factor of the project that motivates developers to contribute. Secondly, no matter how good the documentation is, newcomers always want to ensure that there is a go-to person whenever they get stuck. Satisfying both of these conditions provides a secure and meaningful environment for developers and a strong first impression for newcomers.
Another reason why open-source projects should be more “proprietary” is that they should focus more on organizing the members within the community. Although joining and contributing are voluntary, there need to be strategies for open-source communities to keep current members and attract new members. For example, some project organizers occasionally set up meetings at locations where most contributors reside to discuss the project’s roadmap, next steps and to share technical knowledge. Another solution is to set up a hierarchy (but keep it flat!) within the community and promote long-term contributors who create major impacts on the community.

Overall, what motivates users/developers to keep contributing to a project is the feeling of having ownership over the project. Ownership does not necessarily mean having the power to control a project, but it means the users are confident that their ideas will be heard, their tickets will be reviewed and their questions will be answered. Building such a community is not a trivial task, but just like running a company, open-source community organizers should put efforts in building and improving the community instead of merely focusing on the product growth. This is where open-source community should learn from companies in order to keep their members and grow the community.
0 notes
Text
Competition & Pricing in Open Source Projects
In some ways, the open-source community can be perceived as a playground for users and developers, where most members have the right to join and leave as they want. As the playground grows in population, it creates competition due to difference of opinion. That is where the downside of open source software emerges, which requires participants of the community to be aware of the potential risks and wrongful behaviors.
The ability to fork an open-source project plays an important role in promoting freedom in free software. It allows contributors to have a separate environment to work on and freely distribute their version of the project if the license allows them to. There are arguments that a “hard fork” (a fork that will not be merged back to the original version) may cause separation in a project’s community, which potentially harms the development of the original project. Although this argument is valid in terms of the effects hard fork may cause, the owners of open-source projects should know that this is inevitable and somewhat expected. On the other hand, a hard fork can be done for a good cause. First, most often the reason for a hard fork is to expand the project differently and to provide a specific set of services/features to users. If we think about hard fork this way, it brings diversity to the open-source community and provides a wider range of options for newcomers as well as users within the community. Secondly, there are cases where a hard fork is done to prevent a project from being modified and excessively controlled. An example of this is MariaDB, which is hard forked from MySQL by its original developers due to the potential acquisition by Oracle Corporation. Although MySQL remains open-source after the acquisition, it is now a separate project with different goals and purposes compared to MariaDB. These two projects both exist to serve different users and use cases in software development.
Another controversial aspect of open-source projects is pricing. Many contributors and users argue that open-source projects should be completely free as it needs to capture as many developers and users as possible to grow. However, I believe all open-source software products should only be free of charge only in these three cases:
The project is only free of charge for some capabilities of the products, which provides enough freedom for new users/developers to get familiar and get started with the project.
The project has other sources of profit such as in-app advertisement and sponsorship from companies.
The project serves educational and/or philanthropic purposes that target people with low income, students,...
Open-source projects, in the end, are still software products. Thus, if someone wants to use it to support a large-scale system, he or she should pay for the resources and the work being done by the developers. Although I support the idea that software products should be paid to be used extensively, I do not disapprove of the idea of completely free-of-charge software.
0 notes
Text
Is free, open-source software the future?
The first open-source software dates back to 1953, and roughly 20 years later, Richard Stallman founded the Free Software Foundation (FSF) to support the free software movement. This movement has indeed led to the development of widely used software such as FreeBSD, FreeCodeCamp, PostgreSQL and Linux OS. However, rather than describing open-source software as the future, we should only consider it as an additional option to proprietary software. Both options should co-exist to support the development of different types of software.
In his introduction of FSF, Richard Stallman described proprietary software as unjust. I do not think it is unjust when users/developers choose to use available software for their own convenience and at their own risks. Let’s consider restaurants. No one calls a restaurant “unjust” because they are not allowed to go to the kitchen and change the way the food is made. The same applies to proprietary software. It targets users who look for well-developed software provided by well-established companies. They want to eliminate the burden of viewing/changing the source code and maintaining the code. This is a valid reason for anyone to use proprietary software, and I believe it will always remain this way because people tend to make their development and their experience easier, not the other way around.

IMG from https://medium.com/@solodev/the-battle-of-open-source-vs-proprietary-systems-68209c365dff
However, open-source software has its right to exist. Let’s come back to our previous analogy to food. Open-source software is like HomeChef, a meal-kit delivery service that provides pre-portioned ingredients and recipes to subscribers. HomeChef has been doing well as it provides the community with a new way to prepare their meal, in which they can add some more salt or pepper to the food they pay for. Similarly, in open-source software, allowing users to customize the source code give them the freedom to make the programs applicable to their own use and to inspect the “ingredients” of the software before using it. Moreover, users can also improve their skills by working on new “recipes” (new types of software) and contribute to the community by suggesting changes to the recipes and the set of ingredients.
The free, open source software movement is also one of the catalysts for the study of a new definition of motivation, which is based on achievements instead of rewards and punishment. Most open-source project contributors are motivated by the joy of their achievements and by the fact that they are doing what they enjoy the most. There have been multiple research claiming that these contributors often perform better than those who are motivated by money and other types of reward. More information on this matter can be found in the book “Drive” written by Daniel Pink.

In conclusion, I believe free, open-source software should not be considered the future of software development, but we cannot deny the benefits it brings to a large group of users/developers. As long as there exist two different types of users as described above (those who prefer restaurants and those who prefer to make their own food), proprietary software and open-source software will still be supported separately for different purposes.
0 notes