#Json reader disk map
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Json reader disk map

#Json reader disk map how to#
#Json reader disk map code#
You can do so with the JSON. You will almost always need to serialize JSON or JavaScript object to a JSON string in Node. You can recover the serialized data by applying the reverse process.ĭeserialization refers to transforming the serialized data structure to its original format. Serialization is the process of modifying an object or data structure to a format that is easy to store or transfer over the internet. We shall also look at some third party npm packages that simplify working with data in the JSON format.
#Json reader disk map how to#
This article is a comprehensive guide on how to use the built-in fs module to read and write data in JSON format. The Node runtime environment has the built-in fs module specifically for working with files. More often than not, this JSON data needs to be read from or written to a file for persistence. JavaScript, and therefore the Node.js runtime environment, is no exception. Note that schema levels in the Select Schema Levels dialog box do not map directly to the folder structure in the Data pane. JSON to Map always gonna be a string/object data type. Most programming languages implement data structures that you can easily convert to JSON and vice versa. (where JSONSOURCE is a File, input stream, reader, or json content String) Share. The simplicity of the JSON syntax makes it very easy for humans and machines to read and write.ĭespite its name, the use of the JSON data format is not limited to JavaScript. JavaScript Object Notation, referred to as JSON in short, is one of the most popular formats for data storage and data interchange over the internet. If False, then don’t infer dtypes at all, applies only to the data.įor all orient values except 'table', default is True.Joseph Mawa Follow A very passionate open source contributor and technical writer Reading and writing JSON files in Node.js: A complete tutorial If True, infer dtypes if a dict of column to dtype, then use those This JavaScript library is the official reference implementation for JSON5 parsing and serialization libraries. The DataFrame columns must be unique for orients 'index', The JSON5 Data Interchange Format (JSON5) is a superset of JSON that aims to alleviate some of the limitations of JSON by expanding its syntax to include some productions from ECMAScript 5.1. Here is another easier possibility to read in a json file: include 'json/json.h' std::ifstream fileinput ('input.json') Json::Reader reader Json::Value root reader. If ‘infer’ and ‘pathorbuf’ is path-like, then detect compression from the following extensions: ‘.gz’, ‘.bz2’, ‘.zip’, ‘. For on-the-fly decompression of on-disk data. The DataFrame index must be unique for orients 'index' and Changed in version 1.2: JsonReader is a context manager. Indication of expected JSON string format.Ĭompatible JSON strings can be produced by to_json() with a If you want to pass in a path object, pandas accepts anyīy file-like object, we refer to objects with a read() method, Our focus here is going to be on the JSONB data type because it allows the contents to be indexed and queried with ease. The key difference between them is that JSON stores data in a raw format and JSONB stores data in a custom binary format. JSON is a text format that is completely language independent but uses. PostgreSQL has two native data types to store JSON documents: JSON and JSONB. It is based on a subset of the JavaScript Programming Language Standard ECMA-262 3rd Edition - December 1999. It is easy for machines to parse and generate. We measured and tweaked and finally got to a pretty good time and decent memory and CPU consumption. We cried, we re-implemented it with streaming parser and a disk-backed Map and it worked again - but was slow.
#Json reader disk map code#
URL schemes include http, ftp, s3, and file. JSON (JavaScript Object Notation) is a lightweight data-interchange format. Fixing JSON out-of-memory error with streaming and MapDB The code Once upon time, an API returned 0.5 GB JSON and our server crashed. Parameters path_or_buf a valid JSON str, path object or file-like objectĪny valid string path is acceptable. In the top navigation menu, click the Dashboard settings (gear) icon. To view the JSON of a dashboard: Navigate to a dashboard. Dashboard metadata includes dashboard properties, metadata from panels, template variables, panel queries, etc. read_json ( path_or_buf = None, orient = None, typ = 'frame', dtype = None, convert_axes = None, convert_dates = True, keep_default_dates = True, numpy = False, precise_float = False, date_unit = None, encoding = None, encoding_errors = 'strict', lines = False, chunksize = None, compression = 'infer', nrows = None, storage_options = None ) ¶Ĭonvert a JSON string to pandas object. Dashboard JSON model A dashboard in Grafana is represented by a JSON object, which stores metadata of its dashboard.
1 note
·
View note
Text
Json reader disk map

Json reader disk map how to#
Json reader disk map drivers#
Json reader disk map driver#
Json reader disk map windows 10#
Json reader disk map software#
Json reader disk map how to#
How to Install Adobe Acrobat Reader on Ubuntu 20.04 Focal Fossa Linux.
