
Statistics
We looked inside some of the posts by sistemasconmelissa and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Librerías de BD en Python
En python, el acceso a bases de datos esta estandarizado por la especificación Database API (DB-API), actualmente en la versión 2.0 (PEP 249: Python Database API Specification v2.0)
Gracias a esto, se puede acceder a cualquier base de datos utlizando la misma interfaz (ya sea un motor remoto, local, ODBC, etc.). Se puede comparar con DAO, ADO, ADO.NET en el mundo Microsoft, o a JDBC en el mundo Java.
O sea, el mismo codigo se podría llegar a usar para cualquier base de datos, tomando siempre los recaudos necesarios (lenguaje SQL estándard, estilo de parametros soportado, etc.)
Por ello, el manejo de bases de datos en python siempre sigue estos pasos:
Importar el conector
Conectarse a la base de datos (función connect del módulo conector)
Abrir un Cursor (método cursor de la conexión)
Ejecutar una consulta (método execute del cursor)
Obtener los datos (método fetch o iterar sobre el cursor)
Cerrar el cursor (método close del cursor)
Ejemplo:
Este es un ejemplo basico de como hacerlo con MySQL:
>>> import MySQLdb >>> db = MySQLdb.connect(host="localhost", user="root", ... passwd="mypassword", db="PythonU")
Una vez establecida la conexion, hay que crear un "cursor". Un cursor es una estructura de control que se usa para recorrer (y eventualmente procesar) los records de un result set.
El metodo para crear el cursor se llama, originalmente, cursor():
>>> cursor = db.cursor()
Ya tenemos la conexion establecida y el cursor creado, es hora de ejecutar algunos comandos SQL:
>>> cursor.execute("SELECT * FROM Students") 5L
El metodo execute se usa para ejecutar comandos SQL. Note que no hace falta agregar el ';' (punto y coma) al final del comando. Ahora es cuestion de recorrer el objeto cursor.
Para obtener un solo elemento, usamos fetchone():
>>> cursor.fetchone() (1L, 'Joe', 'Campbell', datetime.date(2006, 2, 10), 'N')
>>> cursor.fetchall()
((1L, 'Joe', 'Campbell', datetime.date(2006, 2, 10), 'N'),
(2L, 'Joe', 'Doe', datetime.date(2004, 2, 16), 'N'),
(3L, 'Rick', 'Hunter', datetime.date(2005, 3, 20), 'N'),
(4L, 'Laura', 'Ingalls', datetime.date(2001, 3, 15), 'Y'),
(5L, 'Virginia', 'Gonzalez', datetime.date(2003, 4, 2), 'N'))
Cual metodo usar dependera de la cantidad de datos que tengamos, la memoria disponible en la PC y sobre todo, de como querramos hacerlo. Si estamos trabajando con datasets limitados, no habra problema con el uso de fetchall(), pero si la base de datos es lo suficientemente grande como para entrar en memoria, se podria implementar una estrategia como la que se encuentra aca:
import MySQLdb db = MySQLdb.connect(host="localhost", user="root",passwd="secret", db="PythonU") cursor = db.cursor() recs=cursor.execute("SELECT * FROM Students") for x in range(recs): print cursor.fetchone()
O directamente:
import MySQLdb db = MySQLdb.connect(host="localhost", user="root",passwd="secret", db="PythonU") cursor = db.cursor() cursor.execute("SELECT * FROM Students") for row in cursor: print row
0 notes
Text
Pip en Python
pip es un sistema de gestión de paquetes utilizado para instalar y administrar paquetes de software escritos en Python. Muchos paquetes pueden ser encontrados en el Python Package Index (PyPI). Python 2.7.9 y posteriores (en la serie Python2), Python 3.4 y posteriores incluyen pip (pip3 para Python3) por defecto.
Pip es un acrónimo recursivo que se puede interpretar como Pip Instalador de Paquetes o Pip Instalador de Python.
