#RealWorldTech
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Understanding Firewalls: What They Are and Why They're Essential for Cybersecurity? (techgabbing.com)
See how firewalls are used in real-world scenarios to protect e-commerce sites, remote workforces, and cloud-based applications from cyber threats.
0 notes
Photo

👾 Exploring Quantum AI's advancements and their real-world applications. 👉 Join us in exploring AI's transformative power. #QuantumClubAI #TechTuesday #QuantumAdvantages #AIApplications #RealWorldTech
0 notes
Text

Crypto Dreams, Real-World Impact" is a journey into the world of cryptocurrency and blockchain technology where imagination meets reality. Explore how these cutting-edge innovations are reshaping finance, technology, and society, and making a lasting impact on our everyday lives. Join us in unraveling the potential of decentralized finance, NFTs, smart contracts, and more as we turn crypto dreams into real-world solutions. #CryptoDreams #blockchainimpact #cryptocurrencyrevolution #realworldtech #defiinnovation #nfts #smartcontracts #DigitalTransformation #Cryptoeconomy #InnovationUnleashed
0 notes
Video
youtube
The standard by which all others fail is our starting point. Continuous innovation and advancement in technology drive Yamaha. Superior off-road capability, comfort, and confidence require a commitment to quality and testing standards that far exceed the competition. Only Yamaha can provide the durability and reliability that is delivered through advanced engineering … welcome to performance that truly is Proven Off-Road. http://yamaha.us/YOdrs
#Yamaha#offroad#realworld#realworldtech#provenoffroad#outdoors#adventure#explore#reliable#comfort#confidence#capability#wolverine#yxz#kodiak#grizzly#viking#wolverinex4#sxs#utv#atv#sidebyside#4x4#4wheeler#realworldtough
0 notes
Photo
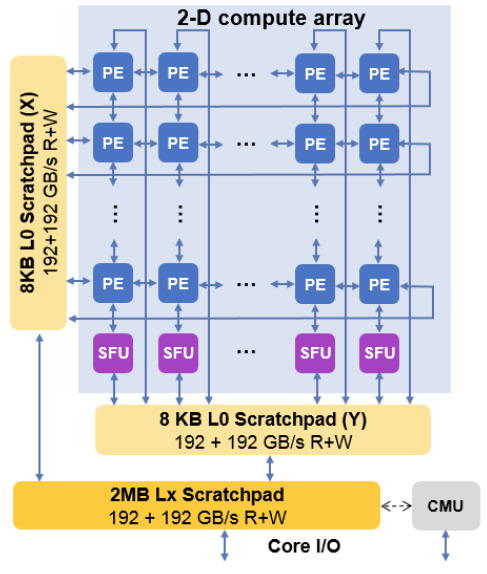
IBM's Machine Learning Accelerator at VLSI 2018 | David Kanter | RealWorldTech https://ift.tt/2PkFY1v
1 note
·
View note
Text
Intel Unveils 10nm ‘SuperFin’ Process Node, Tiger Lake Details
Intel unleashed a great deal of information about its upcoming products this morning, including new details on Tiger Lake, its upcoming mobile chip. There’s been no small amount of speculation about what kind of performance the new CPU would offer, especially after Ice Lake received mixed reviews on the CPU side. While the 10nm chip’s GPU was a significant jump forward for Intel, the CPU’s higher IPC was balanced by a lower maximum frequency. Overall, Intel had to give up almost exactly as much frequency as it gained in IPC and performance, outside a few specific cases, was largely static against Intel’s 14nm family of chips.
Tiger Lake is intended to change that by reclaiming the frequency that Intel had to give up last generation. The company has made a number of improvements to its 10nm process node and it’s collectively marketing them as “SuperFin.”
Tiger Lake’s gate pitch is larger, meaning Intel decreased its density slightly to improve its electrical characteristics. This isn’t surprising, the company did something similar over the lifetime of 14nm as well. Improvements to channel mobility and reduced resistance lower the overall buildup of heat within the chip and increase the effective frequency the CPU can reach.
Intel has also developed an improved metal-insulator-metal capacitor. This is a type of on-die capacitor used to respond rapidly to transient current spikes. David Kanter of RealWorldTech wrote a deep dive into MIMs and how they compare to MOSFETs and deep trench capacitors if you want more information on the topic.
