#Andhra vs Mumbai
Text
VSI Crusher, Jaw And Cone Crusher, Artificial Sand Making Machine
We are Manufacturer, Supplier, Exporter of VSI Crusher, Jaw And Cone Crusher, Artificial Sand Making Machine, Finopactor from India.
Artificial Sand, Artificial Sand Making, Artificial Sand Making Machine, Artificial Sand Making Machines, Sand Making, Sand Making Machine, Sand Making Machines, Crush Sand, Crushed Sand, Sand Crusher, Sand Crushers, Stone Crusher, Stone Crushers, Jaw Crusher, Jaw Crushers, Cone Crusher, Cone Crushers, Hammer Crusher, Hammer Crushers, Finopactor, Plaster Sand Making Machine, Plaster Sand Making Machines, Sand Washing Plant, Sand Washing Plants, Benefication Plant, Benefication Plants, Conveyors Silo, Conveyors Silos, Hoppers, Constructional Machine, Constructional Machines, Constructional Machine Accessories, Concrete Mixer, Concrete Mixers, Hand Driven Concrete Mixer, Hand Driven Concrete Mixers, Semi Automatic Concrete Mixer, Semi Automatic Concrete Mixers, Semi-Automatic Concrete Mixer, Semi-Automatic Concrete Mixers, Concrete Block Machine, Concrete Block Machines, Vibratory Screen, Vibrating Compactor, Vibrating Compactors, Autoramming Block Machine, Autoramming Block Machines, Auto Ramming Block Machine, Auto Ramming Block Machines, Hydraulic Block Laying Machine, Hydraulic Block Laying Machines, Block Machines For Different Profiles, Dust Separator, Dust Separators, Dust Seperating Unit, Dust Seperating Units, Dust Free Product, Dust Free Products, Road Roller, Road Rollers, Oil Cooling System, Oil Cooling Systems, Drier Drum, Host Winch, Builders Hoist, Builders Hoists, Tower Hoist, Tower Hoists, VSI Crusher, Special VSI Crusher, VS Rotopactor, Bajree Sand, Bajaree Sand, Bajari Sand, Bajri Sand, Mining Sand, Construction Machinery, Stone Processing Machinery, Stone Cutting Machinery, Stone Crushing Machinery, Road Building Machinery, Granite Sand, Manufacturer, Supplier, Exporter, Karnataka, Mysore, Gulbarga, Chitradurga, Kolar, Bijapur, Dakshina Kannada, Raichur, Bellary, Belgaum, Hassan, Dharwad, Bangalore Rural, Shimoga, Mandya, Chickmagalur, Bangalore Urban, Madikeri, Tumkur, Bidar, Karwar, Udupi, Davanagare, Chamrajnagar, Koppal, Haveri, Gadak, Yadgir, Andhra Pradesh, Nellore, Cuddapah, Karim Nagar, Kurnool, West Godavari, Srikakulam, Anantpur, Adilabad, Chittor, East Godavari, Guntur, Hyderabad Urban, Khammam, Krishna, Mehboobnagar, Medak, Nalgonda, Nizamabad, Prakasam, Ranga Reddy, Vishakapatnam, Vizianagaram, Warangal, Madhya Pradesh, Sindi, Vidisha, Jabalpur, Bhopal, Hoshangabad, Indore, Rewa, Satna, Shahdol, Chhindwara, Ratlam, Balaghat, Betul, Bhind, Mandla, Chhattarpur, Damoh, Datia, Dewas, Dhar, Guna, Gwalior, Jhabua, Sehore, Mandsaur, Narsinghpur, Panna, Raisen, Rajgarh, Sagar, Seoni, Morena, Shivpuri, Shajapur, Tikamgarh, Ujjain, Khandwa, Khargone, Dindori, Umaria, Badwani, Sheopur, Katni, Neemuch, Harda, Anooppur, Burhanpur, Ashoknagar, asia, asian, india, indian, mumbai, maharashtra, industrial, industries, thane, pune, nashik, aurangabad, ratnagiri, nagpur, ahmednagar, akola, amravati, chandrapur, dhule, jalgaon, raigad, sangli, satara, belgaum, kolhapur, belgaon.
0 notes
Text
Ranji Trophy Live Score, Round 3 Day 3 update:Tamil Nadu bowls Railways out for 246; Karnataka leads Goa by 75 runs, Nikin nears 100
Andhra 257/3, 188 vs Assam 160
Odisha 158/9, 130 vs J&K 180
Bengal 381/8 vs Chhatisgarh (Delayed due to bad light)
Services 128/2 vs Jharkhand 316
Maharashtra 164/4, 189 vs Rajasthan 270
Mumbai 189/1, 251 vs Kerala 244
Railways 237/8 vs Tamil Nadu 489
Vidarbha 26/1, 78 vs Saurashtra 206, 244
Karnataka 396/4 vs Goa 321
Madhya Pradesh 251, 171 vs Delhi 205
Uttarakhand 27/3, 123 vs Pondicherry…

View On WordPress
0 notes
Text
Vijay Hazare Live Score 2023, Teams, Match Details, Live Telecast
The Vijay Hazare Trophy is a 50-over cricket tournament in India. It is one of the premier domestic tournaments in India, and it is named after Vijay Hazare, a former Indian cricketer.
Vijay Hazare Live Score 2023, Teams, Match Details, Live Telecast
The Vijay Hazare Trophy 2023 features 38 teams, which are divided into five groups of eight teams each. The groups are as follows:
Group A:
Saurashtra
Mumbai
Kerala
Punjab
Himachal Pradesh
Odisha
Goa
Group B:
Tamil Nadu
Karnataka
Haryana
Maharashtra
Gujarat
Chhattisgarh
Jammu & Kashmir
Group C:
Andhra Pradesh
Uttar Pradesh
Rajasthan
Madhya Pradesh
Tripura
Chandigarh
Nagaland
Group D:
Bengal
Baroda
Vidarbha
Hyderabad
Assam
Railways
Manipur
Group E:
Delhi
Services
Jharkhand
Uttarakhand
Sikkim
Arunachal Pradesh
Mizoram
Match Details
The Vijay Hazare Trophy 2023 will be played from November 23, 2023 to December 16, 2023. The group stage matches will be played from November 23 to December 9, 2023. The knockout stage matches will be played from December 11 to December 16, 2023.
Live Telecast
The Vijay Hazare Trophy 2023 matches will be live streamed on the JioCinema app and website. Unfortunately, there will be no live telecast of the matches.
Here is the schedule for the upcoming matches:
December 4:
Kerala vs Puducherry, KSCA Cricket (2) Ground, Alur - 9:00 AM
December 5:
Gujarat vs Himachal Pradesh, Sector 16 Stadium, Chandigarh - 9:00 AM
December 9:
Preliminary Quarter-Final - TBC vs TBC, Saurashtra Cricket Association Stadium C, Rajkot - 9:00 AM
December 11:
1st Quarter-Final - TBC vs TBC, Saurashtra Cricket Association Stadium, Rajkot - 9:00 AM
December 13:
1st Semi-Final - TBC vs TBC, Saurashtra Cricket Association Stadium, Rajkot - 9:00 AM
December 16:
Final - TBC vs TBC, Saurashtra Cricket Association Stadium, Rajkot - 9:00 AM
1 note
·
View note
Text
Focus on Ajinkya Rahane and Sanju Samson as Ranji Trophy kicks off with blockbuster match, Follow Ranji Trophy Live
Focus on Ajinkya Rahane and Sanju Samson as Ranji Trophy kicks off with blockbuster match, Follow Ranji Trophy Live
Ranji Trophy Round 1 Live: India’s domestic red-ball season begins on Tuesday. Andhra vs Mumbai, Maharashtra vs Delhi, Hyderabad vs Tamil Nadu, Karnataka vs Services, Madhya Pradesh vs Punjab and Jharkhand vs Kerala are some of the top matches in Round 1. With India’s current Test team on the verge of a turnaround, eyes will be on the next-gen stars. However, Ajinkya Rahane and Ishant Sharma will…

View On WordPress
0 notes
Text
Vijay Hazare Trophy: Samarth guides Karnataka to emphatic win; TN thumps Bengal
Vijay Hazare Trophy: Samarth guides Karnataka to emphatic win; TN thumps Bengal
Karnataka bounced back into contention with a seven-wicket win over defending champion Mumbai in a Elite Group B match of the Vijay Hazare Trophy cricket tournament at the KCA Stadium, Murukumpuzha here on Saturday.
Opener R.Samarth (96 not out) showed loads of patience and temperament on a tricky pitch to carry Karnataka to an emphatic win. Samarth and Rohan Kadam (44) added 95 runs for the…
View On WordPress
#ambati rayudu#andhra pradesh vs jammu and kashmir#cricket news#india cricket news#mumbai vs karnataka#r samarth#tamil nadu vs bengal#vijay hazare trophy 2021/22#vijay hazare trophy results#vijay hazare trophy schedule
0 notes
Photo

48 honourable poets have sent one beautiful poem each till June 24 ,2021 for the 7th DOIEPFest-2021 to be held with Google Meet App on June, 27,2021 Sunday at 6.00 PM Indian Standard Time/GMT+5.30 hours. 1.Sarala Balachandran-Kolkata, India 2.Saptaparnee Adhikari-Kalyani,West Bengal,India 3.Sasmita Dash-Bhubaneshwar,Odisha, India. 4.Molly Joseph--Kerala, India 5.Rajendra Ojha--Nepal 6.Rajeev Moothedoth-Bengaluru,Karnataka, India 7.Germain Drogenbroodt--Belgium and Spain, Europe 8.Ranjana Saran Sinha--Nagpur,Maharashtra, India 9.Pierra Pistilli-Naples, Italy, Europe 10.Prasanthi Susha--Vishakhapatnam,Andhra Pradesh, India 11.Madhu Khandelwal--Jaipur, Rajasthan, India 12.Tangirala Sreelatha-Vijayawada, India 13Jayashri Ray--New Delhi 14Tarik Gunersel--Turkey 15.Vandita Gautam--New Delhi 16.Naheed Akhtar--Hyderabad, India 17.Manisha Singh--Lucknow, India 18.Richard Spisak--USA, North America. 19.Meher Pestonji--Mumbai 20.Anuradha Bhattacharyya--Chandigarh, India 21.Anna Keiko---China 22.Yashpaul Karla--Gujarat, India 23.Shibabrata Guha--Kolkata 24.Taghrid M Fayad--Lebanan &Egypt 25.KKumar Prasanna-Andhra Pradesh, India 26.Poonam Nigam Sahay-Ranchi, India 27.Annie Pothen-Hyderabad, India 28.A'zam Obidov--Uzbekistan 29.Farhana Sait--Chennai, India 30.Gloria Sofia-Cape Verde, Africa 31.Lopamudra Mishra--Bhubaneswar, India 32.Xanthi Hondrou Hill--Greece, Europe 33.Priyanka Ghosh-Burdwan, India 34.Manju VS--Kerala, India 35.Sujatha Sairam--Chennai, India 36.Bidyutprabha Gantayat--Odisha, India 37.Archana B Zutshi--Lucknow, India 38.Gulseli Inal--Turkey 39.Sindhu Rana-Jalandhar, India. 40.Sushant Thapa--Nepal 41.Bagawath Bhandari--Bhutan 42.Bwocha Nyagemi Bwocha--Kenya 43.Mai Hoa Do--Hanoi, Vietnam 44.Johana Dayavu Lawrie-Switzerland & India 45.Gelda Castro--Brazil, South America 46.Mircea Dan Duta-Romania, Europe 47.Narendra Gadge--Nagpur, India 48.Yunisha Satyal--Nepal https://m.facebook.com/story.php?story_fbid=2775310006113300&id=100009029841990&sfnsn=wiwspwa https://www.instagram.com/p/CQpvJp-jtYu/?utm_medium=tumblr
0 notes
Text
Top companies for tiles export in India
Gone are the days when tiles were restricted only to bathrooms and kitchens. Tiles today are the silent heroes of home décor, finding its place in every bedroom, living room and flooring throughout the residential and commercial spaces. Wall tiles too are a trending décor variant with new digital printing technology bringing in more creativity. Considering the options available, making a choice becomes a tad bit difficult. But we are here to help. Check out the top tile manufacturing companies in India.
