#ANSI SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
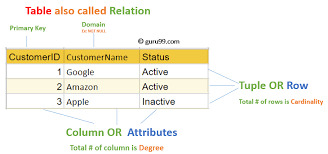
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
Different Types of SQL JOINs:
Q01: What is INNER JOIN? Q02: What is NON-ANSI JOIN? Q03: What is ANSI JOIN? Q04: What is SELF JOIN? Q05: What is OUTER JOIN? Q06: What is LEFT OUTER JOIN? Q07: What is RIGHT OUTER JOIN? Q08: What is FULL OUTER JOIN? Q09: What is CROSS JOIN? Q10: What is the difference between FULL JOIN vs CROSS JOIN?
#sqljoin#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#techpoint
3 notes
·
View notes
Text
Senior Data Engineer
Job title: Senior Data Engineer Company: Yodlee Job description: : Python, PySpark, ANSI SQL, Python ML libraries Frameworks/Platform: Spark, Snowflake, Airflow, Hadoop , Kafka Cloud… with remote teams AWS Solutions Architect / Developer / Data Analytics Specialty certifications, Professional certification… Expected salary: Location: Thiruvananthapuram, Kerala Job date: Thu, 22 May 2025 03:39:21…
0 notes
Text
Cài đặt PostgreSQL 16 trên AlmaLinux 8
## Cài đặt PostgreSQL 16 trên AlmaLinux 8 #PostgreSQL #AlmaLinux #CSDL #Database #Linux #Installation #HướngDẫn PostgreSQL, một hệ quản trị cơ sở dữ liệu quan hệ mã nguồn mở (ORDBMS) nổi tiếng với khả năng mở rộng, tuân thủ chuẩn SQL ANSI, hỗ trợ JSON và các tính năng NoSQL, cùng với khả năng bảo mật cao, đang được sử dụng rộng rãi trong các ứng dụng web và doanh nghiệp quy mô lớn. Bài viết này…
0 notes
Text
Firebird to Cassandra Migration
In this article, we delve into the intricacies of migrating from Firebird to Cassandra. We will explore the reasons behind choosing Cassandra over Firebird, highlighting its scalability, high availability, and fault tolerance. We'll discuss key migration steps, such as data schema transformation, data extraction, and data loading processes. Additionally, we'll address common challenges faced during migration and provide best practices to ensure a seamless transition. By the end of this article, you'll be equipped with the knowledge to effectively migrate your database from Firebird to Cassandra.
What is Firebird
Firebird is a robust, open-source relational database management system renowned for its versatility and efficiency. It offers advanced SQL capabilities and comprehensive ANSI SQL compliance, making it suitable for various applications. Firebird supports multiple platforms, including Windows, Linux, and macOS, and is known for its lightweight architecture. Its strong security features and performance optimizations make it an excellent choice for both embedded and large-scale database applications. With its active community and ongoing development, Firebird continues to be a reliable and popular database solution for developers.
What is Cassandra
Cassandra is a highly scalable, open-source NoSQL database designed to handle large amounts of data across many commodity servers without any single point of failure. Known for its distributed architecture, Cassandra provides high availability and fault tolerance, making it ideal for applications that require constant uptime. It supports dynamic schema design, allowing flexible data modeling, and offers robust read and write performance. With its decentralized approach, Cassandra ensures data replication across multiple nodes, enhancing reliability and resilience. As a result, it is a preferred choice for businesses needing to manage massive datasets efficiently and reliably.
Advantages of Firebird to Cassandra Migration
Scalability: Cassandra’s distributed architecture allows for seamless horizontal scaling as data volume and user demand grow.
High Availability: Built-in replication and fault-tolerance mechanisms ensure continuous availability and data integrity.
Performance: Write-optimized design handles high-velocity data, providing superior read and write performance.
Flexible Data Model: Schema-less support allows agile development and easier management of diverse data types.
Geographical Distribution: Data replication across multiple data centers enhances performance and disaster recovery capabilities.
Method 1: Migrating Data from Firebird to Cassandra Using the Manual Method
Firebird to Cassandra migration manually involves several key steps to ensure accuracy and efficiency:
Data Export: Begin by exporting the data from Firebird, typically using SQL queries or Firebird's export tools to generate CSV or SQL dump files.