The result of these improvements is a dramatic leap in overall dynamic range and frequency response. Intel doesn’t formally claim that Tiger Lake can hit 5GHz, but if you look at the curve above, the implication is there:
One major change Intel is making with Tiger Lake is the switch from an inclusive L2 to a larger, non-inclusive L2. This was one of the more surprising disclosures about Tiger Lake; Intel’s L2 cache was just 512KB on Ice Lake and was inclusive of its 32KB L1i / 48KB L1d caches. Tiger Lake also allocates a larger L3 cache — up to 3MB per core, compared to 2MB for Ice Lake. I don’t want to speculate on exactly what kind of impact we should expect from this change until we’ve actually seen the CPU.
What all this adds up to, according to Intel, is one mammoth performance jump:
Intel isn’t really using its “+” nomenclature, but what we’ve heard from the company in the past is that the barely-there Cannon Lake counts as 10nm, Ice Lake is 10nm+, and Tiger Lake is built on 10nm++. The slide above applies a bit of a redefinition, with Ice Lake now “10nm” and Tiger Lake positioned as the 10nm intranode. Regardless, Intel is claiming to have delivered the same degree of performance improvement from ICL to TGL as it delivered across all of its 14nm product lines. Note that the y-axis isn’t measuring absolute performance improvement, but performance improvement at the same leakage.
Tiger Lake will also add additional EUs and move to Intel’s Xe graphics. This will be the first place we see Intel’s upcoming graphics architecture and there’s a fair bit of excitement and curiosity over what the firm will launch. Nobody expects Xe to be an Nvidia-killer out of the gate — initial architectures from a new company (which is what Intel basically is in this space) don’t really do that — but a three-way race would push all competitors to evolve GPU technology more quickly.
There’s a lot more to talk about and I’m going to have more to say about it later this morning, but I want to take a moment to speak to how Tiger Lake looks overall, particularly against AMD. If Intel can deliver the improvement in clock speeds that it claims it can, AMD is going to facing serious competition in mobile this year. It wouldn’t be surprising if Intel leaps ahead with Tiger Lake, only for AMD to pull even (or ahead) when Zen 3 APUs debut for mobile. That kind of back-and-forth between the two companies was normal on desktop from early 2017 – mid-2019.
It isn’t surprising to see Intel debut a significantly improved 10nm — the company signaled confidence in the node when it canceled its lower-end 14nm Cooper Lake Xeons last year. The question is, can Intel ship these parts in significant volume? We’ll know more when we see how Intel positions any remaining 14nm CPUs in the 11th Generation (presumed) mobile Core family as opposed to 10nm parts, and how easy they are to find on store shelves.
The implication of Intel’s last conference call is that the company is going to take a margin hit as it scales up 10nm production more aggressively. The company has carefully managed its available production for the past few years, ceding ground in low-end chips to focus its production on enterprise and server parts.
It would be premature to declare that Intel had turned a corner on 10nm until we’ve seen Tiger Lake in action and have evidence that the chips are available in volume, but Intel is claiming a solid set of improvements for its next iteration of 10nm.
Now Read:
Happy Birthday to the PC: Either the Best or Worst Thing to Happen to Computing
Rumor: TSMC Won’t Build New Capacity for Intel, Views Orders as Temporary
Intel Core i9-10850K: A Little Less Clock, but (Maybe) a Lot More Traction
from ExtremeTechExtremeTech https://www.extremetech.com/computing/313733-intel-unveils-10nm-superfin-process-node-tiger-lake-details from Blogger http://componentplanet.blogspot.com/2020/08/intel-unveils-10nm-superfin-process.html
0 notes
Photo

It’s been a little while… Alright, back here at budget tech review we got a winner for you. Scored the Anker sound core mini. This little guy right here is perfect for your desk top/work station. The sound is perfectly clear and the bass is Damn good. Loud enough to drown out anyone at the office or at home. You can score one for less than 30 bucks at Wal-Mart
#buget #techreview #cellphone #realworldtech
0 notes
Text
What ought to the hotly anticipated Mac Pro refresh resemble? We ought to see double attachment Sandy Bridge Xeons and an upgraded case, at least.
Apple hasn't refreshed its Mac Pro workstation in about two years, leaving numerous ace clients thinking about whether Apple may execute the item out and out. That is a continuous wellspring of tension to experts in inventive businesses and somewhere else who depend on Apple equipment and OS X programming to carry out their occupations. They've seen Intel discharge ever-speedier processors since summer 2010, which can feel like an unfathomable length of time as far as PC equipment, making a portion of the more established Mac Pros feel decidedly antiquated.
Late part number holes emphatically recommend, in any case, that Apple will in truth disclose a refresh one week from now at its yearly Worldwide Developers Conference. To comprehend why it has taken so long to refresh the Mac Pro, it's informative to take a gander at how the Xeon CPU lineup advances in contrast with Intel's other desktop and versatile CPUs.