1 Blizzard vitrifiedtiles Gujarat
Website - https://www.naveentile.com/
Naveentile
Blizzard Vitrified LLP is located in out skirts of Morbi - The ceramic hub of India.
Company is equipped with fully automatic advance Italian technology. Our manufacturing system ensures reduces wastage and lowest pollution is emitted which directly save ENVIRONMENT, WATER, ELECTRICITY and ENERGY.
Our innovation never stops and all products are being produced strictly in accordance with international standard and national standard of India.
Every phase of the production process is carried out in its whole using advanced technology, in order to guaranty maximum precision in every step of the production processes, obtaining an unbeatable quality for all products.
We are highly aware of everything that concerns the environment
Kajaria Ceramics Limited
Founded in mid-1988, Kajaria Ceramics Limited is the largest ceramic tile producer and manufacturer of vitrified/ceramic tiles in India. It is the only Indian tile company to have received the prestigious ‘Asia’s most promising brand’ award in the premium tiles category. The ultima, gres tough and duratech are the most trending products of Kajaria. Kajaria range of floor and wall tiles covers all areas including bathrooms, kitchens, living rooms, bedrooms, outdoors and commercial spaces. Its manufacturing units are equipped with cutting-edge technology comprising intense automation, robotic car application and zero chance for human error. Its annual manufacturing capacity is 73 mn. sq. meters.
The company exports tiles to more than 35 countries world-wide. It majorly deals into the following three categories in tiles:
Polished Vitrified Tiles
Glazed Vitrified Tiles
Ceramic Wall and Floor Tiles
Kajaria’s manufacturing facilities are distributed in 6 Indian states:
Sikandrabad, Uttar Pradesh
Gailpur, Rajasthan
Malootana, Rajasthan
Srikalahasti, Andhra Pradesh
Vijaywada, Andhra Pradesh
Morbi, Gujarat (3 Plants)
All the Kajaria plants fulfill international norms and have received the ISO 9001, OHSAS 18001, SA-8000, ISO 22000 and ISO 50001 certifications.
Somany:
Founded in 1969, Somany Ceramics is an internationally acclaimed tile manufacturing company with a presence in Africa, India, United Kingdom, Middle East and Russia. With a total production capacity of 60 million square meters annually, Somany offers complete décor solutions. Their tile size ranges from 148×600 mm to 1200x2400mm. They have numerous applications in bedrooms, living rooms, kitchens, bathrooms, kid’s rooms, outdoor and terrace wall cladding. With 9 manufacturing plants spread across the country, they manufacture tiles that come with 100% imported Italian technology.
The brand offers tiles under the following categories:
Polished Vitrified Tiles
Digital Tiles
Glazed Vitrified Tiles
Ceramic Wall And Floor Tiles
Sanitaryware and Bath Fittings
Tile Laying Solutions
The tiles are available in the following finishes: Dazzle, Durastone, Digital Durastone, Full Polished, Glossy, Lapato, Lucido, Matt, Metallic, Rustic, Rustic Matt, Satin, Semi Glossy, Soluble Salts, Stone, Sugar Hone, Satin Matt, Twin Charge, Ultra Charge, Wood, Crystalo Polish.
The company’s manufacturing operations are held at Kadi (Gujarat) and Kassar (Haryana) along with other joint venture plants.
NITCO Limited:
Headquartered in Mumbai, India, NITCO Group consists of NITCO wall and floor tiles, NITCO Art and NITCO Marble. The company was established in 1953 with the production of ‘Terrazzo tiles’. NITCO is the first tile manufacturing company to be awarded with GreenPro certification for ceramic and GVT Tiles. Its range of floor and wall tiles cover all spaces such as bathrooms, living rooms, kitchens, bedrooms, outdoors and commercial tiles. It is the only Indian company to manufacture tiles in Italy. NITCO is the tile supplier to over 40 countries including Nepal, Belgium, South Africa, Ireland, UAE, Bhutan, Uganda, Bahrain, Taiwan, Australia, Maldives, Zambia, Kenya, Ethiopia, Kenya, Canada and more.
NITCO has 7 major categories in tiles:
Ceramic Wall Tiles
Ceramic Floor Tiles
Glazed Vitrified tiles
Vitrified DCH Tiles
Vitrified Heavy Duty Tiles
Vitrified SST Tiles
Made in Italy Tiles
NITCO’s manufacturing units for tiles are situated in Alibaug and Morbi, for marble in Silvassa and for Mosaico in Mumbai. Its branch offices are spread across 20 Indian states.
Orientbell Limited:
Founded in 1977, Orientbell is one of the leading Indian tile brands manufacturing a variety of tiles covering a wide range of applications. The company has more than 2500 outlets spread across the country along with 9 flagship stores known as Orientbell Tile Boutiques. Its production capacity is close to 30 million square meters.
Orientbell has the following categories in tiles:
Ceramic Tiles
Vitrified Tiles
Glazed Vitrified Tiles
Polished Vitrified Tiles
Double Charge Vitrified Tiles
Porcelain Tiles
Nano Tiles
Full Body Vitrified Tiles
Designer Tiles
Cool Tiles
Forever Tiles
Anti-skid Tiles
The tiles are available in natural/matt, glossy, metallic, sugar/lapato, super glossy and rocker/reactive finishes.
The company’s manufacturing plants are located at 3 key locations namely Sikanderpur in UP, Hoskote in Karnataka and Dora in Gujarat.
Asian Granito India Limited:
Set up in the year 2000, Asian Granito India Ltd. is one of the largest ceramic companies in India. The company has a pan India presence with more than 300 showrooms spread across the country. It also exports to more than 58 countries. It is the first-ever Indian tile company to have launched the largest showroom in Johannesburg, South Africa. The company’s first plant for vitrified tiles was set up at Himatnagar, Gujarat in the year 2003 with a production capacity of 4000 square meters per day.
The company deals into the following category of tiles:
Wall tiles
Polished Vitrified Tiles
Ceramic Floor Tiles
Glazed Vitrified Collection (Grestek)
GrestekMarblex
Outdoor Tiles
Tac Tiles
Composite Marble Tiles
Quartz Tiles
The company has 8 ultra-modern plants spread over an area of 3,20,000 sq.mt across Gujarat.
Tiles add to the space’s aesthetics, beauty and value and thereby, hold high importance in the matter of selection. Since they play a pivotal role in deciding the look and feel of the space, one wouldn’t want to compromise in its selection. BuildSupply is a one-stop destination for all building material requirements including tiles. It gives buyers an option to choose from a wide range of tile brands at one single platform.
Top Tile Manufacturing Companies in India
1 Blizzard vitrifiedtiles Gujarat
· Kajaria Ceramics Limited. Founded in mid-1988, Kajaria Ceramics Limited
· the largest ceramic tile producer and manufacturer of vitrified/ceramic tiles in India. ...
· Somany: ...
· NITCO Limited: ...
· Orientbell Limited: ...
· Asian Granito India Limited:
Which company tiles are best in India
Best Tile Brands in India As Per Market Cap
Sr.No. Best Tiles Brand in India Market Cap in Percentage
1 Kajaria Ceramics Ltd 36.05 %
2 Grindwell Norton Ltd 23.74 %
3 Johnson Tiles 14.51 %
4 Cera Sanitaryware Limited 14.29 %
Which is better Somany vs kajaria
PAT Margin of Kajaria cearmics is 7.75%. While the percentage of PAT margin for Somany is 2.73% and for Asian Granito is 1.74%. We can see there is a considerable difference in the PAT margin percentage figures of Kajaria and Somany as well as Asian Granito. So, here also Kajaria ceramics is a clear winner.
What is the best tile brand?
The 10 Best Tile Manufacturers And Tile Brands In The U.S.
Pave Tile And Stone. ...
Susan Jablon Mosaics. ...
Bedrosians. ...
Florida Tile. ...
Hakatai. ...
Bisazza. ...
Clayhaus Ceramics. ...
Modwalls. This is a company that is considered online only in the industry, but their collection is a force to be reckoned with.
Which country makes the best tiles?
China
Global leading ceramic tile manufacturing countries 2019. In 2019, China was by far the leading ceramic tile manufacturer worldwide, producing roughly 5.2 billion square meters of ceramic tile that year. India was the second largest producer, at 1.27 billion square meters that year.
Which is better glazed vitrified vs polished vitrified tiles?
Polished Glazed Vitrified Tiles:
This also makes them less slip-resistant and scratch-resistant compared to unpolished glazed vitrified tiles. However due to the non-porous liquid glass coat polished glazed vitrified tiles show highe
0 notes
Text
Mumbai, Saurashtra, Uttar Pradesh and Kerala through to Vijay Hazare quarter-finals - ESPNcricinfo
Mumbai, Saurashtra, Uttar Pradesh and Kerala through to Vijay Hazare quarter-finals – ESPNcricinfo
News
The last remaining spot will go to the winner of the Delhi vs Uttarakhand game
Mumbai, Saurashtra, Uttar Pradesh, and Kerala have filled up the last four automatic qualification spots for the quarter-final stage of the Vijay Hazare Trophy. They join Gujarat, Andhra, and Karnataka, who had sealed qualification on Sunday by topping their respective groups. The eighth quarter-finalist will be…

View On WordPress
0 notes
Text
Artificial Sand Making Machines, VSI Crushers, Jaw And Cone Crushers
We are Manufacturer, Supplier, Exporter of Artificial Sand Making Machines, Jaw And Cone Crushers, Finopactor, Special VSI Crushers from India.
