#Maps web scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
Top 5 Google Maps Scraper APIs Compared – Features, Pricing & Performance
Explore the 5 best Google Maps Scraper APIs tested for data accuracy, speed, and value. A must-read for developers and businesses looking to extract location data at scale.
0 notes
Text
How To Extract 1000s of Restaurant Data from Google Maps?

In today's digital age, having access to accurate and up-to-date data is crucial for businesses to stay competitive. This is especially true for the restaurant industry, where trends and customer preferences are constantly changing. One of the best sources for this data is Google Maps, which contains a wealth of information on restaurants around the world. In this article, we will discuss how to extract thousands of restaurant data from Google Maps and how it can benefit your business.
Why Extract Restaurant Data from Google Maps?
Google Maps is the go-to source for many customers when searching for restaurants in their area. By extracting data from Google Maps, you can gain valuable insights into the current trends and preferences of customers in your target market. This data can help you make informed decisions about your menu, pricing, and marketing strategies. It can also give you a competitive edge by allowing you to stay ahead of the curve and adapt to changing trends.
How To Extract Restaurant Data from Google Maps?
There are several ways to extract restaurant data from Google Maps, but the most efficient and accurate method is by using a web scraping tool. These tools use automated bots to extract data from websites, including Google Maps, and compile it into a usable format. This eliminates the need for manual data entry and saves you time and effort.
To extract restaurant data from Google Maps, you can follow these steps:
Choose a reliable web scraping tool that is specifically designed for extracting data from Google Maps.
Enter the search criteria for the restaurants you want to extract data from, such as location, cuisine, or ratings.
The tool will then scrape the data from the search results, including restaurant names, addresses, contact information, ratings, and reviews.
You can then export the data into a spreadsheet or database for further analysis.
Benefits of Extracting Restaurant Data from Google Maps
Extracting restaurant data from Google Maps can provide numerous benefits for your business, including:
Identifying Trends and Preferences
By analyzing the data extracted from Google Maps, you can identify current trends and preferences in the restaurant industry. This can help you make informed decisions about your menu, pricing, and marketing strategies to attract more customers.
Improving SEO
Having accurate and up-to-date data on your restaurant's Google Maps listing can improve your search engine optimization (SEO). This means that your restaurant will appear higher in search results, making it easier for potential customers to find you.
Competitive Analysis
Extracting data from Google Maps can also help you keep an eye on your competitors. By analyzing their data, you can identify their strengths and weaknesses and use this information to improve your own business strategies.
conclusion:
extracting restaurant data from Google Maps can provide valuable insights and benefits for your business. By using a web scraping tool, you can easily extract thousands of data points and use them to make informed decisions and stay ahead of the competition. So why wait? Start extracting restaurant data from Google Maps today and take your business to the next level.
#food data scraping services#restaurant data scraping#restaurantdataextraction#food data scraping#zomato api#fooddatascrapingservices#web scraping services#grocerydatascraping#grocerydatascrapingapi#Google Maps Scraper#google maps scraper python#google maps scraper free#web scraping service#Scraping Restaurants Data#Google Maps Data
0 notes
Text
Outsource Google Maps Scraper And Reduce Business Overhead
Explore RPA and AI-driven end-to-end Google Maps scraperv from Outsource Bigdata and increase your customer reach at a fraction of operational cost. Outsource Bigdata focuses on outcome-based Google Maps scraper solutions and related data preparations including IT application integration. The rapid turnaround of our services can be attributed to our 'Automation First' approach.
For more information visit: https://outsourcebigdata.com/data-automation/web-scraping-services/google-maps-scraper/
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered projects in IT & digital transformation, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
An ISO 9001:2015 and ISO/IEC 27001:2013 certified
Served 750+ customers
11+ Years of industry experience
98% client retention
Great Place to Work® certified
Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform
APYSCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution
AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services
On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution
An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub
APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations:
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
Email: [email protected]
0 notes
Text
A year in illustration, 2023 edition (part two)

(This is part two; part one is here.)

The West Midlands Police were kind enough to upload a high-rez of their surveillance camera control room to Flickr under a CC license (they've since deleted it), and it was the perfect frame for dozens of repeating clown images with HAL9000 red noses. This worked out great. The clown face is from a 1940s ad for novelty masks.
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop

I spent an absurd amount of time transforming a photo I took of three pinball machines into union-busting themed tables, pulling in a bunch of images from old Soviet propaganda art. An editorial cartoon of Teddy Roosevelt with his big stick takes center stage, while a NLRB General Counsel Jennifer Abruzzo's official portrait presides over the scene. I hand-made the eight-segment TILT displays.
https://pluralistic.net/2023/09/06/goons-ginks-and-company-finks/#if-blood-be-the-price-of-your-cursed-wealth

Working with the highest-possible rez sources makes all the difference in the world. Syvwlch's extremely high-rez paint-scraper is a gift to people writing about web-scraping, and the Matrix code waterfall mapped onto it like butter.
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/

This old TWA ad depicting a young man eagerly pitching an older man has incredible body-language – so much so that when I replaced their heads with raw meat, the intent and character remained intact. I often struggle for background to put behind images like this, but high-rez currency imagery, with the blown up intaglio, crushes it.
https://pluralistic.net/2023/10/04/dont-let-your-meat-loaf/#meaty-beaty-big-and-bouncy

I transposed Photoshop instructions for turning a face into a zombie into Gimp instructions to make Zombie Uncle Sam. The guy looking at his watch kills me. He's from an old magazine illustration about radio broadcasting. What a face!
https://pluralistic.net/2023/10/18/the-people-no/#tell-ya-what-i-want-what-i-really-really-want

The mansplaining guy from the TWA ad is back, but this time he's telling a whopper. It took so much work to give him that Pinnocchio nose. Clearly, he's lying about capitalism, hence the Atlas Shrugged cover. Bosch's "Garden of Earthly Delights" makes for an excellent, public domain hellscape fit for a nonconensual pitch about the miracle of capitalism.
https://pluralistic.net/2023/10/27/six-sells/#youre-holding-it-wrong

There's no better image for stories about techbros scamming rubes than Bosch's 'The Conjurer.' Throw in Jeff Bezos's head and an Amazon logo and you're off to the races. I boobytrapped this image by adding as many fingers as I could fit onto each of these figures in the hopes that someone could falsely accuse me of AI-generating this. No one did.
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens

Once again, it's Bosch to the rescue. Slap a different smiley-face emoji on each of the tormented figures in 'Garden of Earthly Delights' and you've got a perfect metaphor for the 'brand safety' problem of hard news dying online because brands don't want to be associated with unpleasant things, and the news is very unpleasant indeed.
https://pluralistic.net/2023/11/11/ad-jacency/#brand-safety

I really struggle to come up with images for my linkdump posts. I'm running out of ways to illustrate assortments and varieties. I got to noodling with a Kellogg's mini-cereal variety pack and I realized it was the perfect place for a vicious gorilla image I'd just found online in a WWI propaganda poster headed 'Destroy This Mad Brute.' I put so many fake AI tells in this one – extra pupils, extra fingers, a super-AI-esque Kellogg's logo.
https://pluralistic.net/2023/11/05/variegated/#nein

Bloodletting is the perfect metaphor for using rate-hikes to fight inflation. A vintage image of the Treasury, spattered with blood, makes a great backdrop. For the foreground, a medieval woodcut of bloodletting quacks – give one the head of Larry Summers, the other, Jerome Powell. For the patient, use Uncle Sam's head.
https://pluralistic.net/2023/11/20/bloodletting/#inflated-ego

I killed a long videoconference call slicing up an old pulp cover showing a killer robot zapping a couple of shrunken people in bell-jars. It was the ideal image to illustrate Big Tech's enshittification, especially when it was decorated with some classic tech slogans.
https://pluralistic.net/2023/11/22/who-wins-the-argument/#corporations-are-people-my-friend

