#web scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Note
Hello! So sorry to bother, but have you had any updates on the Word-Stream/Speechify situation?
Just one: like I posted on Xitter and Bluesky last night, as of yesterday afternoon, the links to individual works as they were listed on WordStream are gone from both Google and Bing. Hurray, right? Surely we’re all sick of this whole debacle and there’s far more important things to worry about. If all is well that ends well, surely there’s no need to still be angry.
Well, I am. Here’s why:
When I checked on Wednesday, the links to my own work on WordStream were still listed. So rather than it taking a week after Cliff Weitzman first hid the fanwork from view, it took a little over a week from the moment he first promised privately that they would be deleted. Which, fine. Perhaps Cliff didn’t really know what he was talking about when he gave that timeframe. Or maybe he told a little white lie to create the impression that he always intended to do the right thing. It seems more likely to me, though, that Cliff still believed—even after the backlash he received—that he would get away with honoring only individual takedown requests. Or worse, that he needed just a little bit more time with the stolen material to figure out an alternative way to profit off it—preferably without us noticing, this time.
But who knows? I certainly don’t! All we can do is speculate, because publicly, Cliff Weitzman has remained completely silent on his copyright infringements. All we got was the initial justifications he and his sockpuppet accounts used in comments on the original Reddit and Tumblr posts. After those were so understandably ill-received, Cliff only ever communicated with a few individual authors who contacted him directly and repeatedly, blocking people who addressed the issue on Twitter and quietly distancing himself from WordStream by deleting a blog he’d posted to Speechify.com dated December 20th—where Cliff promoted WordStream’s platform specifically to fanfiction readers. (See my enormous timeline post for details and screenshots of said posts before they were taken down.)
And this is why I’m still angry: As long as Cliff Weitzman faces no real consequences for his actions, he won’t see a need to own up to his mistake; and as long as he’s able to delay taking responsibility, this isn’t over. This didn’t end well.
After all, wasn’t this the next-best scenario for Cliff, second only to him turning WordStream into a (for him) effortless, infinite money-making machine? He took something we provided for free and fed it to AI so he could more easily put it behind a paywall; we found out and protested; Cliff quietly erased all evidence of his crime; and we went—almost equally quietly—away.
I want to make sure you know that I continue to be genuinely amazed and intensely grateful for how quickly the news about WordStream’s copyright infringement was shared—and continues to be shared—throughout fandom, on tumblr in particular. If it hadn’t been for our collective outcry here and on Reddit, WordStream would very likely still be up in its original form, and Weitzman would be reaping the benefits (those subscription prices were steep) today.
But it’s been frustrating to see that, with the exception of mentions in articles on Substack and Fansplaining (the latter of which is a particularly awesome and thorough read on fandom’s decontextualization) and a Fanlore listing, our outrage never really spilled out beyond the safely insulated, out-of-the-way spaces that are tumblr, a handful of subreddits and bluesky. And I believe that—unfortunately—we are collectively responsible for that part, as well.
Most of us seemed content to only spread the word by circulating the same two posts on tumblr. (Have we all given up completely on every other social media platform? Am I the only remaining straggler?) And soon after Cliff Weitzman hid WordStream’s fanfiction category from view, our interest in the issue took a sharp dive even there. Are we genuinely deceived into believing the issue has been fully resolved? Do we truly fail to realize that Weitzman’s refusal to admit that what he did was wrong left the door wide open for the next greed-driven tech bro to wander through? Or is the true naivety in thinking that, as a community, we can keep this kind of attack on fandom from happening again? Has our disillusionment already gotten that bad?
However the situation spins out from here, Cliff’s actions will set a precedent. If we fail to show Cliff and his ilk that attempts to profit off fandom’s unpaid labor have consequences, their tech companies will keep trying until something eventually sticks. They might be a little smarter about it next time; obscure their sources a bit better, maybe leave the titles and the authors’ names off. Or maybe they’ll go a bolder route: maybe next time they cross the line they’ll do it boldly enough for IP holders to take notice and stop tolerating fanwork entirely.
Doesn’t that make you angry, too?