Schema Mapping: Map the Firebird database schema to Cassandra’s column-family data model, ensuring proper alignment of data types and structures.
Data Transformation: Transform the exported data to fit Cassandra’s schema, making necessary adjustments to comply with Cassandra’s requirements and best practices.
Data Loading: Use Cassandra’s loading utilities, such as CQLSH COPY command or bulk loading tools, to import the transformed data into the appropriate keyspaces and column families.
Verification and Testing: After loading, verify data integrity and consistency by running validation queries and tests to ensure the migration was successful and accurate.
Disadvantages of Migrating Data from Firebird to Cassandra Using the Manual Method
High Error Risk: Manual efforts significantly increase the risk of errors during the migration process.
Need to do this activity again and again for every table.
Difficulty in Data Transformation: Achieving accurate data transformation can be challenging without automated tools.
Dependency on Technical Resources: The process heavily relies on technical resources, which can strain teams and increase costs.
No Automation: Lack of automation requires repetitive tasks to be done manually, leading to inefficiencies and potential inconsistencies.
Limited Scalability: For every table, the entire process must be repeated, making it difficult to scale the migration.
No Automated Error Handling: There are no automated methods for handling errors, notifications, or rollbacks in case of issues.
Lack of Logging and Monitoring: Manual methods lack direct automated logs and tools to track the amount of data transferred or perform incremental loads (Change Data Capture).
Method 2: Migrating Data from Firebird to Cassandra Using ETL Tools
There are certain advantages in case if you use an ETL tool to migrate the data
Extract Data: Use ETL tools to automate the extraction of data from Firebird, connecting directly to the database to pull the required datasets.
Transform Data: Configure the ETL tool to transform the extracted data to match Cassandra's schema, ensuring proper data type conversion and structure alignment.
Load Data: Use the ETL tool to automate the loading of transformed data into Cassandra, efficiently handling large volumes of data and multiple tables.
Error Handling and Logging: Utilize the ETL tool’s built-in error handling and logging features to monitor the migration process, receive notifications, and ensure data integrity.
Incremental Loads: Leverage the ETL tool's Change Data Capture (CDC) capabilities to perform incremental data loads, migrating only updated or new data to optimize performance.
Testing and Verification: After loading the data, use the ETL tool to verify data accuracy and consistency, running validation checks to ensure the migration was successful.
Scalability: ETL tools support scalable migrations, allowing for easy adjustments and expansions as data volume and complexity increase.
Challenges of Using ETL Tools for Data Migration
Initial Setup Complexity: Configuring ETL tools for data extraction, transformation, and loading can be complex and time-consuming.
Cost: Advanced ETL tools can be expensive, increasing the overall cost of the migration.
Resource Intensive: ETL processes can require significant computational resources, impacting system performance.
Data Mapping Difficulties: Mapping data between different schemas can be challenging and error-prone.
Customization Needs: Standard ETL tools may require custom scripts to meet specific migration needs.
Dependency on Tool Features: The success of migration depends on the capabilities of the ETL tool, which may have limitations.
Maintenance and Support: Ongoing maintenance and vendor support are often needed, adding to long-term operational costs.
Why Ask On Data is the Best Tool for Migrating Data from Firebird to Cassandra
Seamless Data Transformation: Automatically handles data transformations to ensure compatibility between Firebird and Cassandra.
User-Friendly Interface: Simplifies the migration process with an intuitive, easy-to-use interface, making it accessible for both technical and non-technical users.
High Efficiency: Automates repetitive tasks, significantly reducing the time and effort required for migration.
Built-In Error Handling: Offers robust error handling and real-time notifications, ensuring data integrity throughout the migration.
Incremental Load Support: Supports incremental data loading, enabling efficient updates and synchronization without duplicating data.
Usage of Ask On Data : A chat based AI powered Data Engineering Tool
Ask On Data is world’s first chat based AI powered data engineering tool. It is present as a free open source version as well as paid version. In free open source version, you can download from Github and deploy on your own servers, whereas with enterprise version, you can use Ask On Data as a managed service.
Advantages of using Ask On Data
Built using advanced AI and LLM, hence there is no learning curve.
