#Common challenges when using labeling machines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Washing Machines: Everything You Need to Know Before Buying
Washing Machines have become an essential appliance in most households, streamlining laundry tasks and saving time. As technology evolves, so do the features, types, and capabilities of these appliances. Choosing the right model can be challenging, especially with the variety of options available today.
This guide offers an in-depth look at Washing Machines, helping consumers make informed decisions based on their needs, space, and usage habits.
Types of Washing Machines
Understanding the basic types of Washing Machines is the first step in narrowing down your choices. The two primary types are:
Front Load Washing Machines
Front load models are known for their energy efficiency and gentle handling of clothes. They typically consume less water and detergent and offer a wider range of washing cycles. These machines are ideal for medium to large households and often come with advanced features like steam cleaning and sanitisation.
Top Load Washing Machines
Top loaders are usually more affordable and have faster cycle times. They’re often easier to load and unload, making them a good option for those with mobility issues or smaller laundry spaces. However, they may consume more water compared to front load models.

Key Features to Consider
When evaluating Washing Machines, consider the following features to find a model that matches your household’s needs:
Capacity
Measured in kilograms, capacity refers to the dry weight of clothes the machine can handle. Smaller households may opt for 6-7 kg machines, while larger families might need 10 kg or more.
Spin Speed
Higher spin speeds result in drier clothes at the end of the cycle. While this feature is beneficial, it may also increase wear on delicate fabrics.
Energy Efficiency
Energy Star ratings or local energy labels help consumers assess power and water usage. More efficient Washing Machines might cost more upfront but save money in the long run.
Noise Levels
For those living in apartments or with open-plan layouts, quieter models with inverter motors are worth considering.
Smart Features and Connectivity
Modern Washing Machines often come with smart technology that allows remote control via smartphone apps. Features like auto-dosing, delayed start, and load sensors can enhance convenience and optimise resource usage.
Maintenance and Longevity
Regular maintenance is essential to keep Washing Machines functioning efficiently. This includes cleaning the drum, filter, and detergent tray, as well as checking for leaks or unusual noises. Proper usage—such as avoiding overloading and using the correct detergent—can extend the machine's lifespan.
Cost vs. Value
Prices can vary significantly depending on brand, features, and capacity. While it's tempting to choose based on cost alone, evaluating long-term energy and water savings can lead to better value over time.
Common Buying Mistakes
Ignoring space constraints: Always measure the laundry area before purchasing.
Overlooking water connections: Some machines require both hot and cold water inlets.
Choosing based on aesthetics alone: Features and functionality should take priority over design.

FAQs About Washing Machines
Q: How long do Washing Machines typically last? A: Most Washing Machines have a lifespan of 8 to 12 years with regular maintenance and proper use.
Q: Can I install a Washing Machine myself? A: While top loaders are relatively simple to set up, front loaders may require professional installation due to their weight and connection needs.
Q: Are high-efficiency Washing Machines worth the cost? A: High-efficiency models often provide long-term savings through reduced energy and water consumption, making them a good investment for many households.
Q: What’s the difference between semi-automatic and fully automatic Washing Machines? A: Semi-automatic machines require manual intervention during cycles, while fully automatic ones complete the entire wash process without input.
Final Thoughts
Choosing the right Washing Machine requires balancing budget, space, and specific household needs. With many models on the market, understanding the differences and key features can make a significant impact on satisfaction and performance over time. Whether prioritising energy efficiency, advanced features, or affordability, the right appliance can make laundry tasks faster, easier, and more effective.
0 notes
Text
Overcoming PPE Compliance Challenges in Industrial Machine by Lattel Workplaces