Artificial Sand, Artificial Sand Making, Artificial Sand Making Machine, Artificial Sand Making Machines, Sand Making, Sand Making Machine, Sand Making Machines, Crush Sand, Crushed Sand, Sand Crusher, Sand Crushers, Stone Crusher, Stone Crushers, Jaw Crusher, Jaw Crushers, Cone Crusher, Cone Crushers, Hammer Crusher, Hammer Crushers, Finopactor, Plaster Sand Making Machine, Plaster Sand Making Machines, Sand Washing Plant, Sand Washing Plants, Benefication Plant, Benefication Plants, Conveyors Silo, Conveyors Silos, Hoppers, Constructional Machine, Constructional Machines, Constructional Machine Accessories, Concrete Mixer, Concrete Mixers, Hand Driven Concrete Mixer, Hand Driven Concrete Mixers, Semi Automatic Concrete Mixer, Semi Automatic Concrete Mixers, Semi-Automatic Concrete Mixer, Semi-Automatic Concrete Mixers, Concrete Block Machine, Concrete Block Machines, Vibratory Screen, Vibrating Compactor, Vibrating Compactors, Autoramming Block Machine, Autoramming Block Machines, Auto Ramming Block Machine, Auto Ramming Block Machines, Hydraulic Block Laying Machine, Hydraulic Block Laying Machines, Block Machines For Different Profiles, Dust Separator, Dust Separators, Dust Seperating Unit, Dust Seperating Units, Dust Free Product, Dust Free Products, Road Roller, Road Rollers, Oil Cooling System, Oil Cooling Systems, Drier Drum, Host Winch, Builders Hoist, Builders Hoists, Tower Hoist, Tower Hoists, VSI Crusher, Special VSI Crusher, VS Rotopactor, Bajree Sand, Bajaree Sand, Bajari Sand, Bajri Sand, Mining Sand, Construction Machinery, Stone Processing Machinery, Stone Cutting Machinery, Stone Crushing Machinery, Road Building Machinery, Granite Sand, Manufacturer, Supplier, Exporter, Karnataka, Mysore, Gulbarga, Chitradurga, Kolar, Bijapur, Dakshina Kannada, Raichur, Bellary, Belgaum, Hassan, Dharwad, Bangalore Rural, Shimoga, Mandya, Chickmagalur, Bangalore Urban, Madikeri, Tumkur, Bidar, Karwar, Udupi, Davanagare, Chamrajnagar, Koppal, Haveri, Gadak, Yadgir, Andhra Pradesh, Nellore, Cuddapah, Karim Nagar, Kurnool, West Godavari, Srikakulam, Anantpur, Adilabad, Chittor, East Godavari, Guntur, Hyderabad Urban, Khammam, Krishna, Mehboobnagar, Medak, Nalgonda, Nizamabad, Prakasam, Ranga Reddy, Vishakapatnam, Vizianagaram, Warangal, Madhya Pradesh, Sindi, Vidisha, Jabalpur, Bhopal, Hoshangabad, Indore, Rewa, Satna, Shahdol, Chhindwara, Ratlam, Balaghat, Betul, Bhind, Mandla, Chhattarpur, Damoh, Datia, Dewas, Dhar, Guna, Gwalior, Jhabua, Sehore, Mandsaur, Narsinghpur, Panna, Raisen, Rajgarh, Sagar, Seoni, Morena, Shivpuri, Shajapur, Tikamgarh, Ujjain, Khandwa, Khargone, Dindori, Umaria, Badwani, Sheopur, Katni, Neemuch, Harda, Anooppur, Burhanpur, Ashoknagar, asia, asian, india, indian, mumbai, maharashtra, industrial, industries, thane, pune, nashik, aurangabad, ratnagiri, nagpur, ahmednagar, akola, amravati, chandrapur, dhule, jalgaon, raigad, sangli, satara, belgaum, kolhapur, belgaon.
#Artificial Sand#Artificial Sand Making#Artificial Sand Making Machine#Artificial Sand Making Machines#Sand Making#Sand Making Machine#Sand Making Machines#Crush Sand#Crushed Sand#Sand Crusher#Sand Crushers#Stone Crusher#Stone Crushers#Jaw Crusher#Jaw Crushers#Cone Crusher#Cone Crushers#Hammer Crusher#Hammer Crushers#Finopactor#Plaster Sand Making Machine#Plaster Sand Making Machines#Sand Washing Plant#Sand Washing Plants#Benefication Plant#Benefication Plants#Conveyors Silo#Conveyors Silos#Hoppers#Constructional Machine
0 notes
Text
Artificial Intelligence vs. Tuberculosis – Part 2
By SAURABH JHA, MD
Clever Hans
Preetham Srinivas, the head of the chest radiograph project in Qure.ai, summoned Bhargava Reddy, Manoj Tadepalli, and Tarun Raj to the meeting room.
“Get ready for an all-nighter, boys,” said Preetham.
Qure’s scientists began investigating the algorithm’s mysteriously high performance on chest radiographs from a new hospital. To recap, the algorithm had an area under the receiver operating characteristic curve (AUC) of 1 – that’s 100 % on multiple-choice question test.
“Someone leaked the paper to AI,” laughed Manoj.
“It’s an engineering college joke,” explained Bhargava. “It means that you saw the questions before the exam. It happens sometimes in India when rich people buy the exam papers.”
Just because you know the questions doesn’t mean you know the answers. And AI wasn’t rich enough to buy the AUC.
The four lads were school friends from Andhra Pradesh. They had all studied computer science at the Indian Institute of Technology (IIT), a freaky improbability given that only hundred out of a million aspiring youths are selected to this most coveted discipline in India’s most coveted institute. They had revised for exams together, pulling all-nighters – in working together, they worked harder and made work more fun.
Preetham ordered Maggi Noodles – the mysteriously delicious Indian instant noodles – to charge their energies. Ennio Morricone’s soundtrack from For a Few Dollars More played in the background. We were venturing into the wild west of deep learning.
The lads had to comb a few thousand normal and a few thousand abnormal radiographs to find what AI was seeing. They were engineers, not radiologists, and had no special training in radiology except for one that comes with looking at thousands of chest radiographs, which they now knew like the lines at the back of their hands. They had carefully fed AI data to teach it radiology. In return, AI taught them radiology – taught them where to look, what to see, and what to find.
They systematically searched the chest radiographs for clues. Radiographs are two-dimensional renditions, mere geometric compressions, maps of sorts. But the real estate they depict have unique personalities. The hila, apices, and tracheobronchial angle are so close to each other that they may as well be one structure, but like the mews, roads, avenues and cul-de-sacs of London, they’re distinct, each real estate expressing unique elements of physiology and pathology.
One real estate which often flummoxes AI is the costophrenic angle (CPA) – a quiet hamlet where the lung meets the diaphragm, two structures of differing capacity to stop x-rays, two opposites which attach. It’s supposedly sharp – hence, an “angle”; the loss of sharpness implies a pleural effusion, which isn’t normal.
The CPA is often blunt. If radiologists called a pleural effusion every time the CPA was blunt half the world would have a pleural effusion. How radiologists deal with a blunted CPA is often arbitrary. Some call pleural effusion, some just describe their observation without ascribing pathology, and some ignore the blunted CPA. I do all three but on different days of the week. Variation in radiology reporting frustrates clinicians. But as frustrating as reports are, the fact is that radiographs are imperfect instruments interpreted by imperfect arbiters – i.e. Imperfection Squared. Subjectivity is unconquerable. Objectivity is farcical.
Because the radiologist’s interpretation is the gospel truth for AI, variation amongst radiologists messes AI’s mind. AI prefers that radiologists be consistent like sheep and the report be dogmatic like the Old Testament, so that it can better understand the ground truth even if the ground truth is really ground truthiness. When all radiologists call a blunted CPA a pleural effusion, AI appears smarter. Perhaps, offering my two cents, the secret to AI’s mysterious super performance was that the radiologists from this new institute were sheep. They all reported the blunted CPA in the same manner. 100 % consistency – like machines.
“I don’t think it’s the CPA, yaar,” objected Tarun, politely. “The problem is probably in the metadata.”
The metadata is a lawless province which drives data scientists insane. Notwithstanding variation in radiology reporting, radiographs – i.e. data – follow well-defined rules, speak a common language, and can be crunched by deep neural networks. But radiographs don’t exist in vacuum. When stored, they’re drenched in the attributes of the local information technology. And when retrieved, they carry these attributes, which are like local dialects, with them. Before feeding the neural networks, the radiographs must be cleared of idiosyncracies in the metadata, which can take months.
It seemed we had a long night ahead. I was looking forward to the second plate of Maggi Noodles.
Around the 50th radiograph, Tarun mumbled, “it’s clever Hans.” His pitch then rose in excitement, “I figured it. AI is behaving like Clever Hans.”
Clever Hans was a celebrity German horse which could allegedly add and subtract. He’d answer by tapping his hoof. Researchers, however, figured out his secret. Hans would continue tapping his hoof until the number of taps corresponded to the right numerical answer, which he’d deduce from the subtle, non-verbal, visual cues in his owner. The horse would get the wrong answer if he couldn’t stare at his owner’s face. Not quite a math Olympiad, Hans was still quite clever, certainly for a horse, but even by human standards.
“What do you see?” Tarun pointed excitedly to a normal and an abnormal chest radiograph placed side by side. Having interpreted over several thousand radiographs I saw what I usually see but couldn’t see anything mysterious. I felt embarrassed – a radiologist was being upstaged by an engineer, AI, and supposedly a horse, too. I stared intently at the CPA hoping for a flash of inspiration.
“It’s not the CPA, yaar,” Tarun said again – “look at the whole film. Look at the corners.”
I still wasn’t getting it.
“AI is crafty, and just like Hans the clever horse, it seeks the simplest cue. In this hospital all abnormal radiographs are labelled – “PA.” None of the normals are labelled. This is the way they kept track of the abnormals. AI wasn’t seeing the hila, or CPA, or lung apices – it detected the mark – “PA” – which it couldn’t miss,” Tarun explained.
The others shortly verified Tarun’s observation. Sure enough, like clockwork – all the abnormal radiographs had “PA” written on them – without exception. This simple mark of abnormality, a local practice, became AI’s ground truth. It rejected all the sophisticated pedagogy it had been painfully taught for a simple rule. I wasn’t sure whether AI was crafty, pragmatic or lazy, or whether I felt more professionally threatened by AI or data scientists.
“This can be fixed by a simple code, but that’s for tomorrow,” said Preetham. The second plate of Maggi Noodles never arrived. AI had one more night of God-like performance.
The Language of Ground Truth
Artificial Intelligence’s pragmatic laziness is enviable. To learn, it’ll climb mountains when needed but where possible it’ll take the shortest path. It prefers climbing molehills to mountains. AI could be my Tyler Durden. It doesn’t give a rat’s tail how or why and even if it cared it won’t tell you why it arrived at an answer. AI’s dysphasic insouciance – its black box – means that we don’t know why AI is right, or that it is. But AI’s pedagogy is structured and continuous.
After acquiring the chest radiographs, Qure’s scientists had to label the images with the ground truth. Which truth, they asked. Though “ground truth” sounds profound it simply means what the patient has. On radiographs, patients have two truths: the radiographic finding, e.g. consolidation – an area of whiteness where there should be lung, and the disease, e.g. pneumonia, causing that finding. The pair is a couplet. Radiologists rhyme their observation with inference. The radiologist observes consolidation and infers pneumonia.
The inference is clinically meaningful as doctors treat pneumonia, not consolidation, with antibiotics. The precise disease, such as the specific pneumonia, e.g. legionella pneumonia, is the whole truth. But training AI on the whole truth isn’t feasible for several reasons.
First, many diseases cause consolidation, or whiteness, on radiographs – pneumonia is just one cause, which means that many diseases look similar. If legionella pneumonia looks like alveolar hemorrhage, why labor to get the whole truth?
Second, there’s seldom external verification of the radiologist’s interpretation. It’s unethical resecting lungs just to see if radiologists are correct. Whether radiologists attribute consolidation to atelectasis (collapse of a portion of the lung, like a folded tent), pneumonia, or dead lung – we don’t know if they’re right. Inference is guesswork.
Another factor is the sample size: preciser the truth fewer cases of that precise truth. There are more cases of consolidation from any cause than consolidation from legionella pneumonia. AI needs numbers, not just to tighten the confidence intervals around the point estimate – broad confidence intervals imply poor work ethic – but for external validity. The more general the ground truth, the more cases of labelled truth AI sees, and the more generalizable AI gets, allowing it to work in Mumbai, Karachi, and New York.
Thanks to Prashant Warier’s tireless outreach and IIT network, Qure.ai acquired a whopping 2.5 million chest radiographs from nearly fifty centers across the world, from afar as Tokyo and Johannesburg and, of course, from Mumbai. AI had a sure shot at going global. But the sheer volume of radiographs made the scientists timorous.