Set Kali root password and enable root login.
How to change from default to alternative Python version on Debian Linux.
Netplan static IP on Ubuntu configuration.
How to enable/disable firewall on Ubuntu 18.04 Bionic Beaver Linux.
How to install Tweak Tool on Ubuntu 20.04 LTS Focal Fossa Linux.
Linux IP forwarding – How to Disable/Enable.
How to use bash array in a shell script.
Json reader disk map driver#
AMD Radeon Ubuntu 20.04 Driver Installation.
How to install missing ifconfig command on Debian Linux.
Json reader disk map windows 10#
Ubuntu 20.04 Remote Desktop Access from Windows 10.
How to find my IP address on Ubuntu 20.04 Focal Fossa Linux.
Json reader disk map drivers#
How to install the NVIDIA drivers on Ubuntu 20.04 Focal Fossa Linux.Import your JSON file into Python and iterate over the resulting data.Create a JSON file with some JSON in it.Instantiate an object from your class and print some data from it.Write a class to load the data from your string.Use the JSON module to convert your string into a dictionary.Crate a dictionary in the form of a string to use as JSON.Create a new Python file an import JSON.That dictionary can be used as a dictionary, or it can be imported into an object as it’s instantiated to transfer data into a new object. By using the json.load methods, you can convert the JSON into a dictionary. It’s really not hard to parse JSON in Python. Otherwise, the process is mostly the same. The other thing to note is the load method replaces loads because this is a file. You will need to read and parse it from files, though, and that’s why you set up that distros.json file.Ī with can simplify the process of reading and closing the file, so that’s the structure to use here. That doesn’t make much sense in practicality. You’re really not going to need to parse JSON from within a Python program. There is a fairly direct way to do it by loading the JSON into an object’s _dict_ property. There are a few ways to do this, but most involve creating a class that you instantiate by populating it with data from the JSON. JSON is actually an object in JavaScript, so it would make sense to want to import it as an object in Python. Next, let’s look at parsing JSON in Python to an object. loaded_json = json.loads(json_data)Īs you can see, loaded_json contains a dictionary, not a string that looks like one. You can save it to a variable and iterate over it to see. It won’t look much different, but Python sees it in a usable form now. Print(json.dumps(parsed_json, indent=4, sort_keys=True)) Try to load and print the JSON data: parsed_json = (json.loads(json_data)) Just know that this form handles data while load handles files. You don’t really need to worry about it too much. Did you notice the quotes around that dictionary that you created for the JSON? That’s because Python treats JSON as a string unless it’s coming from a file. Python uses the loads method from the json to load JSON from a string. That’s what you’ll be working with first. Take a step back to that simple line of JSON that you created earlier. Put the JSON below in the file [Įverything’s ready. Use your text editor of choice to make one and name it distros.json. If you’re not familiar, they are text files with the. The next thing that you’ll need is a JSON file. It shares almost identical syntax with a dictionary, so make a dictionary, and Python can use it as JSON. First, create a Python file that will hold your code for these exercises. There are a few things that you’ll need to set up first. $ – requires given linux commands to be executed as a regular non-privileged userīefore you can start to parse JSON in Python, you’ll need some JSON to work with. # – requires given linux commands to be executed with root privileges either directly as a root user or by use of sudo command Privileged access to your Linux system as root or via the sudo command.
Json reader disk map software#
Requirements, Conventions or Software Version Used How to parse JSON data in Python Software Requirements and Linux Command Line Conventions Category It is possible to parse JSON directly from a Linux command, however, Python has also no problem reading JSON. It’s used in most public APIs on the web, and it’s a great way to pass data between programs. JSON is a favorite among developers for serializing data. The objective of this article is to describe how to parse JSON data in Python.
0 notes
Text
data persistence
What is a data persistence??
Information systems process data and convert it into information. The data should persist for later use
To maintain the status
For logging purposes
To further process and derive knowledge (data science)
Data can be stored, read, updated/modified, and deleted. At run time of software systems, data is stored in main memory, which is volatile (computer storage that only maintains its data while the device is powered (RAM),Data should be stored in non-volatile storage for persistence(Hard disk)
Two main ways of storing data
Files
Databases, in here many formats for storing data.
Plain Text
JSON
Tables
Text files
Images
What is a Data, Database, Database Server, Database Management System??