Protecting workers in industrial settings is a top priority. This is especially true when operating powerful equipment like an Industrial Machine by Lattel. One key way to keep employees safe is through proper personal protective equipment (PPE) use.
However, many workplaces struggle with PPE compliance. Workers might forget to wear it, find it uncomfortable, or skip it altogether. This can lead to serious injuries or costly accidents.
"Proper PPE use is the frontline defense for every employee working near an Industrial Machine by Lattel."
In this article, we'll explore common compliance challenges and practical ways to overcome them.
Common PPE Compliance Challenges
Discomfort and Poor Fit
One major reason workers avoid PPE is discomfort. For example, a tight respirator or heavy gloves can make it hard to perform tasks. Moreover, ill-fitting gear increases the risk of accidents.
The solution is choosing PPE designed for comfort and available in different sizes. For example, lightweight helmets or adjustable safety glasses can improve compliance rates.
Lack of Training and Awareness
Some employees may not understand the importance of PPE. For example, they might not realize the risks involved when working with an Industrial Machine by Lattel.
Moreover, without regular training, workers forget the proper way to wear or care for their gear.
Strategies to Improve PPE Compliance
Make PPE Readily Available
If PPE isn’t easy to find, workers are less likely to wear it. For example, place extra gloves, earplugs, and eye protection near each Industrial Machine by Lattel.
Moreover, keep backup supplies stocked and in plain sight to encourage use.
Focus on Comfort and Usability
Invest in high-quality, comfortable PPE. For example, lightweight coveralls and padded harnesses improve employee satisfaction.
Moreover, involve workers in selecting PPE so they can choose items that fit well and meet their needs.
“When workers are comfortable in their PPE, compliance improves across every Industrial Machine by Lattel workstation.”
Building a Strong PPE Culture
Leadership Support
Managers must lead by example. For example, supervisors should wear proper PPE when visiting a site with an Industrial Machine by Lattel.
Moreover, rewarding positive behavior, like consistent PPE use, helps build a safety-first culture.
Encourage Open Communication
Employees should feel comfortable reporting PPE issues. For example, if a face shield fogs up while working, workers should be able to request a better option.
Moreover, holding regular safety meetings ensures concerns are heard and addressed quickly.
Enhancing PPE Training Programs
Regular Safety Sessions
Conduct frequent training sessions covering PPE use around Industrial Machine by Lattel equipment. For example, demonstrate how to properly wear, adjust, and clean each item.
Moreover, include real-life scenarios to explain why compliance is critical.
Use Visual Reminders
Place clear signs and posters in key areas. For example, display PPE requirement posters near machine entrances and break rooms.
Moreover, color-coded labels or floor markings make it easier to remember safety zones.
Addressing PPE Compatibility Challenges
Avoid Gear Interference
Some PPE items can get in the way of each other. For example, wearing earmuffs and a helmet together might be awkward.
Moreover, combining protective clothing and harnesses near an Industrial Machine by Lattel could cause discomfort if not properly coordinated.
Test Gear Combinations
Test PPE items together before use. For example, check if safety goggles and respirators fit without gaps.
Moreover, involve workers in these tests to gather feedback and improve compliance.
Using Technology for Better Compliance
PPE Management Apps
Many companies now use apps to track PPE inventory and training. For example, an app might send reminders when it’s time to replace safety gloves.
Moreover, tracking PPE use by task helps identify areas for improvement near Industrial Machine by Lattel stations.
Digital Training Tools
Use videos and online quizzes for safety training. For example, short tutorials on proper PPE donning procedures improve recall.
Moreover, digital tools make it easy to refresh training anytime.
Measuring and Improving PPE Compliance
Perform Regular Safety Audits
Schedule routine PPE checks. For example, confirm that all employees near an Industrial Machine by Lattel are using the correct PPE.
Moreover, use checklists to record findings and quickly fix any issues.
Gather Employee Feedback
Ask workers how to improve PPE use. For example, they might request new glove styles or better helmet padding.
Moreover, acting on this feedback shows that management values their comfort and safety.
Conclusion: A Safer Workplace Starts With PPE Compliance
Improving PPE compliance is not just about rules. It’s about creating a culture where safety matters to everyone — especially around powerful equipment like an Industrial Machine by Lattel.
For example, providing comfortable gear, regular training, and open communication makes it easier for workers to follow PPE guidelines. Moreover, involving employees in safety programs boosts morale and trust.
"A strong PPE culture ensures every Industrial Machine by Lattel operation runs safely and efficiently."
By addressing these challenges, companies protect their employees and keep production lines running smoothly.
0 notes
Text
Understanding Machine Learning: The Future of Intelligent Systems
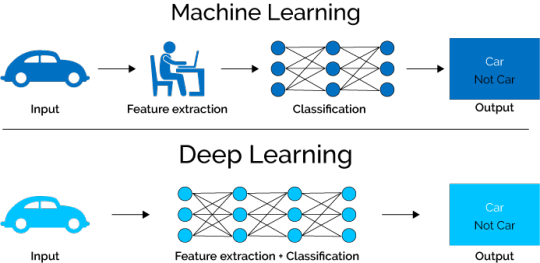
Machine Learning (ML) is one of the most exciting fields in technology today. It refers to the ability of computers to learn from data without being explicitly programmed. Instead of following static instructions, ML algorithms use statistical methods to identify patterns, make decisions, and improve their performance over time.
At its core, machine learning is about prediction and pattern recognition. For example, when you watch movies on a streaming platform and receive recommendations, machine learning is behind the scenes analyzing your viewing habits and suggesting content based on that data. Similarly, ML powers voice assistants like Siri and Alexa, fraud detection in banking, spam filters in email, and even medical diagnostics.
There are three main types of machine learning: supervised, unsupervised, and reinforcement learning.
Supervised Learning: This is the most common type. It involves training an algorithm on a labeled dataset — meaning the data includes both inputs and correct outputs. For instance, a model might be trained to recognize handwritten digits using thousands of labeled images of numbers. Over time, the algorithm learns the relationship between the images and the numbers they represent.
Unsupervised Learning: In this type, the data has no labels. The algorithm must discover hidden patterns or structures in the input. A common application is customer segmentation, where businesses group customers based on purchasing behavior without predefined categories.
Reinforcement Learning: This approach is inspired by how humans learn through reward and punishment. The algorithm, known as an agent, learns to make decisions by interacting with an environment and receiving feedback in the form of rewards. This is the foundation for game-playing AIs, like the ones that have mastered chess and Go.
The success of machine learning depends heavily on data. The more high-quality data an algorithm has, the better it can learn and make accurate predictions. However, this also brings challenges, such as ensuring privacy, avoiding bias, and maintaining data security.
Machine learning is part of the broader field of artificial intelligence (AI), but it’s important to distinguish between the two. AI refers to machines that can perform tasks that typically require human intelligence, while ML is a specific technique used to achieve that goal.
In recent years, the rise of deep learning — a subset of ML inspired by the structure of the human brain — has taken the field to new heights. Deep learning uses neural networks with many layers (hence the term “deep”) to perform tasks like image recognition, language translation, and autonomous driving.
As machine learning continues to evolve, it holds immense potential to transform industries and solve complex global problems. From predicting climate change effects to personalizing education and improving healthcare outcomes, its applications are vast and growing.
Yet, with this power comes responsibility. Developers and organizations must consider the ethical implications of ML systems and strive for transparency, fairness, and accountability in their algorithms.
Machine learning is not just a trend — it’s a foundational technology that is shaping our digital future
0 notes
Text
Top-Quality Masking Tape Manufacturers in Chennai for Industrial and Commercial Needs
Masking tapes might look like simple tools, but they play a major role across various industries—from automotive and construction to painting and packaging. Whether you're an individual working on a DIY home improvement project or an industrial buyer looking for bulk orders, choosing the right masking tape is essential for precision and quality. That’s where Masking Tape Manufacturers in Chennai come into the picture.
Chennai, being one of India’s most rapidly growing industrial hubs, is home to several top-tier manufacturers producing high-quality masking tapes tailored to different needs. With a strong infrastructure, skilled workforce, and evolving technology, this city has emerged as a trusted source for masking tape supply.
Why Is Masking Tape So Essential?
Masking tape is a type of pressure-sensitive tape made with an easy-to-tear paper backing and an adhesive that is gentle yet strong enough to stick to various surfaces. Its primary use is to mask off areas that shouldn’t be painted or exposed to certain processes. However, its usage has now expanded far beyond painting.
Some of the most common applications include:
Automotive Industry: For clean paint jobs and precise detailing.
Construction and Interior Design: For protecting areas during painting or remodeling.
Electronics and Electricals: Temporary insulation and cable labeling.
Arts and Crafts: For neat lines and borders in artwork.
General Purpose Home Use: Labeling, packaging, and sealing.
This wide range of applications demands different types of masking tapes with varied adhesive strengths, heat resistance, and durability. This is where expertise from experienced Masking Tape Manufacturers in Chennai becomes essential.
Types of Masking Tapes Available
Manufacturers in Chennai understand the need for versatility in their products. Most of them offer various types of masking tapes such as:
General Purpose Masking Tape: Ideal for home use and basic applications.
Automotive Masking Tape: Heat-resistant and perfect for spray painting.
High-Temperature Masking Tape: Suitable for use in high-heat environments.
UV-Resistant Masking Tape: Designed for outdoor applications.
Custom Size Masking Tape: For businesses that need specific dimensions.
These manufacturers ensure each tape is designed for optimal performance, providing clean removal without leaving sticky residue, high tensile strength, and resistance to moisture or solvents.
What Makes Chennai a Manufacturing Hub for Masking Tapes?
There are a few key reasons why Masking Tape Manufacturers in Chennai are widely trusted:
Modern Manufacturing Facilities: Equipped with advanced coating, slitting, and packing machines, manufacturers here can ensure consistent quality and large-scale production.
Skilled Workforce: From engineers to quality control specialists, the teams involved in manufacturing understand the importance of precision and consistency.
Cost Efficiency: Due to the strong industrial ecosystem in Chennai, production costs are generally lower—without compromising on quality.
Customization Capabilities: Many manufacturers provide customization options to suit niche industry needs, such as unique adhesive levels, width, or core diameter.
How to Choose the Right Masking Tape
While all masking tapes may appear similar, they are not all created equal. Here’s what to look for when sourcing:
Adhesive Quality: Should stick well to surfaces without peeling off too early or leaving residue.
Paper Strength: Must resist tearing when applied or removed.
Heat and Water Resistance: Important for applications in challenging environments.
Clean Removal: Especially crucial for painting and finishing tasks.
Reliable Masking Tape Manufacturers in Chennai conduct quality checks and testing to ensure each roll meets industry standards.
Industries That Rely on Masking Tapes
The demand for masking tapes isn’t limited to just one or two industries. They are used widely in:
Automotive Plants
Electronics and Electrical Factories
Construction Sites
Paint Shops and Workshops
Educational Institutions for Projects
Home Décor and Interior Designing
Due to such diverse applications, manufacturers continuously innovate their offerings to stay ahead of industry needs.
The Benefits of Sourcing Locally from Chennai
By choosing local Masking Tape Manufacturers in Chennai, businesses can enjoy multiple benefits:
Faster Delivery: Proximity reduces transit time.
Lower Costs: Reduced shipping and bulk pricing.
Better Communication: Easier to discuss requirements and receive after-sales support.
Eco-Friendly: Many local manufacturers are moving towards sustainable materials.
Supporting local manufacturers also helps in boosting the regional economy while ensuring that you receive trustworthy service and timely delivery.
Masking tapes may seem like small tools, but their significance in both simple and complex tasks is massive. The quality of masking tape can directly impact the outcome of a project—whether it’s a wall painting at home or a professional spray paint job in an automotive plant. That’s why it’s important to choose wisely.
With a str“Top-Quality Masking Tape Manufacturers in Chennai for Industrial and Commercial Needs”ong reputation for delivering top-tier products across various industries, Masking Tape Manufacturers in Chennai have earned their place as reliable partners in operational efficiency. If you’re in the market for durable, affordable, and customizable masking tapes, consider sourcing from Chennai’s top manufacturers for a blend of quality and value.
Whether your requirement is small-scale or bulk, the right supplier can make all the difference. So the next time you need masking tape that performs under pressure—think Chennai.
0 notes
Text
Machine Learning: A Comprehensive Overview
Introduction
In recent years, machine learning (ML) has emerged as a transformative force across nearly every industry, from healthcare and finance to entertainment and autonomous systems. At its core, machine learning is a subset of artificial intelligence (AI) that empowers systems to learn and improve from experience without being explicitly programmed. It enables computers to discover patterns in data, make predictions, and automate decision-making processes.
As we navigate the age of big data, the significance of machine learning continues to grow. Organizations leverage ML to gain insights from massive datasets, automate routine tasks, enhance customer experiences, and make strategic decisions. But what exactly is machine learning, how does it work, and what challenges and opportunities lie ahead?
This essay explores machine learning in depth, covering its history, key concepts, algorithms, applications, limitations, and future directions.
1. The Origins and Evolution of Machine Learning
Machine learning as a concept dates back to the 1950s when computer scientists and mathematicians began experimenting with algorithms that could “learn” from data. Alan Turing, in his seminal 1950 paper “Computing Machinery and Intelligence,” posed the question: Can machines think? This foundational inquiry laid the groundwork for AI and ML.
In 1959, Arthur Samuel defined machine learning as the “field of study that gives computers the ability to learn without being explicitly programmed.” His work on a checkers-playing program was one of the first examples of an adaptive machine.
Over the decades, ML evolved alongside advancements in computing power and the explosion of data. Key milestones include:
The development of neural networks in the 1980s
The rise of support vector machines in the 1990s
The explosion of deep learning in the 2010s, largely driven by big data and GPU computing
Today, machine learning is no longer a niche academic field — it’s a cornerstone of modern technology.
2. What is Machine Learning?
Machine learning is a method of data analysis that automates analytical model building. It is based on the idea that systems can learn from data, identify patterns, and make decisions with minimal human intervention.
Types of Machine Learning
Machine learning is broadly categorized into three main types:
a) Supervised Learning
In supervised learning, the algorithm is trained on a labeled dataset, meaning that each training example is paired with an output label. The goal is to learn a mapping from inputs to outputs.
Examples:
Spam detection in emails
Predicting house prices
Image classification
Common algorithms:
Linear Regression
Logistic Regression
Decision Trees
Support Vector Machines (SVM)
Neural Networks
b) Unsupervised Learning
Unsupervised learning works with data that has no labels. The system tries to learn the patterns and structure from the data without any predefined outcomes.
Examples:
Customer segmentation
Market basket analysis
Anomaly detection
Common algorithms:
K-Means Clustering
Hierarchical Clustering
Principal Component Analysis (PCA)
Autoencoders
c) Reinforcement Learning
Reinforcement learning involves training agents to make a sequence of decisions by rewarding or punishing them based on their actions. It is widely used in robotics, gaming, and navigation systems.
Examples:
AlphaGo (by DeepMind)
Robotics
Autonomous vehicles
Common techniques:
Q-learning
Deep Q-Networks (DQN)
Policy Gradient Methods
3. Key Concepts in Machine Learning
Understanding machine learning requires familiarity with several fundamental concepts:
a) Training and Testing
Data is typically split into training and testing sets. The training set is used to teach the model, and the testing set is used to evaluate its performance.
b) Features and Labels
Features are input variables (e.g., age, income).
Labels are the outcomes we want to predict (e.g., loan default: yes or no).
c) Overfitting and Underfitting
Overfitting occurs when the model learns noise and details in the training data that negatively impact performance on new data.
Underfitting happens when the model is too simple to capture the underlying structure of the data.
d) Bias-Variance Tradeoff
Bias is error due to overly simplistic assumptions.
Variance is error due to too much complexity in the model. Achieving the right balance is crucial for good performance.
e) Loss Functions
Loss functions measure how well the model’s predictions align with the actual data. Common loss functions include:
Mean Squared Error (MSE)
Cross-Entropy Loss
Hinge Loss
4. Popular Machine Learning Algorithms
Let’s delve deeper into some widely-used ML algorithms:
a) Linear Regression
Used for predicting continuous variables, linear regression models the relationship between input features and an output variable using a linear equation.
b) Logistic Regression
Despite the name, logistic regression is used for classification tasks. It models the probability that a given input belongs to a particular class.
c) Decision Trees
These are flowchart-like structures that split data into branches based on feature values, making them interpretable and easy to visualize.
d) Random Forest
An ensemble method that builds multiple decision trees and merges their results to improve accuracy and control overfitting.
e) Support Vector Machines (SVM)
SVMs classify data by finding the hyperplane that best separates different classes.
f) K-Nearest Neighbors (KNN)
A lazy learning algorithm that assigns labels based on the majority class of the k nearest points in the training set.
g) Neural Networks and Deep Learning
Deep learning involves neural networks with multiple layers (deep neural networks). These models have achieved state-of-the-art results in computer vision, natural language processing (NLP), and more.
5. Tools and Frameworks for Machine Learning
Several tools and libraries have made ML development more accessible:
Scikit-learn: A Python library for simple ML tasks
TensorFlow: Open-source framework for deep learning by Google
PyTorch: Facebook’s deep learning framework, popular in research
Keras: High-level API for neural networks, runs on TensorFlow
XGBoost: Powerful library for gradient boosting
LightGBM: Fast and efficient gradient boosting framework
These tools provide pre-built algorithms, data handling utilities, and GPU acceleration for training large models.
6. Real-World Applications of Machine Learning
Machine learning has made its way into countless industries and day-to-day applications:
a) Healthcare
Disease diagnosis (e.g., cancer detection from images)
Predicting patient readmissions
Drug discovery
b) Finance
Fraud detection
Credit scoring
Algorithmic trading
c) Retail and E-Commerce
Recommendation engines (e.g., Amazon, Netflix)
Customer segmentation
Inventory forecasting
d) Transportation
Route optimization
Predictive maintenance
Self-driving cars
e) Marketing
Customer lifetime value prediction
Targeted advertising
Churn prediction
f) Natural Language Processing (NLP)
Machine translation
Sentiment analysis
Chatbots and virtual assistants
7. Ethical Considerations in Machine Learning
With great power comes great responsibility. As machine learning becomes more prevalent, ethical issues must be addressed:
a) Bias and Fairness
ML systems can inherit and amplify biases in training data. For example, facial recognition systems have shown higher error rates for people of color.
b) Privacy
Models trained on personal data can leak sensitive information. Techniques like federated learning and differential privacy aim to protect user data.
c) Transparency
Many ML models, especially deep learning ones, are “black boxes.” Interpretable models or explainable AI (XAI) help users understand decision-making processes.
d) Job Displacement
Automation via ML may replace some human jobs. While it creates new opportunities, it also necessitates workforce reskilling and ethical deployment.
8. Challenges in Machine Learning
Despite its promise, machine learning faces several technical and practical challenges:
a) Data Quality and Quantity
ML models require large, clean, and representative datasets. Poor data can lead to inaccurate predictions.
b) Computational Resources
Training complex models can be resource-intensive, requiring powerful GPUs and high storage capacity.
c) Model Interpretability
Understanding how a model arrives at a prediction is crucial in high-stakes fields like healthcare or law.
d) Generalization
Models must perform well on unseen data, not just the training set. Generalization remains one of the toughest challenges in ML.
9. Future Trends in Machine Learning
The future of machine learning looks incredibly promising, with several trends gaining momentum:
a) AutoML (Automated Machine Learning)
AutoML aims to automate the process of model selection, feature engineering, and hyperparameter tuning.
b) Federated Learning
This technique trains models across decentralized devices, allowing for privacy-preserving machine learning.
c) TinyML
Machine learning on edge devices (like smartphones and IoT sensors) with minimal resources.
d) Explainable AI (XAI)
As ML is increasingly used in critical applications, the need for interpretable and transparent models is growing.
0 notes
Text
Top 25 Machine Learning Interview Questions in 2025
The field of machine learning is constantly evolving with the onset of rapid technological advancements over the past few years. This has made it an extremely exciting yet challenging field. It doesn’t matter if you’re a fresher or an experienced professional, jobs in the field of machine learning are booming, and you could be the one who lands one of the best offers!
However, before landing a job, comes the tasking feat of answering the machine learning interview questions you’ll be definitely asked once your application makes it through. These questions assess your theoretical knowledge as well as your practical experience and ultimately decide if you’re the candidate they should really hire for the role. This blog covers the top 25 machine learning interview questions that will help you ace your next interview.
1. What is machine learning?
This is one of the machine learning basic interview questions that every candidate should be prepared for. Understanding the fundamentals of machine learning is key to tackling more advanced questions.
Answer: Machine learning is a subset of artificial intelligence that enables computers to learn from data without being explicitly programmed. It involves creating algorithms that can improve their performance over time as they are exposed to more data.
2. What are the different types of machine learning?
Another fundamental question in machine learning interview questions for freshers. The answer to this question will test your understanding of the primary categories in ML.
Answer: There are three main types of machine learning:
Supervised learning: The algorithm learns from labeled data to make predictions.
Unsupervised learning: The algorithm works with unlabeled data and identifies patterns.
Reinforcement learning: The algorithm learns by interacting with an environment and receiving feedback from actions taken.

