#CodeSample
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
The Encapsulation contribute to achieving data hiding in OOP?
Encapsulation is a fundamental concept in object-oriented programming (OOP) that contributes to achieving data hiding, one of the core principles of OOP. Data hiding is the idea that an object’s internal state should not be directly accessible from outside the object; instead, it should be accessed through well-defined methods or interfaces. Encapsulation is the mechanism that allows you to…
View On WordPress
#AccessModifiers#CodeSample#DataEncapsulation#DataHiding#Encapsulation#EncapsulationInJava#Java#JavaExample#ObjectOrientation#OOP#Programming
0 notes
Link
ConcurrentHashMap Examples #JavaInspires #CodeJava #CodeSamples
0 notes
Text
Speech To Text Transcription

Conversation Transcription is a speech-to-text solution that combines speech recognition, speaker identification, and sentence attribution to each speaker (also known as diarization) to provide real-time and/or asynchronous transcription of any conversation.
Speech To Text Transcriptions
Speech To Text Transcription Software
Speech To Text Transcription Free
Speech To Text Transcription On Mac
Speech To Text Transcription Going shopping for the latest speech to text app? At Transcriptionstar we understand the awning need for errorless text transcripts of recorded speech. The dime a dozen, speech to text applications, have done little or nothing to cater to the huge need for speech transcription services, the world over. Using A.I., Transcribe can turn any voice or video memo into a transcription in over 80 different languages and dialects. After recording, you can drop your file in this app and export your raw text into another app such as DropBox.
Built with Speech to Text KPMG streamlines call transcription KPMG uses Speech to Text to transcribe and catalog thousands of hours of calls, reducing compliance costs for its clients by as much as 80 percent.
Biden’s Speech to Congress: Full Transcript President Biden unveiled a major proposal to invest in education and families, describing it as “a blue-collar blueprint to build America.”.
-->
In this overview, you learn about the benefits and capabilities of the speech-to-text service.Speech-to-text, also known as speech recognition, enables real-time transcription of audio streams into text. Your applications, tools, or devices can consume, display, and take action on this text as command input. This service is powered by the same recognition technology that Microsoft uses for Cortana and Office products. It seamlessly works with the translation and text-to-speech service offerings. For a full list of available speech-to-text languages, see supported languages.
The speech-to-text service defaults to using the Universal language model. This model was trained using Microsoft-owned data and is deployed in the cloud. It's optimal for conversational and dictation scenarios. When using speech-to-text for recognition and transcription in a unique environment, you can create and train custom acoustic, language, and pronunciation models. Customization is helpful for addressing ambient noise or industry-specific vocabulary.
This documentation contains the following article types:
Quickstarts are getting-started instructions to guide you through making requests to the service.
How-to guides contain instructions for using the service in more specific or customized ways.
Concepts provide in-depth explanations of the service functionality and features.
Tutorials are longer guides that show you how to use the service as a component in broader business solutions.
Note
Bing Speech was decommissioned on October 15, 2019. If your applications, tools, or products are using the Bing Speech APIs, we've created guides to help you migrate to the Speech service.
Important
Transport Layer Security (TLS) 1.2 is now enforced for all HTTP requests to this service. For more information, see Azure Cognitive Services security.
Get started
See the quickstart to get started with speech-to-text. The service is available via the Speech SDK, the REST API, and the Speech CLI.
Sample code
Sample code for the Speech SDK is available on GitHub. These samples cover common scenarios like reading audio from a file or stream, continuous and single-shot recognition, and working with custom models.

Customization
In addition to the standard Speech service model, you can create custom models. Customization helps to overcome speech recognition barriers such as speaking style, vocabulary and background noise, see Custom Speech. Customization options vary by language/locale, see supported languages to verify support.
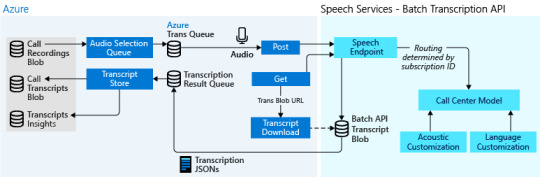
Batch transcription
Batch transcription is a set of REST API operations that enable you to transcribe a large amount of audio in storage. You can point to audio files with a shared access signature (SAS) URI and asynchronously receive transcription results. See the how-to for more information on how to use the batch transcription API.