There's something meditative about manually cutting out Tenniel engravings from Alice – the Jabberwock was insane. But it was worth it for this Tron-inflected illustration using a distorted Cartesian grid to display the enormous difference between e/acc and AI doomers, and everyone else in the world.
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Multilayer source images for your remixing pleasure:
Scientist in chemlabhttps://craphound.com/images/scientist-in-chem-lab.psd
Humpty Dumpty and the millionaires https://craphound.com/images/humpty-dumpty-and-the-millionaires.psd
Demon summoning https://craphound.com/images/demon-summoning.psd
Killer Robot and People in Bell Jars https://craphound.com/images/killer-robot-and-bell-jars.psd
TWA mansplainer https://craphound.com/images/twa-mansplainer.psd
Impatient boss https://craphound.com/images/impatient-boss.psd
Destroy This Mad Brute https://craphound.com/images/destroy-this-mad-brute.psd
(Images: Heinz Bunse, West Midlands Police, Christopher Sessums, CC BY-SA 2.0; Mike Mozart, Jesse Wagstaff, Stephen Drake, Steve Jurvetson, syvwlch, Doc Searls, https://www.flickr.com/photos/mosaic36/14231376315, Chatham House, CC BY 2.0; Cryteria, CC BY 3.0; Mr. Kjetil Ree, Trevor Parscal, Rama, “Soldiers of Russia” Cultural Center, Russian Airborne Troops Press Service, CC BY-SA 3.0; Raimond Spekking, CC BY 4.0; Drahtlos, CC BY-SA 4.0; Eugen Rochko, Affero; modified)
201 notes
·
View notes
Link
#LocalScraperv7.190Cracked#LocalScraperv7.193Cracked#LocalScraperv7.197Cracked#LocalScraperv7.199Cracked#LocalScraperv7.200Cracked#LocalScraperv7.201Cracked#LocalScraperv7.202Cracked#LocalScraperv7.203Cracked
0 notes
Text
Why Businesses Need Reliable Web Scraping Tools for Lead Generation.
The Importance of Data Extraction in Business Growth
Efficient data scraping tools are essential for companies looking to expand their customer base and enhance their marketing efforts. Web scraping enables businesses to extract valuable information from various online sources, such as search engine results, company websites, and online directories. This data fuels lead generation, helping organizations find potential clients and gain a competitive edge.
Not all web scraping tools provide the accuracy and efficiency required for high-quality data collection. Choosing the right solution ensures businesses receive up-to-date contact details, minimizing errors and wasted efforts. One notable option is Autoscrape, a widely used scraper tool that simplifies data mining for businesses across multiple industries.

Why Choose Autoscrape for Web Scraping?
Autoscrape is a powerful data mining tool that allows businesses to extract emails, phone numbers, addresses, and company details from various online sources. With its automation capabilities and easy-to-use interface, it streamlines lead generation and helps businesses efficiently gather industry-specific data.
The platform supports SERP scraping, enabling users to collect information from search engines like Google, Yahoo, and Bing. This feature is particularly useful for businesses seeking company emails, websites, and phone numbers. Additionally, Google Maps scraping functionality helps businesses extract local business addresses, making it easier to target prospects by geographic location.
How Autoscrape Compares to Other Web Scraping Tools
Many web scraping tools claim to offer extensive data extraction capabilities, but Autoscrape stands out due to its robust features:
Comprehensive Data Extraction: Unlike many free web scrapers, Autoscrape delivers structured and accurate data from a variety of online sources, ensuring businesses obtain quality information.
Automated Lead Generation: Businesses can set up automated scraping processes to collect leads without manual input, saving time and effort.
Integration with External Tools: Autoscrape provides seamless integration with CRM platforms, marketing software, and analytics tools via API and webhooks, simplifying data transfer.
Customizable Lead Lists: Businesses receive sales lead lists tailored to their industry, each containing 1,000 targeted entries. This feature covers sectors like agriculture, construction, food, technology, and tourism.
User-Friendly Data Export: Extracted data is available in CSV format, allowing easy sorting and filtering by industry, location, or contact type.
Who Can Benefit from Autoscrape?
Various industries rely on web scraping tools for data mining and lead generation services. Autoscrape caters to businesses needing precise, real-time data for marketing campaigns, sales prospecting, and market analysis. Companies in the following sectors find Autoscrape particularly beneficial:
Marketing Agencies: Extract and organize business contacts for targeted advertising campaigns.
Real Estate Firms: Collect property listings, real estate agencies, and investor contact details.
E-commerce Businesses: Identify potential suppliers, manufacturers, and distributors.
Recruitment Agencies: Gather data on potential job candidates and hiring companies.
Financial Services: Analyze market trends, competitors, and investment opportunities.
How Autoscrape Supports Business Expansion
Businesses that rely on lead generation services need accurate, structured, and up-to-date data to make informed decisions. Autoscrape enhances business operations by:
Improving Customer Outreach: With access to verified emails, phone numbers, and business addresses, companies can streamline their cold outreach strategies.
Enhancing Market Research: Collecting relevant data from SERPs, online directories, and Google Maps helps businesses understand market trends and competitors.
Increasing Efficiency: Automating data scraping processes reduces manual work and ensures consistent data collection without errors.
Optimizing Sales Funnel: By integrating scraped data with CRM systems, businesses can manage and nurture leads more effectively.

Testing Autoscrape: Free Trial and Accessibility
For businesses unsure about committing to a web scraper tool, Autoscrapeoffers a free account that provides up to 100 scrape results. This allows users to evaluate the platform's capabilities before making a purchase decision.
Whether a business requires SERP scraping, Google Maps data extraction, or automated lead generation, Autoscrape delivers a reliable and efficient solution that meets the needs of various industries. Choosing the right data scraping tool is crucial for businesses aiming to scale operations and enhance their customer acquisition strategies.
Investing in a well-designed web scraping solution like Autoscrape ensures businesses can extract valuable information quickly and accurately, leading to more effective marketing and sales efforts.
0 notes
Text
Games Production (Feb 12th)
An Overview
this week was surprisingly productive - I have been suffering from burnout recently, and have been taking it slow, but I have significantly improved the Workflow Toolkit website, fixed some significant bugs in all three projects, and added some functionality to QuickBlock.
Star In The Making
This project hasn't been progressed much, but I finally added an audio system that allows all songs to be listened to during playing.

the Audio Manager Singleton plays the menu song in the menu scene, and the array of Game Music in the game scene. I was thinking about randomising the songs (so there is no order) but felt that this was nicer, like you're listening to an EP while playing - However this is subject to change.
Workflow Toolkit - Project
firstly, Portuguese (EU) has been added to Workflow Toolkit - making it the fourth language in this project. The translations were made by my cousin (and I am very thankful)

I will have to get a few more translations done because I had changed some text around to make it more understandable, but this is incredibly easy to do.
Workflow Toolkit - Website
I have made some great strides with the website, making documentation easier to understand as it is separated clearly and looks professional.
Firstly, I have now added a footer to the website that points to Chomp Games' (a studio I am planning to make) Social Medias (where in my marketing plan, I am posting weekly updates & information on the project)

The buttons from left to right are Instagram, BlueSky and YouTube.
I have also been working on the website's documentation page - currently just improving the UI and layout behind it, with plans to add more in depth documentation (like a record of functions, localisation language trackers and more)
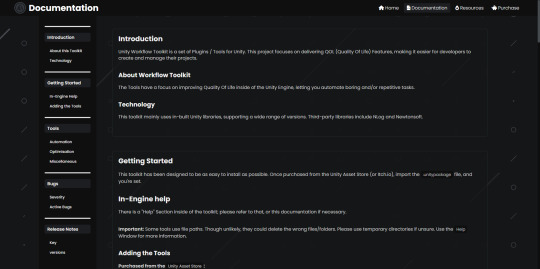


I have also redesigned the dropdowns that explain what the project do, and it looks and feels nicer.

in comparison with the old website, here are some images:




in terms of the website, some other enhancements include Embeds and web scraping/crawling improvements:
Here's the embed:

to make this work, I added OpenGraph meta tags to each file (so I could make a different embed for each page)

To improve web scraping and crawling, I added two files to the root of the website; SiteMap.xml and Robots.txt - SiteMap.xml tells search engines the important pages to cache. Due to how small the website is, I have told it to cache all pages.
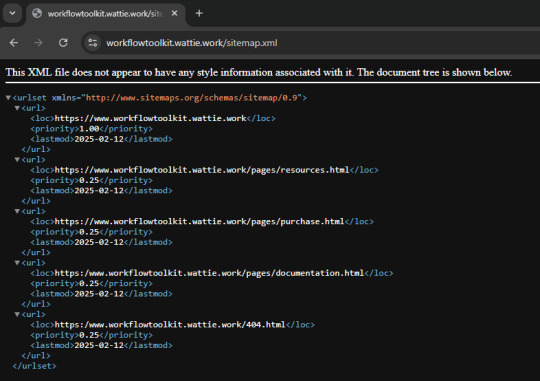
Robots.txt tells web scrapers if they are welcome to scrape this website (although they do not have to adhere to this)

I have disabled scraping for all robots apart from Google's Scraper and Archive.org's scraper - I have a soft spot for everything related to archiving, and hence have allowed it through.
Googlebot has been allowed to enable it to get a high up link for SEO purposes.
I added a very slight overlay to the background of all pages (barring documentation.html) to make the website feel more lively. Here's a comparison:

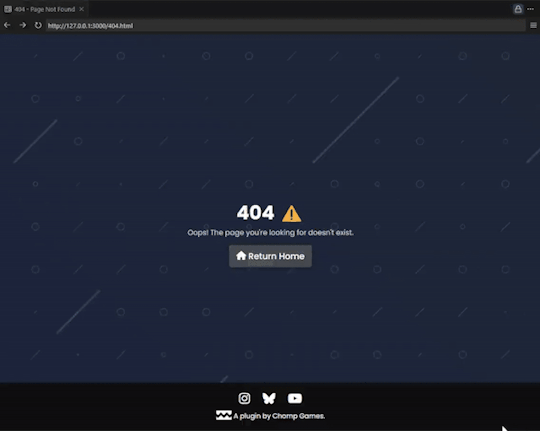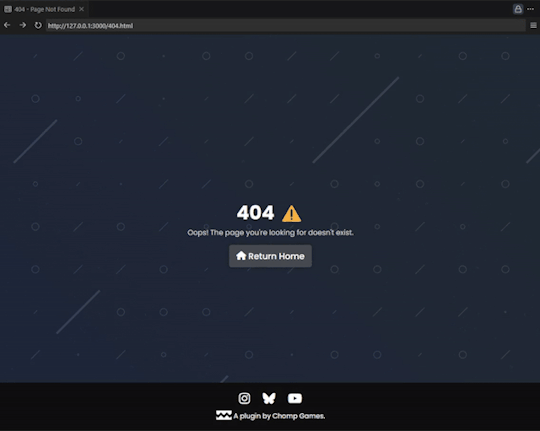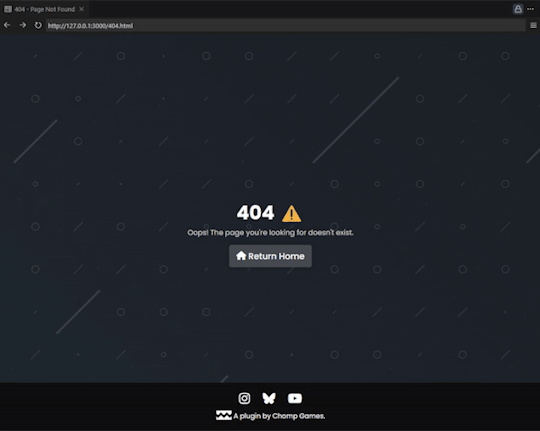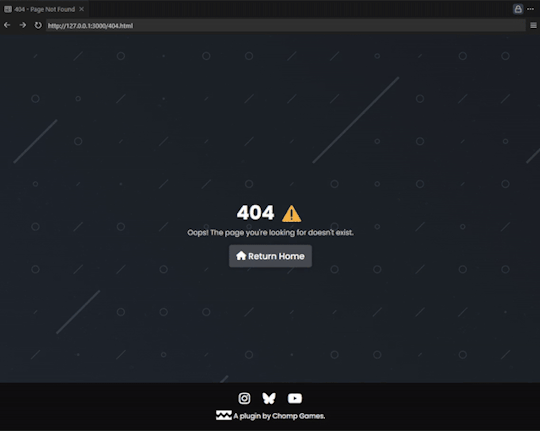
I then added a 404 error page incase somebody goes to the wrong page, it'll display that (instead of the default github pages one). The animation is 20 seconds long, so I have shown a sped up one below:
I also refactored the whole website because of internal frustration - it fixed some annoyances (but do not harm the website) like all spaces in download links being replaced by "%20".
QuickBlock
I refactored the asset loading of this project to be much more efficient, fixed some critical bugs in Grid Snapping, imported all of the assets that were made for me and worked on transformations of the placed assets:

These shapes allow you to fully customise your map (and more will be added!)

Firstly, I fixed the asset loading, and made it much more optimised. Before, there were hard-coded directories that connected to Enums, so you'd have to load an asset based on an enum and it was very ineffective, now, there is a ResourceManager Singleton that loads every asset based on it's "type".
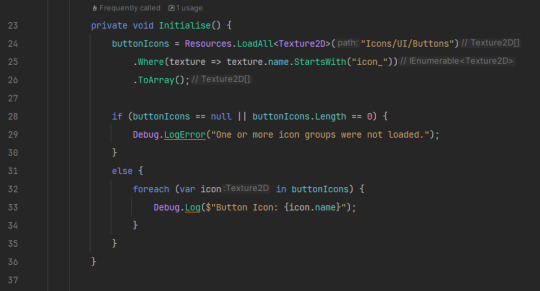
For simplicity in terms of this screenshot, I have deleted the other initialisations (logos, materials, textures etc).
you can then freely use the loaded assets like this:

This change has made the project feel more professional and optimised.
I then fixed some grid snapping issues that made it impossible for differently tagged items (for example, a block versus a ramp) to have different grid snapping. this lead fixed a major concern, and I can already now build simple areas with the blocks, walls, floors and ramps I have.
This week, I also added transform modifiers. I am very happy about this.
I have also started working on Palettes (will discuss this after my future plans), but no functionality yet

it also creates a little swatch of your palette, I love this!

A lot more ideas will be worked on throughout this next week, as I do think that QuickBlock has a lot of potential.
These Include:
Texture Customisation (choose between textures)
Scaling
Commenting (comment in-editor while you're building)
Palette Implementation
Palette Implementation will allow you to colour specific parts of your build automatically - just by creating a palette. There will also be "Dark" modes and "Light" modes.
Ramps = yellow, foliage = green, floors = white,
walls = blue, misc = red.
DARK MODE
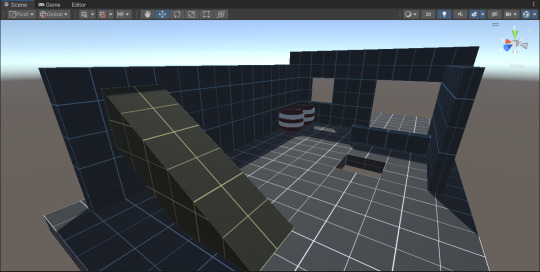
LIGHT MODE
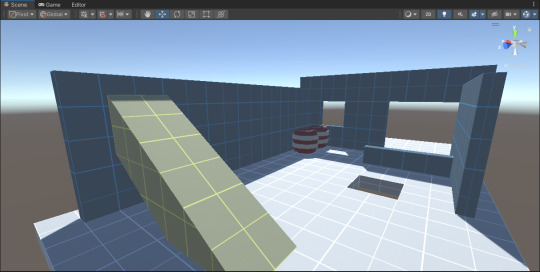
This will automatically be done with tag checking.
I hopefully will have this fully implemented by next week.
================================================
Performance Evaluation
[ I feel quite relieved that despite going through burnout, my ability to find less significant (but still important) tasks contribute to the momentum of these projects, without sacrificing my mental health.
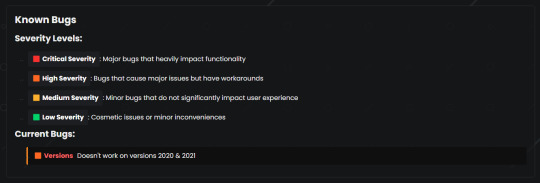
Essentially, while these features (a .404 error page, colour palette, or music) isn't critical to the core functionality of these projects, it will enhance the final projects. ]
[ This however, is a double-edged sword, I need to be aware enough about feature creep, and knowing where and when to stop, then divert my attention to the necessary features of these projects, otherwise it can create a backlog of essential tasks, which would be challenging to come back from when I have just recovered from burnout. ]
================================================
Action Plan
This following week will be about organisation; but I need to be careful and plan for contingencies in terms of my mental health - and follow my Risk Assessment & Mitigation plan

Firstly, I will create a task tracker for Workflow Toolkit, QuickBlock and Star In The Making, I will not separate tasks by project, as this causes further frustration, but do any task I can tick off without further hurting my burnout.
This task tracker will be updated every two weeks, and I should be aiming to complete at least 2 tasks from this tracker every day (but allow less or none during tough days). I will make sure these tasks are measurable, and able to be completed.
I will make sure this tracker has some tasks that can easily be done, in case I am having a rough day in particular, but still need a task to be completed.
Once the bi-weekly tracker needs to be refreshed, I will delete all tasks and re-add them, to make sure my priorities will shift to more important areas.
================================================
1 note
·
View note
Text

Best Full Stack Python training Hyderabad at APEC gives you hands-on learning on how to use it to analyze, visualize and present data, create a web-mapping app, desktop app, web scraper etc. A Full Stack Python has been gaining popularity and has the potential to become the programming language of choice for both individuals and enterprises going forward. Today, a large number of organizations are migrating and transitioning to Python.
0 notes
Text
Learn how to automate lead generation from Google Maps with this step-by-step guide using Make.com. Perfect for marketers, freelancers, and local business consultants!
0 notes
Text
Challenges in Web Scraping iFood Restaurant Location Data