*InterviewBit
3. What is the difference between classification and regression?
One of the common machine learning algorithms interview questions that assess your knowledge of basic ML techniques.
Answer: Classification is the task of predicting a discrete label (e.g., classifying emails as spam or not), while regression involves predicting a continuous value (e.g., predicting housing prices).
4. Explain the concept of overfitting and underfitting.
This is a common topic in AI and machine learning interview questions because it is essential to evaluate a candidate’s understanding of model performance.
Answer:
Overfitting occurs when the model learns the noise in the training data, causing it to perform poorly on new data.
Underfitting happens when the model is too simple to capture the underlying patterns in the data, leading to poor performance on both training and test sets.
5. What are the different evaluation metrics for classification problems?
Evaluating classification models is a critical step in ML, and this question tests your knowledge of metrics used in machine learning interview questions.
Answer: Common evaluation metrics for classification include accuracy, precision, recall, F1 score, and ROC-AUC.
6. What is cross-validation, and why is it important?
Cross-validation is often tested in machine learning interview questions for freshers as it is a basic yet crucial concept in evaluating model performance.
Answer: Cross-validation is a technique used to assess how the results of a model generalize to an independent dataset. It helps reduce overfitting by using multiple data splits for training and testing.
7. Explain the bias-variance tradeoff.
The bias-variance tradeoff is a critical concept that often comes up in machine learning basic interview questions.
Answer:
Bias refers to the error introduced by approximating a real-world problem with a simplified model.
Variance refers to the error caused by the model’s sensitivity to small fluctuations in the training data. The tradeoff is about balancing the two to achieve the best model performance.
8. What are decision trees, and how do they work?
Decision trees are one of the most fundamental machine learning algorithms. They often appear in machine learning algorithms interview questions.
Answer: A decision tree is a supervised learning algorithm that splits the data into subsets based on feature values. It builds a tree-like structure with decision nodes and leaf nodes that represent the output predictions.
9. What is a random forest?
This question is commonly asked when discussing machine learning algorithms, interview questions and tests your knowledge of ensemble methods.
Answer: A random forest is an ensemble of decision trees that work together to improve the accuracy of predictions. It reduces overfitting by averaging the predictions of multiple trees.
10. What are k-nearest neighbors (KNN)?
KNN is another common topic that often comes up in AI and machine learning interview questions.
Answer: KNN is a supervised learning algorithm that classifies a data point based on the majority class of its k-nearest neighbors. It is simple but effective for classification tasks.
11. How does gradient descent work?
Gradient descent is a critical optimization technique and a key part of many ML algorithms. This question is frequently asked in machine learning interview questions.
Answer: Gradient descent is an optimization algorithm used to minimize the cost function by iteratively adjusting the parameters of the model in the direction of the steepest gradient.
12. What is the difference between L1 and L2 regularization?
This is a machine learning basic interview question that assesses your understanding of techniques to prevent overfitting.
Answer:
L1 regularization adds the absolute value of the coefficients to the cost function.
L2 regularization adds the square of the coefficients to the cost function. Both techniques help reduce overfitting by penalizing large coefficients.
13. What is the role of a confusion matrix?
A confusion matrix is essential for understanding the performance of a classification model, and this question is often asked in machine learning interview questions for freshers.
Answer: A confusion matrix is a table that shows the true positive, true negative, false positive, and false negative values for a classification model. It helps evaluate the accuracy and other metrics.
14. Explain the difference between bagging and boosting.
Machine learning algorithms interview questions often test your understanding of ensemble techniques like bagging and boosting.
Answer:
Bagging involves training multiple models independently and then combining their predictions, which helps reduce variance.
Boosting trains models sequentially, with each model learning from the errors of the previous one, helping to reduce bias.
15. What is the purpose of support vector machines (SVM)?
Support Vector Machines are frequently tested in AI and machine learning interview questions due to their widespread use in classification tasks.
Answer: SVM is a supervised learning algorithm that finds the hyperplane that best separates the data points into different classes. It works well for both linear and non-linear classification tasks.
16. How would you handle missing data in a dataset?
This is a practical question that tests your ability to preprocess data, commonly asked in machine learning interview questions.
Answer: Missing data can be handled by:
Imputing with mean, median, or mode.
Using algorithms that support missing values.
Dropping rows or columns with missing data, depending on the extent of missing values.
17. What is feature selection, and why is it important?
Feature selection is a crucial part of machine learning and is often covered in machine learning interview questions for freshers.
Answer: Feature selection is the process of choosing the most important features for your model. It helps improve performance by reducing overfitting, simplifying the model, and decreasing computation time.
18. What is principal component analysis (PCA)?
PCA is an essential technique for dimensionality reduction and is often tested in machine learning basic interview questions.
Answer: PCA is a statistical technique that transforms high-dimensional data into fewer dimensions by finding the principal components that capture the most variance in the data.
19. Can you explain the term "Deep Learning"?
Deep Learning is an area that is becoming increasingly relevant in machine learning interview questions.
Answer: Deep learning is a subset of machine learning that uses neural networks with many layers to model complex patterns in data. It is especially effective for tasks like image and speech recognition.
*LinkedIn
20. What is the role of neural networks in machine learning?
This is another common machine learning interview question that evaluates your understanding of advanced machine learning techniques.
Answer: Neural networks are used to model complex relationships between inputs and outputs. They are particularly useful for tasks involving unstructured data, such as images, audio, and text.
21. How would you deal with imbalanced datasets?
In many practical machine learning problems, datasets are imbalanced, and this question tests how you approach such scenarios in AI and machine learning interview questions.
Answer: Techniques for dealing with imbalanced datasets include:
Resampling techniques such as oversampling the minority class or undersampling the majority class.
Using appropriate evaluation metrics like the F1 score or balanced accuracy.
Using algorithms like Random Forest or XGBoost that are less sensitive to class imbalance.
22. What is transfer learning?
Transfer learning is an important concept in deep learning, and this question may appear in machine learning interview questions for freshers.
Answer: Transfer learning involves using a pre-trained model on a new task. It leverages the knowledge gained from the original task and adapts it to a similar but different task, reducing the need for a large dataset.
23. How do you assess the performance of a regression model?
In machine learning basic interview questions, candidates are often asked to evaluate the performance of regression models.
Answer: Performance of regression models can be assessed using metrics like Mean Squared Error (MSE), R-squared, and Root Mean Squared Error (RMSE).
24. What is the difference between a generative and a discriminative model?
This is a more advanced question you might encounter in machine learning algorithms interview questions.
Answer:
Generative models model the joint probability distribution of the input and output data (e.g., Naive Bayes).
Discriminative models focus on modeling the conditional probability of the output given the input data (e.g., logistic regression, SVM).
25. What are some common challenges in deploying machine learning models?
Finally, this machine learning interview question tests your ability to move from the theoretical to the practical side of machine learning.
Answer: Common challenges in deploying machine learning models include handling real-time data, ensuring model scalability, model interpretability, and managing the lifecycle of models in production.
Final Thoughts on Machine Learning Interview Questions
Machine learning continues to evolve rapidly, and staying updated with the latest techniques and theories is crucial for success in 2025. The interview questions on machine learning discussed above cover fundamental concepts, algorithms, and practical applications that will be key to your success in any machine learning role. Preparing for these questions will give you the confidence to handle the most common challenges you may face during your interviews.
If you are looking to enhance your machine learning knowledge or need assistance in preparing for your next machine learning interview questions, consider enrolling in the Advanced Certificate Programme in Machine Learning, Gen AI & LLMs for Business Applications – IITM Pravartak Technology Innovation Hub of IIT Madras, offered in partnership with Jaro Education. This programme will provide you with a comprehensive overview of everything you need to know about machine learning. All the best!
0 notes
Text
# Cleaning and Labeling Data: Best Practices for AI Success