Reference docs
The Speech service provides two SDKs. The first SDK is the primary Speech SDK and provides most of the functionalities needed to interact with the Speech service. The second SDK is specific to devices, appropriately named the Speech Devices SDK. Both SDKs are available in many languages.
Speech SDK reference docs
Use the following list to find the appropriate Speech SDK reference docs:
Tip
The Speech service SDK is actively maintained and updated. To track changes, updates and feature additions refer to the Speech SDK release notes.
Speech Devices SDK reference docs
The Speech Devices SDK is a superset of the Speech SDK, with extended functionality for specific devices. To download the Speech Devices SDK, you must first choose a development kit.
REST API references
For references of various Speech service REST APIs, refer to the listing below:
Next steps
Voice search is becoming increasingly prevalent as the years tick on, as increasing amounts of users access the Internet via mobile devices and with the help of voice assistants like Alexa. 41% of adults report using voice search on a daily basis.
Voice search is becoming an essential component of eCommerce, as well. 50% of consumers report making a purchase using voice search in the last year. Neglecting voice is like leaving money on the table, not to mention potentially alienating your audience.
Voice is also highly useful for segmenting your audience. Voice search is used most widely by affluent, highly-educated consumers. You could potentially integrate voice into a digital marketing campaign, as part of your marketing funnel, segmenting your audience in all manner of useful ways.
The fact that voice search could possibly alert you to members of your audience with money to burn and a willingness to spend is reason enough to investigate voice and integrate it into your existing workflow.
But how do you go about integrating voice recognition into your website or app? Isn’t that the domain of uber-rich companies with heavy investments in machine learning and virtual reality?
Speech To Text Transcriptions
Not necessarily.
There are numerous speech-to-text web APIs you can use to power your app or website. We’re going to dig into some of our favorite, most useful APIs for voice search.
The 5 Best APIs For Speech-To-Text
Ranking tech solutions from best to worst is always going to be subjective. What constitutes the best API will largely depend on what you’re going to be using voice recognition for.
We’ll be segmenting our favorite speech-to-text APIs by application, as a way to help you figure out which API will best suit your particular needs.
Speech-To-Text APIs for Short Online Searches
The phrases people tend to use to look things up online tend to be short, sweet, and to the point. Voice search APIs for online applications won’t need to be as thorough or have as many technical considerations, like grammar or syntax, to consider. This means these APIs tend to be lighter, faster, and quicker to load.
1. Google Speech-To-Text
Considering that Google is essentially the nervous system of the Internet at this point, it’s no surprise their Speech-To-Text API is among the most popular – and most powerful – APIs available to developers.
Google Speech-To-Text was unveiled in 2018, just one week after their text-to-speech update. Google’s Speech-To-Text API makes some audacious claims, reducing word errors by 54% in test after test. In certain areas, the results are even more encouraging.
One of the reasons for the APIs impressive accuracy is the ability to select between different machine learning models, depending on what your application’s being used for. This also makes Google Speech-To-Text a suitable solution for applications other than short web searches. It can also be configured for audio from phone calls or videos. There’s a fourth setting, as well, which Google recommends using as default.
Speech To Text Transcription Software
The Speech-To-Text API also features an impressive update for extended punctuation options. This is designed to make more useful transcriptions, with fewer run-on sentences or punctuation errors.
The newest update also allows developers to tag their transcribed audio or video with basic metadata. This is more for the company’s benefit than for the developers, however, as it will allow Google to decide which features are most useful for programmers.
The Google Speech-To-Text API isn’t free, however. It is free for speech recognition for audio less than 60 minutes. For audio transcriptions longer than that, it costs $0.006 per 15 seconds.
For video transcriptions, it costs $0.006 per 15 seconds for videos up to 60 minutes in length. For video longer than one hour, it costs $0.012 for every 15 seconds. Make sure you factor that into your pricing models when developing applications and web services.
Pros
Recognizes over 120 languages
Multiple machine learning models for increased accuracy
Automatic language recognition
Text transcription
Proper noun recognition
Data privacy
Noise cancellation for audio from phone calls and video
Cons
Costs money
Limited custom vocabulary builder
2. Microsoft Cognitive Services
Microsoft is also a major player in the world of voice recognition APIs. Microsoft Cognitive Services is more than just another speech recognition API, however. It’s also a part of the Microsoft Trust Services which offer unparalleled security options for developers looking for the most secure data for their applications.
The main thing that separates Microsoft Cognitive Services’ Speech to Text API is the Speaker Recognition function. This is the auditory version of security software like face recognition. Think of it as a retina scan for the sound of the user’s voice. It makes it incredibly easy for different levels of users.