Una ventaja importante de pip es la facilidad de su interfaz de línea de comandos, el cual permite instalar paquetes de software de Python fácilmente desde solo una orden:
pip install nombre-paquete
Los usuarios también pueden fácilmente desinstalar algún paquete:
pip uninstall nombre-paquete
Otra característica particular de pip es que permite gestionar listas de paquetes y sus números de versión correspondientes a través de un archivo de requisitos. Esto nos permite una recreación eficaz de un conjunto de paquetes en un entorno separado (p. ej. otro ordenador) o entorno virtual. Esto se puede conseguir con un archivo correctamente formateado requisitos.txt y la siguiente orden:
pip install -r requisitos.txt
Con pip es posible instalar un paquete para una versión concreta de Python, sólo es necesario reemplazar ${versión} por la versión de Python que queramos: 2, 3, 3.4, etc:
pip${versión} install nombre-paquete

0 notes
Text
Macro del segmento de datos
Macro cargue un mensaje del segmento de datos a AX, así nos ahorramos 3 lineas de código al momento de imprimir una cadena.
inicio macro ;declaramos la macro, le damos el nombre de inicio mov ax,data ;Cargamos el segmento de datos. mov ds,ax mov dx,ax endm
.model small .stack 64 .data msj db "Este es mi primer macro",10,13,"$" .code
inicio ;Llamamos al macro, lo unico que hace es cargar msj del segmento de datos. mov ah,09h lea dx,msj ;puede ser mov dx,offset msj int 21h ;interrupcion mov ax,4c00h ;Sale del programa int 21h ;interrupcion end
0 notes
Text
Macros Ensamblador
Programa que coloca el cursor en algun lugar en pantalla con macros e imprime un caracter.
gotoxy macro fila,col ;declaracion de macro con los parametros fila,col
mov ah,02h
mov dh,fila ;utiliza el parametro fila que es recibido al llamar el macro
mov dl,col ;utiliza el parametro col que es recibido al llamar el macro
mov bh,0h
int 10h
endm ;fin de macro
pantalla macro que ;declaracion de macro con el parametro llamado que
mov ah,02h
mov dl,que
int 21h
endm ;fin de macro
.model small
.data
.code
startup:
mov ax,@data
mov ds,ax
mov ax,0003h
int 10h
gotoxy 10,10 ;llama macro gotoxy y envia los parametros 10,10 para fila y col
pantalla 41h ;llama macro pantalla el cual imprime un caracter en pantalla 41h es A
mov ah,01h
int 21h
mov ax,4c00h
int 21h
end startup
0 notes
Text
Macros en Emu8086
Programa que coloca un carácter en la posición dada de acuerdo a parámetros ingresados por teclado
TITLE Cadena que solicita una cadena y una posicion para mostrarla gotoxy macro fila,col ;declaracion de macro gotoxy parametros:fila,col mov ah,02h ;complemento interrupcion 10h modo video colocacion cursor mov dh,fila ;coordenada x para colocacion de cursor dh mov dl,col ;coordenada y para colocacion de cursor dl mov bh,0h int 10h ;interrupcion de video endm ;fin de macro pantalla macro que ;declaracion de macro pantalla parametro que mov ah,02h ;complemento interrupcion 21h mov dl,que ;que es el caracter capturado int 21h ;interrupcion DOS endm ;fin de macro imprime macro eztryng ;declaracion de macro con parametro eztryng mov dx,offset eztryng ;coloca mensajes en dx mov ah,9 ;complemento para la interrupcion 21h para impresion de txto int 21h ;interrupcion DOS endm ;fin de macro .data ;variables mensaje DB "INGRESE UN CARACTER: ","$" mensaje2 DB "INGRESE X del 0 al 9: ","$" mensaje3 DB "INGRESE Y del 0 al 9: ","$" caracter DB 40 varx DB ? vary DB ? vtext db 100 dup('$') .code startup: mov ax,@data ;asignacion de datos ax mov ds,ax ;asignacion de datos al segmento de datos imprime mensaje ;llama macro imprime con el parametro 'mensaje' mov si,00h ;limpia el apuntador SI leer: ;declaracion de metodo leer mov ax,0000 ;limpia ax mov ah,01h ;complemento para interrupcion 21h captura int 21h ;interrupcion DOS mov caracter[si],al ;guarda el dato capturado en variable caracter inc si ;incrementa apuntador si cmp al,0dh ;compara si la ultima tecla presionada fue Intro ja coordenadas ;si cumple brinca a coordenadas jb leer ;sino cumple vuelve a ejecutar leer coordenadas: ;declaracion de metodo coordenadas mov dx,offset caracter ;coloca en dx el caracter ingresado mov ah,0ah ;complemento de interrupcion 21h lee cadena de texto por teclado int 21h ;interrupcion DOS imprime caracter ;llama macro imprime con parametro caracter mov ax,0003h ;complemento interrupcion 10h modo texto int 10h imprime mensaje2 ;llama macro imprime con parametro mensaje2 mov ah,01h ;complemento de interrupcion 21h Eco de un caracter int 21h ;interrupcion DOS sub al,30h ;resta 30h para convertir al valor numerico mov bl,al ;mueve al a bl mov varx,al ;guarda al en varx (coordenada x) mov ax,0003h ;complemento interrupcion 10h modo texto int 10h imprime mensaje3 ;//////////////se repite///////// mov ah,01h int 21h sub al,30h mov bl,al mov vary,al ;//////////////////////// mov ax,0003h ;complemento interrupcion 10h modo texto int 10h ;interupccion de video gotoxy vary,varx ;llama macro gotxy con los parametros vary y varx como columna y fila pantalla caracter[0] ;llama macro pantalla con el caracter capturado como parametro mov ah,01h ;complemento de interrupcion 21h Eco de un caracter int 21h ;interrupcion DOS mov ax,4c00h ;complemento interrupcion 21h fin de probrama int 21h ;interrupcion DOS end startup ;fin de funcion principal
0 notes
Text
Procedimientos almacenados y funciones MySQL
Los procedimientos almacenados y funciones son nuevas funcionalidades de la versión de MySQL 5.0. Un procedimiento almacenado es un conjunto de comandos SQL que pueden almacenarse en el servidor. Una vez que se hace, los clientes no necesitan relanzar los comandos individuales pero pueden en su lugar referirse al procedimiento almacenado.
Algunas situaciones en que los procedimientos almacenados pueden ser particularmente útiles:
-Cuando múltiples aplicaciones cliente se escriben en distintos lenguajes o funcionan en distintas plataformas, pero necesitan realizar la misma operación en la base de datos.
-Cuando la seguridad es muy importante. Los bancos, por ejemplo, usan procedimientos almacenados para todas las oparaciones comunes. Esto proporciona un entorno seguro y consistente, y los procedimientos pueden asegurar que cada operación se loguea apropiadamente. En tal entorno, las aplicaciones y los usuarios no obtendrían ningún acceso directo a las tablas de la base de datos, sólo pueden ejectuar algunos procedimientos almacenados.
Los procedimientos almacenados pueden mejorar el rendimiento ya que se necesita enviar menos información entre el servidor y el cliente. El intercambio que hay es que aumenta la carga del servidor de la base de datos ya que la mayoría del trabajo se realiza en la parte del servidor y no en el cliente. Considere esto si muchas máquinas cliente (como servidores Web) se sirven a sólo uno o pocos servidores de bases de datos.
Los procedimientos almacenados le permiten tener bibliotecas o funciones en el servidor de base de datos. Esta característica es compartida por los lenguajes de programación modernos que permiten este diseño interno, por ejemplo, usando clases. Usando estas características del lenguaje de programación cliente es beneficioso para el programador incluso fuera del entorno de la base de datos.
Procedimientos almacenados y las tablas de permisos
Los procedimientos almacenados requieren la tabla proc en la base de datos mysql. Esta tabla se crea durante la isntalación de MySQL 5.0. Si está actualizando a MySQL 5.0 desde una versión anterior, asegúrese de actualizar sus tablas de permisos para asegurar que la tabla proc existe. Consulte Sección 2.10.2, “Aumentar la versión de las tablas de privilegios”.
Desde MySQL 5.0.3, el sistema de permisos se ha modificado para tener en cuenta los procedimientos almacenados como sigue:
El permiso CREATE ROUTINE se necesita para crear procedimientos almacenados.
El permiso ALTER ROUTINE se necesita para alterar o borrar procedimientos almacenados. Este permiso se da automáticamente al creador de una rutina.