Introduction
Artificial Intelligence datasets (AI) relies heavily on the quality of the data that supports it. Regardless of the sophistication of the model architecture, subpar data can undermine performance, introduce biases, and restrict predictive accuracy. Consequently, data cleaning and labeling are essential components of the AI development process. Without well-organized and accurately labeled data, even the most advanced models will find it challenging to produce dependable outcomes.
In this article, we will explore the significance of data cleaning and labeling, the common mistakes to avoid, and the best practices to ensure that your AI models are positioned for success.
The Importance of Cleaning and Labeling
AI models derive insights from the data on which they are trained. Clean and precisely labeled data enables models to generalize effectively and make accurate predictions in practical applications. Here are the reasons these processes are crucial:
Enhanced Model Accuracy: Clean and uniform data minimizes noise, allowing models to discern patterns with greater precision.
Accelerated Training: Eliminating irrelevant or incorrect data hastens the training process and enhances convergence.
Mitigated Bias: Properly labeled data promotes balanced learning and diminishes the likelihood of biased predictions.
Greater Interpretability: Well-defined and organized labels facilitate the assessment of model performance.
Substandard data quality equates to suboptimal AI performance. It is imperative to establish robust data foundations to avoid this issue.
Step 1: Mastering Data Cleaning
Data cleaning entails identifying and rectifying issues that may distort the learning process. Here are effective strategies for cleaning data:
1. Eliminate Duplicate Records
Duplicate entries can exaggerate the significance of certain patterns and mislead the model.
Utilize automated scripts to detect and remove duplicates.
Ensure that data integrations do not inadvertently create duplicate entries.
Example: If customer purchase records are duplicated, a model may inaccurately assess purchasing behavior patterns.
2. Address Missing Data with Care
Missing values can lead to misinterpretation of patterns within the model. Possible approaches include:
Deletion: Eliminate rows or columns that contain a significant number of missing values.
Imputation: Substitute missing values with the mean, median, or mode of the dataset.
Prediction: Employ a separate machine learning model to estimate missing values based on available data points.
Example: When dealing with customer age data, using the median age to fill in missing values helps avoid bias introduced by extreme outliers.
3. Standardize Data Formats
Inconsistent data formats can create confusion for models and result in inaccurate predictions.
Ensure that all dates adhere to a uniform format (e.g., YYYY-MM-DD).
Convert measurements (e.g., inches to centimeters) to a standardized unit.
Normalize textual data (e.g., convert to lowercase, eliminate special characters).
Example: If transaction dates are recorded in both American and European formats, this inconsistency could mislead time-series analyses.
4. Remove Outliers When Necessary
While outliers can skew model training, they are not always irrelevant.
Utilize visualization methods (e.g., box plots) to detect outliers.
Discard outliers that arise from data entry mistakes.
Retain significant outliers (e.g., sales increases during holiday periods).
Example: A single transaction of 1,000 units may appear as an outlier; however, if it corresponds to a Black Friday promotion, it constitutes valuable information.
5. Achieve Balance Across Classes
Class imbalance can lead models to favor the majority class, resulting in suboptimal performance.
Use SMOTE (Synthetic Minority Over-sampling Technique) to increase the representation of the minority class.
Under sample the majority class to mitigate its dominance.
Assign class weights to ensure equitable learning.
Example: In fraud detection scenarios, legitimate transactions typically outnumber fraudulent ones. Balancing the dataset enhances the model's ability to identify fraudulent activities.
Step 2: Mastering Data Labeling
Data labeling involves the assignment of meaningful tags to data points, which is crucial for the effectiveness of supervised learning models. The following steps outline the proper approach:
1. Establish a Comprehensive Labeling Strategy
Before initiating the labeling process, it is important to define categories and guidelines.
Create a well-structured taxonomy for the labels.
Ensure uniformity among the labeling team.
Provide illustrative examples to minimize confusion.
Example: In an image dataset featuring animals, determine whether the term "dog" encompasses both mixed breeds and purebreds.
2. Implement Automation Where Feasible
Manual labeling can be labor-intensive and susceptible to inaccuracies.
Utilize pre-trained models to propose labels.
Employ active learning, allowing the model to seek human validation for uncertain labels.
Utilize natural language processing (NLP) models to facilitate automated labeling of text.
Example: A facial recognition system can automatically label recognized faces while requesting human input for those it does not recognize.
3. Address Ambiguous Data Through Multi-Labeling
Certain data points may fit into multiple categories.
Apply hierarchical or multi-label classification methods.
Ensure that human reviewers validate the final labels.
Example: An image depicting a dog inside a car could be classified under both "dog" and "vehicle."
4. Engage in Continuous Review and Refinement
Labeling is not a one-off task; it necessitates ongoing adjustments.
Conduct tests to assess inter-labeler agreement and consistency.
Perform random checks on a sample of labeled data to identify errors.
Utilize feedback from models to refine label categories over time.
Example: If a sentiment analysis model frequently misclassifies sarcasm, revise the labeling guidelines to enhance accuracy.
Step 3: Monitor and Sustain Data Quality
AI models are dynamic, and your data must reflect that evolution.
Conduct regular audits of datasets to detect shifts in patterns or data drift.
Revise labeling guidelines as new data types are introduced.
Implement performance monitoring to pinpoint areas of weakness in the model.
Example: A chatbot designed to handle customer inquiries should undergo periodic retraining to adapt to changes in language and user behavior over time.
How GTS complete this project?
Cleaning and labeling data are essential for AI success. High-quality, well-structured data improves model accuracy, reduces bias, and enhances predictive performance. Globose Technology Solutions ensures top-tier data quality through automated cleaning, precise labeling, and continuous monitoring, setting the foundation for reliable and scalable AI models.
Conclusion
While cleaning and labeling data may not be the most thrilling aspect of AI development, it is undeniably one of the most essential. High-quality data contributes to superior model performance, expedited training, and more dependable predictions. By adhering to these best practices, you will position your AI models for enduring success and save significant time on debugging in the future.
Interested in enhancing your AI with pristine and well-labeled data? Visit Globose Technology Solutions to discover how we can assist you in creating smarter, more precise models.
0 notes
Text
Machine Learning: Transforming the Future of Technology
Machine Learning (ML) is a branch of artificial intelligence (AI) that enables computers to learn and make decisions without explicit programming. By analyzing large datasets, ML algorithms identify patterns, improve predictions, and automate complex tasks. From recommendation systems on Netflix to self-driving cars, machine learning is revolutionizing industries and shaping the future of technology.
### **How Machine Learning Works**
Machine learning relies on algorithms that process vast amounts of data and improve their accuracy over time. It involves three main types of learning:
1. **Supervised Learning** – The algorithm is trained on labeled data, meaning the input and output are known. It learns by making predictions and correcting errors. Examples include spam email detection and speech recognition.
2. **Unsupervised Learning** – The algorithm identifies hidden patterns in data without predefined labels. Clustering and anomaly detection are common techniques used in market segmentation and fraud detection.
3. **Reinforcement Learning** – The algorithm learns through trial and error, receiving rewards for correct actions. This method is widely used in robotics, game playing (like AlphaGo), and automated trading systems.
### **Applications of Machine Learning**
Machine learning has transformed various industries by enhancing efficiency, accuracy, and decision-making. Some of its key applications include:
- **Healthcare** – ML helps in disease diagnosis, personalized treatment plans, and medical imaging analysis. AI-powered models can detect cancer and predict patient outcomes.
- **Finance** – Banks use ML for fraud detection, risk assessment, and algorithmic trading to enhance security and efficiency.
- **Retail & E-commerce** – Recommendation engines analyze user behavior to suggest products, improving customer experience.
- **Autonomous Vehicles** – Self-driving cars use ML to process real-time data from sensors and navigate safely.
Natural Language Processing (NLP) – Virtual assistants like Siri and Google Assistant use ML to understand and respond to human language.
Challenges in Machine Learning
Despite its advantages, machine learning faces several challenges:
Data Quality – ML models require vast amounts of high-quality data. Biased or incomplete data can lead to inaccurate predictions.
Computational Costs– Training ML models demands powerful hardware, increasing costs and energy consumption.
Ethical Concerns_Privacy issues arise when personal data is used for training models. Bias in algorithms can lead to unfair outcomes in hiring, law enforcement, and lending.
The Future of Machine Learning
Machine learning continues to evolve, with advancements in deep learning, neural networks, and AI ethics shaping its future. Researchers are working on making ML models more transparent, reducing bias, and improving energy efficiency. The integration of quantum computing and ML is expected to accelerate computational capabilities, unlocking new possibilities.
Conclusion
Machine learning is revolutionizing industries by automating processes, improving decision-making, and enhancing user experiences. While challenges remain, continuous advancements in AI and ML will drive innovation across sectors. As businesses and researchers refine these technologies, machine learning will play an even greater role in shaping the future of technology and society. #topuniversitiesinuttarakhand
0 notes
Text
Image Datasets for Machine Learning: The Backbone of AI Vision Systems