A substantial piece of the deferral is evidently because of Intel's Xeon processor refresh timetable. Xeon is the brand Intel provides for its workstation and server-class processors, which come in three fundamental levels: Xeon E3, for single attachment frameworks, Xeon E5, for 2–4 attachment frameworks, and Xeon E7, for at least 4 attachment frameworks. (These levels were in the past marked Xeon 3000, 5000, and 7000, separately.) Intel doesn't refresh all levels in bolt step, be that as it may. As the quantity of bolstered attachments goes up, so does the size, cost, and multifaceted nature of each chip. So while the E3 territory is refreshed as frequently as Intel's desktop processors—Xeon E3s are generally re-badged renditions of the normal mass-advertise desktop chips—the E5 and E7 ranges enhance at a to some degree slower pace.
In the course of the most recent two years, the desktop processors and Xeon E3 level have had their microarchitecture updated twice; in mid 2011 they went from Westmere to Sandy Bridge, and most as of late, from Sandy Bridge to Ivy Bridge. The Xeon E5, then again, has been redesigned only once, from Westmere-EP to Sandy Bridge-EP—and this update occurred in March of this current year. The Xeon E7 hasn't changed for a year, when Intel supplanted the Nehalem-EX Xeon 7000s with Westmere-EX Xeon E7s.
The present Mac Pros utilize Westmere-EP Xeon 5000s, which utilize around six centers for each chip, empowering Apple to offer a "dodeca-center" Mac Pro. This long hole between the Westmere-EP Xeon 5000s and the Sandy Bridge-EP Xeon E5s is a major some portion of why Apple hasn't redesigned the Mac Pros for so long: until prior this year, there simply wasn't anything better in Intel's two-attachment line-up.The explanation behind the postponement, as per equipment master and RealWorldTech Editor David Kanter, is generally identified with pass on size. "With any new procedure, yields are not that extraordinary. With another procedure, you need to begin with something generally little," Kanter told Ars. Desktop and portable Ivy Bridge processors fit that bill much superior to a Sandy Bridge-EP kick the bucket, which is around three times bigger.
"The catch is that when you take a gander at the yield, it's non-direct," Kanter said. "In the event that you have a chip that is three times as expansive, the quantity of good chips per [silicon] wafer aren't only 33%; it's generally more regrettable. Less of the bigger bite the dust will fit, yet the effect of any deformity [in the wafer] is more prominent."
Basically, any deformity in the silicon wafer where a specific processor bite the dust is scratched will render that processor futile, diminishing yields.
"Intel will put out these vast server chips around six to twelve months after another procedure; they'll have the capacity to put through a huge number of wafers and have room schedule-wise to work out the yield issues," Kanter said.
In this way, the most recent Xeon E5s, which propelled only a couple of months prior, are worked around the Sandy Bridge-EP design. Not at all like the Westmere-EP Xeons, which were basically a change on the standard desktop assortment Nehalems to empower multi-attachment designs, the Sandy Bridge-EP is altogether unique in relation to the Core i5 or Core i7 processors found in late Macs. That by itself brought about a more drawn out than anticipated deferral on Intel's part.
Since there's all of a sudden such a great amount of enthusiasm for a potential Mac Pro refresh, we chose to start thinking critically and consider what changes are probably going to go to the Mac Pro, ought to Apple uncover another one come Monday.
Sandy Bridge-EP
Intel happens to make a couple Ivy Bridge-based Xeons, however those processors are single-attachment as it were. What's more, Ivy Bridge doesn't essentially adjust or upgrade the CPU engineering of Sandy Bridge. The larger part of Ivy Bridge upgrades are in the coordinated illustrations, which Xeon E5 chips don't have, and the power reserve funds of its 22nm procedure, which won't go to the Xeon E5 line for another year.That doesn't mean Sandy Bridge-EP has nothing to offer. The general engineering is more effective than the Westmere-EP design it replaces. It likewise enormously pumps up the reserve region and QPI interconnect between every one of the centers, altogether boosting execution on multithreaded workloads.
As indicated by benchmarking by RealWorldTech, Sandy Bridge-EP is approximately 20 percent more effective than Westmere-EP "when looking at a similar total execution level." Additionally, Sandy Bridge-EP scales higher, with both more centers per processor and higher clock speeds. What's more, it does this with a 30 percent decrease out of gear power.