There’s this whole other mess of thoughts I would love to be able to untangle about how commercial influence is contributing to the steady erosion of fandom’s foundations, but I’m tired, and other people have said it all much more eloquently than I ever could. Seriously, go read that article on Fansplaining. Or listen to the podcast version of it. Better yet, as long as you’re wearing your noise-canceling headphones, go listen to a podfic of one of your favorite fandoms’ works, and enjoy the collaborative joy and creativity of the people who Cliff Weitzman refuses to believe exist. (In one of Speechify’s other blogs, Cliff claims there are only 272 podfics on AO3. Would you like to run that ChatGPT prompt again, Cliff?). Honestly, much like Cliff Weitzman’s infuriating denial of the fact that fandom fucking has this covered, thank you very much, there’s so. Many. More. Things for us to talk about. There’s the connotations of WordStream’s dubious ‘upload’ button, for instance, or the fact that the app scraped (and in some cases, allegedly, still lists) copyright-protected original fiction as well, or WordStream’s complete lack of contact information, which is illegal for an internationally operating app. And oh! Has anyone reported more thoroughly on Cliff’s app’s options to ‘simplify’ or ‘modernize’ uploaded works, or—my own very favorite abomination—to translate them into something Cliff calls ‘Gen-Z Language’? Much like his atrocious AI book covers, it would be hilarious, if it didn’t make steam come out of my ears.
Anyway, there it is. I highly recommend you do all of that. And then, if you aren’t familiar with it already, go do some research re: fair use and your rights as the copyright owner of your works. A good number of people commenting on this controversy expressed stunned surprise or fearful hesitation about claiming any sort of ownership of their fanfiction. The more informed we are about our rights, the more willing we will be to defend them.
Please don’t stop writing or sharing your work. If you can’t bring yourself to work on your WIPs today (trust me, I get it), post about this situation instead. Tweets, skeets, whateverthefucks—about WordStream’s theft, about how this reflects on Speechify’s already shady business practices, about how Cliff’s actions and justifications have personally affected you. You’re welcome to share or copy my posts on these platforms, but since Cliff already blocked me, I very much prefer you post your own. If you do, call Cliff Weitzman by his full name and tag or include both WordStream and Speechify to ensure Weitzman will recognize he has both a personal as well as a professional stake in handling the situation with integrity. Leave your concerns in reviews on the Speechify app. (We weren’t provided with a more appropriate place to put them, after all!) Consider calling for a Speechify boycott until Cliff accepts accountability for his actions.
Do avoid making exaggerated claims, and don’t call for physical retaliation against Cliff’s person or his property. We don’t want to give him or Speechify even the weakest of grounds to claim defamation or threats of violence. Focus on the facts: they’re incriminating enough by themselves. Show Cliff that we’re determined to keep bringing up his company’s wrongdoings in public spaces until he demonstrates that he understands why taking these freely shared fanworks and monetizing them was wrong, and takes steps to ensure it won’t happen again.
One last thing—and this is really more of a general reminder—please stop suggesting I handle this situation for you. People have come to me asking for action items. The resulting flashbacks to my days as an office assistant were extremely upsetting. In all seriousness, casting me as some sort of coordinator or driving force behind this backlash actively hurts the cause. Not only does it downplay fandom’s collective efforts, it also makes our message extremely vulnerable. It would be all too easy for Cliff to silence one singular source. Wikipedia will not maintain mentions of this controversy as long as it leads only to Easter Kingston’s attempt to summarize what happened as it was happening. You only know my name because I stumbled upon WordStream’s theft and decided to get my friends involved. I am not more knowledgeable, more skilled or more angrily invested in this issue than you are (or can, or should, be). I draw pictures and I write stories and I worry about the shift I’m seeing in fandom after having been on this ride for even a few pre-livejournal rounds.
I’m not going to stop doing any of those things. But I am going to allow myself to step away for a bit, make my wife dinner, and catch up on our shows.
I trust you’ve got it from here.
#word-stream#cliff weitzman#plagiarism#speechify#AO3#writers on tumblr#fanfiction#independent authors#web scraping#fandom activism#ask me things!#(which is my ask tag please don’t send me asks about things i’ve already answered in the main post)#anonymous
205 notes
·
View notes
Text
The Washington Post has an article called „Inside the secret list of websites that make AI like ChatGPT sound smart“
AO3 is #516 on the list, meaning the 516th largest item in the tokens of the dataset.

https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
99 notes
·
View notes
Text
When in doubt, scrape it out!
Come find me on TikTok!