In recent years, Artificial Intelligence (AI) has made great strides, especially in computer vision. The AI-aided vision systems are transforming industries-from facial recognition and medical diagnostics to driving vehicles and product recommendation in e-commerce. However, the success of such models relies almost completely on one element: fine image datasets.
Image datasets for machine learning are used to train, test, and fine-tune AI models so that these can adeptly identify objects, patterns, and contexts. In this article, we will look into what these image datasets represent, how to curate such datasets, and how they contribute to the development of AI vision systems.
Why Image Datasets Matter for AI Vision
Machine learning models are trained to find patterns in vast amounts of labeled data. The performance of AI vision systems heavily depends on the quality, diversity, and quantity of image datasets. Here is why image datasets are critical:
Improvement of Model Accuracy: A well-labeled dataset empowers AI models to accurately identify objects and categorize images. The further along diversity and high quality get in a dataset, the more capable the AI becomes in generalizing toward real-life situations.
Minimization of the Bias Factor in AI Models: If AI models are trained on imbalanced datasets, there is bound to be a bias. For instance, a facial recognition system trained mainly on light-skinned individuals might fail to perform well on darker-skinned persons. With properly curated datasets, such biases can be minimized for fair AI outcomes.
Improvement of AI Flexibility: AI models trained on varied datasets can adapt well to different environments, lighting conditions, and angles, making them more robust in real-life applications.
Powering Innovation Across Industries: AI-driven computer vision is finding its utility in detecting diseases in healthcare, monitoring crop health in agriculture, providing surveillance for security, and cultivating customer insights in retail, meaning high-quality image datasets are ushering the revolution.
Challenges in Building Image Datasets
Having analysed the context around the reasons prohibiting high-quality data set development, some of the challenges include:
Data privacy and ethical concerns: With an increase in the need for more security for data, organizations have to develop their operations considering these privacy regulations, such as the Roman Catholic Church, GDPR, and HIPAA, when handling sensitive images such as sensitive medical scans and personal pictures.
Large data size and complexity: With millions of high-resolution images needing processing and storage, it takes almost supercomputer-level strength of computational power and cloud storage solutions to resolve such scared data.
Annotation costs and time: Dictionary annotation is labor-intensive and costly; many furl companies have relied on AI-assisted annotation.
Dataset bias and representation: Training AI models on diversified data sets will help minimize or mask bias, creating policiability across different demographics and environmental conditions.
Popular Image Datasets Used in AI Research
There the handful of large open-source datasets that have been hotbeds for the advancement of AI vision systems. A few are given below:
ImageNet: One of the most recognized datasets is composed of 14+ million labeled images for object detection and classification purposes.
COCO (Common Objects in Context): With 330,000+ images with many objects per image, the COCO dataset provides a large-scale resource for segmentation and scene understanding.
OpenImages: Google's OpenImages dataset consists of many millions of annotated photos that cover an astonishing variety of categories and complex scenarios.
MNIST: An introductory dataset of handwritten digits used extensively to train AI on digit detection.
CelebA: The CelebA dataset contains over 200,000 celebrity faces and is fielded for facial recognition and attribute prediction.
Industries Benefiting from Image Datasets in AI
Healthcare: AI-enabled imaging systems diagnose conditions like cancer, pneumonia, and eye disease using carefully annotated images of diseases.
Autonomous vehicles: Self-driving cars depend on extensive data sets to identify pedestrians, vehicles, stop lights, and traffic signs to ensure safe processes and navigation.
E-Commerce and retail: AI models take in images of the products to create various recommendation systems for virtual try-ons and inventory tracking.
Security and surveillance: Facial recognition AI works by creating large datasets of images to identify people and strengthen security monitoring.
Agriculture: AI models and satellite or drone imaging would be used to find crop diseases and determine soil and irrigation conditions.
Future Trends in Image-Datasets of AI Vision
Synthetic datasets: With Generative AI taking center stage, synthetic datasets could be created to imitate real-world scenarios, bringing down the price tag for data collecting.
Real-Time Data Annotation: Edge computing, combined with the ingestion of images by AI models, will allow real-time annotation of images and greater speed and efficiency.
Federated Learning: This technique entails federated learning in AI models to train decentralized image datasets without exchanging sensitive data, thus providing better privacy.
Ethical AI Development: Developers will aim to develop future AI systems utilizing transparent and bias-free datasets for a fair representation across genders, ethnicities, and geographical regions.
Conclusion
Image datasets are the backbone upon which AI vision systems have made progress in several industries. The continued evolution of AI will drive the demand for high-quality, diverse, and ethically sourced datasets.
AI's accuracy and fairness will improve with advanced curation techniques, minimized bias in datasets, and the addition of synthetic data, toward a smarter and more inclusive future. The role of image datasets in determining the next generation of AI vision technology can't be underestimated.
Visit Globose Technology Solutions to see how the team can speed up your image dataset for machine learning projects.
0 notes
Text
Navigating Challenges In The Salt Packaging Industry