Simply type and you can do the required transformations like cleaning, wrangling, transformations and loading
No dependence on technical resources
Super fast to implement (at the speed of typing)
No technical knowledge required to use
Below are the steps to do the data migration activity
Step 1: Connect to Firebird(which acts as source)
Step 2 : Connect to Cassandra (which acts as target)
Step 3: Create a new job. Select your source (Firebird) and select which all tables you would like to migrate.
Step 4 (OPTIONAL): If you would like to do any other tasks like data type conversion, data cleaning, transformations, calculations those also you can instruct to do in natural English. NO knowledge of SQL or python or spark etc required.
Step 5: Orchestrate/schedule this. While scheduling you can run it as one time load, or change data capture or truncate and load etc.
For more advanced users, Ask On Data is also providing options to write SQL, edit YAML, write PySpark code etc.
There are other functionalities like error logging, notifications, monitoring, logs etc which can provide more information like the amount of data transferred, logs, any error information if the job did not run and other kind of monitoring information etc.
Trying Ask On Data
You can reach out to us on mailto:[email protected] for a demo, POC, discussion and further pricing information. You can make use of our managed services or you can also download and install on your own servers our community edition from Github.
0 notes
Text


Wish you a happy new year students.2025 is your turning path for great success.
DOT Institute Trichy Chathiram Branch 12A,3rd Floor,Periyasamy Tower,Chathiram Bus Stand,Trichy-2. Ph: +91 999 42 99 879 +91 75 98 009 444 +91 75 98 010 444 www.dotinstitute.co.in [email protected]
Our Courses
Mechanical CAD
AutoCAD Solidworks Creo CATIA Inventor Fusion 360 Ansys
Civil CAD
AutoCAD Revit 3ds Mas Sketchup Staad.Pro Tekla Revit MEP
Programming
C C++ Java Python Full Stack Web Design Web Development Sql,Database
Office Administration
MS Office Tally
Graphic Design
Photoshop Coreldraw Illustrator Indesign
#python#pythonfullstack#fullstack#webdesign#webdevelopment#java#pythonadvance#pythonlearners#pythoninstitutenearme#pythoncourses#pythoninstitute#pythontraining#bestpythontraining#pythonlaguage#pythonprogramming#programming#coding#codinginstitutenearme#codingclassesnearme#codingcourses#codingcoursesforbeginners#codingsession#codingtraining#codingtraini#autocad#solidworks#creo#catia#ansys#mechanicalcad
0 notes
Text
Syntax Highlighting SQL in Terminal
Do you ever find yourself doing some debugging with error_log() or its friends? Does that debugging ever involve SQL queries? Are you tired of staring at grey queries all the time? I have just the product for you! Introducing Syntax Highlighting SQL in Terminal! Brought to you by our friends at Large Language Models, Incorporated, this new PHP function will use ANSI escape sequences to colorize…
0 notes
Text
Top SQL Training Course in Ahmedabad

Structured Query Language (SQL) is a programming language for storing and processing information in a relational database. A relational database stores information in a tabular form, with rows and columns representing various data attributes and various relationships between data values.
This database language is primarily designed for maintaining data in relational database management systems. A specialized tool used by data professionals to handle structured data (data that is stored in the form of tables). It is also designed for stream processing in RDSMS.
You can easily create and modify databases, access and modify table rows and columns etc. This query language became an ANSI standard in 1986 and an ISO standard in 1987.
If you want to get a job in the field of data science, it is the most important query language to learn. Large enterprises like Facebook, Instagram and LinkedIn use SQL to store data in the back-end.
SQL TCCI has the following topics:
SQL Basics, More Advanced SQL Queries, Relational Queries, Database Modification
TCCI Computer Classes at Bopal and ISKCON Ambli Road, Ahmedabad provide the best training in SQL programming through various learning methods/media. Learn SQL from industry experts with hands-on projects, flexible hours, and job-oriented training. Enroll today to advance your career in database management!
Call us @ +91 98256 18292
Visit us @ http://tccicomputercoaching.com/
#TCCI computer coaching institute#best computer institute near me#SQL course in Ahmedabad#best computer class in Bopal Ahmedabad#best computer class in iscon-ambli road-Ahmedabad
0 notes
Text
SQL JOIN
As the name shows, JOIN means to combine something. In case of SQL, JOIN means "to combine two or more tables".
The SQL JOIN clause takes records from two or more tables in a database and combines it together.