Data: In computing, data is information that has been translated into a form that is efficient for movement or processing
Data Types
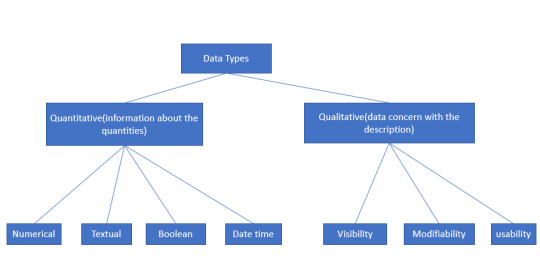
Database: A database is a collection of information that is organized so that it can be easily accessed, managed and updated
Database types
Hierarchical databases: data is stored in a parent-children relationship nodes. In a hierarchical database, besides actual data, records also contain information about their groups of parent/child relationships.
Network databases: Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computer.
Relational databases: In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Non-relational databases (NoSQL)
Object-oriented databases: In this Model we have to discuss the functionality of the object-oriented Programming. It takes more than storage of programming language objects.
Graph databases: Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Document databases: Document databases (Document DB) are also NoSQL database that store data in form of documents. Each document represents the data, its relationship between other data elements, and attributes
Database Server: The term database server may refer to both hardware and software used to run a database, according to the context. As software, a database server is the back-end portion of a database application, following the traditional client-server model. This back-end portion is sometimes called the instance. It may also refer to the physical computer used to host the database. When mentioned in this context, the database server is typically a dedicated higher-end computer that hosts the database.
Database Management System: A database management system (DBMS) is system software for creating and managing database. The DBMS provides users and programmers with a systematic way to create, retrieve, update and manage data.
Files and databases

Advantages of storing data in files
Higher productivity
Lower costs
Time saving
Disadvantages of storing data in files
Data redundancy
Data inconsistency
Integrity problem
Security problem
Advantages of storing data in database
Excellent data integrity independence from application programs
Improve data access to users through the use of hos and query language
Improve data security storage and retrieval
Disadvantages of storing data in database
Complex, difficult and time consuming to design
Substantial hardware and software start-up cost.
Initial training required for all programmers and users
Data arrangements
Un-structured - Unstructured data has internal structure but is not structured via pre-defined data models or schema. It may be textual or non-textual, and human- or machine-generated. It may also be stored within a non-relational database like NoSQL
E.g. – paragraph, essay
Semi- structured - Semi-structured data is a data type that contains semantic tags, but does not conform to the structure associated with typical relational databases. Semi-structured data is one of many different types of data.
Structured - Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis. This persistence technique is better for these arrangements.
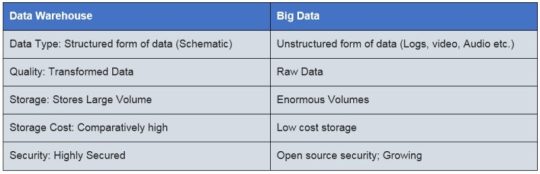
Data Warehouse is an architecture of data storing or data repository. Whereas Big Data is a technology to handle huge data and prepare the repository. ... Data warehouse only handles structure data (relational or not relational), but big data can handle structure, non-structure, semi-structured data.
APPLICATION TO FILES/DB
Files and DBs are external components.They are existing outside the software system. Software can connect to the files/DBs to perform CRUD operations on data
File –File path, URL
DB –connection string
To process data in DB ,
SQL statements
Statement interface is used to execute normal SQL queries. You can’t pass the parameters to SQL query at run time using this interface. This interface is preferred over other two interfaces if you are executing a particular SQL query only once. The performance of this interface is also very less compared to other two interfaces. In most of time, Statement interface is used for DDL statements like CREATE, ALTER, DROP etc. For example,
//Creating The Statement Object
Statement stmt = con.createStatement();
//Executing The Statement
stmt.executeUpdate("CREATE TABLE STUDENT(ID NUMBER NOT NULL, NAME VARCHAR)");
Prepared statements
Prepared Statement is used to execute dynamic or parameterized SQL queries. Prepared Statement extends Statement interface. You can pass the parameters to SQL query at run time using this interface. It is recommended to use Prepared Statement if you are executing a particular SQL query multiple times. It gives better performance than Statement interface. Because, Prepared Statement are precompiled and the query plan is created only once irrespective of how many times you are executing that query. This will save lots of time.