Did you know the word "salary" comes from the Latin "Sal(t)"? Salt, a common kitchen staple, was such a valuable commodity that army soldiers were sometimes paid with salt instead of money in the Roman Times. This ancient high-value commodity still carries its significance to the present. However, it only matters if it reaches the consumer in the optimal condition.
This is where Salt Packaging enters the picture. The salt packaging industry faces multiple challenges at times due to external factors or sometimes due to salt properties. It needs to go through a troublesome journey to ensure the delivery to the consumer is in its optimal state.
Let's check out some of these key challenges in Salt Packaging.
Key Challenges of Salt Packaging
Moisture Control:
Salt's hygroscopic nature i.e. its property to absorb and hold water molecules from the air causes clumping and degradation. To avoid this meddling with salt's actual form and purity, the packaging needs to have a strong barrier to moisture ingress, such as desiccant packets. Also, to extend the shelf life of the product the salt packaging machine needs to remove air from the package to minimize moisture exposure.
Material Compatibility:
Salt also has corrosive properties that cause compatibility concerns with certain packaging materials. This fumbles up the ethnicity of the salt. Using multi-layered films of materials like plastics, treated containers, or other non-reactive materials for salt packaging pouches could effectively tackle this issue.
Packaging Accuracy:
Manual operations often cause errors like overfilling or overuse of packaging material. To save on such potential wastage, using automated salt packaging machines with precise dispensing mechanisms is essential. It will ensure each package contains the correct amount of salt. Even small variations in the quantity of the matter filled can impact consumer perception.
Sustainability Concerns:
With the world being overwhelmed due to pollution the consumer demand for eco-friendly packaging options is on the rise. This requires recyclable or biodegradable packaging solutions that fulfil the essential barrier properties to maintain the integrity of the salt. In order to make amends for this growing demand, salt packaging solutions must use biodegradable or compostable materials to align with sustainability goals and consumer preferences.
Regulatory Compliance:
Adhering to safety and industry regulations is vital when implementing automation in the salt packaging industry. This includes the safety regulations regarding labelling, material standards, and contaminant control. Keeping up with evolving regulations and embedding compliance is crucial for avoiding legal challenges and preserving your company's reputation.
Transportation and Storage:
Considering the hygroscopic and corrosive properties of the salt, we have understood the challenges and potential solutions to overcome them. However, going beyond the packaging aspect, salt also needs to go through troublesome times of storage and transportation. The packaging needs to be designed to withstand stacking pressure during storage and transport without damage or contamination.
Multiple Challenges, One Solution: Nichrome
Nichrome is a leading packaging solutions provider and has been delivering innovative and effective solutions to overcome various packaging challenges for several years. Nichrome's advanced salt packaging machines are one of the best solutions to address these challenges.
SALTPACK, Nichrome’s Vertical Form Fill Seal (VFFS) Machine is a high-speed packaging solution for the salt industry. It is a robust machine engineered with an open construction, and high-grade materials designed for salt handling, ensuring durability and ease of maintenance. Its low running cost is ensured by a CE-marked PLC housed in a dust-tight electrical panel, delivering precise and dependable machine control.
Also, for a stick pack pouch packaging, Nichrome offers MULTILANE STICKPACK with Volumetric Multiple Cavity Filler. It caters to the salt packaging needs of food chains and travel and hospitality industries.
With Nichrome's Salt Packaging Solutions, you get enhanced efficiency and product safety, consistent precision and quality, cost-effective operations and even versatility in packaging options. It also offers a user-friendly interface that simplifies operation and control. These features bring ease and convenience into salt packaging by overcoming all the challenges.
Conclusion
Salt packaging has evolved into more eco-friendly, premium, and visually appealing ways. Transparency has been a key factor showcasing its purity and quality. Yet, there are several challenges that this packaging faces. With the right strategies and advanced technologies, manufacturers can overcome these hurdles while meeting consumer and environmental expectations. Nichrome continues to lead the way in providing versatile and sustainable solutions for the salt packaging industry with new-age machines designed for durability and long-term reliability. Check out Nichrome’s offerings on our website and attain consistent precision and quality with every pouch packed.
0 notes
Text
Image Data Collection: Pioneering the Future with Globose Technology Solutions (GTS)

Introduction:
With their recent rise, artificial intelligence (AI) and machine learning (ML) have made a complete turnaround in industries across the globe. Availability of high-quality and diverse datasets to train AI models forms the backbone of this transformation. Image data collection, enabling applications ranging from facial recognition to autonomous vehicles, is amongst the most important types of data. Globose Technology Solutions is at the forefront of such innovation, providing leading imagery data collection services in order to empower organizations to build smarter, more efficient AI solutions.
What is Image Data Collection?
Image data collection refers to gathering various visual data from various sources to create datasets for training AI and ML models. This solution involves taking images, to. organizing them into categories, and annotating them with information specific to the particular use case.
For example:
Facial Recognition: The picture of different faces is collected to train models to recognize the identity of the individual or their emotions.
Object Detection: While images of ordinary objects support classification and recognition in ai.
Medical Imaging: High-resolution CTs are used to train disease-diagnostic tools.
Globose Technology Solutions specializes in curating datasets of images that fit specific desires across diverse industries.
Applications of Image Data Collection
The applications are numerous and far-reaching, with their number ever on the increase. Some key areas where image data collection plays a vital role:
Autonomous Vehicles: Training self-driving cars to identify pedestrians, road signs, and other vehicles.
Retail and E-commerce: High-quality visual search support tools for algorithmic identification and enhanced personalized shopping experiences.
Healthcare: Facilitating disease diagnosis through medical imaging.
Agriculture: Imagery of a crop to monitor and detect pests.
Civil Applications and Security: Serves as the engine for facial recognition securities.
At GTS, we truly realize that precision and diversity in image data collection do matter. Our solutions are industry-sensitive to ensure the successful execution of AI projects.
The GTS Approach to Image Data Collection
At Globose Technology Solutions, we take an extremely careful approach to ensure the highest image data collection quality.
Worldwide Reach: Inner-circles of contributors aid in gathering pictures encompassing variations in geography and cultures-allowing datasets to be representative and inclusive.
Advanced Annotation Tools: We make use of the latest, sophisticated tools for image annotation ensuring that each dataset is precise enough and ready for AI training.
Custom Solutions: In an interactive dialog with clients, special datasets are designed to suit specific objectives-pediatric, automotive, or retail.
Ethical Standards: GTS emphasizes ethical data collection while abiding by the international regulations on privacy that protect the common social and economical citizens of the world, like GDPR.
Challenges Encountered with Image Data Collection
While the collection of image data is important, there are challenges that come along with it:
Diversity of Data: The need for diversity in environments, demographics, and scenes in the datasets.
Quality Control: The picture-still quality and precision ought to be high enough to minimize errors in AI training.
Annotation Complexity: Labelling pictures with technical metadata is often a demanding endeavor, particularly when it comes to complicated uses like medical imaging.
Ethical Problems: Privacy protection of all people whose images were annotated into datasets.
Globose Technology Solutions combines advanced technology and humans to counter these significant challenges. Thus, ethical yet highly accurate datasets are to be documented.
Reasons Why You Should Choose GTS for Image Data Collection
Globose Technology Solutions is a respected data collection partner for organizations searching for the finest image data. Here's why:
Experience and Expertise: GTS knows just how to properly develop effective image datasets from years of data collection experience.
Advanced Technology: Our seamless integration of AI-based tools allows us to commit our data annotation tasks much faster and greater accuracy levels.
Scalable: Solutions from GTS at the scale from small-scale projects to corporate-level requisites.
Ethical Standards: GTS works under strict ethical guidelines and within responsible data collection and usage.
Image Data Collection in Future
As AI continues to develop further, the need for image data collection techniques will also evolve. A few on the horizon are:
3D Imaging: Collecting 3D image data for virtual reality and augmented reality applications.
Synthetic Data: Growing synthetic images by means of AI for rare or hard-to-capture scenarios.
Real-Time Data Capture: That involves continuous streams of image data using IoT devices and drones.
Automated Annotation: AI-based software is helping significantly streamline the task of labeling.
Those trends will help Globose Technology Solutions to keep growing and developing forward to provide their clients with fresh opportunities in image data collection.
Conclusion
Image data collection forms one of the pillars of AI development, offering solutions that are creative across multiple industries. Globose Technology Solutions (GTS) is proud to be one of the forerunners in this field, one that has provided an array of high-quality custom datasets contributing directly to the success of numerous AI projects. Our competence, advanced tools, and ethical approach offer businesses the ways to leverage the full benefits of AI.
So visit our webpage to know more about our image data collection services and to establish GTS's part in your journey toward reaching your AI goals.
0 notes
Text
Supervised vs. Unsupervised Learning: Understanding the Basics