El permiso EXECUTE se requiere para ejectuar procedimientos almacenados. Sin embargo, este permiso se da automáticamente al creador de la rutina. También, la característica SQL SECURITY por defecto para una rutina es DEFINER, lo que permite a los usuarios que tienen acceso a la base de datos ejecutar la rutina asociada.

CREATE PROCEDURE y CREATE FUNCTION
Estos comandos crean una rutina almacenada. Desde MySQL 5.0.3, para crear una rutina, es necesario tener el permiso CREATE ROUTINE , y los permisos ALTER ROUTINE y EXECUTE se asignan automáticamente a su creador. Si se permite logueo binario necesita también el permisos SUPERcomo se describe en Sección 19.3, “Registro binario de procedimientos almacenados y disparadores”.
Por defecto, la rutina se asocia con la base de datos actual. Para asociar la rutina explícitamente con una base de datos, especifique el nombre como db_name.sp_name al crearlo.
Si el nombre de rutina es el mismo que el nombre de una función de SQL, necesita usar un espacio entre el nombre y el siguiente paréntesis al definir la rutina, o hay un error de sintaxis. Esto también es cierto cuando invoca la rutina posteriormente.
La cláusula RETURNS puede especificarse sólo con FUNCTION, donde es obligatorio. Se usa para indicar el tipo de retorno de la función, y el cuerpo de la función debe contener un comando RETURN value.
La lista de parámetros entre paréntesis debe estar siempre presente. Si no hay parámetros, se debe usar una lista de parámetros vacía () . Cada parámetro es un parámetro IN por defecto. Para especificar otro tipo de parámetro, use la palabra clave OUT o INOUT antes del nombre del parámetro. Especificando IN, OUT, o INOUT sólo es valido para una PROCEDURE.
El comando CREATE FUNCTION se usa en versiones anteriores de MySQL para soportar UDFs (User Defined Functions) (Funciones Definidas por el Usuario). Consulte Sección 27.2, “Añadir nuevas funciones a MySQL”. UDFs se soportan, incluso con la existencia de procedimientos almacenados. Un UDF puede tratarse como una función almacenada externa. Sin embargo, tenga en cuenta que los procedimientos almacenados comparten su espacio de nombres con UDFs.
Un marco para procedimientos almacenados externos se introducirá en el futuro. Esto permitira escribir procedimientos almacenados en lenguajes distintos a SQL. Uno de los primeros lenguajes a soportar será PHP ya que el motor central de PHP es pequeño, con flujos seguros y puede empotrarse fácilmente. Como el marco es público, se espera soportar muchos otros lenguajes.
Un procedimiento o función se considera “determinista” si siempre produce el mismo resultado para los mismos parámetros de entrada, y “no determinista” en cualquier otro caso. Si no se da niDETERMINISTIC ni NOT DETERMINISTIC por defecto es NOT DETERMINISTIC.
Para replicación, use la función NOW() (o su sinónimo) o RAND() no hace una rutina no determinista necesariamente. Para NOW(), el log binario incluye el tiempo y hora y replica correctamente. RAND()también replica correctamente mientras se invoque sólo una vez dentro de una rutina. (Puede considerar el tiempo y hora de ejecución de la rutina y una semilla de número aleatorio como entradas implícitas que son idénticas en el maestro y el esclavo.)
Actualmente, la característica DETERMINISTIC se acepta, pero no la usa el optimizador. Sin embargo, si se permite el logueo binario, esta característica afecta si MySQL acepta definición de rutinas. Consulte Sección 19.3, “Registro binario de procedimientos almacenados y disparadores”.
Varias características proporcionan información sobre la naturaleza de los datos usados por la rutina. CONTAINS SQL indica que la rutina no contiene comandos que leen o escriben datos. NO SQL indica que la rutina no contiene comandos SQL . READS SQL DATA indica que la rutina contiene comandos que leen datos, pero no comandos que escriben datos. MODIFIES SQL DATA indica que la rutina contiene comandos que pueden escribir datos. CONTAINS SQL es el valor por defecto si no se dan explícitamente ninguna de estas características.