This same voice recognition capability allows software to adapt to specific user’s speech styles and patterns. It also offers more custom vocabulary options than Google, as an additional benefit.
Beyond that, Microsoft Cognitive Service’s speech recognition API has many of the same benefits of other voice APIs. It can perform real-time transcription, as well as converting text-into-speech. Thus, Microsoft Cognitive Services can cover most of your text and speech-based needs. It can also be used for call center log analysis, if you’ve got large amounts of audio that needs to be analyzed.
Considering the widespread popularity of Microsoft products and services, Microsoft Cognitive Services is growing faster than many of the other APIs on our list. If you’re looking to join in with a vibrant, active community of developers, Microsoft Cognitive Services could be a good fit.
Pros
Enhanced data security via voice-recognition algorithms
Real-time transcription
Real-time translation
Customizable vocabulary
Text-to-speech capabilities for natural speech patterns
Cons
Built-in constraints due to the API being created for general purposes
Uses microservices, which can be useful for solving individual problems but falls short for larger problems
3. Dialogflow (Formerly API.AI, Speaktoit)
Dialogflow is also owned by Google. The main advantage over other voice APIs is Dialogflow’s ability to take context into consideration when analyzing speech, which makes for more accurate transcriptions. It also allows developers to customize their voice-based commands for different devices, such as smart devices, phones, wearables, cars, and smart speakers.

Dialogflow’s earlier incarnation, Api.ai, was used to power the Assistant app, one of the earliest virtual voice-based assistants, way back in 2014. It’s since been discontinued but demonstrates that Dialogflow has been in the AI/machine learning/voice recognition game for longer than most.
The Dialogflow voice recognition API also has a number of analytics built into the platform. You can measure user engagement or session metrics, as well as usage patterns or latency issues. This is bound to be helpful when getting investors, sales and marketing teams, and developers on the same page.
Speech To Text Transcription Free
Dialogflow currently only supports 14 languages, however. This makes it less useful for multilingual software than Google Speech-To-Text or Microsoft Cognitive Services.
Pros
Free
Easy to use
Easy to set up
Integrates with a wide variety of software
Easily integrated with other web services
Can integrate with non-Google devices like Amazon’s Alexa
Cons
Cannot handle math functions
Cannot match intent with common phrases
Cannot create clickable links in the text box
Cannot search across intents
Can only provide one webhook
Voice Recognition APIs for Longform and Offline Processing
4. IBM Watson
It’s no secret we’re generating, processing, and analyzing larger quantities of data than any other time in history. Not all of that data is going to be clean and well-organized, especially if you’re designing or developing an API. As API developers, it’s our job to make sure that the data is organized and usable.
IBM Watson is perhaps one of the purest expressions of AI as a virtual assistant. IBM Watson is very adept at processing natural language patterns, which is one of the holy grails of AI and machine learning developers.
The IBM Watson Speech to Text API is particularly robust in understanding context, relying on hypothesis generation and evaluation in its response formulation. It’s also able to differentiate between multiple speakers, which makes it suitable for most transcription tasks. You can even set a number of filters, eliminating profanities, adding word confidence, and formatting options for speech-to-text applications.
IBM Watson offers three different interfaces for developers. There’s a WebSocket interface, an HTTP REST interface, and an asynchronous HTTP interface.
IBM Watson is simple to set up and implement, which makes it a wonderful option for those looking for a Speech-To-Text API but aren’t completely technically proficient. IBM provides extensive documentation and one of the most thorough API reference manuals on the market. If you’re looking for a speech-to-text API that’s simple to set up and start using immediately, IBM Watson might be a good fit.
Of course, IBM Watson is more than just a speech-to-text API. It’s one of the most fully-developed machine learning libraries in existence. It continues to learn and evolve, the more you use it. This makes it suitable for preventing outages and disruptions as well as accelerating research and data. Most applications that would benefit from structuring unstructured data will benefit from using the IBM Watson API.
As one of the best-developed machine learning APIs out there, IBM Watson isn’t cheap. It is quick to get up and running, however, meaning you won’t waste money on downtime or having to hire multiple developers just to get started. The peace of mind of a nearly plug-and-play Speech-To-Text API may be worth the cost of admission alone.