Supervised vs. Unsupervised Learning:
Understanding the Basics Machine learning, a cornerstone of artificial intelligence, can be broadly
categorized into two types:
supervised and unsupervised learning.
Each has distinct methodologies and applications, making them essential tools for solving different kinds of problems.
In this blog, we’ll explore the key differences, concepts, and use cases of supervised and unsupervised learning to build a solid foundation for understanding these approaches.
What Is Supervised Learning?
Supervised learning involves training a machine learning model on a labeled dataset, where each input is paired with a corresponding output.
The goal is to learn a mapping function from inputs to outputs, enabling the model to make predictions or classifications on new, unseen data.
Key Features of Supervised Learning:
Labeled Data:
The training data includes both input features and their corresponding outputs (labels).
Prediction-Oriented:
It focuses on predicting outcomes or making classifications.
Types of Tasks: Common tasks include:
Regression:
Predicting continuous values (e.g., stock prices, temperature).
Classification:
Categorizing data into discrete classes (e.g., spam vs. non-spam emails).
Examples of Supervised Learning Algorithms:
Linear Regression Logistic Regression Support Vector Machines (SVM) Decision Trees Random Forests Neural Networks Applications of
Supervised Learning: Fraud detection in financial transactions Image and speech recognition Customer churn prediction Medical diagnostics.
What Is Unsupervised Learning?
Unsupervised learning deals with unlabeled data, where the model aims to identify patterns, structures, or relationships within the dataset without predefined outputs.
The objective is to uncover hidden insights and groupings that might not be immediately apparent.
Key Features of Unsupervised Learning:
Unlabeled Data: The data lacks explicit labels or outcomes. Exploratory Analysis: It focuses on discovering structures or patterns.
Types of Tasks: Common tasks include: Clustering: Grouping similar data points together (e.g., customer segmentation).
Dimensionality Reduction: Reducing the number of features while retaining important information (e.g., PCA).
Examples of Unsupervised Learning Algorithms:
K-Means
Clustering Hierarchical
Clustering Principal
Component Analysis (PCA)
DBSCAN Autoencoders Applications of Unsupervised Learning:
Customer segmentation for targeted marketing Anomaly detection in network security Recommendation systems

When to Use Which?
Supervised Learning is the right choice when labeled data is available, and the objective is prediction or classification.
Unsupervised Learning is ideal for exploratory data analysis, identifying patterns, or discovering hidden relationships when labels are unavailable.
Conclusion
Understanding the basics of supervised and unsupervised learning is crucial for selecting the right approach to solve a given problem.
While supervised learning is prediction-focused and relies on labeled data, unsupervised learning is more exploratory and thrives on uncovering hidden patterns in unlabeled data.
Together, they form the foundation of modern machine learning, empowering data scientists to tackle diverse challenges across industries.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/

0 notes
Text
The Strategic Transformation of Crane Parts Management

While consulting for a construction company last year, I encountered a revealing scenario. The site manager, Tom, had a perfectly organized storage room for crane parts—everything labeled, cataloged, and stored with precision. Yet, the company still faced frequent delays and operational headaches. The problem wasn’t organization; it was their approach to spare parts management.
If you’re managing crane operations, this might sound familiar. You think you’re doing everything right, but something isn’t working. Let’s explore why your current crane parts strategy might be failing and how to fix it.
The "Just in Time" Misstep
Many companies pride themselves on lean operations, keeping minimal Kobelco crane parts in stock and ordering only when needed. While this approach works in manufacturing consumer goods, it’s a disaster for crane maintenance. I’ve seen operations come to a standstill while waiting for critical crane parts to arrive from their supplier.
Consider this: When a crane breaks down, every hour of downtime costs thousands in lost productivity. The savings from minimizing inventory are insignificant compared to the financial impact of weeks-long delays for specialized components.
The Risk of a Single Supplier
Another common mistake is relying on just one crane parts supplier. It feels safe—you’ve built a relationship, they understand your equipment, and their prices seem reasonable. But this comfort zone can be dangerous.
I recall working with a port facility that had used the same crane parts supplier for ten years. When that supplier faced supply chain disruptions during a critical repair, the facility had no backup plan. They learned the hard way that supplier diversification is a crucial risk management strategy, not just business jargon.
Shifting to Predictive Maintenance
If you’re constantly scrambling to order crane parts after a breakdown, you’re already behind. This reactive approach is like waiting for your car to break down on the highway before considering maintenance. Forward-thinking crane operators are adopting predictive maintenance, using data and regular inspections to anticipate component failures.
Building a Better Strategy
A successful crane parts strategy involves building relationships with multiple suppliers while maintaining a well-planned inventory of critical components. Focus on identifying parts that frequently fail or have long lead times, and ensure you have these essentials on hand. This isn’t about stockpiling everything—it’s about intelligent inventory management based on real-world needs.
The Human Element
Effective spare parts management isn’t just about spreadsheets and inventory levels; it’s about people. Your maintenance team needs confidence in their resources to perform effectively. Your crane parts suppliers should feel like partners in your success, not just vendors.
I’ve seen maintenance teams transform when they shift from frantically chasing parts to executing planned maintenance with confidence. Stress levels drop, efficiency improves, and everyone feels more in control.
Taking Action
Begin by analyzing your current crane parts strategy. Identify the gaps, the stressors for your team, and the parts that consistently cause delays. Use these insights to develop a more robust approach.
The goal isn’t to stockpile every possible part but to have the right parts available when you need them most. This requires understanding your equipment, usage patterns, and maintenance needs.
Your crane parts strategy should operate like a well-oiled machine, not a constant firefight. When executed correctly, it becomes a competitive advantage, not a source of stress. Invest the time to build a comprehensive approach, and you’ll see the difference in your operations and bottom line.
The most successful crane operations treat their spare parts strategy as a living system—constantly evolving, adapting to new challenges, and improving based on experience. Isn’t it time your strategy did the same?
0 notes
Text
Achieve Seamless Categorization Using Automatic Fashion Product Tagging Solutions
In the dynamic and ever-evolving world of e-commerce, effective categorization plays a pivotal role in enhancing the customer experience and boosting sales. For fashion retailers, categorization is particularly crucial as it ensures that customers can easily find the products they’re looking for in a crowded digital marketplace.
The advent of automatic fashion product tagging has revolutionized how businesses manage their inventories, making operations more efficient while delivering tailored shopping experiences to customers.

Understanding Automatic Fashion Product Tagging
It refers to the use of advanced technologies, including artificial intelligence (AI) and machine learning (ML), to assign descriptive labels or tags to fashion products. These tags are derived from analyzing product attributes such as color, size, material, style, and more. By automating the tagging process, retailers can achieve accuracy, consistency, and scalability that is often unachievable with manual tagging methods.
Why Categorization Matters in Fashion E-Commerce
Proper categorization is the backbone of a smooth shopping experience. It ensures that customers can quickly navigate through vast inventories and discover products that meet their preferences. For instance, a shopper looking for “blue denim jeans” expects to find exactly that without scrolling through irrelevant results. Accurate categorization powered by fashion product tagging ensures this precision.
When executed correctly, categorization:
Enhances product discoverability
Reduces cart abandonment rates
Improves search engine rankings
Supports targeted marketing campaigns
Benefits
1. Improved Efficiency
Manually tagging thousands of products is time-consuming and prone to human error. Automatic systems can process large inventories within minutes, allowing businesses to allocate resources to more strategic tasks.
2. Enhanced Accuracy
AI-driven tagging minimizes inconsistencies and errors common in manual processes. Tags generated are uniform and precise, leading to better search results and a seamless shopping experience.
3. Scalability
As businesses expand and inventories grow, automatic tagging systems scale effortlessly. Whether a catalog contains hundreds or thousands of items, the system ensures consistent tagging standards.
4. Personalized Shopping Experiences
By leveraging data from automatic fashion product tagging, businesses can offer personalized recommendations tailored to individual preferences, increasing customer satisfaction and loyalty.
5. SEO Optimization
Search engines rely on accurate product descriptions and metadata to rank pages. Automated tagging ensures that each product is enriched with SEO-friendly attributes, improving visibility and driving organic traffic.
The Process Behind Automatic Fashion Product Tagging
Image Analysis AI algorithms analyze product images to detect attributes such as color, texture, and patterns. For example, a red floral dress might be tagged with terms like "red," "floral," "dress," and "spring fashion."
Natural Language Processing (NLP) For products with accompanying descriptions, NLP extracts relevant keywords and integrates them into the tagging process.
Taxonomy Matching Tags are aligned with predefined taxonomies that categorize products into logical groupings, such as "Women’s Footwear > Sneakers" or "Men’s Apparel > Formal Shirts.
Real-Time Updates Modern tagging solutions update product tags dynamically, ensuring they remain relevant to current trends and customer demands.
Challenges in Manual Fashion Product Tagging
1. Inconsistency
Human operators may interpret product attributes differently, leading to inconsistent tags that confuse customers.
2. Time and Resource Intensive
Manually tagging products for a large inventory is laborious and diverts resources from other critical business functions.
3. Limited Scalability
As inventories grow, maintaining a manual tagging system becomes increasingly unmanageable and error-prone.
4. Missed Opportunities for Personalization
Manual tagging often lacks the granularity needed to create highly personalized shopping experiences, which are key to modern retail success.
Best Practices for Implementing Automatic Fashion Product Tagging
1. Define a Clear Taxonomy
Establish a well-structured categorization framework that aligns with your brand’s inventory and customer preferences.
2. Leverage Advanced AI Tools
Invest in robust AI solutions capable of handling complex tagging requirements. Ensure the technology can adapt to emerging trends and customer behaviors.
3. Conduct Regular Audits
Periodically review and refine tagging algorithms to ensure they align with evolving business goals and market demands.
4. Incorporate Customer Feedback
Use insights from customer reviews and search queries to enhance tagging accuracy and relevance.
5. Focus on SEO Optimization
Ensure that tags include relevant keywords to maximize visibility on search engines and improve click-through rates.
The Role of Automatic Tagging in Future Trends
Sustainability Tags: Highlighting eco-friendly products to cater to the growing demand for sustainable fashion.
Voice Search Optimization: Ensuring tags align with voice search queries as this technology gains popularity.
Integration with Augmented Reality (AR): Enabling immersive shopping experiences where tags power virtual try-ons and product simulations.
How to Get Started
Implementing an automatic tagging solution doesn’t have to be daunting. Start by assessing your current catalog management system and identifying gaps in efficiency or accuracy. Collaborate with technology providers specializing in fashion product tagging to develop a tailored solution for your business.
Conclusion
In today’s competitive retail landscape, achieving seamless categorization is a must for success. Automatic fashion product tagging provides the tools to streamline operations, enhance customer satisfaction, and stay ahead of industry trends. By embracing this technology, businesses can unlock new opportunities for growth and differentiation.
Are you ready to revolutionize your product tagging process? Contact us today to discover how automatic fashion product tagging solutions can elevate your e-commerce strategy and help you achieve unparalleled success!
Visit Us, https://clasifai.com/
0 notes
Text
Introduction to Machine Learning: Transforming Industries and Innovation