“I said to Prashant, we’ll be here till the next century if we have to search two million medical records for the ground truth, or label two million radiographs” recalls Preetham. AI could neither be given a blank slate nor be spoon fed. The way around it was to label a few thousand radiographs with anatomical landmarks such as hila, diaphragm, heart, a process known as segmentation. This level of weak supervision could be scaled.
For the ground truth, they’d use the radiologist’s interpretation. Even so, reading over a million radiology reports wasn’t practical. They’d use Natural Language Processing (NLP). NLP can search unstructured (free text) sentences for meaningful words and phrases. NLP would tell AI whether the study was normal or abnormal and what the abnormality was.
Chest x-ray reports are diverse and subjective, with inconsistency added to the mix. Ideally, words should precisely and consistently convey what radiologists see. Radiologists do pay heed to March Hare’s advice to Alice: “then you should say what you mean,” and to Alice’s retort: “at least I mean what I say.” The trouble is that different radiologists say different things about the same disease and mean different things by the same descriptor.
One radiologist may call every abnormal whiteness an “opacity”, regardless of whether they think the opacity is from pneumonia or an innocuous scar. Another may say “consolidation” instead of “opacity.” Still another may use “consolidation” only when they believe the abnormal whiteness is because of pneumonia, instilling connation in the denotation. Whilst another may use “infiltrate” for viral pneumonia and “consolidation” for bacterial pneumonia.
The endless permutations of language in radiology reports would drive both March Hare and Alice insane. The Fleischner Society lexicon makes descriptors more uniform and meaningful. After perusing several thousand radiology reports, the team selected from that lexicon the following descriptors for labelling: blunted costophrenic angle, cardiomegaly, cavity, consolidation, fibrosis, hilar enlargement, nodule, opacity and pleural effusion.
Not content with publicly available NLPs, which don’t factor local linguistic culture, the team developed their own NLP. They had two choices – use machine learning to develop the NLP or use humans (programmers) to make the rules. The former is way faster. Preetham opted for the latter because it gave him latitude to incorporate qualifiers in radiology reports such as “vague” and “persistent.” The nuances could come in handy for future iterations.
Starting off with simple rules such as negation detection so that “no abnormality” or “no pneumonia” or “pneumonia unlikely” would be the same as “normal”, then broadening the rules to incorporate synonyms such as “density” and “lesion”, including the protean “prominent”, a word which can mean anything except what it actually means and like “awesome” has been devalued by overuse, the NLP for chest radiograph accrued nearly 2500 rules, rapidly becoming more biblical than the regulations of Obamacare.
The first moment of reckoning arrived: does the NLP even work? Testing the NLP is like testing the tester – if the NLP was grossly inaccurate, the whole project would crash. NLP determines the accuracy of the labelled truth – e.g. whether the radiologist truly said “consolidation” in the report. If NLP correctly picks “consolidation” in nine out of ten reports and doesn’t in one out of ten, the radiograph with “consolidation” but labelled “normal” doesn’t confuse AI. AI can tolerate occasional misclassification; indeed, it thrives on noise. You’re allowed to fool it once, but you can’t fool it too often.
After six months of development, the NLP was tested on 1930 reports to see if it flagged the radiographic descriptors correctly. The reports, all 1930 of them, were manually checked by radiologists blinded to NLP’s answers. The NLP performed respectively, with sensitivities/ specificities for descriptors ranging from 93 % to 100 %.
For “normal”, the most important radiological diagnosis, NLP had a specificity of 100 %. This means that in 10, 000 reports the radiologists called or implied abnormal, none would be falsely extracted by the NLP as “normal.” NLP’s sensitivity for “normal” was 94 %. This means that in 10, 000 reports the radiologist called or implied normal, 600 would be falsely extracted by NLP as “abnormal.” NLP’s accuracy reflected language ambiguity, which is a proxy of radiologist’s uncertainty. Radiologists are less certain and use more weasel words when they believe the radiograph is normal.
Algorithm Academy
After deep learning’s success using Image Net to spot cats and dogs, prominent computer scientists prophesized the extinction of radiologists. If AI could tell cats apart from dogs it could surely read CAT scans. They missed a minor point. The typical image resolution in Image Net is 64 x 64 pixels. The resolution of chest radiographs can be as high as 4096 x 4096 pixels. Lung nodules on chest radiographs are needles in haystacks. Even cats are hard to find.
The other point missed is more subtle. When AI is trying to classify a cat in a picture of a cat on the sofa, the background is irrelevant. AI can focus on the cat and ignore the sofa and the writing on the wall. On chest radiographs the background is both the canvass and the paint. You can’t ignore the left upper lobe just because there’s an opacity in the right lower lobe. Radiologists don’t enjoy satisfaction of search. All lungs must be searched with unyielding visual diligence.
Radiologists maybe awkward people, imminently replaceable, but the human retina is a remarkable engineering feat, evolutionarily extinction-proof, which can discern lot more than fifty shades of gray. For the neural network, 4096 pixels is too much information. Chest radiographs had to be down sampled to 256 pixels. The reduced resolution makes pulmonary arteries look like nodules. Radiologists should be humbled that AI starts at a disadvantage.
Unlike radiologists, AI doesn’t take bathroom breaks or check Twitter. It’s indefatigable. Very quickly, it trained on 50, 000 chest radiographs. Soon AI was ready for the end of semester exam. The validation cases come from the same source as the training cases. Training-validation is a loop. Data scientists look at AI’s performance on validation cases, make tweaks, and give it more cases to train on, check its performance again, make tweaks, and so on.
When asked “is there consolidation?”, AI doesn’t talk but expresses itself in a dimensionless number known as confidence score – which runs between 0 and 1. How AI arrives at a particular confidence score, such as 0.5, no one really understands. The score isn’t a measure of probability though it probably incorporates some probability. Nor does it strictly measure confidence, though it’s certainly a measure of belief, which is a measure of confidence. It’s like asking a radiologist – “how certain are you that this patient has pulmonary edema – throw me a number?” The number the radiologist throws isn’t empirical but is still information.
The confidence score is mysterious but not meaningless. For one, you can literally turn the score’s dial, like adjusting the brightness or contrast of an image, and see the trade-off between sensitivity and specificity. It’s quite a sight. It’s like seeing the full tapestry of radiologists, from the swashbuckling under caller to the “afraid of my shadow” over caller. The confidence score can be chosen to maximize sensitivity or specificity, or using Youden’s index, optimize both.
To correct poor sensitivity and specificity, the scientists looked at cases where the confidence scores were at the extremes, where the algorithm was either nervous or overconfident. AI’s weaknesses were radiologist’s blind spots, such as the lung apices, the crowded bazaar of the hila, and behind the ribs. It can be fooled by symmetry. When the algorithm made a mistake, it’s reward function, also known as loss function, was changed so that it was punished if it made the same mistake and rewarded when it didn’t. Algorithms, who have feelings, too, responded favorably like Pavlov’s dogs, and kept improving.
Validation case. The algorithm called “consolidation” in the left lower lobe. The radiologist called the x-ray normal. The radiologist is the gold standard so this was a false positive.
The Board Exam
After eighteen months of training-validation, and seeing over million radiographs, the second moment of reckoning arrived: the test, the real test, not the mock exam. This important part of algorithm development must be rigorous because if the test is too easy the algorithm can falsely perform. Qure.ai wanted their algorithms validated by independent researchers and that validation published in peer review journals. But it wasn’t Reviewer 2 they feared.
“You want to find and fix the algorithm’s weaknesses before deployment. Because if our customers discover its weaknesses instead of us, we lose credibility,” explained Preetham.
Preetham was alluding to the inevitable drop in performance when algorithms are deployed in new hospitals. A small drop in AUC such as 1-2 %, which doesn’t change clinical management, is fine; a massive drop such as 20 % is embarrassing. What’s even more embarrassing is if AI misses an obvious finding such a bleedingly-obvious consolidation. If radiologists miss obvious findings they could be sued. If the algorithm missed an obvious finding it could lose its jobs, and Qure.ai could lose future contracts. A single drastic error can undo months of hard work. Healthcare is an unforgiving market.
In the beginning of the training, AI missed a 6 cm opacity in the lung, which even toddlers can see. Qure’s scientists were puzzled, afraid, and despondent. It turned out that the algorithm had mistaken the large opacity for a pacemaker. Originally, the data scientists had excluded radiographs with devices so as not to confuse AI. When the algorithm saw what it thought was a pacemaker it remembered the rule, “no devices”, so denied seeing anything. The scientists realized that in their attempt to not confuse AI, they had confused it even more. There was no gain in mollycoddling AI. It needed to see the real world to grow up.
The test cases came from new sources – hospitals in Calcutta, Pune and Mysore. The ground truth was made more stringent. Three radiologists read the radiographs independently. If two called “consolidation” and the third didn’t, the majority prevailed, and the ground truth was “consolidation”. If two radiologists didn’t flag a nodule, and a third did, the ground truth was “no nodule.” For both validation and the test cases, radiologists were the ground truth – AI was prisoner to radiologists’ whims, but by using three radiologists as the ground truth for test cases, the interobserver variability was reduced – the truth, in a sense, was the golden mean rather than consensus.
Test case. Algorithm called “opacity” in the left lower lobe. You can see why – notice the subtle but real increased density in left vs right lower lobe. One radiologist called said “opacity”, two disagreed. This was a false positive.
What’s the minimum number of abnormalities AI needs to see; its numbers needed to learn (NNL)? This depends on several factors – how sensitive you think the algorithm will be, the desired tightness of the confidence interval, desired precision (paucity of false positives) and, crucially, rarity of the abnormality. The rarer the abnormality the more radiographs AI needs to see. To be confident of seeing eighty cases – the NNL was derived from a presumed sensitivity of 80 % – of a specific finding, AI would have to see 15, 000 radiographs. NNL wasn’t a problem in either training or validation – recall, there were 100, 000 radiographs for validation which is a feast even for training. But gathering test cases was onerous and expensive. Radiologists aren’t known to work for free.
Qure’s homegrown NLP flagged chest radiographs with radiology descriptors in the new hospitals. There were normals, too, which were randomly distributed in the test, but the frequency of abnormalities was different from the training cases. In the latter, the frequency reflected actual prevalences of radiographic abnormalities. Natural prevalences don’t guarantee sufficient abnormals in a sample of two thousand. Through a process called “enrichment”, the frequency of each abnormality in the test pool was increased, so that 80 cases each of opacity, nodule, consolidation, etc, were guaranteed in the test.
The abnormals in the test were more frequent than in real life. Contrived? Yes. Unfair? No. In the American board examination, radiologists are shown only abnormal cases.
Like anxious parents, Qure’s scientists waited for the exam result, the AUC.
“We expected sensitivities of 80 %. That’s how we calculated our sample size. A few radiologists advised us that we not develop algorithms for chest radiographs, saying that it was a fool’s errand because radiographs are so subjective. We could hear their warnings.” Preetham recalled with subdued nostalgia.
The AUC for detecting an abnormal chest radiograph was 0.92. Individual radiologists, unsurprisingly, did better as they were part of the truth, after all. As expected, the degree of agreement between radiologists, the inter-observer variability, affected AI’s performance, which was the highest when radiologists were most in agreement, such as when calling cardiomegaly. The radiologists had been instructed to call “cardiomegaly” when the cardiothoracic ratio was greater than 0.5. For this finding, the radiologists agreed 92 % of the time. For normal, radiologists agreed 85 % of the time. For cardiomegaly, the algorithm’s AUC was 0.96. Given the push to make radiology more quantitative and less subjective, these statistics should be borne in mind.