La característica SQL SECURITY puede usarse para especificar si la rutina debe ser ejecutada usando los permisos del usuario que crea la rutina o el usuario que la invoca. El valor por defecto es DEFINER. Esta característica es nueva en SQL:2003. El creador o el invocador deben tener permisos para acceder a la base de datos con la que la rutina está asociada. Desde MySQL 5.0.3, es necesario tener el permiso EXECUTE para ser capaz de ejecutar la rutina. El usuario que debe tener este permiso es el definidor o el invocador, en función de cómo la característica SQL SECURITY .
MySQL almacena la variable de sistema sql_mode que está en efecto cuando se crea la rutina, y siempre ejecuta la rutina con esta inicialización.
La cláusula COMMENT es una extensión de MySQL, y puede usarse para describir el procedimiento almacenado. Esta información se muestra con los comandos SHOW CREATE PROCEDURE y SHOW CREATE FUNCTION .
MySQL permite a las rutinas que contengan comandos DDL (tales como CREATE y DROP) y comandos de transacción SQL (como COMMIT). Esto no lo requiere el estándar, y por lo tanto, es específico de la implementación.
Los procedimientos almacenados no pueden usar LOAD DATA INFILE.
0 notes
Text
Procedimientos en MySQL
Creacion de procedimientos en mysql: 12 CREATE PROCEDURE nombre (parámetros) [características] definición Ejemplo: DELIMITER $$create procedure EDITORIAL_CONSULTA(IN dato int)beginselect * from editoriales where id_editorial = dato;end call CONSULTA_EDITORIAL(1); Usando los procedimientos permite facilitar de uso de sentencias.
0 notes
Text
Bases de datos y Manejadores de Bases de datos
Requerimientos para la instalación.
Antes de instalar cualquier SGBD es necesario conocer los requerimientos de hardware y software, el posible software a desinstalar previamente, verificar el registro de Windows y el entorno del sistema, así como otras características de configuración especializadas como pueden ser la reconfiguración de los servicios TCP/IP y la modificación de los tipos archivos HTML para los diversos navegadores.Se presenta a continuación una serie de requerimientos mínimos de hardware y software para instalar oracle 11g Express y MySQL estándar versión 5.1. en Windows Seven y Ubuntu 10.

1. La regla general para determinar el tamaño de la memoria virtual depende del tamaño de memoria RAM instalada. Si su sistema tiene menos de 4 GB de RAM por lo general el espacio de intercambio debe ser de al menos dos veces este tamaño. Si usted tiene más de 8 GB de memoria RAM instalada puede considerar usar el mismo tamaño como espacio de intercambio. Cuanta más memoria RAM tenga instalada, es menos probable usar el espacio de intercambio, a menos que tenga un proceso inadecuado.
Un SGBD permite el almacenamiento, manipulación y consulta de datos pertenecientes a una base de datos organizada en uno o varios ficheros. En el modelo más extendido (base de datos relacional) la base de datos consiste, de cara al usuario, en un conjunto de tablas entre las que se establecen relaciones. A pesar de sus semejanzas (ambos manejan conjuntos de tablas) existen una serie de diferencias fundamentales entre un SGBD y un programa de hoja de cálculo, la principal es que un SGBD permite: El método de almacenamiento y el programa que gestiona los datos (servidor) son independientes del programa desde el que se lanzan las consultas (cliente).

En lugar de primarse la visualización de toda la información, el objetivo fundamental es permitir consultas complejas, cuya resolución está optimizada, expresadas mediante un lenguaje formal. El almacenamiento de los datos se hace de forma eficiente aunque oculta para el usuario y normalmente tiene, al contrario de lo que ocurre con las hojas de cálculo, poco que ver con la estructura con la que los datos se presentan al usuario. El acceso concurrente de múltiples usuarios autorizados a los datos, realizando operaciones de actualización y consulta de los mismos garantizando la ausencia de problemas de seguridad (debidos a accesos no autorizados) o integridad (pérdida de datos por el intento de varios usuarios de acceder al mismo fichero al mismo tiempo.
El programa servidor suele activarse al arrancar el ordenador, podría compararse a un bibliotecario que recibe peticiones (consultas) de diferentes programas clientes de base de datos, consulta la base de datos y entrega al cliente el resultado de la consulta realizada. Si dos usuarios solicitan al mismo tiempo una modificación de los datos, el programa servidor se encarga de hacerlas ordenadamente para evitar perder datos (lo que ocurriría si ambos usuarios abrieran y modificaran a la vez un fichero con la base de datos.