Machine learning (ML) is a subset of artificial intelligence (AI) that enables computers to learn from data and improve their performance without explicit programming. By analyzing large amounts of data, ML algorithms can identify patterns, make predictions, and even automate complex tasks. The technology is rapidly evolving and reshaping numerous industries, from healthcare and finance to entertainment and transportation.
How Machine Learning Works
At the core of machine learning is data. ML algorithms learn from historical data (known as training data) and use statistical techniques to identify trends and patterns. These models are then tested and refined to ensure they can make accurate predictions or decisions when exposed to new, unseen data.
There are three main types of machine learning:
Supervised Learning: In this approach, the model is trained on labeled data, where each input is paired with a known output. The algorithm learns to predict the output based on the input data. Common applications include classification tasks, such as image recognition or email spam detection.
Unsupervised Learning: Here, the algorithm is provided with data that has no labeled output. It attempts to find hidden structures or patterns in the data, such as clustering similar items together. This is commonly used in customer segmentation or anomaly detection.
Reinforcement Learning: This method involves training models through a system of rewards and penalties. The algorithm learns by interacting with its environment and improving its actions based on feedback. Reinforcement learning has been successfully applied in areas like robotics and gaming.
Applications of Machine Learning
Machine learning's potential is vast and growing. Here are a few notable applications:
Healthcare: ML algorithms can help in diagnosing diseases, predicting patient outcomes, and recommending treatments. Systems like IBM Watson have demonstrated the ability to analyze medical data and assist doctors in decision-making.
Finance: ML is used in fraud detection, algorithmic trading, and risk management. By analyzing transaction patterns, machine learning models can identify fraudulent behavior in real time.
Transportation: Self-driving cars are one of the most exciting ML applications, where algorithms process sensor data to navigate roads, avoid obstacles, and make split-second decisions.
Entertainment: Streaming services like Netflix and Spotify use ML to recommend content based on users' preferences, increasing user engagement and satisfaction.
Challenges and Future of Machine Learning
While machine learning offers remarkable opportunities, it also comes with challenges. The reliance on large datasets can lead to biases if the data is not diverse or representative. Additionally, the "black-box" nature of many ML models makes it difficult to understand how decisions are made, raising concerns in sectors like healthcare and law.
The future of machine learning is incredibly promising. As the field continues to evolve, advancements in explainable AI, ethical guidelines, and data privacy will help address current concerns. With more powerful algorithms and increased computational capabilities, machine learning is set to drive further innovation across industries.
Explore, Learn, and Innovate – Join Our Tech Community
1 note
·
View note
Text
What are the Typical Approaches for a Successful Address Parsing?
Address parsing is a vital process for any business dealing with customer addresses, whether for e-commerce, logistics, or any service requiring precise address management. It involves analyzing and breaking down a complete address string into its structured components—like street, city, state, zip code, etc. Successful address parsing ensures improved data quality, smoother operations, and enhanced customer satisfaction. Let’s dive into the typical approaches for effective address parsing, covering rule-based methods, machine learning approaches, and hybrid techniques.

1. Rule-Based Parsing
The rule-based approach is one of the oldest and most straightforward methods for address parsing. Here, pre-defined rules or regular expressions (regex) are applied to identify different components of an address.
Regular Expressions (Regex): Regex can be used to identify and extract address components based on patterns. For instance, zip codes in the U.S. typically follow a five-digit pattern, so a regex like \d{5} can help identify zip codes. However, this approach can be challenging due to variations in address formats across different regions.
Tokenization: In tokenization, an address string is split into tokens (words or phrases) based on delimiters like spaces, commas, and periods. After tokenization, each part is matched against known patterns for address components.
Dictionary Matching: This approach uses dictionaries of common street names, cities, states, and country names. When a token matches a dictionary entry, it can be classified as a particular component, such as a city or state.
Advantages:
Simple and quick to implement.
Effective for predictable address formats.
Challenges:
Limited flexibility with variations in address structure.
Can struggle with incomplete or ambiguous addresses.
2. Machine Learning-Based Parsing
Machine learning (ML) techniques have gained traction due to their ability to handle complex, unstructured data. In this approach, models are trained on large datasets of labeled addresses, allowing them to identify patterns and recognize address components.
Supervised Learning Models: These models require a labeled dataset where each component of the address is already marked. Models like Conditional Random Fields (CRFs) or Recurrent Neural Networks (RNNs) are trained on these datasets to predict address components based on learned patterns.
Natural Language Processing (NLP): NLP models are particularly useful for parsing unstructured data like addresses. Named Entity Recognition (NER), a subset of NLP, can be applied to identify parts of an address such as street names, cities, and zip codes by recognizing entities.
Advantages:
Adaptable to various address formats and ambiguities.
Can handle multilingual addresses and diverse regions.
Challenges:
Requires large labeled datasets for accurate training.
Computationally expensive and may require significant resources.
3. Hybrid Approach
The hybrid approach combines rule-based and machine learning methods to leverage the strengths of both. For instance, a rule-based system can parse addresses for known formats, while machine learning models handle complex, unstructured addresses.
Combining Regex and ML Models: In this setup, regex patterns might be used to quickly identify straightforward components like zip codes or states. The remaining address string is then passed through a machine learning model to identify more complex components like street names or landmarks.
Active Learning: This technique involves using a model to parse addresses and flag uncertain parts, which are then corrected by a human expert. The corrected addresses are added back to the dataset to improve the model's accuracy over time.
Advantages:
Offers flexibility and accuracy across a broad range of address formats.
Efficiently combines simple and complex processing techniques.
Challenges:
Requires careful coordination of rule-based and machine learning methods.
Can be time-consuming to set up and fine-tune.
4. Context-Based Parsing
Context-based parsing relies on understanding the context of each component in the address. For instance, “Los Angeles” could be recognized as a city, but in a different context, it could also refer to a county. This approach is often used in tandem with NLP techniques.
Semantic Analysis: By analyzing the semantic meaning of words within an address, context-based parsing can improve accuracy in distinguishing between similar terms. For example, recognizing “Washington” as a city, state, or street based on the surrounding words.
Entity Recognition with Contextual Clues: Using contextual clues to differentiate between similar address components improves accuracy. For instance, understanding that "Ave" often precedes street names or that zip codes typically come at the end.
Advantages:
Better accuracy for ambiguous or context-sensitive addresses.
Can handle a wider variety of address formats and regional conventions.
Challenges:
Requires advanced NLP capabilities and a large labeled dataset.
Computationally intensive.
5. Evaluation and Optimization of Parsing Approaches
It’s essential to evaluate the effectiveness of address parsing methods regularly. Key metrics include:
Precision and Recall: Measures the model’s ability to correctly identify components without missing any or including false positives.
Accuracy and Error Rate: These metrics provide a straightforward measure of overall performance.
Processing Time: In high-volume operations, speed is crucial, so measuring processing time per address is necessary.
Final Thoughts
Successful address parsing relies on selecting the right approach based on the complexity, volume, and diversity of addresses you need to process. For simpler, structured addresses, rule-based methods may suffice. For complex, unstructured data, machine learning and hybrid approaches offer better flexibility and accuracy. Consistent evaluation and optimization are key to keeping address parsing efficient and reliable.
youtube
SITES WE SUPPORT
Parsing USPS Mailers – Wix
1 note
·
View note