What Challenges Should Businesses Expect While Web Scraping iFood Restaurant Location Data?
In the fast-paced world of food delivery and restaurant services, data-driven decision- making is crucial for businesses aiming to strengthen their local presence. Web scraping iFood restaurant location data has emerged as a vital tool for gathering insights from the iFood platform, which connects consumers with various dining options. By scraping iFood restaurant location data, businesses can unlock valuable information about restaurant placements, customer preferences, and market trends. This data extraction process enhances understanding of local market dynamics and informs strategic planning, helping companies stand out in a competitive environment. Extracting iFood restaurant data allows businesses to identify opportunities, monitor competitor activity, and tailor their offerings to meet consumer demands effectively. In summary, leveraging web scraping techniques gives businesses insights into how to thrive in the ever-evolving food delivery landscape.
Understanding iFood and Its Market
iFood is a prominent food delivery service operating primarily in Brazil and Latin America. Founded in 2011, it has become one of the largest platforms in the region, connecting customers with a wide range of restaurants, cafes, and food vendors. With a user-friendly app and website, iFood lets consumers browse menus, place orders, and enjoy seamless food delivery experiences.
Understanding the dynamics of the iFood platform is crucial for local businesses. The competition is fierce, and the ability to analyze restaurant locations, their proximity to customers, and the type of cuisine offered can provide valuable insights for strategic planning. By leveraging iFood's extensive database, local businesses can uncover trends, identify gaps in the market, and tailor their offerings to meet customer preferences.
The Value of Location Data
Location data is one of the most valuable assets for any business operating in the food industry. It provides insights into where customers are located, how far they are willing to travel for food, and what types of cuisines are popular in specific areas. By analyzing restaurant location data from iFood, businesses can comprehensively understand their target market and refine their marketing strategies.
1. Identifying Market Trends: Extract iFood food delivery data to monitor restaurant location data over time, helping businesses identify emerging trends. For instance, if certain cuisines or restaurant types are increasingly concentrated in specific neighborhoods, businesses can adjust their offerings accordingly. This trend analysis can also inform decisions about where to open new locations, ensuring businesses remain competitive and relevant in the ever-changing food landscape.
2. Understanding Competitor Placement: Knowing competitors' locations is vital for any business. Web scraping iFood allows businesses to map the presence of competitors in their area. By visualizing this data, local businesses can determine whether they are entering a saturated market or if there is an opportunity for growth. Understanding competitor placement helps businesses differentiate themselves by identifying unique selling propositions and untapped niches. Utilizing an iFood food delivery data scraper can enhance this process significantly.
3. Targeted Marketing Strategies: Location data can also enhance marketing efforts. By analyzing restaurant locations' customer demographics and preferences, businesses can create targeted marketing campaigns. For example, if a local business discovers that a specific cuisine is trending in a particular neighborhood, it can tailor promotions or advertising efforts to appeal to that audience. This localized approach increases the likelihood of attracting new customers and fostering brand loyalty. Furthermore, an iFood restaurant data scraping API can streamline data extraction, enabling businesses to make informed decisions quickly.
Web Scraping iFood: Data Points to Consider
When scraping iFood for restaurant location data, several key data points can provide valuable insights. These include:
1. Restaurant Names and Types: Gathering restaurant names and type information is fundamental for understanding the competitive landscape. Businesses can categorize competitors based on cuisine types, such as Italian, Mexican, or vegetarian, allowing for a comprehensive analysis of the local food scene.
2. Geographic Coordinates: Extracting restaurants' geographic coordinates (latitude and longitude) enables businesses to create detailed maps and visualize their location data. This geographic insight is critical for understanding the distribution of restaurants and identifying areas with high or low concentrations of dining options.
3. Delivery Zones: Understanding the delivery zones of various restaurants is essential for businesses that offer delivery services. By scraping this data, local businesses can identify areas that may be underserved by competitors, allowing them to target these regions strategically for their delivery services.
4. Customer Reviews and Ratings: While primarily focused on location data, analyzing customer reviews and ratings can provide qualitative insights into competitors' strengths and weaknesses. By understanding what customers appreciate or criticize about local restaurants, businesses can better adapt their offerings to meet consumer demands.
5. Promotional Offers: Collecting information about promotional offers and discounts can provide insights into competitors' marketing strategies. This data can help businesses understand pricing trends and identify opportunities to attract customers through competitive promotions.
Legal and Ethical Considerations
While web scraping can provide valuable insights, businesses must navigate the legal and ethical implications associated with data extraction. Many websites, including iFood, have terms of service that outline how data can be used. Businesses should ensure compliance with these regulations to avoid potential legal issues related to using iFood restaurant datasets.
Additionally, ethical considerations should guide web scraping restaurant data practices. Businesses should prioritize transparency, respect user privacy, and avoid using scraped data for malicious purposes. Implementing responsible scraping practices fosters trust and integrity in the data collection process.
Challenges of Web Scraping iFood
While web scraping iFood offers significant benefits, it presents specific challenges businesses must navigate. These challenges include:
1. Dynamic Web Pages: Many modern websites, including iFood, utilize dynamic content that can make scraping more complex. Dynamic pages may load content asynchronously, complicating the restaurant menu data scraping extraction process. Businesses must employ advanced scraping techniques and tools to collect data from such sites effectively.
2. IP Blocking and Rate Limiting: Frequent scraping attempts may trigger anti-bot measures, resulting in IP blocking or rate limiting. Businesses should implement strategies to mitigate these risks, such as using rotating proxies or adjusting scraping frequency to mimic human behavior. Utilizing reliable food delivery app scraping services can also help manage these challenges effectively.
3. Data Quality and Accuracy: Ensuring the accuracy and quality of scraped data is crucial. Only accurate or updated information can lead to good business decisions. Businesses should establish validation processes to confirm the reliability of the data collected from iFood, mainly when using a restaurant menu data scraper to extract specific information.
Practical Applications of Scraped Data
The insights derived from web scraping iFood restaurant location data can be applied in several ways to enhance business operations:
1. Location Selection for New Ventures: Entrepreneurs and business owners looking to open new restaurant locations can use data-driven insights to guide location selection. By analyzing competitor density, customer demographics, and market trends, businesses can make informed decisions about where to establish new outlets, minimizing risk and maximizing potential success.
2. Menu Development and Customization: Understanding local preferences is essential for creating a menu that resonates with customers. Analyzing the types of cuisines offered by competitors in specific areas can help businesses refine their menus to align with local tastes, ensuring a higher likelihood of attracting customers.
3. Optimizing Delivery Operations: For businesses offering delivery services, location data is crucial for optimizing delivery routes and zones. By understanding the geographic distribution of customers and competitors, businesses can streamline their delivery operations, reducing costs and improving service efficiency.
4. Enhancing Customer Engagement: Businesses can leverage location data through targeted marketing campaigns and promotions to enhance customer engagement. For instance, if a particular area strongly prefers a specific cuisine, businesses can run localized advertising campaigns to attract customers from that region.
Conclusion
In today's data-driven business landscape, the ability to extract and analyze information from platforms like iFood is essential for local businesses aiming to thrive in competitive markets. Web scraping iFood restaurant location data provides invaluable insights that can inform strategic decisions, enhance marketing efforts, and optimize operations. However, businesses must approach this practice with a focus on legal and ethical considerations, ensuring compliance with regulations while maintaining integrity in data collection.
As the food delivery industry continues to grow and evolve, businesses that harness the power of web scraping iFood restaurant location data to gather location insights will be well-positioned to adapt to changing consumer preferences and market dynamics. By leveraging these insights, local businesses can survive and thrive in an increasingly competitive landscape, leading to sustained success and growth. Additionally, utilizing restaurant menu datasets can further enhance their understanding of customer preferences and enable more informed decision-making.
Experience top-notch web scraping service and mobile app scraping solutions with iWeb Data Scraping. Our skilled team excels in extracting various data sets, including retail store locations and beyond. Connect with us today to learn how our customized services can address your unique project needs, delivering the highest efficiency and dependability for all your data requirements.
Source: https://www.iwebdatascraping.com/challenges-in-web-scraping-ifood-restaurant-location-data.php
#ScrapingIFoodRestaurantLocationData#WebScrapingIFoodRestaurantData#ExtractIFoodFoodDeliveryData#ScrapeRestaurantData#FoodDeliveryAppScrapingServices
0 notes
Text
Advanced Steps For Scraping Google Reviews For Informed Decision-Making

Google reviews are crucial to business's and buyer’s information-gathering processes. They play the role in providing validation to customers. There may be actual customers who would read other’s opinions in order to decide whether they want to buy from a specific business place or to use a particular product or even a service. This means that positive reviews will, in a way, increase the trust people have for the product, and new buyers will definitely be attracted. Hence, the acts of positively enhancing the image of different business entities through public endorsements are critical determinants for building a reputable market niche on the World Wide Web.
What is Google Review Scraping?
Google Review Scraping is when automated tools collect customer reviews and related information from Google. This helps businesses and researchers learn what customers think about their products or services. By gathering this data using a Google Maps data scraper, organizations can analyze it to understand how people feel. This includes using tools to find the right business to study, using web scraping to get the data, and organizing it neatly for study.
It's important to follow Google's rules and laws when scraping reviews. Doing it wrong or sending too many requests can get you in trouble, such as being banned or facing legal problems.
Introduction to Google Review API
Google Review API, also known as Google Places API, is a service Google offers developers. It enables them to learn more about places in Google Maps, such as restaurants or stores. This API has remarkable characteristics that permit developers to pull out reviews, ratings, photos, and other significant data about these places.
However, before using the Google Review API, the developers are required to obtain a unique code known as the API key from Google. This key is kind of like a password that allows their apps or websites to ask Google for information. Subsequently, developers can request the API for details regarding a particular place, such as a restaurant's reviews and ratings. Finally, the API provides the details in a form that a programmer can readily incorporate into the application or website in question, commonly in the form of JSON.
Companies and developers employ the Google Review API to display customer reviews about service quality and experience on their websites and then work on the feedback. It is helpful for anyone who seeks to leverage Google's large pool of geographic data to increase the utility of his applications or web pages.
Features of Google Reviews API