#greek tumblr#greek posts#ελληνικο ποστ#ελληνικά#greek post#greek#ελληνικο tumblr#ελληνικο ταμπλρ#ελληνικα#python#python language#python programming#python ninja#python for web scraping#web scraping#web scraping api#python is fun#python is life
2 notes
·
View notes
Text

i've combined myself a new workflow blogging automation... 👀 prepare for massive queues.
8 notes
·
View notes
Text

2 notes
·
View notes
Text

"Il sorriso che ha attraversato i secoli e i cuori."
(The smile that has crossed centuries and hearts)
"Une énigme artistique qui défie le temps."
(An artistic enigma that defies time)
--------
Tried to digitise but she is still a mystery ❤️
2 notes
·
View notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
2 notes
·
View notes
Text
another tumblr web scraper update.
i implemented reblog trails, but now some post appear more than once! should i do something about that? 🤔
here's a demo for Randy, so he doesn't have to see slugcat spoilers
but i also discovered this horrible bug:

it only happens to this gradient. all the other secret colors rendered perfectly fine!
#textpost#neocities#web scraping#codeblr#does anyone want to suggest some design thingies?#i need to draw polls somehow
11 notes
·
View notes
Text

Lensnure Solution provides top-notch Food delivery and Restaurant data scraping services to avail benefits of extracted food data from various Restaurant listings and Food delivery platforms such as Zomato, Uber Eats, Deliveroo, Postmates, Swiggy, delivery.com, Grubhub, Seamless, DoorDash, and much more. We help you extract valuable and large amounts of food data from your target websites using our cutting-edge data scraping techniques.
Our Food delivery data scraping services deliver real-time and dynamic data including Menu items, restaurant names, Pricing, Delivery times, Contact information, Discounts, Offers, and Locations in required file formats like CSV, JSON, XLSX, etc.
Read More: Food Delivery Data Scraping
#data extraction#lensnure solutions#web scraping#web scraping services#food data scraping#food delivery data scraping#extract food ordering data#Extract Restaurant Listings Data
2 notes
·
View notes
Text
Cakelin Fable over at TikTok scraped the information from Project N95 a few months ago after Project N95 announcing shutting down December 18, 2023 (archived copy of New York Times article) then compiled the data into an Excel spreadsheet [.XLSX, 18.2 MB] with Patrick from PatricktheBioSTEAMist.
You can access the back up files above.
The webpage is archived to Wayback Machine.
The code for the web-scraping project can be found over at GitHub.
Cakelin's social media details:
Website
Beacons
TikTok
Notion
Medium
Substack
X/Twitter
Bluesky
Instagram
Pinterest
GitHub
Redbubble
Cash App
Patrick's social media details:
Linktree
YouTube
TikTok
Notion
Venmo
#Project N95#We Keep Us Safe#COVID-19#SARS-CoV-2#Mask Up#COVID is not over#pandemic is not over#COVID resources#COVID-19 resources#data preservation#web archival#web scraping#SARS-CoV-2 resources#Wear A Mask
2 notes
·
View notes
Text
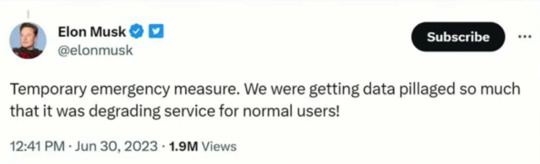
Fascinated that the owners of social media sites see API usage and web scraping as "data pillaging" -- immoral theft! Stealing! and yet, if you or I say that we should be paid for the content we create on social media the idea is laughed out of the room.
Social media is worthless without people and all the things we create do and say.
It's so valuable that these boys are trying to lock it in a vault.
#socail media#data mining#web scraping#twitter#reddit#you are the product#free service#free as in privacy invasion#pay me for that banger tweet you wretched nerd
8 notes
·
View notes
Text
More on web scraping
Something I thought about last night regarding my last post is that I forgot to mention that pulling out numbers and verses from a copyrighted Bible website involved a little knowledge of HTML's Document Object Model (DOM) and CSS. Most of that information I gleaned from when I used to program JavaScript a lot for work and (lately) from Mozilla Developer's Network and Node.js documentation.
It's exciting to me because I want to share as much as I can. These technologies have changed so much since the last time I developed against them for work, so I'm learning a lot.
Back to sharing: It would be cool to show some of the data hacking I do, once I have the data ready to hack, and it should be fun to describe more about what I did without giving away all the details. By that, I mean that I'm working against clearly proprietary content, so it's not my place to publish too many specifics about how I did the web scraping and how I pulled the Bible data. What I can share is *how* my process developed and my thinking behind each step. Hopefully my notes are good enough for that.