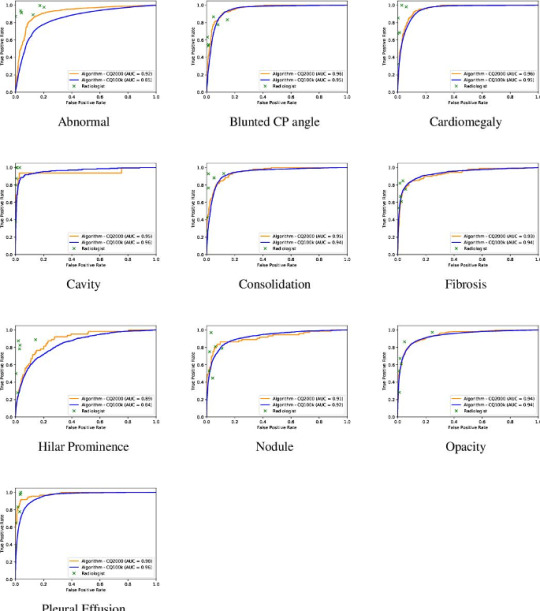
The AUC of algorithm performance in test and validation cases. The individual crosses represent radiologists. Radiologists did better than the algorithm.
For all abnormalities, both measures of diagnostic performance were over 90 %. The algorithm got straight As. In fact, the algorithm performed better on the test (AUC – 0.92) than validation cases (AUC – 0.86) at discerning normal – a testament not to its less-is-more philosophy but the fact that the test sample had fewer gray zone abnormalities, such as calcification of the aortic knob, the type of “abnormality” that some radiologists report and others ignore. This meant that AI’s performance had reached an asymptote which couldn’t be overcome by more data because the more radiographs it saw the more “gray zone” abnormalities it’d see. This curious phenomenon mirrors radiologists’ performance. The more chest radiographs we see the better we get. But we get worse, too, because we know what we don’t know and become more uncertain. After a while there’s little net gain in performance by seeing more radiographs.
Nearly three years after the company was conceived, after several dead ends, and morale-lowering frustrations with the metadata, the chest radiograph algorithm had matured. It was actually not a single algorithm but a bunch of algorithms which helped each other and could be combined into a meta-algorithm. The algorithms moved like bees but functioned like a platoon.
As the team was about to open the champagne, Ammar Jagirdar, Product Manager, had news.
“Guys, the local health authority in Baran, Rajasthan, is interested in our TB algorithm.”
Ammar, a former dentist with a second degree in engineering, also from IIT, isn’t someone you can easily impress. He gave up his lucrative dental practice for a second career because he found shining teeth intellectually bland.
“I was happy with the algorithm performance,” said Ammar, “but having worked in start-ups, I knew that building the product is only 20 % of the task. 80 % is deployment.”
Ammar had underestimated deployment. He had viewed it as an engineering challenge. He anticipated mismatched IT systems which could be fixed by clever codes or I-phone apps. Rajashtan would teach him that the biggest challenge to deployment of algorithms wasn’t the AUC, or clever statisticians arguing endlessly on Twitter about which outcome measures the value of AI, or overfitting. It was a culture of doubt. A culture which didn’t so much fear change as couldn’t be bothered changing. Qure’s youthful scientists, who looked like characters from a Netflix college movie, would have to labor to be taken seriously.
Saurabh Jha (aka @RogueRad) is a contributing editor to The Health Care Blog. This is Part 2 of a 3-part series.
The post Artificial Intelligence vs. Tuberculosis – Part 2 appeared first on The Health Care Blog.
Artificial Intelligence vs. Tuberculosis – Part 2 published first on https://venabeahan.tumblr.com
0 notes
Text
Artificial Intelligence vs. Tuberculosis – Part 2
By SAURABH JHA, MD
Clever Hans
Preetham Srinivas, the head of the chest radiograph project in Qure.ai, summoned Bhargava Reddy, Manoj Tadepalli, and Tarun Raj to the meeting room.
“Get ready for an all-nighter, boys,” said Preetham.
Qure’s scientists began investigating the algorithm’s mysteriously high performance on chest radiographs from a new hospital. To recap, the algorithm had an area under the receiver operating characteristic curve (AUC) of 1 – that’s 100 % on multiple-choice question test.
“Someone leaked the paper to AI,” laughed Manoj.
“It’s an engineering college joke,” explained Bhargava. “It means that you saw the questions before the exam. It happens sometimes in India when rich people buy the exam papers.”
Just because you know the questions doesn’t mean you know the answers. And AI wasn’t rich enough to buy the AUC.
The four lads were school friends from Andhra Pradesh. They had all studied computer science at the Indian Institute of Technology (IIT), a freaky improbability given that only hundred out of a million aspiring youths are selected to this most coveted discipline in India’s most coveted institute. They had revised for exams together, pulling all-nighters – in working together, they worked harder and made work more fun.
Preetham ordered Maggi Noodles – the mysteriously delicious Indian instant noodles – to charge their energies. Ennio Morricone’s soundtrack from For a Few Dollars More played in the background. We were venturing into the wild west of deep learning.
The lads had to comb a few thousand normal and a few thousand abnormal radiographs to find what AI was seeing. They were engineers, not radiologists, and had no special training in radiology except for one that comes with looking at thousands of chest radiographs, which they now knew like the lines at the back of their hands. They had carefully fed AI data to teach it radiology. In return, AI taught them radiology – taught them where to look, what to see, and what to find.
They systematically searched the chest radiographs for clues. Radiographs are two-dimensional renditions, mere geometric compressions, maps of sorts. But the real estate they depict have unique personalities. The hila, apices, and tracheobronchial angle are so close to each other that they may as well be one structure, but like the mews, roads, avenues and cul-de-sacs of London, they’re distinct, each real estate expressing unique elements of physiology and pathology.
One real estate which often flummoxes AI is the costophrenic angle (CPA) – a quiet hamlet where the lung meets the diaphragm, two structures of differing capacity to stop x-rays, two opposites which attach. It’s supposedly sharp – hence, an “angle”; the loss of sharpness implies a pleural effusion, which isn’t normal.
The CPA is often blunt. If radiologists called a pleural effusion every time the CPA was blunt half the world would have a pleural effusion. How radiologists deal with a blunted CPA is often arbitrary. Some call pleural effusion, some just describe their observation without ascribing pathology, and some ignore the blunted CPA. I do all three but on different days of the week. Variation in radiology reporting frustrates clinicians. But as frustrating as reports are, the fact is that radiographs are imperfect instruments interpreted by imperfect arbiters – i.e. Imperfection Squared. Subjectivity is unconquerable. Objectivity is farcical.
Because the radiologist’s interpretation is the gospel truth for AI, variation amongst radiologists messes AI’s mind. AI prefers that radiologists be consistent like sheep and the report be dogmatic like the Old Testament, so that it can better understand the ground truth even if the ground truth is really ground truthiness. When all radiologists call a blunted CPA a pleural effusion, AI appears smarter. Perhaps, offering my two cents, the secret to AI’s mysterious super performance was that the radiologists from this new institute were sheep. They all reported the blunted CPA in the same manner. 100 % consistency – like machines.
“I don’t think it’s the CPA, yaar,” objected Tarun, politely. “The problem is probably in the metadata.”
The metadata is a lawless province which drives data scientists insane. Notwithstanding variation in radiology reporting, radiographs – i.e. data – follow well-defined rules, speak a common language, and can be crunched by deep neural networks. But radiographs don’t exist in vacuum. When stored, they’re drenched in the attributes of the local information technology. And when retrieved, they carry these attributes, which are like local dialects, with them. Before feeding the neural networks, the radiographs must be cleared of idiosyncracies in the metadata, which can take months.
It seemed we had a long night ahead. I was looking forward to the second plate of Maggi Noodles.
Around the 50th radiograph, Tarun mumbled, “it’s clever Hans.” His pitch then rose in excitement, “I figured it. AI is behaving like Clever Hans.”
Clever Hans was a celebrity German horse which could allegedly add and subtract. He’d answer by tapping his hoof. Researchers, however, figured out his secret. Hans would continue tapping his hoof until the number of taps corresponded to the right numerical answer, which he’d deduce from the subtle, non-verbal, visual cues in his owner. The horse would get the wrong answer if he couldn’t stare at his owner’s face. Not quite a math Olympiad, Hans was still quite clever, certainly for a horse, but even by human standards.
“What do you see?” Tarun pointed excitedly to a normal and an abnormal chest radiograph placed side by side. Having interpreted over several thousand radiographs I saw what I usually see but couldn’t see anything mysterious. I felt embarrassed – a radiologist was being upstaged by an engineer, AI, and supposedly a horse, too. I stared intently at the CPA hoping for a flash of inspiration.
“It’s not the CPA, yaar,” Tarun said again – “look at the whole film. Look at the corners.”
I still wasn’t getting it.
“AI is crafty, and just like Hans the clever horse, it seeks the simplest cue. In this hospital all abnormal radiographs are labelled – “PA.” None of the normals are labelled. This is the way they kept track of the abnormals. AI wasn’t seeing the hila, or CPA, or lung apices – it detected the mark – “PA” – which it couldn’t miss,” Tarun explained.
The others shortly verified Tarun’s observation. Sure enough, like clockwork – all the abnormal radiographs had “PA” written on them – without exception. This simple mark of abnormality, a local practice, became AI’s ground truth. It rejected all the sophisticated pedagogy it had been painfully taught for a simple rule. I wasn’t sure whether AI was crafty, pragmatic or lazy, or whether I felt more professionally threatened by AI or data scientists.
“This can be fixed by a simple code, but that’s for tomorrow,” said Preetham. The second plate of Maggi Noodles never arrived. AI had one more night of God-like performance.
The Language of Ground Truth
Artificial Intelligence’s pragmatic laziness is enviable. To learn, it’ll climb mountains when needed but where possible it’ll take the shortest path. It prefers climbing molehills to mountains. AI could be my Tyler Durden. It doesn’t give a rat’s tail how or why and even if it cared it won’t tell you why it arrived at an answer. AI’s dysphasic insouciance – its black box – means that we don’t know why AI is right, or that it is. But AI’s pedagogy is structured and continuous.
After acquiring the chest radiographs, Qure’s scientists had to label the images with the ground truth. Which truth, they asked. Though “ground truth” sounds profound it simply means what the patient has. On radiographs, patients have two truths: the radiographic finding, e.g. consolidation – an area of whiteness where there should be lung, and the disease, e.g. pneumonia, causing that finding. The pair is a couplet. Radiologists rhyme their observation with inference. The radiologist observes consolidation and infers pneumonia.
The inference is clinically meaningful as doctors treat pneumonia, not consolidation, with antibiotics. The precise disease, such as the specific pneumonia, e.g. legionella pneumonia, is the whole truth. But training AI on the whole truth isn’t feasible for several reasons.
First, many diseases cause consolidation, or whiteness, on radiographs – pneumonia is just one cause, which means that many diseases look similar. If legionella pneumonia looks like alveolar hemorrhage, why labor to get the whole truth?
Second, there’s seldom external verification of the radiologist’s interpretation. It’s unethical resecting lungs just to see if radiologists are correct. Whether radiologists attribute consolidation to atelectasis (collapse of a portion of the lung, like a folded tent), pneumonia, or dead lung – we don’t know if they’re right. Inference is guesswork.
Another factor is the sample size: preciser the truth fewer cases of that precise truth. There are more cases of consolidation from any cause than consolidation from legionella pneumonia. AI needs numbers, not just to tighten the confidence intervals around the point estimate – broad confidence intervals imply poor work ethic – but for external validity. The more general the ground truth, the more cases of labelled truth AI sees, and the more generalizable AI gets, allowing it to work in Mumbai, Karachi, and New York.