The Google Reviews API offers several features that help developers access, manage, and use customer reviews for businesses listed on Google. Here are the main features:
Access to Reviews
You can get all reviews for a specific business, including text reviews and star ratings. Each review includes the review text, rating, reviewer's name, review date, and any responses from the business owner.
Ratings Information
When integrated with Google Map data scraper, the API provides a business's overall star ratings, calculated from all customer reviews. You can see each review's star rating to analyze specific feedback.
Review Metadata
Access information about the reviewer, such as their name and profile picture (if available). Each review includes timestamps for when it was created and last updated. Those responses are also available if the business owner has responded to a review.
Pagination
The API supports pagination, allowing you to retrieve reviews in smaller, manageable batches. This is useful for handling large volumes of reviews without overloading your application.
Sorting and Filtering
You can sort reviews by criteria such as most recent, highest, lowest rating, or most relevant ratings. The API allows you to filter reviews based on parameters like minimum rating, language, or date range.
Review Summaries
Access summaries of reviews, which provide insights into customers' common themes and sentiments.
Sentiment Analysis
Some APIs might offer sentiment analysis, giving scores or categories indicating whether the review sentiment is positive, negative, or neutral.
Language Support
The API supports reviews in multiple languages, allowing you to access and filter reviews based on language preferences.
Integration with Google My Business
The Reviews API integrates with Google My Business, enabling businesses to manage their online presence and customer feedback in one place.
Benefits of Google Reviews Scraping

Google Reviews data scraping can help businesses analyze trends, monitor competitors, and make strategic decisions. Google Maps scraper can be beneficial in different ways. Let’s understand the benefits :
Understanding Customers Better
Through reviews, management can always understand areas customers appreciate or dislike in products or services offered. This enables them to advance their prospects in a way that will enhance the delivery of services to the customers.
Learning from Competitors
Businesses can use the reviews to compare themselves to similar companies. It assists them in visually discovering areas in which they are strong and areas with room for improvement. It is like getting a sneak peek at what other competitors are up to as a means of countering them.
Protecting and Boosting Reputation
Reviews enable business organizations to monitor their image on social media. Renters feel that companies can show engagement by addressing them when they post negative comments, demonstrating that the business wants to improve their experiences. Prospective consumers also benefit when positive reviews are given as much attention as negative ones from a seller's standpoint.
Staying Ahead in the Market
The review allows businesses to see which products customers are most attracted to and the current trend. This assists them in remaining competitive and relevant in the market, allowing them to make the necessary alterations when market conditions change.
Making Smarter Decisions
Consumer feedback is highly reliable as a source of information for making conclusions. Hence, no matter what the business is doing, be it improving its products, planning the following marketing strategy, or identifying areas of focus, the data from the reviews should be handy.
Saving Time and Effort
Automated methods are easier to use to collect reviews than manual methods, which is one reason why they are preferred. This implies that they will spend less time gathering the data and, therefore, can devote adequate time using it to transform their business.
Steps to Extract Google Reviews
It is easy to utilize Google Review Scraper Python for the effective extraction of reviews and ratings. Scraping Google reviews with Python requires the following pre-determined steps mentioned below:
Modules Required
Scraping Google reviews with Python requires the installation of various modules.
Beautiful Soup: This tool scrapes data by parsing the DOM (Document Object Model). It extracts information from HTML and XML files.# Installing with pip pip install beautifulsoup4 # Installing with conda conda install -c anaconda beautifulsoup4
Scrapy: An open-source package designed for scraping large datasets. Being open-source, it is widely and effectively used.
Selenium: Selenium can also be utilized for web scraping and automated testing. It allows browser automation to interact with JavaScript, handle clicks, scrolling, and move data between multiple frames.# Installing with pip pip install selenium # Installing with conda conda install -c conda-forge selenium
Driver manager of Chrome
# Below installations are needed as browsers # are getting changed with different versions pip install webdriver pip install webdriver-manager
Web driver initialization
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager # As there are possibilities of different chrome # browser and we are not sure under which it get # executed let us use the below syntax driver = webdriver.Chrome(ChromeDriverManager().install())
Output
[WDM] – ====== WebDriver manager ====== [WDM] – Current google-chrome version is 99.0.4844 [WDM] – Get LATEST driver version for 99.0.4844 [WDM] – Driver [C:\Users\ksaty\.wdm\drivers\chromedriver\win32\99.0.4844.51\chromedriver.exe] found in cache
Gather reviews and ratings from Google
In this case, we will attempt to get three entities—books stores, restaurants, and temples—from Google Maps. We will create specific requirements and combine them with the location using a Google Maps data scraper. from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import ElementNotVisibleException from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException from bs4 import BeautifulSoup driver = webdriver.Chrome(ChromeDriverManager().install()) driver.maximize_window() driver.implicitly_wait(30) # Either we can hard code or can get via input. # The given input should be a valid one location = "600028" print("Search By ") print("1.Book shops") print("2.Food") print("3.Temples") print("4.Exit") ch = "Y" while (ch.upper() == 'Y'): choice = input("Enter choice(1/2/3/4):") if (choice == '1'): query = "book shops near " + location if (choice == '2'): query = "food near " + location if (choice == '3'): query = "temples near " + location driver.get("https://www.google.com/search?q=" + query) wait = WebDriverWait(driver, 10) ActionChains(driver).move_to_element(wait.until(EC.element_to_be_clickable( (By.XPATH, "//a[contains(@href, '/search?tbs')]")))).perform() wait.until(EC.element_to_be_clickable( (By.XPATH, "//a[contains(@href, '/search?tbs')]"))).click() names = [] for name in driver.find_elements(By.XPATH, "//div[@aria-level='3']"): names.append(name.text) print(names)
Output
The output of the given command will provide the required data in a specific format.