Pros
Processes unstructured data
Assists humans instead of replacing them
Helps overcome human limitations
Improves productivity be delivering relevant data
Improves user experience
Can process large quantities of data
Easy to set up and get started with
Cons
Doesn’t directly support structured data
Expensive to switch to
Requires maintenance
Only supports a limited number of languages
Takes time to implement fully
Requires education and training to make full use of its resources
5. Speechmatics
Speechmatics offers an easy-to-use cloud-based API for automatic transcription services. Its main claim to fame is that it supports a wide range of file formats, meaning it can be used for offline file processing.
Speech To Text Transcription On Mac
It also supports a truly impressive array of languages, so you won’t be limited to English. It’s also been found to be more accurate than most of the other speech recognition APIs out there, so you won’t have to proofread your transcriptions quite as extensively, so you can focus on other things.
The Speechmatics API is also highly adept at speaker recognition. It processes an impressive array of different variables, from confidence values to timing and speaker indications. This makes Speechmatics useful for machine learning applications, as it gets to know a speaker more thoroughly with each iteration.
Speechmatics has been found to be one of the fastest and most reliable automatic transcription APIs available for developers. It also supports nine languages, including different variants on English, including British and Australian English.
There are a couple of drawbacks to the Speechmatics API, however, although none of them are major enough to be a dealbreaker. First and most notably, there’s no app interface. If you’ll be using the transcription services, you’ll need to upload the audio to the website.
Secondly, each query does cost money. It costs .06 GBP per 1 minute of processed audio. If you’re going to be using the Speechmatics API for any sort of commercial app or web service, make sure to consider that when setting your processing. They do offer a discount for over 1000 minutes of processed audio. Perhaps you can work out some sort of bulk rate if you’re going to be using the Speechmatics API extensively.
Pros
Fast
Easy to use
Accurate
Supports multiple languages
Supports multiple English variants
Multi-speaker support
Multiple file formats supported
Does well with noisy audio
Easily integrated via REST API
Speaker recognition
Can be used for cloud-based transcription services and private usage, using the same API
Cons
No app interface
Costs money for each query
Final Thoughts
Not all Voice-To-Text APIs are created equal. In fact, think of a voice recognition API as a toolbox rather than a product you’d buy off the shelf. Each one has different strengths and weaknesses. Knowing which Speech-To-Text API is right for your product largely depends on what you’ll be using it for.
These five APIs certainly aren’t the only ones you can use for voice-related functions, either. Some other noteworthy voice recognition APIs are worthy of a look.
Other Noteworthy Voice Recognition APIs include:
Each one of the speech-to-text APIs has its strengths. If you need transcription or to decode noisy audio, Google Speech-To-Text is an excellent contender. If you’re looking for real-time translation and transcription functionality, Microsoft Cognitive Services is probably going to be your best bet. If you’re looking for a plug-and-play voice recognition API that easily configures for numerous devices and software environments, Dialogflow might be right for you.
If you’re going to be dealing with large amounts of unstructured data, however, IBM Watson is going to be the best suited for your particular needs. If you’re going to be needing speaker separation or easy integration with additional software, Speechmatics will make your life as easy as possible, with its convenient REST API.
Considering the rise of mobile and hands-free devices, virtual assistants, and AI, it’s safe to say that voice integration isn’t going anywhere. It’s only going to get more prevalent, as technology continues to intertwine with the fabric of our daily lives.
0 notes
Text
Code Sample Posted: Get & Use Proxy List
C#.NET sample of consuming dynamically populated / auto-refreshed list of open proxies and using said list to request resources with retries has been posted to GitHub.
https://github.com/AttributionLabs/OpenProxyList
Hope such is helpful to developers of any flavor.
0 notes
Text
XmlSerializer - How to serialize object *with type* to string?
I need this quite often so I post it here for my future self!
public static object DeSerializeFromString(string xml, Type type) { XmlSerializer serializer = new XmlSerializer(type); using (StringReader reader = new StringReader(xml)) { return serializer.Deserialize(reader); } } public static string SerializeToString(object obj) { XmlSerializer serializer = new XmlSerializer(obj.GetType()); using (StringWriter writer = new StringWriter()) { serializer.Serialize(writer, obj); return writer.ToString(); } }
0 notes
Link
PipedInputStream in Java #Java #JavaInspires #CodeSamples #CodeJava
0 notes
Link
StreamTokenizer in Java #JavaInspires #CodeSamples #Java
0 notes
Link
FileWriter in Java #JavaInspires #CodeSamples #Java
0 notes
Link
FileReader class in Java #JavaInspires #CodeSamples #Java
0 notes