Thanks to Prashant Warier’s tireless outreach and IIT network, Qure.ai acquired a whopping 2.5 million chest radiographs from nearly fifty centers across the world, from afar as Tokyo and Johannesburg and, of course, from Mumbai. AI had a sure shot at going global. But the sheer volume of radiographs made the scientists timorous.
“I said to Prashant, we’ll be here till the next century if we have to search two million medical records for the ground truth, or label two million radiographs” recalls Preetham. AI could neither be given a blank slate nor be spoon fed. The way around it was to label a few thousand radiographs with anatomical landmarks such as hila, diaphragm, heart, a process known as segmentation. This level of weak supervision could be scaled.
For the ground truth, they’d use the radiologist’s interpretation. Even so, reading over a million radiology reports wasn’t practical. They’d use Natural Language Processing (NLP). NLP can search unstructured (free text) sentences for meaningful words and phrases. NLP would tell AI whether the study was normal or abnormal and what the abnormality was.
Chest x-ray reports are diverse and subjective, with inconsistency added to the mix. Ideally, words should precisely and consistently convey what radiologists see. Radiologists do pay heed to March Hare’s advice to Alice: “then you should say what you mean,” and to Alice’s retort: “at least I mean what I say.” The trouble is that different radiologists say different things about the same disease and mean different things by the same descriptor.
One radiologist may call every abnormal whiteness an “opacity”, regardless of whether they think the opacity is from pneumonia or an innocuous scar. Another may say “consolidation” instead of “opacity.” Still another may use “consolidation” only when they believe the abnormal whiteness is because of pneumonia, instilling connation in the denotation. Whilst another may use “infiltrate” for viral pneumonia and “consolidation” for bacterial pneumonia.
The endless permutations of language in radiology reports would drive both March Hare and Alice insane. The Fleischner Society lexicon makes descriptors more uniform and meaningful. After perusing several thousand radiology reports, the team selected from that lexicon the following descriptors for labelling: blunted costophrenic angle, cardiomegaly, cavity, consolidation, fibrosis, hilar enlargement, nodule, opacity and pleural effusion.
Not content with publicly available NLPs, which don’t factor local linguistic culture, the team developed their own NLP. They had two choices – use machine learning to develop the NLP or use humans (programmers) to make the rules. The former is way faster. Preetham opted for the latter because it gave him latitude to incorporate qualifiers in radiology reports such as “vague” and “persistent.” The nuances could come in handy for future iterations.
Starting off with simple rules such as negation detection so that “no abnormality” or “no pneumonia” or “pneumonia unlikely” would be the same as “normal”, then broadening the rules to incorporate synonyms such as “density” and “lesion”, including the protean “prominent”, a word which can mean anything except what it actually means and like “awesome” has been devalued by overuse, the NLP for chest radiograph accrued nearly 2500 rules, rapidly becoming more biblical than the regulations of Obamacare.
The first moment of reckoning arrived: does the NLP even work? Testing the NLP is like testing the tester – if the NLP was grossly inaccurate, the whole project would crash. NLP determines the accuracy of the labelled truth – e.g. whether the radiologist truly said “consolidation” in the report. If NLP correctly picks “consolidation” in nine out of ten reports and doesn’t in one out of ten, the radiograph with “consolidation” but labelled “normal” doesn’t confuse AI. AI can tolerate occasional misclassification; indeed, it thrives on noise. You’re allowed to fool it once, but you can’t fool it too often.
After six months of development, the NLP was tested on 1930 reports to see if it flagged the radiographic descriptors correctly. The reports, all 1930 of them, were manually checked by radiologists blinded to NLP’s answers. The NLP performed respectively, with sensitivities/ specificities for descriptors ranging from 93 % to 100 %.
For “normal”, the most important radiological diagnosis, NLP had a specificity of 100 %. This means that in 10, 000 reports the radiologists called or implied abnormal, none would be falsely extracted by the NLP as “normal.” NLP’s sensitivity for “normal” was 94 %. This means that in 10, 000 reports the radiologist called or implied normal, 600 would be falsely extracted by NLP as “abnormal.” NLP’s accuracy reflected language ambiguity, which is a proxy of radiologist’s uncertainty. Radiologists are less certain and use more weasel words when they believe the radiograph is normal.
Algorithm Academy
After deep learning’s success using Image Net to spot cats and dogs, prominent computer scientists prophesized the extinction of radiologists. If AI could tell cats apart from dogs it could surely read CAT scans. They missed a minor point. The typical image resolution in Image Net is 64 x 64 pixels. The resolution of chest radiographs can be as high as 4096 x 4096 pixels. Lung nodules on chest radiographs are needles in haystacks. Even cats are hard to find.
The other point missed is more subtle. When AI is trying to classify a cat in a picture of a cat on the sofa, the background is irrelevant. AI can focus on the cat and ignore the sofa and the writing on the wall. On chest radiographs the background is both the canvass and the paint. You can’t ignore the left upper lobe just because there’s an opacity in the right lower lobe. Radiologists don’t enjoy satisfaction of search. All lungs must be searched with unyielding visual diligence.
Radiologists maybe awkward people, imminently replaceable, but the human retina is a remarkable engineering feat, evolutionarily extinction-proof, which can discern lot more than fifty shades of gray. For the neural network, 4096 pixels is too much information. Chest radiographs had to be down sampled to 256 pixels. The reduced resolution makes pulmonary arteries look like nodules. Radiologists should be humbled that AI starts at a disadvantage.
Unlike radiologists, AI doesn’t take bathroom breaks or check Twitter. It’s indefatigable. Very quickly, it trained on 50, 000 chest radiographs. Soon AI was ready for the end of semester exam. The validation cases come from the same source as the training cases. Training-validation is a loop. Data scientists look at AI’s performance on validation cases, make tweaks, and give it more cases to train on, check its performance again, make tweaks, and so on.
When asked “is there consolidation?”, AI doesn’t talk but expresses itself in a dimensionless number known as confidence score – which runs between 0 and 1. How AI arrives at a particular confidence score, such as 0.5, no one really understands. The score isn’t a measure of probability though it probably incorporates some probability. Nor does it strictly measure confidence, though it’s certainly a measure of belief, which is a measure of confidence. It’s like asking a radiologist – “how certain are you that this patient has pulmonary edema – throw me a number?” The number the radiologist throws isn’t empirical but is still information.
The confidence score is mysterious but not meaningless. For one, you can literally turn the score’s dial, like adjusting the brightness or contrast of an image, and see the trade-off between sensitivity and specificity. It’s quite a sight. It’s like seeing the full tapestry of radiologists, from the swashbuckling under caller to the “afraid of my shadow” over caller. The confidence score can be chosen to maximize sensitivity or specificity, or using Youden’s index, optimize both.
To correct poor sensitivity and specificity, the scientists looked at cases where the confidence scores were at the extremes, where the algorithm was either nervous or overconfident. AI’s weaknesses were radiologist’s blind spots, such as the lung apices, the crowded bazaar of the hila, and behind the ribs. It can be fooled by symmetry. When the algorithm made a mistake, it’s reward function, also known as loss function, was changed so that it was punished if it made the same mistake and rewarded when it didn’t. Algorithms, who have feelings, too, responded favorably like Pavlov’s dogs, and kept improving.
Validation case. The algorithm called “consolidation” in the left lower lobe. The radiologist called the x-ray normal. The radiologist is the gold standard so this was a false positive.
The Board Exam
After eighteen months of training-validation, and seeing over million radiographs, the second moment of reckoning arrived: the test, the real test, not the mock exam. This important part of algorithm development must be rigorous because if the test is too easy the algorithm can falsely perform. Qure.ai wanted their algorithms validated by independent researchers and that validation published in peer review journals. But it wasn’t Reviewer 2 they feared.
“You want to find and fix the algorithm’s weaknesses before deployment. Because if our customers discover its weaknesses instead of us, we lose credibility,” explained Preetham.
Preetham was alluding to the inevitable drop in performance when algorithms are deployed in new hospitals. A small drop in AUC such as 1-2 %, which doesn’t change clinical management, is fine; a massive drop such as 20 % is embarrassing. What’s even more embarrassing is if AI misses an obvious finding such a bleedingly-obvious consolidation. If radiologists miss obvious findings they could be sued. If the algorithm missed an obvious finding it could lose its jobs, and Qure.ai could lose future contracts. A single drastic error can undo months of hard work. Healthcare is an unforgiving market.
In the beginning of the training, AI missed a 6 cm opacity in the lung, which even toddlers can see. Qure’s scientists were puzzled, afraid, and despondent. It turned out that the algorithm had mistaken the large opacity for a pacemaker. Originally, the data scientists had excluded radiographs with devices so as not to confuse AI. When the algorithm saw what it thought was a pacemaker it remembered the rule, “no devices”, so denied seeing anything. The scientists realized that in their attempt to not confuse AI, they had confused it even more. There was no gain in mollycoddling AI. It needed to see the real world to grow up.
The test cases came from new sources – hospitals in Calcutta, Pune and Mysore. The ground truth was made more stringent. Three radiologists read the radiographs independently. If two called “consolidation” and the third didn’t, the majority prevailed, and the ground truth was “consolidation”. If two radiologists didn’t flag a nodule, and a third did, the ground truth was “no nodule.” For both validation and the test cases, radiologists were the ground truth – AI was prisoner to radiologists’ whims, but by using three radiologists as the ground truth for test cases, the interobserver variability was reduced – the truth, in a sense, was the golden mean rather than consensus.
Test case. Algorithm called “opacity” in the left lower lobe. You can see why – notice the subtle but real increased density in left vs right lower lobe. One radiologist called said “opacity”, two disagreed. This was a false positive.
What’s the minimum number of abnormalities AI needs to see; its numbers needed to learn (NNL)? This depends on several factors – how sensitive you think the algorithm will be, the desired tightness of the confidence interval, desired precision (paucity of false positives) and, crucially, rarity of the abnormality. The rarer the abnormality the more radiographs AI needs to see. To be confident of seeing eighty cases – the NNL was derived from a presumed sensitivity of 80 % – of a specific finding, AI would have to see 15, 000 radiographs. NNL wasn’t a problem in either training or validation – recall, there were 100, 000 radiographs for validation which is a feast even for training. But gathering test cases was onerous and expensive. Radiologists aren’t known to work for free.
Qure’s homegrown NLP flagged chest radiographs with radiology descriptors in the new hospitals. There were normals, too, which were randomly distributed in the test, but the frequency of abnormalities was different from the training cases. In the latter, the frequency reflected actual prevalences of radiographic abnormalities. Natural prevalences don’t guarantee sufficient abnormals in a sample of two thousand. Through a process called “enrichment”, the frequency of each abnormality in the test pool was increased, so that 80 cases each of opacity, nodule, consolidation, etc, were guaranteed in the test.
The abnormals in the test were more frequent than in real life. Contrived? Yes. Unfair? No. In the American board examination, radiologists are shown only abnormal cases.
Like anxious parents, Qure’s scientists waited for the exam result, the AUC.
“We expected sensitivities of 80 %. That’s how we calculated our sample size. A few radiologists advised us that we not develop algorithms for chest radiographs, saying that it was a fool’s errand because radiographs are so subjective. We could hear their warnings.” Preetham recalled with subdued nostalgia.
The AUC for detecting an abnormal chest radiograph was 0.92. Individual radiologists, unsurprisingly, did better as they were part of the truth, after all. As expected, the degree of agreement between radiologists, the inter-observer variability, affected AI’s performance, which was the highest when radiologists were most in agreement, such as when calling cardiomegaly. The radiologists had been instructed to call “cardiomegaly” when the cardiothoracic ratio was greater than 0.5. For this finding, the radiologists agreed 92 % of the time. For normal, radiologists agreed 85 % of the time. For cardiomegaly, the algorithm’s AUC was 0.96. Given the push to make radiology more quantitative and less subjective, these statistics should be borne in mind.