0 notes
Text
Arquitectura de base de datos
Arquitectura de base de datos La arquitectura de un sistema de base de datos está influenciada en gran medida por el sistema informático subyacente en el que se ejecuta el sistema de base de datos. En la arquitectura de un sistema de base de datos se reflejan aspectos como la conexión de red, el paralelismo y la distribución. • La conexión de red: de varias computadoras permite que algunas tareas se ejecuten en un sistema servidor y que otras se ejecuten en los sistemas clientes. Esta división de trabajo ha conducido al desarrollo de sistemas de base de datos cliente-servidor.
• El procesamiento paralelo: dentro de una computadora permite acelerar las actitudes del sistema de base de datos, proporcionando a las transacciones una respuesta más rápida, así como la capacidad de ejecutar más transacciones por segundo. • La distribución de datos: A través de las distintas sedes o departamentos de una organización permite que estos datos residan donde han sido generados o donde son más necesarios, pero continuar siendo accesibles desde otros lugares o departamentos diferentes. Niveles de abstracción: Podemos destacar tres niveles principales según la visión y la función que realice el usuario sobre la base de datos:- Nivel físico: El nivel más bajo de abstracción describe como se almacenan realmente los datos. En el nivel físico se describen en detalle las estructuras de datos complejas de bajo nivel.- Nivel conceptual: Que es el siguiente nivel más alto de abstracción, se describe cuáles son los datos reales que están almacenados en la base de datos y qué relaciones existen entre los datos. Nivel lógico: El siguiente nivel más alto de abstracción describe que datos se almacenan en la base de datos y que relaciones existen entre esos datos. La base de datos completa se describe así en términos de un número pequeño de estructuras relativamente simples en el nivel físico, los usuarios del nivel lógico no necesitan preocuparse de esta complejidad. Los administradores de base de datos, que deben decidir la información que se mantiene en la base de datos, usan el nivel lógico de abstracción. • Independencia lógica y física de los datos: El concepto de independencia de datos lo podemos definir como la capacidad para modificar el esquema en un nivel del sistema sin tener que modificar el esquema del nivel inmediato superior. Se pueden definir dos tipos de independencia de datos:
• La Independencia lógica: Es la capacidad de modificar el esquema conceptual sin tener que alterar los esquemas externos ni los programas de aplicación. Se puede modificar el esquema conceptual para ampliar la base de datos o para reducirla. Si, por ejemplo, se reduce la base de datos eliminando una entidad, los esquemas externos que no se refieran a ella no deberán verse afectados. La independencia física: Es la capacidad de modificar el esquema interno sin tener que alterar el esquema conceptual (o los externos). Por ejemplo, puede ser necesario reorganizar ciertos ficheros físicos con el fin de mejorar el rendimiento de las operaciones de consulta o de actualización de datos. Dado que la independencia física se refiere sólo a la separación entre las aplicaciones y las estructuras físicas de almacenamiento, es más fácil de conseguir que la independencia lógica.