//Creating PreparedStatement object
PreparedStatement pstmt = con.prepareStatement("update STUDENT set NAME = ? where ID = ?");
//Setting values to place holders using setter methods of PreparedStatement object
pstmt.setString(1, "MyName"); //Assigns "MyName" to first place holder
pstmt.setInt(2, 111); //Assigns "111" to second place holder
//Executing PreparedStatement
pstmt.executeUpdate();
Callable statements
Callable Statement is used to execute the stored procedures. Callable Statement extends Prepared Statement. Usng Callable Statement, you can pass 3 types of parameters to stored procedures. They are : IN – used to pass the values to stored procedure, OUT – used to hold the result returned by the stored procedure and IN OUT – acts as both IN and OUT parameter. Before calling the stored procedure, you must register OUT parameters using registerOutParameter() method of Callable Statement. The performance of this interface is higher than the other two interfaces. Because, it calls the stored procedures which are already compiled and stored in the database server.
/Creating CallableStatement object
CallableStatement cstmt = con.prepareCall("{call anyProcedure(?, ?, ?)}");
//Use cstmt.setter() methods to pass IN parameters
//Use cstmt.registerOutParameter() method to register OUT parameters
//Executing the CallableStatement
cstmt.execute();
//Use cstmt.getter() methods to retrieve the result returned by the stored procedure
Useful objects
Connection
Statement
Reader
Result set
OBJECT RELATIONAL MAPPING (ORM)
There are different structures for holding data at runtime
Application holds data in objects
Database uses tables (entities)
Mismatches between relational and object models
Granularity: Object model has more granularity than relational model.
Subtypes: Subtypes (means inheritance) are not supported by all types of relational databases.
Identity: Like object model, relational model does not expose identity while writing equality.
Associations: Relational models cannot determine multiple relationships while looking into an object domain model.
Data navigation: Data navigation between objects in an object network is different in both models
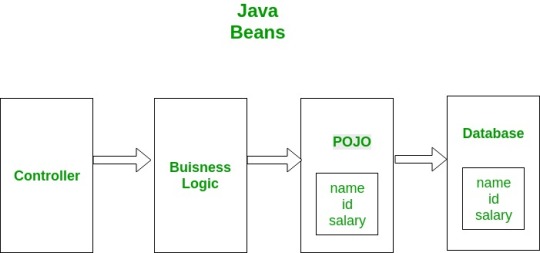
Beans use POJO
stands for Plain Old Java Object. It is an ordinary Java object, not bound by any special restriction other than those forced by the Java Language Specification and not requiring any class path. POJOs are used for increasing the readability and re-usability of a program. POJOs have gained most acceptance because they are easy to write and understand. They were introduced in EJB 3.0 by Sun microsystems.
A POJO should not:
Extend pre-specified classes.
Implement pre-specified interfaces.
Contain pre-specified annotations.
Beans
•Beans are special type of Pojos. There are some restrictions on POJO to be a bean. All JavaBeans are POJOs but not all POJOs are JavaBeans. Serializable i.e. they should implement Serializable interface. Still some POJOs who don’t implement Serializable interface are called POJOs because Serializable is a marker interface and therefore not of much burden. Fields should be private. This is to provide the complete control on fields. Fields should have getters or setters or both. A no-AR constructor should be there in a bean. Fields are accessed only by constructor or getter setters.
POJO/Bean to DB
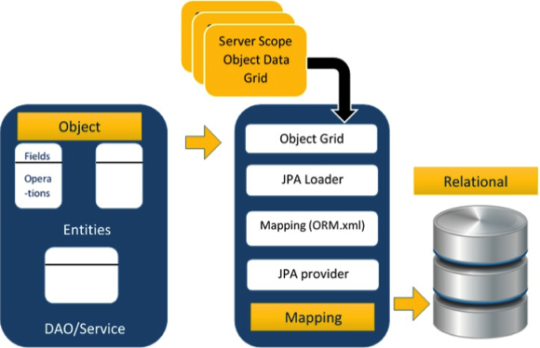
Java Persistence API (JPA)
An API/specification for ORM.
Uses
POJO classes
XML based mapping file (represent the DB)
A provider (implementation of JPA)
JPA Architecture
JPA implementations
Hybernate
JDO
EclipseLink
ObjectDB
NOSQL AND HADOOP
Not Only SQL (NOSQL)
Relational DBs are good for structured data.For semi-structured and un-structured data, some other types of DBs can be used
Key-value stores
Document databases
Wide-column stores
Graph stores
Benefits of NoSQL
When compared to relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several issues that the relational model is not designed to address:
Large volumes of rapidly changing structured, semi-structured, and unstructured data.
NoSQL DB servers
MongoDB
Cassandra
Redis
Amazon DynamoDB
Hbase
Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Hadoop core concepts
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop Map Reduce: A YARN-based system for parallel processing of large data sets.
INFORMATION RETRIEVAL
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
Keyword search
Full-text search
The output can be
Text
Multimedia
0 notes