How to Scrape Google Reviews Without Getting Blocked

Scraping Google Reviews without getting blocked involves several best practices to ensure your scraping activities remain undetected and compliant with Google's policies. If you're making a Google review scraper for a company or project, here are ten tips to avoid getting blocked:
IP Rotation
If you use the same IP address for all requests, Google can block you. Rotate your IP addresses or use new ones for each request. To scrape millions of pages, use a large pool of proxies or a Google Search API with many IPs.
User Agents
User Agents identify your browser and device. Using the same one for all requests can get you blocked. Use a variety of legitimate User Agents to make your bot look like a real user. You can find lists of User Agents online.
HTTP Header Referrer
The Referrer header tells websites where you came from. Setting the Referrer to "https://www.google.com/" can make your bot look like a real user coming from Google.
Make Scraping Slower
Bots scrape faster than humans, which Google can detect. Add random delays (e.g., 2-6 seconds) between requests to mimic human behavior and avoid crashing the website.
Headless Browser
Google's content is often dynamic, relying on JavaScript. Use headless browsers like Puppeteer JS or Selenium to scrape this content. These tools are CPU intensive but can be run on external servers to reduce load.
Scrape Google Cache
Google keeps cached copies of websites. Scraping cached pages can help avoid blocks since requests are made to the cache, not the website. This works best for non-sensitive, frequently changing data.
Change Your Scraping Pattern
Bots following a single pattern can be detected. To make your bot look like a real user, you must use human behavior with random clicks, scrolling, and other activities.
Avoid Scraping Images
Images are large and loaded with JavaScript, consuming extra bandwidth and slowing down scraping. Instead, focus on scraping text and other lighter elements.
Adapt to Changing HTML Tags
Google changes its HTML to improve user experience, which can break your scraper. Regularly test your parser to ensure it's working, and consider using a Google Search API to avoid dealing with HTML changes yourself.
Captcha Solving
Captchas differentiate humans from bots and can block your scraper. Use captcha-solving services sparingly, as they are slow and costly. Spread out your requests to reduce the chances of encountering captchas.
Conclusion
It can also be said that Google reviews affect the local SEO strategy in particular. It was noted that the number and relevance of reviews can affect the business’s ranking in the local searches. Increased ratings and favorable reviews tell search engines that the industry is credible and provides relevant goods and/or services to the particular locality, which in turn boosts its likelihood of ranking higher in SERPs. ReviewGators has extensive expertise in creating customized and best Google Maps scrapers to ease the extraction process. Therefore, Google reviews are purposefully maintained and utilized as business promotion tools in the sphere of online marketing to increase brand awareness, attract local clientele, and, consequently, increase sales and company performance.
Know more https://www.reviewgators.com/advanced-steps-to-scraping-google-reviews-for-decision-making.php
0 notes
Text
Automatic image tagging with Gemini AI
I used multimodal generative AI to tag my archive of 2,500 unsorted images. It was surprisingly effective.
I’m a digital packrat. Disk space is cheap, so why not save everything? That goes double for things out on the internet, especially those on third party servers, where you can’t be sure they’ll live forever. One of the sites that hasn’t lasted is ffffound!, a pioneering image bookmarking website, which I was lucky enough to be a member of.
Back around 2013 I wrote a quick Ruby web scraper to download my images, and ever since I’ve wondered what to do with the 2,500 or so images. ffffound was deliberately minimal - you got only the URL of the site it was saved from and a page title - so organising them seemed daunting.
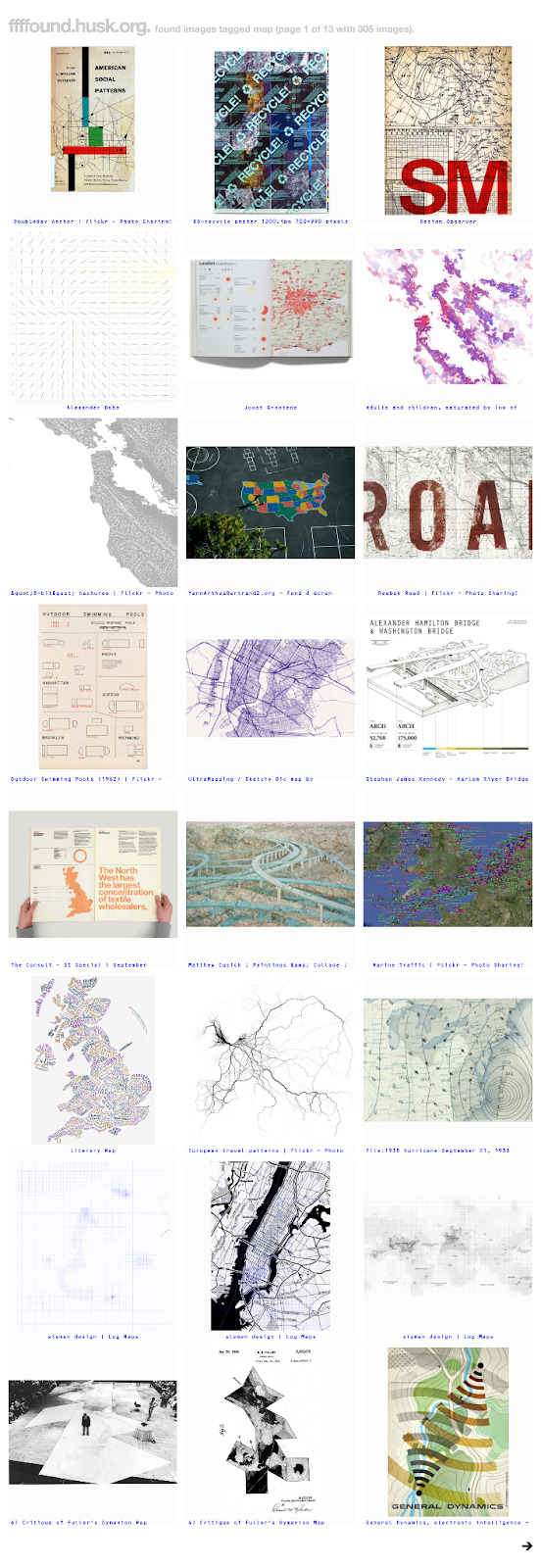
A little preview- this is what got pulled out tagged "maps".
The power of AI compels you!
As time went on, I thought about using machine learning to write tags or descriptions, but the process back then involved setting up models, training them yourself, and it all seemed like a lot of work. It's a lot less work now. AI models are cheap (or at least, for the end user, subsidised) and easy to access via APIs, even for multimodal queries.
After some promising quick explorations, I decided to use Google’s Gemini API to try tagging the images, mainly because they already had my billing details in Google Cloud and enabling the service was really easy.
Prototyping and scripting
My usual prototyping flow is opening an iPython shell and going through tutorials; of course, there’s one for Gemini, so I skipped to “Generate text from image and text inputs”, replaced their example image with one of mine, tweaked the prompt - ending up with ‘Generate ten unique, one to three word long, tags for this image. Output them as comma separated, without any additional text’ - and was up and running.
With that working, I moved instead to writing a script. Using the code from the interactive session as a core, I wrapped it in some loops, added a little SQL to persist the tags alongside the images in an existing database, and set it off by passing in a list of files on the command line. (The last step meant I could go from running it on the six files matching images/00\*.jpg up to everything without tweaking the code.) Occasionally it hit rather baffling errors, which weren’t well explained in the tutorial - I’ll cover how I handled them in a follow up post.
You can see the resulting script on GitHub. Running it over the entire set of images took a little while - I think the processing time was a few seconds per image, so I did a few runs of maybe an hour each to get all of them - but it was definitely much quicker than tagging by hand. Were the tags any good, though?
Exploring the results
I coded up a nice web interface so I was able to surf around tags. Using that, I could see what the results were. On the whole? Between fine and great. For example, it turns out I really like maps, with 308 of the 2,580 or so images ending up with the tag ‘map’ which are almost all, if not actual maps, do at least look cartographic in some way.
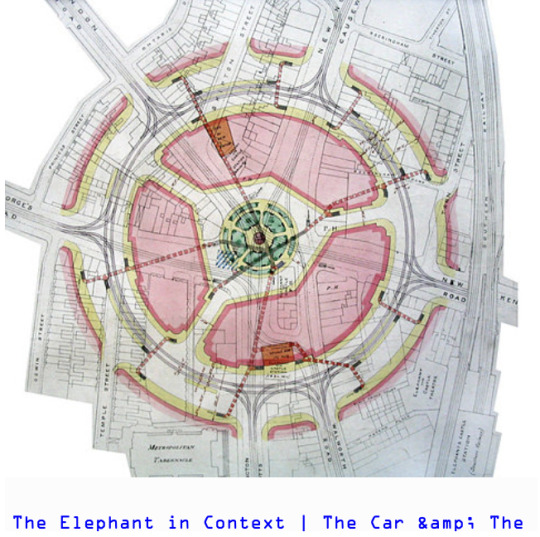
The vast majority of the most common tags I ended up with were the same way - the tag was generally applicable to all of the images in some way, even if it wasn’t totally obvious at first why. However, it definitely wasn’t perfect. One mistake I noticed was this diagram of roads tagged “rail” - and yet, I can see how a human would have done the same.
Another small criticism? There was a lack of consistency across tags. I can think of a few solutions, including resubmitting the images as a group, making the script batch images together, or adding the most common tags to the prompt so the model can re-use them. (This is probably also a good point to note it might also be interesting to compare results with other multimodal models.)


Finally, there were some odd edge cases to do with colour. I can see why most of these images are tagged ‘red’, but why is the telephone box there? While there do turn out to be specks of red in the diagram at the bottom right, I’d also go with “black and white” myself over “black”, “white”, and “red” as distinct tags.