Viably, quad-center and hexa-center clients getting another machine will see incremental enhancements in speed with essentially cooler, bring down power operation on existing workloads. Clients that pick an entire 16-center experience will see the same, and in addition the possibility to scale considerably higher at pedal to the metal. As we noted just about two years prior, notwithstanding, having 16 centers to utilize is no assurance that your product will take full preferred standpoint of them.Thunderbolt
It looks as if, with PC motherboard producers coordinating Thunderbolt into their most recent outlines, Apple will at long last add Thunderbolt to its genius level workstation. The question is: how precisely will that work?
The confounding issue is that Thunderbolt conveys rapid PCIe information, as well as convey DisplayPort video also. On every single other Mac, GPUs—regardless of whether coordinated or discrete—are settled. This makes it simple to pipe the DisplayPort yield to the Thunderbolt port, which fills in as both a fast interconnect and in addition the association for an outer screen. The Mac Pro, then again, has removable PCIe-based illustrations cards. In what capacity will Apple get the yield of these cards into the Thunderbolt controller?
The no doubt arrangement is a Mini DisplayPort passthrough link. ASUS is utilizing an outer DisplayPort link to add Thunderbolt to its most recent motherboard plans, however that appears to be unequivocally "un-Apple-like." There might be a more exquisite arrangement in progress, for example, coordinating the card's yield over the PCIe transport straightforwardly to the Thunderbolt controller, yet as indicated by our sources, no present representation cards work that way. Given that reality, we think Apple will utilize an interior link joined with GPUs including an inner smaller than normal DP connector.Thunderbolt's PCIe-based outline is maybe most helpful to versatile applications, since it permits journals access to equipment that generally would just go ahead a PCIe card. Be that as it may, despite the fact that the Mac Pro has PCIe spaces inside, it doesn't bode well to just leave the port off the Mac Pro. The sorts of top of the line stockpiling, video, sound, and different gadgets that are receiving Thunderbolt will probably be utilized by similar experts that would select a Mac Pro on the desktop, regardless of the possibility that they utilize a MacBook Pro or MacBook Air in the field.
While an inside link isn't what we would call "exquisite," it's a down to earth arrangement until Apple or Intel thinks of a superior one.
USB 3.0
Intel's controller chips for Ivy Bridge at long last include local support for USB 3.0. It's an easy decision that Apple will receive this standard over its frameworks, particularly since it is completely in reverse perfect with USB 2.0 gadgets. While USB 3.0 bolster isn't local on the controller chips for Xeon E5, we don't think Apple would hold back on redesigning the standard on its untouchable expert workstations. Apple should include an extra controller, yet we anticipate that USB 3.0 support will be there.
FireWire 800 will likewise likely keep on existing on the Mac Pro for years to come; there is no favorable position to dropping local support for FireWire now in the diversion, particularly as Thunderbolt is still in its earliest stages.
Nonetheless, Intel's Xeon E5 chipsets do bolster the most recent SATA 3.0 standard, giving inside drives a 6Gbps association with the motherboard. Clients can expect better drive execution in general, particularly when utilizing the most recent SSDs.
At long last, there's support for PCIe 3.0. This most recent refresh to the PCI Express standard evacuates a portion of the bottlenecks for certain high-transmission capacity applications, including huge GPU calculations and gushing huge amounts of video or other information to RAID exhibits.
Basically, the Sandy Bridge-EP stage will bring heaps of little lifts all around, which in total ought to make for a snappier machine.
Optical drive
The Mac Pro has two optical drive narrows, yet in this age of the Mac App Store, iTunes, and Netflix, staying gleaming plastic and metal circles into a PC has turned into an uncommon event for a few clients. An optical drive isn't even a choice on the most recent Mac smaller than usual (and never was on the MacBook Air).
Apple and its Mac Pro clients won't not be prepared to dump optical drive completely, but rather we do speculate that a changed Mac Pro may just have one optical narrows. Like the last era Mac smaller than usual, in any case, we think Apple may offer an alternative to supplant the optical drive with at least one HDD or SSD stockpiling gadgets.
0 notes
Text
Understanding Firewalls: What They Are and Why They're Essential for Cybersecurity? (techgabbing.com)
See how firewalls are used in real-world scenarios to protect e-commerce sites, remote workforces, and cloud-based applications from cyber threats.
0 notes
Photo

What is the meaning of 7.5T, 9T, etc in process technology?
I've been wondering this for a while as I didn't fully understand it but found a great comment on the realworldtech forums (David Kanter's site). Below are quotes from this thread
Cell "height" in metal track count, where "width" is direction of the gates laid out side-by-side. It is more of a measure of the layout design than a flat dimensional measurement, but the gist of it is lower T = more fancy tricks with contact, metal routing, etc.