ANSI standard SQL defines five types of JOIN :

0 notes
Link
0 notes
Text
0 notes
Text
SQL에서 "조인(Join)"은 두 개 이상의 테이블에서 열을 결합하여 데이터를 조회하는 과정을 말합니다. 조인을 사용하면 관련된 데이터가 여러 테이블에 분산되어 있을 때 이를 통합하여 조회할 수 있습니다. 다양한 종류의 조인이 있으며, 각각 특정한 유형의 결과를 반환합니다.
주요 조인 유형:
SQL에서 "조인(Join)"은 두 개 이상의 테이블에서 열을 결합하여 데이터를 조회하는 과정을 말합니다. 조인을 사용하면 관련된 데이터가 여러 테이블에 분산되어 있을 때 이를 통합하여 조회할 수 있습니다. 다양한 종류의 조인이 있으며, 각각 특정한 유형의 결과를 반환합니다.
주요 조인 유형:
내부 조인 (INNER JOIN):
두 테이블 간에 일치하는 행만 반환합니다. 즉, 양쪽 테이블 모두에서 일치하는 데이터가 있는 경우에만 해당 행들이 결과에 포함됩니다.
구문:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
외부 조인 (OUTER JOIN):
외부 조인은 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN으로 나뉩니다.
LEFT (OUTER) JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 일치하는 행을 반환합니다. 오른쪽 테이블에 일치하는 행이 없는 경우 NULL 값으로 반환합니다.
RIGHT (OUTER) JOIN: 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 일치하는 행을 반환합니다. 왼쪽 테이블에 일치하는 행이 없는 경우 NULL 값으로 반환합니다.
FULL (OUTER) JOIN: 왼쪽과 오른쪽 테이블 모두에서 일치하는 행을 반환합니다. 어느 한쪽에만 있는 행도 포함되며, 일치하는 행이 없는 쪽은 NULL 값으로 반환합니다.
크로스 조인 (CROSS JOIN):
두 테이블 간의 모든 가능한 조합을 반환합니다. 이는 두 테이블의 각 행이 다른 테이블의 모든 행과 결합됩니다.
구문:sqlCopy codeSELECT columns FROM table1 CROSS JOIN table2;
자체 조인 (SELF JOIN):
테이블이 자기 자신과 조인되는 경우입니다. 이는 별칭(Alias)을 사용하여 동일한 테이블을 두 번 참조함으로써 수행됩니다.
표준 조인 (ANSI SQL-92 조인 구문):
표준 조인은 SQL-92 표준에서 도입된 조인 구문으로, 조인을 명확하게 표현할 수 있게 해줍니다. 표준 조인 구문은 조인의 종류를 명시적으로 기술하여 가독성과 관리의 용이성을 높입니다.
예를 들어, INNER JOIN은 다음과 같이 표현됩니다:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
표준 조인 구문은 특히 조인의 유형을 명확하게 하여 복잡한 쿼리에서 의도를 분명히 드러내는 데 유용합니다.
조인을 사용하면 데이터베이스 내 여러 테이블 간의 관계를 기반으로 복잡한 쿼리를 생성하고, 필요한 데이터를 효율적으로 추출할 수 있습니다.
표준 조인 (ANSI SQL-92 조인 구문):
표준 조인은 SQL-92 표준에서 도입된 조인 구문으로, 조인을 명확하게 표현할 수 있게 해줍니다. 표준 조인 구문은 조인의 종류를 명시적으로 기술하여 가독성과 관리의 용이성을 높입니다.
예를 들어, INNER JOIN은 다음과 같이 표현됩니다:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
표준 조인 구문은 특히 조인의 유형을 명확하게 하여 복잡한 쿼리에서 의도를 분명히 드러내는 데 유용합니다.
조인을 사용하면 데이터베이스 ��� 여러 테이블 간의 관계를 기반으로 복잡한 쿼리를 생성하고, 필요한 데이터를 효율적으로 추출할 수 있습니다.
0 notes
Text
Important aspects of Relational Database
A relational database is a collection of data items that have predefined relationships between them. These items are organized into a set of tables with columns and rows. The table is used to hold information about the objects to be represented in the database. Each column in the table holds a specific type of data, and the field stores the actual value of the property. The rows in the table represent a collection of related values for an object or entity. Each row in a table can be marked with a unique identifier called a primary key, and foreign keys can be used to establish associations between rows in multiple tables. This data can be accessed in many different ways without having to reorganize the database table itself.