Worth doing?
On the whole, though, I think this experiment was pretty much a success. Tagging the images cost around 25¢ (US) in API usage, took a lot less time than doing so manually, and nudged me into exploring and re-sharing the archive. If you have a similar library, I’d recommend giving this sort of approach a try.
1 note
·
View note
Text
Cutting-Edge Scraping Algorithms
QuickScrape's advanced scraping algorithms are designed to navigate complex web pages and extract relevant business data with precision. Whether you're looking for company details, contact information, or customer reviews, QuickScrape delivers accurate results every time. Plus, with real-time updates, you can trust that you're always working with the latest information.
Streamlined Data Collection Process
With QuickScrape, data collection has never been easier. Our intuitive interface allows users to specify their search criteria and retrieve relevant business data in a matter of seconds. Whether you're conducting market research, lead generation, or competitor analysis, QuickScrape streamlines the process, allowing you to focus on leveraging insights to drive business growth.
Comprehensive Business Insights
QuickScrape provides access to a wealth of business insights, including company names, addresses, phone numbers, and more. Our platform aggregates data from multiple sources, ensuring that you have access to comprehensive and reliable information. Whether you're a small business owner or a large enterprise, QuickScrape equips you with the tools needed to make informed decisions and stay ahead of the competition.
Google Maps Scraper
1 note
·
View note
Text
How to Extract GrabFood Delivery Websites Data for Manila Location?
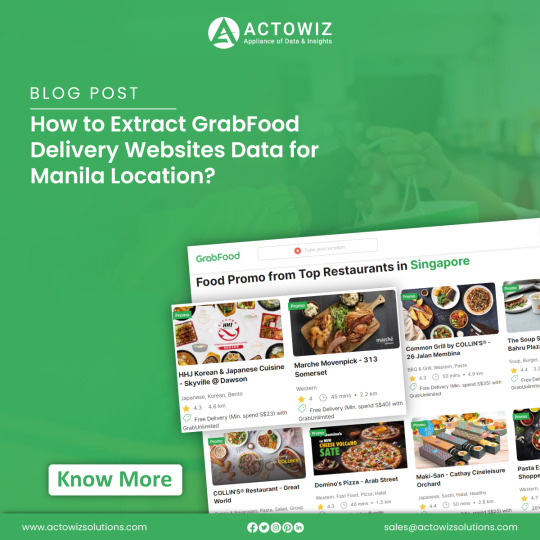
Introduction
In today's digital era, the internet abounds with culinary offerings, including GrabFood, a prominent food delivery service featuring diverse dining options across cities. This blog delves into web scraping methods to extract data from GrabFood's website, concentrating on Manila's restaurants. We uncover valuable insights into Grab Food's extensive offerings through web scraping, contributing to food delivery data collection and enhancing food delivery data scraping services.
Web Scraping GrabFood Website
Embarking on our exploration of GrabFood's website entails using automation through Selenium for web scraping Grab Food delivery website. By navigating to the site (https://food.grab.com/sg/en/), our focus shifts to setting the search location to Manila. Through this process, we aim to unveil the array of restaurants available near Manila and retrieve their latitude and longitude coordinates. Notably, we accomplish this task without reliance on external mapping libraries such as Geopy or Google Maps, showcasing the power of Grab Food delivery data collection.
This endeavor contributes to the broader landscape of food delivery data collection, aligning with the growing demand for comprehensive insights into culinary offerings. By employing Grab Food delivery websites scraping, we enhance the efficiency and accuracy of data extraction processes. This underscores the significance of web scraping in facilitating food delivery data scraping services, catering to the evolving needs of consumers and businesses alike in the digital age.
Furthermore, the use of automation with Selenium underscores the adaptability of web scraping Grab Food delivery website to various platforms and websites. This versatility positions web scraping as a valuable tool for extracting actionable insights from diverse sources, including GrabFood's extensive repository of culinary information. As we delve deeper into web scraping, its potential to revolutionize data collection and analysis in the food delivery industry becomes increasingly apparent.
Scraping Restaurant Data
Continuing our data extraction journey, we focus on scraping all restaurants in Manila from GrabFood's website. This task involves automating the "load more" feature to systematically reveal additional restaurant listings until the complete dataset is obtained. Through this iterative process, we ensure comprehensive coverage of Manila's diverse culinary landscape, capturing a wide array of dining options available on GrabFood's platform.
By leveraging a Grab Food delivery websites scraper tailored to GrabFood's website, we enhance the efficiency and accuracy of data collection. This systematic approach enables us to extract valuable insights into Manila's culinary offerings, contributing to the broader landscape of food delivery data collection.
Our commitment to automating the "load more" feature underscores the importance of thoroughness in Grab Food delivery data collection. By meticulously uncovering all available restaurant listings, we provide a comprehensive overview of Manila's vibrant dining scene, catering to the needs of consumers and businesses alike.
This endeavor aligns with the growing demand for reliable and up-to-date data in the food delivery industry. Our Grab Food delivery websites scraping efforts empower businesses to make informed decisions and consumers to explore an extensive range of dining options conveniently accessible through GrabFood's platform.
Code Implementation
Use Cases of GrabFood Delivery Websites Scraping
Web scraping Grab Food delivery website presents a plethora of promising opportunities for growth and success across various industries and sectors. Let's delve into some of these key applications:
Market Research: By scraping GrabFood delivery websites, businesses can gain valuable insights into consumer preferences, popular cuisines, and emerging food trends. This data can inform market research efforts, helping businesses identify opportunities for expansion or product development.
Competitor Analysis: The data from scraping GrabFood delivery websites equips businesses with a powerful tool to monitor competitor activity, including menu offerings, pricing strategies, and promotional campaigns. With this information, businesses can stay ahead of the game and adapt their strategies accordingly.
Location-based Marketing: With data collected from GrabFood delivery websites, businesses can identify popular dining locations and target their marketing efforts accordingly. This includes tailoring promotions and advertisements to specific geographic areas based on consumer demand.
Menu Optimization: By analyzing menu data scraped from GrabFood delivery websites, restaurants can identify which dishes are most popular among consumers. This insight can inform menu optimization efforts, helping restaurants streamline their offerings and maximize profitability.
Pricing Strategy: Scraped data from GrabFood delivery websites can provide valuable insights into pricing trends across different cuisines and geographic locations. Businesses can use this information to optimize their pricing strategy and remain competitive in the market.
Customer Insights: The data extracted from GrabFood delivery websites can provide businesses with invaluable insights into customer behavior, preferences, and demographics. This information is a goldmine for businesses, enabling them to craft targeted marketing campaigns and deliver personalized customer experiences.
Compliance Monitoring: Businesses can use web scraping to monitor compliance with food safety regulations and delivery standards on GrabFood delivery websites. This ensures that restaurants are meeting regulatory requirements and maintaining high standards of service.
Overall, web scraping GrabFood delivery websites offers businesses a wealth of opportunities to gather valuable data, gain insights, and make informed decisions across various aspects of their operations.
Conclusion
At Actowiz Solutions, we unlock insights into Manila's culinary scene through GrabFood's restaurant listings using web scraping. Our approach ensures data collection without reliance on external mapping libraries, enhancing flexibility and efficiency. As we delve deeper into web scraping, endless opportunities emerge for culinary and data enthusiasts alike. Explore the possibilities with Actowiz Solutions today! You can also reach us for all your mobile app scraping, data collection, web scraping, and instant data scraper service requirements.
#WebScrapingGrabFoodwebsite#GrabFoodWebsitesScraping#GrabFoodDataCollection#GrabFoodWebsitesScraper#ExtractGrabFoodWebsites
0 notes
Text
Are you looking for web data extraction, web scraping software, google maps scraper, ebay product scraper, linked contact extractor, email id scraper, web content extractor contact iwebscraping the indian base web scraping company.
For More Information:-
#E-commerce Web Scraping API Services#Scrape or Extract API from eCommerce Website#Web Scraping API#eCommerce Website
0 notes
Text
VeryUtils AI Marketing Tools is your all-in-one Marketing platform. VeryUtils AI Marketing Tools includes Email Scraper, Email Sender, Email Verifier, Whatsapp Sender, SMS Sender, Social Media Marketing etc. tools.
VeryUtils AI Marketing Tools is your all-in-one Marketing platform. VeryUtils AI Marketing Tools includes Email Scraper, Email Sender, Email Verifier, Whatsapp Sender, SMS Sender, Social Media Marketing etc. tools. You can use VeryUtils AI Marketing Tools to find and connect with the people that matter to your business.
Artificial Intelligence (AI) Marketing Tools are revolutionizing almost every field, including marketing. Many companies of various scales rely on VeryUtils AI Marketing Tools to promote their brands and businesses. They should be a part of any business plan, whether you're an individual or an organization, and they have the potential to elevate your marketing strategy to a new level.
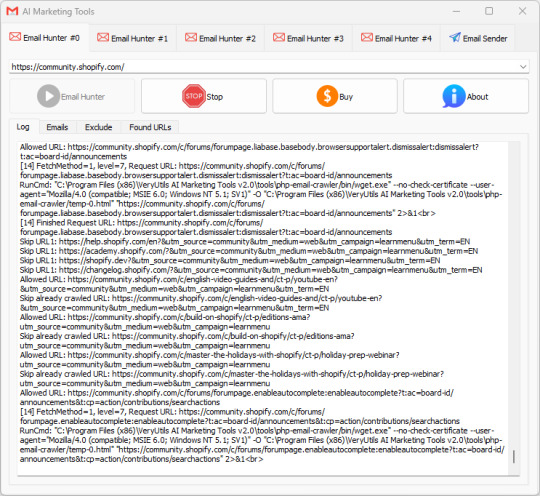
VeryUtils AI Marketing Tools are software platforms that help automate decision-making based on collected and analyzed data, making it easier to target buyers and increase sales.
VeryUtils AI Marketing Tools can handle vast amounts of information from various sources like search engines, social media, and email. Everyone knows that data is key to marketing, and AI takes it a step further while also saving a significant amount of money and time.
✅ Types of marketing tools The different types of marketing tools you'll need fall under the following categories:
Email marketing
Social media marketing
Content marketing
SEO
Direct mail
Lead generation
Lead capture and conversion
Live chat
Design and visuals
Project management
SMS marketing
Analytics and tracking
Brand marketing
Influencer and affiliate marketing
Loyalty and rewards
✅ VeryUtils AI Marketing Tools for Every Business. VeryUtils AI Marketing Tools include the following components:
Email Collection Tools (Hunt email addresses from Google, Bing, Yahoo, LinkedIn, Facebook, Amazon, Instagram, Google Maps, etc.)
Email Sending Automation Tools
Phone Number Collection Tools
WhatsApp Automation Tools (coming soon)
Social Media Auto Posting Robot (coming soon)
SMS Marketing (upon request)