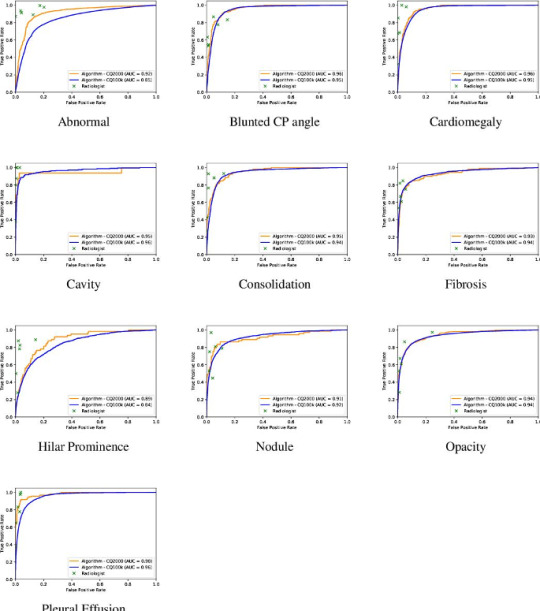
The AUC of algorithm performance in test and validation cases. The individual crosses represent radiologists. Radiologists did better than the algorithm.
For all abnormalities, both measures of diagnostic performance were over 90 %. The algorithm got straight As. In fact, the algorithm performed better on the test (AUC – 0.92) than validation cases (AUC – 0.86) at discerning normal – a testament not to its less-is-more philosophy but the fact that the test sample had fewer gray zone abnormalities, such as calcification of the aortic knob, the type of “abnormality” that some radiologists report and others ignore. This meant that AI’s performance had reached an asymptote which couldn’t be overcome by more data because the more radiographs it saw the more “gray zone” abnormalities it’d see. This curious phenomenon mirrors radiologists’ performance. The more chest radiographs we see the better we get. But we get worse, too, because we know what we don’t know and become more uncertain. After a while there’s little net gain in performance by seeing more radiographs.
Nearly three years after the company was conceived, after several dead ends, and morale-lowering frustrations with the metadata, the chest radiograph algorithm had matured. It was actually not a single algorithm but a bunch of algorithms which helped each other and could be combined into a meta-algorithm. The algorithms moved like bees but functioned like a platoon.
As the team was about to open the champagne, Ammar Jagirdar, Product Manager, had news.
“Guys, the local health authority in Baran, Rajasthan, is interested in our TB algorithm.”
Ammar, a former dentist with a second degree in engineering, also from IIT, isn’t someone you can easily impress. He gave up his lucrative dental practice for a second career because he found shining teeth intellectually bland.
“I was happy with the algorithm performance,” said Ammar, “but having worked in start-ups, I knew that building the product is only 20 % of the task. 80 % is deployment.”
Ammar had underestimated deployment. He had viewed it as an engineering challenge. He anticipated mismatched IT systems which could be fixed by clever codes or I-phone apps. Rajashtan would teach him that the biggest challenge to deployment of algorithms wasn’t the AUC, or clever statisticians arguing endlessly on Twitter about which outcome measures the value of AI, or overfitting. It was a culture of doubt. A culture which didn’t so much fear change as couldn’t be bothered changing. Qure’s youthful scientists, who looked like characters from a Netflix college movie, would have to labor to be taken seriously.
Saurabh Jha (aka @RogueRad) is a contributing editor to The Health Care Blog. This is Part 2 of a 3-part series.
The post Artificial Intelligence vs. Tuberculosis – Part 2 appeared first on The Health Care Blog.
Artificial Intelligence vs. Tuberculosis – Part 2 published first on https://wittooth.tumblr.com/
0 notes
Text
Tanhaji Vs Chhapaak box office day 8: Ajay Devgn film earns Rs 128.41cr, Deepika Padukone’s film collects Rs 29.13cr - bollywood

Ajay Devgn’s latest offering, Tanhaji The Unsung Warrior continued to rule the domestic ticket windows even as the film entered the second week on Friday. Collections for Deepika Padukone’s Chhapaak, on the other hand, dropped majorly. Tanhaji: The Unsung Warrior stands strong at Rs 128.41 crore while Chhapaak has a total of Rs 29.13 crore.As per a Boxofficeindia report, Tanhaji The Unsung Warrior has collected an estimated Rs 9.5 crore on the eighth day of the release. While it is a 15% drop from Thursday’s collections as per the report, the earnings are impressive for the second Friday. The report added that “over 50% of its all India business is going to come from Maharashtra on its second Friday”. The circuits that fall have centres in Maharashtra are Mumbai, CP Berar and Nizam / Andhra and these are the best circuits for the film, it added.Also read: Chhapaak and Tanhaji: Factors that decided box office run of Deepika Padukone, Ajay Devgn’s filmsMeanwhile, Chhapaak earned an estimated Rs 75 lakh on Friday, the report added. Directed by Meghna Gulzar, the film traces the journey of Malti (Deepika) and is loosely based on the life of Delhi’s acid attack survivor Laxmi Agarwal.While Deepika’s Jawaharlal Nehru University visit was assumed to have affected the film’s performance, film exhibitor Akshay Rathi had said social media is not the reflection of the ground level reality. “All the hype around it is on the social media. There are so many CAA and NRC supporters who have made the appeal to watch the film. If social media was a reflection of the reality, the numbers would have been something else. Any Rohit Shetty movie is slammed by the critics, but look at the numbers they do!” he told Hindustan Times. Asked if the controversy actually hampered Chhapaak’s box office run, film trade analyst Girish Johar said, “No, I don’t think so. The film performs on the basis of what it is. The weekend has been decent, Monday is critical for the film. Both the films have an advantage of partial holidays and can improve.”Tanhaji: The Unsung Warrior has been directed by Om Raut and also features Saif Ali Khan and Kajol in lead roles.Follow @htshowbiz for more
Read the full article
#$5entertainmentbook#$5entertainmentcouponbook#0151entertainment#08.05entertainment#1entertainmentbedford#1entertainmentbouncycastle#1entertainmentdj#1entertainmentevents#1entertainmentinc#1entertainmentltd#1entertainmentmusicandmanagementgroup#1entertainmentpass#1entertainmentreviews#1entertainmentsittingbourne#12841cr#2entertainmentmanagementltd#2entertainmentnews#2/0entertainmentcable#2913cr#3artsentertainment#3ballentertainment#3entertainmentproducts#4entertainmentawards#4entertainmentcreditcard#4entertainmentgroup#4entertainmentgroupllc#4entertainmentgrouplosangeles#4entertainmentjobs#4entertainmentlogo#5entertainmentab
0 notes
Text
Vijay Hazare Trophy live score: Delhi bowls first vs Jharkhand; TN bats first vs Mumbai
Vijay Hazare Trophy live score: Delhi bowls first vs Jharkhand; TN bats first vs Mumbai
Hello and welcome to Sportstar’s live updates from the Vijay Hazare Trophy matches across six centres.
TOSS AND MID-INNINGS UPDATES ONLY.
Delhi batter Shikhar Dhawan will be in action today. – Shayan Acharya
From Mohali: Shayan Acharya pings: “Delhi players are playing a friendly game ahead of their opening fixture. One can see Delhi coach and Virat Kohli’s mentor Rajkumar Sharma.”
Delhi…

View On WordPress
#Andhra vs Odisha#Karnataka vs Pondicherry#Live Cricket Score#Live score#MP vs Maharashtra#Tamil Nadu vs Mumbai#vijay hazare trophy#vijay hazare trophy live score#vijay hazare trophy news#vijay hazare trophy score#vijay hazare trophy updates
0 notes
Text

MARBLE IN INDIA
BY D.C BHANDARI
CEO
BHANDARI MARBLE GROUP
SINCE 1631
INDIAN MARBLE
BHANDARI MARBLE
We are a top leading Indian Marble Manufacturers, Exporters, Supplier based in Kishangarh Rajasthan India and Wholesale Suppliers of different types of colour Indian Marbles & the high quality & highly demanding Indian Green Marble, Makrana White Marble, Indian Onyx Marble and Marble Stone. BHANDARI MARBLE are suppliers of Indian Marble in all over World: USA, UK, UAE, INDIA, SINGAPORE, HONG KONG, SHRI LANKA, DUBAI, FRANCE, AUSTRALIA, NEWZILAND, Bangalore, Delhi, Kolkata, Mumbai, Hyderabad, Chanai, Pune, Jaipur, Ahmedabad, jammu, Ludhiana, Jalandhar, Pathankot, Punjab, Simla, Hamirpur, Himachal pardesh, Chandigarh, Panchkula, Mohali, Sirsa, Gurugram, Hariyana, Delhi, Noyada, Delhi NCR, Kanpur, Agara, Lucknow, Uttar Pradesh, Patna, Bihar, Bhuwneswar, Katak, Urisa, Siliguri, Kolkatta, Hawara, West bangal, Gohati, Asam, Kathmandu, Virat nagar, Nepal, Sikkim, Hyderabad, Vishakhapattnam, Vijaywara, Andhra pardesh, Telangana, Banglore, Manglore, Masore, Hubli, Karnataka, Chanai, Erode, Salem, Trichi, Madurai, Coimbatore, Tamilnadu, Kochi, kolam, kalikat, Kanoor, Kaghikode, Kerala, Goa, Pandichery, Belgaon, Mumbai, Navi Mumbai, Pune, Jalgoan, Jalana, Nagpur, Maharastra, Bhopal , Ujjain, Indore, Madhay pardesh, Surat, Ahemdabad, Rajkot, Gujrat, Jaipur, Jodhpur, Udaipur, Kishangarh, Makrana, Ajmer, Bharatpur, Rajasthan and other Cities.
Bhandari Marble World is one of the largest Manufacturers, Suppliers and Exporters of Marble, White marble, Latin marble, Slabs, Floor Tiles, Blocks, Green Marble Slabs, Tiles, Rainforest Green Marble Slabs, Tiles, Marble Counter Top and Marble Stone.
If you are in looking of Indian Marble, Green Marble, Forest Green Marble, Indian Onyx Marble, Green Onyx Marble, Makrana Marble, White Marble, Kishangarh Marble, Morwad Marble, Katni Marble. Please get in touch for the best quality marble, color, varieties and drop us an email with your requirements for affordable Indian Marble Prices.
We are supplying our Indian Granite to Delhi, Bangalore, Mumbai, Kolkata etc
Indian Marble Image
www.bhandarimarblegroup.com/showroom/
Or
www.bhandarimarblegroup.com/ebook/
Indian vs Italian Marble: What Works Best For Your Home?
No doubt INDIAN MARBLE
When it comes to marble, you have two options that are immensely popular in Indian homes. Both Indian marble and Italian marble are amazing choices for your flooring or surface top needs. But how do you pick the right marble that’s INDIAN MARBLE perfect for your home and budget?
While there’s a lot of info out there and it’s easy to get overwhelmed, here are the basic differences you need to know between Indian and Italian marble.
INDIAN MARBLE,
BHANDARI MARBLE GROUP
Indian marble is quarried extensively in North India. This makes it a cost-effective choice with a wide variety of colors and textures.
INDIAN MARBLE
BHANDARI MARBLE GROUP
On the other hand, Italian marble is quarried in Italy and is now easily available in India as well. It is widely appreciated for its high lustre and imparting visual appeal to the area where it’s used.