To add to what others have said, this has become more of an issue with finFETs. Before finFETs, you could create a "stronger" transistor, one that drove more current at a given voltage, by making it wider. (Essentially z dimension and x dimension control the overall performance and are as small as the tech allows, and y dimension could be variably scaled to whatever "strength" you needed). But finFETs introduce a kind of quantization into transistor strength, since the fins are the same along all three dimensions. What do you do to vary drive current?
It would seem that you could make fins with varying height. TSMC certainly has mentioned this, but for whatever reason this does not seem to have become a mainstream technology. So the path that has been adopted is to use variable numbers of fins to construct a single transistor. Hence, for example, your mainstream transistors, the ones used for the bulk of your device, might be constructed of 4 fins, so that a single transistor pair (one n, one p, to make up CMOS and save power) might consist of 4 p fins above to 4 n fins. Each fin is essentially the minimum width the lithography can print, which is also more or less the minimum the minimum wire width the lithography can print, so the total package (one "effective transistor") is about 10 units high once you throw in some spacing.
Now an obvious question every time the process is improved (and every time a CPU is designed) is "how strong do I REALLY need my transistors to be"? (a) If you're going for high performance rather than maximum density, you'll want more fins, so you'll go for larger cells, with say 5+5 fins. (b) Part of what you get at each shrink is (hopefully) the need to move fewer electrons to actually get something to be "noticed" (lower RC), and perhaps slightly taller fins; so you can get away with fewer fins. And so the next generation, for your high density cell, you might drop from 4+4 to 3+3 fins, lower your total footprint from, say, 10 units high down to maybe 7.5 units high.
The hope is to keep doing this with each new process. It's also the case that n and p fins are not perfectly matched (because they use different materials) so in a given process you might be able to match say 3n+2p fins before, in the next process, dropping down to 2n+2p fins.
The endpoint of this is 1+1 fin, but before that is expected to happen, the geometry will change slightly to some sort of gate-all-around that wraps the entire "fin" (not just the left+right sides+top with the gate that's controlling the flow of electrons. Regardless, once you hit 1+1 and can't shrink further, the next obvious step is to stack the n transistor vertically on the p transistor. (This is called a CFET). This sounds "trivial" (except for more layers of manufacturing) but there are tricky issues of how you direct the wiring into this complex to get everything connected to the right voltage... Fortunately that's a problem for a few years from now, right now we're still at about 3+3 or 3+2.
Finally all this is about shrinking the "unit transistor" size in the y dimension by more than just lithography shrink. There are a different set of techniques going on to likewise shrink along the x dimension by more than just lithography shrink.
Scotten Jones at Semiwiki is the best guy to read about this. Here's an example article
www.semiwiki.com/forum/content/7343-leading-edge-logic-landscape-2018-a.html
and if you read a few more of them, you'll start to see the patterns.
To which someone replied
There is no compelling reason not to just use the maximum fin height you can reliably produce all the time. You save no area and without making all fins shorter you can't save thickness either.
That sounds reasonable. However this article describes why you want (if possible) some sort of fine control over the relative strength of different transistors in an SRAM cell, in order to maximize stability (ie low noise during different operations like read vs write).
Likewise this is TSMC's patent for how you might manufacture these:
https://patents.google.com/patent/US9425102
There are a number of these TSMC patents (I guess various improvements over the years) but none of the patents describe WHY you might want to to this, just HOW to do it.
Intel have also got into the act:
https://patents.google.com/patent/US20110147848
They're a little more helpful in their patent, saying:" There are two significant reasons for increasing fin height. +The first reason is that an increase in drive current can be attained (without increasing the footprint) and +the second is that an improved (decreased) Vccmin (minimum power supply voltage required to operate a device) can be attained, which is a result of the increase area of the gate from the increase in the transistor fin height. +However, increasing the transistor fin height also results in an increased gate capacitance, which will result in a degradation of dynamic capacitance.
As microelectronic devices can contain numerous components, such as logic components, memory components, etc., fabrication on a single substrate, an embodiment of the present disclosure uses transistor fins of multiple heights, rather than simply finding a uniform fin height for all of the transistor components. These multiple fin heights may be used for different components or may be used within the individual or single component. Thus, the use of multiple fin heights may provide a solution to the problem of increased dynamic capacitance by matching the device fin height to the circuit requirements of specific circuits. "
Of course none of this means the techniques are in actual real-world use. I can't find anything that settles this one way or the other. It may be, for example, that the foundries have decided this technique works for standard SRAM (where it's hidden behind the compiler) but is too finicky to be exposed to designers of custom logic?
1 note
·
View note