Custom Development of any tools to best meet your specific requirements.
VeryUtils AI Marketing Tools can help you tackle the manual parts of marketing, precisely locate your customers from the vast internet, and promote your products to these customers.
✅ 1. Email Collection Tools Do you need to scrape email addresses from web pages, and don’t know how to do it or don’t have a tool capable?
VeryUtils AI Marketing Tools has a powerful multi-threaded email scraper which can harvest email addresses from webpages, it also has proxy support so each request is randomly assigned a proxy from from your list to keep your identity hidden or prevent sites blocking your by IP address due to too many queries.
The VeryUtils AI Marketing Tools email harvester also works with https URL’s so it can work with sites like FaceBook and Twitter that require a secure connection. It also has an adjustable user-agent option, so you can set your user-agent to Googlebot to work with sites like SoundCloud.com or you can set it as a regular browser or even mobile device for compatibility with most sites. When exporting you also have the option to save the URL along with the scraped email address so you know where each email came from as well as filter options to extract only specific emails.
Because the Email Grabber function is multi-threaded, you can also select the number of simultaneous connections as well as the timeout so you can configure it for any connection type regardless if you have a powerful server or a home connection. Another unique thing the email grabber can do is extract emails from files stored locally on your computer, if you have a .txt file or .sql database which contains various information along with emails you can simply load the file in to VeryUtils AI Marketing Tools and it will extract all emails from the file!
If you need to harvest URL’s to scrape email addresses from, then VeryUtils AI Marketing Tools has a powerful Search Engine Harvester with 30 different search engines such as Google, Bing, Yahoo, AOL, Blekko, Lycos, AltaVista as well as numerous other features to extract URL lists such as the Internal External Link Extractor and the Sitemap Scraper.
Also recently added is an option to scrape emails by crawling a site. What this does is allows you to enter a domain name and select how many levels deep you wish to crawl the site, for example 4 levels. It will then fetch the emails and all internal links on the site homepage, then visit each of those pages finding all the emails and fetching the internal links from those pages and so on. This allows you to drill down exacting emails from a specific website.
So this makes it a great email finder software for extracting published emails. If the emails are not published on the pages, you can use the included Whois Scraper Addon to scrape the domains registrant email and contact details.
Find email addresses & automatically send AI-personalized cold emails
Use our search email address tool to find emails and turn your contacts into deals with the right cold emailing.
Easy setup with your current email provider
Deep AI-personalization with Chat GPT (soon)
Safe sending until reply
High deliverability
Smart scheduling of email sequences
Complete A/B testing for best results
Create and edit templates
Email tracking and analytics
-- Bulk Email Verifier Make cold mailing more effective with email verification process that will guarantee 97% deliverability
-- Collect email addresses from Internet Email Collection Tools can automatically collect email addresses of your target customers from platforms like Google, Bing, Yahoo, LinkedIn, Facebook, Amazon, Instagram, Google Maps, etc., making it convenient to reach out to these potential clients.
-- Collect email addresses from email clients Email Collection Tools can also extract email addresses from email clients like Microsoft Outlook, Thunderbird, Mailbird, Mailbird, Foxmail, Gmail, etc.
-- Collect email addresses from various file formats Email Collection Tools can extract email addresses from various file formats such as Text, PDF, Word, Excel, PowerPoint, ZIP, 7Z, HTML, EML, EMLX, ICS, MSG, MBOX, PST, VCF.
-- Various tools and custom development services
-- Domain Search Find the best person to contact from a company name or website.
-- Email Finder Type a name, get a verified email address. Our high match rate helps you get the most from your lists.
-- Email Verifier Avoid bounces and protect your sender reputation.
-- Find emails by domain Find all email addresses on any domain in a matter of minutes.
-- Find emails by company Use VeryUtils AI Marketing Tools to find just the companies you need by industry, company size, location, name and more.
-- Get emails from names Know your lead's name and company domain but not their email? We can find it for you. Use this feature to complete your prospects lists with quality contacts.
-- Find potential customers based on information Use key parameters like prospect's job position, location, industry or skills to find only relevant leads for your business.
✅ 2. Email Marketing Tools
VeryUtils AI Marketing Tools provides Fast and Easy Email Sender software to help you winning the business. All the email tools you need to hit the inbox. Discover our easy-to-use software for sending your email marketing campaigns, newsletters, and automated emails.
-- Easy to use Only two steps, importing a mail list file, select email account and template, the software will start email sending automatically.
-- Fast to run The software will automatically adjust the number of threads according to the network situation, to maximize the use of network resources.
-- Real-time display email sending status
Displaying the number of total emails
Displaying the number of sent emails
Displaying the number of success emails
Displaying the number of failure emails
Displaying the different sending results through different colors.
Displaying the time used of email sending.
-- Enhance ROI with the industry-leading email marketing platform Take your email marketing to a new level, and deliver your next major campaign and drive sales in less time.
-- Easy for beginners, powerful for professional marketers Our email marketing platform makes it easy for marketers of any type of business to effortlessly send professional, engaging marketing emails. VeryUtils AI Marketing Tools are designed to help you sell more products - regardless of the complexity of your business.
-- Being a leader in deliverability means your emails get seen Unlike other platforms, VeryUtils AI Marketing Tools ensure your marketing emails are delivered. We rank high in email deliverability, meaning more of your emails reach your customers, not just their spam folders.
-- Leverage our powerful AI and data tools to make your marketing more impactful The AI in VeryUtils AI Marketing Tools can be the next expert marketer on your team. VeryUtils AI Marketing Tools analyze your product information and then generate better-performing email content for you. Generate professionally written, brand-consistent marketing emails with just a click of a button.
-- Get started easily with personalized onboarding services Receive guidance and support from an onboarding specialist. It's real-time, hands-on, and already included with your subscription.
-- We offer friendly 24/7 customer service Our customer service team is available at all times, ready to support you.
-- Collaborate with our experts to launch your next major campaign Bring your questions to our expert community and find the perfect advice for your campaigns. We also offer exclusive customer success services.
✅ FAQs:
What is email marketing software? Email marketing software is a marketing tool companies use to communicate commercial information to customers. Companies may use email marketing services to introduce new products to customers, promote upcoming sales events, share content, or perform any other action aimed at promoting their brand and engaging with customers.
What does an email marketing platform do? Email marketing platforms like VeryUtils AI Marketing Tools simplify the process of creating and sending email marketing campaigns. Using email marketing tools can help you create and manage audience groups, configure email marketing campaigns, and monitor their performance, all on one platform.
How effective is email marketing? Email marketing can be a powerful part of any company's marketing strategy. By leveraging effective email marketing tools, you can interact with your audience by creating personalized messages tailored to their interests. Additionally, using email marketing tools is a very cost-effective way of marketing your business.
What are the types of email marketing campaigns? There are many types of email marketing campaigns. However, there are four main types of marketing emails, including:
Promotional emails: These emails promote a company's products or services, often by advertising sales, discounts, seasonal events, company events, etc.
Product update emails: These emails inform customers about new or updated products.
Digital newsletters: Digital newsletters are regularly sent to a company's email list to inform customers of company or industry updates by providing interesting articles or relevant news.
Transactional emails: These emails are typically triggered by a customer's action. For example, if a customer purchases a product, they may receive a confirmation email or a follow-up email requesting their feedback.
How to optimize email marketing campaigns? When executing a successful email marketing strategy, there are several best practices to follow:
Create short, attention-grabbing subject lines: The subject line is the first copy your reader will see, so ensure it's enticing and meaningful. Spend time optimizing your subject line to improve click-through rates.
Keep it concise: When writing the email body, it's important to keep the content concise. You may only have your reader's attention for a short time, so it's crucial to craft a message that is clear, concise, and to the point.
Make it easy to read: Utilize headings, subheadings, bold text, font, and short paragraphs to make your email skimmable and easy to digest.
Fast loading visuals and images: Including images and visuals make email content more interesting and help break up the text. However, it's important that all elements load properly.
Include a call to action (CTA): Every email marketing content should include a call to action, whether you want the reader to shop the sale on your website or read your latest blog post.
How to start email marketing? Email marketing can serve as a cornerstone of any company's digital marketing strategy. If you don't already have an email marketing strategy in place or you're interested in improving your company's email marketing campaigns, use VeryUtils AI Marketing Tools. With our email marketing services, you can quickly and easily organize audience groups, segment customers, write and design emails, set timing preferences and triggers, and evaluate your performance.
0 notes