If things end up particularly interesting, I might go a step further with my hacked data and perhaps index it with the ELK (Elastic) stack. There's no need to go that far, but all of this is purely for the joy of functional learning. The modus operandi has been to do an excessively silly thing I could have done with publicly available KJV content, which is to take the word "Lord" and see what it looks like replaced with things like "Duke" or "Earl". Probably it will qualify under fair use as parody. That content I *should presumably* be able to share.
2 notes
·
View notes
Video
youtube
Scrap flipkart product using nodejs in simple way
2 notes
·
View notes
Text
Using indeed jobs data for business
The Indeed scraper is a powerful tool that allows you to extract job listings and associated details from the indeed.com job search website. Follow these steps to use the scraper effectively:
1. Understanding the Purpose:
The Indeed scraper is used to gather job data for analysis, research, lead generation, or other purposes.
It uses web scraping techniques to navigate through search result pages, extract job listings, and retrieve relevant information like job titles, companies, locations, salaries, and more.
2. Why Scrape Indeed.com:
There are various use cases for an Indeed jobs scraper, including:
Job Market Research
Competitor Analysis
Company Research
Salary Benchmarking
Location-Based Insights
Lead Generation
CRM Enrichment
Marketplace Insights
Career Planning
Content Creation
Consulting Services
3. Accessing the Indeed Scraper:
Go to the indeed.com website.
Search for jobs using filters like job title, company name, and location to narrow down your target job listings.
Copy the URL from the address bar after performing your search. This URL contains your search criteria and results.
4. Using the Apify Platform:
Visit the Indeed job scraper page
Click on the “Try for free” button to access the scraper.
5. Setting up the Scraper:
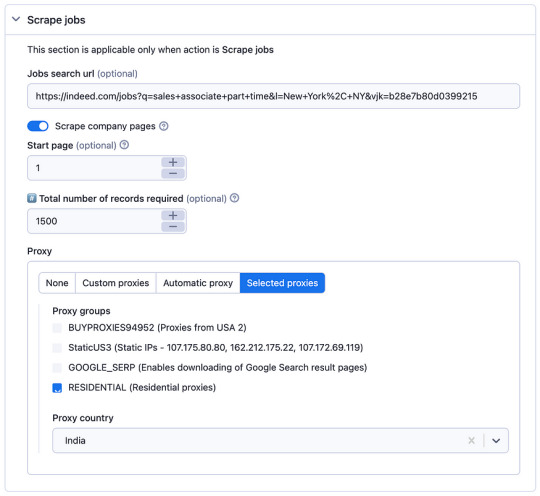
In the Apify platform, you’ll be prompted to configure the scraper:
Insert the search URL you copied from indeed.com in step 3.
Enter the number of job listings you want to scrape.
Select a residential proxy from your country. This helps you avoid being blocked by the website due to excessive requests.
Click the “Start” button to begin the scraping process.
6. Running the Scraper:
The scraper will start extracting job data based on your search criteria.
It will navigate through search result pages, gather job listings, and retrieve details such as job titles, companies, locations, salaries, and more.
When the scraping process is complete, click the “Export” button in the Apify platform.
You can choose to download the dataset in various formats, such as JSON, HTML, CSV, or Excel, depending on your preferences.
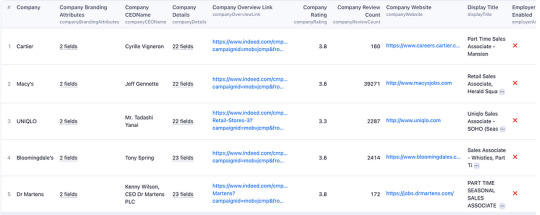
8. Review and Utilize Data:
Open the downloaded data file to view and analyze the extracted job listings and associated details.
You can use this data for your intended purposes, such as market research, competitor analysis, or lead generation.
9. Scraper Options:
The scraper offers options for specifying the job search URL and choosing a residential proxy. Make sure to configure these settings according to your requirements.
10. Sample Output: — You can expect the output data to include job details, company information, and other relevant data, depending on your chosen settings.
By following these steps, you can effectively use the Indeed scraper to gather job data from indeed.com for your specific needs, whether it’s for research, business insights, or personal career planning.
2 notes
·
View notes