Important aspects of Relational Database
SQL. SQL (structured query language) is the main interface for communicating with relational databases. SQL became a standard of the American National Standards Institute (ANSI) in 1986. All popular relational database engines support standard ANSI SQL, and some of them extend ANSI SQL to support features specific to that engine. SQL can be used to add, update, or delete rows of data, retrieve a subset of data from a transaction processing and analysis application, and manage all aspects of the database.
Data integrity. Data integrity refers to the overall integrity, accuracy and consistency of the data. Relational databases use a set of constraints to enforce the integrity of the data in the database. They include primary keys, foreign keys, "Not NULL" constraints, "Unique" constraints, "Default" constraints, and "Check" constraints. These integrity constraints help enforce business rules on the data in the table to ensure the accuracy and reliability of the data. In addition, most relational databases allow custom code to be embedded in triggers that are performed based on operations on the database.
Transaction processing. A database transaction is one or more SQL statements executed as a sequence of operations that make up a single logical unit of work. The transaction provides an "all or no" proposition, which means that the entire transaction must be completed as a unit and written to the database, otherwise none of the components of the transaction should be executed. In relational database terminology, transactions result in COMMIT or ROLLBACK. Each transaction is processed independently of other transactions in a coherent and reliable manner.
ACID complianc. All database transactions must comply with ACID, that is, they must be atomic, consistent, isolated, and persistent to ensure data integrity.
Atomicity requires the transaction to execute successfully as a whole, and if any part of the transaction fails, the entire transaction will be invalid. Consistency states that data written to the database as part of a transaction must comply with all defined rules and restrictions, including constraints, cascading, and triggers. Isolation is critical to achieving concurrency control, ensuring that each transaction is independent of itself. Persistence requires that all changes made to the database are permanent after the successful completion of the transaction.

0 notes
Text
ATLANTA COMPUTER INSTITUTE in Nagpur is Central India's Leading and Best Computer Education Institute in Nagpur. Atlanta Computer Institute Nagpur Centers has been conducting IT Training Classes from last 27 years. Atlanta Computer Institute Nagpur is An ISO 9001 : 2015 Certified Company. The Computer and IT courses taught are Basic Courses, MS-Office , C , C++, Java , Advance Java , Python, SQL, Web Page Designing , PHP, MySQL, AutoCAD , 3d Studio Max , Revit , Staad Pro , Pro-e , Creo, CATIA , Ansys , Unigraphics NX , CAD CAM, Solidworks, ArchiCAD, Hardware , Networking , Photoshop , Coreldraw , Graphic Design, Web Site Development, Oracle , Animation Courses, Visual Basic, VB.Net , ASP.Net , C#.Net , Joomla, Wordpress, Revit MEP, Ansys CFD, PHP Framework, Search Engine Optimization, Animation Courses, MS Excel Course, Software Testing, Primavera, MS Project, Embedded Systems, Matlab, Programming Courses, Coding Classes, Dot Net Courses, Advance Dot Net LINQ, AJAX, MVC, Android, Multimedia, Illustrator, Google, Sketchup, Lumion, Rhino, V-Ray, Video Editing, Maya, ISTQB Software Testing, CCNA, CCNP, CCIE, MCSE, MCITP, MCP, MCTS, MCDBA, MCPD, MCTP, Red Hat Linux, Angular Js, HTML5 CSS3, Magento, Codeigniter, Cake PHP, Full Stack Web Development, Full Stack Developer Course, UI UX Design Course, Laravel, Bootstrap, Vmware, Data Analytics, Business Analytics, Power BI, Tableau, Data Science, Machine Learning, Big Data, R Programming, Python, Django, IT Training, Ecommerce, Matlab, Android, Robotics, Arduino, IoT - Internet of Things, Ethical Hacking, Java Hibernate, Java Spring, Data Mining, Java EJB, Java UML, Share Market Training, Ruby on Rails, DTP, Inventor, VBA, Cloud Computing, Data Mining, R Programming, Machine Learning, Big Data, Hadoop, Amazon Web Services AWS, ETABS, Revit MEP, HVAC, PCB Design, VLSI, VHDL, Adobe After Effects, VFx, Windows Azure, SalesForce, SAS, Game Programming , Unity, CCC, Computer Typing, GCC TBC, SPSS, ChatGPT, QuarkXpress, Foreign Language Classes of German Language, French Language, Spanish Language, Business Analyst Course, PLC SCADA, Flash , University Syllabus of BE, Poly, BCCA, BCA, MCA, MCM, BCom, BSc, MSc, 12th Std State CBSE and Live Projects. Project Guidance is provided for Final Year students. Crash and Fast Track and Regular Batches for every course is available. Atlanta Computer Institute conducts classroom and online courses with certificates for students all over the world.