ITALIAN MARBLE
BHANDARI MARBLE GROUP
Popular Types of Indian and Italian Marbles
BHANDARI MARBLE GROUP
Indian marble: It comes in an astonishing array of colors such as white, pink, yellow, green, red and black. Some of the popular varieties include:
INDIAN MARBLE
BHANDARI MARBLE GROUP
white Makrana marble (famously used in the Taj Mahal)
MAKRANA MARBLE
BHANDARI MARBLE GROUP
High-quality white Ambaji marble from Gujarat
AMBAJI MARBLE
BHANDARI MARBLE GROUP
The widely exported Indian green marble
GREEN MARBLE
BHANDARI MARBLE GROUP
Onyx marble which gets its name from the thick bands of alternating color
ONYX MARBLE
BHANDARI MARBLE GROUP
Italian marble: Like its Indian counterpart, this comes in a variety of color and textures. Though there are a few varieties which are instantly recognizable, such as:
ITALIAN MARBLE
BHANDARI MARBLE GROUP
The much valued Statuario marble which is characterised by its white color shot with grey or gold veins
STATUARIO MARBLE
BHANDARI MARBLE GROUP
Golden hued Botticino marble which seems to be l
from within
BOTTICINO MARBLE
BHANDARI MARBLE GROUP
Light grey Carrera marble which features dispersed, fine, feathery veining
CARRARA MARBLE
BHANDARI MARBLE GROUP
MARBLE PRICE
Indian marble: While the cost of marble varies from city to city and vendor to vendor, Indian marble starts from as low as ₹30 per sq ft for some varieties of Indian green marble. It goes up to ₹150 per sq ft for other varieties.
INDIAN MARBLE PRICE
BHANDARI MARBLE GROUP
Italian marble: Since this is available in a wide variety, prices could range from ₹150 to ₹5,00 per sq ft, and sometimes more.
ITALIAN MARBLE PRICE
BHANDARI MARBLE GROUP
MARBLE FITTING COST
BHANDARI MARBLE GROUP
The cost of laying both Indian and Italian marble are different in price, Indian marble which is between 20 to ₹50 per sq ft. Italian marble 75 to 150 RS per sq feet & Laying marble involves creating a base of cement and river sand.
Monuments made up of White Marble from India..
BY BHANDARI MARBLE GROUP
There are many monuments that are made up of White Marble India they are like:
The TajMahal
BHANDARI MARBLE GROUP
The TajMahal, that is fully made up of white Indian marble, TajMahal is located in Agra, and made by a Mughal Emperor Shahjahan in the memory of his beloved wife. The TajMahal is one of the seven wonders of the world. The TajMahal means “CROWN OF PALACES” according to Persians and Arabics, Its garden has lot of trees and fountains, The other one is:
The Lake Palace
BHANDARI MARBLE GROUP
The Lake Palace, formerly known as Jag-Nivas, it’s a luxury hotel in Udaipur, Rajasthan, India. it is made up of Indian White Marble, and it is located on a natural foundation of 4 acres (16,000 sq mt.) on the Jag-Nivas island in lake Pichola Udaipur India. It was built in 1743 in the supervision of Maharana Jagat Singh 2. and was called Jag-Niwas after its founder, the successive Ruler used this place is as their summer resort holding their Darbar in its cortyart with columns terraces fountains and gardens. and another one is:
BHANDARI MARBLE GROUP
KILA OF
Jaipur, Jodhpur, Bikaner and other places in Rajasthan.
BHANDARI MARBLE GROUP
To know more about Indian White Marble please visit
www .bhandarimarblegroup.com
white marble
Gold Marble
Katni "Marble
BHANDARI MARBLE GROUP
White wonder Marble:
BHANDARI MARBLE GROUP
Lady onyx Marble
BHANDARI MARBLE GROUP
Makran white marble
BHANDARI MARBLE GROUP
Jaisalmer Gold marble
BHANDARI MARBLE GROUP
Kishangarh White marble
BHANDARI MARBLE GROUP
Marble Products
BHANDARI MARBLE GROUP
Sandstones
0 notes
Text
RTE – 71 Years And Still A Distant Dream…
The journey of providing Universal Elementary Education “Right to Free and Compulsory Education” in our country began in the year 1946, during the task of the framing of our Constitution. It took 60 years, after completing a full circle to come back to what was envisaged in the year 1947.
The Constituent Assembly began its task in the year 1946. In 1947, the Ways and Means (Kher) Committee was set up to explore ways and means of achieving Universal Elementary Education within ten years.
The Constituent Assembly (Sub-committee on Fundamental Rights) placed the right to free and compulsory education on the list of Fundamental Rights and suggested Clause 23.
“Clause 23: Every citizen is entitled as of a right to free primary education and it shall be the duty of the State to provide within a period of ten years from the commencement of this Constitution for free and compulsory primary education for all children until they complete the age of fourteen years.”
The same year the Advisory Committee of the Constituent Assembly rejected the suggestion to provide free and compulsory education as a fundamental right quoting the costs as a reason and sent Clause 23 to the list of “Non-Justiciable Fundamental Rights” which was later termed as ‘Directive Principles of State Policy’.
In 1949, during the debate in the Constituent Assembly, it was decided to remove the first line of ‘Article 36’…“Every citizen is entitled as of right to free primary education and it shall be the duty of the State to..” and was replaced with “The State shall endeavour to..”
Finally, in the year 1950, Article 45 was placed and accepted under the head of Directive Principles of State Policy. Article 45 – “The State shall endeavour to provide, within a period of ten years from the commencement of this Constitution, for free and compulsory education for all children until they complete the age of fourteen years”.
From 1950 to 1993, the directive principle embodied in Article 45 remained in hibernation, till the Supreme Court, in Unni Krishnan J.P. vs. State of Andhra Pradesh, held that Article 45 as originally enacted by the framers of the Constitution was in force. Justice B.P. Jeevan Reddy, speaking for the majority, held that the right to free and compulsory education was a fundamental right under Article 21. Justice S. Mohan, in his concurring opinion, held that Article 45 has to be read as a part of Article 21, and that therefore “the right to free education up to the age of 14 years is a fundamental right”.
In 1997, a Bill was brought in the Rajya Sabha proposing to insert Article 21A in the Constitution of India and make education for children in the age group of 6 to 14 years a fundamental right. Yet again, this was diluted by entrusting this task to the State Government by stating that “State shall enact laws for ensuring the free and compulsory education.”
Subsequently, in 2002, a Constitution Bench of the Supreme Court (11 judges) in T.M.A. Pai affirmed the finding in Unnikrishanan that primary education is a fundamental right and that Article 45 as it then stood had to be read into Article 21. The Constitution (Eighty-Sixth Amendment) Act, 2002 formalised this constitutional interpretation of the Supreme Court by a newly engrafted Article 21A. The Eighty-Sixth Amendment Act made three changes: (i) bodily lifted wordings of Article 45 and transposed them with slight modifications into Article 21A; (ii) added new words in Article 45 to confine the directive principle to children below the age of six years; and (iii) added a Fundamental Duty on all parents and guardians in clause (k) of Article 51A.
However the amendment remained in slumber and was not brought into force till 2010. Finally, on 1st April 2010, Part III relating to Fundamental Rights of the Constitution of India was amended by inserting and bringing into force Article 21A and the Right of Children to Free and Compulsory Education (RTE) Act, 2009 was enacted. The statement of objects and reasons and the parliamentary debate reflects that it was the joint duty of the Central and the State Governments to provide free education in pursuance of Article 21A. In fact, the Ninth Five Year Plan reflected that this sharing of duty would be in the ratio of 15:85 for the first five years; 25:75 in the next five years and finally 50:50 in the subsequent five years.
Correspondingly, the Constitution was also amended to insert Clause (k) in Article 51A in Chapter IV-A (Fundamental Duties), whereby an obligation was cast on every parent or guardian to provide opportunity for education to his child between the age of 6 to 14 years. Curiously, the parliamentary debates indicate that though there was a consensus that it was a duty of the parents to provide opportunity for education to their children, the penalty for non-compliance of this fundamental duty was quantified to only 50 paise to 1 Rupee.
UNESCO report of 2016 says that over 60 million children in India receive little or no formal education and the country has over 11.1 million out-of-school students in the lower secondary level, highest in the world.
A recent survey by CRY of 122 schools in Pune, Ahmednagar, Gadchiroli, Parbhani, Aurangabad, Latur, Beed and Mumbai revealed:
57 percent of the schools did not have a principal or head of school.
In 69 percent of the schools, students and teachers themselves were responsible for cleaning the toilets.
13 percent of the schools did not have proper buildings and 37 percent did not have compound walls.
63 percent schools did not make available even filtered drinking water to students despite the mandate under RTE.
“Education is a fundamental right and the basis for progress in every country. Parents need information about health and nutrition if they are to give their children the start in life they deserve. Prosperous countries depend on skilled and educated workers. The challenges of conquering poverty, combatting climate change and achieving truly sustainable development in the coming decades compel us to work together. With partnership, leadership and wise investments in education, we can transform individual lives, national economies and our world”.
United Nations Secretary-General Ban Ki-moon
The RTE Act crucially leaves children between 3 and 6 years of age – the most formative years of a child’s life – out of its purview. 15 to 18 year olds find themselves in a similar situation, with little chance of completing their education if they cannot pay for it. The Act does not offer much to ensure learning outcomes for children, which is fundamental for any education system to be meaningful.
The vision of the founding fathers to provide free elementary education to all citizens within ten years from the framing of the Constitution has remained a distant dream and a mere illusion even after 71 years.
Originally posted: https://www.zelican.com/2018/12/71-years-and-still-a-distant-dream/
0 notes
Text
Big sports events today - Times of India
New Post has been published on https://apzweb.com/big-sports-events-today-times-of-india-20/
Big sports events today - Times of India
NEW DELHI: Here are the big sports events lined up for Saturday (February 15) that comprise Indian men’s team semifinal match at the Badminton Asia Team Championships and action from football world.
(All timings in IST)
1:00 am (Football – Bundesliga)
Dortmund vs Eintracht
1:30 am (Football – English Premier League)
Wolves vs Leicester City
1:30 am (Football – La Liga)
Valencia vs Atletico Madrid
3:30 am (Cricket – 3-Day Practice Match, Day 2)
New Zealand XI vs India
9:30 am (Cricket – Ranji Trophy, Round 9, Day 4)
Saurashtra vs Tamil Nadu
Mumbai vs Madhya Pradesh
Hyderabad vs Vidarbha
Gujarat vs Andhra
Delhi vs Rajasthan
Uttar Pradesh vs Himachal Pradesh
Chhattisgarh vs Services
Jammu and Kashmir vs Haryana
Assam vs Tripura
Odisha vs Jharkhand
Maharashtra vs Uttarakhand
1:30 pm (Badminton – Badminton Asia Team Championships)
Indonesia vs India in men’s semifinal
5:00 pm (Football – I-League)
Churchill Brothers vs Aizawl FC
6:00 pm (Football – English Premier League)
Southampton vs Burnley FC
7:30 pm (Football – Indian Super League)
Kerala Blasters FC vs Bengaluru FC
8:30 pm (Football – La Liga)
Barcelona vs Getafe CF
10:00 pm (Football – Ligue 1)
Amiens SC vs PSG
11:00 pm (Football – English Premier League)
Norwich City vs Liverpool
Source link
0 notes
Last Seen Blogs

itsclicheiknow
wtmtm

rscyborg
Sin título

meghalszharanezel18-blog
i hate you everything

riense
riense

nami-ramen
Nameless/Nami