0 notes
Text
Aportación Emmanuel y Lourdes Emu8086 y Jonathan Guzman Turbo Assambler

BIOS EQU 10H DOS EQU 21H FIN EQU 4C00H .DATA TITULO DB 'Agnax & Alizz ' COLORES DB 5BH DB 5FH DB 5BH DB 5FH DB 5BH DB 00H DB 0F0H DB 00H DB 09CH DB 09FH DB 09CH DB 09FH DB 09CH DB 00H DB 0CH .CODE INICIO PROC NEAR: MOV AX, @DATA MOV DS, AX ;Esta parte de aqui no es necesaria INT BIOS MOV CX, 15 BUCLE: ;Ponemos esto para no agarrar basura MOV DX,SI ADD DX,35 ;columna MOV DH, 12 ;renglon CALL COLOCA MOV AL, [SI+OFFSET TITULO] MOV BL, [SI+OFFSET COLORES] CALL COLOR INC SI LOOPNZ BUCLE MOV AH, 0 INT DOS CALL COLOCA MOV AX, FIN INT DOS COLOR PROC MOV AH, 9 INT BIOS RET COLOCA PROC MOV AH,2 INT BIOS RET END INICIO
----
BIOS EQU 10H DOS EQU 21H FIN EQU 4C00H TEXTO EQU 3 PILA SEGMENT STACK DB 64 DUP('PILA ') PILA ENDS DATOS SEGMENT assume ds:DATOS,SS:PILA,cs:codigo TITULO DB 'YO Y MI PAREJA ' colores db 5bh DB 5FH DB 5BH DB 5FH db 5BH DB 5FH DB 5BH DB 5FH db 5BH DB 5FH DB 5BH DB 5FH db 5BH DB 5FH DB 5BH DB 5FH db 5BH DATOS ENDS codigo segment COLO PROC FAR mov AX, DATOS mov ds,ax mov ax,texto int bios mov cx,16 xor si,si bucle: push cx mov dx,si add dx,35 mov dh,12 call coloca mov al,[si+offset titulo] mov bl,[si+offset colores] call color pop cx inc si loopnz bucle mov ah,8 int dos xor dx,dx call coloca mov ax,fin int dos colo endp color proc mov ah,9 xor bh,bh int bios ret color endp coloca proc mov ah,2 xor bx,bx int bios ret coloca endp codigo ends end colo
0 notes
Text
Arquitectura de un manejador de bases de datos (DBMS)
DBMS: Es un sistema robusto que es capaz de emplear algoritmos de almacenamiento y recuperación de información para poder implementar un modelo de datos de manera física garantizando que todas las transacciones que se realizan con respecto a dichos datos sean "ácidas" (Atomicity, Consistency, Isolation, Duration).
Una base de datos en ejecución consta de 3 cosas:
Control (ctl): almacenan información acerca de la estructura de archivos de la base.
Rollback (rbs): cuando se modifica el valor de alguna tupla en una transacción, los valores nuevos y anteriores se almacenan en un archivo, de modo que si ocurre algún error, se puede regresar (rollback) a un estado anterior.
Redo (rdo): bitácora de toda transacción, en muchos dbms incluye todo tipo de consulta incluyendo aquellas que no modifican los datos.
Datos (dbf): el tipo más común, almacena la información que es accesada en la base de datos.
Indices (dbf) (dbi): archivos hermanos de los datos para acceso rápido.
Temp (tmp): localidades en disco dedicadas a operaciones de ordenamiento o alguna actividad particular que requiera espacio temporal adicional.
Shared Global Area (SGA): es el área más grande de memoria y quizás el más importante
Program Global Area (PGA): información del estado de cursores/apuntadores
User Global Area(UGA): información de sesión, espacio de stack
Shared Pool: es una caché que mejora el rendimiento ya que almacena parte del diccionario de datos y el parsing de algunas consultas en SQL
Redo Log Buffer: contiene un registro de todas las transacciones dentro de la base, las cuales se almacenan en el respectivo archivo de Redo y en caso de siniestro se vuelven a ejecutar aquellos cambios que aún no se hayan reflejado en el archivo de datos (commit).
Large Pool: espacio adicional, generalmente usado en casos de multithreading y esclavos de I/O.
Java Pool: usado principalmente para almacenar objetos Java
Threading
System Monitor: despierta periódicamente y realiza algunas actividades entre las que se encuentran la recuperación de errores, recuperación de espacio libre en tablespaces y en segmentos temporales.
Process Monitor: limpia aquellos procesos que el usuario termina de manera anormal, verificando consistencias, liberación de recursos, bloqueos.
Database Writer: escribe bloques de datos modificados del buffer al disco, aquellas transacciones que llegan a un estado de commit.