0 notes
Text
Azure Data Fundamentals - Part1
Data is generated everywhere using different system, application and devices, in multiple structures and format
Data is a valuable asset , which provide useful information and help to take critical business decisions when analyzed properly
It is necessary to store, analyze and capture data since it has become a primary requirement for every company across the globe.
Finding out Different Data Formats
Data structure in which the data is organized represent entities, And each entity has one ore more attributes or characteristics.
Data can be classified into different formats -Structured -Unstructured -Semi-Structure
Structured This is fixed schema and has different fields and properties. Schema is organized in a tabular format in rows and columns. Rows represent each instance of a data entity and column represent attribute of the entity.
Semi-Structured This has some structure and allow variation between entity instances. One example of semi-structured data is JSON(JavaScript Object Notation)
Unstructured This has data without any structure. Example can be document, images, audio, video and binary files.
Various options to store data in files
Two broad categories of data store in common use
File store Storing the data on a hard disk or removable media such as USB drives or on central shared location in the cloud
File Format used to store data depends on a number of factors including
Type of the data being stored
Application that will need ro read/write and process data
Data files readable by human or optimized for efficient storage and processing
Common File Formats
Delimited text files Data is separated with field delimiters and row terminators. Most commonly used format is CSV Data
-JSON Data is represented in hierarchical document schema which is used define object that have multiple attributes.
Databases
-XML Data is represented using tags enclosed in angle brackets to define elements and attributes.
-BLOB Data is stored in binary format 0's and 1's.Common type of data stored as binary include images, audio, video and application specific documents.
-Optimized File Format Some specialized file formats that enable compression, indexing and efficient storage and processing have been developed.
Common optimized file format include Avro, Optimized Row Columnar Format(ORC) and Parquet.
Various options to store data in database
Two ways data are stored in database -Relational Database -Non-Relational Database
-Relational Database This is used to store and query structured data. Data stored in the represent entities. Each instance of an entity is assigned a primary key which uniquely identifies and these keys are used to reference the entity instance in another table. Table are managed and queried using SQL which is based on ANSI standard.
-Non-Relational Databases This is often referred as NOSQL Database. There are 4 common types of nonrelational database commonly used
KeyValue Database - Each record consist of a unique key and associated value
Document Database - Specific form of Key Value database
Column Family Database - Store tabular data in rows and columns
Graph Database - Which store entities as nodes with link to define relationship between them
Understand Transactional data processing solutions
A system records transaction that encapsulate specific events that the organization want to track. Transaction system are often high volume handling millions of transaction every day often referred as Online Transactional Processing OLTP. OLTP system support so called ACID semantics
Atomicity-Each transaction is a single unit which either fails or succeed completely. Consistency-Transaction can only take data in the database from valid state to another. Isolation- Concurrent transaction cannot interfere with each other. Durability-When a transaction is committed, it remains committed.
OLTP is often used for supporting Line of Business Application
Understand Analytical data processing solutions
Analytics can be based on a snapshot of the data at a given point in time or a series of snapshot. It uses read-only system that store vast volumes of historical data.
Analytic usually look like
Data file stored in central data lake for analysis
ETL process copies data from files and OLTP DB into a Datawarehouse. 3.Data in data warehouse is aggregated into OLAP(Online analytical processing) model. 4.Data in data lake, data warehouse and OLAP can be queried to produce reports, visualization and dashboards.
Different Types of user might perform data analytic work at different stages -Data Scientist might work directly with files in a a data lake to explore and model data -Data Analyst query table directly to produce reports and visualization -Business user consume aggregated data in the form of reports and dashboards.
Keep Learning! Keep Enjoying!
0 notes