Log Writer: escribe todo lo que se encuentra en el redo log buffer hacia el redo file
Checkpoint: sincroniza todo lo que se tenga en memoria, con sus correspondientes archivos en disco


0 notes
Text
Estructura de SGA Base de datos
SGA (Área Global del Sistema) es una estructura básica de memoria de Oracle que sirve para facilitar la transferencia de información entre usuarios y también almacena la información estructural de la BD más frecuentemente requerida. El área global del sistema y un conjunto de procesos de la base de datos constituyen una instancia de una base de datos Oracle. La base de datos Oracle automáticamente reserva memoria para el área global del sistema cuando se inicia una instancia, y el sistema operativo reclama la memoria cuando se apaga dicha instancia. Cada instancia tiene su propia SGA. Está compuesto por: - Database Buffer Cache (Buffers de BD) Es el caché que almacena los bloques de datos leidos de los segmentos de datos de la BD, tales como tablas, índices y clusters. Los bloques modificados se llamas bloques sucios. El tamaño de buffer caché se fija por el parámetro DB_BLOCK_BUFFERS. - Buffer Redo Log Los registros Redo describen los cámbios realizados en la BD y son escritos en los ficheros redo log para que puedan ser utilizados en las operaciones de recuperación hacia adelante, roll-forward, durante las recuperaciones de la BD. Pero antes de ser escritos en los ficheros redo log son escritos en un caché de la SGA llamado redo log buffer. El servidor escribe periódicamente los registrosredo log en los ficheros redo log. El tamaño del buffer redo log se fija por el parámetro LOG_BUFFER. - Shared SQL Pool (Área de SQL Compartido, ) En esta zona se encuentran las sentencias SQL que han sido analizadas. El analisis sintáctico de las sentencias SQL lleva su tiempo y Oracle mantiene las estructuras asociadas a cada sentencia SQL analizada durante el tiempo que pueda para ver si puede reutilizarlas. Antes de analizar una sentencia SQL, Oracle mira a ver si encuentra otra sentencia exactamente igual en la zona de SQL compartido. Si es así, no la analiza y pasa directamente a ejecutar la que mantinene en memoria. El tamaño del caché está gestionado internamente por el servidor, pero es parte del shared pool, cuyo tamaño viene determinado por el parámetro SHARED_POOL_SIZE.

0 notes
Text
Uso de Commit y Rollback en Mysql
ROLLBACK
En tecnologías de base de datos, un rollback es una operación que devuelve a la base de datos a algún estado previo. Los Rollbacks son importantes para la integridad de la base de datos, a causa de que significan que la base de datos puede ser restaurada a una copia limpia incluso después de que se han realizado operaciones erróneas. Son cruciales para la recuperación de caidas de un servidor de base de datos; realizando rollback(devuelto) cualquier transacción que estuviera activa en el tiempo del crash, la base de datos es restaurada a un estado consistente.
COMMIT
Marca el final de una transacción correcta, implícita o explícita


0 notes
Text
Ejercicio Explicado- Melissa Ruiz
Video:
https://youtu.be/U5tPmSMSSZ8
0 notes
Text
Practica Assambler: 4 mensajes y color de fondo


0 notes
Text
USO DE CONSTANTES Y FUNCIONES EMU-TASSAMBLER












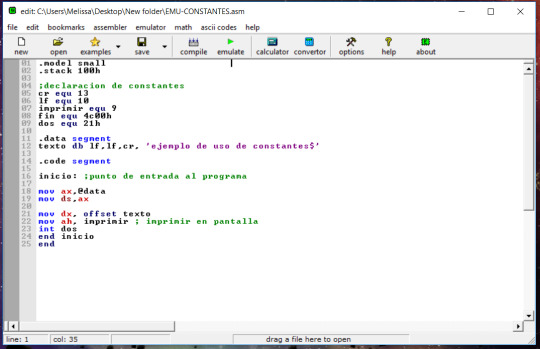

0 notes
Text
Registro de Punteros

Registros de Punteros
SP = Puntero de pila (stack pointer).
Apunta a la cabeza de la pila. Utilizado en las instrucciones de manejo de la pila.
BP = Puntero base (base pointer).
Es un puntero de base, que apunta a una zona dentro de la pila dedicada al almacenamiento de datos (variables locales y parámetros de las funciones en los programas compilados).
SI = Índice fuente (source index).
Utilizado como registro de índice en ciertos modos de direccionamiento indirecto, también se emplea para guardar un valor de desplazamiento en operaciones de cadenas.
DI = Índice destino (destination index).
Se usa en determinados modos de direccionamiento indirecto y para almacenar un desplazamiento en operaciones con cadenas.
IP = Puntero de instrucción (instruction pointer).
Marca el desplazamiento de la instrucción en curso dentro del segmento de código. Es automáticamente modificado con la lectura de una instrucción.
0 notes